Python爬虫基础之如何对爬取到的数据进行解析
目录
- 1. 前言
- 2. Xpath
- 2.1 插件/库安装
- 2.2 基础使用
- 2.3 Xpath表达式
- 2.4 案例演示
- 2.4.1 某度网站案例
- 3. JsonPath
- 3.1 库安装
- 3.2 基础使用
- 3.2 JsonPath表达式
- 3.3 案例演示
- 4. BeautifulSoup
- 4.1 库安装
- 4.2 基础使用
- 4.3 常见方法
- 4.4 案例演示
- 参考文献
原文地址:https://www.program-park.top/2023/04/13/reptile_2/
1. 前言
在上一篇博客中,讲了如何使用 urllib 库爬取网页的数据,但是根据博客流程去操作的人应该能发现,我们爬取到的数据是整个网页返回的源码,到手的数据对我们来说是又乱又多的,让我们不能快速、准确的定位到所需数据,所以,这一篇就来讲讲如何对爬取的数据进行解析,拿到我们想要的部分。
下面会依次讲解目前市场上用的比较多的解析数据的三种方式:Xpath、JsonPath、BeautifulSoup,以及这三种方式的区别。
2. Xpath
XPath(XML Path Language - XML路径语言),它是一种用来确定 XML 文档中某部分位置的语言,以 XML 为基础,提供用户在数据结构树中寻找节点的能力,Xpath 被很多开发者亲切的称为小型查询语言。
2.1 插件/库安装
首先,我们要安装 Xpath Helper 插件,借助 Xpath Helper 插件可以帮助我们快速准确的定位并获取 Xpath 路径,解决无法正常定位 Xpath 路径的问题,链接如下:https://pan.baidu.com/s/1tXW9ZtFDDiH5ZCIEpx2deQ,提取码:6666 。
安装教程如下:
- 打开 Chrome 浏览器,点击右上角小圆点 → 更多工具 → 扩展程序;

- 拖拽 Xpath 插件到扩展程序中(需开启开发者模式);
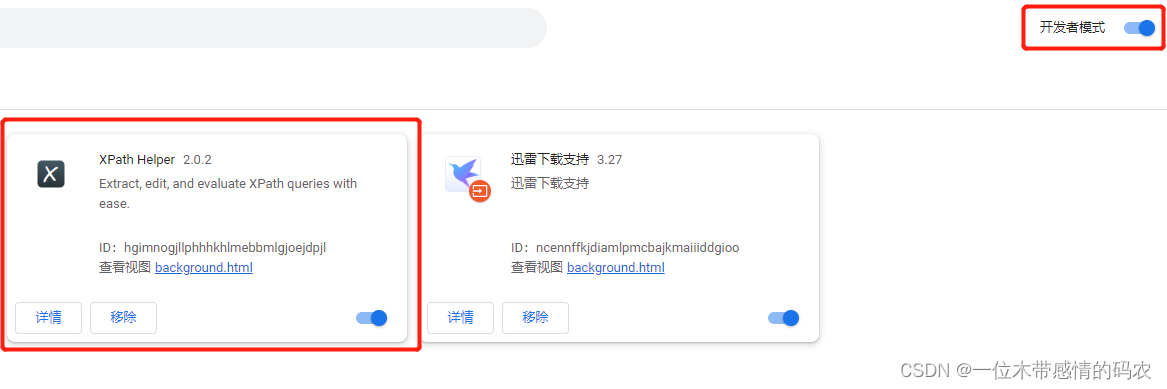
- 关闭浏览器重新打开,打开
www.baidu.com,使用快捷键ctrl + shift + x,出现小黑框即代表安装完毕。
安装 Xpath Helper 插件后,我们还需要在本地的 Python 环境上安装 lxml 库,命令如下:pip3 install lxml。

