传统机器学习(四)聚类算法DBSCAN
传统机器学习(四)聚类算法DBSCAN
1.1 算法概述
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。
该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
1.1.1 基本概念
核心对象: 若某个点的密度达到算法设定的阈值,则其为核心点(即r 邻域内点的数量不小于 minPts )
e-邻域的距离阈值:设定的半径
直接密度可达: 若某点p在点q的 r 域内,且q是核心点,则p-q直接密度可达
密度可达: 若有一个点的序列q0、q1、…qk,对任意qi-qi-1是直接密度可达的则称从q0到qk密度可达,这实际上是直接密度可达的“传播”
边界点:属于某一个类的非核心点,不能发展下线了
噪声点: 不属于任何一个类簇的点,从任何一个核心点出发都是密度不可达的

上面这些点是分布在样本空间的众多样本,现在我们的目标是把这些在样本空间中距离相近的聚成一类。
我们发现A点附近的点密度较大,红色的圆圈根据一定的规则在这里滚啊滚,最终收纳了A附近的5个点,标记为红色也就是定为同一个簇。
其它没有被收纳的根据一样的规则成簇。
形象来说,我们可以认为这是系统在众多样本点中随机选中一个,围绕这个被选中的样本点画一个圆,规定这个圆的半径以及圆内最少包含的样本点,如果在指定半径内有足够多的样本点在内,那么这个圆圈的圆心就转移到这个内部样本点,继续去圈附近其它的样本点,类似传销一样,继续去发展下线。
等到这个滚来滚去的圈发现所圈住的样本点数量少于预先指定的值(minPts),就停止了。那么我们称最开始那个点为核心点,如A,停下来的那个点为边界点,如B、C,没得滚的那个点为离群点,如N)。
基于密度这点有什么好处呢?
我们知道kmeans聚类算法只能处理球形的簇,也就是一个聚成实心的团(这是因为算法本身计算平均距离的局限)。但往往现实中还会有各种形状,比如下面图,环形和不规则形,这个时候,那些传统的聚类算法显然就悲剧了。

1.1.2 DBSCAN工作流程

1.1.3 参数选择及可视化
参数选择
DBSCAN算法的两个参数,这两个参数比较难指定:
-
半径: 半径是最难指定的 ,大了,圈住的就多了,簇的个数就少了;反之,簇的个数就多了,这对我们最后的结果是有影响的。这个时候,K距离可以帮助我们来设定半径r,也就是要找到突变点。
首先选中一个点,计算它和所有其它点的距离,从小到大排序,d1,d2,d3,d4等等,假如我们发现 d3 和 d4 之间的差异很大,于是认为前面的距离是比较合适的,那么就可以指定出来 r 半径的大小。虽然是一个可取的方式,但是有时候比较麻烦 ,大部分还是都试一试进行观察,用k距离需要做大量实验来观察,很难一次性把这些值都选准。
- MinPts: 这个参数就是圈住的点的个数,也相当于是一个密度,一般这个值都是偏小一些,然后进行多次尝试。
可视化
有一个网站(https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/)可以把我们DBSCAN的迭代过程动态图画出来

设置好参数,点击GO! 就开始聚类了!

1.1.4 DNSCAN优缺点
优点
-
不需要指定簇个数
-
可以发现任意形状的簇
-
擅长找到离群点( 检测任务)
-
两个参数就够了
缺点
-
高维数据有些困难(可以做降维)
-
参数难以选择(参数对结果的影响非常大)
-
Sklearn中效率很慢(数据削减策略)
1.2 DBScan算法案例
1.2.1 不同半径对算法结果影响
1.2.1.1 利用sklearn中make_moons方法产生数据集
make_moons是函数用来生成数据集,在sklearn.datasets里,具体用法如下:
sklearn.datasets.make_moons(n_samples=100, *, shuffle=True, noise=None, random_state=None)
主要参数作用如下:
n_numbers:生成样本数量
shuffle:是否打乱,类似于将数据集random一下
noise:默认是false,数据集是否加入高斯噪声
random_state:生成随机种子,给定一个int型数据,能够保证每次生成数据相同。
import numpy as np
import os
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
np.random.seed(42)# 导入make_moons
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05, random_state=42)# 绘制图像
plt.plot(X[:,0],X[:,1],'b.')

