实验6 TensorFlow基础
1. 实验目的
掌握TensorFlow低阶API,能够运用TensorFlow处理数据以及对数据进行运算。
2.实验内容
①实现张量维度变换,部分采样等;
②实现张量加减乘除、幂指对数运算;
③利用TensorFlow对数据集进行处理。
3.实验过程
题目一:
加载波士顿房价数据集,并按照以下要求选择属性、计算并绘图。(20分)
⑴ 以二维数组的形式显示属性NOX、RM和LSTAT,其中每一行为一个样本,每一列为一个属性或房价。(4分)
⑵ 选择属性RM和房价,绘制散点图。其中每个样本的属性值为xix_{i}xi,每个样本的房价为yiy_{i}yi, iii为样本的索引值。(2分)
⑶ 使用TensorFlow分别计算www和bbb,并输出结果。(10分)
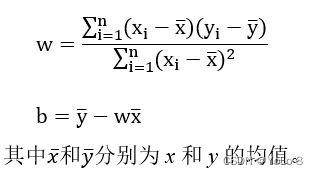
⑶ 以w为斜率,b为截距,做出一条直线,和第⑵问的散点图绘制在同一张图上。(3分)
⑷ 观察这条直线和散点之间的位置关系,你有什么发现或者猜测。(1分)
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
boston_housing = tf.keras.datasets.boston_housing(train_x,train_y),(text_x,text_y) = boston_housing.load_data(test_split=0)#设置rc参数
plt.rcParams["font.family"] = "SimHei"#设置默认字体为中文黑体
plt.rcParams['axes.unicode_minus'] = False #坐标轴上负号的显示可能会出错titles = ["CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX","PTRATIO", "B-1000", "LSTAT", "MEDV"
]nox = [[train_x[:,4]],[train_y]]
rm = [[train_x[:,5]],[train_y]]
latat = [[train_x[:,12]],[train_y]]plt.figure(figsize=(4,4))plt.scatter(train_x[:,5],train_y)
plt.xlabel("RM")
plt.ylabel("Price($1000's)")
