Okio 网络提速
文章目录
- 网络数据处理流程
- Page Cache
- 传统 I/O 拷贝的性能问题
- 零拷贝技术
- DMA 技术
- 零拷贝技术分类
- mmap
- sendfile
- splice
- Direct I/O
- 零拷贝技术性能分析
- 小结
- Okio
- Okio 的使用
- Okio 网络提速的原理
- Okio 总结
- 总结
网络数据处理流程
在讲 Okio 之前,为了能更好的了解 Okio 的优化方向和原理需要先了解一些前提知识,比如网络数据的处理流程和不同 I/O 的实现差异。
首先我们看下设备与设备之间到底是如何将网络数据传输送达的,如下图:

上图是一次网络数据的接收过程,涉及到几个角色:
-
os:系统内核,内核实际上也是一套软件
-
网卡:负责链路数据处理,主要是处理以太网帧数据,解析过渡到网络层 IP 数据片段
-
内核协议栈:内核网络处理模块中有封装好的对于每一层协议的解析方案
-
CPU:负责数据处理时的上下文切换和计算处理
上图从数据链路层到应用层对网络数据的处理步骤如下:
-
当一个网络帧到达网卡后,网卡会通过 DMA 方式,把这个网络包放到收包队列中,即数据推到了内核
-
通过硬中断,处理中断处理程序(在处理硬中断时先关闭 CPU 中断,等处理完硬中断再开启 CPU 中断),一些耗时的处理交给软中断 softirq 处理
-
网卡中断处理程序会为网络帧分配内核数据结构 sk_buffer,并将其拷贝到 sk_buffer 缓冲区中,再通过软中断,通知内核收到了新的数据帧
-
内核协议栈从缓冲区中取出网络帧,并通过网络协议栈从下到上逐层处理这个网络帧
-
网络层取出 IP 头,判断网络包下一步的走向,交给上层处理还是转发;当网络层确认这个包是要发送到本机后,就会取出上层协议的类型(比如 TCP 还是 UDP),去掉 IP 头,再交给传输层处理
-
传输层取出 TCP 头或者 UDP 头后,根据 [源 IP、源端口、目的 IP、目的端口] 找出对应的 socket,并把数据拷贝到 socket 的接收缓存中
-
应用层就可以使用 socket api 读取到新接收到的数据
大致了解整个网络数据处理流程,是为了后续能分析整个流程中有哪些优化方向。我们继续往下分析。
Page Cache

上图是传统 I/O 的数据流向图,分别是用户空间从磁盘读文件,以及网络数据从网卡到用户空间的数据处理。
可以发现流程中的数据并不是直接到内存,而是先经过 Page Cache。那什么是 Page Cache?
CPU 如果要访问外部磁盘上的文件,需要首先将这些文件的内容拷贝到内存中,由于硬件限制,从磁盘到内存的数据传输速度是很慢的;假设现在物理内存有空余,是可以考虑用这些空闲内存来缓存一些磁盘文件内容,而这部分用作缓存磁盘文件的空闲内存就是 Page Cache。
简单理解 Page Cache 就是为了提高磁盘到内存传输速度单独分配出来的一块空闲内存。
传统 I/O 拷贝的性能问题
我们重新回顾下上个节点传统 I/O 的数据流向图,先分析从磁盘读文件的流程:
-
用户空间发起 read 要从磁盘读文件,先到 Page Cache 查找缓存,如果没有命中缓存,则到磁盘读文件
-
从磁盘文件读文件将数据拷贝到 Page Cache 后,再将数据从 Page Cache 拷贝到用户空间
接下来是网卡将数据给到用户空间的流程:
-
网卡将数据拷贝到 Page Cache
-
Page Cache 将数据再拷贝到 socket 的接收缓冲区
-
内核空间的 socket 接收缓冲区的数据可以提供给用户空间,通过 socket api 将数据拷贝到用户缓冲区
通过上面两个流程的分析可以发现,传统 I/O 的数据处理流程暴露了两个性能问题:
-
会有多次数据拷贝,成本昂贵
-
用户空间和内核空间之间的交互会有上下文切换
上下文切换:就是用户空间的进程是由内核操控的,内核有进程管理系统;例如 CPU 调度到内核空间的进程需要处理数据,此时用户空间的进程就会被挂起并保存当前进程的状态,等内核空间的进程处理完后休眠,再重新把用户空间的进程重新唤醒
从磁盘读文件的流程有两次拷贝和四次上下文切换,网卡给数据到用户空间有三次拷贝和两次上下文切换。
如果是我们要做网络提速的优化,重点就是将上面的两个指标:数据拷贝、上下文切换,将这的次数降下来。
其中数据拷贝指标在内核也有一套零拷贝机制做了这方面的优化。
有 DMA 技术后,磁盘/网卡到 Page Cache 的走向不再需要走 CPU 上下文切换,而是直接硬件之间能直接将数据推到 Page Cache,减少了一次上下文切换。目前的计算机基本都有 DMA 技术。
零拷贝技术
零拷贝(Zero-Copy)技术是一个思想,是一种 I/O 操作优化技术,可以快速高效地将数据在文件系统移动和网络接口之间传输数据,而不需要将其从内核空间拷贝到用户空间。
零拷贝并不代表一次数据拷贝都没有,是单指的用户空间和内核空间之间减少或没有数据拷贝,硬件设备到内核之间的数据拷贝即 Page Cache 到内核之间的数据拷贝还是必要的。
DMA 技术
DMA 技术(Direct Memory Access)是零拷贝中的一项核心技术,其意思是 “存储器直接访问”,它是指一种高速的数据传输操作,允许在外部设备和存储器之间直接读写数据,即不通过 CPU,也不需要 CPU 干预。

