【计算机视觉 | 目标检测】OVD:Open-Vocabulary Object Detection 论文工作总结(共八篇)
文章目录
- 一、2D open-vocabulary object detection的发展和研究现状
- 二、基于大规模外部图像数据集
- 2.1 OVR-CNN:Open-Vocabulary Object Detection Using Captions,CVPR 2021
- 2.2 Open Vocabulary Object Detection with Pseudo Bounding-Box Labels,ECCV 2022
- 2.2.1 伪标签的生成
- 2.2.2 检测模型训练
- 2.3 Detic: Detecting Twenty-thousand Classes using Image-level Supervision,ECCV 2022
- 2.4 Grounded Language-Image Pre-training (CVPR 2022 oral)
- 三、总结
- 四、基于多模态大模型
- 4.1 ViLD:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation,ICLR 2022
- 4.2 RegionCLIP: Region-based Language-Image Pretraining,CVPR 2022
- 4.3 Aligning Bag of Regions for Open-Vocabulary Object Detection
- 4.4 CORA: Adapting CLIP for Open-Vocabulary Detection with Region Prompting and Anchor Pre-Matching
一、2D open-vocabulary object detection的发展和研究现状
Open-Vocabulary Object Detection (OVD)可以翻译为**“面向开放词汇下的目标检测”,**该任务和 zero-shot object detection 非常类似,核心思想都是在可见类(base class)的数据上进行训练,然后完成对不可见类(unseen/ target)数据的识别和检测,除了核心思想类似外,很多论文其实对二者也没有进行很好的区分。
2D OVD 任务是由Shih-Fu Chang在CVPR2021上发表的论文 “Open-Vocabulary Object Detection Using Captions”(OVR-CNN)中提出,其出发点是制定一种更加通用的目标检测问题,目的是借助于大量的 image-caption 数据来覆盖更多的Object Concept,使得Object Detection不再受限于带标注数据的少数类别,从而实现更加泛化的Object Detection,识别出更多novel的物体类别。
随着OVR-CNN的提出,越来越多的OVD工作涌现出来。例如:ViLD、RegionCLIP、GLIP、VL-PLM、Detic、VL-Det等。本节将按照如下两个方面对上述文章进行整理和汇总。
二、基于大规模外部图像数据集
