数据湖 Hudi 核心概念
文章目录
- 什么是 Hudi ?
- Hudi 是如何对数据进行管理的?
- Hudi 表结构
- Hudi 核心概念
什么是 Hudi ?
Hudi 是一个用于处理大数据湖的开源框架。
大数据湖是指一个大规模的、中心化的数据存储库,其中包含各种类型的数据,如结构化数据、半结构化数据和非结构化数据,目的是为企业提供一个集中的数据存储库,从而更容易地进行数据分析和洞察。
Hudi支持数据操作模式:Insert、Update 和 Delete。这些操作是原子性的,因此在多个客户端并发访问时,数据的一致性得到了保证。另外,Hudi 支持基于时间戳的查询,使得可以轻松地查询某个时间点的数据快照。Hudi 还支持增量式处理,可以高效地处理大量的数据更新。
Hudi 是如何对数据进行管理的?
Hudi 通过管理数据的元数据,实现了对数据的管理。
具体来说,Hudi 将数据分为两个部分:数据本身和元数据。数据本身是指实际的数据,而元数据是指描述数据的数据,包括数据的结构、位置、格式、版本等信息。
Hudi 使用元数据来跟踪数据的变化,包括数据的插入、更新和删除等操作,并提供高效的查询功能,支持各种查询条件和时间点的查询。
在 Hudi 中,每个数据集都有一个元数据文件,用于描述数据集的结构、版本、位置等信息。每当数据集发生变化时,Hudi 会更新元数据文件,以便跟踪数据的变化。此外,Hudi还提供了一些工具,如命令行界面和 API,用于管理和查询数据集的元数据信息。
Hudi 还提供了两种不同的数据格式: Write-Optimized Format 和 Read-Optimized Format。
Write-Optimized Format 针对写入操作进行了优化,可以高效地插入和更新数据,但查询性能较差。
Read-Optimized Format 则针对查询操作进行了优化,可以快速地读取数据,但写入性能较差。
Hudi 表结构
Hudi 是一种基于 Hadoop 的数据管理框架,可用于在分布式环境中管理大规模数据集。它提供了一种用于存储和处理数据的表结构,该结构被称为 Hudi 表。
Hudi 表由多个文件组成,这些文件位于 Hadoop 分布式文件系统(HDFS)或其他支持 Hadoop API 的文件系统中。Hudi 表的文件结构基于 Apache Parquet 格式,并且可以通过 Hudi 提供的 API 进行读写操作。
Hudi 的表结构在 HDFS 上的目录结构是比较复杂的,由以下几部分组成:
1. 表根目录(Table Root)
表根目录是Hudi表的顶级目录,它包含了表的元数据、数据文件以及其他Hudi特定的文件和目录。它的目录结构如下:
<Table Root>
├── .hoodie
│ ├── _SUCCESS
│ ├── .temp
│ ├── .tmp
│ ├── archive
│ ├── meta.properties
│ ├── metadata
│ ├── timeline.json
│ ├── version
│ ├── write.lock
│ └── ...
├── partition_1
│ ├── .hoodie_partition_metadata
│ ├── .hoodie_partition_metadata.json
│ ├── 2021/01/01
│ │ ├── file1_20210101.parquet
│ │ ├── file2_20210101.parquet
│ │ └── ...
│ ├── 2021/01/02
│ │ ├── file1_20210102.parquet
│ │ ├── file2_20210102.parquet
│ │ └── ...
│ └── ...
├── partition_2
│ ├── .hoodie_partition_metadata
│ ├── .hoodie_partition_metadata.json
│ ├── 2021/01/01
│ │ ├── file1_20210101.parquet
│ │ ├── file2_20210101.parquet
│ │ └── ...
│ ├── 2021/01/02
│ │ ├── file1_20210102.parquet
│ │ ├── file2_20210102.parquet
│ │ └── ...
│ └── ...
├── ...
└── .hoodie_partition_metadata
-
.hoodie目录是 Hudi 表的核心目录,它包含了 Hudi 表的元数据和其他相关文件和目录 -
.temp目录用于存储正在写入的数据 -
.tmp目录用于存储已完成写入但尚未提交的数据 -
archive目录用于存储归档数据 -
metadata目录包含了所有分区的元数据信息 -
timeline.json文件包含了表的时间轴信息 -
version文件包含了表的版本信息 -
write.lock文件用于控制并发写入
2.分区目录(Partition Directory)
分区目录是按照分区键组织的目录,每个分区目录下都包含了该分区下的所有数据文件和 .hoodie_partition_metadata 文件。
.hoodie_partition_metadata 文件包含了该分区的元数据信息,例如分区键、分区路径等。
3. 数据文件(Data File)
数据文件是 Hudi 表中实际存储数据的文件,通常采用 Apache Parquet 格式存储。每个数据文件都包含了数据记录,其中记录由多个列组成。列可以是原始类型(如整数和字符串)或复杂类型(如数组和嵌套结构)。
Hudi 核心概念
Copy-on-Write (写时复制)
Copy-on-Write是 Hudi 最重要的概念之一。当 Hudi 写入数据时,它不会覆盖原有的数据,而是将新数据写入到新的文件中,然后通过元数据的方式将新旧数据进行关联,这种方式称为写时复制。这个过程保证了数据的一致性和可靠性。
Delta Stream
Delta Stream是指数据的增量变化,Hudi 能够实时监控这些变化,并将它们存储为新的 Delta 文件。Delta Stream 可以实现多种格式的数据输入和输出,包括 Kafka、Flume、HDFS、S3 等。
Table
Table是 Hudi 中数据存储的基本单元,每个 Table 都包含了一系列的数据文件和元数据文件。Table 可以支持多种数据格式,包括 Parquet、ORC 等。
Partition
Partition是指将 Table 按照一定的规则划分为多个子集,每个子集称为一个 Partition。Partition 可以按照日期、地区等方式进行划分,以便更好地管理和查询数据。
Write Handle
Write Handle是 Hudi 中用于写入数据的组件,它可以将数据写入到 Hudi Table 中,并将数据写入的过程进行优化。Write Handle 包括了多种优化技术,例如 Bloom Filter、Compaction 等。
Query Handle
Query Handle是 Hudi 中用于查询数据的组件,它可以通过 SQL 或者 API 的方式查询数据。Query Handle 会自动将查询请求路由到正确的 Partition 和文件中,以便更快地检索数据。
Index
Index是 Hudi 中用于优化数据查询性能的组件。它可以将数据中的某些字段进行索引,并将索引存储在内存中,以便更快地查询数据。
Hoodie Timeline
Hoodie Timeline是 Hudi 中用于管理数据版本的组件。它可以将每个数据文件的元数据存储为一个时间轴,以便更好地跟踪数据的变化。Hoodie Timeline 还可以用于数据回滚和恢复操作。
相关文章:

数据湖 Hudi 核心概念
文章目录 什么是 Hudi ?Hudi 是如何对数据进行管理的?Hudi 表结构Hudi 核心概念 什么是 Hudi ? Hudi 是一个用于处理大数据湖的开源框架。 大数据湖是指一个大规模的、中心化的数据存储库,其中包含各种类型的数据,如结构化数据、半结构化…...

爬虫请求头Content-Length的计算方法
重点:使用node.js 环境计算,同时要让计算的数据通过JSON.stringify从对象变成string。 1. Blob size var str 中国 new Blob([str]).size // 6 2、Buffer.byteLength # node > var str 中国 undefined > Buffer.byteLength(str, utf8) 6 原文…...
Open Inventor 2023.1 Crack
发行说明 Open Inventor 2023.1(次要版本) 文档于 2023 年 4 月发布。 此版本中包含的增强功能和新功能: Open Inventor 10 版本编号更改体积可视化 单一分辨率的体绘制着色器中与裁剪和 ROI 相关的新功能MeshVizXLM 在 C 中扩展的剪辑线提…...
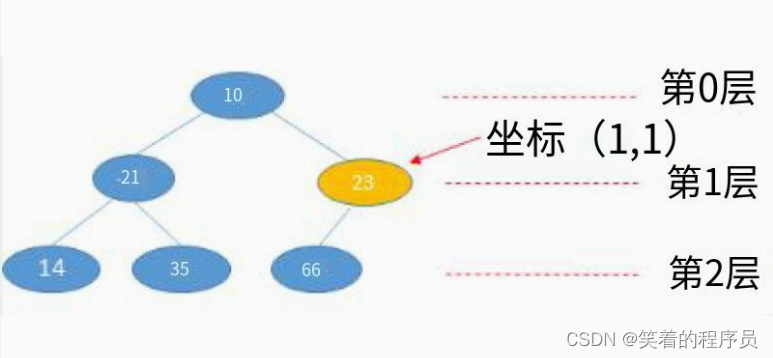
【华为OD机试真题】查找树中元素(查找二叉树节点)(javaC++python)100%通过率
查找树中元素 知识点树BFSQ搜索广搜 时间限制:1s空间限制:256MB限定语言:不限 题目描述: 已知树形结构的所有节点信息,现要求根据输入坐标(x,y)找到该节点保存的内容 值;其中: x表示节点所在的层数,根节点位于第0层,根节点的子节点位于第1层,依次类推; y表示节…...