2.2 基础使用
首先,我们打开Pycharm,创建新脚本,实例化一个etree的对象,并将被解析的页面源码数据加载到该对象中。在用 Xpath 解析文件时,会有两种情况,一种是将本地的文档源码数据加载到etree中:
from lxml import etree# 解析本地文件
tree = etree.parse('XXX.html')
tree.xpath('Xpath表达式')
另一种是将从互联网上获取的源码数据加载到etree中:
from lxml import etree# 解析互联网页面源码数据
tree = etree.HTML(response.read().decode('utf‐8'))
tree.xpath('Xpath表达式')
使用 Xpath 解析数据,最重要的便是 Xpath 表达式的书写,对 Xpath 表达式的熟悉程度将直接影响到数据解析的效率和精确度。
2.3 Xpath表达式
| 表达式 | 描述 |
|---|---|
| / | 表示的是从根节点开始定位,表示的是一个层级 |
| // | 表示的是多个层级,可以表示从任意位置开始定位 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是 text 节点 |
示例:
| 路径表达式 | 描述 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点 |
| /bookstore | 选取根元素 bookstore(加入路径起始于 /,则此路径始终代表到某元素的绝对路径) |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素 |
| bookstore/book[1] | 选取属于 bookstore 的子元素的第一个 book 元素 |
| bookstore/book[last()] | 选取属于 bookstore 的子元素的最后一个 book 元素 |
| bookstore/book[last()-1] | 选取属于 bookstore 的子元素的倒数第二个 book 元素 |
| bookstore/book[position()<3] | 选取属于 bookstore 的子元素的前两个 book 元素 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置 |
| bookstore//book | 选择属于 bookstore 元素的后代的素有 book 元素,而不管它们位于 bookstore 之下的什么位置 |
| //@lang | 选取名为 lang 的所有属性 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素 |
| //title[@lang='eng'] | 选取所有title元素,且这些元素拥有值为 eng 的 lang 属性 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00 |
| //book/title | //book/price | 选取 book 元素的所有 title 或 price 元素 |
| child::book | 选取所有属于当前节点的子元素的 book 节点 |
| attribute::lang | 选取当前节点的 lang 属性 |
| child::* | 选取当前节点的所有子元素 |
| attribute::* | 选取当前节点的属性 |
| child::text() | 选取当前节点的所有文本子节点 |
| child::node() | 选取当前节点的所有子节点 |
| descendant::book | 选取当前节点的所哟 book 后代 |
| ancestor::book | 选择当前节点的所有 book 先辈 |
| ancestor-or-self::book | 选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
| child::*/child::price | 选取当前节点的所有 price 孙节点 |
| //li[contains(@id,"h")] | 选取 id 属性中包含 h 的 li 标签(模糊查询) |
| //li[starts-with(@id,"h")] | 选取 id 属性中以 h 为开头的 li 标签 |
| //li[@id="h1" and @class="h2"] | 选取 id 属性为 h1 且 class 属性为 h2 的 li 标签 |
2.4 案例演示
2.4.1 某度网站案例
需求: 获取某度一下。
import urllib.request
from lxml import etreeurl = 'https://www.某du.com/'headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')# 解析服务器响应的文件
tree = etree.HTML(content)
# 获取想要的路径
result = tree.xpath('//input[@id="su"]/@value')[0]
print(result)
3. JsonPath
JsonPath 是一种信息抽取类库,是从 JSON 文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript、Python、PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 Xpath 对于 XML。
官方文档:http://goessner.net/articles/JsonPath
3.1 库安装
在本地的 Python 环境上安装 JsonPath 库,命令如下:pip3 install jsonpath。
3.2 基础使用
JsonPath 和 Xpath 的区别在于,JsonPath 只能对本地文件进行操作:
import json
import jsonpathobj = json.load(open('json文件', 'r', encoding='utf‐8'))
ret = jsonpath.jsonpath(obj, 'jsonpath语法')
3.2 JsonPath表达式
| JsonPath | 释义 |
|---|---|
| $ | 根节点/元素 |
| . 或 [] | 子元素 |
| .. | 递归下降(从 E4X 借用了这个语法) |
| @ | 当前节点/元素 |
| ?() | 应用过滤表达式,一般需要结合 [?(@ )] 来使用 |
| [] | 子元素操作符,(可以在里面做简单的迭代操作,如数据索引,根据内容选值等) |
| [,] | 支持迭代器中做多选,多个 key 用逗号隔开 |
| [start:end:step] | 数组分割操作,等同于切片 |
| () | 脚本表达式,使用在脚本引擎下面 |
更多表达式用法可查看官方文档:http://goessner.net/articles/JsonPath。
3.3 案例演示
需求: 获取淘票票数据。
import json
import jsonpath
import urllib.requestheaders = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36','cookie': 'miid=536765677517889060; t=78466542de5dbe84715c098fa2366f87; cookie2=11c90be2b7bda713126ed897ab23e35d; v=0; _tb_token_=ee5863e335344; cna=jYeFGkfrFXoCAXPrFThalDwd; xlly_s=1; tfstk=cdlVBIX7qIdVC-V6pSNwCDgVlVEAa8mxXMa3nx9gjUzPOZeuYsAcXzbAiJwAzG2c.; l=eBxbMUncLj6r4x9hBO5aourza77T6BAb4sPzaNbMiInca6BOT3r6QNCnaDoy7dtjgtCxretPp0kihRLHR3xg5c0c07kqm0JExxvO.; isg=BHBwrClf5nUOJrpxMvRIOGsqQT7CuVQDlydQ-WrHREsaJRDPEsmVk5EbfS1FtQzb','referer': 'https://dianying.taobao.com/','content-type': 'text/html;charset=UTF-8'
}def create_request():res_obj = urllib.request.Request(url="https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1644570795658_173&jsoncallback=jsonp174&action=cityAction&n_s=new&event_submit_doGetAllRegion=true",headers=headers)return res_objdef get_context(req_obj):resp = urllib.request.urlopen(req_obj)origin_context = resp.read().decode('utf-8')result = origin_context.split('jsonp174(')[1].split(')')[0]return resultdef download_and_parse(context):with open('jsonpath_淘票票案例.json','w',encoding='utf-8') as fp:fp.write(context)def parse_json():obj = json.load(open('jsonpath_淘票票案例.json', mode='r', encoding='utf-8'))region_name_list = jsonpath.jsonpath(obj, '$..regionName')print(region_name_list)print(len(region_name_list))if __name__ == '__main__':req_obj = create_request()context = get_context(req_obj)download_and_parse(context)parse_json()
