17.网络爬虫—Scrapy入门与实战
这里写目录标题
- Scrapy基础
- Scrapy运行流程原理
- Scrapy的工作流程
- Scrapy的优点
- Scrapy基本使用(豆瓣网为例)
- 创建项目
- 创建爬虫
- 配置爬虫
- 运行爬虫
- 如何用python执行cmd命令
- 数据解析
- 打包数据
- 打开管道
- pipeline使用注意点
- 后记
前言:
🏘️🏘️个人简介:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证
📝📝第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一。
🧾 🧾第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
🧾 🧾第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
🧾 🧾第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八,领域热榜第二
🧾 🧾第十三篇文章《13.网络爬虫—多进程详讲(实战演示)》全站热榜第十二。
🧾 🧾第十四篇文章《14.网络爬虫—selenium详讲》测试领域热榜第二十。
🧾 🧾第十六篇文章《网络爬虫—字体反爬(实战演示)》全站热榜第二十五。
🎁🎁《Python网络爬虫》专栏累计发表十六篇文章,上榜七篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
Scrapy基础
🧾 🧾Scrapy是一个用于爬取网站数据和提取结构化数据的Python应用程序框架。Scrapy的设计是用于Web爬虫,也可以用于提取数据和自动化测试。
Scrapy提供了一个内置的HTTP请求处理器,可以通过编写自定义的中间件来扩展其功能。Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。
🧾 Scrapy的主要组件包括:
ScrapyEngine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到Responses交还给ScrapyEngine(引擎),由引擎交给Spider来处理。Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):一个可以自定扩展和操作引擎和Spider中间通信的功能组件。
Scrapy运行流程原理
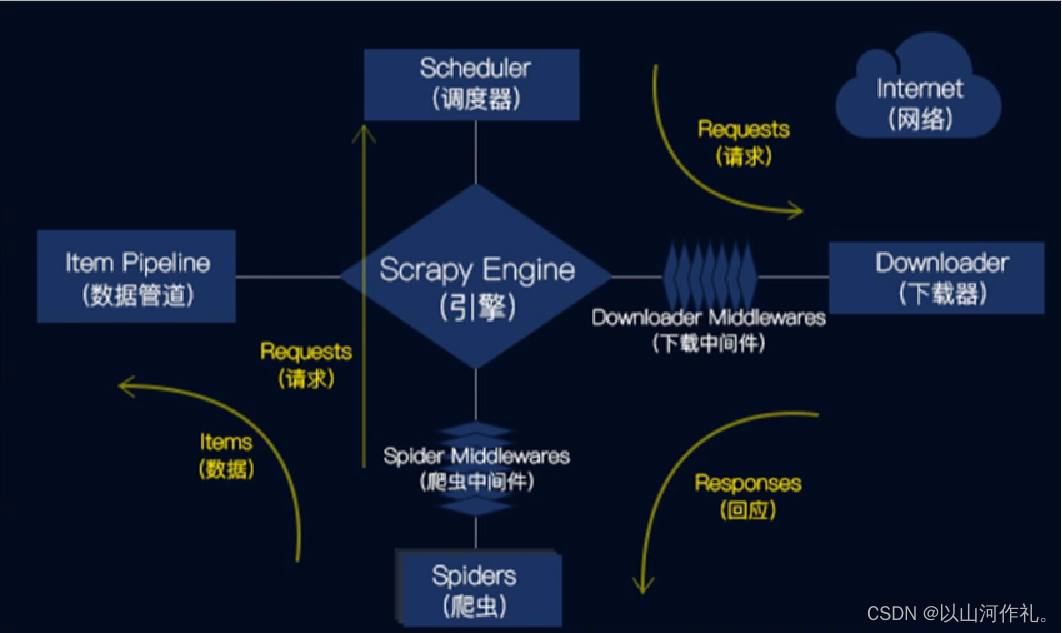
Scrapy的工作流程
1.引擎从爬虫的起始URL开始,发送请求至调度器。
2.调度器将请求放入队列中,并等待下载器处理。
3.下载器将请求发送给网站服务器,并下载网页内容。
4.下载器将下载的网页内容返回给引擎。
5.引擎将下载的网页内容发送给爬虫进行解析。
6.爬虫解析网页内容,并提取需要的数据。
7.管道将爬虫提取的数据进行处理,并保存到本地文件或数据库中。
Scrapy的优点
1.高效:Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。
2.可扩展:Scrapy提供了丰富的扩展接口,可以通过编写自定义的中间件来扩展其功能。
3.灵活:Scrapy支持多种数据格式的爬取和处理,包括HTML、XML、JSON等。
4.易于使用:Scrapy提供了丰富的文档和示例,可以快速入门。
Scrapy基本使用(豆瓣网为例)
🧾 安装scrapy模块:
pip install Scrapy
创建项目
🧾 🧾选择需要创建项目的位置
🎯进入cmd命令窗口(win+r),或者pycharm中打开终端也可以。
第一种方式:
第二种方式:
🎯进入到需要创建文件的盘符,在命令窗口使用命令(C:/D:/E:/F:)进入对应的盘符

