【论文笔记】Attention Augmented Convolutional Networks(ICCV 2019 入选文章)
目录
一、摘要
二、介绍
三、相关工作
卷积网络Convolutional networks:
网络中注意力机制Attention mechanisms in networks:
四、方法
1. 图像的自注意力Self-attention over images:
二维位置嵌入Two-dimensional Positional Encodings:
相对位置嵌入Relative positional embeddings:
2. 注意力增强卷积Attention Augmented Convolution:
连接卷积和注意力特征图Concatenating convolutional and attentional feature maps:
参数数量影响Effect on number of parameters:
注意力增强卷积架构Attention Augmented Convolutional Architectures:
五、实验
六、讨论
一、摘要
核心内容:We propose to augment convolutional operators with this self-attention mechanism by concatenating convolutional feature maps with a set of feature maps produced via self-attention.我们提出用这种自注意机制来增强卷积算子,方法是将卷积特征映射与通过自注意产生的一组特征映射连接起来。
卷积操作具有显着的弱点,因为它仅在局部邻域上操作,因此缺少全局信息。Self-attention已经成为捕获远程交互的技术,但主要应用于序列建模和生成建模任务。在本文中,我们考虑将Self-attention用于判别性视觉任务作为卷积的替代。我们引入了一种新颖的二维相对自注意力机制,证明在取代卷积作为独立的图像分类计算原语方面具有竞争力。我们在对照实验中发现,当结合卷积和自注意力时,获得了最好的结果。因此,我们建议通过将卷积特征映射与通过自注意力产生的一组特征映射相结合来增强卷积算子的自注意力机制。
二、介绍
首先了解卷积操作本身两点特性:
局部性:locality via a limited receptive field
等变性:translation equivariance via weight sharing
CNN中的卷积操作中的参数共享使得它对平移操作有等变性,而一些池化操作对平移有近似不变性。
来源:CNN中的translation equivariant和translation invariant_muyuu的博客-CSDN博客
尽管这些属性被证明了是设计在图像上操作的模型时至关重要的归纳偏置(inductive biase)。但是卷积的局部性质(the local nature of the convolutional kernel)阻碍了其捕获全局的上下文信息(global context),而这些信息对于图像识别是很必要的,这是卷积的重要的弱点。(convolution operator is limited by its locality and lack of understandingof global contexts)
归纳偏置:其实就是一种先验知识,一种提前做好的假设。归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则 (heuristics),然后对模型做一定的约束,从而可以起到 “模型选择” 的作用,类似贝叶斯学习中的 “先验”。例如,深度神经网络就偏好性地认为,层次化处理信息有更好效果;卷积神经网络认为信息具有空间局部性 (Locality),可用滑动卷积共享权重的方式降低参数空间;循环神经网络则将时序信息考虑进来,强调顺序重要性。
来源:归纳偏置 (Inductive Bias) - 知乎 (zhihu.com)
而在捕获长距离交互关系(long range interaction)上,最近的Self-attention表现的很不错(has emerged as a recent advance)。自注意力背后的关键思想是生成从隐藏单元计算的值的加权平均值。不同于卷积操作或者池化操作,这些权重是动态的根据输入特征,通过隐藏单元之间的相似性函数产生的(produced dynamically via a similarity function between hidden units)。因此输入信号之间的交互依赖于信号本身,而不是像在卷积中,被预先由他们的相对位置而决定。
所以本文尝试将自注意力计算应用到卷积操作中,来实现长距离交互。在判别性视觉任务(discriminative visual tasks)中,考虑使用自注意力替换普通的卷积。 引入a novel two-dimensional relative self-attention mechanism, 其在注入(being infused with)相对位置信息的同时可以保持translation equivariance,使其非常适合图像。
