数据分析:麦当劳食品营养数据探索并可视化

系列文章目录
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
| 专栏案例:数据分析 |
|---|
| 数据分析:某电商优惠卷数据分析 |
| 数据分析:旅游景点销售门票和消费情况分析 |
| 数据分析:消费者数据分析 |
| 数据分析:餐厅订单数据分析 |
| 数据分析:基于随机森林(RFC)对酒店预订分析预测 |
| 数据分析:基于K-近邻(KNN)对Pima人糖尿病预测分析 |
文章目录
- 系列文章目录
- 1、实验简介
- 2、数据说明
- 2.1数据集的整体特征
- 2.2属性描述
- 3、实验环境
- 4、实验步骤
- 4.1数据准备
- 4.2数据质量检查
- 4.3探索性分析
- 4.4通过轮廓图和相关图来比较特征
1、实验简介
麦当劳(McDonald’s)是源自美国南加州的跨国连锁快餐店,也是全球最大的快餐连锁店,主要贩售汉堡包及薯条、炸鸡、汽水、冰品、沙拉、水果、咖啡等快餐食品。近年来,越来越多的人意识到快餐食品的不健康性,麦当劳也成了“垃圾食品”的代名词。美国纪录片《Super Size Me》记录了一个人一个月内只吃麦当劳后的身体变化,更引起了人们对于快餐食品营养超标的担忧。本分析旨在通过实证方法评估麦当劳数据集中260个产品的营养成分,我们先从一些标准的数据探索分析开始,之后讨论并使用Plotly绘制交互式散点图以展示不同的营养指标。
2、数据说明
2.1数据集的整体特征
|数据集名称 |数据类型 |特征数 |实例数 |值缺失 |相关任务|
| 数据集名称 | 数据类型 | 特征数 | 实例数 | 值缺失 | 相关任务 |
|---|---|---|---|---|---|
| 麦当劳餐品营养成分数据集 | 字符、数值数据 | 24 | 260 | 0 | 可视化 |
2.2属性描述
| 属性 | 数据类型 | 字段描述 |
|---|---|---|
| Category | String | 食物类别 |
| Item | String | 食品名称 |
| Serving Size | String | 食用分量 |
| Calories | Integer | 卡路里 |
| Calories from Fat | Integer | 来自脂肪的卡路里 |
| Total Fat | Integer | 脂肪总量 |
| Total Fat (% Daily Value) | Integer | 脂肪总量占每日推荐摄入量的百分比 |
| Saturated Fat | Integer | 饱和脂肪 |
| Saturated Fat (% Daily Value) | Integer | 饱和脂肪占每日推荐摄入量的百分比 |
| Trans Fat | Integer | 反式脂肪 |
| Cholesterol | Integer | 胆固醇 |
| Cholesterol (% Daily Value) | Integer | 胆固醇占每日推荐摄入量的百分比 |
| Sodium | Integer | 钠 |
| Sodium (% Daily Value) | Integer | 钠占每日推荐摄入量的百分比 |
| Carbohydrates | Integer | 碳水化合物 |
| Carbohydrates (% Daily Value) | Integer | 碳水化合物占每日推荐摄入量的百分比 |
| Dietary Fiber | Integer | 膳食纤维 |
| Dietary Fiber (% Daily Value) | Integer | 膳食纤维占每日推荐摄入量的百分比 |
| Sugars | Integer | 糖分 |
| Protein | Integer | 蛋白质 |
| Vitamin A (% Daily Value) | Integer | 维他命A占每日推荐摄入量的百分比 |
| Vitamin C (% Daily Value) | Integer | 维他命C占每日推荐摄入量的百分比 |
| Calcium (% Daily Value) | Integer | 钙占每日推荐摄入量的百分比 |
| Iron (% Daily Value) | Integer | 铁占每日推荐摄入量的百分比 |
3、实验环境
Python 3.9
Anaconda
Jupyter Notebook
4、实验步骤
4.1数据准备
加载需要的模块
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.tools as tls
import warnings
warnings.filterwarnings('ignore')
加载数据
#加载数据集
menu = pd.read_csv("/home/mw/mcdonald_s_menu.csv")#预览数据集前5行
menu.head()
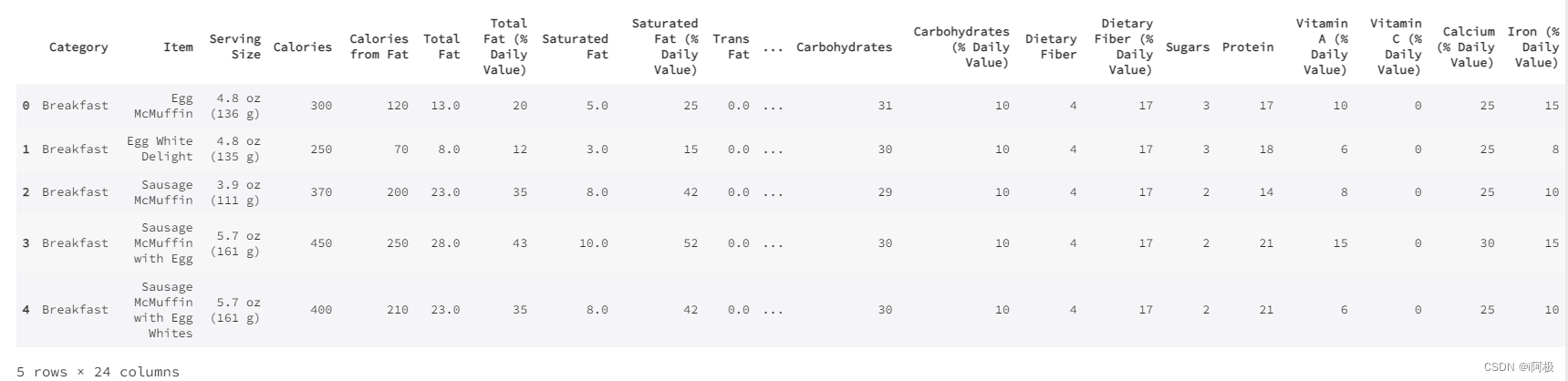
查看数据集行列数
print("该数据集共有 {} 行 {} 列".format(menu.shape[0],menu.shape[1]))