2.1 OVR-CNN:Open-Vocabulary Object Detection Using Captions,CVPR 2021
Open-Vocabulary Object Detection的初衷就是利用大规模的 image-caption 数据来改善对未知类的检测能力。基于此,OVR-CNN是该领域的第一篇工作。
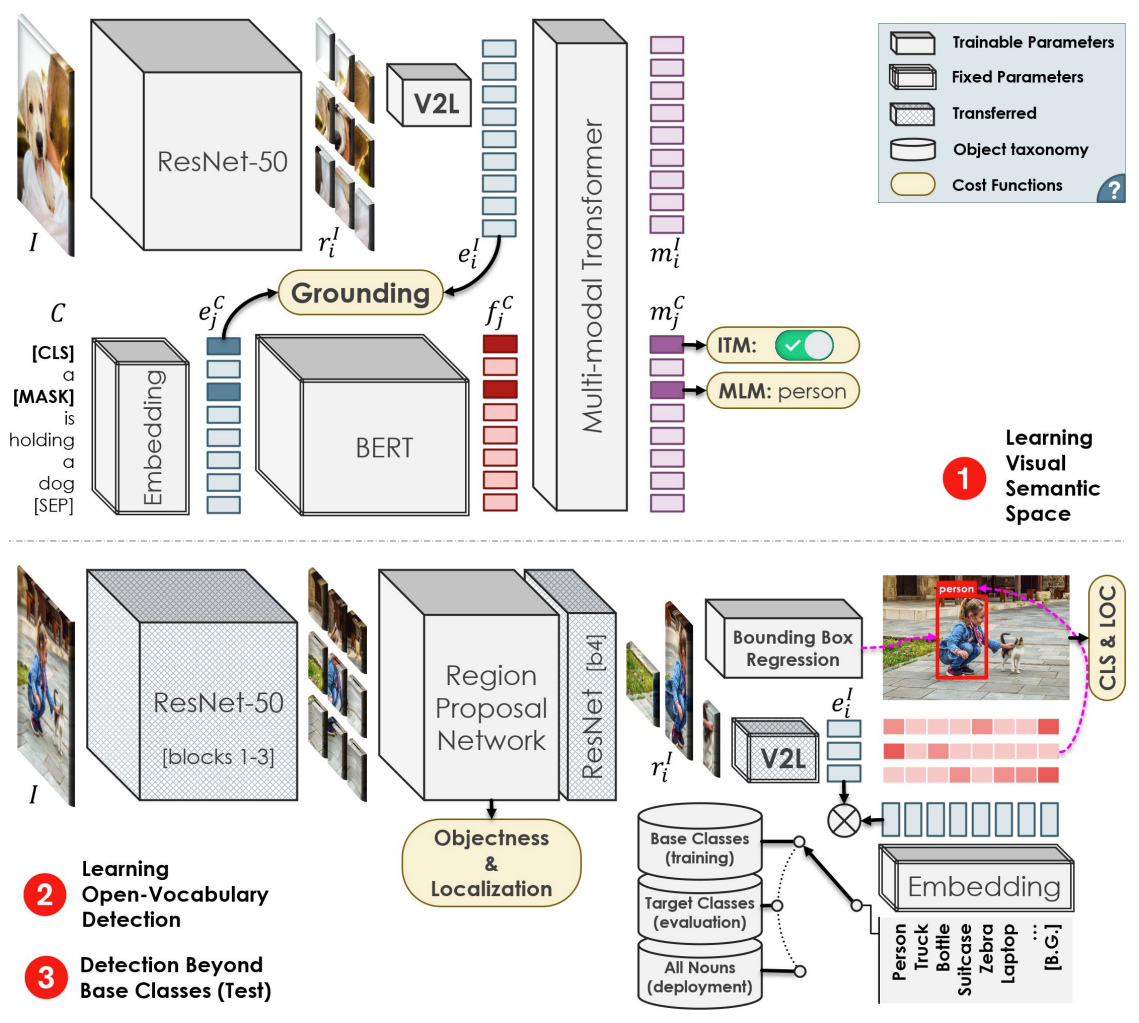
该工作的核心主要是利用image-caption数据来对视觉编码器进行pre-training。由于caption中存在着丰富的对于图像区域等细粒度特征的描述单词和短语,能够覆盖更多的物体类别,因此经过大规模image-caption的预训练,Vision encoder便能够学习到更加泛化的视觉-语义对应空间。因此训练好的vision encoder便可以用于替换faster-rcnn中encoder,提告检测模型的zero-shot检测能力。
展开讨论预训练流程,整体的预训练流程有些类似于PixelBert,可参考如下:
- 分别输入image和对应的caption,视觉编码器和文本编码器将分别提取特征。
- 在vision embedding和text embedding的基础上,利用V2L层对视觉embedding映射到文本embedding空间,构建grounding任务,计算对应图文对的grounding分数,然后利用对比学习拉近匹配对图文,推远非匹配对图文。这样利用word-region级别的grounding任务,实现丰富语义信息的学习。
- 后续利用Transformer模型进行多模态融合,同时构建下游MLM、ITM代理任务进行预训练。
一旦预训练结束后,trained vision encoder和trained V2L层,便可以替换至Faster RCNN框架中,通过在base数据集上进行finetune vision encoder,使其适配ROI区域特征,固定V2L层,保持其学习到的泛化的视觉-语义空间,即可进行target类别数据的检测。
总结来看,OVR-CNN通过在Image-Caption数据集上的预训练,学习到了丰富的文本词汇和图像区域表征,这样泛化的表征空间覆盖的物体类别,是远超过现阶段的带标注的目标检测数据集中物体的类别数。
2.2 Open Vocabulary Object Detection with Pseudo Bounding-Box Labels,ECCV 2022
该工作的动机和出发点是现阶段的OVD和zero-shot检测都是受限于base class数据,即使OVD引入了外部数据知识来进行泛化,但是还是无法摆脱base class数据有限的问题,从而无法泛化到非常不同的novel class数据。
因此,该工作提出:
- 能否通过自动生成的方式得到更多的物体bounding box标注,以此来scale现存的数据?
- 生成的未标注能否改善open-vocabulary object detection?
由此本工作可分为两部分来阐述:(1)伪标签的生成(2)检测模型的训练
2.2.1 伪标签的生成
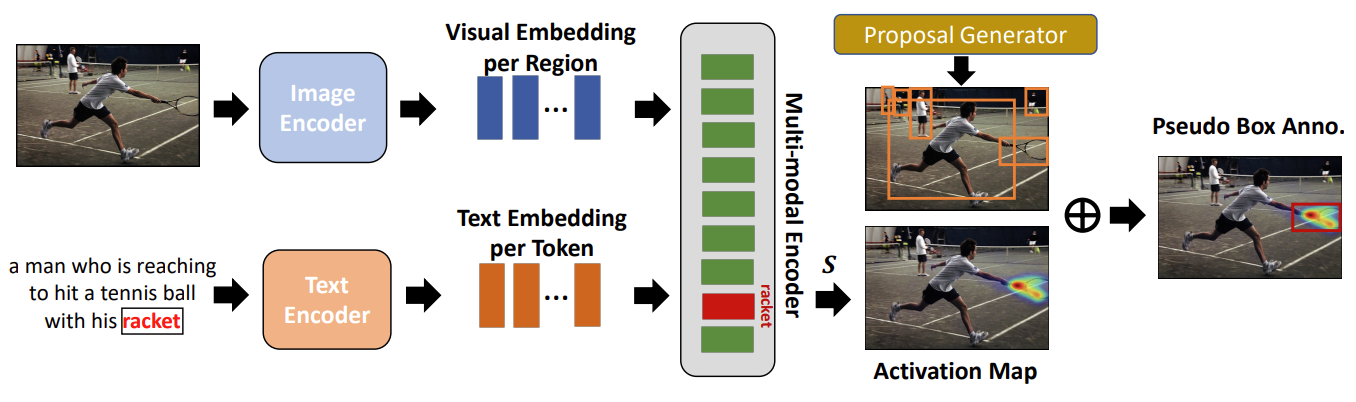
