FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
论文地址:https://arxiv.org/pdf/2303.14189.pdf
概述
本文提出了一种通用的 CNN 和 Transformer 混合的视觉基础模型
移动设备和 ImageNet 数据集上的精度相同的前提下,FastViT 比 CMT 快3.5倍,比 EfficientNet 快4.9倍,比 ConvNeXt 快1.9倍
本文是 MobileOne 原班人马打造,可以看做是 MobileOne 的方法在 Transformer 上的一个改进型的应用
作者取名 FastViT,是一种 CNN,Transformer 混合架构的低延时模型
作者引入了一种新的 token mixer,叫做 RepMixer,它使用结构重新参数化技术,通过删除网络中的 Shortcut 来降低内存访问成本
进一步使用大核卷积使得 FastViT 精度得到提升,而且不怎么影响延时
在移动设备和 ImageNet 数据集上的精度相同的前提下,FastViT 比 CMT 快3.5倍,比 EfficientNet 快4.9倍,比 ConvNeXt 快1.9倍
在类似的延迟下,FastViT 在 ImageNet 上获得的 Top-1 准确率比 MobileOne 高 4.2%,是一种极具竞争力的混合架构模型
背景
本文的目标是做一个卷积,Attention 的低延时混合架构
因为这种架构有效地结合了 CNN 和 Transformer 的优势,在多个视觉任务上有竞争力
本文的目标是建立一个模型,实现 SOTA 的精度-延时 Trade-off
像 CMT,LIT等 CNN 和 Transformer 混合架构的模型都遵循 MetaFormer的架构
它由带有 skip-connection 的 token mixer 和带有 skip-connection 的前馈网络 (Feed Forward Network) 组成
由于增加了内存访问成本 (memory access cost),这些跳过连接在延迟方面占了很大的开销
为了解决这个延迟开销,本文提出 RepMixer,这是一个完全可以重参数化的混合器
它的特点有:
- 是使用结构重参数化来删除 skip-connection
- 在训练期间为主要的层添加一些过参数化的额外的分支,以在训练时提升模型的精度,在推理时全部消除
- 在网络中使用了大核卷积在前几个阶段替换掉 Self-Attention
具体是在前馈网络 (FFN) 层和 Patch Embedding 层中加入了大核卷积
这些更改对模型的总体延迟影响很小,同时提高了性能
对于性能这块作者在 iPhone 12 Pro 设备和 NVIDIA RTX-2080Ti desktop GPU 上进行了详尽的分析