可以看到加入 DMA 技术后,上图从硬件设备到内核空间是没有 CPU 参与数据拷贝和上下文切换,而是有 DMA 技术直接将数据推到 Page Cache。
简单理解就是,DMA 技术能够做到硬件设备到内核空间的流程减少了一次数据拷贝和上下文切换。
目前的计算机都有加入的 DMA 技术,所以我们网络优化的目标就是降低内核空间到用户空间之间的数据拷贝和上下文切换次数。
零拷贝技术分类
为了内核空间和用户空间之间也得到对应的优化给了一系列函数出来。
零拷贝技术更具体细分可以分为两种:
-
基于 Page Cache 的零拷贝技术:sendfile、mmap、splice
-
脱离 Page Cache 的零拷贝技术:Direct I/O
这些零拷贝技术只是为了更方便我们清晰理解网络提速的关键节点和方向,除了 mmap 对 Android 开发必须掌握外,相关的技术仅作为了解即可。
mmap


在 Android 中最常提到 mmap 的场景就是 Binder 的使用减少了一次内存拷贝提高了性能。这里将 mmap 函数的参数简单说明下:
void *mmap(void *addr,size_t length,int prot,int flags,int fd, off_t offset);
-
addr:指向欲映射的内存的起始地址,通常设为 NULL,代表让系统自动选定地址,映射后返回该地址
-
length:将文件中多大的部分映射到内存
-
prot:指定映射区域的读写权限
-
flags:指定映射时的特性,比如是否允许其他进程映射这段内存
-
fd:指定映射内存的文件描述符
-
offset:指定映射位置的偏移量,一般为 0
mmap 函数有两种用法:
-
映射磁盘文件到用户空间
-
匿名映射,不映射磁盘文件,而是向映射区申请一块内存,此时的 fd 入参传 -1
mmap 能做到将内核空间地址映射为用户空间地址,以此来达到减少内存拷贝的目的。
mmap 一般会使用在比如将一个普通文件映射到内存中,在需要对文件进行频繁读写时,用内存读写取代 IO 读写,能获得较高的性能。
sendfile
sendfile 技术简单理解就是在用户空间和内核空间之间不进行数据拷贝,内核空间的 fd 之间进行数据拷贝。不同的 Linux 版本 sendfile 有所不同,下图是 Linux 2.1-2.4 版本的 sendfile:

可以看到只进行了内核空间之间的一次 CPU 数据拷贝,两次 DMA 数据拷贝和两次上下文切换,用户空间不需要提供缓冲区(byte 数组存数据)额外存储数据。

在 Linux 2.4 版本之后内核空间的一次数据拷贝也做了优化,sendfile 通过 DMA Gather Copy 技术组合实现两次 DMA 数据拷贝和两次上下文切换。
但这种只适用于将数据从文件拷贝到 socket 的传输过程,这种技术需要硬件和驱动的支持。
splice
Linux 在 2.6.17 版本引入 splice 系统调用,不仅不需要硬件支持,还实现了两个 fd 之间的数据零拷贝。在 Linux 2.6.23 版本中,sendfile 机制的实现已经没有了,但是其 API 及相应的功能还在,只不过 API 及相应的功能是利用了 splice 机制来实现的。
与 sendfile 不同的是,splice 允许任意两个文件互相连接,而并不只是文件与 socket 进行数据传输。如下图:

上图简单理解就是,splice 机制是将两个 fd 通过管道连接起来,将管道的进流转到出流,这样就能互通,即发了什么数据对方就收到什么数据。
一般这种技术的使用场景是处理转发机制。
Direct I/O
脱离 Page Cache 的零拷贝技术 Direct I/O,其实就是数据不经过内核空间,直接从硬件设备到达用户空间。

