对标ChatGPT的开源中文方案

目录
前言
一、Meta发布大语言模型LLaMA
二、斯坦福基于 Meta 的 LLaMA 7B 模型微调出Alpaca
三、基于TencentPretrain训练中文LLaMA大规模语言模型
四、基于斯坦福Alpaca训练中文对话大模型BELLE
五、 清华开源项目ChatGLM中文对话模型
六、基于LLaMA的开源中文语言模型“骆驼”
总结
前言
新年伊始,火爆全网的 ChatGPT,仿佛开启了第四次工业革命,它像个无所不能的六边形战士,可以聊天、写代码、修改 bug、做表格、写论文、写作业、做翻译、搜索答案等……
自发布以来,ChatGPT 便已摧枯拉朽之势席卷各个行业,不仅 5 天时间便突破百万用户,月活用户更是仅用时 2 个月便突破 1 亿,成为史上增速最快的消费级应用,远超其他知名应用。
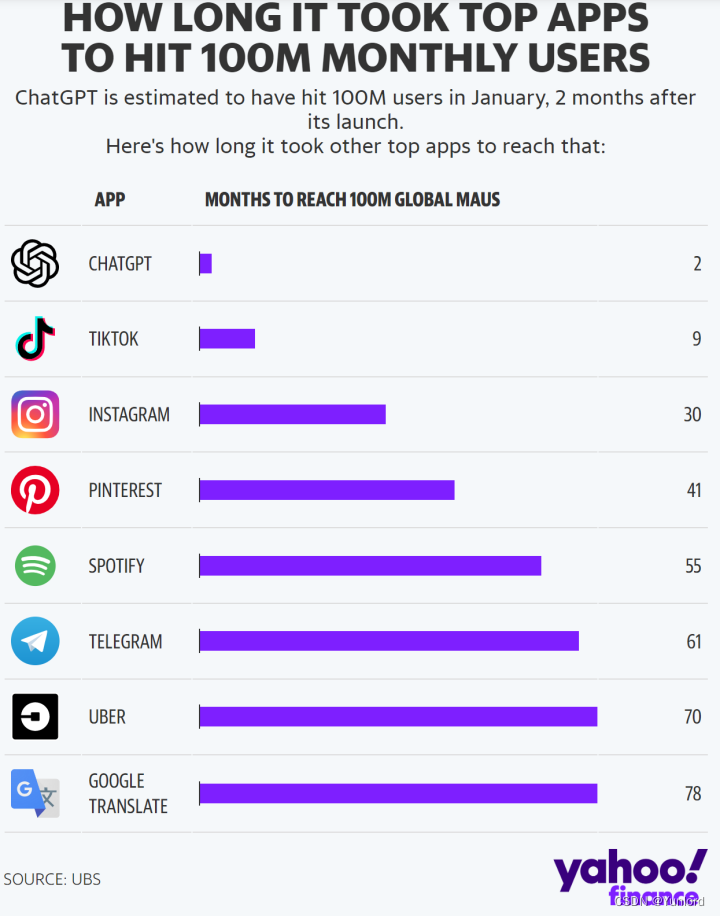
然而由于 OpenAI 没有开源 ChatGPT,如何有效的复现针对中文的 ChatGPT 已成为摆在大家面前的头号难题。
下面我会介绍一些对标ChatGPT的中文开源方案,代码地址也列在每个项目的介绍最上面,希望这些方案能够对大家有所帮助!
一、Meta发布大语言模型LLaMA
项目地址:GitHub - facebookresearch/llama: Inference code for LLaMA models
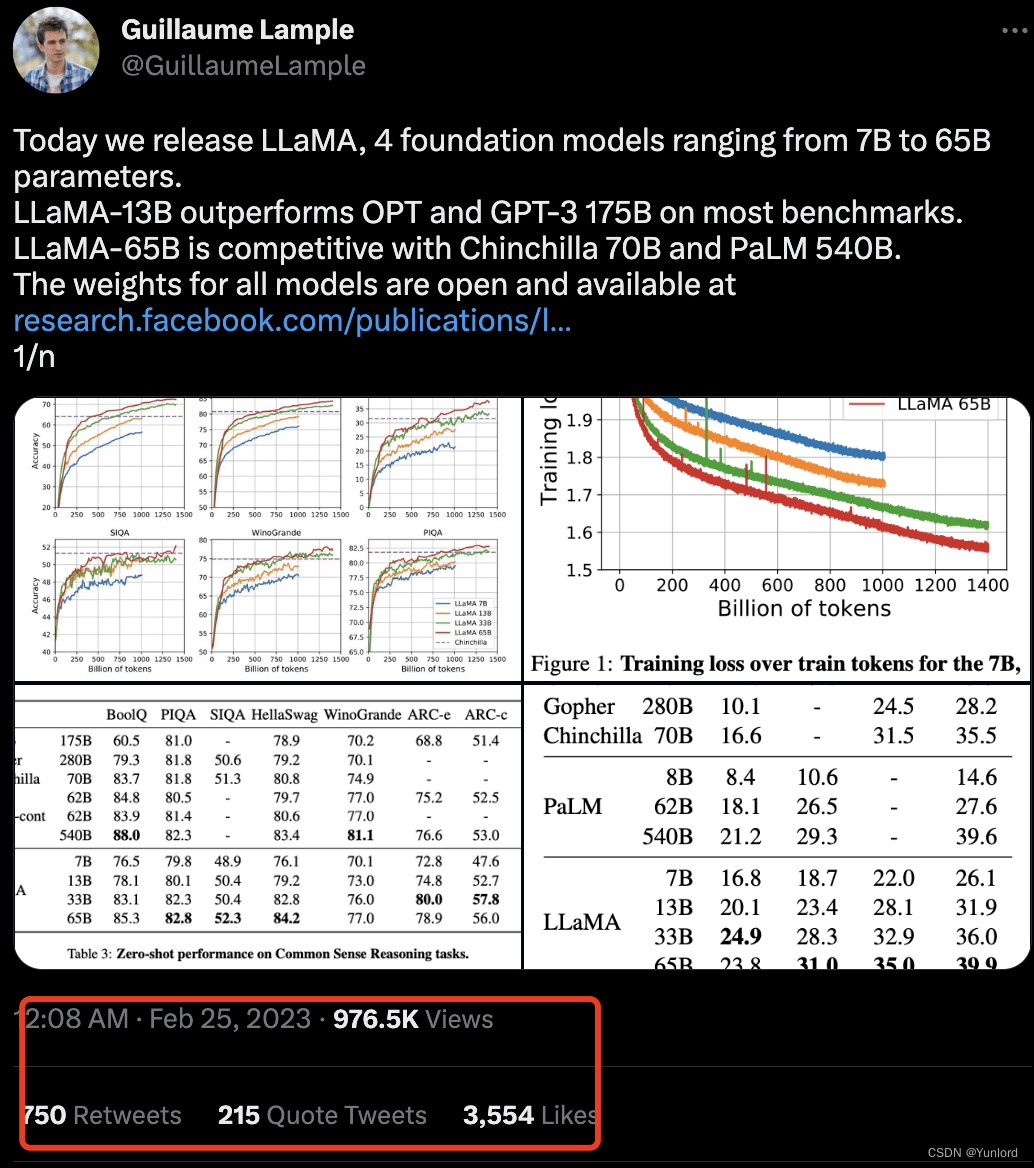
Meta一次性发布四种尺寸的大语言模型 LLaMA:7B、13B、33B和65B。还声称, 效果好过GPT,偏向性更低,更重要的是所有尺寸均开源,甚至13B的LLaMA在 单个GPU上就能运行。
Meta发布的LLaMA是 通用大语言模型,原理就不多赘述,和以往的大语言模型一样:将一系列单词作为输入,并预测下一个单词以递归生成文本。
这次,Meta之所以一次给出不同大小的LLaMA模型,论文中给出了这样的解释:
近来的研究表明,对于给定的计算预算,最佳性能不是由最大的模型实现的,而是由 基于更多数据训练的 更小的模型实现的。也就是说,较小的模型规模加上比较大的数据集,获得的性能可能会比更大规模模型的要好很多。一方面,小规模模型需要的计算能力和资源相对来说都会少很多,另一方面,它还能基于更多数据集 训练更多token,更容易针对特定的潜在产品用例进行重新训练和微调。
除了一次性给出四种尺寸的LLaMA,Meta这次还直接开源了这个大语言模型。更重要的是,Meta为了让自己的工作与开源兼容,使用的都是公开的数据。
二、斯坦福基于 Meta 的 LLaMA 7B 模型微调出Alpaca
项目地址:https://github.com/tatsu-lab/stanford_alpaca
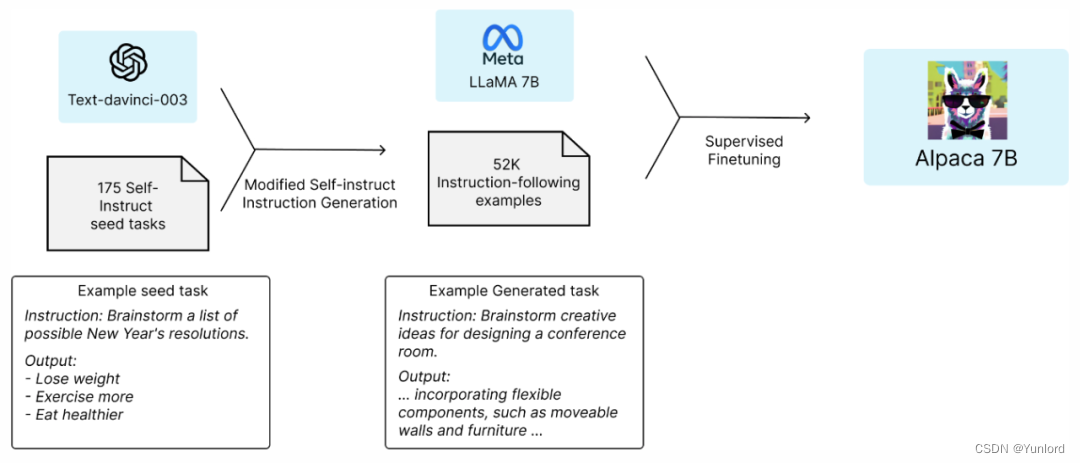