该工作提出使用VLP模型来帮助生成伪标签。首先输入image-caption数据,利用VLP模型的双编码器对image和text进行编码,以此得到各自模态的feature embedding,然后利用cross-attention计算图像区域和文本单词之间的注意力权重,利用GradCAM对上述注意力权重进行可视化,得到感兴趣名词(racket)的Activation Map区域;同时利用RPN网络生成ROI区域,得到和Activation Map区域重叠程度最大的ROI,此ROI和感兴趣名词(racket)一起构成了伪标签区域。
2.2.2 检测模型训练
基于得到的伪标签数据,便可以训练open-vocabulary object detection模型了,OVD检测的过程和传统的目标检测相比,使用Text Embedding替换掉了之前的Classification Head。因此,图像数据根据伪标签获取ROI,经过编码器得到vision embedding,base class文本经过文本编码器得到text embedding,之后计算跨模态embedding的相似度,并根据伪标签计算交叉熵损失函数。
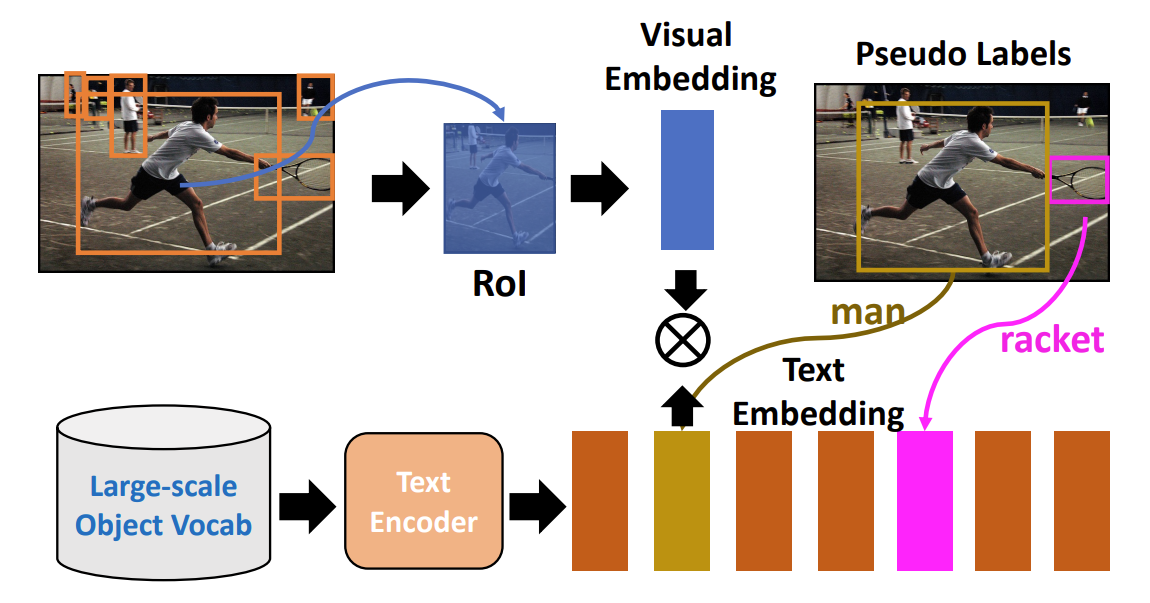
总结来看,这篇文章最主要的验证了利用VLP大模型生成的伪标签,即使带有噪声,但也是可以改善OVD任务的性能的。在后续的内容中,我们还会看到其他使用伪标签的工作。
2.3 Detic: Detecting Twenty-thousand Classes using Image-level Supervision,ECCV 2022
Detic与OVR-CNN和GradOVD相比,想法更加直接,做法更加粗暴。
实际上对比目标检测模型来说,真正限制其OVD能力的不是Regression Head,而是Classification Head。或者说OVD的最终目标是检测模型能够识别出更多novel的类别。基于此,Detic提出直接使用ImageNet21K的分类图像数据集和目标检测数据集一起,对检测模型进行联合训练。具体步骤如下:
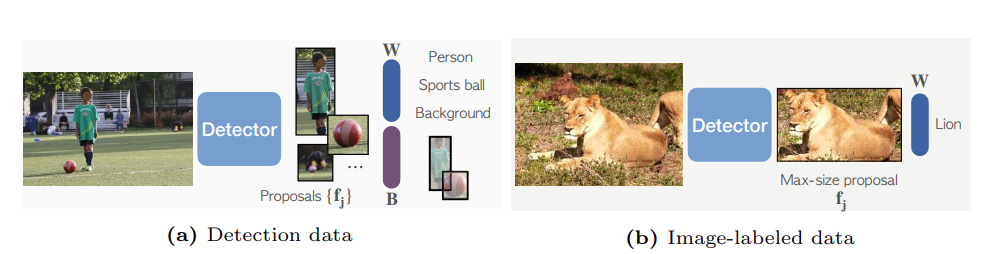
- minibatch中包含目标检测数据和ImageNet21K的分类图像数据;
- 如果是检测数据,则直接进行正常的两阶段目标检测流程,由RPN获取ROI,Reg Head回归bbox,Classification Head分类;
- 如果是ImageNet21K图像数据,则使用检测器检测Max-size的图像区域并截取,然后送入Classification Head进行分类;
- 通过共享Classification Head实现更多的ImageNet21K中的object concept知识的迁移。
2.4 Grounded Language-Image Pre-training (CVPR 2022 oral)
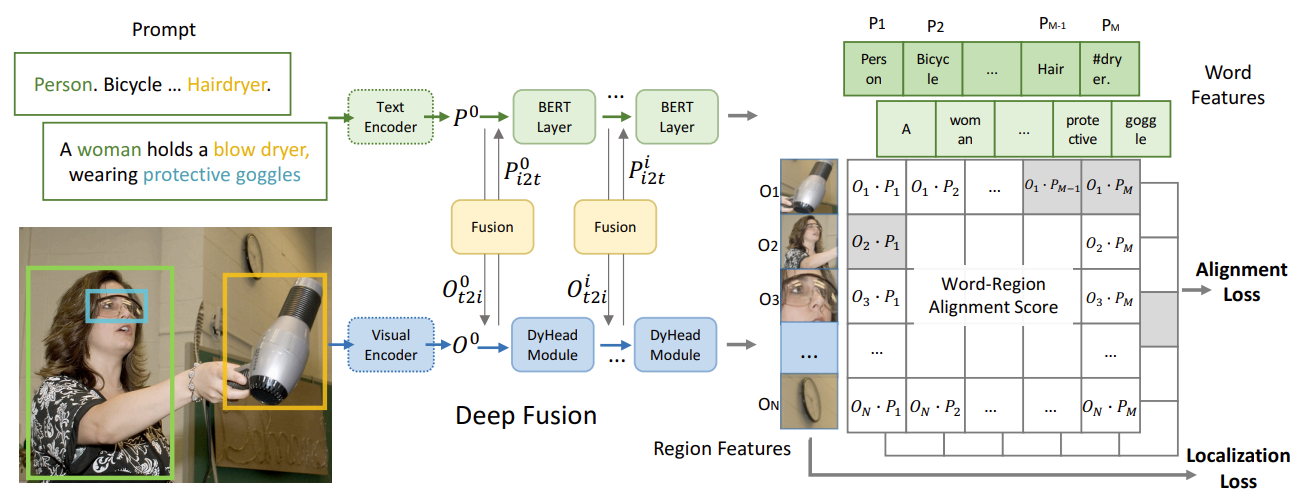
大名鼎鼎的GLIP,这篇工作不愧是Oral,立意和出发点很不一样,同时这篇工作的野心和目标也很宏大,他们不再局限于提高OVD的性能,而是将OVD和Visual Grounding进行了统一,完成了region-word级别的大规模预训练,实际上是相当于CLIP,只不过CLIP是在image-language 层面的。
