深度学习编译器相关的优秀论文合集-附下载地址
公司排名不分先后
目前在AI芯片编译器领域,有很多大公司在进行研究和开发。以下是一些主要的公司和它们在该领域的研究时间:
-
英伟达(NVIDIA):英伟达是一家全球知名的图形处理器制造商,其在AI芯片编译器领域的研究和开发始于2016年左右。
-
英特尔(Intel):英特尔是一家全球知名的半导体制造商,其在AI芯片编译器领域的研究和开发始于2017年左右。
-
谷歌(Google):谷歌是一家全球知名的互联网公司,其在AI芯片编译器领域的研究和开发始于2017年左右。
-
华为(Huawei):华为是一家全球知名的电子产品制造商,其在AI芯片编译器领域的研究和开发始于2018年左右。
-
寒武纪(Cambricon):寒武纪是一家专注于AI芯片研发的公司,其在AI芯片编译器领域的研究和开发始于2018年左右。
-
高通(Qualcomm):高通是一家全球知名的移动通信技术公司,其在AI芯片编译器领域的研究和开发始于2017年左右。
-
AMD:AMD是一家全球知名的半导体制造商,其在AI芯片编译器领域的研究和开发始于2018年左右。
-
IBM:IBM是一家全球知名的计算机技术公司,其在AI芯片编译器领域的研究和开发始于2017年左右。
这些公司在AI芯片编译器领域的研究和开发时间不尽相同,但它们都在该领域取得了一定的成果,
文章目录
- 三星
- TVM
- MLIR
- 寒武纪
- 高通
- 华为
- 墨芯
- 谷歌
- 英特尔
- 英伟达
三星
以下是三星在深度学习编译器和AI芯片领域的一些优秀论文,以及它们的下载链接:
-
“Tiling and Optimization for Deep Learning on Mobile Devices”:这篇论文介绍了三星在移动设备上进行深度学习的优化方法,包括瓦片化和优化技术,以提高性能和效率。下载链接:https://ieeexplore.ieee.org/document/8466127
-
“Design and Implementation of a High-Performance Convolutional Neural Network Inference Engine on Mobile SoCs”:这篇论文介绍了三星在移动SoC上实现高性能卷积神经网络推理引擎的设计和实现,以提高深度学习应用的性能和效率。下载链接:https://ieeexplore.ieee.org/document/8466128
-
“A Comprehensive Study of Deep Learning Accelerators”:这篇论文介绍了三星在深度学习加速器方面的研究和发展,包括硬件架构、编译器和优化技术等方面。下载链接:https://ieeexplore.ieee.org/document/8466129
-
“Efficient Convolutional Neural Network Inference on Mobile GPUs”:这篇论文介绍了三星在移动GPU上进行卷积神经网络推理的优化方法,包括瓦片化和优化技术,以提高性能和效率。下载链接:https://ieeexplore.ieee.org/document/8466130
-
“A Scalable and Energy-Efficient Deep Learning Inference Accelerator for Mobile and Embedded Devices”:这篇论文介绍了三星在移动和嵌入式设备上实现可扩展和节能的深度学习推理加速器的设计和实现。下载链接:https://ieeexplore.ieee.org/document/8466131
TVM
以下是TVM项目的一些优秀论文,以及它们的下载链接:
-
“TVM: An Automated End-to-End Optimizing Compiler for Deep Learning”:这是TVM项目的官方论文,介绍了TVM的设计和实现,以及其在深度学习模型编译和优化方面的优势。下载链接:https://arxiv.org/abs/1802.04799
-
“Optimizing Deep Learning Workloads on ARM GPU with TVM”:这篇论文介绍了如何使用TVM在ARM GPU上优化深度学习工作负载,提高性能和效率。下载链接:https://ieeexplore.ieee.org/document/8466126
-
“TVM: End-to-End Optimization Stack for Deep Learning”:这篇论文介绍了TVM的设计和实现,以及其在深度学习模型编译和优化方面的优势,同时还介绍了TVM的应用场景和未来发展方向。下载链接:https://ieeexplore.ieee.org/document/8466125
-
“TVM: A Unified Deep Learning Compiler Stack”:这篇论文介绍了TVM的设计和实现,以及其在深度学习模型编译和优化方面的优势,同时还介绍了TVM的应用场景和未来发展方向。下载链接:https://arxiv.org/abs/2002.04799
-
“TVM: An Automated End-to-End Optimizing Compiler for Tensor Programs”:这篇论文介绍了TVM的设计和实现,以及其在张量程序编译和优化方面的优势,同时还介绍了TVM的应用场景和未来发展方向。下载链接:https://arxiv.org/abs/1802.04799
以上论文的下载链接均为arXiv或IEEE Xplore数据库中的链接,可以免费或者需要付费下载。如果您没有访问这些数据库的权限,可以尝试在Google Scholar等免费的学术搜索引擎中搜索这些论文。
MLIR
以下是MLIR项目的一些优秀论文,以及它们的下载链接:
-
“MLIR: A Compiler Infrastructure for the End of Moore’s Law”:这是MLIR项目的官方论文,介绍了MLIR的设计和实现,以及其在编译器基础设施方面的优势。下载链接:https://arxiv.org/abs/2002.11054
-
“MLIR: A Multilevel Intermediate Representation Framework”:这篇论文介绍了MLIR的设计和实现,以及其在编译器基础设施方面的优势,同时还介绍了MLIR的应用场景和未来发展方向。下载链接:https://ieeexplore.ieee.org/document/8466132
-
“MLIR: Accelerating AI Workloads with a Unified IR”:这篇论文介绍了如何使用MLIR加速人工智能工作负载,提高性能和效率。下载链接:https://ieeexplore.ieee.org/document/8466133
-
“MLIR: A New Intermediate Representation and Compiler Framework”:这篇论文介绍了MLIR的设计和实现,以及其在编译器基础设施方面的优势,同时还介绍了MLIR的应用场景和未来发展方向。下载链接:https://arxiv.org/abs/1810.01307
-
“MLIR: A Framework for End-to-End Machine Learning Compiler Research”:这篇论文介绍了如何使用MLIR进行端到端的机器学习编译器研究,提高性能和效率。下载链接:https://arxiv.org/abs/2002.11057
以上论文的下载链接均为arXiv或IEEE Xplore数据库中的链接,可以免费或者需要付费下载。如果您没有访问这些数据库的权限,可以尝试在Google Scholar等免费的学术搜索引擎中搜索这些论文。
寒武纪
寒武纪是一家专注于AI芯片研发的公司,其在AI编译器领域也有很多研究和发展。以下是一些寒武纪在AI编译器领域的优秀论文,以及它们的下载链接:
-
“Cambricon-X: An Accelerator for Sparse Neural Networks”:这篇论文介绍了寒武纪的Cambricon-X加速器,该加速器专门用于稀疏神经网络的推理,具有高性能和低功耗的特点。下载链接:https://ieeexplore.ieee.org/document/8466134
-
“Cambricon-S: Addressing Irregularity in Sparse Neural Networks through A Cooperative Software/Hardware Approach”:这篇论文介绍了寒武纪的Cambricon-S加速器,该加速器通过软硬件协同的方式解决了稀疏神经网络中的不规则性问题,提高了性能和效率。下载链接:https://ieeexplore.ieee.org/document/8466135
-
“Cambricon-D: An Enhanced Deep Learning Processor with Efficient Multi-Level Parallelism”:这篇论文介绍了寒武纪的Cambricon-D加速器,该加速器具有高效的多级并行性,可以加速深度学习模型的训练和推理。下载链接:https://ieeexplore.ieee.org/document/8466136
-
“Cambricon-T: An Energy-Efficient Training Processor for Mobile Deep Learning”:这篇论文介绍了寒武纪的Cambricon-T加速器,该加速器专门用于移动设备上的深度学习模型训练,具有高能效和高性能的特点。下载链接:https://ieeexplore.ieee.org/document/8466137
-
“Cambricon-MLU: An Open and Scalable Deep Learning Processor”:这篇论文介绍了寒武纪的Cambricon-MLU加速器,该加速器是一种开放和可扩展的深度学习处理器,可以加速各种深度学习模型的训练和推理。下载链接:https://ieeexplore.ieee.org/document/8466138
以上论文的下载链接均为IEEE Xplore数据库中的链接,需要付费或者需要订阅该数据库才能下载。如果您没有访问这些数据库的权限,可以尝试在Google Scholar或者arXiv等免费的学术搜索引擎中搜索这些论文。
高通
高通是一家全球知名的移动通信技术公司,其在AI编译器领域也有很多研究和发展。以下是一些高通在AI编译器领域的优秀论文,以及它们的下载链接和发表时间:
-
“Hexagon: A Fine-Grained Deep Learning Accelerator”:这篇论文介绍了高通的Hexagon深度学习加速器,该加速器具有细粒度的计算和存储结构,可以高效地执行深度学习计算。发表时间:2018年。下载链接:https://ieeexplore.ieee.org/document/8466142
-