三月初,斯坦福基于 Meta 的 LLaMA 7B 模型微调出一个新模型 Alpaca。该研究让 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 指令遵循(instruction-following)样本,以此作为 Alpaca 的训练数据。研究团队已将训练数据、生成训练数据的代码和超参数开源,后续还将发布模型权重和训练代码。
实验结果表明,Alpaca 的很多行为都与 text-davinci-003 类似。也就是说,只有 7B 参数的轻量级模型 Alpaca 性能可媲美 GPT-3.5 这样的超大规模语言模型。
三、基于TencentPretrain训练中文LLaMA大规模语言模型
项目地址:https://github.com/Tencent/TencentPretrain
TencentPretrain 是 UER-py 预训练框架的多模态版本,支持 BERT、GPT、T5、ViT、Dall-E、Speech2Text 等模型,支持文本、图像和语音模态预训练及下游任务。TencentPretrain 基于模块化设计,用户可以通过模块组合的方式构成各种模型,也可以通过复用已有的模块进行少量修改来实现新的模型。例如,LLaMA 的模型架构基于 Transformer 有三项改动:前置 normalization [GPT3]、SwiGLU 激活函数[PaLM]、旋转位置编码[GPTNeo]。
得益于模块化特性,该项目在 TencentPretrain 中基于 GPT2 模型的已有模块,仅添加约 100 行代码就能实现以上三个改动从而训练 LLaMA 模型。
效果如下所示:
| Human | Computer |
| 中国的首都在哪里 | 中国首都是北京。 |
| 北京9月的平均气温是多少 | 秋分,中国北京的平均气温为25.5℃。 |
| 列出一些能用于登山的装备 | To climb mountains, you should bring a lot of > climbing equipment, including a compass, a climbing harness, a helmet, > gloves, good shoes with plenty of ankle support, and a backpack. |
| 介绍一下自然语言处理技术 | Natural language processing (NLP) is the study and design of algorithms that are able to understand and manipulate human language. |
| 帮我解答这个数学题: 6+3*2 | 6+3*2=11 |
| 生成一段代码来创建一个从1到100的列表 | def gen_list(n): """Generate a list from 1 to n""" return [i for i in range(1, n+1)] |
