【Transformer系列(4)】Transformer模型结构超详细解读

前言
前一篇我们一起读了Transformer的论文《Attention Is All You Need》,不知道大家是否真的理解这个传说中的神(反正俺是没有~)
这两天我又看了一些视频讲解,感谢各位大佬的解读,让我通透了不少。
这篇文章就和大家分享一下我的理解!

 🍀前期回顾
🍀前期回顾
【Transformer系列(1)】encoder(编码器)和decoder(解码器)
【Transformer系列(2)】注意力机制、自注意力机制、多头注意力机制、通道注意力机制、空间注意力机制超详细讲解
【Transformer系列(3)】 《Attention Is All You Need》论文超详细解读(翻译+精读)
目录
前言
🌟一、Transformer 整体结构
🌟二、编码器:Encoder
2.1输入
2.1.1词嵌入:Word Embedding层
2.1.2位置编码器:Position Embedding层
2.2注意力机制
2.2.1自注意力机制:Self-Attention
2.2.2多头注意力机制:Multi-Head Attention
2.3残差连接
2.4LN和BN
2.5前馈神经网络:FeedForward
🌟三、解码器:Decoder
3.1第一个 Multi-Head Attention
3.1.1掩码:Mask
3.1.2具体实现步骤
3.2第二个 Multi-Head Attention
3.3Linear和softmax
 🌟一、Transformer 整体结构
🌟一、Transformer 整体结构
首先我们回顾一下这个神图:
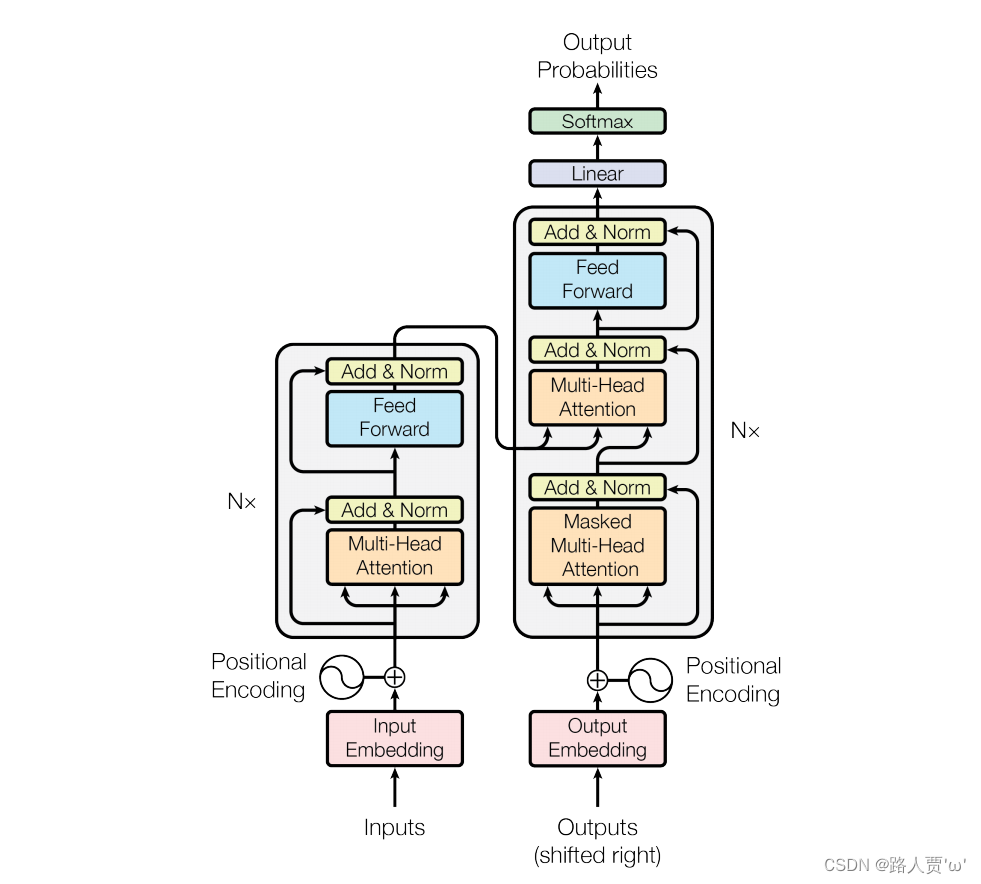
这张图小白刚看时会觉得很复杂有木有?其实Transformer主要就做了这件事:

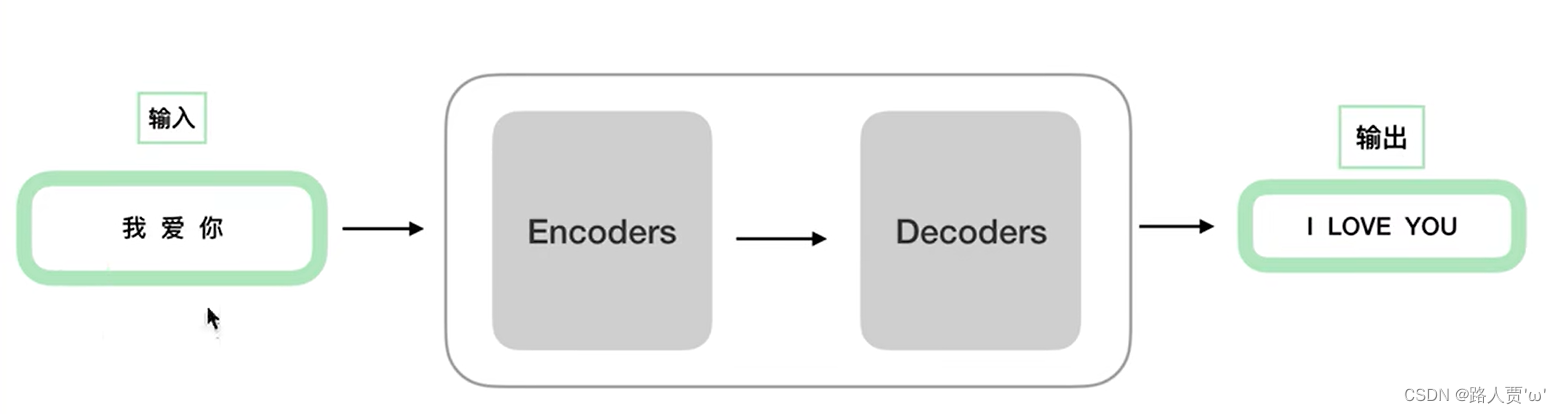
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder把输入读进去,Decoder得到输出:
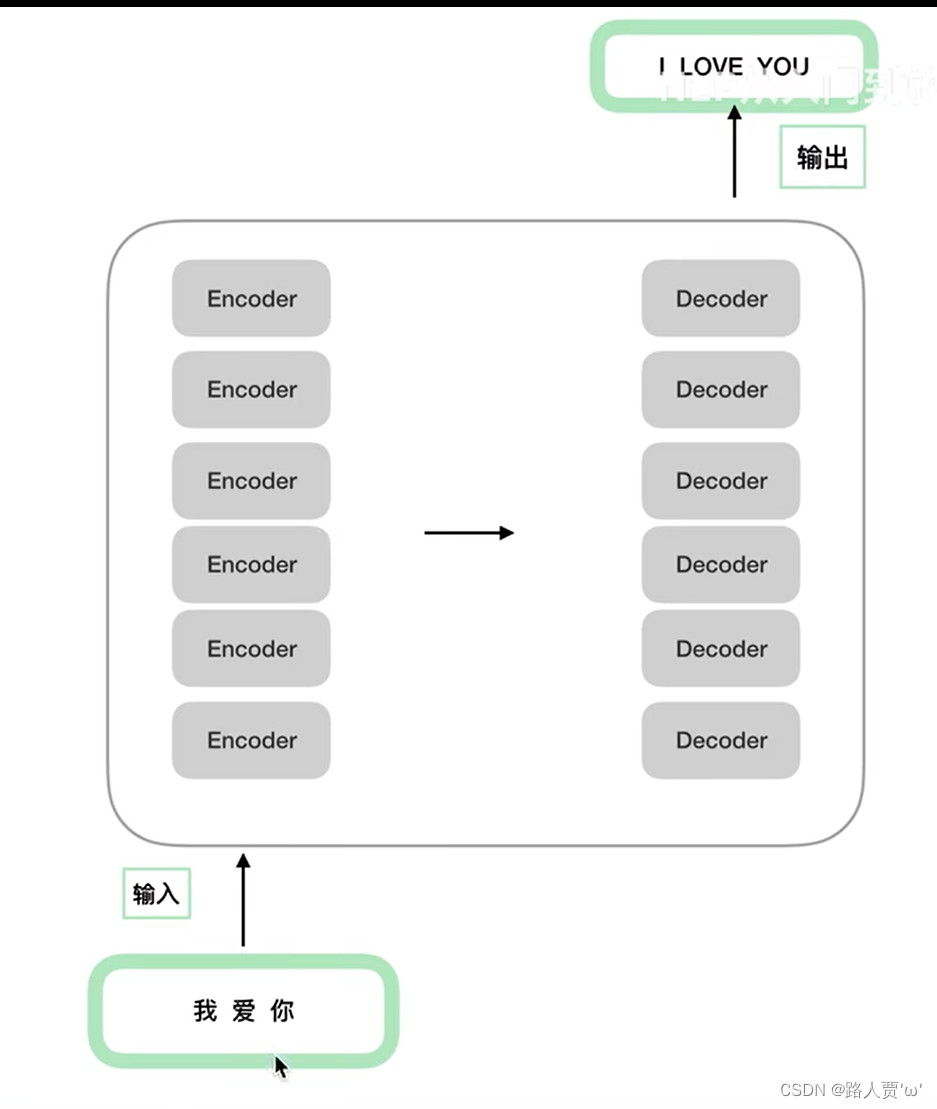
Encoder 和 Decoder 都包含 6 个 block。这6个block结构相同,但参数各自随机初始化。(
Encoder和Decoder不一定是6层,几层都可以,原论文里采用的是6层。)
🌟二、编码器:Encoder
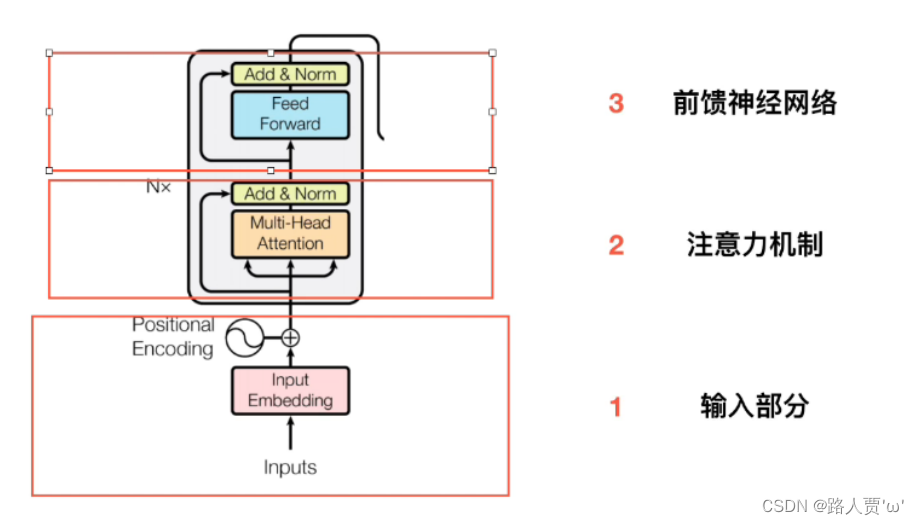
Encoder由三个部分组成:输入、多头注意力、前馈神经网络。
2.1输入
Transformer 中单词的输入表示 x由 Word Embedding 和 Position Embedding相加得到。
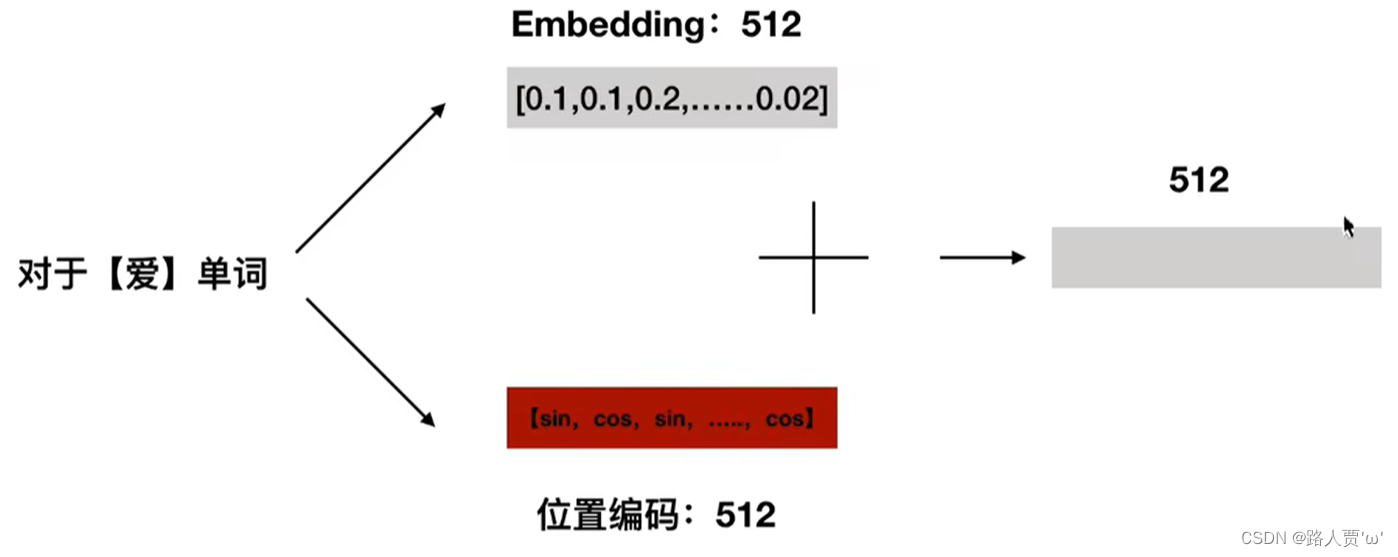
2.1.1词嵌入:Word Embedding层
词嵌入层 负责将自然语言转化为与其对应的独一无二的词向量表达。将词汇表示成特征向量的方法有多种:
(1)One-hot编码
One-hot编码使用一种常用的离散化特征表示方法,在用于词汇向量表示时,向量的列数为所有单词的数量,只有对应的词汇索引为1,其余都为0。
举个栗子,“我爱我的祖国”这句话,总长为6,但只有5个不重复字符,用One-hot表示后为6*5的矩阵,如图所示:
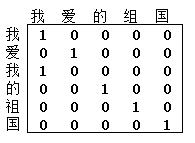
但是这种数据类型十分稀疏,即便使用很高的学习率,依然不能得到良好的学习效果。
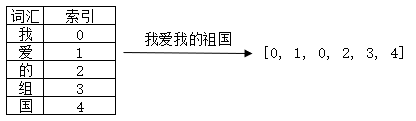
(2)数字表示
数字表示是指用整个文本库中出现的词汇构建词典,以词汇在词典中的索引来表示词汇。所以与其叫做“数字表示”,还不如叫“索引表示”。
举个栗子,还是“我爱我的祖国”这句话,就是我们整个语料库,那么整个语料库有5个字符,假设我们构建词典{'我':0, '爱':1, '的':2, '祖':3, '':4},“我爱我的祖国”这句话可以转化为向量:[0, 1, 0, 2, 3, 4]。如图所示。这种方式存在的问题就是词汇只是用一个单纯且独立的数字表示,难以表达出词汇丰富的语义。
2.1.2位置编码器:Position Embedding层
Transformer 中除了Word Embedding,还需要使用Position Embedding 表示单词出现在句子中的位置。因为 Transformer 不采用 RNN 的结构,而是使用全局信息,因此是无法捕捉到序列顺序信息的,例如将K、V按行进行打乱,那么Attention之后的结果是一样的。但是序列信息非常重要,代表着全局的结构,因此必须将序列的分词相对或者绝对position信息利用起来。
Position Embedding 用 PE表示,PE 的维度与Word Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:
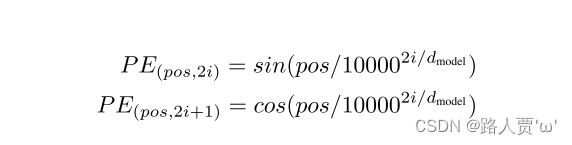
其中 pos 表示positionindex, i 表示dimension index。
2.2注意力机制

