《深入探讨:AI在绘画领域的应用与生成对抗网络》
目录
前言:
一 引言
二 生成对抗网络(GAN)
1 生成对抗网络(GAN)简介
2.使用GAN生成艺术作品的实现方法
3,生成图像
三 GAN在艺术创作中的应用
1 风格迁移
2 图像生成:
3 图像修复:
四 使用GAN生成艺术作品的实现方法
五 成功案例
六 总结
前言:
这篇文章中,我们将深入研究AI在绘画领域的应用,以及如何使用生成对抗网络(GAN)创作艺术作品。
一 引言
在本文中,我们将深入探讨AI在绘画领域的应用,重点关注生成对抗网络(GAN)如何被用于创作具有独特风格和技巧的艺术作品。我们还将介绍一些具体的实现方法,通过实例演示如何使用GAN生成艺术作品,并分享一些成功案例。
二 生成对抗网络(GAN)
-
生成对抗网络(GAN)简介
生成对抗网络(GAN)是一种深度学习模型,由两个神经网络组成:生成器(Generator)和判别器(Discriminator)。生成器负责生成逼真的图像,判别器则负责判断图像是否为真实的。在训练过程中,生成器和判别器相互竞争,不断优化,直到生成器生成的图像足够逼真,以至于判别器无法区分真实图像和生成图像。
2.使用GAN生成艺术作品的实现方法
以下是实现这个示例所需的关键代码:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator# 数据预处理
def load_and_preprocess_data(data_dir, img_size, batch_size):datagen = ImageDataGenerator(rescale=1./255)data = datagen.flow_from_directory(data_dir,target_size=(img_size, img_size),batch_size=batch_size,class_mode=None)return data# 构建生成器
def build_generator(latent_dim, img_size):model = tf.keras.Sequential([tf.keras.layers.Dense(128, activation='relu', input_dim=latent_dim),tf.keras.layers.BatchNormalization(),tf.keras.layers.Dense(256, activation='relu'),tf.keras.layers.BatchNormalization(),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.BatchNormalization(),tf.keras.layers.Dense(img_size * img_size * 3, activation='tanh'),tf.keras.layers.Reshape((img_size, img_size, 3))])return model# 构建判别器
def build_discriminator(img_size):model = tf.keras.Sequential([tf.keras.layers.Flatten(input_shape=(img_size, img_size, 3)),tf.keras.layers.Dense(512, activation='relu'),tf.keras.layers.Dense(256, activation='relu'),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(1, activation='sigmoid')])return model# 训练模型
def train_gan(generator, discriminator, dataset, epochs, latent_dim, batch_size):# 定义优化器和损失函数generator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)discriminator_optimizer = tf.keras.optimizers.Adam(learning_rate=0.0002, beta_1=0.5)loss_fn = tf.keras.losses.BinaryCrossentropy()# 训练循环for epoch in range(epochs):for batch in dataset:# 训练判别器real_images = batchnoise =np.random.normal(0, 1, size=(batch_size, latent_dim))fake_images = generator.predict(noise)real_labels = np.ones((batch_size, 1))fake_labels = np.zeros((batch_size, 1))real_loss = loss_fn(real_labels, discriminator.predict(real_images))fake_loss = loss_fn(fake_labels, discriminator.predict(fake_images))d_loss = 0.5 * (real_loss + fake_loss)with tf.GradientTape() as tape:predictions = discriminator(real_images)real_loss = loss_fn(real_labels, predictions)predictions = discriminator(fake_images)fake_loss = loss_fn(fake_labels, predictions)d_loss = 0.5 * (real_loss + fake_loss)grads = tape.gradient(d_loss, discriminator.trainable_weights)discriminator_optimizer.apply_gradients(zip(grads, discriminator.trainable_weights))# 训练生成器noise = np.random.normal(0, 1, size=(batch_size, latent_dim))real_labels = np.ones((batch_size, 1))with tf.GradientTape() as tape:fake_images = generator(noise)predictions = discriminator(fake_images)g_loss = loss_fn(real_labels, predictions)grads = tape.gradient(g_loss, generator.trainable_weights)generator_optimizer.apply_gradients(zip(grads, generator.trainable_weights))# 输出每轮的损失值print(f"Epoch: {epoch + 1}, D Loss: {d_loss:.4f}, G Loss: {g_loss:.4f}")
3,生成图像
import osp# 生成图像并显示
def generate_and_display_images(generator, latent_dim, num_images):noise = np.random.normal(0, 1, size=(num_images, latent_dim))generated_images = generator.predict(noise)generated_images = (generated_images + 1) / 2 # 将图像的值映射到0-1范围fig, axes = plt.subplots(1, num_images, figsize=(num_images * 2, 2))for i, image in enumerate(generated_images):axes[i].imshow(image)axes[i].axis('off')plt.savefig(f"generated_image_{i}.png")plt.show()
4,主程序
# 主程序
if __name__ == "__main__":data_dir = "path/to/your/impressionist_dataset"img_size = 64batch_size = 32latent_dim = 100epochs = 500dataset = load_and_preprocess_data(data_dir, img_size, batch_size)generator = build_generator(latent_dim, img_size)discriminator = build_discriminator(img_size)train_gan(generator, discriminator, dataset, epochs, latent_dim, batch_size)generate_and_display_images(generator, latent_dim, num_images=5)
当您运行主程序时,它将在训练GAN后生成并显示五幅具有印象派风格的图像。
三 GAN在艺术创作中的应用
GAN已经被广泛应用于艺术创作。以下是几个主要的应用场景:
- 风格迁移:将一种艺术风格应用于另一种风格的图像,例如将照片转换为具有梵高或毕加索风格的画作。
- 图像生成:根据输入的描述或示例生成全新的艺术作品,如生成具有特定风格的油画。
- 图像修复:使用GAN修复受损或缺失部分的艺术作品。
1 风格迁移
在这里,我们将详细讨论GAN在艺术创作中的应用,并提供一个使用CycleGAN进行风格迁移的例子。CycleGAN是一种特殊类型的GAN,它允许将一种风格的图像转换成另一种风格,而不需要成对的训练数据。
我们将使用TensorFlow实现一个简单的CycleGAN模型,将著名画家梵高的画风应用到普通照片上。以下是实现这个示例所需的关键代码:
首先,需要安装tensorflow和tensorflow-addons:
pip install tensorflow tensorflow-addons
然后,编写以下Python代码:
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, Conv2DTranspose, LayerNormalization, ReLU, Activation
