HADOOP--yarn ,, git
Yarn架构体系
主从架构
也是采用 master(Resource Manager)- slave (Node Manager)架构,Resource Manager 整个集群只有一个,一个可靠的节点。
1、 每个节点上可以负责该节点上的资源管理以及任务调度,Node Manager 会定时向Resource Manager汇报本节点上 的资源使用情况和任务运行状态, 2、 Resource Manager会通过心跳应答的机制向Node Manager下达命令或者分发新的任务, 3、 Yarn 将某一资源分配给该应用程序后,应用程序会启动一个Application Master, 4、 Application Master为应用程序负责向Resource Manager申请资源,申请资源之后,再和申请到的节点进行通信,运行内部任务。
Resource Manager
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
Schedule 资源调度器是一个可插拔的组件,用户可根据自己需要设计资新的源调度器,YARN提供多个可直接使用的资源调度器。资源调度器将系统中的资源分配给正在运行的程序,不负责监控或跟踪应用的执行状态,不负责重启失败的任务。
Applications Manager 应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
Node Manager
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
ApplicationMaster
用户提交的每个应用程序均包含一个AM,主要功能包括:
1.与RM调度器协商以获取资源(用Container表示);
2.将得到的任务进一步分配给内部的任务
3.与NM通信以启动/停止任务;
4.监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
注:RM只负责监控AM,在AM运行失败时候启动它,RM并不负责AM内部任务的容错,这由AM来完成。
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。yarn的container容器是yarn虚拟出来的一个东西,属于虚拟化的,它是由memory+vcore组成,是专门用来运行任务的
Yarn的安装
etc/hadoop/目录下 yarn-site.xml文件
cd /opt/apps/hadoop-3.1.1/etc/hadoop/vi yarn-site.xml<!-- resource,manager主节点所在机器 --> <property><name>yarn.resourcemanager.hostname</name><value>linux01</value> </property><!-- 为mr程序提供shuffle服务 --> <property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value> </property><!-- 一台NodeManager的总可用内存资源 --> <property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value> </property> <!-- 一台NodeManager的总可用(逻辑)cpu核数 --> <property><name>yarn.nodemanager.resource.cpu-vcores</name><value>4</value> </property><!-- 是否检查容器的虚拟内存使用超标情况vmem为true 指的是默认检查虚拟内存,容器使用的虚拟内存不能超过我们设置的虚拟内存大小 --> <property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value> </property><!-- 容器的虚拟内存使用上限:与物理内存的比率 --> <property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value> </property>将 yarn-site.xml 同步给其他Linux scp yarn-site.xml linux02:$PWD scp yarn-site.xml linux03:$PWD
配置一键启停
cd /opt/apps/hadoop-3.1.1/sbin vi start-yarn.sh vi stop-yarn.shYARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=rootstart-yarn.sh 一键启动 启动后可以访问 http://linux01:8088 查看页面解决linux连接部上 网卡出现问题 systemctl stop NetworkManager systemctl diable NetworkManager systemctl restart network
MR程序提交到Yarn上运行
使用idea提交程序
配置mapred-site.xml文件 添加到resources目录下
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.1.1</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.1.1</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/opt/apps/hadoop-3.1.1</value></property></configuration>day05.com.doit.demo06;
修改提交任务的代码 maven打jar包的命令为 package
public class Test02 {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {System.setProperty("HADOOP_USER_NAME", "root");Configuration conf = new Configuration();//操作HDFS数据conf.set("fs.defaultFS", "hdfs://linux01:8020");//设置运行模式conf.set("mapreduce.framework.name", "yarn");//设置ResourceManager位置conf.set("yarn.resourcemanager.hostname", "linux01");// 设置MapReduce程序运行在windows上的跨平台参数conf.set("mapreduce.app-submission.cross-platform","true");Job job = Job.getInstance(conf, "WordCount");//设置jar包路径job.setJar("D:\\IdeaProjects\\hadoop\\target\\test_yarn.jar");job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReduce.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//设置路径为HDFS路径FileInputFormat.setInputPaths(job,new Path("/wc/input/word.txt"));FileOutputFormat.setOutputPath(job,new Path("/wc/out4"));job.waitForCompletion(true);}
