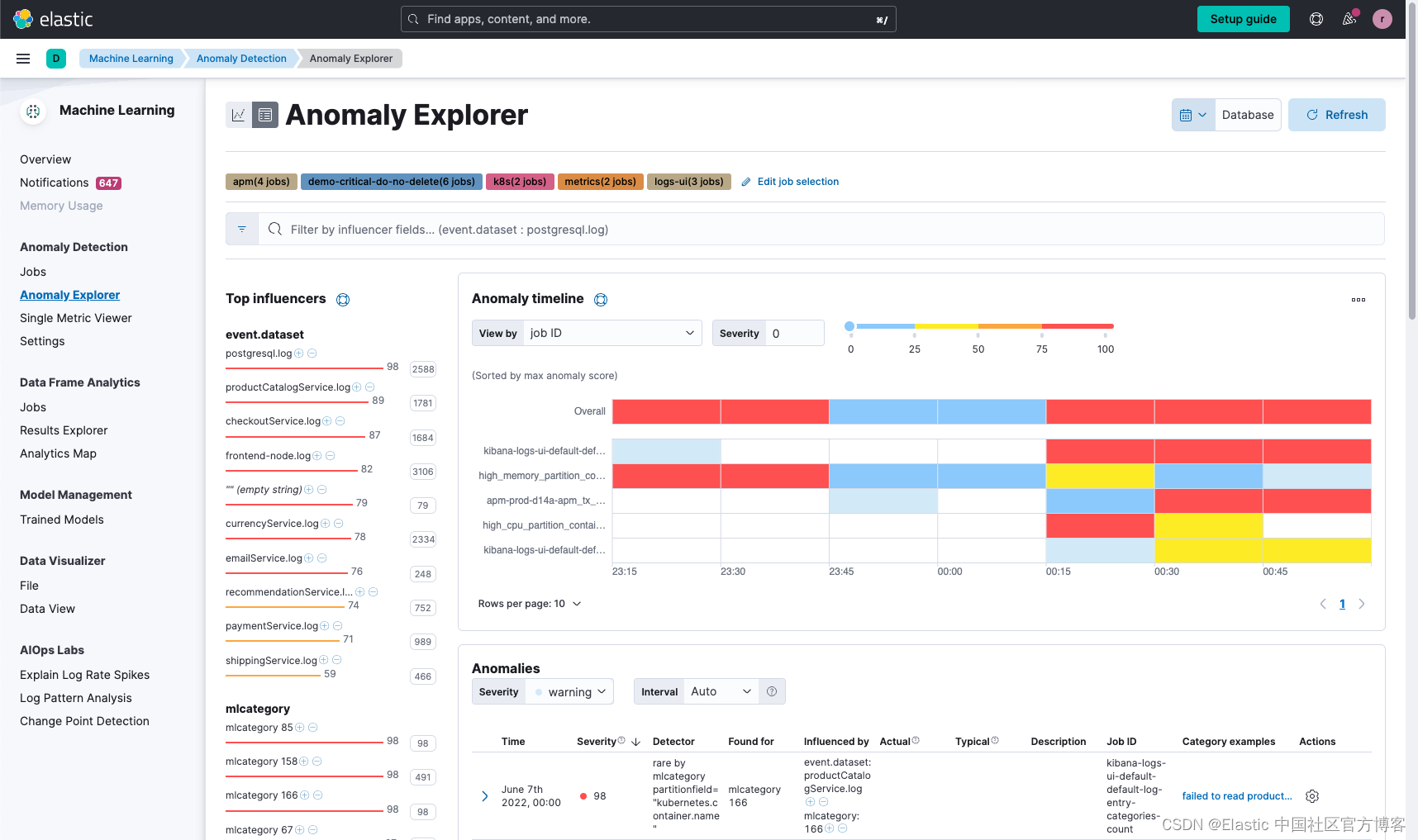
有效日志管理在软件开发和运营中的作用
作者:Luca Wintergerst, David Hope, Bahubali Shetti

当今存在的快速软件开发过程需要扩展和复杂的基础架构和应用程序组件,并且操作和开发团队的工作不断增长且涉及多个方面。 有助于管理和分析遥测数据的可观察性是确保应用程序和基础架构的性能和可靠性的关键。 特别是,日志是开发人员启用的主要默认信号,为调试、性能分析、安全性和合规性管理提供了大量详细信息。 那么,你如何定义一个策略来充分利用你的日志呢?
在这篇博文中,我们将探讨:
- 日志记录之旅,回顾日志的收集、处理和丰富、分析和合理化
- 从日志中管理结构化数据和非结构化数据的区别
- 追踪(traces)是否应该代替日志
- 通过了解如何减少转换时间、集中式与分散式日志存储以及如何以及何时减少存储内容,提高日志的运营效率
通过深入了解这些主题,你将能够更好地有效管理日志并确保应用程序和基础架构的可靠性、性能和安全性。
记录日志之旅
日志记录过程涉及三个基本步骤:

让我们介绍应如何收集和摄取日志,什么是正确的解析和处理,以及如何分析和合理化日志。 此外,我们还将讨论如何通过应用程序性能监控 (APM)、指标和安全事件来加强这一旅程。
日志收集
日志记录之旅的第一步是将你拥有的所有日志收集到一个中央位置。 这涉及识别你所有的应用程序和系统并收集它们的日志。 在此阶段,你无需担心日志格式或任何丰富操作。 目标是确保你的基础设施中没有可能阻碍未来调查问题的盲点。
日志收集的一个重要方面是确保你以低成本获得足够的摄取能力。 在进行此评估时,你可能需要谨慎对待对高基数数据收取多倍费用的解决方案。 一些可观察性解决方案将为此收取高额费用,这就是为什么在此步骤中了解扩展能力和成本至关重要。
处理和丰富日志
收集日志后,你就可以开始处理日志文件并将它们放入标准模式中。 这有助于使你的日志标准化,并更容易聚合最重要的信息。 标准化模式还允许更轻松地跨源数据关联。 在将日志数据处理成标准化模式时,你需要考虑:
- 大多数可观察性工具都具有开箱即用的集成功能,可将数据转换为特定的已知模式。 如果没有开箱即用的集成可用,则可以使用正则表达式或类似方法来解析信息。
- 管理日志处理通常在某种摄取管道中完成。 你可以利用可扩展的复杂架构,包括使用 Kafka、Azure 服务总线或 Pulsar 的流数据管道,甚至可以使用 Logstash 或 Kafka Streams 等处理框架。 没有对错之分,但我们的建议是要小心,不要在这里增加太多的复杂性。 存在一个危险,如果你在此处添加流数据处理步骤,你最终可能会得到一个耗时数月的项目和大量需要维护的代码。
一旦数据被摄取,就可能需要提取和丰富这些数据,也许还需要根据日志文件中的数据创建指标。 做这件事有很多种方法:
- 一些可观察性仪表板功能可以执行运行时转换,以动态地从未解析的源中提取字段。 这通常称为读取模式。 这在处理可能不以标准化格式记录数据的遗留系统或自定义应用程序时很有用。 然而,运行时解析可能是耗时且资源密集型的,尤其是对于大量数据。
- 另一方面,写时模式提供了更好的性能和对数据的更多控制。 模式是预先定义的,数据是在编写时结构化和验证的。 这允许更快地处理和分析数据,这有利于丰富。
有关运行时字段,请阅读文章 “Elasticsearch:Runtime fields 入门, Elastic 的 schema on read 实现 - 7.11 发布”。
日志分析
搜索、模式匹配和仪表板
一个合乎逻辑且传统的下一步是构建仪表板并设置警报以帮助你实时监控日志。 仪表板提供日志的可视化表示,从而更容易识别模式和异常。 警报可以在特定事件发生时通知你,使你能够快速采取行动。 使用全文搜索的强大功能,可以轻松地从日志中创建指标。 例如,你可以搜索术语 “error”,搜索功能将查找所有来源中的所有匹配条目。 然后可以将结果可视化或发出警报。 此外,你还将在仪表板时搜索日志并寻找模式(patterns)。
然后可以使用机器学习来分析日志并识别通过手动分析可能看不到的模式。 机器学习可用于检测日志中的异常情况,例如异常流量或错误。 此外,诸如日志分类功能之类的功能可以自动跟踪正在索引的日志数据类型并检测该模式中的任何更改,这些功能也很有用。 这可用于检测新的应用程序行为或你可能错过的其他有趣事件。
机器学习 —— 找到潜伏在日志文件中的未知数
建议组织使用各种机器学习算法和技术,以帮助你更有可能有效地发现日志文件中的未知数。
无监督机器学习算法,如聚类(x 均值、BIRCH)、时间序列分解、贝叶斯推理和相关分析,应该用于实时数据的异常检测,并根据严重程度进行速率控制警报。
通过自动识别影响者(influencers),用户可以获得用于自动根本原因分析 (RCA) 的有价值的上下文。 日志模式分析为非结构化日志带来分类,而日志速率分析和变化点检测有助于识别日志数据峰值的根本原因。 这些方法结合起来提供了一种强大的方法来发现日志文件中隐藏的见解和问题。
除了帮助 RCA、发现未知和改进故障排除之外,组织还应该寻找预测功能来帮助他们预测未来需求和校准业务目标。
增强旅程
最后,在收集日志时,你可能还想收集指标或 APM 数据。 指标可以让你深入了解系统的性能,例如 CPU 使用率、内存使用率和网络流量,而 APM 可以帮助你识别应用程序的问题,例如响应时间慢或错误。 虽然不是必需的,但尤其是指标数据与你的日志数据密切相关,而且设置起来也非常容易。 如果你已经在从系统中收集日志,那么另外收集指标通常不会超过几分钟。 作为操作,你始终不仅要跟踪部署的安全性,还要跟踪部署的人员和内容,因此通过 APM 和指标添加和使用安全事件有助于完成这幅图景。
结构化日志与非结构化日志?
日志记录之旅的一个普遍挑战是管理非结构化和结构化日志 —— 特别是在摄取期间进行解析。
使用已知模式管理日志