四、基于斯坦福Alpaca训练中文对话大模型BELLE
项目地址:https://github.com/LianjiaTech/BELLE
为了提升在中文上的效果,本项目基于Stanford Alpaca优化了中文种子任务,对生成代码进行了一些修改,同时选用BLOOMZ-7B作为基础模型训练得到了一个可以更好支持中文指令的开源模型 - BELLE。同时基于Alpaca的数据收集代码,基于这段代码生成了约100万条中文数据,结合Alpaca的5万条英文数据,在BLOOMZ-7B模型训练得到的checkpoint上传在Hugging Face。
项目包含以下内容:
- 175个中文种子任务
- 生成数据的代码
- 1M + 0.5M生成的中文数据集
- 基于BLOOMZ-7B1-mt优化后的模型
效果如下所示:
| Human | Computer |
| 小明的爸爸有三个孩子,老大叫王一,老二叫王二,老三叫什么? |
小明
|
| 用python写一个二分查找的代码 | def binary_search(arr, target): low = 0 high = len(arr) - 1 while (low <= high): mid = low + high // 2 if arr[mid] == target: return mid elif target < arr[mid]: low = mid + 1 else: high = mid - 1 return -1 |
| 今天天气怎么样,把这句话翻译成英语 | What's the weather like today? |
| 怎么让自己精力充沛,列5点建议 | 以下是一些可以让你保持精力充沛的建议: 1. 睡眠充足。确保每天晚上得到充足的睡眠时间。 2. 多运动。进行适度的有氧运动,如慢跑、游泳等,可以帮助你提高能量和耐力。 3. 吃健康食品。选择富含蛋白质的食物,如鸡肉、鱼肉和鸡蛋,以及新鲜的水果和蔬菜。 4. 减少咖啡因的摄入量。尽量避免在白天喝含咖啡因的饮料或吃含有咖啡因的食物。 5. 放松身心。尝试冥想、瑜伽或其他形式的放松活动来减轻压力和焦虑感。 |
| 推荐几本金庸的武侠小说 | 以下是三本我最喜欢的金庸武侠小说的推荐: 1. 《射雕英雄传》 - 一部充满智慧和机智的小说,讲述了郭靖、黄蓉夫妇的故事。 2. 《神雕侠侣》- 这是一部浪漫而感人的故事,讲述了一对情侣小龙女与杨过之间的爱情故事。 3. 《倚天屠龙记》- 这是一个宏伟而壮观的故事,描绘了明教领袖张无忌如何成为一位出色的英雄 |
五、 清华开源项目ChatGLM中文对话模型
项目地址:https://github.com/THUDM/ChatGLM-6B
据官方介绍,ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
效果如下所示:

六、基于LLaMA的开源中文语言模型“骆驼”
项目地址:https://github.com/LC1332/Chinese-alpaca-lora
这个模型是在Meta开源的LLaMA基础上,参考Alpaca和Alpaca-LoRA两个项目,对中文进行了训练,0.1版本的模型取得了基础的中文会话能力。
效果如下所示:
| Human | Computer |
| 中国的首都在哪里? | 中国的首都是北京。 |
| 麦当劳是哪个国家的? | 美国 |
| 2017年美国总统是谁? | 特朗普 |
| 华中师范大学在哪里? | 华中师范大学在武汉市。 |
总结
ChatGPT掀起的新一轮人工智能狂欢下,隐藏在背后的“大模型”正进入越来越多开发者的视野。正如有一句话说的那样:数据是燃料、模型是引擎、算力是加速器。ChatGPT的出现,恰如其分地诠释了数据、模型和算力的“化学反应”。
如何在垂直领域做出更有针对性模型也是未来的发展方向之一,尤其是算力以及数据不那么充足的情况下。
大家如果有什么好的想法和项目,也欢迎在评论区里留言评论!
参考:
1.开源方案复现ChatGPT流程!1.62GB显存即可体验,单机训练提速7.73倍_数据派THU的博客-CSDN博客
2.对标ChatGPT有哪些开源的方案? - 知乎
3.训练中文LLaMA大规模语言模型 - 知乎
4.【开源GPT】三位华人小哥开源中文语言模型“骆驼”,单卡即可完成训练部署,花费几百训练自己的中文聊天模型 - 知乎
相关文章:
对标ChatGPT的开源中文方案
目录 前言 一、Meta发布大语言模型LLaMA 二、斯坦福基于 Meta 的 LLaMA 7B 模型微调出Alpaca 三、基于TencentPretrain训练中文LLaMA大规模语言模型 四、基于斯坦福Alpaca训练中文对话大模型BELLE 五、 清华开源项目ChatGLM中文对话模型 六、基于LLaMA的开源中文语言模型…...