它的使用方式和 C 语言打开文件的函数相同,只是需要 flags 指定 O_DIRECT:
int fd = open("/tmp/direct_io_test", O_CREATE | O_RDWR | O_DIRECT);
需要注意的是,Direct I/O 技术是有很大的限制:buffer 内存地址、每次读写数据的大小、文件的 offset 三者都要与底层设备的逻辑块大小对齐 512 byte;即硬件设备调块的管理策略是 512 byte,所以硬件设备给到用户空间每次只能操作 512 byte 的数据,而用户空间开辟的缓冲区也只能是 512 byte 或 512 byte 的倍数,否则就会出错。
零拷贝技术性能分析
上面我们简单的梳理了基于 Page Cache 和脱离 Page Cache 的零拷贝技术,这里再对它们的网络提速指标做一个整理:
| CPU 拷贝 | DMA 拷贝 | 系统调用 | 上下文切换 | |
|---|---|---|---|---|
| 传统 I/O | 2 | 2 | read/write | 4 |
| mmap | 1 | 2 | mmap/write | 4 |
| sendfile | 1 | 2 | sendfile | 2 |
| scatter/gather copy | 0 | 2 | sendfile | 2 |
| splice | 0 | 2 | splice | 2 |
| direct I/O | 0 | 2 | open(O_DIRECT) |
并不是指标越小越好,还要考虑对应技术的使用场景,例如 Direct I/O 就有比较大的限制。
硬件设备和内核空间之间的两次 DMA 数据拷贝是少不了的,零拷贝技术带来的是内核空间和用户空间之间的 CPU 数据拷贝和上下文切换次数的减少。
小结
但是对于我们上层应用 Android 开发者而言,Java/kotlin 程序才是处理上层的读写业务逻辑的开发语言,不是自己底层去写 C/C++ 用 mmap 等这些零拷贝技术,那么 上层应用的网络优化方向就在于常规数据传递,比如用户空间使用的缓冲区来减少数据拷贝和上下文切换的次数,BufferOutputStream 就是一个典型的官方参考。
public
class BufferedOutputStream extends FilterOutputStream {protected byte buf[]; // 默认 8k 缓冲区public BufferedOutputStream(OutputStream out) {this(out, 8192); }public BufferedOutputStream(OutputStream out, int size) {super(out);if (size <= 0) {throw new IllegalArgumentException("Buffer size <= 0");}buf = new byte[size];}
}
所以应用开发者在不考虑自己写底层读写业务的情况下,网络提速的优化重点是在于如何设计缓冲区。
Okio
Okio 是 square 公司开发的 IO 框架,也是 OkHttp 底层的 IO 操作库,相比原生的 Java IO 特别是在网络场景有更好的读写性能。
Okio 的使用
Okio 的使用非常简单,最主要的就是调用 Okio.source() 和 Okio.sink() 分别创建 Source 输入流和 Sink 输出流处理读写操作,不过我们一般还会包上一层 Okio.buffer() 具有缓存功能来提高读写效率。
使用基本如下:
// 写数据
File file = new File(filepath);
try (BufferedSink sink = Okio.buffer(Okio.sink(file))) {sink.write("byte code write".getBytes());sink.writeString("this is some thing import \n", Charset.forName("utf-8"));sink.writeString("this is also some thing import\n", Charset.forName("utf-8"));
}// 读数据
try (BufferedSource source = Okio.buffer(Okio.source(file)) {String str = source.readByteString().string(Charset.forName("utf-8"));Log.v("TAG", str);
}
Okio 网络提速的原理
在网络传输场景,网络数据的数量级大多是在 1-512KB 之间,Okio 为了能做到在不同数据量级下也能高效读写,对缓冲区做了动态申请的设计,在对应数量级申请对应的缓冲区大小做读写,以此来达到高效读写网络提速的目的。

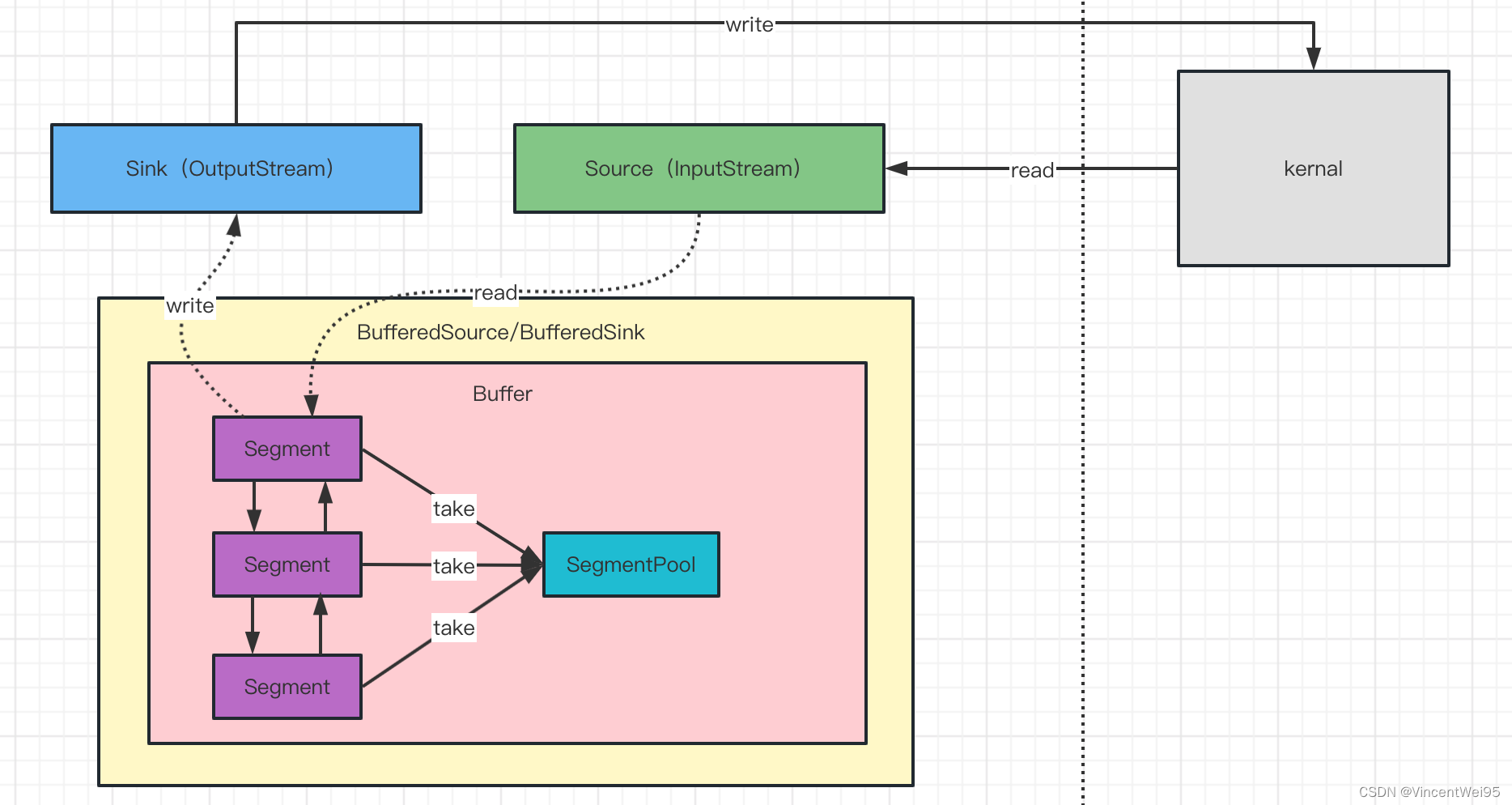
上图是 Okio 的结构图,最主要关注的是 Source、Sink、BufferedSource、BufferedSink、 Buffer、Segment 和 SegmentPool。我们从 Okio 的使用角度分析下是如何做到的动态申请缓冲区。
首先分析 Segment 和 SegmentPool:
Segment.javafinal class Segment {static final int SIZE = 8192; // 默认 8kfinal byte[] data; // 缓冲区// 双向链表Segment next;Segment prev;Segment() {this.data = new byte[SIZE];...}
}SegmentPool.javafinal class SegmentPool {// 缓冲区最大值,即最多有 8 个 Segmentstatic final long MAX_SIZE = 64 * 1024; // 64 KiB.// 享元模式设计思路static @Nullable Segment next;static long byteCount;private SegmentPool() {}static Segment take() {synchronized (SegmentPool.class) {if (next != null) {Segment result = next;next = result.next;result.next = null;byteCount -= Segment.SIZE;return result;}}return new Segment(); // Pool is empty. Don't zero-fill while holding a lock.}static void recycle(Segment segment) {if (segment.next != null || segment.prev != null) throw new IllegalArgumentException();if (segment.shared) return; // This segment cannot be recycled.synchronized (SegmentPool.class) {if (byteCount + Segment.SIZE > MAX_SIZE) return; // Pool is full.byteCount += Segment.SIZE;segment.next = next;segment.pos = segment.limit = 0;next = segment;}}
}

