LoadRunner参数化最佳实践:让你的性能测试更加出色!
距离上次使用loadrunnr 已经有一年多的时间了。初做测试时在项目中用过,后面项目中用不到,自己把重点放在了工具之外的东西上,认为性能测试不仅仅是会用工具,最近又想有一把好的利器毕竟可以帮助自己更好的完成性能测试工作。这算是一个认知的过程吧!
在次安装打开loadrunner时,发现虽然自己的思想还在,但已经非常生疏了,好多设置都找不到了具体的位置。下面说参数化参数化是性能测试中时最常用的一种技巧吧!这里需要说明的是,不是只有loadrunner才可以设置参数化,我以前所使用的JMeter同样也有类似的设置。
我们知道性能测试工具是模拟多个用户对系统的性能进行验证(这种说法不完全正确),有些系统允许多个完全相同的用户同时对完全相同的数据做完全相同的操作,有些则不允许。比如,邮箱一般允许同一个账号在多处登陆。而我们的QQ账号肯定是不允许的。再比如,你注册某个系统时,用户名是不能有重复。但密码却可以。所以,这么多个情况都要用到参数化技巧。
我们这里通过loadurnner录制一个139邮箱的登陆。下面是截取的一小段代码
........
web_submit_form("Login.ashx", "Snapshot=t3.inf", ITEMDATA, "Name=UserName", "Value=chongshi", ENDITEM, "Name=Password", "Value=123456", ENDITEM, "Name=VerifyCode", "Value=", ENDITEM, "Name=auto", "Value=<OFF>", ENDITEM, EXTRARES,
......下面看一下如何通过loadrunner对用户名密码参数化。标红的内容就是登陆的用户名和密码。
参数化的方法
选中要参数化的内容。
方法一,右键---【Replace with a new parameter】
方法二,菜单【insert】----【new Parameter…】
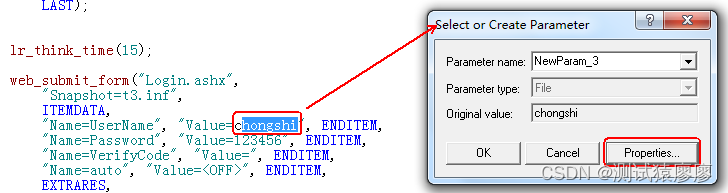