我们再来看一下这个图,图中红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder 包含一个 Multi-Head Attention,而 Decoder 包含两个 Multi-Head Attention (其中有一个用到 Masked)。
Multi-Head Attention 上方还包括一个 Add & Norm 层:
- Add: 表示残差连接 (Residual Connection) 用于防止网络退化
- Norm: 表示 Layer Normalization,用于对每一层的激活值进行归一化
2.2.1自注意力机制:Self-Attention
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制的关键点在于,Q、K、V是同一个东西,或者三者来源于同一个X,三者同源。通过X找到X里面的关键点,从而更关注X的关键信息,忽略X的不重要信息。不是输入语句和输出语句之间的注意力机制,而是输入语句内部元素之间或者输出语句内部元素之间发生的注意力机制。
如何运用自注意力机制?
第1步:得到Q,K,V的值
对于每一个向量x,分别乘上三个系数 ,
,
,得到的Q,K和V分别表示query,key和value
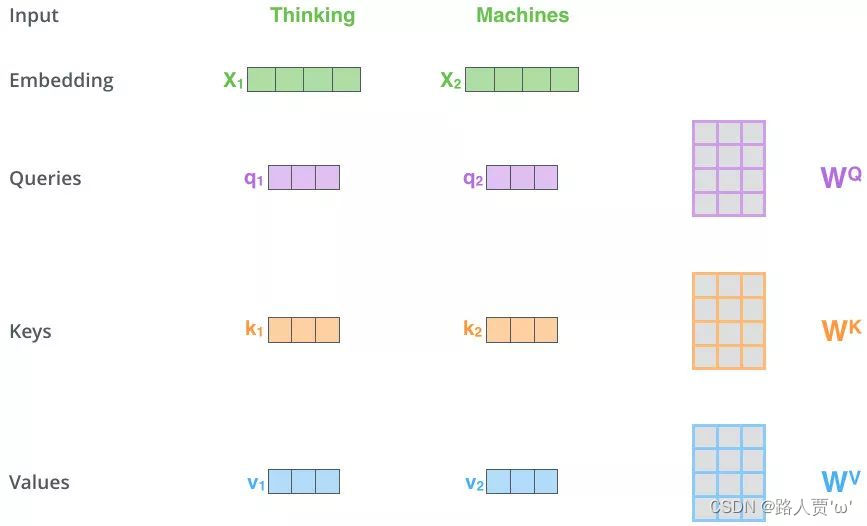
【注意】三个W就是我们需要学习的参数。
第2步:Matmul
利用得到的Q和K计算每两个输入向量之间的相关性,一般采用点积计算,为每个向量计算一个score:score =q · k

第3步:Scale+Softmax
将刚得到的相似度除以,再进行Softmax。经过Softmax的归一化后,每个值是一个大于0且小于1的权重系数,且总和为0,这个结果可以被理解成一个权重矩阵。
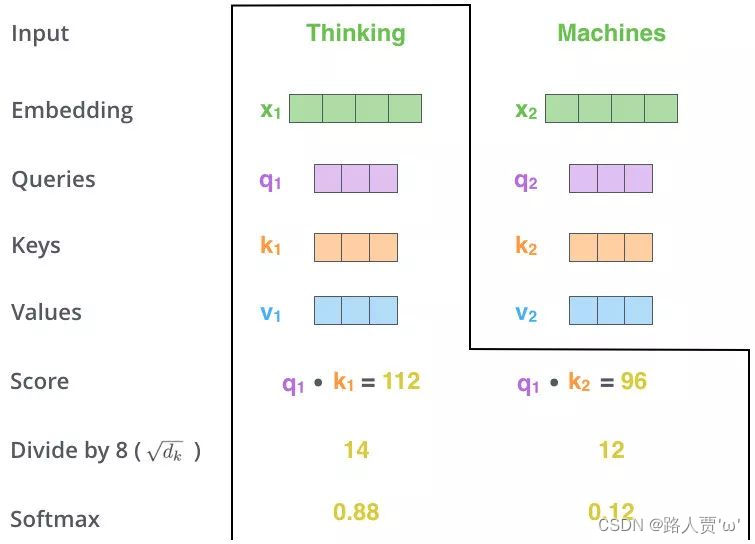
第4步:Matmul
使用刚得到的权重矩阵,与V相乘,计算加权求和。

