十、CNN卷积神经网络实战
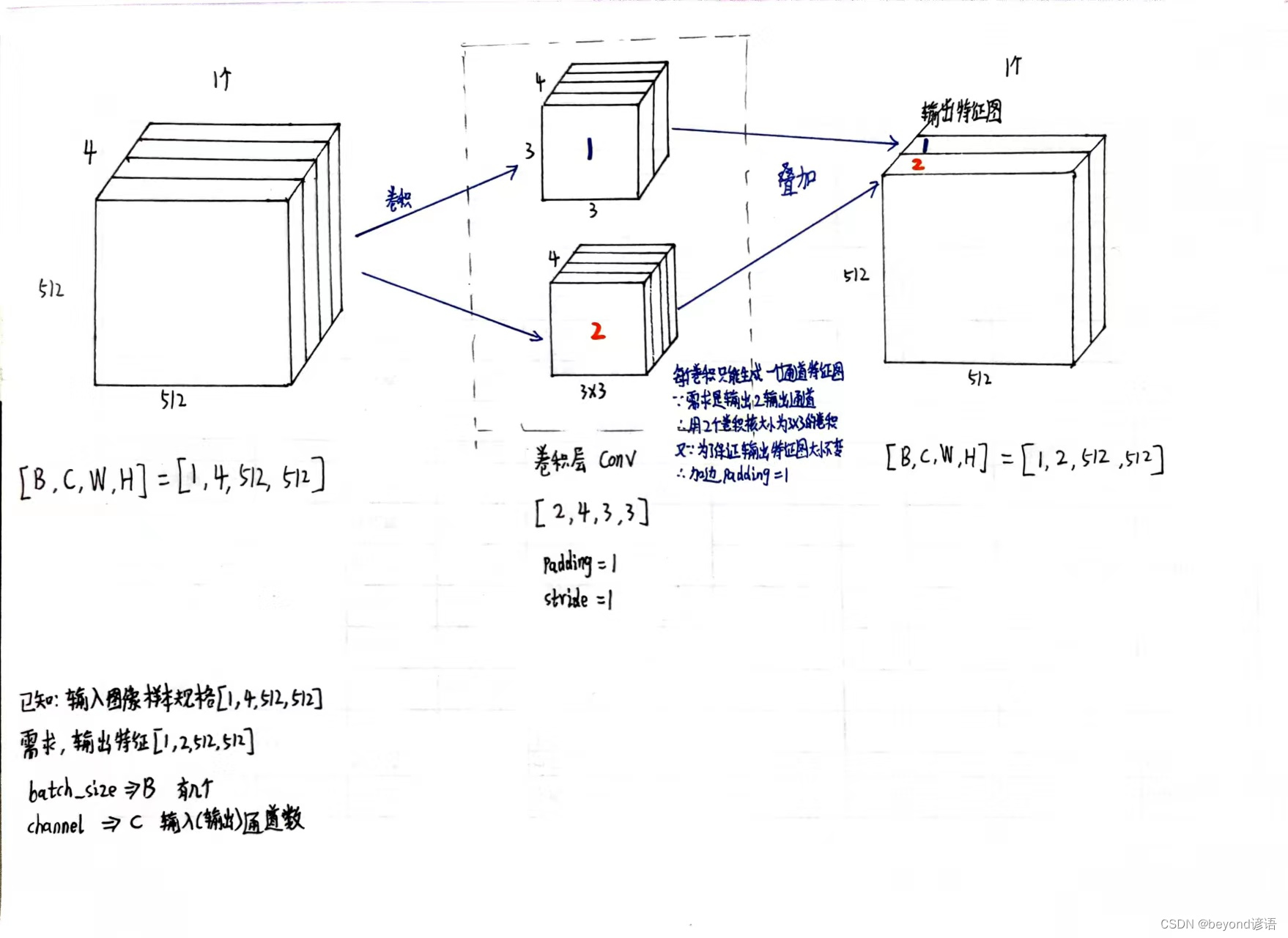
一、确定输入样本特征和输出特征
输入样本通道数4、期待输出样本通道数2、卷积核大小3×3
具体卷积层的构建可参考博文:八、卷积层
设定卷积层
torch.nn.Conv2d(in_channels=in_channel,out_channels=out_channel,kernel_size=kernel_size,padding=1,stride=1)
必要参数:输入样本通道数in_channels、输出样本通道数out_channels、卷积核大小kernel_size
padding是否加边,默认不加,这里为了保证输出图像的大小不变,加边数设为1
stride步长设置,默认为1
import torch
in_channel, out_channel = 4, 2
width, heigh = 512, 512
batch_size = 1
inputs = torch.randn(batch_size,in_channels,width,heigh)#[B,C,W,H]kernel_size = 3conv_layer = torch.nn.Conv2d(in_channels=in_channel,out_channels=out_channel,kernel_size=kernel_size,padding=1,stride=1)
outputs = conv_layer(inputs)print(inputs.shape)
"""
torch.Size([1, 4, 512, 512])
"""
print(outputs.shape)
"""
torch.Size([1, 2, 512, 512])
"""
print(conv_layer.weight.shape)#看下卷积层核参数信息
# 卷积层权重参数大小,因为batch_size为1,故卷积核参数的B也为1;
# 因为输入样本的通道数是3,故卷积层传入参数的channel也为3;
# 因为输出样本的通道数是1,故卷积层传入参数的
"""
torch.Size([2, 4, 3, 3])
"""
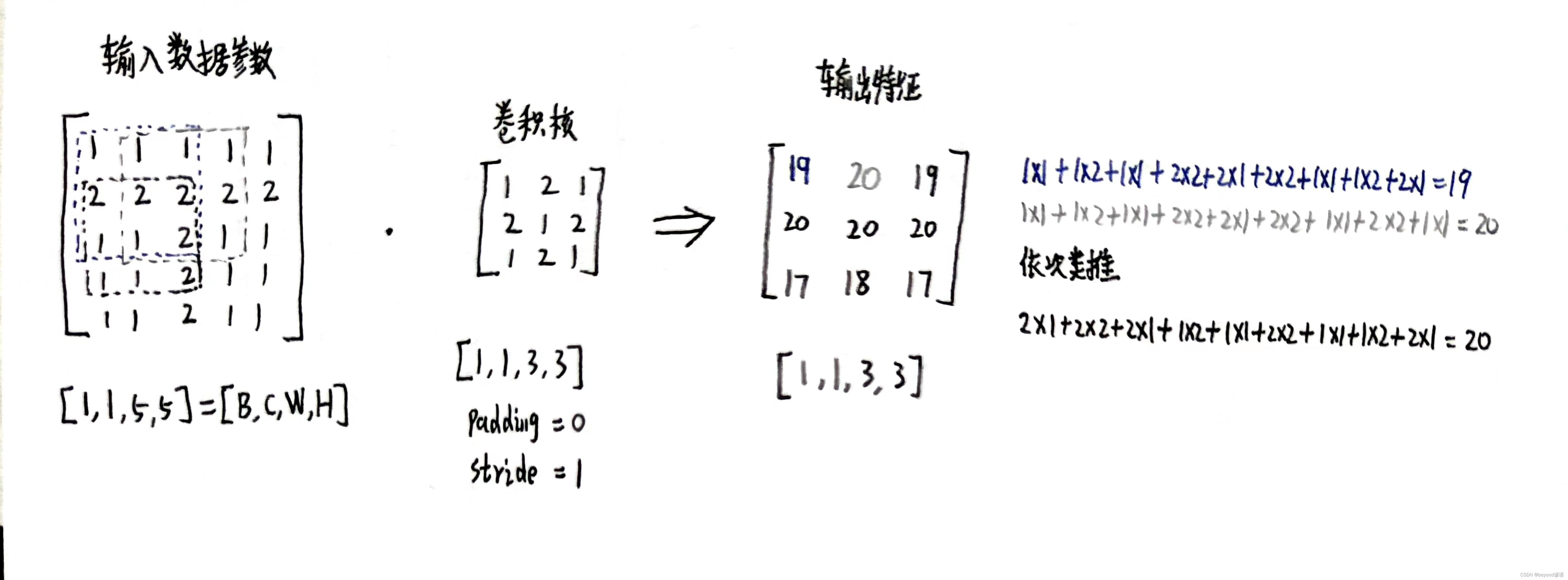
二、确定卷积核内容进行卷积
import torch
inputs = [1,1,1,1,1,2,2,2,2,2,1,1,2,1,1,1,1,2,1,1,1,1,2,1,1]inputs = torch.Tensor(inputs).view(1,1,5,5)kernel_size = 3
padding = 0
stride = 1kernel = torch.Tensor([1,2,1,2,1,2,1,2,1]).view(1,1,3,3)conv_layer = torch.nn.Conv2d(1,1,kernel_size=kernel_size,padding=padding,stride=stride,bias=False)
conv_layer.weight.data = kernel.dataoutputs = conv_layer(inputs)print(outputs)
"""
tensor([[[[19., 20., 19.],[20., 20., 20.],[17., 18., 17.]]]], grad_fn=<SlowConv2DBackward0>)
