【Python】【进阶篇】二十六、Python爬虫的Scrapy爬虫框架
目录
- 二十六、Python爬虫的Scrapy爬虫框架
- 26.1 Scrapy下载安装
- 26.2 创建Scrapy爬虫项目
- 1) 创建第一个Scrapy爬虫项目
- 26.3 Scrapy爬虫工作流程
- 26.4 settings配置文件
二十六、Python爬虫的Scrapy爬虫框架
Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。
提示:Twisted 是一个基于事件驱动的网络引擎框架,同样采用 Python 实现。
26.1 Scrapy下载安装
Scrapy 支持常见的主流平台,比如 Linux、Mac、Windows 等,因此你可以很方便的安装它。本节以 Windows 系统为例,在 CMD 命令行执行以下命令:
python -m pip install Scrapy
由于 Scrapy 需要许多依赖项,因此安装时间较长,大家请耐心等待,关于其他平台的安装方法,可参考官方文档《Scrapy安装指南》。
验证安装,如下所示:
C:\Users\Administrator>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 19:29:22) [MSC v.1916 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import scrapy
>>> exit()
如果可以正常执行exit()操作,并且没有出现 ERROR 错误,则说明安装成功。
26.2 创建Scrapy爬虫项目
Scrapy 框架提供了一些常用的命令用来创建项目、查看配置信息,以及运行爬虫程序。常用指令如下所示:
1) 创建第一个Scrapy爬虫项目
下面创建名为 Baidu 的爬虫项目,打开 CMD 命令提示符进行如下操作:
C:\Users\Administrator>cd DesktopC:\Users\Administrator\Desktop>scrapy startproject Baidu
New Scrapy project 'Baidu', using template directory 'd:\python\python37\lib\site-packages\scrapy\templates\project', created in:C:\Users\Administrator\Desktop\Baidu
# 提示后续命令操作
You can start your first spider with:cd Baiduscrapy genspider example example.com
打开新建的项目“Baidu”会有以下项目文件,如图所示:

接下来,创建一个爬虫文件,如下所示:
C:\Users\Administrator\Desktop>cd Baidu
C:\Users\Administrator\Desktop\Baidu>scrapy genspider baidu www.baidu.com
Created spider 'baidu' using template 'basic' in module:Baidu.spiders.baidu
下面呈现了项目的目录树结构,以及各个文件的作用:
Baidu # 项目文件夹
├── Baidu # 用来装载项目文件的目录
│ ├── items.py # 定义要抓取的数据结构
│ ├── middlewares.py # 中间件,用来设置一些处理规则
│ ├── pipelines.py # 管道文件,处理抓取的数据
│ ├── settings.py # 全局配置文件
│ └── spiders # 用来装载爬虫文件的目录
│ ├── baidu.py # 具体的爬虫程序
└── scrapy.cfg # 项目基本配置文件
从上述目录结构可以看出,Scrapy 将整个爬虫程序分成了不同的模块,让每个模块负责处理不同的工作,而且模块之间紧密联系。因此,您只需要在相应的模块编写相应的代码,就可以轻松的实现一个爬虫程序。
26.3 Scrapy爬虫工作流程
Scrapy 框架由五大组件构成,如下所示:
Scrapy 五大组件
| 名称 | 作用说明 |
|---|---|
| Engine(引擎) | 整个 Scrapy 框架的核心,主要负责数据和信号在不同模块间传递。 |
| Scheduler(调度器) | 用来维护引擎发送过来的 request 请求队列。 |
| Downloader(下载器) | 接收引擎发送过来的 request 请求,并生成请求的响应对象,将响应结果返回给引擎。 |
| Spider(爬虫程序) | 处理引擎发送过来的 response, 主要用来解析、提取数据和获取需要跟进的二级URL,然后将这些数据交回给引擎。 |
| Pipeline(项目管道) | 用实现数据存储,对引擎发送过来的数据进一步处理,比如存 MySQL 数据库等。 |
在整个执行过程中,还涉及到两个 middlewares 中间件,分别是下载器中间件(Downloader Middlewares)和蜘蛛中间件(Spider
Middlewares),它们分别承担着不同的作用:
- 下载器中间件,位于引擎和下载器之间,主要用来包装 request 请求头,比如 UersAgent、Cookies 和代理 IP 等
- 蜘蛛中间件,位于引擎与爬虫文件之间,它主要用来修改响应对象的属性。
Scrapy 工作流程示意图如下所示:

上述示意图描述如下,当一个爬虫项目启动后,Scrapy 框架会进行以下工作:
- 第一步:由“引擎”向爬虫文件索要第一个待爬取的 URL,并将其交给调度器加入 URL 队列当中(对应图中1/2步骤)。
- 第二步:调度器处理完请求后, 将第一个 URL 出队列返回给引擎;引擎经由下载器中间件将该 URL 交给下载器去下载 response 对象(对应3/4步骤)。
- 第三步:下载器得到响应对象后,将响应结果交给引擎,引擎收到后,经由蜘蛛中间件将响应结果交给爬虫文件(对应5/6步骤)。
- 第四步:爬虫文件对响应结果进行处理、分析,并提取出所需要的数据。
- 第五步:最后,提取的数据会交给管道文件去存数据库,同时将需要继续跟进的二级页面 URL 交给调度器去入队列(对应7/8/9步骤)。
上述过程会一直循环,直到没有要爬取的 URL 为止,也就是 URL 队列为空时才会停止。
26.4 settings配置文件
在使用 Scrapy 框架时,还需要对配置文件进行稍微改动。下面使用 Pycharm 打开刚刚创建的“Baidu”项目,对配置文件进行如下修改:
# 1、定义User-Agent
USER_AGENT = 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)'
# 2、是否遵循robots协议,一般设置为False
ROBOTSTXT_OBEY = False
# 3、最大并发量,默认为16
CONCURRENT_REQUESTS = 32
# 4、下载延迟时间
DOWNLOAD_DELAY = 1
其余常用配置项介绍:
# 设置日志级别,DEBUG < INFO < WARNING < ERROR < CRITICAL
LOG_LEVEL = ' '
# 将日志信息保存日志文件中,而不在终端输出
LOG_FILE = ''
# 设置导出数据的编码格式(主要针对于json文件)
FEED_EXPORT_ENCODING = ''
# 非结构化数据的存储路径
IMAGES_STORE = '路径'
# 请求头,此处可以添加User-Agent、cookies、referer等
DEFAULT_REQUEST_HEADERS={'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8','Accept-Language': 'en',
}
# 项目管道,300 代表激活的优先级 越小越优先,取值1到1000
ITEM_PIPELINES={'Baidu.pipelines.BaiduPipeline':300
}
# 添加下载器中间件
DOWNLOADER_MIDDLEWARES = {}
想要了解更多关于 Scrapy 框架的知识,可参考官方文档:https://docs.scrapy.org/en/latest/index.html
相关文章:
【Python】【进阶篇】二十六、Python爬虫的Scrapy爬虫框架
目录 二十六、Python爬虫的Scrapy爬虫框架26.1 Scrapy下载安装26.2 创建Scrapy爬虫项目1) 创建第一个Scrapy爬虫项目 26.3 Scrapy爬虫工作流程26.4 settings配置文件 二十六、Python爬虫的Scrapy爬虫框架 Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架…...

PyTorch 深度学习实用指南:6~8
原文:PyTorch Deep Learning Hands-On 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如何实现目…...

数据湖 Hudi 核心概念
文章目录 什么是 Hudi ?Hudi 是如何对数据进行管理的?Hudi 表结构Hudi 核心概念 什么是 Hudi ? Hudi 是一个用于处理大数据湖的开源框架。 大数据湖是指一个大规模的、中心化的数据存储库,其中包含各种类型的数据,如结构化数据、半结构化…...

爬虫请求头Content-Length的计算方法
重点:使用node.js 环境计算,同时要让计算的数据通过JSON.stringify从对象变成string。 1. Blob size var str 中国 new Blob([str]).size // 6 2、Buffer.byteLength # node > var str 中国 undefined > Buffer.byteLength(str, utf8) 6 原文…...
Open Inventor 2023.1 Crack
发行说明 Open Inventor 2023.1(次要版本) 文档于 2023 年 4 月发布。 此版本中包含的增强功能和新功能: Open Inventor 10 版本编号更改体积可视化 单一分辨率的体绘制着色器中与裁剪和 ROI 相关的新功能MeshVizXLM 在 C 中扩展的剪辑线提…...
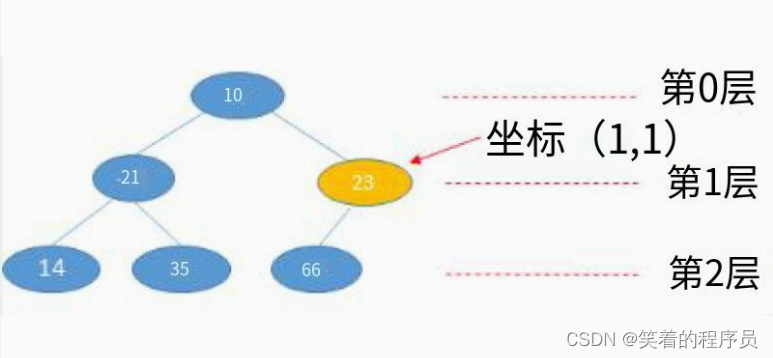
【华为OD机试真题】查找树中元素(查找二叉树节点)(javaC++python)100%通过率
查找树中元素 知识点树BFSQ搜索广搜 时间限制:1s空间限制:256MB限定语言:不限 题目描述: 已知树形结构的所有节点信息,现要求根据输入坐标(x,y)找到该节点保存的内容 值;其中: x表示节点所在的层数,根节点位于第0层,根节点的子节点位于第1层,依次类推; y表示节…...