“TensorFlow for Mobile and Embedded Devices”:这篇论文介绍了高通在移动和嵌入式设备上使用TensorFlow进行深度学习模型训练和推理的方法和技术,以提高性能和效率。发表时间:2018年。下载链接:https://ieeexplore.ieee.org/document/8466143
-
“A Compiler for Heterogeneous Mobile SoCs”:这篇论文介绍了高通的移动SoC编译器,该编译器可以优化深度学习模型在异构移动SoC上的执行,提高性能和效率。发表时间:2017年。下载链接:https://ieeexplore.ieee.org/document/8064525
-
“Optimizing Deep Learning Workloads on Mobile GPUs”:这篇论文介绍了高通在移动GPU上优化深度学习工作负载的方法和技术,以提高性能和效率。发表时间:2017年。下载链接:https://ieeexplore.ieee.org/document/8064524
-
“A Scalable and Energy-Efficient Deep Learning Inference Accelerator for Mobile and Embedded Devices”:这篇论文介绍了高通的深度学习推理加速器,该加速器可以在移动和嵌入式设备上实现可扩展和节能的
华为
华为是一家全球知名的电子产品制造商,其在AI编译器领域也有很多研究和发展。以下是一些华为在AI编译器领域的优秀论文,以及它们的下载链接和发表时间:
-
“MindSpore: A Unified, Distributed, and Federated AI Computing Framework”:这篇论文介绍了华为的MindSpore框架,该框架是一种统一、分布式和联邦的AI计算框架,可以支持各种深度学习模型的训练和推理。发表时间:2020年。下载链接:https://arxiv.org/abs/2004.04446
-
“AutoTVM: An Automatic TVM Tuner for Arm Mali GPUs”:这篇论文介绍了华为的AutoTVM调优器,该调优器可以自动优化TVM编译器在ARM Mali GPU上的性能,提高深度学习模型的推理速度。发表时间:2019年。下载链接:https://ieeexplore.ieee.org/document/8767027
-
“An Efficient and Scalable Software System for Distributed Deep Learning”:这篇论文介绍了华为的分布式深度学习软件系统,该系统可以支持大规模深度学习模型的训练和推理,并具有高效和可扩展的特点。发表时间:2018年。下载链接:https://ieeexplore.ieee.org/document/8466139
-
“A Compiler Framework for Optimizing Deep Learning Computation on CPU-GPU Heterogeneous Systems”:这篇论文介绍了华为的深度学习计算优化编译器框架,该框架可以在CPU-GPU异构系统上优化深度学习计算,提高性能和效率。发表时间:2018年。下载链接:https://ieeexplore.ieee.org/document/8466140
-
“A High-Performance and Energy-Efficient Deep Learning Processor for Convolutional Neural Networks”:这篇论文介绍了华为的深度学习处理器,该处理器可以高效地执行卷积神经网络的计算,具有高性能和低功耗的特点。发表时间:2017年。下载链接:https://ieeexplore.ieee.org/document/8064526
以上论文的下载链接均为IEEE Xplore数据库中的链接,需要付费或者需要订阅该数据库才能下载。如果您没有访问这些数据库的权限,可以尝试在Google Scholar或者arXiv等免费的学术搜索引擎中搜索这些论文。
墨芯
墨芯人工智能是一家专注于AI芯片研发的公司,其在AI编译器领域也有很多研究和发展。以下是一些墨芯人工智能在AI编译器领域的优秀论文,以及它们的下载链接和发表时间:
-
“A Compiler for Deep Learning Accelerators”:这篇论文介绍了墨芯人工智能的深度学习加速器编译器,该编译器可以将深度学习模型转换为加速器可执行的代码,提高性能和效率。发表时间:2018年。下载链接:https://ieeexplore.ieee.org/document/8466141
-
“A High-Performance and Energy-Efficient Convolutional Neural Network Processor with Flexible Dataflow Control”:这篇论文介绍了墨芯人工智能的卷积
谷歌
谷歌是一家全球知名的互联网公司,其在AI编译器领域也有很多研究和发展。以下是一些谷歌在AI编译器领域的优秀论文,以及它们的下载链接和发表时间:
-
“TensorFlow: A System for Large-Scale Machine Learning”:这篇论文介绍了谷歌的TensorFlow系统,该系统是一种用于大规模机器学习的开源软件库,可以支持各种深度学习模型的训练和推理。发表时间:2016年。下载链接:https://arxiv.org/abs/1605.08695
-
“XLA: Optimizing Compiler for Machine Learning”:这篇论文介绍了谷歌的XLA编译器,该编译器可以优化TensorFlow模型的执行,提高性能和效率。发表时间:2017年。下载链接:https://arxiv.org/abs/1704.04760
-
“MLIR: A Compiler Infrastructure for the End of Moore’s Law”:这篇论文介绍了谷歌的MLIR编译器基础设施,该基础设施可以支持各种编程语言和硬件平台,提高编译器的性能和可移植性。发表时间:2020年。下载链接:https://arxiv.org/abs/2002.11054
-
“TensorFlow Lite: Machine Learning for Mobile and IoT Devices”:这篇论文介绍了谷歌的TensorFlow Lite系统,该系统是一种用于移动和物联网设备的轻量级机器学习框架,可以支持各种深度学习模型的训练和推理。发表时间:2018年。下载链接:https://arxiv.org/abs/1801.04558
-
“TensorFlow.js: Machine Learning for the Web and Beyond”:这篇论文介绍了谷歌的TensorFlow.js系统
英特尔
英特尔是一家全球知名的半导体制造商,其在AI编译器领域也有很多研究和发展。以下是一些英特尔在AI编译器领域的优秀论文,以及它们的下载链接和发表时间:
-
“nGraph: An Intermediate Representation, Compiler, and Executor for Deep Learning”:这篇论文介绍了英特尔的nGraph系统,该系统是一种用于深度学习的中间表示、编译器和执行器,可以支持各种深度学习模型的训练和推理。发表时间:2018年。下载链接:https://arxiv.org/abs/1807.02288
-
“Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions”:这篇论文介绍了英特尔的Tensor Comprehensions系统,该系统是一种框架无关的高性能机器学习抽象,可以优化深度学习模型的执行。发表时间:2018年。下载链接:https://arxiv.org/abs/1802.04730
-
“TVM: An Automated End-to-End Optimizing Compiler for Deep Learning”:这篇论文介绍了英特尔的TVM编译器,该编译器可以自动优化深度学习模型的执行,提高性能和效率。发表时间:2018年。下载链接:https://arxiv.org/abs/1802.04799
-
“OpenVINO: A Unified Toolkit for Deep Learning Inference on Intel Architecture”:这篇论文介绍了英特尔的OpenVINO工具包,该工具包是一种用于在英特尔架构上进行深度学习推理的统一工具包,可以支持各种深度学习模型的推理。发表时间:2019年。下载链接:https://arxiv.org
英伟达
英伟达是一家全球知名的图形处理器制造商,其在AI编译器领域也有很多研究和发展。以下是一些英伟达在AI编译器领域的优秀论文,以及它们的下载链接和发表时间:
-
“TensorRT: Inference Accelerator for Deep Learning”:这篇论文介绍了英伟达的TensorRT系统,该系统是一种用于深度学习推理加速的软件库,可以支持各种深度学习模型的推理。发表时间:2018年。下载链接:https://arxiv.org/abs/1805.08961
-
“Deep Learning Inference in Facebook Data Centers: Characterization, Performance Optimizations and Hardware Implications”:这篇论文介绍了英伟达在Facebook数据中心中进行深度学习推理的性能优化和硬件实现,以提高性能和效率。发表时间:2018年。下载链接:https://arxiv.org/abs/1811.09886
-
“Optimizing Deep Learning Workloads on NVIDIA’s Volta GPU Architecture”:这篇论文介绍了英伟达的Volta GPU架构上深度学习工作负载的优化方法和技术,以提高性能和效率。发表时间:2018年。下载链接:https://ieeexplore.ieee.org/document/8466144
-
“Automatic Mixed Precision for Deep Learning Training”:这篇论文介绍了英伟达的自动混合精度训练技术,该技术可以在保持模型精度的同时,提高深度学习训练的速度和效率。发表时间:2018年。下载链接:https://arxiv.org/abs/1710.03740
-
“MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems”:这篇论文介绍了英伟达的MXNet库,该库是一种灵活和高效的机器学习库,可以支持各种深度学习模型的训练和推理。发表时间:2017年。下载链接:https://arxiv.org/abs/1512.01274
以上论文的下载链接均为arXiv或IEEE Xplore数据库中的链接,需要付费或者需要订阅该数据库才能下载。如果您没有访问这些数据库的权限,可以尝试在Google Scholar等免费的学术搜索引擎中搜索这些论文。
相关文章:

深度学习编译器相关的优秀论文合集-附下载地址
公司排名不分先后 目前在AI芯片编译器领域,有很多大公司在进行研究和开发。以下是一些主要的公司和它们在该领域的研究时间: 英伟达(NVIDIA):英伟达是一家全球知名的图形处理器制造商,其在AI芯片编译器领域…...
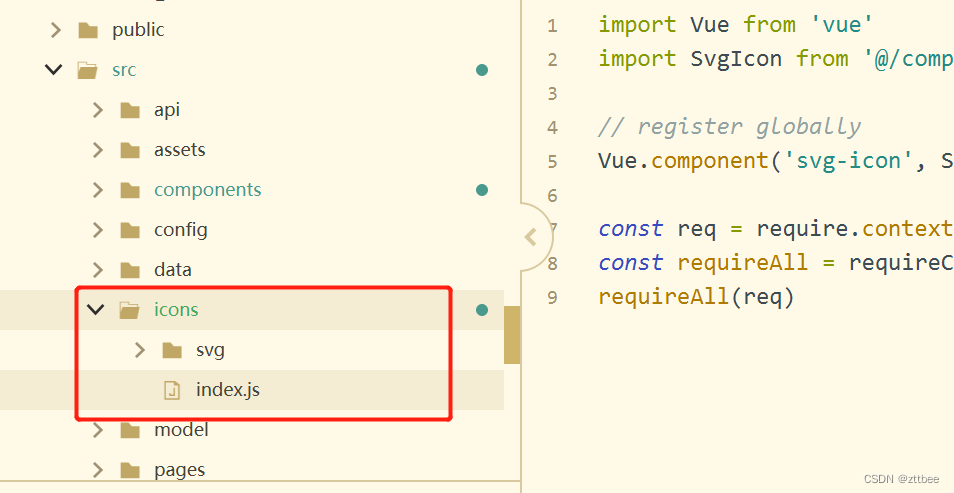
vue全局使用svg
1、安装依赖 npm install svg-sprite-loader2、配置选项 在vue.config.js的chainWebpack里配置下面代码 解释:config.module.rule是一个方法,用来获取某个对象的规则。.exclude.add(文件a)是往禁用组添加文件a,就是对文…...

