哈希(C++)
哈希
- unordered系列关联式容器
- unordered_map
- 介绍
- 底层结构
- 哈希概念
- 哈希冲突
- 哈希函数
- 哈希冲突解决方式
- 闭散列
- 开散列
- 模拟实现
- 哈希表的改造
- 哈希应用
- 位图
- 概念
- 实现
- 布隆过滤器
- 提出
- 概念
unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率很高,即使最差的情况下需要红黑树的高度次,当树中的节点非常多时,查询的效率不理想;最理想的查询是:进行很少的比较次数就能够将元素找到,因此在C++11中,STL有提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同
unordered_map
介绍
unordered_map是存储键值对pair<K,V>的关联式容器,允许通过键值key快速查找到与其对应的实值value- 在
unordered_map中,键值通常唯一地标识元素,而映射值是一个对象,其内容与键值关联,键值和映射对象类型可能不同 - 在内部,
unordered_map没有将键值对按照任何特定顺序进行排序(无序),为了能在常数范围内找到键值对应的实值,unordered_map将相同哈希值的键值对存放在相同的桶中 unordered_map实现了直接访问操作符operator[],允许使用键值作为参数直接访问实值- 迭代器只能向前
底层结构
unordered系列关联式容器之所以效率高,是因为底层结构是哈希,接下来深入了解这个结构
哈希概念
顺序结构和平衡树中,元素的键值与其存储的位置无关,因此在查找某一个元素时,必须通过键值进行多次比较;搜索的效率取决于搜索过程中元素的比较次数
哈希结构提供一种搜索方式:通过数组实现的结构;不经过任何比较,直接从其结构中搜索待查找的元素;通过某种函数将元素的键值与存储位置之间建立联系也就是映射关系,在查找时便可通过该函数快速找到该元素
插入元素:根据元素的键值,通过此函数计算出该元素的存储位置并存放
查找元素:对元素的键值进行同样的计算,将求得的函数值当作元素的存储位置,在结构中此位置取元素进行比较,若键值相等,则搜索成功
哈希方法中使用的转换函数称为哈希函数:hash(key)=key%size(),结构称为哈希表
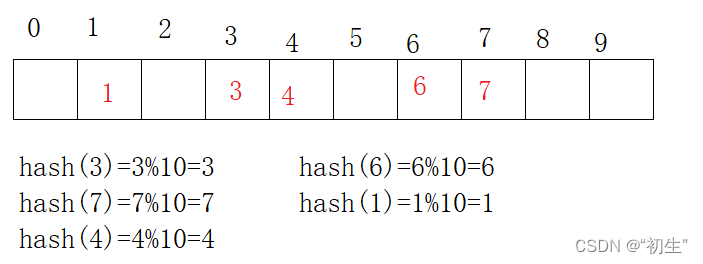
例如:
int arr[]={3,6,7,1,4}
哈希函数:hash(key)=key%size();size()存储元素底层空间的大小
哈希冲突
按照上述哈希方式,再次向表中插入元素14结果会怎样呢???
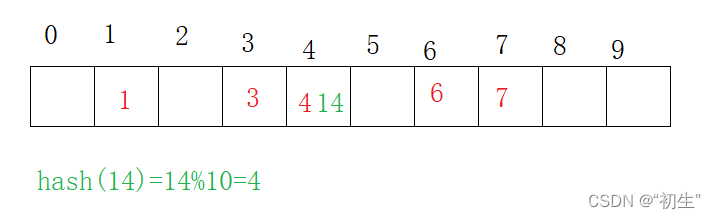
从图中可以发现,在表中下标为4的格子中,同时出现两个元素,此时如果进行元素查找便可能会出现问题
对于两个元素的键值通过哈希函数计算之后相等的情景称为哈希冲突
既然问题已经存在,首先是要找到解决方法,接下来慢慢揭晓
哈希函数
造成哈希冲突的其中一个原因可能是:哈希函数设计的不合理
设计原则
- 哈希函数的定义域必须包括要存储的全部键值,如果表中允许有
n个地址时,其值域必须在[0,n-1]之间 - 哈希函数计算出的地址能均匀分布在整个表中
常见哈希函数,这里只介绍一种除留余数法
设表中允许的地址数为 n,取一个不大于 n,但最接近或者等于 n的数 p作为除数,按照哈希函数: hash(key)=key%p(p<=n),将键值转换为哈希地址;有点类似于基数排序
哈希冲突解决方式
解决哈希冲突的两种常见方法:闭散列和开散列
闭散列
也称开放定址法,当发生哈希冲突时,如果哈希表还未被装满,表明在表中还有空余地址,便可以将冲突的键值存放到冲突位置的“下一个”空地址中;那么又该如何去寻找空地址呢???
这里只简单介绍一种寻找空地址的方法:线性探测
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空地址为止
插入:通过哈希函数获取待插入元素在表中的位置;当发生哈希冲突时,使用线性探测寻找下一个空地址,插入新元素
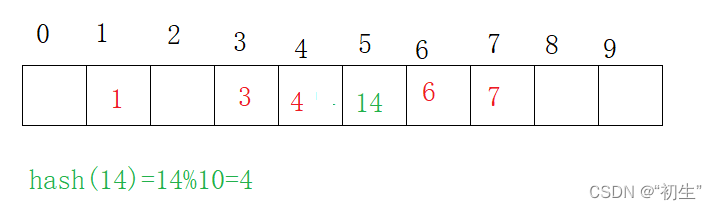
删除
采取闭散列处理哈希冲突时,不可以随便删除表中的元素,如果直接删除元素,会影响其他元素的查找;比如,直接删除元素 4,当查找元素 14时,便会显示元素不存在,但实际上该元素是存在的,所以还表中的每个地址都需要一个标记,来表示当前位置的状态
在模拟实现之前,先介绍新的概念:负载因子,即元素个数除以表格的大小,在闭散列中负载因子永远小于1,范围是 (0,1),这样的做法是为了保障效率;一般规定负载因子的大小为 0.7,一旦超过此大小,哈希表便需要进行扩容
//标识位置的状态enum State{EXIST,EMPTY,DELETE,};//表中每个位置的结构template<class K,class V>struct Hashnode{pair<K, V> _kv;State _state = EMPTY;};//表的结构template<class K,class V,class Hash=HashFunc<K>>class Hashtable{typedef Hashnode<K, V> Data;public:Hashtable():_n(0){_table.resize(10);}Data* find(const K& key){Hash hf;size_t hashi = hf(key) % _table.size();while (_table[hashi]._state != EMPTY){if (_table[hashi]._state == EXIST&& _table[hashi]._kv.first == key){return &_table[hashi];}hashi++;hashi %= _table.size();}return nullptr;}bool insert(const pair<K, V>& kv){if (find(kv.first)){return false;}//大于规定负载因子,扩容if (_n * 10 / _table.size() >= 7){//旧表的元素,重写计算,映射到新表中Hashtable<K, V, Hash> newht;newht._table.resize(_table.size() * 2);for (auto& e : _table){if (e._state == EXIST){newht.insert(e._kv);}}_table.swap(newht._table);}Hash hf;size_t hashi = hf(kv.first) % _table.size();while (_table[hashi]._state == EXIST){//线性探测++hashi;hashi %= _table.size();}_table[hashi]._kv = kv;_table[hashi]._state = EXIST;++_n;return true;}bool erase(const K& key){Hash hf;size_t hashi = hf(key) % _table.size();while (_table[hashi]._state != EMPTY){if (_table[hashi]._state == EXIST&& _table[hashi]._kv.first == key){return &_table[hashi];}++hashi;hashi %= _table.size();}return nullptr;}private:vector<Data> _table;size_t _n = 0;//表中存储元素的有效个数};
测试
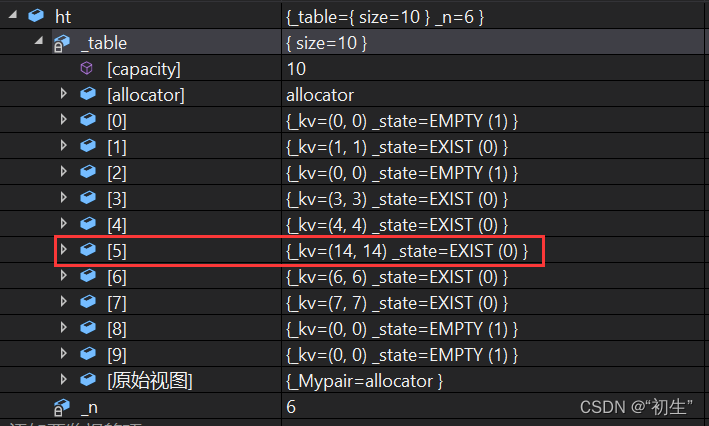
void test(){int arr[] = { 3,6,7,1,4,14};Hashtable<int, int>ht;for (auto e : arr){ht.insert(make_pair(e,e));}}
运行结果
上面的测试对象是整型数组,当遇到字符串又该如何呢???
由于哈希只能处理整型,所以需要将字符串转换成整型,之后再通过哈希函数计算位置进行各种操作;采取仿函数 HashFunc()来将各种数据类型转换成整型,也就是为什么在创建Hashtable类时模板中存在 class Hash=HashFunc<K>缺省值的原因