常用设计模式
里氏替换原则:子类可以扩展父类的功能,但是不要更改父类的已经实现的方法子类对父类的方法尽量不要重写和重载。(我们可以采用final的手段强制来遵循)创建型模式 单例模式:维护线程数据安全 懒汉式 public class Test{ 饿汉式 private static final Test…...
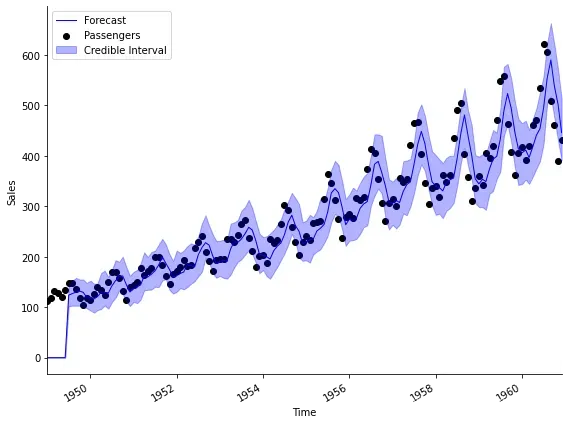
时序分析 49 -- 贝叶斯时序预测(一)
贝叶斯时序预测(一) 时序预测在统计分析和机器学习领域一直都是一个比较重要的话题。在本系列前面的文章中我们介绍了诸如ARIMA系列方法,Holt-Winter指数平滑模型等多种常用方法,实际上这些看似不同的模型和方法之间都具有千丝万缕…...