plt.title(str(6)+ "." + "RM - Price")x = tf.constant(train_x[:,5],tf.float32)
y = tf.constant(train_y,tf.float32)average_x = tf.reduce_mean(x)
average_y = tf.reduce_mean(y)sum1 = tf.reduce_sum(tf.multiply(tf.subtract(x,average_x),tf.subtract(y,average_y)))
sum2 = tf.reduce_sum(tf.square(tf.subtract(x,average_x)))w = sum1 / sum2
b= average_y - w * average_x#画拟合直线
x = np.linspace(4,9,50)
y = w * x + b
plt.plot(x,y,color = "r")print("W=%f",w)
print("b=%f",b)plt.show()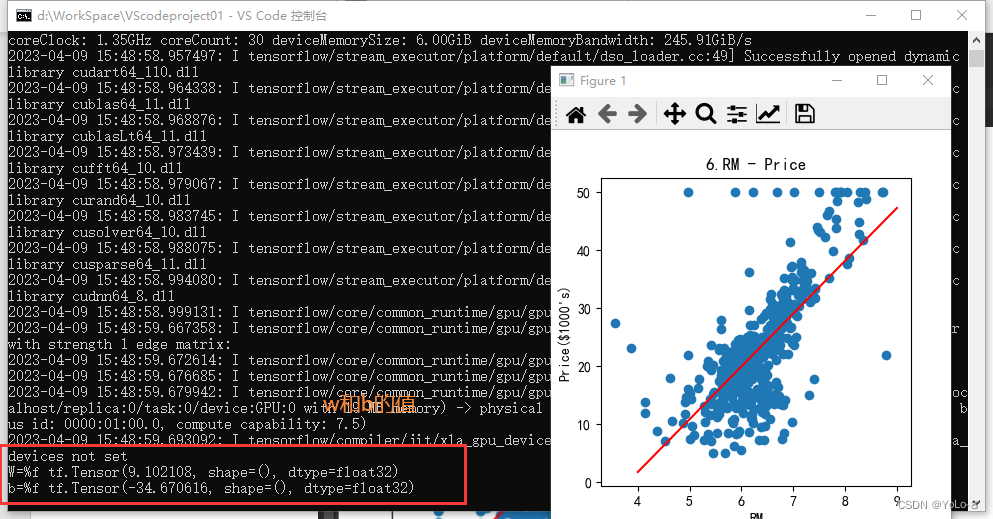
答:近似拟合为一条直线
题目二:
使用TensorFlow张量运算计算w和b,并输出结果。(20分)
已知:
x=[ 64.3, 99.6, 145.45, 63.75, 135.46, 92.85, 86.97, 144.76, 59.3, 116.03]
y=[ 62.55, 82.42, 132.62, 73.31, 131.05, 86.57, 85.49, 127.44, 55.25, 104.84]
计算:
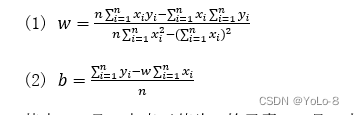
其中,xix_{i}xi是x中索引值为i的元素;yiy_{i}yi是y中索引值为i的元素;n是张量中元素的个数;
(3)分别输出w和b的结果。
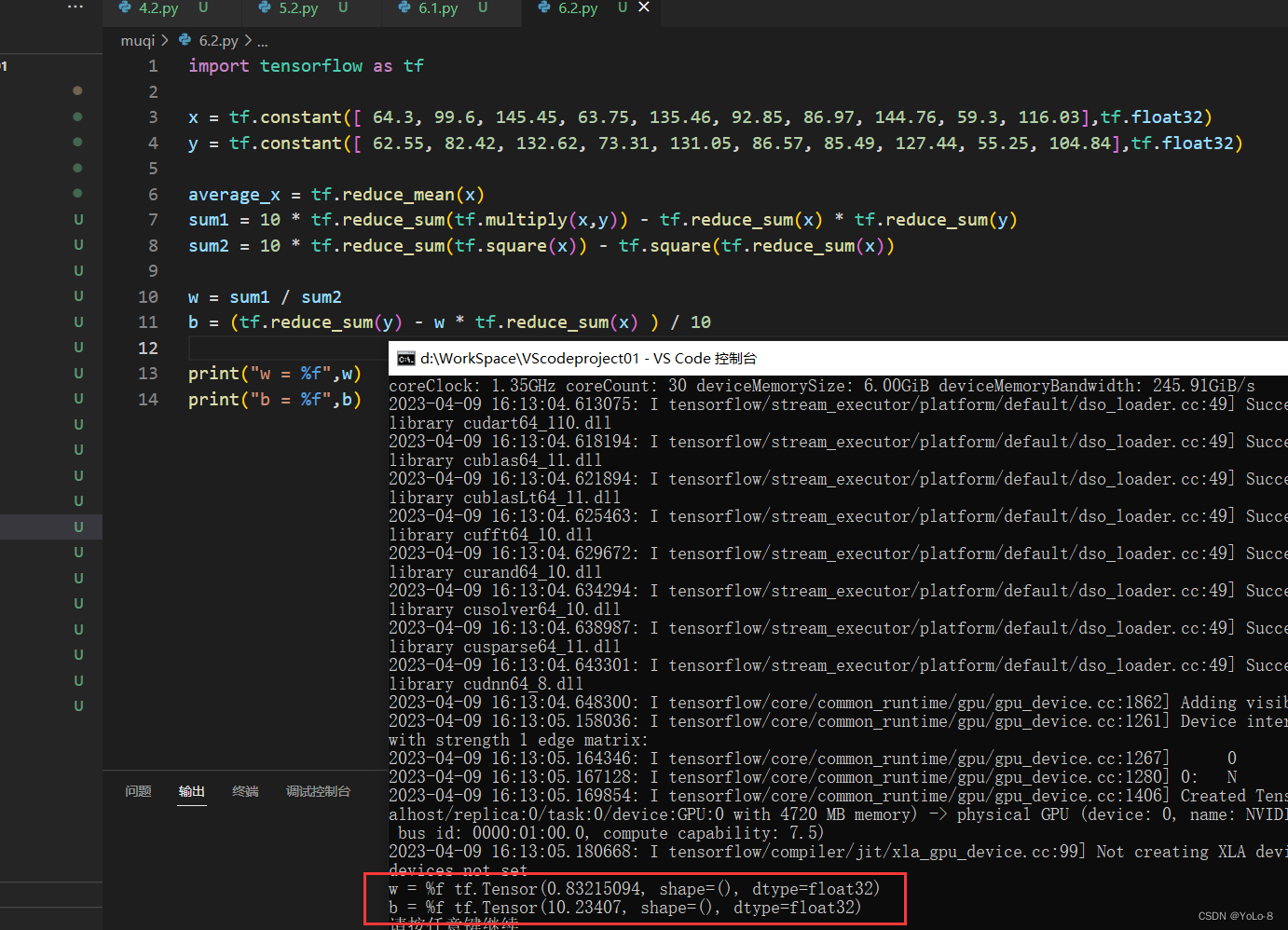
import tensorflow as tfx = tf.constant([ 64.3, 99.6, 145.45, 63.75, 135.46, 92.85, 86.97, 144.76, 59.3, 116.03],tf.float32)