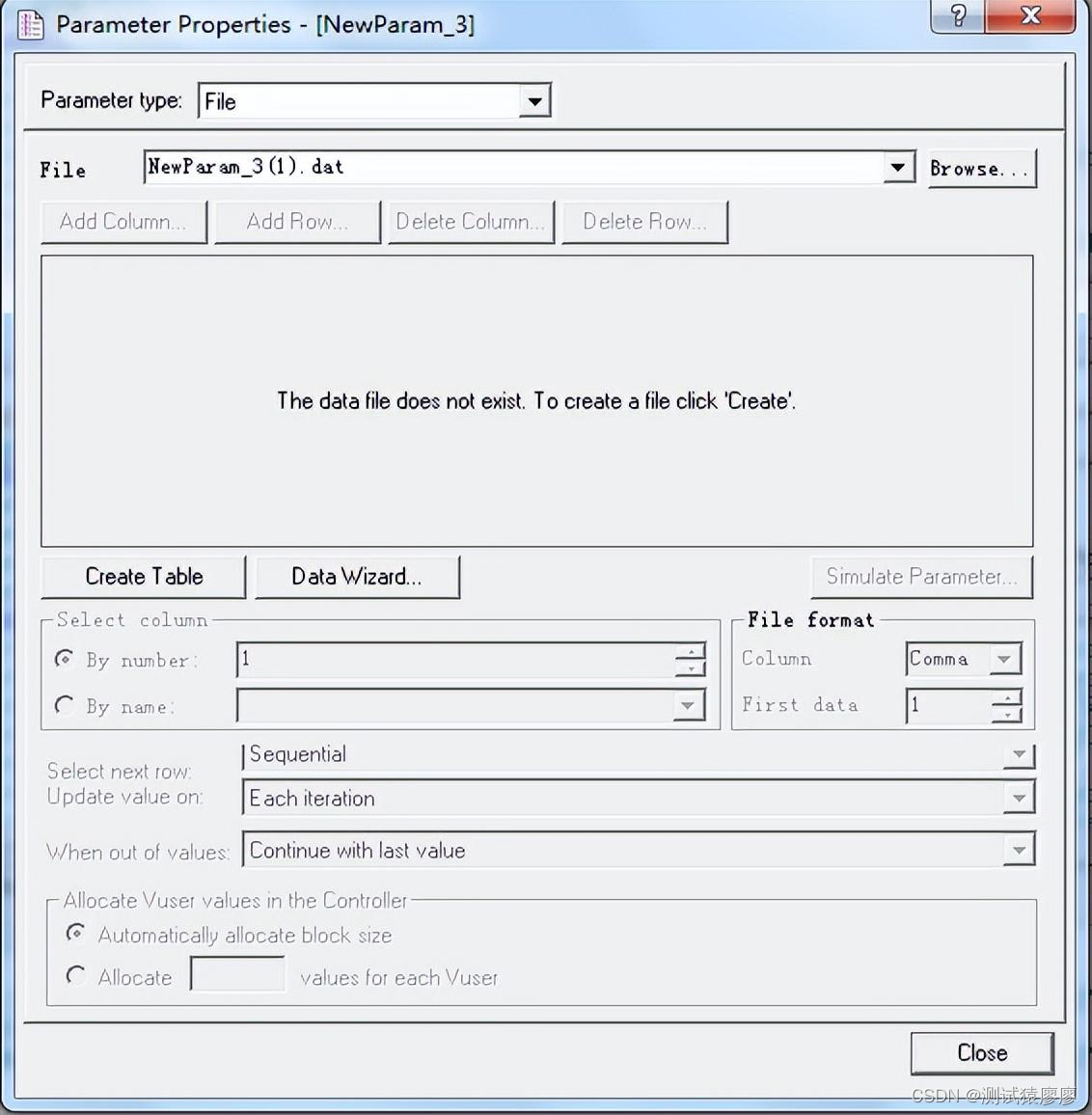
Parameter Properties (参数属性对话框)----我们的参数化设置就通过这个对话框完成。
参数化的方式:
其实参数化得方式有很多种,这里简述几种比较常见人方式。其实方式略有不同,但其结果都是将数据添加进来。
1、 编辑数据
点击Create Table 会出现表格,在表格,再次点击Edit with Notepad ,然后会打开一个记事本,我们可以对记事本进行添加数据
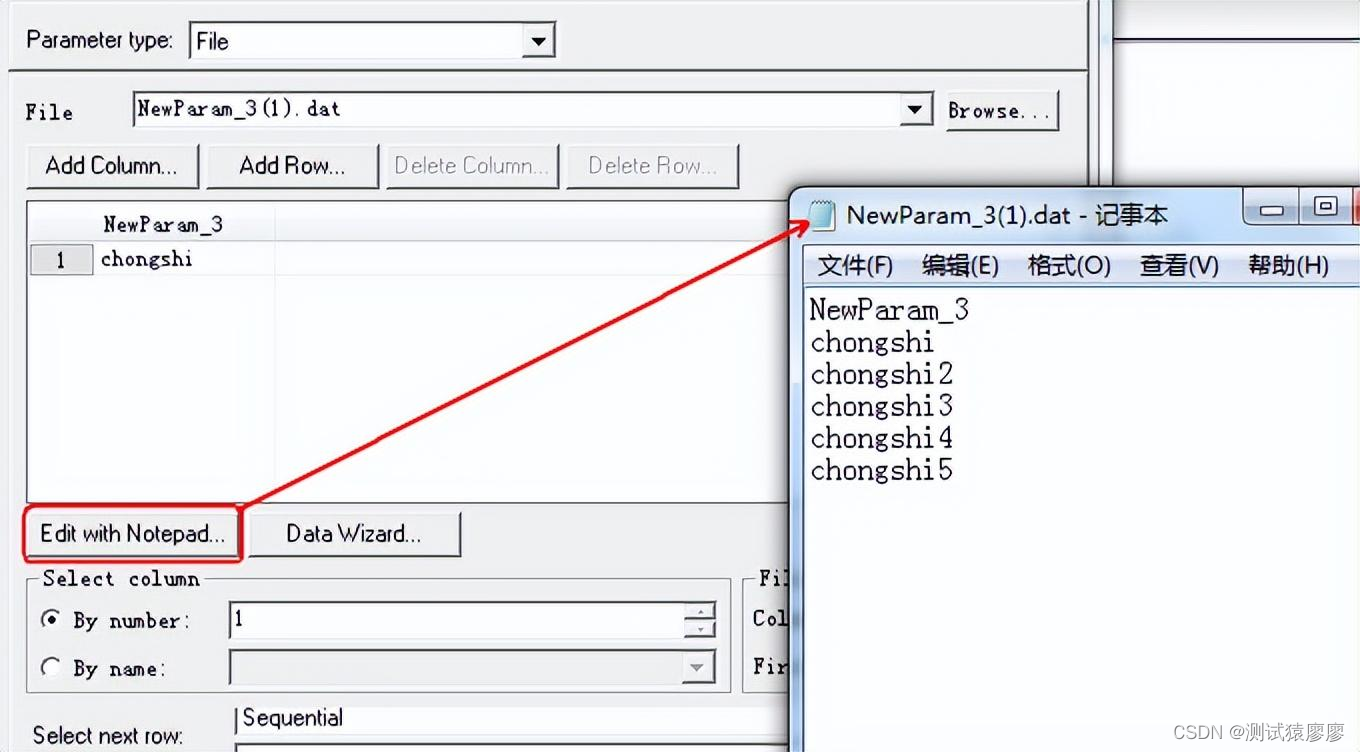
2、 添加dat数据文件
点击File输入框后面的“Browse..”按钮,找到本地的txt数据文件,进行添加就可以了。
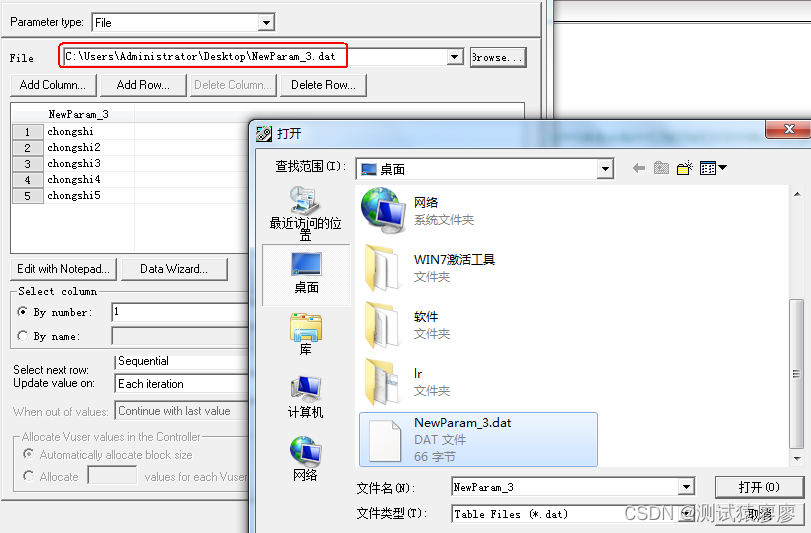
需要注意的是,文件里面的数据不要乱写,每条数据一行,不然会读取有误。
3、 数据库添加数据
在很多情况下,我添加的数据不是十条二十条,也不是一百两百,如果还通过上面的两种方式添加,我想会是一件非常纠结的事情。所以我们可以通过数据库将数据导入。你是否疑虑数据库的数据怎么弄,数据库的数据生成非常简单,可以写一段简单的代码生成,也可以通过数据库数据生成工具来完成
点击Date Wizard 打开连接数据库向导。
这里先告诉你有这种方式,后面再介绍具体操作。^_^
4、 其他类型设置
如果我们要参数化的不是一个文件,比如是特定的日期时间,可以从Parameter type 列表中进行选择
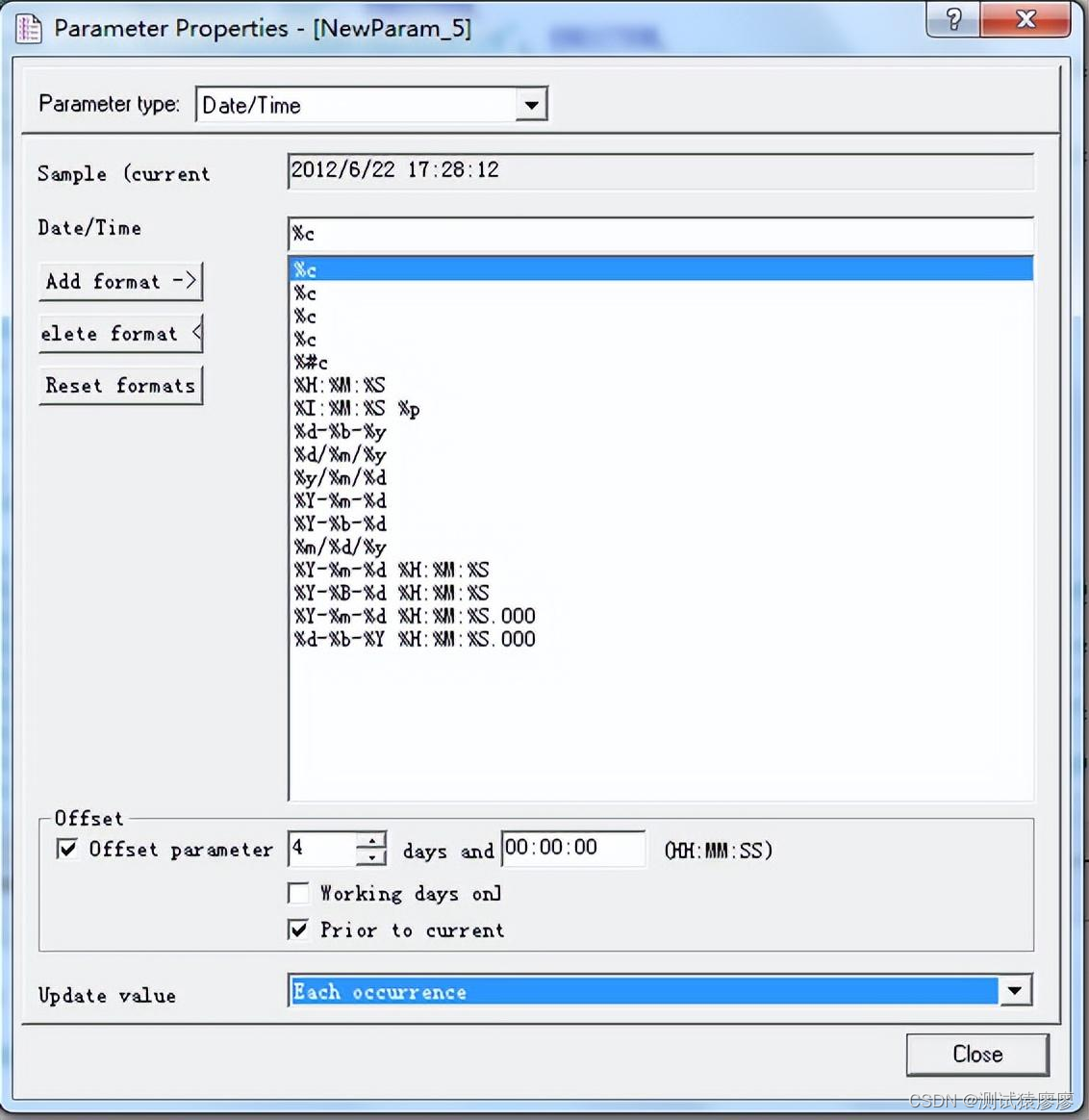
这里可以设置日期时间格式,循环迭代方式,不过除了file类型外,其他用的不多。其他类型用法我也不是十分了解。
参数化之间的关联
前面我们已经对用户名进行了参数化,或对密码进行了参数化,这样是不是脚本就能正常跑了,不好说。因为用户名和密码不是一一对应关系,每次运行脚本时取的用户名和密码没有对应上的话肯定就会出问题。
假设,我们已经对用户名已经进行了参数化,参数名为【username】,下面设置密码参数化与用户名关联。

