尚硅谷大数据技术Hadoop教程-笔记04【Hadoop-MapReduce】
视频地址:尚硅谷大数据Hadoop教程(Hadoop 3.x安装搭建到集群调优)
- 尚硅谷大数据技术Hadoop教程-笔记01【大数据概论】
- 尚硅谷大数据技术Hadoop教程-笔记02【Hadoop-入门】
- 尚硅谷大数据技术Hadoop教程-笔记03【Hadoop-HDFS】
- 尚硅谷大数据技术Hadoop教程-笔记04【Hadoop-MapReduce】
- 尚硅谷大数据技术Hadoop教程-笔记05【Hadoop-Yarn】
- 尚硅谷大数据技术Hadoop教程-笔记06【Hadoop-生产调优手册】
- 尚硅谷大数据技术Hadoop教程-笔记07【Hadoop-源码解析】
目录
04_尚硅谷大数据技术之Hadoop(MapReduce)V3.3
P067【067_尚硅谷_Hadoop_MapReduce_课程介绍】04:23
P068【068_尚硅谷_Hadoop_MapReduce_概述&优点缺点】10:00
P069【069_尚硅谷_Hadoop_MapReduce_核心思想】09:42
P070【070_尚硅谷_Hadoop_MapReduce_官方WC源码&序列化类型】07:08
P071【071_尚硅谷_Hadoop_MapReduce_编程规范】07:09
P072【072_尚硅谷_Hadoop_MapReduce_WordCount案例需求分析】06:56
P073【073_尚硅谷_Hadoop_MapReduce_WordCount案例环境准备】04:11
P074【074_尚硅谷_Hadoop_MapReduce_WordCount案例Mapper】14:14
P075【075_尚硅谷_Hadoop_MapReduce_WordCount案例Reducer】08:46
P076【076_尚硅谷_Hadoop_MapReduce_WordCount案例Driver】10:59
P077【077_尚硅谷_Hadoop_MapReduce_WordCount案例Debug调试】15:22
P078【078_尚硅谷_Hadoop_MapReduce_WordCount案例集群运行】12:42
P079【079_尚硅谷_Hadoop_MapReduce_序列化概述】06:30
P080【080_尚硅谷_Hadoop_MapReduce_自定义序列化步骤】08:19
P081【081_尚硅谷_Hadoop_MapReduce_序列化案例需求分析】09:09
P082【082_尚硅谷_Hadoop_MapReduce_序列化案例FlowBean】06:52
P083【083_尚硅谷_Hadoop_MapReduce_序列化案例FlowMapper】09:00
P084【084_尚硅谷_Hadoop_MapReduce_序列化案例FlowReducer】04:50
P085【085_尚硅谷_Hadoop_MapReduce_序列化案例FlowDriver】06:21
P086【086_尚硅谷_Hadoop_MapReduce_序列化案例debug调试】07:54
P087【087_尚硅谷_Hadoop_MapReduce_切片机制与MapTask并行度决定机制】15:19
P088【088_尚硅谷_Hadoop_MapReduce_Job提交流程】20:35
P089【089_尚硅谷_Hadoop_MapReduce_切片源码】19:17
P090【090_尚硅谷_Hadoop_MapReduce_切片源码总结】05:00
P091【091_尚硅谷_Hadoop_MapReduce_FileInputFormat切片机制】03:14
P092【092_尚硅谷_Hadoop_MapReduce_TextInputFormat】04:39
P093【093_尚硅谷_Hadoop_MapReduce_CombineTextInputFormat】10:18
P094【094_尚硅谷_Hadoop_MapReduce_MapReduce工作流程】16:43
P095【095_尚硅谷_Hadoop_MapReduce_Shuffle机制】06:22
P096【096_尚硅谷_Hadoop_MapReduce_默认HashPartitioner分区】12:50
P097【097_尚硅谷_Hadoop_MapReduce_自定义分区案例】07:20
P098【098_尚硅谷_Hadoop_MapReduce_分区数与Reduce个数的总结】07:21
P099【099_尚硅谷_Hadoop_MapReduce_排序概述】14:14
P100【100_尚硅谷_Hadoop_MapReduce_全排序案例】15:26
P101【101_尚硅谷_Hadoop_MapReduce_二次排序案例】03:07
P102【102_尚硅谷_Hadoop_MapReduce_区内排序案例】06:53
P103【103_尚硅谷_Hadoop_MapReduce_Combiner概述】07:18
P104【104_尚硅谷_Hadoop_MapReduce_Combiner案例】12:33
P105【105_尚硅谷_Hadoop_MapReduce_outputformat概述】03:42
P106【106_尚硅谷_Hadoop_MapReduce_自定义outputformat案例需求分析】04:22
P107【107_尚硅谷_Hadoop_MapReduce_自定义outputformat案例mapper&reducer】04:33
P108【108_尚硅谷_Hadoop_MapReduce_自定义outputformat案例执行】12:33
P109【109_尚硅谷_Hadoop_MapReduce_MapTask工作机制】03:46
P110【110_尚硅谷_Hadoop_MapReduce_ReduceTask工作机制&并行度】09:00
P111【111_尚硅谷_Hadoop_MapReduce_MapTask源码】16:57
P112【112_尚硅谷_Hadoop_MapReduce_ReduceTask源码】15:25
P113【113_尚硅谷_Hadoop_MapReduce_ReduceJoin案例需求分析】09:22
P114【114_尚硅谷_Hadoop_MapReduce_ReduceJoin案例TableBean】07:09
P115【115_尚硅谷_Hadoop_MapReduce_ReduceJoin案例Mapper】12:34
P116【116_尚硅谷_Hadoop_MapReduce_ReduceJoin案例完成】12:27
P117【117_尚硅谷_Hadoop_MapReduce_ReduceJoin案例debug】04:15
P118【118_尚硅谷_Hadoop_MapReduce_MapJoin案例需求分析】06:57
P119【119_尚硅谷_Hadoop_MapReduce_MapJoin案例完成】13:11
P120【120_尚硅谷_Hadoop_MapReduce_MapJoin案例debug】02:49
P121【121_尚硅谷_Hadoop_MapReduce_ETL数据清洗案例】15:11
P122【122_尚硅谷_Hadoop_MapReduce_MapReduce开发总结】10:51
P123【123_尚硅谷_Hadoop_MapReduce_压缩概述】16:05
P124【124_尚硅谷_Hadoop_MapReduce_压缩案例实操】10:22
04_尚硅谷大数据技术之Hadoop(MapReduce)V3.3
P067【067_尚硅谷_Hadoop_MapReduce_课程介绍】04:23

P068【068_尚硅谷_Hadoop_MapReduce_概述&优点缺点】10:00
MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
MapReduce优缺点
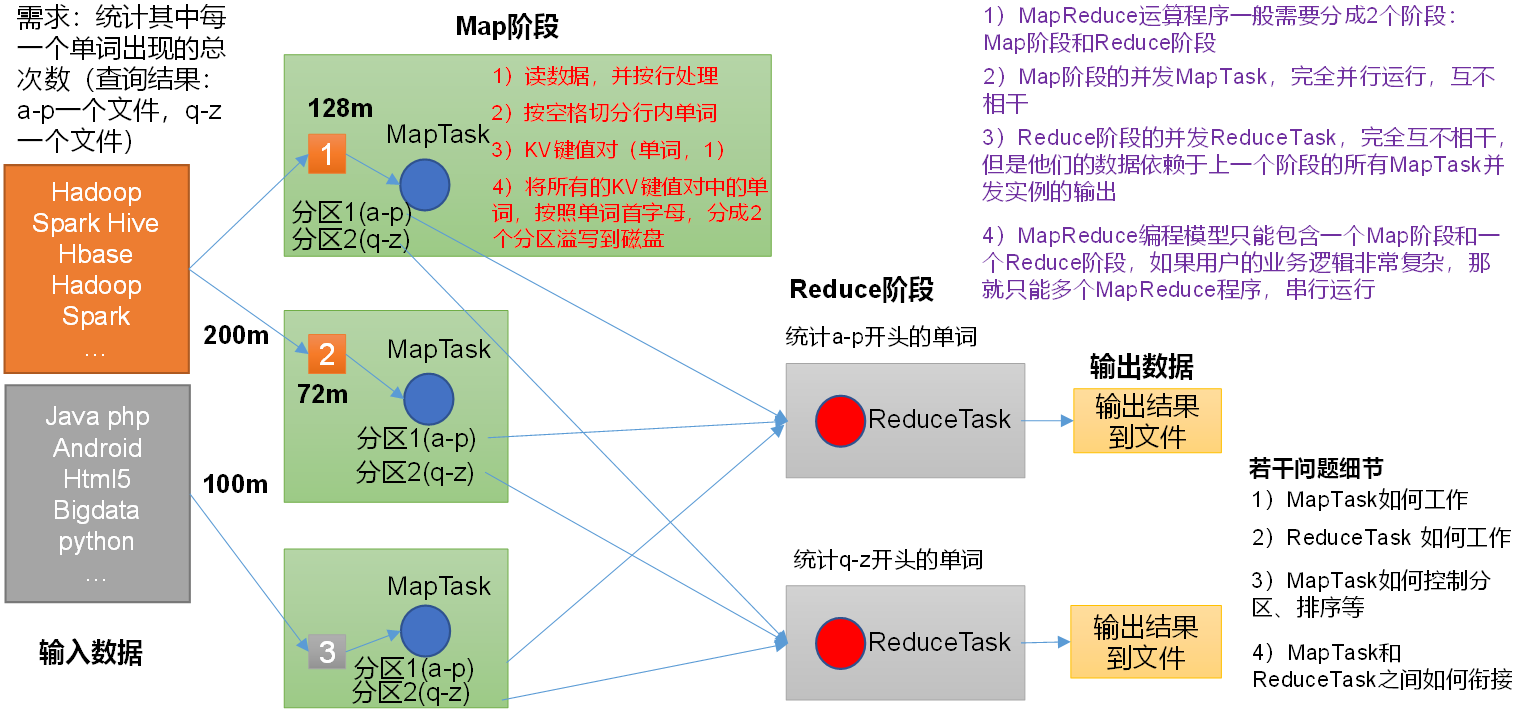
P069【069_尚硅谷_Hadoop_MapReduce_核心思想】09:42
P070【070_尚硅谷_Hadoop_MapReduce_官方WC源码&序列化类型】07:08
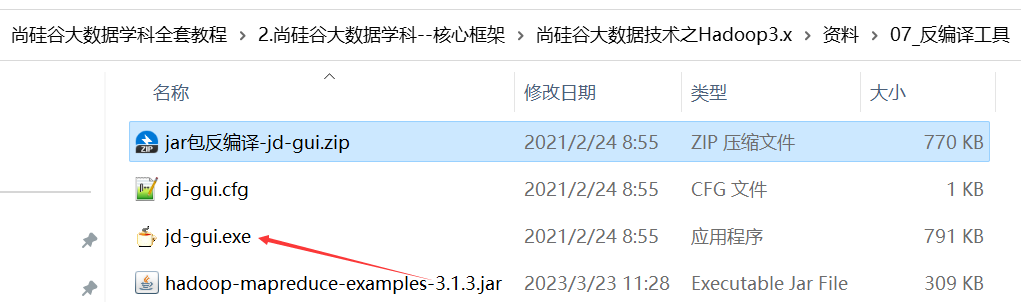
package org.apache.hadoop.examples;import java.io.IOException;
import java.io.PrintStream;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class WordCount
{public static void main(String[] args)throws Exception{Configuration conf = new Configuration();String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < otherArgs.length - 1; i++) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job, new Path(otherArgs[(otherArgs.length - 1)]));System.exit(job.waitForCompletion(true) ? 0 : 1);}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)throws IOException, InterruptedException{int sum = 0;for (IntWritable val : values) {sum += val.get();}this.result.set(sum);context.write(key, this.result);}}public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{private static final IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException{StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {this.word.set(itr.nextToken());context.write(this.word, one);}}}
}P071【071_尚硅谷_Hadoop_MapReduce_编程规范】07:09
MapReduce编程规范,用户编写的程序分成三个部分:Mapper、Reducer和Driver。
1.Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper中的业务逻辑写在map()方法中
(4)Mapper的输出数据是KV对的形式(KV的类型可自定义)
(5)map()方法(MapTask进程)对每一个调用一次
2.Reducer阶段
(1)用户自定义的Reducer要继承自己的父类
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3)Reducer的业务逻辑写在reduce()方法中
(4)ReduceTask进程对每一组相同k的组调用一次reduce()方法
3.Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象。
P072【072_尚硅谷_Hadoop_MapReduce_WordCount案例需求分析】06:56

