限流:计数器、漏桶、令牌桶 三大算法的原理与实战(史上最全)
限流
限流是面试中的常见的面试题(尤其是大厂面试、高P面试)

注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请到文末《技术自由圈》公号获取
为什么要限流
简单来说:
限流在很多场景中用来限制并发和请求量,比如说秒杀抢购,保护自身系统和下游系统不被巨型流量冲垮等。
以微博为例,例如某某明星公布了恋情,访问从平时的50万增加到了500万,系统的规划能力,最多可以支撑200万访问,那么就要执行限流规则,保证是一个可用的状态,不至于服务器崩溃,所有请求不可用。
参考图谱
系统架构知识图谱(一张价值10w的系统架构知识图谱)
https://www.processon.com/view/link/60fb9421637689719d246739
秒杀系统的架构
https://www.processon.com/view/link/61148c2b1e08536191d8f92f
限流的思想
在保证可用的情况下尽可能多增加进入的人数,其余的人在排队等待,或者返回友好提示,保证里面的进行系统的用户可以正常使用,防止系统雪崩。
日常生活中,有哪些需要限流的地方?
像我旁边有一个国家景区,平时可能根本没什么人前往,但是一到五一或者春节就人满为患,这时候景区管理人员就会实行一系列的政策来限制进入人流量,
为什么要限流呢?
假如景区能容纳一万人,现在进去了三万人,势必摩肩接踵,整不好还会有事故发生,这样的结果就是所有人的体验都不好,如果发生了事故景区可能还要关闭,导致对外不可用,这样的后果就是所有人都觉得体验糟糕透了。
限流的算法
限流算法很多,常见的有三类,分别是计数器算法、漏桶算法、令牌桶算法,下面逐一讲解。
限流的手段通常有计数器、漏桶、令牌桶。注意限流和限速(所有请求都会处理)的差别,视
业务场景而定。
(1)计数器:
在一段时间间隔内(时间窗/时间区间),处理请求的最大数量固定,超过部分不做处理。
(2)漏桶:
漏桶大小固定,处理速度固定,但请求进入速度不固定(在突发情况请求过多时,会丢弃过多的请求)。
(3)令牌桶:
令牌桶的大小固定,令牌的产生速度固定,但是消耗令牌(即请求)速度不固定(可以应对一些某些时间请求过多的情况);每个请求都会从令牌桶中取出令牌,如果没有令牌则丢弃该次请求。
计数器算法
计数器限流定义:
在一段时间间隔内(时间窗/时间区间),处理请求的最大数量固定,超过部分不做处理。
简单粗暴,比如指定线程池大小,指定数据库连接池大小、nginx连接数等,这都属于计数器算法。
计数器算法是限流算法里最简单也是最容易实现的一种算法。
举个例子,比如我们规定对于A接口,我们1分钟的访问次数不能超过100个。
那么我们可以这么做:
- 在一开 始的时候,我们可以设置一个计数器counter,每当一个请求过来的时候,counter就加1,如果counter的值大于100并且该请求与第一个请求的间隔时间还在1分钟之内,那么说明请求数过多,拒绝访问;
- 如果该请求与第一个请求的间隔时间大于1分钟,且counter的值还在限流范围内,那么就重置 counter,就是这么简单粗暴。
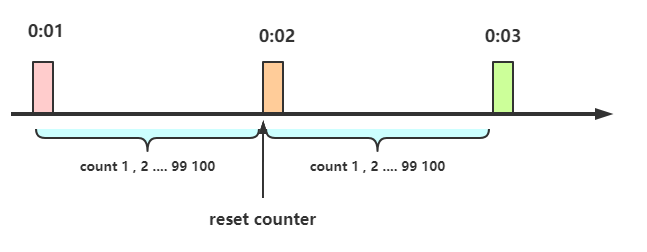
计算器限流的实现
package com.crazymaker.springcloud.ratelimit;import lombok.extern.slf4j.Slf4j;
import org.junit.Test;import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;// 计速器 限速
@Slf4j
public class CounterLimiter
{// 起始时间private static long startTime = System.currentTimeMillis();// 时间区间的时间间隔 msprivate static long interval = 1000;// 每秒限制数量private static long maxCount = 2;//累加器private static AtomicLong accumulator = new AtomicLong();// 计数判断, 是否超出限制private static long tryAcquire(long taskId, int turn){long nowTime = System.currentTimeMillis();//在时间区间之内if (nowTime < startTime + interval){long count = accumulator.incrementAndGet();if (count <= maxCount){return count;} else{return -count;}} else{//在时间区间之外synchronized (CounterLimiter.class){log.info("新时间区到了,taskId{}, turn {}..", taskId, turn);// 再一次判断,防止重复初始化if (nowTime > startTime + interval){accumulator.set(0);startTime = nowTime;}}return 0;}}//线程池,用于多线程模拟测试private ExecutorService pool = Executors.newFixedThreadPool(10);@Testpublic void testLimit(){// 被限制的次数AtomicInteger limited = new AtomicInteger(0);// 线程数final int threads = 2;// 每条线程的执行轮数final int turns = 20;// 同步器CountDownLatch countDownLatch = new CountDownLatch(threads);long start = System.currentTimeMillis();for (int i = 0; i < threads; i++){pool.submit(() ->{try{for (int j = 0; j < turns; j++){long taskId = Thread.currentThread().getId();long index = tryAcquire(taskId, j);if (index <= 0){// 被限制的次数累积limited.getAndIncrement();}Thread.sleep(200);}} catch (Exception e){e.printStackTrace();}//等待所有线程结束countDownLatch.countDown();});}try{countDownLatch.await();} catch (InterruptedException e){e.printStackTrace();}float time = (System.currentTimeMillis() - start) / 1000F;//输出统计结果log.info("限制的次数为:" + limited.get() +",通过的次数为:" + (threads * turns - limited.get()));log.info("限制的比例为:" + (float) limited.get() / (float) (threads * turns));log.info("运行的时长为:" + time);}}计数器限流的严重问题
这个算法虽然简单,但是有一个十分致命的问题,那就是临界问题,我们看下图:
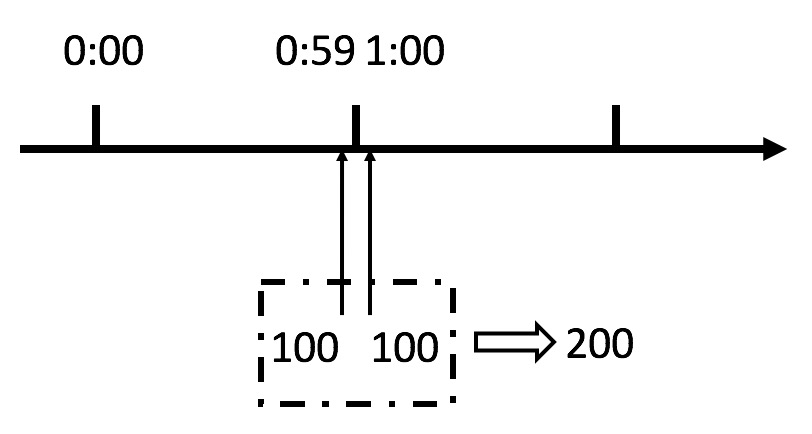
从上图中我们可以看到,假设有一个恶意用户,他在0:59时,瞬间发送了100个请求,并且1:00又瞬间发送了100个请求,那么其实这个用户在 1秒里面,瞬间发送了200个请求。
我们刚才规定的是1分钟最多100个请求(规划的吞吐量),也就是每秒钟最多1.7个请求,用户通过在时间窗口的重置节点处突发请求, 可以瞬间超过我们的速率限制。
用户有可能通过算法的这个漏洞,瞬间压垮我们的应用。
说明:本文会持续更新,更多最新尼恩3高笔记PDF,请从下面的链接获取: 码云
漏桶算法
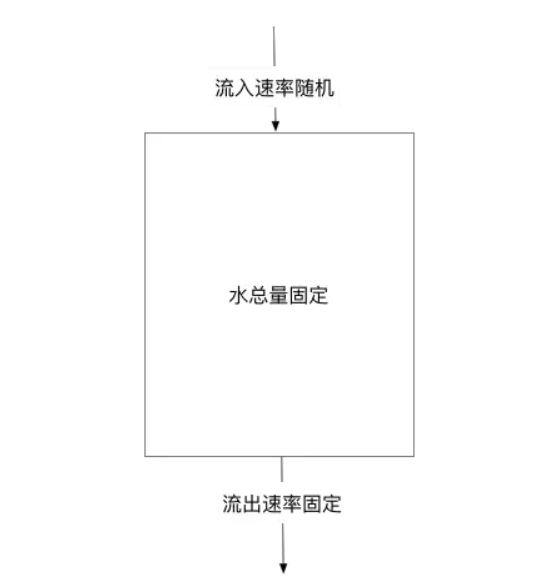
漏桶算法限流的基本原理为:水(对应请求)从进水口进入到漏桶里,漏桶以一定的速度出水(请求放行),当水流入速度过大,桶内的总水量大于桶容量会直接溢出,请求被拒绝,如图所示。
大致的漏桶限流规则如下:
(1)进水口(对应客户端请求)以任意速率流入进入漏桶。
(2)漏桶的容量是固定的,出水(放行)速率也是固定的。
(3)漏桶容量是不变的,如果处理速度太慢,桶内水量会超出了桶的容量,则后面流入的水滴会溢出,表示请求拒绝。
漏桶算法原理
漏桶算法思路很简单:
水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会超过桶可接纳的容量时直接溢出。
可以看出漏桶算法能强行限制数据的传输速率。
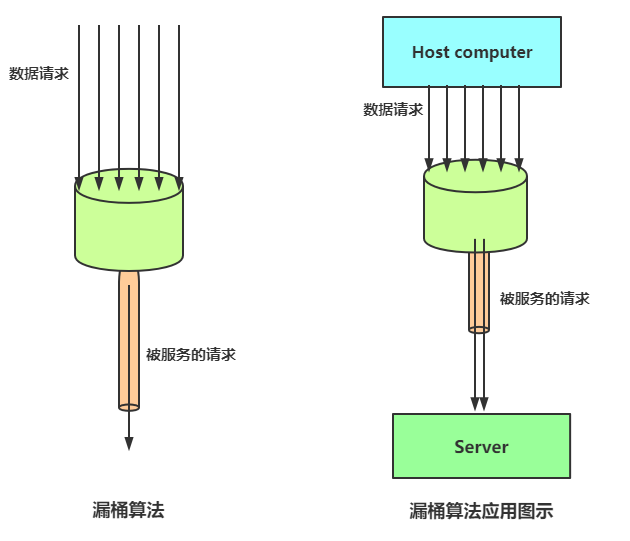
漏桶算法其实很简单,可以粗略的认为就是注水漏水过程,往桶中以任意速率流入水,以一定速率流出水,当水超过桶容量(capacity)则丢弃,因为桶容量是不变的,保证了整体的速率。
以一定速率流出水,
削峰:有大量流量进入时,会发生溢出,从而限流保护服务可用
缓冲:不至于直接请求到服务器,缓冲压力
消费速度固定 因为计算性能固定
漏桶算法实现
