在Github中77k星的王炸AutoGPT,会独立思考,直接释放双手
文章目录
- 1 前言
- 1.1 什么是AutoGPT
- 1.2 为什么是AutoGPT
- 2 AutoGPT部分实例
- 2.1 类似一个Workflow
- 2.2 市场调研
- 2.3 自己写播客
- 2.4 接入客服
- 3 安装和使用AutoGPT
- 3.1 安装
- 3.2 基础用法
- 3.3 配置OpenAI的API
- 3.4 配置谷歌API
- 3.5 配置Pinecone API
- 4.讨论
1 前言
迄今为止,Github已经7.7万stars了,项目真的顶
GitHub 地址:https://github.com/torantulino/auto-gpt
这里提前下载好了,如果登不上Github或者下载失败的可以在后台回复
autogpt领取v0.2.1的源码压缩包
1.1 什么是AutoGPT
十分重磅!GPT3.5都还没玩明白,傍着GPT4的AutoGPT就又要乱杀了,特斯拉前 AI 总监、刚刚回归 OpenAI 的 Andrej Karpathy也提到**“AutoGPT”将成为提示工程的下一个前沿**,网上很多人只提突破性,不提局限性,twitter的原话是prompt engineering领域,因此其他领域还是坐观新测
Auto-GPT 是一个实验性的开源 Python 应用程序,它使用GPT-4自主运行。听名字也知道,auto,自主人工智能,这意味着 Auto-GPT 可以在几乎没有人为干预的情况下执行任务,并且可以自我提示。一言以蔽之,AutoGPT可以实现:分配一个任务,它能自行生成一个结果及任务的每一个提示,其实这类的AI还有AgentGPT、BabyAGI,但,真不够AutoGPT火,其也有火的道理
1.2 为什么是AutoGPT
Auto-GPT 可以将 AI 的行为分解为“思想”、“推理”和“批评”,这展示了 GPT 令人印象深刻的文本生成能力。此功能使用户能够准确了解 AI 在做什么以及为什么这样做。简单说是,**有一个人能帮你完成任务,还会告诉你怎么做。**例如,就 Chef-GPT 而言,AI 的第一个“想法”是“搜索即将发生的事件以找到合适的事件来创建独特的食谱”。这一行动背后的“原因”是“找到即将发生的事件将帮助我想出一个相关且令人兴奋的食谱。”