1.2.2.2 DBScan算法
from sklearn.cluster import DBSCAN# 设置半径为0.05,阈值为5
dbscan = DBSCAN(eps = 0.05,min_samples=5)
dbscan.fit(X)


不同半径对聚类结果的影响
dbscan2 = DBSCAN(eps = 0.2,min_samples=5)
dbscan2.fit(X)
# 图像展示
def plot_dbscan(dbscan, X, size, show_xlabels=True, show_ylabels=True):core_mask = np.zeros_like(dbscan.labels_, dtype=bool)core_mask[dbscan.core_sample_indices_] = Trueanomalies_mask = dbscan.labels_ == -1non_core_mask = ~(core_mask | anomalies_mask)cores = dbscan.components_anomalies = X[anomalies_mask]non_cores = X[non_core_mask]plt.scatter(cores[:, 0], cores[:, 1],c=dbscan.labels_[core_mask], marker='o', s=size, cmap="Paired")plt.scatter(cores[:, 0], cores[:, 1], marker='*', s=20, c=dbscan.labels_[core_mask])plt.scatter(anomalies[:, 0], anomalies[:, 1],c="r", marker="x", s=100)plt.scatter(non_cores[:, 0], non_cores[:, 1], c=dbscan.labels_[non_core_mask], marker=".")if show_xlabels:plt.xlabel("$x_1$", fontsize=14)else:plt.tick_params(labelbottom='off')if show_ylabels:plt.ylabel("$x_2$", fontsize=14, rotation=0)else:plt.tick_params(labelleft='off')plt.title("eps={:.2f}, min_samples={}".format(dbscan.eps, dbscan.min_samples), fontsize=14)
plt.figure(figsize=(12, 4))plt.subplot(121)
plot_dbscan(dbscan, X, size=100)plt.subplot(122)
plot_dbscan(dbscan2, X, size=600, show_ylabels=False)plt.show()

1.2.2 鸢尾花数据集的DBSCAN的聚类案例
import pandas as pd
from sklearn.datasets import load_iris
# 导入数据,sklearn自带鸢尾花数据集
iris = load_iris().data
iris[:5]

from sklearn.cluster import DBSCAN
iris_db = DBSCAN(eps=0.6,min_samples=4).fit_predict(iris)# 设置半径为0.6,最小样本量为2,建模
db = DBSCAN(eps=10, min_samples=2).fit(iris)# 统计每一类的数量
counts = pd.value_counts(iris_db,sort=True)
counts

# 可视化
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = [u'Microsoft YaHei']fig,ax = plt.subplots(1,2,figsize=(12,12))# 画真实数据结果
ax1 = ax[0]
ax1.scatter(x=iris[:,0],y=iris[:,1],s=250,c=load_iris().target)
ax1.set_title('真实分类',fontsize=20)# 画聚类后的结果
ax2 = ax[1]
ax2.scatter(x=iris[:,0],y=iris[:,1],s=250,c=iris_db)
ax2.set_title('DBSCAN聚类结果',fontsize=20)plt.show()

我们可以从上面这个图里观察聚类效果的好坏,但是当数据量很大,或者指标很多的时候,观察起来就会非常麻烦。
这时候可以使用轮廓系数来判定结果好坏,聚类结果的轮廓系数,定义为S,是该聚类是否合理、有效的度量。
聚类结果的轮廓系数的取值在[-1,1]之间,值越大,说明同类样本相距约近,不同样本相距越远,则聚类效果越好。
轮廓系数以及其他的评价函数都定义在sklearn.metrics模块中,在sklearn中函数silhouette_score()计算所有点的平均轮廓系数。
from sklearn import metrics# 就是下面这个函数可以计算轮廓系数
score = metrics.silhouette_score(iris,iris_db)
score# 0.42300259179079075
1.2.3 k-means和DBSCAN聚类对比
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.cluster import KMeans
from sklearn import datasets
# 生成数据
x, y = datasets.make_circles(n_samples=2000, factor=0.5, noise=0.05)# k-means方法聚类
kmeans_model = KMeans(n_clusters=2)
kmeans_model.fit(x)
kmeans_result = kmeans_model.predict(x)# DBSCAN方法聚类
dbscan_model = DBSCAN(eps=0.2, min_samples=50)
dbscan_model.fit(x)
dbscan_result = dbscan_model.fit_predict(x)# 绘制图像
plt.figure(figsize=(12, 4))
plt.subplot(121)
plt.scatter(x[:, 0], x[:, 1], c=kmeans_result)
plt.title('kmeans_model')plt.subplot(122)
plt.scatter(x[:, 0], x[:, 1], c=dbscan_result)
plt.title('dbscan_result')plt.show()