常用设计模式
里氏替换原则:子类可以扩展父类的功能,但是不要更改父类的已经实现的方法子类对父类的方法尽量不要重写和重载。(我们可以采用final的手段强制来遵循)创建型模式 单例模式:维护线程数据安全 懒汉式 public class Test{ 饿汉式 private static final Test…...
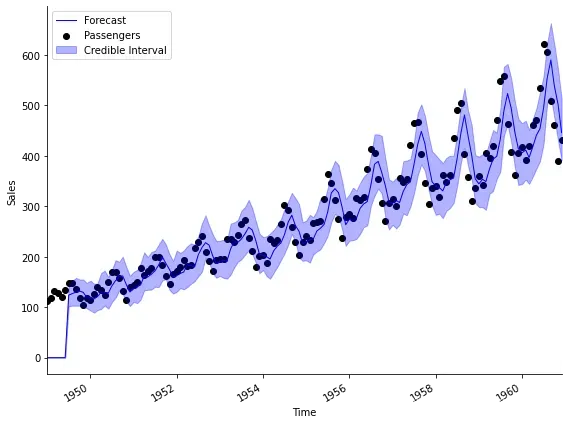
时序分析 49 -- 贝叶斯时序预测(一)
贝叶斯时序预测(一) 时序预测在统计分析和机器学习领域一直都是一个比较重要的话题。在本系列前面的文章中我们介绍了诸如ARIMA系列方法,Holt-Winter指数平滑模型等多种常用方法,实际上这些看似不同的模型和方法之间都具有千丝万缕…...