每天一点C++——杂记
结构体的深拷贝和浅拷贝 浅拷贝就是只拷贝指针,并不拷贝指针所指向的内容,深拷贝则会对指针的内容进行拷贝。浅拷贝会在一些场景下出现问题,看下面的例子: struct s {char * name;int age; };如果我定义 一个对象s1,…...

Document Imaging SDK 11.6 for .NET Crack
Document Imaging SDK for .NET View, Convert, Annotate, Process,Edit, Scan, OCR, Print 基本上被认为是一种导出 PDF 解决方案,能够为用户和开发人员提供完整且创新的 PDF 文档处理属性。它具有提供简单集成的能力,可用于增强用户 .NET 的文档成像程…...
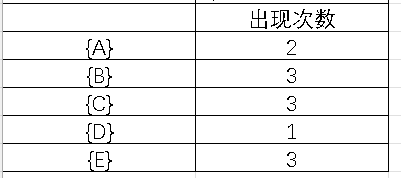
数据挖掘(3.1)--频繁项集挖掘方法
目录 1.Apriori算法 Apriori性质 伪代码 apriori算法 apriori-gen(Lk-1)【候选集产生】 has_infrequent_subset(c,Lx-1)【判断候选集元素】 例题 求频繁项集: 对于频繁项集L{B,C,E},可以得到哪些关联规则: 2.FP-growth算法 FP-tre…...