package com.crazymaker.springcloud.ratelimit;import lombok.extern.slf4j.Slf4j;
import org.junit.Test;import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;// 漏桶 限流
@Slf4j
public class LeakBucketLimiter {// 计算的起始时间private static long lastOutTime = System.currentTimeMillis();// 流出速率 每秒 2 次private static int leakRate = 2;// 桶的容量private static int capacity = 2;//剩余的水量private static AtomicInteger water = new AtomicInteger(0);//返回值说明:// false 没有被限制到// true 被限流public static synchronized boolean isLimit(long taskId, int turn) {// 如果是空桶,就当前时间作为漏出的时间if (water.get() == 0) {lastOutTime = System.currentTimeMillis();water.addAndGet(1);return false;}// 执行漏水int waterLeaked = ((int) ((System.currentTimeMillis() - lastOutTime) / 1000)) * leakRate;// 计算剩余水量int waterLeft = water.get() - waterLeaked;water.set(Math.max(0, waterLeft));// 重新更新leakTimeStamplastOutTime = System.currentTimeMillis();// 尝试加水,并且水还未满 ,放行if ((water.get()) < capacity) {water.addAndGet(1);return false;} else {// 水满,拒绝加水, 限流return true;}}//线程池,用于多线程模拟测试private ExecutorService pool = Executors.newFixedThreadPool(10);@Testpublic void testLimit() {// 被限制的次数AtomicInteger limited = new AtomicInteger(0);// 线程数final int threads = 2;// 每条线程的执行轮数final int turns = 20;// 线程同步器CountDownLatch countDownLatch = new CountDownLatch(threads);long start = System.currentTimeMillis();for (int i = 0; i < threads; i++) {pool.submit(() ->{try {for (int j = 0; j < turns; j++) {long taskId = Thread.currentThread().getId();boolean intercepted = isLimit(taskId, j);if (intercepted) {// 被限制的次数累积limited.getAndIncrement();}Thread.sleep(200);}} catch (Exception e) {e.printStackTrace();}//等待所有线程结束countDownLatch.countDown();});}try {countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}float time = (System.currentTimeMillis() - start) / 1000F;//输出统计结果log.info("限制的次数为:" + limited.get() +",通过的次数为:" + (threads * turns - limited.get()));log.info("限制的比例为:" + (float) limited.get() / (float) (threads * turns));log.info("运行的时长为:" + time);}
}漏桶的问题
漏桶的出水速度固定,也就是请求放行速度是固定的。
网上抄来抄去的说法:
漏桶不能有效应对突发流量,但是能起到平滑突发流量(整流)的作用。
实际上的问题:
漏桶出口的速度固定,不能灵活的应对后端能力提升。比如,通过动态扩容,后端流量从1000QPS提升到1WQPS,漏桶没有办法。
令牌桶限流
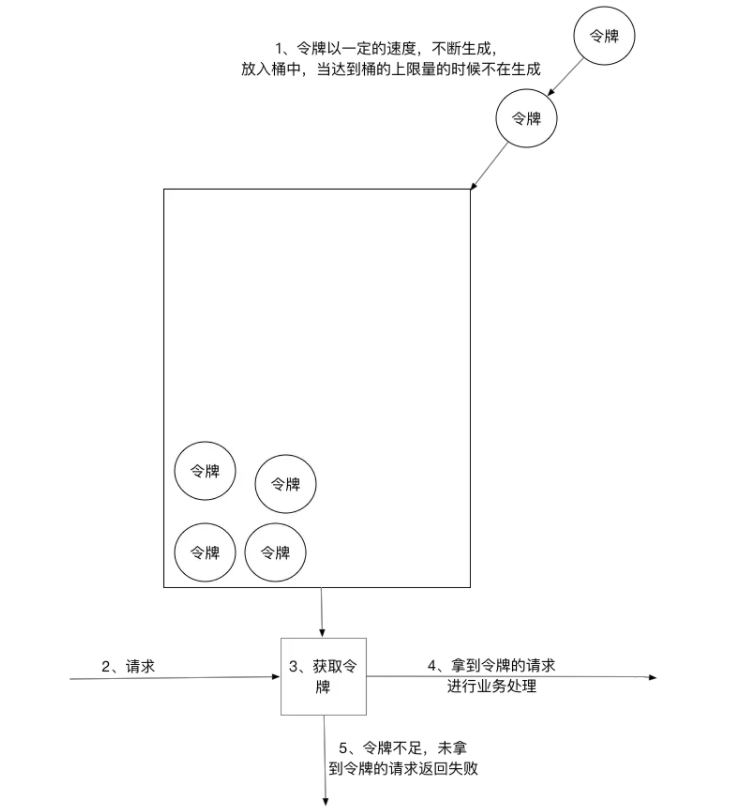
令牌桶算法以一个设定的速率产生令牌并放入令牌桶,每次用户请求都得申请令牌,如果令牌不足,则拒绝请求。
令牌桶算法中新请求到来时会从桶里拿走一个令牌,如果桶内没有令牌可拿,就拒绝服务。当然,令牌的数量也是有上限的。令牌的数量与时间和发放速率强相关,时间流逝的时间越长,会不断往桶里加入越多的令牌,如果令牌发放的速度比申请速度快,令牌桶会放满令牌,直到令牌占满整个令牌桶,如图所示。
令牌桶限流大致的规则如下:
(1)进水口按照某个速度,向桶中放入令牌。
(2)令牌的容量是固定的,但是放行的速度不是固定的,只要桶中还有剩余令牌,一旦请求过来就能申请成功,然后放行。
(3)如果令牌的发放速度,慢于请求到来速度,桶内就无牌可领,请求就会被拒绝。
总之,令牌的发送速率可以设置,从而可以对突发的出口流量进行有效的应对。
令牌桶算法
令牌桶与漏桶相似,不同的是令牌桶桶中放了一些令牌,服务请求到达后,要获取令牌之后才会得到服务,举个例子,我们平时去食堂吃饭,都是在食堂内窗口前排队的,这就好比是漏桶算法,大量的人员聚集在食堂内窗口外,以一定的速度享受服务,如果涌进来的人太多,食堂装不下了,可能就有一部分人站到食堂外了,这就没有享受到食堂的服务,称之为溢出,溢出可以继续请求,也就是继续排队,那么这样有什么问题呢?
如果这时候有特殊情况,比如有些赶时间的志愿者啦、或者高三要高考啦,这种情况就是突发情况,如果也用漏桶算法那也得慢慢排队,这也就没有解决我们的需求,对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。如图所示,令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
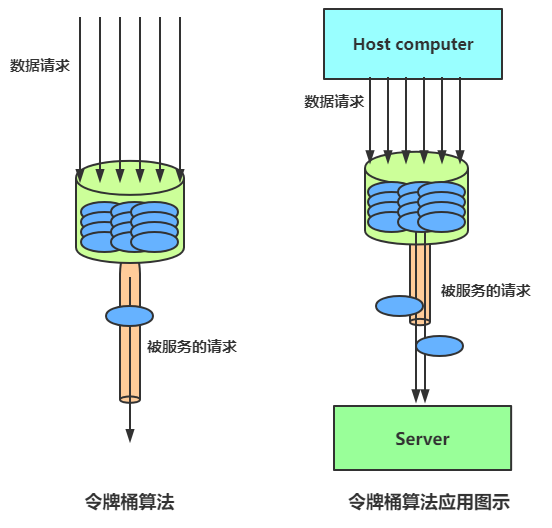
令牌桶算法实现
package com.crazymaker.springcloud.ratelimit;import lombok.extern.slf4j.Slf4j;
import org.junit.Test;import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;// 令牌桶 限速
@Slf4j
public class TokenBucketLimiter {// 上一次令牌发放时间public long lastTime = System.currentTimeMillis();// 桶的容量public int capacity = 2;// 令牌生成速度 /spublic int rate = 2;// 当前令牌数量public AtomicInteger tokens = new AtomicInteger(0);;//返回值说明:// false 没有被限制到// true 被限流public synchronized boolean isLimited(long taskId, int applyCount) {long now = System.currentTimeMillis();//时间间隔,单位为 mslong gap = now - lastTime;//计算时间段内的令牌数int reverse_permits = (int) (gap * rate / 1000);int all_permits = tokens.get() + reverse_permits;// 当前令牌数tokens.set(Math.min(capacity, all_permits));log.info("tokens {} capacity {} gap {} ", tokens, capacity, gap);if (tokens.get() < applyCount) {// 若拿不到令牌,则拒绝// log.info("被限流了.." + taskId + ", applyCount: " + applyCount);return true;} else {// 还有令牌,领取令牌tokens.getAndAdd( - applyCount);lastTime = now;// log.info("剩余令牌.." + tokens);return false;}}//线程池,用于多线程模拟测试private ExecutorService pool = Executors.newFixedThreadPool(10);@Testpublic void testLimit() {// 被限制的次数AtomicInteger limited = new AtomicInteger(0);// 线程数final int threads = 2;// 每条线程的执行轮数final int turns = 20;// 同步器CountDownLatch countDownLatch = new CountDownLatch(threads);long start = System.currentTimeMillis();for (int i = 0; i < threads; i++) {pool.submit(() ->{try {for (int j = 0; j < turns; j++) {long taskId = Thread.currentThread().getId();boolean intercepted = isLimited(taskId, 1);if (intercepted) {// 被限制的次数累积limited.getAndIncrement();}Thread.sleep(200);}} catch (Exception e) {e.printStackTrace();}//等待所有线程结束countDownLatch.countDown();});}try {countDownLatch.await();} catch (InterruptedException e) {e.printStackTrace();}float time = (System.currentTimeMillis() - start) / 1000F;//输出统计结果log.info("限制的次数为:" + limited.get() +",通过的次数为:" + (threads * turns - limited.get()));log.info("限制的比例为:" + (float) limited.get() / (float) (threads * turns));log.info("运行的时长为:" + time);}
}
令牌桶的好处
令牌桶的好处之一就是可以方便地应对 突发出口流量(后端能力的提升)。
比如,可以改变令牌的发放速度,算法能按照新的发送速率调大令牌的发放数量,使得出口突发流量能被处理。
Guava RateLimiter
Guava是Java领域优秀的开源项目,它包含了Google在Java项目中使用一些核心库,包含集合(Collections),缓存(Caching),并发编程库(Concurrency),常用注解(Common annotations),String操作,I/O操作方面的众多非常实用的函数。 Guava的 RateLimiter提供了令牌桶算法实现:平滑突发限流(SmoothBursty)和平滑预热限流(SmoothWarmingUp)实现。
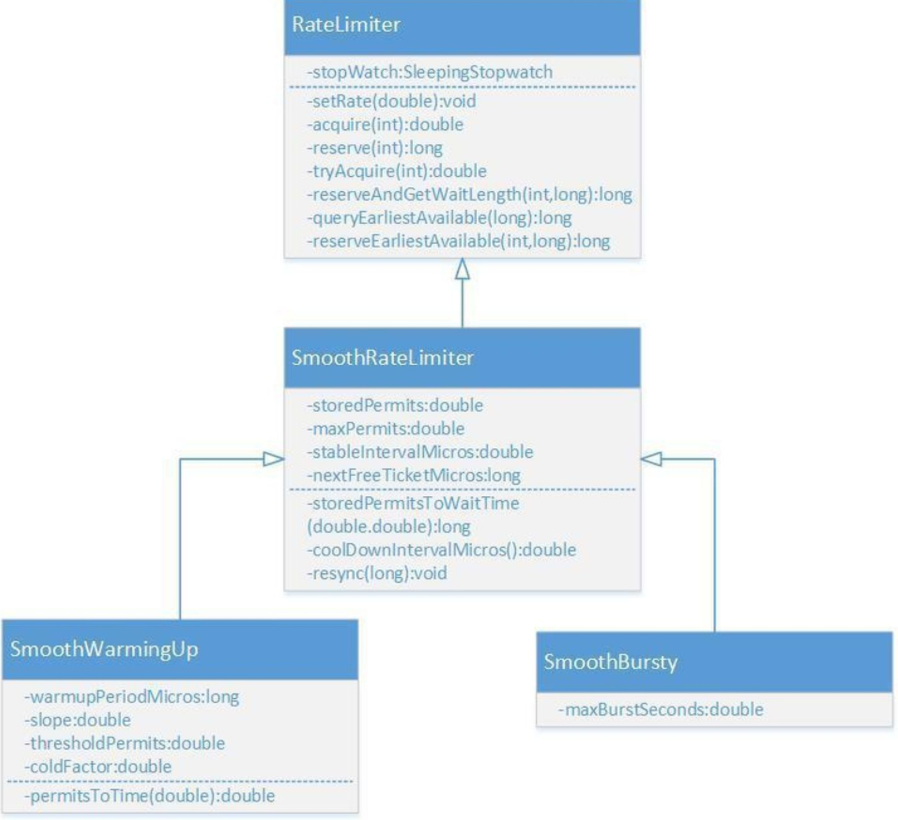
RateLimiter的类图如上所示,
Nginx漏桶限流
Nginx限流的简单演示
每六秒才处理一次请求,如下
limit_req_zone $arg_sku_id zone=skuzone:10m rate=6r/m;limit_req_zone $http_user_id zone=userzone:10m rate=6r/m;limit_req_zone $binary_remote_addr zone=perip:10m rate=6r/m;limit_req_zone $server_name zone=perserver:1m rate=6r/m;这是从请求参数里边,提前参数做限流
这是从请求参数里边,提前参数,进行限流的次数统计key。
在http块里边定义限流的内存区域 zone。
limit_req_zone $arg_sku_id zone=skuzone:10m rate=6r/m;limit_req_zone $http_user_id zone=userzone:10m rate=6r/m;limit_req_zone $binary_remote_addr zone=perip:10m rate=6r/m;limit_req_zone $server_name zone=perserver:1m rate=10r/s;在location块中使用 限流zone,参考如下:
# ratelimit by sku idlocation = /ratelimit/sku {limit_req zone=skuzone;echo "正常的响应";
}
测试
[root@cdh1 ~]# /vagrant/LuaDemoProject/sh/linux/openresty-restart.sh
shell dir is: /vagrant/LuaDemoProject/sh/linux
Shutting down openrestry/nginx: pid is 13479 13485
Shutting down succeeded!
OPENRESTRY_PATH:/usr/local/openresty
PROJECT_PATH:/vagrant/LuaDemoProject/src
nginx: [alert] lua_code_cache is off; this will hurt performance in /vagrant/LuaDemoProject/src/conf/nginx-seckill.conf:90
openrestry/nginx starting succeeded!
pid is 14197[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
正常的响应
root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
正常的响应
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
限流后的降级内容
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
限流后的降级内容
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
限流后的降级内容
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
限流后的降级内容
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
限流后的降级内容
[root@cdh1 ~]# curl http://cdh1/ratelimit/sku?sku_id=1
正常的响应
从Header头部提前参数
1、nginx是支持读取非nginx标准的用户自定义header的,但是需要在http或者server下开启header的下划线支持:
underscores_in_headers on;
2、比如我们自定义header为X-Real-IP,通过第二个nginx获取该header时需要这样:
$http_x_real_ip; (一律采用小写,而且前面多了个http_)
underscores_in_headers on;limit_req_zone $http_user_id zone=userzone:10m rate=6r/m;server {listen 80 default;server_name nginx.server *.nginx.server;default_type 'text/html';charset utf-8;# ratelimit by user idlocation = /ratelimit/demo {limit_req zone=userzone;echo "正常的响应";}location = /50x.html{echo "限流后的降级内容";}error_page 502 503 =200 /50x.html;}
测试
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
正常的响应
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:1" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER_ID:2" http://cdh1/ratelimit/demo
正常的响应
[root@cdh1 ~]# curl -H "USER_ID:2" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]#
[root@cdh1 ~]# curl -H "USER_ID:2" http://cdh1/ratelimit/demo
限流后的降级内容
[root@cdh1 ~]# curl -H "USER-ID:3" http://cdh1/ratelimit/demo
正常的响应
[root@cdh1 ~]# curl -H "USER-ID:3" http://cdh1/ratelimit/demo
限流后的降级内容Nginx漏桶限流的三个细分类型,即burst、nodelay参数详解
每六秒才处理一次请求,如下
limit_req_zone $arg_user_id zone=limti_req_zone:10m rate=10r/m;
不带缓冲队列的漏桶限流
limit_req zone=limti_req_zone;
- 严格依照在limti_req_zone中配置的rate来处理请求
- 超过rate处理能力范围的,直接drop
- 表现为对收到的请求无延时
假设1秒内提交10个请求,可以看到一共10个请求,9个请求都失败了,直接返回503,
接着再查看 /var/log/nginx/access.log,印证了只有一个请求成功了,其它就是都直接返回了503,即服务器拒绝了请求。

