TI在物联网和AI边缘计算中落伍了吗?
摘要:本文介绍一下TI在边缘计算工作中所做的努力。

发明“人工智能”这个term的老头儿也不会想到人工智能在中国有多火。
不管是懂还是不懂,啥东西披上“人工智能“的面纱都能瞬间成为大项目。
学习AI 的年轻人认识NVIDIA,可能不太知道DSP是啥玩意儿了。
我们上学那会,NVIDIA仅仅是”显卡“代名词而已,DSP是绝对的天花板。
现在,貌似DSP都赶不上FPGA了,因为FPGA加速AI应用好像更快一点。
不过,TI没有沉睡,相信下一次的浪潮会是他引领。
我的理由比较简单--乘法比加法更需要实力(大家意会)。
1.TI想让AI模型在自己的DSP上跑一跑
AI最重要的就是模型,这个面纱不揭开,大家都以为神圣的不得了,本文也不揭开它,让它继续神圣。通用AI才是集模型之大成,通用AI取得飞跃之前,尤其是能够拜托超级计算能力之前,现在仍然处于一个相对不那么高的阶段。为了模仿人类学习的过程,大家用一大堆服务器,一大堆GPU(很贵,一般我们购买云服务)从一大堆数据中训练出来一个模型,那么这个模型可以对你想要的事情进行分类或者回归(根本上来说,它俩应该是统一的)。比如你让这个模型分辨一下输入的一张图片中的动物是猫还是狗。
当然这只是初级的模型,要想实现ChatGPT等通用模型,那么所需要的硬件和数据就更多更多了。
但是根本上还是模型。
有的模型就很小,或者不太大,体积恰好可以放进”边缘计算“设备。例如华为的Atlas 500,或者很多厂家声称的Jetson XXX,这些设备可以跑一跑训练好的“模型”。
那么TI DSP呢?也能够跑一跑。
我想说的是,边缘计算跑一个模型浪费不?
在古老的嵌入式系统领域,崇尚的是“够用就好”,在AI时代,好像不怎么提了。
功耗?成本?统统不用考虑,因为跟其他开支相比,这个根本就不是个事。
其实AI时代需要冷静一下,尽管AI寒冬的时候,那几个坚持下来的老头儿的确是非常值得尊敬的。我们需要考虑,AI怎么样才能为我们带来最合适的科技舒适感。并不是说,处处都有人脸识别,每个汽车都装一个激光雷达,我们的生活就一下子提升到了24小时都是幸福指数拉满的水平。毕竟我们只是一个时代的沙尘而已。
以前大家开玩笑说,汽车时速表上的一大部分空间是没有用过的,现在可以说,自动驾驶也没有太多人敢于彻底放松地上车就享受它们。
arduino有一款板子,也可以跑简单的AI模型,例如识别简单的语音指令。
TI也有。它想实现的是把模型放在这个DSP上来执行。看上去它并不太像是一个DSP,而是一个ARM内核的CPU而已。
有一篇技术文章讲述了如何这么做
https://www.ti.com.cn/cn/lit/an/zhcabs1/zhcabs1.pdf?ts=1681788583275&ref_url=https%253A%252F%252Fwww.ti.com.cn%252Fproduct%252Fcn%252FTDA4VM

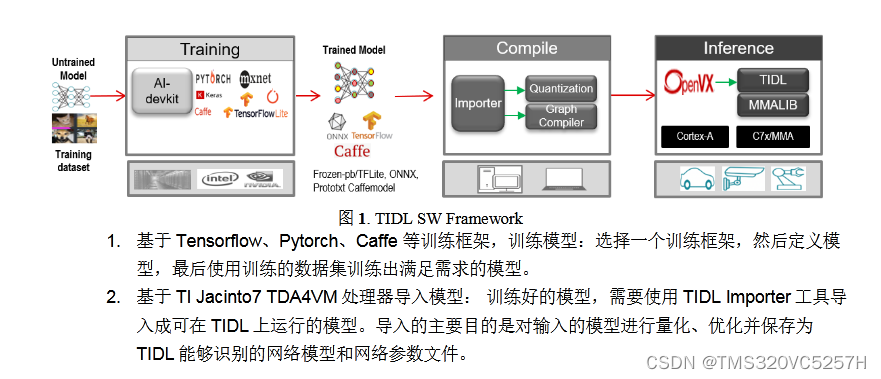
2.具有深度学习、视觉功能和多媒体加速器的双核 Arm® Cortex®-A72 SoC 和 C7x DSP
它是名字叫做TDA4VM
具有深度学习、视觉功能和多媒体加速器的双核 Arm® Cortex®-A72 SoC 和 C7x DSP
适用于 L2、L3 和近场分析系统且采用深度学习的汽车片上系统
可以运行Linux, QNX, RTOS
硬件上,有1 Deep learning accelerator, 1 Depth and Motion accelerator, 1 Vision Processing accelerator, 1 video encode/decode accelerator
2 个Arm Cortex-A72核

