大数据实战 --- 美团外卖平台数据分析
目录
开发环境
数据描述
功能需求
数据准备
数据分析
RDD操作
Spark SQL操作
创建Hbase数据表
创建外部表
统计查询
开发环境
Hadoop+Hive+Spark+HBase
启动Hadoop:start-all.sh
启动zookeeper:zkServer.sh start
启动Hive:
nohup hiveserver2 1>/dev/null 2>&1 &
beeline -u jdbc:hive2://192.168.152.192:10000
启动Hbase:
start-hbase.sh
hbase shell
启动Spark:
spark-shell
数据描述
meituan_waimai_meishi.csv 是美团外卖平台的部分外卖 SPU(Standard Product Unit , 标准产品单元)数据,包含了外卖平台某地区一时间的外卖信息。具体字段说明如下:
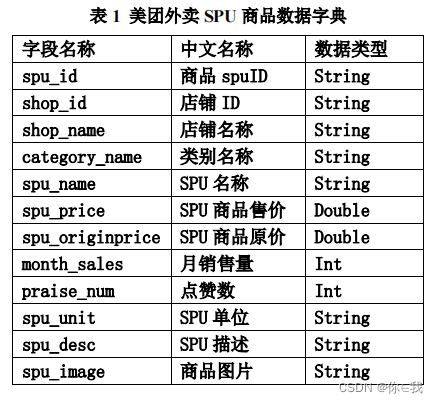
功能需求
数据准备
创建文件
hdfs dfs -mkdir -p /app/data/exam上传目录
hdfs dfs -put ./meituan_waimai_meishi.csv /app/data/exam查看文件行数
hdfs dfs -cat /app/data/exam/meituan_waimai_meishi.csv | wc -l
数据分析
RDD操作
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("exam").getOrCreate()val sc: SparkContext = spark.sparkContextval lines: RDD[String] = sc.textFile("hdfs://192.168.152.192:9000/app/data/exam/meituan_waimai_meishi.csv")val lines1: RDD[Array[String]] = lines.filter(x => x.startsWith("spu_id") == false).map(x => x.split(","))lines1.map(x => (x(2), 1)).reduceByKey(_ + _).collect().foreach(println)②统计每个店铺的总销售额。
lines1.map(x => (x(2), Try(x(5).toDouble).toOption.getOrElse(0.0) *Try(x(7).toInt).toOption.getOrElse(0))).reduceByKey(_ + _).collect().foreach(println)③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其
//方法一lines1.map(x => (x(2), x(4), Try(x(5).toDouble).toOption.getOrElse(0.0) *Try(x(7).toInt).toOption.getOrElse(0))).filter(x => x._3 > 0).groupBy(x => x._1).mapValues(value => value.toList.sortBy(x => -x._3).take(3)) //负号(-)降序.flatMapValues(x => x).collect().foreach(println)//方法二lines1.map(x => (x(2), x(4), Try(x(5).toDouble).toOption.getOrElse(0.0) *Try(x(7).toInt).toOption.getOrElse(0))).filter(x => x._3 > 0).groupBy(x => x._1).flatMap(x => x._2.toList.sortBy(y => 0 - y._3).take(3)).foreach(println)//方法三lines1.map(x => (x(2), x(4), Try(x(5).toDouble).toOption.getOrElse(0.0) *Try(x(7).toInt).toOption.getOrElse(0))).filter(x => x._3 > 0).groupBy(x => x._1).map(x => {var shop_name: String = x._1;var topThree: List[(String, String, Double)] = x._2.toList.sortBy(item => 0 - item._3).take(3);var shopNameAndSumMoney: List[String] = topThree.map(it => it._2 + " " + it._3);(shop_name, shopNameAndSumMoney)}).foreach(println)Spark SQL操作
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("exam").getOrCreate()val sc: SparkContext = spark.sparkContextval spuDF: DataFrame = spark.read.format("csv").option("header", true).load("hdfs://192.168.152.192:9000/app/data/exam/meituan_waimai_meishi.csv")spuDF.createOrReplaceTempView("sputb")①统计每个店铺分别有多少商品(SPU)。
spark.sql("select * from sputb").show()spark.sql("select shop_name,count(shop_name) as num from sputb group by shop_name").show()③统计每个店铺销售额最高的前三个商品,输出内容包括店铺名,商品名和销售额,其 中销售额为 0 的商品不进行统计计算,例如:如果某个店铺销售为 0,则不进行统计。
spark.sql("select shop_name, sum(spu_price * month_sales) as sumMoney from sputb group by shop_name").show()
创建Hbase数据表
在 HBase 中创建命名空间(namespace)exam,在该命名空间下创建 spu 表,该表下有
create 'exam:spu','result'创建外部表
请 在 Hive 中 创 建 数 据 库 spu_db
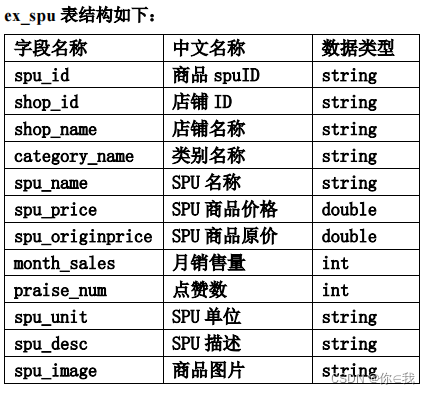
create database spu_db;在 该 数 据 库 中 创 建 外 部 表 ex_spu 指 向 /app/data/exam 下的测试数据 ;
create external table if not exists ex_spu (spu_id string,shop_id string,shop_name string,category_name string,spu_name string,spu_price double,spu_originprice double,month_sales int,praise_num int,spu_unit string,spu_desc string,spu_image string
)
row format delimited fields terminated by ","
stored as textfile location "/app/data/exam"
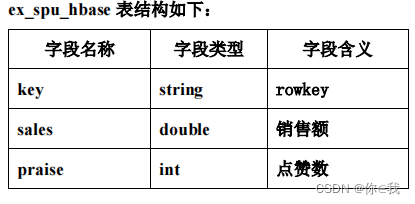
tblproperties ("skip.header.line.count"="1");创建外部表 ex_spu_hbase 映射至 HBase 中的 exam:spu 表的 result 列族
create external table if not exists ex_spu_hbase
(key string,sales double,praise int
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with
serdeproperties ("hbase.columns.mapping"=":key,result:sales,result:praise")
tblproperties ("hbase.table.name"="exam:spu");统计查询
insert into ex_spu_hbase
select concat(tb.shop_id,tb.shop_name) as key, tb.sales,tb.praise from
(select shop_id,shop_name,sum(spu_price*month_sales) as sales, sum(praise_num) as praise
from ex_spu group by shop_id,shop_name) tb;hive > select * from ex_spu_hbase;hbase(main):007:0> scan 'exam:spu'相关文章:
大数据实战 --- 美团外卖平台数据分析
目录 开发环境 数据描述 功能需求 数据准备 数据分析 RDD操作 Spark SQL操作 创建Hbase数据表 创建外部表 统计查询 开发环境 HadoopHiveSparkHBase 启动Hadoop:start-all.sh 启动zookeeper:zkServer.sh start 启动Hive: nohup …...