如何统一object detection和Visual Grounding?
本文的观点是:object detection实际上是context-free的visual grounding任务,而visual grounding是contextualized的object detection任务。从这点出发,本文将检测任务转换为Visual grounding任务,然后采用统一的框架结构进行训练。这样做的好处是,统一的架构使得可以同时在Visual grounding数据集上进行训练,而不局限于检测数据集。要强调的是,Visual Grounding数据集包含了十分rich的视觉物体名词和概念,这可以极大的促进OVD和Zero-shot目标检测性能的提升,有趣的是,在论文中,作者也不断强调grounding数据的重要,称其为gold data。
具体的流程:
- 将检测转为visual grounding,输入检测图像,文本端为所有检测类别的逗号字符串连接。
- 将GLIP预训练在检测数据集和grounding数据集上,通过双编码器提取feature embedding,经过中间的Deep Fusion模块,直接进行类似于CLIP的cross-modal embedding alignment。
总体流程就是这么简单,但是GLIP是首个建立在groudning任务上,同时实现了细粒度跨模态对齐的工作,与CLIP一样,它同样具备着强大的zero-shot能力。在后文的讨论环节中,本文还会涉及到GLIP的拓展前景。
三、总结
利用大规模外部数据特别是caption数据来提升OVD的性能,也是OVD任务的初衷。不过无论是使用什么类型的外部数据,例如ImageNet、Image-caption、Grounding data,其本质目的都是希望挖掘更多的物体名词语义信息,使其不再受限于少量的base class数据。这才是OVD相较于Zero-shot更加成功、更加泛化的关键。
四、基于多模态大模型
除了将大规模外部数据引入之外,OVD的另外一个分支是引入多模态模型的预训练知识来改善性能。
4.1 ViLD:Open-vocabulary Object Detection via Vision and Language Knowledge Distillation,ICLR 2022
引入多模态模型例如CLIP来促进OVD性能,ViLD应该是开山之作了。
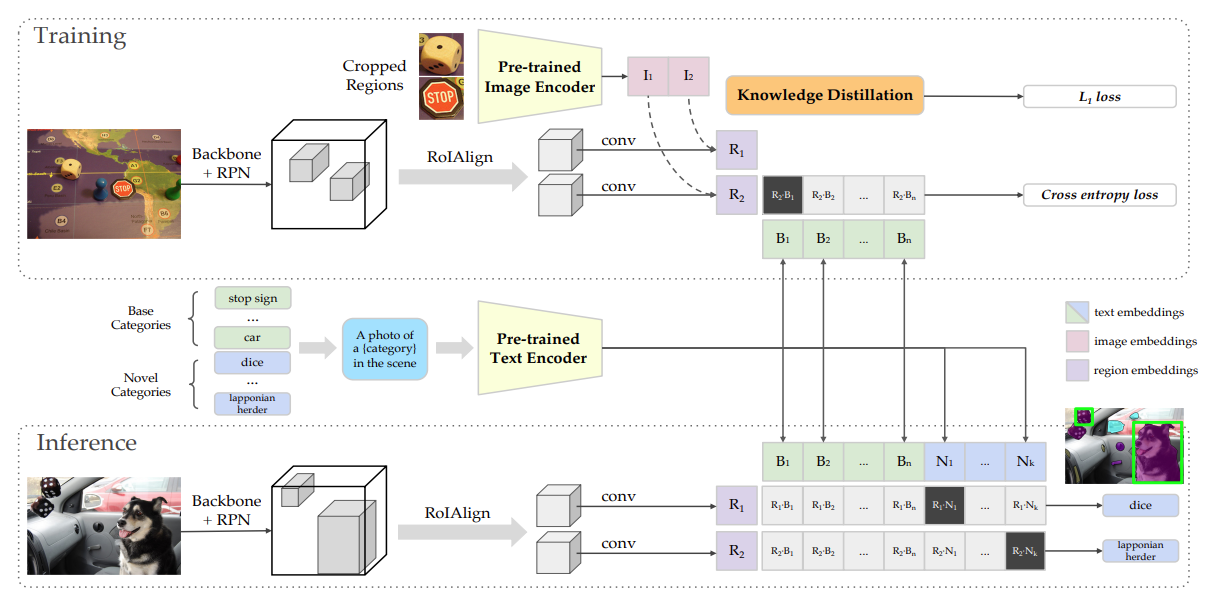
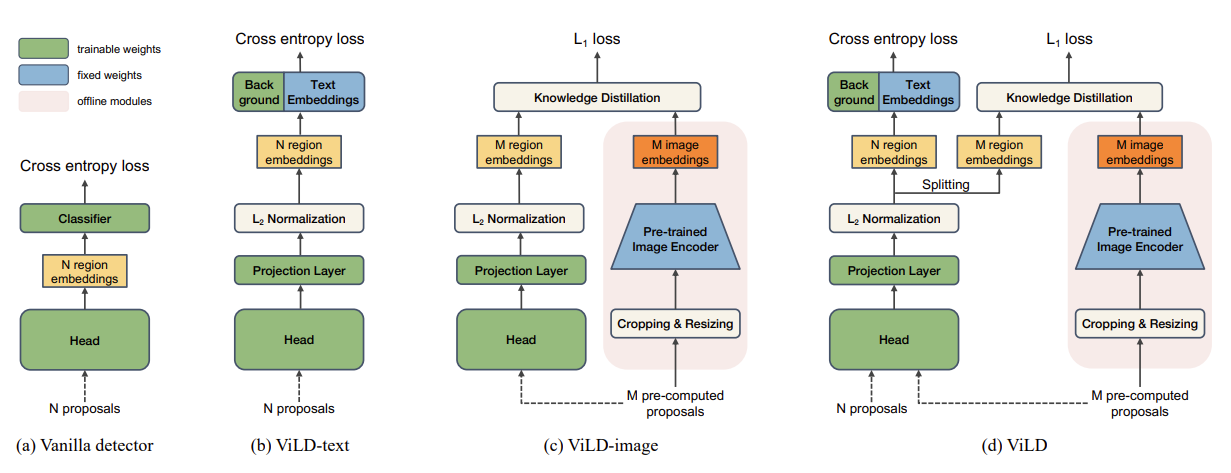
整体的流程如下:
- 输入base class的待检测图像,同时基于base class构建CLIP形式的text prompt输入至CLIP text encoder端得到Embedding,然后图像输入至Mask RCNN中得到ROI区域的图像特征,然后进行跨模态特征匹配。