性能强大,但是怎么看怎么像是迎合AI应用所做。
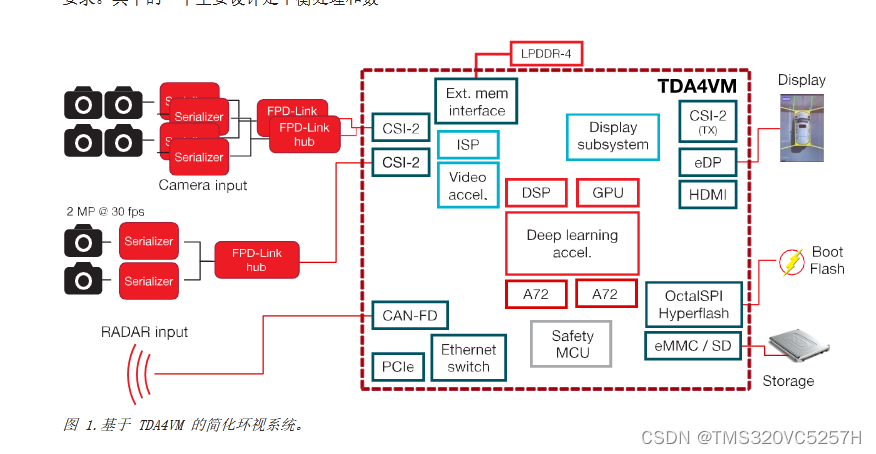
比如它可以做环视泊车,我们叫做全景影像。可是似乎这也没啥,现在街上的车辆,带全景影像的好像很多,解决方案并不一定用的的TI的。
3.TI的边缘云计算[1]
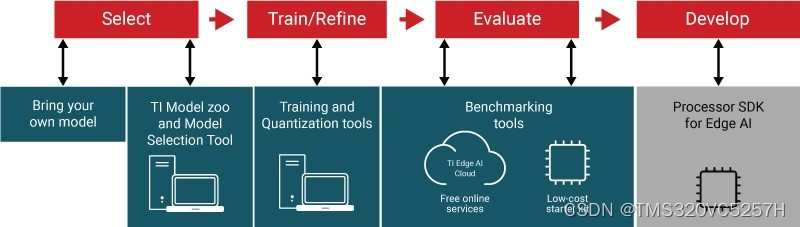
如果在没有嵌入式处理器供应商提供的合适工具和软件的支持下,既想设计高能效的边缘人工智能(AI)系统,同时又要加快产品上市时间,这项工作难免会冗长乏味。面临的一系列挑战包括选择恰当的深度学习模型、针对性能和精度目标对模型进行训练和优化,以及学习使用在嵌入式边缘处理器上部署模型的专用工具。从模型选择到在处理器上部署,TI可免费提供相关工具、软件和服务,为您深度神经网络(DNN)开发工作流程的每一步保驾护航。
第1步:选择模型
边缘AI系统开发的首要任务是选择合适的DNN模型,同时要兼顾系统的性能、精度和功耗目标。GitHub上的TI边缘AI Model Zoo等工具可助您加速此流程。
Model Zoo广泛汇集了TensorFlow、PyTorch和MXNet框架中常用的开源深度学习模型。这些模型在公共数据集上经过预训练和优化,可以在TI适用于边缘AI的处理器上高效运行。TI会定期使用开源社区中的新模型以及TI设计的模型对Model Zoo进行更新,为您提供性能和精度经过优化的广泛模型选择。
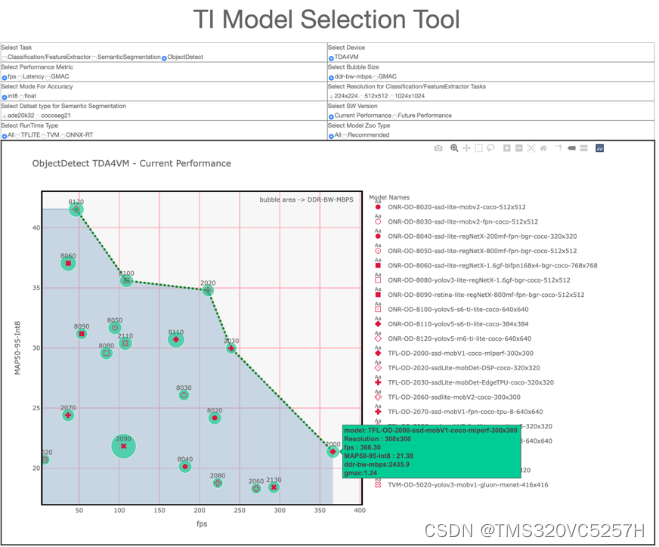
Model Zoo囊括数百个模型,TI模型选择工具(如图2所示)可以帮助您在不编写任何代码的情况下,通过查看和比较性能统计数据(如推理吞吐量、延迟、精度和双倍数据速率带宽),快速比较和找到适合您AI任务的模型。
第2步:训练和优化模型
选择模型后,下一步是在TI处理器上对其进行训练或优化,以获得出色的性能和精度。凭借我们的软件架构和开发环境,您可随时随地训练模型。
从TI Model Zoo中选择模型时,借助训练脚本可让您在自定义数据集上为特定任务快速传输和训练模型,而无需花费较长时间从头开始训练或使用手动工具。训练脚本、框架扩展和量化感知培训工具可帮助您优化自己的DNN模型。
第3步:评估模型性能
在开发边缘AI应用之前,需要在实际硬件上评估模型性能。
TI提供灵活的软件架构和开发环境,您可以在TensorFlow Lite、ONNX RunTime或TVM和支持Neo AI DLR的SageMaker Neo运行环境引擎三者中选择习惯的业界标准Python或C++应用编程接口(API),只需编写几行代码,即可随时随地训练自己的模型,并将模型编译和部署到TI硬件上。在这些业界通用运行环境引擎的后端,我们的TI深度学习(TIDL)模型编译和运行环境工具可让您针对TI的硬件编译模型,将编译后的图或子图部署到深度学习硬件加速器上,并在无需任何手动工具的情况下实现卓越的处理器推理性能。
在编译步骤中,训练后量化工具可以自动将浮点模型转换为定点模型。该工具可通过配置文件实现层级混合精度量化(8位和16位),从而能够足够灵活地调整模型编译,以获得出色的性能和精度。
不同常用模型的运算方式各不相同。同样位于GitHub上的TI边缘AI基准工具可帮助您为TI Model Zoo中的模型无缝匹配DNN模型功能,并作为自定义模型的参考。
评估TI处理器模型性能的方式有两种:TDA4VM入门套件评估模块(EVM)或TI Edge AI Cloud,后者是一项免费在线服务,可支持远程访问TDA4VM EVM,以评估深度学习推理性能。借助针对不同任务和运行时引擎组合的数个示例脚本,五分钟之内便可在TI硬件上编程、部署和运行加速推理,同时收集基准测试数据。
第4步:部署边缘AI应用程序
您可以使用开源Linux®和业界通用的API来将模型部署到TI硬件上。然而,将深度学习模型部署到硬件加速器上只是难题的冰山一角。
为帮助您快速构建高效的边缘AI应用,TI采用了GStreamer框架。借助在主机Arm®内核上运行的GStreamer插件,您可以自动将计算密集型任务的端到端信号链加速部署到硬件加速器和数字信号处理内核上。
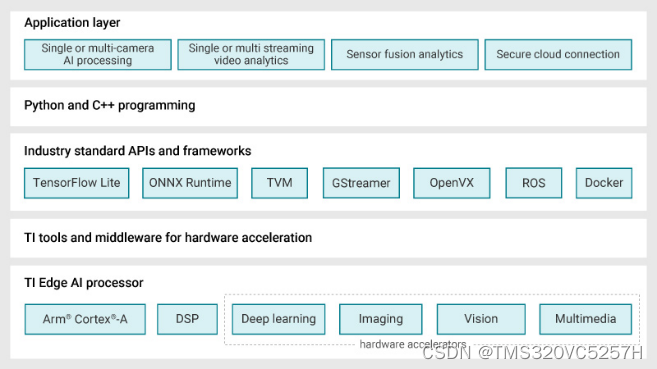
下图是一个视频的应用

