精通线程池,看这一篇就够了
一:什么是线程池
当我们运用多线程技术处理任务时,需要不断通过new的方式创建线程,这样频繁创建和销毁线程,会造成cpu消耗过多。那么有没有什么办法避免频繁创建线程呢?
当然有,和我们以前学习过多连接池技术类似,线程池通过提前创建好线程保存在线程池中,在任务要执行时取出,任务结束时再放回去,由此大大提高线程利用率,避免频繁创建销毁带来的开销
二:Java提供的线程池有哪些
那么我们怎么才能创建一个线程池呢?可以通过Executors的以下方法创建
newFixedThreadPool 固定线程池数量
newSingleThreadExecutor 只有一个线程的线程池
newCachedThreadPool 可以缓存的线程池
newScheduledThreadPool 按周期执行的线程池
例如
ExecutorService executorService = Executors.newFixedThreadPool(3);//创建一个拥有三个线程的线程池
这些方法可以创建线程池,但是实际工作中并不推荐使用这种方式,因为这里阻塞队列使用的是LinkedBlockingQueue,是无界的,如果不断有任务添加进去,占用内存越来越多,可能导致OOM
所以更多时候,可以通过手动创建线程池
那么如何手动创建线程池呢?可以先点开上面提到的几个方法,会发现这些方法本质上都是最后构造一个ThreadPoolExecutor实例
如下是Executors的newFixedThreadPool方法
public class Executors {public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());}
所以手动创建线程池,只需要创建ThreadPoolExecutor就可以了,在创建之前,我们先要弄懂构造方法中的参数含义,才能创建合适的线程池
三:线程池参数
从以上源代码中可以看到构造ThreadPoolExecutor,需要一些参数,那么这些参数分别是什么意思呢?先看一下ThreadPoolExecutor的构造方法
public ThreadPoolExecutor(int corePoolSize, //控制核心线程数int maximumPoolSize,//控制最大线程数(核心线程+救急线程)long keepAliveTime,//生存时间:针对救急线程#这里是一个数字TimeUnit unit,//时间单位#这里可以是秒,毫秒等BlockingQueue<Runnable> workQueue,//阻塞队列ThreadFactory threadFactory,//可以为线程创建时起个好名字RejectedExecutionHandler handler)//拒绝策略
那么什么是核心线程?什么又是救急线程呢?
核心线程: 执行完任务后需要保留在线程池中的
救急线程: 线程执行任务后不需要保留在线程池中的线程
阻塞队列: 对任务做缓冲作用,例如三个核心线程都在执行任务,这时候来了第四个任务怎么办?就将新任务放入workQueue队列中,等核心线程执 行完任务空闲了,就会从队列中获取任务
救急线程:如果核心线程已满,队列已满,这时候又来任务怎么办?就由救急线程来执行
拒绝策略:核心线程放满了,任务队列也满了,救急线程不能无限创建啊 这时候再来线程怎么办
四:线程池状态
线程池状态
ThreadPoolExecutor
使用int的高三位表示线程池状态
低29位表示线程数量
RUNNING 111
SHUTDOWN 000 线程池调用SHUTDOWN 方法,不会接受新任务,但是会处理阻塞队列中的任务
STOP 001 不会接受新任务,正在执行的任务也会停止,阻塞队列任务抛弃
TIDYING 010 任务执行完毕
TERMINATED 011 终结状态
这些信息存储在一个原子变量ctl中,目的是将线程池状态与
线程池个数合二为一,这样就可以通过一次CAS操作进行赋值
五:execute方法
public void execute(Runnable command) {if (command == null)throw new NullPointerException();int c = ctl.get(); //拿到32位intif (workerCountOf(c) < corePoolSize) { //workerCountOf(c)获取工作线程数 corePoolSize 核心线程数if (addWorker(command, true)) //addWorker(command, true)创建核心线程数return;c = ctl.get();}if (isRunning(c) && workQueue.offer(command)) { // 1 isRunning判断线程池是否是Running状态 // 2 workQueue.offer(command) 将线程添加到阻塞队列int recheck = ctl.get(); // 3 成功,再次Ctl.get ()拿到32位intif (! isRunning(recheck) && remove(command))// 4 isRunning(recheck)再次判断是否是Running// 5 如果不是Running,remove(command)移除任务reject(command);else if (workerCountOf(recheck) == 0) // 6 获取当前工作的线程个数,如果是0addWorker(null, false); // 7 阻塞队列有任务,但是没有工作线程,添加一个任务为空} else if (!addWorker(command, false)) // 8 如果7的判断是running,创建非核心线程处理任务reject(command); // 9 如果上一步创建失败 拒绝策略 reject(command);
}
其中拒绝策略在第三节讲参数的时候提到,那么具体有哪些拒绝策略呢?
下图是拒绝策略的实现