from tensorflow.keras.models import Sequential
import tensorflow_addons as tfa
import os
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import ImageDataGeneratordef load_and_preprocess_data(data_dir, img_size, batch_size):# ...与前面的实现相同...passdef build_generator(img_size):# ...与前面的实现相同...passdef build_discriminator(img_size):# ...与前面的实现相同...passdef build_cyclegan(generator, discriminator, img_size):gen_g = generatorgen_f = build_generator(img_size)disc_x = discriminatordisc_y = build_discriminator(img_size)return gen_g, gen_f, disc_x, disc_ydef train_cyclegan(gen_g, gen_f, disc_x, disc_y, dataset_x, dataset_y, epochs, img_size, batch_size):# ...训练CycleGAN的代码,需要根据CycleGAN的特点进行修改...passdef generate_images(gen_g, dataset_x, num_images):# ...与前面的实现相同,但需要使用gen_g将输入图像转换为目标风格...pass# 主程序
if __name__ == "__main__":data_dir_photos = "path/to/your/photos_dataset"data_dir_paintings = "path/to/your/van_gogh_paintings_dataset"img_size = 256batch_size = 1epochs = 100dataset_x = load_and_preprocess_data(data_dir_photos, img_size, batch_size)dataset_y = load_and_preprocess_data(data_dir_paintings, img_size, batch_size)generator = build_generator(img_size)discriminator = build_discriminator(img_size)gen_g, gen_f, disc_x, disc_y = build_cyclegan(generator, discriminator, img_size)train_cyclegan(gen_g, gen_f, disc_x, disc_y, dataset_x, dataset_y, epochs, img_size, batch_size)num_images = 5generate_images(gen_g, dataset_x, num_images)
在这个示例中,我们首先加载和预处理了包含普通照片和梵高画作的两个数据集。然后,我们构建了生成器和判别器网络,并使用build_cyclegan函数创建了CycleGAN模型。接下来,我们使用自定义的训练循环
训练CycleGAN模型。请注意,这里的训练函数需要根据CycleGAN的特点进行修改。在这个示例中,我们没有提供详细的train_cyclegan函数实现,您可以查看相关文献和开源实现以获取更多信息。最后,我们使用训练好的CycleGAN生成器gen_g将输入图像转换为梵高风格的图像。
这是一个简化的示例,为了获得更好的效果,您可能需要使用更复杂的模型、训练策略和数据预处理方法。此外,您可以将这个示例扩展到其他艺术家的画风,甚至是其他艺术领域,如音乐、舞蹈等。
以下是一个简化的train_cyclegan函数示例,供您参考:
def train_cyclegan(gen_g, gen_f, disc_x, disc_y, dataset_x, dataset_y, epochs, img_size, batch_size):cycle_consistency_loss = tf.keras.losses.MeanAbsoluteError()adversarial_loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)for epoch in range(epochs):print(f"Starting epoch {epoch+1}/{epochs}")for batch_x, batch_y in zip(dataset_x, dataset_y):# 训练判别器with tf.GradientTape(persistent=True) as tape:fake_y = gen_g(batch_x, training=True)fake_x = gen_f(batch_y, training=True)disc_x_real_preds = disc_x(batch_x, training=True)disc_y_real_preds = disc_y(batch_y, training=True)disc_x_fake_preds = disc_x(fake_x, training=True)disc_y_fake_preds = disc_y(fake_y, training=True)disc_x_loss_real = adversarial_loss(tf.ones_like(disc_x_real_preds), disc_x_real_preds)disc_y_loss_real = adversarial_loss(tf.ones_like(disc_y_real_preds), disc_y_real_preds)disc_x_loss_fake = adversarial_loss(tf.zeros_like(disc_x_fake_preds), disc_x_fake_preds)disc_y_loss_fake = adversarial_loss(tf.zeros_like(disc_y_fake_preds), disc_y_fake_preds)disc_x_loss = 0.5 * (disc_x_loss_real + disc_x_loss_fake)disc_y_loss = 0.5 * (disc_y_loss_real + disc_y_loss_fake)disc_x_grads = tape.gradient(disc_x_loss, disc_x.trainable_variables)disc_y_grads = tape.gradient(disc_y_loss, disc_y.trainable_variables)discriminator_optimizer.apply_gradients(zip(disc_x_grads, disc_x.trainable_variables))discriminator_optimizer.apply_gradients(zip(disc_y_grads, disc_y.trainable_variables))# 训练生成器with tf.GradientTape(persistent=True) as tape:fake_y = gen_g(batch_x, training=True)fake_x = gen_f(batch_y, training=True)reconstructed_x = gen_f(fake_y, training=True)reconstructed_y = gen_g(fake_x, training=True)disc_x_fake_preds = disc_x(fake_x, training=True)
disc_y_fake_preds = disc_y(fake_y, training=True)gen_g_loss = adversarial_loss(tf.ones_like(disc_y_fake_preds), disc_y_fake_preds)gen_f_loss = adversarial_loss(tf.ones_like(disc_x_fake_preds), disc_x_fake_preds)cycle_loss_g = cycle_consistency_loss(batch_x, reconstructed_x)cycle_loss_f = cycle_consistency_loss(batch_y, reconstructed_y)total_cycle_loss = cycle_loss_g + cycle_loss_ftotal_gen_g_loss = gen_g_loss + total_cycle_losstotal_gen_f_loss = gen_f_loss + total_cycle_lossgen_g_grads = tape.gradient(total_gen_g_loss, gen_g.trainable_variables)gen_f_grads = tape.gradient(total_gen_f_loss, gen_f.trainable_variables)generator_optimizer.apply_gradients(zip(gen_g_grads, gen_g.trainable_variables))generator_optimizer.apply_gradients(zip(gen_f_grads, gen_f.trainable_variables))print(f"Epoch {epoch+1}/{epochs} completed")
上述`train_cyclegan`函数提供了一个简化的训练过程,它涵盖了CycleGAN的主要特点。实际上,训练CycleGAN需要耗费大量的时间和计算资源,因此这里的示例仅用于说明目的。在实际应用中,您可能需要在更大的数据集上进行更长时间的训练,以及调整超参数和模型结构以获得更好的效果。
总之,这个示例展示了如何使用CycleGAN在艺术创作中将一种风格的图像转换成另一种风格。您可以将这个方法扩展到其他艺术领域,例如音乐、舞蹈等。此外,您还可以通过使用更先进的GAN模型和训练策略来改进这个示例。