template<class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//特化
template<>
struct HashFunc<string>
{size_t operator()(const string& key){size_t hash = 0;for (auto e : key){e *= 131;hash += e;}return hash;}
};
总结
线性探测的优点:实现起来非常简单
线性探测的缺点:一旦发生哈希冲突,所有的冲突连在一起,容易产生数据堆积,从而导致效率降低
开散列
又称地址法,首先对键值通过哈希函数计算位置,具有相同的位置的键值归于同一个子集,每一个子集称为一个桶,每个桶中的元素通过一个单链表连接起来,每个链表的头节点存储在哈希表中;此时的哈希表就是一个指针数组,此结构也称哈希桶
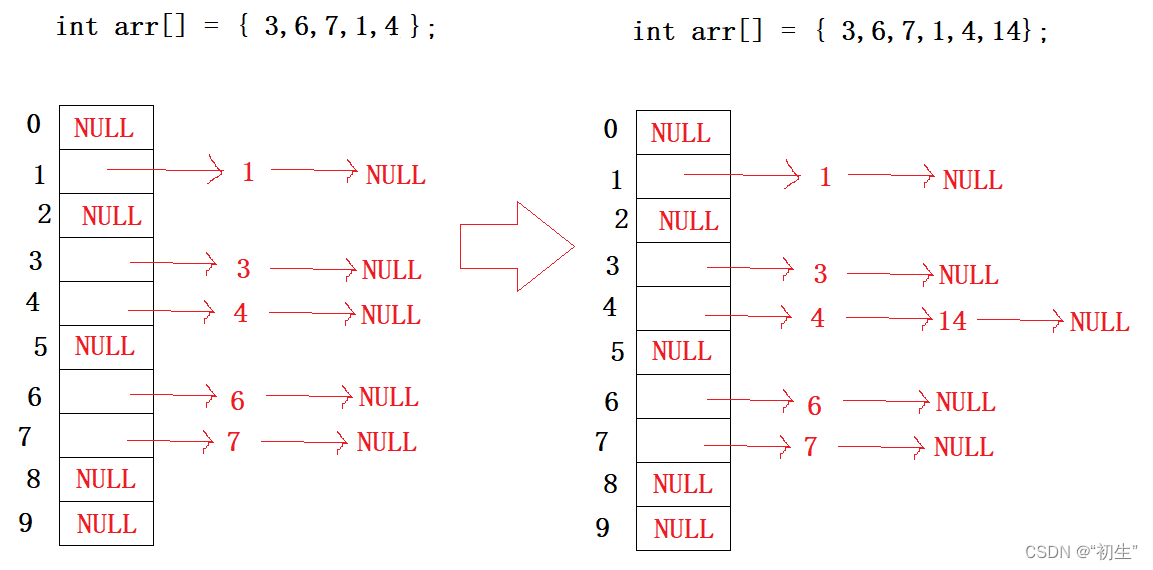
从上图可以发现,开散列中每个桶中存放的都是发生哈希冲突的元素;开散列的负载因子一般规定不超过1,一旦超过便会进行扩容操作
template<class K, class V>struct Hashnode{pair<K, V> _kv;Hashnode<K, V>* _next;Hashnode(const pair<K, V>& kv):_kv(kv), _next(nullptr){}};template<class K, class V, class Hash = HashFunc<K>>class Hashbucket{typedef Hashnode<K, V> node;public:Hashbucket():_n(0){_table.resize(10);}~Hashbucket(){for (size_t i = 0; i < _table.size(); i++){node* cur = _table[i];while (cur){node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}node* find(const K& key){size_t hashi = Hash()(key) % _table.size();node* cur = _table[hashi];while (cur){if (cur->_kv.first == key){return cur;}else{cur = cur->_next;}}return nullptr;}bool insert(const pair<K, V>& kv){if (find(kv.first)){return false;}if (_table.size() == n){vector<node*> newtable;newtable.resize(2 * _table._size());for (size_t i = 0; i < _table.size(); i++){while (cur){node* next = cur->_next;size_t hashi = Hash()(cur->_kv.first) % _table.size();//头插到新表cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);}size_t hashi = Hash()(kv.first) % _table.size();node* newnode = new node(kv);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return true;}bool erase(const K& key){size_t hashi = Hash()(key) % _table.size();node* prev = nullptr;node* cur = _table[hashi];while (cur){if (cur->_kv.first = key){//准备删除//没有哈希冲突if (cur == _table[hashi]){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}else{prev = cur;cur = cur->_next;}}return false;}private:vector<node*> _table;size_t _n = 0;//表中存储元素的有效个数};
测试
void test(){int arr[] = { 3,6,7,1,4,14 };Hashtable<int, int>ht;for (auto e : arr){ht.insert(make_pair(e, e));}}
运行结果
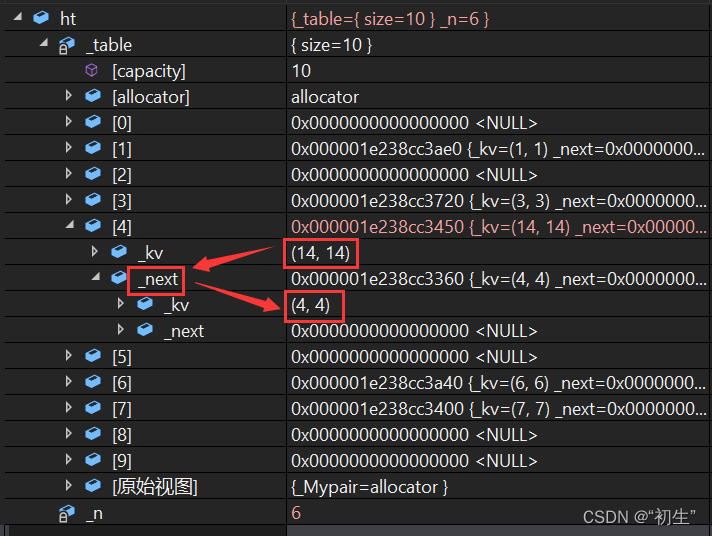
闭散列和开散列的比较
应用地址法处理哈希冲突,需要增设链表指针,似乎增加了存储开销;实际上:由于地址法必须保持大量的空闲空间以确保搜索效率,而哈希表所占空间又比指针大得多,所以开散列比闭散列更加地节省存储空间
模拟实现
哈希表的改造
增加迭代器
template<class K, class T, class Hash, class KeyofT>struct _Hashiterator{typedef Hashnode<T> node;typedef _Hashiterator<K, T, Hash, KeyofT> Self;typedef Hashbucket<K, T, Hash, KeyofT> HB;node* _node;//指向哈希桶的指针,用来获取HB* _hb;_Hashiterator(node* node, HB* hb):_node(node), _hb(hb){}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}bool operator!=(const Self& s)const{return _node != s._node;}bool operator==(const Self& s)const{return _node == s._node;}Self& operator++(){if (_node->_next){_node = _node->_next;}else{//当前的桶已经遍历完,需要到下一个桶进行遍历KeyofT kot;Hash hash;size_t hashi = hash(kot(_node->_data)) % _hb->_table.size();++hashi;while (hashi < _hb->_table.size()){if (_hb->_table[hashi]){_node = _hb->_table[hashi];break;}else{++hashi;}}if (hashi == _hb->_table.size()){_node = nullptr;}}return *this;}};
哈希表中每个元素的设计
template<class T>struct Hashnode{T _data;Hashnode<T>* _next;Hashnode(const T& data):_data(data), _next(nullptr){}};
这里同样考虑到数据T,可能是键值key,也可能是键值对pair<K,V>;所以许还需要一个能够通过键值key获取实值value的仿函数KeyofT,此仿函数的实现在模拟实现的类对象中实现