从传统管理到智慧水务:数字化转型的挑战与机遇
概念 智慧水务是指利用互联网、物联网、大数据、人工智能等技术手段,将智能化、信息化、互联网等技术与水务领域相结合,通过感知、传输、处理水质、水量、水价等数据信息,对水资源进行全面监测、综合管理、智能调度和优化配置的智能化水务系…...
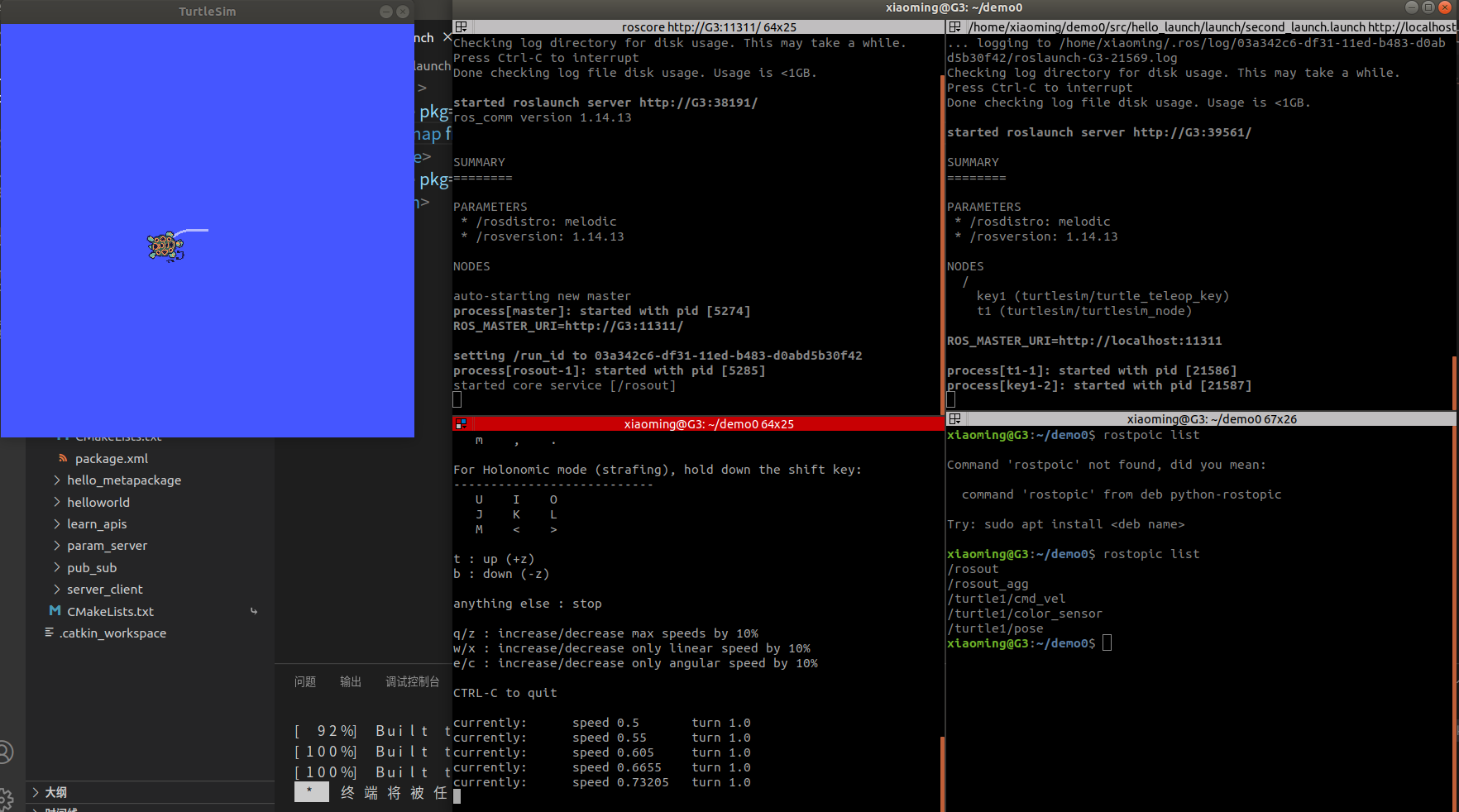
ROS学习第十八节——launch文件(详细介绍)
1.概述 关于 launch 文件的使用已经不陌生了,之前就曾经介绍到: 一个程序中可能需要启动多个节点,比如:ROS 内置的小乌龟案例,如果要控制乌龟运动,要启动多个窗口,分别启动 roscore、乌龟界面节点、键盘控制节点。如果…...
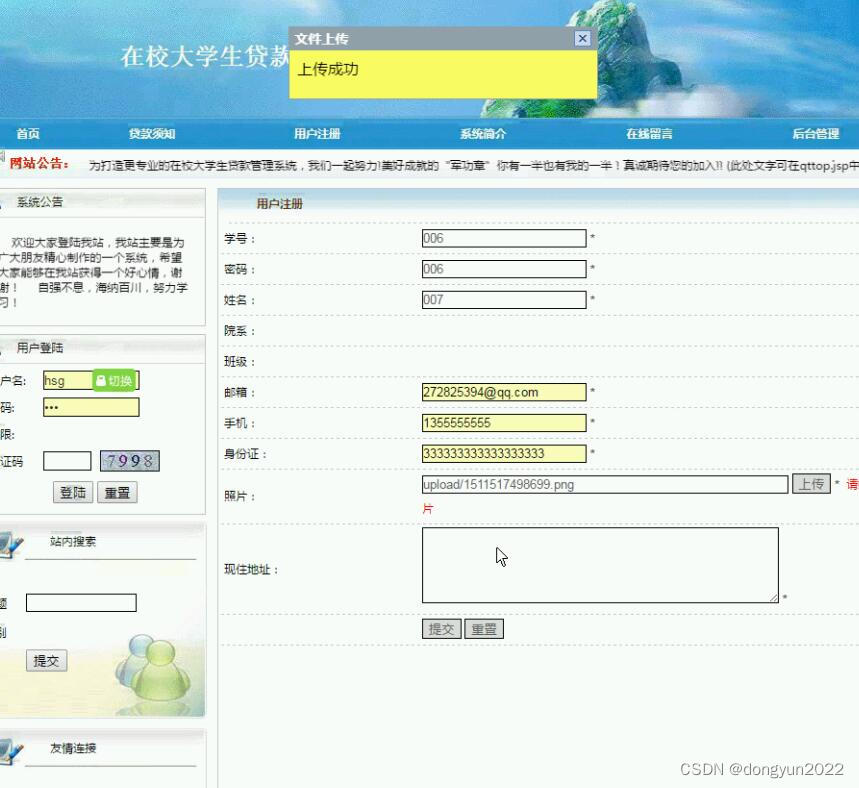