三大本土化战略支点,大陆集团扩大中国市场生态合作「朋友圈」
“在中国,大陆集团已经走过30余年的发展与耕耘历程,并在过去10年间投资了超过30亿欧元。中国市场也成为了我们重要的‘增长引擎’与‘定海神针’。未来,我们将继续深耕中国这个技术导向的市场。”4月19日上海车展上,大陆集团首席执…...

为什么停更ROS2机器人课程-2023-
机器人工匠阿杰肺腑之言: 我放弃了ROS2课程 真正的危机不是同行竞争,比如教育从业者相互竞争不会催生ChatGPT…… 技术变革的突破式发展通常是新势力带来的而非传统行业的升级改革。 2013年也就是10年前在当时主流视频网站开启分享: 比如 …...
【SpringCloud常见面试题】
SpringCloud常见面试题 1.微服务篇1.1.SpringCloud常见组件有哪些?1.2.Nacos的服务注册表结构是怎样的?1.3.Nacos如何支撑阿里内部数十万服务注册压力?1.4.Nacos如何避免并发读写冲突问题?1.5.Nacos与Eureka的区别有哪些ÿ…...

ChatGPT+智能家居在AWE引热议 OpenCPU成家电产业智能化降本提速引擎
作为家电行业的风向标和全球三大消费电子展之一,4月27日-30日,以“智科技、创未来”为主题的AWE 2023在上海新国际博览中心举行,本届展会展现了科技、场景等创新成果,为我们揭示家电与消费电子的发展方向。今年展馆规模扩大至14个…...

拷贝构造函数和运算符重载
文章目录 拷贝构造函数特点分析拷贝构造函数情景 赋值运算符重载运算符重载operator<运算符重载 赋值运算符前置和后置重载 拷贝构造函数 在创建对象的时候,是不是存在一种函数,使得能创建一个于已经存在的对象一模一样的新对象,那么接下…...

本周热门chatGPT之AutoGPT-AgentGPT,可以实现完全自主实现任务,附部署使用教程
AutoGPT 是一个实验性的开源应用程序,它由GPT-4驱动,但有别于ChatGPT的是, 这与ChatGPT的底层语言模型一致。 AutoGPT 的定位是将LLM的"思想"串联起来,自主地实现你设定的任何目标。 简单的说,你只用提出…...