//前置声明template<class K,class T,class Hash,class KeyofT>class Hashbucket;template<class K, class T, class Hash, class KeyofT>struct _Hashiterator{typedef Hashnode<T> node;typedef _Hashiterator<K, T, Hash, KeyofT> Self;typedef Hashbucket<K, T, Hash, KeyofT> HB;node* _node;//指向哈希桶的指针,用来获取HB* _hb;_Hashiterator(node* node, HB* hb):_node(node), _hb(hb){}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}bool operator!=(const Self& s)const{return _node != s._node;}bool operator==(const Self& s)const{return _node == s._node;}Self& operator++(){if (_node->_next){_node = _node->_next;}else{//当前的桶已经遍历完,需要到下一个桶进行遍历KeyofT kot;Hash hash;size_t hashi = hash(kot(_node->_data)) % _hb->_table.size();++hashi;while (hashi < _hb->_table.size()){if (_hb->_table[hashi]){_node = _hb->_table[hashi];break;}else{++hashi;}}if (hashi == _hb->_table.size()){_node = nullptr;}}return *this;}};template<class K, class T, class Hash,class KeyofT>class Hashbucket{typedef Hashnode<T> node;template<class K,class T,class Hash,class KeyofT>friend struct _Hashiterator;public:typedef _Hashiterator<K, T, Hash, KeyofT> iterator;Hashbucket():_n(0){_table.resize(10);}~Hashbucket(){for (size_t i = 0; i < _table.size(); i++){node* cur = _table[i];while (cur){node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}iterator begin(){for (size_t i = 0; i < _table.size(); i++){//寻找第一个不为空的位置if (_table[i]){return iterator(_table[i], this);}}return iterator(nullptr, this);}iterator end(){return iterator(nullptr, this);}iterator find(const K& key){KeyofT kot;size_t hashi = Hash()(key) % _table.size();node* cur = _table[hashi];while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}else{cur = cur->_next;}}return end();}pair<iterator,bool> insert(const T&data){KeyofT kot;iterator it = find(kot(data));if (it != end()){return make_pair(it, false);}if (_table.size() == _n){vector<node*>newtable;newtable.resize(_table.size() * 2);for (size_t i = 0; i < _table.size(); i++){node* cur = _table[i];while (cur){node* next = cur->_next;size_t hashi = Hash()(kot(data)) % newtable.size();//头插到新表中cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newtable);}size_t hashi = Hash()(kot(data)) % _table.size();//头插node* newnode = new node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return make_pair(iterator(newnode, this), true);}bool erase(const K& key){size_t hashi = Hash()(key) % _table.size();node* prev = nullptr;node* cur = _table[hashi];while (cur){if (cur->_kv.first = key){//准备删除//没有哈希冲突if (cur == _table[hashi]){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;--_n;return true;}else{prev = cur;cur = cur->_next;}}return false;}private:vector<node*> _table;size_t _n = 0;//表中存储元素的有效个数};
模拟实现unordered_map
仿函数MapKeyofT的实现
struct MapKeyofT{const K& operator()(const pair<const K, V>& kv){return kv.first;}};
完整代码
template<class K,class V,class Hash=HashFunc<K>>class unordered_map{ struct MapKeyofT{const K& operator()(const pair<const K, V>& kv){return kv.first;}};public:typedef typename yjm::Hashbucket<K, pair<const K, V>, Hash, MapKeyofT>::iterator iterator;iterator begin(){return _hb.begin();}iterator end(){return _hb.end();}pair<iterator, bool> insert(const pair<K, V>& data){return _hb.insert(data);}V& operator[](const K& key){pair<iterator, bool> ret = _hb.insert(make_pair(key, V()));return ret.first->second;}private:yjm::Hashbucket<K, pair<const K, V>, Hash, MapKeyofT> _hb;};
测试
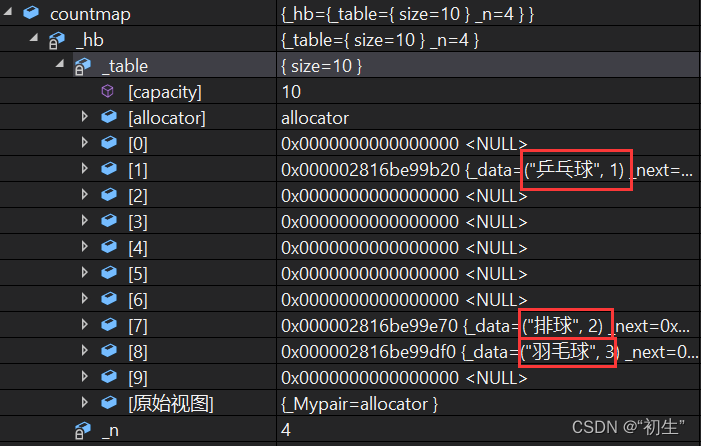
void test(){string arr[] = { "篮球","羽毛球","排球","乒乓球","羽毛球" ,"羽毛球" ,"排球" };unordered_map<string, int> countmap;for (auto& e : arr){countmap[e]++;}}
运行结果
哈希应用
位图
概念
所谓位图就是用每一位来存放某种状态,适用海量数据,数据无重复的场景,通常是用来判断某个数据存在或者不存在的信息,如果二进制比特位(byte) 1代表存在;0代表不存在
举个栗子
int arr[] = { 3,6,7,1,4,14 };
每个字节共有8个比特位,可以保存8个数据的状态(存在或不存在)
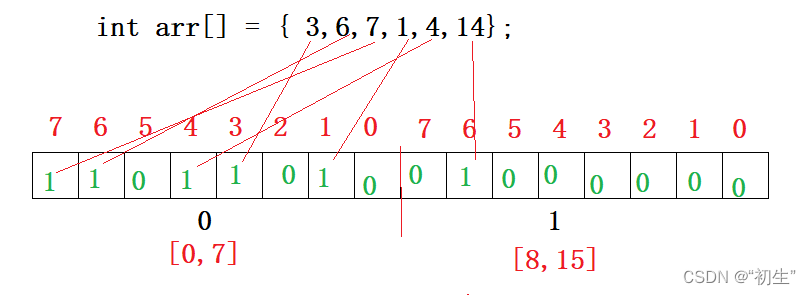
通过位图的概念解决一个问题
给40亿个不重复的无符号整数,没有排过序;给定一个无符号整数,如何快速判断这个数是否在这40亿个数中???
如果没有位图的概念,可能会想着将这些数放到红黑树或者哈希中,但是40亿个整数所需的内存大概是16G,所以这种想法不切实际;接下来就通过位图的概念进行解题
通过位图概念,首先要确定数据的位置,这里采用直接定址法:数据的值是几,就将第几个位标记成1