AbortPolicy(线程池默认的拒绝策略):丢弃任务,并抛出拒绝执行 RejectedExecutionException 异常信息。
必须处理好抛出的异常,否则会打断当前的执行流程,影响后续的任务执行。
CallerRunsPolicy :当触发拒绝策略,并且线程池没有关闭时,则使用父线程直接运行任务这会阻塞父进程继续往线程池中添加新的任务。个人认为仅仅适用于比较特殊的场景
DiscardPolicy:直接丢弃,不抛出任何一场,适用于比较特殊的场景
DiscardOldestPolicy :当触发拒绝策略,只要线程池没有关闭的话,丢弃阻塞队列 workQueue 中最老的一个任务,并将新任务加入
六:线程池参数如何设置
通过以上,我们了解了线程池各个参数的含义,但是当我们自己创建线程池时,应该如何选择合适的参数呢?
这里需要重点考虑的就是:核心线程数 如何设置这里主要难点在于任务类型无法控制,例如:任务有CPU密集型、IO密集型
CPU密集型:系统硬盘、内存性能相对CPU要好很多,此时,系统运作 大部分状况是CPU Loading 100%,CPU读写IO(内存/硬盘)在短时间内可以完成,而CPU还有许多运算要处理CPU Loading很高
IO密集型:CPU相对系统硬盘、内存性能要好很多,此时系统运作,大部分状况是CPU在等IO内存/硬盘)读写,此时CPU Loading 不高
IO密集型通常设置 2n+1,n是CPU核心数
CPU密集型通常设置为 n+1
实际中IO密集型较多,但是按照2n+的公式,在实际中可能不理想,如果增大线程数,会显著提高消息的处理能力
怎么判断需要增加更多线程呢?
可以使用jstack命令查看进程的线程栈,如果线程池中线程都处于等待状态,说明线程够用, 如果大部分线程处于运行状态,可以适当调高线程数
可以套用这个公式:
线程数=CPU核心数/(1-阻塞系数(通常0.8))
相关文章:
精通线程池,看这一篇就够了
一:什么是线程池 当我们运用多线程技术处理任务时,需要不断通过new的方式创建线程,这样频繁创建和销毁线程,会造成cpu消耗过多。那么有没有什么办法避免频繁创建线程呢? 当然有,和我们以前学习过多连接池技术类似&…...

解决图片、视频地址加密问题
const getImgUrl async () > {const imgUrl 远程链接地址const response await fetch(imgUrl)//取出blob二进制const blob await response.blob()//url转为类似blob:http://localhost:9587/cf3265b9-75eb-4722-8e11-5048dec2564d//赋值给需要展示的地方const url URL.c…...

GPT引领学习之旅:一篇让程序员轻松掌握Elasticsearch的攻略
一、引言 随着大数据技术的飞速发展,程序员们面临着越来越多的挑战。Elasticsearch作为一款流行的开源搜索和分析引擎,已成为许多项目的重要组成部分。那么如何高效地学习并掌握Elasticsearch呢?在这篇文章中,我们将探讨如何运用…...
)
23种设计模式-仲裁者模式(Android应用场景介绍)
仲裁者模式是一种行为设计模式,它允许将对象间的通信集中到一个中介对象中,以减少对象之间的耦合度。本文将通过Java语言实现仲裁者模式,并介绍如何在安卓开发中使用该模式。 实现仲裁者模式 我们将使用一个简单的例子来说明仲裁者模式的实…...
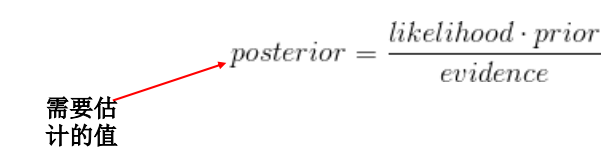
【数据统计】— 极大似然估计 MLE、最大后验估计 MAP、贝叶斯估计
【数据统计】— 极大似然估计 MLE、最大后验估计 MAP、贝叶斯估计 极大似然估计、最大后验概率估计(MAP),贝叶斯估计极大似然估计(Maximum Likelihood Estimate,MLE)MLE目标例子: 扔硬币极大似然估计—高斯分布的参数 矩估计 vs LSE vs MLE贝叶斯公式&am…...