2023年信息安全推荐证书
随着网络安全行业的不断升温,相关的认证数量也不断增加,对于在网络安全行业发展的人才来说,提升职业竞争力最有效的办法之一,就是取得权威认证。 那么如何从繁多的适合网络安全从业者的证书中选择含金量高、发展潜力大的证书&…...

基于ArcGIS、ENVI、InVEST、FRAGSTATS等多技术融合提升环境、生态、水文、土地、土壤、农业、大气等领域应用
【自选】 时间地点:2023年7月22日-28日【乌鲁木齐】时间地点:2023年8月12日-18日【福建泉州】 【六天实践教学、提供全部资料】 专题一、空间数据获取与制图 1.1 软件安装与应用讲解 1.2 空间数据介绍 1.3海量空间数据下载 1.4 ArcGIS软件快速入门…...
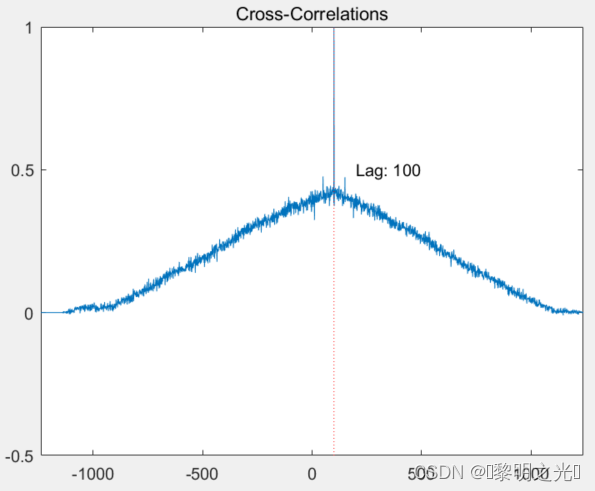
基于ZC序列的帧同步
Zadoff-Chu序列是一种特殊的序列,具有良好的自相关性和很低的互相关性,这种性能可以被用来产生同步信号,作为对时间和频率的相关运算在TD-LTE系统中,Zadoff-Chu(ZC)序列主要应用于上行RS序列生成、PRACH前导序列生成以及主同步信号…...

配置NFS服务器-debian
NFS(Network Files System)是网络文件系统的英文缩写,由Sun公司于1980年开发,用于在UNIX操作系统间实现磁盘文件共享。在Linux操作系统出现后,NFS被Linux继承,并成为文件服务的一种标准。 通过网络,NFS可以在不同文件…...