幸运的是,一些工具为流行的资源提供了广泛的内置集成,例如 Apache、Nginx、Docker 和 Kubernetes 等等。 这些集成使得从不同来源收集日志变得容易,而无需花时间构建自定义解析规则或仪表板。 这节省了时间和精力,并允许团队专注于分析日志而不是解析或可视化它们。
如果你没有来自流行来源的日志,例如自定义日志,你可能需要定义自己的解析规则。 许多可观察性日志记录工具将为你提供此功能。
因此,结构化日志通常比非结构化日志更好,因为它们提供更多价值并且更易于使用。 结构化日志具有预定义的格式和字段,可以更轻松地提取信息和执行分析。
非结构化日志呢?
可观察性工具中的全文搜索功能有助于减少对非结构化日志潜在限制的担忧。 全文搜索是一种强大的工具,可用于通过索引日志从非结构化日志中提取有意义的信息。 全文搜索允许用户在日志中搜索特定的关键字或短语,即使日志没有被解析。
默认情况下索引日志的主要优点之一是它有助于以有效的方式搜索它们。 即使是大量数据也可以快速搜索,以便找到你正在寻找的特定信息(如果事先已编制索引)。 这可以在分析日志时节省时间和精力,并可以帮助你更快地发现问题。 通过对所有内容进行索引和搜索,你不必编写正则表达式、学习复杂的查询语言或等待很长时间才能完成搜索。
你应该将日志转换到跟踪中吗?
长期以来,日志一直是应用程序监控和调试的基石。 然而,虽然日志是任何监控策略不可或缺的一部分,但它们并不是唯一可用的选项。
例如,跟踪是对日志的宝贵补充,可以提供对特定事务或请求路径的更深入洞察。 事实上,如果实施得当,跟踪作为应用程序(相对于基础设施)的一种附加检测手段是对日志记录的补充,尤其是在云原生环境的上下文中。 跟踪可以提供更多的上下文信息,尤其擅长跟踪环境中的依赖关系。 与日志数据相比,任何连锁反应在跟踪数据中都更容易看到,因为在你的服务中端到端地跟踪单个交互。
尽管跟踪可以提供很多优势,但重要的是要考虑使用跟踪的局限性。 只能对你拥有的应用程序实施跟踪,并且你不会获得基础设施的跟踪,因为它仍然仅限于应用程序。 并非所有开发人员都完全支持将跟踪作为日志记录的替代品。 许多开发人员仍然默认将日志记录作为检测的主要方式,这使得很难将跟踪作为一种监控策略来完全接受。
因此,结合日志记录和跟踪策略非常重要,其中跟踪覆盖较新的检测应用程序,日志记录将支持你不拥有其源代码的遗留应用程序和系统,以及了解你不拥有的系统的状态。
提高日志的运行效率
在管理日志时,主要有三个方面会降低运营效率:
- 耗时的转换日志
- 管理日志信息的存储和检索
- 何时删除或从日志中删除什么
我们将在下面讨论管理这些的策略。
减少转换数据所花费的时间
由于具有不同模式集的大量日志,甚至是非结构化日志,组织可能将更多时间花在不必要的数据转换上,而不是了解问题、分析根本原因或优化操作。
通过根据通用架构构建数据,运营团队将能够专注于识别、解决和预防问题,同时缩短平均解决时间 (MTTR)。 操作还可以通过没有重复数据和不必处理数据来规范化来降低成本。
该行业正在通过 OpenTelemetry 语义约定项目实现这种规范化,该项目试图为日志、指标、跟踪和安全事件实现一个通用模式。 由于 Elastic Common Schema (ECS) 最近对 OpenTelemetry 的贡献,日志尤其强大,这有助于加强通用模式旅程。
一个简单的说明性示例是当客户端的 IP 地址从多个源发送时,这些源正在监视或管理有关客户端的遥测数据。
src:10.42.42.42
client_ip:10.42.42.42
apache2.access.remote_ip: 10.42.42.42
context.user.ip:10.42.42.42
src_ip:10.42.42.42以多种方式表示 IP 地址会给分析潜在问题甚至识别问题带来复杂性。
使用通用模式,所有传入数据都采用标准化格式。 以上面的例子为例,每个来源都将以相同的方式识别客户端的 IP 地址。
source.ip:10.42.42.42这有助于减少花时间转换数据的需要。
集中式与分散式日志存储
在管理日志数据时,数据局部性是一个重要的考虑因素。 传入和传出大量日志数据的成本可能高得令人望而却步,尤其是在与云提供商打交道时。
在没有区域冗余要求的情况下,你的组织可能没有令人信服的理由将所有日志数据发送到一个中央位置。 你的日志记录解决方案应该提供一种方法,使你的组织能够将其日志数据保存在生成它的数据中心本地。 这种方法有助于降低与通过网络传输大量数据相关的入口和出口成本。
跨集群(或交叉部署)搜索功能使用户能够同时搜索多个日志集群。 这有助于减少需要通过网络传输的数据量。请详细阅读 “Elasticsearch:跨集群搜索 Cross-cluster search (CCS)”。
如果你的组织需要在发生灾难时保持业务连续性,则跨集群复制是你可能需要考虑的另一个有用功能。 通过跨集群复制,组织可以通过自动将数据复制到第二个目的地来确保即使在其中一个数据中心发生中断的情况下也可以使用数据。 通常这种方法只用于最关键的数据,同时利用上述数据局部性来处理最大的数据源。请详细阅读 “Elasticsearch:跨集群搜索 Cross-cluster search(CCS)及安全”。