4. BeautifulSoup
BeautifulSoup 是 Python 的一个 HTML 的解析库,我们常称之为 bs4,可以通过它来实现对网页的解析,从而获得想要的数据。
在用 BeautifulSoup 库进行网页解析时,还是要依赖解析器,BeautifulSoup 支持 Python 标准库中的 HTML 解析器,除此之外,还支持一些第三方的解析器,如果我们不安装第三方解析器,则会试用 Python 默认的解析器,而在第三方解析器中,我推荐试用 lxml,它的解析速度快、容错能力比较强。
| 解析器 | 使用方法 | 优势 |
|---|---|---|
| Python 标准库 | BeautifulSoup(markup, “html.parser”) | Python 的内置标准库、执行速度适中、文档容错能力强 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快、文档容错能力强 |
| lxml XML 解析器 | BeautifulSoup(markup, [“lxml”, “xml”]) 或 BeautifulSoup(markup, “xml”) | 速度快、唯一支持 XML 的解析器 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成 HTML5 格式的文档、不依赖外部扩展 |
4.1 库安装
在本地的 Python 环境上安装 BeautifulSoup 库,命令如下:pip3 install bs4。
4.2 基础使用
from bs4 import BeautifulSoup# 默认打开文件的编码格式是gbk,所以需要指定打开编码格式
# 服务器响应的文件生成对象
# soup = BeautifulSoup(response.read().decode(), 'lxml')
# 本地文件生成对象
soup = BeautifulSoup(open('1.html'), 'lxml')
BeautifulSoup类基本元素:
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字,<p>…</p> 的名字是 ’p’,格式:<tag>.name |
| Attributes | 标签的属性,字典组织形式,格式:<tag>.attrs |
| NavigableString | 标签内非属性字符串,<>…</>中字符串,格式:<tag>.string |
| Comment | 标签内字符串的注释部分,一种特殊的 Comment 类型 |
4.3 常见方法
soup.title # 获取html的title标签的信息
soup.a # 获取html的a标签的信息(soup.a默认获取第一个a标签,想获取全部就用for循环去遍历)
soup.a.name # 获取a标签的名字
soup.a.parent.name # a标签的父标签(上一级标签)的名字
soup.a.parent.parent.name # a标签的父标签的父标签的名字
type(soup.a) # 查看a标签的类型
soup.a.attrs # 获取a标签的所有属性(注意到格式是字典)
type(soup.a.attrs) # 查看a标签属性的类型
soup.a.attrs['class'] # 因为是字典,通过字典的方式获取a标签的class属性
soup.a.attrs['href'] # 同样,通过字典的方式获取a标签的href属性
soup.a.string # a标签的非属性字符串信息,表示尖括号之间的那部分字符串
type(soup.a.string) # 查看标签string字符串的类型
soup.p.string # p标签的字符串信息(注意p标签中还有个b标签,但是打印string时并未打印b标签,说明string类型是可跨越多个标签层次)
soup.find_all('a') # 使用find_all()方法通过标签名称查找a标签,返回的是一个列表类型
soup.find_all(['a', 'b']) # 把a标签和b标签作为一个列表传递,可以一次找到a标签和b标签for t in soup.find_all('a'): # for循环遍历所有a标签,并把返回列表中的内容赋给tprint('t的值是:', t) # link得到的是标签对象print('t的类型是:', type(t))print('a标签中的href属性是:', t.get('href')) # 获取a标签中的url链接for i in soup.find_all(True): # 如果给出的标签名称是True,则找到所有标签print('标签名称:', i.name) # 打印标签名称soup.find_all('a', href='http://www.xxx.com') # 标注属性检索
soup.find_all(class_='title') # 指定属性,查找class属性为title的标签元素,注意因为class是python的关键字,所以这里需要加个下划线'_'
soup.find_all(id='link1') # 查找id属性为link1的标签元素
soup.head # head标签
soup.head.contents # head标签的儿子标签,contents返回的是列表类型
soup.body.contents # body标签的儿子标签
len(soup.body.contents) # 获得body标签儿子节点的数量
soup.body.contents[1] # 通过列表索引获取第一个节点的内容
type(soup.body.children) # children返回的是一个迭代对象,只能通过for循环来使用,不能直接通过索引来读取其中的内容for i in soup.body.children: # 通过for循环遍历body标签的儿子节点print(i.name) # 打印节点的名字
4.4 案例演示
需求: 获取星巴克数据。
from bs4 import BeautifulSoup
import urllib.requesturl = 'https://www.starbucks.com.cn/menu/'resp = urllib.request.urlopen(url)
context = resp.read().decode('utf-8')
soup = BeautifulSoup(context,'lxml')
obj = soup.select("ul[class='grid padded-3 product'] div[class='preview circle']")
for item in obj:completePicUrl = 'https://www.starbucks.com.cn'+item.attrs.get('style').split('url("')[1].split('")')[0]print(completePicUrl)
参考文献
【1】https://blog.csdn.net/qq_54528857/article/details/122202572
【2】https://blog.csdn.net/qq_46092061/article/details/119777935
【3】https://www.php.cn/python-tutorials-490500.html
【4】https://zhuanlan.zhihu.com/p/313277380
【5】https://blog.csdn.net/xiaobai729/article/details/124079260
【6】https://blog.51cto.com/u_15309652/3154785
【7】https://blog.csdn.net/qq_62789540/article/details/122500983
【8】https://blog.csdn.net/weixin_58667126/article/details/126105955
【9】https://www.cnblogs.com/surpassme/p/16552633.html
【10】https://www.cnblogs.com/yxm-yxwz/p/16260797.html
【11】https://blog.csdn.net/weixin_54542209/article/details/123282142
【12】http://blog.csdn.net/luxideyao/article/details/77802389
【13】https://achang.blog.csdn.net/article/details/122884222
【14】https://www.bbsmax.com/A/gGdXBNBpJ4/
【15】https://www.cnblogs.com/huskysir/p/12425197.html
【16】https://zhuanlan.zhihu.com/p/27645452
【17】https://zhuanlan.zhihu.com/p/533266670
【18】https://blog.csdn.net/qq_39314932/article/details/99338957
【19】https://www.bbsmax.com/A/A7zgADgP54/
【20】https://blog.csdn.net/qq_44690947/article/details/126236736
相关文章:
Python爬虫基础之如何对爬取到的数据进行解析
目录1. 前言2. Xpath2.1 插件/库安装2.2 基础使用2.3 Xpath表达式2.4 案例演示2.4.1 某度网站案例3. JsonPath3.1 库安装3.2 基础使用3.2 JsonPath表达式3.3 案例演示4. BeautifulSoup4.1 库安装4.2 基础使用4.3 常见方法4.4 案例演示参考文献原文地址:https://www.…...