P073【073_尚硅谷_Hadoop_MapReduce_WordCount案例环境准备】04:11
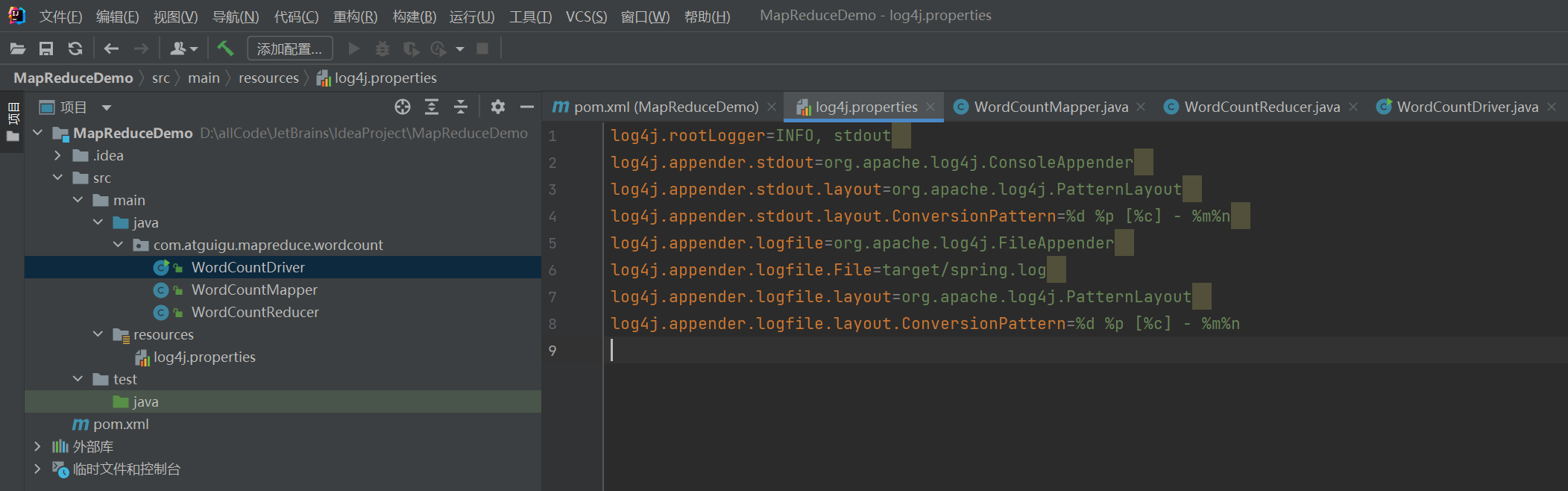
P074【074_尚硅谷_Hadoop_MapReduce_WordCount案例Mapper】14:14
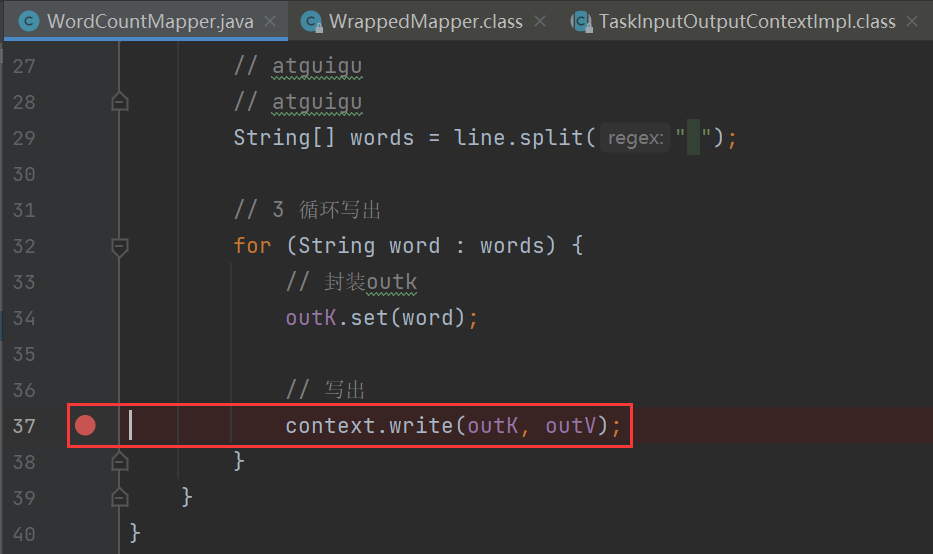
package com.atguigu.mapreduce.wordcount;import java.io.IOException;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;/*** KEYIN,map阶段输入的key的类型:LongWritable* VALUEIN,map阶段输入value类型:Text* KEYOUT,map阶段输出的Key类型:Text* VALUEOUT,map阶段输出的value类型:IntWritable*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private Text outK = new Text();private IntWritable outV = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1.获取一行//atguigu atguiguString line = value.toString();//2.切割//atguigu//atguiguString[] words = line.split(" ");//3.循环写出(输出)for (String word : words) {//封装outkoutK.set(word);//写出context.write(outK, outV);}}
}P075【075_尚硅谷_Hadoop_MapReduce_WordCount案例Reducer】08:46
package com.atguigu.mapreduce.wordcount;import java.io.IOException;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;/*** KEYIN, reduce阶段输入的key的类型:Text* VALUEIN, reduce阶段输入value类型:IntWritable* KEYOUT, reduce阶段输出的Key类型:Text* VALUEOUT, reduce阶段输出的value类型:IntWritable*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable outV = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;//atguigu, (1,1)//累加for (IntWritable value : values) {sum += value.get();}outV.set(sum);//写出context.write(key, outV);}
}P076【076_尚硅谷_Hadoop_MapReduce_WordCount案例Driver】10:59
package com.atguigu.mapreduce.wordcount;import java.io.IOException;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
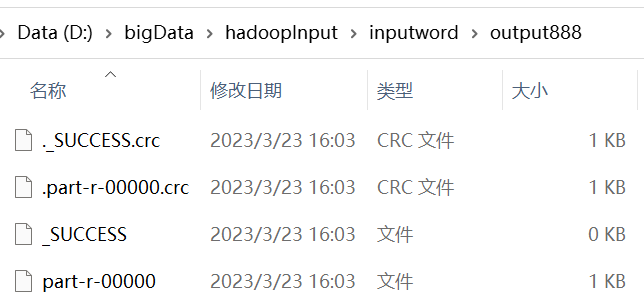
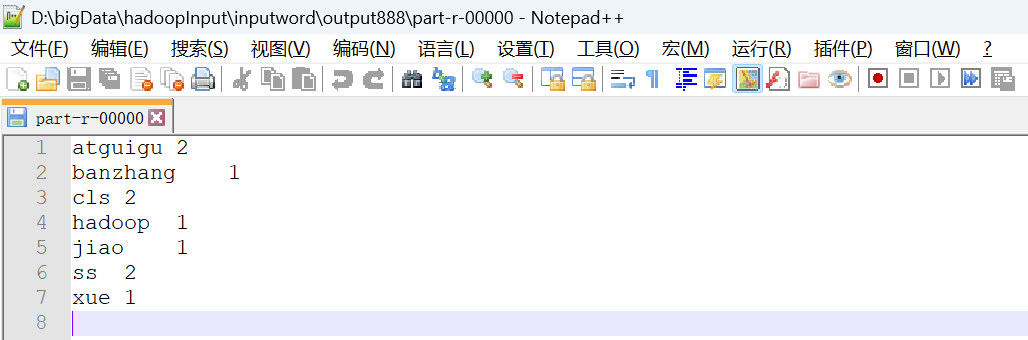
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//1.获取job,获取配置信息以及获取job对象Configuration conf = new Configuration();Job job = Job.getInstance(conf);//2.设置jar包路径,关联本Driver程序的jarjob.setJarByClass(WordCountDriver.class);//3.关联Mapper和Reducer的jarjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);//4.设置Mapper输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//5.设置最终输出的kV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//6.设置输入路径和输出路径FileInputFormat.setInputPaths(job, new Path("D:\\bigData\\hadoopInput\\inputword"));FileOutputFormat.setOutputPath(job, new Path("D:\\bigData\\hadoopInput\\inputword\\output888"));//7.提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}P077【077_尚硅谷_Hadoop_MapReduce_WordCount案例Debug调试】15:22
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:640)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:1223)
at org.apache.hadoop.fs.FileUtil.list(FileUtil.java:1428)
at org.apache.hadoop.fs.RawLocalFileSystem.listStatus(RawLocalFileSystem.java:468)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1868)
at org.apache.hadoop.fs.FileSystem.listStatus(FileSystem.java:1910)
at org.apache.hadoop.fs.FileSystem$4.<init>(FileSystem.java:2072)
at org.apache.hadoop.fs.FileSystem.listLocatedStatus(FileSystem.java:2071)
at org.apache.hadoop.fs.ChecksumFileSystem.listLocatedStatus(ChecksumFileSystem.java:693)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:312)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:274)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:396)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:310)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:327)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:200)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1570)
at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1567)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1567)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1588)
at com.atguigu.mapreduce.wordcount.WordCountDriver.main(WordCountDriver.java:39)进程已结束,退出代码1
错误Exception in thread “main“ java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO_"exception in thread \"main\" 2: no such file"
不需要启动Linux hadoop集群,是在Windows本地运行的。
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
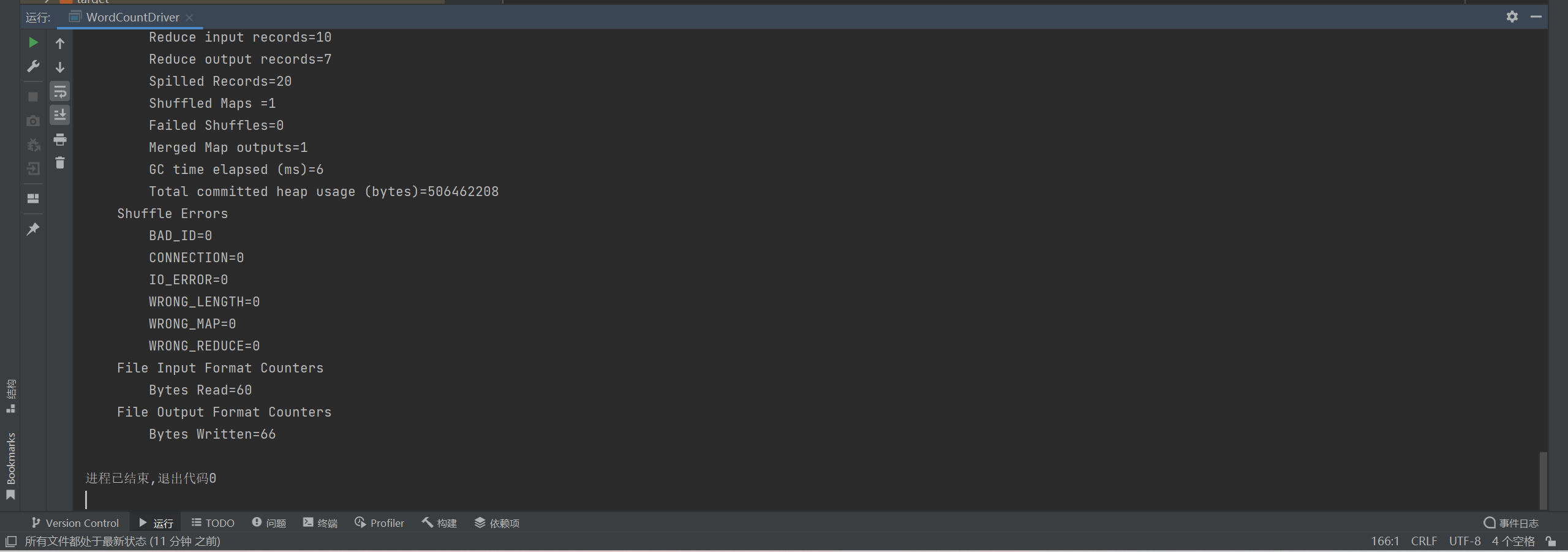
P078【078_尚硅谷_Hadoop_MapReduce_WordCount案例集群运行】12:42
[atguigu@node1 hadoop-3.1.3]$ hadoop jar wc.jar com.atguigu.mapreduce.wordcount2.WordCountDriver /input /output
Exception in thread "main" java.lang.ClassNotFoundException: com.atguigu.mapreduce.wordcount2.WordCountDriver
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:348)
at org.apache.hadoop.util.RunJar.run(RunJar.java:311)
at org.apache.hadoop.util.RunJar.main(RunJar.java:232)
[atguigu@node1 hadoop-3.1.3]$
企业开发,通常环境下是:在Windows环境下搭建hadoop环境编写代码,编写好代码后进行打包,打包好之后上传到hdfs执行命令。
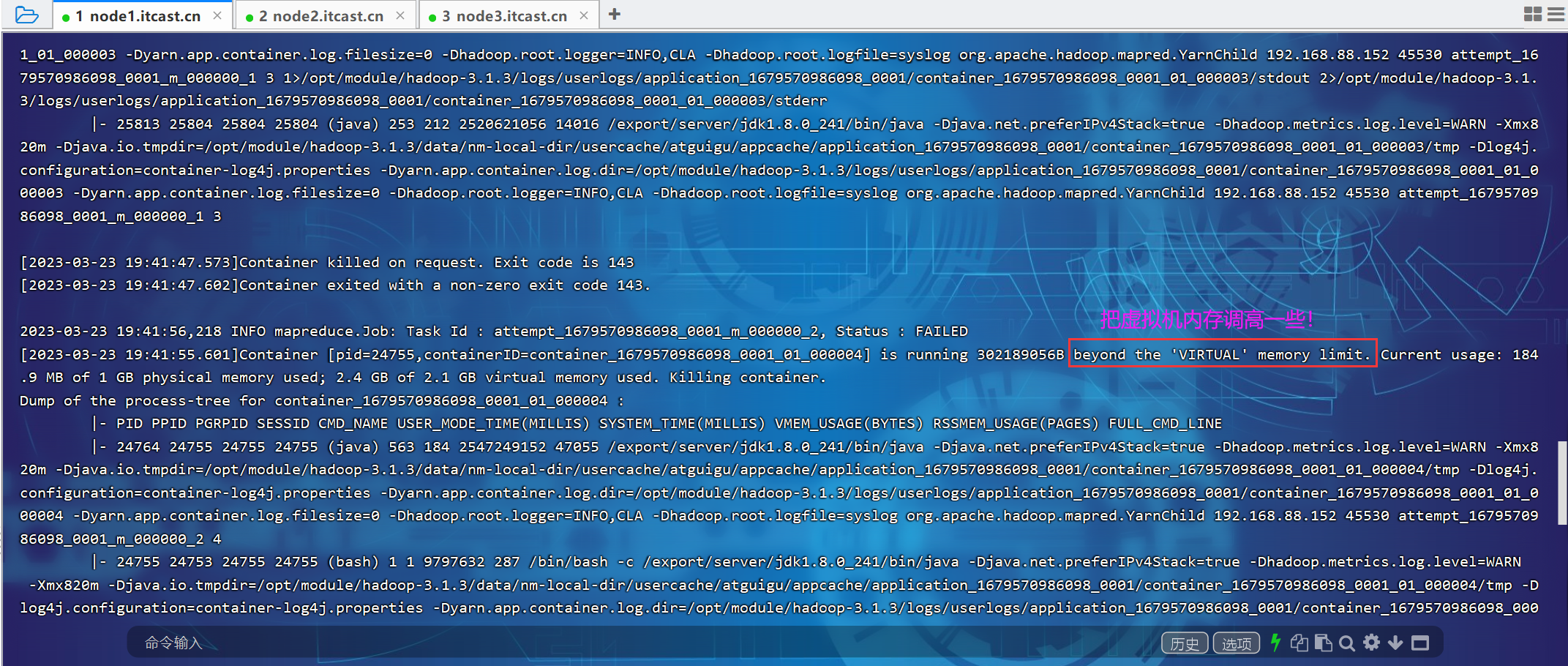
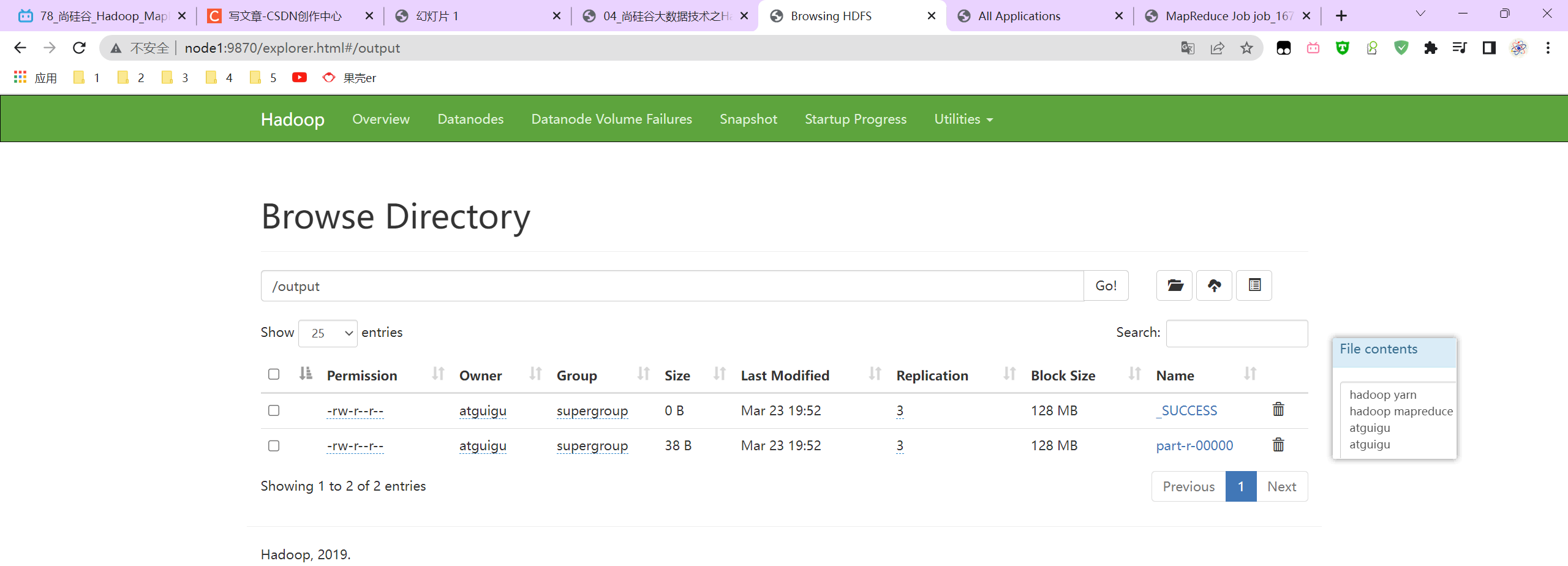
在node1中执行如下命令:
bin/myhadoop.sh start
jpsall
pwd
cd /opt/module/hadoop-3.1.3/
ll
hadoop jar wc.jar com.atguigu.mapreduce.wordcount2.WordCountDriver /input /output # 报错,找不到类,重新打包上传!
hadoop jar wc2.jar com.atguigu.mapreduce.wordcount2.WordCountDriver /input /output
history
P079【079_尚硅谷_Hadoop_MapReduce_序列化概述】06:30
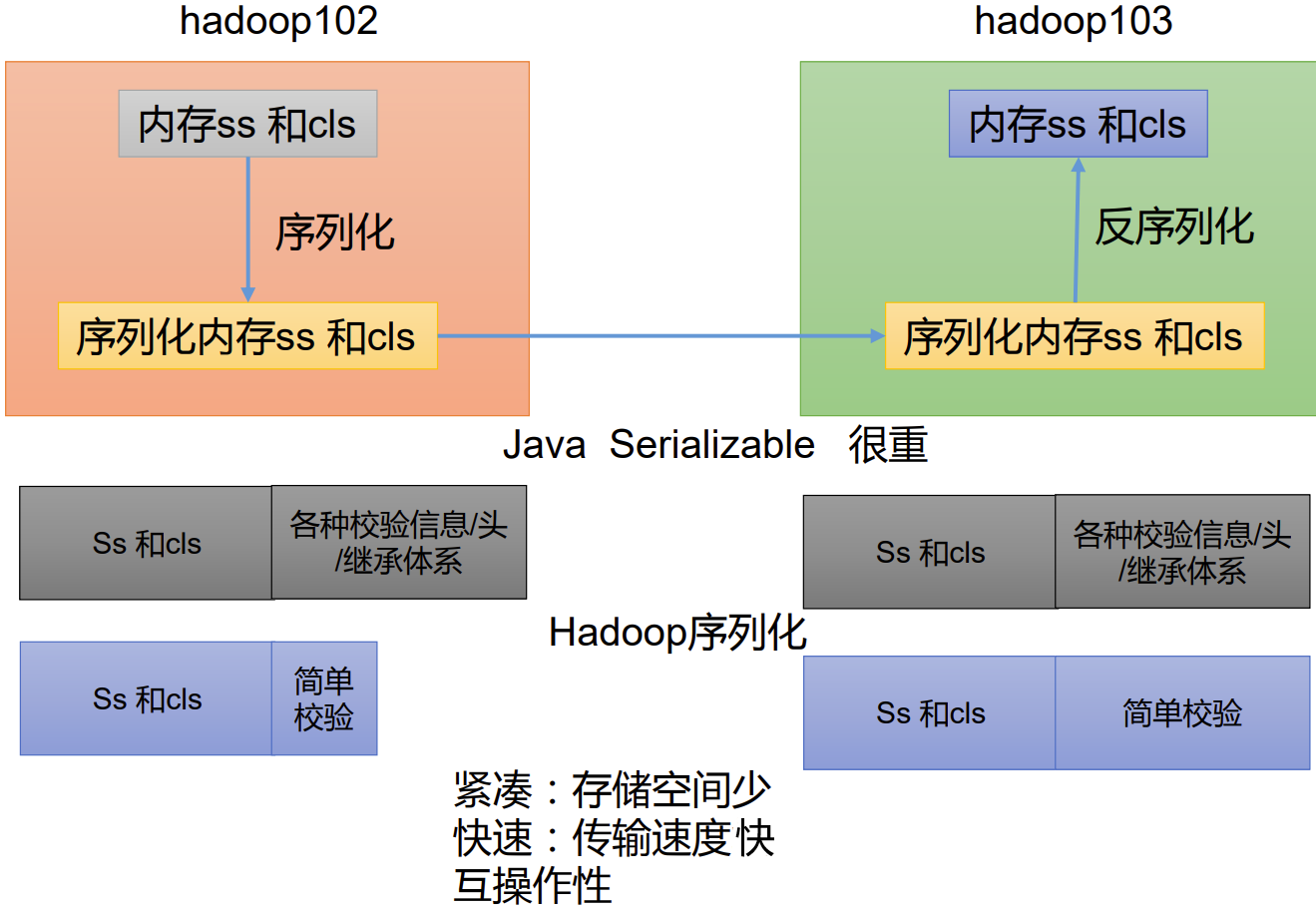
P080【080_尚硅谷_Hadoop_MapReduce_自定义序列化步骤】08:19
自定义bean对象实现序列化接口(Writable)
在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。
具体实现bean对象序列化步骤如下7步。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public FlowBean() {
super();
}
(3)重写序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
(4)重写反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
(6)要想把结果显示在文件中,需要重写toString(),可用"\t"分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。详见后面排序案例。
@Override
public int compareTo(FlowBean o) {
// 倒序排列,从大到小
return this.sumFlow > o.getSumFlow() ? -1 : 1;
}