另一个值得考虑的相关主题是供应商锁定。 一些日志记录解决方案在数据被摄取后锁定数据,如果组织想要切换供应商,则很难或不可能提取数据。
并非每个供应商都是这种情况,组织应该检查以确保他们可以随时完全访问所有原始数据。 这种灵活性对于希望能够在不被锁定在专有日志记录解决方案中的情况下切换供应商的组织来说至关重要。
处理大量日志数据 —— 记录所有内容,丢弃所有内容,还是减少使用量?
处理大量日志数据可能是一项具有挑战性的任务,尤其是在系统和应用程序生成的数据量持续增长的情况下。 此外,合规性要求可能会强制记录某些数据,在某些情况下,所有系统的日志记录可能都不受你的控制。 减少数据量似乎不切实际,但有一些优化可能会有所帮助:
- 收集一切,但制定日志删除政策。 组织可能想要评估它收集了哪些数据以及在什么时间收集。如果你发现需要这些数据进行故障排除或分析,那么在源头丢弃数据可能会导致以后的担忧。 评估何时删除数据。 如果可能,设置策略以自动删除旧数据,以帮助减少手动删除日志的需要和意外删除你仍然需要的日志的风险。一个好的做法是尽早丢弃 DEBUG 日志甚至 INFO 日志,并尽早删除开发和暂存环境日志。 根据你使用的产品,你可以灵活地为每个日志源设置保留期。 例如,你可以将暂存日志保留 7 天,开发日志保留一天,生产日志保留一年。 你甚至可以更进一步,按应用程序或其他属性拆分它。
- 进一步的优化是聚合短时间窗口的相同日志行,例如,这对于 TCP 安全事件日志记录特别有用。 简单地聚合相同的日志行并生成一个计数,加上一个开始和结束时间戳。 这可以很容易地以提供足够保真度并节省大量存储空间的方式展开。 可以使用预处理工具来执行此操作。你可以详细阅读文章 “Logstash:使用 aggregation filter 把事件流聚合为一个事件”。
- 对于你控制的应用程序和代码,你可能会考虑将一些日志移动到跟踪中,这将有助于减少日志量。 但跟踪仍将构成额外的数据。
把它放在一起
在这篇文章中,我们提供了日志记录之旅的视图以及本文中需要考虑的几个挑战。 在涵盖涉及三个基本步骤(收集和摄取、解析和处理以及分析和合理化)的日志记录过程中,我们强调了以下几点:
- 重要的是要确保在日志收集阶段你的基础架构没有盲点,并专注于在源头制作结构化日志。
- 提取数据和丰富日志可以通过读取模式或写入模式方法来实现,机器学习可以用于分析日志并识别通过手动分析可能不可见的模式。
- 组织还应该收集指标或 APM 数据来增强他们的日志记录之旅。
我们讨论了几个关键挑战:
- 结构化日志更易于使用并提供更多价值,但非结构化日志可以通过全文搜索功能进行管理。
- 跟踪可以提供对特定 transactions 和依赖关系的更深入洞察,有可能取代日志记录作为检测的主要手段,但由于限制和开发人员采用,组合的日志记录和跟踪策略很重要。
- 组织可以通过专注于减少转换数据所花费的时间、在集中式或分散式日志存储之间进行选择以及通过实施日志删除策略和聚合相同日志行的短窗口来处理大量日志数据来帮助提高日志的操作效率。
额外资源
在以下链接中了解有关日志记录旅程步骤以及如何应对上面讨论的一些挑战的更多信息:
- Managing unstructured logs
- Enriching logs
- Using machine learning based anomaly detection and log categorization for root cause analysis with logs
- Using AIOps against logs for root cause analysis
- Example use case: AWS VPC Log analysis
- Understanding AIOps in Observability
相关文章:
有效日志管理在软件开发和运营中的作用
作者:Luca Wintergerst, David Hope, Bahubali Shetti 当今存在的快速软件开发过程需要扩展和复杂的基础架构和应用程序组件,并且操作和开发团队的工作不断增长且涉及多个方面。 有助于管理和分析遥测数据的可观察性是确保应用程序和基础架构的性能和可靠…...
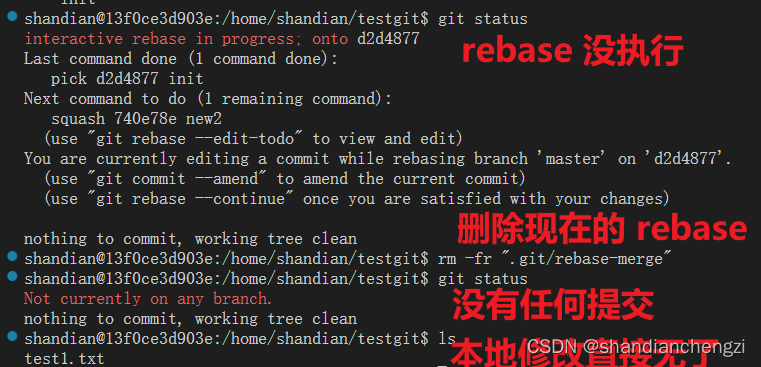
【五一创作】【笔记】Git|如何将仓库中所有的 commit 合成一个?又名,如何清除所有 git 提交记录?(附 git rebase 机制的简要分析)
在对代码进行开源时,我们往往并不希望代码开发过程中的提交记录被其他人看到,因为提交的过程中往往会涵盖一些敏感信息。因此会存在 将仓库中所有 commit 合成一个 的需求。 直觉上,往往会用 rebase 和 squash 或 reset,不过我尝…...