🎯进入需要创建的路径:cd 路径
cd D:\新建文件夹\pythonProject1\测试\scrapy入门

🎯 当输入命令的前面部分出现对应的路径,代表进入成功

🎯检测scrapy是否成功,直接输入scrapy按确认,
注意:如果没有成功(需要配置pip的环境变量,检测scrapy是否下载成功,是否安装到了其他的解释器中)
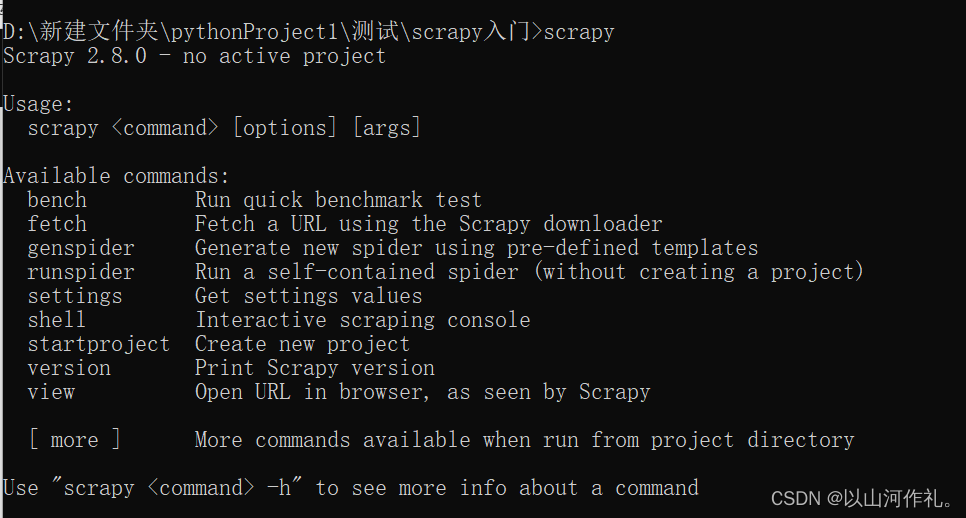
🎯创建项目,使用命令在命令窗口输入:
scrapy startproject douban # douban是项目的名称
🎯确认输入的命令后,会在当前路径下创建一个项目,以下为成功案例:

New Scrapy project 'douban', using template directory 'D:\Python3.10\Lib\site-packages\scrapy\templates\project', created in:D:\新建文件夹\pythonProject1\测试\scrapy入门\doubanYou can start your first spider with:cd doubanscrapy genspider example example.com
🎯创建完成后,如果没有出现文件,进行刷新即可