Segment 是内部持有 byte 数组缓冲区的双向循环链表,缓冲区大小是 8192 byte 即 8k。
SegmentPool 是 Segment 缓存池,使用了享元模式内部维持一条单链表保存被回收的 Segment,缓存池最大为 64k 即最多存储 8 个 Segment,也就是一次最多能读写 64k 数据。
Okio 以 Segment 作为读写单位,能够处理的数据大小最多是 64k。
举个例子,比如一个数据是 8193 byte,那么就会分配两个 Segment,一个 Segment 的数据是 8192 byte,另一个 Segment 的数据是 1 byte,两个 Segment 用链表的结构串连起来,也能保证数据有效性。
继续分析 Okio 的读写操作,以写文件数据为例子:
BufferedSink sink = Okio.buffer(Okio.sink(file));
sink.write("xxx".getBytes());Okio.javapublic final class Okio {public static BufferedSink buffer(Sink sink) {return new RealBufferedSink(sink);}public static Sink sink(File file) throws FileNotFoundException {if (file == null) throw new IllegalArgumentException("file == null");return sink(new FileOutputStream(file));}public static Sink sink(OutputStream out) {return sink(out, new Timeout()); }private static Sink sink(final OutputStream out, final Timeout timeout) {...return new Sink() {...};}
}RealBufferedSink.javafinal class RealBufferedSink implements BufferedSink {public final Buffer buffer = new Buffer();public final Sink sink;boolean closed;RealBufferedSink(Sink sink) {if (sink == null) throw new NullPointerException("sink == null");this.sink = sink;}
}
Okio.sink() 创建输出流 FileOutputStream 代理给 Sink,Sink 只是 FileOutputStream 的封装,最终的读写实际上还是交由 FileOutputStream 处理,这个后面会讲到。
Okio.buffer() 创建 RealBufferedSink,并且持有的 Sink 输出流,也是一个代理。
RealBufferedSink.java// RealbufferedSink 只是一个代理
final class RealBufferedSink implements BufferedSink {public final Buffer buffer = new Buffer();public final Sink sink;boolean closed;@Override public BufferedSink write(byte[] source) throws IOException {if (closed) throw new IllegalStateException("closed");buffer.write(source); // 转交给 buffer 处理return emitCompleteSegments();}@Override public BufferedSink emitCompleteSegments() throws IOException {if (closed) throw new IllegalStateException("closed");// 整理要写的数据字节大小long byteCount = buffer.completeSegmentByteCount();// sink 是 Okio.sink() 创建的包装了 OutputStream 的输出流if (byteCount > 0) sink.write(buffer, byteCount); return this;}
}Buffer.java// Buffer 持有 Segment 链表头,是 Segment 的具体管理策略
public final class Buffer implements BufferedSource, BufferedSink, Cloneable {...// 持有 Segment 的链表头,相当于持有整个 Segment 链表Segment head;// 存储的数据大小long size;@Override public Buffer write(byte[] source) {if (source == null) throw new IllegalArgumentException("source == null");return write(source, 0, source.length); }@Override public Buffer write(byte[] source, int offset, int byteCount) {...int limit = offset + byteCount;while (offset < limit) {// 申请 SegmentSegment tail = writableSegment(1);int toCopy = Math.min(limit - offset, Segment.SIZE - tail.limit);System.arraycopy(source, offset, tail.data, tail.limit, toCopy);offset += toCopy;tail.limit += toCopy;}size += byteCount;return this;}Segment writableSegment(int minimumCapacity) {...// 没有链表头节点,创建一个 Segment 作为头节点if (head == null) {head = SegmentPool.take();return head.next = head.prev = head;}Segment tail = head.prev;if (tail.limit + minimumCapacity > Segment.SIZE || !tail.owner) {tail = tail.push(SegmentPool.take());}return tail;}
}
可以发现 RealBufferedSink 只是一个代理。
Buffer 是 Segment 的具体管理策略,持有的 Segment 的链表头,也相当于持有整个 Segment 链表。
在 Buffer 根据数据大小处理 Segment 的分配,最终是交由 Okio.sink() 创建的 Sink 写数据,Sink 实际上就是 OutputStream 的包装类。
public final class Okio {private static Sink sink(final OutputStream out, final Timeout timeout) {...return new Sink() {@Override public void write(Buffer source, long byteCount) throws IOException {checkOffsetAndCount(source.size, 0, byteCount);while (byteCount > 0) {timeout.throwIfReached();Segment head = source.head;// 计算写缓冲区的范围int toCopy = (int) Math.min(byteCount, head.limit - head.pos);// 最终还是交由 OutputStream 写文件out.write(head.data, head.pos, toCopy);// 重新计算下一次写文件的范围head.pos += toCopy;byteCount -= toCopy;source.size -= toCopy;if (head.pos == head.limit) {source.head = head.pop();SegmentPool.recycle(head); // 写完数据后回收 Segment} }}...};}
}
最终的写数据还是交由 OutputStream 处理。
梳理下 Okio 缓冲区的动态申请的原理:Okio 是以 Segment 的 8k 为一个单位,每 8k 数据分配一个 Segment,最多申请 8 个 Segment 即 64k 数据,保证 64k 数据只有一次数据拷贝和一次上下文切换,以此来达到高效读写的目的。
Okio 总结
Okio 简单来说就是一个对原生 IO 封装的三方库,Okio 最重要的是对缓冲区的设计。
Okio 读写效率高是因为动态的缓冲区构建,缓冲区以 Segment 作为读写单位,每 8k 数据分配一个 Segment,最多 8 个 Segment 保证了至少在 64k 数据内只有一次数据拷贝一次上下文切换,减少用户空间和内核空间的交互次数,以达到在常规读写业务达到网络读写提速的目的。
总结
网络提速的目的其实就是去降低数据拷贝和上下文切换的次数,因为高频次的数据拷贝和上下文切换会导致资源损耗的提升,大批量的情况会拉满 CPU。
根据不同的业务场景选择不同的处理策略:
-
特殊业务走底层开发即自己用 C/C++ 开发读写业务,使用零拷贝技术 sendfile/mmap/Direct IO 等技术支撑
-
常规业务走应用上层对缓冲区设计,对于缓冲区进行控制达到网络提速目的
相关文章:
Okio 网络提速
文章目录网络数据处理流程Page Cache传统 I/O 拷贝的性能问题零拷贝技术DMA 技术零拷贝技术分类mmapsendfilespliceDirect I/O零拷贝技术性能分析小结OkioOkio 的使用Okio 网络提速的原理Okio 总结总结网络数据处理流程 在讲 Okio 之前,为了能更好的了解 Okio 的优…...