4.DSP还有机会吗?
FPAG的结构特点
片内有大量的逻辑门和触发器,多为查找表结构,实现工艺多为SRAM。规模大,集成度高,处理速度快,执行效率高。能完成复杂的时序逻辑设计,且编程灵活,方便,简单,可多次重复编程。许多FPAG可无限重复编程。利用重新配置可减少硬件的开销
DSP作为专门的微处理器,主要用于计算,优势是软件的灵活性。适用于条件进程,特别是复杂的多算法任务。采用数据和程序分离的哈佛结构和改进的哈佛结构,执行指令速度更快。独立的累加器及加法器,一个周期内可同时完成相乘及累加运算。
我们知道,AI算法的核心就是大量的乘加/乘累加。再传统的FPGA中乘累加是依靠DSP模块实现的。为了追求较高的灵活性,普通的DSP模块就是一个或者两个乘法器,外加一个加法器构成。这样就可以基于这种基本的DSP模块配合FPGA的其它部分构成各种不同的运算算法。
但AI运算不是一般的乘加,而是一种“张量”运算。简单的说就是一组数据先乘后加,乘加之间还有级联。因此提升FPGA执行AI算法的最好方法自然就是把DSP模块升级为更加适应AI张量运算的模块。
大量的乘法器,不同模块之间的级联通道,以及对应的加法。这非常符合张量运算先乘后加,多维运算的运算过程。这样让底层运算结构与算法高度匹配,就可以保证算法的执行效率。
DSP的先天优势就是哈弗总线,以及单周期执行乘加操作。
尽管人工智能目前所需的计算是“张量”,但是从它的理论提出来初期,就是用一个简单的网络结构来代替的,因此才导致了必须使用特别巨大的计算资源和功耗来实现一个人类小孩就可以完成的分类操作。所以在GPU运行算法发现之前,技术停滞了相当长的一段时间。人类小孩并没有利用身体之外的巨大计算资源来学习就能逐渐成长,所以要想实现比较低的计算资源完成比较复杂的运算在未来的时候也许是可以的。这一点,希望DSP通过结构优化能够帮得上忙。
参考资料:
1.嵌入式边缘AI应用开发简化指南 - 嵌入式处理 - 技术文章 - E2E™ 设计支持
2.为什么不经常看到利用DSP作为机器学习硬件加速器的文章或者新闻? - 知乎
3.人工智能计算领域的领导者 | NVIDIA
4.两大FPGA公司的“AI技术路线”
相关文章:
TI在物联网和AI边缘计算中落伍了吗?
摘要:本文介绍一下TI在边缘计算工作中所做的努力。 发明“人工智能”这个term的老头儿也不会想到人工智能在中国有多火。 不管是懂还是不懂,啥东西披上“人工智能“的面纱都能瞬间成为大项目。 学习AI 的年轻人认识NVIDIA,可能不太知道DSP是…...