相关文章:
传统机器学习(四)聚类算法DBSCAN
传统机器学习(四)聚类算法DBSCAN 1.1 算法概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在…...
)
“华为杯”研究生数学建模竞赛2020年-【华为杯】A题:ASIC 芯片上的载波恢复 DSP 算法设计与实现(附获奖论文及matlab代码实现)
目录 摘 要: 1.问题重述 1.1 问题背景 1.2 问题提出 1.3 研究基础 2.模型假设和已知...

1043.分隔数组以得到最大和
题目: 给你一个整数数组 arr,请你将该数组分隔为长度 最多 为 k 的一些(连续)子数组。分隔完成后,每个子数组的中的所有值都会变为该子数组中的最大值。 返回将数组分隔变换后能够得到的元素最大和。本题所用到的测试…...
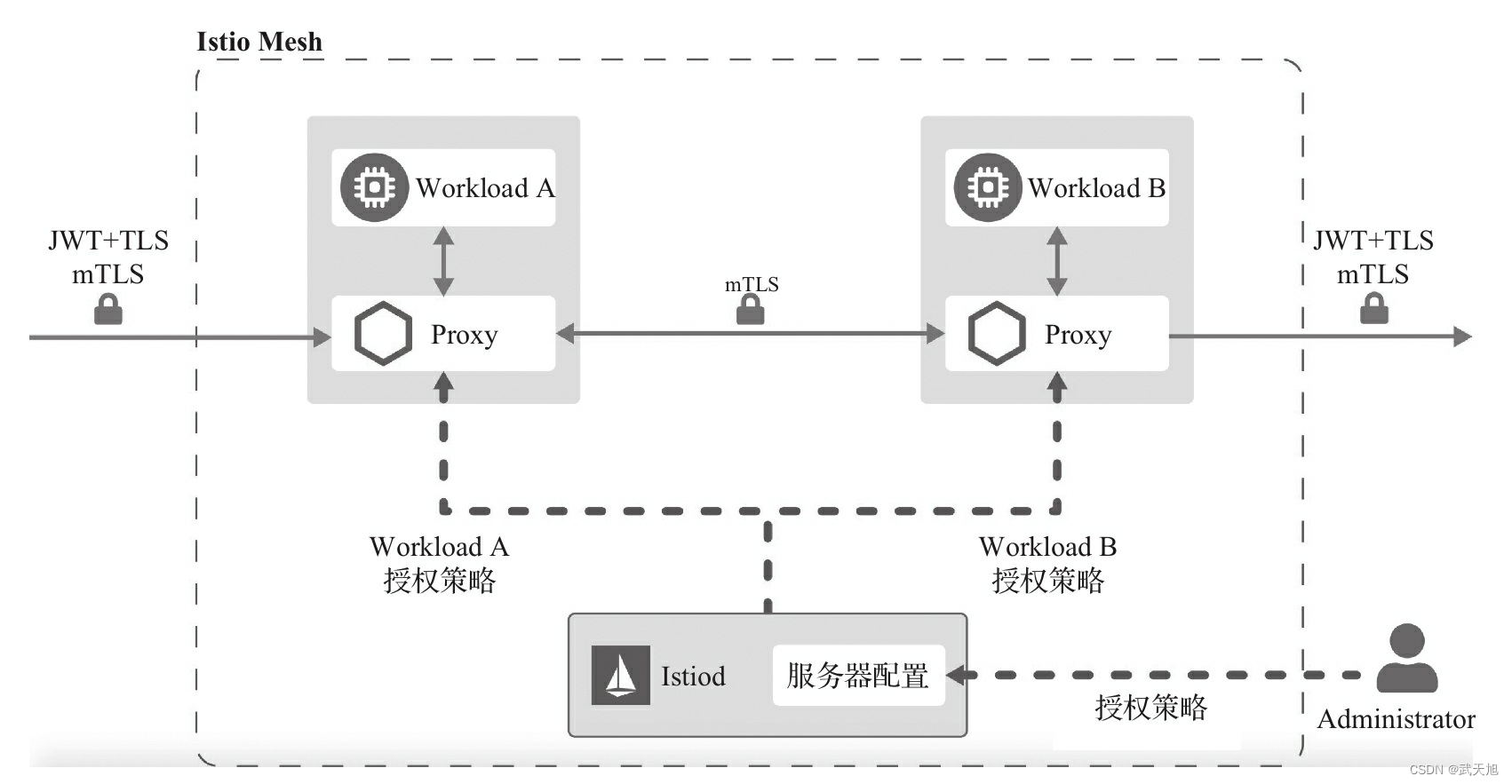
微服务治理框架(Istio)的认证服务与访问控制