以上是对Thinking Machines这句话进行自注意力的全过程,最终得到z1和z2两个新向量。
其中z1表示的是thinking这个词向量的新的向量表示(通过thinking这个词向量,去查询和thinking machine这句话里面每个单词和thinking之间的相似度)。
也就是说新的z1依然是 thinking 的词向量表示,只不过这个词向量的表示蕴含了 thinking machines 这句话对于 thinking 而言哪个更重要的信息 。
2.2.2多头注意力机制:Multi-Head Attention
与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的h组(一般h=8)不同的线性投影来变换Q、K和V。
然后,这h组变换后的Q、K和V将并行地送到注意力汇聚中。 最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 这种设计被称为多头注意力(multihead attention)。
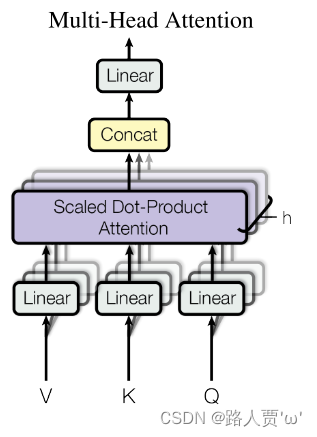
如何运用多头注意力机制?
第1步:定义多组W,生成多组Q、K、V
刚才我们已经理解了,Q、K、V是输入向量X分别乘上三个系数 ,
,
分别相乘得到的,
,
,
是可训练的参数矩阵。
现在,对于同样的输入X,我们定义多组不同的 ,
,
,比如
、
、
,
、
、
每组分别计算生成不同的Q、K、V,最后学习到不同的参数。
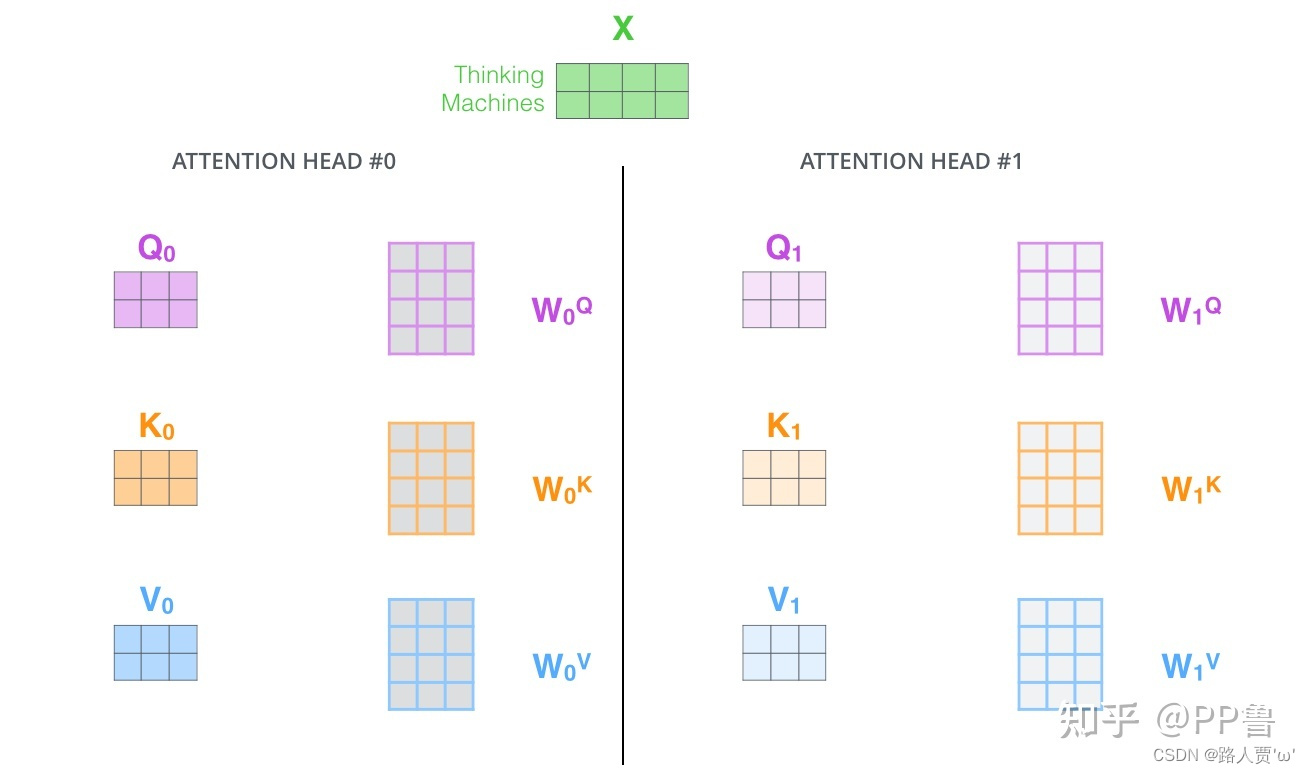
第2步:定义8组参数
对应8组 ,
,
,再分别进行self-attention,就得到了
-
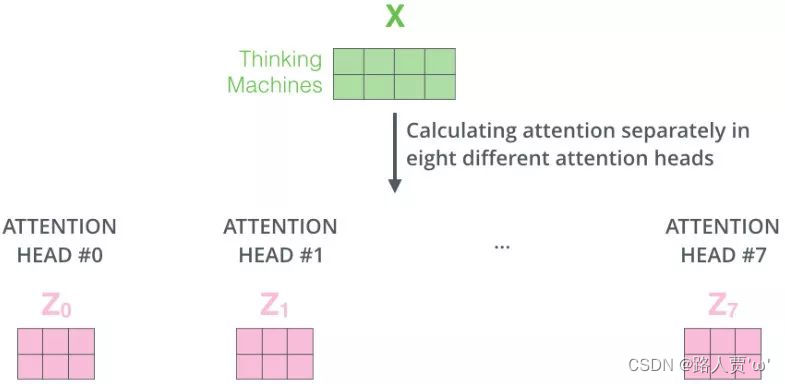
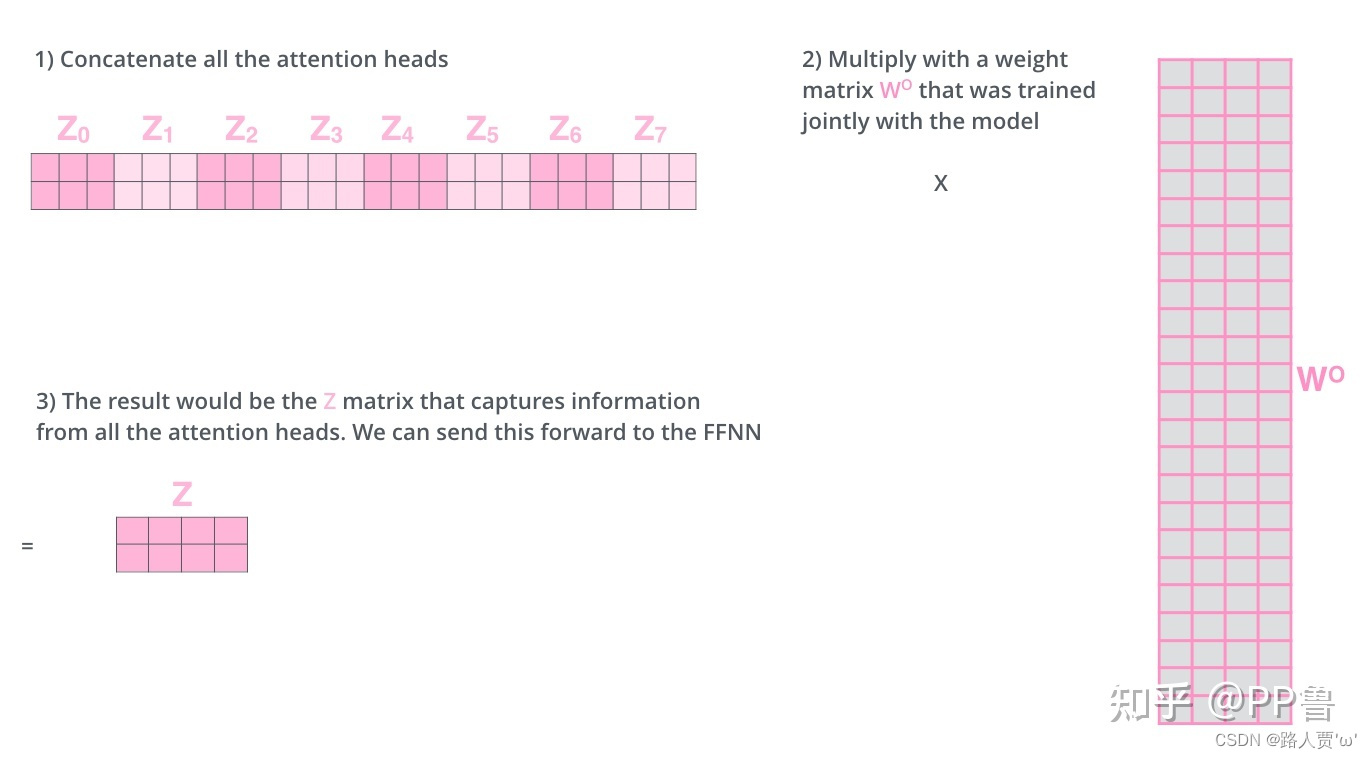
第3步:将多组输出拼接后乘以矩阵以降低维度
首先在输出到下一层前,我们需要将-
concat到一起,乘以矩阵
做一次线性变换降维,得到Z。
完整流程图如下:(感谢翻译的大佬!)
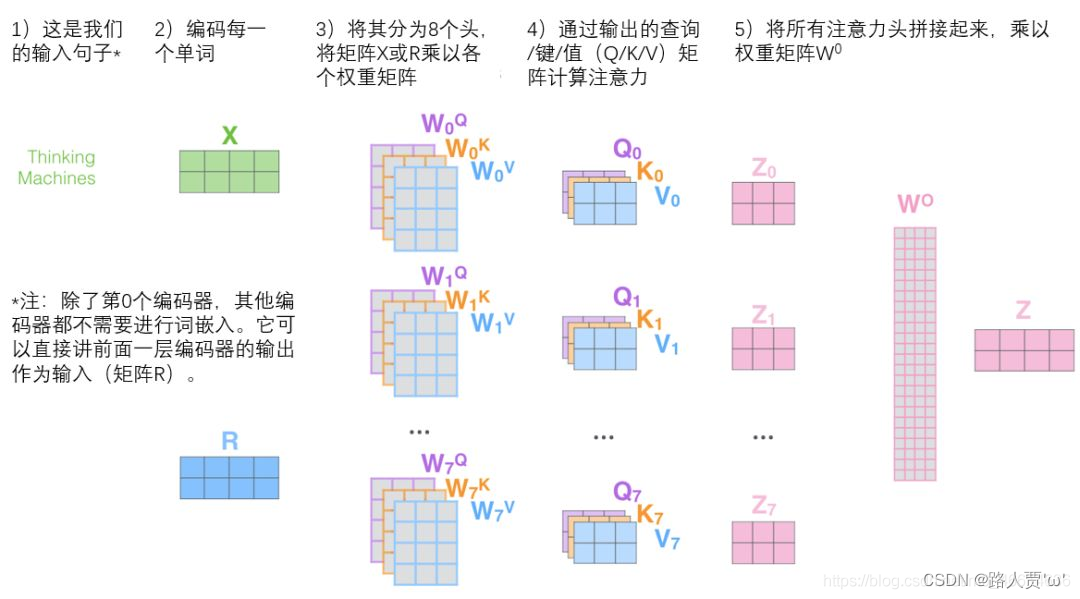
【注意】对于上图中的第2)步,当前为第一层时,直接对输入词进行编码,生成词向量X;当前为后续层时,直接使用上一层输出。
2.3残差连接
每个编码器的每个子层(Self-Attention 层和 FFN 层)都有一个残差连接,再执行一个层标准化操作。
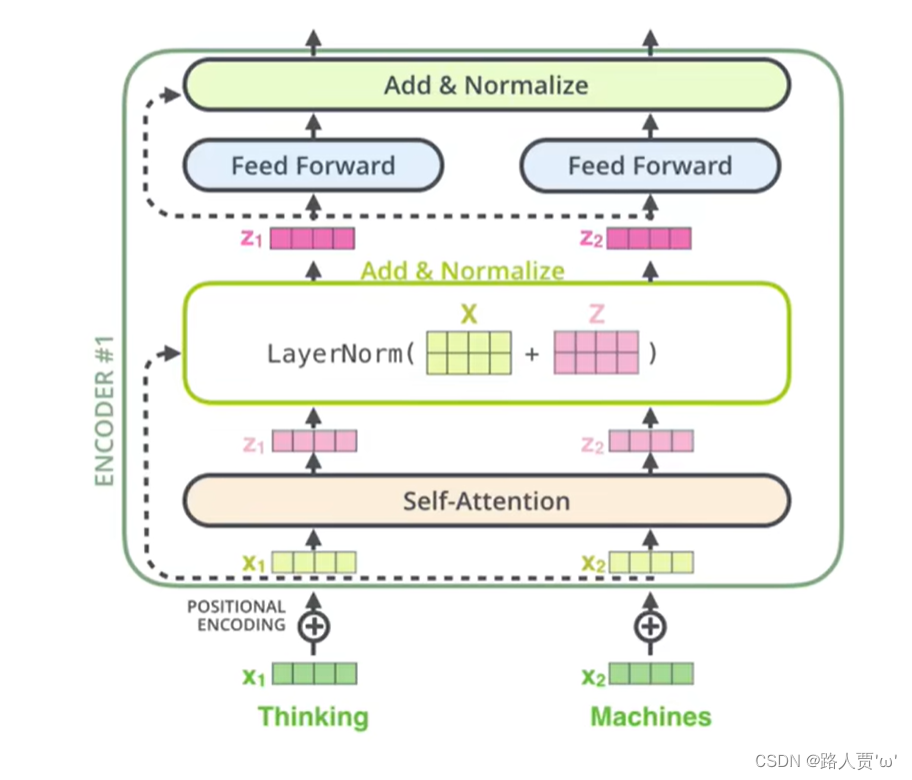
把得到的两个词的Attention值摞在一起后,将“加入位置编码后的词向量X”与“摞在一起后输出的Attention值Z” 相加。残差连接减小了梯度消失的影响。加入残差连接,就能保证层次很深的模型不会出现梯度消失的现象。
2.4LN和BN
- LN:Layer Normalization,LN是“横”着来的,对同一个样本,不同的特征做归一化。
- BN:Batch Normalization,BN是“竖”着来的,对不同样本,同一特征做归一化。
二者提出的目的都是为了加快模型收敛,减少训练时间。
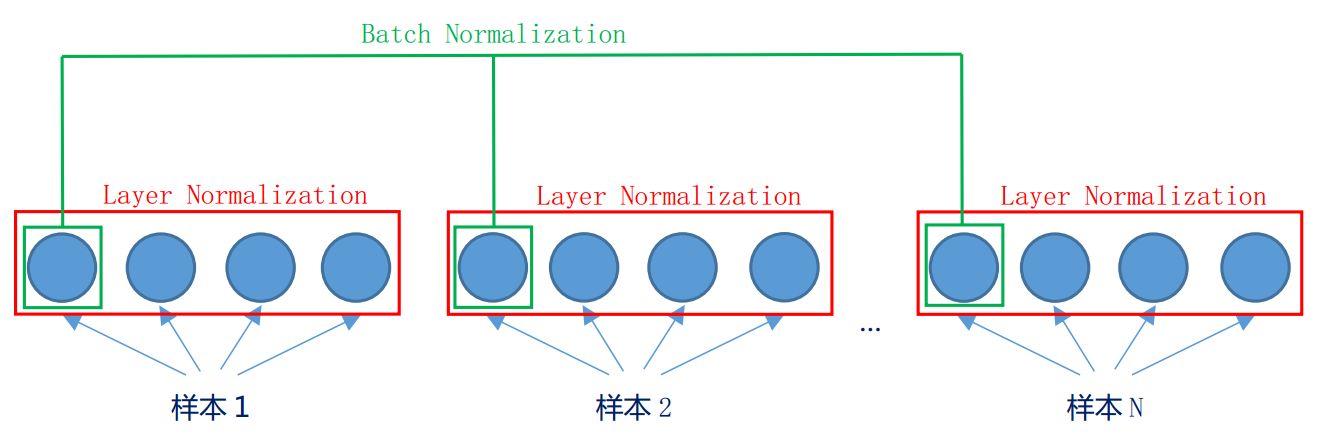
【注意】在NLP任务中,一般选用的都是LN,不用BN。因为句子长短不一,每个样本的特征数很可能不同,造成很多句子无法对齐,所以不适合用BN。
2.5前馈神经网络:FeedForward
在进行了Attention操作之后,Encoder和Decoder中的每一层都包含了一个全连接前向网络,对每个position的向量分别进行相同的操作,包括两个线性变换和一个ReLU激活输出:
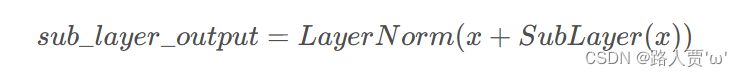
假设多头注意力部分有两个头,那么输出的两个注意力头Zi分别通过两个Feed Forward,然后接一个残差连接,即Zi和Feed Forward的输出Add对位相加。最后把相加的结果进行一次LN标准化。
🌟三、解码器:Decoder
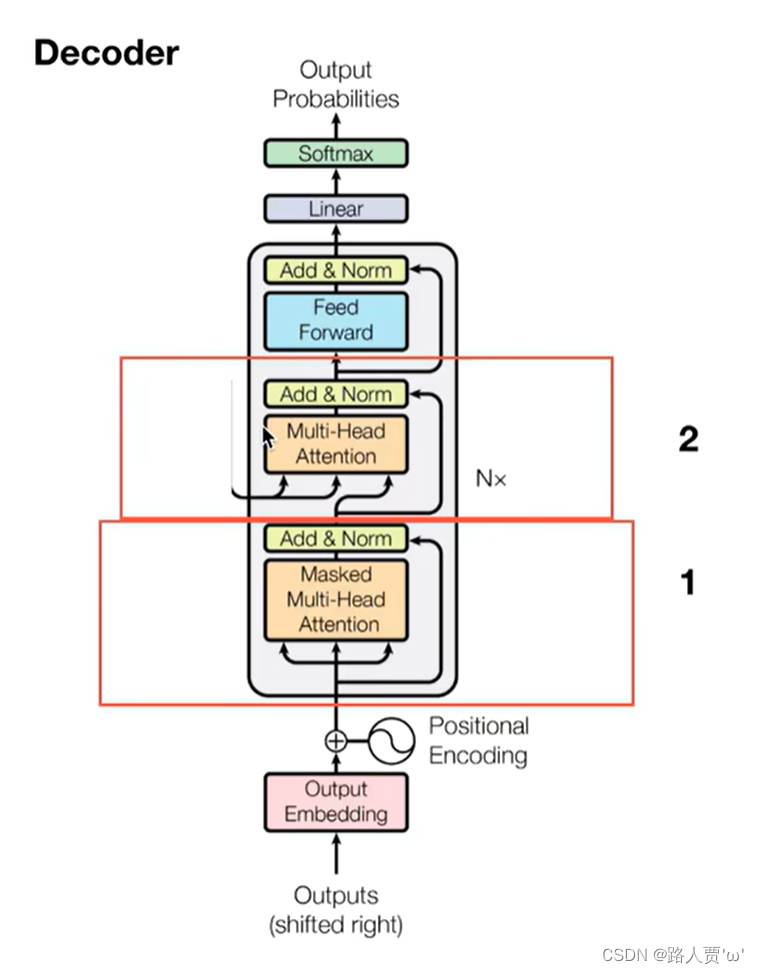
上图红色框框为 Transformer 的 Decoder 结构,与 Encoder 相似,但是存在一些区别。
Decoder 包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder的输出计算。
- 最后有一个 Softmax 层计算下一个翻译单词的概率。
3.1第一个 Multi-Head Attention
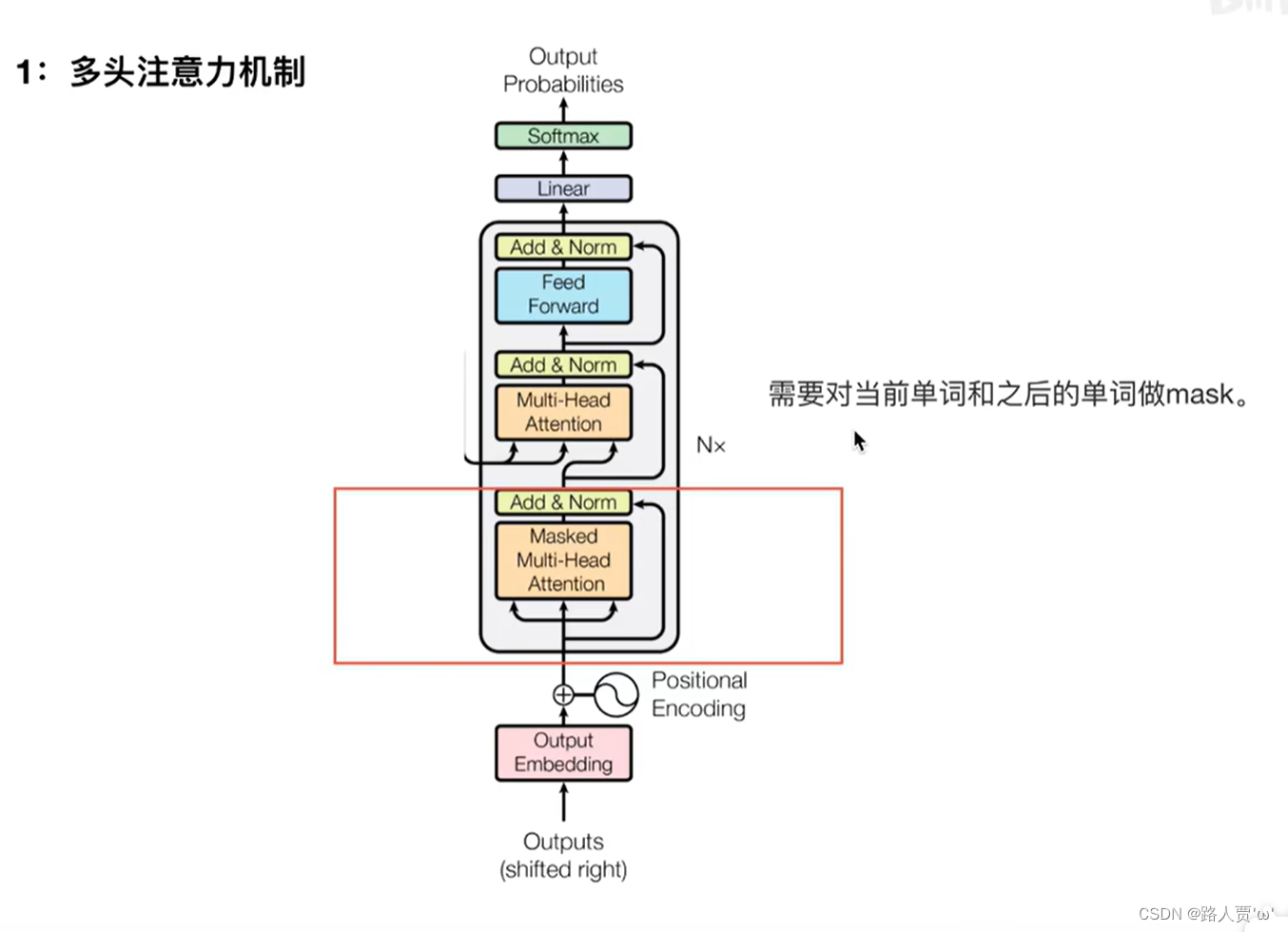
3.1.1掩码:Mask
Mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 Padding Mask 和 Sequence Mask。其中,Padding Mask 在所有的 scaled dot-product attention 里面都需要用到,而 Sequence Mask 只有在 Decoder 的 Self-Attention 里面用到。
为什么需要Mask?