javaweb在校大学生贷款管理系统ns08a9
1系统主要实现:学生注册、填写详细资料、申请贷款、学校审核、银行审核、贷后管理等功能, (1) 学生注册:学生通过注册用户,提交自己的详细个人资料,考虑现实应用中的安全性,资料提交后不可修改;…...
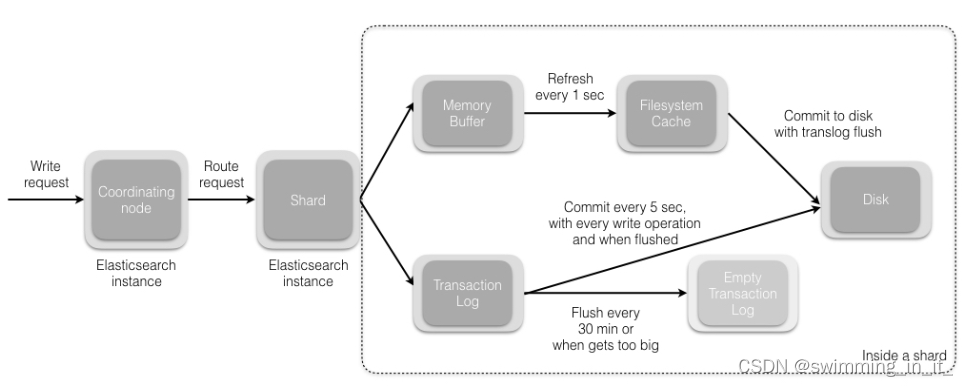
分布式之搜索解决方案es
一 ES初识 1.1 概述 ElasticSearch:是基于 Lucene 的 Restful 的分布式实时全文搜索引擎,每个字段都被索引并可被搜索,可以快速存储、搜索、分析海量的数据。是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表…...