从传统管理到智慧水务:数字化转型的挑战与机遇
概念 智慧水务是指利用互联网、物联网、大数据、人工智能等技术手段,将智能化、信息化、互联网等技术与水务领域相结合,通过感知、传输、处理水质、水量、水价等数据信息,对水资源进行全面监测、综合管理、智能调度和优化配置的智能化水务系…...
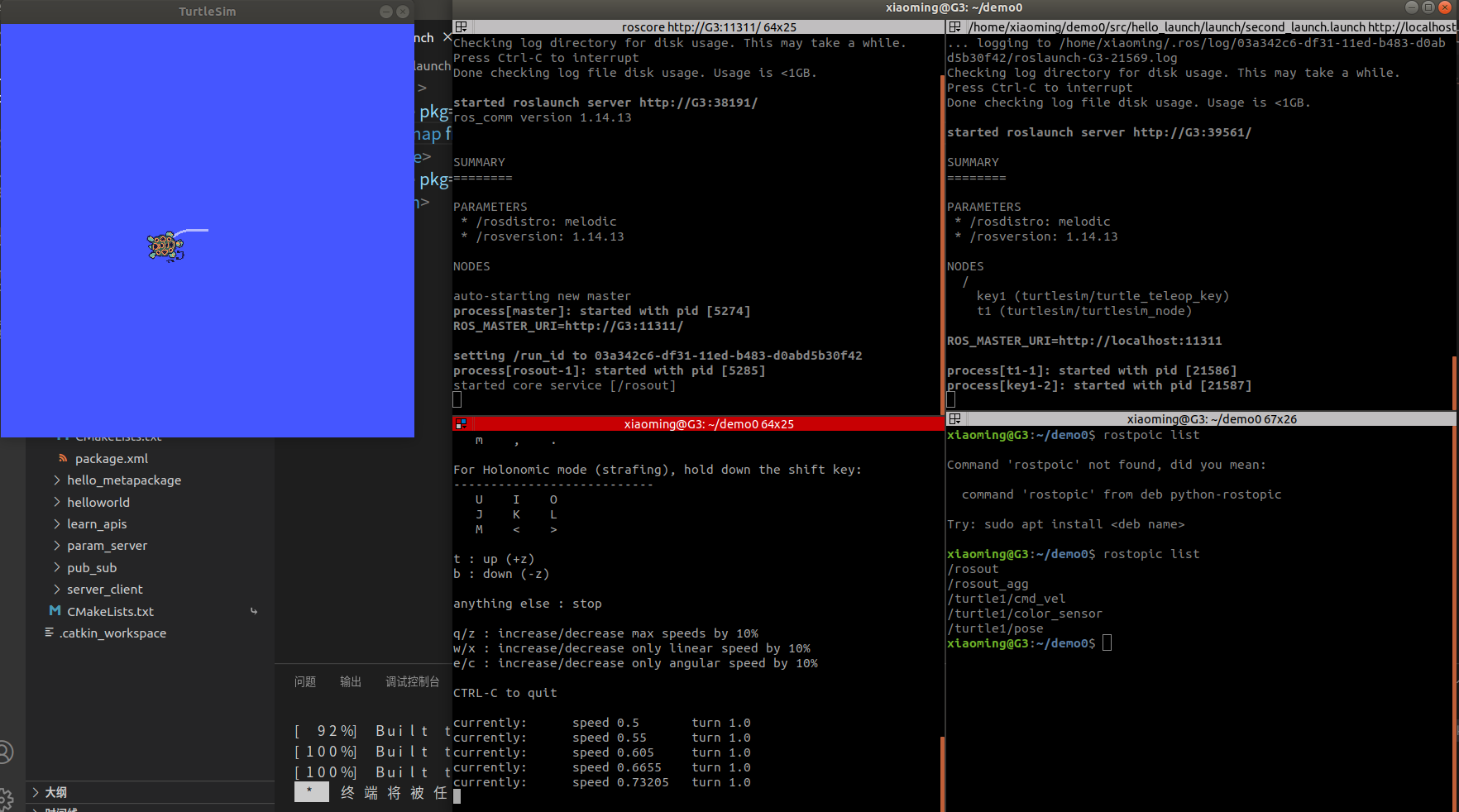
ROS学习第十八节——launch文件(详细介绍)
1.概述 关于 launch 文件的使用已经不陌生了,之前就曾经介绍到: 一个程序中可能需要启动多个节点,比如:ROS 内置的小乌龟案例,如果要控制乌龟运动,要启动多个窗口,分别启动 roscore、乌龟界面节点、键盘控制节点。如果…...
javaweb在校大学生贷款管理系统ns08a9
1系统主要实现:学生注册、填写详细资料、申请贷款、学校审核、银行审核、贷后管理等功能, (1) 学生注册:学生通过注册用户,提交自己的详细个人资料,考虑现实应用中的安全性,资料提交后不可修改;…...
分布式之搜索解决方案es
一 ES初识 1.1 概述 ElasticSearch:是基于 Lucene 的 Restful 的分布式实时全文搜索引擎,每个字段都被索引并可被搜索,可以快速存储、搜索、分析海量的数据。是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表…...

CSDN 编程竞赛四十六期题解
地址:CSDN 编程竞赛四十六期 思路:通过找规律可以知道,在周期第一个位置的数的下标都有一个规律:除以三的余数为 1 。而第二个位置,第三个位置的余数分别为 2 , 0 。 因此可以开一个长度为 3 的总和数组&am…...
Linux——进程
进程介绍及其使用 1、认识冯诺依曼体系2、操作系统如何理解操作系统对硬件做管理? 3、进程如何创建进程进程状态 1、认识冯诺依曼体系 在计算机的硬件结构中,有着图灵和冯诺依曼俩位举足轻重的人物。对于计算机的发展来说有着十分重要的意义。冯诺依曼结…...

计及氢能的综合能源优化调度研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

基于Bert的知识库智能问答系统
项目完整地址: 可以先看一下Bert的介绍。 Bert简单介绍 一.系统流程介绍。 知识库是指存储大量有组织、有结构的知识和信息的仓库。这些知识和信息被存储为实体和实体关系的形式,通常用于支持智能问答系统。在一个知识库中,每个句子通常来说…...

