04-Mysql常用操作
1. DDL
常见数据库操作
# 查询所有数据库
show databases;
# 查询当前数据库
select databases();# 使用数据库
use 数据库名;# 创建数据库
create database [if not exits] 数据库名; # []代表可选可不选# 删除数据库
drop database [if exits] 数据库名;常见表操作
创建表:
create table 表名(字段1 字段类型 [约束] [comment 字段1备注信息],...字段n 字段类型 [约束] [comment 字段n备注信息]
)[comment 表备注信息];# eg:
create table tb_user(id int primary key comment 'ID,唯一标识',username varchar(20) not null unique comment '用户名',name varchar(20) not null comment '姓名',age int comment '年龄',gender char(1) default '女' comment '性别'
)comment '用户表';常见约束:

# 查询当前数据库的所有表
show tables;
# 查询表结构
desc 表名;
# 查询建表语句
show create table 表名;
# 添加字段
alter table 表名 add 字段名 类型(长度) [comment 备注信息] [约束];
# 修改字段类型
alter table 表名 modify 字段名 新数据类型(长度);
# 修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment 备注信息] [约束];
# 删除字段
alter table 表名 drop column 字段名;
# 修改表名
rename table 表名 to 新表名;2. DML(数据操作语言)
插入(insert)
# 指定字段添加数据
insert into 表名(字段1,字段2) values(值1,值2);
# 全部字段添加信息
insert into 表名 values(值1,值2);
# 批量添加数据(指定字段)
insert into 表名(字段1,字段2) values(值1,值2),(值1,值2);
# 批量添加数据(全部字段)
insert into 表名 values(值1,值2),(值1,值2);注意事项:
1. 插入数据时,指定的字段顺序需要与值的顺序一一对应
2. 字符串和日期型数据应该包含在引号中
更新(update)
# 修改数据
update 表名 set 字段名1=值1,字段名2=值2 [where 条件];删除(delete)
# 删除数据
delete from 表名 [where 条件];注意事项:
1. 如果没有where 条件,则会清空表
2. delete不能删除某一个字段的值(如果要操作,可以使用update,将该字段的值设为null)
3. DQL(数据查询语言) (select)
# 语法
select 字段名1,字段名2 from table 表1,表2
where 条件列表
group by 分组字段列表
having 分组后条件列表
order by 排序字段列表
limit 分页参数基本查询:
# 查询多个字段
select 字段1,字段2 from 表名;
# 查询所有字段
select * from 表名;
# 设置表名
select 字段1 as 别名1,字段2 as 别名2 from 表名;
# 去除重复记录
select distinct 字段列表 from 表名;条件查询(where)