在取代卷积作为独立计算单元方面被证明是有竞争力的。但是需要注意的是,在控制实验中发现,将自注意力和卷积组合起来的情况可以获得最好的结果。因此并没有完全抛弃卷积,而是提出使用self-attention mechanism来增强卷积(augment convolutions),即将强调局部性的卷积特征图和基于self-attention产生的能够建模更长距离依赖(capable of modeling longer range dependencies)的特征图拼接来获得最终结果。
在多个实验中,注意力增强卷积都实现了一致的提升,另外对于完全的自注意模型(不用卷积那部分),这可以看作是注意力增强模型的一种特殊情况,在ImageNet上仅比它们的完全卷积结构略差,这表明自注意机制是一种用于图像分类的强大独立的计算原语(a powerful standalone computational primitive)。
相对于现有的方法,这里要提出的结构不依赖于对应的(counterparts)完全卷积模型的预训练,而是整个网络都使用了self-attention mechanism。另外multi-head attention的使用使得模型同时关注空间子空间和特征子空间。 (多头注意力就是将特征划沿着通道划分为不同的组,不同组内进行单独的变换,可以获得更加多样化的特征表达)
另外,为了增强图像上的自注意力的表达能力,这里扩展[Self attention with relative position representations, Music transformer]中的相对自注意力到二维形式, 这使得可以以有原则(in a principled way)地模拟平移等变性(translation equivariance)。
这样的结构可以直接产生额外的特征图,而不是通过加法(可能是乘法)[Non-local neural networks, Self-attention generative adversarial networks]或门控[Squeeze-and-excitation networks, Gather-excite: Exploiting feature context in convolutional neural networks, Bam: bottleneck attention module, Cbam: Convolutional block attention module]重新校准卷积特征。这一特性允许灵活地调整注意力通道的比例,考虑从完全卷积到完全注意模型的一系列架构(a spectrum of architectures, ranging from fully convolutional to fully attentional models)。
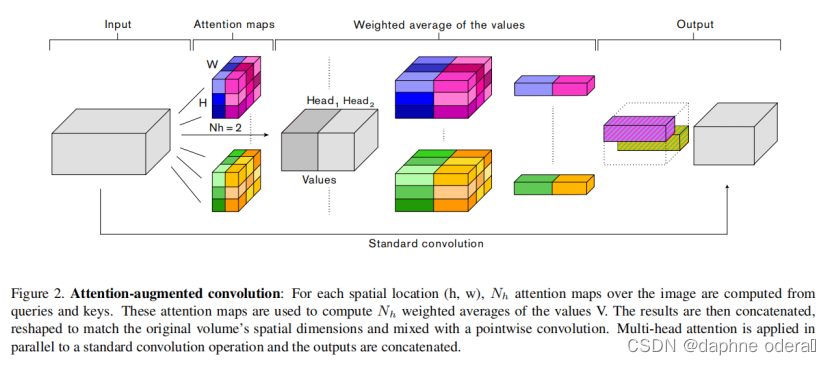 H, W, Fin:输入特征图的height, weight, 通道数 Nh, dv, dk:heads的数量, values的深度(也就是特征图通道数), queries和keys的深度(这几个参数都是MHA, multi-head attention的一些参数), 这里有要求, dv和dk必须可以被Nh整除, 这里使用dhv和dhk来作为每个head中值的深度和查询/键的深度
H, W, Fin:输入特征图的height, weight, 通道数 Nh, dv, dk:heads的数量, values的深度(也就是特征图通道数), queries和keys的深度(这几个参数都是MHA, multi-head attention的一些参数), 这里有要求, dv和dk必须可以被Nh整除, 这里使用dhv和dhk来作为每个head中值的深度和查询/键的深度
三、相关工作
卷积网络Convolutional networks:
现代计算机视觉建立在图像分类任务(如CIFAR-10和imageNet)上学习的强大图像特征上。这些数据集已被用作基准,用于描述更广泛的任务中更好的图像特征和网络架构。例如,改进“骨架”网络通常会导致对象检测和图像分割的改进。这些观察结果激发了新架构的研究和设计,这些架构通常来自跨空间尺度和跳过连接的卷积运算的组合。
网络中注意力机制Attention mechanisms in networks:
作为用于建模序列的计算模块,Attention已被广泛采用,因为其能够捕获长距离交互。self-attention的Transformer架构在机器翻译中实现了最先进的结果。与卷积合作使用self-attention是最近自然语言处理领域工作所共有的主题。
四、方法
1. 图像的自注意力Self-attention over images:
输出tensor的形状为(H,W,Fin),将其展平为(HW,Fin),在最经典的《attention is all you need》文章中,提到了multihead-attention,其中的single head如下:
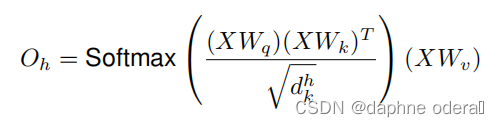
将多个single head结果进行拼接,然后进行线性变换得到最终结果:
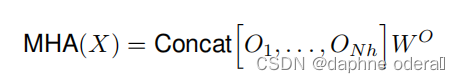
二维位置嵌入Two-dimensional Positional Encodings:
这里的"二维"实际上是相对于原始针对语言的一维信息的结构而言,这里输入的是二维图像数据。
由于没有显式的位置信息的利用,所以自注意力满足交换律:

这里的表示对于像素位置的任意置换。这反映出来self-attention具有 permutation equivariant(置换等变性)。这样的性质使得对于模拟高度结构化的数据(例如图像)而言,不是很有效。
排列不变性(permutation invariance):指输入的顺序改变不会影响输出的值。
排列等变性(permutation equivariant):指输入序列的顺序变化时结果也不同。
多个使用显式的空间信息来增强激活图的位置编码已经被提出来处理相关的问题:
一为Image Transformer,将原始Transformer中引入的正弦波扩展到二维输入;二为CoordConv,将位置通道与激活映射连接到一起。在文章的实验中发现, 在图像分类和目标检测上, 这些编码方法并不好用, 作者们将其归因于虽然这些策略可以打破置换等变性(permutation equivariant), 但是却不能保证图像任务需要的平移等变性(translation equivariance)。为此,作者们提出将[Self attention with relative position representations]扩展到二维中,并提出了一种基于Music Transformer 的高效内存实现方法。
相对位置嵌入Relative positional embeddings:
relative self-attention通过relative position encodings增强了self-attention,并且能够在满足非排列等变的情况下实现平移等变,通过独立添加相关高度信息与相关宽度信息实现二维relative self-attention。

单个头h的输出变成了:

这里的两个都是的矩阵, 表示沿着宽高维度的相对位置logits。

2. 注意力增强卷积Attention Augmented Convolution:
多个先前提出的关于图像的注意力机制表明卷积算子受其局部性和对全局上下文缺乏理解的限制。这些方法通过重新校准卷积特征映射来捕获远程依赖性。特别是,Squeeze-and-Excitation(SE)和GatherExcite(GE)执行通道重新加权,而BAM和CBAM 独立地重新加权通道和空间位置。
与这些方法相反,我们1)使用注意力机制共同关注空间和特征子空间(每个head对应一个特征子空间)和2)引入额外的特征映射(feature maps)而不是细化精炼它们。图2总结了我们提出的增强卷积。

连接卷积和注意力特征图Concatenating convolutional and attentional feature maps:
将卷积特征映射与self-attention特征映射concat到一起:

与卷积类似,所提出的注意力增强卷积1)对平移是等变的,2)可以很容易地对不同空间维度的输入进行操作。我们在附录A.3中包含了用于提出的注意力增强卷积的Tensorflow代码。
参数数量影响Effect on number of parameters:
为了简单起见,我们忽略了相对位置嵌入引入的参数,因为这些参数可以忽略不计。在实践中,这导致替换3x3卷积时参数略有减少,替换1x1卷积时参数略有增加。有趣的是,我们在实验中发现,注意力增强网络在使用更少参数的情况下,仍然显著优于完全卷积网络。
注意力增强卷积架构Attention Augmented Convolutional Architectures:
所有实验中,AAConv后都会跟着BN来放缩卷积层和注意力层特征图的共享。每个残差块使用一次AAConv。由于QK的结果具有较大的内存占用,所以是按照从深到浅的顺序使用,直到达到内存上限。
五、实验
实验结果总结参考:
用自注意力增强卷积:这是新老两代神经网络的对话(附实现) | 机器之心 (jiqizhixin.com)
六、讨论
在这项工作中,我们考虑使用视觉模型的自我注意作为卷积的替代方案。我们引入了一种新的图像二维相对自注意机制,首次实现了对图像分类的竞争性全自注意视觉模型的训练。我们提出用这种自注意机制来增强卷积算子,并验证了这种方法相对于其他注意方案的优越性。大量的实验表明,注意力增强可以在广泛的架构和计算设置上对图像分类和对象检测任务进行系统改进。
这项工作还有几个悬而未决的问题。在未来的工作中,我们将专注于完全注意机制,并探索不同的注意机制如何在计算效率与表征能力之间进行权衡。例如,确定一个本地注意机制可能会导致一个有效和可扩展的计算机制,可以防止使用平均池的下采样[34]。此外,在完全依赖卷积时非常适合的架构设计选择在使用自注意机制时是次优的,这是合理的。因此,如果在自动架构搜索过程中使用注意力增强(AttentionAugmentation)作为原始元素,可以发现比以前在图像分类[55]、对象检测[12]、图像分割[6]和其他领域[5,1,35,8]中发现的更好的模型,这将是很有趣的。最后,人们可能会问,完全注意力模型在多大程度上可以取代卷积网络来完成视觉任务。
PyTorch 实现地址:
GitHub - leaderj1001/Attention-Augmented-Conv2d: Implementing Attention Augmented Convolutional Networks using Pytorch
笔记参考:
(7条消息) 【阅读笔记】《Attention augmented convolutional networks》-CSDN博客
(7条消息) Attention Augmented Convolutional Networks_风吴痕的博客-CSDN博客
注意力机制之Attention Augmented Convolutional Networks_51CTO博客_注意力机制详解
相关文章:
【论文笔记】Attention Augmented Convolutional Networks(ICCV 2019 入选文章)
目录 一、摘要 二、介绍 三、相关工作 卷积网络Convolutional networks: 网络中注意力机制Attention mechanisms in networks: 四、方法 1. 图像的自注意力Self-attention over images: 二维位置嵌入Two-dimensional Positional Enco…...

虚幻图文笔记:Character Creator 4角色通过AutoSetup For Unreal Engine插件导入UE5.1的过程笔记
在UE5端安装AutoSetup For Unreal Engine插件 AutoSetup For Unreal Engine是Reallusion官方提供的免费插件,官方下载地址,下载到的是一个可执行文件,点击安装,记住安装的位置⬇ 看装完毕后会打开一个文件夹,这里就是对…...
JAVAWeb04-DOM
1. DOM 1.1 概述 1.1.1 官方文档 地址: https://www.w3school.com.cn/js/js_htmldom.asp 1.1.2 DOM 介绍 DOM 全称是 Document Object Model 文档对象模型就是把文档中的标签,属性,文本,转换成为对象来管理 1.2 HTML DOM(文档…...

C++内存管理基础知识
C 内存管理 C内存管理是一个重要的主题,因为它涉及到程序运行时资源的分配和释放。它可以分为三种类型:静态内存、栈内存和堆内存。 静态内存 静态内存(Static Memory):静态内存用于存储全局变量、静态变量和常量。这…...
命令执行漏洞概述
命令执行漏洞概述 命令执行定义命令执行条件命令执行成因命令执行漏洞带来的危害远程命令执行漏洞相关函数assert()preg_replace()call_user_func() a ( a( a(b)可变函数远程命令执行漏洞的利用系统命令执行漏洞相关函数system()exec()shell_exec()passthru(&#x…...