P081【081_尚硅谷_Hadoop_MapReduce_序列化案例需求分析】09:09

P082【082_尚硅谷_Hadoop_MapReduce_序列化案例FlowBean】06:52
package com.atguigu.mapreduce.writable;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;/*** 1、定义类实现writable接口* 2、重写序列化和反序列化方法* 3、重写空参构造* 4、toString方法*/
public class FlowBean implements Writable {private long upFlow; //上行流量private long downFlow; //下行流量private long sumFlow; //总流量//空参构造public FlowBean() {}public long getUpFlow() {return upFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public long getDownFlow() {return downFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public long getSumFlow() {return sumFlow;}public void setSumFlow(long sumFlow) {this.sumFlow = sumFlow;}public void setSumFlow() {this.sumFlow = this.upFlow + this.downFlow;}@Overridepublic void write(DataOutput out) throws IOException {out.writeLong(upFlow);out.writeLong(downFlow);out.writeLong(sumFlow);}@Overridepublic void readFields(DataInput in) throws IOException {this.upFlow = in.readLong();this.downFlow = in.readLong();this.sumFlow = in.readLong();}@Overridepublic String toString() {return upFlow + "\t" + downFlow + "\t" + sumFlow;}
}P083【083_尚硅谷_Hadoop_MapReduce_序列化案例FlowMapper】09:00
package com.atguigu.mapreduce.writable;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {private Text outK = new Text();private FlowBean outV = new FlowBean();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1、获取一行// 1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200String line = value.toString();//2、切割// 1,13736230513,192.196.100.1,www.atguigu.com,2481,24681,200 7 - 3= 4位// 2 13846544121 192.196.100.2 264 0 200 6 - 3 = 3位String[] split = line.split("\t");//3、抓取想要的数据// 手机号:13736230513// 上行流量和下行流量:2481,24681String phone = split[1];String up = split[split.length - 3];String down = split[split.length - 2];//4、封装outK.set(phone);outV.setUpFlow(Long.parseLong(up));outV.setDownFlow(Long.parseLong(down));outV.setSumFlow();//5、写出context.write(outK, outV);}
}P084【084_尚硅谷_Hadoop_MapReduce_序列化案例FlowReducer】04:50
package com.atguigu.mapreduce.writable;import org.apache.hadoop.io.Text;
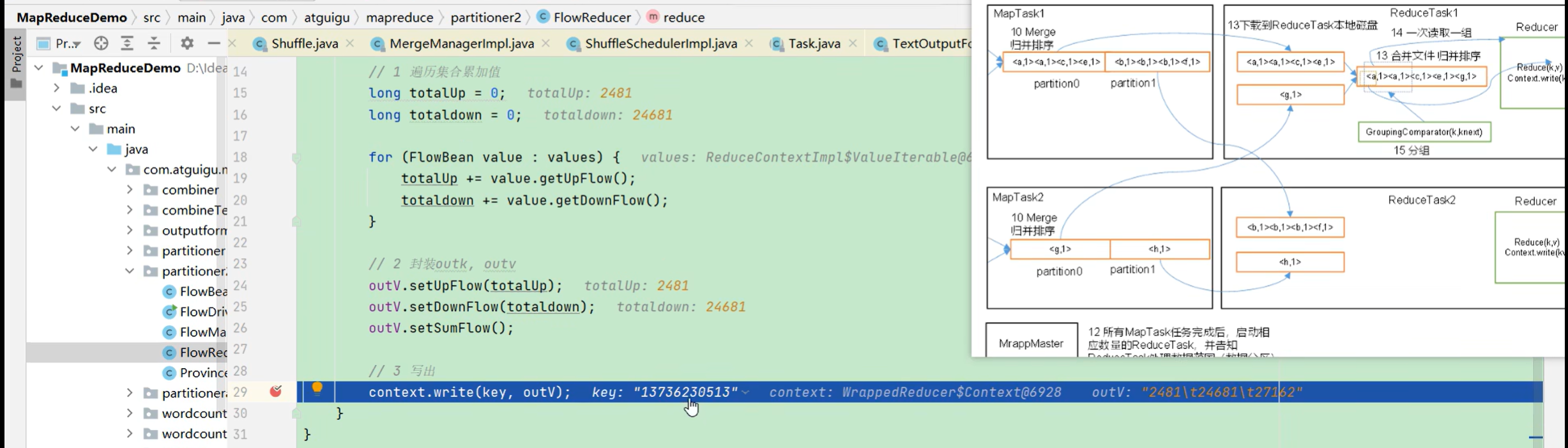
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {private FlowBean outV = new FlowBean();@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {//1、遍历集合累加值long totalUp = 0;long totaldown = 0;for (FlowBean value : values) {totalUp += value.getUpFlow();totaldown += value.getDownFlow();}//2、封装outk和outvoutV.setUpFlow(totalUp);outV.setDownFlow(totaldown);outV.setSumFlow();//3、写出context.write(key, outV);}
}P085【085_尚硅谷_Hadoop_MapReduce_序列化案例FlowDriver】06:21
package com.atguigu.mapreduce.writable;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class FlowDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//1、获取jobConfiguration conf = new Configuration();Job job = Job.getInstance(conf);//2、设置jarjob.setJarByClass(FlowDriver.class);//3、关联mapper和Reducerjob.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);//4、设置mapper输出的key和value类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);//5、设置数据最终输出的key和value类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);//6、设置数据的输入路径和输出路径FileInputFormat.setInputPaths(job, new Path("D:\\bigData\\hadoopInput\\inputflow"));FileOutputFormat.setOutputPath(job, new Path("D:\\bigData\\hadoopInput\\inputflow\\output"));//7、提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}P086【086_尚硅谷_Hadoop_MapReduce_序列化案例debug调试】07:54
P087【087_尚硅谷_Hadoop_MapReduce_切片机制与MapTask并行度决定机制】15:19
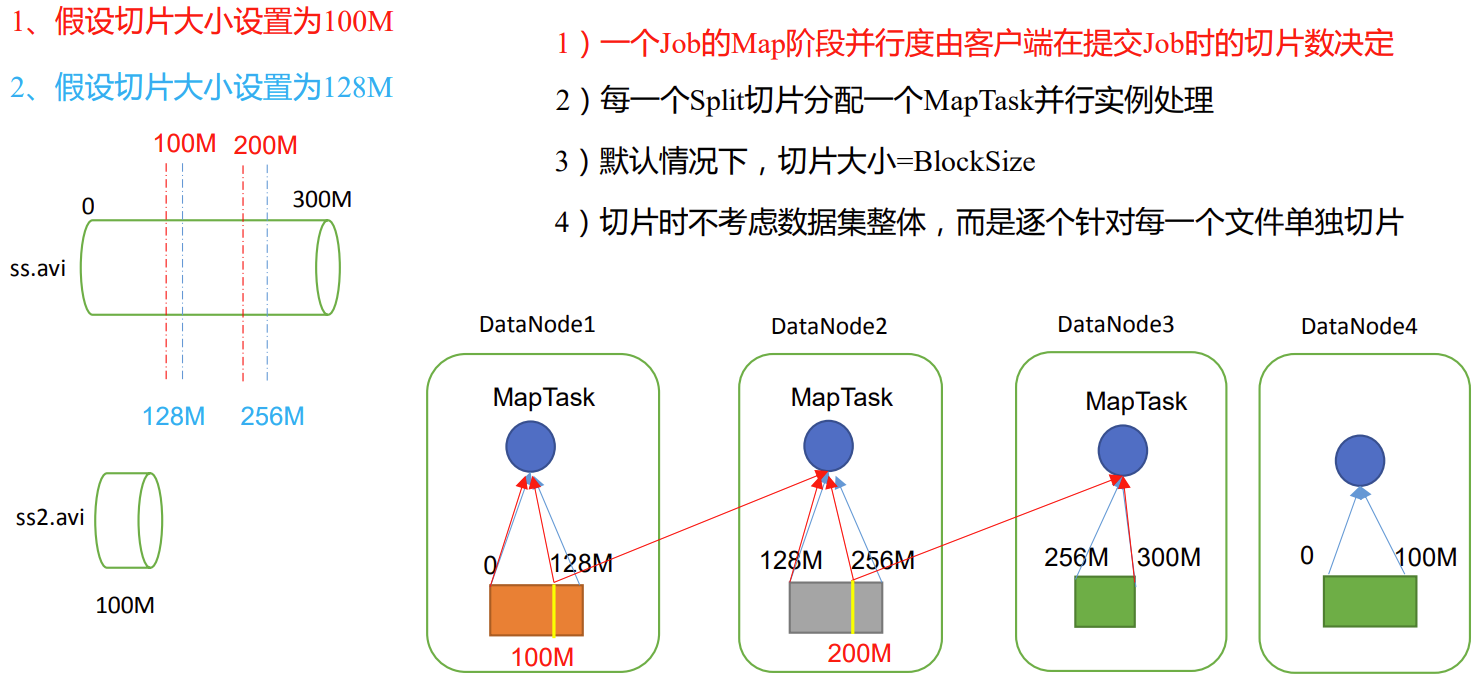
第3章 MapReduce框架原理
数据切片与MapTask并行度决定机制
P088【088_尚硅谷_Hadoop_MapReduce_Job提交流程】20:35
章节3.1.2,省流:18:46
1)Job提交流程源码详解
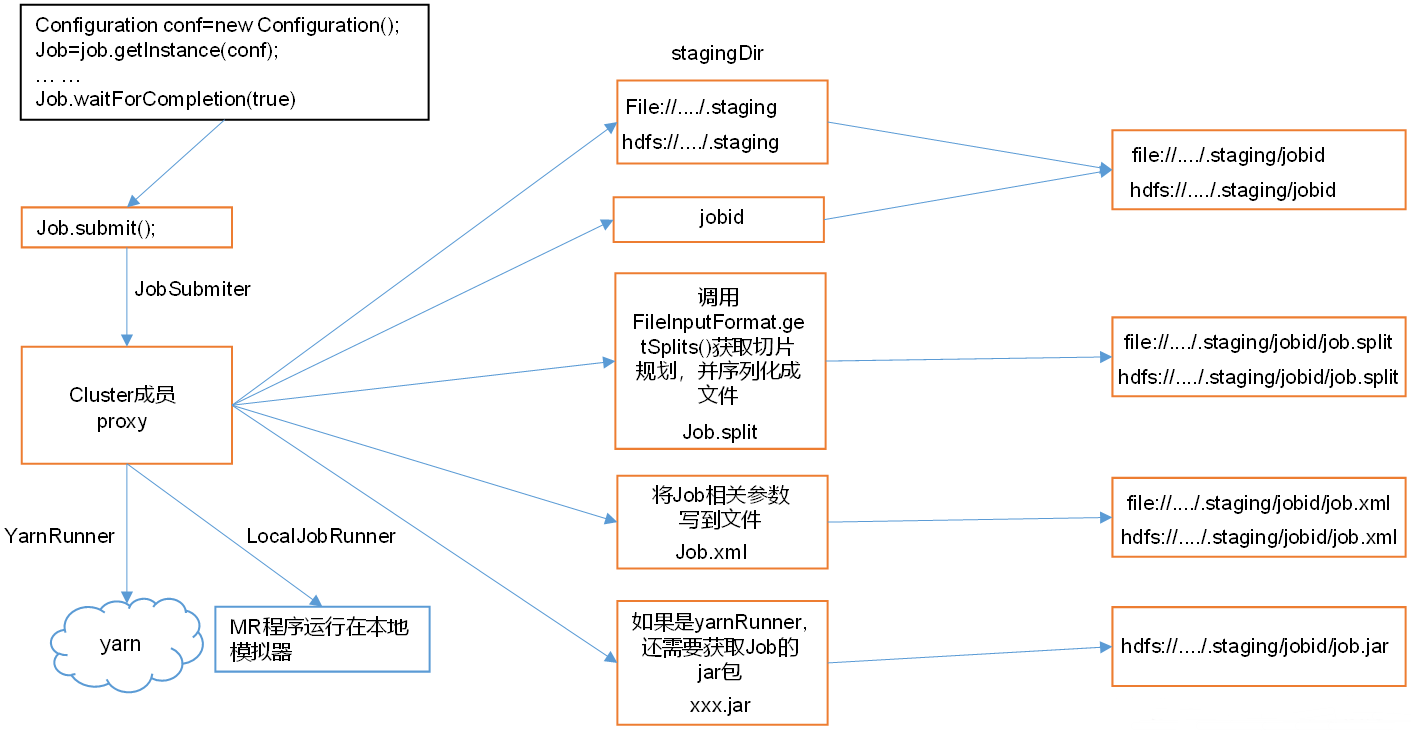
waitForCompletion()submit();// 1建立连接connect(); // 1)创建提交Job的代理new Cluster(getConfiguration());// (1)判断是本地运行环境还是yarn集群运行环境initialize(jobTrackAddr, conf); // 2 提交job
submitter.submitJobInternal(Job.this, cluster)// 1)创建给集群提交数据的Stag路径Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);// 2)获取jobid ,并创建Job路径JobID jobId = submitClient.getNewJobID();// 3)拷贝jar包到集群copyAndConfigureFiles(job, submitJobDir); rUploader.uploadFiles(job, jobSubmitDir);// 4)计算切片,生成切片规划文件writeSplits(job, submitJobDir);maps = writeNewSplits(job, jobSubmitDir);input.getSplits(job);// 5)向Stag路径写XML配置文件writeConf(conf, submitJobFile);conf.writeXml(out);// 6)提交Job,返回提交状态status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());P089【089_尚硅谷_Hadoop_MapReduce_切片源码】19:17
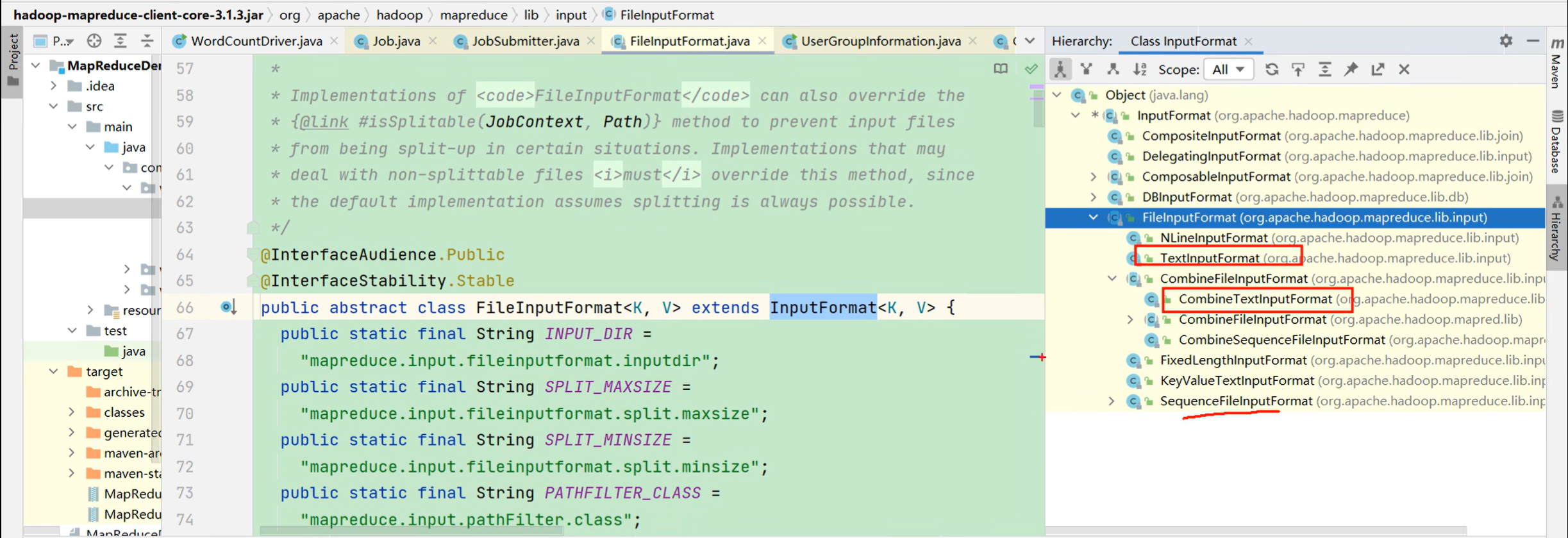
P090【090_尚硅谷_Hadoop_MapReduce_切片源码总结】05:00
2)FileInputFormat切片源码解析(input.getSplits(job))
- (1)程序先找到你数据存储的目录。
- (2)开始遍历处理(规划切片)目录下的每一个文件。
- (3)遍历第一个文件ss.txt
- a)获取文件大小fs.sizeOf(ss.txt)
- b)计算切片大小,computeSplitSize(Math.max(minSize, Math.min(maxSize, blocksize)))=blocksize=128M
- c)默认情况下,切片大小=blocksize
- d)开始切,形成第1个切片:ss.txt—0:128M、第2个切片ss.txt—128:256M、第3个切片ss.txt—256M:300M(每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分一块切片)
- e)将切片信息写到一个切片规划文件中。
- f)整个切片的核心过程在getSplit()方法中完成。
- g)InputSplit只记录了切片的元数据信息,比如起始位置、长度以及所在的节点列表等。
- (4)提交切片规划文件到YARN上,YARN上的MrAppMaster就可以根据切片规划文件计算开启MapTask个数。
P091【091_尚硅谷_Hadoop_MapReduce_FileInputFormat切片机制】03:14
3.1.3 FileInputFormat 切片机制
FileInputFormat切片机制
FileInputFormat切片大小的参数配置
P092【092_尚硅谷_Hadoop_MapReduce_TextInputFormat】04:39
3.1.4 TextInputFormat
P093【093_尚硅谷_Hadoop_MapReduce_CombineTextInputFormat】10:18
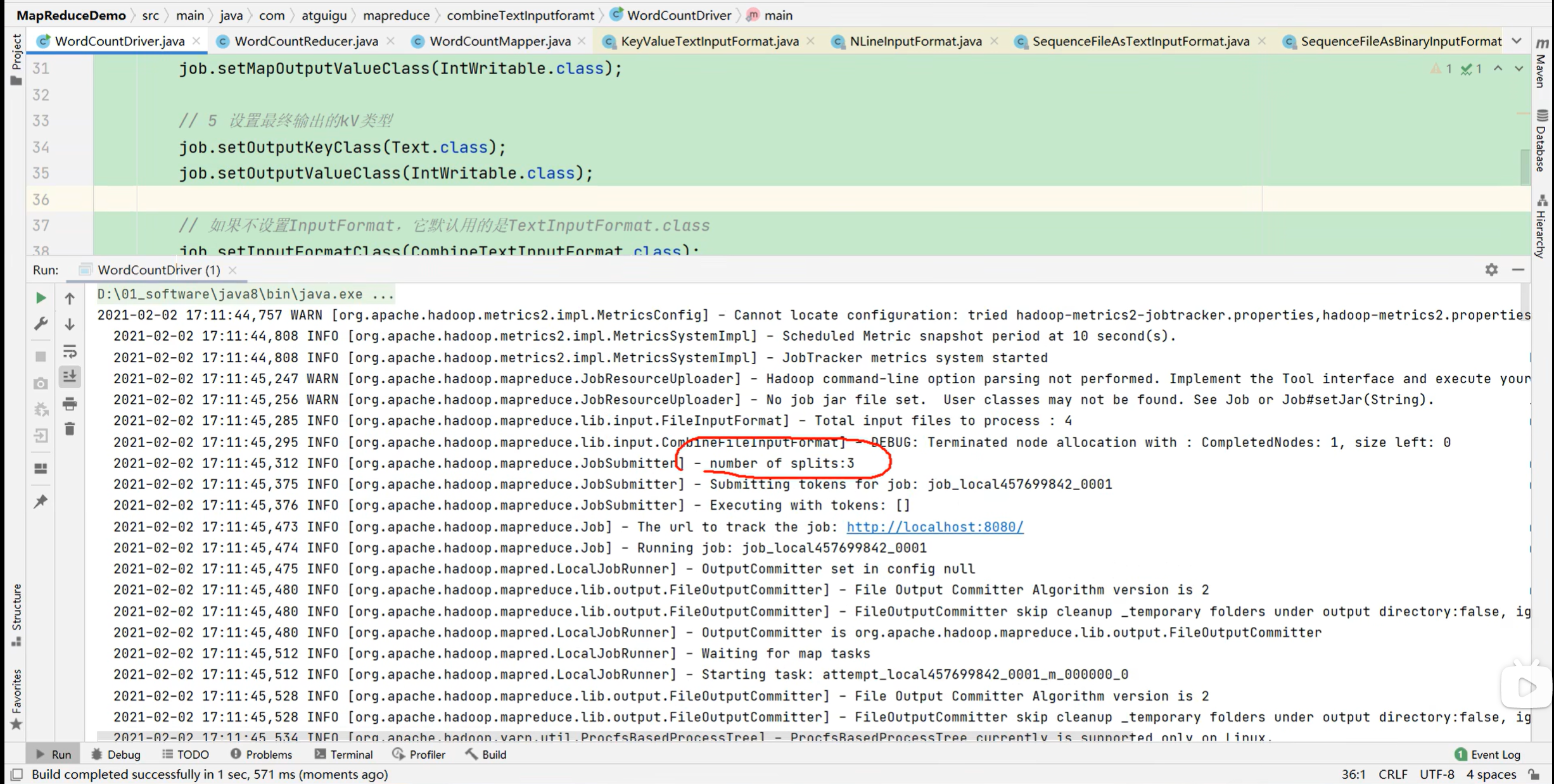
3.1.5 CombineTextInputFormat切片机制