"""print(inputs)
"""
tensor([[[[1., 1., 1., 1., 1.],[2., 2., 2., 2., 2.],[1., 1., 1., 1., 1.],[2., 2., 2., 2., 2.],[1., 1., 1., 1., 1.]]]])
"""
print(kernel)
"""
tensor([[[[1., 2., 1.],[2., 1., 2.],[1., 2., 1.]]]])
"""
print(inputs.shape)
"""
torch.Size([1, 1, 5, 5])
"""
print(outputs.shape)
"""
torch.Size([1, 1, 3, 3])
"""
print(kernel.shape)
"""
torch.Size([1, 1, 3, 3])
"""
print(conv_layer.weight.shape)
"""
torch.Size([1, 1, 3, 3])
"""
三、根据需求进行网络模型搭建
①准备数据集
还是以MNIST手写数字数据集为例,数据集细节可参考博文:九、多分类问题
设置batch_size=64,每个batch中有64张样本,至于一共有多少个batch,取决于数据集的总数量
使用transforms.Compose(),组合操作,把数据集都转换为Tensor数据类型,并且全部都取均值和标准差,方便训练,强化训练效果,这里的值都是经过计算过的,直接用就行
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #为了使用relu激活函数
import torch.optim as optim batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),#把图片变成张量形式transforms.Normalize((0.1307,),(0.3081,)) #均值和标准差进行数据标准化,这俩值都是经过整个样本集计算过的
])
②加载数据集
pytorch提供MNIST接口,直接调用相关函数即可
datasets中
参数root表示数据集路径;
参数train表示是否是训练集,True表示下载训练集,False则表示下载测试集;
参数download表示是否下载,True表示若指定路径不存在数据集则联网下载;
将所有的数据集都经过上面定义的transforms组合操作,转换成Tensor格式和均值标准差归一化。
DataLoader中
参数train_dataset指定数据集datasets;
参数shuffle表示是否将数据集中的样本打乱顺序,训练集需要,测试集不需要
参数batch_size表示一次(batch)取多少个样本,至于一共取多少次取决于数据集总样本数
train_dataset = datasets.MNIST(root='./',train=True,download=True,transform = transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)test_dataset = datasets.MNIST(root="./",train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
③模型构建
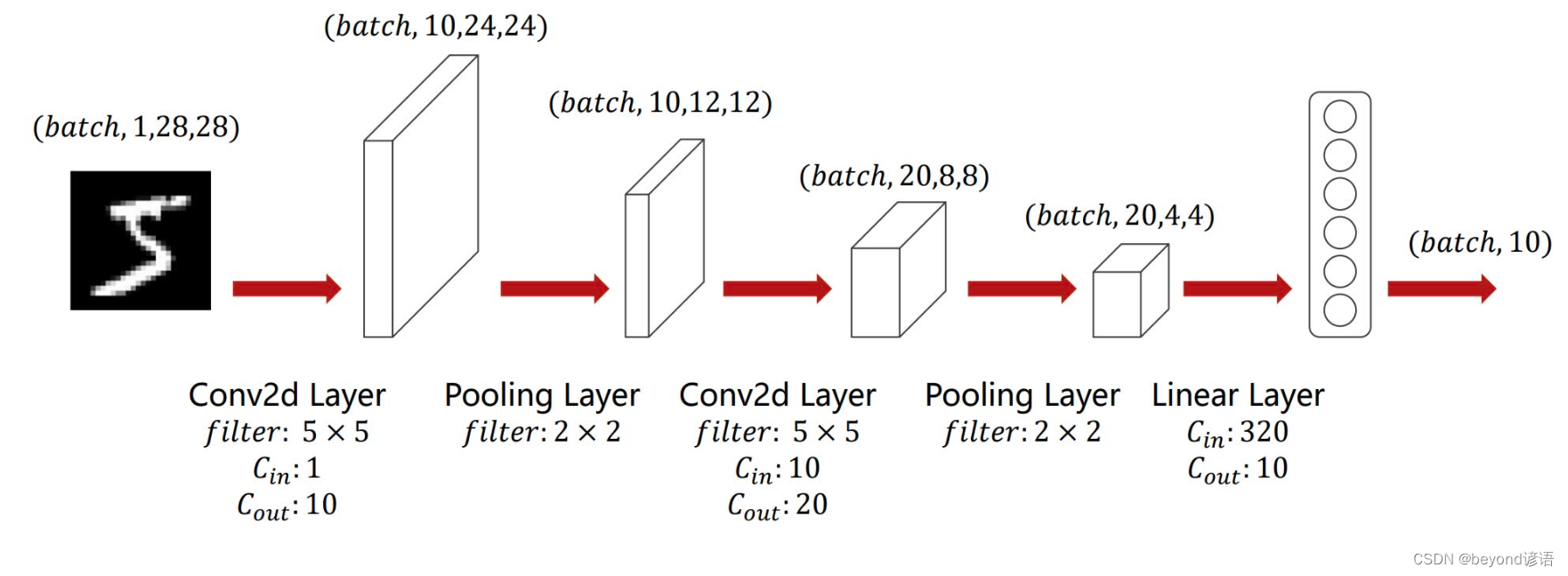