Auto-GPT 的“批评”分析了对其行为的潜在约束或限制,进一步展示了其在实现用户设定的目标的同时自主运行的能力。此外,Auto-GPT 具有长期和短期记忆功能,以及通过 ElevenLabs 进行的文本转语音功能。这些功能的融合使 Auto-GPT 更像人,增强了它与人互动的能力。
有人会问
ChatGPT和Auto-GPT区别,哪个更好?
都好,且不同一个纬度,无法平行比较。首先知道一下人工智能AI和通用人工智能AGI的区别:人工智能 (AI) 是一个广义术语,指的是能够执行需要人类智能才能完成的任务的计算机系统。然而,通用人工智能 (AGI) 指的是可以像人类一样使用自己的过程、推理和智力执行任务的人工智能。
尽管 ChatGPT 是一个非常有能力的聊天机器人,但它仍然只是一个聊天机器人。作为聊天机器人,它仅限于仅对通过提示立即询问的内容做出回应。因此,它可以完成惊人的事情,但只有通过人类的指导。 Auto-GPT 的能力远不止于此,可以要求它完成一项一无所知的任务,然后看着它完成所有工作。即:ChatGPT需要人去引导他,得到自己想要的东西;AutoGPT是给他指令,他自己去思考,自己去想办法完成结果交付。这可以很明显看出后者的特色Auto,更自主化。
2 AutoGPT部分实例
2.1 类似一个Workflow
生成一个 GPT-4 代理来完成添加到待办事项列表中的任何任务
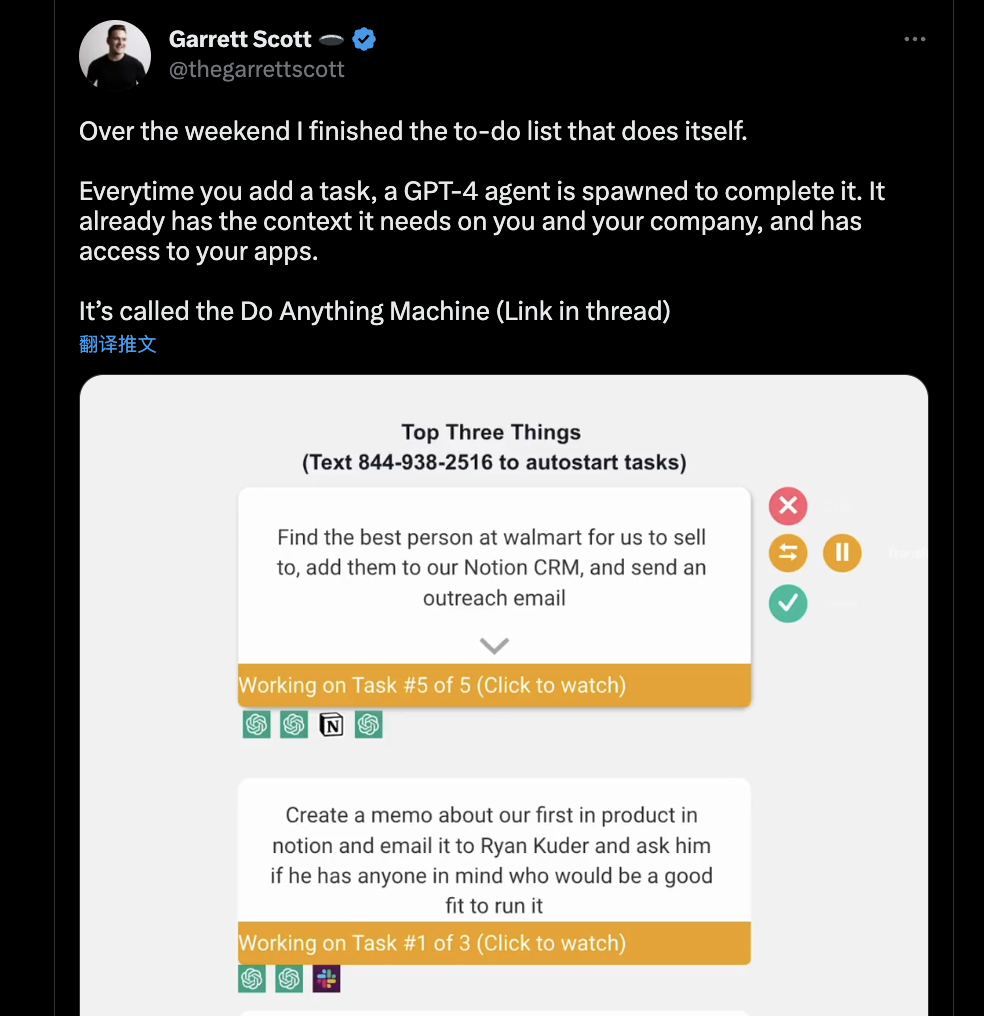
视频链接:https://twitter.com/i/status/1645918390413066240
2.2 市场调研
运营一个 AI 代理,负责进行产品研究并撰写有关最佳耳机的摘要
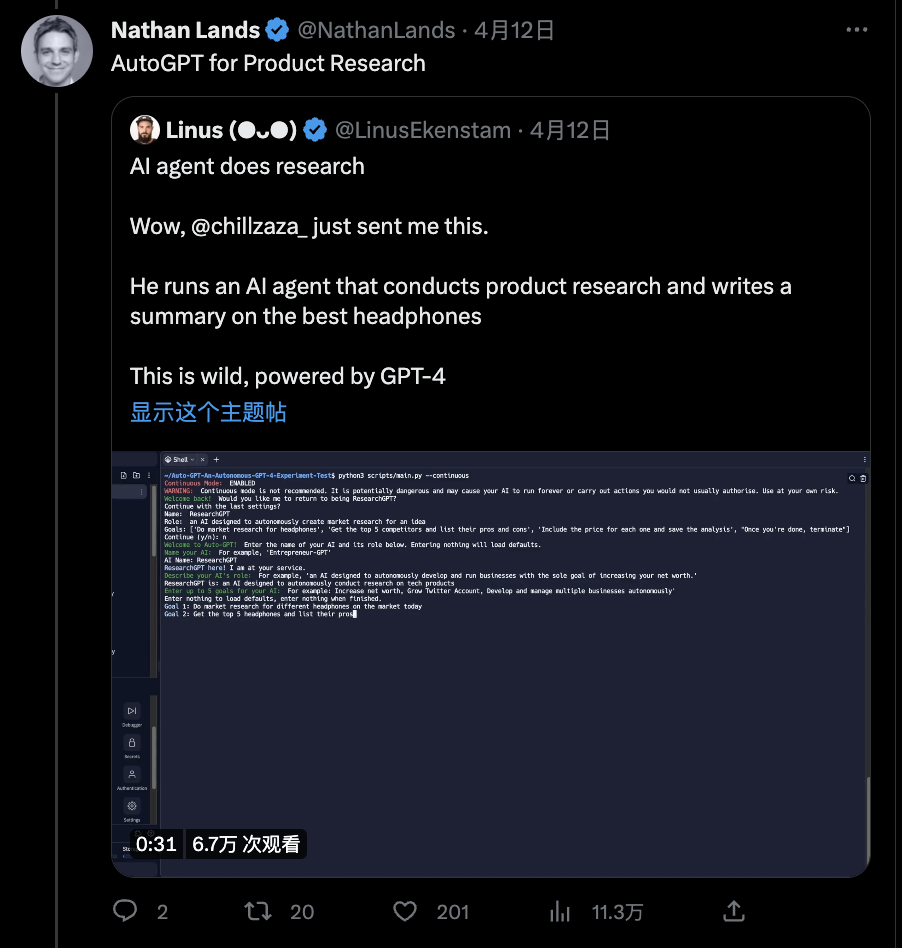
第二个视频是关于博客研究的,此外Nathan Lands还展示了用于销售勘探的 BabyAGI