LoadRunner参数化最佳实践:让你的性能测试更加出色!
距离上次使用loadrunnr 已经有一年多的时间了。初做测试时在项目中用过,后面项目中用不到,自己把重点放在了工具之外的东西上,认为性能测试不仅仅是会用工具,最近又想有一把好的利器毕竟可以帮助自己更好的完成性能测试工作。这算…...

软件测试工程师需要达到什么水平才能顺利拿到 20k 无压力?
最近有粉丝朋友问:软件测试员需要达到什么水平才能顺利拿到 20k 无压力? 这里写一篇文章来详细说说: 目录 扎实的软件测试基础知识:具备自动化测试经验和技能:熟练掌握编程语言:具备性能测试、安全测试、全…...

RabbitMQ-高级篇
服务异步通信-高级篇 消息队列在使用过程中,面临着很多实际问题需要思考: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D6S1iAs7-1681919354777)(assets/image-20210718155003157.png)] 1.消息可靠性 消息从发送&#x…...
深度学习_Learning Rate Scheduling
我们在训练模型时学习率的设置非常重要。 学习率的大小很重要。如果它太大,优化就会发散,如果它太小,训练时间太长,否则我们最终会得到次优的结果。其次,衰变率同样重要。如果学习率仍然很大,我们可能会简…...
)
snmp服务利用(端口:161、199、391、705、1993)
服务介绍 简单网络管理协议 是一种广泛应用于TCP/IP网络的网络管理标准协议(应用层协议),它提供了一种通过运行网络管理软件的中心计算机(即网络管理工作站)来监控和管理计算机网络的标准化管理框架(方法)。目前已颁布了SNMPv1、SNMPv2c和SNMPv3三个版本,广泛应用于网…...
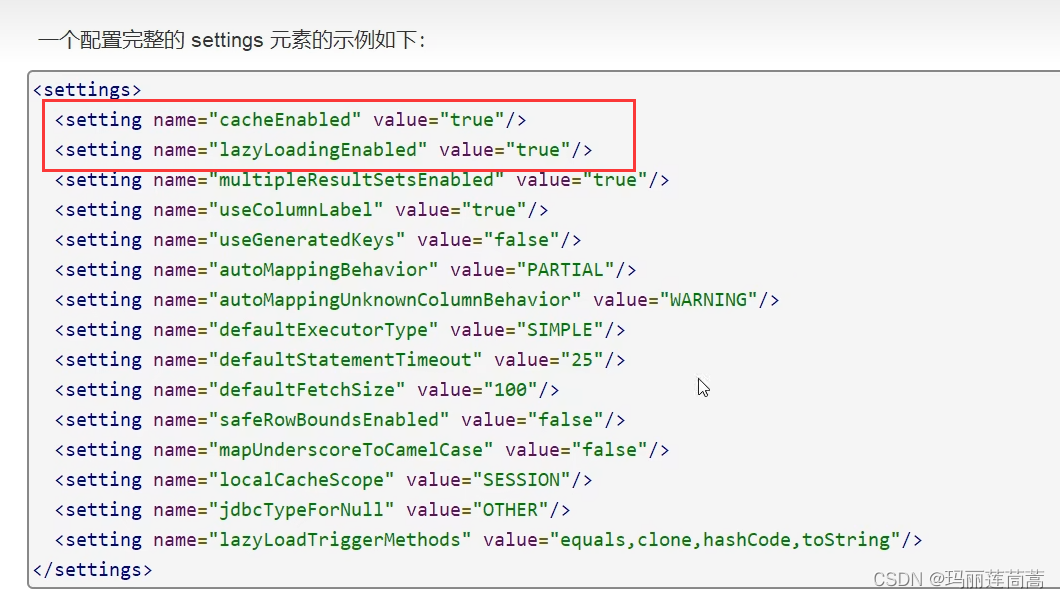
MyBatis(二)—— 进阶
一、详解配置文件 1.1 核心配置文件 官方建议命名为mybatis-config.xml,核心配置文件里可以进行如下的配置: <environments> 和 <environment> mybatis可以配置多套环境(开发一套、测试一套、、、), 在…...
婚恋交友app开发中需要注意的安全问题
前言 随着移动设备的普及,婚恋交友app已经成为了人们生活中重要的一部分。但是,这些应用的开发者需要确保应用的安全性,以保护用户的隐私和数据免受攻击。本文将介绍在婚恋交友app开发中需要注意的安全问题。 在当今数字化时代,…...