有一些生成的attention张量中的值计算有可能已知了未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性进行Embedding,但是理论上解码器的的输出却不是一次就能产生最终结果的,而是一次次通过上一次结果综合得出的,因此,未来的信息可能被提前利用。所以,Attention中需要使用掩码张量掩盖未来信息。
我们可以这么来理解Mask的作用:我们建模目的就是为了达到预测的效果,所谓预测,就是利用过去的信息(此前的序列张量)对未来的状态进行推断,如果把未来需要进行推断的结果,共同用于推断未来,那叫抄袭,不是预测。当然,这么做的话训练时模型的表现会很好,但是在测试(test)时,模型表现会很差。
换句话说,我们是用一句话中的前N − 1 个字预测第N 个字,那么我们在预测第N 个字时,就不能让模型看到第N个字之后的信息,所以这里们把预测第N 个字时,第N 包括)个字之后的字都Masked掉。
我们来举个栗子:
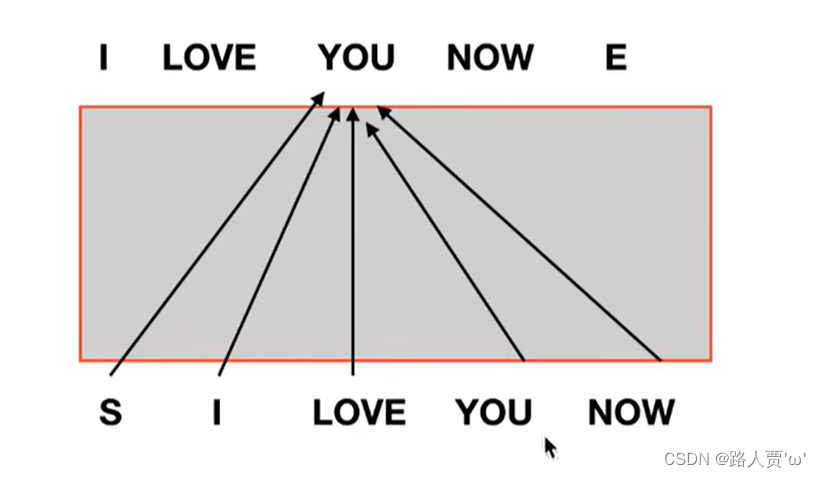
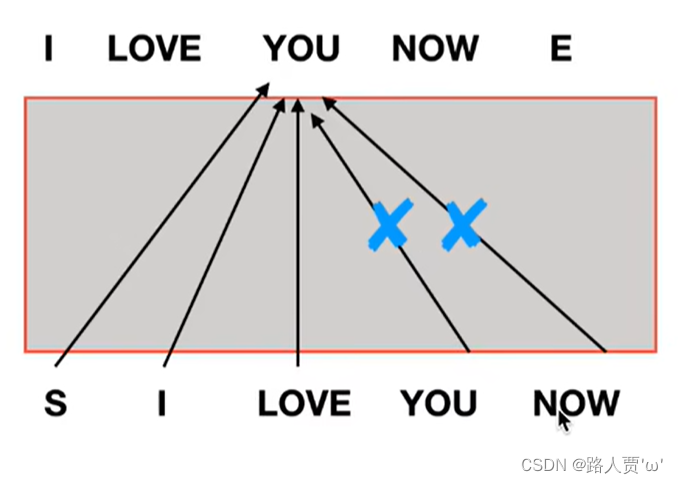
如果像Encoder的注意力机制那里一样没有Mask,那么在训练Decoder时,如果要生成预测结果you,就需要用到下面整个句子的所有词(s,I,Love,You,Now)。但是在真正预测的时候,并看不到未来的信息(即还轮不到You和Now呢)。
所以在预测阶段,预测的第一步生成第一个词I的时候,用起始词<start>做self-attention;然后预测的第二步生成第二个词Love的时候,就做<start>和I两个词的self-attention,后面的词被掩盖了。以此往复,预测的每一步在该层都有一个输出Q,Q要送入到中间的Multi-Head Attention层,和encoder部分输出的K,V做attention。
3.1.2具体实现步骤
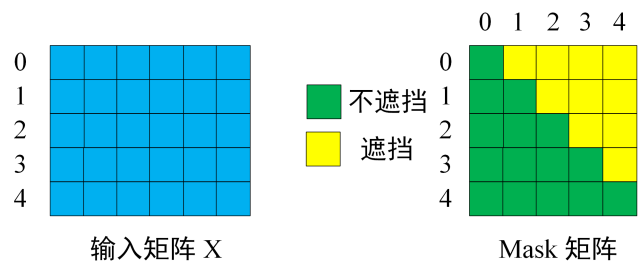
第一步:是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 "<Start> I Love You Now" (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
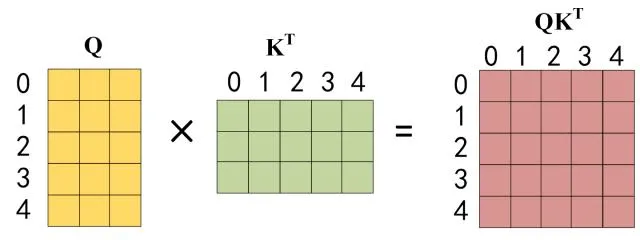
第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X计算得到Q,K,V矩阵。然后计算Q和的乘积
。
第三步:在得到 之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
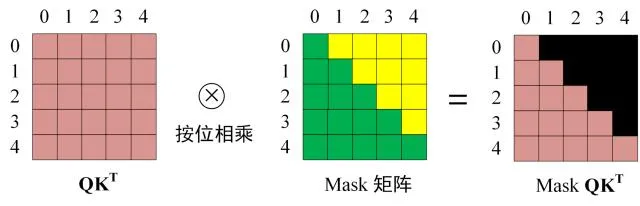
得到 Mask 之后在 Mask
上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
第四步:使用 Mask 与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 Z1 是只包含单词 1 信息的。
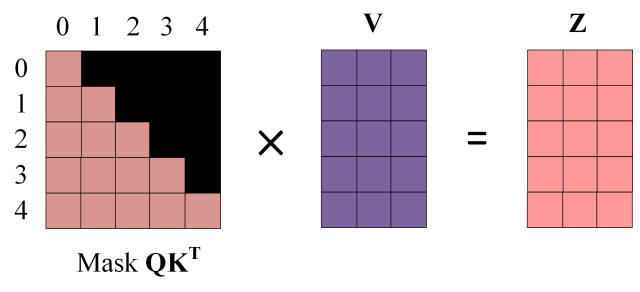
第五步:通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵Zi ,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出Zi然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样。
3.2第二个 Multi-Head Attention
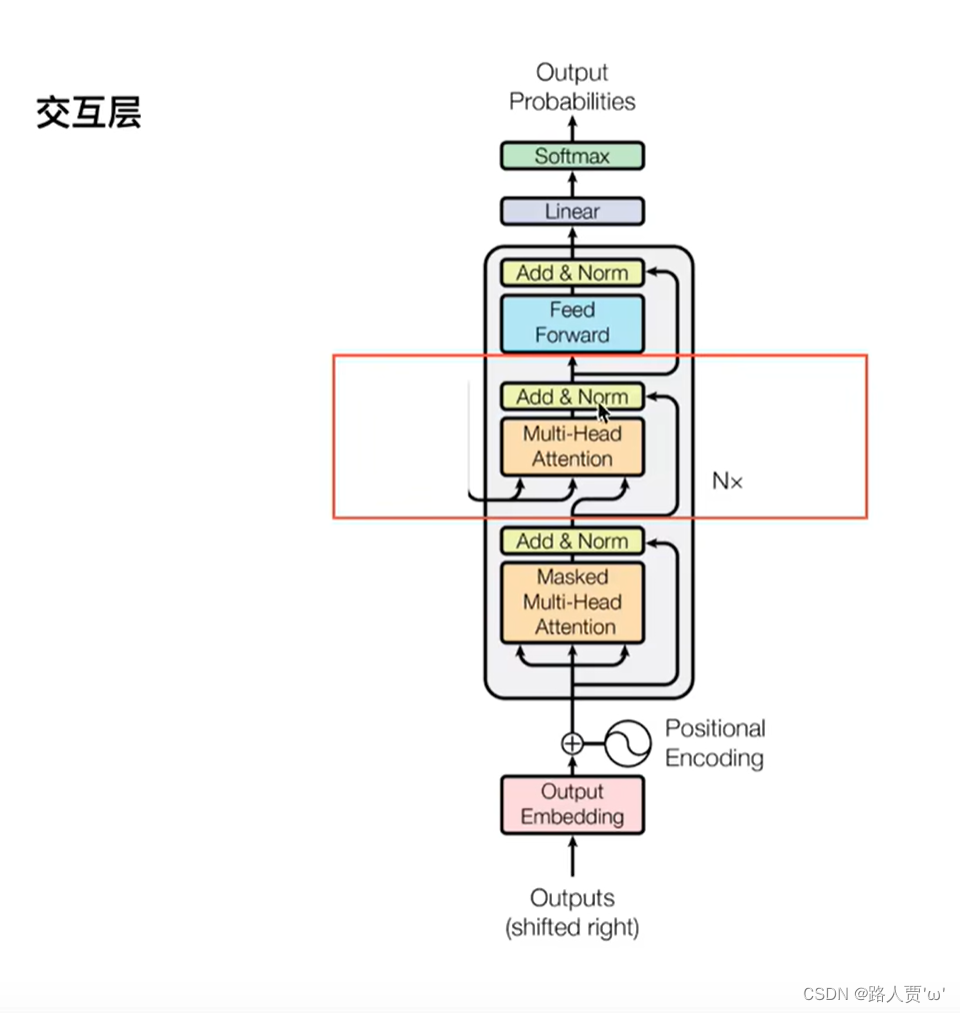
其实这块与上文 Encoder 中 的 Multi-Head Attention 具体实现细节上完全相同,区别在于Encoder的多头注意力里的Q、K、V是初始化多个不同的,
,
矩阵得到的。而Decoder的K、V是来自于Encoder的输出,Q是上层Masked Self-Attention的输出。
Encoder 中 的 Multi-Head Attention只有一个输入,把此输入经过三个linear映射成Q 、K 、V , 而这里的输入有两个:
- 一个是Decoder的输入经过第一个大模块传过来的值
- 一个是Encoder最终结果
是把第一个值通过一个linear映射成了Q,然后通过两个linear把第二个值映射成K、V ,其它的与上文的完全一致。这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)。
3.3Linear和softmax
Decoder最后会输出一个实数向量。那我们如何把浮点数变成一个单词?这便是线性变换层Linear层要做的工作,它之后就是Softmax层。
Linear层是一个简单的全连接神经网络,它可以把Decoder产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。

