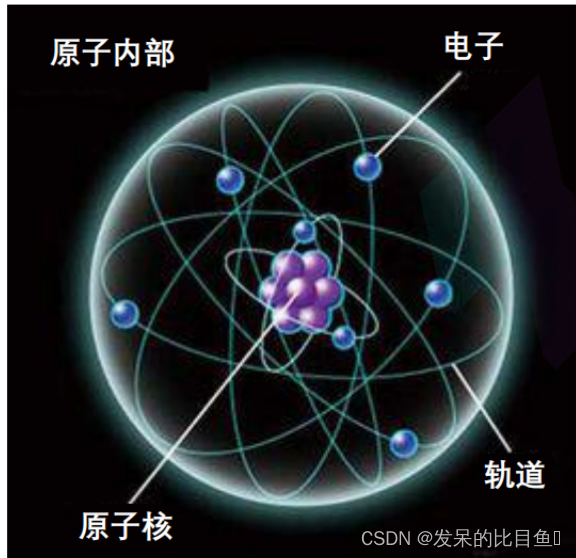
分子动力学基础知识
分子动力学基础知识
目前主要存在两种基本模型:其一为量子统计力学, 其二为经典统计力学。
量子统计力学
- 基于量子力学原理, 适用 于微观的, 小尺度, 短时 间的模拟,可以描述电子 的结构分布,原子间的成 键断键等化学性质。
经典纭计力学
- 基于牛顿经典力学, 模拟 的尺度和时间相比于量子 统计力学较大, 它以每个 原子作为一个质点, 主要 研究课题的物理性质。
分子动力学历史
分子力学思想的萌芽-D. H. Andrews(1930年工作)
在分子内部, 化学键都有 “自然” 的键长值和 键角值。整个分子有如下构象转变趋势:分子的键 长和键角趋于 “自然”状态, 同时, 非键作用(van der Waals) 力也趋于最低状态。以达到原子核排布 的最佳位置。在某些有张力的分子体系中分子的张 力可以计算出来。
分子经典力学模型一T. L. Hill(1946年工作)
T.L.Hill提出用van der Waals相互作用 和键长、键角的形变势能来计算分子的能 量, 用以优化分子空间构型的标准和路径 方向。
该理论认为分子内部的空间作用服从 以下规律:1)基团或原子之间靠近时则两 者之间排斥作用增强;2)为了减少这种排 斥作用,基团或原子间就有相互远离的趋 势, 但是这种运动又会导致键长伸长或键 角发生弯曲, 从而导致相应的能量升高。
分子力学基本假设
在玻恩 - 奥本海默近似下, 体系波函数可以被 写为电子波函数与原子核波函数的乘积: Ψ total = χ electronic × ϕ nuclear \Psi_{\text {total }}=\chi_{\text {electronic }} \times \phi_{\text {nuclear }} Ψtotal =χelectronic ×ϕnuclear
假设一: 原子的自身运动服从Born-Oppenheimer Approximation, 又称绝热近似 或定核近似:电子与核的质量相差极大, 当核的分布发生微小变化时, 电子能够迅速调整其运动状态以适应新的核势场,而核对电子在其轨道 上的迅速变化却不敏感。通俗讲:原子核的运动与电子的运动可以看成是相互独立的。
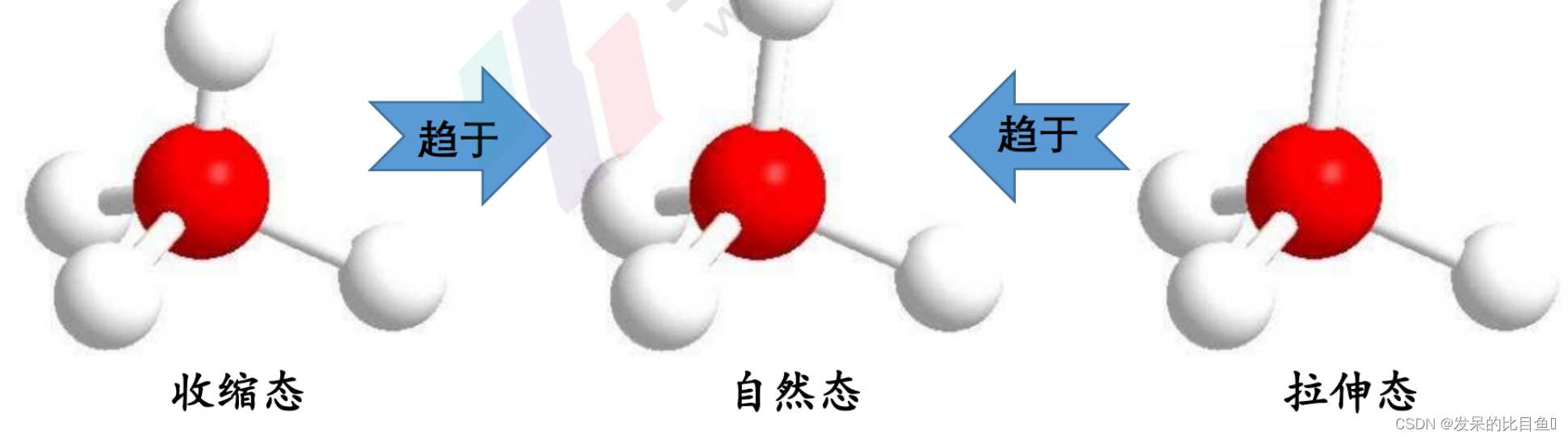
假设二: 分子是一组靠各种作用力维系在一起的原子集合。这些原子在空间上若 过于靠近, 便相互排斥; 但又不能远离, 否则连接它们的化学键以及由 这些键构成的键角等会发生变化,即出现键的拉伸或压缩、键角的扭变 等, 会引起分子内部应力的增加。每个真实的分子结构, 都是在上述几 种作用达到平衡状态的表现。
“化学键以及由这些键构成的键角等会发生变化, 即出现键的拉伸或压缩、键角的扭 变” 所代表的总能量变化能描述和它有关的 “化学过程”。最重要的是, 这个过程中 你并不需要解薛定谔方程! 所以看上去,你忽略了电子。但其实电子的信息早已经在 势能参数里面了。
这个势能可以叫做当前甲烷的分子动力学 “力场”。有了它,你就可以在波恩一奥本海 默近似下描述原子的运动了。
分子模拟
- 分子模拟将原子、分子按经典粒子处理, 可提 供微观结构、运动过程以及它们与宏观性质相 关的数据和直观图象
- 分子模拟结果取决于所采用的粒子间作用势的 合理、精确程度。又称为 “计算机实验” , 是 理论与真实实验之间的桥梁
分子模拟的两种主要方法:
(1) 分子动力学法 (MD , Molecular Dynamics)一基于粒子 运动的经典轨迹
(2) Monte Carlo法 (MC)一基于统计力学
针对那些有概率分布或概率密度函数的变 量, 我们构建一系列样本集, 使得满足该 种概率条件, 然后每个样本根据具体物理 事件推演, 得到目标的样本集, 最终进行 统计分析, 得到我们需要的目标概率分布 或概率密度函数等。
Metropolis算法一移动然后选择接受这个移动还是拒绝这个移动
- 从起始构型 x ( i ) \mathbf{x}^{(i)} x(i) ,计算能量 E ( i ) E^{(i)} E(i) ;
- 随机移动一些构型坐标得到一个trial构型 x ( i + 1 ′ ) \mathbf{x}^{\left(i+1^{\prime}\right)} x(i+1′) ,并计算该构型的能量 E ( i + 1 ′ ) E^{\left(i+1^{\prime}\right)} E(i+1′) ;
- 决定是否接受这个移动:
(1)如果 E ( i + 1 ′ ) ≤ E ( i ) E^{\left(i+1^{\prime}\right)} \leq E^{(i)} E(i+1′)≤E(i) ,那么100%接受这个移动,正式的下一步构型就是 x ( i + 1 ) = x ( i + 1 ′ ) \mathbf{x}^{(i+1)}=\mathbf{x}^{\left(i+1^{\prime}\right)} x(i+1)=x(i+1′) 了;
(2) 如果 E ( i + 1 ′ ) > E ( i ) E^{\left(i+1^{\prime}\right)}>E^{(i)} E(i+1′)>E(i) ,那么产生一个0到1之间的随机数R,并跟转移概率 w i → i + 1 ′ = exp ( β Δ E i , i + 1 ′ ) w_{i \rightarrow i+1^{\prime}}=\exp \left(\beta \Delta E_{i, i+1^{\prime}}\right) wi→i+1′=exp(βΔEi,i+1′) 比较,如果 w i → i + 1 ′ > R w_{i \rightarrow i+1^{\prime}}>R wi→i+1′>R 那就接受这个移动 x ( i + 1 ) = x ( i + 1 ′ ) \mathbf{x}^{(i+1)}=\mathbf{x}^{\left(i+1^{\prime}\right)} x(i+1)=x(i+1′) ,否则就拒绝这个移动 x ( i + 1 ) = x ( i ) \mathbf{x}^{(i+1)}=\mathbf{x}^{(i)} x(i+1)=x(i) ; - 回到第二步,直到累积 N \mathrm{N} N 个构型。
分子模拟的两种主要方法比较:

1、算法的难易程度。一般说来, M D M D MD 的算法比 M C M C MC 要复杂一些。这是因为, 对于 M C M C MC 而言, 每产 生一帧新的构型只要计算能量然后根据acceptance ratio移动粒子就足够了。但对于 M D M D MD, 每产生一帧新的构型所需要的不只是能量, 还需要每个粒子的速度和受力来对牛顿运动方程 进行数值积分, 这就加大了计算量。如果还要考虑为了提高计算效率的Verlet neighbor list 等设置,MD的算法会更复杂一些。
2、所能计算性质的多少。很明显, M D M D MD 能比 M C M C MC 计算更多的性质, M C M C MC 只能计算一些与动力学无 关的平衡态性质, 比如能量、比热容等等, M D M D MD 既可以计算与动力学无关的性质, 也可以计算 与动力学相关的性质, 比如扩散系数、热导率、黏度、态与态之间的跃迁速率, 光谱等等。 这是因为, 使用Metropolis算法的MC, 为了快速得到平衡态的分布, 把整个系统简化为一条 马尔可夫链, 第 N N N 个构型只和第 N − 1 N-1 N−1 个构型有关联, 与第 N − 2 N-2 N−2 或者更早的构型没有什么关联。 在实际情况中不是这样的, 系统是有记忆的, 在 t 0 t_0 t0 时刻处于相空间中 ( p 0 , q 0 ) \left(p_0, q_0\right) (p0,q0) 点的系统与在 t 1 t_1 t1 时刻处于 ( p 1 , q 1 ) \left(p_1, q_1\right) (p1,q1) 的系统是有关联的, 它们之间的关联可以用条件概率 P ( p 1 , q 1 ; t 1 ∣ p 0 , q 0 ; t 0 ) P\left(p_1, q_1 ; t_1 \mid p_0, q_0 ; t_0\right) P(p1,q1;t1∣p0,q0;t0) 来描述。很多动力学性质都和这样的条件概率有关系, 而MD产生的数据是可以计算这些概率 分布的。所以世界上没有免费的午餐, M C M C MC 虽然算法简单, 但大体上只能计算静态性质, 如果 要计算动力学性质还是要上MD。
3、可使用的软件。可使用的 M D M D MD 的软件远多于 M C M C MC 的软件。很大程度上是由于 M D M D MD 能够计算 的性质远比 M C M C MC 多, 并且数据可视化后给人更多直观的感受。比如说, 你可以把 M D M D MD 模拟蛋白 质折叠的轨迹文件用软件可视化之后做成动画, 动画就比较直观地演示了蛋白质结构随时间 的变化。可是如果用 M C M C MC 做同样一个体系的模拟, 把轨迹可视化之后看到的可能就是一堆原 子像无头苍蝇一样乱动, 最后稳定在某个构型附近。一般来讲, MD软件的开发也不难, 一 旦把积分牛顿方程的engine写好, 往里面添加新的相互作用势并不难, 这样每添加一点新的 功能, MD软件就可以适用于更多的体系。相比起MD软件的百花齐放, 分子模拟中学术界 通用的 M C M C MC 软件并不多, 很多课题组都是自己写 M C M C MC 代码, 但适用范围仅限于自己研究的体 系。
4、增强抽样 (enhanced sampling)。这是分子模拟中的一个大坑, 不管MD还是MC都会 面临在系综中采样不足的问题。
分子动力学模拟
原理:模拟过程是在一定系统及分子势能函数已知 的条件下,从计算分子间作用力着手,求解 牛顿运动方程,得到每个时刻各个分子的坐 标与动量, 即在相空间的运动轨迹, 再利用 统计计算方法得到多体系统的静态和动态特 性,从而得到系统的宏观性质。因此分子动 力学方法可以看作是体系在一段时间内的发 展过程的模拟。系统的初始位形和初始速度 可以通过实验数据、或理论模型、或两者的 结合来决定。
优势:分子动力学模拟是分子模拟中最接近实验条 件的模拟方法, 能够从原子层面给出体系的 微观演变过程, 直观的展示实验现象发生的 机理与规律, 促使我们的研究向着更高效, 更经济, 更有预见性的方向发展, 因此, 分 子动力学模拟在生物, 药学, 化学, 材料科 学的研究中发挥着越来越重要的作用。
计算机模拟形式
计算机模拟的主要表现形式
- 分子动力学法(MD, Molecular Dynamics ) – 牛顿方程
- 蒙特卡洛法(MC, Monte Carlo) – 郎之万方程
- 量子力学法(Quantum Mechanics) – 薛定谔方程
分子动力学法
在分子动力学法中,设想把 N \mathrm{N} N 个粒子 (可以是原子、分于或离子)的体系放在一个体 积单元(一般是正方体)中,每个粒子的初位置和初速度事先给定,随后的各粒子的运动 状态是按照一定的时间步长 Δ t \Delta \mathbf{t} Δt ,求解牛顿运动方程(对球对称分子)或耦合的牛顿-欧拉运 动方程(对非球对称的刚性分子除平动自由度还有转动自由度)而确定的。
体系的平衡性质, 可用时间平均来计算
⟨ A ⟩ = 1 T ∫ 0 T A ( t ) d t ≈ 1 M ∑ m = 1 M A ( m Δ t ) \langle A\rangle=\frac{1}{T} \int_0^T A(t) d t \approx \frac{1}{M} \sum_{m=1}^M A(m \Delta t) ⟨A⟩=T1∫0TA(t)dt≈M1m=1∑MA(mΔt)
式中的 A \mathrm{A} A 可以是动能 (由它可以计算温度值), > > >> >> 表示平均, A \mathrm{A} A 也可以是维里(由它可 计算压强值)等等。上式假定 t = 0 t=0 t=0 时体系处于初步平衡态, T \mathrm{T} T 是足够长的时间,一般是从初 步平衡态开始计算机模拟的整个时间, t t t 为时间步长, m m m 为总步数。可知,除了初条件(座 标、速度)是事先选定输入计算机的外, 原则上讲以后整个的计算过程是完全确定的。
蒙特卡洛法
在蒙特卡洛法中,随机性是本质的。体积单元中 N \mathrm{N} N 个粒子的坐标是逐次由计算机控制 而随机变化的,但这种变化是要使体系在相空间中,每个位形出现的频率与特定统计系综 的相应几率密度成正比(例如,对正则系综,几率密度为:
ρ = exp ( − v N k T ) \rho=\exp \left(-\frac{v_N}{k T}\right) ρ=exp(−kTvN)
其中 V V V 为体系势能, k k k 为波尔兹曼常数, T T T 为温度。这样, 粒子坐标函数的系综平均(例 如势能或维里)即可作为上述由计算机给出的一系列位形的无权重平均而得到。
就上述意义讲, 在蒙特卡洛模拟中, 各个分子坐标的变动, 并不与分子的实际运动相联系, 它没有明确的物理意义, 只是一种随机取样。一般是采用重要性取样(importance sampling), 即按照一定的几率给出一系列位形。为了得到可靠的结果, 往往要采用 1 0 3 ∼ 1 0 6 10^3 \sim 10^6 103∼106 个位形。位形出现的先后次序也没有特殊意义。所以用蒙特卡洛法模拟, 所估算的物理量 是对系综平均求的。但随着蒙特卡洛技术的发展,现已在某种意义上把它理解为 “时间”平 均(这里的“时间”只表征一系列状态在先后次序上的标号, 并非物理函义上的时间)。在这 种认识的基础上 发屏了解决非平衡讨程的技术。