- 输入base class的待检测图像,同时基于base class构建CLIP形式的text prompt输入至CLIP text encoder端得到Embedding,然后图像输入至Mask RCNN中得到ROI区域的图像特征,然后进行跨模态特征匹配。
- 推理的时候,利用CLIP文本编码器替换检测模型的分类头,进行分类。
总结来看,ViLD主要是依靠蒸馏学习将CLIP视觉端的能力迁移至检测模型中,再利用文本编码器完成和检测模型的识别工作。
4.2 RegionCLIP: Region-based Language-Image Pretraining,CVPR 2022
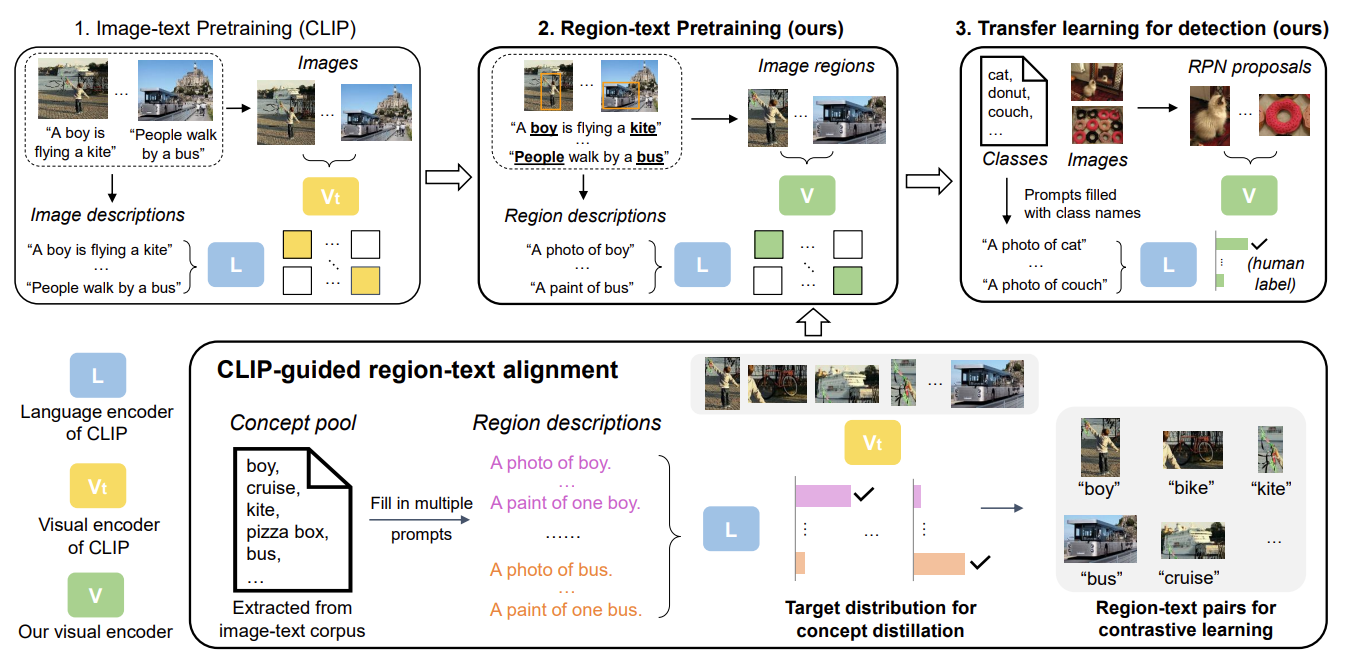
可以将RegionCLIP理解为CLIP在Region-word级别的拓展。
本文的出发点是观察到CLIP在Region区域上的识别很差,这是由于CLIP是在Image-Language level上进行的预训练导致的。因此,RegionCLIP从这一点出发,将CLIP在region图像和单词层面进行了预训练,提高了区域级别的检测能力。
主要流程如下:
- 首先利用文本数据,构建object名词语料库;
- 利用RPN网络提取图像上的object区域,输入至CLIP视觉编码器,同时输入语料库至CLIP文本编码器得到文本特征,然后做匹配对提取的图像区域进行伪标签标注;
- 在得到伪标签标注区域图像的基础上,构建视觉文本双编码器,在Region层面上进行CLIP式的预训练;
- 训练损失主要就是区域级别的对比损失+原始CLIP的对比损失+RegionCLIP-CLIP的视觉端蒸馏损失。
这篇文章提出的问题,也就是CLIP无法对区域级别的图像进行很好的识别,这一点其实在很多其他的文章中也有涉及,比如在ViLD中用RPN的分数来辅助CLIP在区域级别的预测。
总之,区域级别的CLIP也被拓展出来了。但是GLIP的性能更强,而且RegionCLIP和GLIP还是同一组的工作,就是pengchuan zhang,也是做了很多VLP工作。
4.3 Aligning Bag of Regions for Open-Vocabulary Object Detection
开放词汇目标检测旨在检测到模型训练中未标注的类别的物体,该任务的常见方法是对预训练过的视觉语言模型进行蒸馏,是检测器模型学到视觉语言模型的表征,从而可以识别训练中未标注的类别的物体。现有的方法主要是让检测器在单个区域上,学习视觉语言模型对单个物体概念的表征。然而在预训练中,视觉语言模型从图像文本对上学到的是对一组语义概念进行表征。
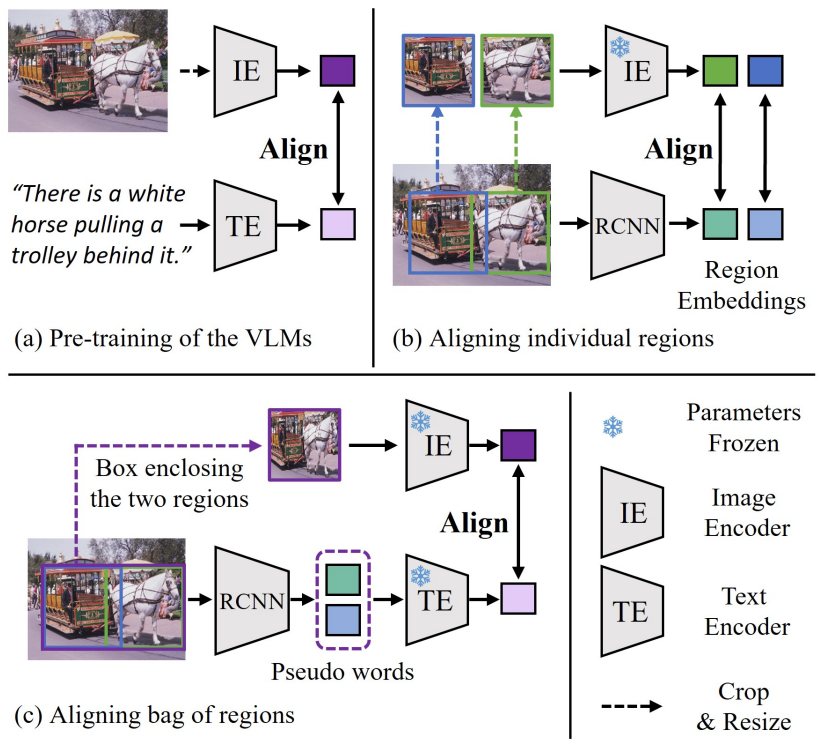
最新论文Aligning Bag of Regions for Open-Vocabulary Object Detection,介绍一种学习视觉语言模型表征的新思路,即在一组区域上进行蒸馏。为了充分利用视觉语言模型对一组语义概念的表征,论文提出在候选区域的邻域进行采样,得到有空间和语义相关性的区域组合(a bag of regions)。为了得到组合起来的区域的表征,论文将区域的表征对齐到词向量空间,将区域组合中的个体视为句子中的词,使得视觉语言模型中的文本编码器可以对一组区域进行表征。论文采用对比学习的方式,通过对齐文本编码器和图像编码器的表征,间接学习到区域表征。