带缓冲队列的漏桶限流
limit_req zone=limti_req_zone burst=5;
- 依照在limti_req_zone中配置的rate来处理请求
- 同时设置了一个大小为5的缓冲队列,在缓冲队列中的请求会等待慢慢处理
- 超过了burst缓冲队列长度和rate处理能力的请求被直接丢弃
- 表现为对收到的请求有延时
假设1秒内提交10个请求,则可以发现在1s内,**在服务器接收到10个并发请求后,先处理1个请求,同时将5个请求放入burst缓冲队列中,等待处理。而超过(burst+1)数量的请求就被直接抛弃了,即直接抛弃了4个请求。**burst缓存的5个请求每隔6s处理一次。
接着查看 /var/log/nginx/access.log日志

带瞬时处理能力的漏桶限流
limit_req zone=req_zone burst=5 nodelay;
如果设置nodelay,会在瞬时提供处理(burst + rate)个请求的能力,请求数量超过**(burst + rate)**的时候就会直接返回503,峰值范围内的请求,不存在请求需要等待的情况。
假设1秒内提交10个请求,则可以发现在1s内,服务器端处理了6个请求(峰值速度:burst+10s内一个请求)。对于剩下的4个请求,直接返回503,在下一秒如果继续向服务端发送10个请求,服务端会直接拒绝这10个请求并返回503。
接着查看 /var/log/nginx/access.log日志