相机的内参和外参介绍
注:以下相机内参与外参介绍除来自网络整理外全部来自于《视觉SLAM十四讲从理论到实践 第2版》中的第5讲:相机与图像,为了方便查看,我将每节合并到了一幅图像中 相机与摄像机区别:相机着重于拍摄静态图像&#x…...

Node【包】
文章目录 🌟前言🌟Nodejs包🌟什么是包?🌟自定义包🌟包配置文件🌟示例🌟Package.json 属性说明🌟语义化版本号🌟package.json示例 🌟符合CommonJS规…...

CHAPTER 2: 《BACK-OF-THE-ENVELOPE ESTIMATION》 第2章 《初略的估计》
CHAPTER 2: BACK-OF-THE-ENVELOPE ESTIMATION 在系统设计面试中,有时您会被要求估计系统容量或使用粗略估计的性能需求。根据杰夫迪恩的说法,谷歌高级研究员,“粗略的计算是你使用结合思想实验和常见的性能数字,以获得良好的感觉…...

RocketMQ高级概念
一 RocketMQ核心概念 1.消息模型(Message Model) RocketMQ主要由 Producer、Broker、Consumer 三部分组成,其中Producer 负责⽣产消息,Consumer 负责消费消息,Broker 负责存储消息。Broker 在实际部署过程中对应⼀台…...