创建爬虫
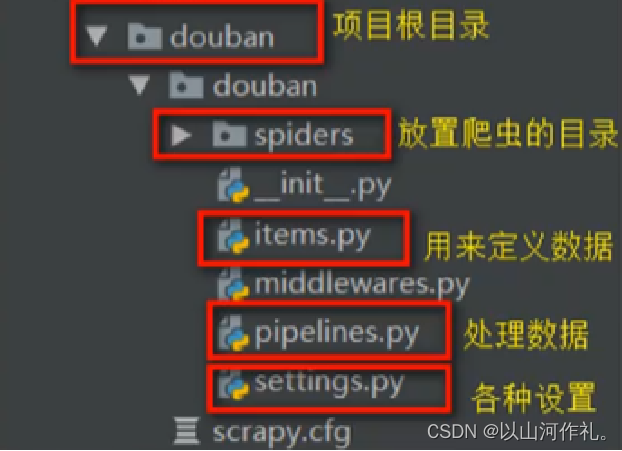
🧾 🧾 进入到spiders文件下创建创建爬虫文件
cd 到spiders文件下
例如:
cd douban\douban\spiders
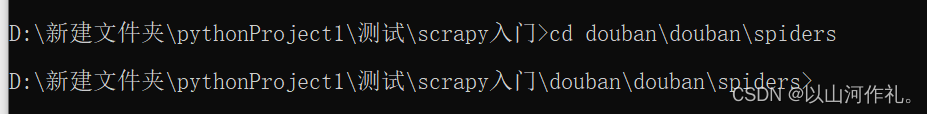
🎯创建爬虫 命令:
[scrapy genspider 爬虫的名称 爬虫网站]
爬虫的名称不能和项目名称一样
爬虫的网站是主网站即可
🎯成功后返回如下
Created spider 'douban_data' using template 'basic' in module:{spiders_module.__name__}.{module}
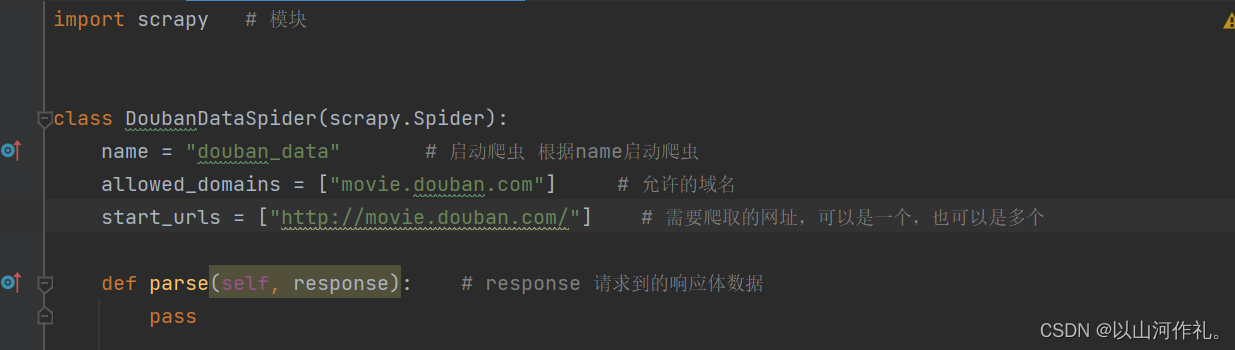
配置爬虫
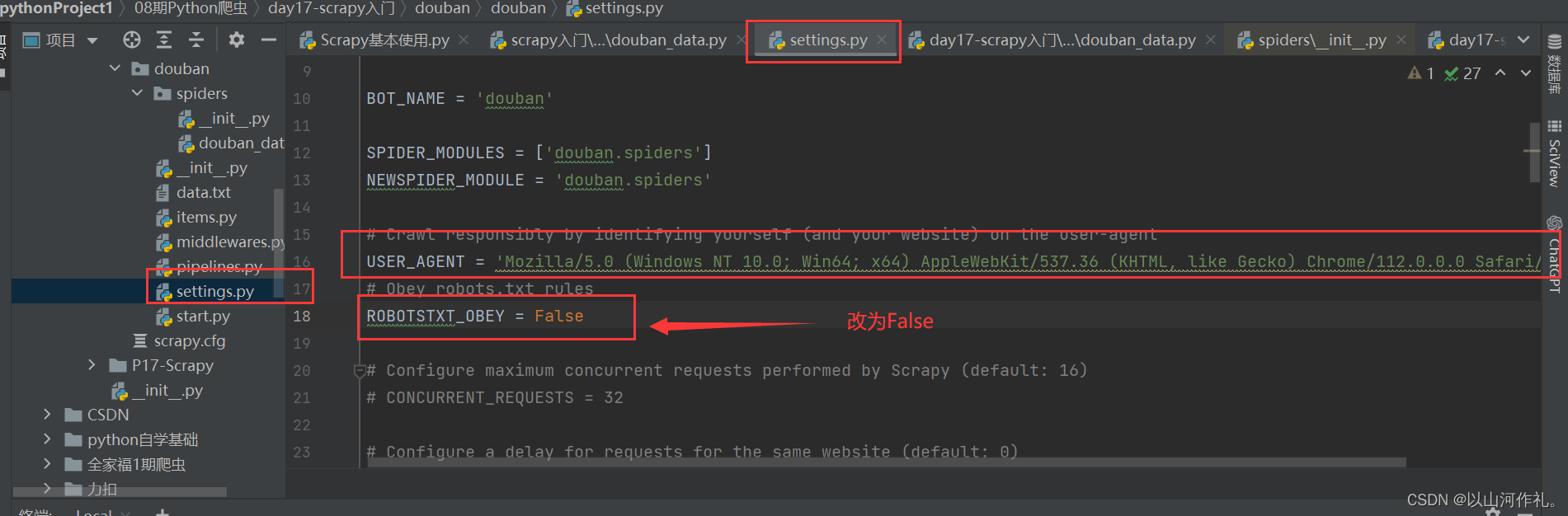
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
运行爬虫
🎯启动爬虫文件 scarpy crawl 爬虫名称
例如
scrapy crawl douban_data
运行结果:
如何用python执行cmd命令
🧾 🧾 终端获取的数据无法进行搜索,所以我们使用python的模块来运行cmd命令,获取相同的数据,方便我们数据的搜索和筛选。
🧾 我们创建一个start的py文件,帮助我们运行程序:
方法/步骤:
- 打开编辑器,导入python的os模块
- 使用os模块中的system方法可以调用底层的cmd,其参数
os.system(cmd) - sublime编辑器执行快捷键Ctrl+B执行代码,此时cmd命令执行
代码如下:
# 'scrapy crawl douban_data'import os
os.system('scrapy crawl douban_data')运行结果(展示部分内容):
🎯红色不是报错,是日志文件,日志输出也是红色。
数据解析
🧾 🧾我们需要对全部数据进行分析,拿到我们想到的数据,电影名称和电影评分:
title = re.findall('<a class="nbg" href=".*?" title="(.*?)">', response.text)print(title)nums = re.findall('<span class="rating_nums">(.*?)</span>', response.text)print(nums)
打包数据
# 打包数据 /在items中定义传输数据的结构(结构可以定义,或者不进行定义)item = DoubanItem()# 需要将一条数据存入到字典中for title, nums in zip(title, nums):item['title'] = titleitem['nums'] = numsyield item