量子力学法
量子动力学是相对于经典力学(classical dynamics)的量子形式。“动”是与静相对的, “量 子”则表明本理论的核心框架是使用含时的薛定谔方程。最近几十年,量子动力学得到广 泛的发展,从量子纠细生物发光现象都得到的了广泛的应用。薛定谔方程:
H φ = E φ H \varphi=E \varphi Hφ=Eφ
H H H 表示哈密顿算子; φ \varphi φ 表示波函数 ; E E E 表示体系的能量。分子包含电子和原子核, 但是 人们往往忽略了它们在分子运动过程中起到的作用。由于多体的薛定谔方程难解, 量子力 学运用到分子领域直到波恩和其导师提出绝热近似,才让薛定谔解多体问题得到一个大大 的进步。
量子动力学主要应用量子力学的方法研究体系的动量和能量的交换.分子量子动力学, 通常简称为量子动力学,是理论化学的一个分支,特点是分子体系中电子与原子核都用量 子力学方法处理。分子量子动力学可被视为量子物理与化学的结合。分子量子动力学,是 运用含时薛定谔方程为理论框架,研究分子动力学。
分子立场
空间简介
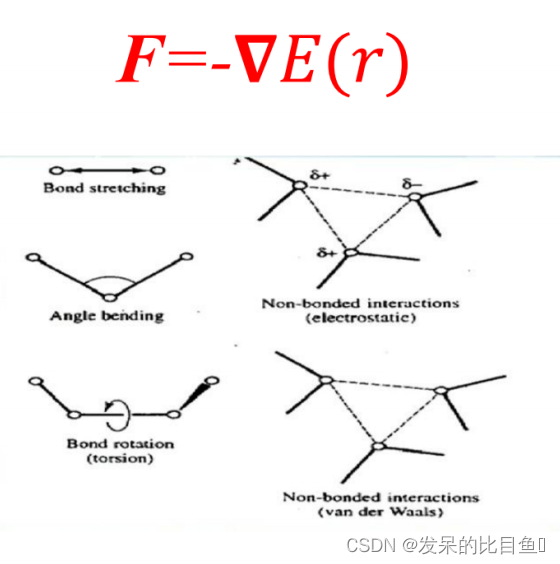
分子力学从几个主要的典型结构参数和作用力出发来讨论分子结构, 即用位能函数 来表示当键长、键角、二面角等结构参数以及非键作用等偏离“理想”值时分子能量(称为 空间能, space energy)的变化。采用优化的方法, 寻找分子空间能处于极小值状态时分 子的构型。
位能函数描述了各种形式的相互作用力对分子位能的影响, 它的有关参数、常数和 表达式通常称为力场。
对于某个分子来说, 空间能是分子构象的函数。由于在分子内部的作用力比较复杂, 作用类型也较多;对于不同类型的体系作用力的情况也有差别。
分子力场原理
分子力场: 在分子体系中, 原子与原子间的相互作用, 用势函数描述.
在分子力学模型中, 每个粒子通常代表一个原子, 在此基础上建立的力场称为全 原子力场。分子力场势能函数来自实验结果的经验公式, 对分子能量的模拟比较 粗粘, 但是相比于精确的量子力学从头计算方法, 分子力场的计算量要小数十倍, 因此对蛋白质复杂体系而言,分子力场方法是一套有效的方法。
E ( r ) = ∑ bonds K b ( b − b 0 ) 2 + ∑ angles K θ ( θ − θ 0 ) 2 + ∑ dihedrals V n 2 ( 1 + cos [ n ϕ − δ ] ) + ∑ n o n b i j [ ( A i j r i j 12 ) − ( B i j r i j 6 ) + ( q i q j r i j ) ] \begin{aligned} E(r)= & \sum_{\text {bonds }} K_b\left(b-b_0\right)^2+\sum_{\text {angles }} K_\theta\left(\theta-\theta_0\right)^2 \\ & +\sum_{\text {dihedrals }} \frac{V_n}{2}(1+\cos [n \phi-\delta]) \\ & +\sum_{n o n b i j}\left[\left(\frac{A_{i j}}{r_{i j}^{12}}\right)-\left(\frac{B_{i j}}{r_{i j}^6}\right)+\left(\frac{q_i q_j}{r_{i j}}\right)\right] \end{aligned} E(r)=bonds ∑Kb(b−b0)2+angles ∑Kθ(θ−θ0)2+dihedrals ∑2Vn(1+cos[nϕ−δ])+nonbij∑[(rij12Aij)−(rij6Bij)+(rijqiqj)]
分子立场分类
分子动力学模拟结果的准确性主要依赖于模拟中所选用的分子力场 目前常用的分子力场有: CHARMM、AMBER、GROMACS、 OPLS/NAMD等等。
动力学求解
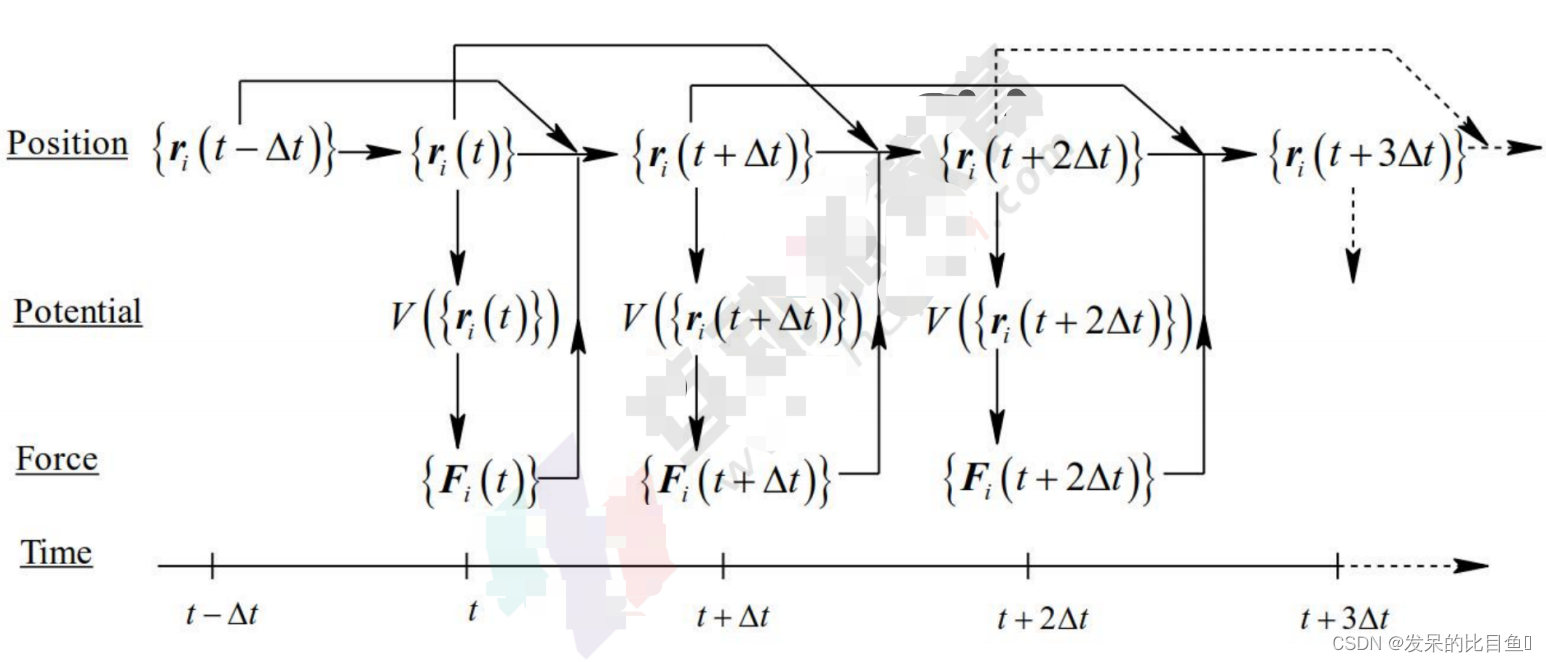
分子动力学模拟中, 分略了量子效应后, 系统中的粒子将遵循牛顿运动定律。为得到原于的运动, 可以采用有限差分方法来求解运动方程。常用的方法有Verlet算法、Leap-frog算法、Velocity Verlet算法等。
有限差分方法的时间步幅的设定是一个重要的问题, 如果太大则 使原子的位置变动太大。一般 (fs 量级) 应该小到足以模拟所有原子 的运动, 也就是要能够计算振动最快的原子的运动。如果做不到这一 点, 则计算分子的内能将是不稳定地, 使计算失败。
有限差分法
有限差分方法的基本思想
把整体的折散成许多小的段, 每一个段通过固定的时间被分隔在时间 t \mathbf{t} t 构型中, 每一质点上的总力等于与其它质点相互作用的矢量加和。
有限差值方法在分子动力学计算中步骤
- 设定粒子的初始位置和速度
- 根据粒子的位置计算每个粒子的受力
- 根据粒子的位置、速度和受力计算粒子新位置和新速度
- 更新粒子的位置和速度, 然后回到第2步
初始速度的设定
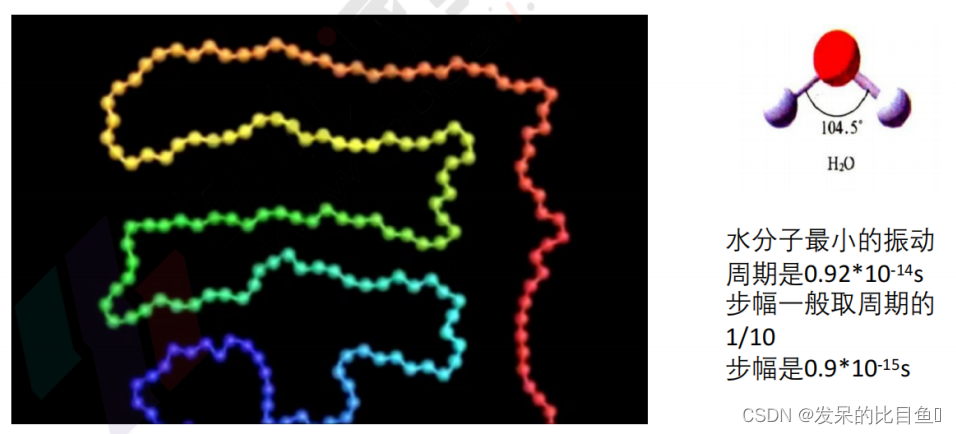
在计算中各原子的运动初速度的设定是一个重要问题。初速度的设定应与体 系的温度相匹配。系统中各原子的初始速度由初始温度分布下的Maxwell–Boltzmann分布来随机选取。
按速度分量的麦克斯韦分布律和分布函数:
f ( v x ) = ( m 2 π k T ) 1 / 2 e − m v x 2 2 k T f\left(v_x\right)=\left(\frac{m}{2 \pi k T}\right)^{1 / 2} e^{-\frac{m v_x^2}{2 k T}} f(vx)=(2πkTm)1/2e−2kTmvx2
求解动力学方程的数值方法
- Verlet算法
- Leap-frog (蛙跳) 算法
- Velocity-Verlet算法
为了得到原子的运动轨迹, 可以采用差分法求解运动方程。对速度和加速度进 行泰勒级数展开:
r ( t + Δ t ) = r ( t ) + v ( t ) Δ t + 1 2 a ( t ) Δ t 2 + ⋯ ⋯ v ( t + Δ t ) = v ( t ) + a ( t ) Δ t + 1 2 b ( t ) Δ t 2 + ⋯ ⋯ a ( t + Δ t ) = a ( t ) + b ( t ) Δ t + ⋯ ⋯ \begin{gathered} \mathbf{r}(t+\Delta t)=\mathbf{r}(t)+\mathbf{v}(t) \Delta t+\frac{1}{2} \mathbf{a}(t) \Delta t^2+\cdots \cdots \\ \mathbf{v}(t+\Delta t)=\mathbf{v}(t)+\mathbf{a}(t) \Delta t+\frac{1}{2} \mathbf{b}(t) \Delta t^2+\cdots \cdots \\ \mathbf{a}(t+\Delta t)=\mathbf{a}(t)+\mathbf{b}(t) \Delta t+\cdots \cdots \end{gathered} r(t+Δt)=r(t)+v(t)Δt+21a(t)Δt2+⋯⋯v(t+Δt)=v(t)+a(t)Δt+21b(t)Δt2+⋯⋯a(t+Δt)=a(t)+b(t)Δt+⋯⋯