每一行代表一样麦当劳产品;24列,包括了产品的类别,名称,大小,以及营养成分(如卡路里,脂肪,胆固醇,钠,碳水化合物,膳食纤维,糖,蛋白质,维他命A,维他命C,钙,铁)等内容。
4.2数据质量检查
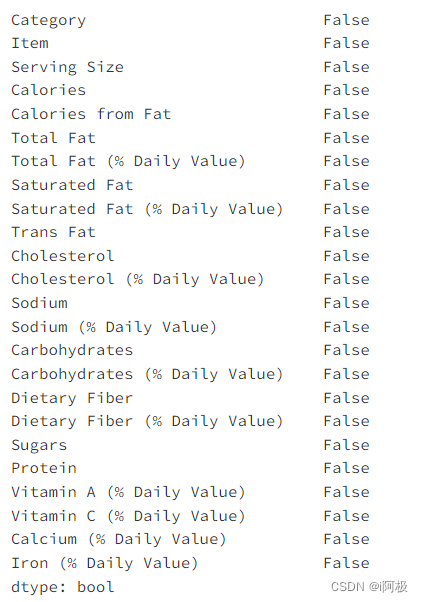
检查空值
menu.isnull().any()
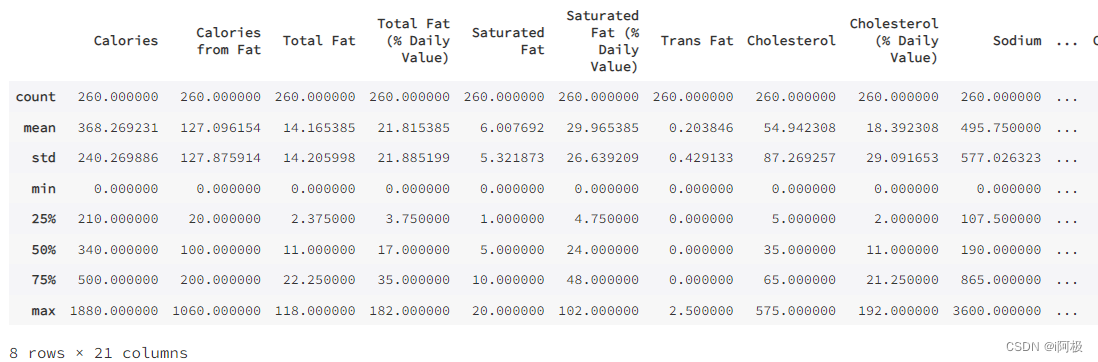
各个column内容的描述性统计
menu.describe()
4.3探索性分析
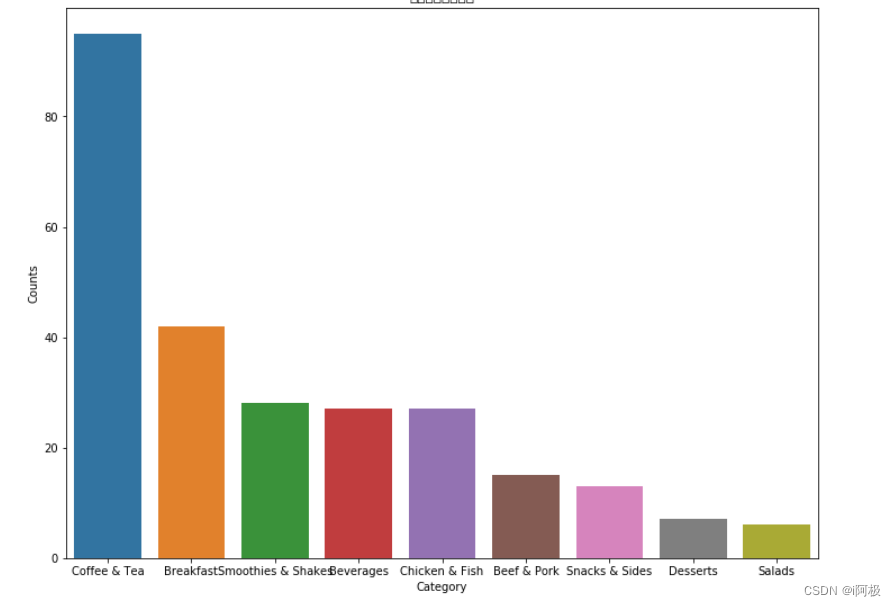
首先,我们看一下每一类食品的数量,并绘图展示:
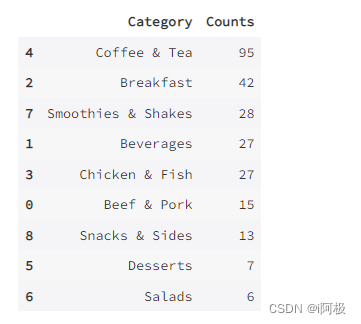
count_by_category = menu[["Category"]].groupby(["Category"]).size().reset_index(name = 'Counts').sort_values(by = "Counts", ascending = False)
count_by_category
#条形图
fig, ax = plt.subplots(figsize = (12,9))
ax = sns.barplot(x="Category", y="Counts", data = count_by_category).set_title("每一类食品的数量")
#饼形图
plt.figure(figsize = (12,9))
plt.pie(x = count_by_category["Counts"], labels=count_by_category["Category"], autopct='%1.0f%%',)
plt.show()
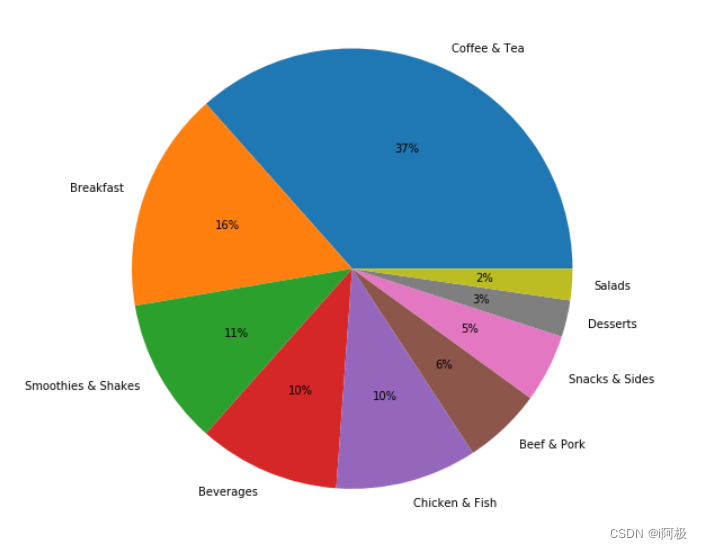
从条形图和饼形图可以看出,数量排名第一的品类是咖啡和茶,高达37%;之后是早餐(16%),冰沙奶昔(11%),饮品(10%),鸡肉鱼肉(10%)和牛肉猪肉(6%)。小吃,甜点和沙拉占比最少,其中沙拉类食品仅占所有食品的2%。
接下来,我们看看,不同品类的食物,其卡路里含量如何
#盒形图
fig, ax = plt.subplots(figsize = (12,9))
ax = sns.boxplot(x = 'Category', y = 'Calories', data = menu).set_title("卡路里")
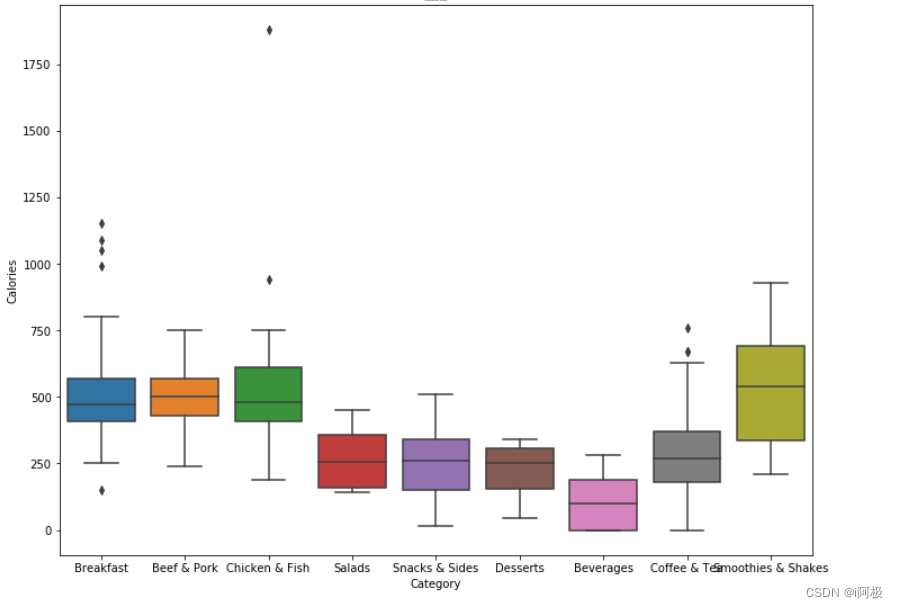
一些有趣的发现:
- 早餐系列、猪肉牛肉系列、鸡肉鱼肉系列的卡路里含量较高(主食),冰沙奶昔系列的卡路里含量最高;
- 沙拉、小食、甜品、咖啡和茶的卡路里含量较低,饮品的卡路里含量最低;
- 早餐系列、鸡肉鱼肉系列和咖啡茶系列有一些异常值(outlier),可能是一些大份食物。
以上分析提醒了我们,食品的卡路里含量(及其他成分含量)会受到其份量的影响,将食品调整至同样的份量可以让之后的分析更加客观。
通过回顾数据集中“Serving Size”一栏,我们发现麦当劳对份量的标注并不完全统一,有如下几种形式:
1)4.8 oz (136 g) 2)1 cookie (33 g) 3)21 fl oz cup 4) 1 carton (236 ml) 5) 6 fl oz (177 ml) 6) 16.9 fl oz
固体食物的份量标注比较统一,都是按1)的形式,标出了oz和g两种重量单位,唯一的特例是2),只标注了g这一重量单位。
半液态和液态食物的份量标注比较杂乱,有些和固体食物一样标注了重量,但大部分属于3)-6),即标注fl oz和/或ml两种体积单位。
因此我们的提取原则是,重量单位优先提取g,没有g再提取oz,并转换为g;体积单位优先提取ml,没有ml再提取fl oz,并转换为ml。
*注:1盎司(oz)=28.35克(g);1美制液体盎司(fl oz)=29.57毫升(ml)
因为重量单位和体积单位的不一致,为了之后的分析方便,我们假设1ml的液体等于1g,并把一些半液态和液态食品的份量从体积转为重量。
将食品调整至同样的份量(按100g计算)
#正则表达式匹配几种不同的份量标注方式
import re
p1 = re.compile(r'[(](.*?)[ g)]')
p2 = re.compile(r'(.*?)[ ]')#定义函数,提取份量数据
def getLambda(x, p1, p2):try: val = float(re.findall(p1,x)[0])except:val = float(re.findall(p2,x)[0]) * 29.57 # 提取的是fl oz,乘以29.57转换为mlreturn val#调整menu数据集
norm_menu = menu.iloc[:,:]
norm_menu["Size g"] = norm_menu["Serving Size"].apply(lambda x: getLambda(x, p1, p2))
norm_menu["Calories per 100g"] = (norm_menu['Calories']/norm_menu["Size g"]) * 100norm_menu.head()
#盒形图
fig, ax = plt.subplots(figsize = (12,9))
sns.boxplot(x = 'Category', y = 'Calories per 100g', data = norm_menu)
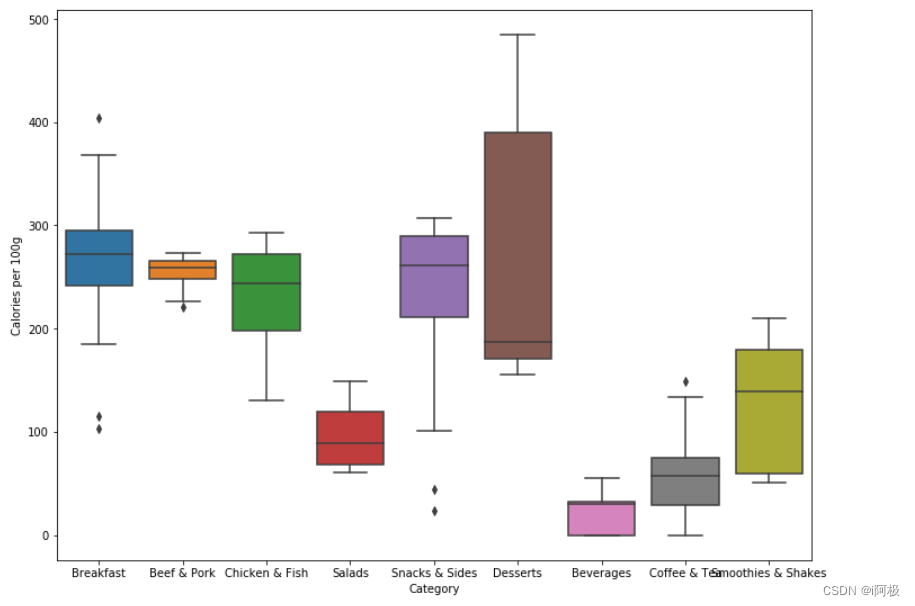