2 图像生成:
我们已经在前面的回答中讨论了使用DCGAN生成印象派风格图像的示例。在这里,我们将使用StyleGAN2进行图像生成。StyleGAN2是一种强大的图像生成模型,能够生成极具真实感的图像。
我们将使用预训练的StyleGAN2模型生成人脸图像。首先,需要安装所需的库:
pip install tensorflow
接下来,我们将使用以下代码生成并显示人脸图像:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as pltdef generate_latent_vectors(num_vectors, latent_dim):return np.random.normal(0, 1, size=(num_vectors, latent_dim))def generate_and_display_images(generator, latent_vectors):generated_images = generator(latent_vectors)generated_images = (generated_images + 1) / 2 # 将图像的值映射到0-1范围fig, axes = plt.subplots(1, len(latent_vectors), figsize=(len(latent_vectors) * 2, 2))for i, image in enumerate(generated_images):axes[i].imshow(image)axes[i].axis('off')plt.savefig(f"generated_image_{i}.png")plt.show()if __name__ == "__main__":stylegan2_model_url = "https://tfhub.dev/google/stylegan2_swapped_1024x1024/1"generator = tf.keras.models.load_model(stylegan2_model_url)latent_dim = 512num_images = 5latent_vectors = generate_latent_vectors(num_images, latent_dim)generate_and_display_images(generator, latent_vectors)
在这个示例中,我们从TensorFlow Hub加载了预训练的StyleGAN2模型,生成了随机的潜在向量,并使用这些潜在向量生成了人脸图像。然后我们将生成的图像显示在屏幕上。
3 图像修复:
我们将使用一个名为Partial Convolutional Neural Networks(PConv)的模型来实现图像修复。PConv模型是一种基于卷积神经网络的图像修复模型,可以修复图像中的缺失部分。
首先,需要安装所需的库:
pip install tensorflow
接下来,我们将使用以下代码进行图像修复:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import load_img, img_to_array, array_to_imgdef load_image(image_path, target_size):img = load_img(image_path, target_size=target_size)img_array = img_to_array(img)img_array = (img_array - 127.5) / 127.5 # 将图像的值映射到-1到1范围return np.expand_dims(img_array, axis=0)def display_image(image_array):image = array_to_img((image_array[0] + 1) / 2) # 将图像的值映射到0-1范围
plt.imshow(image)
plt.axis('off')
plt.savefig("repaired_image.png")
plt.show()if name == "main":
pconv_model_url = "https://tfhub.dev/google/pconv_imagenet_512/1"
inpainter = tf.keras.models.load_model(pconv_model_url)image_path = "your_image_path_here" # 替换为您的输入图像路径
mask_path = "your_mask_path_here" # 替换为您的遮罩图像路径image_size = (512, 512)
image = load_image(image_path, image_size)
mask = load_image(mask_path, image_size)repaired_image = inpainter.predict([image, mask])display_image(repaired_image)
在这个示例中,我们从TensorFlow Hub加载了预训练的PConv模型,然后加载了输入图像和遮罩图像。输入图像是需要修复的图像,而遮罩图像定义了需要修复的区域(白色区域表示需要修复的部分,黑色区域表示不需要修复的部分)。接着我们使用PConv模型对输入图像进行修复,最后将修复后的图像显示在屏幕上。
通过这两个示例,您可以了解到GAN在艺术创作中图像生成和图像修复方面的应用。您可以根据实际需求调整示例代码,以适应不同的输入数据和输出要求。此外,还可以尝试使用其他先进的GAN模型和技术来改进这些示例。
四 使用GAN生成艺术作品的实现方法
在这里,我们将详细讨论使用GAN生成艺术作品的方法。我们将使用一个名为"BigGAN"的模型来生成高分辨率的艺术图像。BigGAN是一个强大的图像生成模型,能生成极具真实感和创意的图像。
首先,需要安装所需的库:
pip install tensorflow
接下来,我们将使用以下代码生成并显示艺术图像:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as pltdef generate_latent_vectors(num_vectors, latent_dim):return np.random.normal(0, 1, size=(num_vectors, latent_dim))def generate_and_display_images(generator, latent_vectors, truncation):generated_images = generator(latent_vectors, truncation)generated_images = (generated_images + 1) / 2 # 将图像的值映射到0-1范围fig, axes = plt.subplots(1, len(latent_vectors), figsize=(len(latent_vectors) * 2, 2))for i, image in enumerate(generated_images):axes[i].imshow(image)axes[i].axis('off')plt.savefig(f"generated_artwork_{i}.png")plt.show()if __name__ == "__main__":biggan_model_url = "https://tfhub.dev/google/biggan-256/2"generator = tf.keras.models.load_model(biggan_model_url)latent_dim = 128num_images = 5latent_vectors = generate_latent_vectors(num_images, latent_dim)truncation = 0.5 # 控制图像生成的多样性(更高的截断值会导致更多样的图像)generate_and_display_images(generator, latent_vectors, truncation)
在这个示例中,我们从TensorFlow Hub加载了预训练的BigGAN模型,生成了随机的潜在向量,并使用这些潜在向量生成了艺术图像。然后我们将生成的图像显示在屏幕上。
要注意的是,BigGAN模型是针对ImageNet数据集训练的,因此它本身并非专为艺术图像生成而设计。然而,由于GAN生成的图像通常具有丰富的纹理和颜色,这使得它们可以被视为具有艺术价值的作品。您可以通过调整潜在向量和截断值来控制生成图像的风格和多样性。
此外,您还可以尝试使用其他先进的GAN模型和技术来改进这个示例,以便更好地生成艺术图像。例如,您可以将BigGAN与其他预训练的艺术风格GAN模型相结合,或者尝试使用自定义数据集训练GAN以生成特定风格的艺术作品。
在这里,我们将实现一个简单的GAN模型,并生成简单的手写数字图像。我们将使用Keras和TensorFlow搭建模型。
首先,需要安装所需的库:
pip install tensorflow
接下来,我们将按照以下步骤实现一个简单的GAN模型:
- 导入所需的库:
import tensorflow as tf from tensorflow.keras.layers import Dense, LeakyReLU, BatchNormalization, Reshape, Flatten from tensorflow.keras.models import Sequential from tensorflow.keras.optimizers import Adam import numpy as np import matplotlib.pyplot as plt - 加载MNIST数据集:
(X_train, _), (_, _) = tf.keras.datasets.mnist.load_data() X_train = X_train / 255.0 # 将图像的值映射到0-1范围 X_train = np.expand_dims(X_train, -1) - 创建生成器模型:
def create_generator(latent_dim):model = Sequential()model.add(Dense(128 * 7 * 7, activation="relu", input_dim=latent_dim))model.add(Reshape((7, 7, 128)))model.add(tf.keras.layers.UpSampling2D())model.add(tf.keras.layers.Conv2D(128, kernel_size=3, padding="same"))model.add(BatchNormalization(momentum=0.8))model.add(LeakyReLU(alpha=0.2))model.add(tf.keras.layers.UpSampling2D())model.add(tf.keras.layers.Conv2D(64, kernel_size=3, padding="same"))model.add(BatchNormalization(momentum=0.8))model.add(LeakyReLU(alpha=0.2))model.add(tf.keras.layers.Conv2D(1, kernel_size=3, padding="same", activation="sigmoid"))return model - 创建判别器模型:
def create_discriminator(input_shape):model = Sequential()model.add(tf.keras.layers.Conv2D(32, kernel_size=3, strides=2, padding="same", input_shape=input_shape))model.add(LeakyReLU(alpha=0.2))model.add(tf.keras.layers.Dropout(0.25))model.add(tf.keras.layers.Conv2D(64, kernel_size=3, strides=2, padding="same"))model.add(BatchNormalization(momentum=0.8))model.add(LeakyReLU(alpha=0.2))model.add(tf.keras.layers.Dropout(0.25))model.add(tf.keras.layers.Conv2D(128, kernel_size=3, strides=2, padding="same"))model.add(BatchNormalization(momentum=0.8))model.add(LeakyReLU(alpha=0.2))model.add(tf.keras.layers.Dropout(0.25))model.add(Flatten())model.add(Dense(1, activation="sigmoid"))return model - 创建GAN模型:
def create_gan(generator, discriminator, latent_dim):discriminator.trainable = Falsegan_input = tf.keras.Input(shape=(latent_dim,))x = generator(gan_input)gan_output = discriminator(x)gan = tf.keras.Model(inputs=gan_input, outputs=gan_output)return gan - 定义训练过程:
def train_gan(epochs, batch_size, latent_dim, generator,discriminator, gan, X_train): valid = np.ones((batch_size, 1)) fake = np.zeros((batch_size, 1)) for epoch in range(epochs):# 训练判别器idx = np.random.randint(0, X_train.shape[0], batch_size)real_images = X_train[idx]noise = np.random.normal(0, 1, (batch_size, latent_dim))gen_images = generator.predict(noise)real_loss = discriminator.train_on_batch(real_images, valid)fake_loss = discriminator.train_on_batch(gen_images, fake)discriminator_loss = 0.5 * np.add(real_loss, fake_loss)# 训练生成器noise = np.random.normal(0, 1, (batch_size, latent_dim))generator_loss = gan.train_on_batch(noise, valid)if epoch % 1000 == 0:print(f"Epoch {epoch}, Discriminator Loss: {discriminator_loss}, Generator Loss: {generator_loss}")# 显示生成的图像generated_images = generator.predict(noise)plot_generated_images(generated_images) def plot_generated_images(images, n=5): fig, axes = plt.subplots(1, n, figsize=(n * 2, 2)) for i, image in enumerate(images[:n]):axes[i].imshow(image.squeeze(), cmap="gray")axes[i].axis("off")plt.show()7. 初始化和训练GAN模型:
latent_dim = 100 input_shape = X_train.shape[1:] epochs = 20000 batch_size = 64generator = create_generator(latent_dim) discriminator = create_discriminator(input_shape) discriminator.compile(optimizer=Adam(0.0002, 0.5), loss="binary_crossentropy", metrics=["accuracy"])gan = create_gan(generator, discriminator, latent_dim) gan.compile(optimizer=Adam(0.0002, 0.5), loss="binary_crossentropy")train_gan(epochs, batch_size, latent_dim, generator, discriminator, gan, X_train)这段代码将创建一个简单的GAN模型,并使用MNIST手写数字数据集进行训练。在训练过程中,每1000个epoch,代码将显示一组生成的图像以展示生成器的进展。
请注意,这个简单的GAN模型可能无法生成非常逼真的手写数字图像。要获得更好的结果,可以尝试使用更复杂的网络架构,例如DCGAN(Deep Convolutional GAN)或其他先进的GAN模型。另外,您还可以尝试使用更大的数据集和更多的训练迭代。
8 生成图像
生成图像是通过生成器(Generator)来实现的。生成器是一个神经网络,它接收一个随机噪声向量作为输入,并输出一个图像。在我们的示例中,我们使用了一个简单的卷积神经网络(CNN)作为生成器。
以下是生成图像的主要部分:生成器模型的创建:
-
def create_generator(latent_dim):model = Sequential()model.add(Dense(128 * 7 * 7, activation="relu", input_dim=latent_dim))model.add(Reshape((7, 7, 128)))model.add(tf.keras.layers.UpSampling2D())model.add(tf.keras.layers.Conv2D(128, kernel_size=3, padding="same"))model.add(BatchNormalization(momentum=0.8))model.add(LeakyReLU(alpha=0.2))model.add(tf.keras.layers.UpSampling2D())model.add(tf.keras.layers.Conv2D(64, kernel_size=3, padding="same"))model.add(BatchNormalization(momentum=0.8))model.add(LeakyReLU(alpha=0.2))model.add(tf.keras.layers.Conv2D(1, kernel_size=3, padding="same", activation="sigmoid"))return model - 使用生成器生成图像:在训练过程中,我们通过以下方式生成图像并展示:
def plot_generated_images(images, n=5):fig, axes = plt.subplots(1, n, figsize=(n * 2, 2))for i, image in enumerate(images[:n]):axes[i].imshow(image.squeeze(), cmap="gray")axes[i].axis("off")plt.show()在
train_gan函数中,我们生成随机噪声向量并将其传递给生成器,以生成图像。然后我们使用plot_generated_images函数展示生成的图像。if epoch % 1000 == 0:print(f"Epoch {epoch}, Discriminator Loss: {discriminator_loss}, Generator Loss: {generator_loss}")# 显示生成的图像generated_images = generator.predict(noise)plot_generated_images(generated_images)这些代码段负责生成图像。生成器模型将随机噪声向量作为输入,并输出一个图像。在训练过程中,每隔1000个周期,我们使用
plot_generated_images函数展示生成的图像。请注意,这个简单的GAN模型可能无法生成非常逼真的手写数字图像。为了获得更好的结果,可以尝试使用更复杂的网络架构,例如DCGAN(Deep Convolutional GAN)或其他先进的GAN模型。
五 成功案例