自动驾驶企业面临哪些数据安全挑战?
近期,“特斯拉员工被曝私下分享用户隐私”不可避免地成了新闻热点,据说连马斯克也不能幸免。 据相关媒体报道,9名前特斯拉员工爆料在2019年至2022年期间,特斯拉员工通过内部消息系统私下分享了一些车主车载摄像头记录的隐私视频和…...

Doris(2):Doris编译部署
1 Doris编译 Apache Doris提供直接可以部署的版本压缩包:https://cloud.baidu.com/doc/PALO/s/Ikivhcwb5 也可以自行编译压缩包后使用(推荐) 1.1 使用 Docker 开发镜像编译(推荐) 这个是官方文档推荐的,…...
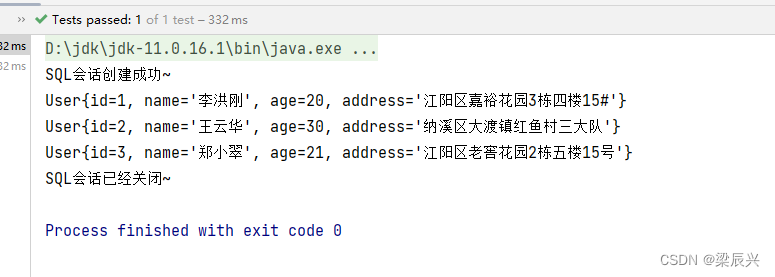
使用MyBatis实现简单查询
文章目录一,创建数据库与表(一)在Navicat里创建MySQL数据库testdb(二)创建用户表 - t_user(三)在用户表里插入3条记录二,案例演示MyBatis基本使用(一)创建Mav…...
[4]和char *point[4])
C指针(*point)[4]和char *point[4]
char (*point)[4] // 数组指针。 a[3][4] // 先申明二维数组,用它来指向这个二维数组. char *point[4] // 指针数组。 a[4][5] // 一连串的指针. char (*point)[4] // 一个指针,指向有4个元素的数组;占内存大小为 4 个字节 ch…...
【Bard】谷歌的人工智能工具—Bard初体验
文章目录一、Bard介绍二、Bard体验1、加入Bard的候补名单2、登入Bard篇3、使用Bard篇(1)提供三种预选方式✨(2)创作生成各类文案(3)无生成图画能力(4)支持语音转文本输入✨ÿ…...
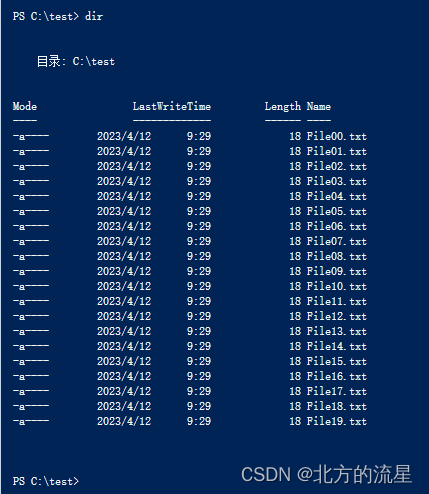
2022国赛30:windows脚本题解析