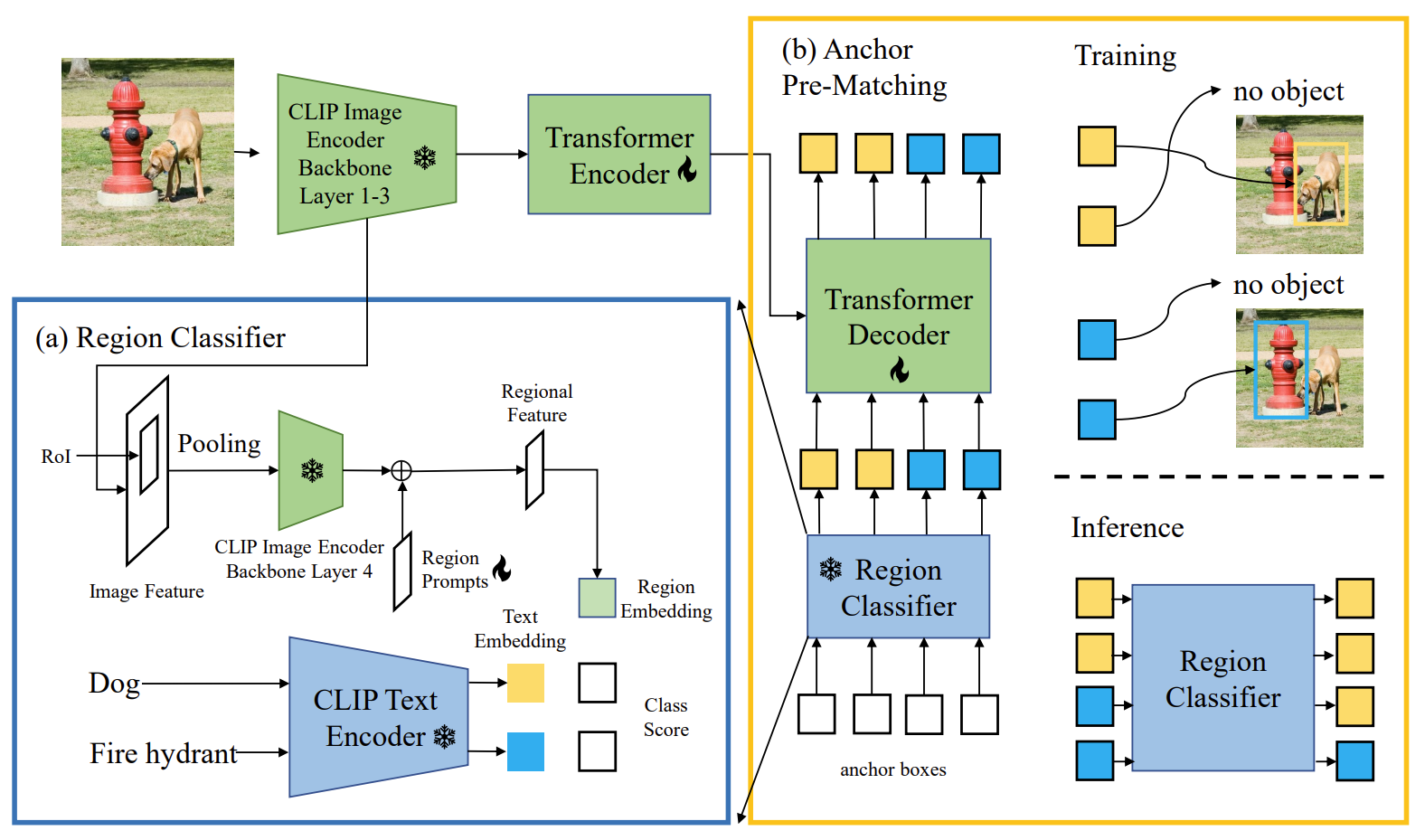
4.4 CORA: Adapting CLIP for Open-Vocabulary Detection with Region Prompting and Anchor Pre-Matching
OVD是一种目标检测任务,旨在检测超出检测器训练基础类别的新类别的对象。最近的OVD方法依赖于大规模的视觉语言预训练模型,例如CLIP,用于识别新对象。
方法:为了克服将这些模型纳入检测器训练时遇到的两个核心障碍,作者提出了CORA,一种DETR风格的框架,通过区域提示和锚点预匹配来适应CLIP进行开放词汇检测。区域提示通过提示基于CLIP的区域分类器的区域特征来减轻整体到区域分布差异。锚点预匹配通过一种类别感知的匹配机制来帮助学习可推广的对象定位。
结果:作者在COCO OVD基准测试中评估了CORA,其中在新类别上实现了41.7 AP50,即使不使用额外的训练数据也比以前的SOTA高出2.4 AP50。当有额外的训练数据时,作者在基于真实标注的基础类别标注和由CORA计算的额外伪边界框标签上训练了CORA+。CORA+在COCO OVD基准测试中实现了43.1 AP50,在LVIS OVD基准测试中实现了28.1 box APr。
相关文章:
【计算机视觉 | 目标检测】OVD:Open-Vocabulary Object Detection 论文工作总结(共八篇)
文章目录 一、2D open-vocabulary object detection的发展和研究现状二、基于大规模外部图像数据集2.1 OVR-CNN:Open-Vocabulary Object Detection Using Captions,CVPR 20212.2 Open Vocabulary Object Detection with Pseudo Bounding-Box Labels&…...
C++入门基础知识[博客园长期更新......]
0.博客园链接 博客的最新内容都在博客园当中,所有内容均为原创(博客园、CSDN同步更新)。 C知识点集合 1.命名空间 在往后的C编程中,将会存在大量的变量和函数,因为有大量的变量和函数,所以C的库会非常多。那么在C语言编程中&a…...
( “树” 之 BST) 501. 二叉搜索树中的众数 ——【Leetcode每日一题】
二叉查找树(BST):根节点大于等于左子树所有节点,小于等于右子树所有节点。 二叉查找树中序遍历有序。 ❓501. 二叉搜索树中的众数 难度:简单 给你一个含重复值的二叉搜索树(BST)的根节点 root…...
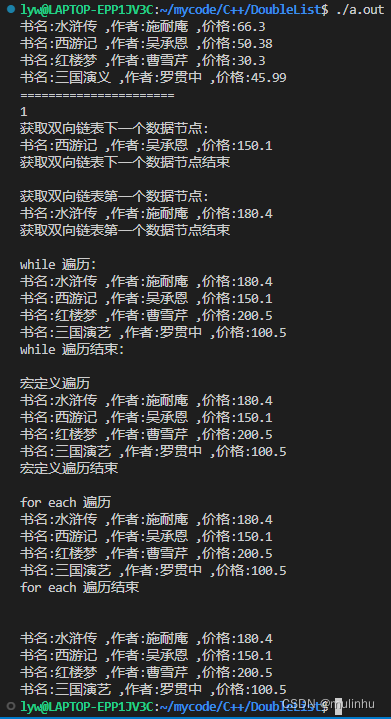
openharmony内核中不一样的双向链表
不一样的双向链表 链表初识别遍历双向链表参考链接 链表初识别 最近看openharmony的内核源码时看到一个有意思的双向链表,结构如下 typedef struct LOS_DL_LIST{struct LOS_DL_LIST *pstPrev; //前驱节点struct LOS_DL_LIST *pstNext; //后继节点 }LOS_DL_LIST;不…...