y = tf.constant([ 62.55, 82.42, 132.62, 73.31, 131.05, 86.57, 85.49, 127.44, 55.25, 104.84],tf.float32)average_x = tf.reduce_mean(x)
sum1 = 10 * tf.reduce_sum(tf.multiply(x,y)) - tf.reduce_sum(x) * tf.reduce_sum(y)
sum2 = 10 * tf.reduce_sum(tf.square(x)) - tf.square(tf.reduce_sum(x))w = sum1 / sum2
b = (tf.reduce_sum(y) - w * tf.reduce_sum(x) ) / 10print("w = %f",w)
print("b = %f",b)
题目三:
已知:x1=[137.97, 104.50, 100.00, 124.32, 79.20, 99.00, 124.00,114.00, 106.69, 138.05, 53.75, 46.91, 68.00, 63.02, 81.26, 86.21]
x2=[3, 2, 2, 3, 1, 2, 3, 2, 2, 3, 1, 1, 1, 1, 2, 2]
y =[145.00, 110.00, 93.00, 116.00, 65.32, 104.00, 118.00,91.00, 62.00, 133.00, 51.00, 45.00, 78.50, 69.65, 75.69, 95.30]
按要求计算:(20分)
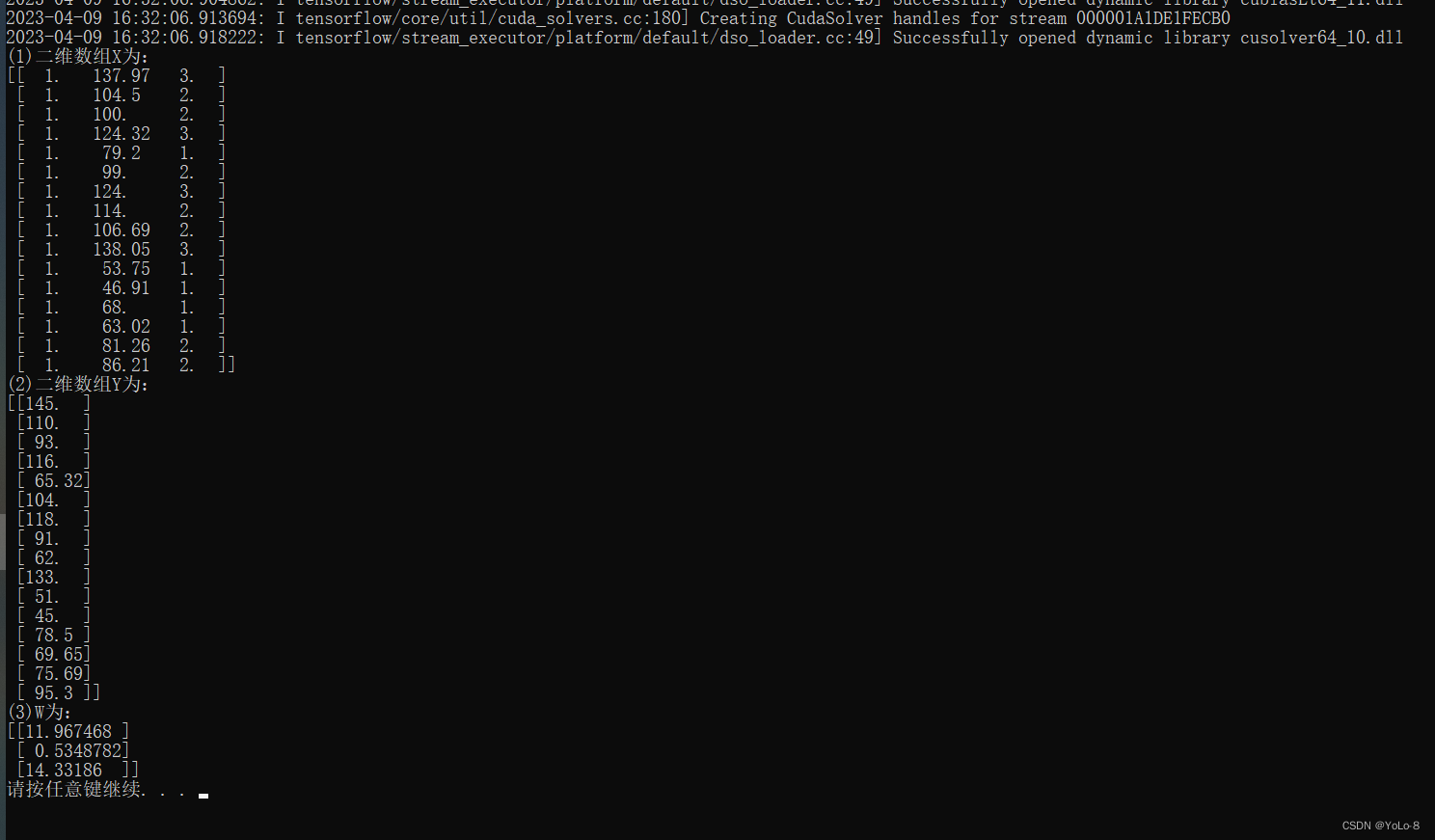
(1) 创建一个16×3的二维数组X,其中第一列全为1,第二列和第三列中分别为数组x1和x2中的数据,并输出。
(2) 将数组y转换为16×1的二维数组Y,并输出。
(3) 根据前两问得出的X和Y,利用如下公式,求W。
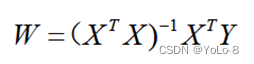
import tensorflow as tfx1 = tf.constant([137.97, 104.50, 100.00, 124.32, 79.20, 99.00, 124.00,114.00, 106.69, 138.05, 53.75, 46.91, 68.00, 63.02, 81.26, 86.21],tf.float32)
x2 = tf.constant([3, 2, 2, 3, 1, 2, 3, 2, 2, 3, 1, 1, 1, 1, 2, 2],tf.float32)