P094【094_尚硅谷_Hadoop_MapReduce_MapReduce工作流程】16:43
3.2章节
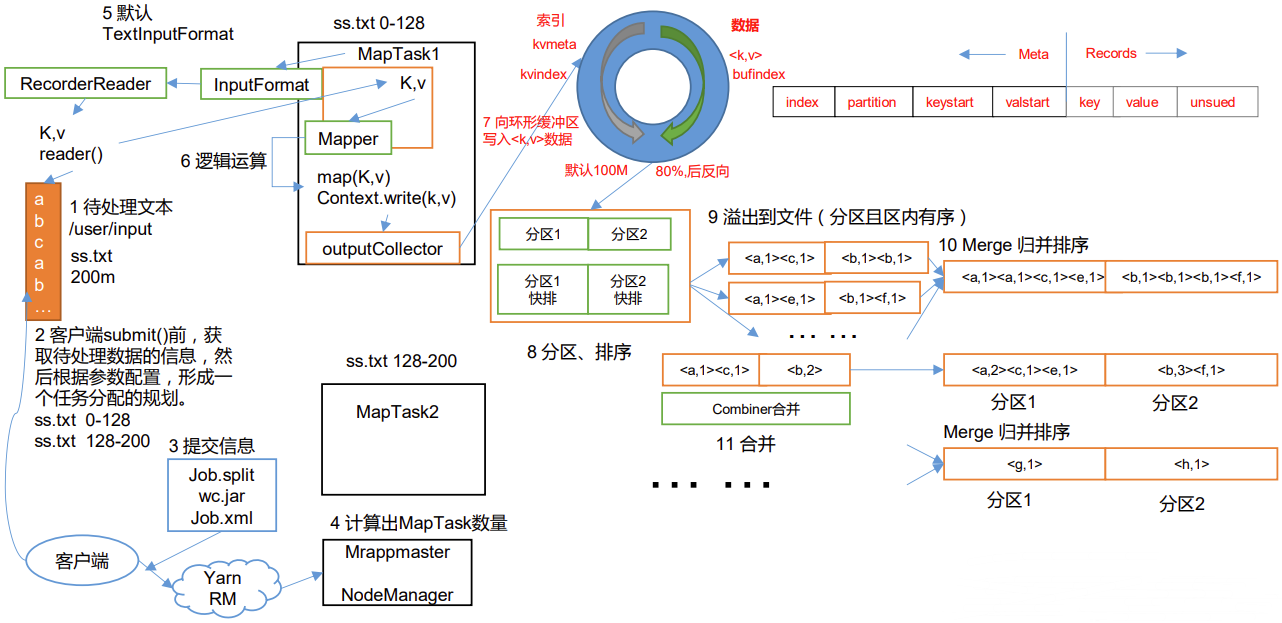
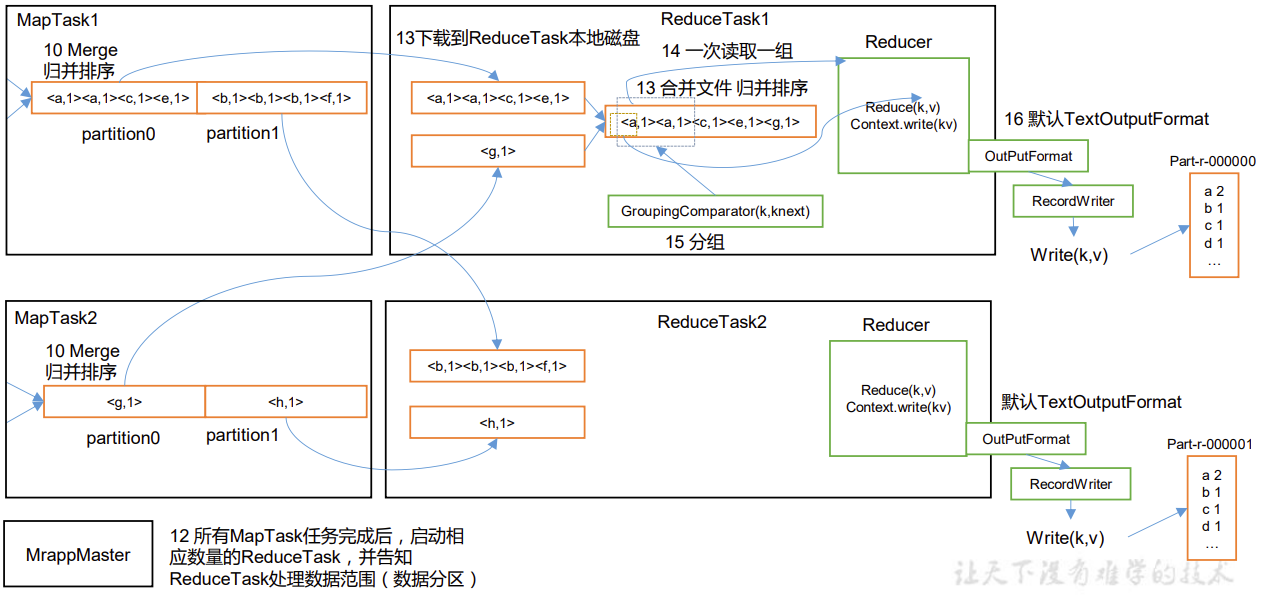
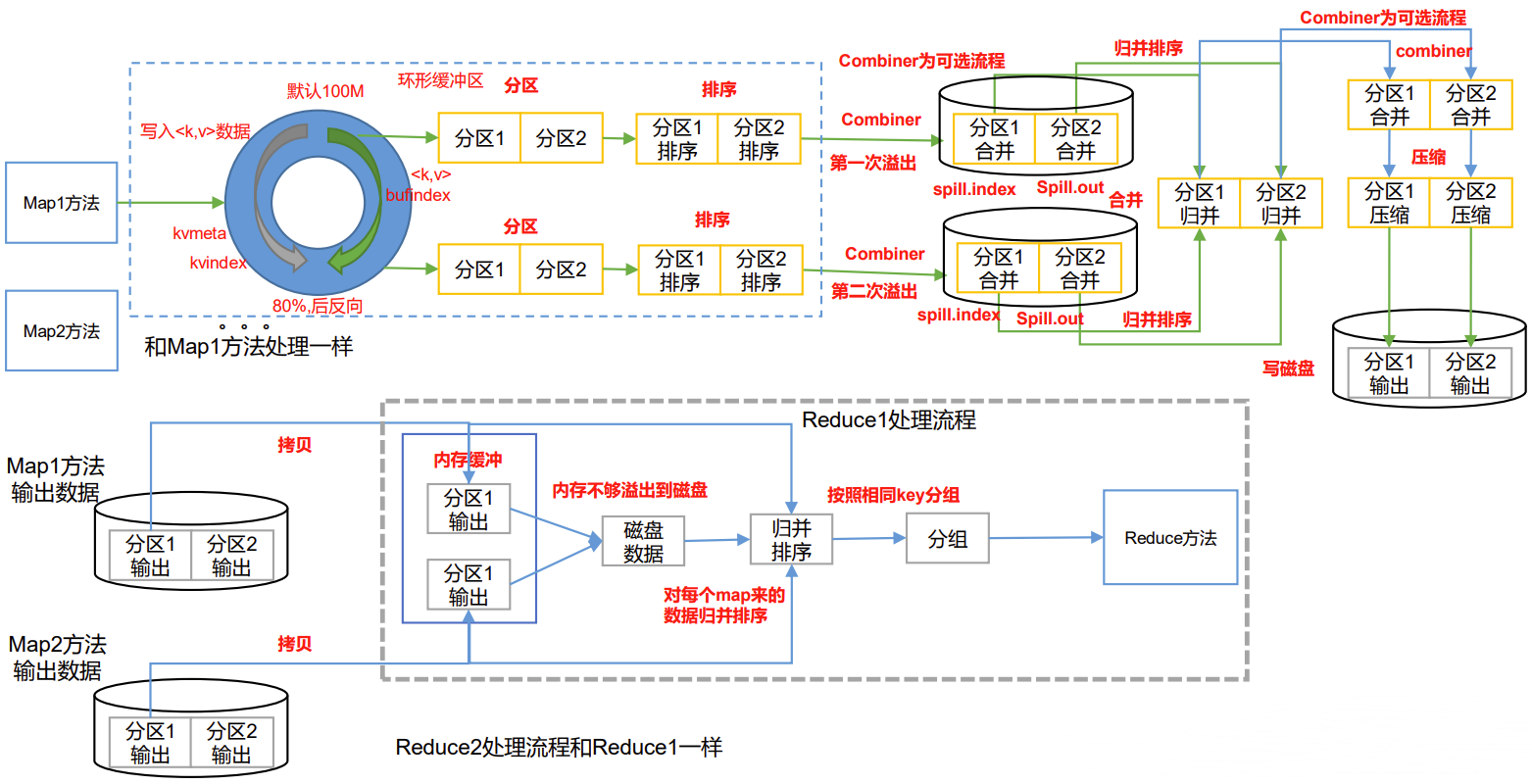
P095【095_尚硅谷_Hadoop_MapReduce_Shuffle机制】06:22
Map方法之后,Reduce方法之前的数据处理过程称之为Shuffle。
Shuffle机制
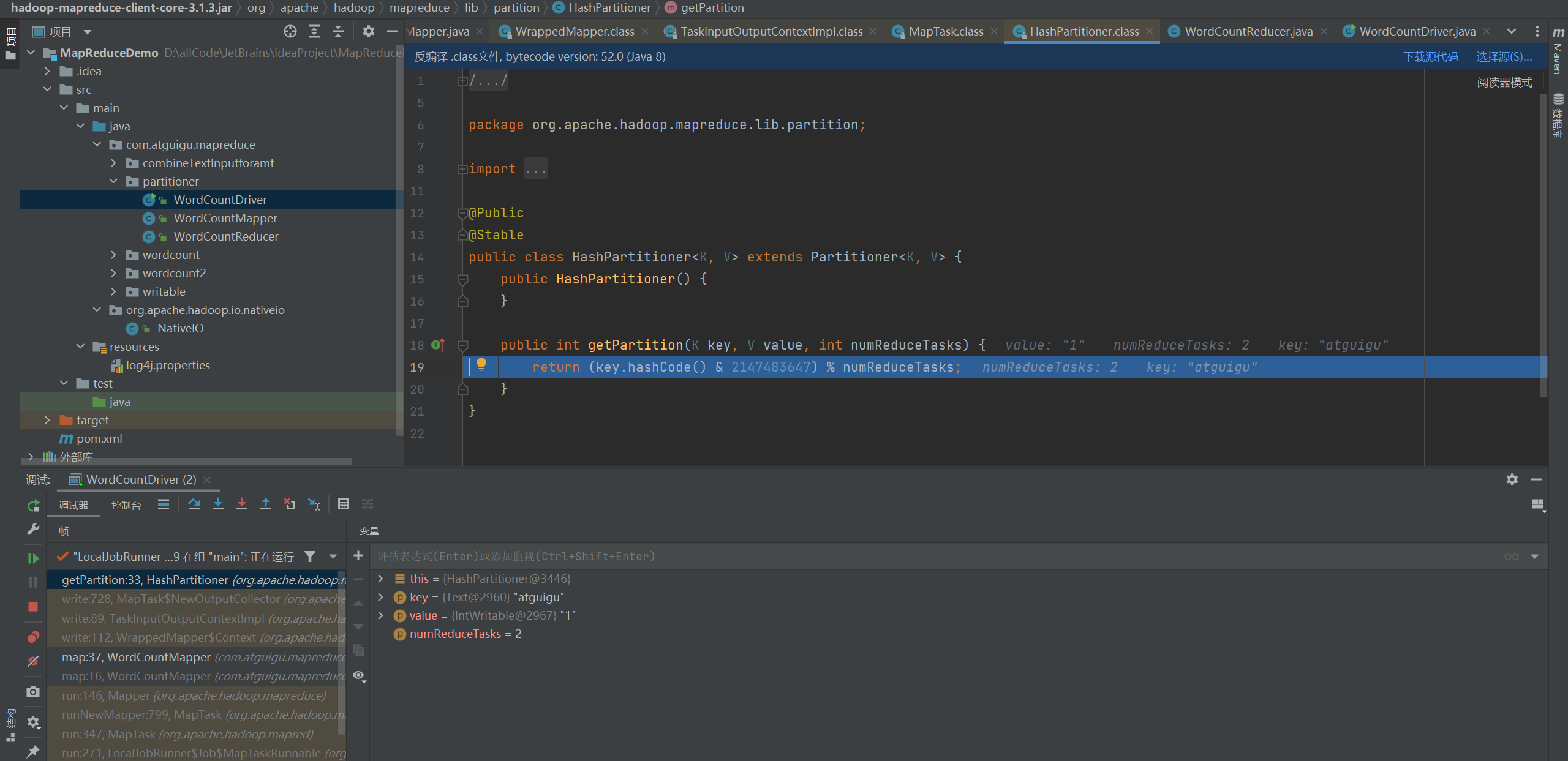
P096【096_尚硅谷_Hadoop_MapReduce_默认HashPartitioner分区】12:50
3.3.2 Partition分区


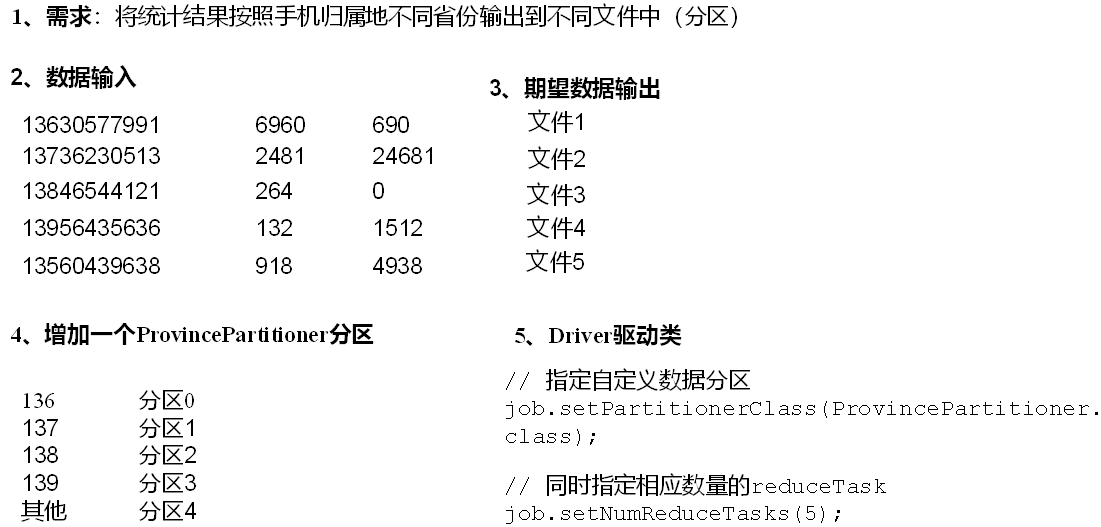
P097【097_尚硅谷_Hadoop_MapReduce_自定义分区案例】07:20
3.3.3 Partition分区案例实操
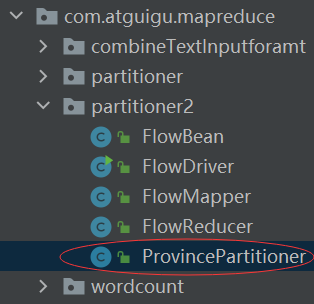
package com.atguigu.mapreduce.partitioner2;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;public class ProvincePartitioner extends Partitioner<Text, FlowBean> {@Overridepublic int getPartition(Text text, FlowBean flowBean, int numPartitions) {//text是手机号String phone = text.toString();String prePhone = phone.substring(0, 3);int partition;if ("136".equals(prePhone)) {partition = 0;} else if ("137".equals(prePhone)) {partition = 1;} else if ("138".equals(prePhone)) {partition = 2;} else if ("139".equals(prePhone)) {partition = 3;} else {partition = 4;}return partition;}
}P098【098_尚硅谷_Hadoop_MapReduce_分区数与Reduce个数的总结】07:21