视频1链接:https://twitter.com/i/status/1646095934177124353
视频2链接:https://twitter.com/i/status/1645898646762782735
2.3 自己写播客
自行阅读近期发生的事件自行总结并且撰写播客内容
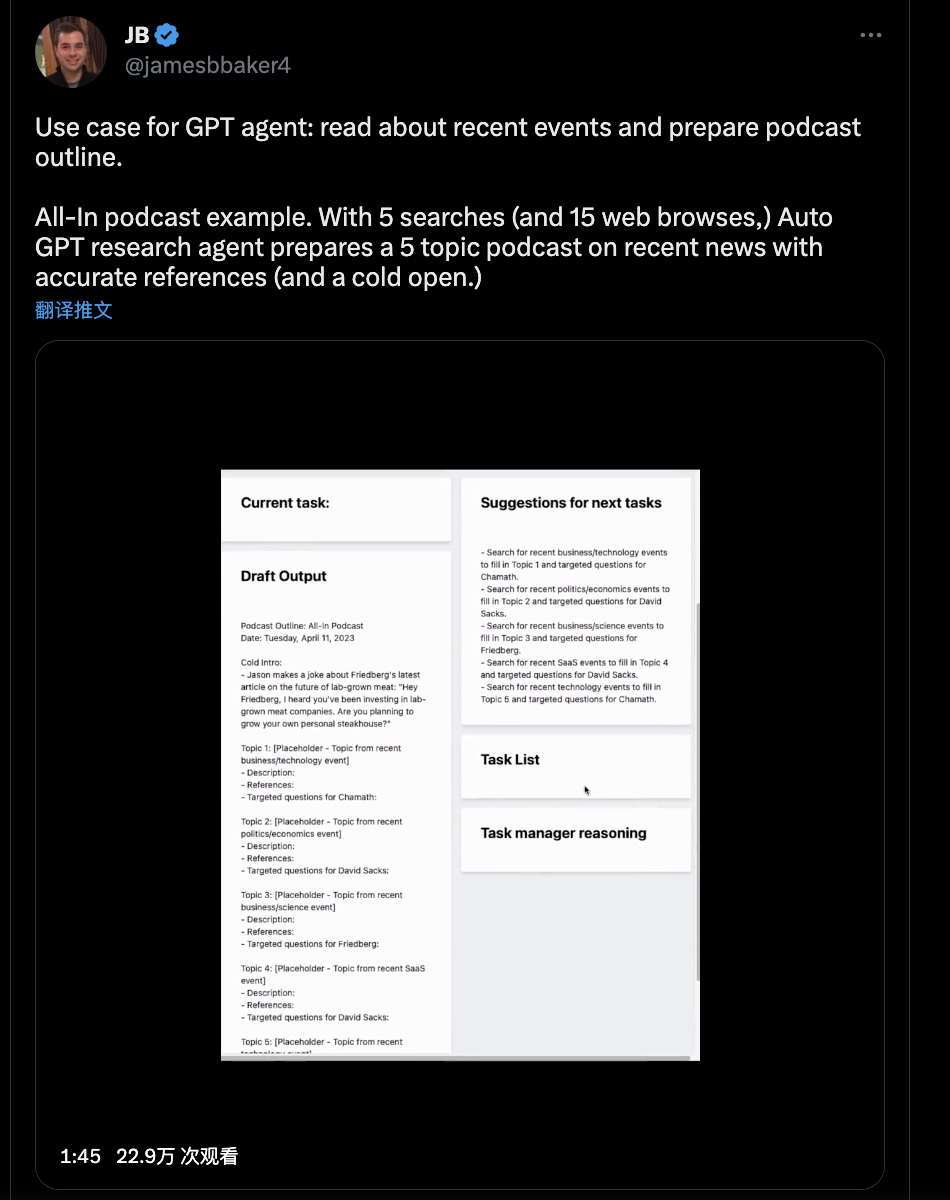
视频链接:https://twitter.com/i/status/1645898646762782735
2.4 接入客服
AutoGPT可以不需要使用者一直输入指令,直接化身24h全天候智能客服,通达全语种,理解客户查询,提供支持,甚至建议追加销售
推文链接:https://twitter.com/gregisenberg/status/1645817335024869376?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1645817335024869376%7Ctwgr%5E1bcdfa0f1f346feb279a7821bda593c41ddc14de%7Ctwcon%5Es1_&ref_url=https%3A%2F%2Fautogpt.net%2Famazing-use-cases-for-auto-gpt-on-twitter%2F
3 安装和使用AutoGPT