数据映射在第几个字节上:x/8;
在这个字节的第几个比特位上:x%8;
找到位置之后需要做的便是,如何设置状态,在之前的学习中位运算可以解决这个问题;接下来就是通过灵活运用位运算对数据的状态进行设置
其他位不变,第j位标记成1
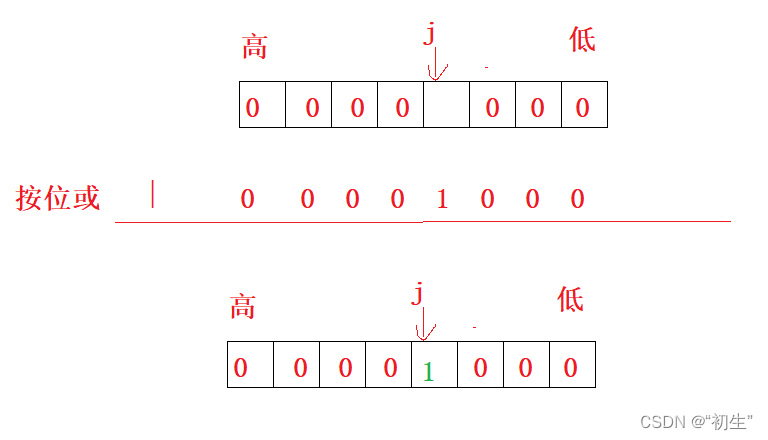
如果第 j位之前就是1,结果也就是1;如果不是1,按位或之后也会变成1
void set(size_t x){size_t i = x / 8;size_t j = x % 8;_bit[i] |= (1 << j);}
其他位不变,第j位标记成0
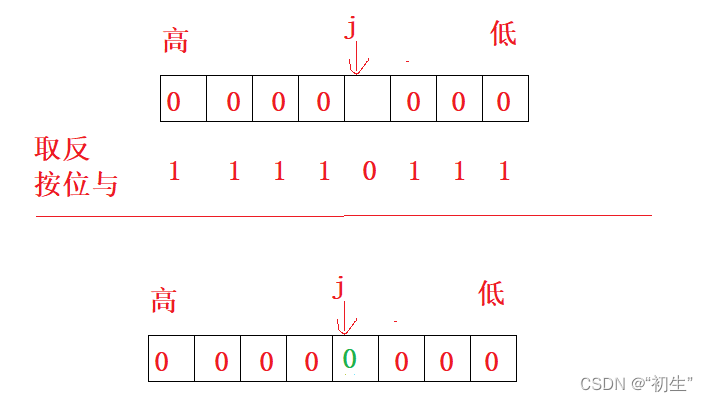
如果第 j位之前就是0,结果也就是0;如果不是0,按位与之后也会变成0
void reset(size_t x){size_t i = x / 8;size_t j = x % 8;_bit[i] &= (~(1 << j));}
测试该位的数据是否存在
bool test(size_t x){size_t i = x >> 3;size_t j = x % 8;return _bit[i] & (1 << j);}
实现
此题目只是判断数据是否存在,一个比特位便可以进行判断: 0,不存在; 1,存在;由于是在40亿个数字中进行判断,所以将40亿个数据放入容量为 size_t int i=-1比特位的容器中进行判断
代码实现
template<size_t N>class bitset{public:bitset(){_bit.resize((N >> 3) + 1, 0);}void set(size_t x){size_t i = x / 8;size_t j = x % 8;_bit[i] |= (1 << j);}void reset(size_t x){size_t i = x / 8;size_t j = x % 8;_bit[i] &= (~(1 << j));}bool test(size_t x){size_t i = x >> 3;size_t j = x % 8;return _bit[i] & (1 << j);}private:vector<char> _bit;};
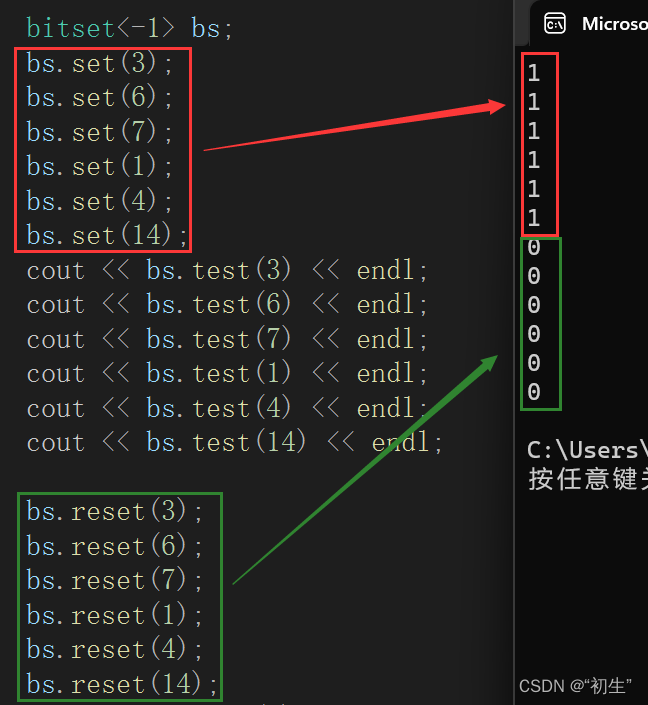
测试
void test(){bitset<-1> bs;bs.set(3);bs.set(6);bs.set(7);bs.set(1);bs.set(4);bs.set(14);cout << bs.test(3) << endl;cout << bs.test(6) << endl;cout << bs.test(7) << endl;cout << bs.test(1) << endl;cout << bs.test(4) << endl;cout << bs.test(14) << endl;bs.reset(3);bs.reset(6);bs.reset(7);bs.reset(1);bs.reset(4);bs.reset(14);cout << bs.test(3) << endl;cout << bs.test(6) << endl;cout << bs.test(7) << endl;cout << bs.test(1) << endl;cout << bs.test(4) << endl;cout << bs.test(14) << endl;}
运行结果
位图的应用:
- 快速查找某个数据是否存在一个集合中
- 排序+去重
- 求两个集合的交集,并集
- 操作系统中对磁盘进行标记
布隆过滤器
提出
当通过哈希函数对字符串映射到位图上时,可能会出现两个字符串同时映射到同一个比特位上,便会出现误判的情况,误判是不可避免的,那么又该如何降低误判呢???
概念
使用多个哈希函数,将一个数据映射到位图结构中,特点是高效地插入和查询,还可以节省大量的内存空间
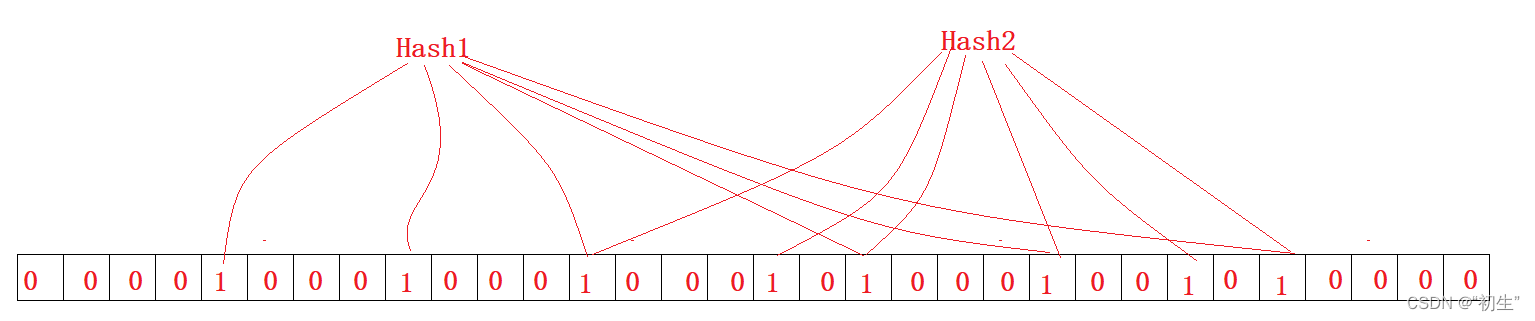
对于一个字符串,通过不止一个哈希函数进行映射,便可以降低误判
对于判断为不存在时一定是正确的;判断存在时,不一定正确,可能存在着冲突
相关文章:
哈希(C++)
哈希 unordered系列关联式容器unordered_map介绍 底层结构哈希概念哈希冲突哈希函数哈希冲突解决方式闭散列开散列 模拟实现哈希表的改造 哈希应用位图概念实现 布隆过滤器提出概念 unordered系列关联式容器 在C98中,STL提供了底层为红黑树结构的一系列关联式容器&…...
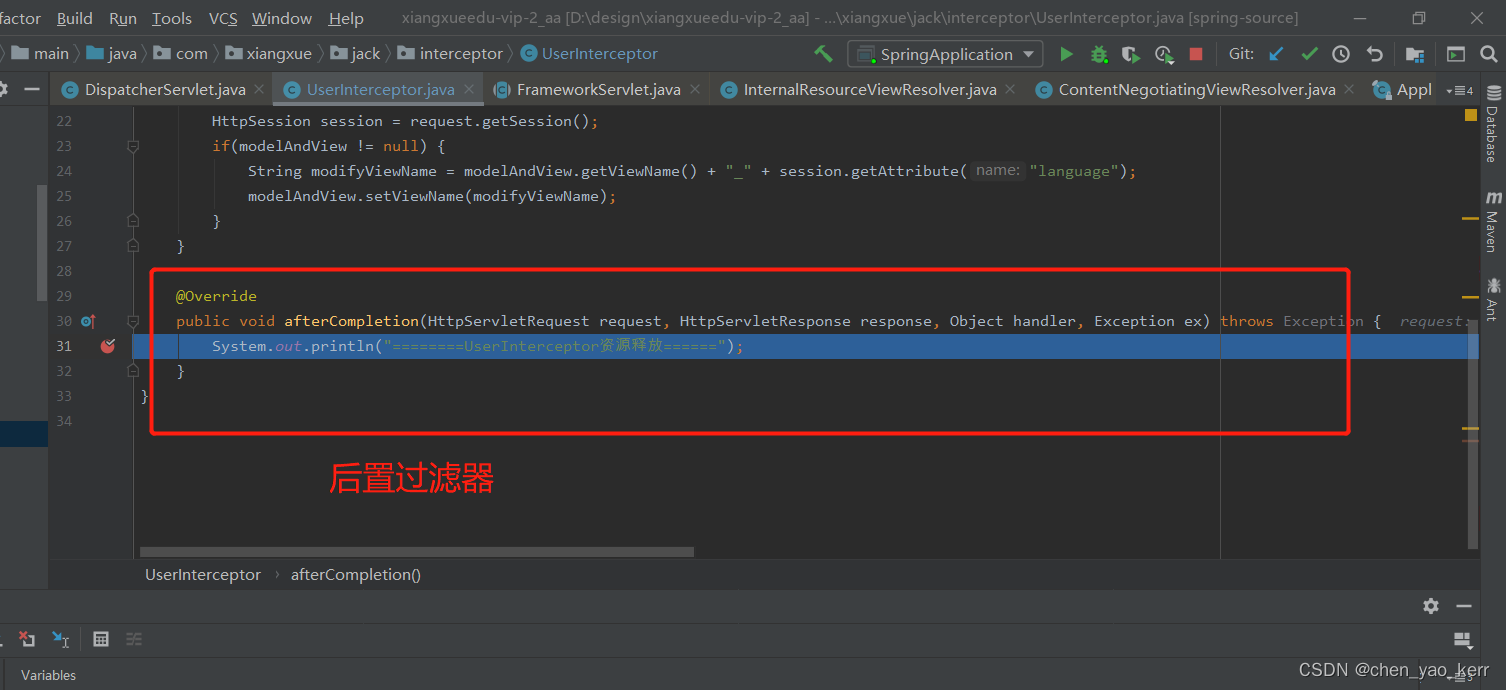
Spring MVC 的调用(12)
目录 SpringMVC流程 源码分析 第一步:用户发起请求到前端控制器(DispatcherServlet) 第二步:前端控制器请求处理器映射器(HandlerMappering)去查找处理器(Handle):通过xml配置或者…...