P099【099_尚硅谷_Hadoop_MapReduce_排序概述】14:14
排序概述
排序是MapReduce框架中最重要的操作之一。MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑上是否需要。默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
自定义排序WritableComparable原理分析
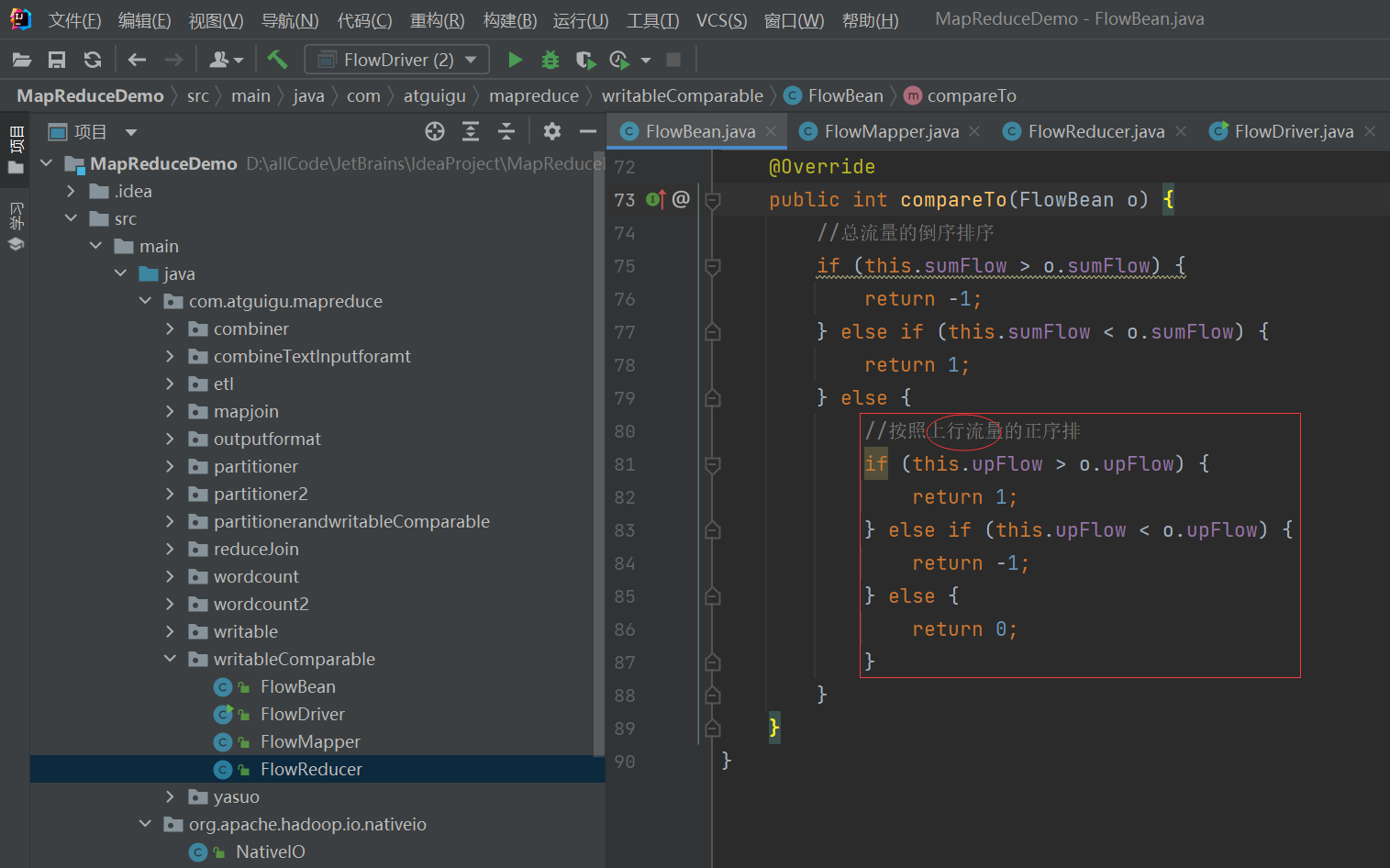
bean对象做为key传输,需要实现WritableComparable接口重写compareTo方法,就可以实现排序。
@Override
public int compareTo(FlowBean bean) {
int result;
// 按照总流量大小,倒序排列
if (this.sumFlow > bean.getSumFlow()) {
result = -1;
}else if (this.sumFlow < bean.getSumFlow()) {
result = 1;
}else {
result = 0;
}
return result;
}
P100【100_尚硅谷_Hadoop_MapReduce_全排序案例】15:26

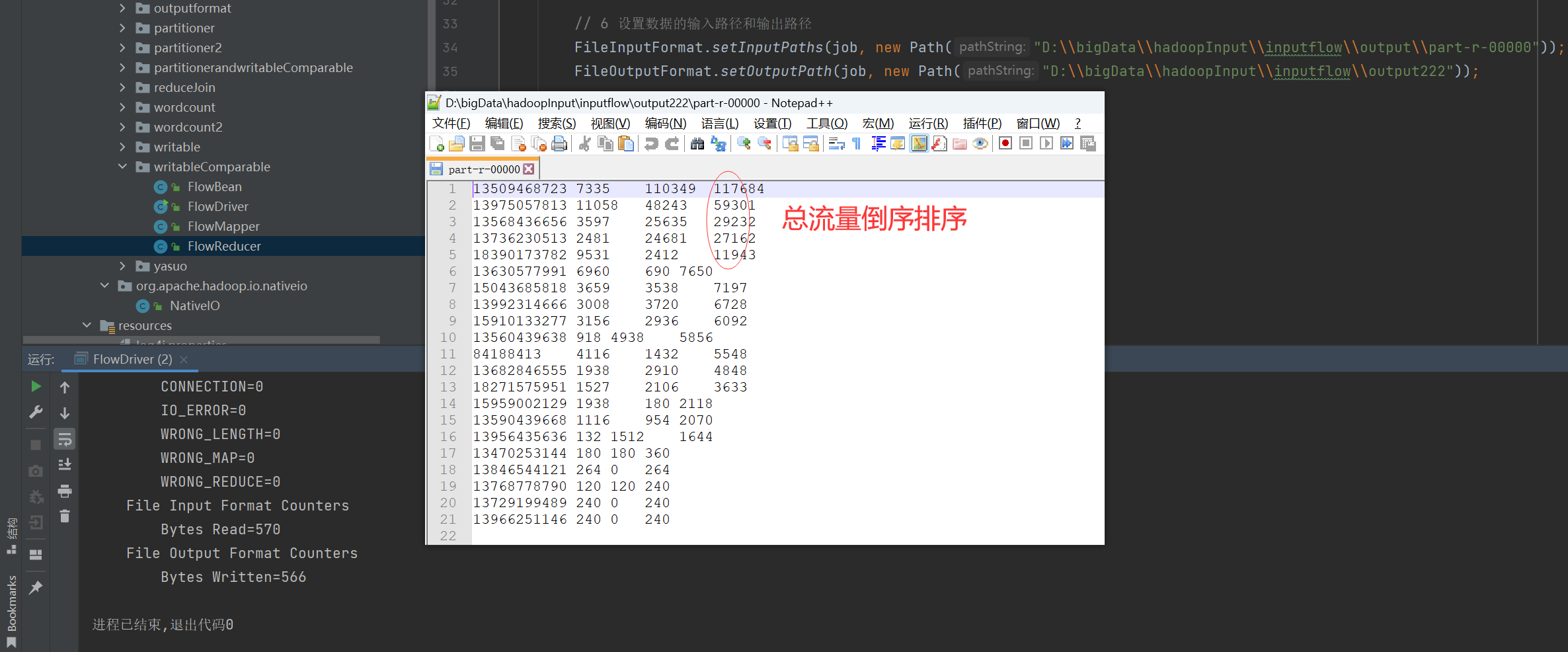
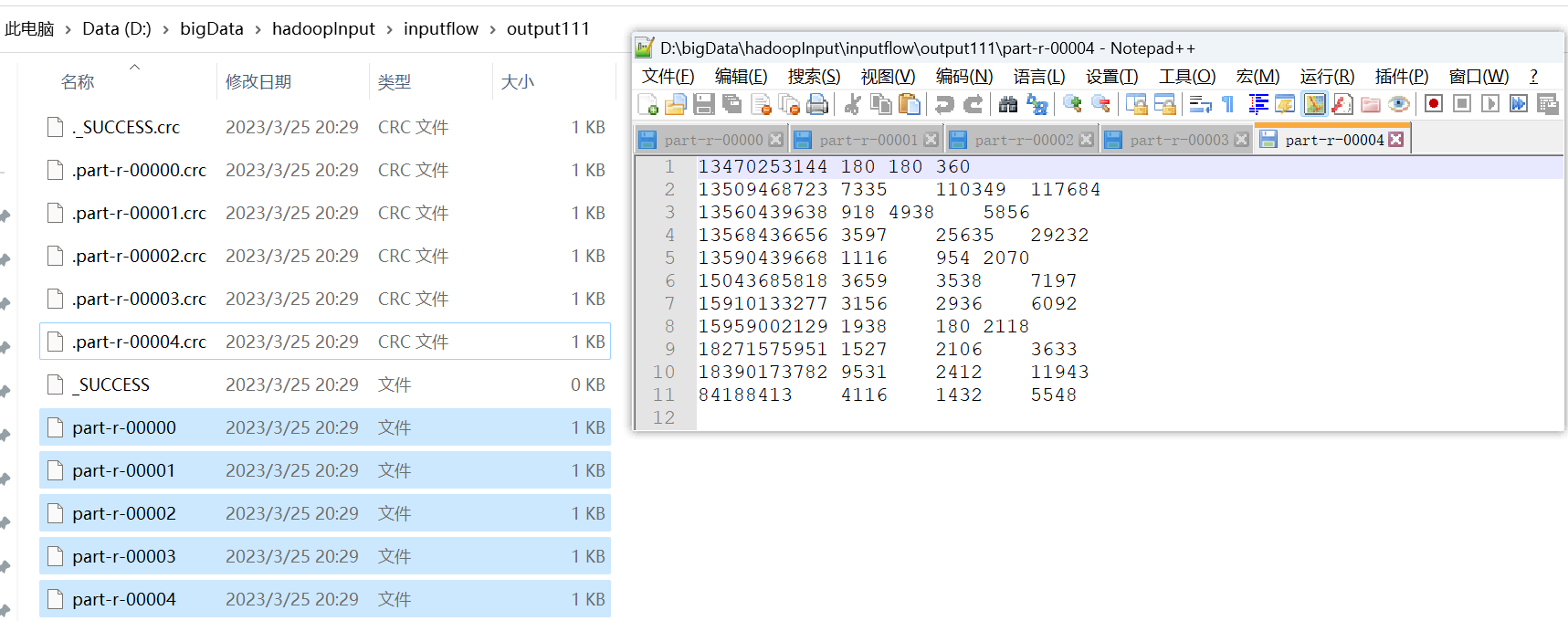
P101【101_尚硅谷_Hadoop_MapReduce_二次排序案例】03:07
P102【102_尚硅谷_Hadoop_MapReduce_区内排序案例】06:53
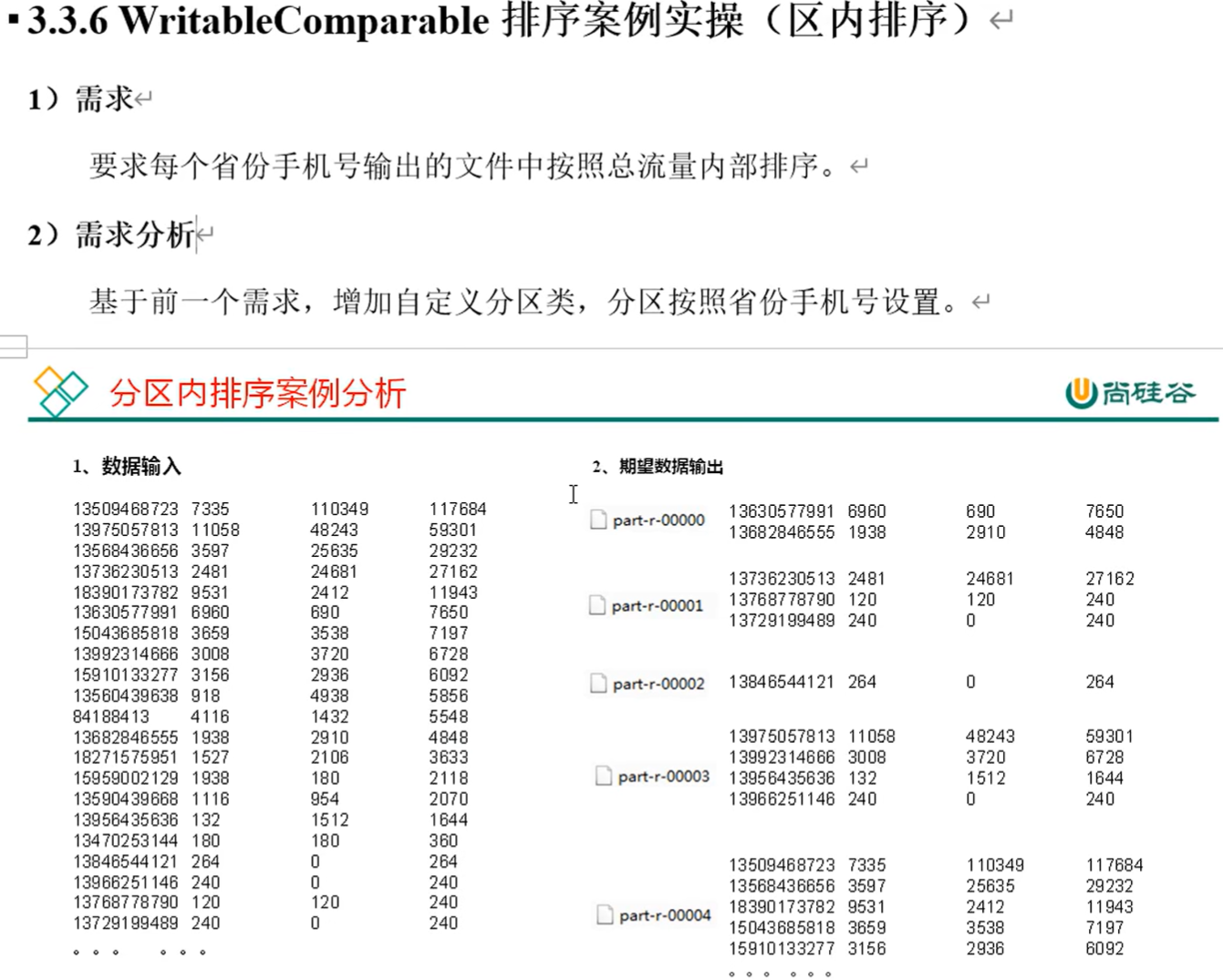
D:\Java\jdk1.8\jdk1.8.0_201\bin\java.exe "-javaagent:D:\JetBrains\IntelliJ IDEA 2021.3\lib\idea_rt.jar=50393:D:\JetBrains\IntelliJ IDEA 2021.3\bin" -Dfile.encoding=UTF-8 -classpath D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\charsets.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\deploy.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\access-bridge-64.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\cldrdata.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\dnsns.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\jaccess.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\jfxrt.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\localedata.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\nashorn.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\sunec.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\sunjce_provider.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\sunmscapi.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\sunpkcs11.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\ext\zipfs.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\javaws.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\jce.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\jfr.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\jfxswt.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\jsse.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\management-agent.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\plugin.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\resources.jar;D:\Java\jdk1.8\jdk1.8.0_201\jre\lib\rt.jar;D:\allCode\JetBrains\IdeaProject\MapReduceDemo\target\classes;D:\maven\maven_repository\org\apache\hadoop\hadoop-client\3.1.3\hadoop-client-3.1.3.jar;D:\maven\maven_repository\org\apache\hadoop\hadoop-common\3.1.3\hadoop-common-3.1.3.jar;D:\maven\maven_repository\com\google\guava\guava\27.0-jre\guava-27.0-jre.jar;D:\maven\maven_repository\com\google\guava\failureaccess\1.0\failureaccess-1.0.jar;D:\maven\maven_repository\com\google\guava\listenablefuture\9999.0-empty-to-avoid-conflict-with-guava\listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar;D:\maven\maven_repository\org\checkerframework\checker-qual\2.5.2\checker-qual-2.5.2.jar;D:\maven\maven_repository\com\google\errorprone\error_prone_annotations\2.2.0\error_prone_annotations-2.2.0.jar;D:\maven\maven_repository\com\google\j2objc\j2objc-annotations\1.1\j2objc-annotations-1.1.jar;D:\maven\maven_repository\org\codehaus\mojo\animal-sniffer-annotations\1.17\animal-sniffer-annotations-1.17.jar;D:\maven\maven_repository\commons-cli\commons-cli\1.2\commons-cli-1.2.jar;D:\maven\maven_repository\org\apache\commons\commons-math3\3.1.1\commons-math3-3.1.1.jar;D:\maven\maven_repository\org\apache\httpcomponents\httpclient\4.5.2\httpclient-4.5.2.jar;D:\maven\maven_repository\org\apache\httpcomponents\httpcore\4.4.4\httpcore-4.4.4.jar;D:\maven\maven_repository\commons-net\commons-net\3.6\commons-net-3.6.jar;D:\maven\maven_repository\commons-collections\commons-collections\3.2.2\commons-collections-3.2.2.jar;D:\maven\maven_repository\org\eclipse\jetty\jetty-servlet\9.3.24.v20180605\jetty-servlet-9.3.24.v20180605.jar;D:\maven\maven_repository\org\eclipse\jetty\jetty-security\9.3.24.v20180605\jetty-security-9.3.24.v20180605.jar;D:\maven\maven_repository\org\eclipse\jetty\jetty-webapp\9.3.24.v20180605\jetty-webapp-9.3.24.v20180605.jar;D:\maven\maven_repository\org\eclipse\jetty\jetty-xml\9.3.24.v20180605\jetty-xml-9.3.24.v20180605.jar;D:\maven\maven_repository\javax\servlet\jsp\jsp-api\2.1\jsp-api-2.1.jar;D:\maven\maven_repository\com\sun\jersey\jersey-servlet\1.19\jersey-servlet-1.19.jar;D:\maven\maven_repository\commons-logging\commons-logging\1.1.3\commons-logging-1.1.3.jar;D:\maven\maven_repository\commons-lang\commons-lang\2.6\commons-lang-2.6.jar;D:\maven\maven_repository\commons-beanutils\commons-beanutils\1.9.3\commons-beanutils-1.9.3.jar;D:\maven\maven_repository\org\apache\commons\commons-configuration2\2.1.1\commons-configuration2-2.1.1.jar;D:\maven\maven_repository\org\apache\commons\commons-lang3\3.4\commons-lang3-3.4.jar;D:\maven\maven_repository\org\apache\avro\avro\1.7.7\avro-1.7.7.jar;D:\maven\maven_repository\org\codehaus\jackson\jackson-core-asl\1.9.13\jackson-core-asl-1.9.13.jar;D:\maven\maven_repository\org\codehaus\jackson\jackson-mapper-asl\1.9.13\jackson-mapper-asl-1.9.13.jar;D:\maven\maven_repository\com\thoughtworks\paranamer\paranamer\2.3\paranamer-2.3.jar;D:\maven\maven_repository\org\xerial\snappy\snappy-java\1.0.5\snappy-java-1.0.5.jar;D:\maven\maven_repository\com\google\re2j\re2j\1.1\re2j-1.1.jar;D:\maven\maven_repository\com\google\protobuf\protobuf-java\2.5.0\protobuf-java-2.5.0.jar;D:\maven\maven_repository\com\google\code\gson\gson\2.2.4\gson-2.2.4.jar;D:\maven\maven_repository\org\apache\hadoop\hadoop-auth\3.1.3\hadoop-auth-3.1.3.jar;D:\maven\maven_repository\com\nimbusds\nimbus-jose-jwt\4.41.1\nimbus-jose-jwt-4.41.1.jar;D:\maven\maven_repository\com\github\stephenc\jcip\jcip-annotations\1.0-1\jcip-annotations-1.0-1.jar;D:\maven\maven_repository\net\minidev\json-smart\2.3\json-smart-2.3.jar;D:\maven\maven_repository\net\minidev\accessors-smart\1.2\accessors-smart-1.2.jar;D:\maven\maven_repository\org\ow2\asm\asm\5.0.4\asm-5.0.4.jar;D:\maven\maven_repository\org\apache\curator\curator-framework\2.13.0\curator-framework-2.13.0.jar;D:\maven\maven_repository\org\apache\curator\curator-client\2.13.0\curator-client-2.13.0.jar;D:\maven\maven_repository\org\apache\curator\curator-recipes\2.13.0\curator-recipes-2.13.0.jar;D:\maven\maven_repository\com\google\code\findbugs\jsr305\3.0.0\jsr305-3.0.0.jar;D:\maven\maven_repository\org\apache\htrace\htrace-core4\4.1.0-incubating\htrace-core4-4.1.0-incubating.jar;D:\maven\maven_repository\org\apache\commons\commons-compress\1.18\commons-compress-1.18.jar;D:\maven\maven_repository\org\apache\kerby\kerb-simplekdc\1.0.1\kerb-simplekdc-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerb-client\1.0.1\kerb-client-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerby-config\1.0.1\kerby-config-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerb-core\1.0.1\kerb-core-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerby-pkix\1.0.1\kerby-pkix-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerby-asn1\1.0.1\kerby-asn1-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerby-util\1.0.1\kerby-util-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerb-common\1.0.1\kerb-common-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerb-crypto\1.0.1\kerb-crypto-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerb-util\1.0.1\kerb-util-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\token-provider\1.0.1\token-provider-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerb-admin\1.0.1\kerb-admin-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerb-server\1.0.1\kerb-server-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerb-identity\1.0.1\kerb-identity-1.0.1.jar;D:\maven\maven_repository\org\apache\kerby\kerby-xdr\1.0.1\kerby-xdr-1.0.1.jar;D:\maven\maven_repository\com\fasterxml\jackson\core\jackson-databind\2.7.8\jackson-databind-2.7.8.jar;D:\maven\maven_repository\com\fasterxml\jackson\core\jackson-core\2.7.8\jackson-core-2.7.8.jar;D:\maven\maven_repository\org\codehaus\woodstox\stax2-api\3.1.4\stax2-api-3.1.4.jar;D:\maven\maven_repository\com\fasterxml\woodstox\woodstox-core\5.0.3\woodstox-core-5.0.3.jar;D:\maven\maven_repository\org\apache\hadoop\hadoop-hdfs-client\3.1.3\hadoop-hdfs-client-3.1.3.jar;D:\maven\maven_repository\com\squareup\okhttp\okhttp\2.7.5\okhttp-2.7.5.jar;D:\maven\maven_repository\com\squareup\okio\okio\1.6.0\okio-1.6.0.jar;D:\maven\maven_repository\com\fasterxml\jackson\core\jackson-annotations\2.7.8\jackson-annotations-2.7.8.jar;D:\maven\maven_repository\org\apache\hadoop\hadoop-yarn-api\3.1.3\hadoop-yarn-api-3.1.3.jar;D:\maven\maven_repository\javax\xml\bind\jaxb-api\2.2.11\jaxb-api-2.2.11.jar;D:\maven\maven_repository\org\apache\hadoop\hadoop-yarn-client\3.1.3\hadoop-yarn-client-3.1.3.jar;D:\maven\maven_repository\org\apache\hadoop\hadoop-mapreduce-client-core\3.1.3\hadoop-mapreduce-client-core-3.1.3.jar;D:\maven\maven_repository\org\apache\hadoop\hadoop-yarn-common\3.1.3\hadoop-yarn-common-3.1.3.jar;D:\maven\maven_repository\javax\servlet\javax.servlet-api\3.1.0\javax.servlet-api-3.1.0.jar;D:\maven\maven_repository\org\eclipse\jetty\jetty-util\9.3.24.v20180605\jetty-util-9.3.24.v20180605.jar;D:\maven\maven_repository\com\sun\jersey\jersey-core\1.19\jersey-core-1.19.jar;D:\maven\maven_repository\javax\ws\rs\jsr311-api\1.1.1\jsr311-api-1.1.1.jar;D:\maven\maven_repository\com\sun\jersey\jersey-client\1.19\jersey-client-1.19.jar;D:\maven\maven_repository\com\fasterxml\jackson\module\jackson-module-jaxb-annotations\2.7.8\jackson-module-jaxb-annotations-2.7.8.jar;D:\maven\maven_repository\com\fasterxml\jackson\jaxrs\jackson-jaxrs-json-provider\2.7.8\jackson-jaxrs-json-provider-2.7.8.jar;D:\maven\maven_repository\com\fasterxml\jackson\jaxrs\jackson-jaxrs-base\2.7.8\jackson-jaxrs-base-2.7.8.jar;D:\maven\maven_repository\org\apache\hadoop\hadoop-mapreduce-client-jobclient\3.1.3\hadoop-mapreduce-client-jobclient-3.1.3.jar;D:\maven\maven_repository\org\apache\hadoop\hadoop-mapreduce-client-common\3.1.3\hadoop-mapreduce-client-common-3.1.3.jar;D:\maven\maven_repository\org\apache\hadoop\hadoop-annotations\3.1.3\hadoop-annotations-3.1.3.jar;D:\maven\maven_repository\junit\junit\4.12\junit-4.12.jar;D:\maven\maven_repository\org\hamcrest\hamcrest-core\1.3\hamcrest-core-1.3.jar;D:\maven\maven_repository\org\slf4j\slf4j-log4j12\1.7.30\slf4j-log4j12-1.7.30.jar;D:\maven\maven_repository\org\slf4j\slf4j-api\1.7.30\slf4j-api-1.7.30.jar;D:\maven\maven_repository\log4j\log4j\1.2.17\log4j-1.2.17.jar;D:\maven\maven_repository\org\apache\maven\plugins\maven-assembly-plugin\3.0.0\maven-assembly-plugin-3.0.0.jar;D:\maven\maven_repository\org\apache\maven\maven-plugin-api\3.0\maven-plugin-api-3.0.jar;D:\maven\maven_repository\org\sonatype\sisu\sisu-inject-plexus\1.4.2\sisu-inject-plexus-1.4.2.jar;D:\maven\maven_repository\org\sonatype\sisu\sisu-inject-bean\1.4.2\sisu-inject-bean-1.4.2.jar;D:\maven\maven_repository\org\sonatype\sisu\sisu-guice\2.1.7\sisu-guice-2.1.7-noaop.jar;D:\maven\maven_repository\org\apache\maven\maven-core\3.0\maven-core-3.0.jar;D:\maven\maven_repository\org\apache\maven\maven-settings\3.0\maven-settings-3.0.jar;D:\maven\maven_repository\org\apache\maven\maven-settings-builder\3.0\maven-settings-builder-3.0.jar;D:\maven\maven_repository\org\apache\maven\maven-repository-metadata\3.0\maven-repository-metadata-3.0.jar;D:\maven\maven_repository\org\apache\maven\maven-model-builder\3.0\maven-model-builder-3.0.jar;D:\maven\maven_repository\org\apache\maven\maven-aether-provider\3.0\maven-aether-provider-3.0.jar;D:\maven\maven_repository\org\sonatype\aether\aether-impl\1.7\aether-impl-1.7.jar;D:\maven\maven_repository\org\sonatype\aether\aether-spi\1.7\aether-spi-1.7.jar;D:\maven\maven_repository\org\sonatype\aether\aether-api\1.7\aether-api-1.7.jar;D:\maven\maven_repository\org\sonatype\aether\aether-util\1.7\aether-util-1.7.jar;D:\maven\maven_repository\org\codehaus\plexus\plexus-classworlds\2.2.3\plexus-classworlds-2.2.3.jar;D:\maven\maven_repository\org\codehaus\plexus\plexus-component-annotations\1.5.5\plexus-component-annotations-1.5.5.jar;D:\maven\maven_repository\org\sonatype\plexus\plexus-sec-dispatcher\1.3\plexus-sec-dispatcher-1.3.jar;D:\maven\maven_repository\org\sonatype\plexus\plexus-cipher\1.4\plexus-cipher-1.4.jar;D:\maven\maven_repository\org\apache\maven\maven-artifact\3.0\maven-artifact-3.0.jar;D:\maven\maven_repository\org\apache\maven\maven-model\3.0\maven-model-3.0.jar;D:\maven\maven_repository\org\apache\maven\shared\maven-common-artifact-filters\3.0.1\maven-common-artifact-filters-3.0.1.jar;D:\maven\maven_repository\org\apache\maven\shared\maven-shared-utils\3.1.0\maven-shared-utils-3.1.0.jar;D:\maven\maven_repository\org\apache\maven\shared\maven-artifact-transfer\0.9.0\maven-artifact-transfer-0.9.0.jar;D:\maven\maven_repository\org\codehaus\plexus\plexus-interpolation\1.24\plexus-interpolation-1.24.jar;D:\maven\maven_repository\org\codehaus\plexus\plexus-archiver\3.4\plexus-archiver-3.4.jar;D:\maven\maven_repository\org\iq80\snappy\snappy\0.4\snappy-0.4.jar;D:\maven\maven_repository\org\tukaani\xz\1.5\xz-1.5.jar;D:\maven\maven_repository\org\apache\maven\shared\file-management\3.0.0\file-management-3.0.0.jar;D:\maven\maven_repository\org\apache\maven\shared\maven-shared-io\3.0.0\maven-shared-io-3.0.0.jar;D:\maven\maven_repository\org\apache\maven\maven-compat\3.0\maven-compat-3.0.jar;D:\maven\maven_repository\org\apache\maven\wagon\wagon-provider-api\2.10\wagon-provider-api-2.10.jar;D:\maven\maven_repository\commons-io\commons-io\2.5\commons-io-2.5.jar;D:\maven\maven_repository\org\apache\maven\shared\maven-filtering\3.1.1\maven-filtering-3.1.1.jar;D:\maven\maven_repository\org\sonatype\plexus\plexus-build-api\0.0.7\plexus-build-api-0.0.7.jar;D:\maven\maven_repository\org\codehaus\plexus\plexus-io\2.7.1\plexus-io-2.7.1.jar;D:\maven\maven_repository\org\apache\maven\maven-archiver\3.1.1\maven-archiver-3.1.1.jar;D:\maven\maven_repository\org\codehaus\plexus\plexus-utils\3.0.24\plexus-utils-3.0.24.jar;D:\maven\maven_repository\commons-codec\commons-codec\1.6\commons-codec-1.6.jar com.atguigu.mapreduce.partitionerandwritableComparable.FlowDriver
2023-03-27 09:31:37,456 WARN [org.apache.hadoop.util.NativeCodeLoader] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable2023-03-27 09:31:37,793 WARN [org.apache.hadoop.metrics2.impl.MetricsConfig] - Cannot locate configuration: tried hadoop-metrics2-jobtracker.properties,hadoop-metrics2.properties2023-03-27 09:31:37,830 INFO [org.apache.hadoop.metrics2.impl.MetricsSystemImpl] - Scheduled Metric snapshot period at 10 second(s).2023-03-27 09:31:37,830 INFO [org.apache.hadoop.metrics2.impl.MetricsSystemImpl] - JobTracker metrics system started2023-03-27 09:31:38,525 WARN [org.apache.hadoop.mapreduce.JobResourceUploader] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.2023-03-27 09:31:38,582 WARN [org.apache.hadoop.mapreduce.JobResourceUploader] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).2023-03-27 09:31:38,596 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input files to process : 12023-03-27 09:31:38,841 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:12023-03-27 09:31:38,997 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local190721450_00012023-03-27 09:31:38,998 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Executing with tokens: []2023-03-27 09:31:39,139 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/2023-03-27 09:31:39,140 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local190721450_00012023-03-27 09:31:39,140 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null2023-03-27 09:31:39,143 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - File Output Committer Algorithm version is 22023-03-27 09:31:39,143 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false2023-03-27 09:31:39,143 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter2023-03-27 09:31:39,242 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks2023-03-27 09:31:39,243 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local190721450_0001_m_000000_02023-03-27 09:31:39,251 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - File Output Committer Algorithm version is 22023-03-27 09:31:39,251 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false2023-03-27 09:31:39,255 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.2023-03-27 09:31:39,282 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@767a27d02023-03-27 09:31:39,287 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: file:/D:/bigData/hadoopInput/inputflow/phone_data.txt:0+11782023-03-27 09:31:39,312 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)2023-03-27 09:31:39,312 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 1002023-03-27 09:31:39,312 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 838860802023-03-27 09:31:39,312 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 1048576002023-03-27 09:31:39,312 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 65536002023-03-27 09:31:39,314 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer2023-03-27 09:31:39,316 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output2023-03-27 09:31:39,451 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.2023-03-27 09:31:39,452 WARN [org.apache.hadoop.mapred.LocalJobRunner] - job_local190721450_0001java.lang.Exception: java.lang.NumberFormatException: For input string: "192.196.100.1"at org.apache.hadoop.mapred.LocalJobRunner$Job.runTasks(LocalJobRunner.java:492)at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:552)
Caused by: java.lang.NumberFormatException: For input string: "192.196.100.1"at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)at java.lang.Long.parseLong(Long.java:589)at java.lang.Long.parseLong(Long.java:631)at com.atguigu.mapreduce.partitionerandwritableComparable.FlowMapper.map(FlowMapper.java:24)at com.atguigu.mapreduce.partitionerandwritableComparable.FlowMapper.map(FlowMapper.java:9)at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:799)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:347)at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:271)at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)at java.util.concurrent.FutureTask.run(FutureTask.java:266)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
2023-03-27 09:31:40,148 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local190721450_0001 running in uber mode : false2023-03-27 09:31:40,150 INFO [org.apache.hadoop.mapreduce.Job] - map 0% reduce 0%2023-03-27 09:31:40,152 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local190721450_0001 failed with state FAILED due to: NA2023-03-27 09:31:40,159 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 0进程已结束,退出代码1P103【103_尚硅谷_Hadoop_MapReduce_Combiner概述】07:18
3.3.7 Combiner合并