【初试复试第一】脱产在家二战上岸——上交819考研经验
笔者来自通信考研小马哥23上交819全程班学员 先介绍一下自己,我今年初试426并列第一,加上复试之后总分600,电子系第一。 我本科上交,本科期间虽然没有挂科但是成绩排名处于中下游水平。参加过全国电子设计大赛,虽然拿…...
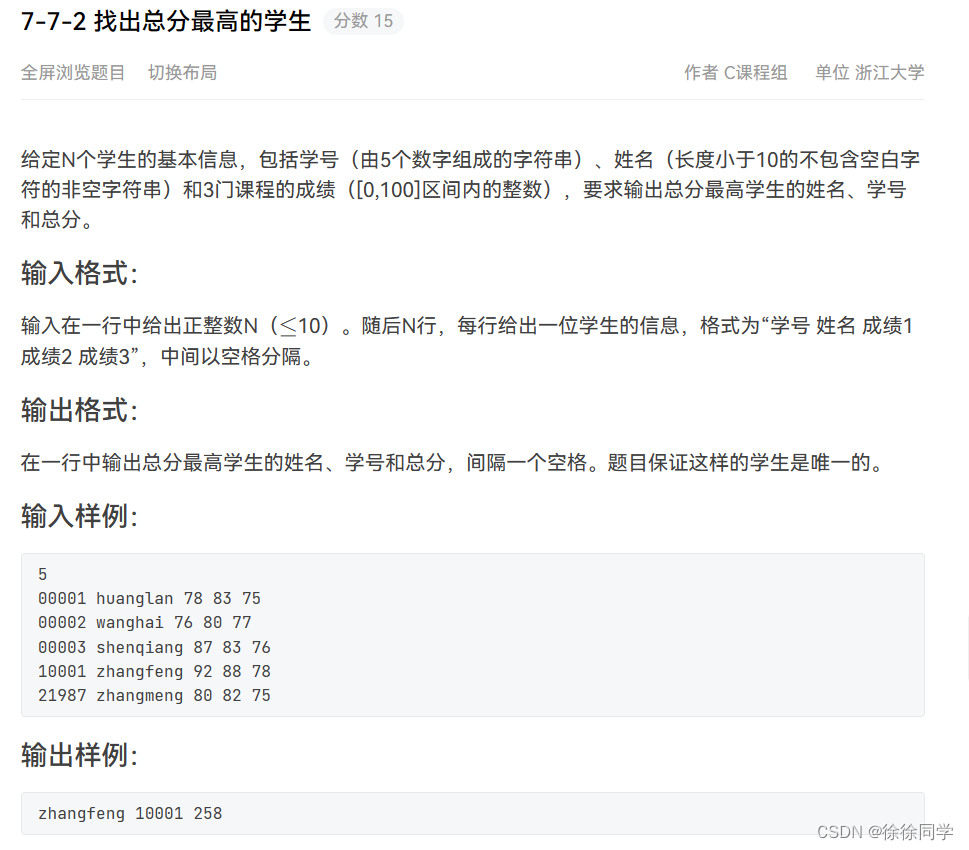
PTA:C课程设计(7)
山东大学(威海)2022级大一下C习题集(7) 函数题7-6-1 递增的整数序列链表的插入7-6-2 查找学生链表7-6-3 统计专业人数7-6-4 建立学生信息链表 编程题7-7-1 查找书籍7-7-2 找出总分最高的学生 函数题 7-6-1 递增的整数序列链表的插…...

POSTGRESQL LINUX 与 PG有关的内存参释义
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共…...

Docker的常见命令
前言:使用Docker得学会的几个常见命令 常见命令前置学习: docker --help这个命令必须得会因为,很多命令是记不住的,得使用他们的官方help下面是一些实例 docker load --help常见命令集合: 一: docker images #查看全部镜像 docker rmi #删除某个镜像(例如:docker rmi redis…...
详细介绍性能测试的方法(含文档)
性能测试是软件测试中的一个重要环节,其目的是评估系统在不同负荷下的性能表现,包括响应时间、吞吐量、并发数等指标。通常可以通过以下几种方法进行性能测试: 1、负载测试 负载测试是模拟多用户同时访问系统,测试系统在高并发、…...