}
在linux上直接提交jar包
public class Test02 {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {Configuration conf = new Configuration();//设置运行模式conf.set("mapreduce.framework.name", "yarn");//设置ResourceManager位置conf.set("yarn.resourcemanager.hostname", "linux01");// 设置MapReduce程序运行在windows上的跨平台参数conf.set("mapreduce.app-submission.cross-platform","true");Job job = Job.getInstance(conf, "WordCount");//设置jar包路径//job.setJar("D:\\IdeaProjects\\hadoop\\target\\test_yarn.jar");job.setJarByClass(Test02.class);job.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReduce.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//设置路径为HDFS路径FileInputFormat.setInputPaths(job,new Path("/wc/input/word.txt"));FileOutputFormat.setOutputPath(job,new Path("/wc/out5"));job.waitForCompletion(true);}
}
打成jar包后
linux上使用
需要查看 mapred-site.xml 如果没有配置 需要配置一下hadoop jar jar包名 运行的类
hadoop jar test_yarn.jar day03.com.doit.demo02.Test02
Map Join
Map端join是指数据达到map处理函数之前进行合并的,效率要远远高于Reduce端join,因为Reduce端join是把所有的数据都经过Shuffle,非常消耗资源。
order.txt order011 u001 order012 u001 order033 u005 order034 u002 order055 u003 order066 u004 order077 u010user.txt u001,hangge,18,male,angelababy u002,huihui,58,female,ruhua u003,guanyu,16,male,chunge u004,laoduan,38,male,angelababy u005,nana,24,femal,huangbo u006,xingge,18,male,laoduan最终结果 u001,hangge,18,male,angelababy,order012 u001,hangge,18,male,angelababy,order011 u002,huihui,58,female,ruhua,order034 u003,guanyu,16,male,chunge,order055 u004,laoduan,38,male,angelababy,order066 u005,nana,24,femal,huangbo,order033 null,order077
一个用户可能会产生多个订单,可能user.txt中的用户非常少,但是订单数据又非常非常多,这时我们可以考虑使用Map端join.一个小文件,一个大文件时,可以使用Map端join,说的简单一些,就是不走reduce,通过Map直接得出结果.
原理:将小文件上传到分布式缓存,保证每个map都可以访问完整的小文件的数据,然后与大文件切分后的数据进行连接,得出最终结果.
package hadoop06.com.doit.demo;import hadoop03.com.doit.demo02.WordCountMapper;
import hadoop03.com.doit.demo02.WordCountReducer;
import hadoop05.com.doit.demo05.Test;
import org.apache.commons.lang.ObjectUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.HashMap;
import java.util.Map;public class MapJoinDemo {public static class JoinMapper extends Mapper<LongWritable,Text,Text, NullWritable>{//定义集合用来存储user.txt的数据 键是uid 值是这一行记录private Map<String,String> userMap = new HashMap<>();private Text k2 = new Text();@Overrideprotected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {//读取本地user.txt文件 由于user.txt添加到了分布式缓存中,会将这个文件 缓存到执行maptask的计算机上//由于这个文件和class文件放在一起 可以直接读取BufferedReader br = new BufferedReader(new FileReader("user.txt"));String line = null;while((line = br.readLine())!=null){//System.out.println(line);String uid = line.split(",")[0];//将uid 和 user的一行记录放入到map中userMap.put(uid,line);}}@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {//得到order的一条记录String line = value.toString();//获取order的 uidString uid = line.split("\\s+")[1];// u001//获取map中 当前uid的 用户信息String userInfo = userMap.get(uid);//拼接字符串写出k2.set(userInfo+","+line.split("\\s+")[0]);context.write(k2, NullWritable.get());}}public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, URISyntaxException {System.setProperty("HADOOP_USER_NAME", "root");Configuration con = new