安装要求
3.1 安装
确保满足安装要求,记得下载git工具,然后在bash或者cmd或者turminal克隆库:
git clone https://github.com/Torantulino/Auto-GPT.git
进入库
cd Auto-GPT
安装依赖项
pip install -r requirements.txt
重命名.env.template为 .env 并填写 OPENAI_API_KEY. 如果打算使用语音模式,也需要填写 ELEVEN_LABS_API_KEY
- OpenAI API 密钥:https: //platform.openai.com/account/api-keys
- ElevenLabs API 密钥(在
个人资料——xi-api-key):https://elevenlabs.io
这样就可以了,如果需要在Azure实例上使用 GPT,请设置USE_AZURE为True然后:
- 重命名
azure.yaml.template为 并提供部分 中相关模型的azure.yaml相关azure_api_base和 所有部署 ID :azure_api_versionazure_model_map -
fast_llm_model_deployment_id:gpt-3.5-turbo 或 gpt-4 部署 ID
-
smart_llm_model_deployment_id:gpt-4 部署 ID
-
embedding_model_deployment_id:text-embedding-ada-002 v2 部署 ID
- 将所有这些值指定为双引号字符串
# Replace string in angled brackets (<>) to your own ID
azure_model_map:fast_llm_model_deployment_id: "<my-fast-llm-deployment-id>"...
- 详细信息可以参考:
https://pypi.org/project/openai/,https://learn.microsoft.com/en-us/azure/cognitive-services/openai/tutorials/embeddings?tabs=command-line
3.2 基础用法
- 在目录运行py文件
python scripts/main.py# 授权单个命令,输入y
# 授权一系列N个连续命令,输入y -N
# 退出程序,进入n
也可以在 AUTO-GPT 的每个动作之后,键入“NEXT COMMAND”以授权它们继续。
要退出程序,请键入“exit”并按 Enter。
- 可以在文件夹中找到活动和错误日志
./output/logs,输出调试日志:
python scripts/main.py --debug
- 语音模式:
python scripts/main.py --speak#目前已有的11个lab id
Rachel : 21m00Tcm4TlvDq8ikWAM
Domi : AZnzlk1XvdvUeBnXmlld
Bella : EXAVITQu4vr4xnSDxMaL
Antoni : ErXwobaYiN019PkySvjV
Elli : MF3mGyEYCl7XYWbV9V6O
Josh : TxGEqnHWrfWFTfGW9XjX
Arnold : VR6AewLTigWG4xSOukaG
Adam : pNInz6obpgDQGcFmaJgB
Sam : yoZ06aMxZJJ28mfd3POQ
- docker:
# 调用和运行
docker build -t autogpt .
docker run -it --env-file=./.env -v $PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt# 或者
docker-compose run --build --rm auto-gpt# 其他参数
docker run -it --env-file=./.env -v $PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt --gpt3only --continuous
docker-compose run --build --rm auto-gpt --gpt3only --continuous
- 命令行常用命令:
# 查看所有可行参数
python -m autogpt --help# 用其他ai设置文件运行
python -m autogpt --ai-settings <filename># 指定内存后端
python -m autogpt --use-memory <memory-backend>
- 内存后端设置
启动redis的docker
docker run -d --name redis-stack-server -p 6379:6379 redis/redis-stack-server:latest
然后配置.env
MEMORY_BACKEND=redis
REDIS_HOST=localhost
REDIS_PORT=6379
REDIS_PASSWORD=<PASSWORD>
- 设置缓存类型
默认情况下,Auto-GPT 将使用 LocalCache 而不是 redis 或 Pinecone。
若要切换到任一值,请将 env 变量更改为所需的值:MEMORY_BACKEND
local(默认值)使用本地 JSON 缓存文件
pinecone使用在 ENV 设置中配置的 Pinecone.io 帐户
redis将使用配置的 Redis 缓存
milvus将使用配置的 milvus 缓存
weaviate将使用配置的编织缓存
- 连续模式
无需用户授权即可运行AI,100%自动化。 不建议使用连续模式。 这是潜在的危险,可能会导致你的 AI 永远运行或执行您通常不会授权的操作。 使用风险自负
python -m autogpt --speak --continuous
Ctrl + C退出程序
- 设置GPT-3.5
如果用不了GPT4可以改成3.5
python -m autogpt --speak --gpt3only
3.3 配置OpenAI的API
大家最熟悉了,https://platform.openai.com/account/api-keys