对比没有调整过的数据画出的盒形图可以得知:
- 固态食品中,主食(早餐,牛肉猪肉,鸡肉鱼肉)依旧是卡路里含量最高的食品。之前我们以为卡路里含量较低的小食、甜点等,其实只是因为份量较小,如果换算成同样的份量,卡路里含量也不低,和主食持平。只有沙拉的卡路里含量远低于其他类食品,其平均值是主食的一半左右。
- 液体及半液体的饮品,卡路里含量总体低于固体食品,但冰沙奶昔的卡路里明显高于饮料和咖啡茶,甚至高于沙拉。
因此,对于一个选择麦当劳就餐的减肥人士来说,为了填饱肚子,最好点一份沙拉。如果还想点一份饮品,不建议点冰沙奶昔。
4.4通过轮廓图和相关图来比较特征
轮廓图
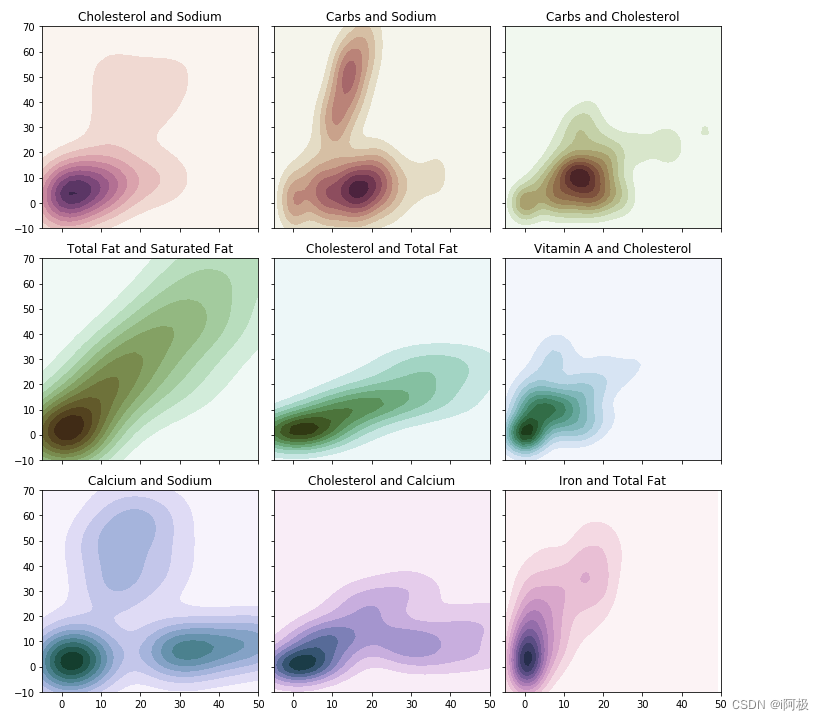
我们首先看看一个特征如何影响其他特征:轮廓图或者KDE图可以提供一个特征相对于另一个特征的分布。简单来讲,这让我们对定量数据有一个快速的感知。调用了Seaborn中的kdeplot函数。我们选取了几个主要特征,并生成了9张轮廓图,如下所示:
# KDE图
f, axes = plt.subplots(3, 3, figsize=(10, 10), sharex=True, sharey=True)s = np.linspace(0, 3, 10)
cmap = sns.cubehelix_palette(start=0.0, light=1, as_cmap=True)# Generate and plot a random bivariate dataset
x = menu['Cholesterol (% Daily Value)'].values
y = menu['Sodium (% Daily Value)'].values
sns.kdeplot(x, y, cmap=cmap, shade=True, cut=5, ax=axes[0,0])
axes[0,0].set(xlim=(-10, 50), ylim=(-30, 70), title = 'Cholesterol and Sodium')cmap = sns.cubehelix_palette(start=0.333333333333, light=1, as_cmap=True)# Generate and plot a random bivariate dataset
x = menu['Carbohydrates (% Daily Value)'].values
y = menu['Sodium (% Daily Value)'].values
sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[0,1])
axes[0,1].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Carbs and Sodium')cmap = sns.cubehelix_palette(start=0.666666666667, light=1, as_cmap=True)# Generate and plot a random bivariate dataset
x = menu['Carbohydrates (% Daily Value)'].values
y = menu['Cholesterol (% Daily Value)'].values
sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[0,2])
axes[0,2].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Carbs and Cholesterol')cmap = sns.cubehelix_palette(start=1.0, light=1, as_cmap=True)# Generate and plot a random bivariate dataset
x = menu['Total Fat (% Daily Value)'].values
y = menu['Saturated Fat (% Daily Value)'].values
sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[1,0])
axes[1,0].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Total Fat and Saturated Fat')cmap = sns.cubehelix_palette(start=1.333333333333, light=1, as_cmap=True)# Generate and plot a random bivariate dataset
x = menu['Total Fat (% Daily Value)'].values
y = menu['Cholesterol (% Daily Value)'].values
sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[1,1])
axes[1,1].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Cholesterol and Total Fat')cmap = sns.cubehelix_palette(start=1.666666666667, light=1, as_cmap=True)# Generate and plot a random bivariate dataset
