【ES】数据同步集群
【ES】数据同步&集群
- 3.数据同步
- 3.1.思路分析
- 3.1.1.同步调用
- 3.1.2.异步通知
- 3.1.3.监听binlog
- 3.1.4.选择
- 3.2.实现数据同步
- 3.2.1.思路
- 3.2.2.导入demo
- 3.2.3.声明交换机、队列
- 1)引入依赖
- 2)声明队列交换机名称
- 3)声明队列交换机
- 3.2.4.发送MQ消息
- 3.2.5.接收MQ消息
- 4.集群
- 4.1.搭建ES集群
- 4.2.集群脑裂问题
- 4.2.1.集群职责划分
- 4.2.2.脑裂问题
- 4.2.3.小结
- 4.3.集群分布式存储
- 4.3.1.分片存储测试
- 4.3.2.分片存储原理
- 4.4.集群分布式查询
- 4.5.集群故障转移
3.数据同步
elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步。

3.1.思路分析
常见的数据同步方案有三种:
- 同步调用
- 异步通知
- 监听binlog
3.1.1.同步调用
方案一:同步调用
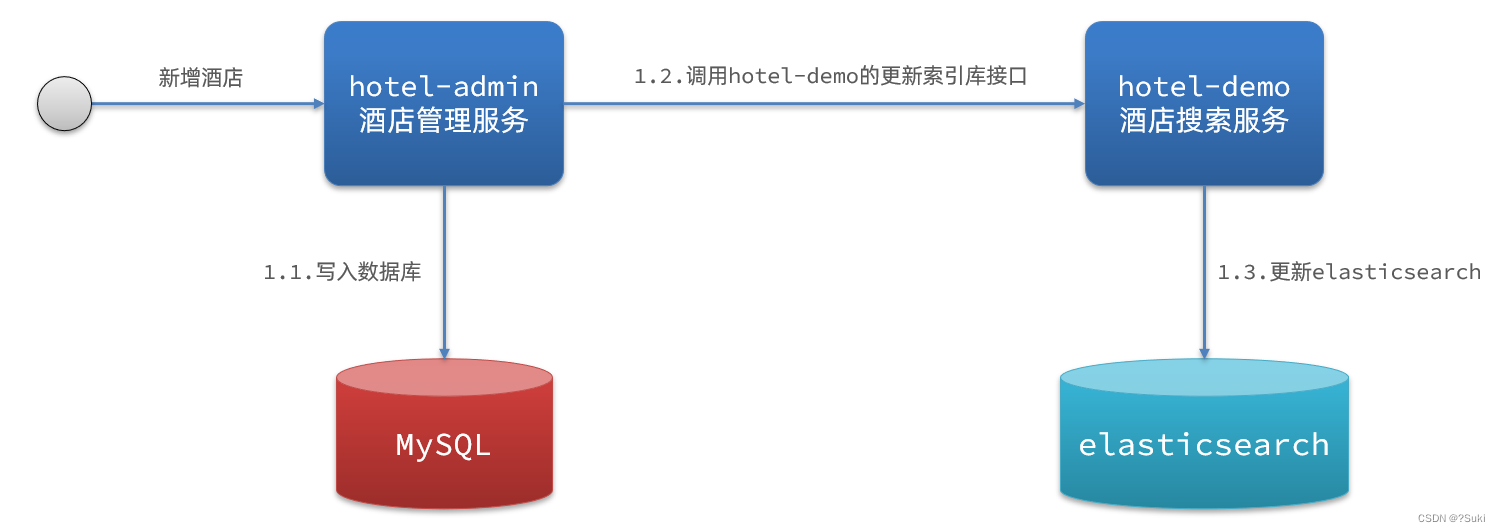
基本步骤如下:
- hotel-demo对外提供接口,用来修改elasticsearch中的数据
- 酒店管理服务在完成数据库操作后,直接调用hotel-demo提供的接口,
3.1.2.异步通知
方案二:异步通知

流程如下:
- hotel-admin对mysql数据库数据完成增、删、改后,发送MQ消息
- hotel-demo监听MQ,接收到消息后完成elasticsearch数据修改
3.1.3.监听binlog
方案三:监听binlog

流程如下:
- 给mysql开启binlog功能
- mysql完成增、删、改操作都会记录在binlog中
- hotel-demo基于canal监听binlog变化,实时更新elasticsearch中的内容
3.1.4.选择
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
3.2.实现数据同步
3.2.1.思路
利用课前资料提供的hotel-admin项目作为酒店管理的微服务。当酒店数据发生增、删、改时,要求对elasticsearch中数据也要完成相同操作。
步骤:
-
导入课前资料提供的hotel-admin项目,启动并测试酒店数据的CRUD
-
声明exchange、queue、RoutingKey
-
在hotel-admin中的增、删、改业务中完成消息发送
-
在hotel-demo中完成消息监听,并更新elasticsearch中数据
-
启动并测试数据同步功能
3.2.2.导入demo
导入课前资料提供的hotel-admin项目:
运行后,访问 http://localhost:8099

其中包含了酒店的CRUD功能:

3.2.3.声明交换机、队列
MQ结构如图:

1)引入依赖
在hotel-admin、hotel-demo中引入rabbitmq的依赖:
<!--amqp-->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
2)声明队列交换机名称
在hotel-admin和hotel-demo中的cn.itcast.hotel.constatnts包下新建一个类MqConstants:
package cn.itcast.hotel.constatnts;public class MqConstants {/*** 交换机*/public final static String HOTEL_EXCHANGE = "hotel.topic";/*** 监听新增和修改的队列*/public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";/*** 监听删除的队列*/public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";/*** 新增或修改的RoutingKey*/public final static String HOTEL_INSERT_KEY = "hotel.insert";/*** 删除的RoutingKey*/public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
3)声明队列交换机
在hotel-demo中,定义配置类,声明队列、交换机:
package cn.itcast.hotel.config;import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
public class MqConfig {@Beanpublic TopicExchange topicExchange(){return new TopicExchange(MqConstants.HOTEL_EXCHANGE, true, false);}@Beanpublic Queue insertQueue(){return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);}@Beanpublic Queue deleteQueue(){return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);}@Beanpublic Binding insertQueueBinding(){return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);}@Beanpublic Binding deleteQueueBinding(){return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);}
}
3.2.4.发送MQ消息
在hotel-admin中的增、删、改业务中分别发送MQ消息:
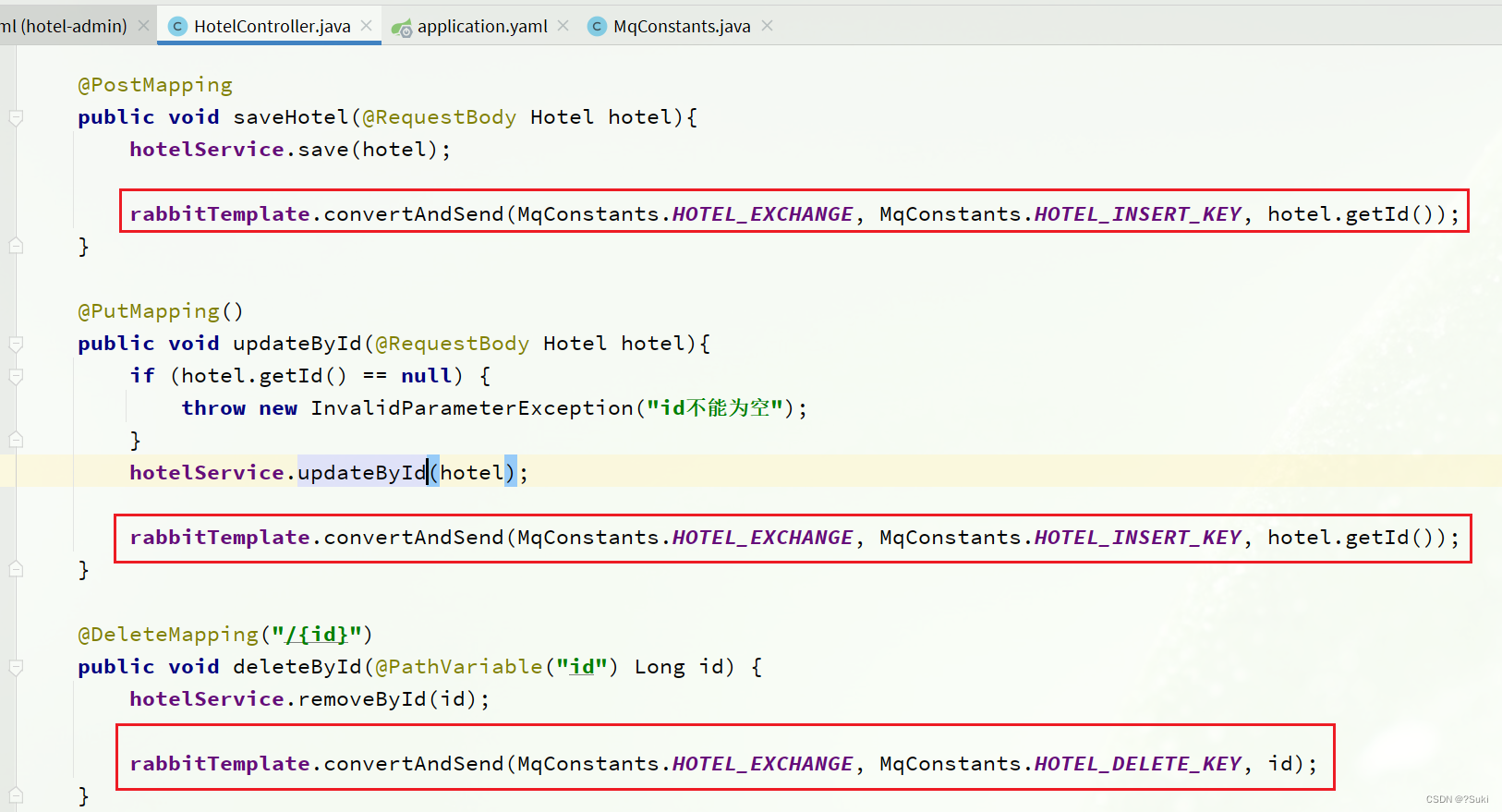
3.2.5.接收MQ消息
hotel-demo接收到MQ消息要做的事情包括:
- 新增消息:根据传递的hotel的id查询hotel信息,然后新增一条数据到索引库
- 删除消息:根据传递的hotel的id删除索引库中的一条数据
1)首先在hotel-demo的cn.itcast.hotel.service包下的IHotelService中新增新增、删除业务
void deleteById(Long id);void insertById(Long id);
2)给hotel-demo中的cn.itcast.hotel.service.impl包下的HotelService中实现业务:
@Override
public void deleteById(Long id) {try {// 1.准备RequestDeleteRequest request = new DeleteRequest("hotel", id.toString());// 2.发送请求client.delete(request, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}
}@Override
public void insertById(Long id) {try {// 0.根据id查询酒店数据Hotel hotel = getById(id);// 转换为文档类型HotelDoc hotelDoc = new HotelDoc(hotel);// 1.准备Request对象IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());// 2.准备Json文档request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);// 3.发送请求client.index(request, RequestOptions.DEFAULT);} catch (IOException e) {throw new RuntimeException(e);}
}
3)编写监听器
在hotel-demo中的cn.itcast.hotel.mq包新增一个类:
package cn.itcast.hotel.mq;import cn.itcast.hotel.constants.MqConstants;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;@Component
public class HotelListener {@Autowiredprivate IHotelService hotelService;/*** 监听酒店新增或修改的业务* @param id 酒店id*/@RabbitListener(queues = MqConstants.HOTEL_INSERT_QUEUE)public void listenHotelInsertOrUpdate(Long id){hotelService.insertById(id);}/*** 监听酒店删除的业务* @param id 酒店id*/@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)public void listenHotelDelete(Long id){hotelService.deleteById(id);}
}
4.集群
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份(replica )
ES集群相关概念:
-
集群(cluster):一组拥有共同的 cluster name 的 节点。
-
节点(node) :集群中的一个 Elasticearch 实例
-
分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
解决问题:数据量太大,单点存储量有限的问题。