如何写出高质量代码?
作为一名资深开发人员,写出高质量的代码是我们必须要追求的目标。然而,在实际开发中,我们常常会遇到各种问题。比如,代码的可读性、可维护性、健壮性和灵活性等,这些都会影响代码的质量。那么,究竟如何才能…...

外卖项目优化-01-redis缓存短信验证码、菜品数据、Spring Cache(注解开发缓存)、(注解开发)缓存套餐数据
文章目录 外卖项目优化-01课程内容前言1. 环境搭建1.1 版本控制解决branch和tag命名冲突 1.2 环境准备 2. 缓存短信验证码2.1 思路分析2.2 代码改造2.3 功能测试 3. 缓存菜品信息3.1 实现思路3.2 代码改造3.2.1 查询菜品缓存3.2.2 清理菜品缓存 3.3 功能测试3.4 提交并推送代码…...
)
Chapter1:控制系统数学模型(下)
第一章:控制系统数学模型 Exercise1.13 已知控制系统结构图如下图所示,求系统的输出 C 1 ( s ) C_1(s) C...
排序算法总结
常见排序算法的时间复杂度、空间复杂度及稳定性分析: 时间复杂度空间复杂度是否有稳定性基于比较的排序算法选择排序 O(N^2)O(1)否 冒泡排序O(N^2)O(1)是插入排序O(N^2)O(1)是归并排序O(N*logN)O(N),每次需要额外一个数组用于拷贝是快排O(N*log…...
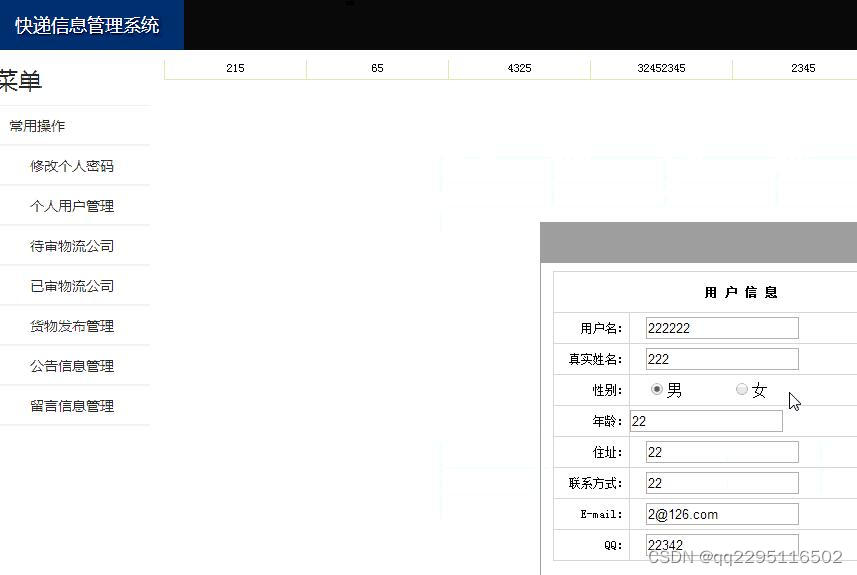
java+jsp企业物流货运快递管理系统servlet
功能需求具体描述: (1)用户功能模块包括用户登录注册,用户信息的修改,用户发布货物信息,给客服人员留言,对运输公司进行评价。 (2)企业功能模块包括企业注册登录,企业信息的修改,受理用户发布的…...