Configuration();//配置到yarn上执行con.set("mapreduce.framework.name", "yarn");//配置操作HDFS数据con.set("fs.defaultFS", "hdfs://linux01:8020");//配置resourceManager位置con.set("yarn.resourcemanager.hostname", "linux01");//配置mr程序运行在windows上的跨平台参数con.set("mapreduce.app-submission.cross-platform","true");Job job = Job.getInstance(con,"wordcount");//分布式缓存user.txt文件job.addCacheFile(new URI("hdfs://linux01:8020/user.txt"));//设置jar包的路径job.setJar("D:\\IdeaProjects\\test_hadoop\\target\\test_hadoop-1.0-SNAPSHOT.jar");//设置Mapperjob.setMapperClass(JoinMapper.class);//设置最后结果的输出类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(NullWritable.class);//设置读取HDFS上的文件 的路径//设置读取文件的位置 可以是文件 也可以是文件夹FileInputFormat.setInputPaths(job,new Path("/join/order.txt"));//设置输出文件的位置 指定一个文件夹 文件夹不已存在 会报错FileOutputFormat.setOutputPath(job,new Path("/join/out"));//提交任务 并等待任务结束job.waitForCompletion(true);}}
public class Test02 {public static void main(String[] args) {int[] arr = {3,4,2,8,5,1,7,3};quickSort(arr,0,arr.length-1);System.out.println(Arrays.toString(arr));}public static void quickSort(int[] arr, int startIndex, int endIndex) {if (startIndex >= endIndex) {return;}// 核心算法部分:分别介绍 双边指针(交换法)int pivotIndex = doublePointerSwap(arr, startIndex, endIndex);// 用分界值下标区分出左右区间,进行递归调用quickSort(arr, startIndex, pivotIndex - 1);quickSort(arr, pivotIndex + 1, endIndex);}private static int doublePointerSwap(int[] arr, int startIndex, int endIndex) {int pivot = arr[startIndex];int leftPoint = startIndex;int rightPoint = endIndex;while (leftPoint < rightPoint) {// 从右向左找出比pivot小的数据while (leftPoint < rightPoint&& arr[rightPoint] > pivot) {rightPoint--;}// 从左向右找出比pivot大的数据while (leftPoint < rightPoint&& arr[leftPoint] <= pivot) {leftPoint++;}// System.out.println(leftPoint+" "+rightPoint);// 没有过界则交换if (leftPoint < rightPoint) {int temp = arr[leftPoint];arr[leftPoint] = arr[rightPoint];arr[rightPoint] = temp;}// System.out.println(Arrays.toString(arr));}// 最终将分界值与当前指针数据交换arr[startIndex] = arr[rightPoint];arr[rightPoint] = pivot;// 返回分界值所在下标return rightPoint;}}
归并排序
package com.doit.demo;import java.util.Arrays;
import java.util.Random;public class Test03 {public static void main(String[] args) {int[] arr = new int[100];//向数组中添加100的 0-1000的随机数for (int i = 0; i < arr.length; i++) {arr[i] = new Random().nextInt(1000);}//调用排序sort(arr,0,arr.length-1);System.out.println(Arrays.toString(arr));}public static void sort(int[] arr,int start,int end){//递归出口if(start>=end){return;}//计算中间索引 拆分数组int mid = start+(end- start)/2; // length = 10 ; 0+9/2 = 4; 左0-4 右 5 - 9;
// //左边有序数组sort(arr,start,mid);//右边有序数组sort(arr,mid+1,end);
////合并merge(arr,start,mid,end);}public static void merge(int[] arr ,int start,int mid, int end){//定义一个辅助数组int[] assist = new int[arr.length] ;int i = start;int leftIndex= start;int rightIndex = mid+1;//循环比较while(leftIndex<=mid && rightIndex<=end){//如果左边数组的元素比右边数组的元素小 则将左边数组的元素放入到辅助数组中if(arr[leftIndex] < arr[rightIndex]){assist[i] = arr[leftIndex];i++;leftIndex++;}else{//如果左边数组的元素比右边的元素大 则将右边的元素放入到辅助数组中assist[i] = arr[rightIndex];i++;rightIndex++;}}//如果左边的数组没走完 将剩下的放入到辅助数组中while(leftIndex<=mid){assist[i] = arr[leftIndex];i++;leftIndex++;}//如果右边的数组没走完 将剩下的放入到辅助数组中while(rightIndex<=end){assist[i]= arr[rightIndex];i++;rightIndex++;}//将辅助数组的值 为 原本的数组赋值for(int index = start;index<=end;index++){arr[index] = assist[index];}}
}
相关文章:

HADOOP--yarn ,, git
Yarn架构体系 主从架构 也是采用 master(Resource Manager)- slave (Node Manager)架构,Resource Manager 整个集群只有一个,一个可靠的节点。 1、 每个节点上可以负责该节点上的资源管理以及任务调度&am…...
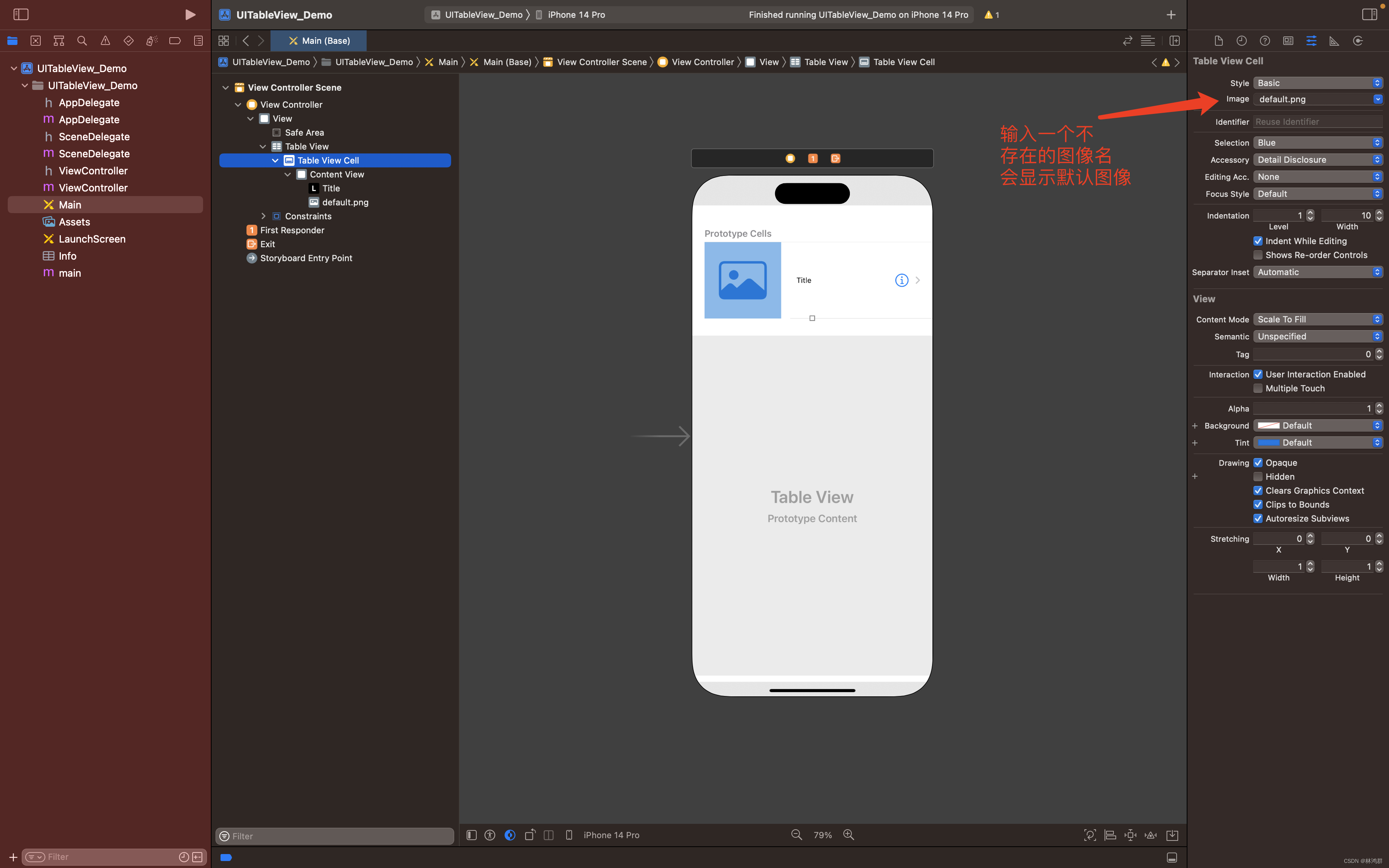
IOS开发指南之UITableView控件使用
1.创建一个IOS单页应用 2.双击Main.storyboard然后拖放UITableView到视图中 3.添加TableViewCell 成功添加Table View Cell 4.修改Table View Cell属性 选中Table View Cell 在右边的Image栏输入default.png回车 到此布局设计完成,现在运行还是显示 空白,要在代码中做相关的实…...