由图可知,输入图像(通道数为1)首先进入一个卷积层,卷积核大小为5×5,输出特征通道数为10,即torch.nn.Conv2d(1,10,kernel_size=5)
之后进入一个ReLU激活函数层,激活函数无需参数,即F.relu()
然后再进入一个核为2×2的MaxPool层,即torch.nn.MaxPool2d(2)
之后将通道数为10的特征参数再送入一个卷积层,卷积核大小为5×5,输出特征通道数为20,即torch.nn.Conv2d(10,20,kernel_size=5)
之后进入一个ReLU激活函数层,激活函数无需参数,即F.relu()
然后再进入一个核为2×2的MaxPool层,即torch.nn.MaxPool2d(2)
有第一张图可知,最终的特征参数个数为20×4×4=320,将这320个特征参数通过线性层(全连接层),转到10个维度上,即torch.nn.Linear(320,10),因为是10分类任务,故需要转到10个维度上
在模型参数函数(def __init__(self):)中,池化层操作都一样,故定义一个即可,最终,卷积操作两个,一个池化操作,一个线性层(全连接)操作
在前向传播函数(def forward(self,x):)中,数据集中x为[B,C,W,H],故通过x.size(0)取出batch_size,即B的值
class yNet(torch.nn.Module):def __init__(self):super(yNet,self).__init__()self.conv_1 = torch.nn.Conv2d(1,10,kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.conv_2 = torch.nn.Conv2d(10,20,kernel_size=5)self.fc = torch.nn.Linear(320,10)def forward(self,x):batch_size = x.size(0)x = self.pooling(F.relu(self.conv_1(x)))x = self.pooling(F.relu(self.conv_2(x)))x = x.view(batch_size,-1)x = self.fc(x)return xmodel = yNet()
GPU加速
只需要通过.to()方法,将模型、训练函数中数据集、测试函数中数据集调用该方法即可
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
④损失函数和优化器
lossf = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.0001,momentum=0.5)
⑤训练函数定义
for i, data in enumerate(train_loader,0):
从train_loader这个DataLoader中进行枚举,0表示从DataLoader下标为0处开始,train_loader返回两个值,索引和数据,其中数据包括两类,x和y
i接收索引、data接收数据
x,y = data,x和y分别接收data中的28×28=784个参数,y为所对应的某一个类别
测试
x,y = test_dataset[0]
x.shape
"""
torch.Size([1, 28, 28])
"""
y
"""
7
"""
完整代码
def ytrain(epoch):loss_total = 0.0for batch_index ,data in enumerate(train_loader,0):x,y = data#x,y = x.to(device), y.to(device)#GPU加速optimizer.zero_grad()y_hat = model(x)loss = lossf(y_hat,y)loss.backward()optimizer.step()loss_total += loss.item()if batch_index % 300 == 299:# 每300epoch输出一次print("epoch:%d, batch_index:%5d \t loss:%.3f"%(epoch+1, batch_index+1, loss_total/300))loss_total = 0.0 #每次epoch都将损失清零,方便计算下一次的损失
⑥测试函数定义
def ytest():correct = 0#模型预测正确的数量total = 0#样本总数with torch.no_grad():#测试不需要梯度,减小计算量for data in test_loader:#读取测试样本数据images, labels = data#images, labels = images.to(device), labels.to(device) #GPU加速pred = model(images)#预测,每一个样本占一行,每行有十个值,后续需要求每一行中最大值所对应的下标pred_maxvalue, pred_maxindex = torch.max(pred.data,dim=1)#沿着第一个维度,一行一行来,去找每行中的最大值,返回每行的最大值和所对应下标total += labels.size(0)#labels是一个(N,1)的向量,对应每个样本的正确答案correct += (pred_maxindex == labels).sum().item()#使用预测得到的最大值的索引和正确答案labels进行比较,一致就是1,不一致就是0print("Accuracy on testset :%d %%"%(100*correct / total))#correct预测正确的样本个数 / 样本总数 * 100 = 模型预测正确率
⑦主函数调用
if __name__ == '__main__':for epoch in range(100):#训练10次ytrain(epoch)#训练一次if epoch%10 == 9:ytest()#训练10次,测试1次
⑧完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #为了使用relu激活函数
import torch.optim as optim batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),#把图片变成张量形式transforms.Normalize((0.1307,),(0.3081,)) #均值和标准差进行数据标准化,这俩值都是经过整个样本集计算过的
])train_dataset = datasets.MNIST(root='./',train=True,download=True,transform = transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)test_dataset = datasets.MNIST(root="./",train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)class yNet(torch.nn.Module):def __init__(self):super(yNet,self).__init__()self.conv_1 = torch.nn.Conv2d(1,10,kernel_size=5)self.pooling = torch.nn.MaxPool2d(2)self.conv_2 = torch.nn.Conv2d(10,20,kernel_size=5)self.fc = torch.nn.Linear(320,10)def forward(self,x):#传入单张样本xbatch_size = x.size(0)x = self.pooling(F.relu(self.conv_1(x)))x = self.pooling(F.relu(self.conv_2(x)))x = x.view(batch_size,-1)x = self.fc(x)return xmodel = yNet()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)lossf = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.0001,momentum=0.5)def ytrain(epoch):loss_total = 0.0for batch_index ,data in enumerate(train_loader,0):x,y = datax,y = x.to(device), y.to(device)#GPU加速optimizer.zero_grad()y_hat = model(x)loss = lossf(y_hat,y)loss.backward()optimizer.step()loss_total += loss.item()if batch_index % 300 == 299:# 每300epoch输出一次print("epoch:%d, batch_index:%5d \t loss:%.3f"%(epoch+1, batch_index+1, loss_total/300))loss_total = 0.0def ytest():correct = 0#模型预测正确的数量total = 0#样本总数with torch.no_grad():#测试不需要梯度,减小计算量for data in test_loader:#读取测试样本数据images, labels = dataimages, labels = images.to(device), labels.to(device) #GPU加速pred = model(images)#预测,每一个样本占一行,每行有十个值,后续需要求每一行中最大值所对应的下标pred_maxvalue, pred_maxindex = torch.max(pred.data,dim=1)#沿着第一个维度,一行一行来,去找每行中的最大值,返回每行的最大值和所对应下标total += labels.size(0)#labels是一个(N,1)的向量,对应每个样本的正确答案correct += (pred_maxindex == labels).sum().item()#使用预测得到的最大值的索引和正确答案labels进行比较,一致就是1,不一致就是0print("Accuracy on testset :%d %%"%(100*correct / total))#correct预测正确的样本个数 / 样本总数 * 100 = 模型预测正确率if __name__ == '__main__':for epoch in range(10):#训练10次ytrain(epoch)#训练一次if epoch%10 == 9:ytest()#训练10次,测试1次
⑨测试一下
x,y = train_dataset[9]#第9个数据x为图片,对应的结果为2
y
"""
2
"""
x = x.view(-1,1,28,28)#因为tensor需要格式为(B,C,W,H)转换一下格式
y_hat = model(x)#放入模型中进行预测,因为时十分类任务,输出十个值
y_hat
"""
tensor([[-2.8711, -2.2891, -0.5218, -2.0884, 6.2099, -0.1559, 1.9904, -0.8938,1.3734, 2.9303]], grad_fn=<AddmmBackward0>)
"""pred_maxvalue, pred_maxindex = torch.max(y_hat,dim=1)#选出值最大的,和相对于的下标索引pred_maxvalue#最大值
"""
tensor([6.2099], grad_fn=<MaxBackward0>)
"""
pred_maxindex#最大值所对应的索引下标值
"""
tensor([4])
"""
预测错了,得多训练几轮
四、课后作业