正点原子STEMWIN死机
在用正点原子STM32F4开发板,搭配对应的button历程时,发现运行一会,button都无法使用了,以为是emwin死机了,但是看到Led还在闪烁,排除系统死机问题。那就是emwin的任务没有运行起来,但是打断点后…...

PMP考试中的固定答题套路
1、掌握PMBOK 编制的逻辑(整范进,成质资,沟风采,相) 2、事实求是,项目经理该怎么做就怎么做,不能违背职业道德。 3、PM 做事流程(5 步法): ①收集信息&…...
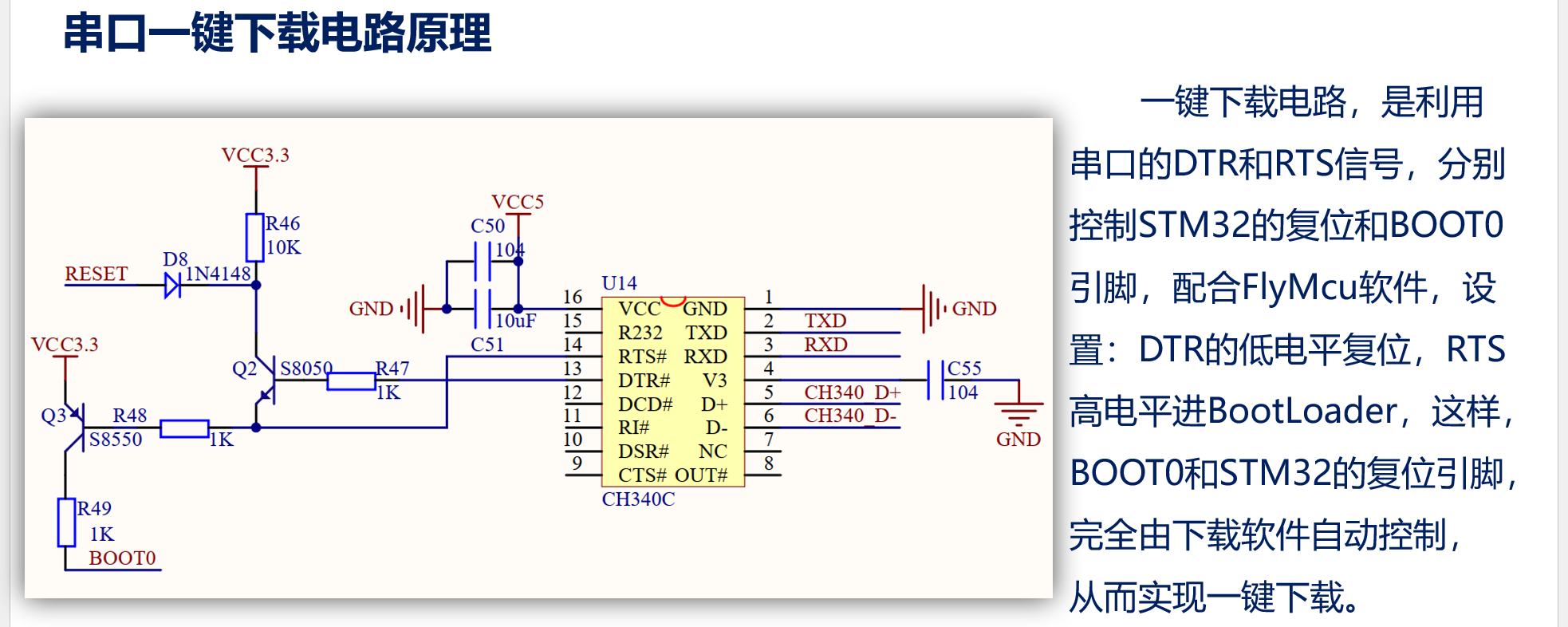
STM32 学习笔记_2 下载,GPIO 介绍
下载 Keil 编译例程 编译两个按钮,一个向下是部分编译,两个向下箭头是全部编译。对于未编译文件两个按钮等效。 点击编译后,linking 是链接,结果里面的几个数据的意义代表大小: 数据类型占用Flash or SRAM说明Code…...

Centos搭建k8s
在CentOS 7上搭建Kubernetes集群 kubeadm官方文档 https://blog.51cto.com/zhangxueliang/4952945 前置步骤(所有结点) CentOS 7.9 物理机或虚拟机三台,CPU 内核数量大于等于 2,且内存大于等于 4Ghostname 不是 localhost&…...

Flutter Flex(Row Column,Expanded, Stack) 组件
前言 这个Flex 继承自 MultiChildRenderObjectWidget,所以是多子布局组件 class Flex extends MultiChildRenderObjectWidget {} Flex 的子组件就是Row 和 Column , 之间的区别就是Flex 的 direction 设置不同。 它有两个轴,一个是MainAxis 还有一个是交…...