C语言中的数据类型
目录 一、数据类型 1.基本类型 2.sizeof运算符 3.signed和unsigned 二、基本数据类型的取值范围 1.比特位 2.字节 3.符号位 4.补码 5.基本数据类型的取值范围 一、数据类型 1.基本类型 (1)整数类型 short intintlong intlong long int &…...
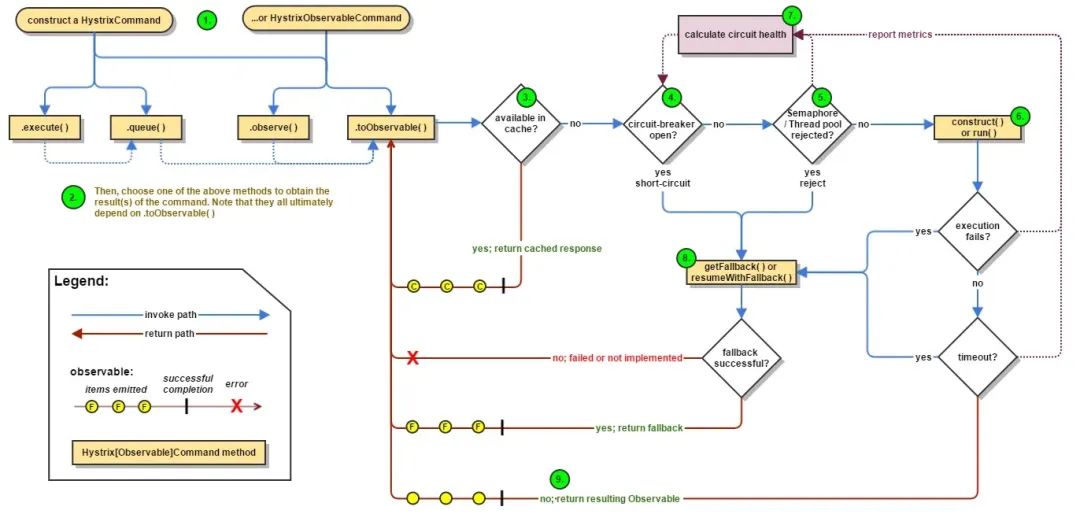
什么是微服务中的熔断器设计模式?
在本文中,我将解释什么是熔断器设计模式以及它解决了什么问题。 我们将仔细研究熔断器设计模式,并探讨如何使用Spring Cloud Netflix Hystrix在Java中实现它。到本文结束时,您将更好地了解如何使用熔断器设计模式提高微服务架构的弹性。 熔断…...