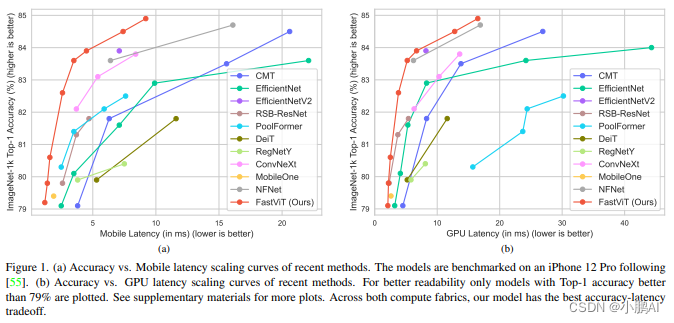
可以看到在两种设备上,FastViT 都实现了最佳的精度-延时的权衡
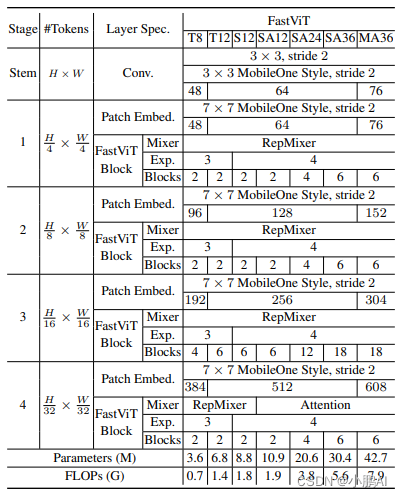
FastViT 模型架构
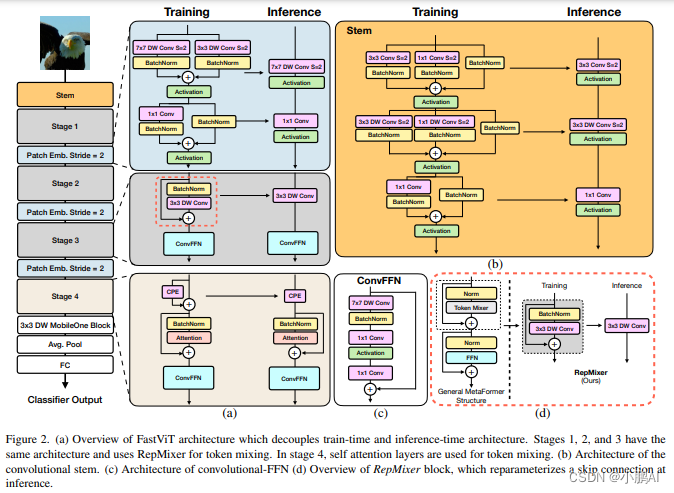
Stage 的内部架构
FastViT 采用了4个 stage 的架构,每个 stage 相对于前一个的分辨率减半,通道数加倍。前3个 stage 的内部架构是一样的
第4个 stage采用 Attention 来作为 token mixer,可能是为了性能考虑,宁愿不采用结构重参数化,牺牲延时成本,以换取更好的性能
值得注意的是,每个 Stage 中的 FFN 使用的并不是传统的 FFN 架构,而是带有大核 7×7 卷积的 ConvFFN 架构
Stem 的结构
Stem 是整个模型的起点,FastViT 的 Stem 在推理时的结构是 3×3 卷积 + 3×3 Depth-wise 卷积 + 1×1 卷积
在训练时分别加上 1×1 分支或者 Identity 分支做结构重参数化
Patch Embedding 的架构
Patch Embedding 是模型在 Stage 之间过渡的部分
FastViT 的 Patch Embedding 在推理时的结构是 7×7 大 Kernel 的 Depth-wise 卷积 + 1×1 卷积
在训练时分别加上 3×3 分支做结构重参数化
位置编码
位置编码使用条件位置编码,它是动态生成的,并以输入 token 的局部邻域为条件
这些编码是由 depth-wise 运算符生成的,并添加到 Patch Embedding 中
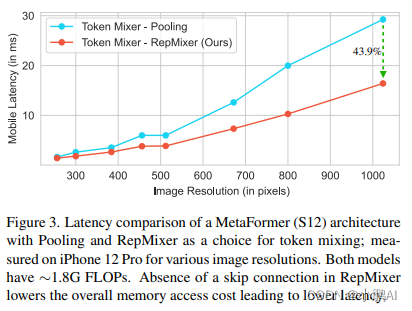
RepMixer 的延时优势
作者对比了 RepMixer 和高效的 Pooling 操作的延时情况
架构使用的是 MetaFormer S12,大概有 1.8 GFLOPs
在 iPhone 12 Pro 移动设备上为从 224×224 到 1024×1024 的各种输入分辨率的模型计时
可以看到 RepMixer 明显优于 Pooling,尤其是在较高分辨率的时候
在分辨率为 384×384 时,使用 RepMixer 可以降低 25.1% 的延迟,而在分辨率为 1024×1024 时
使用 RepMixer 可以降低 43.9% 的延迟
FastViT 的大核卷积
RepMixer 的感受野是局部的
我们知道 Self-Attention 操作的感受野是全局的,但是 Self-Attention 操作计算量昂贵