点击“Properites…”会打开编辑用户名参数化窗口。File列表框中,刚才保存用户名信息的文件"username.dat"。
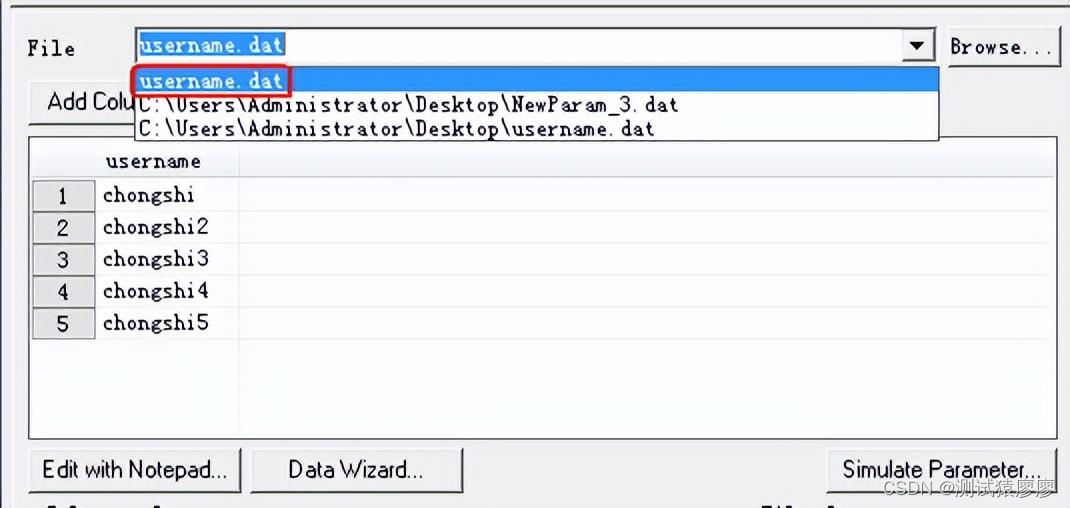
点击“Add Column…”,添加新的一列信息,用于放置密码。
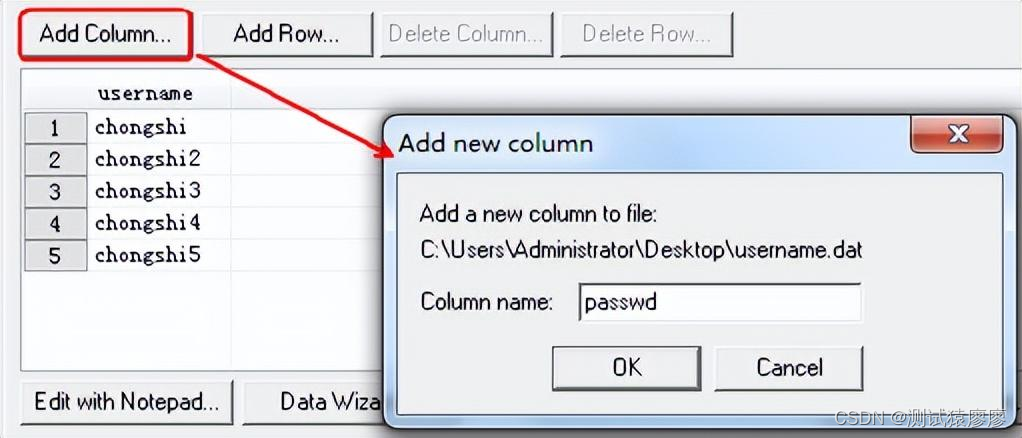
点击“Edit with Notepad”再次编辑参数化数据文件,使用户名密码建立一一对应关系。
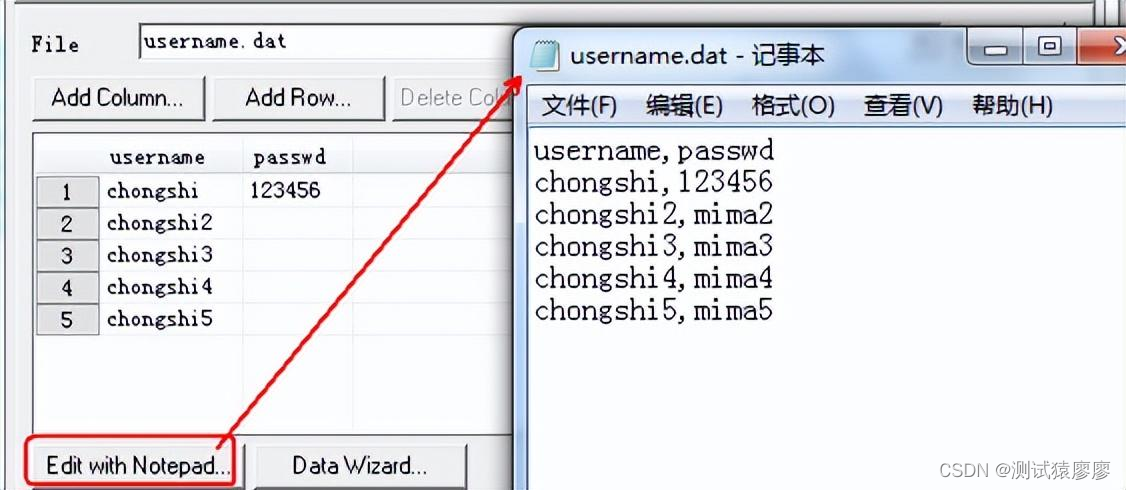
完成之后,我们已经成功对用户名和密码进行了参数化,并且让用户名和密码形成了对应关系。
数据分配与更新方式
脚本设置完参数化,脚本运行的每一遍所取的参数化的值都不一样,那么这个值按照个什么情况来取呢?会有很多种方式
Select next row【选择下一行】:

每次迭代(Each iteration) :每次迭代时取新的值,假如50个用户都取第一条数据,称为一次迭代;完了50个用户都取第二条数据,后面以此类推。
每次出现(Each occurrence):每次参数时取新的值,这里强调前后两次取值不能相同。
只取一次(once) :参数化中的数据,一条数据只能被抽取一次。(如果数据轮次完,脚本还在运行将会报错)
上面两个选项都有三种情况,如果将他们进行组合,将产生九种取值方式。
| Select Next Row 【选择下一行】 | Update Value On 【更新时的值】 | Replay Result 【结果】 |
| 顺序(Sequential) | 每次迭代(Each iteration) | 结果:分别将15条数据写入数据表中 功能说明:每迭代一次取一行值,从第一行开始取。当所有的值取完后,再从第一行开始取 如:如果参数化文件中有15条数据,而迭代设置为16次,那执行结果中,参数化文件第一行的数据有两条 |
| 顺序(Sequential) | 每次出现(Each occurrence) | 结果:分别将15条数据写入数据表中 功能说明:每迭代一次取一行值,从第一行开始取。当所有的值取完后,再从第一行开始取 如:如果参数化文件中有15条数据,而迭代设置为16次,那执行结果中,参数化文件第一行的数据有两条 |
| 顺序(Sequential) | 只取一次(once) | 结果:表中写入15条一模一样的数据。 功能说明:每次迭代都取参数化文件中第一行的数据。 |
| 随机(Random) | 每次迭代(Each iteration) | 结果:表中写入15条数据,但可能有重复数据出现 功能说明:每次从参数化文件中随机选择一行数据进行赋值 |
| 随机(Random) | 每次出现(Each occurrence) | 结果:表中写入15条数据,但可能有重复数据出现 功能说明:每次从参数化文件中随机选择一行数据进行赋值 |
| 随机(Random) | 只取一次(once) | 结果:表中写入15条相同数据 功能说明:第一次迭代时随机从参数化文件中取一行数据,后面每次迭代都用第一次迭代的数据。 |
| 唯一(Unique) | 每次迭代(Each iteration) 自动分配块大小 | 结果:分别将15条数据写入数据表中 功能说明:第一次迭代取参数化文件中的第一条数据,第二次迭代取第二条数据,以此类推。 注:如果设置迭代次数为16次。结果:在执行第16次迭代时会抛异常,异常日志可在LoadRunner的回放日志(replayLog)中看到。 |
| 唯一(Unique) | 每次出现(Each occurrence) 步长为1 | 结果:分别将15条数据写入数据表中 功能说明:第一次迭代取参数化文件中的第一条数据,第二次迭代取第二条数据,以此类推。 注:如果设置迭代次数为16次,而参数化文件中只有15条数据,明显数据不够。此时可以设置“when out of values”属性来判断当数据不够时的处理方式 Abort Vuser:中断虚拟用户 Countinue in a cylic manage:循环取参数化文件中的值,即:当参数化文件中的值取完后又从参数化文件的第一行开始取值。 Countinue with last value:继续用最后一条数据 |
| 唯一(Unique) | 只取一次(once) | 结果:表中写入15条相同数据 功能说明:每次都取参数文件中的第一条数据进行赋值 |
Ps:关于调用数据库实现参数化的方式,放在后一篇细说。被一个蛋疼的问题和这篇文章折腾一天。
相关文章:
LoadRunner参数化最佳实践:让你的性能测试更加出色!
距离上次使用loadrunnr 已经有一年多的时间了。初做测试时在项目中用过,后面项目中用不到,自己把重点放在了工具之外的东西上,认为性能测试不仅仅是会用工具,最近又想有一把好的利器毕竟可以帮助自己更好的完成性能测试工作。这算…...