用粒子在时刻 t t t 的坐标和速度以及粒子在 前一时刻 t − Δ t t-\Delta t t−Δt 的坐标, 来计算粒子在 t + Δ t t+\Delta t t+Δt 时刻的坐标
r ( t + Δ t ) = r ( t ) + Δ t v ( t ) + 1 2 Δ t 2 a ( t ) + ⋯ ⋯ r ( t − Δ t ) = r ( t ) − Δ v ( t ) + 1 2 Δ t 2 a ( t ) + ⋯ ⋯ \begin{aligned} \mathbf{r}(t+\Delta t) & =r(t)+\Delta t \mathrm{v}(t)+\frac{1}{2} \Delta t^2 \mathbf{a}(t)+\cdots \cdots \\ \mathbf{r}(t-\Delta t) & =\mathbf{r}(t)-\Delta \mathbf{v}(t)+\frac{1}{2} \Delta t^2 \mathbf{a}(t)+\cdots \cdots \end{aligned} r(t+Δt)r(t−Δt)=r(t)+Δtv(t)+21Δt2a(t)+⋯⋯=r(t)−Δv(t)+21Δt2a(t)+⋯⋯
把这两个方程相加减并忽略高级项, 得到:
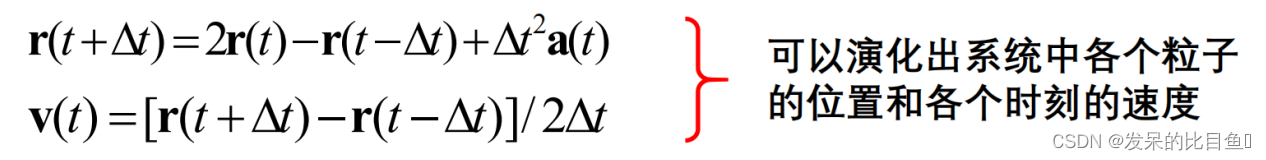
Verlet算法
r ( t + δ t ) = r ( t ) + d d t r ( t ) δ t + 1 2 ! d 2 d t 2 r ( t ) ( δ t ) 2 + … r ( t − δ t ) = r ( t ) − d d t r ( t ) δ t + 1 2 ! d 2 d t 2 r ( t ) ( δ t ) 2 + … \begin{aligned} & r(t+\delta t)=r(t)+\frac{d}{d t} r(t) \delta t+\frac{1}{2 !} \frac{d^2}{d t^2} r(t)(\delta t)^2+\ldots \\ & r(t-\delta t)=r(t)-\frac{d}{d t} r(t) \delta t+\frac{1}{2 !} \frac{d^2}{d t^2} r(t)(\delta t)^2+\ldots \end{aligned} r(t+δt)=r(t)+dtdr(t)δt+2!1dt2d2r(t)(δt)2+…r(t−δt)=r(t)−dtdr(t)δt+2!1dt2d2r(t)(δt)2+…
两式相加, 忽略高阶小量
r ( t + δ t ) = − r ( t − δ t ) + 2 r ( t ) + d 2 d t 2 r ( t ) ( δ t ) 2 r(t+\delta t)=-r(t-\delta t)+2 r(t)+\frac{d^2}{d t^2} r(t)(\delta t)^2 r(t+δt)=−r(t−δt)+2r(t)+dt2d2r(t)(δt)2
两式相减, 忽略高阶小量, 除以 2 δ t 2 \delta t 2δt
v ( t ) = d r d t = 1 2 δ t [ r ( t + δ t ) − r ( t − δ t ) ] v(t)=\frac{d r}{d t}=\frac{1}{2 \delta t}[r(t+\delta t)-r(t-\delta t)] v(t)=dtdr=2δt1[r(t+δt)−r(t−δt)]
分子动力学
Verlet算法 - 应用最为广泛, 计算简明扼要, 但是精度较差, 没有显式速度项, 需要下一步的坐标计算速度。
Leap-frog-Verlet(蛙跳)算法 - Verlet算法的一种变化形式, 轨迹与前者完全一 样, 计算量较小, 包含显式速度项, 但是速度 与位置计算不同步。
Velocity-Verlet算法 Velocity-Verlet算法是Verlet算法的另一种变化形 式, 计算量适中, 可以同时给出位置, 速度和 加速度, 目前应用比较广泛。
时间步长选择
步长太小,轨迹将覆盖, 只有一个限定的相空间性质;
步长太大, 不稳定性在积分算法中可能升高, 由于原子间高能重叠。导致能量和 线性动量守恒的破坏
系统理论
系综( ensemble )代表一大群相类似的体系的集合。对一类相同性质的体 系, 其微观状态(比如每个粒子的位置和速度)仍然可以大不相同。 (实际上, 对于一个宏观体系, 所有可能的微观状态数是天文数字。)统计物理的一个基 本假设(各态历经假设)是:对于一个处于平衡的体系, 物理量的时间平均, 等 于对对应系综里所有体系进行平均的结果。体系的平衡态的物理性质可以对 不同的微观状态求和来得到。系综的概念是由约西亚. 威拉德-吉布斯 (J.Willard Gibbs) 在 1878 年提出。
常用系综:
微正则系综(microcanonical ensemble, NVE)
正则系综(canonical ensemble, NVT)
巨正则系综(grand canonical ensemble, μ V T ) \mu VT) μVT)
等温等压系综(isothermal-isobaric ensemble, NPT)
等压等焓系综(contant-pressure,constant-enthalpy, NPH)
微正则系综(microcanonical ensemble, NVE): _系综里的每个体系具有相同 的能量(通常每个体系的粒子数和体积也是相同的)。
正则系综(canonical ensemble, NVT): 系综里的每个体系都可以和其他体系 交换能量(每个体系的粒子数和体积仍然是固定且相同的),但是系综里所 宥体系的能量总和是固定的。系综内各体系有相同的温度。
巨正则系综 (grand canonical ensemble, μ V T \mu \mathrm{VT} μVT ): 正则系综的推广, 每个体 系都可以和其他体系交换能量和粒子, 但系综内各体系的能量总和以及粒子 数总和都是固定的… (系综内各体系的体积相同。)系综内各个体系有相同的温 度和化学势。
等温等压系综(isothermal-isobaric ensemble, NPT): 正则系综的推广,体系 间可交换能量和体积, 但能量总和以及体积总和都是固定的。(系综内各体系 有相同的粒子数。)正如它的名字, 系综内各个体系有相同的温度和压强。
相关文章:
分子动力学基础知识
分子动力学基础知识 目前主要存在两种基本模型:其一为量子统计力学, 其二为经典统计力学。 量子统计力学 基于量子力学原理, 适用 于微观的, 小尺度, 短时 间的模拟,可以描述电子 的结构分布,原子间的成 键断键等化学性质。 经典纭计力学…...