深入剖析 Qt QHash :原理、应用与技巧
目录标题 引言QHash 基础用法基础用法示例基础用法综合示例 QHash 的高级用法迭代器:遍历 QHash 中的元素(Iterators: Traversing Elements in QHash )QHash和其他容器的对比QHash 和 std::unordered\_map QHash的底层原理和内存管理QHash 的…...
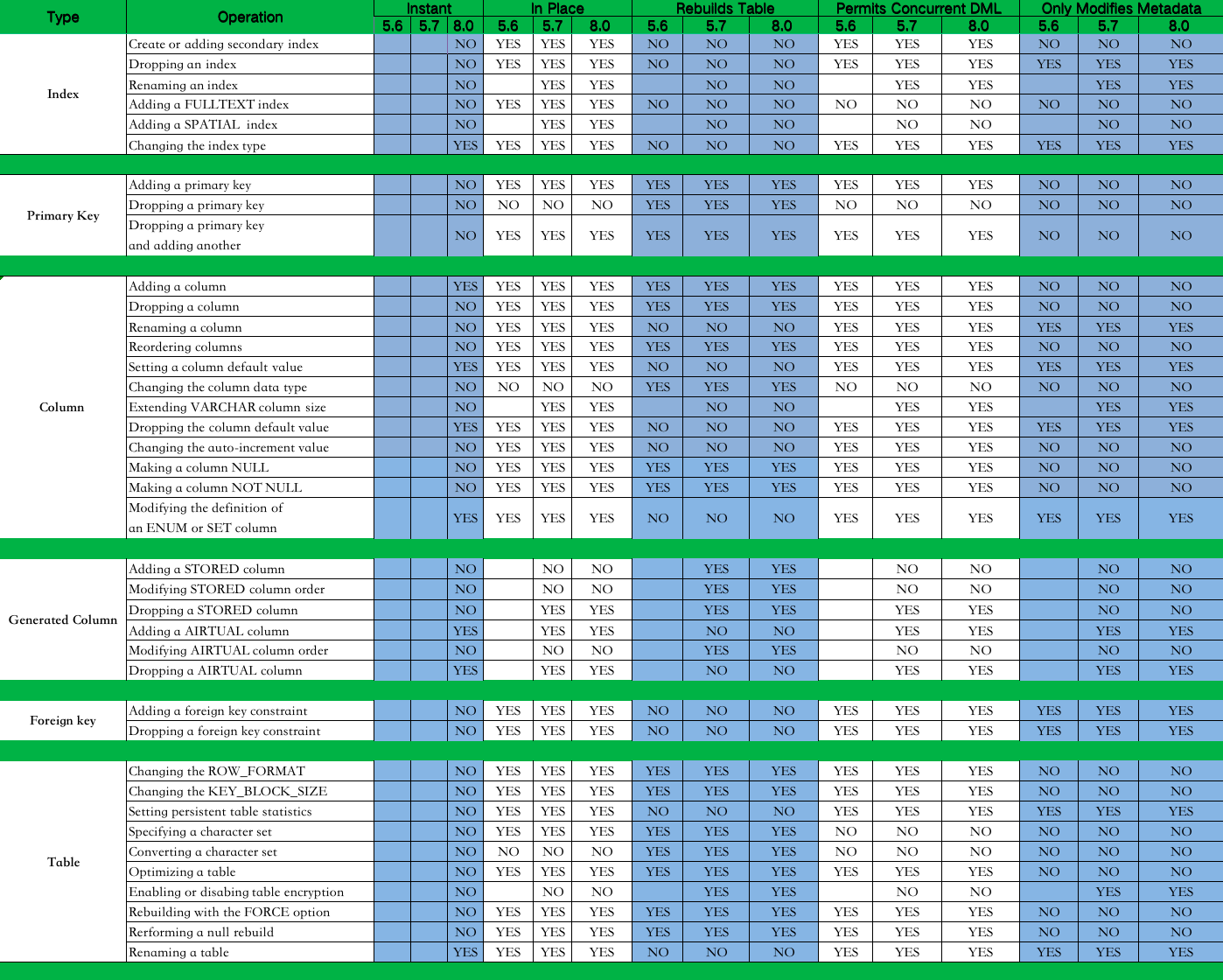
技术分享 | MySQL级联复制下进行大表的字段扩容
作者:雷文霆 爱可生华东交付服务部 DBA 成员,主要负责Mysql故障处理及相关技术支持。爱好看书,电影。座右铭,每一个不曾起舞的日子,都是对生命的辜负。 本文来源:原创投稿 *爱可生开源社区出品,…...
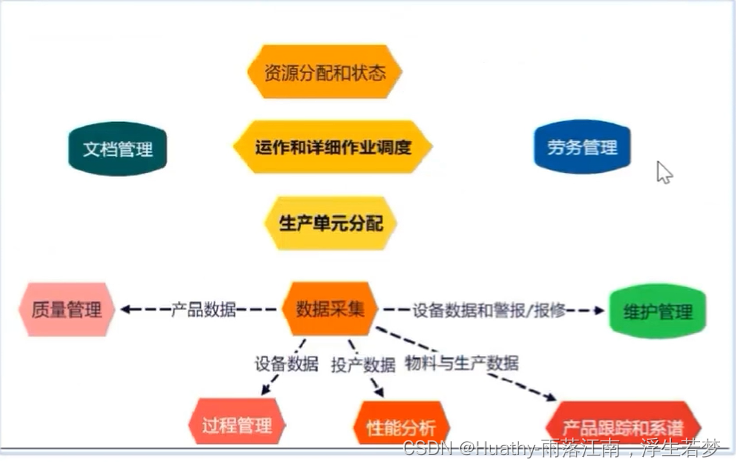
工业互联网业务知识