一个著名的成功案例是DeepArt.io,它使用一种称为"神经风格迁移"的技术将一幅图像的风格迁移到另一幅图像上。神经风格迁移是一种优化技术,它使用卷积神经网络(CNN)来混合两幅图像的内容和风格。
以下是使用TensorFlow实现神经风格迁移的简单示例:
- 首先,需要安装所需的库:
pip install tensorflow - 导入必要的库:
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt - 下载VGG19预训练模型:
vgg = tf.keras.applications.vgg19.VGG19(include_top=False, weights='imagenet') - 定义内容和风格损失函数:
def content_loss(content, target):return tf.reduce_mean(tf.square(content - target))def gram_matrix(input_tensor):channels = int(input_tensor.shape[-1])a = tf.reshape(input_tensor, [-1, channels])n = tf.shape(a)[0]gram = tf.matmul(a, a, transpose_a=True)return gram / tf.cast(n, tf.float32)def style_loss(style, gram_target):gram_style = gram_matrix(style)return tf.reduce_mean(tf.square(gram_style - gram_target)) - 为图像创建风格迁移模型:
def style_transfer_model(content_layers, style_layers, vgg_model):vgg_model.trainable = Falsestyle_outputs = [vgg_model.get_layer(name).output for name in style_layers]content_outputs = [vgg_model.get_layer(name).output for name in content_layers]model_outputs = style_outputs + content_outputsreturn tf.keras.Model(vgg_model.input, model_outputs) - 风格迁移的实现:
def transfer_style(content_image, style_image, content_weight, style_weight, variation_weight, epochs, steps_per_epoch):content_layers = ['block5_conv2']style_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1']content_image = tf.keras.applications.vgg19.preprocess_input(content_image * 255)style_image = tf.keras.applications.vgg19.preprocess_input(style_image * 255)content_image = tf.image.resize(content_image, (224, 224))style_image = tf.image.resize(style_image, (224, 224))content_targets = vgg(content_image)[:-1]style_targets = [gram_matrix(style_layer) for style_layer in vgg(style_image)[:-1]]transfer_model = style_transfer_model(content_layers, style_layers, vgg)def total_loss(outputs, content_weight, style_weight, variation_weight):style_outputs = outputs[:len(style_targets)]content_outputs = outputs[len(style_targets):]content_losses = [content_loss(content_output, content_target) for content_output, content_target in zip(content_outputs, content_targets)]style_losses = [style_loss(style_output, style_target) for style_output, style_target in zip(style_outputs, style_targets)]content_total_loss = tf.reduce_sum(content_losses)style_total_loss = tf.reduce_sum(style_losses)content_loss_scaled = content_weight * content_total_lossstyle_loss_scaled = style_weight * style_total_lossvariation_loss_scaled = variation_weight * tf.image.total_variation(outputs[-1])return content_loss_scaled + style_loss_scaled + variation_loss_scaledopt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)image = tf.Variable(content_image)for epoch in range(epochs):print(f"Epoch {epoch + 1}/{epochs}")for step in range(steps_per_epoch):with tf.GradientTape() as tape:outputs = transfer_model(image)loss = total_loss(outputs, content_weight, style_weight, variation_weight)grads = tape.gradient(loss, image)opt.apply_gradients([(grads, image)])clipped_image = tf.clip_by_value(image, 0, 1)image.assign(clipped_image)return image.numpy().squeeze()7. 加载和预处理图像:
def load_image(image_path):image = tf.io.read_file(image_path)image = tf.image.decode_image(image, channels=3)image = tf.image.convert_image_dtype(image, tf.float32)image = tf.expand_dims(image, axis=0)return imagecontent_image_path = "path/to/your/content/image.jpg" style_image_path = "path/to/your/style/image.jpg"content_image = load_image(content_image_path) style_image = load_image(style_image_path)8.开始风格迁移并显示结果:
content_weight = 1e4 style_weight = 1e-2 variation_weight = 30 epochs = 10 steps_per_epoch = 100output_image = transfer_style(content_image, style_image, content_weight, style_weight, variation_weight, epochs, steps_per_epoch)plt.imshow(output_image) plt.axis('off') plt.show()这段代码将执行神经风格迁移,将风格图像的风格应用于内容图像。根据所选图像,模型参数和迭代次数,您可能需要调整权重参数(
content_weight、style_weight和variation_weight)以获得理想的结果。
六 总结
在本专栏的第一周,我们重点关注了AI在艺术和创意产业中的应用。我们详细讨论了以下几个方面:
-
人工智能如何改变艺术创作过程:我们讲述了AI如何为艺术家提供新的创作工具和技术,使他们能够以前所未有的方式进行创作。这包括利用深度学习技术自动生成艺术作品、为艺术家提供启发以及帮助他们更高效地工作。
-
生成对抗网络(GAN)简介:我们详细介绍了生成对抗网络(GAN)的基本原理、结构和工作机制。GAN是一种强大的深度学习技术,通过对抗训练生成器和判别器来生成逼真的图像、音频和其他类型的数据。
-
GAN在艺术创作中的应用:我们探讨了如何利用GAN生成艺术作品,包括生成新的图像、音乐和其他类型的创意作品。我们还讨论了如何使用GAN进行图像修复和增强,以提高艺术作品的质量和视觉效果。
-
GAN生成艺术作品的实现方法:我们提供了一个简单的实现示例,使用TensorFlow创建了一个基本的GAN模型,并用它生成手写数字图像。我们强调了为了获得更好的结果,可以尝试使用更复杂的网络架构,例如DCGAN(Deep Convolutional GAN)或其他先进的GAN模型。
-
成功案例:我们介绍了一些使用AI技术创作艺术作品的著名案例,包括神经风格迁移和DeepArt.io等。我们提供了一个简单的神经风格迁移实现示例,展示了如何将一幅图像的风格迁移到另一幅图像上。
通过本专栏,我们希望为读者提供一个关于AI在艺术和创意产业中应用的全面概述。人工智能为艺术家和创作者提供了新的工具和技术,使他们能够以更高效、更创新的方式进行创作。尽管目前这个领域仍有许多挑战和发展空间,但我们相信AI将继续为艺术和创意产业带来更多的机遇和可能性。
相关文章:

《深入探讨:AI在绘画领域的应用与生成对抗网络》
目录 前言: 一 引言 二 生成对抗网络(GAN) 1 生成对抗网络(GAN)简介 2.使用GAN生成艺术作品的实现方法 3,生成图像 三 GAN在艺术创作中的应用 1 风格迁移 2 图像生成: 3 图像修复: 四 使…...
al文章生成-文章生成工具
ai文章生成器 AI文章生成器是一种利用人工智能和自然语言处理技术生成文章的工具。它使用先进的算法、机器学习和深度学习技术,深度挖掘和提取大量数据背后的信息,自主学习并合并新的信息,生成优质、原创的文章。 使用AI文章生成器的优点如下…...

【云原生之Docker实战】使用docker部署webterminal堡垒机
【云原生之Docker实战】使用docker部署webterminal堡垒机 一、webterminal介绍1.webterminal简介2.webterminal特点二、检查本地docker环境1.检查docker版本2.检查操作系统版本3.检查docker状态4.检查docker compose版本三、下载webterminal镜像四、部署webterminal1.创建安装目…...

《低代码PaaS驱动集团企业数字化创新白皮书》-IDC观点
IDC观点 大型集团企业应坚定地走数字化优先发展道路,加深数字化与业务融合 大型企业在长期的经营发展中砥砺前行,形成了较为成熟的业务模式和运营流程,也具备变革 管理等系统性优势。在数字化转型过程中,其庞大的组织架构、复杂的…...