【Python游戏】坦克大战、推箱子小游戏怎么玩?学会这些让你秒变高高手—那些童年的游戏还记得吗?(附Pygame合集源码)
前言 下一个青年节快到了,想小编我也是过不了几年节日了呢!! 社交媒体上流传着一张照片——按照国家规定“14岁到28岁今天都应该放半天假!”不得不说, 这个跨度着实有点儿大,如果按整自然年来算年龄&…...
python3 DataFrame一些好玩且高效的操作
pandas在处理Excel/DBs中读取出来,处理为DataFrame格式的数据时,处理方式和性能上有很大差异,下面是一些高效,方便处理数据的方法。 map/apply/applymaptransformagg遍历求和/求平均shift/diff透视表切片,索引&#x…...
幻灯片)
如何从 PowerPoint 导出高分辨率(高 dpi)幻灯片
如何从 PowerPoint 导出高分辨率(高 dpi)幻灯片更改导出分辨率设置将幻灯片导出为图片限制你可以通过将幻灯片保存为图片格式来更改 Microsoft PowerPoint 的导出分辨率。 此过程有两个步骤:使用系统注册表更改导出的幻灯片的默认分辨率设置&…...

JAVA数据结构之冒泡排序,数组元素反转,二分查找算法的联合使用------JAVA入门基础教程
//二分查找与冒泡排序与数组元素反转的连用 int[] arr2 new int[]{2,4,5,8,12,15,19,26,29,37,49,51,66,89,100}; int[] po new int[arr2.length]; //复制一个刚好倒叙的数组po for (int i arr2.length - 1; i > 0; i--) {po[arr2.length - 1 - i] arr2[i]; }//arr2 po…...