Zookeeper学习笔记
Zookeeper入门 Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的Apache 项目。 Zookeeper工作机制 Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,…...
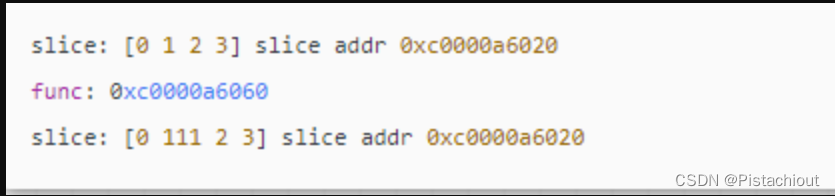
go语言切片做函数参数传递+append()函数扩容
go语言切片函数参数传递append()函数扩容 给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。 二叉树递归go代码: var ans [][]int func pathSum(root *TreeNode, targetSum int) ( [][…...
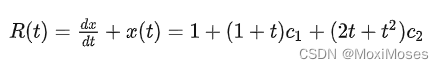
2023.04.16 学习周报
文章目录 摘要文献阅读1.题目2.摘要3.简介4.Dual-Stage Attention-Based RNN4.1 问题定义4.2 模型4.2.1 Encoder with input attention4.2.2 Decoder with temporal attention4.2.3 Training procedure 5.实验5.1 数据集5.2 参数设置和评价指标5.3 实验结果 6.结论 MDS降维算法…...
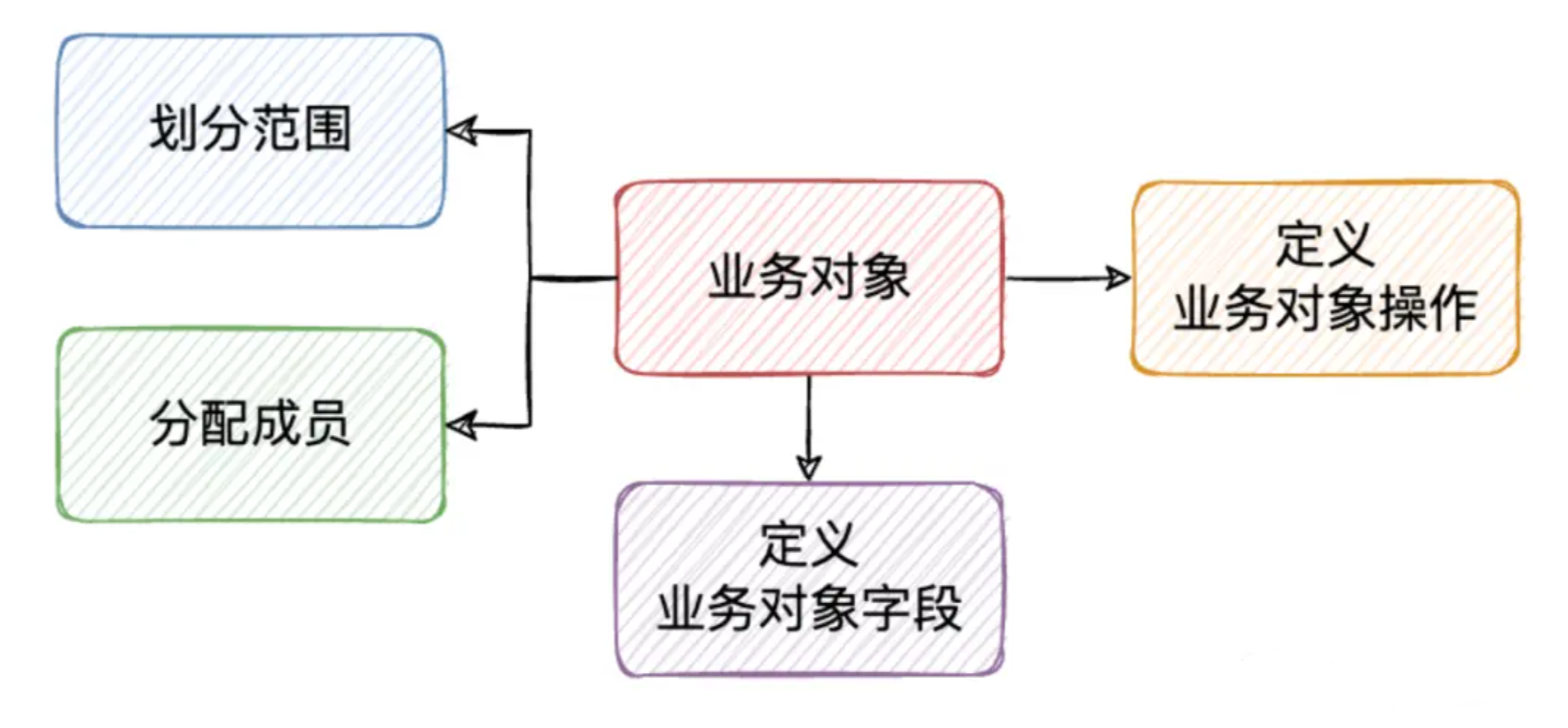
【面试】如何设计SaaS产品的数据权限?
文章目录 前言数据权限是什么?设计原则整体方案RBAC模型怎么控制数据权限?1. 数据范围权限控制2. 业务对象操作权限控制3. 业务对象字段权限控制 总结 前言 一套系统的权限可以分为两类,数据权限和功能权限,今天我们从以下几个点…...