【ROS仿真实战】获取机器人在gazebo位置真值的三种方法(三)
文章目录 前言一. 使用ROS tf库二、 使用Gazebo Model Plugin三、 使用libgazebo_ros_p3d插件四、总结 前言 在ROS和Gazebo中,获取机器人的位置信息通常通过ROS消息传递进行。在这篇文章中,我们将介绍三种获取机器人在Gazebo中位置真值的方法࿱…...
——FontDialog(史上最全))
Winform从入门到精通(35)——FontDialog(史上最全)
文章目录 前言一、属性1、Name2、AllowScriptChange3、AllowSimulations4、AllowVectorFonts5、AllowVerticalFonts6、Color7、FixedPitchOnly8、Font9、FontMustExist10、MaxSize11、MinSize12、 ScriptsOnly13、ShowApply14、ShowColor15、ShowEffects16、ShowHelp...

AcWing 854. Floyd求最短路Floyd模板
Floyd算法: 标准弗洛伊德算法,三重循环,基于动态规划。 循环结束之后 d[i][j]存储的就是点 i 到点 j 的最短距离。 需要注意循环顺序不能变:第一层枚举中间点,第二层和第三层枚举起点和终点。 特点: 1.复杂…...
Graph Theory(图论)
一、图的定义 图是通过一组边相互连接的顶点的集合。 In this graph, V { A , B , C , D , E } E { AB , AC , BD , CD , DE } 二、图的类型 2.1 Finite Graph A graph consisting of finite number of vertices and edges is called as a finite graph. Null Graph Tri…...

[Python]生成 txt 文件
前段时间有位客户问: 你们的程序能不能给我们生成个 txt 文件,把新增的员工都放进来,字段也不需要太多,就要 员工姓名/卡号/员工编号/员工职位/公司 这些字段就行了,然后我们的程序会去读取这个 txt 文件,拿里面的内容,读完之后会这个文件删掉 我: 可以接受延迟吗?可能没办法实…...

GeoTools实战指南: 自定义矢量样式并生成截图
GeoTools实战指南: 自定义矢量样式并生成截图 介绍 本段代码的主要功能是将矢量数据(Shapefile)渲染成一张图片。 准备环境 首先,您需要将GeoTools库添加到您的项目中。使用Maven或Gradle添加依赖项,或者直接下载GeoTools的jar文件并添加到您的类路径中。 Maven <…...

深度学习超参数调整介绍
文章目录 深度学习超参数调整介绍1. 学习率2. 批大小3. 迭代次数4. 正则化5. 网络结构总结 深度学习超参数调整介绍 深度学习模型的性能很大程度上取决于超参数的选择。超参数是指在训练过程中需要手动设置的参数,例如学习率、批大小、迭代次数、网络结构等等。选择…...
Bootloader
本篇不作太过的技术了解,仅可作为初学者的参考。用嘴简单的语言讲清楚一件事。 项目中遇到Bootloader升级MCU,我很好这是什么软件,逻辑是什么,怎么升级的。 术语及定义 指纹信息fingerprint诊断仪用于标识特定的下载尝试的信息 …...