分组查询(group by)
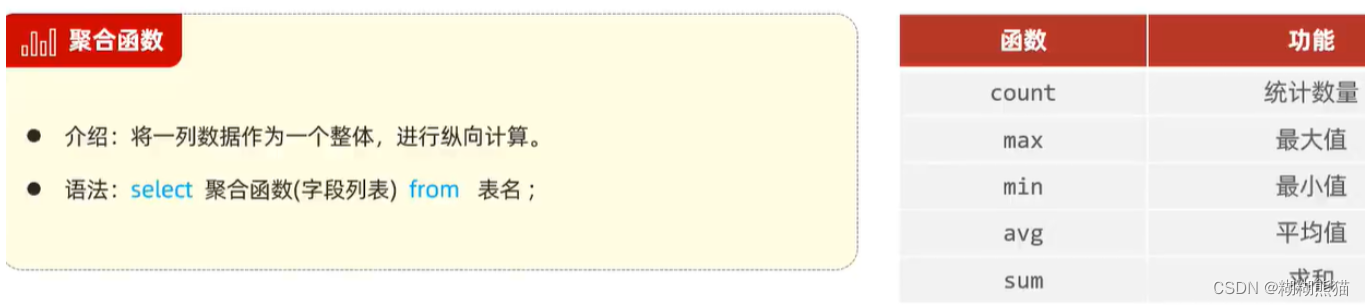
注意事项:
1. null 不参与所有聚合函数运算
2. 统计数量推荐使用 :count(*)
# 语法
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组过滤条件];# eg:查询入职时间在‘2015-01-01’(包含)以前的员工,并对结果根据职位分组,获取庺数量大于等于2的职位
select job,count(*) from tb_emp where entrydate <= ‘2015-01-01’ group by job having count(*) >=2;排序查询(order by)
# 语法
select 字段列表 from 表名 [where 条件列表] [group by 分组字段] order by 字段1 排序方式1,字段2 排序方式2;默认排序方式:asc(升序)
desc(降序)
如果是多字段值排序,只有在前一个字段值相同的情况下,才会根据下一个字段排序
分页查询(limit)
select 字段列表 from 表名 limit 起始索引,查询记录数;注意事项:
1. 起始索引从0开始,起始索引=(查询页码-1)* 每页显示的记录数
2. 如果查询的是第一页数据,起始索引可以省略,直接简写 limit 查询记录数
补充:if条件语句
if条件语句:
if(条件表达式,true取值,false取值)
case表达式
case 表达式 when 值1 then 结果1 when 值2 then 结果2 else 其他结果 end
# eg1: 性别存储时,男存储的1,女存的2
select if(gender = 1 ,'男','女') 性别, count(*) from tb_emp group by gender;
# eg2: 职位在存储时,1:班主任 2:讲师 3:学工主管 4:教研主管 else 未分配职位
select (case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管' when 4 then '教研主管' else '未分配职位') 职位, count(*)
from tb_emp group by job;4.多表操作
外键:
# 创建表时指定
create table 表名(...[constraint] 外键名称 foreign key(外键字段名) references 主表(字段名)
);
# 建完表后,添加外键
alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(字段名);
内连接:
# 隐式内连接
select 字段列表 from 表1,表2 where 条件;
# 显示内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件;外连接:
# 左外连接
select 字段列表 from 表1 left join 表2 on 连接条件;
# 右外连接
select 字段列表 from 表1 right join 表2 on 连接条件;5. 事务
概念:事务是一组操作的集合,它是不可分割的工作单位。事务会把所有操作作为一个整体一起向系统提交或撤销操作请求,即操作要么同时成功,要么同事失败。
事务控制:
# 开启事务
start transaction; / begin;
... (操作语句)
# 提交事务
commit;
# 回滚事务
rollback;四大特性(ACID):
原子性: 事务是不可分割的最小单元,要么全部成功,要么全部失败
一致性: 事务完成时,必须使所有的数据都保持一致的状态
隔离性: 数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
持久性: 事务一旦提交或回滚,它对数据库中的数据的改变就是永久性的
6. 索引
概念:索引是帮助数据库高效获取数据的数据结构(默认B+Tree多路平衡搜索树)
优点:提高查询和排序的效率
缺点:占用磁盘空间、降低了insert、update、delete的效率
语法:
# 创建索引
create [unique] index 索引名 on 表名(字段名,...);
# 查看索引
show index from 表名;
# 删除索引
drop index 索引名 on 表名;注意事项:
1. 主键字段,在建表时,会自动创建主键索引
2. 添加唯一索引约束时,数据库会添加唯一索引
相关文章:
04-Mysql常用操作
1. DDL 常见数据库操作 # 查询所有数据库 show databases; # 查询当前数据库 select databases();# 使用数据库 use 数据库名;# 创建数据库 create database [if not exits] 数据库名; # []代表可选可不选# 删除数据库 drop database [if exits] 数据库名; 常见表操作 创建…...

TensorFlow 2 和 Keras 高级深度学习:1~5
原文:Advanced Deep Learning with TensorFlow 2 and Keras 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象&#x…...
UML类图
一、UML 1、什么是UML? UML——Unified modeling language UML(统一建模语言),是一种用于软件系统分析和设计的语言工具,它用于帮助软件开发人员进行思考和记录思路的结果。UML本身是一套符号的规定,就像数学符号和化学符号一样&…...

【Python】【进阶篇】二十六、Python爬虫的Scrapy爬虫框架
目录 二十六、Python爬虫的Scrapy爬虫框架26.1 Scrapy下载安装26.2 创建Scrapy爬虫项目1) 创建第一个Scrapy爬虫项目 26.3 Scrapy爬虫工作流程26.4 settings配置文件 二十六、Python爬虫的Scrapy爬虫框架 Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架…...

PyTorch 深度学习实用指南:6~8
原文:PyTorch Deep Learning Hands-On 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如何实现目…...

数据湖 Hudi 核心概念
文章目录 什么是 Hudi ?Hudi 是如何对数据进行管理的?Hudi 表结构Hudi 核心概念 什么是 Hudi ? Hudi 是一个用于处理大数据湖的开源框架。 大数据湖是指一个大规模的、中心化的数据存储库,其中包含各种类型的数据,如结构化数据、半结构化…...