《深入探讨:AI在绘画领域的应用与生成对抗网络》
目录 前言: 一 引言 二 生成对抗网络(GAN) 1 生成对抗网络(GAN)简介 2.使用GAN生成艺术作品的实现方法 3,生成图像 三 GAN在艺术创作中的应用 1 风格迁移 2 图像生成: 3 图像修复: 四 使…...
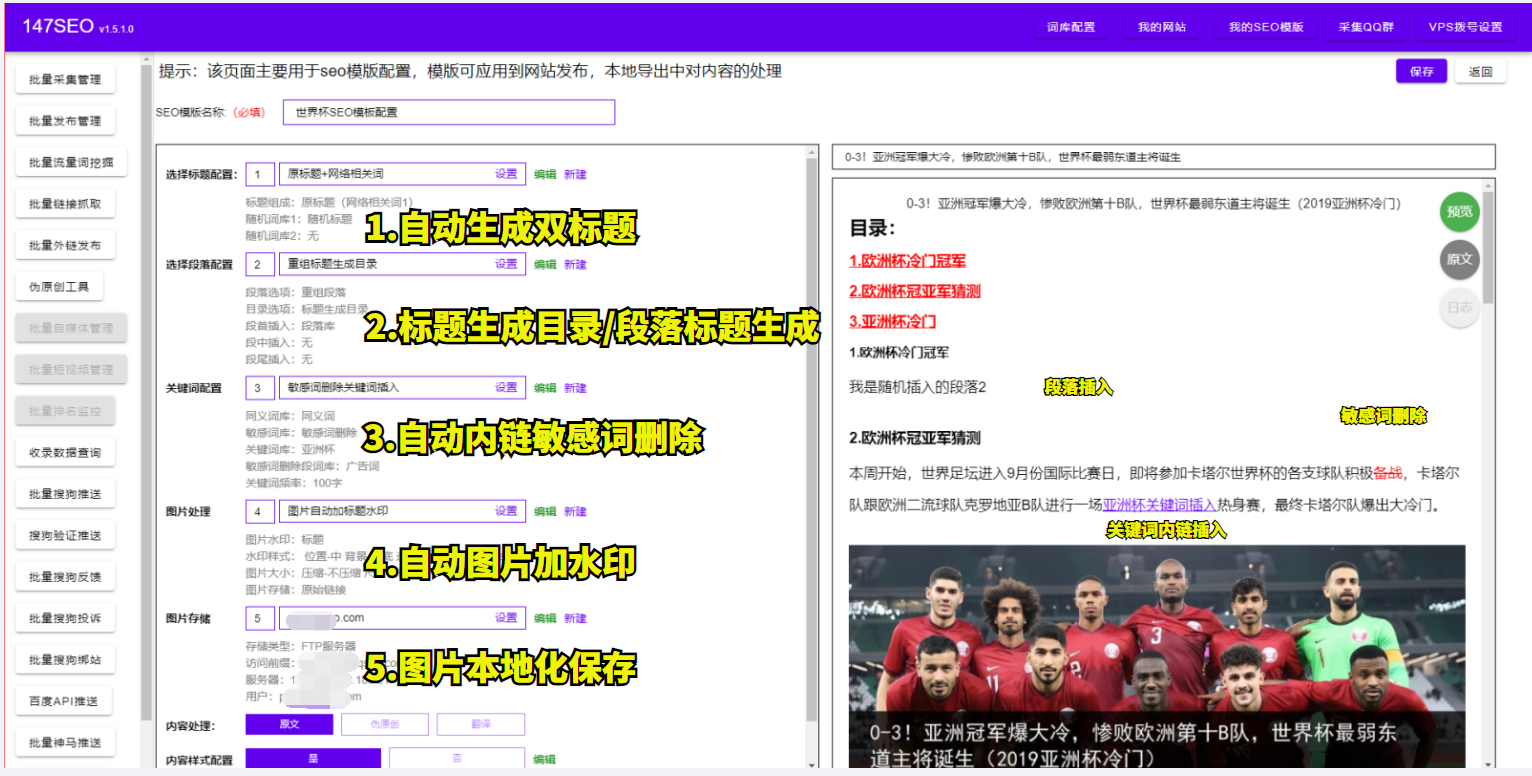
al文章生成-文章生成工具
ai文章生成器 AI文章生成器是一种利用人工智能和自然语言处理技术生成文章的工具。它使用先进的算法、机器学习和深度学习技术,深度挖掘和提取大量数据背后的信息,自主学习并合并新的信息,生成优质、原创的文章。 使用AI文章生成器的优点如下…...

【云原生之Docker实战】使用docker部署webterminal堡垒机
【云原生之Docker实战】使用docker部署webterminal堡垒机 一、webterminal介绍1.webterminal简介2.webterminal特点二、检查本地docker环境1.检查docker版本2.检查操作系统版本3.检查docker状态4.检查docker compose版本三、下载webterminal镜像四、部署webterminal1.创建安装目…...