文章目录 背景第四次工业革命带动制造业产业升级主要工业大国不同路径 架构ISA95体系架构变革趋势基础通用架构数据采集平台 工业互联网应用软件工业互联网全要素连接产品视角:产销服务企业的业务流程企业数字化改造:车间级全要素连接 工业互联网的产品体…...
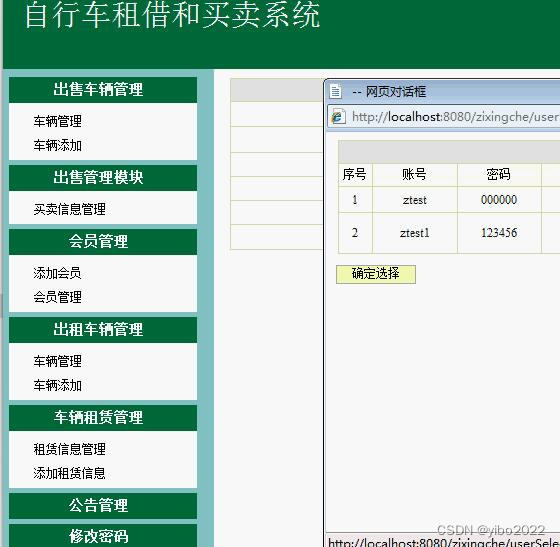
jsp+java自行车租赁租借和买卖系统
自行车租借和买卖系统 系统包括四个模块。1,系统模块,2,车辆管理模块,3.租借车管理模块,4,买卖车管理模块。 1,系统模块包括: 连接数据库,工作人员登录,退出。 2&#…...
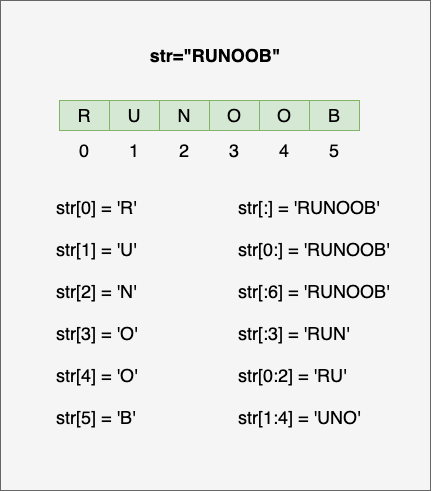
Python3 字符串
Python3 字符串 字符串是 Python 中最常用的数据类型。我们可以使用引号( 或 " )来创建字符串。 创建字符串很简单,只要为变量分配一个值即可。例如: var1 Hello World! var2 "Runoob" Python 访问字符串中的值 Python 不支持单字符…...