安卓开发_广播机制_广播的最佳实践:实现强制下线功能
安卓开发_广播机制_广播的最佳实践:实现强制下线功能 ActivityCollector类用于管理所有的ActivityBaseActivity类作为所有Activity的父类创建一个LoginActivity来作为登录界面布局LoginActivity 在MainActivity中加入强制下线功能布局MainActivity在BaseActivity中注…...
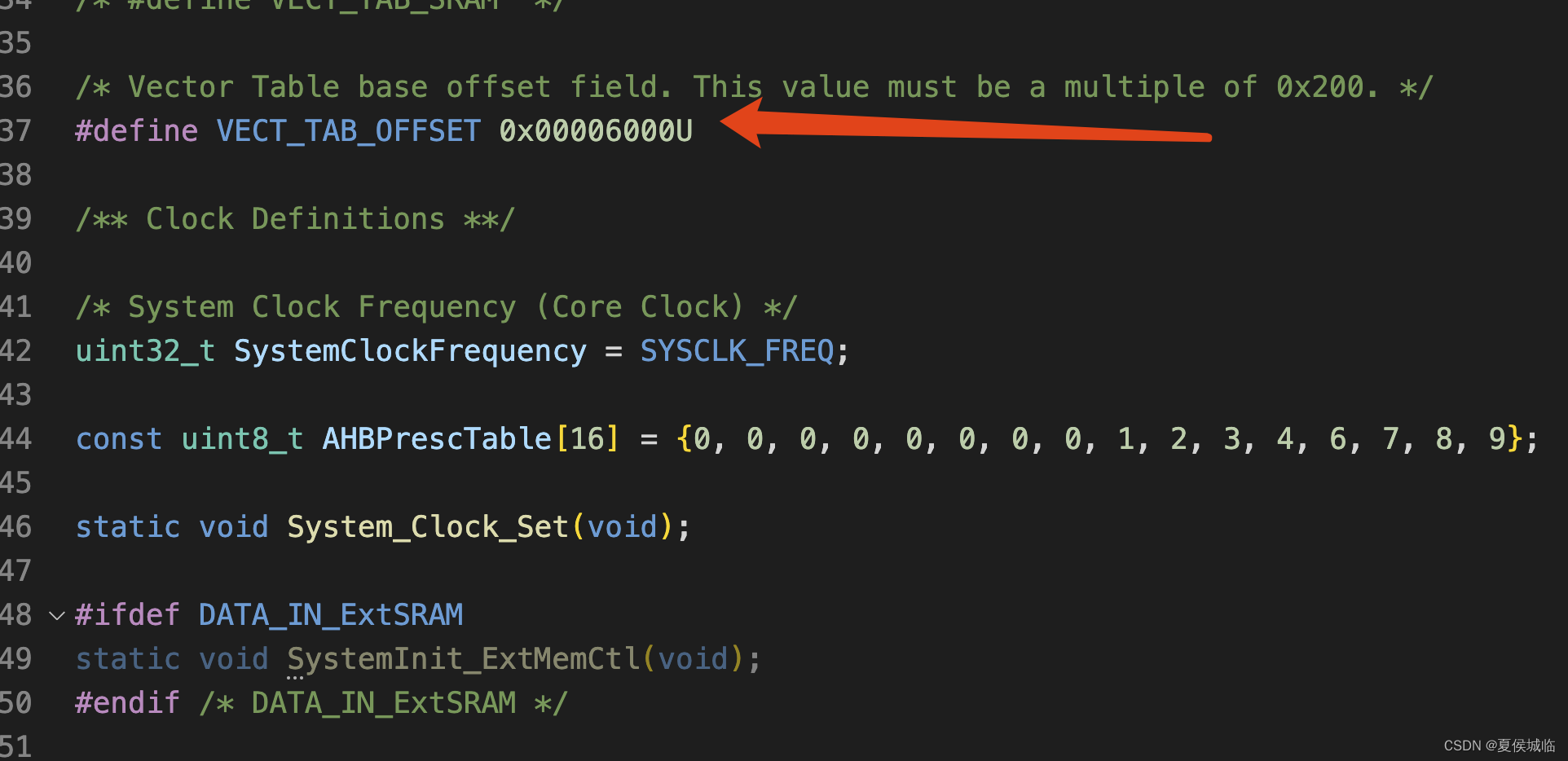
国民技术N32G430开发笔记(10)- IAP升级 Application 的制作
IAP升级 Application 的制作 1、App程序跟Bootloader程序最大的区别就是, 程序的执行地址变成了之前flash设定的0x08006000处, 大小限制为20KB 所以修改Application工程的ld文件 origin 改成 0x08006000 length 改成0x5000 烧录是起始地址也要改为x0x…...