CSDN 编程竞赛四十六期题解
地址:CSDN 编程竞赛四十六期 思路:通过找规律可以知道,在周期第一个位置的数的下标都有一个规律:除以三的余数为 1 。而第二个位置,第三个位置的余数分别为 2 , 0 。 因此可以开一个长度为 3 的总和数组&am…...
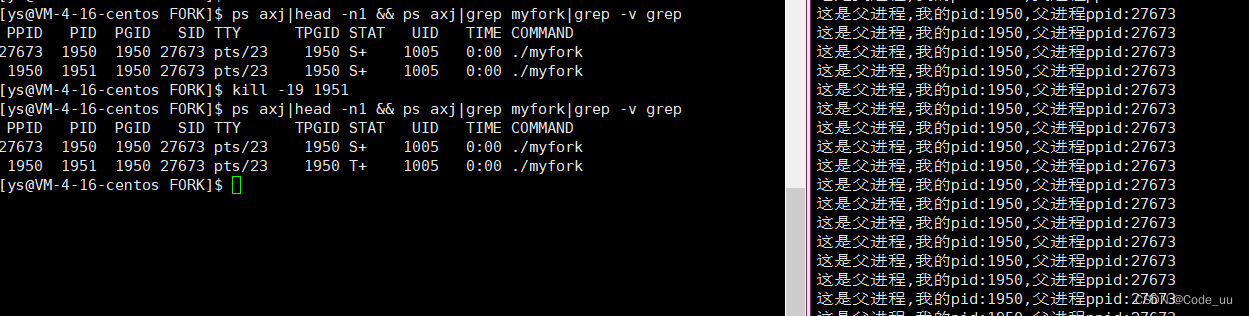
Linux——进程
进程介绍及其使用 1、认识冯诺依曼体系2、操作系统如何理解操作系统对硬件做管理? 3、进程如何创建进程进程状态 1、认识冯诺依曼体系 在计算机的硬件结构中,有着图灵和冯诺依曼俩位举足轻重的人物。对于计算机的发展来说有着十分重要的意义。冯诺依曼结…...