3.4 配置谷歌API
在谷歌云控制台https://console.cloud.google.com/,在左栏中找到API,新建一个项目,命名随意,这里用了demo
然后create 一个 credentials,API
每日免费自定义搜索配额最多只允许 100 次搜索。要增加此限制,需要为项目分配一个计费帐户,以从每天多达 10,000 次搜索中获利
设置自定义搜索引擎:https://cse.google.com/cse/all,命名随性,搜索范围可以全网,或者自定义。建议按领域来,像做生物生命科学的定向pubmed和谷歌学术镜像,可以稍微省时
准备好了API,开始设置环境变量:
Windows 用户:
setx GOOGLE_API_KEY "YOUR_GOOGLE_API_KEY"
setx CUSTOM_SEARCH_ENGINE_ID "YOUR_CUSTOM_SEARCH_ENGINE_ID"
macOS 和 Linux 用户:
export GOOGLE_API_KEY="YOUR_GOOGLE_API_KEY"
export CUSTOM_SEARCH_ENGINE_ID="YOUR_CUSTOM_SEARCH_ENGINE_ID"
3.5 配置Pinecone API
- 去Pineconehttps://app.pinecone.io/并创建一个帐户。
- 选择计划以避免被收费。
Starter - 在左侧边栏的默认项目下找到
API密钥和区域
windows用户:
setx PINECONE_API_KEY "<YOUR_PINECONE_API_KEY>"
setx PINECONE_ENV "<YOUR_PINECONE_REGION>" # e.g: "us-east4-gcp"
setx MEMORY_BACKEND "pinecone"
macOS 和 Linux 用户:
export PINECONE_API_KEY="<YOUR_PINECONE_API_KEY>"
export PINECONE_ENV="<YOUR_PINECONE_REGION>" # e.g: "us-east4-gcp"
export MEMORY_BACKEND="pinecone"
4.讨论
这个虽然是刚出来的实验性项目,但是潜力,真的很大很大,关于Memory pre-seeding,Image Generation,Milvus笔者这里没有提,内容太多太干太硬了,跟着上面的代码可以部署体验一波,需要重度使用务必仔细研究Github
相关文章:
在Github中77k星的王炸AutoGPT,会独立思考,直接释放双手
文章目录 1 前言1.1 什么是AutoGPT1.2 为什么是AutoGPT 2 AutoGPT部分实例2.1 类似一个Workflow2.2 市场调研2.3 自己写播客2.4 接入客服 3 安装和使用AutoGPT3.1 安装3.2 基础用法3.3 配置OpenAI的API3.4 配置谷歌API3.5 配置Pinecone API 4.讨论 1 前言 迄今为止,…...
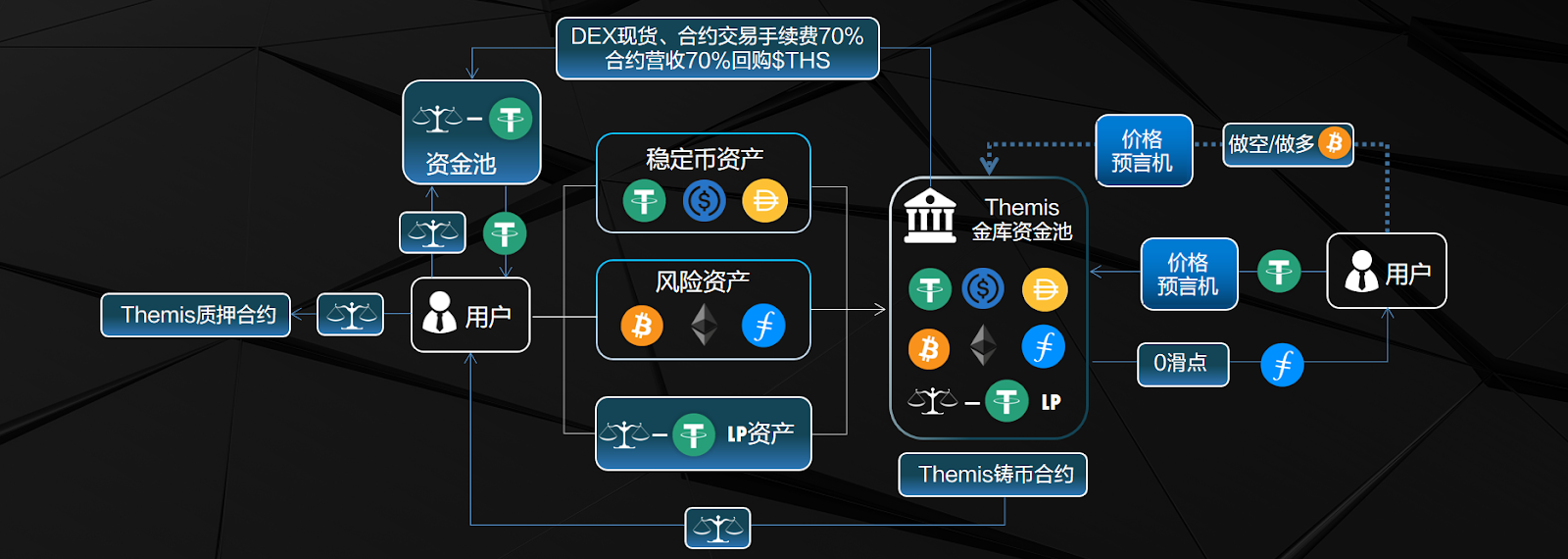
FVM链的Themis Pro,5日ido超百万美元
交易一直是 DeFi 乃至web3领域最经久不衰的话题,也因此催生了众多优秀的去中心化协议,如 Uniswap 和 Curve。这些协议逐渐成为了整个系统的基石。 在永续合约方面,DYDX 的出现将 WEB2 时代的订单簿带回了web3。其链下交易的设计,仿…...