爬虫请求头Content-Length的计算方法
重点:使用node.js 环境计算,同时要让计算的数据通过JSON.stringify从对象变成string。 1. Blob size var str 中国 new Blob([str]).size // 6 2、Buffer.byteLength # node > var str 中国 undefined > Buffer.byteLength(str, utf8) 6 原文…...
Open Inventor 2023.1 Crack
发行说明 Open Inventor 2023.1(次要版本) 文档于 2023 年 4 月发布。 此版本中包含的增强功能和新功能: Open Inventor 10 版本编号更改体积可视化 单一分辨率的体绘制着色器中与裁剪和 ROI 相关的新功能MeshVizXLM 在 C 中扩展的剪辑线提…...
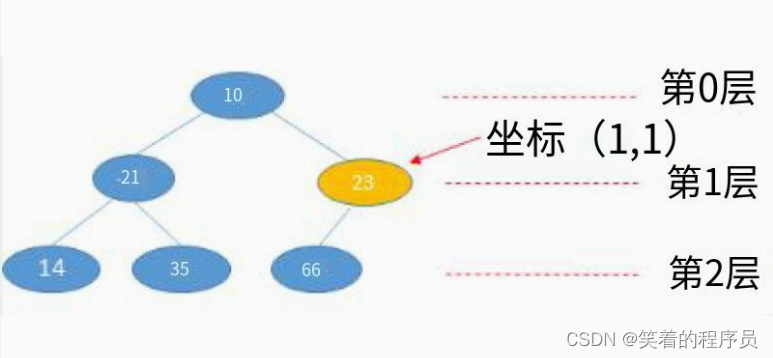
【华为OD机试真题】查找树中元素(查找二叉树节点)(javaC++python)100%通过率
查找树中元素 知识点树BFSQ搜索广搜 时间限制:1s空间限制:256MB限定语言:不限 题目描述: 已知树形结构的所有节点信息,现要求根据输入坐标(x,y)找到该节点保存的内容 值;其中: x表示节点所在的层数,根节点位于第0层,根节点的子节点位于第1层,依次类推; y表示节…...

常用设计模式
里氏替换原则:子类可以扩展父类的功能,但是不要更改父类的已经实现的方法子类对父类的方法尽量不要重写和重载。(我们可以采用final的手段强制来遵循)创建型模式 单例模式:维护线程数据安全 懒汉式 public class Test{ 饿汉式 private static final Test…...
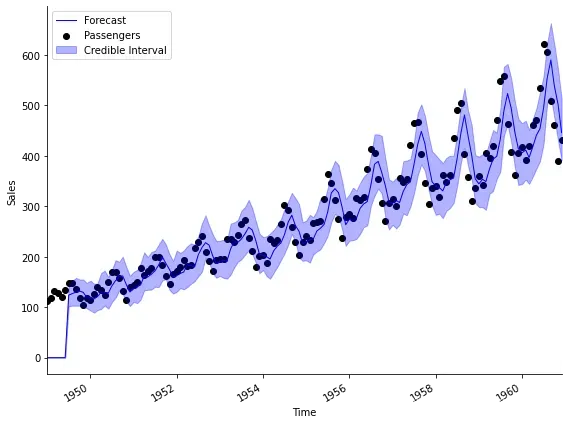
时序分析 49 -- 贝叶斯时序预测(一)
贝叶斯时序预测(一) 时序预测在统计分析和机器学习领域一直都是一个比较重要的话题。在本系列前面的文章中我们介绍了诸如ARIMA系列方法,Holt-Winter指数平滑模型等多种常用方法,实际上这些看似不同的模型和方法之间都具有千丝万缕…...