LoRA 指南之 LyCORIS 模型使用
LoRA 指南之 LyCORIS 模型使用 在C站看到这个模型,一眼就非常喜欢 在经历几番挣扎之后终于成功安装 接下来,我们一起开始安装使用吧! 1、根据原作大佬的提示,需要安装两个插件 https://github.com/KohakuBlueleaf/a1111-sd-web…...

[C#]IDisposable
在C#中,继承IDisposable接口的主要作用是在使用一些需要释放资源的对象时,可以显式地管理和释放这些资源,以避免内存泄漏和其他潜在问题。 如果一个类继承了IDisposable接口,那么该类就必须实现Dispose方法。在该类的实例不再需要…...
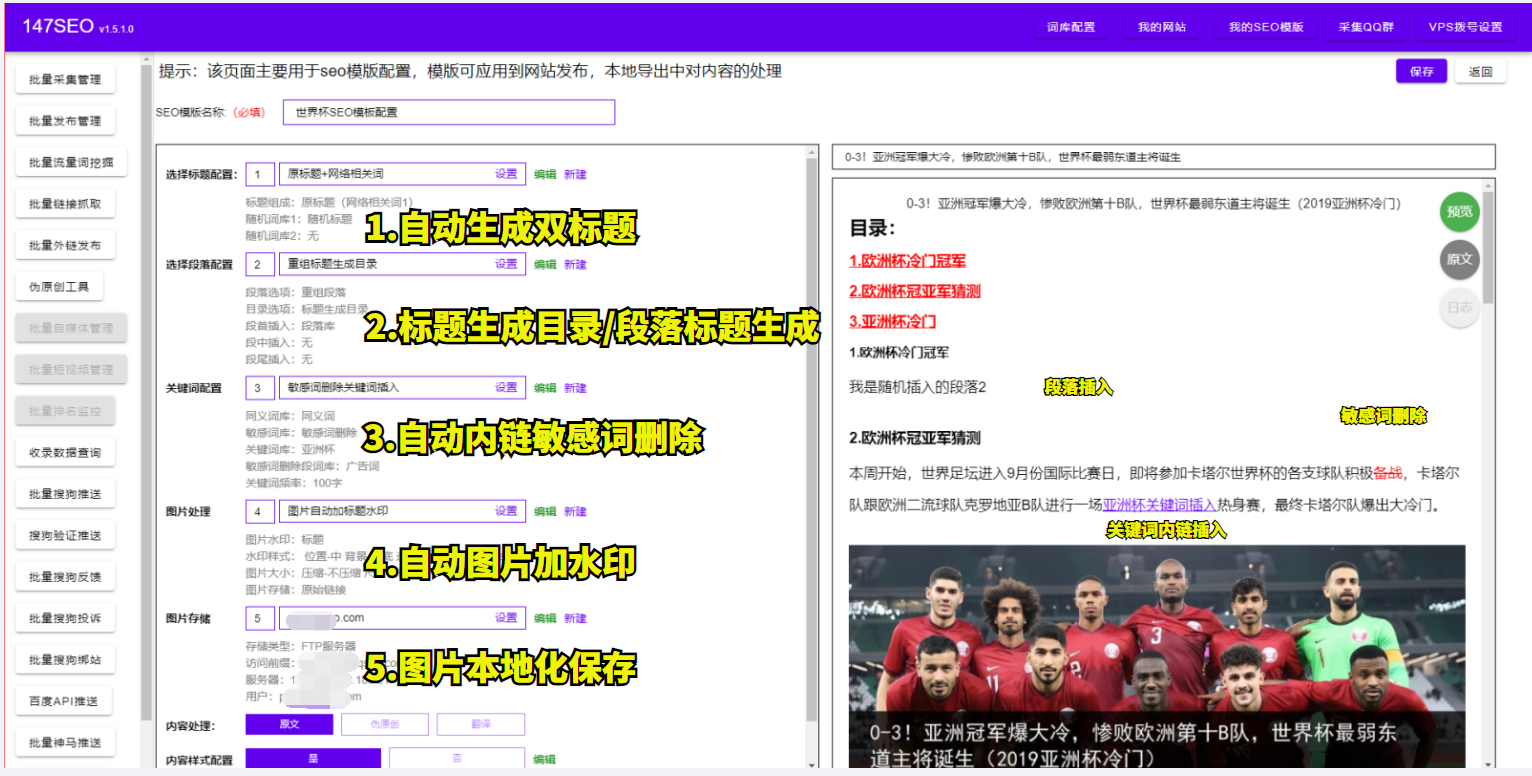
ROS开发之如何使用RPLidar A1二维激光雷达?
文章目录0.引言1.创建工作空间2.获取rplidar_ros包并编译3.检查雷达端口4.启动launch显示雷达扫描结果0.引言 笔者研究课题涉及多传感器融合,除了前期对ROS工具的学习,还需要用雷达获取数据,进行点云处理。虽然激光雷达已经应用很广泛&#x…...
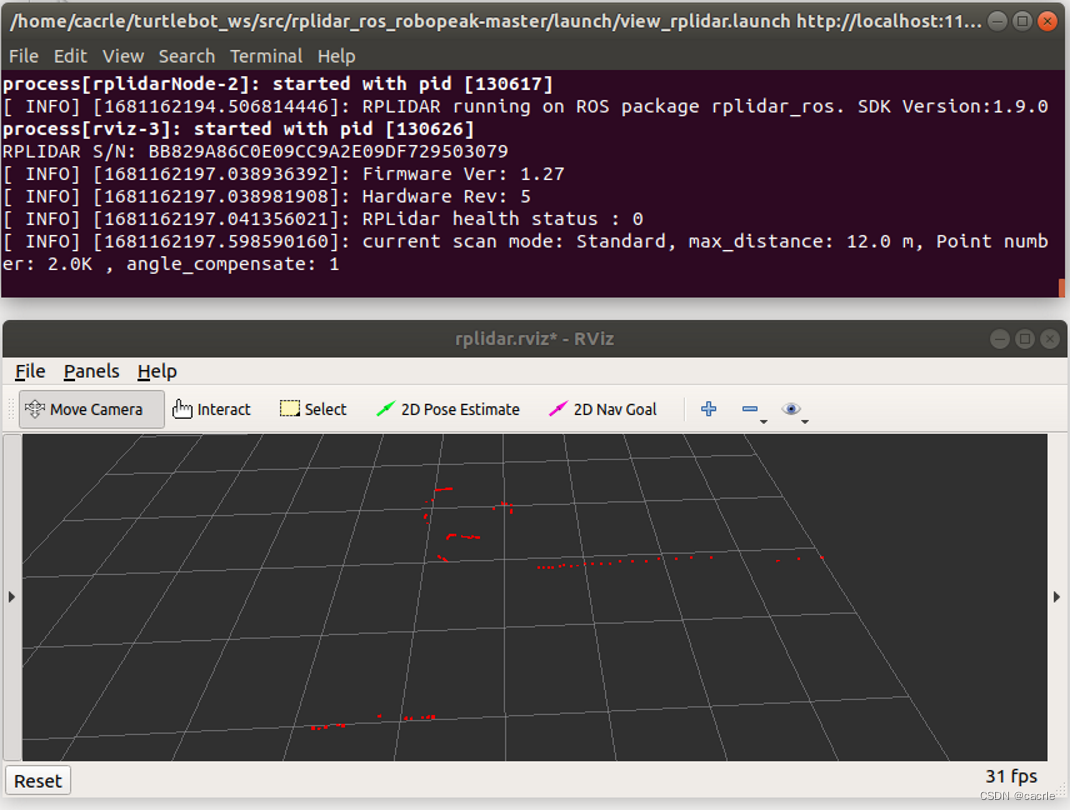
【谷粒商城之JSR303数据校验和集中异常处理】
本笔记内容为尚硅谷谷粒商城JSR303数据校验和集中异常处理部分 目录 一、简介 二、SR303数据校验使用步骤 1、引入依赖 2、给参数对象添加校验注解 常见的注解 3、接口参数前增加Valid 开启校验 三、异常的统一处理 四、分组解决校验 1、创建Groups 2、添加分组 …...
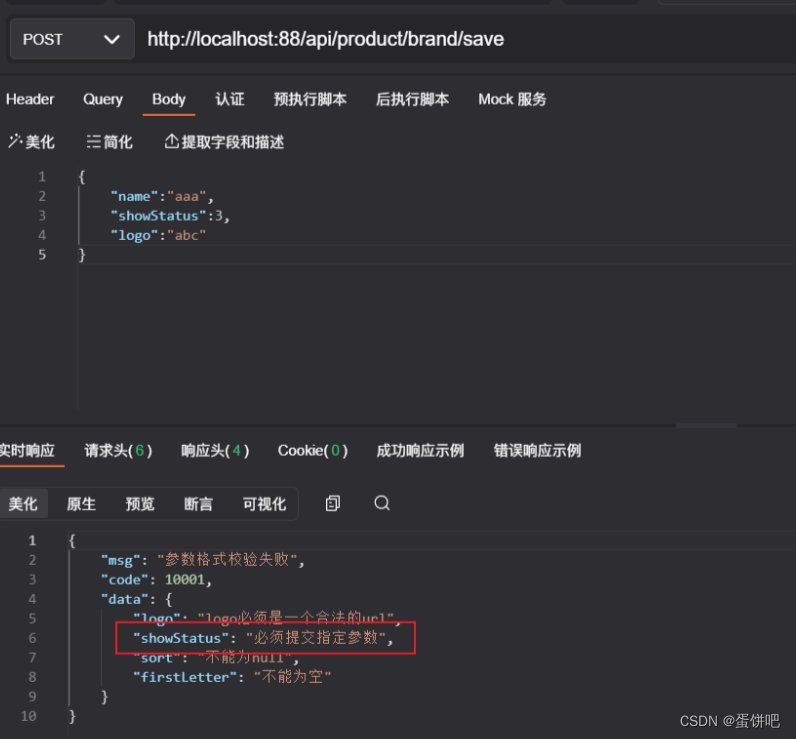
限流算法(计数器、滑动时间窗口、漏斗、令牌)原理以及代码实现
文章目录前言1、计数器(固定时间窗口)算法原理代码实现存在的问题2、滑动时间窗口算法原理代码实现存在的问题3、漏桶算法原理代码实现存在的问题4、令牌桶算法原理代码实现最后本文会对这4个限流算法进行详细说明,并输出实现限流算法的代码示…...
C++回溯算法---图的m着色问题01
C回溯算法---图的m着色问题 图的m着色问题是指给定一个图以及m种不同的颜色,尝试将每个节点涂上其中一种颜色,使得相邻的节点颜色不相同。这个问题可以转化为在解空间树中寻找可行解的问题,其中每个分支结点都有m个儿子结点,最底层…...
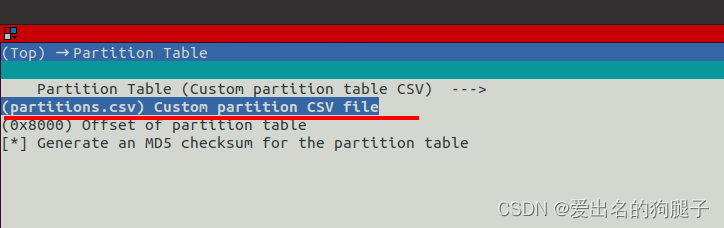
ESP32 分区表
ESP32 分区表 1. 分区表概述 ESP32 针对 flash 进行划分,划分为不同的区域用作不同的功能,并在flash的 0x8000 位置处烧写了一张分区表用来描述分区信息。 分区表可以根据自己的需要进行配置,每一个分区都有其特定的作用,可根据…...