除网络模型外,其他的都可以复用
这里就不再赘述,直接对模型结构进行搭建
查看下官网给的卷积层padding的计算公式

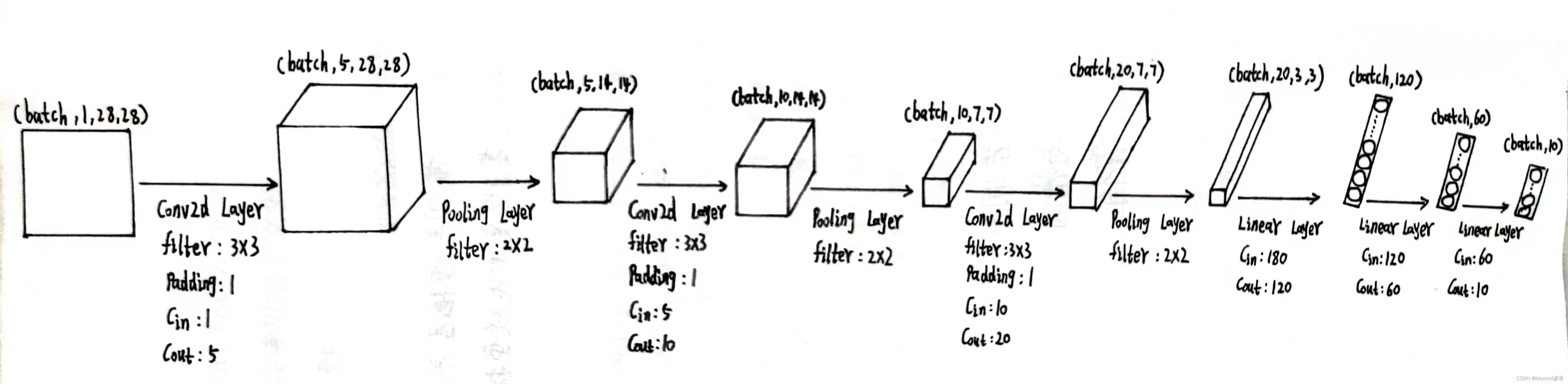
以下是我个人设计的网络模型,接下来开始去实现模型架构
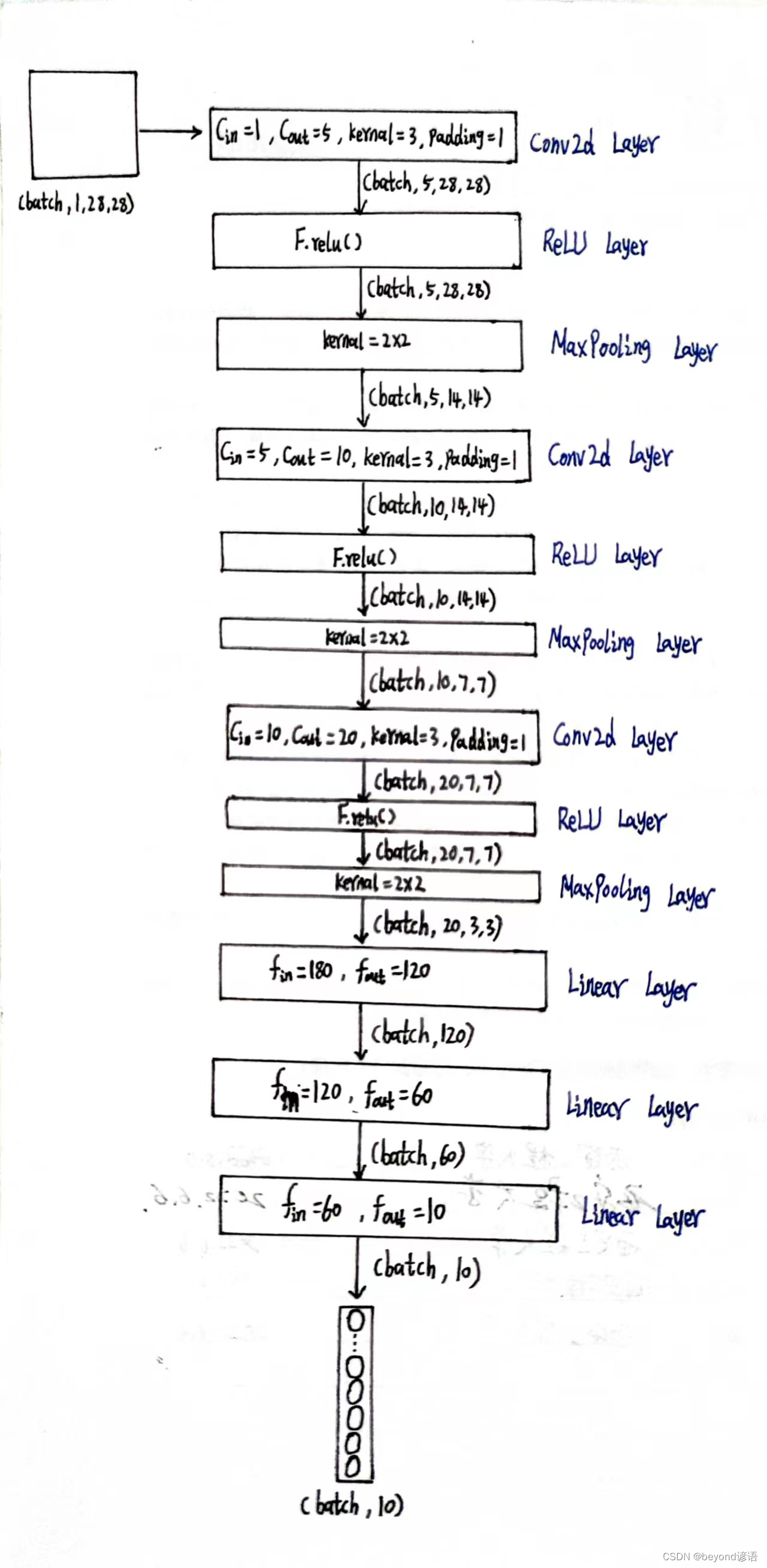
①调试
加载数据集
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #为了使用relu激活函数
import torch.optim as optim batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),#把图片变成张量形式transforms.Normalize((0.1307,),(0.3081,)) #均值和标准差进行数据标准化,这俩值都是经过整个样本集计算过的
])train_dataset = datasets.MNIST(root='./',train=True,download=True,transform = transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)test_dataset = datasets.MNIST(root="./",train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)#这里取测试集中的一个样本
x,y = test_dataset[1]x.shape
"""
torch.Size([1, 28, 28])
"""
y
"""
2
"""
第一个卷积层
因为数据集中样本shape是torch.Size([1, 28, 28]),而pytorch提供的接口都得适应[B,C,W,H]形式,故需要先通过x = x.view(-1,1,28,28)转换一下类型
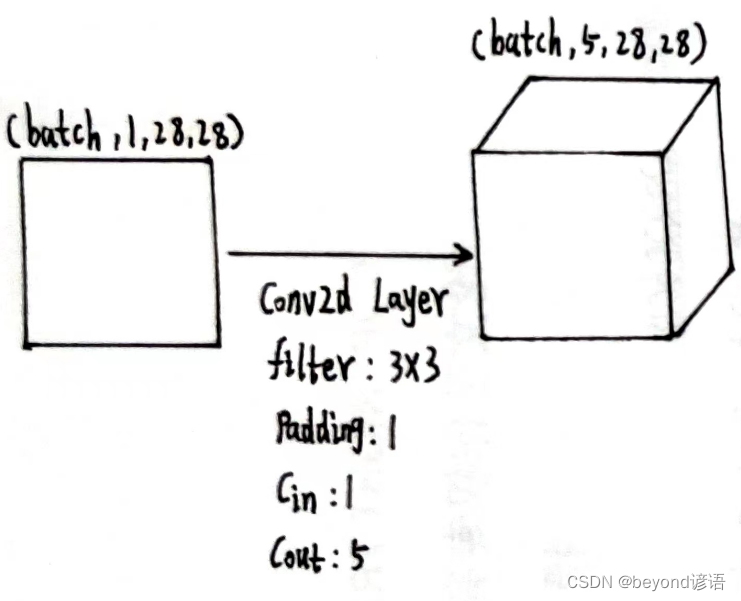
根据结构需要,定义第一个卷积层,为了后续计算方便,这里加边padding=1,保证输入和输出特征图大小一致,这里仅为了测试,batch取1
conv_1 = torch.nn.Conv2d(1,5,kernel_size=3,padding=1)
x = x.view(-1,1,28,28)
x.shape
"""
torch.Size([1, 1, 28, 28])
"""
conv_1 = torch.nn.Conv2d(1,5,kernel_size=3,padding=1)
x1 = conv_1(x)
x1.shape
"""
torch.Size([1, 5, 28, 28])
"""
由输出结果可知,通过第一个卷积层之后,特征图x1为[1,5,28,28]
将x1传入第一个最大池化层
第一个最大池化层
x1的形状为[1,5,28,28]
定义最大池化层:pooling = torch.nn.MaxPool2d(2)
将x1传入最大池化层,得到特征x2
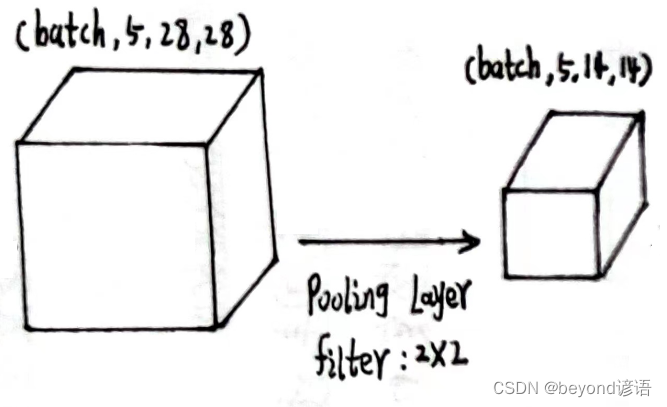
pooling = torch.nn.MaxPool2d(2)
x2 = pooling(x1)
x2.shape
"""
torch.Size([1, 5, 14, 14])
"""
输出结果x2的形状为[1, 5, 14, 14]
将x2传入第二个卷积层中
第二个卷积层
x2的形状为[1, 5, 14, 14]
定义第二个卷积层:conv_2 = torch.nn.Conv2d(5,10,kernel_size=3,padding=1)
将x2传入第二个卷积层,得到特征x3
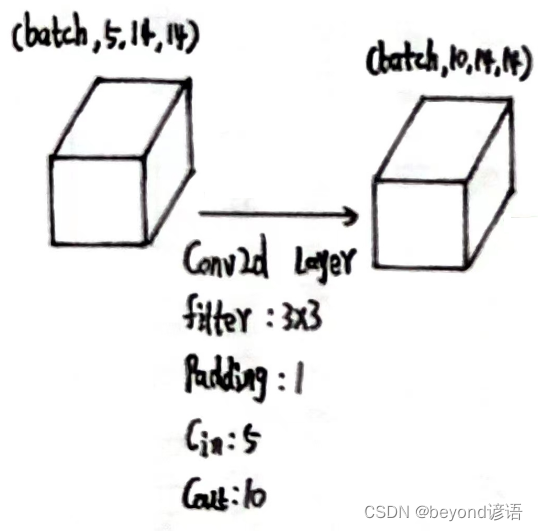
conv_2 = torch.nn.Conv2d(5,10,kernel_size=3,padding=1)
x3 = conv_2(x2)
x3.shape
"""
torch.Size([1, 10, 14, 14])
"""
输出结果x3的形状为[1, 10, 14, 14]
将x3传入第二个最大池化层中
第二个最大池化层
x3的形状为[1, 10, 14, 14]
使用上述同样的最大池化层:pooling = torch.nn.MaxPool2d(2)
将x3传入第二个最大池化层,得到特征x4
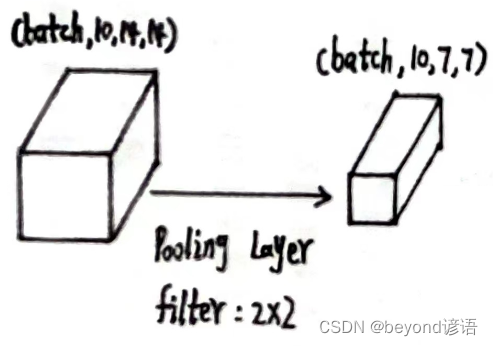
pooling = torch.nn.MaxPool2d(2)
x4 = pooling(x3)
x4.shape
"""
torch.Size([1, 10, 7, 7])
"""
输出结果x4的形状为[1, 10, 7, 7]
将x4传入第三个卷积层中
第三个卷积层
x4的形状为[1, 10, 7, 7]
定义第三个卷积层:conv_3 = torch.nn.Conv2d(10,20,kernel_size=3,padding=1)
将x4传入第三个卷积层,得到特征x5
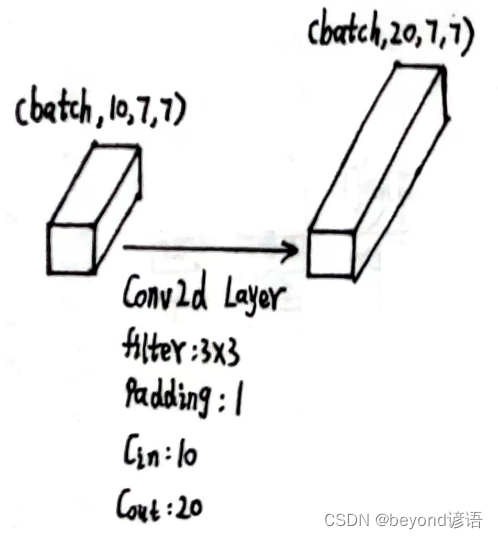
conv_3 = torch.nn.Conv2d(10,20,kernel_size=3,padding=1)
x5 = conv_3(x4)
x5.shape
"""
torch.Size([1, 20, 7, 7])
"""
输出结果x5的形状为[1, 20, 7, 7]
将x5传入第三个最大池化层中
第三个最大池化层
x5的形状为[1, 20, 7, 7]
使用上述同样的最大池化层:pooling = torch.nn.MaxPool2d(2)
将x5传入第二个最大池化层,得到特征x6
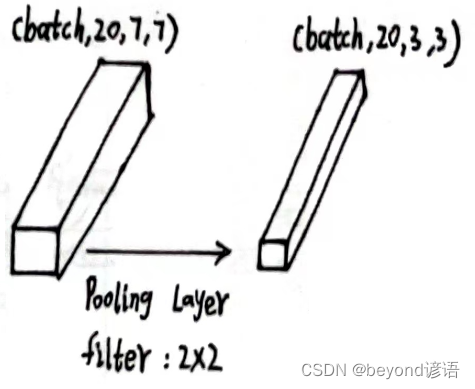
pooling = torch.nn.MaxPool2d(2)
x6 = pooling(x5)
x6.shape
"""
torch.Size([1, 20, 3, 3])