9.Java面向对象----封装
Java面向对象—封装 面向对象简称 OO(Object Oriented),20 世纪 80 年代以后,有了面向对象分析(OOA)、 面向对象设计(OOD)、面向对象程序设计(OOP)等新的系统…...

【react 全家桶】组合组件
本人大二学生一枚,热爱前端,欢迎来交流学习哦,一起来学习吧。 <专栏推荐> 🔥:js专栏 🔥:vue专栏 🔥:react专栏 文章目录09 【组合组件】1.包含关系2.特例关系问题…...
VUE_学习笔记
一、 xx 二、模板语法 1.模板语法之差值语法 :{{ }} 主要研究:{{ 这里可以写什么}} 在data中声明的变量、函数等都可以。常量只要是合法的javascript表达式,都可以。模板表达式都被放在沙盒中,只能访问全局变量的一个白名单&a…...
【分布式事务AT模式 SpringCloud集成Seata框架】分布式事务框架Seata详细讲解
前言 上篇文章我们讲述了如何启动seata的本地服务,并且注册到nacos使用,这篇文章将在SpringCloud中整合Seata框架 上篇文章传送门:https://blog.csdn.net/Syals/article/details/130102851?spm1001.2014.3001.5501 本篇主要内容ÿ…...

系统集成项目管理工程师软考第三章习题(每天更新)
第一章指路:系统集成项目管理工程师软考第一章习题(已完结)_程序猿幼苗的博客-CSDN博客 第二章指路:系统集成项目管理工程师软考第二章习题(已完结)_程序猿幼苗的博客-CSDN博客 第3章信息系统集成专业技术…...
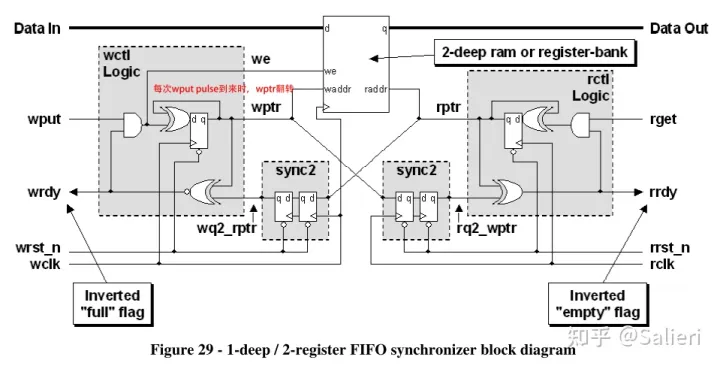
FIFO的工作原理及其设计
1.简介 FIFO( First Input First Output)简单说就是指先进先出。FIFO存储器是一个先入先出的双口缓冲器,即第一个进入其内的数据第一个被移出,其中一个口是存储器的输入口,另一个口是存储器的输出口。 对于单片FIFO来说,主要有两种…...

「UG/NX」Block UI 通过浏览器选择文件File Selection with Browse
目录 控件说明界面效果公有属性对话框标题 DialogLabel(仅创建)控件灰显 Enable分组 Group(仅创建)控件显隐 Show控件标题 Label国籍文本 AllowInternationalTextInput(仅创建)显示密文 IsPassword(仅创建)本地化 Localize(仅创建)保存值 RetainValue属性界面代码实现…...
面试官:如何搭建Prometheus和Grafana对业务指标进行监控?
Prometheus和Grafana都是非常流行的开源监控工具,可以协同使用来实现对各种应用程序、系统、网络和服务器等的监视和分析。 下面对Prometheus和Grafana进行简要介绍: Prometheus Prometheus是一款开源、云原生的系统和服务监控工具,它采用p…...

SQL Server 创建登录账号、创建用户名并为数据库赋予db_owner权限
服务器级的固定角色及其权限 sysadminsysadmin 固定服务器角色成员可以在服务器执行任何操作serveradminserveradmin 固定服务器角色的成员可以更该服务器范围的配置选项和关闭服务器sercurityadmin sercurityadmin 固定服务器角色的成员管理登录名及其属性,他们可以grant、de…...
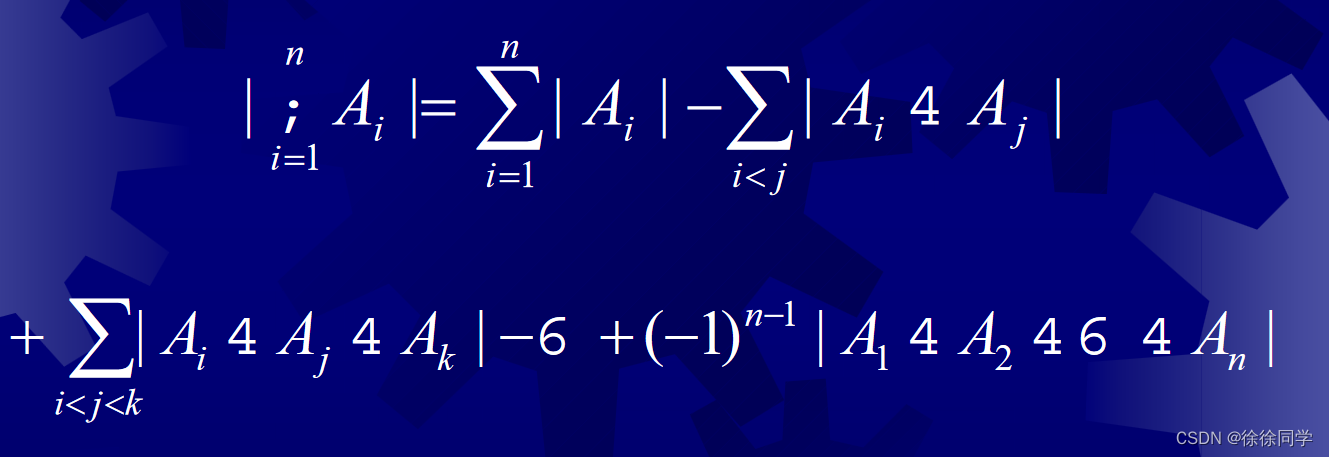
离散数学_第二章:基本结构:集合、函数、序列、求和和矩阵(1)
集合与函数2.1 集合 2.1.1 集合的基本概念 2.1.2 集合的表示方法 2.1.3 文氏图 2.1.4 证明集合相等 2.1.5 集合的大小 ——基 2.1.6 幂集 2.1.7 集族、指标集 2.1.8 笛卡尔积 2.1.9 容斥原理2.1 集合 2.1.1 集合的基本概念 定义1:集合 是不同对象的一个无序的聚…...