软件测试工程师需要达到什么水平才能顺利拿到 20k 无压力?
最近有粉丝朋友问:软件测试员需要达到什么水平才能顺利拿到 20k 无压力? 这里写一篇文章来详细说说: 目录 扎实的软件测试基础知识:具备自动化测试经验和技能:熟练掌握编程语言:具备性能测试、安全测试、全…...

RabbitMQ-高级篇
服务异步通信-高级篇 消息队列在使用过程中,面临着很多实际问题需要思考: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D6S1iAs7-1681919354777)(assets/image-20210718155003157.png)] 1.消息可靠性 消息从发送&#x…...
深度学习_Learning Rate Scheduling
我们在训练模型时学习率的设置非常重要。 学习率的大小很重要。如果它太大,优化就会发散,如果它太小,训练时间太长,否则我们最终会得到次优的结果。其次,衰变率同样重要。如果学习率仍然很大,我们可能会简…...
)
snmp服务利用(端口:161、199、391、705、1993)
服务介绍 简单网络管理协议 是一种广泛应用于TCP/IP网络的网络管理标准协议(应用层协议),它提供了一种通过运行网络管理软件的中心计算机(即网络管理工作站)来监控和管理计算机网络的标准化管理框架(方法)。目前已颁布了SNMPv1、SNMPv2c和SNMPv3三个版本,广泛应用于网…...
MyBatis(二)—— 进阶
一、详解配置文件 1.1 核心配置文件 官方建议命名为mybatis-config.xml,核心配置文件里可以进行如下的配置: <environments> 和 <environment> mybatis可以配置多套环境(开发一套、测试一套、、、), 在…...
婚恋交友app开发中需要注意的安全问题
前言 随着移动设备的普及,婚恋交友app已经成为了人们生活中重要的一部分。但是,这些应用的开发者需要确保应用的安全性,以保护用户的隐私和数据免受攻击。本文将介绍在婚恋交友app开发中需要注意的安全问题。 在当今数字化时代,…...

相机的内参和外参介绍
注:以下相机内参与外参介绍除来自网络整理外全部来自于《视觉SLAM十四讲从理论到实践 第2版》中的第5讲:相机与图像,为了方便查看,我将每节合并到了一幅图像中 相机与摄像机区别:相机着重于拍摄静态图像&#x…...

Node【包】
文章目录 🌟前言🌟Nodejs包🌟什么是包?🌟自定义包🌟包配置文件🌟示例🌟Package.json 属性说明🌟语义化版本号🌟package.json示例 🌟符合CommonJS规…...

CHAPTER 2: 《BACK-OF-THE-ENVELOPE ESTIMATION》 第2章 《初略的估计》
CHAPTER 2: BACK-OF-THE-ENVELOPE ESTIMATION 在系统设计面试中,有时您会被要求估计系统容量或使用粗略估计的性能需求。根据杰夫迪恩的说法,谷歌高级研究员,“粗略的计算是你使用结合思想实验和常见的性能数字,以获得良好的感觉…...