打开管道
🎯解除注释,打开管道

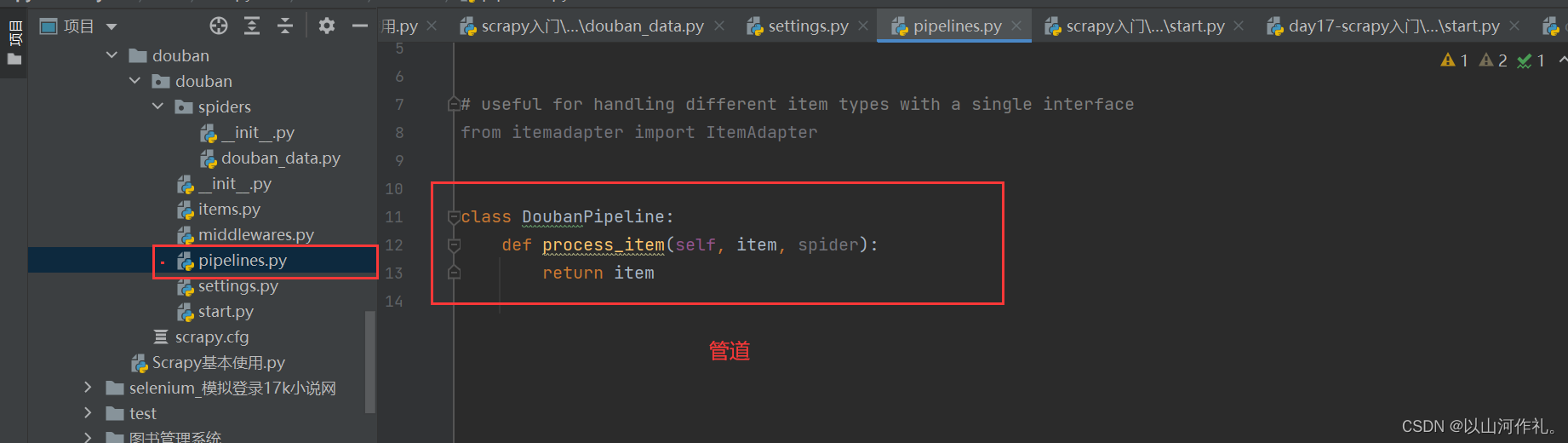
pipeline使用注意点
1. 使用之前需要在settings中开启
2. pipeline在setting中键表示位置(即pipeline在项目中的位置可以自定义),值表示距离引擎的远近,越近数据会越先经过:权重值小的优先执行
3. 有多个pipeline的时候,process_item的方法必须return item,否则后一个pipeline取到的数据为None值
4. pipeline中process_item的方法必须有,否则item没有办法接受和处理
5. process_item方法接受item和spider,其中spider表示当前传递item过来的spider
6. open_spider(self, spider) :能够在爬虫开启的时候执行一次
7. close_spider(self, spider) :能够在爬虫关闭的时候执行一次
8. 上述俩个方法经常用于爬虫和数据库的交互,在爬虫开启的时候建立和数据库的连接,在爬虫关闭的时候断开和数据库的连接
🎯打开管道将数据写入txt文件中
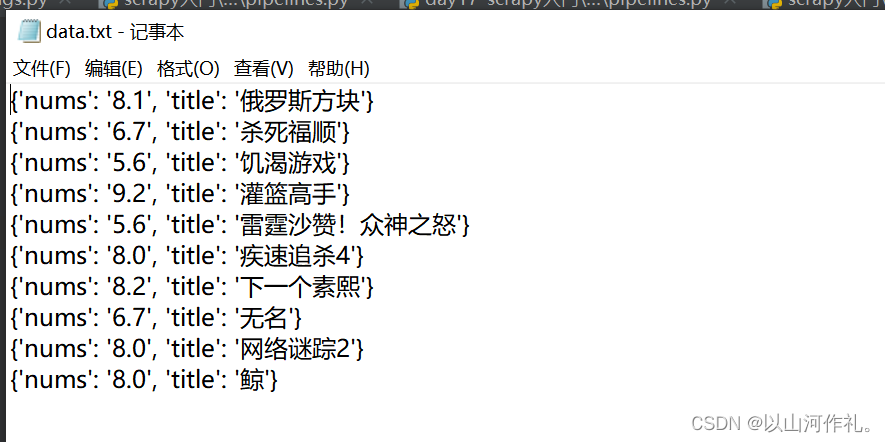
class DoubanPipeline:def __init__(self):self.f = open('data.txt', 'w+', encoding='utf-8')def process_item(self, item, spider):self.f.write(f'{item}\n')return itemdef close_spider(self, spider):self.f.close()print('文件写入完成')🎯运行结果:
后记
👉👉本专栏所有文章是博主学习笔记,仅供学习使用,爬虫只是一种技术,希望学习过的人能正确使用它。
博主也会定时一周三更爬虫相关技术更大家系统学习,如有问题,可以私信我,没有回,那我可能在上课或者睡觉,写作不易,感谢大家的支持!!🌹🌹🌹
相关文章:
17.网络爬虫—Scrapy入门与实战
这里写目录标题 Scrapy基础Scrapy运行流程原理Scrapy的工作流程Scrapy的优点 Scrapy基本使用(豆瓣网为例)创建项目创建爬虫配置爬虫运行爬虫如何用python执行cmd命令数据解析打包数据打开管道pipeline使用注意点 后记 前言: 🏘️🏘️个人简介…...

【面试题】JavaScript 中 try...catch 的使用技巧 ?
大厂面试题分享 面试题库 前后端面试题库 (面试必备) 推荐:★★★★★ 地址:前端面试题库 web前端面试题库 VS java后端面试题库大全 作为一位 Web 前端工程师,JavaScript 中的 try...catch 是我们常用的特性之一。…...

Java 命名格式规范
Java 命名格式规范 概述 简洁清爽的代码风格应该是大多数开发工程师所期待的。在编码过程中笔者常常因为起名字而纠结,夸张点可以说是编程 5 分钟,命名两小时!究竟为什么命名成为了编码中的拦路虎。 每个公司都有不同的标准,目…...

【C++】STL中的容器适配器 stack queue 和 priority_queue 的模拟实现
STL中的容器适配器 一、容器适配器1、什么是容器适配器2、STL标准库中的容器适配器 二、stack的模拟实现1、stack的简单介绍2、栈的模拟实现 三、queue的模拟实现1、queue的简单介绍2、queue的模拟实现 四、priority_queue的模拟实现1、priority_queue的简单介绍2、priority_qu…...