Ubuntu查看系统日志的几种方法
在 Ubuntu 22.10 中,你可以查看系统日志来排查错误。以下是几种查看日志的方法: 一、Journalctl 命令: 使用 journalctl 命令可以查看系统日志信息,包括引起闪退的错误信息。你可以运行以下命令来查看最新的系统日志:…...

【ubuntu】安装ZIP
【ubuntu】安装ZIP 输入如下命令安装zip $ sudo apt-get install zip 输出信息如下: Reading package lists... Done Building dependency tree Reading state information... Done The following additional packages will be installed: unzip The follo…...

DiffDock源码解析
DiffDock源码解析 数据预处理 数据输入方式 df pd.read_csv(args.protein_ligand_csv), 使用的是csv的方式输入, 格式: 不管受体还是配体, 输入可以是序列或者3维结构的文件 如果蛋白输入的是序列,需要计算蛋白的三维结构&am…...
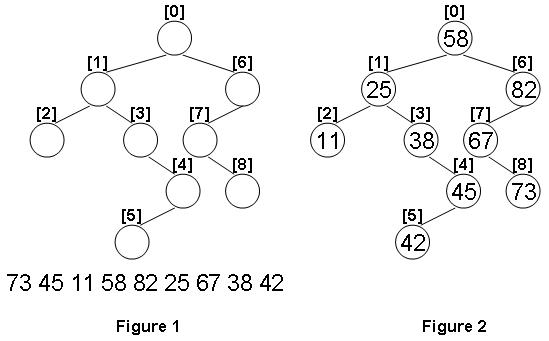
1099 Build A Binary Search Tree(超详细注解+38行代码)
分数 30 全屏浏览题目 作者 CHEN, Yue 单位 浙江大学 A Binary Search Tree (BST) is recursively defined as a binary tree which has the following properties: The left subtree of a node contains only nodes with keys less than the nodes key.The right subtree…...
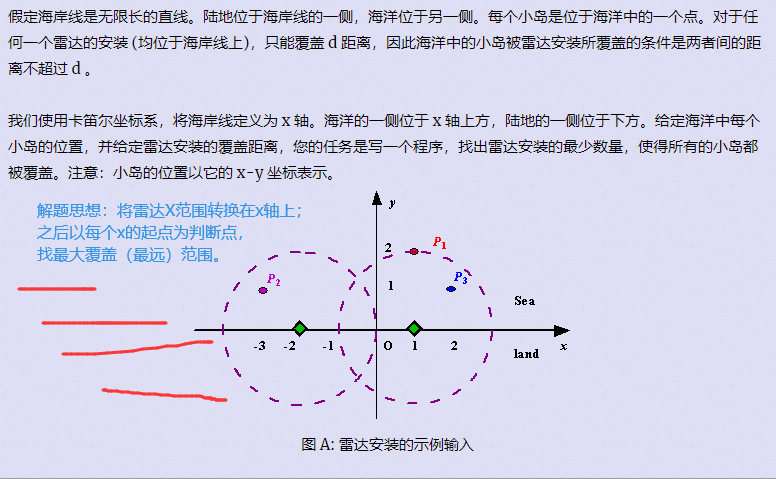
[刷题]贪心入门
文章目录 贪心区间问题区间选点区间合并区间覆盖 哈夫曼树(堆)合并果子 排序不等式排队打水 绝对值不等式货仓选址 推出来的不等式耍杂技的牛 以前的题 贪心 贪心:每一步行动总是按某种指标选取最优的操作来进行, 该指标只看眼前&…...
项目集战略一致性
项目集战略一致性是识别项目集输出和成果,以便与组织的目标和目的保持一致的绩效领域。 本章内容包括: 1 项目集商业论证 2 项目集章程 3 项目集路线图 4 环境评估 5 项目集风险管理战略 项目集应与组织战略保持一致,并促进组织效益的实现。为…...
Linux学习 Day3
目录 1. 时间相关的指令 2. cal指令 3. find指令:(灰常重要) -name 4. grep指令 5. zip/unzip指令 6. tar指令(重要):打包/解包,不打开它,直接看内容 7. bc指令 8. uname –…...