ansible管理变量
ansible变量简介 变量用于存储值,便于重复使用,可以简化项目的创建和维护。 变量命令规则 ansible变量的名称必须以字母开头,平且只能包含字母、数字和下划线,不允许有其他特殊字符。 变量范围 全局范围:从命令行…...

一种轻量级日志采集解决方案
前言 目前各大公司生产部署很多都是采用的集群微服务的部署方式,如果让日志散落在各个主机上,查询起来会非常的困难,所以目前我了解到的都是采用的日志中心来统一收集管控日志,日志中心的实现方案大多基于ELK(即Elasticsearch、L…...
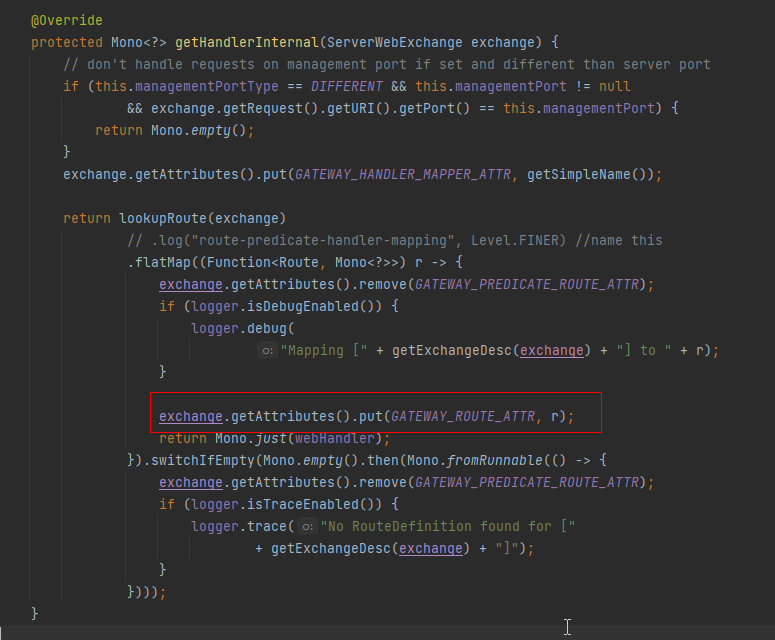
【源码】Spring Cloud Gateway 是在哪里匹配路由的?
我们知道,经过网关的业务请求会被路由到后端真实的业务服务上去,假如我们使用的是Spring Cloud Gateway,那么你知道Spring Cloud Gateway是在哪一步去匹配路由的吗? 源码之下无秘密,让我们一起从源码中寻找答案。 入…...