本博客地址:https://security.blog.csdn.net/article/details/130152887 一、认证服务 1.1、基于JWT的认证 在微服务架构下,每个服务是无状态的,由于服务端需要存储客户端的登录状态,因此传统的session认证方式在微服务中不再适…...
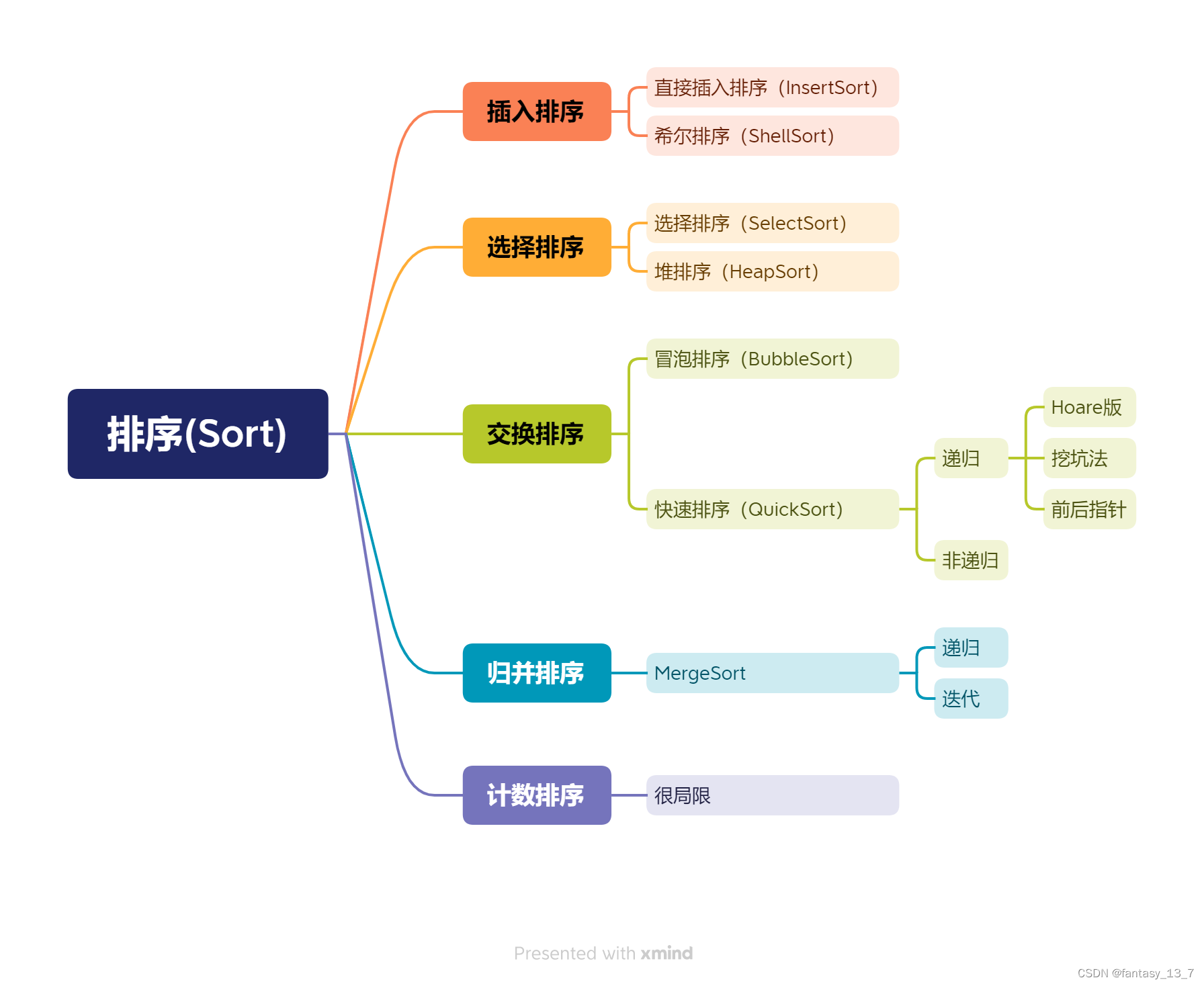
数据结构 | 排序 - 总结
排序的方式 排序的稳定性 什么是排序的稳定性? 不改变相同数据的相对顺序 排序的稳定性有什么意义? 假定一个场景: 一组成绩:100,88,98,98,78,100(按交卷顺序…...
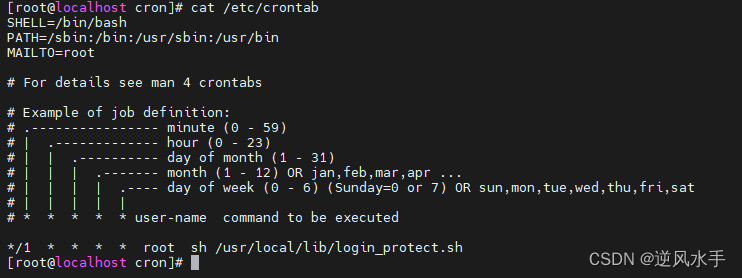
crontab -e 系统定时任务
crontab -e解释 crontab 是由 “cron” 和 “table” 两个单词组成的缩写。其中,“cron” 是一个在 Linux 和类 Unix 操作系统中用于定时执行任务的守护进程,而 “table” 则是指一个表格或者列表,因此 crontab 就是一个用于配置和管理定时任…...