前端开发推荐vscode安装什么插件?
前言 可以参考一下下面我推荐的插件,注意:插件的目的是用于提高开发的效率,节约开发的时间,像类似检查一些bug、拼写错误等这些可以使用插件快速的识别,避免在查找错误上浪费过多的时间,但切记不要过度依赖…...

如何打造完整的客户服务体系?
对于企业来说,提供优质的客户服务是保持竞争力和赢得市场份额的关键因素之一。一个高效、专业、人性化的客户服务体系,对于企业吸引和留住客户,提升品牌声誉,甚至增加销售额都有着不可忽视的作用。本文将从多个方面来阐述如何打造…...

裸奔时代,隐私何处寻?
随着互联网的普及,人工智能时代的大幕初启,数据作为人工智能的重要支撑,数据之争成为“兵家必争之地”,随之而来的就是,各种花式手段“收割”个人信息,用户隐私暴露程度越来越高,隐私保护早已成…...
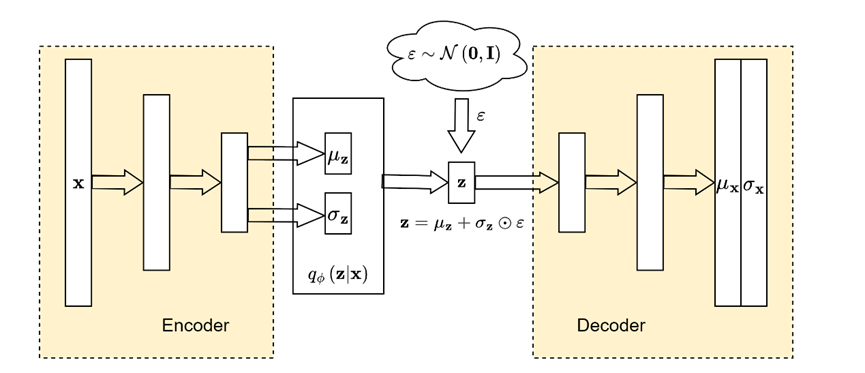
从期望最大化(EM)到变分自编码器(VAE)
本文主要记录了自己对变分自编码器论文的理解。 Kingma D P, Welling M. Auto-encoding variational bayes[J]. arXiv preprint arXiv:1312.6114, 2013. https://arxiv.org/abs/1312.6114 1 带有潜在变量的极大似然估计 假设我们有一个有限整数随机数发生器 z ∼ p θ ( z ) …...

【数学杂记】表达式中的 s.t. 是什么意思
今天写题的时候遇见了这个记号:s.t.,查了一下百度。 s.t.,全称 subject to,意思是“使得……满足”。 比如这个: 意思是存在 i i i,使得 i i i 满足 A i ≠ B i A_i\neq B_i AiBi. 运用这个记号…...

flink watermark介绍及watermark的窗口触发机制
Flink的三种时间 在谈watermark之前,首先需要了解flink的三种时间概念。在flink中,有三种时间戳概念:Event Time 、Processing Time 和 Ingestion Time。其中watermark只对Event Time类型的时间戳有用。这三种时间概念分别表示: …...

Spring Cloud: 云原生微服务实践
文章目录 1. Spring Cloud 简介2. Spring Cloud Eureka:服务注册与发现在Spring Cloud中使用Eureka 3. Spring Cloud Config:分布式配置中心在Spring Cloud中使用Config 4. Spring Cloud Hystrix:熔断器在Spring Cloud中使用Hystrix 5. Sprin…...

存bean和取bean
准备工作存bean获取bean三种方式 准备工作 bean:一个对象在多个地方使用。 spring和spring boot:spring和spring boot项目;spring相当于老版本 spring boot本质还是spring项目;为了方便spring项目的搭建;操作起来更加简单 spring…...