BAT批处理基本命令
什么是 BAT 批处理脚本语言? BAT 批处理脚本语言是 Windows 系统自带的一种脚本语言,主要用于批量处理文件、目录、注册表、系统设置等任务。使用 BAT 批处理脚本语言可以节省大量手动操作的时间和精力。 如何编写 BAT 批处理脚本? 使用记事本…...
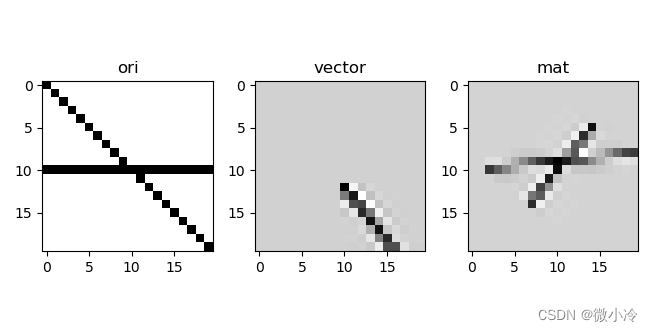
Python数组仿射变换
文章目录 仿射变换坐标变换的逻辑scipy实现 仿射变换 前面提到的平移、旋转以及缩放,都可以通过一个变换矩阵来实现,以二维空间中的变换矩阵为例,记点的坐标向量为 ( x , y , 1 ) (x,y,1) (x,y,1),则平移矩阵可表示为 [ 1 0 T x …...

“==“和equals方法究竟有什么区别?
操作符专门用来比较两个变量的值是否相等,也就是用于比较变量所对应的内存中所存储的数值是否相同,要比较两个基本类型的数据或两个引用变量是否相等,只能用操作符。 如果一个变量指向的数据是对象类型的,那么,这时候…...
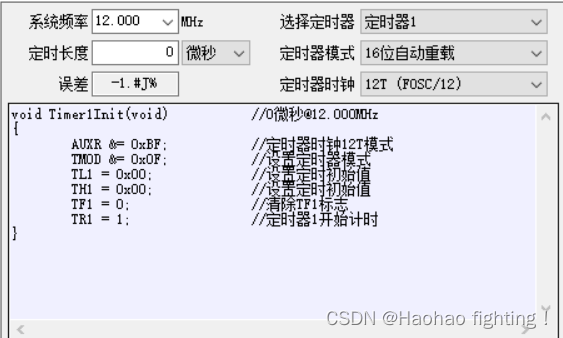
蓝桥杯15单片机--超声波模块
目录 一、超声波工作原理 二、超声波电路图 三、程序设计 1-设计思路 2-具体实现 四、程序源码 一、超声波工作原理 超声波时间差测距原理超声波发射器向某一方向发射超声波,在发射时刻的同时开始计时,超声波在空气中传播,途中碰到障碍…...

【学习笔记】ARC159
D - LIS 2 因为没有让你求方案数,所以还是比较好做的。 如果每一个连续段都退化成一个点,那么答案就是直接求 L I S LIS LIS。 否则,假设我们选了一些连续段把它们拼起来形成答案,显然我们有 r i 1 ≥ l i r_{i1}\ge l_i ri1…...

2023/4/16总结
图的存储 链式前向星 链式前向星和邻接表很相似,只是存储方式变成了数组。 链式前向星一般要用到一个结构体数组和一个一维数组,结构体数组edges中包括三个变量。结构体数组的大小一般由边的大小决定。 edges数组中的to代表的是某条边的终点v。w代表的是这条边的…...

【剑指offer】常用的数据增强的方法
系列文章目录 BN层详解 梯度消失和梯度爆炸 交叉熵损失函数 反向传播 1*1卷积的作用 文章目录 系列文章目录常用的数据增强的方法示例代码 常用的数据增强的方法 数据增强是指通过对原始数据进行一系列变换来生成更多的训练数据,从而提高模型的泛化能力。常用的数…...