前后端交互系列之Axios详解(包括拦截器)
目录 前言一,服务器的搭建二,Axios的基本使用2.1 Axios的介绍及页面配置2.2 如何安装2.3 Axios的前台代码2.4 Axios的基本使用2.5 axios请求响应结果的结构2.6 带参数的axios请求2.7 axios修改默认配置 三,axios拦截器3.1 什么是拦截器3.2 拦…...
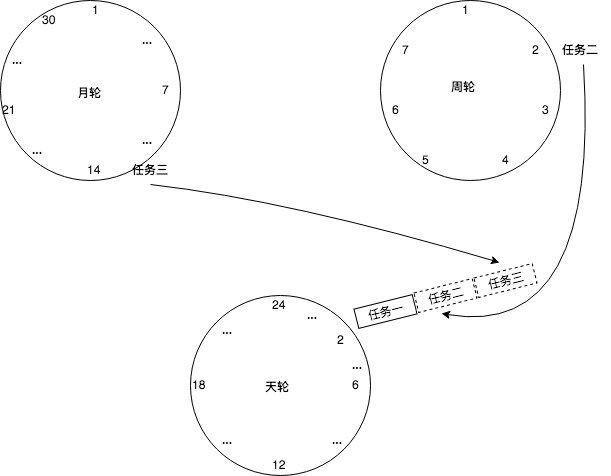
定时任务之时间轮算法
初识时间轮 我们先来考虑一个简单的情况,目前有三个任务A、B、C,分别需要在3点钟,4点钟和9点钟执行,可以把时间想象成一个钟表。 如上图中所示,我只需要把任务放到它需要被执行的时刻,然后等着时针转到这个…...
实验4 Matplotlib数据可视化
1. 实验目的 ①掌握Matplotlib绘图基础; ②运用Matplotlib,实现数据集的可视化; ③运用Pandas访问csv数据集。 2. 实验内容 ①绘制散点图、直方图和折线图,对数据进行可视化; ②下载波士顿数房价据集,并…...