RocketMQ高级概念
一 RocketMQ核心概念 1.消息模型(Message Model) RocketMQ主要由 Producer、Broker、Consumer 三部分组成,其中Producer 负责⽣产消息,Consumer 负责消费消息,Broker 负责存储消息。Broker 在实际部署过程中对应⼀台…...
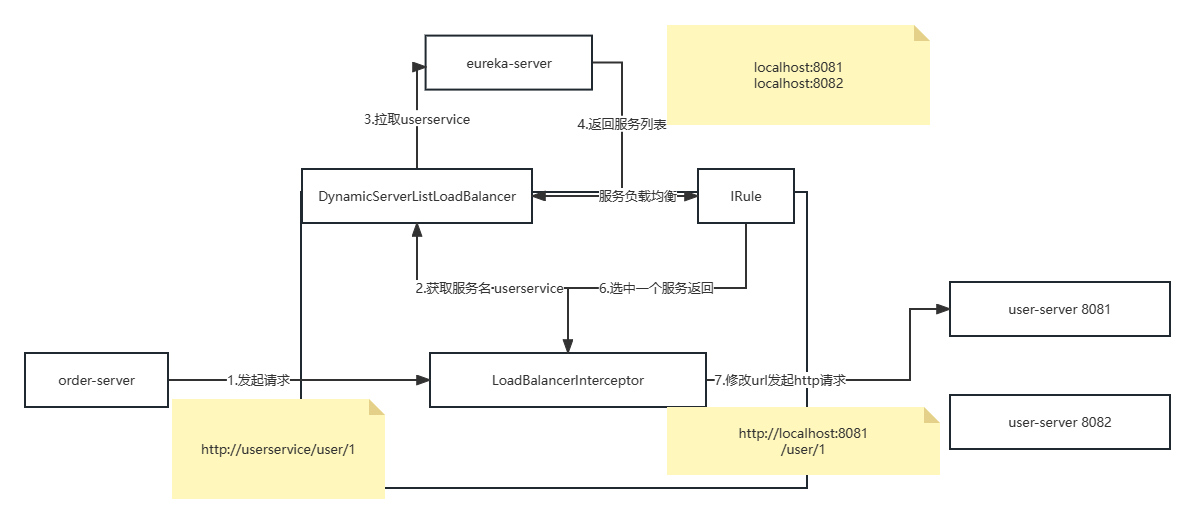
eureka注册中心和RestTemplate
eureka注册中心和restTemplate的使用说明 eureka的作用 消费者该如何获取服务提供者的具体信息 1.服务者启动时向eureka注册自己的信息 2.eureka保存这些信息 3.消费者根据服务名称向eureka拉去提供者的信息 如果有多个服务提供者,消费者该如何选择? 服…...
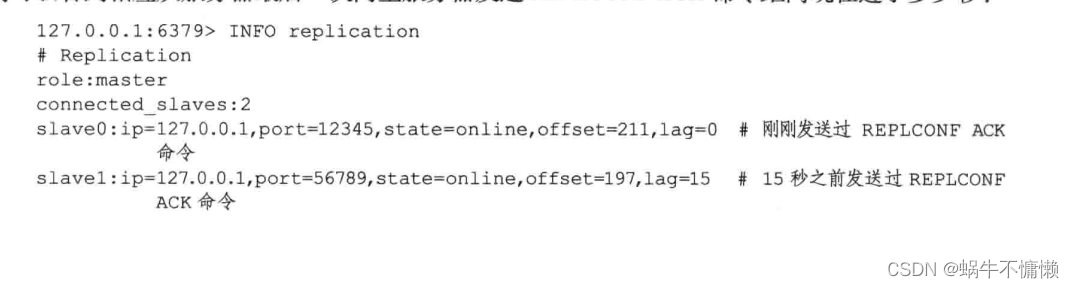
redis复制的设计与实现
一、复制 1.1旧版功能的实现 旧版Redis的复制功能分为 同步(sync)和 命令传播。 同步用于将从服务器更新至主服务器的当前状态。命令传播用于 主服务器状态变化时,让主从服务器状态回归一致。 1.1.1同步 当客户端向服务端发送slaveof命令…...
Docker更换国内镜像源