y = tf.constant([145.00, 110.00, 93.00, 116.00, 65.32, 104.00, 118.00,91.00, 62.00, 133.00, 51.00, 45.00, 78.50, 69.65, 75.69, 95.30],tf.float32)x0 = tf.ones(16,tf.float32)X = tf.stack((x0,x1,x2),axis=1)Y = tf.reshape(y,[16,1])Xt = tf.transpose(X)W = tf.linalg.inv(Xt @ X) @ Xt @ Y print("(1)二维数组X为:")
print(X.numpy())
print("(2)二维数组Y为:")
print(Y.numpy())
print("(3)W为:")
print(W.numpy())
4. 实验小结&讨论题
① 实验过程中遇到了哪些问题,你是如何解决的?
没有问题。
② 在实现数组运算时,采用NumPy和TensorFlow各有什么特点?你认为编程时如何选择或使用它们更合理?需要注意哪些问题?
Numpy是用来处理数组的科学计算库,其在深度学习兴起之前就已经存在,其不能很好的支持GPU计算,也不能支持自动求导。而tf正是为了弥补这些缺点而产生的。
在tf中我们经常会见到一些类型。Scalar代表一个标量(一维向量代表的是一个1*1的矩阵,其运算规则是遵循线性代数中的矩阵运算规则。而标量只是一个常数,它参与的是数乘运算。),其维度为0。Vector代表向量其维度为1,
Matrix代表一个矩阵。严格意义上的定义,当rank>2时,才能把矩阵叫做tensor,但是在TF中我们通常把维度为1的数据也可以叫做tensor。在此处从数学意义上说,不够严谨,但是在工程表达中没有差别。
③ 在题目基本要求的基础上,你对每个题目做了那些扩展和提升?或者你觉得在编程实现过程中,还有哪些地方可以进行优化?(可以从如何提高代码的简洁度来谈谈这个问题)
没有扩展和提升,按照题目要求写的。一堆重复的变量可以删除。
相关文章:
实验6 TensorFlow基础
1. 实验目的 掌握TensorFlow低阶API,能够运用TensorFlow处理数据以及对数据进行运算。 2.实验内容 ①实现张量维度变换,部分采样等; ②实现张量加减乘除、幂指对数运算; ③利用TensorFlow对数据集进行处理。 3.实验过程 题目…...