大赛试题内容: ( 九) ) 脚本 【任务描述】 为了减少重复性任务的工作量,节省人力和时间,请采用脚本,实现快速批量的操作。 1.在 windows4 上编写 C:\CreateFile.ps1 的 powershell 脚本,创建20 个文件 C:\test\File00.txt 至 C:\test\File19.txt,如果文件存在,则首先删除…...
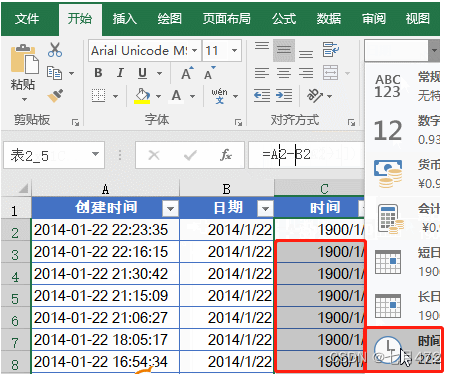
Excel常用函数公式20例
目录 一、【IF函数条件判断】 二、【多条件判断】 三、【条件求和】 四、【多条件求和】 五、【条件计数】 六、【多条件计数】 七、【条件查找】 八、【多条件查找】 九、【计算文本算式】 十、【合并多个单元格内容】 十一、【合并带格式的单元格内容】 十二、…...
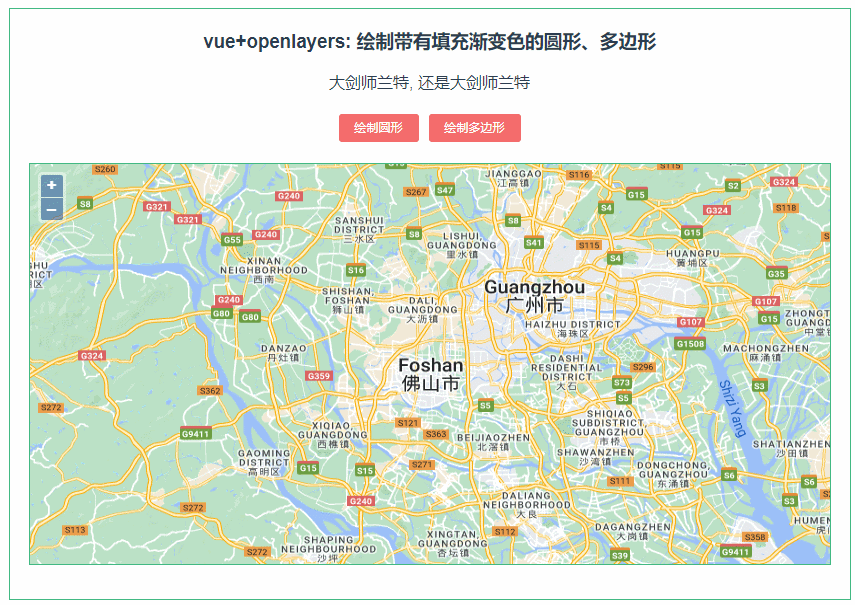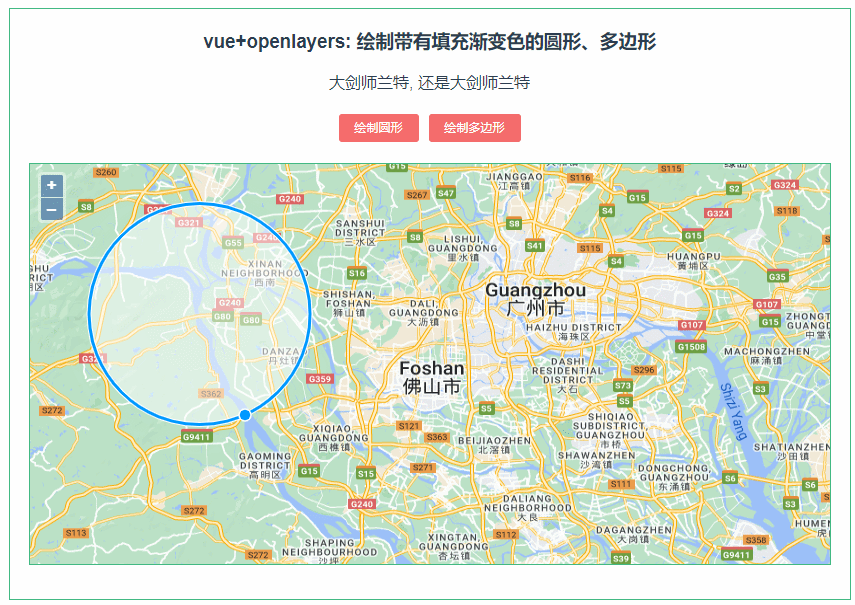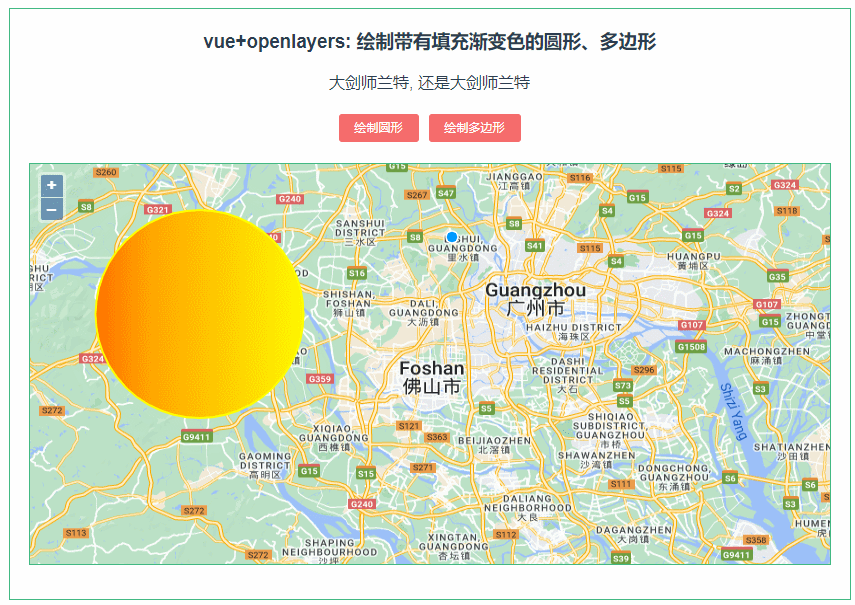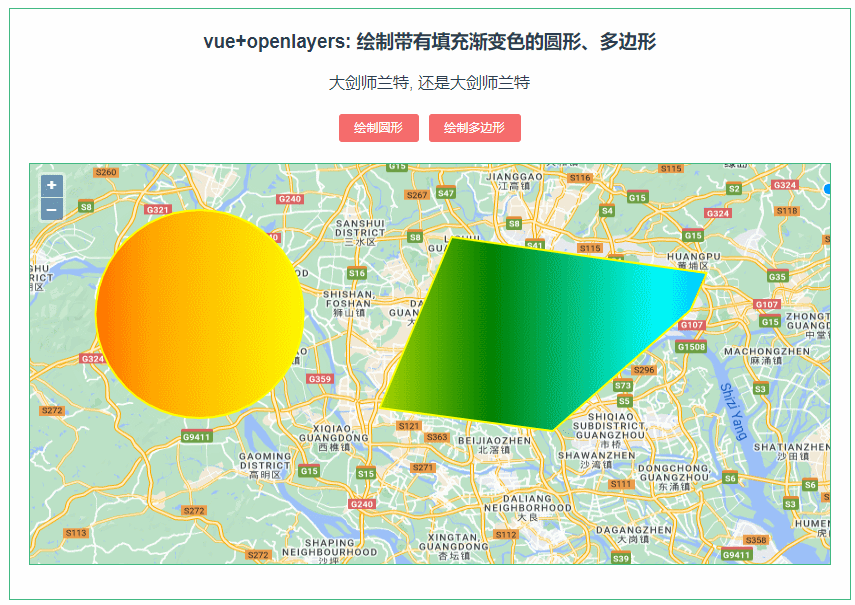
233:vue+openlayers绘制渐变填充色的圆形、多边形
第233个 点击查看专栏目录 本示例的目的是介绍如何在vue+openlayer中绘制带有渐变填充色的圆形、多边形。这里用canvas的方式去渲染,用到了DEVICE_PIXEL_RATIO,设备上的物理像素与设备无关像素 (dips) 之间的比率 (window.devicePixelRatio)。 直接复制下面的 vue+openlayer…...
Flink的窗口机制
窗口机制 tumble(滚动窗口) hop(滑动窗口) session(会话窗口) cumulate(渐进式窗口) Over(聚合窗口) 滚动窗口(tumble) 概念 滚…...