Day943.持续集成流水线 -系统重构实战
持续集成流水线 Hi,我是阿昌,今天学习记录的是关于持续集成流水线的内容。 从团队协作的角度上来看,在版本发布过程中,经常出现测试依赖开发手工生成制品、版本发布也从开发本地出版本的问题。而且项目架构如果从单体演进至组件…...

How to use CCS to debug a running M4F core that was started by Linux?
参考FAQ:AM62x & AM64x: How to use CCS to debug a running M4F core that was started by Linux? 问题记录: 1.使用SD卡启动模式,板上运行Linux。 当Linux系统启动后,9表示M4F core: am64xx-evm login: root rootam64xx…...

216、组合总数III
难度:中等 找出所有相加之和为 n 的 k 个数的组合,且满足下列条件: 只使用数字1到9 每个数字 最多使用一次 返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。 示例 1: 输入: k 3, n 7…...

简单的重装系统教程
郁闷,最近电脑一直蓝屏重启,用 2 分钟就蓝屏一次,遂产生重装系统的想法。 准备 U盘(8G或以上) PE 工具: 微PE工具箱快速指引 | 微PE优盘使用说明书 (wepe.com.cn) 系统镜像: 官网 Windows 10 官网 Windows 11 M…...

机器学习---集成学习报告
1.原理以及举例 1.1原理 集成学习(Ensemble Learning)是一种机器学习策略,它通过结合多个基学习器(base learners)的预测来提高模型的性能。集成学习的目标是创建一个比单个基学习器更准确、更稳定的最终预测模型。这…...

瑞萨RZ/V2N:15 TOPS能效比AI视觉芯片,赋能边缘智能应用
1. 瑞萨RZ/V2N:一颗为“看得懂”而生的中端AI视觉芯在嵌入式视觉AI这个赛道上,开发者们常常面临一个经典的“选择题”:是追求极致的性能,上马功耗和成本都更高的高端方案,还是为了控制预算和功耗,在性能上做…...

2026 免费在线照片换背景底色怎么做?详细操作方法 + 工具实测
想要快速改变照片背景底色却不知道怎么操作?本文为你盘点了最实用的免费在线照片换背景底色工具,涵盖详细的操作步骤和使用场景,让你轻松搞定各类背景处理需求。为什么需要在线换背景底色?在日常生活中,很多时候我们拍…...

告别黑盒调试:手把手教你用ControlDesk的Bus Navigator虚拟通道抓取CAN信号
告别黑盒调试:手把手教你用ControlDesk的Bus Navigator虚拟通道抓取CAN信号 在汽车电子开发中,硬件在环(HIL)测试往往面临一个典型困境:当物理ECU或CAN卡尚未就绪时,如何提前开展总线信号验证?传…...
)
从新手到认证专家:NotebookLM总结能力跃迁路径图(含Google官方未公开的评估矩阵V2.1)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM总结能力跃迁路径总览 NotebookLM 是 Google 推出的面向研究者与开发者的情境化 AI 助手,其核心突破在于将用户上传的文档(PDF、TXT、Google Docs)转化为可…...

前端开发自救指南:不用写测试代码,5分钟用Playwright录制生成E2E测试脚本
前端开发自救指南:5分钟零代码生成E2E测试脚本的Playwright实战 最近在重构公司后台管理系统时,我遇到了一个典型的前端开发困境:每次修改表单验证逻辑后,都需要手动点击十几个字段组合来验证是否会影响其他功能。直到团队里的测…...

KeyboardChatterBlocker:拯救老旧机械键盘的终极免费防连击方案
KeyboardChatterBlocker:拯救老旧机械键盘的终极免费防连击方案 【免费下载链接】KeyboardChatterBlocker A handy quick tool for blocking mechanical keyboard chatter. 项目地址: https://gitcode.com/gh_mirrors/ke/KeyboardChatterBlocker 你是否曾经在…...

从双非到科软:我的22408备考复盘与实战指南
1. 双非逆袭科软:我的备考心路历程 作为一名双非院校的计算机专业学生,我深知考研这条路有多难走。去年这个时候,我也和屏幕前的你一样,在知乎、贴吧疯狂搜索各种经验贴,既期待又忐忑。现在回想起来,从3月到…...

Claude Code质量崩了?Anthropic认错;3人+100个AI月烧130万美元,炸了
每天更新,带你读懂科技圈。 今日看点: Anthropic正式发布Claude Code质量事故复盘;OpenClaw之父晒出130万美元月账单——3人100个AI agent震撼业界;Hermes团队砍掉预训练六成成本;GitHub Copilot推桌面应用狙击AI编程对…...

告别Keil报错!手把手教你用MDK为国民技术N32G030K8L7搭建标准工程模板
国民技术N32G030K8L7开发实战:从零构建MDK工程模板的避坑指南 引言:为什么你的Keil工程总是编译失败? 刚拿到国民技术N32G030K8L7开发板时,许多开发者会直接套用STM32的工程模板习惯,结果在MDK环境下遭遇各种"玄学…...

国产巴伦替代 Mini-Circuits TCM1‑63AX+,H3‑TCM1‑63AX+ 现货可原位替代
最近很多做射频 / 通信 / 无线项目的朋友都在找Mini TCM1‑63AX 的国产替代,既要性能对标、又要现货快交、还要价格友好。给大家分享一款恒利泰 H3‑TCM1‑63AX,完全原位替代 TCM1‑63AX,参数一致、脚位兼容,直接替换不用改板。 ✅…...