linux对动态库的搜索知识梳理
一.动态库优先搜索路径顺序 之前的文章我有整理过,这里再列出来一次 1. 编译目标代码时指定的动态库搜索路径; 2. 环境变量LD_LIBRARY_PATH指定的动态库搜索路径; 3. 配置文件/etc/ld.so.conf中指定的动态库搜索路径; 4. 默认…...

R -- 用psych包做因子分析
因子分析 因子分析又称为EFA,是一系列用来发现一组变量的潜在结构的办法。它通过寻找一组更小的,潜在的结构来解释已观测到的显式的变量间的关系。这些虚拟的、无法观测的变量称为因子(每个因子被认为可以解释多个观测变量间共有的方差&…...

既然操作系统层已经提供了page cache的功能,为什么还要在应用层加缓存?
Page Cache是一种在操作系统内核中实现的缓存机制,用于缓存文件系统中的数据块。当一个进程请求读取一个文件时,操作系统会首先在Page Cache中查找数据块,如果找到了相应的数据块,则直接返回给进程;如果没有找到&#…...
Redis应用问题解决
16. Redis应用问题解决 16.1 缓存穿透 16.1.1 问题描述 key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库…...

Qemu虚拟机读取物理机的物理网卡的流量信息方法
项目背景: 比如我有三个项目 A,B,C;其中A项目部署在物理机上,B,C项目部署在 虚拟机V1,V2中,三个项目接口需要相互调用。 需要解决的问题点: 1,因为A,B&#x…...
面试题之vue的响应式
文章目录前言一、响应式是什么?二、Object.defineProperty二、简单模拟vue三、深度监听四、监听数组总结前言 为了应对面试而进行的学习记录,可能不够有深度甚至有错误,还请各位谅解,并不吝赐教,共同进步。 一、响应式…...