MongoDB 聚合管道中使用算术表达式运算符
算术表达式运算符主要用于实现数字之间的算术运算,主要包含了对加、减、乘、除、余数、截取、舍入等算术操作。 下面我们进行详细介绍: 一、准备数据 初始化商品数据 db.goods.insertMany([{ "_id": 1, name: "薯片", size: &q…...

代码随想录算法训练营第四十三天-动态规划5|1049. 最后一块石头的重量 II , 494. 目标和 , 474.一和零
最后一块石头重量转化为将一个集合分隔成两个集合,两个集合之间的差值最小,就是最后剩下最小的石头重量。这里可以求集合的一个平均值,如果正好等于平均值,说明可以抵消,这时候重量为0,如果不行,…...

《淘宝网店》:计算总收益
目录 一、题目 二、思路 1、当两个年份不一样的时候 (1)from年剩余之后的收益 (2)中间年份的全部收益 (3)to年有的收益 2、同一个年份 三、代码 详细注释版本: 简化注释版本ÿ…...

2023年03月青少年软件编程C语言一级真题答案——持续更新.....
1.字符长方形 给定一个字符,用它构造一个长为4个字符,宽为3个字符的长方形,可以参考样例输出。 时间限制:1000 内存限制:65536 输入 输入只有一行, 包含一个字符。 输出 该字符构成的长方形,长4个字符,宽3个字符。 样例输入 * 样例输出 **** **** ****#include<bi…...

家用洗地机好用吗?好用的洗地机分享
洗地机是一种高效、节能、环保的清洁设备,广泛应用于各种场所的地面清洁工作。它不仅可以快速清洁地面,还可以有效去除污渍、油渍等难以清洁的污染物,让地面恢复光洁如新的状态。同时,洗地机还可以减少清洁人员的劳动强度…...
《分解因数》:质因数分解
目录 一、题目: 二、思路: 三、代码: 一、题目: 分解因数 《分解因数》题目链接 所谓因子分解,就是把给定的正整数a,分解成若干个素数的乘积,即 a a1 a2 a3 ... an,并且 1 < a1…...
(排序10)归并排序的外排序应用(文件排序)
TIPS 在一些文件操作函数当中,fputc与fgetc这两个函数都是针对字符的,如果说你需要往文件里面去放入整形啊等等,不是字符的类型,这时候就用fprintf,fscanf在参数里面数据类型控制一下就可以。但是话说回来,…...
浅谈根号分治与分块
文章目录 1. 根号分治哈希冲突 2. 线性分块引入教主的魔法[CQOI2011] 动态逆序对[国家集训队] 排队[HNOI2010] 弹飞绵羊蒲公英 1. 根号分治 哈希冲突 题目1 n n n 个数, m m m 次操作。操作 1 为修改某一个数的值,操作 2 为查询所有满足下标模 x x x …...
(OpenAI)ChatGPT注册登录常见问题错误代码及其解决方法
在使用 ChatGPT 的时候我们可能会碰到一些错误的代码,本文统一来介绍一下每一种错误以及解决方法。 错误代码1. 不能在当前国家使用 出现场景:一般在注册或登录的时候会出现。 原因:主要是ChatGPT检测到当前访问所在的地区不允许访问导致。 …...
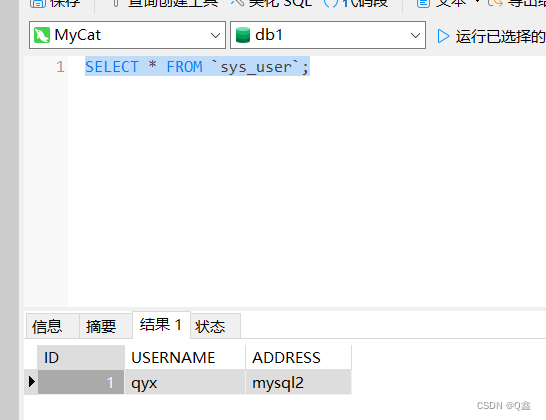
MySQL主从复制、读写分离(MayCat2)实现数据同步
文章目录 1.MySQL主从复制原理。2.实现MySQL主从复制(一主两从)。3.基于MySQL一主两从配置,完成MySQL读写分离配置。(MyCat2) 1.MySQL主从复制原理。 MySQL主从复制是一个异步的复制过程,底层是基于Mysql数…...