死磕内存篇 --- JAVA进程和linux内存间的大小关系
运行个JAVA 用sleep去hold住 package org.hjb.test; public class TestOnly { public static void main(String[] args) { System.out.println("sleep .."); try { Thread.sleep(10000000); } catch (InterruptedException e) { e.printStackTrace(); } } } java -…...
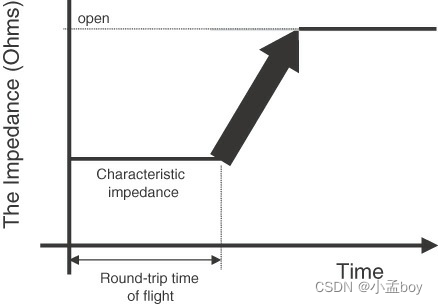
信号完整性分析:关于传输线的三十个问题解答(三)
21.FR4 中 50 欧姆传输线的单位长度电感是多少?如果阻抗加倍怎么办?(What is the inductance per length of a 50-Ohm transmission line in FR4? What if the impedance doubles?) FR4 中的所有 50 欧姆传输线的单位长度电感约…...

Java基础:Stream流常用方法
获取Stream流的方式 java.util.stream.Stream 是Java 8新加入的流接口。(并不是一个函数式接口) 获取一个流非常简单,有以下几种常用的方式: 所有 Collection 集合都可通过 stream 默认方法获取流(顺序流)…...
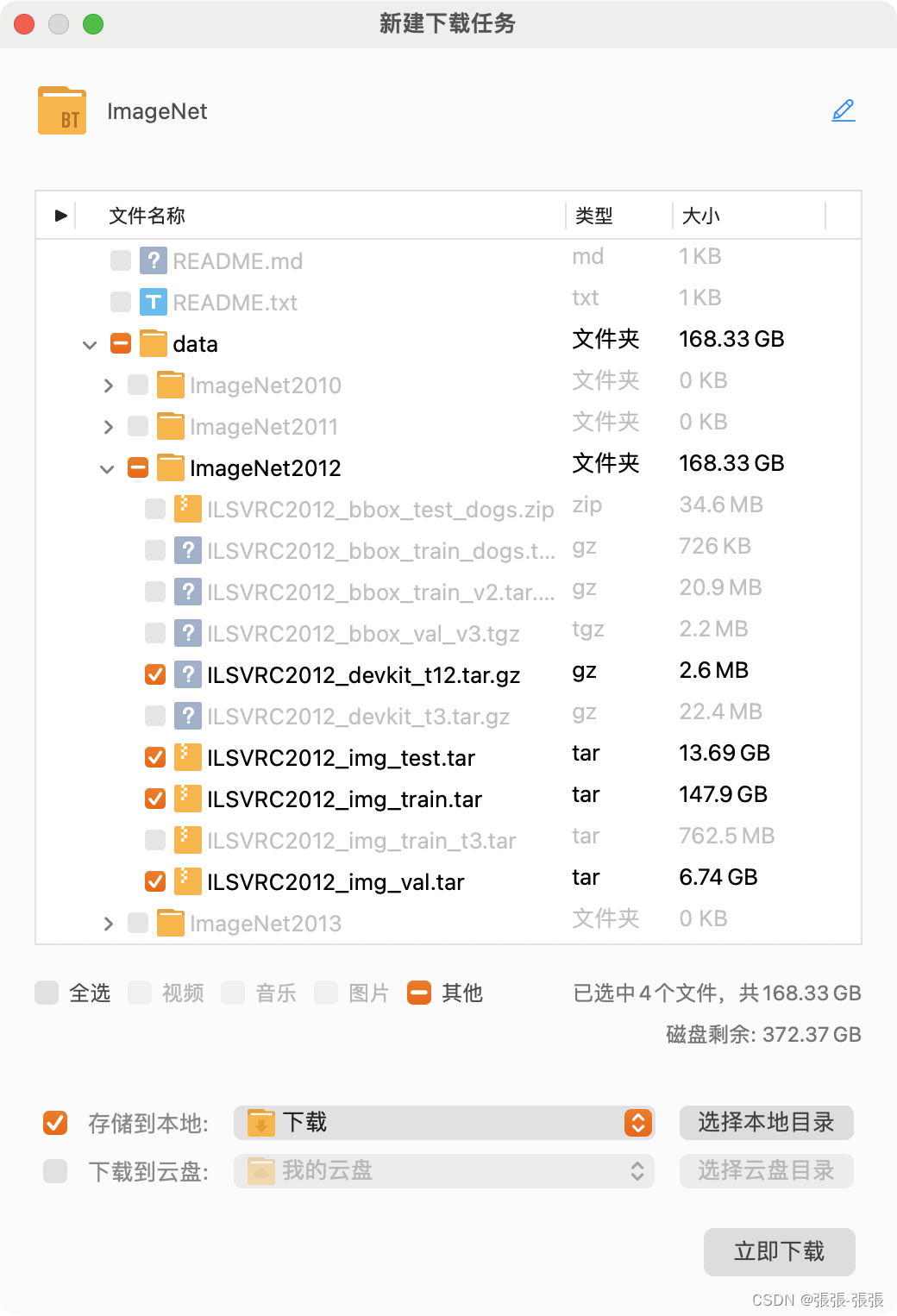
ImageNet使用方法(细节)自用!
学习记录,自用。 1. 下载数据集 点击以下链接下载种子文件,然后使用迅雷进行下载,仅下载勾选的文件即可。 https://hyper.ai/datasets/4889/c107755f6de25ba43c190f37dd0168dbd1c0877e 2. 解压 找到下载好的ILSVRC2012_img_train.tar 和…...

C/C++外观模式解析:简化复杂子系统的高效方法
C外观模式揭秘:简化复杂子系统的高效方法 引言设计模式的重要性外观模式简介与应用场景外观模式在现代软件设计中的地位与价值 外观模式基本概念外观模式的定义与核心思想提供简单接口隐藏复杂子系统设计原则与外观模式的关系外观模式实现外观模式的UML图 外观模式的…...

追梦之旅【数据结构篇】——详解小白如何使用C语言实现堆数据结构
详解小白如何使用C语言实现堆数据结构 “痛”撕堆排序~😎 前言🙌什么是堆?堆的概念及结构 堆的性质:堆的实现堆向下调整算法画图分析:堆向下调整算法源代码分享:向下调整建小堆向下调整建大堆 堆向上调整算…...
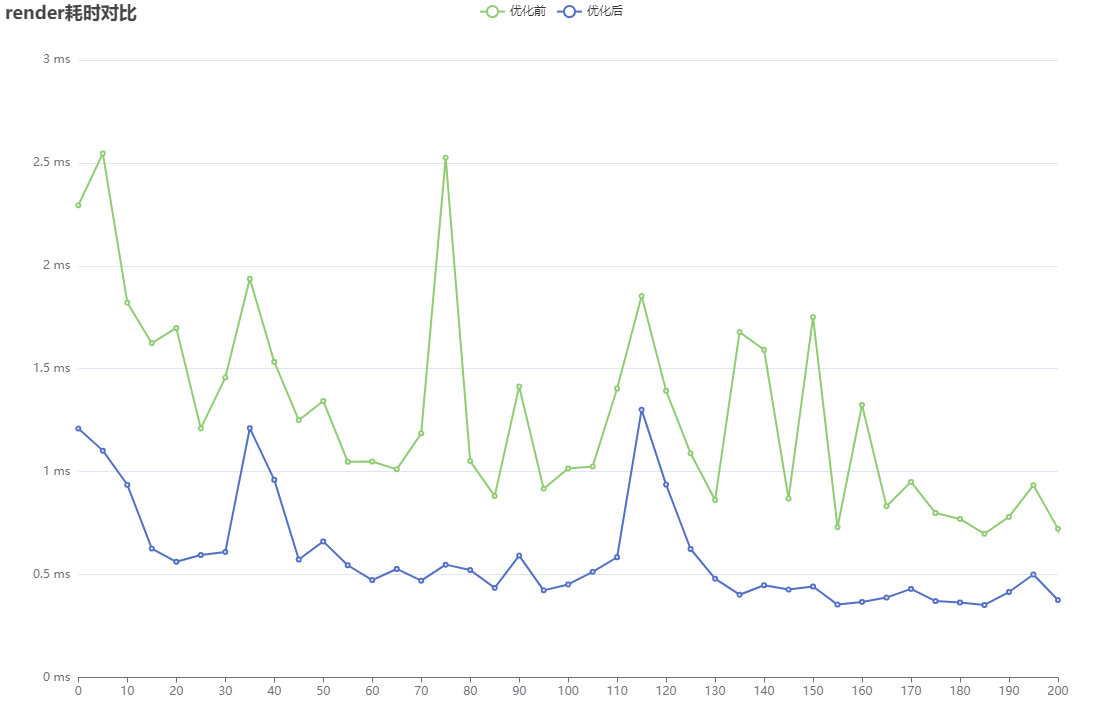
cocoscreator性能优化4-Sprite颜色数据去除
前言 Sprite是游戏内容的一个基本组成元素,包括ui、道具、立绘等各种地方都会用到。大部分情况下美术会帮我们调好图片颜色,我们只要把图片直接放到游戏里就行了。Sprite默认的渲染顶点数据中包含了颜色数据,由于我们并不需要去修改颜色&…...