Python爬虫基础之如何对爬取到的数据进行解析
目录1. 前言2. Xpath2.1 插件/库安装2.2 基础使用2.3 Xpath表达式2.4 案例演示2.4.1 某度网站案例3. JsonPath3.1 库安装3.2 基础使用3.2 JsonPath表达式3.3 案例演示4. BeautifulSoup4.1 库安装4.2 基础使用4.3 常见方法4.4 案例演示参考文献原文地址:https://www.…...

【Python游戏】坦克大战、推箱子小游戏怎么玩?学会这些让你秒变高高手—那些童年的游戏还记得吗?(附Pygame合集源码)
前言 下一个青年节快到了,想小编我也是过不了几年节日了呢!! 社交媒体上流传着一张照片——按照国家规定“14岁到28岁今天都应该放半天假!”不得不说, 这个跨度着实有点儿大,如果按整自然年来算年龄&…...
python3 DataFrame一些好玩且高效的操作
pandas在处理Excel/DBs中读取出来,处理为DataFrame格式的数据时,处理方式和性能上有很大差异,下面是一些高效,方便处理数据的方法。 map/apply/applymaptransformagg遍历求和/求平均shift/diff透视表切片,索引&#x…...
幻灯片)
如何从 PowerPoint 导出高分辨率(高 dpi)幻灯片
如何从 PowerPoint 导出高分辨率(高 dpi)幻灯片更改导出分辨率设置将幻灯片导出为图片限制你可以通过将幻灯片保存为图片格式来更改 Microsoft PowerPoint 的导出分辨率。 此过程有两个步骤:使用系统注册表更改导出的幻灯片的默认分辨率设置&…...