可以发现在1s内,服务器端处理了6个请求(峰值速度:burst+原来的处理速度)。对于剩下的4个请求,直接返回503。
但是,总数额度和速度*时间保持一致, 就是额度用完了,需要等到一个有额度的时间段,才开始接收新的请求。如果一次处理了5个请求,相当于占了30s的额度,6*5=30。因为设定了6s处理1个请求,所以直到30
s 之后,才可以再处理一个请求,即如果此时向服务端发送10个请求,会返回9个503,一个200
说明:本文会以pdf格式持续更新,更多最新尼恩3高pdf笔记,请从下面的链接获取:语雀 或者 码云
分布式限流组件
why
但是Nginx的限流指令只能在同一块内存区域有效,而在生产场景中秒杀的外部网关往往是多节点部署,所以这就需要用到分布式限流组件。
高性能的分布式限流组件可以使用Redis+Lua来开发,京东的抢购就是使用Redis+Lua完成的限流。并且无论是Nginx外部网关还是Zuul内部网关,都可以使用Redis+Lua限流组件。
理论上,接入层的限流有多个维度:
(1)用户维度限流:在某一时间段内只允许用户提交一次请求,比如可以采取客户端IP或者用户ID作为限流的key。
(2)商品维度的限流:对于同一个抢购商品,在某个时间段内只允许一定数量的请求进入,可以采取秒杀商品ID作为限流的key。
什么时候用nginx限流:
用户维度的限流,可以在ngix 上进行,因为使用nginx限流内存来存储用户id,比用redis 的key,来存储用户id,效率高。
什么时候用redis+lua分布式限流:
商品维度的限流,可以在redis上进行,不需要大量的计算访问次数的key,另外,可以控制所有的接入层节点的访问秒杀请求的总量。
redis+lua分布式限流组件
--- 此脚本的环境: redis 内部,不是运行在 nginx 内部---方法:申请令牌
--- -1 failed
--- 1 success
--- @param key key 限流关键字
--- @param apply 申请的令牌数量
local function acquire(key, apply)local times = redis.call('TIME');-- times[1] 秒数 -- times[2] 微秒数local curr_mill_second = times[1] * 1000000 + times[2];curr_mill_second = curr_mill_second / 1000;local cacheInfo = redis.pcall("HMGET", key, "last_mill_second", "curr_permits", "max_permits", "rate")--- 局部变量:上次申请的时间local last_mill_second = cacheInfo[1];--- 局部变量:之前的令牌数local curr_permits = tonumber(cacheInfo[2]);--- 局部变量:桶的容量local max_permits = tonumber(cacheInfo[3]);--- 局部变量:令牌的发放速率local rate = cacheInfo[4];--- 局部变量:本次的令牌数local local_curr_permits = 0;if (type(last_mill_second) ~= 'boolean' and last_mill_second ~= nil) then-- 计算时间段内的令牌数local reverse_permits = math.floor(((curr_mill_second - last_mill_second) / 1000) * rate);-- 令牌总数local expect_curr_permits = reverse_permits + curr_permits;-- 可以申请的令牌总数local_curr_permits = math.min(expect_curr_permits, max_permits);else-- 第一次获取令牌redis.pcall("HSET", key, "last_mill_second", curr_mill_second)local_curr_permits = max_permits;endlocal result = -1;-- 有足够的令牌可以申请if (local_curr_permits - apply >= 0) then-- 保存剩余的令牌redis.pcall("HSET", key, "curr_permits", local_curr_permits - apply);-- 为下次的令牌获取,保存时间redis.pcall("HSET", key, "last_mill_second", curr_mill_second)-- 返回令牌获取成功result = 1;else-- 返回令牌获取失败result = -1;endreturn result
end
--eg
-- /usr/local/redis/bin/redis-cli -a 123456 --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua key , acquire 1 1-- 获取 sha编码的命令
-- /usr/local/redis/bin/redis-cli -a 123456 script load "$(cat /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua)"
-- /usr/local/redis/bin/redis-cli -a 123456 script exists "cf43613f172388c34a1130a760fc699a5ee6f2a9"-- /usr/local/redis/bin/redis-cli -a 123456 evalsha "cf43613f172388c34a1130a760fc699a5ee6f2a9" 1 "rate_limiter:seckill:1" init 1 1
-- /usr/local/redis/bin/redis-cli -a 123456 evalsha "cf43613f172388c34a1130a760fc699a5ee6f2a9" 1 "rate_limiter:seckill:1" acquire 1--local rateLimiterSha = "e4e49e4c7b23f0bf7a2bfee73e8a01629e33324b";---方法:初始化限流 Key
--- 1 success
--- @param key key
--- @param max_permits 桶的容量
--- @param rate 令牌的发放速率
local function init(key, max_permits, rate)local rate_limit_info = redis.pcall("HMGET", key, "last_mill_second", "curr_permits", "max_permits", "rate")local org_max_permits = tonumber(rate_limit_info[3])local org_rate = rate_limit_info[4]if (org_max_permits == nil) or (rate ~= org_rate or max_permits ~= org_max_permits) thenredis.pcall("HMSET", key, "max_permits", max_permits, "rate", rate, "curr_permits", max_permits)endreturn 1;
end
--eg
-- /usr/local/redis/bin/redis-cli -a 123456 --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua key , init 1 1
-- /usr/local/redis/bin/redis-cli -a 123456 --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua "rate_limiter:seckill:1" , init 1 1---方法:删除限流 Key
local function delete(key)redis.pcall("DEL", key)return 1;
end
--eg
-- /usr/local/redis/bin/redis-cli --eval /vagrant/LuaDemoProject/src/luaScript/redis/rate_limiter.lua key , deletelocal key = KEYS[1]
local method = ARGV[1]
if method == 'acquire' thenreturn acquire(key, ARGV[2], ARGV[3])
elseif method == 'init' thenreturn init(key, ARGV[2], ARGV[3])
elseif method == 'delete' thenreturn delete(key)
else--ignore
end在redis中,为了避免重复发送脚本数据浪费网络资源,可以使用script load命令进行脚本数据缓存,并且返回一个哈希码作为脚本的调用句柄,
每次调用脚本只需要发送哈希码来调用即可。
分布式令牌限流实战
可以使用redis+lua,实战一票下边的简单案例:
令牌按照1个每秒的速率放入令牌桶,桶中最多存放2个令牌,那系统就只会允许持续的每秒处理2个请求,
或者每隔2 秒,等桶中2 个令牌攒满后,一次处理2个请求的突发情况,保证系统稳定性。
商品维度的限流
当秒杀商品维度的限流,当商品的流量,远远大于涉及的流量时,开始随机丢弃请求。
Nginx的令牌桶限流脚本getToken_access_limit.lua执行在请求的access阶段,但是,该脚本并没有实现限流的核心逻辑,仅仅调用缓存在Redis内部的rate_limiter.lua脚本进行限流。
getToken_access_limit.lua脚本和rate_limiter.lua脚本的关系,具体如图10-17所示。
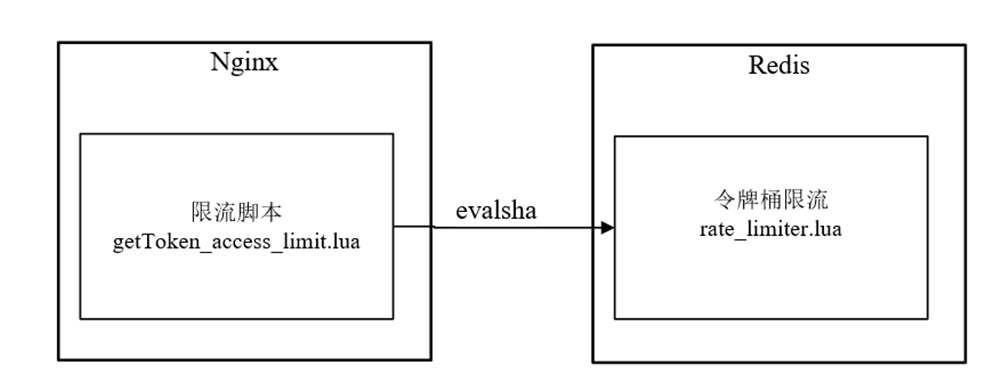
图10-17 getToken_access_limit.lua脚本和rate_limiter.lua脚本关系
什么时候在Redis中加载rate_limiter.lua脚本呢?
和秒杀脚本一样,该脚本是在Java程序启动商品秒杀时,完成其在Redis的加载和缓存的。
还有一点非常重要,Java程序会将脚本加载完成之后的sha1编码,去通过自定义的key(具体为"lua:sha1:rate_limiter")缓存在Redis中,以方便Nginx的getToken_access_limit.lua脚本去获取,并且在调用evalsha方法时使用。
注意:使用redis集群,因此每个节点都需要各自缓存一份脚本数据
/**
* 由于使用redis集群,因此每个节点都需要各自缓存一份脚本数据
* @param slotKey 用来定位对应的slot的slotKey
*/
public void storeScript(String slotKey){
if (StringUtils.isEmpty(unlockSha1) || !jedisCluster.scriptExists(unlockSha1, slotKey)){//redis支持脚本缓存,返回哈希码,后续可以继续用来调用脚本unlockSha1 = jedisCluster.scriptLoad(DISTRIBUTE_LOCK_SCRIPT_UNLOCK_VAL, slotKey);}
}
常见的限流组件
redission分布式限流采用令牌桶思想和固定时间窗口,trySetRate方法设置桶的大小,利用redis key过期机制达到时间窗口目的,控制固定时间窗口内允许通过的请求量。
spring cloud gateway集成redis限流,但属于网关层限流
技术自由的实现路径:
实现你的 架构自由:
《吃透8图1模板,人人可以做架构》
《10Wqps评论中台,如何架构?B站是这么做的!!!》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《100亿级订单怎么调度,来一个大厂的极品方案》
《2个大厂 100亿级 超大流量 红包 架构方案》
… 更多架构文章,正在添加中
实现你的 响应式 自由:
《响应式圣经:10W字,实现Spring响应式编程自由》
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
《Linux命令大全:2W多字,一次实现Linux自由》
实现你的 网络 自由:
《TCP协议详解 (史上最全)》
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
4000页《尼恩Java面试宝典 》 40个专题
以上尼恩 架构笔记、面试题 的PDF文件更新,请到《技术自由圈》公号获取↓↓↓
相关文章:
限流:计数器、漏桶、令牌桶 三大算法的原理与实战(史上最全)
限流 限流是面试中的常见的面试题(尤其是大厂面试、高P面试) 注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请到文末《技术自由圈》公号获取 为什么要限流 简单来说: 限流在很多场景中用来…...
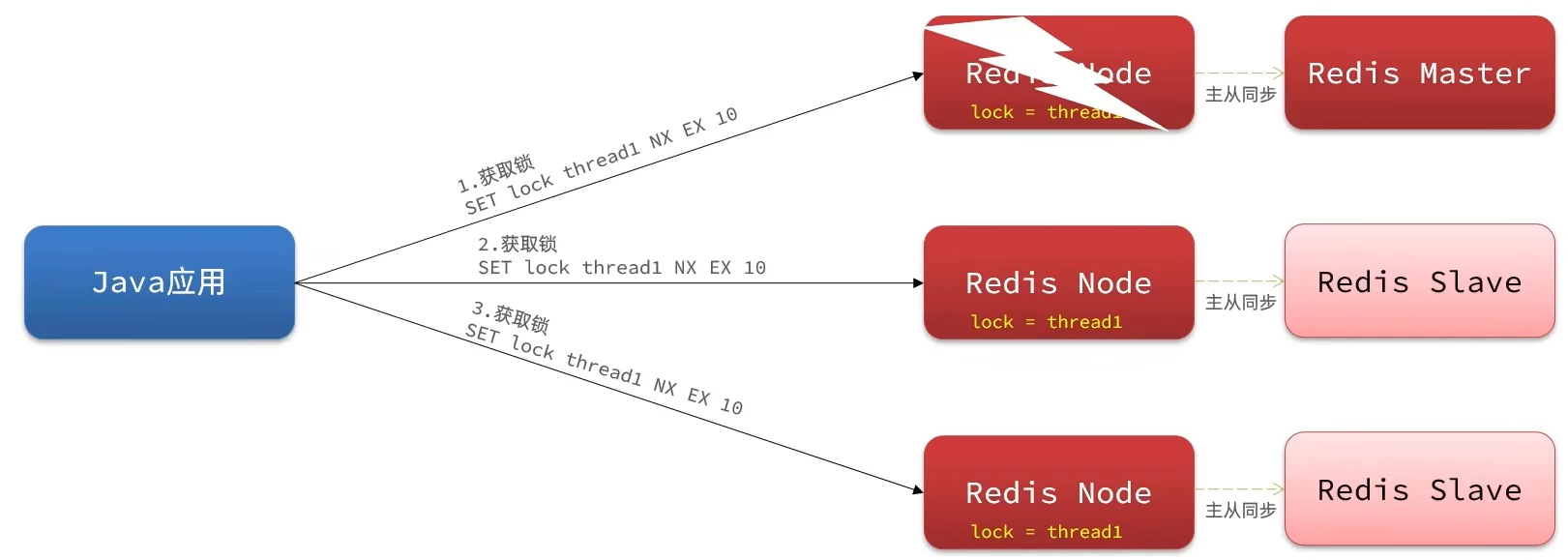
Redis用于全局ID生成器、分布式锁的解决方案
全局ID生成器 每个店铺都可以发布优惠卷 当用户抢购时,就会生成订单并保存到tb_voucher_order这张表中,而订单表如果使用数据库自增id就存在一些问题: 1.id的规律性太明显 2.受单表数据量的限制 全局ID生成器,是一种在分布式系…...
OpenTex 企业内容管理平台
OpenText 企业内容管理平台 将内容服务与领先应用程序集成,弥合内容孤岛、加快信息流并扩大治理 什么是内容服务集成? 内容服务集成通过将内容管理平台与处于流程核心的独立应用程序和系统连接起来,支持并扩展了 ECM 的传统优势。 最好的内…...