【软件工程】为什么要选择软件工程专业?
个人主页:【😊个人主页】 文章目录 前言软件工程💻💻💻就业岗位👨💻👨💻👨💻就业前景🛩️🛩️🛩️工作环…...

5类“计算机”专业很吃香,人才缺口巨大,就业前景良好
说到目前最热门的专业,计算机绝对占有一席之地,是公认的发展前景好、人才缺口大的专业。有人称该专业人数如此众多,势必会导致人才饱和,但是从当前社会互联网发展的趋势来看,计算机专业在很长一段时间都是发展很好的专…...

数仓选型对比
1、数仓选型对比如下(先列举表格,后续逐个介绍) 数仓应用目标产品特点适用于 适用数据类型数据处理速度性能拓展 实施难度运维难度性能优化成本传统数仓(SQLServer、Oracle等关系型数据库)面向主题设计的,为 分析数据而设计基于Oracle、 SQLServer、MyS…...
Java详解与代码实现)
二叉树的遍历(前序、中序、后序)Java详解与代码实现
递归遍历 前序,中序,后序 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val val; }* TreeNode(int val, Tree…...

如何找出消耗CPU最多的线程?
如何找出消耗CPU最多的线程? 1.使用 top -c 找出所有当前进程的运行列表 top -c 2.按P(Shiftp)对所有进程按CPU使用率进行排序,找出消耗最高的线程PID 显示Java进程 PID 为 136 的java进程消耗最 3.使用 top -Hp PID,查出里面消…...

【论文笔记】Attention Augmented Convolutional Networks(ICCV 2019 入选文章)
目录 一、摘要 二、介绍 三、相关工作 卷积网络Convolutional networks: 网络中注意力机制Attention mechanisms in networks: 四、方法 1. 图像的自注意力Self-attention over images: 二维位置嵌入Two-dimensional Positional Enco…...

虚幻图文笔记:Character Creator 4角色通过AutoSetup For Unreal Engine插件导入UE5.1的过程笔记
在UE5端安装AutoSetup For Unreal Engine插件 AutoSetup For Unreal Engine是Reallusion官方提供的免费插件,官方下载地址,下载到的是一个可执行文件,点击安装,记住安装的位置⬇ 看装完毕后会打开一个文件夹,这里就是对…...
JAVAWeb04-DOM
1. DOM 1.1 概述 1.1.1 官方文档 地址: https://www.w3school.com.cn/js/js_htmldom.asp 1.1.2 DOM 介绍 DOM 全称是 Document Object Model 文档对象模型就是把文档中的标签,属性,文本,转换成为对象来管理 1.2 HTML DOM(文档…...

C++内存管理基础知识
C 内存管理 C内存管理是一个重要的主题,因为它涉及到程序运行时资源的分配和释放。它可以分为三种类型:静态内存、栈内存和堆内存。 静态内存 静态内存(Static Memory):静态内存用于存储全局变量、静态变量和常量。这…...
命令执行漏洞概述
命令执行漏洞概述 命令执行定义命令执行条件命令执行成因命令执行漏洞带来的危害远程命令执行漏洞相关函数assert()preg_replace()call_user_func() a ( a( a(b)可变函数远程命令执行漏洞的利用系统命令执行漏洞相关函数system()exec()shell_exec()passthru(&#x…...

【初试复试第一】脱产在家二战上岸——上交819考研经验
笔者来自通信考研小马哥23上交819全程班学员 先介绍一下自己,我今年初试426并列第一,加上复试之后总分600,电子系第一。 我本科上交,本科期间虽然没有挂科但是成绩排名处于中下游水平。参加过全国电子设计大赛,虽然拿…...