从传统管理到智慧水务:数字化转型的挑战与机遇
概念 智慧水务是指利用互联网、物联网、大数据、人工智能等技术手段,将智能化、信息化、互联网等技术与水务领域相结合,通过感知、传输、处理水质、水量、水价等数据信息,对水资源进行全面监测、综合管理、智能调度和优化配置的智能化水务系…...
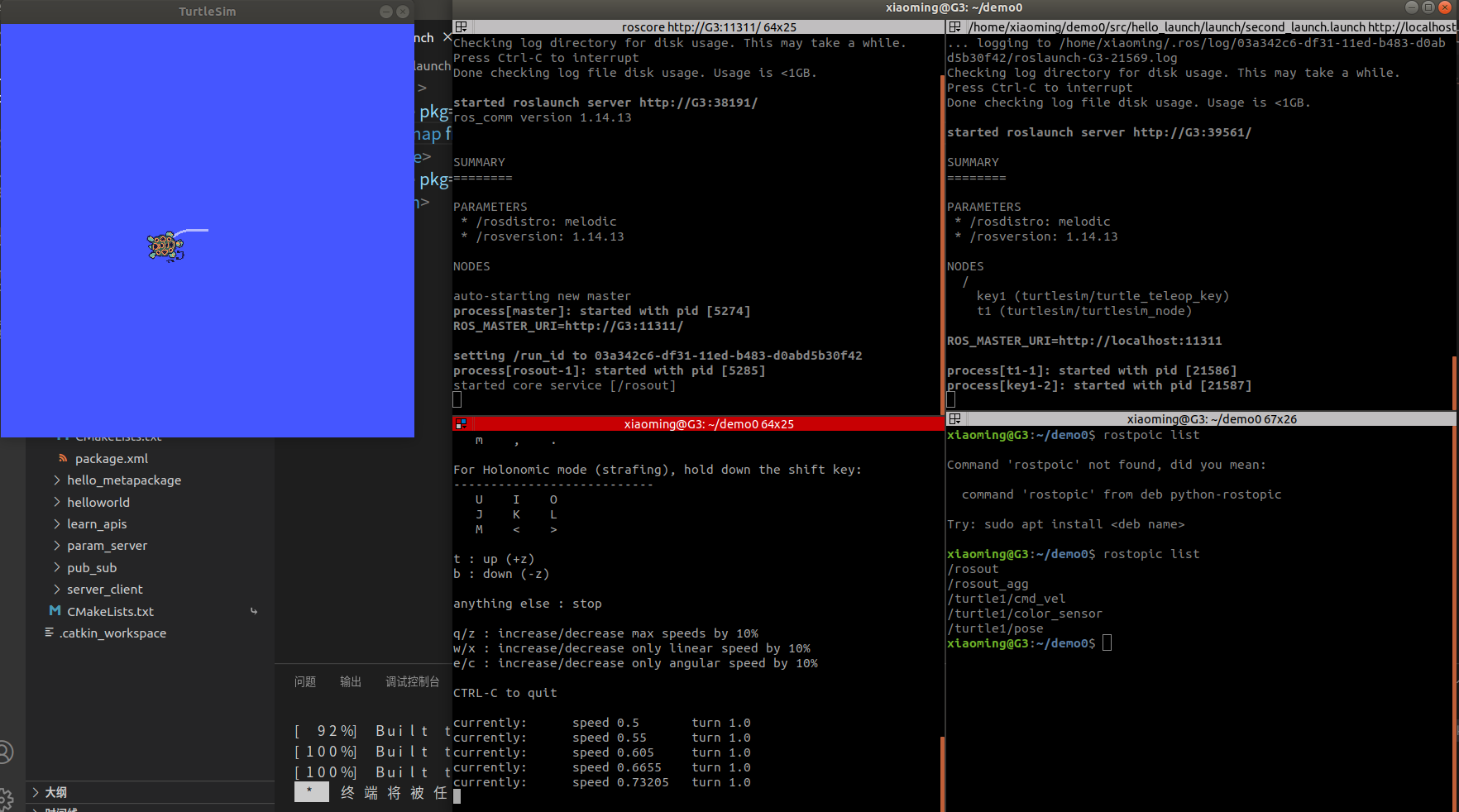
ROS学习第十八节——launch文件(详细介绍)
1.概述 关于 launch 文件的使用已经不陌生了,之前就曾经介绍到: 一个程序中可能需要启动多个节点,比如:ROS 内置的小乌龟案例,如果要控制乌龟运动,要启动多个窗口,分别启动 roscore、乌龟界面节点、键盘控制节点。如果…...
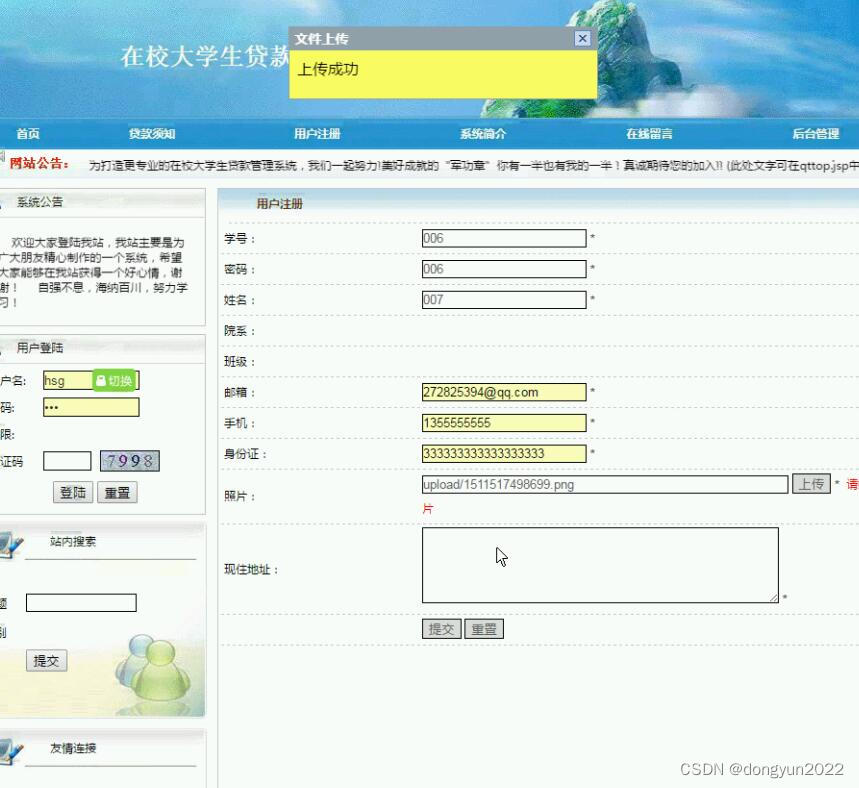
javaweb在校大学生贷款管理系统ns08a9
1系统主要实现:学生注册、填写详细资料、申请贷款、学校审核、银行审核、贷后管理等功能, (1) 学生注册:学生通过注册用户,提交自己的详细个人资料,考虑现实应用中的安全性,资料提交后不可修改;…...
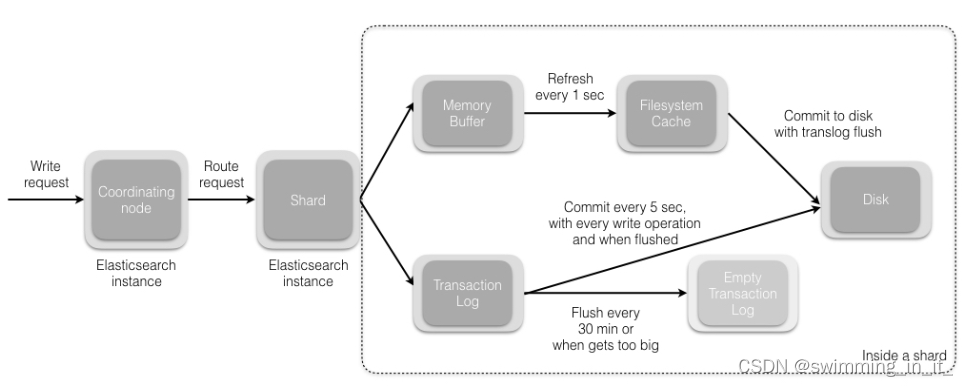
分布式之搜索解决方案es
一 ES初识 1.1 概述 ElasticSearch:是基于 Lucene 的 Restful 的分布式实时全文搜索引擎,每个字段都被索引并可被搜索,可以快速存储、搜索、分析海量的数据。是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表…...