USB转UART转串口芯片 GP232RNL国产低成本替代FT232RL/FT232RNL
近期收到很多人咨询FT232RL跟新版FT232RNL两者有什么区别,实际上就是内部做了一点升级,FT232RNL支持Windows11系统,参数并没有改动,完全可以直接替换使用。 今天小编给大家讲讲FT232RNL国产低成本替代芯片–GP232RNL GP232RNL 是…...
第03讲:SpringCloudStream实现分布式事务
需求分析 本案例是通过一个发送短信验证码的功能来实验MQ发送消息时实现分布式事务,思路分析如下 消息生产者生产发送验证码的半消息 生产者执行本地事务(将验证码保存到数据库),并记录事务的ID,如果整个过程不出现异…...
【从零开始学Skynet】高级篇(一):Protobuf数据传输
1、什么是Protobuf Protobuf是谷歌发布的一套协议格式,它规定了一系列的编码和解 码方法,比如对于数字,它要求根据数字的大小选择存储空间,小于等于15的数字只用1个字节来表示,大于15的数用2个字节表示,以此…...

快速入门Lombok
Lombok是一个Java库,可以通过注解的方式来简化Java代码,它可以自动生成Getter、Setter、构造函数等代码,从而减少重复的模板代码。下面是Lombok的使用详情: 1. 添加Lombok依赖 在使用Lombok之前,我们需要先添加Lombo…...
Linux 常见命令与常见问题解决思路
Linux 常见命令 Linux 基础命令目录相关查看文件(日志)查看普通的文件查看压缩的文件 解压压缩Linux 系统调优topvmstatpidstatps vi/vim 编辑文件查找文件属性相关定时任务scp 复制文件和目录awk 分隔cutsort 与 uniq常见问题处理思路CPU 高系统平均负载…...