"""
输出结果x6的形状为[1, 20, 3, 3]
将x6传入第一个线性层中
第一个全连接层
x6的形状为[1, 20, 3, 3],此时特征图x6共有1×20×3×3=180个参数
因为线性层传入的特征是二维矩阵形式,每个batch占一行,每行存放单个样本的所有参数信息,故需要将x6形状进行转变,x6.size(0)获取batch,这里的batch是1,剩下的,系统进行自动排列,x_all = x6.view(x6.size(0),-1),此时的x_all的形状为[1,180]
之后根据需求,定义第一个线性层:fc_1 = torch.nn.Linear(180,120),这里的输入180,必须和最终的特征x_all吻合
将x_all传入第一个全连接层,得到特征x_x1
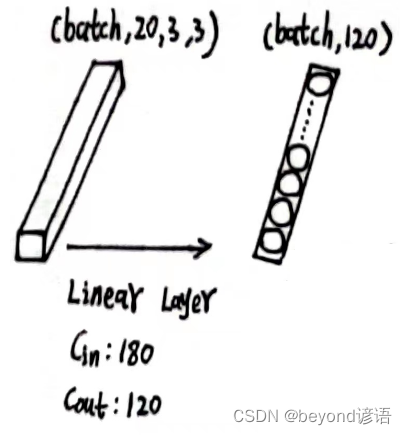
x6.shape
"""
torch.Size([1, 20, 3, 3])
"""
x6.size(0)
"""
1
"""x_all = x6.view(x6.size(0),-1)
x_all.shape
"""
torch.Size([1, 180])
"""fc_1 = torch.nn.Linear(180,120)
x_x1 = fc_1(x_all)
x_x1.shape
"""
torch.Size([1, 120])
"""
输出结果x_x1的形状为[1, 120]
将x_x1传入第二个全连接层中
第二个全连接层
x_x1的形状为[1, 120]
根据需求,定义第二个全连接层,fc_2 = torch.nn.Linear(120,60)
将x_x1传入第二个全连接层,得到特征x_x2
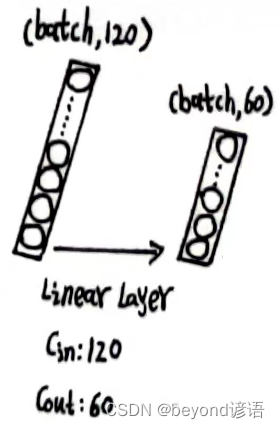
fc_2 = torch.nn.Linear(120,60)
x_x2 = fc_2(x_x1)
x_x2.shape
"""
torch.Size([1, 60])
"""
输出结果x_x2的形状为[1, 60]
将x_x2传入第三个全连接层中
第三个全连接层
x_x2的形状为[1, 60]
根据需求,定义第三个全连接层,fc_3 = torch.nn.Linear(60,10)
将x_x2传入第三个全连接层,得到特征x_x3
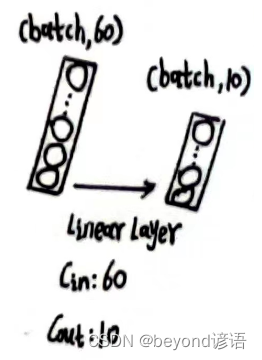
fc_3 = torch.nn.Linear(60,10)
x_x3 = fc_3(x_x2)
x_x3.shape
"""
torch.Size([1, 10])
"""
最终结果为x_x3,形状为[1, 10],十分类任务,十个概率值,取最大的,就是最终预测的结果
②模型构建
class yNet(torch.nn.Module):def __init__(self):super(yNet,self).__init__()self.conv_1 = torch.nn.Conv2d(1,5,kernel_size=3,padding=1)self.pooling = torch.nn.MaxPool2d(2)self.conv_2 = torch.nn.Conv2d(5,10,kernel_size=3,padding=1)self.conv_3 = torch.nn.Conv2d(10,20,kernel_size=3,padding=1)self.fc_1 = torch.nn.Linear(180,120)self.fc_2 = torch.nn.Linear(120,60)self.fc_3 = torch.nn.Linear(60,10)def forward(self,x):batch_size = x.size(0)x = self.pooling(F.relu(self.conv_1(x)))x = self.pooling(F.relu(self.conv_2(x)))x = self.pooling(F.relu(self.conv_3(x)))x = x.view(batch_size,-1)x = self.fc_1(x)x = self.fc_2(x)x = self.fc_3(x)return xmodel = yNet() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#GPU加速
model.to(device)
③完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F #为了使用relu激活函数
import torch.optim as optim batch_size = 64
transform = transforms.Compose([transforms.ToTensor(),#把图片变成张量形式transforms.Normalize((0.1307,),(0.3081,)) #均值和标准差进行数据标准化,这俩值都是经过整个样本集计算过的
])train_dataset = datasets.MNIST(root='./',train=True,download=True,transform = transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)test_dataset = datasets.MNIST(root="./",train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)class yNet(torch.nn.Module):def __init__(self):super(yNet,self).