OpenCV实战——尺度不变特征检测器
OpenCV实战——尺度不变特征检测器 0. 前言1. SURF 特征检测器2. SIFT 特征检测算法3. 完整代码相关链接0. 前言 特征检测的不变性是一个重要概念,虽然方向不变性(即使图像旋转也能检测到相同特征点)能够被简单特征点检测器(例如 FAST 特征检测器等)处理,但难以实现在图像尺…...

如何快速建立一个podman环境
本文介绍如何安装podman,并创建podman容器 环境 Centos8 安装podman Podman 是一个容器环境,首先在主机上安装 Podman。执行下面命令来安装podman: [rootlocalhost ~]# yum -y install podman然后修改一下用户命名空间的大小:…...

计算机视觉:人工智能领域当下火热的计算机视觉技术综述
计算机视觉技术发展火热,是当前人工智能技术核心领域之一,计算机视觉是人工智能领域的一颗明珠,它是目前人工智能领域最早得到应用的技术之一,拥有广大的发展空间,目前很多技术产品已经得到应用,并改变着这个世界。 当下火热的技术 1. 目标检测:通过计算机视觉技术,检…...

EMC 专用名词大全~骚扰波形
2.1 瞬态(的) transient (adjective and noun) 在两相邻稳定状态之间变化的物理量或物理现象,其变化时间小于所关注的时间尺度。 2.2 脉冲 Pulse 在短时间内突变,随后又迅速返回其初…...

14:24面试,14:32就出来了 ,问的实在是太...
从外包出来,没想到算法死在另一家厂子,自从加入这家公司,每天都在加班,钱倒是给的不少,所以也就忍了。没想到8月一纸通知,所有人不许加班,薪资直降30%,顿时有吃不起饭的赶脚。 好在有…...

高频算法题
排序 冒泡排序快速排序选择排序归并排序堆排序 912. 排序数组 - 力扣(LeetCode) 数组中重复的数字 数组 删除有序数组中的重复项 26. 删除有序数组中的重复项 - 力扣(LeetCode) 最小的K个数 最小K个数 - 最小K个数 - 力扣&a…...

AI工程师眼中的未来 | 年轻人如何求职选方向
一个人的命运不仅要看个人的奋斗 也要看历史的选择 如果能顺应未来的趋势选择对了方向 就能让财富巨增瞬间起飞 但是如果选择错了方向 随着社会的发展 有很多工作的机会会渐渐的消失 而我们自己也会更容易被社会所淘汰 所以未来的趋势是什么 我们应该如何选择不同的方向 这对现…...
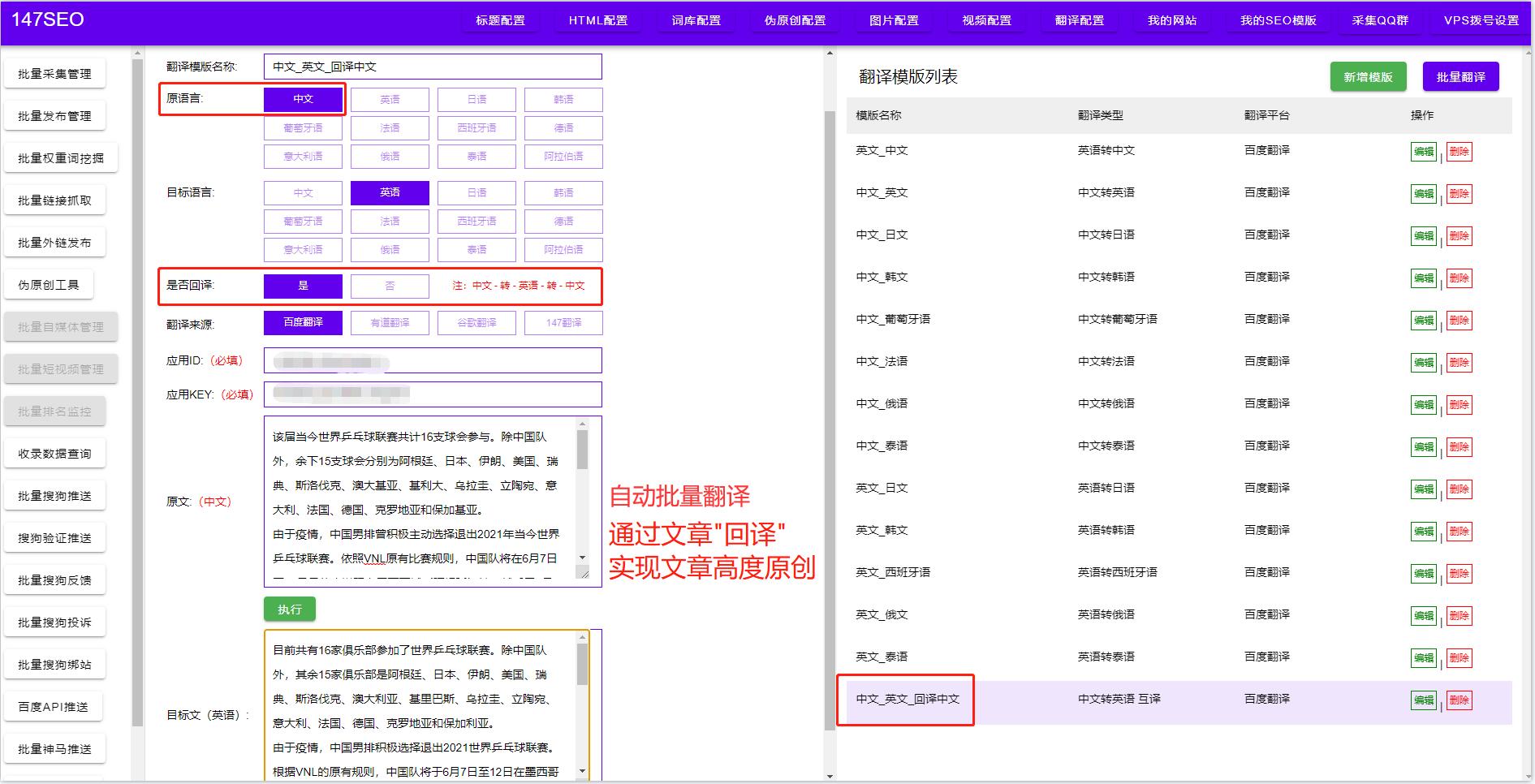
能自动翻译的软件-最精准的翻译软件
批量翻译软件是一种利用自然语言处理技术和机器学习算法,可以快速翻译大量文本内容的工具。批量翻译软件可以处理多种格式的文本,包括文档、网页、邮件、PDF等等,更符合掌握多语言的计算机化需求。 147CGPT翻译软件特点: 1.批量任…...
)
7.1 大学排行榜分析(project)
大学排名没有绝对的公正与权威,文件(alumni.txt, soft.txt)中为按照不同评价体系给出的国内大学前100名排行,对比两个排行榜单前m的学校的上榜情况,分析不同排行榜排名的差异。 输入输出 第一行输入1,第二行输入m&…...