了解分布式Session
大家好,我这名CRUD工程师又来了,最近我的一个同事突然在看分布式Seesion的问题,然后我们两个也是互相讨论了一下,今天我就想着把分布式Session的知识点好好的梳理一下。 在很多系统中,用户的登录功能都是用Session去实…...

仿真创新大赛—国三省一 智能鱼缸(proteus)(stm32)
⏩ 大家好哇!我是小光,嵌入式爱好者,一个想要成为系统架构师的大三学生。 ⏩去年下半年参加了全国仿真创新大赛,也是取得了国赛三等奖,省赛一等奖的好成绩。 ⏩本篇文章对我们的参赛作品《智能鱼缸》做一个简介。 ⏩感…...

【ARMv8 编程】A64 数据处理指令——位域字节操作指令
有些指令将字节、半字或字扩展到寄存器大小,可以是 X 或 W。这些指令存在于有符号(SXTB、SXTH、SXTW)和无符号(UXTB、UXTH)变体中,并且是适当的位域操作指令。 这些指令的有符号和无符号变体都将字节、半字…...

ctfshow 愚人杯菜狗杯部分题目(flasksession伪造ssti)
目录 <1>愚人杯 (1) easy_signin (2) easy_ssti(无过滤ssti) (3) easy_flask(flash-session伪造) (4) easy_php(C:开头序列化数据) <2> 菜狗杯 (1) 抽老婆(flask_session伪造) (2) 一言既出,驷马难追(intval) (3) 传说之下(js控制台&…...

linux拓展笔记——【补充学习知识点】
文章目录1. ./configure --prefix中的prefix详解1. ./configure --prefix中的prefix详解 源码的安装一般由3个步骤组成:配置(configure)、编译(make)、安装(makeinstall)。 Configure是一个可执行脚本,在待安装的源码路径下使用命令./configure–help输…...