此处,我们把数据分成3片:shard0、shard1、shard2
-
主分片(Primary shard):相对于副本分片的定义。
-
副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
- 首先对数据分片,存储到不同节点
- 然后对每个分片进行备份,放到对方节点,完成互相备份
这样可以大大减少所需要的服务节点数量,如图,我们以3分片,每个分片备份一份为例:
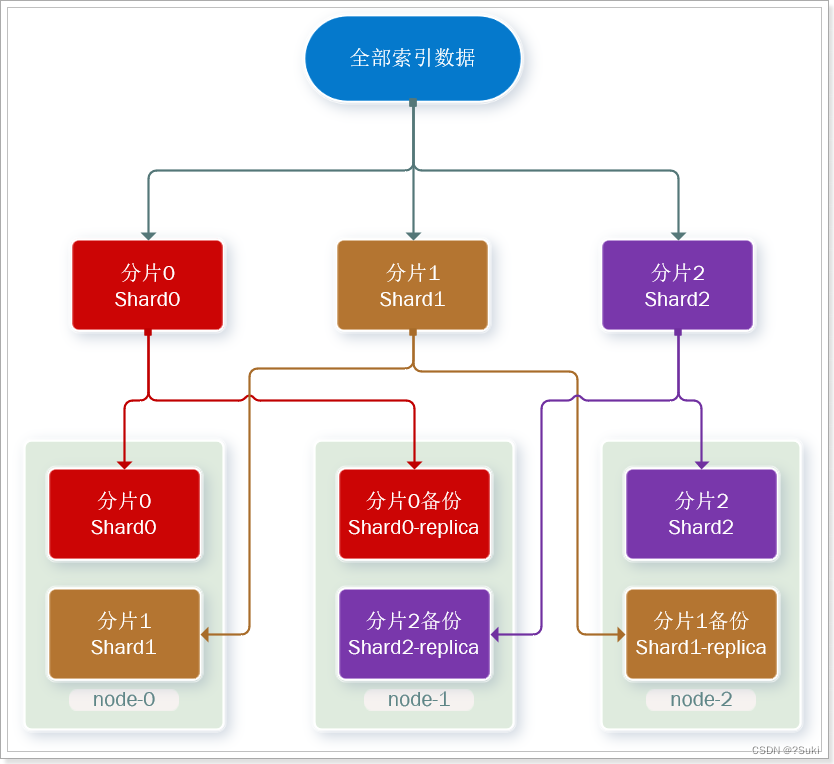
现在,每个分片都有1个备份,存储在3个节点:
- node0:保存了分片0和1
- node1:保存了分片0和2
- node2:保存了分片1和2
4.1.搭建ES集群
参考课前资料的文档:

其中的第四章节:

4.2.集群脑裂问题
4.2.1.集群职责划分
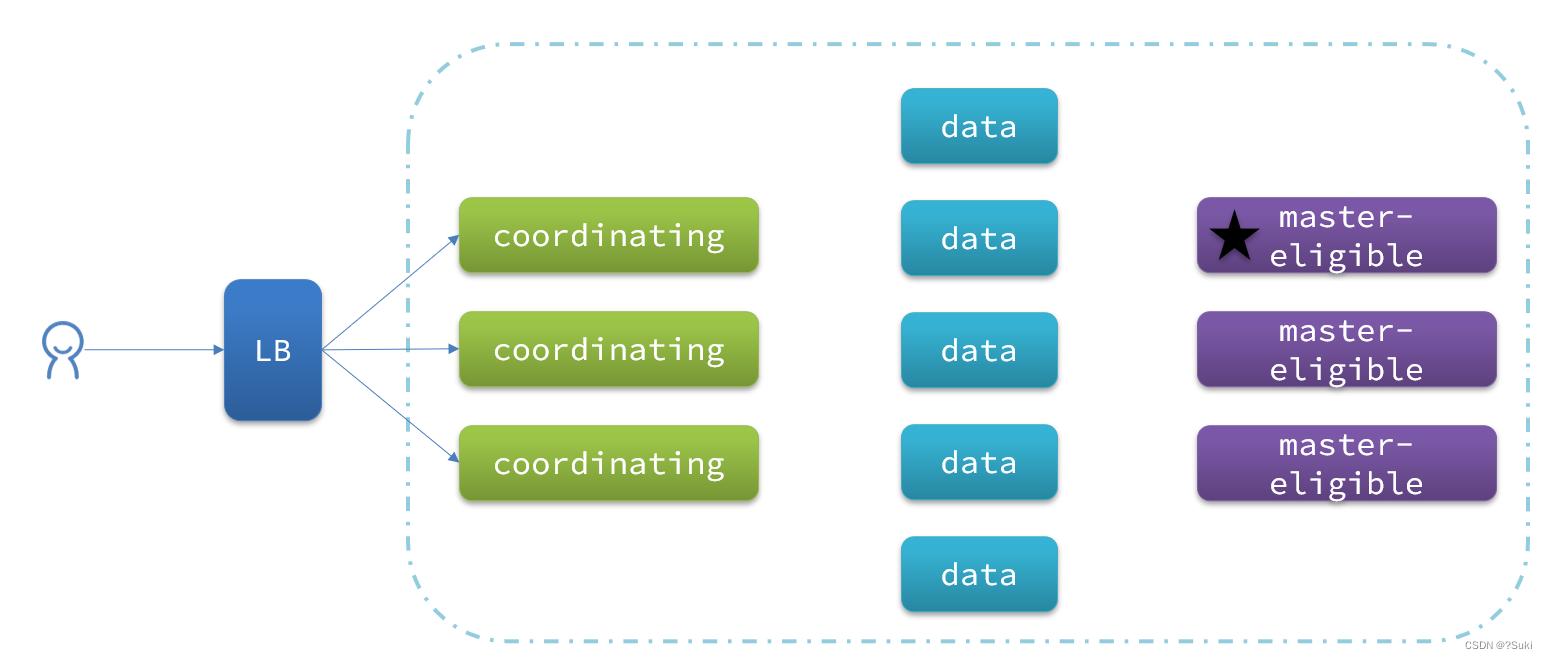
elasticsearch中集群节点有不同的职责划分:

默认情况下,集群中的任何一个节点都同时具备上述四种角色。
但是真实的集群一定要将集群职责分离:
- master节点:对CPU要求高,但是内存要求第
- data节点:对CPU和内存要求都高
- coordinating节点:对网络带宽、CPU要求高
职责分离可以让我们根据不同节点的需求分配不同的硬件去部署。而且避免业务之间的互相干扰。
一个典型的es集群职责划分如图:
4.2.2.脑裂问题
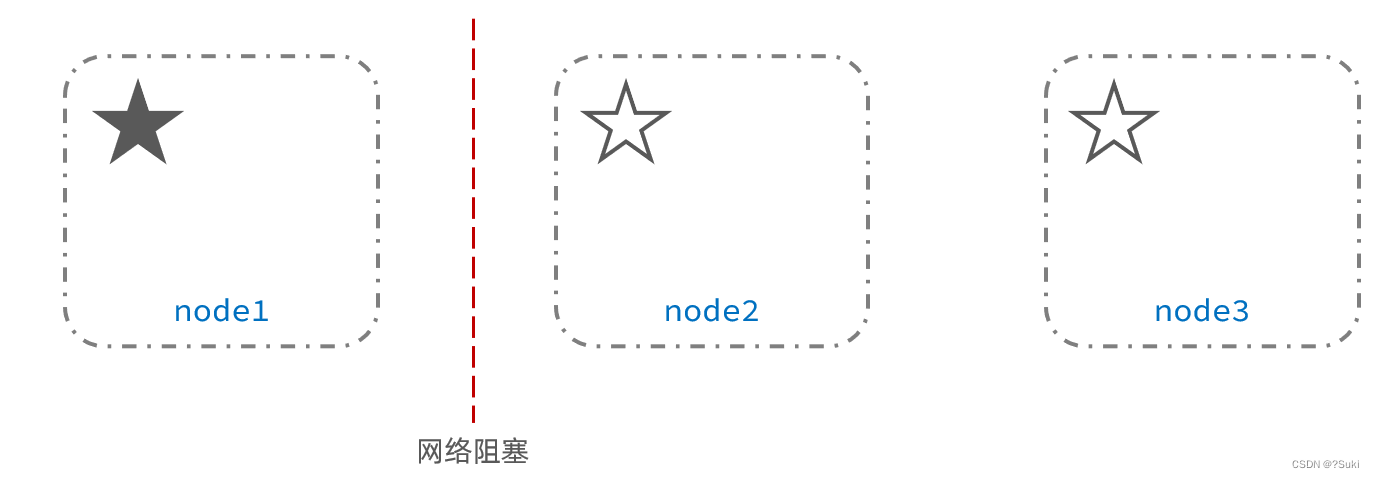
脑裂是因为集群中的节点失联导致的。
例如一个集群中,主节点与其它节点失联:
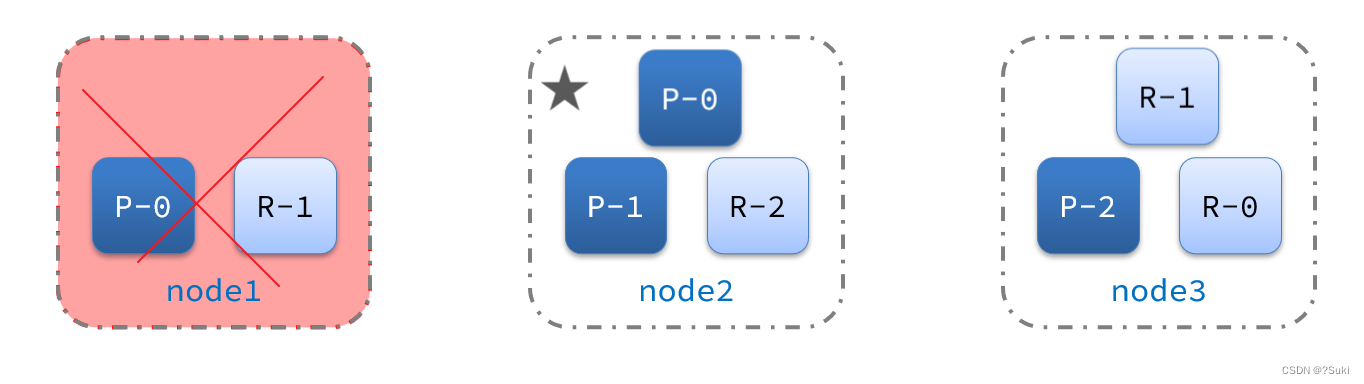
此时,node2和node3认为node1宕机,就会重新选主:
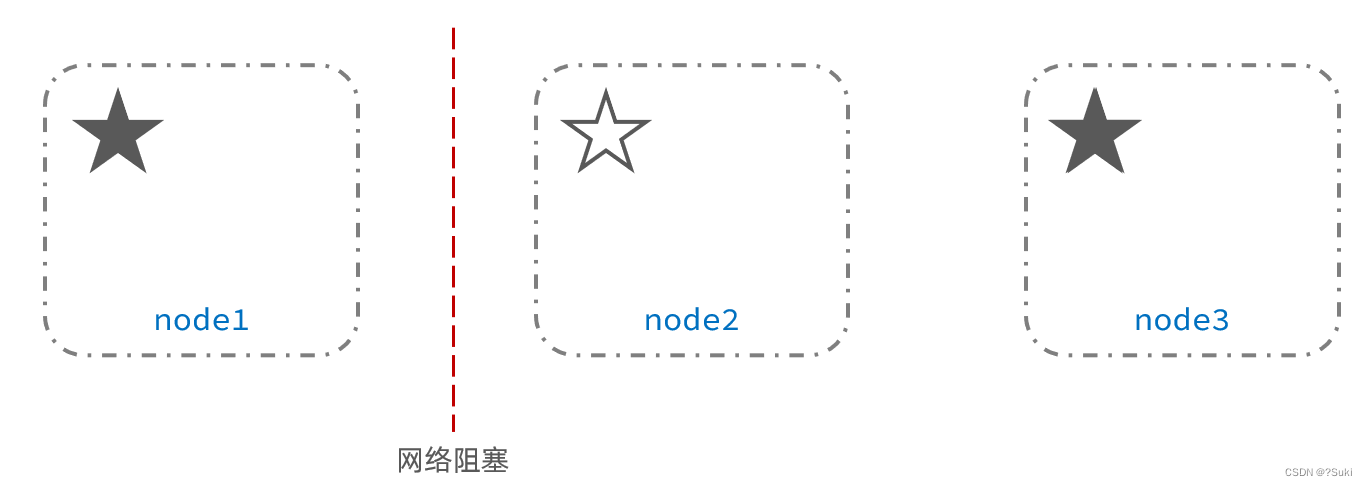
当node3当选后,集群继续对外提供服务,node2和node3自成集群,node1自成集群,两个集群数据不同步,出现数据差异。
当网络恢复后,因为集群中有两个master节点,集群状态的不一致,出现脑裂的情况:

解决脑裂的方案是,要求选票超过 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
例如:3个节点形成的集群,选票必须超过 (3 + 1) / 2 ,也就是2票。node3得到node2和node3的选票,当选为主。node1只有自己1票,没有当选。集群中依然只有1个主节点,没有出现脑裂。
4.2.3.小结
master eligible节点的作用是什么?
- 参与集群选主
- 主节点可以管理集群状态、管理分片信息、处理创建和删除索引库的请求
data节点的作用是什么?
- 数据的CRUD
coordinator节点的作用是什么?
-
路由请求到其它节点
-
合并查询到的结果,返回给用户
4.3.集群分布式存储
当新增文档时,应该保存到不同分片,保证数据均衡,那么coordinating node如何确定数据该存储到哪个分片呢?
4.3.1.分片存储测试
插入三条数据:

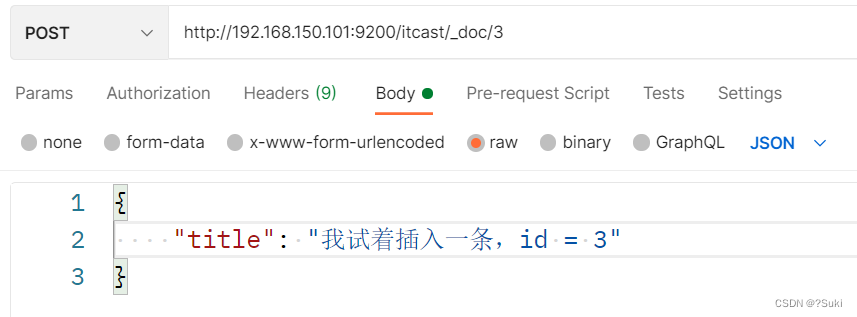

测试可以看到,三条数据分别在不同分片:
结果:

4.3.2.分片存储原理
elasticsearch会通过hash算法来计算文档应该存储到哪个分片:

说明:
- _routing默认是文档的id
- 算法与分片数量有关,因此索引库一旦创建,分片数量不能修改!
新增文档的流程如下:

解读:
- 1)新增一个id=1的文档
- 2)对id做hash运算,假如得到的是2,则应该存储到shard-2
- 3)shard-2的主分片在node3节点,将数据路由到node3
- 4)保存文档
- 5)同步给shard-2的副本replica-2,在node2节点
- 6)返回结果给coordinating-node节点
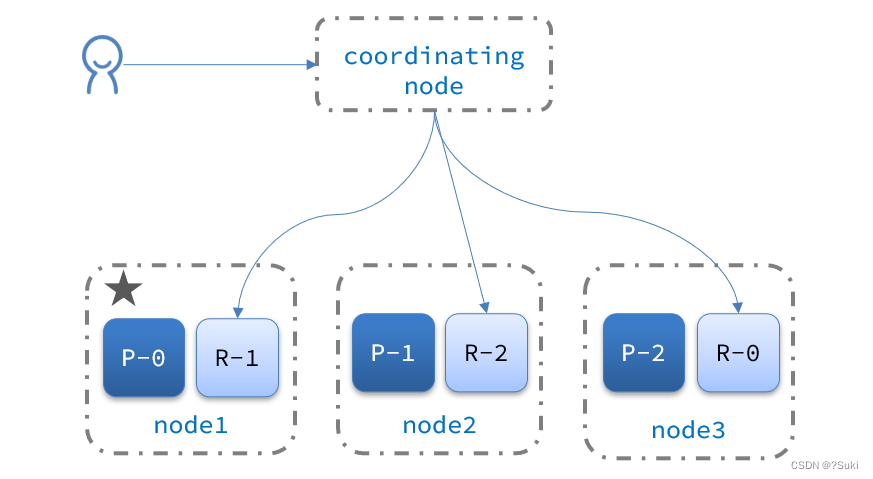
4.4.集群分布式查询
elasticsearch的查询分成两个阶段:
-
scatter phase:分散阶段,coordinating node会把请求分发到每一个分片
-
gather phase:聚集阶段,coordinating node汇总data node的搜索结果,并处理为最终结果集返回给用户
4.5.集群故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
1)例如一个集群结构如图:
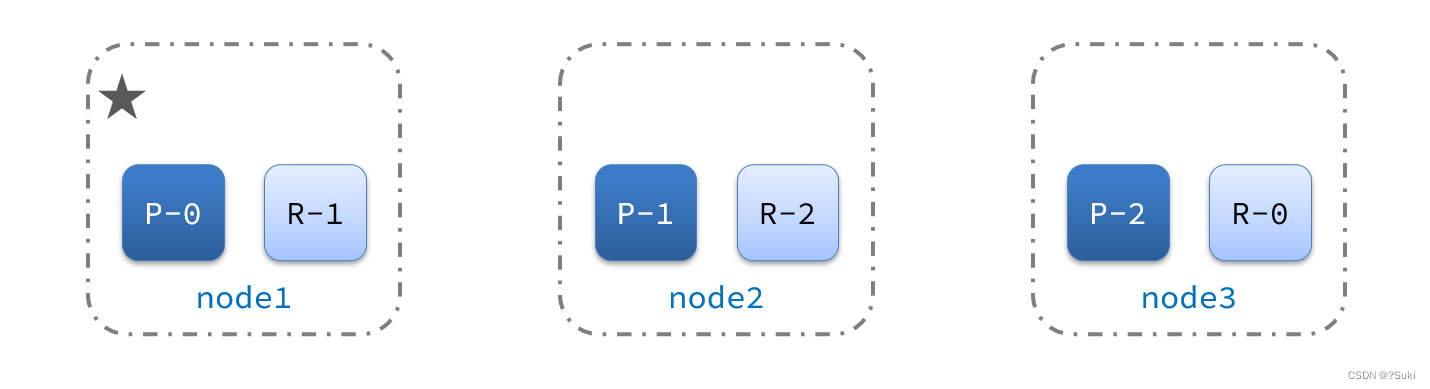
现在,node1是主节点,其它两个节点是从节点。
2)突然,node1发生了故障:
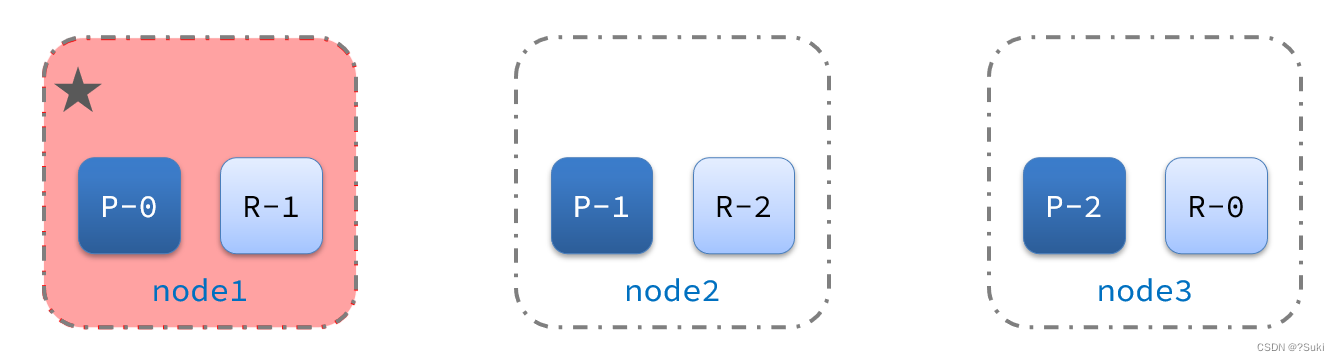
宕机后的第一件事,需要重新选主,例如选中了node2:

node2成为主节点后,会检测集群监控状态,发现:shard-1、shard-0没有副本节点。因此需要将node1上的数据迁移到node2、node3:
学习笔记 from 黑马程序员
By – Suki 2023/4/9
相关文章:
【ES】数据同步集群
【ES】数据同步&集群3.数据同步3.1.思路分析3.1.1.同步调用3.1.2.异步通知3.1.3.监听binlog3.1.4.选择3.2.实现数据同步3.2.1.思路3.2.2.导入demo3.2.3.声明交换机、队列1)引入依赖2)声明队列交换机名称3)声明队列交换机3.2.4.发送MQ消息…...