大文件删除不在回收站里怎么找回
在日常办公中,总会有一些新的文件产生,和用完后的文件清理掉。有时候不小心误删文件也是常有的事。但如果大文件删除不在回收站里怎么找回呢?遇到的小伙伴们请不要别急,只要按照下面的方法做就行了。 正常情况下删除会进入到回收站中&#x…...

Ubuntu22.04部署Pytorch2.0深度学习环境
文章目录 安装Anaconda创建新环境安装Pytorch2.0安装VS CodeUbuntu下实时查看GPU状态的方法小实验:Ubuntu、Windows10下GPU训练速度对比 Ubuntu安装完显卡驱动、CUDA和cudnn后,下面部署深度学习环境。 (安装Ubuntu系统、显卡驱动、CUDA和cudn…...

php的面试集结(会持续更新)
PHP 高级工程面试题汇总 php面试 1.大型的分页查询 发现当表中有很多上万条数据时,越后的数据用limit分页显示就越慢(>2秒),可能是mysql的特性所致。所以花了点时间总结实现了更优解决方案,最终实现毫秒级响应。…...

谁在成为产业经济发展的推车人?
区域发展的新蓝图中,京东云能做什么?它的角色是什么?这个问题背后,隐藏的不仅是京东云自身的能力和价值,更是其作为中国互联网云厂商的代表之一,对“技术产业”的新论证。 作者|皮爷 出品|产业家 关于云…...
上海无纺布制造商【盈兹】申请纳斯达克IPO上市,募资1100万美元
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,来自上海的无纺布制造商【盈兹】,近期已向美国证券交易委员会(SEC)提交招股书,申请在纳斯达克IPO上市,股票代码为(ETZ&#…...
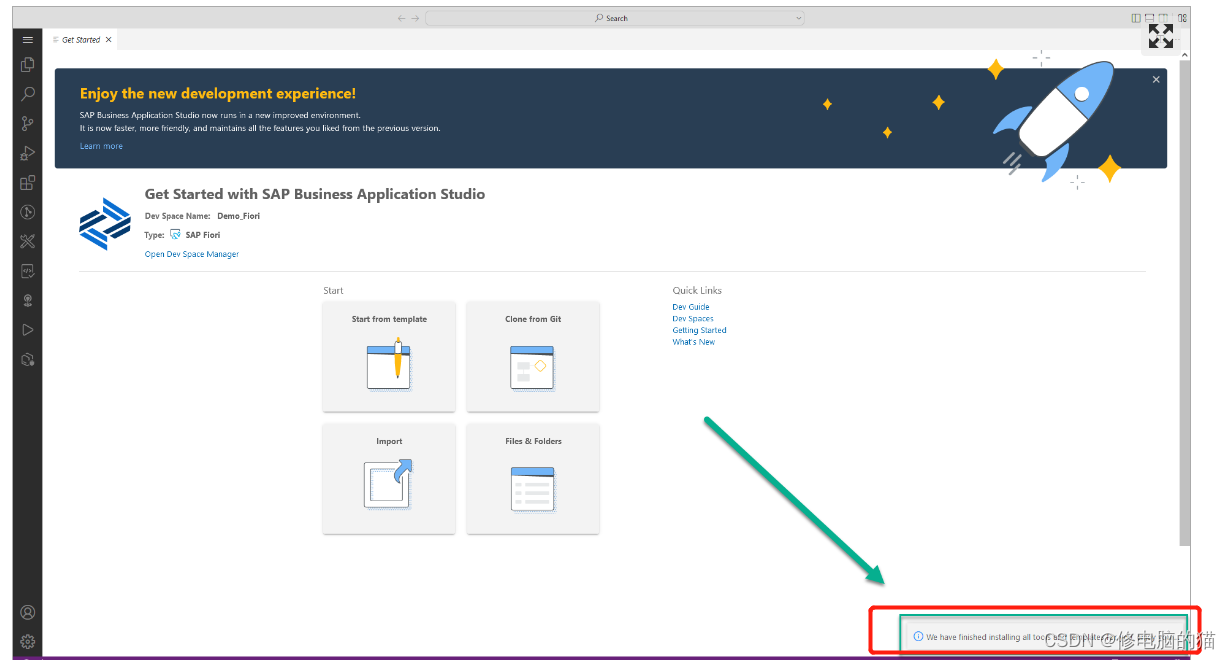
Build an SAP Fiori App(一)后面更新中
1.登录 SAP BTP Trial 地址: https://account.hanatrial.ondemand.com 流程可以参考 点击 serviced marketplace 搜索studio 点击创建 点击创建,点击view subscription 点击go to application 创建完成后 添加新链接 Field Value Name ES5 - if you’…...
关于GNSS技术介绍(二)
在上期文章中,我们介绍了GNSS技术的发展历程、原理,并对不同类型的定位技术进行了介绍,在本期文章中我们将继续讨论GNSS的优点与应用及其测试方法和解决方案。 GNSS的优点与应用 目前GNSS技术已经成为日常生活不可或缺的一部分,几…...