P104【104_尚硅谷_Hadoop_MapReduce_Combiner案例】12:33
3.3.8 Combiner合并案例实操
需求:对每一个MapTask的输出局部汇总(Combiner)。


package com.atguigu.mapreduce.combiner;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable outV = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable value : values) {sum += value.get();}outV.set(sum);context.write(key, outV);}
}P105【105_尚硅谷_Hadoop_MapReduce_outputformat概述】03:42
3.4 OutputFormat数据输出
3.4.1 OutputFormat接口实现类
P106【106_尚硅谷_Hadoop_MapReduce_自定义outputformat案例需求分析】04:22

P107【107_尚硅谷_Hadoop_MapReduce_自定义outputformat案例mapper&reducer】04:33
package com.atguigu.mapreduce.outputformat;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;public class LogMapper extends Mapper<LongWritable, Text, Text, NullWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//http://www.baidu.com//http://www.google.com//(http://www.google.com, NullWritable)//map阶段不作任何处理context.write(value, NullWritable.get());}
}package com.atguigu.mapreduce.outputformat;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class LogReducer extends Reducer<Text, NullWritable, Text, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {// http://www.baidu.com// http://www.baidu.com// 防止有相同数据,丢数据for (NullWritable value : values) {context.write(key, NullWritable.get());}}
}P108【108_尚硅谷_Hadoop_MapReduce_自定义outputformat案例执行】12:33
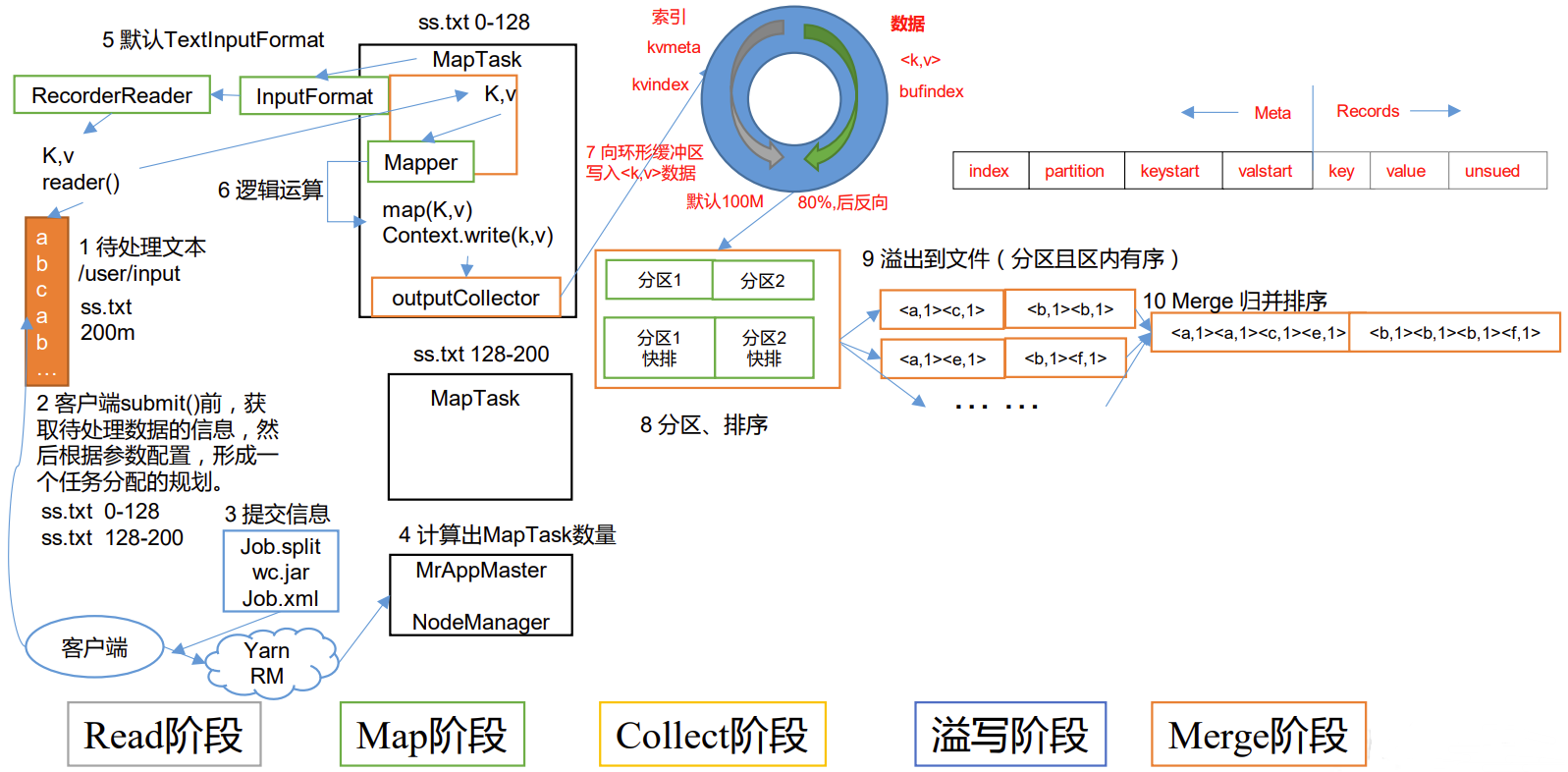
P109【109_尚硅谷_Hadoop_MapReduce_MapTask工作机制】03:46
3.5 MapReduce内核源码解析
3.5.1 MapTask工作机制
P110【110_尚硅谷_Hadoop_MapReduce_ReduceTask工作机制&并行度】09:00
3.5.2 ReduceTask工作机制
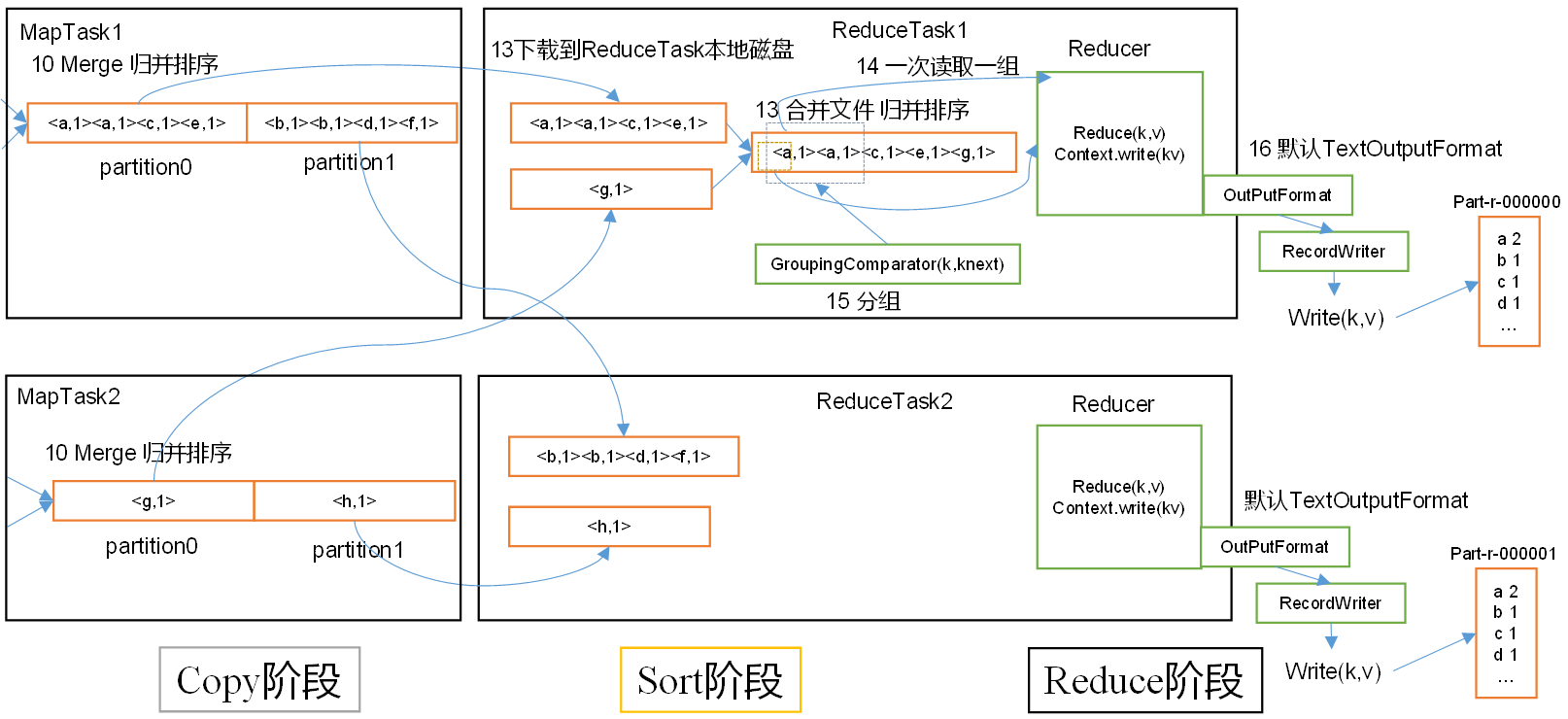
3.5.3 ReduceTask并行度决定机制
1)设置ReduceTask并行度(个数)
ReduceTask的并行度同样影响整个Job的执行并发度和执行效率,但与MapTask的并发数由切片数决定不同,ReduceTask数量的决定是可以直接手动设置:
// 默认值是1,手动设置为4
job.setNumReduceTasks(4);
2)实验:测试ReduceTask多少合适
(1)实验环境:1个Master节点,16个Slave节点:CPU:8GHZ,内存: 2G
(2)实验结论:
表 改变ReduceTask(数据量为1GB)
MapTask =16
ReduceTask
1
5
10
15
16
20
25
30
45
60
总时间
892
146
110
92
88
100
128
101
145
104
P111【111_尚硅谷_Hadoop_MapReduce_MapTask源码】16:57
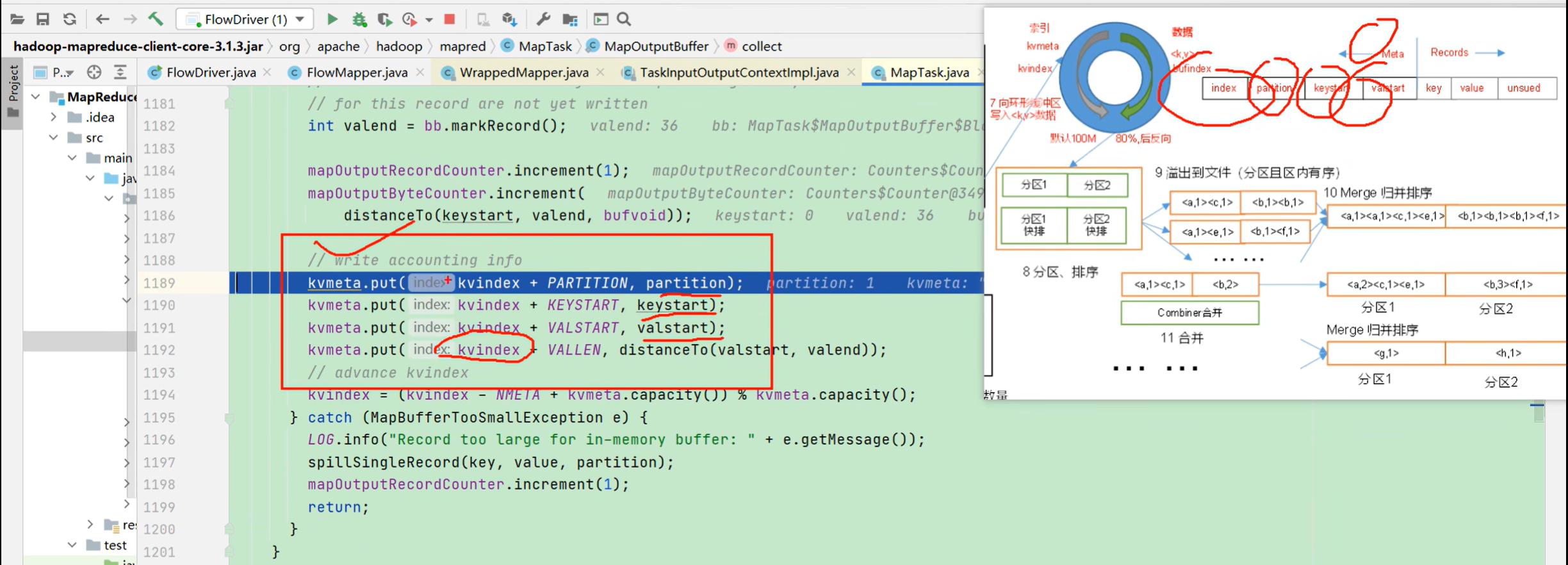
P112【112_尚硅谷_Hadoop_MapReduce_ReduceTask源码】15:25
3.5.4 MapTask & ReduceTask源码解析
1)MapTask源码解析流程
2)ReduceTask源码解析流程
P113【113_尚硅谷_Hadoop_MapReduce_ReduceJoin案例需求分析】09:22
3.6 Join应用
3.6.1 Reduce Join
P114【114_尚硅谷_Hadoop_MapReduce_ReduceJoin案例TableBean】07:09
package com.atguigu.mapreduce.reduceJoin;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class TableBean implements Writable {private String id; //订单idprivate String pid; //商品idprivate int amount; //商品数量private String pname;//商品名称private String flag; //标记是什么表 order pd//空参构造public TableBean() {}public String getId() {return id;}public void setId(String id) {this.id = id;}public String getPid() {return pid;}public void setPid(String pid) {this.pid = pid;}public int getAmount() {return amount;}public void setAmount(int amount) {this.amount = amount;}public String getPname() {return pname;}public void setPname(String pname) {this.pname = pname;}public String getFlag() {return flag;}public void setFlag(String flag) {this.flag = flag;}@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(id);out.writeUTF(pid);out.writeInt(amount);out.writeUTF(pname);out.writeUTF(flag);}@Overridepublic void readFields(DataInput in) throws IOException {this.id = in.readUTF();this.pid = in.readUTF();this.amount = in.readInt();this.pname = in.readUTF();this.flag = in.readUTF();}@Overridepublic String toString() {// id pname amountreturn id + "\t" + pname + "\t" + amount;}
}P115【115_尚硅谷_Hadoop_MapReduce_ReduceJoin案例Mapper】12:34
package com.atguigu.mapreduce.reduceJoin;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;import java.io.IOException;public class TableMapper extends Mapper<LongWritable, Text, Text, TableBean> {private String fileName;private Text outK = new Text();private TableBean outV = new TableBean();@Overrideprotected void setup(Context context) throws IOException, InterruptedException {//初始化 order pdFileSplit split = (FileSplit) context.getInputSplit();fileName = split.getPath().getName();}@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1、获取一行String line = value.toString();//2、判断是哪个文件的if (fileName.contains("order")) {// 处理的是订单表String[] split = line.split("\t");//封装k和voutK.set(split[1]);outV.setId(split[0]);outV.setPid(split[1]);outV.setAmount(Integer.parseInt(split[2]));outV.setPname("");outV.setFlag("order");} else {//处理的是商品表String[] split = line.split("\t");outK.set(split[0]);outV.setId("");outV.setPid(split[0]);outV.setAmount(0);outV.setPname(split[1]);outV.setFlag("pd");}//写出context.write(outK, outV);}
}P116【116_尚硅谷_Hadoop_MapReduce_ReduceJoin案例完成】12:27
package com.atguigu.mapreduce.reduceJoin;import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;public class TableReducer extends Reducer<Text, TableBean, TableBean, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<TableBean> values, Context context) throws IOException, InterruptedException {
// 01 1001 1 order
// 01 1004 4 order
// 01 小米 pd//准备初始化集合ArrayList<TableBean> orderBeans = new ArrayList<>();TableBean pdBean = new TableBean();//循环遍历for (TableBean value : values) {if ("order".equals(value.getFlag())) {//订单表TableBean tmptableBean = new TableBean();try {BeanUtils.copyProperties(tmptableBean, value);} catch (IllegalAccessException e) {e.printStackTrace();} catch (InvocationTargetException e) {e.printStackTrace();}orderBeans.add(tmptableBean);} else {//商品表try {BeanUtils.copyProperties(pdBean, value);} catch (IllegalAccessException e) {e.printStackTrace();} catch (InvocationTargetException e) {e.printStackTrace();}}}//循环遍历orderBeans,赋值pdnamefor (TableBean orderBean : orderBeans) {orderBean.setPname(pdBean.getPname());context.write(orderBean, NullWritable.get());}}
}P117【117_尚硅谷_Hadoop_MapReduce_ReduceJoin案例debug】04:15
P118【118_尚硅谷_Hadoop_MapReduce_MapJoin案例需求分析】06:57
3.6.3 Map Join
1)使用场景
Map Join适用于一张表十分小、一张表很大的场景。
2)优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
3)具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在Driver驱动类中加载缓存。
//缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file:///e:/cache/pd.txt"));
//如果是集群运行,需要设置HDFS路径
job.addCacheFile(new URI("hdfs://hadoop102:8020/cache/pd.txt"));
3.6.4 Map Join案例实操

P119【119_尚硅谷_Hadoop_MapReduce_MapJoin案例完成】13:11

package com.atguigu.mapreduce.mapjoin;import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.HashMap;public class MapJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> {private HashMap<String, String> pdMap = new HashMap<>();private Text outK = new Text();@Overrideprotected void setup(Context context) throws IOException, InterruptedException {//获取缓存的文件,并把文件内容封装到集合,pd.txtURI[] cacheFiles = context.getCacheFiles();FileSystem fs = FileSystem.get(context.getConfiguration());FSDataInputStream fis = fs.open(new Path(cacheFiles[0]));//从流中读取数据BufferedReader reader = new BufferedReader(new InputStreamReader(fis, "UTF-8"));String line;while (StringUtils.isNotEmpty(line = reader.readLine())) {//切割String[] fields = line.split("\t");//赋值pdMap.put(fields[0], fields[1]);}//关流IOUtils.closeStream(reader);}@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//处理order.txtString line = value.toString();String[] fields = line.split("\t");//获取pidString pname = pdMap.get(fields[1]);//获取订单id和订单数量//封装outK.set(fields[0] + "\t" + pname + "\t" + fields[2]);context.write(outK, NullWritable.get());}
}package com.atguigu.mapreduce.mapjoin;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;public class MapJoinDriver {public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {// 1 获取job信息Configuration conf = new Configuration();Job job = Job.getInstance(conf);// 2 设置加载jar包路径job.setJarByClass(MapJoinDriver.class);// 3 关联mapperjob.setMapperClass(MapJoinMapper.class);// 4 设置Map输出KV类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(NullWritable.class);// 5 设置最终输出KV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);// 加载缓存数据job.addCacheFile(new URI("file:///D:/bigData/hadoopInput/tablecache/pd.txt"));// Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0job.setNumReduceTasks(0);// 6 设置输入输出路径FileInputFormat.setInputPaths(job, new Path("D:\\bigData\\hadoopInput\\inputtable2\\order.txt"));FileOutputFormat.setOutputPath(job, new Path("D:\\bigData\\hadoopInput\\inputtable2\\output111"));// 7 提交boolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}
}P120【120_尚硅谷_Hadoop_MapReduce_MapJoin案例debug】02:49
P121【121_尚硅谷_Hadoop_MapReduce_ETL数据清洗案例】15:11
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(Extract)、转换(Transform)、加载(Load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
运行截图
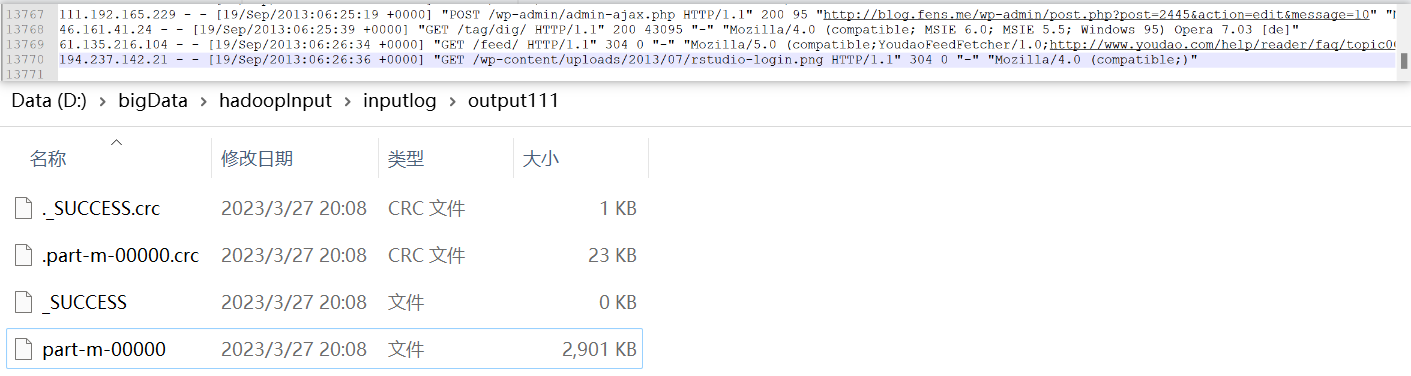
ETL清洗规则