ChatGPT想干掉开发人员,做梦去吧
很多人都发现ChatGPT可以做一些代码相关的工作,不仅可以写一些基础的类似python、java、js的代码段,还可以做一定量的调优,于是就开始担忧起来,到哪天我的开发工作会不会被ChatGPT这个工具给取代了? 目录 1. ChatGPT…...
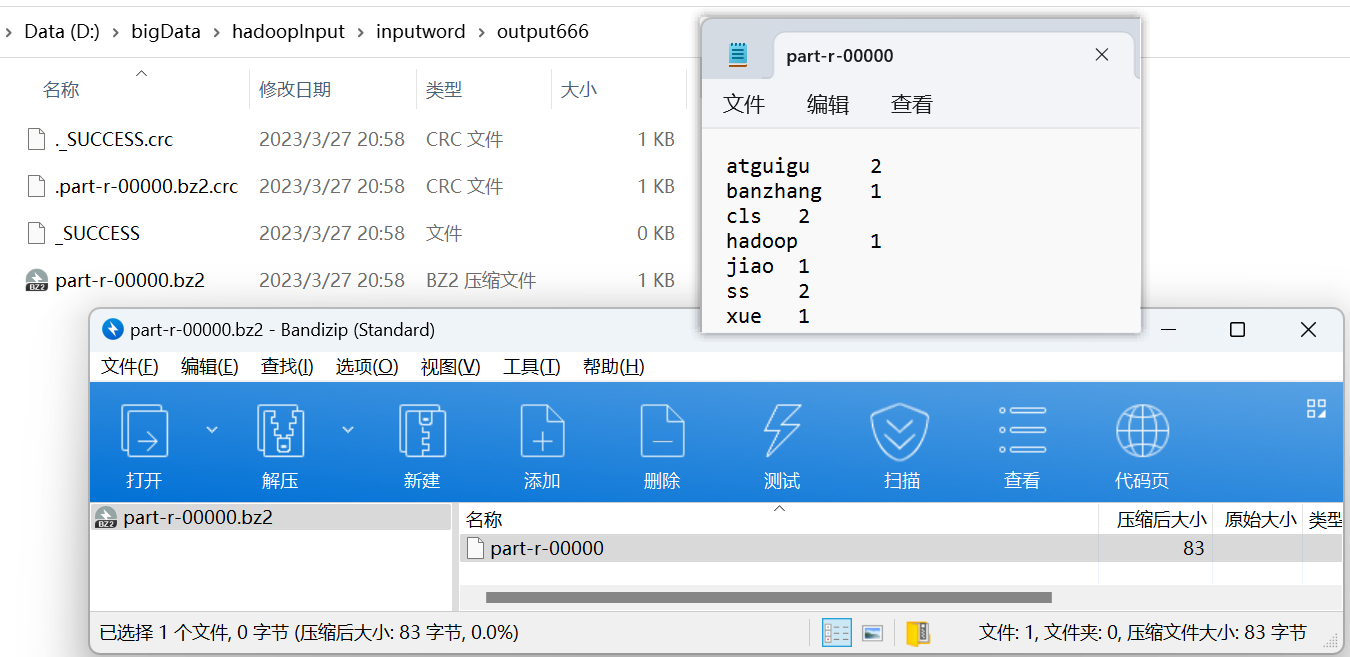
尚硅谷大数据技术Hadoop教程-笔记04【Hadoop-MapReduce】
视频地址:尚硅谷大数据Hadoop教程(Hadoop 3.x安装搭建到集群调优) 尚硅谷大数据技术Hadoop教程-笔记01【大数据概论】尚硅谷大数据技术Hadoop教程-笔记02【Hadoop-入门】尚硅谷大数据技术Hadoop教程-笔记03【Hadoop-HDFS】尚硅谷大数据技术Ha…...
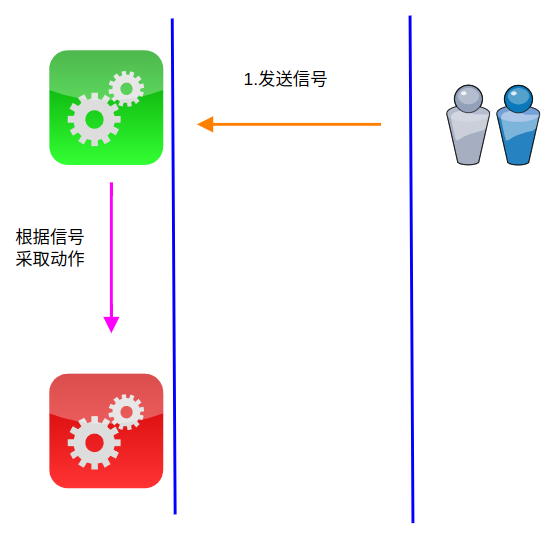
Linux信号sigaction / signal
Linux信号sigaction / signal 文章目录Linux信号sigaction / signal目的函数原型struct sigaction信号枚举值ISO C99 signals.Historical signals specified by POSIX.New(er) POSIX signals (1003.1-2008, 1003.1-2013).Nonstandard signals found in all modern POSIX system…...