x = menu['Vitamin A (% Daily Value)'].values
y = menu['Cholesterol (% Daily Value)'].values
sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[1,2])
axes[1,2].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Vitamin A and Cholesterol')cmap = sns.cubehelix_palette(start=2.0, light=1, as_cmap=True)# Generate and plot a random bivariate dataset
x = menu['Calcium (% Daily Value)'].values
y = menu['Sodium (% Daily Value)'].values
sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[2,0])
axes[2,0].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Calcium and Sodium')cmap = sns.cubehelix_palette(start=2.333333333333, light=1, as_cmap=True)# Generate and plot a random bivariate dataset
x = menu['Calcium (% Daily Value)'].values
y = menu['Cholesterol (% Daily Value)'].values
sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[2,1])
axes[2,1].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Cholesterol and Calcium')cmap = sns.cubehelix_palette(start=2.666666666667, light=1, as_cmap=True)# Generate and plot a random bivariate dataset
x = menu['Iron (% Daily Value)'].values
y = menu['Total Fat (% Daily Value)'].values
sns.kdeplot(x, y, cmap=cmap, shade=True, ax=axes[2,2])
axes[2,2].set(xlim=(-5, 50), ylim=(-10, 70), title = 'Iron and Total Fat')f.tight_layout()
Pearson相关图
现在绘制Pearson相关图,检查不同营养指标之间的相关程度。这次,我们调用了Plotly的交互式绘图功能,绘制特征之间相关性的热图(Heatmap),如下所示:
data = [go.Heatmap(z = menu.iloc[:, 3:].corr().values,x = menu.columns.values,y = menu.columns.values,colorscale = 'Viridis',text = menu.iloc[:, 3:].corr().round(2).astype(str),opacity = 1.0)
]layout = go.Layout(title = '各个营养指标的Pearson相关图',xaxis = dict(ticks='', nticks=36),yaxis = dict(ticks=''),width = 900, height = 700,
)fig = go.Figure(data = data, layout = layout)
py.iplot(fig, filename = 'labelled-heatmap')
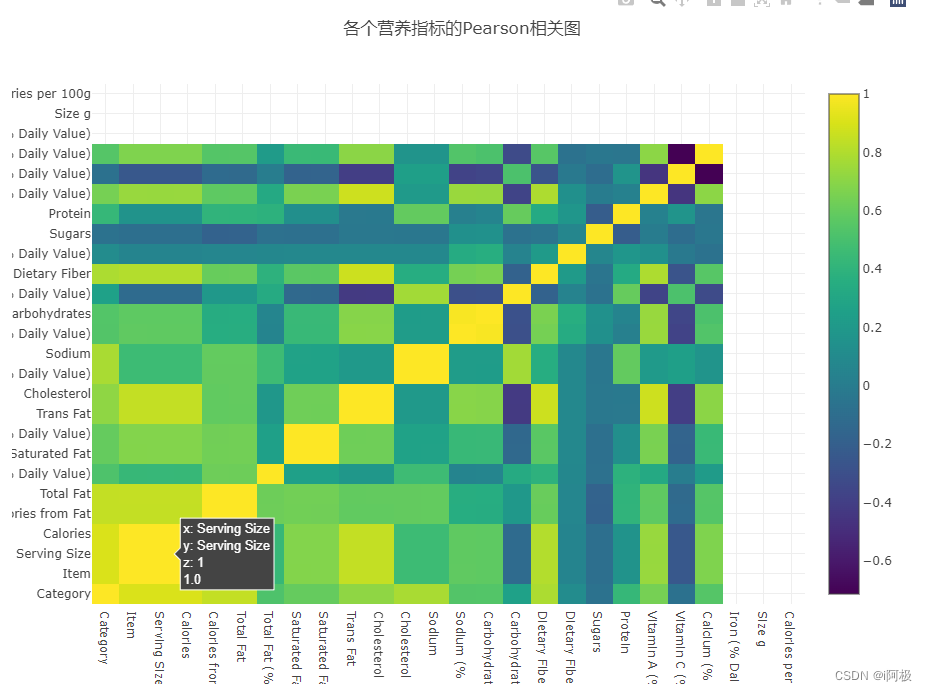
点击不同的方格,可以查看某两个特征的相关性。颜色越趋近于黄色,说明两者正相关性越强。颜色越趋近于紫色,说明两者负相关性越强。
- 从相关图中可以看出明显相关的特征,例如份量和卡路里的相关性高达0.9。
- 然而,有一些相关性非常不直观。例如,总脂肪和饱和脂肪/反式脂肪之间存在相当弱的相关性,但在我们普通人的认知中,这两者理应早存一定相关性。
- 热图也从负相关图(深蓝/黑)的斑点中引出了有趣的发现。例如,它表明碳水化合物通常与反式脂肪,胆固醇,钠,膳食纤维和维生素A呈负相关。这与碳水化合物的负相关性确实很多。
数据质量是否存在任何问题?
- 现在很明显,碳水化合物列与其他列负相关程度很强,这是符合常识的。然而,或许存在如下可能性:含碳水化合物的食物可能除了碳水化合物之外没有其他东西,从而导致了上面提到的负相关性,这也是需要在分析中结合实际情况思考的。
订阅热门专栏:
《数据分析之道》
《数据分析之术》
《机器学习案例》
《数据分析案例》
📢文章下方有交流学习区!一起学习进步!💪💪💪
📢首发CSDN博客,创作不易,如果觉得文章不错,可以点赞👍收藏📁评论📒
📢你的支持和鼓励是我创作的动力❗❗❗
相关文章:
数据分析:麦当劳食品营养数据探索并可视化
系列文章目录 作者:i阿极 作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒关注…...