Linux 云服务器好用吗?(解读Linux云服务器的特点优势)
如今,云计算越来越受欢迎,许多公司正在将业务转移到那里。企业向云过渡的主要原因是它提供的众多服务,包括安全和充足的存储、数据库、服务器和其他关键元素。 作为相对前|沿的技术之一,云建立在虚拟服务器上。Linux 服务器…...
研读Rust圣经解析——Rust learn-8(match,if-let简洁控制流,包管理)
研读Rust圣经解析——Rust learn-8(match,if-let简洁控制流,包管理) matchother和占位符_区别 easy matchenum matchno valuematch inner Option matchmore better way if-let整洁控制包管理模块(mod)拆分声明modpub公开use展开引用拆解模块结…...

G8期刊《全体育》期刊简介及投稿要求
G8期刊《全体育》期刊简介及投稿要求 《全体育》是由湖南体育产业集团有限公司主管、体坛传媒集团股份有限公司主办、中教体育 出版发行的体育综合性期刊。 主管:湖南体育产业集团有限公司 主办:体坛传媒集团股份有限公司 国内刊号:CN4…...
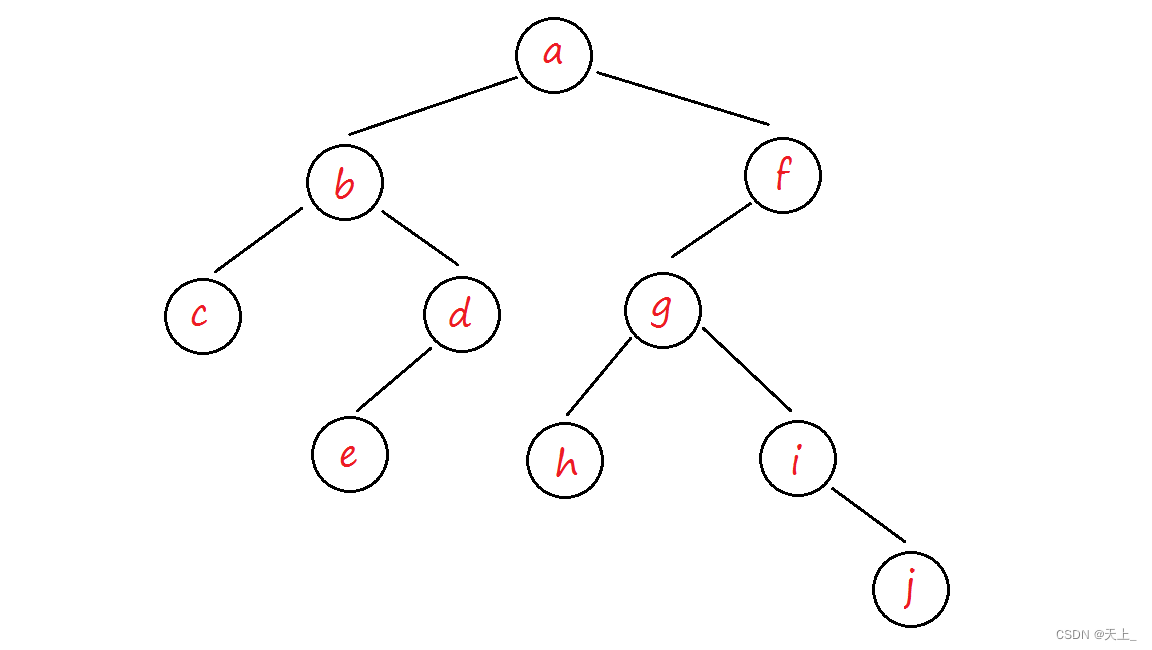
数据结构和算法学习记录——层序遍历(层次遍历)、二叉树遍历的应用(输出二叉树中的叶节点、求二叉树的高度、二元运算表达式树及其遍历、由两种遍历序列确定二叉树)
目录 层序遍历 思路图解 代码实现 二叉树遍历的应用 输出二叉树中的叶节点 代码实现 求二叉树的高度 思路图解 代码实现 二元运算表达式树及其遍历 由两种遍历序列确定二叉树 层序遍历 层序遍历可以通过一个队列来实现,其基本过程为: 先根…...
、查询、删除数据库等操作解析(Cypher语句))
【Neo4j数据库】图数据库_Neo4j增加节点(关系)、查询、删除数据库等操作解析(Cypher语句)
【Neo4j数据库】图数据库_Neo4j增加节点(关系)、查询、删除操作解析(Cypher语句) 文章目录 【Neo4j数据库】图数据库_Neo4j增加节点(关系)、查询、删除操作解析(Cypher语句)1. 介绍2…...
命令)
Linux移动文件和文件夹(目录)命令
命令mv 英文move 翻译移动 mv命令可以移动文件或文件夹(目录),也可以重命令(覆盖)文件。 1. 移动文件/重命名 单纯地移动某一个文件直接使用: mv <源文件名称/地址> <新文件名称/地址>这个方法…...