不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。
接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间的输出。
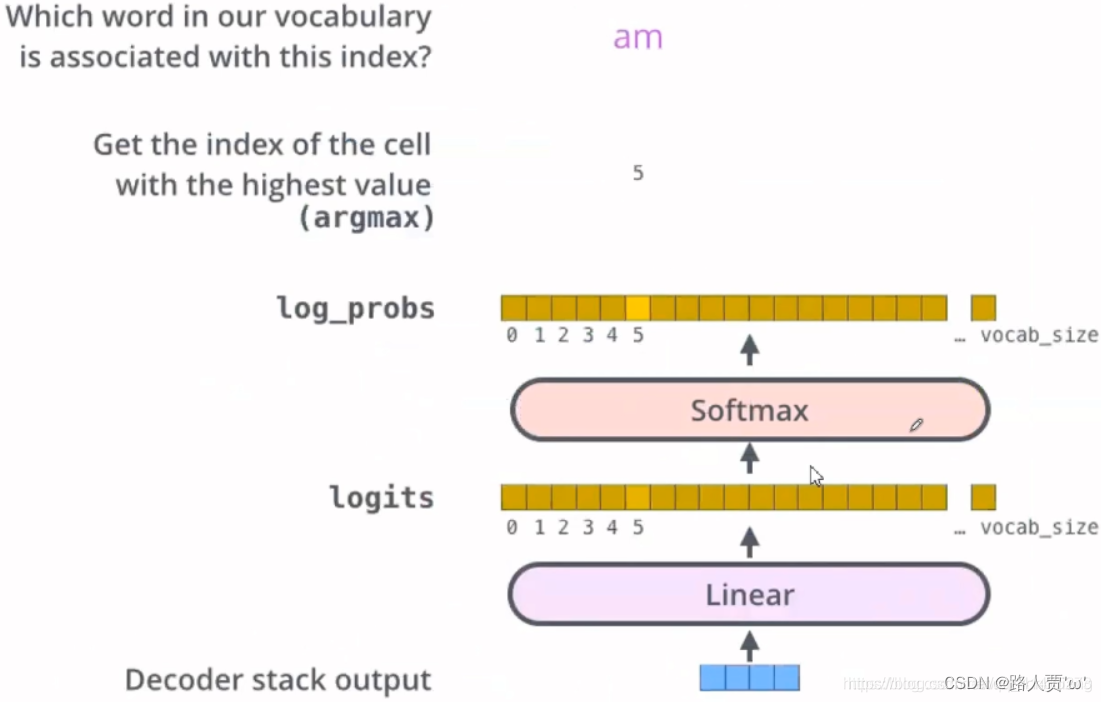
这张图片从底部以解码器组件产生的输出向量开始。之后它会转化出一个输出单词。
以上就是Transformer模型结构的全部解读了~
在这里如果想更清楚的了解,推荐大家看看大佬的讲解(感谢各位大佬,阿里嘎多!)
b站:【Transformer从零详细解读(可能是你见过最通俗易懂的讲解)】
知乎:Transformer模型详解(图解最完整版) - 知乎 (zhihu.com)