Mysql 优化LEFT JOIN语句
1.首先说一下个人对LEFT JOIN 语句的看法,原先我是没注意到LEFT JOIN 会影响到性能的,因为我平时在项目开发中,是比较经常见到很多个关联表的语句的。 2.阿里巴巴手册说过,连接表的语句最好不超过3次,但是我碰到的项目…...

全栈成长-python学习笔记之数据类型
python数据类型 数字类型 类型类型转换整型 intint() 字符串类型转换 浮点型保留整数 int(3.14)3 int(3.94)3浮点型 floatfloat() #####字符串类型 类型类型转换字符串 strstr() 将其他数据类型转为字符串 布尔类型与空类型 布尔类型 类型类型转换布尔型 boolbool()将其他…...

面试|兴盛优选数据分析岗
1.离职原因、离职时间点 2.上一份工作所在的部门、小组、小组人员数、小组内的分工 3.个人负责的目标,具体是哪方面的成本 4.为了降低专员成本,做了哪些方面的工作 偏向于机制、分析方法、思维,当下主要是对于部分高收入专员收入不合理的情况…...
主从复制master-slave replication)
Redis(08)主从复制master-slave replication
文章目录 redis主从复制一. 配置文件的方式设置1. 主节点配置:2. 从节点1配置:3. 从节点2配置: 二. 命令的方式设置1. 创建服务2. 设置主从节点3. 测试 三. 从节点升级为主节点四. 查看主从关系 redis主从复制 Redis主从复制是将一个Redis实例的数据复制到多个Redis实例&#…...
被chatGPT割了一块钱韭菜
大家好,才是真的好。 chatGPT热度一直上升,让我萌生了一个胆大而创新的想法, 把chatGPT嵌入到Notes客户机中来玩。 考虑到我已经下载了一个chatGPT的Notes应用(请见《ChatGPT APIs for HCL DOMINO》),想着…...
vue3+ts+pinia+vite一次性全搞懂
vue3tspiniavite项目 一:新建一个vue3ts的项目二:安装一些依赖三:pinia介绍、安装、使用介绍pinia页面使用pinia修改pinia中的值 四:typescript的使用类型初识枚举 一:新建一个vue3ts的项目 前提是所处vue环境为vue3&…...

Apache安装与基本配置
1. 下载apache 地址:www.apache.org/download.cgi,选择“files for microsoft windows”→点击”ApacheHaus”→点击”Apache2.4 VC17”,选择x64/x86,点击右边download下面的图标。 2. 安装apache (1)把…...

哈夫曼树【北邮机试】
一、哈夫曼树 机试考察的最多的就是WPL,是围绕其变式展开考察。 哈夫曼树的构建是不断选取集合中最小的两个根节点进行合并,而且在合并过程中排序也会发生变化,因此最好使用优先队列来维护单调性,方便排序和合并。 核心代码如下…...
thinkphp:数值(保留小数点后N位,四舍五入,左侧补零,格式化货币,取整,生成随机数,数字与字母进行转换)
一、保留小数点后N位/类似四舍五入(以保留小数点后三位为准) number_format()函数:第一个参数为要格式化的数字,第二个参数为保留的小数位数 方法一: public function test() {$num 12.56789; // 待格式化的数字$r…...

用Flutter你得了解的七个问题
Flutter是Google推出的一款用于构建高性能、高保真度移动应用程序、Web和桌面应用程序的开源UI工具包。Flutter使用自己的渲染引擎绘制UI,为用户提供更快的性能和更好的体验。 Flutter使用Dart语言,具有强大的类型、效率和易学能力,基本上你…...

Nmap使用手册
Nmap语法 -A 全面扫描/综合扫描 nmap-A 127.0.0.1 扫描指定网段 nmap 127.0.0.1 nmap 127.0.0.1/24Nmap 主机发现 -sP ping扫描 nmap -sP 127.0.0.1-P0 无ping扫描备注:【协议1,协设2〕【目标】扫描 nmap -P0 127.0.0.1如果想知道是如何判断目标主机是否存在可…...
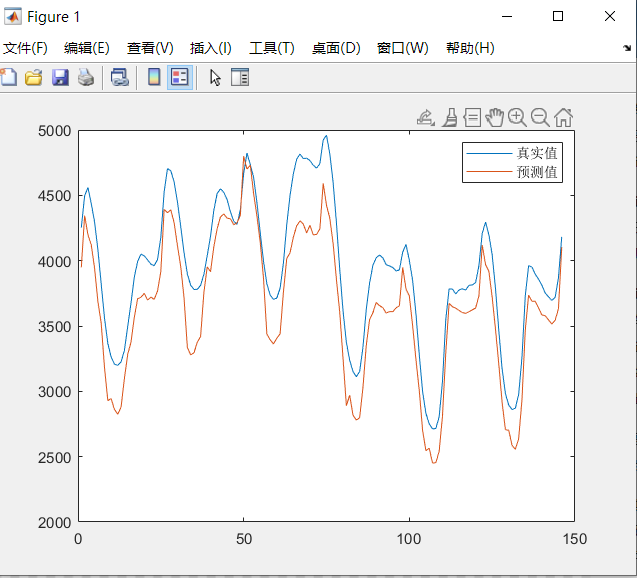
基于ResNet-attention的负荷预测
一、attention机制 注意力模型最近几年在深度学习各个领域被广泛使用,无论是图像处理、语音识别还是自然语言处理的各种不同类型的任务中,都很容易遇到注意力模型的身影。从注意力模型的命名方式看,很明显其借鉴了人类的注意力机制。我们来看…...
)
华为校招机试 - 批量初始化次数(20230426)
题目描述 某部门在开发一个代码分析工具,需要分析模块之间的依赖关系,用来确定模块的初始化顺序是否有循环依赖等问题。 "批量初始化”是指一次可以初始化一个或多个模块。 例如模块1依赖模块2,模块3也依赖模块2,但模块1和3没有依赖关系,则必须先"批量初始化”…...