CSDN 编程竞赛四十六期题解
地址:CSDN 编程竞赛四十六期 思路:通过找规律可以知道,在周期第一个位置的数的下标都有一个规律:除以三的余数为 1 。而第二个位置,第三个位置的余数分别为 2 , 0 。 因此可以开一个长度为 3 的总和数组&am…...
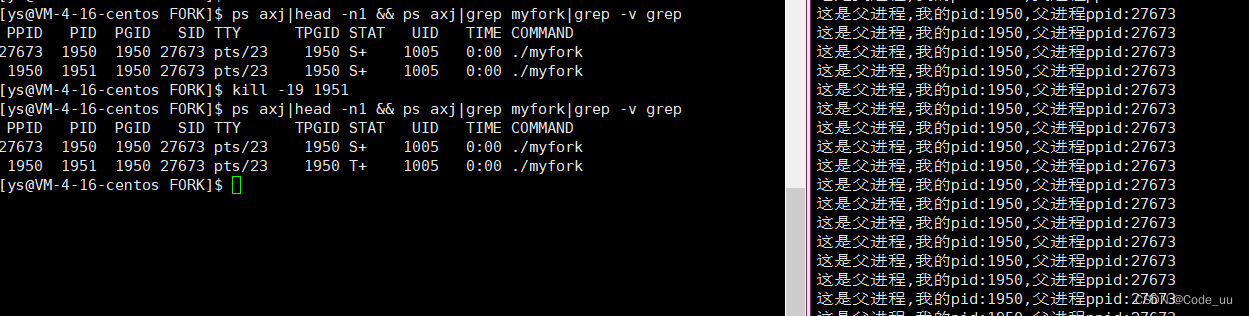
Linux——进程
进程介绍及其使用 1、认识冯诺依曼体系2、操作系统如何理解操作系统对硬件做管理? 3、进程如何创建进程进程状态 1、认识冯诺依曼体系 在计算机的硬件结构中,有着图灵和冯诺依曼俩位举足轻重的人物。对于计算机的发展来说有着十分重要的意义。冯诺依曼结…...