JJJ-2 init_IRQ
void __init init_IRQ(void) {int ret;if (IS_ENABLED(CONFIG_OF) && !machine_desc->init_irq)irqchip_init();else // init_irq成员定义为imx6ul_init_irq,会走这个分支machine_desc->init_irq(); if (IS_ENABLED(CONFIG_OF) && IS_ENABLED…...

【NLP实战】基于Bert和双向LSTM的情感分类【下篇】
文章目录前言简介第一部分关于pytorch lightning保存模型的机制关于如何读取保存好的模型完善测试代码第二部分第一次训练出的模型的过拟合问题如何解决过拟合后记前言 本文涉及的代码全由博主自己完成,可以随意拿去做参考。如对代码有不懂的地方请联系博主。 博主…...

程序设计方法学
体育竞技分析 问题分析 体育竞技分析 需求:毫厘是多少? 如何科学分析体育竞技比赛? 输入:球员的水平 输出:可预测的比赛成绩 体育竞技分析:模拟N场比赛 计算思维:抽象 自动化 模拟&am…...

Hadoop之Yarn篇
目录 编辑 Yarn的工作机制: 全流程作业: Yarn的调度器与调度算法: FIFO调度器(先进先出): 容量调度器(Capacity Scheduler): 容量调度器资源分配算法࿱…...

Spring Cloud Nacos使用总结
目录 安装Nacos服务器 服务发现与消费 服务发现与消费-添加依赖 服务发现-配置文件 服务发现-注解 服务发现-Controller 服务消费-配置文件 服务消费-注解与Ribbon消费代码 服务消费-运行 配置管理 配置管理-添加依赖 配置管理-配置文件 配置管理-注解 配置管理-…...

目标检测框架yolov5环境搭建
目前,目标检测框架中,yolov5 是很火的,它基于pytorch框架,集成opencv等框架,项目地址:https://github.com/ultralytics/yolov5,对我来说,机器学习、深度学习才开始接触,本…...
Vulnhub:Digitalworld.local (JOY)靶机
kali:192.168.111.111 靶机:192.168.111.130 信息收集 端口扫描 nmap -A -v -sV -T5 -p- --scripthttp-enum 192.168.111.130 使用enum4linux枚举目标smb服务,发现两个系统用户 enum4linux -a 192.168.111.130 ftp可以匿名登陆ÿ…...

STL源码剖析-六大部件, 部件的关系,复杂度, 区间表示
C标准库-体系结构与内核分析 根据源代码来分析 介绍 自学C侯捷老师的STL源码剖析的个人笔记,方便以后进行学习,查询。 为什么要学STL?按侯捷老师的话来说就是:使用一个东西,却不明白它的道理,不高明&…...

总有一个可用的连接,metaIPC1.2进入智能连接新时代
概述 metaIPC有1.0和2.0两个产品系列,2.0版本是可视对讲IPC,1.0新版本1.2在全面兼容ICE规范基础上进行了扩展,使metaIPC1.2进入智能化连接新时代。 metaIPC1.2在host/stun/turn/srs/zlm/janus/freeswitch等p2p/sfu/mcu进行全方位连通测试&a…...

ThinkPad双风扇终极控制指南:TPFanControl2完全使用教程
ThinkPad双风扇终极控制指南:TPFanControl2完全使用教程 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否为ThinkPad笔记本的风扇噪音而烦恼ÿ…...

屏蔽壳设计全解:材料选型、接地策略与EMC实战优化
摘要: 在高速数字电路、射频模块及工业通信设备中,电磁干扰(EMI/EMC)往往是产品认证路上的“拦路虎”。屏蔽壳(电磁屏蔽罩)作为抑制辐射骚扰最直接的手段,其材料选择、开孔尺寸、接地方式及结构…...

2026 年我作为资深工程师如何使用 LLM Agent:从副驾到主驾的真实工作流转变
从副驾到主驾,2026 年资深工程师的 LLM Agent 实战工作流:哪些交给 Agent,哪些必须自己做。 原文链接:AI 小老六 一年之差:Agent 从「勉强能用」变成了「几乎离不开」 2025 年初,行业里最强的推理模型还是…...

京沪高铁涨价了,传说中的“牛马专列”要坐不起了?
一直以来,京沪高铁因为其连通北京上海这两大重要城市,成为了最受关注的高铁线路,然而就在最近京沪高铁的涨价引发了市场的热议,让人不禁想问传说中的“牛马专列”要坐不起了? 一、京沪高铁涨价了? 据南方都…...

抖音批量下载开源工具:3个核心模块打造高效无水印下载工作流
抖音批量下载开源工具:3个核心模块打造高效无水印下载工作流 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback…...

AArch64调试异常机制与自托管调试实践
1. AArch64调试异常机制概述在AArch64架构中,调试异常是处理器响应调试事件的核心机制。当程序执行过程中遇到预设的调试条件时,处理器会暂停正常执行流,转而进入异常处理流程。这种机制使得开发者能够在不引入额外硬件调试器的情况下&#x…...

跨越物种与时空:TO-GCN方法在植物发育与光合作用调控网络解析中的创新实践
1. TO-GCN方法:突破传统共表达网络分析的时空局限 在植物生物学研究中,基因共表达网络分析一直是揭示复杂调控机制的重要工具。传统方法如WGCNA(加权基因共表达网络分析)虽然应用广泛,但在处理跨物种、跨条件或跨组织的…...
)
保姆级教程:Win10/Win11下彻底解决原神启动器Qt插件初始化失败(附环境变量排查与恢复指南)
深度解析Windows环境下Qt插件初始化失败的终极解决方案 当你在Windows 10或11系统上双击原神启动器,却看到"no Qt platform plugin could be initialized"的错误提示时,那种挫败感不言而喻。这个问题看似简单,实则涉及系统环境变量…...

MacOS MySQL安装
1、安装包下载地址 MySQL Community Server:开源版本,适用于个人和小型企业。MySQL Enterprise Edition:商业版本,提供额外的功能和技术支持。MySQL Cluster:分布式数据库系统,适用于高可用性和高并发场景…...
)
你的电机为什么抖?排查STM32F4 PWM驱动TB6612的5个常见硬件坑(附示波器实测)
你的电机为什么抖?排查STM32F4 PWM驱动TB6612的5个常见硬件坑(附示波器实测) 电机控制系统中,PWM信号的质量直接影响着驱动芯片和电机的性能表现。许多工程师在使用STM32F4系列MCU配合TB6612驱动模块时,常常遇到电机抖…...