__init__()self.conv_1 = torch.nn.Conv2d(1,5,kernel_size=3,padding=1)self.pooling = torch.nn.MaxPool2d(2)self.conv_2 = torch.nn.Conv2d(5,10,kernel_size=3,padding=1)self.conv_3 = torch.nn.Conv2d(10,20,kernel_size=3,padding=1)self.fc_1 = torch.nn.Linear(180,120)self.fc_2 = torch.nn.Linear(120,60)self.fc_3 = torch.nn.Linear(60,10)def forward(self,x):batch_size = x.size(0)x = self.pooling(F.relu(self.conv_1(x)))x = self.pooling(F.relu(self.conv_2(x)))x = self.pooling(F.relu(self.conv_3(x)))x = x.view(batch_size,-1)x = self.fc_1(x)x = self.fc_2(x)x = self.fc_3(x)return xmodel = yNet()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)lossf = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.0001,momentum=0.5)def ytrain(epoch):loss_total = 0.0for batch_index ,data in enumerate(train_loader,0):x,y = datax,y = x.to(device), y.to(device)#GPU加速optimizer.zero_grad()y_hat = model(x)loss = lossf(y_hat,y)loss.backward()optimizer.step()loss_total += loss.item()if batch_index % 300 == 299:# 每300epoch输出一次print("epoch:%d, batch_index:%5d \t loss:%.3f"%(epoch+1, batch_index+1, loss_total/300))loss_total = 0.0def ytest():correct = 0#模型预测正确的数量total = 0#样本总数with torch.no_grad():#测试不需要梯度,减小计算量for data in test_loader:#读取测试样本数据images, labels = dataimages, labels = images.to(device), labels.to(device) #GPU加速pred = model(images)#预测,每一个样本占一行,每行有十个值,后续需要求每一行中最大值所对应的下标pred_maxvalue, pred_maxindex = torch.max(pred.data,dim=1)#沿着第一个维度,一行一行来,去找每行中的最大值,返回每行的最大值和所对应下标total += labels.size(0)#labels是一个(N,1)的向量,对应每个样本的正确答案correct += (pred_maxindex == labels).sum().item()#使用预测得到的最大值的索引和正确答案labels进行比较,一致就是1,不一致就是0print("Accuracy on testset :%d %%"%(100*correct / total))#correct预测正确的样本个数 / 样本总数 * 100 = 模型预测正确率if __name__ == '__main__':for epoch in range(10):#训练10次ytrain(epoch)#训练一次if epoch%10 == 9:ytest()#训练10次,测试1次
④测试一下
x,y = train_dataset[12]#第12个数据x为图片,对应的结果为3
y
"""
3
"""
x = x.view(-1,1,28,28)#因为tensor需要格式为(B,C,W,H)转换一下格式
y_hat = model(x)#放入模型中进行预测,因为时十分类任务,输出十个值
y_hat
"""
tensor([[ 0.0953, 0.0728, 0.0505, 0.0618, -0.0512, -0.1338, -0.0261, -0.0677,-0.0265, 0.0236]], grad_fn=<AddmmBackward0>)
"""pred_maxvalue, pred_maxindex = torch.max(y_hat,dim=1)#选出值最大的,和相对于的下标索引pred_maxvalue#最大值
"""
tensor([0.0953], grad_fn=<MaxBackward0>)
"""
pred_maxindex#最大值所对应的索引下标值
"""
tensor([0])
"""
好家伙,又预测错了,确实得多训练几轮
又是动笔画,又是单步调试,若各位客官姥爷有所收获,还请点个小小的赞,这将是对我的最大的鼓励,万分感谢~
相关文章:
十、CNN卷积神经网络实战
一、确定输入样本特征和输出特征 输入样本通道数4、期待输出样本通道数2、卷积核大小33 具体卷积层的构建可参考博文:八、卷积层 设定卷积层 torch.nn.Conv2d(in_channelsin_channel,out_channelsout_channel,kernel_sizekernel_size,padding1,stride1) 必要参数&a…...
App 自动化测试
一、移动端测试基础 1 移动端自动化环境搭建 1.1 java安装 1.2 Android SDK安装 SDK (Software Development Kit) 软件开发工具包是软件开发工程师用于为特定的软件包、软件框架、硬件平台、操作系统等建立应用软件的开发工具的集合。Android SDK 就是 Android 专属的软件开…...