JAVA数据结构之冒泡排序,数组元素反转,二分查找算法的联合使用------JAVA入门基础教程
//二分查找与冒泡排序与数组元素反转的连用 int[] arr2 new int[]{2,4,5,8,12,15,19,26,29,37,49,51,66,89,100}; int[] po new int[arr2.length]; //复制一个刚好倒叙的数组po for (int i arr2.length - 1; i > 0; i--) {po[arr2.length - 1 - i] arr2[i]; }//arr2 po…...

linux对动态库的搜索知识梳理
一.动态库优先搜索路径顺序 之前的文章我有整理过,这里再列出来一次 1. 编译目标代码时指定的动态库搜索路径; 2. 环境变量LD_LIBRARY_PATH指定的动态库搜索路径; 3. 配置文件/etc/ld.so.conf中指定的动态库搜索路径; 4. 默认…...

R -- 用psych包做因子分析
因子分析 因子分析又称为EFA,是一系列用来发现一组变量的潜在结构的办法。它通过寻找一组更小的,潜在的结构来解释已观测到的显式的变量间的关系。这些虚拟的、无法观测的变量称为因子(每个因子被认为可以解释多个观测变量间共有的方差&…...

既然操作系统层已经提供了page cache的功能,为什么还要在应用层加缓存?
Page Cache是一种在操作系统内核中实现的缓存机制,用于缓存文件系统中的数据块。当一个进程请求读取一个文件时,操作系统会首先在Page Cache中查找数据块,如果找到了相应的数据块,则直接返回给进程;如果没有找到&#…...
Redis应用问题解决
16. Redis应用问题解决 16.1 缓存穿透 16.1.1 问题描述 key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库…...