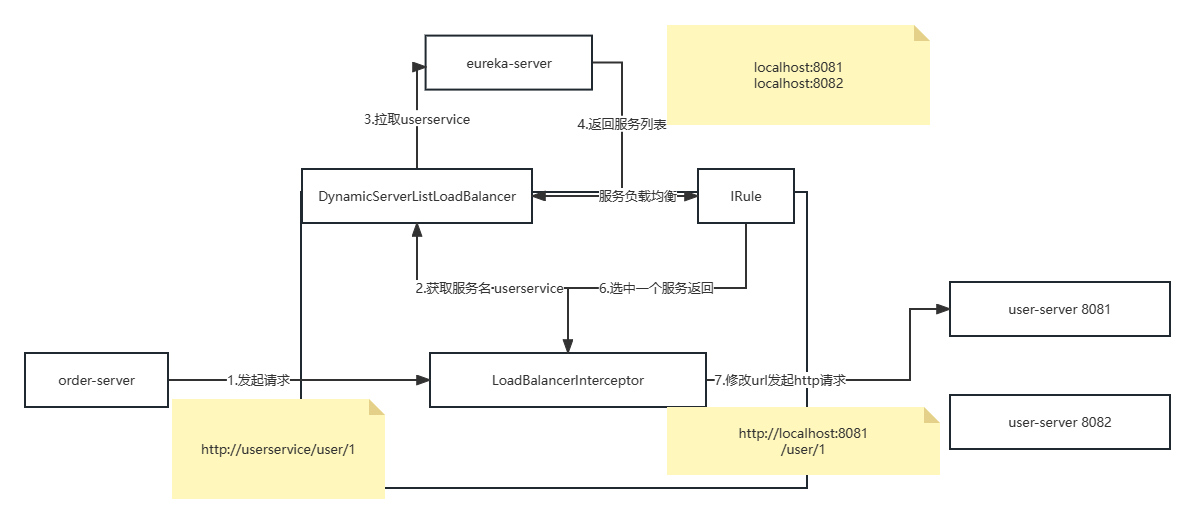
eureka注册中心和RestTemplate
eureka注册中心和restTemplate的使用说明 eureka的作用 消费者该如何获取服务提供者的具体信息 1.服务者启动时向eureka注册自己的信息 2.eureka保存这些信息 3.消费者根据服务名称向eureka拉去提供者的信息 如果有多个服务提供者,消费者该如何选择? 服…...
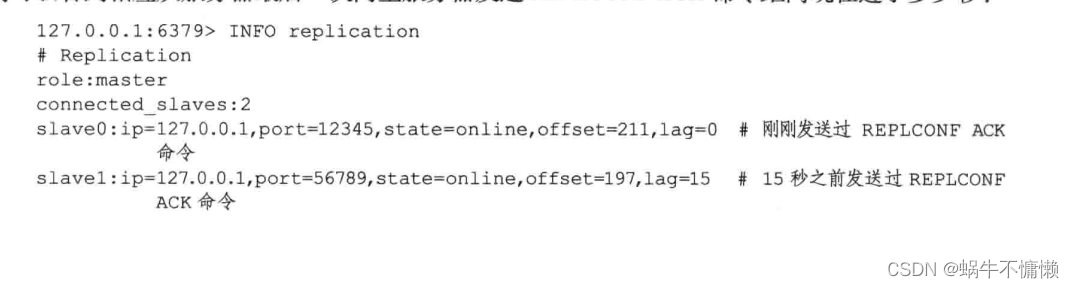
redis复制的设计与实现
一、复制 1.1旧版功能的实现 旧版Redis的复制功能分为 同步(sync)和 命令传播。 同步用于将从服务器更新至主服务器的当前状态。命令传播用于 主服务器状态变化时,让主从服务器状态回归一致。 1.1.1同步 当客户端向服务端发送slaveof命令…...
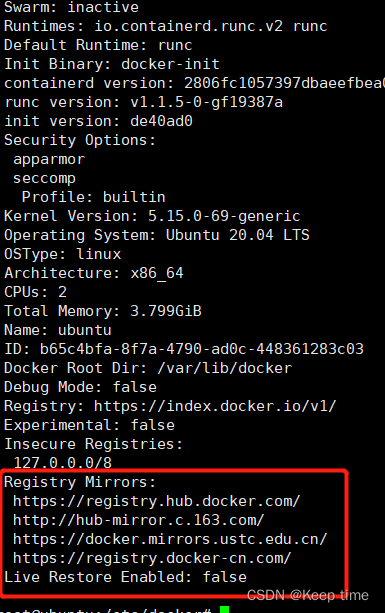
Docker更换国内镜像源
什么是Docker Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。 容器是完全…...