考研英语知识点
考研英语知识点 一、在考研英语考试中,常考的英语时态 1.一般现在时 (Simple Present Tense) 一般现在时指的是现在正在进行或经常发生的事情。它用于描述普遍真理,频繁的习惯,以及现在正在发生的事情。例如:我每天早上六点起床…...
IPSEC实验(IPSECVPN点到点,DSVPN,IPSECVPN旁挂)
目录 一、复现实验1、防火墙的IPSECVPN点到点实验-1,拓扑图的搭建-2,配置IP,开通ping,并且设置策略-3,在网络中的IPSEC进行配置第一阶段:发出的UDP500流量第二阶段 发出的ESP流量二台防火墙建立策略禁用其它策略,在IPSEC上配置策略…...

从4k到42k,软件测试工程师的涨薪史,给我看哭了
清明节一过,盲猜大家已经无心上班,在数着日子准备过五一,但一想到银行卡里的余额……瞬间心情就不美丽了。 最近,2023年高校毕业生就业调查显示,本科毕业月平均起薪为5825元。调查一出,便有很多同学表示自己…...

tomcat作业
简述静态网页和动态网页的区别。 静态网页和动态网页是网站的两种基本类型。它们的主要区别在于它们如何生成和呈现网页内容。 静态网页是一种由服务器直接发送给用户的固定HTML文件,其中包含所有网页的内容和样式。这些页面不会随着用户的操作而改变,它…...
除了Java,还可以培训学习哪些IT技术?
除了Java,还可以培训学习哪些IT技术? 转行IT学Java似乎已经成为很多人的首选,原因无非是开发技术含量高、开发有前景、开发是一个互联网企业的核心岗位,最重要的是开发薪资待遇高。但其实只单纯因为薪资选择Java的话,小…...
-- sql语句优化概述及数据库优化)
Mysql优化(一)-- sql语句优化概述及数据库优化
1. sql语句优化 1.1 优化查询过程中的数据访问 访问数据太多导致查询性能下降确定应用程序是否在检索大量超过需要的数据,可能是太多行或列确认MySQL服务器是否在分析大量不必要的数据行避免犯如下SQL语句错误 查询不需要的数据。解决办法:使用limit解…...

深度学习快速参考:1~5
原文:Deep Learning Quick Reference 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如何实现目…...

软件设计师笔记-----程序设计语言与语言处理程序基础
文章目录 七、程序设计语言与语言处理程序基础7.1、编译与解释(低频)7.2、文法(低频)7.3、有限自动机与正规式(几乎每次都会考到)有限自动机正规式 7.4、表达式(偶尔考到)7.5、传值和…...
WebRTC 系列(三、点对点通话,H5、Android、iOS)
WebRTC 系列(二、本地 demo,H5、Android、iOS) 上一篇博客中,我已经展示了各端的本地 demo,大家应该知道 WebRTC 怎么用了。在本地 demo 中是用了一个 RemotePeerConnection 来模拟远端,可能理解起来还有点…...