39. 组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。 candidates 中的 同一个 数字可以 无限制重复被选取 。如…...

避坑指南:RuoYi-Vue2集成Flowable 6.7.2时,关于database-schema-update和nullCatalogMeansCurrent的配置详解
深度解析:RuoYi-Vue2集成Flowable 6.7.2的数据库配置陷阱与实战策略 当企业级应用需要引入工作流引擎时,Flowable因其轻量化和高性能成为许多开发团队的首选。然而在RuoYi-Vue2框架中集成Flowable 6.7.2版本时,数据库配置环节往往成为开发者的…...

Day4 Python的函数和参数机制
函数的定义与调用最基本的函数结构如下:def greet(name): return f"Hello, {name}!" print(greet("Alice")) def 定义函数调用时传入对应参数如果参数数量或顺序不匹配,就会报错,这是最常见的问题之一。默认参数默认参数…...

如何用tiny11builder打造轻量Windows 11系统:绕过硬件限制的完整指南
如何用tiny11builder打造轻量Windows 11系统:绕过硬件限制的完整指南 【免费下载链接】tiny11builder Scripts to build a trimmed-down Windows 11 image. 项目地址: https://gitcode.com/GitHub_Trending/ti/tiny11builder 老旧电脑无法流畅运行Windows 11…...

C#开发者的福音:用SqlSugar封装一个通用数据访问层,支持SQLite/SQL Server/MySQL一键切换
构建企业级数据访问层:SqlSugar多数据库适配架构实战 在当今快速迭代的软件开发环境中,数据访问层作为连接业务逻辑与持久化存储的关键桥梁,其设计质量直接影响着系统的可维护性和扩展性。对于C#开发者而言,SqlSugar以其轻量级和高…...
【C++】)
CCF-CSP 39-2 水印检查(watermark)【C++】
题目 https://sim.csp.thusaac.com/contest/39/problem/1https://sim.csp.thusaac.com/contest/39/problem/1 思路参考: 80分 暴力求解,遍历所有可能的k,检验是否满足条件,可得80分 时间复杂度:O(L*n^2)࿰…...

终极指南:在PC上完美运行PS4游戏的秘密武器
终极指南:在PC上完美运行PS4游戏的秘密武器 【免费下载链接】shadPS4 PS4 emulator for Windows,Linux,MacOS 项目地址: https://gitcode.com/gh_mirrors/shad/shadPS4 你是否曾经梦想过在电脑上畅玩那些只能在PS4上体验的独占大作?今天ÿ…...

我的LVDS信号有振铃?可能是端接电阻没选对!从仿真到实测的端接方案选择指南
LVDS信号振铃问题全解析:从端接电阻选择到实测验证 振铃现象是LVDS信号传输中最令人头疼的问题之一。当你在示波器上看到信号边沿出现振荡波形时,第一反应可能是怀疑PCB布局或信号源质量。但经验丰富的工程师都知道,80%的振铃问题根源在于端接…...

3个强力功能解决微信聊天记录永久保存难题的完整指南
3个强力功能解决微信聊天记录永久保存难题的完整指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg 你…...

从零开始:使用Deepspeed ZeRO3优化Qwen3-8B微调,解决多卡显存不足问题
从零开始:使用Deepspeed ZeRO3优化Qwen3-8B微调,解决多卡显存不足问题 当你面对一个8B参数规模的大语言模型时,单卡训练往往显得力不从心。显存不足的报错就像一堵高墙,阻挡着许多开发者的探索之路。而多卡并行训练又带来了新的挑…...

OpenClaw调试技巧:百川2-13B任务失败时的日志分析与修复
OpenClaw调试技巧:百川2-13B任务失败时的日志分析与修复 1. 当自动化任务突然罢工时 上周三凌晨2点,我的OpenClaw突然停止了工作——这个本该在深夜自动整理会议纪要并归档的助手,悄无声息地宕机了。监控屏幕显示它卡在"正在调用百川2…...