ES6标准
ECMAScript 6.0(以下简称 ES6)是 JavaScript 语言的下一代标准 前端es6是模块化开发;es6模块化规范就是浏览器端与服务器端通用的模块化开发规范,其中定义了每一个JavaScript文件都是一个独立的模块,导入其他模块成员…...
ASP一个物流商品运输系统的设计与实现
物流运输行业的今天正朝着追求高效、低成本、稳定可靠的方向发展。本文详细介绍了网上物流管理系统,涉及到客户端运输线路设计、过程跟踪等功能模块以及管理员端的相应模块的具体实现,分析了整个系统的架构、工作原理、实现功能等。系统采用ASPMS SQL以B…...

肖 sir_就业课__009ui自动化讲解
ui自动化讲解 1、你做过自动化测试吗?做过 ui自动化测试、接口自动化、app自动化 2、你讲下你做的ui接口自动化? (1)第一种:按照线性流程讲解 :pythonselenium 库做ui自动化 (2)第二…...

「线性DP」花店橱窗
花店橱窗 https://ac.nowcoder.com/acm/contest/24213/1005 题目描述 小q和他的老婆小z最近开了一家花店,他们准备把店里最好看的花都摆在橱窗里。 但是他们有很多花瓶,每个花瓶都具有各自的特点,因此,当各个花瓶中放入不同…...