RabbitMQ( 发布订阅模式 ==> DirectExchange)
本章目录: 何为DirectExchangeDirectExchange具体使用 一、何为DirectExchange 在上一篇文章中,讲述了FanoutExchange,其中publish向交换机发送消息时,我们并没有指定routkingKey,如下图所示 我们看看官方文档 之前使…...
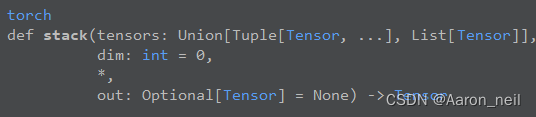
Pytorch基础 - 5. torch.cat() 和 torch.stack()
目录 1. torch.cat(tensors, dim) 2. torch.stack(tensors, dim) 3. 两者不同 torch.cat() 和 torch.stack()常用来进行张量的拼接,在神经网络里经常用到。且前段时间有一个面试官也问到了这个知识点,虽然内容很小很细,但需要了解。 1. t…...

基于AIGC的3D场景创作引擎概述
通过改变3D场景制作流程复杂、成本高、门槛高、流动性差的现状,让商家像玩转2D一样去玩转3D,让普通消费者也能参与到3D内容创作和消费中,真正实现内容生产模式从PGC/UGC过渡到AIGC,是我们3D场景智能创作引擎一直追求的目标。 前言…...

C++算法恢复训练之快速排序
快速排序(Quick Sort)是一种基于分治思想的排序算法,它通过将待排序数组分成两个子数组,其中一个子数组的所有元素都比另一个子数组的元素小,然后对这两个子数组递归地进行排序,最终将整个数组排序。快速排…...

事务的特性
四大特性 原子性(atomicity) 事务的一系列操作,要么所有操作所有都成功,要么一个操作都不做 一致性(consistency) 指数据的规则,在事务前/后应保持一致,事务的原子性保证了一致性 隔离性&a…...

Python 计算三角形的面积、Python 阶乘实例
Python 计算三角形的面积 以下实例为通过用户输入三角形三边长度,并计算三角形的面积: # -*- coding: UTF-8 -*-# Filename : test.py # author by : www.w3cschool.cna float(input(输入三角形第一边长: )) b float(input(输入三角形第二边长: )) c …...

C++入门教程||C++ 重载运算符和重载函数||C++ 多态
C 重载运算符和重载函数 C 重载运算符和重载函数 C 允许在同一作用域中的某个函数和运算符指定多个定义,分别称为函数重载和运算符重载。 重载声明是指一个与之前已经在该作用域内声明过的函数或方法具有相同名称的声明,但是它们的参数列表和定义&…...
docker+docker-compose+nginx前后端分离项目部署
文章目录 1.安装docker1.1 基于centos的安装1.2 基于ubuntu 2.配置国内加速器2.1 配置阿里云加速器🍀 找到相应页面🍀 创建 docker 目录🍀 创建 daemon.json 文件🍀 重新加载服务配置文件🍀 重启 docker 引擎 2.2 配置…...
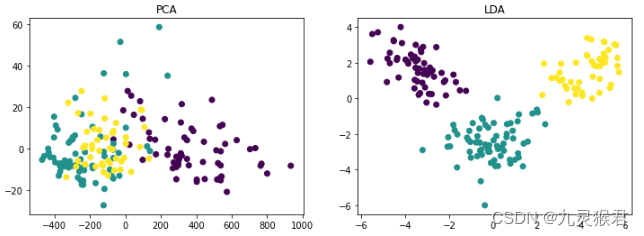
基于PCA与LDA的数据降维实践
基于PCA与LDA的数据降维实践 描述 数据降维(Dimension Reduction)是降低数据冗余、消除噪音数据的干扰、提取有效特征、提升模型的效率和准确性的有效途径, PCA(主成分分析)和LDA(线性判别分析࿰…...

Apache RocketMQ 5.0 架构解析:如何基于云原生架构支撑多元化场景
本文将从技术角度了解 RocketMQ 的云原生架构,了解 RocketMQ 如何基于一套统一的架构支撑多元化的场景。 文章主要包含三部分内容。首先介绍 RocketMQ 5.0 的核心概念和架构概览;然后从集群角度出发,从宏观视角学习 RocketMQ 的管控链路、数…...

【亲测免费】 Teigha各版本使用汇总
Teigha各版本使用汇总 【下载地址】Teigha各版本使用汇总 这份汇总不仅提供了这些版本的下载链接,更重要的是,它详细记录了在C#环境下,特别是使用VS2010作为开发平台时,针对每个版本的测试与使用经验。无论是构建Web应用程序还是W…...
)
洛谷P7071 ‘优秀的拆分’背后:如何用对拍程序验证你的C++代码正确性(附Win10批处理脚本)
洛谷P7071 优秀的拆分背后:如何用对拍程序验证你的C代码正确性(附Win10批处理脚本) 在编程竞赛中,写出能通过样例的代码只是第一步。真正考验选手的是代码在各种边界条件下的稳定性。很多选手都有这样的经历:提交代码后…...

2025最新 SpringCloud 教程,Seat-原理-四种事务模式,总结,笔记72,笔记73
2025最新 SpringCloud 教程,Seat-原理-四种事务模式,总结,笔记72,笔记73 一、参考资料 Seat-原理-四种事务模式 🔗 总结 🔗 二、笔记总结...

Discourse Docker持续集成:自动化构建与部署完整指南 [特殊字符]
Discourse Docker持续集成:自动化构建与部署完整指南 🚀 【免费下载链接】discourse_docker A Docker image for Discourse 项目地址: https://gitcode.com/gh_mirrors/dis/discourse_docker Discourse Docker持续集成是现代论坛部署的最佳实践&a…...
:普通模式与DMA模式,附完整可用代码)
STM32 ADC采样详解(标准库版):普通模式与DMA模式,附完整可用代码
前言 ADC(模数转换器)是嵌入式开发中测量模拟信号的核心外设,从简单的电压读取到复杂的传感器数据采集都离不开它。STM32F103 内置 12 位逐次逼近型 ADC,最多支持 18 个通道,在 72MHz 主频下最高采样率达 1Msps&#x…...

5分钟掌握UABEA:解锁Unity游戏资源编辑的终极指南
5分钟掌握UABEA:解锁Unity游戏资源编辑的终极指南 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 你是否曾想修改游戏角色皮肤却无从下手?面对Unity打包的.asset和.bundle文件感…...

gptree:为AI生成项目结构报告,提升代码分析与协作效率
1. 项目概述与核心价值最近在整理个人项目和代码库时,我遇到了一个几乎所有开发者都会头疼的问题:项目越做越多,文件夹嵌套越来越深,README写得再好,时间一久也记不清某个具体功能的实现细节藏在哪个文件的哪个角落里。…...

关于光缆,这些事儿通信人一定要知道
随着5G网络的全面铺开和持续深耕,通信工程师的工作边界正在不断拓展。过去,后台网优工程师可能更多地专注于参数调整、信令分析和性能优化;而如今,越来越多的项目要求前后台协同作业,网优人员也需要熟悉现场施工规范&a…...

基于wechat_bot_sdk的微信机器人开发:从协议模拟到工程化实践
1. 项目概述与核心价值最近在折腾一个需要对接微信消息通知的项目,发现市面上很多现成的机器人框架要么太重,要么封装得过于“黑盒”,想改点东西得扒好几层源码。后来在GitHub上翻到了waro163/wechat_bot_sdk这个项目,看名字就知道…...