Qemu虚拟机读取物理机的物理网卡的流量信息方法
项目背景: 比如我有三个项目 A,B,C;其中A项目部署在物理机上,B,C项目部署在 虚拟机V1,V2中,三个项目接口需要相互调用。 需要解决的问题点: 1,因为A,B&#x…...
面试题之vue的响应式
文章目录前言一、响应式是什么?二、Object.defineProperty二、简单模拟vue三、深度监听四、监听数组总结前言 为了应对面试而进行的学习记录,可能不够有深度甚至有错误,还请各位谅解,并不吝赐教,共同进步。 一、响应式…...

聚焦弹性问题,杭州铭师堂的 Serverless 之路
作者:王彬、朱磊、史明伟 得益于互联网的发展,知识的传播有了新的载体,使用在线学习平台的学生规模逐年增长,越来越多学生在线上获取和使用学习资源,其中教育科技企业是比较独特的存在,他们担当的不仅仅是…...
NDK RTMP直播客户端二
在之前完成的实战项目【FFmpeg音视频播放器】属于拉流范畴,接下来将完成推流工作,通过RTMP实现推流,即直播客户端。简单的说,就是将手机采集的音频数据和视频数据,推到服务器端。 接下来的RTMP直播客户端系列ÿ…...

Python3--垃圾回收机制
一、概述 Python 内部采用 引用计数法,为每个对象维护引用次数,并据此回收不在需要的垃圾对象。由于引用计数法存在重大缺陷,循环引用时由内存泄露风险,因此Python还采用 标记清除法 来回收在循环引用的垃圾对象。此外,…...
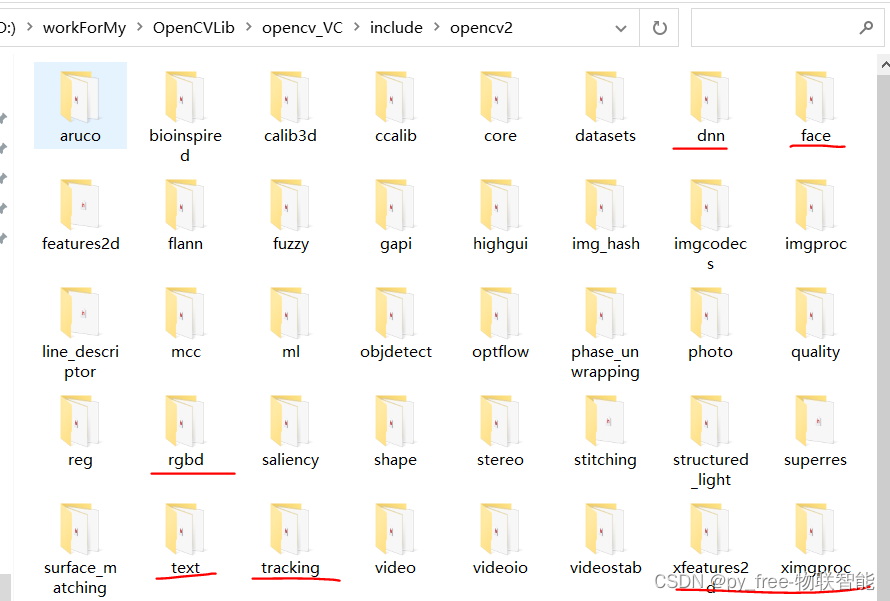
C/C++开发,认识opencv各模块
目录 一、opencv模块总述 二、opencv主要模块 2.1 opencv安装路径及内容 2.2 opencv模块头文件说明 2.3 成熟OpenCV主要模块 2.4 社区支持的opencv_contrib扩展主要模块 2.5 关于库文件的引用 一、opencv模块总述 opencv的主要能力在于图像处理,尤其是针对二维图…...
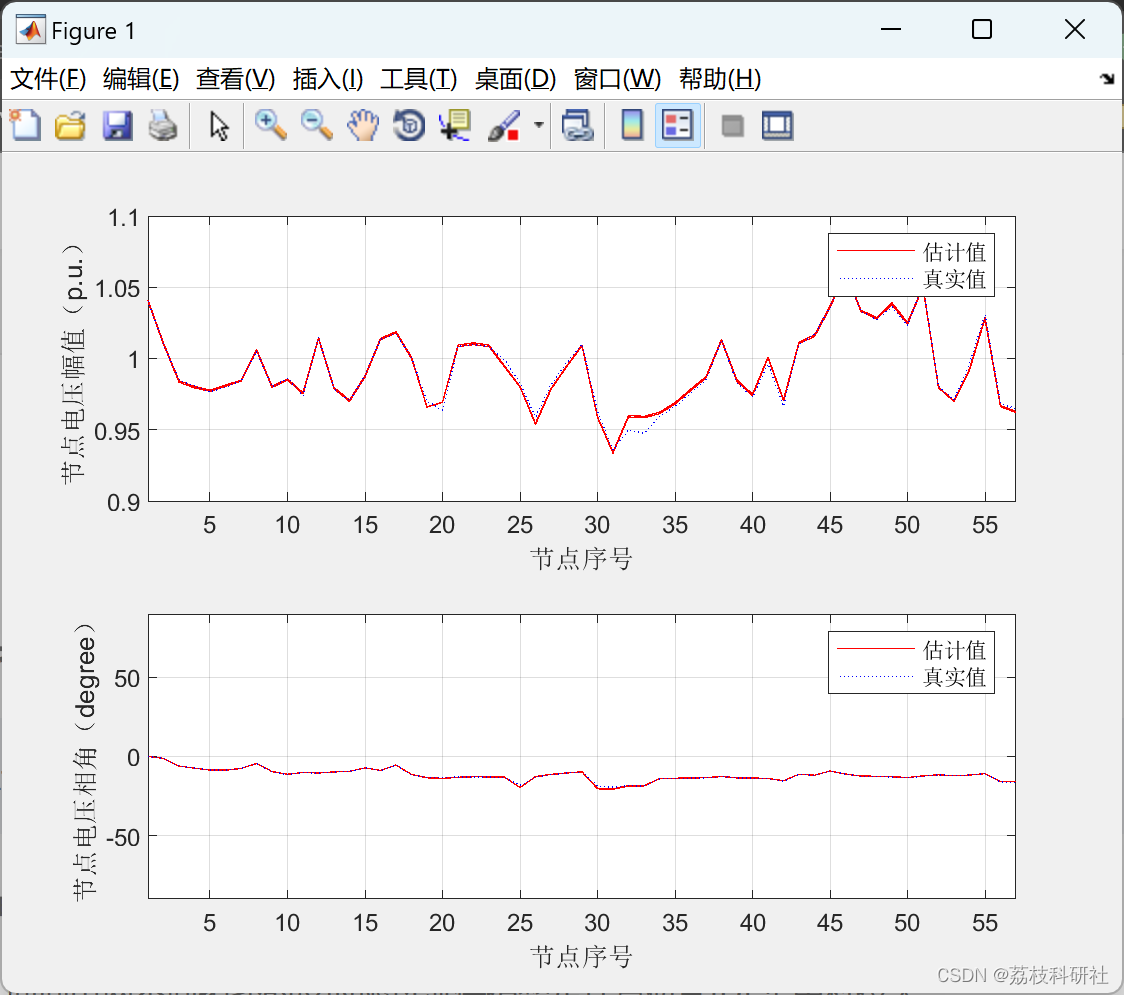
【WLSM、FDM状态估计】电力系统状态估计研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

准备2023(2024)蓝桥杯
前缀和 一维前缀和 s[i]s[i-1]a[i]二维前缀和(子矩阵的和) s[i][j]s[i-1][j]s[i][j-1]-s[i-1][j-1]a[i][j] 差分 一维数组 //b是差分数组b[i]c;b[j1]-c;例题 #include<iostream> using namespace std; int n,m; int b[100002],a[100002]; vo…...

剑指 Offer 60. n个骰子的点数
剑指 Offer 60. n个骰子的点数 难度:middle\color{orange}{middle}middle 题目描述 把n个骰子扔在地上,所有骰子朝上一面的点数之和为s。输入n,打印出s的所有可能的值出现的概率。 你需要用一个浮点数数组返回答案,其中第 i 个…...