数组的去重方法
1、ES6的Set方法去重 new Set是ES6新推出的一种类型。它和数组的区别在于,Set类型中的数据不可以有重复的值。当然,数组的一些方法Set也无法调用。 使用方法:将一个数组转化为Set数据,再转化回来,就完成了去重。 cons…...

ESP32-LORA通信
文章目录好久没更新博客了,今天清明节,写个LORA通信。在此记念在天堂的外婆。祝她安好LORA通信简介一、模块二、使用步骤1.电脑通过USB串口模块联接LORA模块2.ESP32连接LORA通信进行收发通信3.电脑运行调试助手,ESP32运行代码。实现LORA通信测…...
博客首页效果
学习来自风宇blog的博客首页效果 全部用的基本上都是原生的html,css,js特别是flex布局的使用,主轴方向可以是横轴,也可以是纵轴,弹性项还可可以使用百分比sticky粘性布局,作为侧边栏,它不会超出…...

【LeetCode】剑指 Offer(29)
目录 题目:剑指 Offer 56 - II. 数组中数字出现的次数 II - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 题目:剑指 Offer 57. 和为s的两个数…...

自然语言处理(八):Lexical Semantics
目录 1. Sentiment Analysis 2. Lexical Database 2.1 What is Lexical Database 2.2 Definitions 2.3 Meaning Through Dictionary 2.4 WordNet 2.5 Synsets 2.6 Hypernymy Chain 3. Word Similarity 3.1 Word Similarity with Paths 3.2 超越路径长度 3.3 Abstra…...

推荐一款 AI 脑图软件,助你神速提高知识体系搭建
觅得一款神器,接近我理想中,搭建知识体系的方法,先来看视频作为数据库开发或管理者,知识体系搭建尤为重要。来看看近些年缺乏足够数据库知识面造成的危害:a/ 数据安全风险:例如,2017年Equifax数…...

掌握这些“学习方法和工具”,让你事半功倍!
在中国这个高竞争的社会环境下,学习成为了每个人都需要掌握的技能。然而,学习并不仅仅是读书和听课,更是需要一系列高效的方法和习惯来提高效率。本文将介绍一些实用的学习经验和方法,以及推荐一些国内好的学习工具和平台…...

MyBatis 源码解析 面试题总结
MyBatis源码学习环境下载 文章目录1、工作原理1.1 初始化1.1.1 系统启动的时候,加载解析全局配置文件和相应的映射文件1.1.2 建造者模式帮助我们解决复杂对象的创建:1.2 处理SQL请求的流程1.2.1 通过sqlSession中提供的API方法来操作数据库1.2.2 获取接口…...