TensorFlow 2.0 的新增功能:第三、四部分
原文:What’s New in TensorFlow 2.0 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如何实现目…...

第1章 如何听起来像数据科学家
第1章 如何听起来像数据科学家 文章目录 第1章 如何听起来像数据科学家1.1.1 基本的专业术语1.1.3 案例:西格玛公司1.2.3 为什么是Python1.4.2 案例:市场营销费用1.4.3 案例:数据科学家的岗位描述 我们拥有如此多的数据,而且正在生…...

哈希表题目:在系统中查找重复文件
文章目录 题目标题和出处难度题目描述要求示例数据范围进阶 解法思路和算法代码复杂度分析 进阶问题答案后记 题目 标题和出处 标题:在系统中查找重复文件 出处:609. 在系统中查找重复文件 难度 6 级 题目描述 要求 给定一个目录信息列表 paths…...
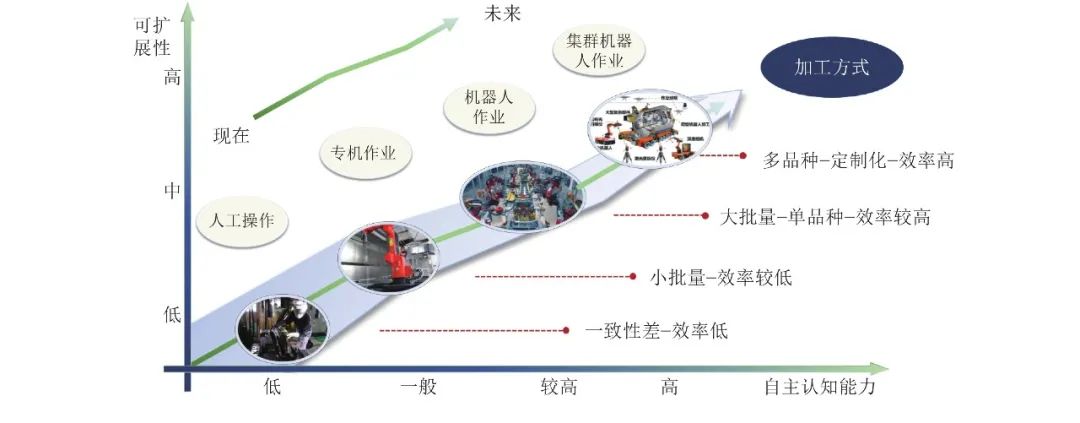
机器人感知与控制关键技术及其智能制造应用
源自:自动化学报 作者:王耀南 江一鸣 姜娇 张辉 谭浩然 彭伟星 吴昊天 曾凯 摘 要 智能机器人在服务国家重大需求, 引领国民经济发展和保障国防安全中起到重要作用, 被誉为“制造业皇冠顶端的明珠”. 随着新一轮工业革命的到来, 世界主要工业国…...

精通线程池,看这一篇就够了
一:什么是线程池 当我们运用多线程技术处理任务时,需要不断通过new的方式创建线程,这样频繁创建和销毁线程,会造成cpu消耗过多。那么有没有什么办法避免频繁创建线程呢? 当然有,和我们以前学习过多连接池技术类似&…...

解决图片、视频地址加密问题
const getImgUrl async () > {const imgUrl 远程链接地址const response await fetch(imgUrl)//取出blob二进制const blob await response.blob()//url转为类似blob:http://localhost:9587/cf3265b9-75eb-4722-8e11-5048dec2564d//赋值给需要展示的地方const url URL.c…...