因此之前有工作说使用大核卷积可以在计算量得到控制的情况下有效增加感受野的大小
FastViT 在两个位置引入了大核卷积,分别是 Patch Embedding 层和 FFN
将 V5 与 V3 进行比较,模型大小增加了 11.2%,延迟增加了 2.3 倍,而 Top-1 精度的增益相对较小,只有 0.4%
说明使用大核卷积来替换 Self-Attention 是一种高效,节约延时的方式
V2 比 V4 大 20%,延时比 V4 高 7.1%,同时在 ImageNet 上获得相似的 Top-1 精度
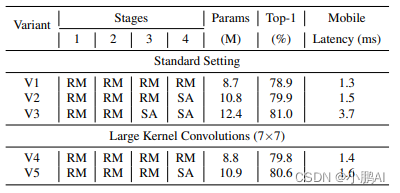
随着感受野的增加,大核卷积也有助于提高模型的鲁棒性,FastViT 各种模型的超参数配置如下
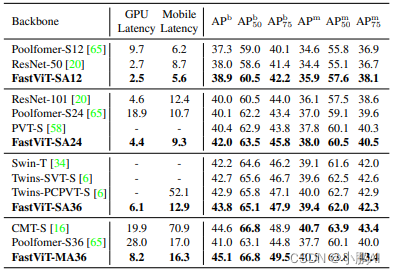
ImageNet-1K 图像分类实验结果
对于 iPhone 设备延时的测量,作者使用 Core ML Tools (v6.0) 导出模型,并在带有 iOS 16 的 iPhone12 Pro Max 上运行
并将所有模型的 Batch Size 大小设置为1
对于 GPU延时的测量,作者把模型导出为 TensorRT (v8.0.1.6) 格式,并在 NVIDIA RTX-2080Ti 上运行
Batch Size 大小为8,报告100次运行的中位数
与 SOTA 模型的性能比较
本文的 FastViT 实现了最佳的精度-延时均衡
比如 FastViT-S12 在 iPhone 12 Pro 上比 MobileOne-S4 快 26.3%,GPU 上快 26.9%
在 83.9% 的 Top-1 精度下,FastViT-MA36 比 iPhone 12 Pro 上优化的 ConvNeXt-B 模型快 1.9倍, GPU上快2.0倍
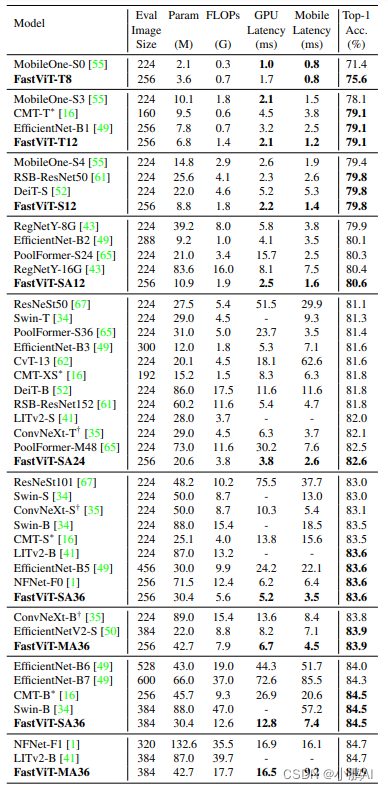
知识蒸馏实验结果
FastViT 作为学生模型的知识蒸馏实验结果
作者遵循 DeiT 中的实验设置,RegNet16GF 作为教师模型,使用 Hard Distillation
其中教师的输出设置为 true label,一共训练300个 Epochs
FastViT 优于最近最先进的模型 EfficientFormer
FastViT-SA24 的性能与 EfficientFormer-L7 相似,但参数少3.8倍,FLOPs 少2.7倍,延迟低2.7倍
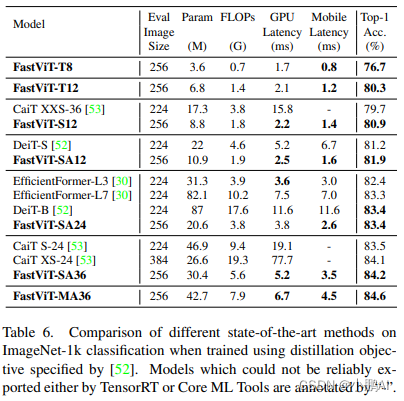
目标检测和语义分割实验结果
对于语义分割,作者在 ADE20k 上验证了模型的性能语义分割模型头使用的是 Semantic FPN
所有的模型都是用预先训练好的对应图像分类模型的权重进行初始化