为何银行各岗位之间的薪酬差别如此之大?
银行里的职位种类相对较多,观观整理了5个最常见的职位,看一下你要申请的职位薪资水平到底是怎样的?根据如信银行考试中心发布: 1、客户经理岗 客户经理分为对公客户经理和对私客户经理,他们的主要工作不同࿰…...
TensorFlow 深度学习第二版:1~5
原文:Deep Learning with TensorFlow Second Edition 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只…...
微前端micro-app的使用
演示效果 子应用的项目 基应用嵌入子应用效果图 目录 前言 一、微前端是什么? 它主要解决了两个问题: 二、使用步骤 1.安装依赖 2.在入口处引入 3.子应用的路由() 4.分配一个路由给子应用(重要)࿰…...

【JUC】Java内存模型之JMM
【JUC】Java内存模型之JMM 文章目录【JUC】Java内存模型之JMM1. 概念2. JMM三大特性2.1 可见性2.2 原子性2.3 有序性3. 多线程对变量的读写过程4. 先行发生原则——happens-before4.1 happens-before八条规则4.1.1 次序规则4.1.2 锁定规则4.1.3 volatile变量规则4.1.4 传递规则…...
Win11快速打开便签和使用技巧分享
Win11快速打开便签和使用技巧分享。Win11系统中为用户提供了一个非常实用的系统组件,就是便签功能,使用这个功能可以帮助我们便捷的进行一些重要内容的记录。那么如何去开启开启这个程序来使用呢?来看看以下的详情分享吧。 详细分享ÿ…...

告别显示器!用VNC Viewer远程玩转树莓派4B的完整配置指南
无显示器玩转树莓派4B:VNC远程配置全攻略 当你刚拿到树莓派4B时,第一反应可能是找显示器、键盘鼠标来配置它。但现实情况往往是:手边没有多余的显示设备,或者你希望将树莓派作为服务器长期运行,根本不需要连接显示器。…...
)
告别JNI内存泄漏:实战中那些容易踩坑的字符串与数组操作(附完整代码示例)
告别JNI内存泄漏:实战中那些容易踩坑的字符串与数组操作(附完整代码示例) 在Android NDK开发和高性能Java服务中,JNI(Java Native Interface)作为连接Java与C的桥梁,其重要性不言而喻。然而&…...

LeetCode 每日一题笔记 日期:2026.05.19 题目:2540. 最小公共值
LeetCode 每日一题笔记 0. 前言 日期:2026.05.19题目:2540. 最小公共值难度:简单标签:数组、双指针、哈希表 1. 题目理解 问题描述: 给定两个按非降序排序的整数数组 nums1 和 nums2,请返回它们的最小公共整…...

三星固件下载器Bifrost:三分钟掌握跨平台官方固件获取指南
三星固件下载器Bifrost:三分钟掌握跨平台官方固件获取指南 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为三星设备找不到官方固件而烦恼吗&am…...

如何用Inkscape实现专业级光学设计?终极免费光线追踪插件完整指南
如何用Inkscape实现专业级光学设计?终极免费光线追踪插件完整指南 【免费下载链接】inkscape-raytracing An extension for Inkscape that makes it easier to draw optical diagrams. 项目地址: https://gitcode.com/gh_mirrors/in/inkscape-raytracing 你…...

Godot-MCP完整指南:如何用AI助手3倍提升游戏开发效率
Godot-MCP完整指南:如何用AI助手3倍提升游戏开发效率 【免费下载链接】Godot-MCP An MCP for Godot that lets you create and edit games in the Godot game engine with tools like Claude 项目地址: https://gitcode.com/gh_mirrors/god/Godot-MCP Godot-…...

月度补丁如何落地?Claude Code 在商业项目中实现版本追新的 4 步更新机制
1. 月度补丁不是“一键升级”,而是四次有节奏的上下文重校准 大多数人把 Claude Code 的月度补丁理解成“换了个模型版本号”——就像给手机系统点一下“更新”。我去年在三个中型商业项目里连续踩了这个坑:每次新补丁发布后,团队反馈“AI 写的代码变奇怪了”,review 通过…...

RK3566安卓11开发板千兆网卡RTL8211F移植避坑指南:从原理图到DTS配置全流程
RK3566安卓11平台RTL8211F千兆网卡移植实战:硬件原理到DTS配置的深度解析 当开发者需要在RK3566安卓11平台上实现千兆以太网功能时,RTL8211F PHY芯片的移植往往成为关键挑战。不同于简单的驱动加载,实际项目中常会遇到"软件配置看似正常…...

高端工程场景实测:OpenAI Codex CLI 在微服务重构中的 3 类能力边界
1. 微服务重构现场:Codex CLI 不是万能胶,但能精准补上三块关键拼图 我接手一个运行了四年的电商微服务集群时,它正卡在「订单履约链路」的重构临界点上。17个服务、32个跨服务调用点、4种异步消息协议、2套数据库分片策略——人工梳理接口契约要两周,写迁移脚本要三天,验…...

基于GAN的AI图像水印移除工具VeoWatermarkRemover实战指南
1. 项目概述:一个开源图像水印移除工具 最近在整理一些老照片和网上下载的素材时,经常被图片上那些碍眼的水印、Logo或者时间戳困扰。手动用PS处理,费时费力,而且对批量操作极不友好。直到我发现了GitHub上一个名为“VeoWatermar…...