终极免费AMD Ryzen硬件调试指南:掌握SMUDebugTool的完整使用技巧
终极免费AMD Ryzen硬件调试指南:掌握SMUDebugTool的完整使用技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: …...

LPA分层审核指标是什么?读懂LPA分层审核指标才能评估审核有效性
在工厂的质量管理体系运行中,LPA(分层过程审核)是确保标准作业落地、问题及时发现和整改的有力工具。但很多企业推行LPA后,仅仅关注有没有做审核,却忽略了审核做得怎么样。结果,审核表填了一大摞࿰…...

MoneyPrinterPlus智能视频创作工具实战指南:从零到批量生产的完整流程
MoneyPrinterPlus智能视频创作工具实战指南:从零到批量生产的完整流程 【免费下载链接】MoneyPrinterPlus AI一键批量生成各类短视频,自动批量混剪短视频,自动把视频发布到抖音,快手,小红书,视频号上,赚钱从来没有这么容易过! 支持本地语音模型chatTTS,fasterwhispe…...
)
2026年版|Java程序员转行大模型开发:从入门到实践(小白必收藏)
在2026年人工智能(AI)技术持续爆发的当下,大模型已从“前沿概念”全面渗透到企业实际应用中,成为驱动数字化转型的核心动力。对于长期深耕Java领域的程序员而言,从传统Java开发转向大模型开发,不再是“可选…...

对比软件模拟I2C:实测GD32F303硬件I2C读写AT24C02的性能与代码差异
硬件I2C与软件模拟I2C实战对比:以GD32F303驱动AT24C02为例 在嵌入式开发中,I2C总线因其简单的两线制结构和多主从设备支持特性,成为传感器、存储芯片等外设的常用接口。面对硬件I2C控制器和GPIO模拟两种实现方式,开发者常陷入选择…...

性能优化实战:在Unity项目里管理多个Video Player,如何避免内存泄漏和卡顿?
Unity多视频管理实战:规避内存泄漏与卡顿的深度优化策略 在沉浸式游戏体验和交互式AR/VR应用中,视频内容已成为提升用户参与度的关键要素。但当场景中同时存在多个Video Player组件时,开发者往往会遭遇突如其来的性能断崖——内存占用飙升、播…...

别再硬刚滑块了!一个Python脚本自动搞定淘宝X5SEC验证码
Python自动化破解淘宝X5SEC滑块验证码实战指南 淘宝作为国内最大的电商平台之一,其反爬机制一直处于行业领先水平。其中X5SEC滑块验证码是淘宝用来识别自动化程序的主要手段之一。对于需要批量采集商品数据或进行价格监控的开发者来说,频繁的手动滑块验证…...

手把手拆解FD-SOI工艺流程:从SOI衬底到应变硅外延的保姆级图解
从SOI衬底到应变硅外延:FD-SOI工艺全流程拆解指南 想象一下建造一座微型城市,每一栋建筑只有头发丝直径的万分之一大小。这就是FD-SOI工艺工程师的日常工作——在硅片上用原子级精度"建造"晶体管。与传统的体硅工艺不同,FD-SOI&…...

【免费下载】 解锁潜能,尽在掌握:深入探索VMware17 Unlocker工具
解锁潜能,尽在掌握:深入探索VMware17 Unlocker工具 【下载地址】VMware17Unlocker解锁工具附用法 本仓库提供了一个用于解锁VMware17的工具——VMware17 Unlocker。该工具可以帮助用户解锁VMware17中的某些限制,使其能够更好地使用虚拟机功能…...

别再只会插卡开机了!手把手带你用APDU命令探索手机SIM卡里的文件迷宫
解码SIM卡文件系统:用APDU命令探索移动通信的微观世界 当你把SIM卡插入手机时,它就像一把打开移动网络大门的钥匙。但鲜为人知的是,这张小小的芯片内部运行着一个完整的文件系统,其复杂程度堪比微型操作系统。本文将带你用APDU命令…...