在 512×512 的设置上估计 FLOPs 和延迟
由于输入图像的分辨率较高,在表9和表10中,GPU 延迟在测量时使用了大小为2的 Batch Size
作者将 FastViT 与最近的工作进行了比较
FastViT-MA36 的 mIoU 比 PoolFormer-M36 高 5.2%,但是 PoolFormer 具有更高的 FLOPs、参数量和延迟
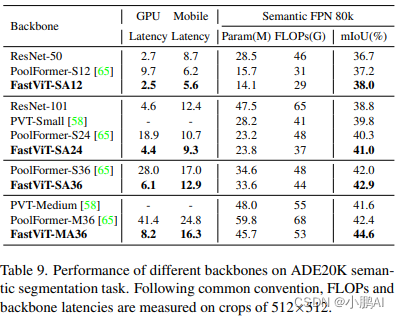
目标检测和实例分割实验实验 MS-COCO 数据集
所有模型都使用 Mask-RCNN 目标检测和实例分割头按照 1x schedule 进行训练
所有的模型都是用预先训练好的对应图像分类模型的权重进行初始化
结果显示出 FastViT 在多种延迟机制下实现了最先进的性能
FastViT-MA36 模型的性能与 CMT-S 相似,但在桌面GPU 和移动设备上分别快2.4倍和4.3倍
总结
本文提出了一种通用的 CNN 和 Transformer 混合的视觉基础模型,是由 MobileOne 原班人马打造
可以看做是 MobileOne 的方法在 Transformer 上的一个改进型的应用
作者引入了一种新的 token mixer,叫做 RepMixer,它使用结构重新参数化技术
通过删除网络中的 Shortcut 来降低内存访问成本,尤其是在较高分辨率时
作者还提出了进一步的架构更改,以提高 ImageNet 分类任务和其他下游任务的性能
在移动设备和 ImageNet 数据集上的精度相同的前提下,FastViT 比 CMT 快3.5倍,比 EfficientNet 快4.9倍,比 ConvNeXt 快1.9倍
在类似的延迟下,FastViT 在 ImageNet 上获得的 Top-1 准确率比 MobileOne 高 4.2%,是一种极具竞争力的混合架构模型
参考文献
- https://arxiv.org/pdf/2303.14189.pdf
- https://arxiv.org/pdf/2107.06263.pdf
- https://arxiv.org/pdf/2105.14217.pdf
- https://arxiv.org/pdf/2105.14217.pdf
- https://mp.weixin.qq.com/s/uqcWy4sx1NQuqOplsGDUlg
相关文章:
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization 论文地址:https://arxiv.org/pdf/2303.14189.pdf 概述 本文提出了一种通用的 CNN 和 Transformer 混合的视觉基础模型 移动设备和 ImageNet 数据集上的精度相同的前提下…...