系统接口幂等性设计探究
前言: 刚开始工作的时候写了一个带UI页面的工具,需要设计登录功能,登录功能也很简单,输入用户名密码点击登录,触发后台查询并比对密码,如果登录成功则返回消息给前端,前端把消息弹出提示一下。…...
C learning_7
目录 1.for循环 1.虽然while循环和for循环本质上都可以实现循环,但是它们在使用方法和场合上还是有一些区别的。 2.while循环中存在循环的三个必须条件,但是由于风格的问题使得三个部分很可能偏离较远,这样 查找修改就不够集中和方便。所以…...
PageRank算法介绍
互联网上有数百亿个网页,可以分为这么几类:不含有用信息的,比如垃圾邮件;少数人比较感兴趣的,但范围不是很广的,比如个人博客、婚礼公告或家庭像册;很多人感兴趣的并且十分有用的,比…...

springboot+vue职称评审管理系统(源码+文档)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的职称评审管理系统。项目源码请联系风歌,文末附上联系信息 。 目前有各类成品java毕设,需要请看文末联系方式 …...
腾讯云4核8G轻量服务器12M支持多少访客同时在线?并发数怎么算?
腾讯云轻量4核8G12M轻量应用服务器支持多少人同时在线?通用型-4核8G-180G-2000G,2000GB月流量,系统盘为180GB SSD盘,12M公网带宽,下载速度峰值为1536KB/s,即1.5M/秒,假设网站内页平均大小为60KB…...
图片英文翻译成中文转换器-中文翻译英文软件
您正在准备一份重要的英文资料或文件,但是您还不是很熟练地掌握英文,需要翻译才能完成您的任务吗?哪个软件能够免费把英文文档翻译成中文?让我们带您了解如何使用我们的翻译软件来免费翻译英文文档为中文。 我们的翻译软件是一款功…...