聚焦弹性问题,杭州铭师堂的 Serverless 之路
作者:王彬、朱磊、史明伟 得益于互联网的发展,知识的传播有了新的载体,使用在线学习平台的学生规模逐年增长,越来越多学生在线上获取和使用学习资源,其中教育科技企业是比较独特的存在,他们担当的不仅仅是…...
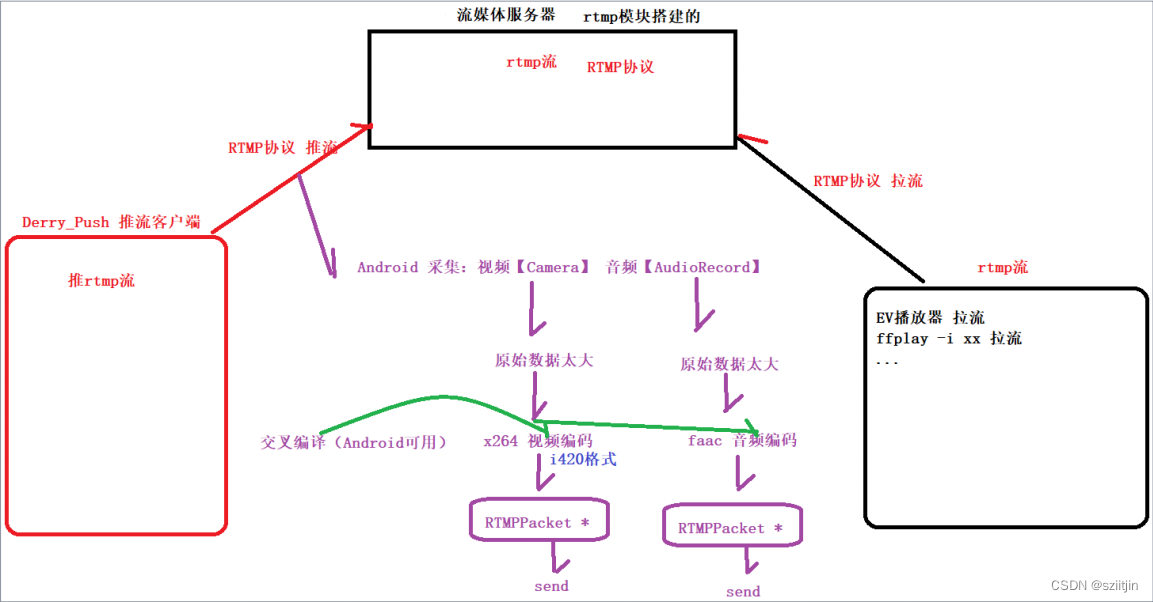
NDK RTMP直播客户端二
在之前完成的实战项目【FFmpeg音视频播放器】属于拉流范畴,接下来将完成推流工作,通过RTMP实现推流,即直播客户端。简单的说,就是将手机采集的音频数据和视频数据,推到服务器端。 接下来的RTMP直播客户端系列ÿ…...