什么是Docker Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。 容器是完全…...
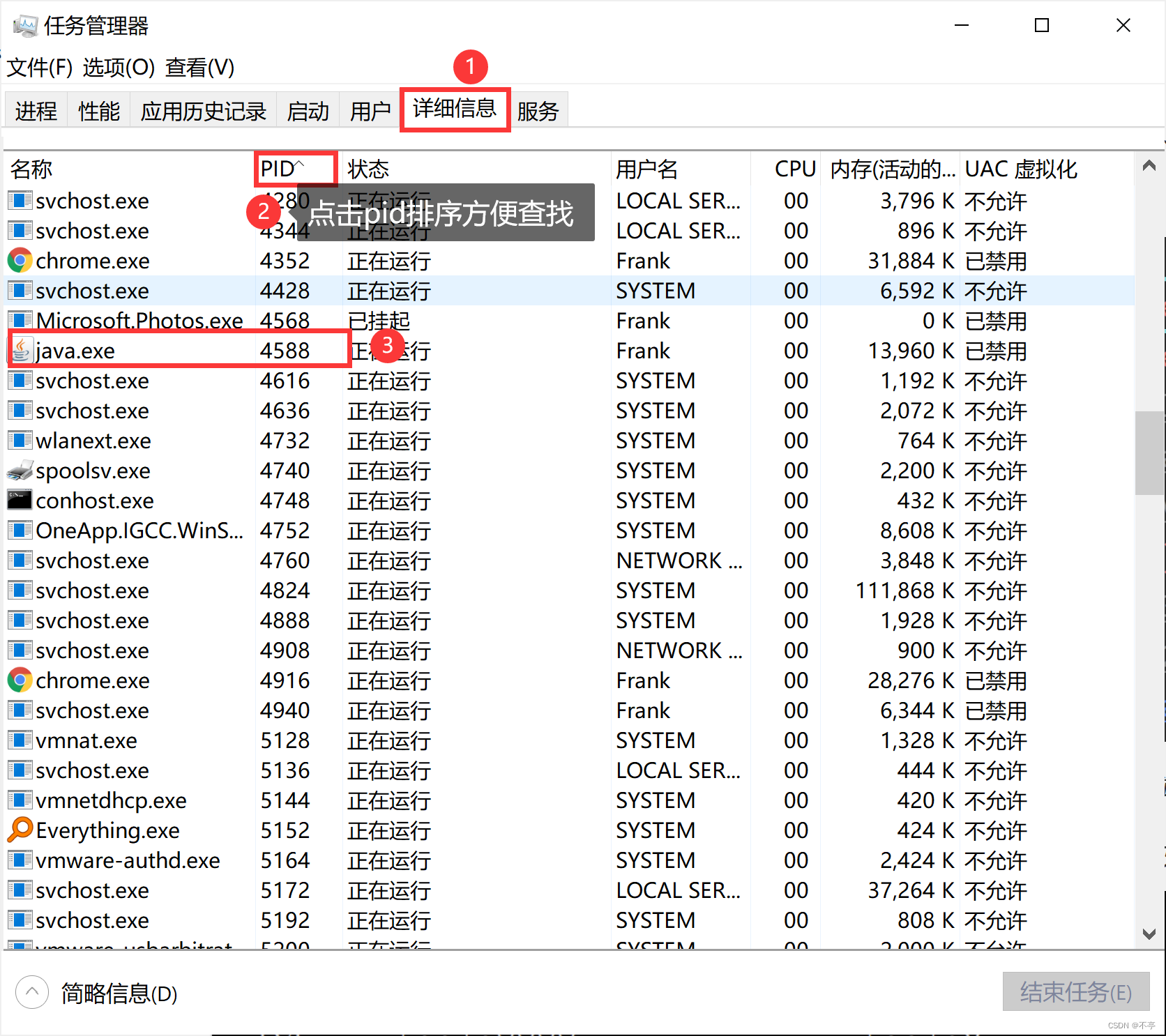
【网络编程】网络套接字,UDP,TCP套接字编程
前言 小亭子正在努力的学习编程,接下来将开启javaEE的学习~~ 分享的文章都是学习的笔记和感悟,如有不妥之处希望大佬们批评指正~~ 同时如果本文对你有帮助的话,烦请点赞关注支持一波, 感激不尽~~ 特别说明:本文分享的代码运行结果…...
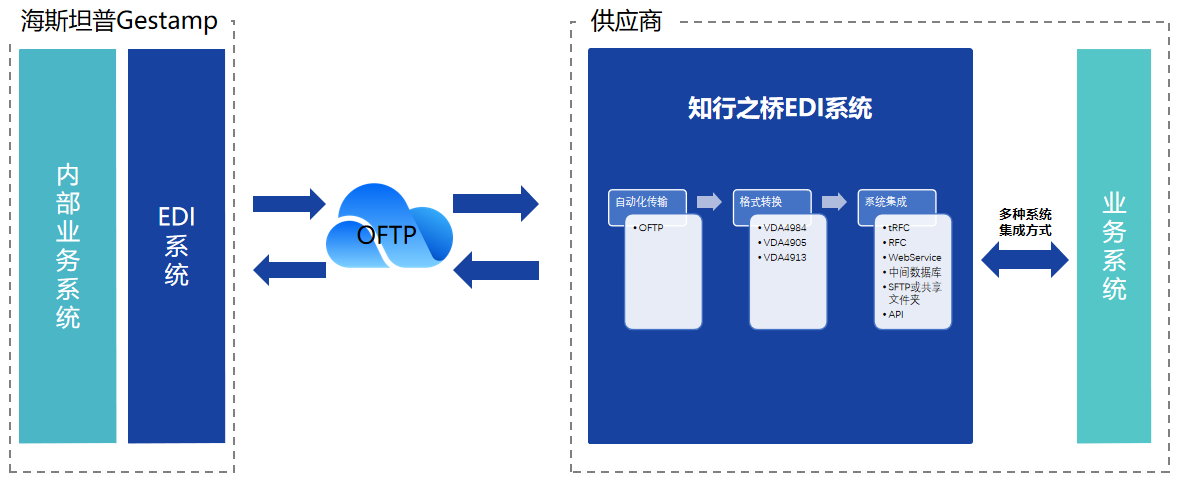
海斯坦普Gestamp EDI 需求分析
海斯坦普Gestamp(以下简称:Gestamp)是一家总部位于西班牙的全球性汽车零部件制造商,目前在全球23个国家拥有超过100家工厂。Gestamp的业务涵盖了车身、底盘和机电系统等多个领域,其产品范围包括钣金、车身结构件、车轮…...
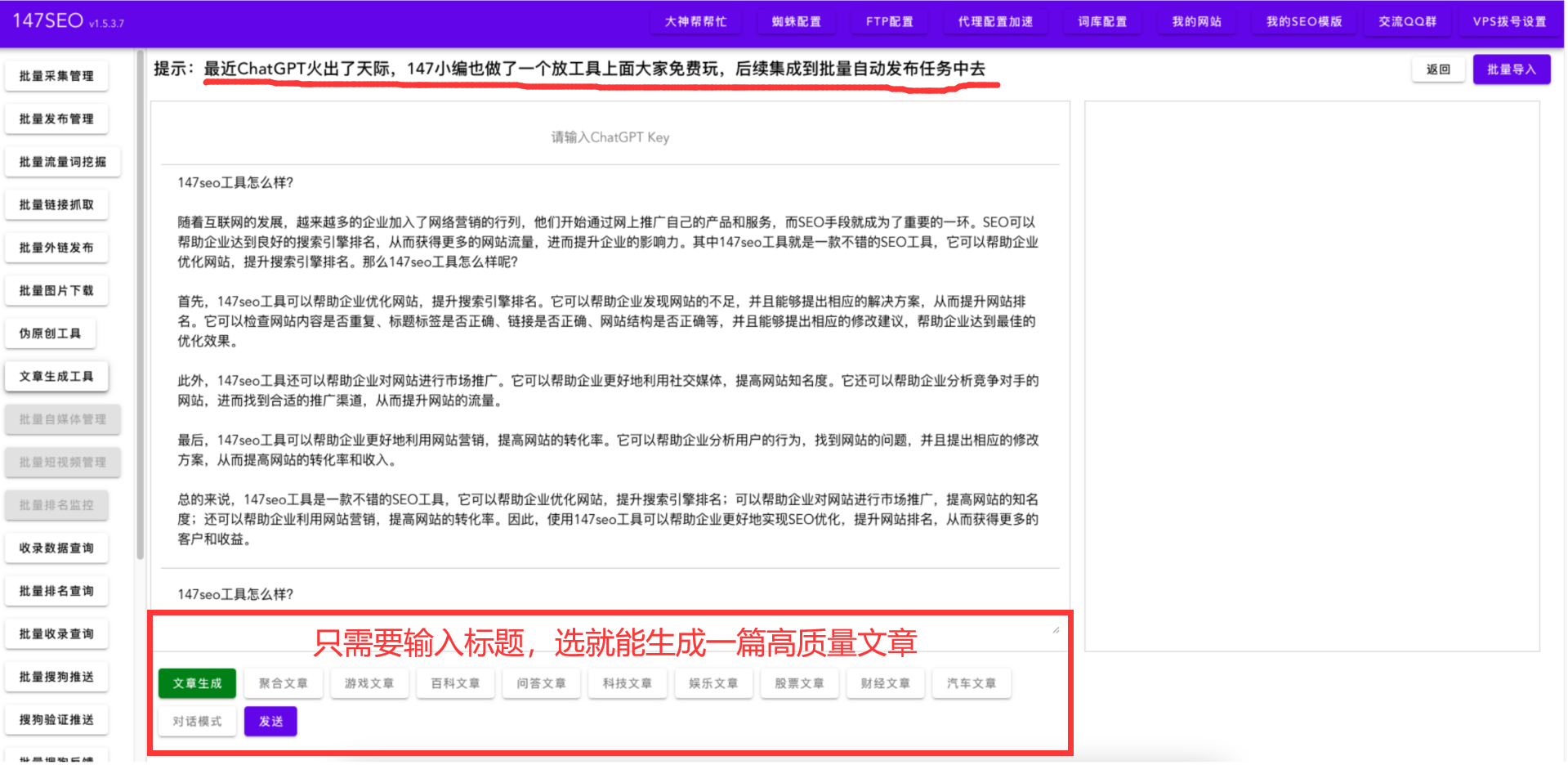
gpt写文章批量写文章-gpt3中文生成教程
怎么用gpt写文章批量写文章 批量写作文章是很多网站、营销人员、编辑等需要的重要任务,GPT可以帮助您快速生成大量自然、通顺的文章。下面是一个简单的步骤介绍,告诉您如何使用GPT批量写作文章。 步骤1:选择好训练模型 首先,选…...