用GPT-4 写2022年天津高考作文能得多少分?
正文共 792 字,阅读大约需要 3 分钟 学生必备技巧,您将在3分钟后获得以下超能力: 积累作文素材 Beezy评级 :B级 *经过简单的寻找, 大部分人能立刻掌握。主要节省时间。 推荐人 | Kim 编辑者 | Linda ●图片由Lexica …...

Django如何把SQLite数据库转换为Mysql数据库
大部分新手刚学Django开发的时候默认用的都是SQLite数据库,上线部署的时候,大多用的却是Mysql。那么我们应该如何把数据库从SQLite迁移转换成Mysql呢? 之前我们默认使用的是SQLite数据库,我们开发完成之后,里面有许多数…...

使用apisix代理静态文件
前言 最近公司考虑用apisix作为公司网关并且部署到k8s上,我这边收到一个小任务:使用apisix代理静态文件 通过apisix官网了解到它构建于 NGINX ngx_lua 的技术基础之上,所以按理应该和nginx代理静态资源是一样的。因为是通过docker容器部署…...
)
[元带你学NVMe协议] NVMe1.4 多路径(Multipathing)
声明 主页:元存储的博客_CSDN博客 依公开知识及经验整理,如有误请留言。 个人辛苦整理,付费内容,禁止转载。 内容摘要 全文9100字, 主要内容 目录 前言 1 多路径(Multipathing)概念...

Elasticsearch:如何使用自定义的证书安装 Elastic Stack 8.x
在我之前的文章 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch”,我详细描述了如何在各个平台中安装 Elastic Stack 8.x。在其中的文章中,我们大多采用默认的证书来安装 Elasticsearch。在今天的文章中,我们用自己创…...