计及氢能的综合能源优化调度研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

基于Bert的知识库智能问答系统
项目完整地址: 可以先看一下Bert的介绍。 Bert简单介绍 一.系统流程介绍。 知识库是指存储大量有组织、有结构的知识和信息的仓库。这些知识和信息被存储为实体和实体关系的形式,通常用于支持智能问答系统。在一个知识库中,每个句子通常来说…...

libapparmor非默认目录构建和安装
在AppArmor零知识学习五、源码构建(2)中,详细介绍了libapparmor的构建步骤,但那完全使用的是官网给出的默认参数。如果需要将目标文件生成到指定目录而非默认的/usr,则需要进行一些修改,本文就来详述如何进…...
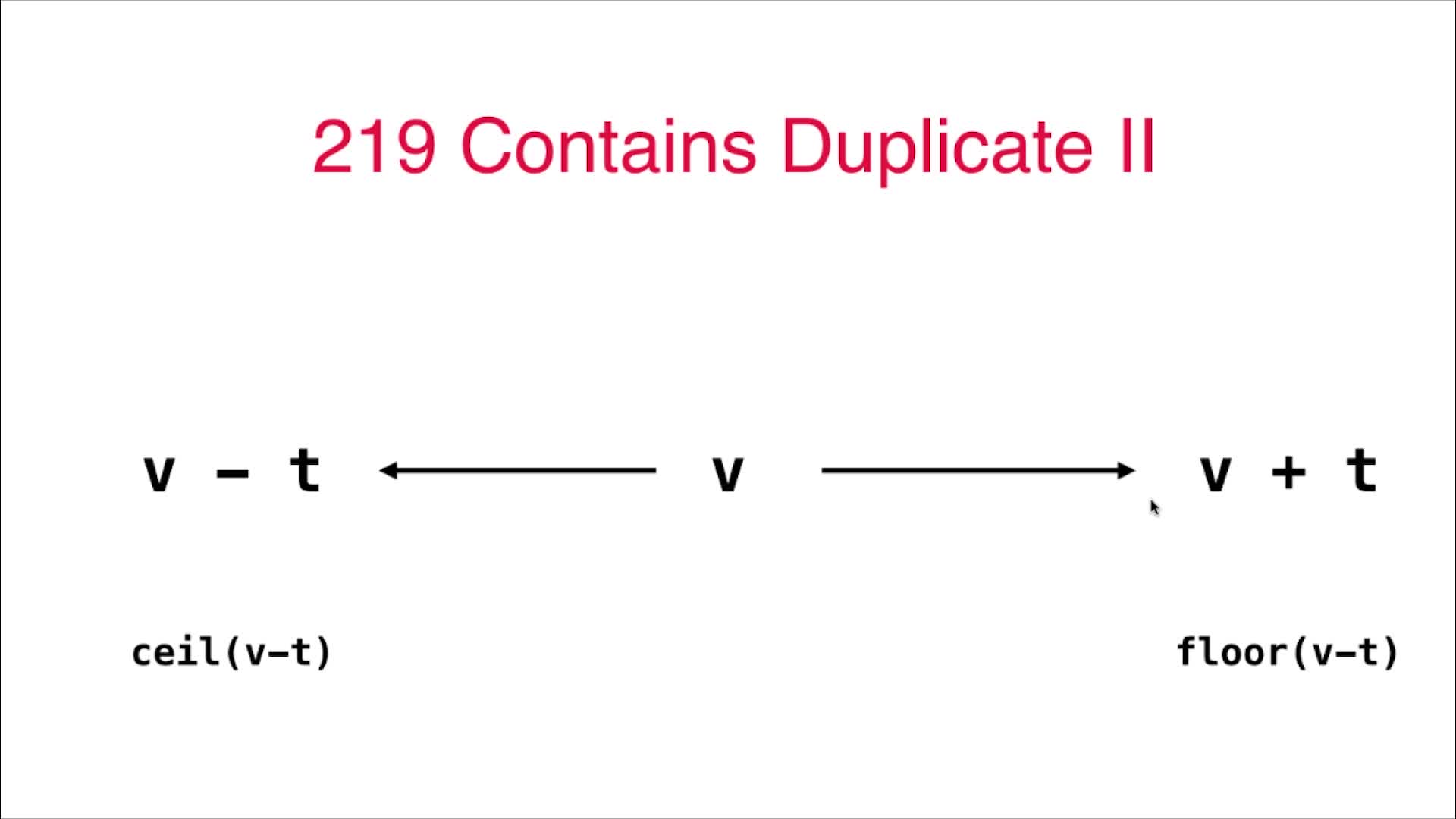
2023-04-14 算法面试中常见的查找表问题
2023-04-14 算法面试中常见的查找表问题 1 Set的使用 LeetCode349号问题:两个数组的交集 给定两个数组,编写一个函数来计算它们的交集。示例 1:输入: nums1 [1,2,2,1], nums2 [2,2] 输出: [2] 示例 2:输入: nums1 [4,9,5], nums2 [9,4,9,8,4] 输出:…...
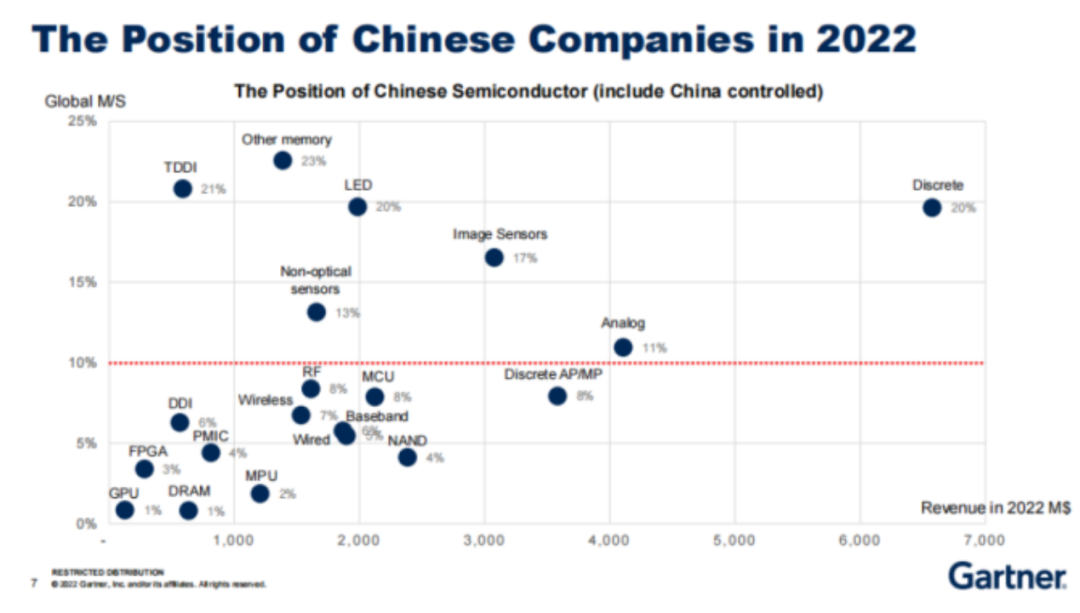
从TOP25榜单,看半导体之变
据SIA报告显示,2022年全球半导体销售额创历史新高达到5740亿美元。尽管2022年下半年,半导体市场出现了周期性的低迷,但其全年的销售额相较2021年增长了3.3%。 近日,市调机构Gartner发布了全球以及中国大陆TOP25名半导体厂商的排名…...