月薪10k和40k的程序员差距有多大?
程序员的薪资一直是大家关注的焦点,相较于其他行业,程序员的高薪也是有目共睹的,而不同等级的程序员处理问题的方式与他们的薪资直接挂钩。 接下来就一起看一下月薪10k、20k、30k、40k的程序员面对问题都是怎么处理的吧! 场景一 …...

gateway整合knife4j(微服务在线文档)
文章目录 knife4j 微服务整合一、微服务与单体项目文档整合的区别二、开始整合1. 搭建一个父子maven模块的微服务,并引入gateway2.开始整合文档 总结 knife4j 微服务整合 由于单个服务的knife4j 整合之前已经写过了,那么由于效果比较好,然后微服务的项目中也想引入,所以开始微…...
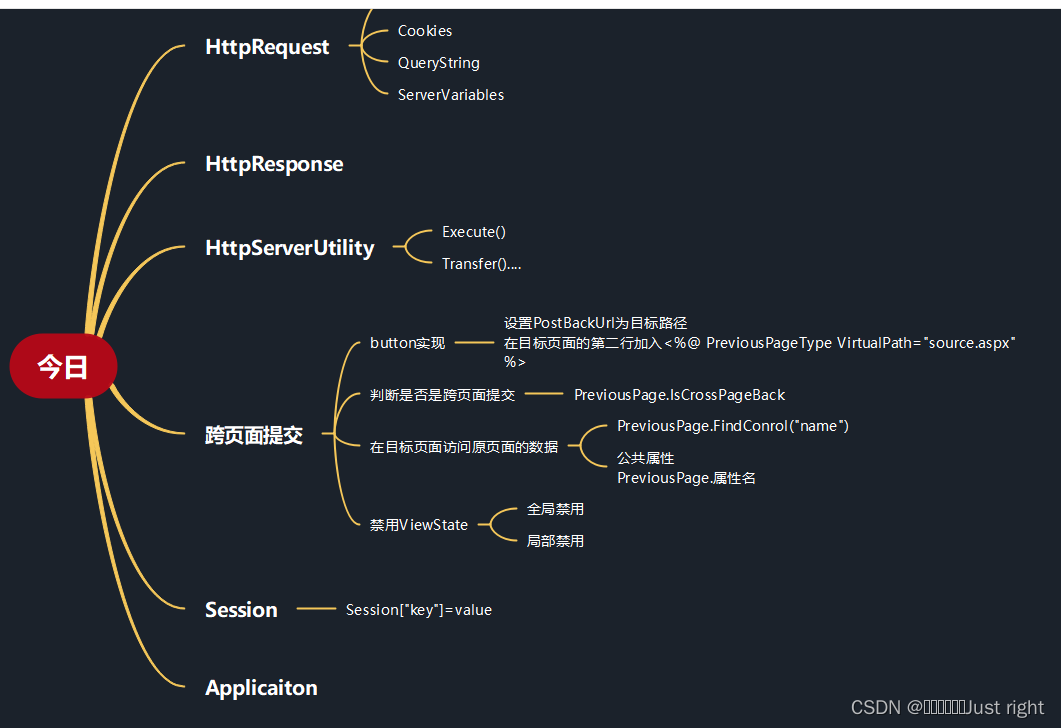
ASP.NET 记录 HttpRequest HttpResponse HttpServerUtility
纯属个人记录,会有错误 HttpRequest Browser是获取客户端浏览器的信息 Cookies是获取客户端的Cookies QueryString是获取客户端提交的数据 ServerVariables是获取服务器端或客户端的环境变量信息 Browser 语法格式: Request.Browser[“浏览器特性名”] 常见的特性名 名称说…...

Python 人工智能:11~15
原文:Artificial Intelligence with Python 协议:CC BY-NC-SA 4.0 译者:飞龙 本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。 不要担心自己的形象,只关心如何…...
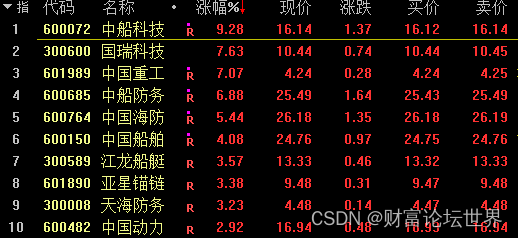
辉煌优配|军工板块逆市上涨,16只概念股已披露一季度业绩预喜
今日,军工股逆市上涨。 4月21日,A股三大股指低开低走,半导体、AI使用、信创工业、软件等科技属性概念领跌,国防军工、食品饮料和电力设备等板块上涨。 工业互联网中心工业规模超1.2万亿元 据央视新闻报道,本年是《工业…...

如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南
如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...

为开源项目OpenClaw配置Taotoken作为后端模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源项目OpenClaw配置Taotoken作为后端模型供应商 OpenClaw是一个功能强大的开源智能体(Agent)框架&…...
)
告别串口线!用STM32CubeMX配置USB-CDC虚拟串口,实现与电脑免驱动通信(附Win7驱动安装指南)
STM32虚拟串口革命:USB-CDC免驱动通信全实战指南 嵌入式开发调试过程中,最令人头疼的莫过于频繁插拔串口线导致的接口松动、接触不良问题。传统串口调试不仅占用宝贵的UART资源,还常常因为物理连接问题浪费大量调试时间。本文将彻底改变这一局…...

AICoverGen终极指南:5分钟用AI制作专业级翻唱歌曲
AICoverGen终极指南:5分钟用AI制作专业级翻唱歌曲 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想不想让AI…...

终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼
终极罗技PUBG鼠标宏配置指南:5步告别压枪烦恼 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 还在为《绝地求生》中疯狂上跳的枪口而…...

Go语言AI编程助手SDK:提升Cursor代码理解与生成精准度
1. 项目概述:一个为AI编程而生的Go语言SDK如果你是一名Go语言开发者,同时又在深度使用Cursor这样的AI辅助编程工具,那么你很可能已经感受到了一个痛点:如何让AI更精准、更高效地理解你的代码库,并在此基础上进行智能操…...

Kubernetes配置管理实战:基于Kustomize的结构化部署与多环境管理
1. 项目概述:一个被低估的Kubernetes配置管理利器如果你和我一样,长期在Kubernetes生态里摸爬滚打,那你一定经历过这样的场景:为了部署一个稍微复杂点的应用,需要维护一堆YAML文件——Deployment、Service、ConfigMap、…...

DLP/SLA光固化3D打印技术解析与Ember打印机实战指南
1. DLP/SLA 3D打印技术深度解析:从光与树脂的对话说起如果你是从FDM(熔丝制造)打印转向树脂打印的,那感觉就像从开手动挡卡车换到了开精密数控机床。DLP(数字光处理)和SLA(立体光刻)…...

Apache Burr:用状态机模式构建Python流式应用
1. 项目概述:一个用于构建流式应用的Python框架最近在折腾一些实时数据处理和模型推理的项目,从简单的日志分析到复杂的在线推荐,总感觉现有的工具链要么太重,要么太散。想要一个既能处理流式数据,又能轻松集成机器学习…...
)
设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测)
更多请点击: https://intelliparadigm.com 第一章:设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测) Midjourney v6.1…...