C/C++文档阅读笔记-A Simple Makefile Tutorial解析
Makefile文件可以使得程序编译变得简单。本博文并不是很系统的讲解makefile,本博文的目标是让读者快速编写自己的makefile文件并能应用到中小项目中。 简单实例 举个例子有下面3个文件,分别是hellomake.c,hellofunc.c,hellomake.…...

GraphSAGE的基础理论
文章目录GraphSAGE原理(理解用)GraphSAGE工作流程GraphSAGE的实用基础理论(编代码用)1. GraphSAGE的底层实现(pytorch)PyG中NeighorSampler实现节点维度的mini-batch GraphSAGE样例PyG中的SAGEConv实现2. …...

Windows 安装 GDAL C++库
Windows 安装 GDAL C库1. 方法1:下载配置网友编译的GDAL版本1.1 下载1.2 配置1.3 测试1.4 缺点2. 方法2:自己编译3. 参考1. 方法1:下载配置网友编译的GDAL版本 1.1 下载 CSDN: GDAL,geos联合编译的库,版本为1.8.0&am…...

二叉树基础概念
1.二叉树种类 1.1 满二叉树 满二叉树:如果一棵二叉树只有度为 0 0 0 的结点和度为 2 2 2 的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。 如图所示: 这棵二叉树为满二叉树,也可以说深度为 k k k&…...

【MySQL】(1)数据库基础,库与表的增删查改,数据库的备份与还原
文章目录服务器,数据库,表关系MySQL 数据存储逻辑SQL 分类存储引擎库的操作查看数据库创建数据库查看创建语句删除数据库选择(切换)数据库查看当前选择的数据库修改数据库字符集和排序规则表的操作创建表查询表查询表结构插入数据…...

Python基础-01 变量
注释 注释的分类 在Python中,支持单行及多行注释 单行注释 使用#对代码进行说明,#右边的所有内容就是注释的内容,起辅助说明作用 # #右边的都是注释,解析器会忽略 print(hello world) #在控制台里打印一段话多行注释 多行注释中,允许换行,使用三个单引号开始,三个单引号结…...
springcloud2.1.0整合seata1.5.2+nacos2.10(附源码)
springcloud2.1.0整合seata1.5.2nacos2.10(附源码) 1.创建springboot2.2.2springcloud2.1.0的maven父子工程如下,不过多描述: 搭建过程中也出现很多问题,主要包括: 1.seataServer.properties配置文件的组…...

map原理
map源码结构体: type hmap struct {count int // 元素的个数B uint8 // buckets 数组的长度就是 2^B 个overflow uint16 // 溢出桶的数量buckets unsafe.Pointer // 2^B个桶对应的数组指针oldbuckets unsafe.Pointer // 发生扩容时࿰…...
概览)
[Ext JS]3.6 Ext JS 表格(Grid)概览
Grid, 翻译过来是网格, 也就是表格。 Grid 的基本构成 面板 :Ext.grid.Panel表格视图 :Ext.view.Table。 不直接使用, 通过面板的viewConfig配置项进行配置。比如可以用来配置表格中行是否跳色显示列: Ext.grid.column.Column。 表格中的列定义store , 表格的数据示例代码…...
关于使用云渲染的五大优势
在不影响质量或性能的情况下节省时间、金钱和资源,对于需要在通常较短且严格的期限内创建高质量 3D 内容的专业人士来说,云渲染都是最好的选择!云渲染作为数字媒体生产的最新趋势,与传统的渲染农场和机器相比具有许多优势…...

CSS基础样式
1.高度和宽度 .c1{height:300px;width:500px; } 注意事项: 宽度,支持百分比 行内标签:默认无效 块级标签:默认有效(右侧区域就算是空白,也不给占用) 2.块级和行内标签 css样式:标签…...

第03章_流程控制语句
第03章_流程控制语句 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 本章专题与脉络 流程控制语句是用来控制程序中各语句执行顺序的语句,可以把语句组合成能完成一定功能的小逻辑模…...
配电网电压调节及通信联系研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