【0基础学爬虫】爬虫基础之数据存储
大数据时代,各行各业对数据采集的需求日益增多,网络爬虫的运用也更为广泛,越来越多的人开始学习网络爬虫这项技术,K哥爬虫此前已经推出不少爬虫进阶、逆向相关文章,为实现从易到难全方位覆盖,特设【0基础学…...
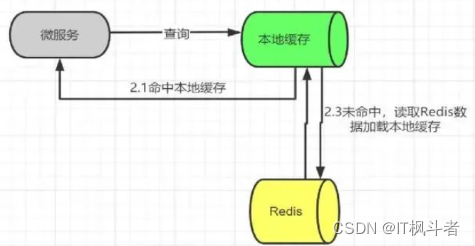
Redis与本地缓存组合使用(IT枫斗者)
Redis与本地缓存组合使用 前言 我们开发中经常用到Redis作为缓存,将高频数据放在Redis中能够提高业务性能,降低MySQL等关系型数据库压力,甚至一些系统使用Redis进行数据持久化,Redis松散的文档结构非常适合业务系统开发…...
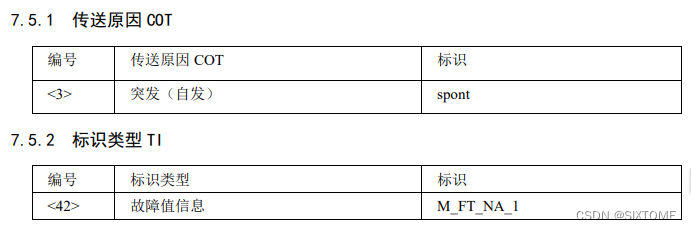
手把手教你学习IEC104协议和编程实现 十 故障事件与复位进程
故障事件 目的 在IEC104普遍应用之前,据我了解多个协议,再综合自动化协议中,有这么一个概念叫“事故追忆”,意思是当变电站出现事故的时候,不但要记录事故的时间,还需记录事故前后模拟量的数据,从而能从一定程度上分析事故产生的原因,这个模拟量就是和今天讲解的故障…...

浅析分布式理论的CAP
大家好,我是易安! 今天让我们来聚焦于分布式系统架构中的重要理论——CAP理论。在分布式系统中,可用性和数据一致性是两个至关重要的因素,而CAP理论就是在这两者之间提供了一种权衡的原则,帮助我们在设计分布式系统时进…...

使用 TensorFlow 构建机器学习项目:6~10
原文:Building Machine Learning Projects with TensorFlow 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象&#x…...
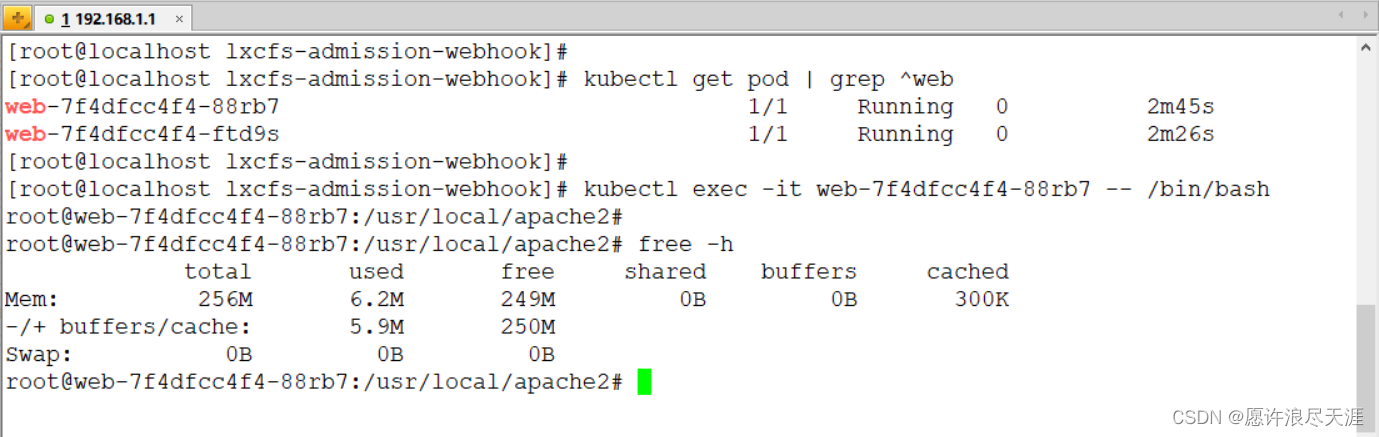
使用 LXCFS 文件系统实现容器资源可见性
使用 LXCFS 文件系统实现容器资源可见性一、基本介绍二、LXCFS 安装与使用1.安装 LXCFS 文件系统2.基于 Docker 实现容器资源可见性3.基于 Kubernetes 实现容器资源可见性前言:Linux 利用 Cgroup 实现了对容器资源的限制,但是当在容器内运行 top 命令时就…...
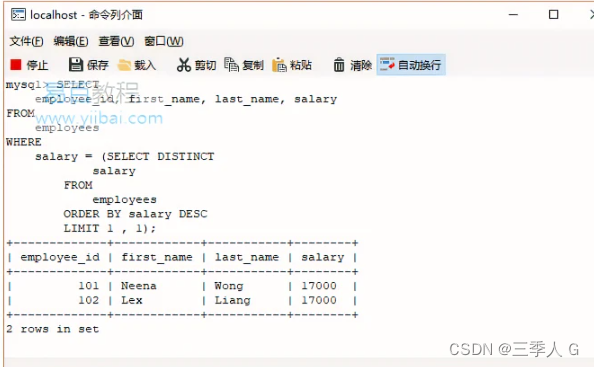
SQL LIMIT
SQL LIMIT SQL LIMIT子句简介 要检索查询返回的行的一部分,请使用LIMIT和OFFSET子句。 以下说明了这些子句的语法: SELECT column_list FROMtable1 ORDER BY column_list LIMIT row_count OFFSET offset;在这个语法中, row_count确定将返…...
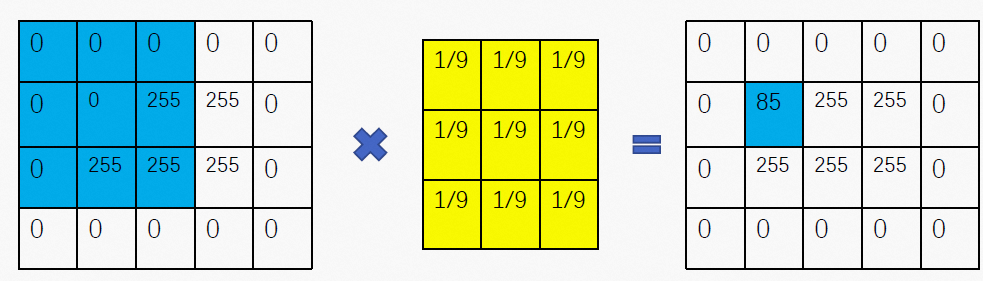
OpenCV实战之人脸美颜美型(六)——磨皮
1.需求分析 有个词叫做“肤若凝脂”,直译为皮肤像凝固的油脂,形容皮肤洁白且光润,这是对美女的一种通用评价。实际生活中我们的皮肤多少会有一些毛孔、斑点等表现,在观感上与上述的“光润感”相反,因此磨皮也成为美颜算法中的一项基础且重要的功能。让皮肤变得更加光润,就…...