GPT引领学习之旅:一篇让程序员轻松掌握Elasticsearch的攻略
一、引言 随着大数据技术的飞速发展,程序员们面临着越来越多的挑战。Elasticsearch作为一款流行的开源搜索和分析引擎,已成为许多项目的重要组成部分。那么如何高效地学习并掌握Elasticsearch呢?在这篇文章中,我们将探讨如何运用…...
)
23种设计模式-仲裁者模式(Android应用场景介绍)
仲裁者模式是一种行为设计模式,它允许将对象间的通信集中到一个中介对象中,以减少对象之间的耦合度。本文将通过Java语言实现仲裁者模式,并介绍如何在安卓开发中使用该模式。 实现仲裁者模式 我们将使用一个简单的例子来说明仲裁者模式的实…...
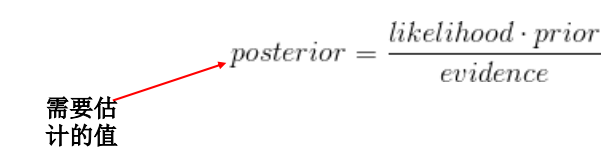
【数据统计】— 极大似然估计 MLE、最大后验估计 MAP、贝叶斯估计
【数据统计】— 极大似然估计 MLE、最大后验估计 MAP、贝叶斯估计 极大似然估计、最大后验概率估计(MAP),贝叶斯估计极大似然估计(Maximum Likelihood Estimate,MLE)MLE目标例子: 扔硬币极大似然估计—高斯分布的参数 矩估计 vs LSE vs MLE贝叶斯公式&am…...
)
学一下PLC2--软件PLC(TODO)
既然你手头有 Raspberry Pi Pico,你甚至不需要买任何新的 PLC 硬件,可以直接把它变成一个标准的工业 PLC! 实现原理: OpenPLC 是一个开源的符合 IEC 61131-3 国际标准的 PLC 软件系统。 它完美支持 Raspberry Pi Pico (RP2040)。…...

LabVIEW与单片机协同开发:构建可交互硬件原型的通信与事件驱动架构
1. 项目概述与核心思路上次我们聊了用LabVIEW制作一个“iPhone”的初步构想和界面设计,很多朋友反馈说对如何将虚拟界面与实际硬件联动起来特别感兴趣。这第二集,我们就来深入聊聊这块硬骨头——如何让LabVIEW这个强大的图形化编程工具,真正驱…...

逆向实战:用X32dbg条件断点精准定位MFC程序的窗口消息处理函数
逆向实战:用X32dbg条件断点精准定位MFC程序的窗口消息处理函数 在逆向分析领域,MFC程序因其复杂的消息映射机制和封装层次,常常让分析者感到无从下手。特别是当我们需要分析某个特定窗口消息(如按钮点击、菜单选择)的处…...

Kubernetes轻量级服务网格Cetus:核心流量治理与Sidecar代理实践
1. 项目概述:一个为Kubernetes而生的智能代理如果你正在管理一个规模不小的Kubernetes集群,并且对服务网格(Service Mesh)的复杂性望而却步,或者觉得像Istio这样的“巨无霸”方案有些杀鸡用牛刀,那么你很可…...

ECU软件刷写核心:拆解UDS的34/36/37服务,如何像拷贝文件一样传输数据?
ECU软件刷写核心:拆解UDS的34/36/37服务,如何像拷贝文件一样传输数据? 想象一下,你需要将一部高清电影从电脑传输到手机——这个过程需要稳定的连接、合理的分块大小和可靠的数据校验。在汽车电子领域,ECU软件刷写同样…...

终极指南:5步快速掌握Aimmy免费AI瞄准辅助工具
终极指南:5步快速掌握Aimmy免费AI瞄准辅助工具 【免费下载链接】Aimmy Universal Second Eye for Gamers with Impairments (Universal AI Aim Aligner (AI Aimbot) - ONNX/YOLOv8 - C#) 项目地址: https://gitcode.com/gh_mirrors/ai/Aimmy 还在为游戏中的瞄…...

ESP32硬件IIC驱动SHT30:从零构建温湿度监测组件
1. ESP32与SHT30传感器入门指南 第一次接触ESP32和SHT30温湿度传感器时,我完全被各种专业术语搞晕了。后来在实际项目中摸爬滚打才发现,这套组合其实特别适合物联网开发新手。ESP32就像个全能型选手,自带Wi-Fi和蓝牙,而SHT30则是瑞…...
)
NotebookLM笔记导出全链路实操指南:从Chrome插件绕过限制到API直连导出(含Python脚本)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM笔记导出全链路概览 NotebookLM 是 Google 推出的基于用户上传文档构建个性化知识代理的 AI 工具,其核心价值在于语义理解与上下文生成,但原生不提供直接导出原始笔记…...

Agent OS:AI智能体开发的操作系统级解决方案
1. 项目概述:一个为AI智能体而生的操作系统最近在AI智能体开发圈子里,一个名为“Agent OS”的项目热度持续攀升。它来自Rivet.dev团队,定位非常清晰:一个专为构建、运行和管理AI智能体而设计的操作系统。如果你正在尝试将大语言模…...

HS2-HF Patch:为《Honey Select 2》注入新生命的魔法补丁
HS2-HF Patch:为《Honey Select 2》注入新生命的魔法补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是不是曾经打开《Honey Select 2》时&am…...