计及氢能的综合能源优化调度研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

基于Bert的知识库智能问答系统
项目完整地址: 可以先看一下Bert的介绍。 Bert简单介绍 一.系统流程介绍。 知识库是指存储大量有组织、有结构的知识和信息的仓库。这些知识和信息被存储为实体和实体关系的形式,通常用于支持智能问答系统。在一个知识库中,每个句子通常来说…...

libapparmor非默认目录构建和安装
在AppArmor零知识学习五、源码构建(2)中,详细介绍了libapparmor的构建步骤,但那完全使用的是官网给出的默认参数。如果需要将目标文件生成到指定目录而非默认的/usr,则需要进行一些修改,本文就来详述如何进…...

如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富!
如何永久珍藏你的微信数字记忆?WeChatMsg让聊天记录成为永恒财富! 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/Gi…...

DaVinci Developer与Configurator Pro联调指南:如何高效设计SWC并集成到ECU工程
DaVinci Developer与Configurator Pro联调实战:从SWC设计到ECU集成的全流程解析 在汽车电子控制单元(ECU)开发领域,工具链的协同效率直接决定了项目进度和质量。作为Vector公司AUTOSAR工具链的核心组件,DaVinci Develo…...

Excel MCP Server终极指南:让AI成为你的Excel自动化助手
Excel MCP Server终极指南:让AI成为你的Excel自动化助手 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了重复的Excel操作&…...

终极免费方案:3步轻松解锁QQ音乐加密文件,让音乐随处可听
终极免费方案:3步轻松解锁QQ音乐加密文件,让音乐随处可听 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾遇到过这样的情况&a…...

如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南
如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management…...

镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书
镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书副标题:聚合动态三维实时重构、无感厘米级定位、全域跨镜连续追踪、身体指纹生物核验四大自研核心,一站式覆盖楼宇、仓储、硐室全场景透明智能管控前言当下城市建筑楼宇、物资仓储…...
研究(Matlab代码实现))
一种用于并网光伏系统的创新型多层逆变器,以降低总谐波失真(THD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 🎁…...

多智能体的协作成本:沟通开销、上下文膨胀与优化手段
多智能体的协作成本:沟通开销、上下文膨胀与优化手段 1. 标题 (Title) 多智能体系统的协作困境:解析沟通开销与上下文膨胀 从理论到实践:优化多智能体协作成本的完整指南 协作的代价:多智能体系统中的沟通、上下文与优化策略 打破协作壁垒:如何有效降低多智能体系统的运行…...
)
别再点‘忽略’了!开机弹出Visual C++ Runtime Library错误的终极排查指南(附Adobe软件关联排查)
Visual C Runtime Library错误:从崩溃到根治的全链路解决方案 每次开机时那个刺眼的Visual C Runtime Library错误弹窗,就像一位不请自来的访客,固执地打断你的工作节奏。对于依赖Adobe Creative Cloud或达芬奇等创意工具的专业人士来说&…...

Unity游戏开发集成MCP协议:AI助手自动化操作指南
1. 项目概述:Unity游戏开发中的MCP革命如果你是一名Unity开发者,最近可能已经注意到一个名为“CoderGamester/mcp-unity”的项目在GitHub上悄然走红。这不仅仅是一个普通的插件或工具包,它代表了一种全新的工作流范式,旨在将大型语…...