「业务架构」需求工程—需求规范(第3部分)
将用户和系统需求记录到文档中。需求规范它是将用户和系统需求写入文档的过程。需求应该是清晰的、容易理解的、完整的和一致的。在实践中,这是很难实现的,因为涉众以不同的方式解释需求,并且在需求中经常存在固有的冲突和不一致。正如我们之…...
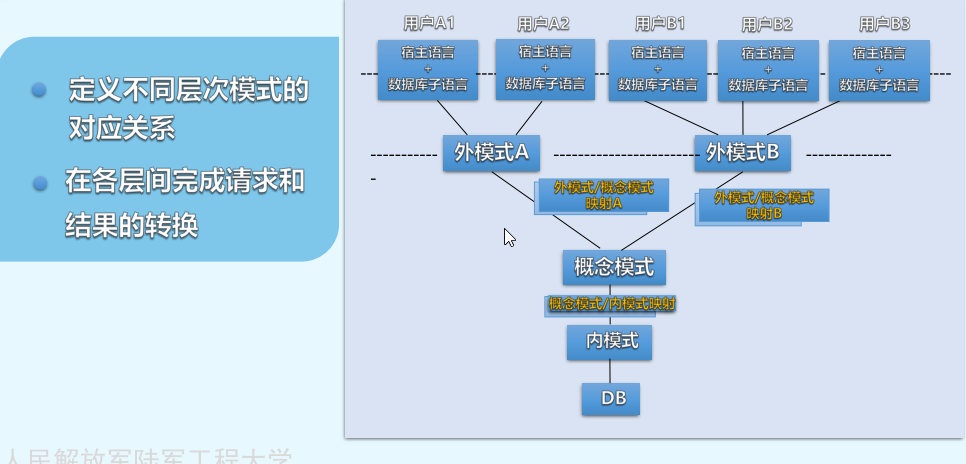
chapter-1数据管理技术的发展
以下课程来源于MOOC学习—原课程请见:数据库原理与应用 数据管理技术的发展 发展三阶段 人工管理【1950前】 采用批处理;主要用于科学计算;外部设备只有磁带,卡片,纸带等 特点:1.数据面向应用2.数据不保…...
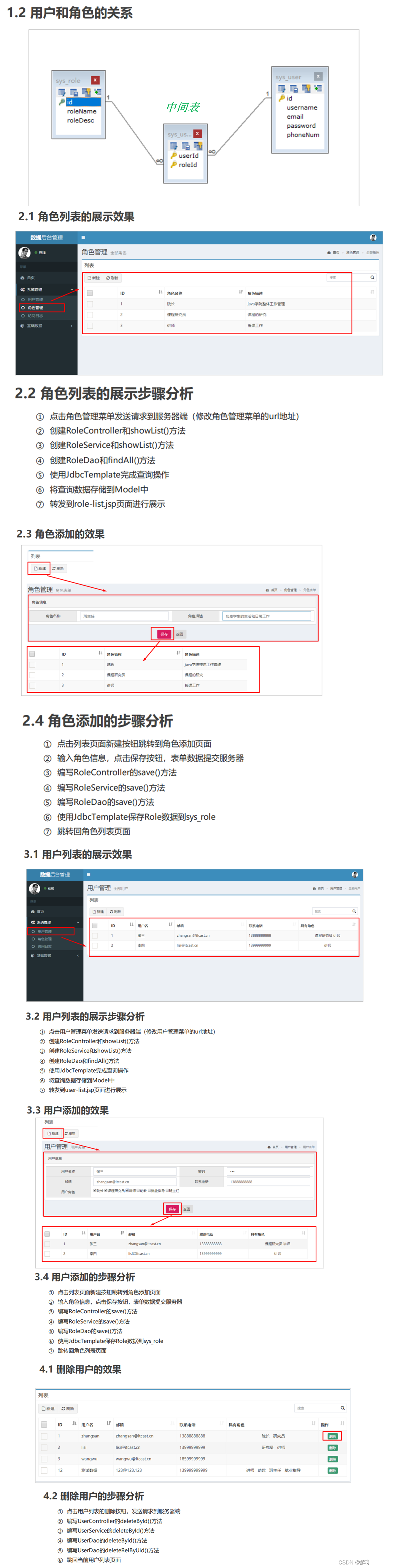
23.Spring练习(spring、springMVC)
目录 一、Spring练习环境搭建。 (1)设置服务器启动的展示页面。 (2)创建工程步骤。 (3)applicationContext.xml配置文件。 (4)spring-mvc.xml配置文件。 (5&#x…...
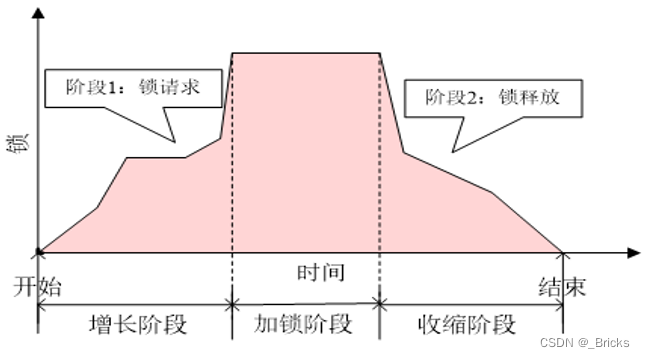
【数据库原理 • 七】数据库并发控制
前言 数据库技术是计算机科学技术中发展最快,应用最广的技术之一,它是专门研究如何科学的组织和存储数据,如何高效地获取和处理数据的技术。它已成为各行各业存储数据、管理信息、共享资源和决策支持的最先进,最常用的技术。 当前…...