拿到新的服务器必做的五件事(详细流程,开发必看)
目录 1. 配置免密登录 基本用法 远程登录服务器: 第一次登录时会提示: 配置文件 创建文件 然后在文件中输入: 密钥登录 创建密钥: 2.部署nginx 一、前提条件 二、安装 Nginx 3.配置python虚拟环境 1.安装虚拟环境 …...

主机防病毒攻略之勒索病毒
勒索病毒并不是某一个病毒,而是一类病毒的统称,主要以邮件、程序、木马、网页挂马的形式进行传播,利用各种加密算法对文件进行加密,被感染者一般无法解密,必须拿到解密的私钥才有可能破解。 已知最早的勒索软件出现于 …...

Win10系统重装过程(一键装机)
相信不少小伙伴都有刷机重装系统的过程,那种镜像,up盘,压缩包等多个复杂过程也折磨的大伙不堪重负,因此本期带来简易版一键装机相应操作。 下载地址: 小心点击下方链接,点击即下载(3.66GB&…...

查询优化之单表查询
建表 CREATE TABLE IF NOT EXISTS article ( id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, author_id INT(10) UNSIGNED NOT NULL, category_id INT(10) UNSIGNED NOT NULL, views INT(10) UNSIGNED NOT NULL, comments INT(10) UNSIGNED NOT NULL, title VARBI…...
ChatGPT写小论文
ChatGPT写小论文 只是个人对写小论文心得?从知乎,知网自己总结的,有问题,可以留个言我改一下 文章目录 ChatGPT写小论文-1.写论文模仿实战(狗头)0.论文组成1.好论文前提:2.标题3.摘要4.关键词5.概述6.实验数据、公式或者设计7.结论,思考8.参考文献 0.模仿1.喂大纲…...
公共资源包发布流程详解
文章目录 公有包发布并使用npm安装git仓库协议创建及使用 npm 私有包创建及使用 group npm 私有包私有仓账密存放位置 当公司各个系统都需要使用特定的业务模块时,这时候将代码抽离,发布到 npm 上,供下载安装使用,是个比较好的方案…...
设计模式简谈
设计模式是我们软件架构开发中不可缺失的一部分,通过学习设计模式,我们可以更好理解的代码的结构和层次。 设计原则 设计原则是早于设计方法出现的,所以的设计原则都要依赖于设计方法。这里主要有八个设计原则。 推荐一个零声学院免费教程&…...

day35—选择题
文章目录 1.把逻辑地址转换程物理地址称为(B)2.在Unix系统中,处于(C)状态的进程最容易被执行3. 进程的控制信息和描述信息存放在(B)4.当系统发生抖动(thrashing)时,可以采取的有效措…...

mybatis的<foreach>标签使用
记录:419 场景:使用MyBatis的<foreach></foreach>标签的循环遍历List类型的入参。使用collection属性指定List,item指定List中存放的对象,separator指定分割符号,open指定开始字符,close指定结…...

2026AI论文写作工具实测排行榜!这几款才是真神器
综合评分 TOP4 为千笔AI(99/100)、毕业之家 (96/100)、DeepSeek Scholar(89/100)、豆包学术版 (88/100)。千笔AI是全流程全能王,毕业之家专注学术合规,DeepSeek 是理工科免费神器,豆包擅长多模态与文献分析。一、测评标准说明(202…...

第11章:故障诊断与处理
第11章:故障诊断与处理 11.1 常见故障类型与原因 集群级故障 故障类型 症状 常见原因 集群Red 存在未分配的主分片 节点故障、磁盘满、分片损坏 集群Yellow 存在未分配的副本分片 节点不足、磁盘满、副本数过多 集群脑裂 多个Master节点 网络分区、Master配置错误 集群无响应…...

百度网盘下载加速终极指南:3步实现高速下载的完整教程
百度网盘下载加速终极指南:3步实现高速下载的完整教程 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB/s的龟速下载而烦恼吗?作为…...
)
数字孪生 · 零基础4周速成学习计划(书籍+实操+项目落地)
适合:零基础、物联网专业、想转行数字孪生、做项目、毕设、求职学习搭配:理论书籍 软件实操 协议打通 完整Demo项目第一周:建立体系(看懂数字孪生到底是什么)📚 阅读书籍:《数字孪生及车间实…...

终极解决方案:在Chrome浏览器中实现密码无缝同步
终极解决方案:在Chrome浏览器中实现密码无缝同步 【免费下载链接】ChromeKeePass Chrome extensions for automatically filling credentials from KeePass 项目地址: https://gitcode.com/gh_mirrors/ch/ChromeKeePass 你是否厌倦了每次登录网站时都要手动从…...

AIoT网关50+AI算法硬核加持,AIoT边缘计算赋能千行百业
在物联网与人工智能深度融合的时代,边缘侧的智能感知与决策能力成为行业数字化转型的核心。计讯物联TG465系列5G AIoT边缘计算机,以50成熟视觉AI算法为核心,搭载工业级强悍硬件,打造"AIIoT深度融合"的多模态智能体&…...

微信好友关系检测完整指南:快速找出谁删了你
微信好友关系检测完整指南:快速找出谁删了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends 你是否曾…...

终极指南:如何用TrafficMonitor股票插件打造桌面投资监控中心
终极指南:如何用TrafficMonitor股票插件打造桌面投资监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为错过重要股票行情而烦恼吗?想在工作时…...

FLUX.1-dev FP8低显存优化版终极指南:破解大模型部署难题
FLUX.1-dev FP8低显存优化版终极指南:破解大模型部署难题 【免费下载链接】flux1-dev 项目地址: https://ai.gitcode.com/hf_mirrors/Comfy-Org/flux1-dev 在AI图像生成领域,显存限制一直是开发者面临的核心挑战。当主流模型动辄需要24GB以上显存…...

TurboVNC终极指南:如何快速搭建高性能远程桌面系统
TurboVNC终极指南:如何快速搭建高性能远程桌面系统 【免费下载链接】turbovnc Main TurboVNC repository 项目地址: https://gitcode.com/gh_mirrors/tu/turbovnc TurboVNC是一个专为高性能图形应用优化的远程桌面解决方案,特别适合3D渲染、视频处…...