Java技术栈—重装系统后不重新安装也能正常使用的设置方式
声明: 最近在重装电脑,重装完后,开发工具会有些功能使用不了,在这做个记录!这里是 JAVA 技术栈 问题描述: git 右键无菜单 111 git git 右键无菜单 参考文章:注册表修复git右键无菜单 git …...
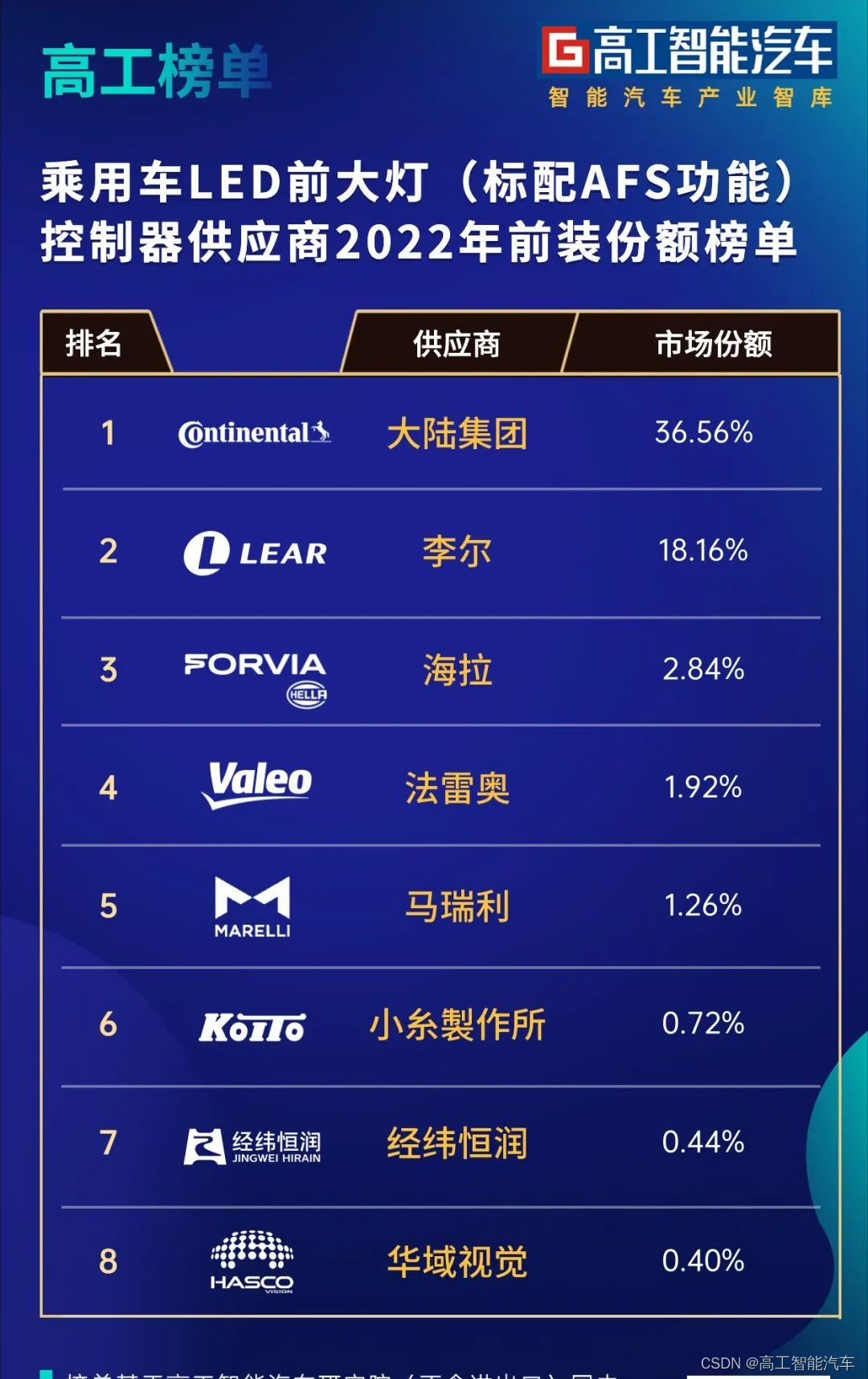
智驾升级!ADB+AFS「起势」
目前,乘用车前大灯已经完成从传统卤素、氙气到LED的转型升级,高工智能汽车研究院监测数据显示,2022年中国市场(不含进出口)乘用车前装标配LED前大灯搭载率达到75.99%,同比2021年提高约7个百分点。 而相比而…...

算法记录 | Day27 回溯算法
39.组合总和 思路: 1.确定回溯函数参数:定义全局遍历存放res集合和单个path,还需要 candidates数组 targetSum(int)目标和。 startIndex(int)为下一层for循环搜索的起始位置。 2.终止条件…...
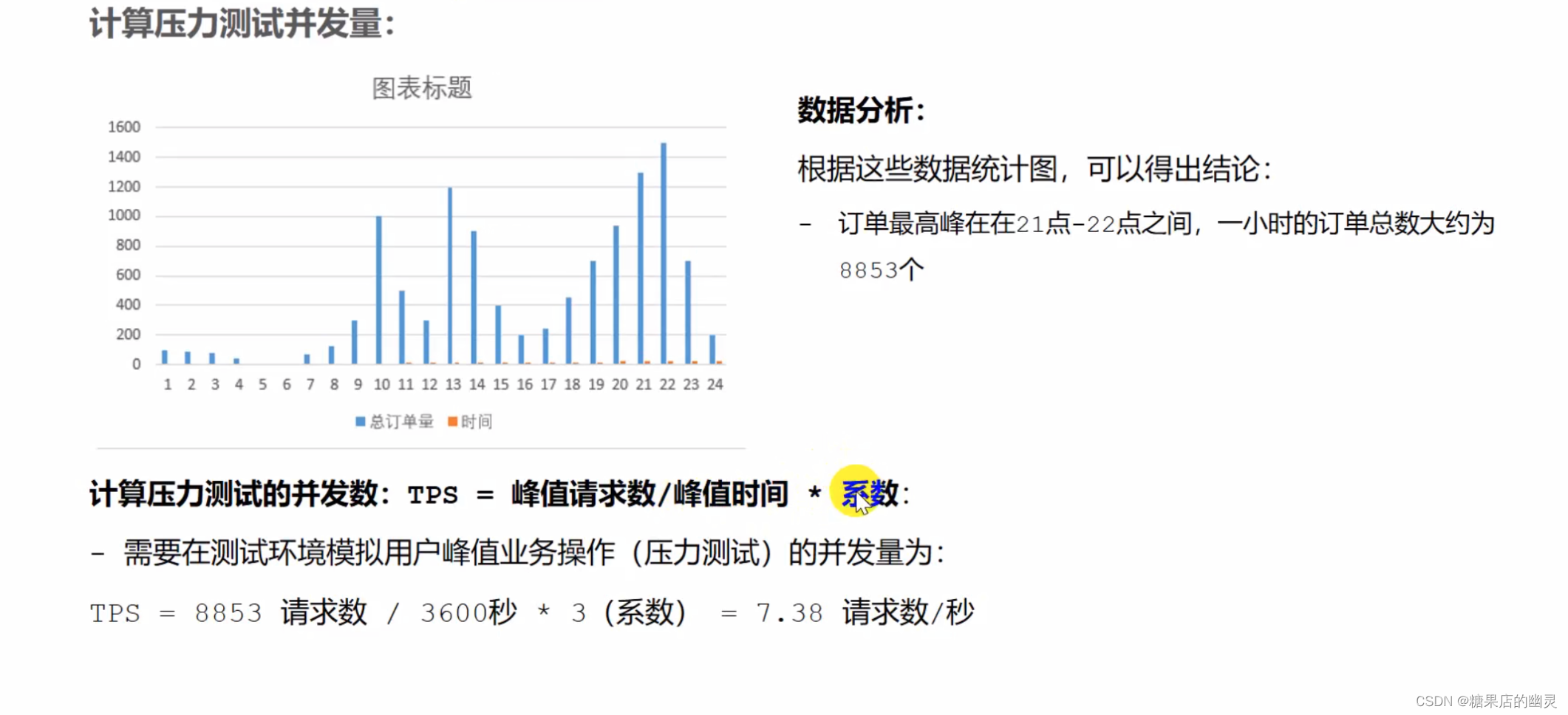
性能测试总结-根据工作经验总结还比较全面
性能测试总结性能测试理论性能测试的策略基准测试负载测试稳定性测试压力测试并发测试性能测试的指标响应时间并发数吞吐量资源指标性能测试流程性能测试工具JMeter基本使用元件构成线程组jmeter的分布式使用jmeter测试报告常用插件性能测试的计算1.根据请求数明细数据计算满足…...