HashMap实现原理
HashMap是基于散列表的Map接口的实现。插入和查询的性能消耗是固定的。可以通过构造器设置容量和负载因子,一调整容易得性能。 散列表:给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字…...

【Java 数据结构】PriorityQueue(堆)的使用及源码分析
🎉🎉🎉点进来你就是我的人了 博主主页:🙈🙈🙈戳一戳,欢迎大佬指点!人生格言:当你的才华撑不起你的野心的时候,你就应该静下心来学习! 欢迎志同道合的朋友一起加油喔🦾&am…...

使用 Kubernetes 运行 non-root .NET 容器
翻译自 Richard Lander 的博客 Rootless 或 non-root Linux 容器一直是 .NET 容器团队最需要的功能。我们最近宣布了所有 .NET 8 容器镜像都可以通过一行代码配置为 non-root 用户。今天的文章将介绍如何使用 Kubernetes 处理 non-root 托管。 您可以尝试使用我们的 non-root…...

USB Cheat Sheet:从物理层到协议栈的终极解码指南
USB Cheat Sheet:从物理层到协议栈的终极解码指南 USB,这个我们每天都在使用的接口,背后隐藏着远超想象的复杂技术体系。从1996年USB 1.0的1.5Mbps,到如今USB4 Version 2.0的80Gbps,传输速率提升了超过五万倍。但更让人…...

Python:4 == 4.0 结果为True的原因
特殊情况:在 Python 中,整数和浮点数进行比较时,如果数值相等,则结果为 True。即 4 4.0 的结果是 True。如果两个对象代表相同的概念或数值,即使类型不同(如 int 和 float),也可能返…...

海光3330E工控机实战:工业边缘计算与国产x86平台部署指南
1. 项目概述:当工业智能化遇见“中国芯”最近在为一个工业视觉检测的项目选型硬件平台,客户的要求很明确:稳定、可靠、能长时间在产线恶劣环境下跑,还得有足够的算力处理实时图像分析。在对比了市面上常见的几款基于x86或ARM架构的…...

深入理解Android网络开发:以OkHttp为核心的全面指南
引言 在移动应用开发中,网络通信是核心功能之一。Android平台提供了丰富的网络库和工具,但开发者常面临挑战,如性能优化、安全配置和弱网环境处理。OkHttp作为Android生态中最流行的HTTP客户端库,由Square公司开发,以其高效、灵活和易扩展的特性成为行业标准。它支持同步…...

Keil µVision TAB显示异常问题分析与解决方案
1. 问题现象与背景分析在Keil Vision集成开发环境中,部分用户遇到了编辑器界面显示异常的问题。具体表现为:当代码中包含TAB字符(制表符)时,屏幕上会出现奇怪的显示错乱,原本应该显示为空白缩进的区域&…...

Java Web中基于JWT的七层权限控制系统设计
1. 为什么JWT不是“万能钥匙”,而是一个需要精心设计的权限信封在Java Web开发中,一提到权限控制,很多人第一反应就是“加个Spring Security,配个JWT,不就完事了?”我去年接手一个医疗SaaS系统的权限模块重…...

嘉立创EDA专业版安装避坑指南:从下载到第一个ESP32项目实战
嘉立创EDA专业版安装避坑指南:从下载到第一个ESP32项目实战 第一次打开嘉立创EDA专业版时,那个深蓝色界面让我想起了学生时代第一次接触电路设计的场景。作为国产EDA工具的后起之秀,它用更符合国人习惯的操作逻辑和实惠的打板政策,…...

GitHub Copilot X:从代码补全到全流程AI协作者的实战指南
1. 项目概述:当代码编辑器遇见“副驾驶”如果你和我一样,每天有超过一半的时间是在代码编辑器里度过的,那你一定对“效率”这个词有着近乎偏执的追求。从语法高亮、代码补全,到后来的LSP(Language Server Protocol&…...

community:CANN开源社区治理指南
前言 想象一下,你开发了一个很棒的算子,想贡献给CANN社区,但不知道从哪入手——怎么提Issue?怎么提PR?代码规范是什么?会不会被拒绝? 我刚接触CANN开源社区那会,就是这样的——写了个…...

别再瞎找了!AI论文写作软件2026最新测评与推荐
2026年真正好用的AI论文写作软件,核心看生成的论文质量、低AI味、格式正确、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...