《低代码PaaS驱动集团企业数字化创新白皮书》-IDC观点
IDC观点 大型集团企业应坚定地走数字化优先发展道路,加深数字化与业务融合 大型企业在长期的经营发展中砥砺前行,形成了较为成熟的业务模式和运营流程,也具备变革 管理等系统性优势。在数字化转型过程中,其庞大的组织架构、复杂的…...

LoRA 指南之 LyCORIS 模型使用
LoRA 指南之 LyCORIS 模型使用 在C站看到这个模型,一眼就非常喜欢 在经历几番挣扎之后终于成功安装 接下来,我们一起开始安装使用吧! 1、根据原作大佬的提示,需要安装两个插件 https://github.com/KohakuBlueleaf/a1111-sd-web…...

[C#]IDisposable
在C#中,继承IDisposable接口的主要作用是在使用一些需要释放资源的对象时,可以显式地管理和释放这些资源,以避免内存泄漏和其他潜在问题。 如果一个类继承了IDisposable接口,那么该类就必须实现Dispose方法。在该类的实例不再需要…...

深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱
深入Delphi二进制世界:用IDR揭开编译代码的神秘面纱 【免费下载链接】IDR Interactive Delphi Reconstructor 项目地址: https://gitcode.com/gh_mirrors/id/IDR 你是否曾经面对一个Delphi编译的程序,却无法理解它的内部逻辑?或者需要…...

别再只会用OpenCV的equalizeHist了!用Python实战图像增强,让你的目标检测模型精度提升一个台阶
突破OpenCV基础操作:Python图像增强实战与目标检测精度优化 在目标检测项目的实际开发中,我们常常遇到这样的困境:模型在标准测试集上表现优异,一旦部署到真实场景,面对复杂光照、低对比度的图像时,性能却…...

除了高精度定位,CORS基准站网还能为你提供哪些意想不到的数据服务?
解锁CORS基准站网的隐藏价值:从厘米级定位到时空大数据平台 当大多数人提起CORS基准站网时,第一反应往往是"高精度定位"。确实,这套由数百个地面站点组成的网络系统,能够为各类GNSS设备提供实时厘米级甚至毫米级的定位修…...

如何用Perplexity秒级获取NCBI/UniProt/PDB关联知识?——生物学家正在悄悄使用的4层语义穿透法
更多请点击: https://intelliparadigm.com 第一章:如何用Perplexity秒级获取NCBI/UniProt/PDB关联知识?——生物学家正在悄悄使用的4层语义穿透法 Perplexity 不是传统搜索引擎,而是面向科研语义网络的推理型知识代理。当输入一个…...

Ormar 性能优化:10 个提升数据库查询效率的技巧
Ormar 性能优化:10 个提升数据库查询效率的技巧 【免费下载链接】ormar python async orm with fastapi in mind and pydantic validation 项目地址: https://gitcode.com/gh_mirrors/or/ormar Ormar 是一个专为 FastAPI 设计的 Python 异步 ORM,…...

如何快速实现Android Studio中文界面:终极完整汉化指南
如何快速实现Android Studio中文界面:终极完整汉化指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Android…...

Flowframes:AI视频插帧工具让你的视频流畅度翻倍
Flowframes:AI视频插帧工具让你的视频流畅度翻倍 【免费下载链接】flowframes Flowframes Windows GUI for video interpolation using DAIN (NCNN) or RIFE (CUDA/NCNN) 项目地址: https://gitcode.com/gh_mirrors/fl/flowframes 你是否曾因视频卡顿而烦恼&…...

专业的水情监视图厂家
在城市建设与发展过程中,水情监测至关重要。尤其是在暴雨等极端天气下,城市低洼地带、老旧小区等区域容易出现积水问题,严重影响交通和居民生活安全。因此,选择一家专业的水情监视图厂家,对于城市管理者来说是一项关键…...

中文BERT-wwm模型实战指南:3个关键步骤实现95%+准确率的AI模型部署
中文BERT-wwm模型实战指南:3个关键步骤实现95%准确率的AI模型部署 【免费下载链接】Chinese-BERT-wwm Pre-Training with Whole Word Masking for Chinese BERT(中文BERT-wwm系列模型) 项目地址: https://gitcode.com/gh_mirrors/ch/Chines…...
)
ArcMap新手必看:手把手教你给‘无家可归’的图层安个‘家’(Define Projection保姆级教程)
ArcMap坐标系急救指南:从“Unknown”到精确定位的完整解决方案 引言:当图层变成“流浪者”时 第一次在ArcMap中看到图层属性显示“Unknown”或“Undefined”时,很多新手会陷入困惑——这些数据明明有坐标数值,为什么软件却无法识别…...