37岁男子不愿熬夜,回乡养鸡每天准时下班,青山绿水中养鸡,直播间里卖鸡蛋...
37岁男子不愿熬夜,回乡养鸡每天准时下班,青山绿水中养鸡,直播间里卖鸡蛋。今天和大家分享一个创业案例,他叫胡铭浩,来自安徽省旌德县,今年37岁,曾做过车床操作工,开过婚纱摄影店&…...

深度学习和人工智能之间是什么样的关系?
深度学习与人工智能概念的潜在联系,我们依然借助维恩图来说明,如图4.1所示。 1、人工智能 “人工智能”这个概念新鲜时髦但又含混模糊,同时包罗万象。尽管如此,我们仍尝试对 人工智能进行定义:用一台机器处理来自其周围环境的信息,然后将这些…...
实战打靶集锦-016-lampiao
提示:本文记录了博主打靶过程中一次曲折的提权经历 文章1. 主机发现2. 端口扫描3. 服务枚举4. 服务探查4.1 80端口探查4.2 1898端口探查4.3 EXP搜索4.3.1 exploit/unix/webapp/drupal_coder_exec4.3.2 exploit/unix/webapp/drupal_drupalgeddon25. 提权5.1 系统信息…...
《Web前端应用开发》考试试卷(模拟题)
一、产品搜索页面 打开“考试文件夹”中的input.html,完成以下步骤: 注意:本题仅能在input.html的(1)为产品名称所在的div添加样式属性,使得产品名称保持在文本框的左边; (2…...
【react全家桶学习】react简介
react是什么? react是用于构建用户界面的JS库,是一个将数据渲染为HTML视图的开源JS库 谁开发的? 由Facebook开发,且开源 为什么要学? 原生JavaScript操作DOM繁琐、效率低 ( DOM-API操作 UI)使用JavaScript直接操作…...
此战成硕,我成功上岸西南交通大学了~~~
友友们,好久不见,很长时间没有更一个正式点的文章了! 是因为我在去年年底忙着准备初试,今年年初在准备复试,直到3月底拟录取后,终于可以写下这篇上岸贴,和大家分享一下考研至上岸的一个过程 文章…...

光耦继电器工作原理及优点概述
光耦继电器是一种电子元器件,也是固态继电器的一种,其主要作用是隔离输入与输出电路,用于保护或者控制电路的正常工作。 光耦继电器工作原理是利用光电转换器将外界信号转化为光信号,通过光纤传输到另一端,再由另一端的…...

【Mysql】mysql8.0.26解压包部署方式
版本背景: 操作系统:centos7.3 mysql版本:mysql-8.0.26-linux-glibc2.12-x86_64.tar 一、前期准备 1、检测操作系统自带安装的mysql和mariadb服务,如存在,需卸载 rpm -qa | grep mysql rpm -qa | grep mariadb 卸载…...
进销存管理系统能为企业带来哪些实际效益?
随着互联网的不断发展,如今的商业世界已经越来越向数字化转型。拥有一套完整的数字化的进销存管理能够极大地提升公司货物进出库存情况的效率和准确性,避免过程中出现不必要的错误和漏洞,从而帮助企业更加稳健地自我发展。那么,一…...
图片怎么转换成pdf格式?这几个方法帮你一键转换
现今电子书籍越来越受到欢迎,其中PDF格式也成为了一种常用的电子书籍格式。无论是工作还是学习,我们都可能会遇到需要将图片转换成PDF格式的情况,例如保存一些资料证明、公文公告、学习资料等。在这篇文章中,我们将为大家介绍三种…...

数据结构exp1_2学生成绩排序
目录 数据结构exp1_2学生成绩排序 程序设计 程序分析 数据结构exp1_2学生成绩排序 【问题描述】 对某班学生成绩排序。从键盘依次输入某班学生的姓名和成绩(一个班级人数最多不超过50人)并保存,然后分别按学生成绩由高到低顺序输出学生姓名和成绩,成绩相同时,则按输…...

在DongshanPI-D1开箱使用分享与折腾记录实现MPU6050数据读取
前言 上一篇文章使用RT-Smart的IIC驱动OLED屏幕,进行基本的字符串显示,在使用过程中对RT-Smart有了一定熟悉,准备使用SPI驱动ST7789,但SPI接口没有引出,本次使用手上已有的传感器MPU6050进行使用。 过程 本次直接开始添加离线包…...

Nature子刊 定制饮食去除半胱氨酸和蛋氨酸可诱导细胞自毁进而治疗脑瘤?
恶性胶质瘤是成人最常见的脑部肿瘤。恶性胶质瘤的致死率为100%,无法治愈,是一种极度的恶性肿瘤。如此糟糕的预后促使研究者及神经外科医生不断学习研究肿瘤生物学,期望创造更好的疗法。神经外科助理教授Dominique Higgins博士从事肿瘤生物学的…...
抛弃 TCP 和 QUIC 的 HTTP
下班路上发了一则朋友圈: 周四听了斯坦福老教授 John Ousterhout 关于 Homa 的分享,基本重复了此前那篇 It’s Time To Rep… 的格调,花了一多半时间喷 TCP… Ousterhout 关于 Homa 和 TCP 之间的论争和论证,诸多反复回执&…...
)
未来公寓智能化设计平台项目(下)
创业场景通过在社区入口附近建设共享办公室,带动海慧园和众汽佳苑创业氛围,也让社区出了居住以外有其它功能,并且结合教育、邻里模块让社区更有活力。住户可通过app查看共享空间的使用情况,以及可以远程控制各种设备。 顺应未来生活与就业、创业融合新趋势,构建“大众创新…...