Python3--垃圾回收机制
一、概述 Python 内部采用 引用计数法,为每个对象维护引用次数,并据此回收不在需要的垃圾对象。由于引用计数法存在重大缺陷,循环引用时由内存泄露风险,因此Python还采用 标记清除法 来回收在循环引用的垃圾对象。此外,…...
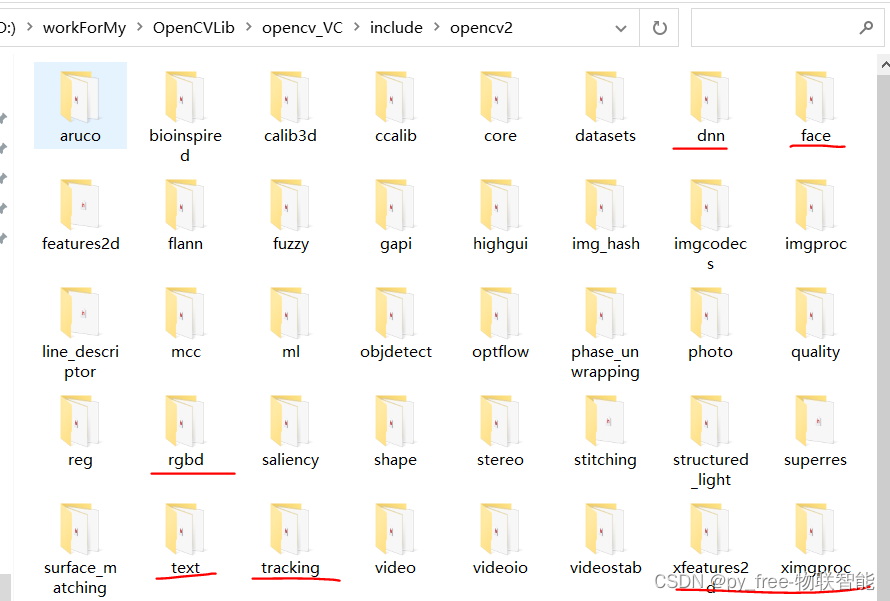
C/C++开发,认识opencv各模块
目录 一、opencv模块总述 二、opencv主要模块 2.1 opencv安装路径及内容 2.2 opencv模块头文件说明 2.3 成熟OpenCV主要模块 2.4 社区支持的opencv_contrib扩展主要模块 2.5 关于库文件的引用 一、opencv模块总述 opencv的主要能力在于图像处理,尤其是针对二维图…...
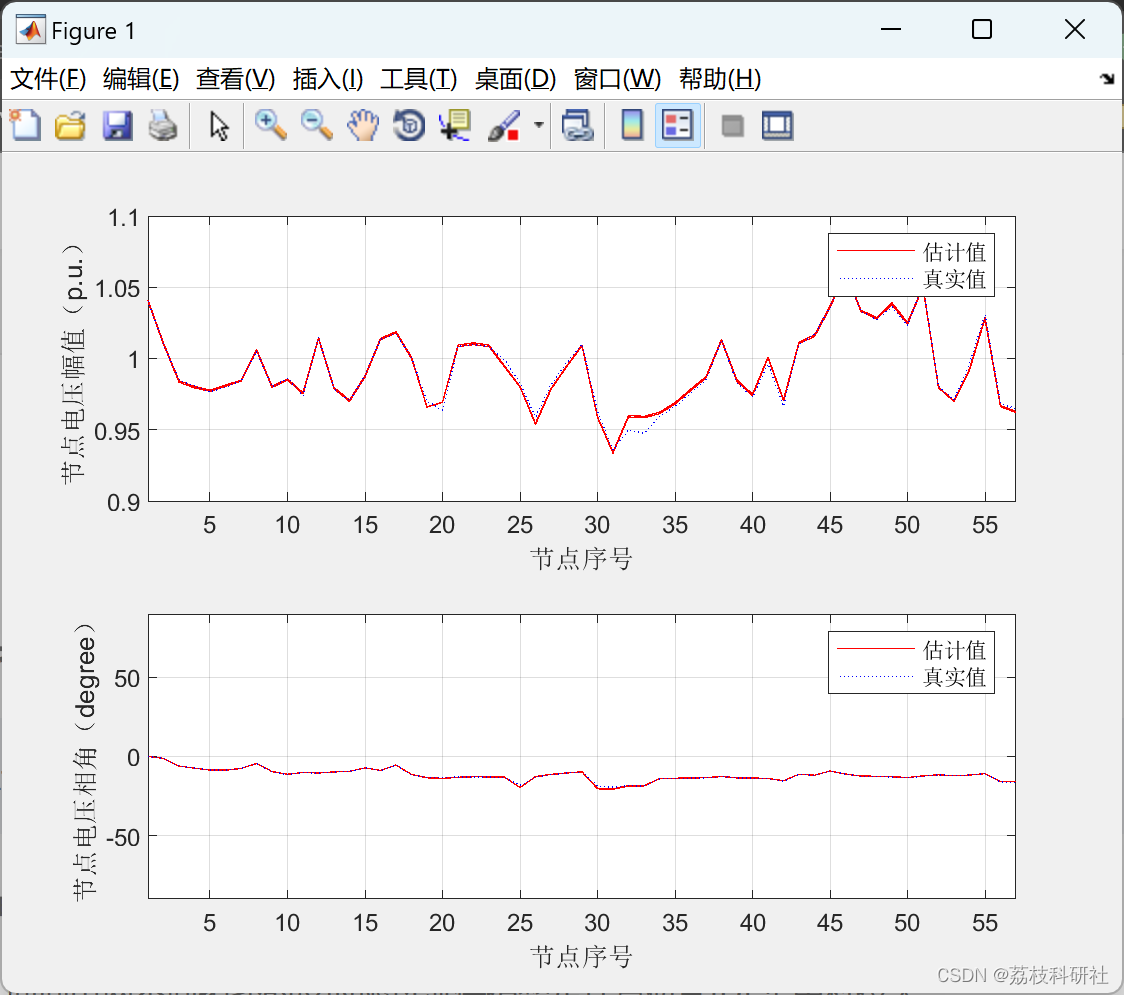
【WLSM、FDM状态估计】电力系统状态估计研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

准备2023(2024)蓝桥杯
前缀和 一维前缀和 s[i]s[i-1]a[i]二维前缀和(子矩阵的和) s[i][j]s[i-1][j]s[i][j-1]-s[i-1][j-1]a[i][j] 差分 一维数组 //b是差分数组b[i]c;b[j1]-c;例题 #include<iostream> using namespace std; int n,m; int b[100002],a[100002]; vo…...

剑指 Offer 60. n个骰子的点数
剑指 Offer 60. n个骰子的点数 难度:middle\color{orange}{middle}middle 题目描述 把n个骰子扔在地上,所有骰子朝上一面的点数之和为s。输入n,打印出s的所有可能的值出现的概率。 你需要用一个浮点数数组返回答案,其中第 i 个…...