阿里巴巴-淘宝搜索排序算法学习
模型效能:模型结构优化 模型效能:减枝 FLOPS:每秒浮点运算的次数 模型效能:量化 基于统计阈值限定,基于学习阈值限定。 平台效能:一站式DL训练平台 平台效能:搜索模型的系统流程 协同关系…...

Taotoken CLI工具安装与一键配置全模型环境指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken CLI工具安装与一键配置全模型环境指南 对于需要接入多个大模型服务的开发团队而言,统一管理API密钥、模型配置…...

Linux内核镜像构建与管理:从源码到部署的工程化实践
1. 项目概述:从“kernel-images”看内核镜像的构建与管理在Linux系统开发、嵌入式设备定制或者云原生基础设施的维护中,我们经常会遇到一个看似简单却至关重要的环节:内核镜像的构建与管理。无论是为了修复一个安全漏洞、启用一个新的硬件驱动…...

DsHidMini技术深度解析:让经典PS3手柄在Windows上重获新生的开源方案
DsHidMini技术深度解析:让经典PS3手柄在Windows上重获新生的开源方案 【免费下载链接】DsHidMini Virtual HID Mini-user-mode-driver for Sony DualShock 3 Controllers 项目地址: https://gitcode.com/gh_mirrors/ds/DsHidMini 你是否有一台尘封已久的Play…...

如何掌握Node.js模块系统:Node.js-Design-Patterns-Third-Edition深度解析
如何掌握Node.js模块系统:Node.js-Design-Patterns-Third-Edition深度解析 【免费下载链接】Node.js-Design-Patterns-Third-Edition Node.js Design Patterns Third Edition, published by Packt 项目地址: https://gitcode.com/gh_mirrors/no/Node.js-Design-Pa…...

MATLAB 2024 升级指南:彻底卸载旧版,高效部署新版
1. 为什么需要彻底卸载旧版MATLAB? 每次MATLAB大版本更新都会带来新功能和性能优化,但很多用户直接覆盖安装后常遇到各种奇怪问题。我去年帮实验室处理过几十台电脑的升级故障,90%的问题都源于旧版残留文件。比如有位同学复现图像处理代码时&…...

AI搜索插件架构解析:如何让大语言模型获取实时信息
1. 项目概述:一个能“思考”的搜索插件 如果你用过ChatGPT或者Claude这类大语言模型,肯定有过这样的体验:当你问它“今天北京的天气怎么样?”或者“帮我查一下最新的显卡天梯图”时,它会礼貌地告诉你,它的知…...

通信中的拆包,残包和多线程互斥锁的注意事项。qt,c++在多线程中一定要使用全局单列互斥锁,否则肯定会崩溃,这边在读这块内存,那边要写。在网络通信中,极有可能丢包,残包,因此要做好拆包,读取,打包
使用互斥锁千万不能重复释放 mute.unlock(); mute.unlock(); 这样的写法会报错我们一定要这样使用互斥锁: // 自动锁,离开作用域自动解锁,不会拷贝锁 QMutexLocker locker(&g_CSR_Mutex);...

Windows热键侦探:3分钟快速找出占用快捷键的程序
Windows热键侦探:3分钟快速找出占用快捷键的程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾经遇到…...

Nginx Server Configs Node.js配置:Node应用部署最佳实践终极指南
Nginx Server Configs Node.js配置:Node应用部署最佳实践终极指南 【免费下载链接】server-configs-nginx Nginx HTTP server boilerplate configs 项目地址: https://gitcode.com/gh_mirrors/se/server-configs-nginx Node.js应用部署常常面临性能优化、安全…...
)
告别重装系统!在Ubuntu 22.04上从零到一搞定ROS2 Humble(附小乌龟测试)
告别重装系统!在Ubuntu 22.04上从零到一搞定ROS2 Humble(附小乌龟测试) 每次看到论坛里"ROS2请用Ubuntu 20.04"的推荐,我都忍不住想:难道新系统就注定与机器人开发无缘?去年我将工作站升级到22.0…...