/lib/lsb/init-functions文件解析
零、背景 在玩AppArmor的时候涉及到了/etc/init.d/apparmor(无论是sudo /etc/init.d/apparmor start还是sudo systemctl start apparmor.service),而这个文件又涉及到了另一个文件、也就是本文的主角:/lib/lsb/init-functions。 …...

SoC与SoM:硬件开发的效率革命与双刃剑效应
1. 项目概述:当“系统”成为商品从业十几年,从画第一块51单片机的板子,到参与设计复杂的通信基站,我亲眼见证了硬件开发模式的剧变。如果说早些年我们还在为如何把CPU、内存、Flash、各种接口控制器塞进一块PCB而绞尽脑汁…...

Hive 3.1.2 避坑指南:手把手解决‘Metastore未初始化’及分区表数据导入那些事儿
Hive 3.1.2 实战避坑:从Metastore初始化到分区表优化的全链路解决方案 当你在Ubuntu 18.04上刚完成Hive 3.1.2的安装,满心欢喜准备大展拳脚时,命令行却无情地抛出"Hive metastore database is not initialized"的错误提示——这场景…...

[物联网入门实战] 从零搭建C51最小系统:Proteus仿真点亮LED全流程解析
1. 为什么选择C51最小系统入门物联网? 很多刚接触物联网开发的朋友都会遇到一个难题:硬件成本高、调试复杂、学习曲线陡峭。我当年自学嵌入式时,烧坏过好几块开发板,后来发现用Proteus仿真C51最小系统是最稳妥的入门方式。这套组合…...

逆向实战:用X32dbg条件断点精准定位MFC程序的窗口消息处理函数
逆向实战:用X32dbg条件断点精准定位MFC程序的窗口消息处理函数 在逆向分析领域,MFC程序因其复杂的消息映射机制和封装层次,常常让分析者感到无从下手。特别是当我们需要分析某个特定窗口消息(如按钮点击、菜单选择)的处…...

ZYNQ PS-PL协同实战:如何设计一个带触发与延时的多通道数据采集卡?
ZYNQ PS-PL协同实战:工业级多通道数据采集卡架构设计精要 在工业自动化与测试测量领域,数据采集系统的性能直接决定了整个系统的可靠性与精度。Xilinx ZYNQ系列SoC凭借其独特的ARM处理器(PS)与可编程逻辑(PL)协同架构,成为构建高性能数据采集…...

弱引用TWeakObjectPtr原理
弱引用的原理:从通用思路到 UE TWeakObjectPtr 原理总结: !!#ff0000 UE 的 GC 体系有一张全局对象表 GUObjectArray,弱引用存了一个索引,以及这个物体创建时的序列号,简单来说是不是弱引用先拿着索引去序列号找一下&am…...
)
【2026最新】应对维普算法升级,5大降AI工具横测,一次稳降至25%(附手改秘籍)
知网和维普的AIGC检测系统又更新了! 在当下的关口,如何在不牺牲质量的前提下,优化初稿表达,安全地降低AI痕迹,成了所有小伙伴们必须解决的一个问题。网络上各种“降AI神器”铺天盖地,这些工具到底靠不靠谱…...

具身智能涉及的交互技术及实施难点
在具身智能(Embodied Intelligence, EI)迈入规模化交付与产线落地的关键阶段 [临近时间验证, ,它与用户为中心交互系统工程(UCI-SE)的融合达到了前所未有的深度 。传统机器人的交互仅限于键盘或教导盒(Pend…...

卫星通信安全认证技术解析与应用指南
1. 卫星通信安全认证技术概述 卫星通信作为现代信息基础设施的重要组成部分,其安全性直接关系到国家安全和经济发展。在近地轨道卫星数量激增、天地一体化网络快速发展的背景下,传统地面网络的安全认证方案已无法满足卫星通信的特殊需求。卫星信道具有长…...

3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南
3步实现AutoHotkey脚本独立运行:Ahk2Exe编译工具完全指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 你是否厌倦了每次运行AutoHotkey脚本都需要安…...