阿里巴巴-淘宝搜索排序算法学习
模型效能:模型结构优化 模型效能:减枝 FLOPS:每秒浮点运算的次数 模型效能:量化 基于统计阈值限定,基于学习阈值限定。 平台效能:一站式DL训练平台 平台效能:搜索模型的系统流程 协同关系…...

〖Python网络爬虫实战⑮〗- pyquery的使用
订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000python项目实战 Python编程基础教程系列(零基础小白搬砖逆袭) 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费…...

突破性创新:Midscene.js如何用AI视觉驱动重塑跨平台自动化测试
突破性创新:Midscene.js如何用AI视觉驱动重塑跨平台自动化测试 【免费下载链接】midscene AI-powered, vision-driven UI automation for every platform. 项目地址: https://gitcode.com/GitHub_Trending/mid/midscene 在当今复杂的软件生态中,跨…...

保姆级教程:用LabVIEW 2023给CANoe做个外挂,实现硬件数据采集与自动化测试
保姆级教程:用LabVIEW 2023给CANoe做个外挂,实现硬件数据采集与自动化测试 在汽车电子测试领域,工程师们常常面临一个核心矛盾:CANoe作为行业标准的总线仿真工具提供了强大的协议分析和测试管理能力,但在面对非标硬件接…...

3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具
3个简单步骤掌握gInk:Windows上最轻量的免费屏幕画笔工具 【免费下载链接】gInk An easy to use on-screen annotation software inspired by Epic Pen. 项目地址: https://gitcode.com/gh_mirrors/gi/gInk gInk屏幕画笔工具是一款专为Windows用户设计的实时…...
)
STM32CubeMX配置I2C驱动ADS1115,从零开始实现高精度电压采集(附完整工程源码)
STM32CubeMX配置I2C驱动ADS1115:从零实现工业级电压采集系统 在嵌入式开发中,高精度模拟信号采集一直是工程师面临的挑战。当我们需要测量微弱电压信号或实现多通道同步采集时,STM32内置ADC往往难以满足精度要求。本文将手把手教你使用STM32C…...

OpenRegistry私有镜像仓库:轻量部署与生产实践指南
1. 项目概述:一个面向容器生态的私有镜像仓库如果你在团队里负责过容器化应用的部署和维护,大概率遇到过镜像管理的痛点。从Docker Hub拉取公共镜像,速度慢不说,安全性和稳定性也完全不可控;把所有镜像都放在开发者的本…...
)
不止于测温:用MAX31855和K型热电偶搭建一个低成本高精度温度监控系统(附STM32源码)
从热电偶到云端:基于MAX31855的高精度温度监测系统全栈开发指南 在工业自动化、实验室监测甚至家庭酿造等场景中,温度数据的精确采集与实时监控往往成为项目成败的关键。传统温度传感器虽然简单易用,但在高温、腐蚀性环境或需要极高精度的场合…...

RISC-V PLIC中断控制器详解:从原理到SiFive U54实战配置
1. 平台级中断控制器(PLIC)是什么?为什么需要它?如果你正在接触基于RISC-V架构的嵌入式系统开发,尤其是像SiFive U54这样的多核处理器,那么“PLIC”这个缩写会频繁地出现在你的视野里。它全称是Platform-Le…...

终极Linux打印机兼容性解决方案:foo2zjs驱动完整实战指南
终极Linux打印机兼容性解决方案:foo2zjs驱动完整实战指南 【免费下载链接】foo2zjs A linux printer driver for QPDL protocol - copy of http://foo2zjs.rkkda.com/ 项目地址: https://gitcode.com/gh_mirrors/fo/foo2zjs foo2zjs是Linux系统上最全面的开源…...

Quectel移远展锐平台5G模组RX500U/RG200U工作模式深度解析:从网卡到路由的实战选择
1. 5G模组工作模式基础认知 第一次接触Quectel移远展锐平台5G模组时,最让我困惑的就是网卡模式和路由模式的区别。记得去年做智能快递柜项目时,就因为没搞清这两种模式的特点,导致现场调试时手忙脚乱。后来在工业网关项目上反复折腾RX500U模组…...

BilibiliDown终极指南:快速下载B站视频的免费高效方案
BilibiliDown终极指南:快速下载B站视频的免费高效方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/b…...