坦克大战第一阶段代码
package tanke.game;import javax.swing.*; import java.awt.*; import java.awt.event.KeyEvent; import java.awt.event.KeyListener; import java.util.Vector;//为了监听键盘事件,实现keylistener public class mypanel extends JPanel implements KeyListener …...
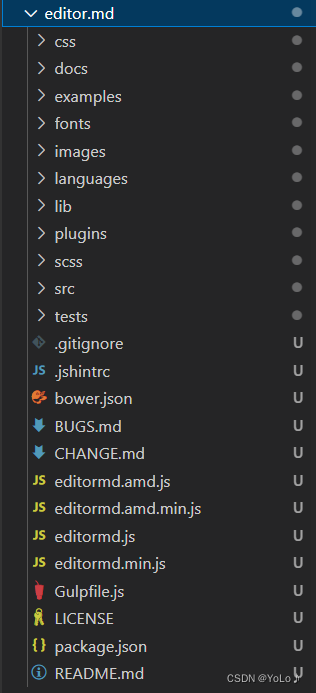
博客系统前端实现
目录 1.预期效果 2.实现博客列表页 3.实现博客正文页 4.实现博客登录页 5.实现博客编辑页面 1.预期效果 对前端html,css,js有大致的了解后,现在我们实现了一个博客系统的前端页面.一共分为四个页面没分别是:登陆页面,博客列表页,博客正文页,博客编辑页 我们看下四个界面…...
ChatGPT技术原理、研究框架,应用实践及发展趋势(附166份报告)
一、AI框架重要性日益突显,框架技术发展进入繁荣期,国内AI框架技术加速发展: 1、AI框架作为衔接数据和模型的重要桥梁,发展进入繁荣期,国内外框架功能及性能加速迭代; 2、Pytorch、Tensorflow占据AI框…...

【屏幕自适应页面适配问题】CSS的@media,为了适应1440×900的屏幕,使用@media解决问题
文章目录bug修改实例CSS3 media 查询CSS 多媒体查询,适配各种设备尺寸bug修改实例 <template><div id"deptAllDown" style"height: 400px;width:880px"/> </template>为了适应1440900的屏幕,使用media解决问题 …...
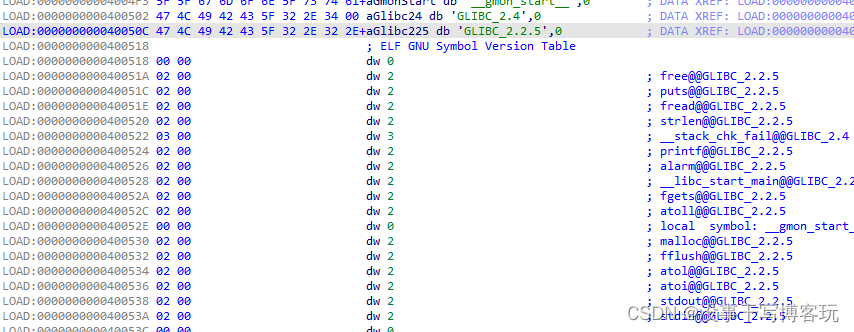
一篇文章理解堆栈溢出
一篇文章理解堆栈溢出引言栈溢出ret2text答案ret2shellcode答案ret2syscall答案栈迁移答案堆溢出 unlink - UAF堆结构小提示向前合并/向后合并堆溢出题答案引言 让新手快速理解堆栈溢出,尽可能写的简单一些。 栈溢出 代码执行到进入函数之前都会记录返回地址到SP…...