libapparmor非默认目录构建和安装
在AppArmor零知识学习五、源码构建(2)中,详细介绍了libapparmor的构建步骤,但那完全使用的是官网给出的默认参数。如果需要将目标文件生成到指定目录而非默认的/usr,则需要进行一些修改,本文就来详述如何进…...
2023-04-14 算法面试中常见的查找表问题
2023-04-14 算法面试中常见的查找表问题 1 Set的使用 LeetCode349号问题:两个数组的交集 给定两个数组,编写一个函数来计算它们的交集。示例 1:输入: nums1 [1,2,2,1], nums2 [2,2] 输出: [2] 示例 2:输入: nums1 [4,9,5], nums2 [9,4,9,8,4] 输出:…...
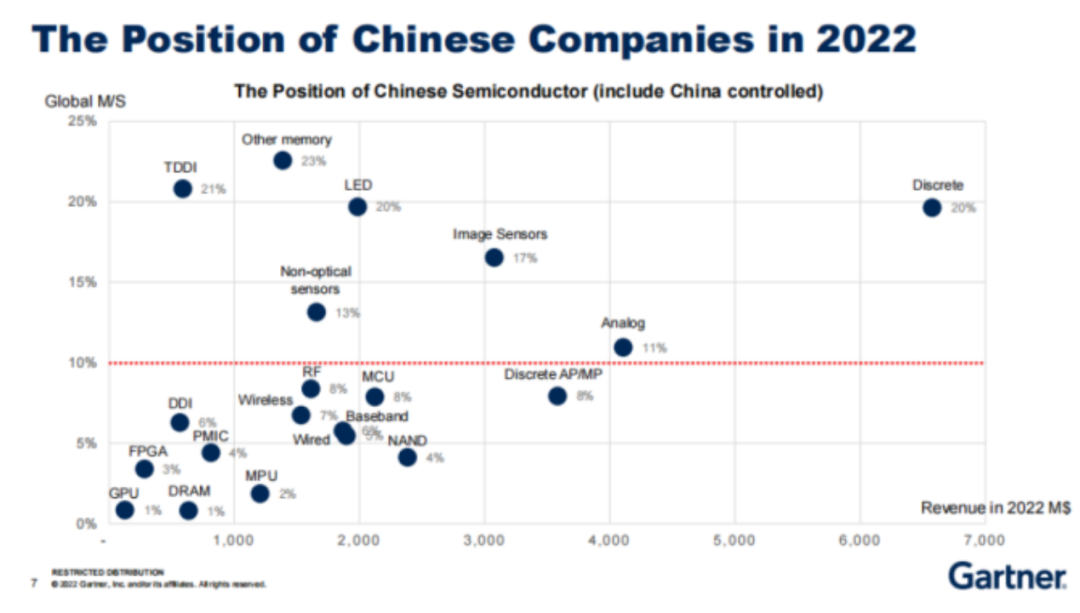
从TOP25榜单,看半导体之变
据SIA报告显示,2022年全球半导体销售额创历史新高达到5740亿美元。尽管2022年下半年,半导体市场出现了周期性的低迷,但其全年的销售额相较2021年增长了3.3%。 近日,市调机构Gartner发布了全球以及中国大陆TOP25名半导体厂商的排名…...

[异常]java常见异常
Java.io.NullPointerException null 空的,不存在的NullPointer 空指针 空指针异常,该异常出现在我们操作某个对象的属性或方法时,如果该对象是null时引发。 String str null; str.length();//空指针异常 上述代码中引用类型变量str的值为…...
)
告别龟速采样!用DDIM加速你的扩散模型推理(附PyTorch代码)
加速扩散模型推理:DDIM核心原理与实战优化指南 在图像生成领域,扩散模型以其卓越的质量表现迅速成为研究热点,但传统DDPM(Denoising Diffusion Probabilistic Models)的致命缺陷在于其缓慢的采样速度——生成一张图片往…...

高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题
高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题 解析几何作为高考数学的压轴题型,常常让考生望而生畏。面对复杂的计算和抽象的条件,如何在有限时间内快速找到突破口?极点极线理论作为高等几何中的重要工具&#x…...

跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组
跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼吗…...

终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载
终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的下载速度而烦恼…...

3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验
3个步骤让Windows任务栏图标居中,打造macOS般的桌面体验 【免费下载链接】TaskbarX Center Windows taskbar icons with a variety of animations and options. 项目地址: https://gitcode.com/gh_mirrors/ta/TaskbarX 你是否厌倦了Windows任务栏图标总是靠左…...

3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍
3分钟掌握猫抓扩展:轻松捕获网页视频的终极秘籍 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过这样的情况࿱…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...

Docker容器化Emacs:构建可移植、一致的开发环境解决方案
1. 项目概述:为什么要在Docker里运行Emacs?如果你是一个Emacs的重度用户,或者是一个开发者,你很可能遇到过这样的困境:你精心配置的Emacs环境,在换了一台新电脑、升级了操作系统,或者需要在多台…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

Kubernetes配置管理实战:基于Kustomize的结构化部署与多环境管理
1. 项目概述:一个被低估的Kubernetes配置管理利器如果你和我一样,长期在Kubernetes生态里摸爬滚打,那你一定经历过这样的场景:为了部署一个稍微复杂点的应用,需要维护一堆YAML文件——Deployment、Service、ConfigMap、…...