LabVIEW项目实战:用‘类+队列’模式管理仪器参数,告别全局变量混乱
LabVIEW工程实践:基于类与队列的仪器参数管理框架设计 在工业自动化测试系统中,仪器参数管理一直是困扰工程师的典型难题。当系统需要同时控制网口、串口、GPIB等多种接口的测试设备时,传统的全局变量方案会导致参数耦合、修改不同步等问题。…...

战略咨询全新定位:结合政策导向规划企业中长期路径
在新形势下、战略咨询的定位逐渐向结合国家政策导向转变和企业在制定中长期发展路径时、须关注政策变化市场动态。在这一背景下政策要素核心在于灵活应对外部环境,企业可以利用定期分析市场动态和政策影响,明确发展方向。结合实际案例与专家观点、这些方…...
)
Spring AI 快速对接 AI 大模型(开箱即用)
一、项目准备(最简依赖)1. 创建 Spring Boot 项目推荐版本:Spring Boot 3.2.x JDK 版本:172. pom.xml 核心依赖<?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.o…...

高并发下是先写数据库,还是先写缓存?
前言 数据库和缓存(比如:redis)双写数据一致性问题,是一个跟开发语言无关的公共问题。尤其在高并发的场景下,这个问题变得更加严重。 我很负责的告诉你,该问题无论在面试,还是工作中遇到的概率…...
的显式与隐式设备管理对比)
PyTorch实战:多GPU环境下torch.cuda.set_device()的显式与隐式设备管理对比
1. 多GPU环境下的设备管理基础 当你在实验室或者公司服务器上看到多块GPU时,是不是既兴奋又有点无从下手?PyTorch为我们提供了多种方式来管理这些计算资源,但选择不当可能会带来意想不到的问题。让我们从一个实际场景开始:假设你正…...

从单摆到机械臂:拉格朗日方程如何统一描述‘运动与力’?一个思维模型讲透
从单摆到机械臂:拉格朗日方程如何统一描述‘运动与力’?一个思维模型讲透 想象你手中握着一根细绳,末端悬挂着一个小球。轻轻推动它,小球便开始左右摆动——这就是经典的单摆系统。看似简单的运动背后,却隐藏着自然界最…...
:助你轻松掌握办公自动化利器)
Excel VBA编程实例(150例):助你轻松掌握办公自动化利器
Excel VBA编程实例(150例):助你轻松掌握办公自动化利器 【下载地址】ExcelVBA编程实例150例资源下载 本仓库提供了一个名为“Excel VBA编程实例(150例)”的资源文件下载。该资源文件包含了150个Excel VBA编程实例,旨在帮助用户通过实际案例学习和掌握Exc…...

让经典重生:D2DX如何让《暗黑破坏神2》在现代电脑上流畅运行
让经典重生:D2DX如何让《暗黑破坏神2》在现代电脑上流畅运行 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还记…...

如何实现微信聊天记录永久保存?开源工具WeChatMsg完整解决方案
如何实现微信聊天记录永久保存?开源工具WeChatMsg完整解决方案 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/…...

HEC-RAS 5.0.7实战:从模型结果到ArcGIS,一步步教你生成并导出淹没范围SHP文件
HEC-RAS 5.0.7与ArcGIS联合作战:专业级淹没分析全流程指南 水利工程师在完成HEC-RAS模型计算后,常面临一个关键挑战:如何将模拟结果转化为实际项目所需的GIS数据?本文将以HEC-RAS 5.0.7为例,详细拆解从模型结果到ArcGI…...