常见分布式消息队列综合对比
本文将从,Kafka、RabbitMQ、ZeroMQ、RocketMQ、ActiveMQ 17 个方面综合对比作为消息队列使用时的差异。 1. 资料文档 Kafka:中,有 kafka 作者自己写的书,网上资料也有一些。 rabbitmq:多,有一些不错的书…...

怎么邀请主流媒体到现场报道
传媒如春雨,润物细无声,大家好 主流媒体通常是指央媒,报纸杂志,电视台,地方重点媒体等,采访形式包括现场取材报道,媒体专访,群访等。通常主流媒体对选题要求较严格,因此在…...

2023年最强手机远程控制横测:ToDesk、向日葵、Airdroid三款APP免Root版本
前言 随着远程办公和远程协作的日益普及,跨设备、系统互通的远程控制软件已经成为职场人士不可或缺的工具之一。在国内,向日葵和ToDesk是最著名的远程控制软件;而在国外,则有微软远程桌面、AirDroid、TeamViewer、AnyDesk、Parse…...

用SQL语句操作oracle数据库--数据查询(上篇)
SQL操作Oracle数据库进行数据查询 Oracle 数据库是业界领先的关系型数据库管理系统之一,广泛应用于企业级应用和数据仓库等场景中。本篇博客将介绍如何使用 SQL 语句对 Oracle 数据库进行数据查询操作。 1.连接到数据库 在开始查询之前,需要使用合适的…...

自建个人知识管理系统Memex:从数据捕获到知识图谱的实践
1. 项目概述:一个私人数字记忆库的诞生几年前,我开始意识到一个严重的问题:我的数字生活正在变得支离破碎。一篇在浏览器里偶然看到的深度文章,一个在社交媒体上转瞬即逝的灵感火花,一段在播客里听到的精彩论述&#x…...

Resemble Enhance:AI语音增强的终极指南,让嘈杂录音秒变专业音频
Resemble Enhance:AI语音增强的终极指南,让嘈杂录音秒变专业音频 【免费下载链接】resemble-enhance AI powered speech denoising and enhancement 项目地址: https://gitcode.com/gh_mirrors/re/resemble-enhance 你是否曾因录音环境嘈杂而烦恼…...

信息量模型避坑指南:搞懂这3个关键点,你的地质灾害评价结果才靠谱
信息量模型避坑指南:搞懂这3个关键点,你的地质灾害评价结果才靠谱 在地质灾害易发性评价领域,信息量模型因其计算简单、结果直观而广受欢迎。然而,许多GIS从业者和科研人员在应用该模型时,常常陷入"流程正确但结果…...

告别玄学烧录:手把手教你排查i.MX6Q的Mfgtools‘Push Error’与设备识别问题
嵌入式工程师实战指南:i.MX6Q烧录故障的模块化诊断方法论 当Mfgtools的进度条突然卡住,红色错误提示框弹出"Push Error"时,许多工程师的第一反应是反复插拔USB线——这种条件反射式的操作往往掩盖了真正的系统性问题。i.MX6Q的烧录…...

工业 DC-DC 性能深度对比解析|钡特电源 DF1-05D15LS 与 E0515S-1WR3 封装互通
在工业控制、仪器仪表、低功耗传感设备等场景中,1W 级隔离工业 DC-DC 模块因体积小、功率密度高、适配性强,成为硬件研发工程师常用的直流电源模块核心器件。随着国产化进程加速,国产工业 DC-DC 模块在性能、稳定性、性价比上逐步实现突破&am…...

远程协助软件推荐 手机怎么远程协助电脑
优质的远程协助工具能大幅提升效率、减少麻烦。日常工作中偶尔会遇到需要远程协助同事处理电脑文件的情况,很多人在寻找手机远程控制电脑的方法时,总会被功能限制、付费套路困扰,而无界趣连2.0能轻松解决这些问题,适配各类远程协助…...

NoFences:彻底告别混乱桌面的免费开源分区神器
NoFences:彻底告别混乱桌面的免费开源分区神器 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否每天面对杂乱无章的Windows桌面感到焦虑?在几十个…...

Nginx Server Configs地理位置路由:基于位置的内容分发终极指南
Nginx Server Configs地理位置路由:基于位置的内容分发终极指南 【免费下载链接】server-configs-nginx Nginx HTTP server boilerplate configs 项目地址: https://gitcode.com/gh_mirrors/se/server-configs-nginx Nginx Server Configs是一套专业的Nginx …...

Airbyte线程管理:10个提升数据同步效率的并发处理优化技巧
Airbyte线程管理:10个提升数据同步效率的并发处理优化技巧 【免费下载链接】airbyte Open-source data movement for ELT pipelines and AI agents — from APIs, databases & files to warehouses, lakes, and AI applications. Both self-hosted and Cloud. …...

C语言实战:从零构建2048游戏,掌握核心算法与图形编程
1. 项目概述与核心思路 作为一个写了十几年代码的老程序员,我始终认为,学习一门编程语言最有效的方式,不是死记硬背语法,而是动手去实现一个完整的、有成就感的项目。今天,我们就来聊聊如何用C语言,从零开始…...