相关文章:
【Transformer系列(4)】Transformer模型结构超详细解读
前言 前一篇我们一起读了Transformer的论文《Attention Is All You Need》,不知道大家是否真的理解这个传说中的神(反正俺是没有~) 这两天我又看了一些视频讲解,感谢各位大佬的解读,让我通透了不少。 这篇文章就和…...
Idea启动运行报错:Error:java: 无效的源发行版: 13
最近在做Springboot项目时,常常出现上述错误,小编也不知道怎么回事,到网上找了这个方面的解决办法,但是却发现根本解决不了,最终通过小编多次尝试,终于发现,为什么会报这个错误。(应该是Java版本…...

【元分析研究方法】学习笔记1.形成问题
步骤1 形成问题 该步骤的作用该步骤中需要注意的问题该步骤中部分知识点我的收获 参考来源:库珀 (Cooper, H. M. )., 李超平, & 张昱城. (2020). 元分析研究方法: A step-by step approach. 中国人民大学出版社. 这章内容很简单:①变量的刻画&#x…...
 等级考试试卷(五级))
2023年3月 青少年软件编程(Python) 等级考试试卷(五级)
一、单选题(共25题,共50分) 1.已知一个列表lst [2,3,4,5,6],lst.append(20),print(lst)的结果是?(C)(2分) A.[10,2,3,4,5,6,20] B.[20,2,10,3,4,5,6] C.[2,3,4,5,6,20] D.[2,3,4,5,…...

必须要知道的hive调优知识(上)
Hive数据倾斜以及解决方案 1、什么是数据倾斜 数据倾斜主要表现在,map/reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其…...

什么是Cache Aside Pattern与延迟双删
Cache Aside Pattern是一种常用的缓存设计模式,用于在应用程序中使用缓存提高系统性能的同时,避免缓存与数据库数据不一致的情况出现。延迟双删是Cache Aside Pattern的一种优化,可以进一步提高系统性能。 以下是关于Cache Aside Pattern和延…...
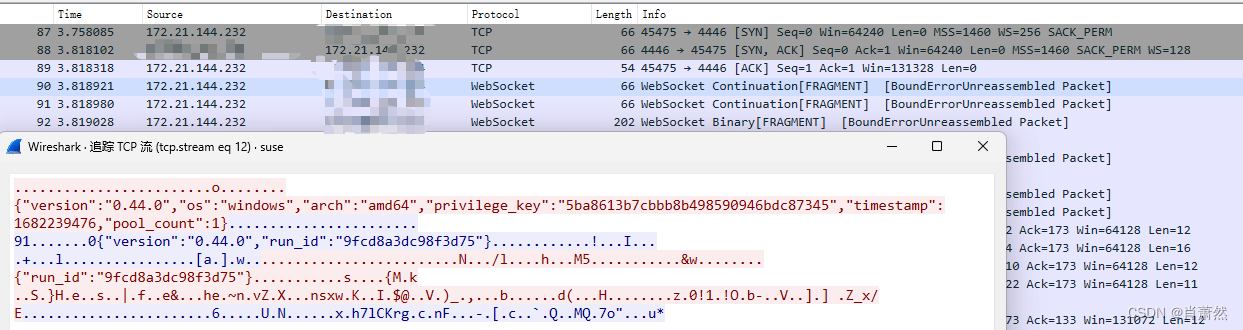
frp 流量特征
frp 流量特征 非常明显的明文流量特征...
Unity --- UGUI(Unity Graphical user interface)--- Canvas画布
1.UI --- User Interface --- 使用者与机器之间的交互界面 1.所谓的自适应系统指的是分辨率的适应: 比如在一个分辨率下做的UI放到另一个分辨率下显示时,如果没有自适应系统的话就会导致UI过大,过小,被辟成一半等等情况ÿ…...
c++积累6-内联函数
1、说明 内联函数是c为提高程序运行速度所做的一项改进。 2、常规函数运行 编译的可执行程序:由一组机器语言指令组成。 程序执行: 1、操作系统将这些指令载入到内存,每条指令都有一个特定的内存地址 2、计算机逐步执行这些指令 3、如果有…...