【网络编程】网络套接字,UDP,TCP套接字编程
前言 小亭子正在努力的学习编程,接下来将开启javaEE的学习~~ 分享的文章都是学习的笔记和感悟,如有不妥之处希望大佬们批评指正~~ 同时如果本文对你有帮助的话,烦请点赞关注支持一波, 感激不尽~~ 特别说明:本文分享的代码运行结果…...
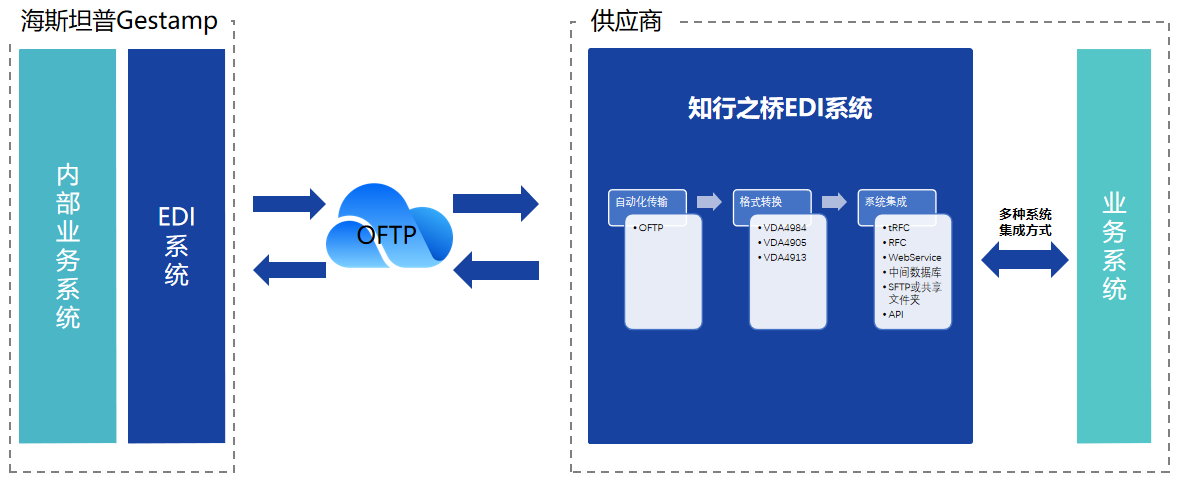
海斯坦普Gestamp EDI 需求分析
海斯坦普Gestamp(以下简称:Gestamp)是一家总部位于西班牙的全球性汽车零部件制造商,目前在全球23个国家拥有超过100家工厂。Gestamp的业务涵盖了车身、底盘和机电系统等多个领域,其产品范围包括钣金、车身结构件、车轮…...
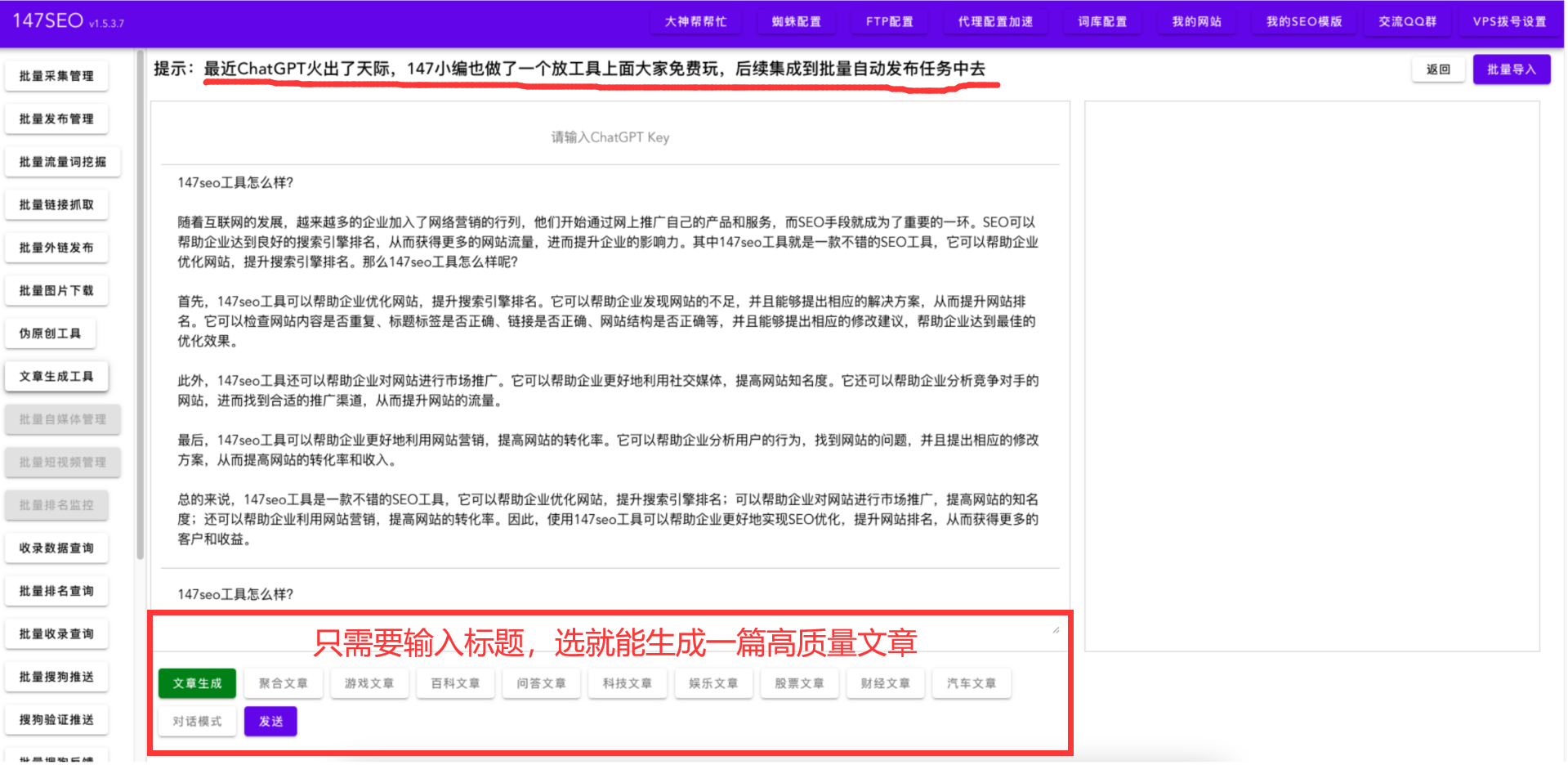
gpt写文章批量写文章-gpt3中文生成教程
怎么用gpt写文章批量写文章 批量写作文章是很多网站、营销人员、编辑等需要的重要任务,GPT可以帮助您快速生成大量自然、通顺的文章。下面是一个简单的步骤介绍,告诉您如何使用GPT批量写作文章。 步骤1:选择好训练模型 首先,选…...