内部人员或给企业造成毁灭性损失
全球每年有近百万企业因数据丢失而倒闭。而媒体几乎每个月都会报道数百起恶意和无意的内部威胁事件,导致的企业机构名誉损失、巨额赔款甚至于面临运营危机。 内部威胁主要有三个来源: 1、疏忽或无意的员工; 2、有意识或恶意的内部人员&…...
【技巧】Word“只读方式”的设置与取消
如果你担心在阅读Word文档的时候,不小心修改并保存了内容,那就给文档设置“只读方式”吧,这样就算不小心做了修改也不能随意保存。 Word文档的“只读方式”有两种模式,对此不清楚的小伙伴,来看看如何设置和取消吧。 模…...
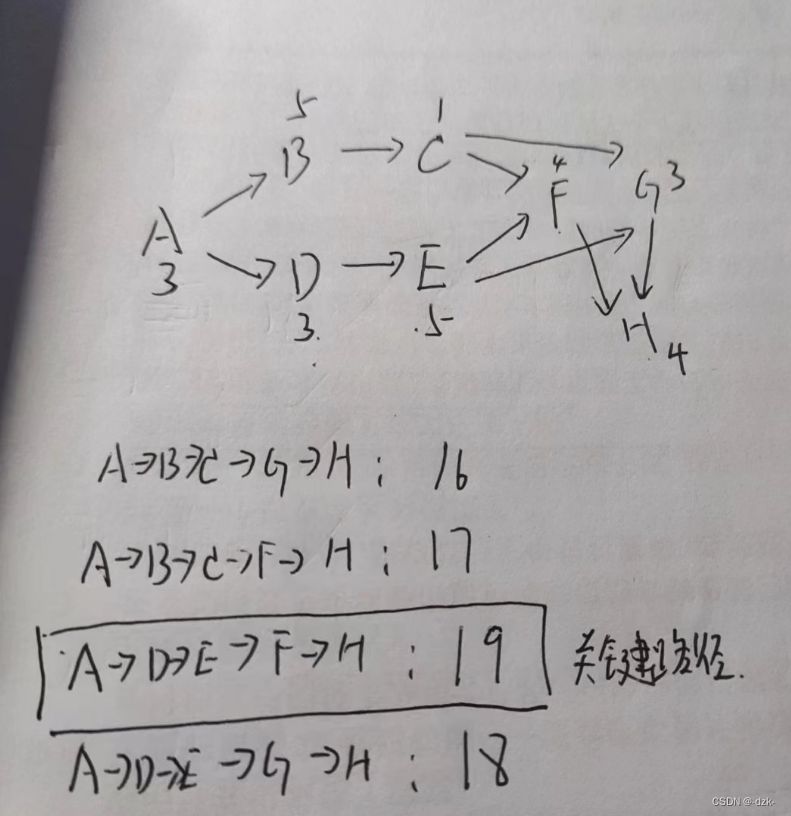
【软考备战·希赛网每日一练】2023年4月12日
文章目录一、今日成绩二、错题总结第一题三、知识查缺题目及解析来源:2023年04月12日软件设计师每日一练 一、今日成绩 二、错题总结 第一题 解析: 依据题目画出PERT图如下: 关键路径长度(从起点到终点的路径中最长的一条&#x…...

RB3201-RBProtocol:ESP32机器人轻量通信协议栈解析
1. RB3201-RBProtocol 库深度解析:面向机器人控制的轻量级嵌入式通信协议栈 1.1 协议背景与工程定位 RB3201-RBProtocol 是由 RoboticsBrno 团队开发的嵌入式通信协议库,专为 ESP32 平台设计,核心目标是实现与 Android 端 RbController 移动…...

2026年项目管理工具选型指南:功能对比、适用场景与避坑建议
项目管理工具早已不只是任务看板,而是连接目标、需求、计划、资源、交付、知识与复盘的管理底座。本文选取 ONES、Tower、Jira、Asana、monday.com、ClickUp、Microsoft Planner、Smartsheet、Notion 九款主流项目管理工具展开评估,帮助企业中高层研发负…...

门店小程序和收银系统有什么区别?
门店小程序和收银系统有什么区别?在门店数字化过程中,很多企业会同时接触到小程序与收银系统,但两者在功能定位和使用场景上存在明显差异。门店小程序和收银系统的本质区别,在于一个偏向“获客与转化入口”,一个偏向“…...

从单工具到插件集:在Coze IDE里用Python/Node.js打造你的专属工具链
从单工具到插件集:在Coze IDE里用Python/Node.js打造你的专属工具链 在当今快速发展的AI应用开发领域,开发者们不再满足于简单的API调用和单一功能实现。随着业务逻辑的复杂化,如何高效地构建、管理和部署一系列相互关联的工具链,…...

GeoServer高效发布SHP文件全攻略:从单文件到批量处理的进阶技巧
GeoServer高效发布SHP文件全攻略:从单文件到批量处理的进阶技巧 在GIS数据发布领域,Shapefile(SHP)作为行业标准格式已有近30年历史,而GeoServer作为开源地图服务器的中流砥柱,二者的结合构成了空间数据服务…...

STM32 TIM编码器模式实战:如何精准计算步进电机闭环控制的脉冲对应关系?
STM32 TIM编码器模式实战:步进电机闭环控制中的脉冲精确换算 步进电机在工业自动化、3D打印和精密仪器中扮演着关键角色,而闭环控制则是确保其运动精度的核心技术。许多工程师在实现闭环控制时,常常困惑于如何准确建立编码器脉冲与电机控制脉…...

忍者像素绘卷效果实测:同一Prompt下不同步数对像素锐度影响对比分析
忍者像素绘卷效果实测:同一Prompt下不同步数对像素锐度影响对比分析 1. 测试背景与目的 忍者像素绘卷作为一款基于Z-Image-Turbo深度优化的图像生成工具,其独特的16-Bit复古游戏美学风格吸引了大量创作者。在实际使用中,我们发现"描绘…...

重构macOS鼠标体验:从痛点到解决方案的技术探索
重构macOS鼠标体验:从痛点到解决方案的技术探索 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 【问题发现:被忽视的交互…...

smart-mqtt v1.5.4发布,认证能力大升级
smart-mqtt v1.5.4正式发布,此次版本聚焦企业级连接认证能力升级,推出全新高级认证插件,在高性能底座上补齐企业级接入能力,还公布了获取方式与未来规划。版本核心亮点v1.5.4重点通过advanced-auth-plugin让连接认证更适配企业真实…...

5步快速上手:百度网盘直链解析工具实现高速下载
5步快速上手:百度网盘直链解析工具实现高速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘的下载速度限制而烦恼吗?百度网盘直链解…...