ESP32学习笔记13-MCPWM主要用于无刷电机驱动
16.MCPWM 16.1概述 ESP32 有两个 MCPWM 单元,可用于控制不同类型的电机。每个单元都有三对PWM输出 每个 A/B 对可由三个定时器定时器 0、1 和 2 中的任何一个计时。 同一定时器可用于为多对PWM输出提供时钟。 每个单元还能够收集输入,例如,检测电机过电流或过电压,以及获得…...

MyBatis-plu 和 JPA 对比
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 MyBatis-plu 和 JPA 前言一、说下相同点二、差异点一、从实现来说:CURD实现方式不一样二、分页上三、雪花id四、伪删除五、子类排除父类的字段 总结 前言 提示&…...

一文详解Python中多进程和进程池的使用方法
这篇文章将介绍Python中多进程和进程池的使用方法,并提供一些实用的案例供大家参考,文中的示例代码讲解详细,感兴趣的小伙伴可以了解一下 目录 Python是一种高级编程语言,它在众多编程语言中,拥有极高的人气和使用率。…...

前端部署发布项目后,如何通知用户刷新页面、清除缓存
以下只是一些思路,有更好的实现方式可以留言一起交流学习 方式一:纯前端 在每次发布前端时,使用webpack构建命令生成一个json文件,json中写个随机生成的一个字符串(比如时间戳),每次打包程序都…...

项目上线|慕尚集团携手盖雅工场,用数字化推动人效持续提升
过去十年,中国零售业以前所未有的速度被颠覆、被重塑,数字化则是其中重要的推动要素。 随着数字化转型的深入,零售企业的数字化不再局限于布局线上渠道,且更关乎其背后企业核心运营能力的全链路数字化改造。而贯穿于运营全链路的…...

Java重载 与封装、继承
方法重载 在同一个类中,出现了方法名相同,参数不同的方法时 ,我们叫方法重载 作用:根据不同参数,选择不同方法 实例 public static void main(String[] args){public int add(int a,int b){return ab;}public double…...

sed正则表达式替换字符方法
在 Linux 命令行中,可以使用 sed 命令来替换指定文件中的指定字符。具体方法如下: sed -i s/<old_string>/<new_string>/g <filename>其中,<old_string> 表示要被替换的字符串,<new_string> 表示替…...

不讲废话普通人了解 ChatGPT——基础篇第一课
wx供重浩:创享日记 获取更多内容 文章目录 前言什么是 ChatGPT它是如何工作的ChatGPT 和其它机器人有什么不同 前言 不知道大家在第一次会使用 ChatGPT 并尝试和他对话时有没有感到震惊。当ChatGPT首次推出时,我立即被它的功能所吸引。 曾经在遇到繁杂…...

MATLAB计算气象干旱指标:SAPEI
MATLAB计算干旱指标:SAPEI 标准化前降水蒸散发指数(Standardized Antecedent Precipitation Evapotranspiration Index, SAPEI)1 指数简介1.1 指数计算原理步骤1:计算潜在蒸散发(potential evapotranspiration, PET)步骤2:计算降水和PET的日差1.2 数据资料1.3 拟合分布的…...

GPT对SaaS领域有什么影响?
GPT火了,Chat GPT真的火了。 突然之间,所有人都在讨论AI,最初的访客是程序员、工程师、AI从业者,从早高峰写字楼电梯里讨论声,到村里大爷们的饭后谈资,路过的狗子都要和它讨论两句GPT的程度。 革命的前夜…...
和zero_grad()在PyTorch中代表什么意思)
backward()和zero_grad()在PyTorch中代表什么意思
文章目录 问:backward()和zero_grad()是什么意思?backward()zero_grad() 问:求导和梯度什么关系问:backward不是求导吗,和梯度有什么关系(哈哈哈哈)问:你可以举一个简单的例子吗问&a…...

SingleFile CLI架构解析:高性能网页批量保存解决方案与实战指南
SingleFile CLI架构解析:高性能网页批量保存解决方案与实战指南 【免费下载链接】SingleFile Web Extension for saving a faithful copy of a complete web page in a single HTML file 项目地址: https://gitcode.com/gh_mirrors/si/SingleFile SingleFile…...

从竞赛到实践:基于TDOA的声源定位系统设计与实现
1. 从竞赛到实战:TDOA声源定位系统设计全解析 第一次接触声源定位是在大三的电子设计竞赛上,当时看着题目要求"用激光笔追踪移动声源",我和队友面面相觑——这玩意儿真能实现吗?三年后,当我负责公司智能会议…...

3D打印螺纹强度提升实战指南:Fusion 360 FDM螺纹优化完整方案
3D打印螺纹强度提升实战指南:Fusion 360 FDM螺纹优化完整方案 【免费下载链接】Fusion-360-FDM-threads 项目地址: https://gitcode.com/gh_mirrors/fu/Fusion-360-FDM-threads 你是否在3D打印螺纹连接件时经常遇到螺纹断裂、装配困难或打印失败的问题&…...

基于大语言模型的学术论文AI阅读助手:从PDF解析到智能问答全流程解析
1. 项目概述:一个为学术论文阅读而生的AI助手 如果你经常需要阅读海量的学术论文,尤其是计算机科学、人工智能领域的英文PDF文献,那你一定对那种“打开一篇新论文,面对几十页的陌生术语和复杂公式,不知从何读起”的无…...
如何用二维图像实现三维物体识别?)
多视角卷积神经网络(MVCNN)如何用二维图像实现三维物体识别?
多视角卷积神经网络(MVCNN)如何用二维图像实现三维物体识别? 【免费下载链接】mvcnn_pytorch MVCNN on PyTorch 项目地址: https://gitcode.com/gh_mirrors/mv/mvcnn_pytorch 在计算机视觉领域,三维物体识别一直是一个具有…...

JetBrains IDE试用期重置完整指南:快速恢复30天免费使用权限
JetBrains IDE试用期重置完整指南:快速恢复30天免费使用权限 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否正在使用JetBrains系列IDE进行开发,却面临试用期到期的问题?…...

087、机器人运动学:雅可比矩阵
087、机器人运动学:雅可比矩阵 一、一个让我熬夜三天的调试故事 去年做六轴协作机器人末端力控的时候,遇到一个诡异的问题:机器人末端在某个位姿下,明明关节速度指令给得很平滑,末端速度却突然跳变,导致力控震荡。当时我盯着示波器上的速度曲线,百思不得其解——运动学…...

【YOLO目标检测全栈实战】33 模型部署的终极形态:ONNX Runtime + TensorRT EP 跨平台推理
还记得上周帮一家做边缘计算盒子的客户调优时,他们遇到一个典型问题:同一份ONNX模型,在Windows服务器上用TensorRT跑出了5ms的推理延迟,可部署到客户的ARM工控机上,却只能用CPU硬扛,延迟直接飙到80ms。 客户老板当场拍桌子:“你们这模型是不是分三六九等?”我拆开部署…...

5分钟快速搭建零配置静态服务器:http-server终极完整指南
5分钟快速搭建零配置静态服务器:http-server终极完整指南 【免费下载链接】http-server A simple, zero-configuration, command-line http server 项目地址: https://gitcode.com/gh_mirrors/ht/http-server 你是否曾在本地开发时,为了预览一个简…...
报错?用Clock.tick()轻松搞定(附完整代码示例))
别慌!Pygame里time.sleep()报错?用Clock.tick()轻松搞定(附完整代码示例)
Pygame时间控制革命:为什么Clock.tick()比time.sleep()更适合游戏开发 在Pygame游戏开发的世界里,时间控制是构建流畅游戏体验的核心要素。许多初学者在从Python标准库转向Pygame时,常常会本能地使用time.sleep()来控制游戏节奏,却…...