stegano(图片隐写、摩斯密码)
附件是PDF,我们在选择内容时发现光标溢出了文本 说明这里还存在一些我们看不到的内容 直接CtrlA全选,CtrlC复制后新建一个纯文本文件 将复制的东西粘贴过去 粘贴后发现果然多出来了一些东西,提取出来 BABA BBB BA BBA ABA AB B AAB ABAA A…...
wsl安装torch_geometric
在官网选择需要的版本 选择安装途径,选择runfile 执行第一行,会下载一个文件到目录下 需要降低C的版本,否则 执行sudo sh cuda_11.1.0_455.23.05_linux.run,会出现 查看对应的文件,会有 可以加上override参数之后,…...
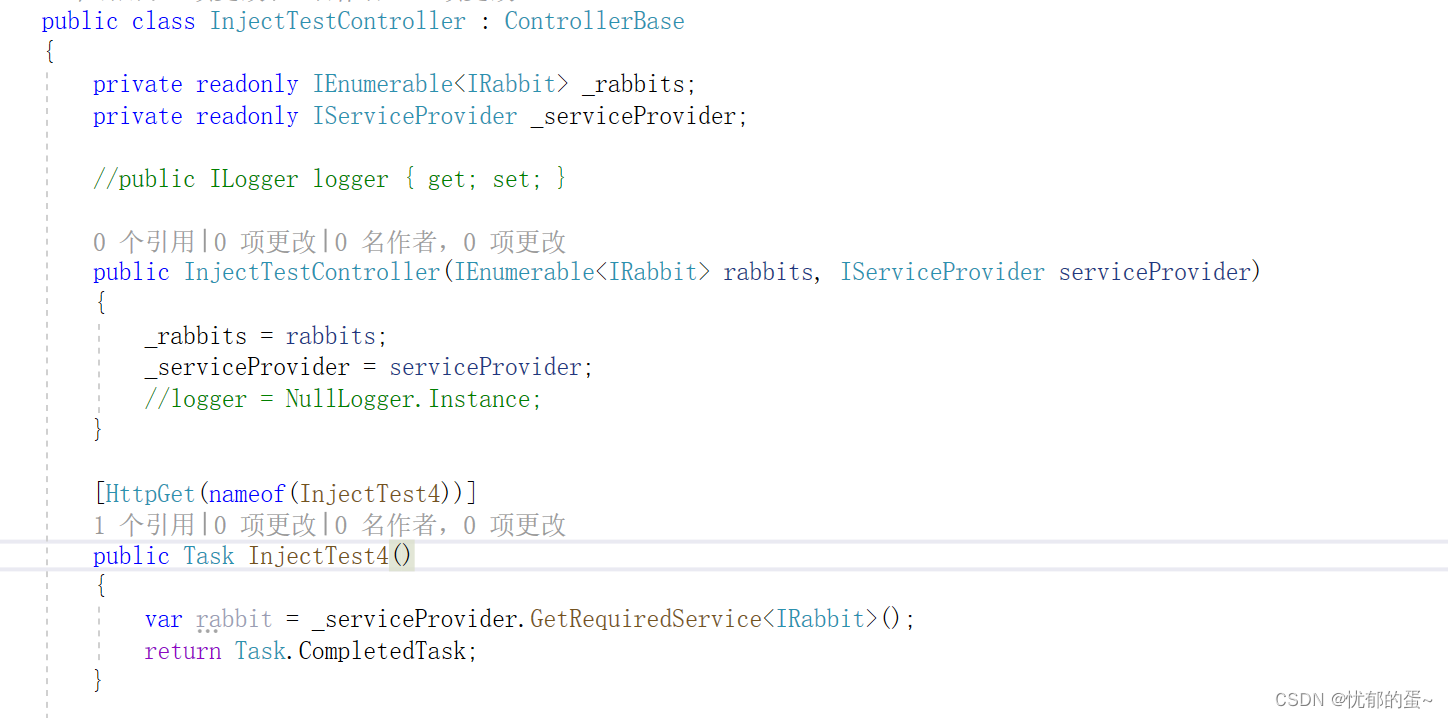
ASP.NET Core - 依赖注入(二)
2,NET Core 依赖注入的基本用法 话接上篇,这一章介绍 .NET Core 框架自带的轻量级 Ioc 容器下服务使用的一些知识点,大家可以先看看上一篇文章 [ASP.NET Core - 依赖注入(一)] 2.3 服务解析 通过 IServiceCollection 注册了服务之后…...

Scala之集合(1)
目录 集合介绍: 不可变集合继承图:编辑 可变集合继承图 数组: 不可变数组: 样例代码: 遍历集合的方法: 1.for循环 2.迭代器 3.转换成List列表: 4.使用foreach()函数&a…...