[异常]java常见异常
Java.io.NullPointerException null 空的,不存在的NullPointer 空指针 空指针异常,该异常出现在我们操作某个对象的属性或方法时,如果该对象是null时引发。 String str null; str.length();//空指针异常 上述代码中引用类型变量str的值为…...
gpt4all保姆级使用教程! 不用联网! 本地就能跑的GPT
原文:gpt4all保姆级使用教程! 不用联网! 本地就能跑的GPT 什么是gpt4all gpt4all是在大量干净数据上训练的一个开源聊天机器人的生态系统。它不用科学上网!甚至可以不联网!本地就能用,像这样↓: 如何使用ÿ…...
AcWing语法基础班 1.1 变量、输入输出、表达式和顺序语句
预备知识 首先先来了解一下最简单的C代码。 本文的所有代码操作均在AcWing的AC Editor中 #include <iostream>using namespace std;int main(){cout << "Hello World" << endl;return 0; }然后使用编译(点击调试,再点击运…...

恶劣环境下LED发光服饰的可靠系统构建:从设计到工艺的工程实践
1. 项目概述与核心挑战如果你曾经尝试过制作一件会发光的服装,无论是为了音乐节、万圣节还是水下表演,你大概都体会过那种“亮一次,修三次”的挫败感。LED灯带在工作室的桌面上测试时完美无瑕,一旦穿到身上,开始活动、…...

基于Readability算法的网页内容提取服务:从原理到工程实践
1. 项目概述:一个为现代阅读而生的开源工具 最近在折腾个人知识库和稍后读系统时,我一直在找一个能完美解决“网页内容净化与结构化”痛点的工具。市面上的方案要么太重,要么太简陋,直到我遇到了 Cat-tj/web-reader 。这不仅仅是…...

3个高效方法:免费获取百度网盘高速下载直链的完整指南
3个高效方法:免费获取百度网盘高速下载直链的完整指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 当我们面对百度网盘缓慢的下载速度时,常常感到无…...

AI驱动的Web可访问性审查:LLM如何成为你的自动化无障碍专家
1. 项目概述:一个为AI智能体而生,却意外照亮了所有人的可访问性审查工具 最近在折腾AI智能体(AI Agent)的开发,一个老问题又浮上水面:怎么确保我造出来的这个“数字员工”,能真正服务好所有人&…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

手把手带你激活Matlab2016b:Windows 64位系统下的完整许可配置指南
1. 准备工作:确保激活环境完整 在开始激活Matlab2016b之前,我们需要做好充分的准备工作。首先确认你已经按照官方流程完成了基础安装,并且安装目录下存在完整的文件结构。我遇到过不少朋友因为安装不完整导致后续激活失败的情况,所…...

ARM Cortex-A5 SCU架构与多核缓存一致性解析
1. ARM Cortex-A5 SCU架构解析SCU(Snoop Control Unit)是Cortex-A5多核处理器中的关键组件,主要负责维护多核间的缓存一致性。当某个CPU核心修改了共享内存区域的数据时,SCU会自动通知其他核心的缓存进行更新或失效操作。这种机制…...

云端生信分析:从零部署RStudio Server避坑指南
1. 为什么需要云端RStudio Server? 做生物信息分析的朋友们肯定深有体会,单细胞测序、转录组这些数据动辄几十GB,用自己电脑跑分析简直是折磨。我去年处理一个肝癌单细胞项目时,光是读取数据就卡了半小时,更别说后续的…...

基于Rust的网页正文提取工具web-reader:从原理到自动化实践
1. 项目概述:一个为现代阅读场景而生的开源利器最近在折腾个人知识库和稍后读工具链,发现市面上的网页内容抓取工具要么太重,要么太“脏”——抓下来的内容常常带着一堆广告、导航栏,甚至还有烦人的弹窗代码。直到我遇到了Cat-tj/…...

RL78/G13单片机实现流水呼吸灯:软件PWM与状态机编程实践
1. 项目概述与核心思路最近在整理手头的瑞萨RL78/G13开发板,想着做点有意思的小项目来熟悉一下这款MCU的GPIO操作和定时器资源。呼吸灯和流水灯算是嵌入式开发的“Hello World”了,但把两者结合起来,做成一个“流水呼吸灯”,既有动…...