类型断言[as语法 | <> 语法
TypeScript中的类型断言[as语法 | <> 语法] https://huaweicloud.csdn.net/638f0fbbdacf622b8df8e283.html?spm1001.2101.3001.6650.1&utm_mediumdistribute.pc_relevant.none-task-blog-2~default~CTRLIST~activity-1-107633405-blog-122438115.2…...
barret reduction原理详解及硬件优化
背景介绍 约减算法,通常应用在硬件领域,因为模运算mod是一个除法运算,在硬件中实现速度会比乘法慢的多,并且还会占用大量资源,因此需要想办法用乘法及其它简单运算来替代模运算。模约减算法可以利用乘法、加法和移位等…...
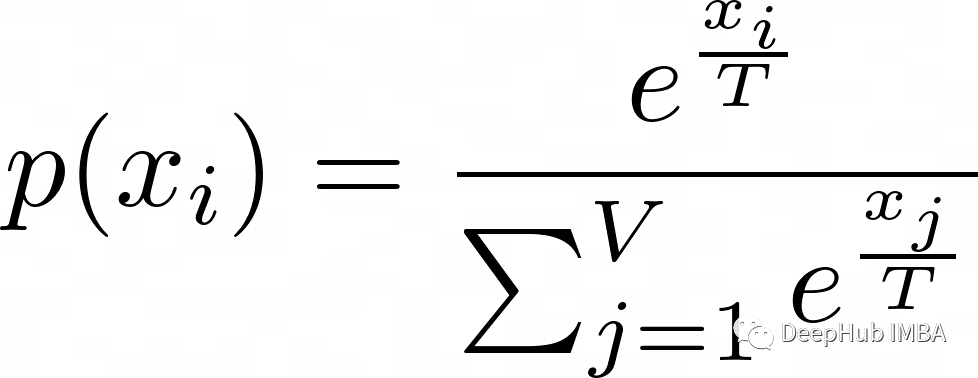
NLP / LLMs中的Temperature 是什么?
ChatGPT, GPT-3, GPT-3.5, GPT-4, LLaMA, Bard等大型语言模型的一个重要的超参数 大型语言模型能够根据给定的上下文或提示生成新文本,由于神经网络等深度学习技术的进步,这些模型越来越受欢迎。可用于控制生成语言模型行为的关键参数之一是Temperature …...

c#快速入门~在java基础上,知道C#和JAVA 的不同即可
☺ 观看下文前提:如果你的主语言是java,现在想再学一门新语言C#,下文是在java基础上,对比和java的不同,快速上手C#,当然不是说学C#的前提是需要java,而是下文是从主语言是java的情况下ÿ…...
nginx--基本配置
目录 1.安装目录 2.文件详解 2.编译参数 3.Nginx基本配置语法 1./etc/nginx/nginx.conf 2./etc/nginx/conf.d/default.conf 3.启动重启命令 4.设置404跳转页面 1./etc/nginx/conf.d/default.conf修改 2. 重启 5.最前面内容模块 6.事件模块 1.安装目录 # etc cd …...

从零构建生产级AI助手:OpenClaw配置实战与自动化工作流指南
1. 项目概述:从零到一,构建你的生产级AI助手工作空间如果你和我一样,已经厌倦了每次配置AI助手时,都要从零开始摸索各种配置文件、脚本和最佳实践,那么这个名为openclaw-config的项目,绝对是你梦寐以求的“…...
)
从Processing到Arduino IDE:一个让硬件编程变简单的GUI故事(附STM32兼容板配置避坑)
从Processing到Arduino IDE:硬件编程的平民化革命与STM32实战指南 2005年,当Massimo Banzi在意大利伊夫雷亚交互设计学院第一次向学生们展示那块蓝色电路板时,他可能没想到这个简单的教学工具会彻底改变嵌入式开发的世界。Arduino IDE的诞生并…...

AbMole丨CL 316243:β3-肾上腺素受体激动剂,在代谢调控与能量消耗研究中的应用
CL 316243是一种高选择性的β3-肾上腺素受体(β3-AR)激动剂,其对β3-AR的选择性远高于β1-AR和β2-AR[1]。CL 316243(CAS No.:138908-40-4)通过激活β3-AR,刺激腺苷酸环化酶(AC&…...

034、LVGL默认主题与自定义主题
LVGL默认主题与自定义主题 一次UI“变脸”引发的血案 上周调试一块基于STM32F429的智能家居面板,LVGL版本8.3.5。客户要求界面风格从“科技蓝”改成“暖木色”,我心想不就是改个颜色主题嘛,简单。结果改完lv_conf.h里的LV_THEME_DEFAULT_COLOR_PRIMARY,编译下载,屏幕一亮…...

JiYuTrainer学习自由解决方案:重新定义课堂自主权的教育技术工具
JiYuTrainer学习自由解决方案:重新定义课堂自主权的教育技术工具 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你还记得那种感觉吗?当老师在讲台上演示关…...

Taotoken CLI工具安装与一键配置全模型环境指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken CLI工具安装与一键配置全模型环境指南 对于需要接入多个大模型服务的开发团队而言,统一管理API密钥、模型配置…...

别再只会用StegSolve了!深入理解LSB隐写原理,手写Python脚本提取隐藏信息
从像素到秘密:手写Python脚本破解LSB隐写的核心技术 当你面对一张看似普通的图片,是否曾想过它可能隐藏着重要信息?在CTF竞赛和数字取证领域,LSB(最低有效位)隐写术是最基础却最常被忽视的技术之一。大多数…...
3. 开源纳米级计量检测设备卡点)
0403开源:第四卷光刻机整机控制与量检测系统(A级 中期集中攻坚)3. 开源纳米级计量检测设备卡点
开源光刻机整机控制与量检测系统(A级 中期集中攻坚) 3. 开源纳米级计量检测设备卡点(全参数开源硬核壁垒拆解喂饭级溯源破局) 前置开源声明 本节全程无保留开源光刻量检测底层原理、设备架构、纳米级计量阈值、国内外参数对标、核…...

DsHidMini技术深度解析:让经典PS3手柄在Windows上重获新生的开源方案
DsHidMini技术深度解析:让经典PS3手柄在Windows上重获新生的开源方案 【免费下载链接】DsHidMini Virtual HID Mini-user-mode-driver for Sony DualShock 3 Controllers 项目地址: https://gitcode.com/gh_mirrors/ds/DsHidMini 你是否有一台尘封已久的Play…...

AI提示词设计指南:从原理到实践的高效人机协作范式
1. 项目概述:一个高质量的AI提示词仓库如果你经常和ChatGPT、Midjourney这类AI工具打交道,肯定有过这样的体验:明明想让它写一份专业的商业计划书,结果它给你生成了一篇小学生作文;或者想让AI画一幅赛博朋克风格的城市…...