优化模型验证关键代码27:多旅行商问题的变体-多起点单目的地问题和多汉密尔顿路径问题
目录 1 多起点单目的地问题(Multiple departures single destination mTSP) 1.1 符号列表 1.2 数学模型 1.4 解的可视化结果...

ARM架构ID_ISAR4寄存器详解与应用
1. ARM架构中的ID_ISAR4寄存器概述在ARMv8架构体系中,系统寄存器扮演着处理器功能特性的关键角色。作为指令集属性寄存器家族的重要成员,ID_ISAR4(Instruction Set Attribute Register 4)专门用于描述处理器在AArch32执行状态下支…...

FakeLocation:安卓应用级位置模拟终极解决方案
FakeLocation:安卓应用级位置模拟终极解决方案 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 在数字时代,位置隐私已成为每个Android用户必须面对的重要问…...

水凝膜、钢化膜、护景贴大对决:一张表看懂该买谁
水凝膜、钢化膜、护景贴大对决:一张表看懂该买谁手机屏幕保护膜主要有三种:水凝膜、普通钢化膜和护景贴(悟赫德为代表)。很多人不知道它们到底有什么区别,我们从六个维度给你讲清楚。材料结构。水凝膜是单层软塑料&…...

CloudBase-MCP:基于MCP协议桥接本地应用与云服务的实践指南
1. 项目概述:一个连接云与本地应用的“智能接线员”如果你正在开发一个应用,需要让它在本地服务器上运行,同时又想无缝地调用云上的各种能力——比如对象存储、数据库、AI模型或者消息队列,你会怎么做?传统的方式可能是…...

AI技能实战:本地部署大模型构建智能摘要工具
1. 项目概述:一个面向AI技能实践的开发者工具箱最近在GitHub上看到一个挺有意思的项目,叫inblog-inc/inblog-ai-skills。光看这个名字,你可能会觉得它又是一个关于“AI技能”的教程合集或者理论文档。但点进去之后,我发现它的定位…...

AI计算工作量化模型:跨硬件效能评估与能效优化
1. AI工作量化模型的核心价值与应用场景在当今AI技术快速渗透到各行各业的背景下,如何准确衡量AI系统的计算效率和工作量成为一个关键问题。传统上,我们使用FLOPs(每秒浮点运算次数)等指标来评估计算性能,但这些指标存…...

Arm DSTREAM调试接口设计与JTAG/SWD协议详解
1. Arm DSTREAM系统与调试接口设计指南1.1 调试接口技术基础1.1.1 JTAG协议架构解析JTAG(Joint Test Action Group)标准IEEE 1149.1定义了五线制调试接口:TCK:测试时钟,同步所有JTAG操作TMS:测试模式选择&a…...

基于大语言模型的智能终端助手:LetMeDoIt的设计、部署与实战
1. 项目概述:一个能听懂人话的AI终端伴侣如果你和我一样,每天有大量时间泡在终端里,那么“如何让命令行更智能、更高效”一定是个永恒的课题。传统的CLI工具链虽然强大,但学习曲线陡峭,命令参数繁多,上下文…...

植物大战僵尸杂交版手机版最新版v3.16.1安卓2026最新下载分享
作为长期沉迷植物大战僵尸改版的老玩家,我近期完整体验了杂交版全新V3.16版本,从植物、关卡到平台适配,逐一实测验证。 整体来说,这是一次诚意满满的更新——既有新鲜玩法创新,又兼顾不同玩家需求。 下载链接&#x…...

Chrome for Testing 终极指南:5个实战技巧让自动化测试更稳定高效
Chrome for Testing 终极指南:5个实战技巧让自动化测试更稳定高效 【免费下载链接】chrome-for-testing 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-for-testing Chrome for Testing 是 Google Chrome Labs 团队专门为浏览器自动化测试设计的 Chr…...