智能视觉瞄准系统:基于YOLOv8的高效游戏辅助解决方案
智能视觉瞄准系统:基于YOLOv8的高效游戏辅助解决方案 【免费下载链接】RookieAI_yolov8 基于yolov8实现的AI自瞄项目 AI self-aiming project based on yolov8 项目地址: https://gitcode.com/gh_mirrors/ro/RookieAI_yolov8 RookieAI_yolov8是一个基于先进视…...

aFileChooser架构设计分析:Fragment、Loader和Intent的最佳实践
aFileChooser架构设计分析:Fragment、Loader和Intent的最佳实践 【免费下载链接】aFileChooser [DEPRECATED] Android library that provides a file explorer to let users select files on external storage. 项目地址: https://gitcode.com/gh_mirrors/af/aFil…...

Zynq开发中XSA文件更新全流程:从硬件修改到软件调试
1. 项目概述:为什么需要更新XSA文件?在基于Xilinx Zynq系列SoC的开发流程里,XSA文件(Xilinx Support Archive)是一个承上启下的核心枢纽。它本质上是一个压缩包,里面封装了硬件平台(Hardware Pl…...

使用Nodejs与Taotoken构建稳定可靠的AI对话服务后端
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Nodejs与Taotoken构建稳定可靠的AI对话服务后端 在构建集成AI能力的后端服务时,开发者常常面临模型选择、API稳定性…...

迪文串口屏界面开发避坑指南:T5L_DGUS Tool变量地址设置与数据通信那些事儿
迪文串口屏界面开发避坑指南:T5L_DGUS Tool变量地址设置与数据通信实战解析 在工业控制、智能家居和物联网设备的人机交互界面开发中,迪文串口屏因其高性价比和易用性广受欢迎。然而,当开发者从基础界面制作进阶到实际数据通信时,…...
)
EEGLab新手避坑:手把手教你搞定EEG数据的Marker、分段与Epoch提取(附完整代码)
EEGLab新手避坑指南:Marker设置、数据分段与Epoch提取全流程解析 在脑电信号处理领域,EEGLab作为MATLAB环境下最常用的开源工具包,其强大的功能和灵活的扩展性深受研究者青睐。但对于刚接触EEGLab的研究生和初级用户来说,从原始EE…...

UML类图实战:从设计到代码的精准映射
1. 为什么需要从UML类图到代码的精准映射? 第一次接触UML类图时,我总觉得它像是一张"纸上谈兵"的设计稿。直到在实际项目中踩过几次坑才明白,类图与代码之间的精准映射能力,是区分普通程序员和架构师的关键技能之一。 …...

STM32CUBEMX+Keil AC6编译提速实战:解决LWIP和绝对地址警告的坑
STM32CUBEMXKeil AC6编译提速实战:解决LWIP和绝对地址警告的坑 当STM32开发者从Keil AC5编译器切换到AC6时,往往会遇到两个典型问题:LWIP编译错误和绝对地址警告。本文将深入分析这些问题的根源,并提供经过验证的解决方案…...

Qt QSettings管理Windows环境变量:原理、实现与实战优化
1. 项目概述最近在做一个Qt开发的桌面工具,里面有个功能点需要动态修改用户的系统环境变量,比如把一些我们自己打包的工具路径加到用户的PATH里,这样用户在其他地方打开命令行也能直接调用。一开始想着用系统API或者直接写注册表,…...

Pearcleaner:Mac应用彻底清理的终极解决方案,告别数字垃圾困扰
Pearcleaner:Mac应用彻底清理的终极解决方案,告别数字垃圾困扰 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 还在为Mac应用卸载后残…...