P122【122_尚硅谷_Hadoop_MapReduce_MapReduce开发总结】10:51
一、Hadoop入门
1、常用端口号
hadoop3.x
HDFS NameNode 内部通常端口:8020/9000/9820
HDFS NameNode 对用户的查询端口:9870
Yarn查看任务运行情况的:8088
历史服务器:19888
hadoop2.x
HDFS NameNode 内部通常端口:8020/9000
HDFS NameNode 对用户的查询端口:50070
Yarn查看任务运行情况的:8088
历史服务器:19888
2、常用的配置文件
3.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml workers
2.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml slaves二、HDFS
1、HDFS文件块大小(面试重点)
硬盘读写速度
在企业中 一般128m(中小公司) 256m (大公司)
2、HDFS的Shell操作(开发重点)
3、HDFS的读写流程(面试重点)三、MapReduce
1、InputFormat
1)默认的是TextInputformat,输入kv,key:偏移量、v:一行内容
2)处理小文件CombineTextInputFormat,把多个文件合并到一起统一切片
2、Mapper
setup():初始化;map():用户的业务逻辑;clearup():关闭资源;
3、分区
默认分区HashPartitioner ,默认按照key的hash值%numreducetask个数
自定义分区
4、排序
1)部分排序,每个输出的文件内部有序。
2)全排序:一个reduce,对所有数据大排序。
3)二次排序:自定义排序范畴,实现writableCompare接口,重写compareTo方法
总流量倒序,按照上行流量,正序
5、Combiner
前提:不影响最终的业务逻辑(求和没问题,求平均值)
提前聚合map => 解决数据倾斜的一个方法
6、Reducer
用户的业务逻辑;
setup():初始化;reduce():用户的业务逻辑;clearup():关闭资源;
7、OutputFormat
1)默认TextOutputFormat,按行输出到文件
2)自定义四、Yarn
P123【123_尚硅谷_Hadoop_MapReduce_压缩概述】16:05
第4章 Hadoop数据压缩
4.1 概述
1)压缩的好处和坏处
压缩的优点:以减少磁盘IO、减少磁盘存储空间。
压缩的缺点:增加CPU开销。
2)压缩原则
(1)运算密集型的Job,少用压缩
(2)IO密集型的Job,多用压缩
P124【124_尚硅谷_Hadoop_MapReduce_压缩案例实操】10:22
4.4 压缩参数配置
package com.atguigu.mapreduce.yasuo;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
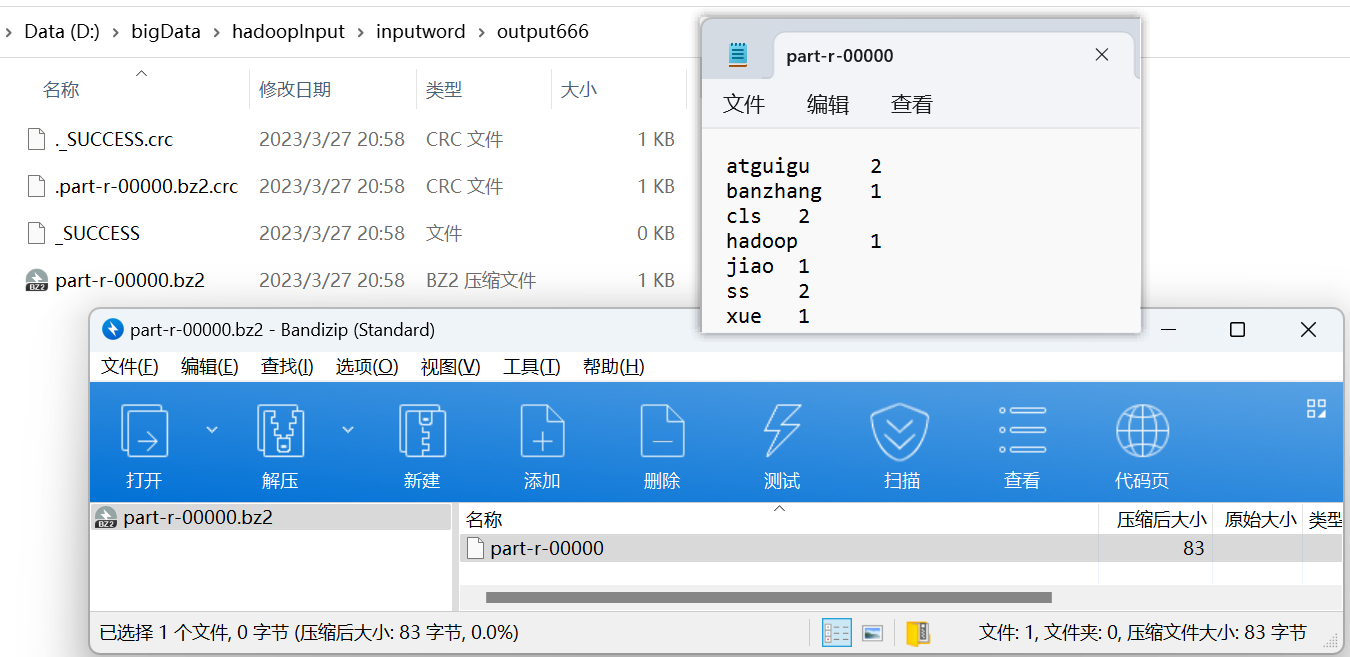
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1 获取jobConfiguration conf = new Configuration();// 开启map端输出压缩conf.setBoolean("mapreduce.map.output.compress", true);// 设置map端输出压缩方式,BZip2Codec、SnappyCodecconf.setClass("mapreduce.map.output.compress.codec", BZip2Codec.class, CompressionCodec.class);Job job = Job.getInstance(conf);// 2 设置jar包路径job.setJarByClass(WordCountDriver.class);// 3 关联mapper和reducerjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4 设置map输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5 设置最终输出的kV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 设置输入路径和输出路径FileInputFormat.setInputPaths(job, new Path("D:\\bigData\\hadoopInput\\inputword\\hello.txt"));FileOutputFormat.setOutputPath(job, new Path("D:\\bigData\\hadoopInput\\inputword\\output777"));// 设置reduce端输出压缩开启FileOutputFormat.setCompressOutput(job, true);// 设置压缩的方式
// FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
// FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class);// 7 提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}相关文章:
尚硅谷大数据技术Hadoop教程-笔记04【Hadoop-MapReduce】
视频地址:尚硅谷大数据Hadoop教程(Hadoop 3.x安装搭建到集群调优) 尚硅谷大数据技术Hadoop教程-笔记01【大数据概论】尚硅谷大数据技术Hadoop教程-笔记02【Hadoop-入门】尚硅谷大数据技术Hadoop教程-笔记03【Hadoop-HDFS】尚硅谷大数据技术Ha…...
Linux信号sigaction / signal
Linux信号sigaction / signal 文章目录Linux信号sigaction / signal目的函数原型struct sigaction信号枚举值ISO C99 signals.Historical signals specified by POSIX.New(er) POSIX signals (1003.1-2008, 1003.1-2013).Nonstandard signals found in all modern POSIX system…...

坦克大战第一阶段代码
package tanke.game;import javax.swing.*; import java.awt.*; import java.awt.event.KeyEvent; import java.awt.event.KeyListener; import java.util.Vector;//为了监听键盘事件,实现keylistener public class mypanel extends JPanel implements KeyListener …...
博客系统前端实现
目录 1.预期效果 2.实现博客列表页 3.实现博客正文页 4.实现博客登录页 5.实现博客编辑页面 1.预期效果 对前端html,css,js有大致的了解后,现在我们实现了一个博客系统的前端页面.一共分为四个页面没分别是:登陆页面,博客列表页,博客正文页,博客编辑页 我们看下四个界面…...
ChatGPT技术原理、研究框架,应用实践及发展趋势(附166份报告)
一、AI框架重要性日益突显,框架技术发展进入繁荣期,国内AI框架技术加速发展: 1、AI框架作为衔接数据和模型的重要桥梁,发展进入繁荣期,国内外框架功能及性能加速迭代; 2、Pytorch、Tensorflow占据AI框…...

【屏幕自适应页面适配问题】CSS的@media,为了适应1440×900的屏幕,使用@media解决问题
文章目录bug修改实例CSS3 media 查询CSS 多媒体查询,适配各种设备尺寸bug修改实例 <template><div id"deptAllDown" style"height: 400px;width:880px"/> </template>为了适应1440900的屏幕,使用media解决问题 …...
一篇文章理解堆栈溢出
一篇文章理解堆栈溢出引言栈溢出ret2text答案ret2shellcode答案ret2syscall答案栈迁移答案堆溢出 unlink - UAF堆结构小提示向前合并/向后合并堆溢出题答案引言 让新手快速理解堆栈溢出,尽可能写的简单一些。 栈溢出 代码执行到进入函数之前都会记录返回地址到SP…...

优化模型验证关键代码27:多旅行商问题的变体-多起点单目的地问题和多汉密尔顿路径问题
目录 1 多起点单目的地问题(Multiple departures single destination mTSP) 1.1 符号列表 1.2 数学模型 1.4 解的可视化结果...
快速搭建第一个SpringCloud程序
目录 1、Spring Boot项目脚手架快速搭建 1.1 生成工程基本配置 1.2 生成工程。 1.3 导入开发工具(此处为Idea) 1.4 运行代码 1.5 验证是否能访问 2、Spring Cloud环境搭建 2.1 版本匹配问题 2.2 Spring Cloud环境测试 3、引入Eureka Server 3…...
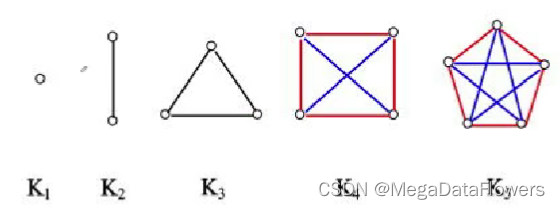
【离散数学】图论
1、有n个点没有边 零图 2、有1个点没有边 平凡图 3、含有平行边的图 多重图 4、简单图 不含有平行边和自回环的图 5、任意两个结点之间都有边 完全图 6、环贡献 两度 7、所有顶点的度数之和等于边数的两倍 8、在有向图中所有顶点的出度之和 或者 入度之和 等于边数 9、度数为…...

代码随想录算法训练营第三十七天-贪心算法6| 738.单调递增的数字 968.监控二叉树 总结
738.单调递增的数字 贪心算法 题目要求小于等于N的最大单调递增的整数,那么拿一个两位的数字来举例。 例如:98,一旦出现strNum[i - 1] > strNum[i]的情况(非单调递增),首先想让strNum[i - 1]--&#…...
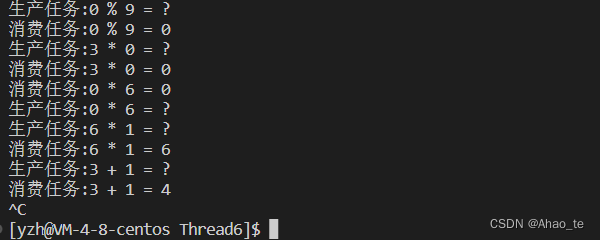
【Linux】线程中的互斥锁、条件变量、信号量(数据安全问题、生产消费模型、阻塞队列和环形队列的实现)
文章目录1、线程互斥1.1 线程间频繁切换导致的问题1.2 使用互斥锁1.3 互斥锁的原理1.4 线程中的数据安全问题2、线程同步之条件变量2.1 生产消费模型2.2 条件变量概念和调用函数2.3 阻塞队列的实现3、线程同步之信号量3.1 理解信号量3.2 信号量接口3.3 环形队列的实现4、小结1、…...

MySQL8.0的安装和配置
🎉🎉🎉点进来你就是我的人了 博主主页:🙈🙈🙈戳一戳,欢迎大佬指点!人生格言:当你的才华撑不起你的野心的时候,你就应该静下心来学习! 欢迎志同道合的朋友一起加油喔🦾&am…...
LinuxGUI自动化测试框架搭建(三)-虚拟机安装(Hyper-V或者VMWare)
(三)-虚拟机安装(Hyper-V或者VMWare)1 Hyper-V安装1.1 方法一:直接启用1.2 方法二:下载安装1.3 打开Hyper-V2 VMWare安装注意:Hyper-V或者VMWare只安装一个,只安装一个,只…...
,包含copypaste、翻转、cutout等八种增强方式)
改进YOLO系列:数据增强扩充(有增强图像和标注),包含copypaste、翻转、cutout等八种增强方式
这里写目录标题 一、简介二、数据增强方法介绍复制-粘贴(Copy-paste)翻转(Flip)Cutout加噪声(Noise)亮度调整(Brightness)平移(Shift)旋转(Rotation)裁剪(Crop)copy-paste的代码一、简介 数据增强是一种通过对原始数据进行随机变换、扰动等操作来生成新的训练样…...
(std::stack)(一))
c++11 标准模板(STL)(std::stack)(一)
定义于头文件 <stack> template< class T, class Container std::deque<T> > class stack;std::stack 类是容器适配器,它给予程序员栈的功能——特别是 FILO (先进后出)数据结构。 该类模板表现为底层容器的包装…...
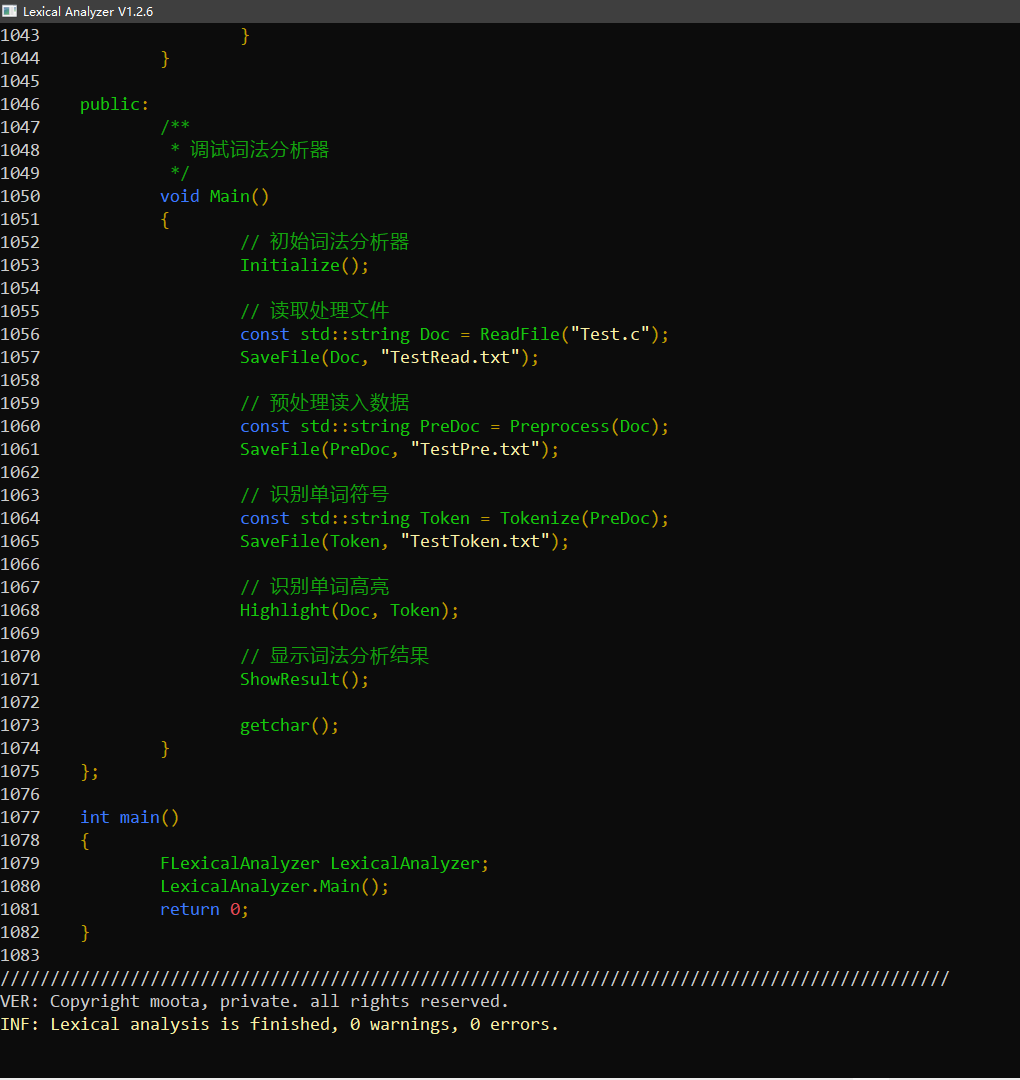
C++-c语言词法分析器
一、运行截图 对于 Test.c 的词法分析结果 对于词法分析器本身的源代码的分析结果 二、主要功能 经过不断的修正和测试代码,分析测试结果,该词法分析器主要实现了以下功能: 1. 识别关键字 实验要求:if else while do for main…...

Maven工具复习
Maven从入门到放弃Maven概述Maven 的配置Maven的基本使用IDEA 配置MAVENMaven坐标IDEA 创建MavenIDEA 导入Maven关于右侧Maven小标签(也就是Maven面板)找不到问题的解决办法关于不小心把IDEA主菜单搞消失的解决办法依赖管理Maven概述 Maven是一个工具提供了一套标准的项目结构…...
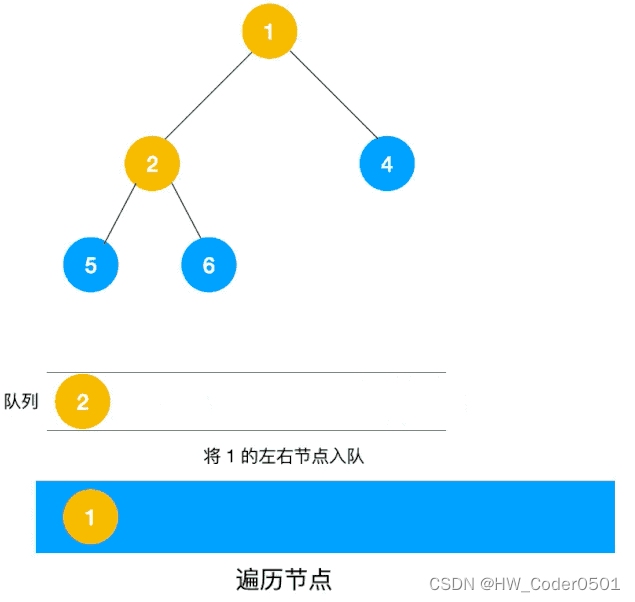
算法总结-深度优先遍历和广度优先遍历
深度优先遍历(Depth First Search,简称DFS) 与广度优先遍历(Breath First Search,简称BFS)是图论中两种非常重要的算法,生产上广泛用于拓扑排序,寻路(走迷宫),搜索引擎,爬虫等。 一、深度优先遍历 深度优先…...

【Linux】Centos安装mvn命令(maven)
🍁博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 文章目录一、下载maven包方法一:官…...

iOS越狱技术深度解析:安全漏洞利用与系统权限获取方案
iOS越狱技术深度解析:安全漏洞利用与系统权限获取方案 【免费下载链接】Jailbreak iOS 26.4 - 26, 17 - 17.7.5 & iOS 18 - 18.7.3 Jailbreak Tools, Cydia/Sileo/Zebra Tweaks & Jailbreak News Updates || AI Jailbreak Finder 👇 项目地址:…...

AI任务管理新范式:结构化描述如何提升人机协作效率
1. 项目概述:一个为AI而生的任务管理范式最近在GitHub上看到一个挺有意思的项目,叫todo-for-ai/todo-for-ai。初看名字,你可能会觉得这又是一个普通的待办事项应用,只不过加了个“AI”的噱头。但当我深入探究其设计哲学和实现细节…...

Denoiser项目快速入门:5分钟完成语音降噪环境搭建
Denoiser项目快速入门:5分钟完成语音降噪环境搭建 【免费下载链接】denoiser Real Time Speech Enhancement in the Waveform Domain (Interspeech 2020)We provide a PyTorch implementation of the paper Real Time Speech Enhancement in the Waveform Domain. I…...

Page Assist终极指南:3步安装本地AI浏览器助手,开启智能网页浏览新时代
Page Assist终极指南:3步安装本地AI浏览器助手,开启智能网页浏览新时代 【免费下载链接】page-assist Use your locally running AI models to assist you in your web browsing 项目地址: https://gitcode.com/GitHub_Trending/pa/page-assist 想…...

从系统光标到个性化指针:动漫主题鼠标指针的完整实现指南
1. 项目概述:从“二次元”到“生产力”的鼠标指针革命如果你和我一样,每天有超过8小时的时间与电脑为伴,那么鼠标指针就是你最亲密的“数字伙伴”。它可能是一个单调的白色箭头,也可能是一个乏味的沙漏。但你想过吗?这…...

Delphi7 突破局限!借助Python扩展程序能力。
在桌面开发领域,Delphi7 凭借其简洁高效的可视化开发能力、稳定的运行性能,至今仍被许多开发者用于工业自动化、金融终端、桌面工具等项目开发。但不可否认的是,Delphi7 在网络数据抓取、AI交互、复杂数据处理等场景中存在天然局限࿰…...
)
微软 Qlib 实战:从零构建跑赢大盘的 AI 智能选股策略(附最新回测与全流程代码)
在 GitHub 的量化投资社区中,微软亚洲研究院开源的 Qlib 毫无疑问是王者级别的存在(13k Stars)。传统的量化策略通常依赖主观经验设定的指标(如:均线突破、MACD背离),而 Qlib 则是让 人工智能&a…...

OpenClaw Studio:基于Web技术的可视化自动化工作流构建平台解析
1. 项目概述:从开源仓库到创意工坊的蜕变 看到 grp06/openclaw-studio 这个项目标题,我的第一反应是:这又是一个在 GitHub 上诞生的、充满潜力的开源工具。 grp06 看起来像是一个团队或个人的标识,而 openclaw-studio 则直…...

搜索广告算法工程师大模型学习--1.计划
大模型时代搜索广告算法专家:理论与数学重构进阶计划 前置约束与学习定调: 核心目标:从传统 NLP 分类思维彻底向大模型生成式思维(Generative)与搜索广告业务思维(Ranking/Retrieval)转型。学…...

SpringBoot+Vue民宿管理系统源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...