HADOOP--yarn ,, git
Yarn架构体系 主从架构 也是采用 master(Resource Manager)- slave (Node Manager)架构,Resource Manager 整个集群只有一个,一个可靠的节点。 1、 每个节点上可以负责该节点上的资源管理以及任务调度&am…...
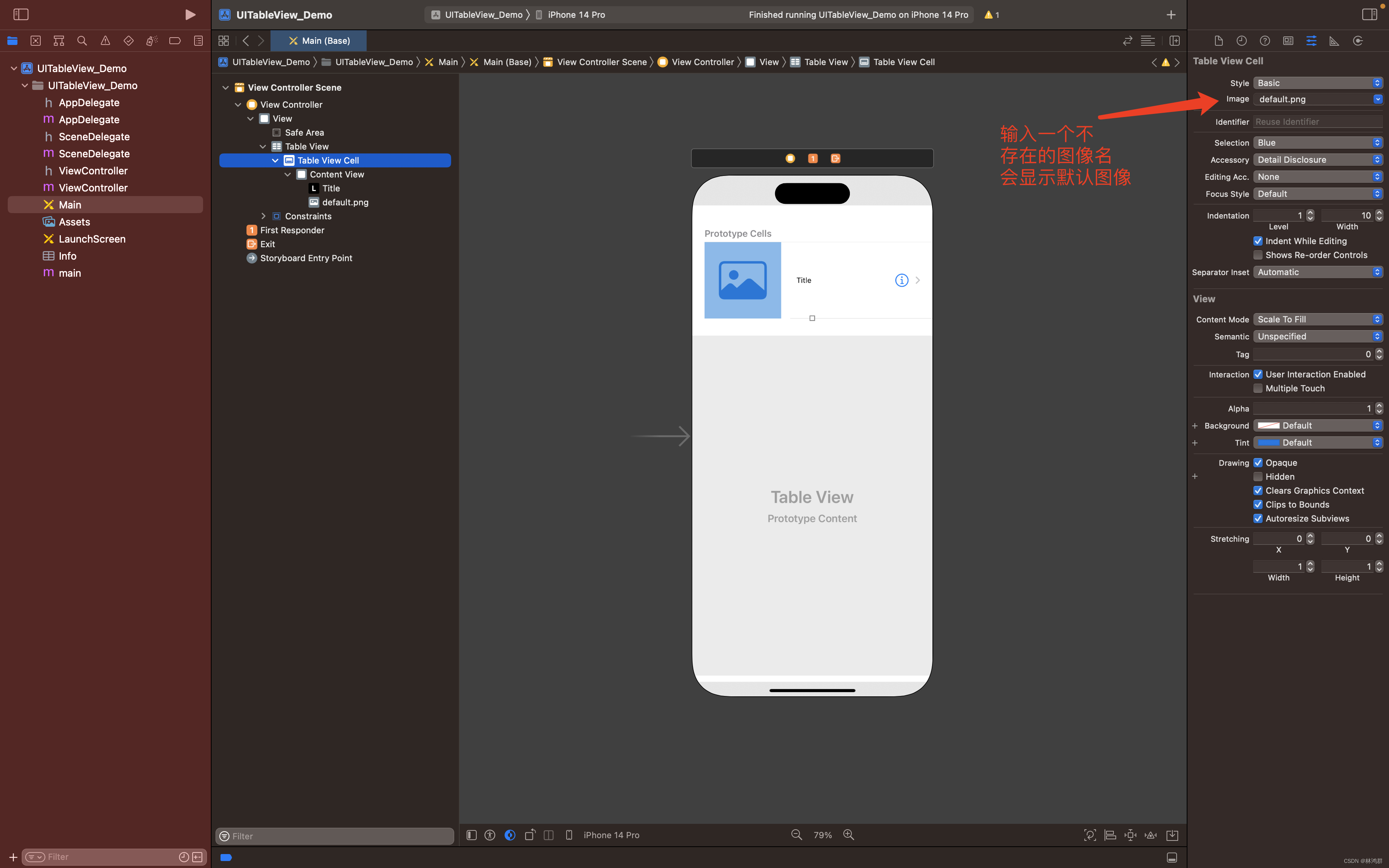
IOS开发指南之UITableView控件使用
1.创建一个IOS单页应用 2.双击Main.storyboard然后拖放UITableView到视图中 3.添加TableViewCell 成功添加Table View Cell 4.修改Table View Cell属性 选中Table View Cell 在右边的Image栏输入default.png回车 到此布局设计完成,现在运行还是显示 空白,要在代码中做相关的实…...
C语言中的数据类型
目录 一、数据类型 1.基本类型 2.sizeof运算符 3.signed和unsigned 二、基本数据类型的取值范围 1.比特位 2.字节 3.符号位 4.补码 5.基本数据类型的取值范围 一、数据类型 1.基本类型 (1)整数类型 short intintlong intlong long int &…...
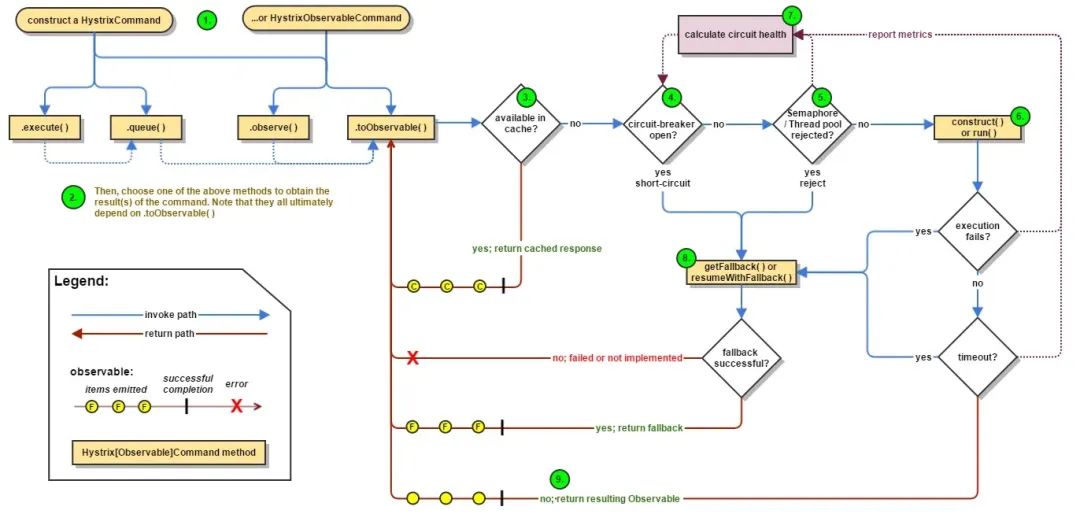
什么是微服务中的熔断器设计模式?
在本文中,我将解释什么是熔断器设计模式以及它解决了什么问题。 我们将仔细研究熔断器设计模式,并探讨如何使用Spring Cloud Netflix Hystrix在Java中实现它。到本文结束时,您将更好地了解如何使用熔断器设计模式提高微服务架构的弹性。 熔断…...

Ubuntu查看系统日志的几种方法
在 Ubuntu 22.10 中,你可以查看系统日志来排查错误。以下是几种查看日志的方法: 一、Journalctl 命令: 使用 journalctl 命令可以查看系统日志信息,包括引起闪退的错误信息。你可以运行以下命令来查看最新的系统日志:…...

【ubuntu】安装ZIP
【ubuntu】安装ZIP 输入如下命令安装zip $ sudo apt-get install zip 输出信息如下: Reading package lists... Done Building dependency tree Reading state information... Done The following additional packages will be installed: unzip The follo…...