公网使用SSH远程登录macOS服务器【内网穿透】
文章目录前言1. macOS打开远程登录2. 局域网内测试ssh远程3. 公网ssh远程连接macOS3.1 macOS安装配置cpolar3.2 获取ssh隧道公网地址3.3 测试公网ssh远程连接macOS4. 配置公网固定TCP地址4.1 保留一个固定TCP端口地址4.2 配置固定TCP端口地址5. 使用固定TCP端口地址ssh远程前言…...
PVE相关的各种一键脚本(一键安装PVE)(一键开设KVM虚拟化的NAT服务器-自带内外网端口转发)
PVE 原始仓库:https://github.com/spiritLHLS/pve 前言 建议debian在使用前尽量使用最新的系统 非debian11可使用 debian一键升级 来升级系统 当然不使用最新的debian系统也没问题,只不过得不到官方支持 请确保使用前机器可以重装系统,…...

初次使用 Taotoken 模型广场进行模型选型与测试的流程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用 Taotoken 模型广场进行模型选型与测试的流程指引 对于刚接触大模型服务的开发者而言,面对众多厂商和模型&…...

Adams新手避坑指南:从几何点、Marker坐标系到立方体,这些基础元素你真的用对了吗?
Adams新手避坑指南:几何元素背后的工程逻辑与实战陷阱 刚接触Adams的工程师常会陷入一个误区——把软件操作手册当作圣经,却忽略了每个几何元素背后的物理意义和工程逻辑。这种"知其然不知其所以然"的学习方式,往往会导致仿真结果失…...

Windows安卓驱动安装终极解决方案:一键自动化ADB Fastboot工具
Windows安卓驱动安装终极解决方案:一键自动化ADB Fastboot工具 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirro…...

为ubuntu上的自动化脚本寻找稳定大模型api源taotoken的接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为 Ubuntu 上的自动化脚本寻找稳定大模型 API 源:Taotoken 的接入方案 在 Ubuntu 环境中运行自动化脚本或智能体时&…...

causal-learn实战指南:从算法选择到因果图解读
1. 为什么你需要causal-learn? 第一次接触因果发现这个概念时,我正被一个电商用户行为分析项目搞得焦头烂额。传统机器学习模型能准确预测用户是否会购买商品,但产品经理总追着我问:"到底哪些因素真正导致了购买行为…...

编码效率翻倍实测:OpenClaw 联动 Claude Code 实现 3 类数字员工协同的 4 步配置
1. 效率翻倍不是幻觉:OpenClaw 联动 Claude Code 的真实瓶颈在哪? 我上线第三个用 OpenClaw + Claude Code 搭建的数字员工协同流水线时,把同一套接口自动化脚本重构任务交给两组人:一组纯人工,一组走 OpenClaw 管道。结果不是“快一点”,而是人工组平均耗时 47 分钟,A…...
)
告别pip install torch:手把手教你离线安装PyTorch 1.5.1(含CUDA 9.2配置)
离线环境下的PyTorch 1.5.1实战部署指南:从依赖解析到CUDA配置 在科研机构封闭网络或企业开发环境中,离线安装深度学习框架往往成为阻碍项目推进的第一道门槛。PyTorch作为动态图计算的代表框架,其离线部署涉及Python环境管理、CUDA驱动适配…...
)
告别手写代码!用Roboflow的Auto-Orient和Mosaic增强你的YOLO数据集(附完整流程)
零代码实现YOLO数据集增强:Roboflow自动化工具全解析 在目标检测领域,数据质量往往直接决定模型性能上限。传统数据增强方法需要开发者手动编写Python脚本调整图像方向、处理标注格式,不仅耗时耗力,还容易因格式兼容性问题导致训练…...

在Nodejs后端服务中集成Taotoken实现统一的大模型调用网关
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken实现统一的大模型调用网关 当你的后端服务需要接入多种大模型能力时,直接对接不同厂商…...

如何在MATLAB中调用Taotoken聚合大模型API进行智能分析
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何在MATLAB中调用Taotoken聚合大模型API进行智能分析 对于使用MATLAB进行科学计算、数据分析或算法开发的工程师和研究人员而言&…...