[计算机图形学]材质与外观(前瞻预习/复习回顾)
一、图形学中的材质 不同的物体表面有着不同的材质,而不同的材质意味着它们与光线的作用不同。那么我们之前在介绍辐射度量学和渲染方程提到过其中一个函数,叫做BRDF,而在实际上,也就是BRDF定义了不同的材质。BRDF决定了光如何被反…...
Java 的简要介绍及开发环境的搭建(超级详细)
图片来源于互联网 目录 | CONTENT Java 简介 一、什么是 Java 二、认识 Java 版本 三、选择哪个版本比较好 搭建 Java 开发环境 一、下载 Java 软件开发工具包 JDK 二、配置环境变量 自动配置 手动配置 三、下载合适的 IDE IntelliJ IDEA Visual Studio Code Eclip…...

每天一道算法练习题--Day15 第一章 --算法专题 --- -----------二叉树的遍历
概述 二叉树作为一个基础的数据结构,遍历算法作为一个基础的算法,两者结合当然是经典的组合了。很多题目都会有 ta 的身影,有直接问二叉树的遍历的,有间接问的。比如要你找到树中满足条件的节点,就是间接考察树的遍历…...

proxy-doctor:自动化诊断与修复开发工具代理配置的利器
1. 项目概述与核心价值最近在折腾一些需要稳定网络连接的项目时,遇到了一个老生常谈但又极其恼人的问题:代理配置。无论是开发环境里的包管理工具,还是日常使用的命令行工具,一旦涉及到网络请求,代理设置不对ÿ…...

终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能
终极显卡调校指南:如何用NVIDIA Profile Inspector释放游戏性能 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专为NVIDIA显卡用户设计的免费优化工具&…...

数据中心碳足迹与可靠性优化框架解析
1. 数据中心碳足迹与可靠性优化的挑战 现代数据中心已成为数字经济的动力引擎,但伴随算力需求的爆炸式增长,其能源消耗与碳排放问题日益凸显。根据最新统计,全球数据中心年耗电量已达4600亿度,占全球总用电量的2%。随着大语言模型…...

AI绘图技能解析:用自然语言驱动Excalidraw自动生成图表
1. 项目概述:一个为Excalidraw注入AI灵魂的绘图技能如果你经常用Excalidraw画流程图、架构图或者白板草图,那你一定体会过那种“想法很丰满,画笔很骨感”的尴尬。脑子里明明有一个清晰的系统架构,但落到画布上,光是调整…...

AI智能体开发实战:从Devin现象到代码辅助智能体构建
1. 项目概述:当开发者遇上AI智能体最近在GitHub上闲逛,发现一个叫“awesome-devins”的仓库热度飙升。点进去一看,好家伙,这简直是一个关于“AI智能体”的宝藏目录。这个由e2b-dev团队维护的项目,本质上是一个精心整理…...

【最新 v2.7.1 版本安装包】5 分钟搞定 OpenClaw,零基础无需命令一键部署保姆级教学
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...

OpenAI GPT Image 2文字准确率95%,企业视觉硬核生产力4大核心升级与商业落地路径
GPT Image 2的4大核心升级能力1. 文字渲染准确率接近95%,多语言直出即用过去用AI生图,最头疼的就是文字。写个中文标题,十次有八次是乱码,英文稍微长一点也会出错。而GPT Image 2的文字渲染准确率做到了接近95%,支持中…...
)
Midjourney Mud印相实战手册(含12组高保真历史文物级Mud Prompt库+对应seed校验表)
更多请点击: https://intelliparadigm.com 第一章:Midjourney Mud印相的技术起源与美学范式 Mud印相(Mud Printing)并非传统暗房工艺的直系衍生物,而是Midjourney V6 模型在高语义控制模式下催生的一种跨模态视觉隐喻…...

Playnite完整指南:高效统一你的跨平台游戏库管理体验
Playnite完整指南:高效统一你的跨平台游戏库管理体验 【免费下载链接】Playnite Video game library manager with support for wide range of 3rd party libraries and game emulation support, providing one unified interface for your games. 项目地址: http…...

为什么你的旁遮普语语音听起来像“机械诵经”?ElevenLabs隐藏参数`stability=0.35`+`similarity_boost=0.72`调优公式首次披露
更多请点击: https://intelliparadigm.com 第一章:旁遮普语语音合成的“机械诵经”现象本质 当旁遮普语(Gurmukhi script)文本被输入主流TTS系统时,常出现一种高度重复、节奏僵硬、缺乏韵律起伏的输出效果——业内戏称…...