DiffDock源码解析
DiffDock源码解析 数据预处理 数据输入方式 df pd.read_csv(args.protein_ligand_csv), 使用的是csv的方式输入, 格式: 不管受体还是配体, 输入可以是序列或者3维结构的文件 如果蛋白输入的是序列,需要计算蛋白的三维结构&am…...
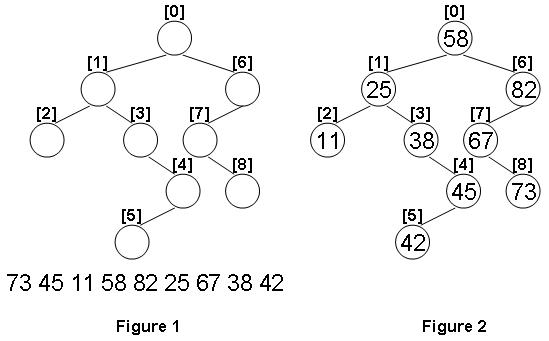
1099 Build A Binary Search Tree(超详细注解+38行代码)
分数 30 全屏浏览题目 作者 CHEN, Yue 单位 浙江大学 A Binary Search Tree (BST) is recursively defined as a binary tree which has the following properties: The left subtree of a node contains only nodes with keys less than the nodes key.The right subtree…...
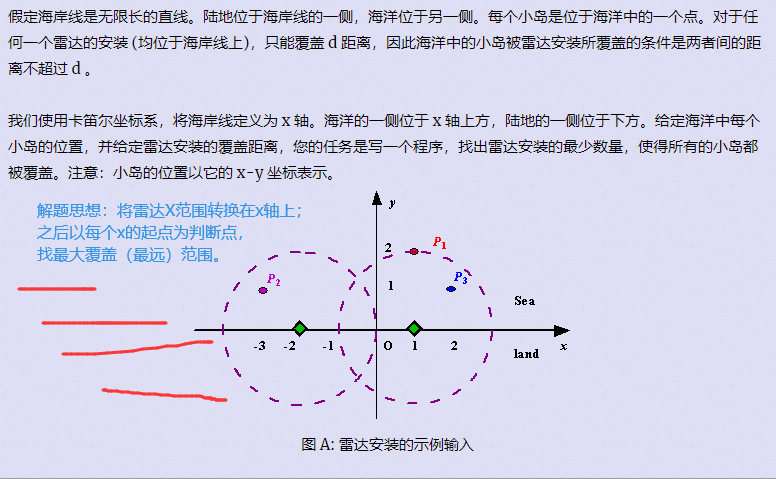
[刷题]贪心入门
文章目录 贪心区间问题区间选点区间合并区间覆盖 哈夫曼树(堆)合并果子 排序不等式排队打水 绝对值不等式货仓选址 推出来的不等式耍杂技的牛 以前的题 贪心 贪心:每一步行动总是按某种指标选取最优的操作来进行, 该指标只看眼前&…...

不用公网IP!用cpolar内网穿透实现PicHome多设备同步的3种方案对比
零公网IP实现PicHome多端同步:cpolar内网穿透全方案解析 在数字资产爆炸式增长的今天,如何安全高效地管理个人媒体库成为现代人的刚需。PicHome作为一款开源网盘系统,凭借其Docker化部署的便捷性和AI增强的媒体管理能力,正在成为家…...

计算机毕业设计springboot智慧校园服务系统 基于SpringBoot的高校智慧校园综合管理平台的设计与实现 基于SpringBoot与微信小程序的数字化校园服务系统的设计与开发
计算机毕业设计springboot智慧校园服务系统 (配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着社会的快速发展和信息技术的全面进步,传统的教育教学模式面临着诸多挑…...
)
SSCOM串口助手5个隐藏技巧:多窗口同步调试效率翻倍(附配置截图)
SSCOM串口助手5个隐藏技巧:多窗口同步调试效率翻倍(附配置截图) 在嵌入式开发和硬件调试领域,串口通信工具的效率直接影响着工程师的工作节奏。SSCOM作为一款广受欢迎的串口调试助手,其简洁界面背后隐藏着许多能显著提…...

解决Qt中使用qmqtt连接ONENet MQTT服务端的版本兼容性问题
1. 问题背景:当qmqtt遇上ONENet 最近在做一个物联网项目,需要用Qt开发一个MQTT客户端连接ONENet平台。按照官方文档,我选择了emqx/qmqtt这个第三方库,结果连接时直接报错。代码明明照着示例写的,参数也都检查过&#x…...

VRCX:重新定义VRChat社交管理的智能伴侣工具
VRCX:重新定义VRChat社交管理的智能伴侣工具 【免费下载链接】VRCX Friendship management tool for VRChat 项目地址: https://gitcode.com/GitHub_Trending/vr/VRCX 在虚拟社交平台VRChat的生态中,社交关系管理常常成为用户体验的痛点。传统方式…...
)
微信小程序蓝牙打印中文乱码?手把手教你GBK编码转换(附完整Demo)
微信小程序蓝牙打印中文乱码终极解决方案:从编码原理到完整实现 蓝牙打印机在零售、餐饮等行业的应用越来越广泛,而微信小程序作为轻量级应用平台,与蓝牙打印机的结合为商家提供了便捷的移动打印方案。但在实际开发中,开发者经常会…...

无线音频桥接实战指南:让传统音响实现跨设备兼容的完整方案
无线音频桥接实战指南:让传统音响实现跨设备兼容的完整方案 【免费下载链接】AirConnect Use AirPlay to stream to UPnP/Sonos & Chromecast devices 项目地址: https://gitcode.com/gh_mirrors/ai/AirConnect 🎶 从"音响孤岛"到&…...

Musicdl革新性全场景音乐解决方案:5个维度揭秘开源音乐下载技术的破局之道
Musicdl革新性全场景音乐解决方案:5个维度揭秘开源音乐下载技术的破局之道 【免费下载链接】musicdl Musicdl: A lightweight music downloader written in pure python. 项目地址: https://gitcode.com/gh_mirrors/mu/musicdl 在数字音乐产业蓬勃发展的今天…...

提升90%效率:OpenCore EFI自动化配置工具OpCore-Simplify实战指南
提升90%效率:OpenCore EFI自动化配置工具OpCore-Simplify实战指南 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 副标题:面向…...

SenseVoice-Small模型在运维监控中的语音告警应用
SenseVoice-Small模型在运维监控中的语音告警应用 1. 运维人员每天都在和告警“搏斗” 你有没有经历过这样的场景:凌晨三点,手机突然震动,一条告警短信跳出来——“数据库连接池使用率98%”。你立刻爬起来打开电脑,连上跳板机&a…...