HashMap实现原理
HashMap是基于散列表的Map接口的实现。插入和查询的性能消耗是固定的。可以通过构造器设置容量和负载因子,一调整容易得性能。 散列表:给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字…...

【Java 数据结构】PriorityQueue(堆)的使用及源码分析
🎉🎉🎉点进来你就是我的人了 博主主页:🙈🙈🙈戳一戳,欢迎大佬指点!人生格言:当你的才华撑不起你的野心的时候,你就应该静下心来学习! 欢迎志同道合的朋友一起加油喔🦾&am…...

Joy-Con Toolkit:3大核心功能让你的Switch手柄重获新生
Joy-Con Toolkit:3大核心功能让你的Switch手柄重获新生 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit 你是否曾为Switch手柄的摇杆漂移而烦恼?是否想过让千篇一律的手柄颜色变得与众不同…...

嵌入式核心板选型实战:从AI加速到工业控制的设计权衡与趋势
1. 展会现场与行业风向初探上周,我作为飞凌嵌入式的一名老员工,亲身参与了2024上海国际嵌入式展。这不仅仅是一次公司产品的展示,更像是一场行业技术趋势的集中检阅。从人头攒动的展台到同行间热烈的技术交流,你能清晰地感受到&am…...

RK3576开发板RTC硬件扩展与Linux时间管理实战指南
1. 项目概述与核心价值在嵌入式开发中,尤其是在像RK3576这类高性能AIoT开发板上,一个稳定可靠的实时时钟(RTC)往往是项目从“玩具”走向“产品”的关键一步。它不仅仅是显示个时间那么简单,更是系统日志时间戳准确、定…...

工业IoT实战:边缘计算+AI在电机预测性维护中的系统架构设计
前言工业物联网(IIoT)场景下,预测性维护(Predictive Maintenance)是AI技术落地价值最明确的方向之一。本文以杭州沃伦森(WARENSEN)电气的AIESA电机智能安康系统为案例,分析其在边缘计…...

武林外传十年之约手游官网下载:武林外传十年之约最新官方下载渠道
《武林外传十年之约》又名《武林外传手游》《武林外传怀旧版》《武林外传正版复刻》,由安徽游昕联合忆往游戏运营的正版武侠 MMORPG 手游。1:1 复刻同福客栈、七侠镇、五霸岗、十八里铺等经典场景,完美还原枪豪、剑客、术士、医师四大职业体系࿰…...

BurpSuite中文乱码根因解析:Java字体渲染与系统编码协同调试
1. 为什么中文设置不是“点一下就完事”——BurpSuite里被低估的本地化陷阱刚接触渗透测试的新手,打开BurpSuite第一反应往往是:界面全是英文,看着费劲。于是搜到“BurpSuite 中文设置”,点开几篇教程,照着复制粘贴几行…...
线上服务卡顿?从一次ES写入超时故障,复盘我是如何调整`refresh_interval`和`translog`参数的
线上服务卡顿?一次Elasticsearch写入超时故障的深度调优实战 凌晨三点,监控系统突然告警——核心服务的API响应时间突破5秒阈值。快速排查发现,所有慢请求都卡在了日志写入环节。作为运维负责人,我立即意识到这又是一次Elasticsea…...

graph-autofusion:算子自动融合框架,让模型性能提升30%
前言 算子融合就像把多个快递包裹合并成一个,减少送货次数。 你有没有想过,为什么模型推理时,每个算子都要单独读写HBM(High Bandwidth Memory)?明明LayerNorm后面紧跟Add,为什么要分开算&#…...

Sunshine游戏串流实战指南:构建跨平台私人云游戏服务器完整方案
Sunshine游戏串流实战指南:构建跨平台私人云游戏服务器完整方案 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经希望将高配置PC上的游戏体验延伸到客厅电视、…...

app应用接入广告的完整流程和方法:从零搭建可持续变现体系
随着移动互联网进入存量竞争阶段,用户流量增长趋于饱和,单纯依靠用户新增实现产品增值的模式已然失效。对于绝大多数免费工具、社交、资讯、游戏类 APP 而言,合规、稳定、可持续的广告变现,已经成为补齐产品商业闭环、维持产品长期…...