Linux 设备驱动程序(二)

系列文章目录
Linux 内核设计与实现
深入理解 Linux 内核(一)
深入理解 Linux 内核(二)
Linux 设备驱动程序(一)
Linux 设备驱动程序(二)
Linux设备驱动开发详解
文章目录
- 系列文章目录
- 十、中断处理
- 1、安装中断处理例程
- (1)内核帮助下的探测
- (2)x86 平台上中断处理的内幕
- 2、 顶半部和底半部
- (1)tasklet
- (2)工作队列
- 3、中断共享
- (1)安装共享的处理例程
- (2)运行处理例程
- 4、快速参考
- 十一、内核的数据类型
- 1、快速参考
- 十二、PCI驱动程序
- 1、PCI接口
- (1)PCI 寻址
- (2)引导阶段
- (3)配置寄存器和初始化
- (4)MODULE_DEVICE_TABLE
- (5)注册 PCI 驱动程序
- (6)激活 PCI 设备
- (7)访问配置空间
- (8)访问 I/O 和内存空间
- (9)PCI 中断
- (10)硬件抽象
- 2、ISA回顾
- 3、PC/104 和 PC/104+
- 4、其他的PC总线
- 5、SBus
- 6、NuBus
- 7、外部总线
- 8、快速参考
- 十三、USB驱动程序
- 1、 USB设备基础
- 2、 USB和Sysfs
- 3、 USB urb
- (1)struct urb
- (2)创建和销毁 urb
- (a)中断 urb
- (b)批量 urb
- (c)控制 urb
- (d)等时 urb
- (3)提交 urb
- (4)结束 urb:结束回调处理例程
- (5)取消 urb
- 4、 编写USB驱动程序
- (1)驱动程序支持哪些设备?
- (2)注册 USB 驱动程序
- (3)探测和断开的细节
- (4)提交和控制 urb
- 5、 不使用urb的USB传输
- (1)usb_bulk_msg
- (2)usb_control_msg
- (3)其他 USB 数据函数
- 6、 快速参考
十、中断处理
1、安装中断处理例程
如果读者确实想 “看到” 产生的中断,那么仅仅通过向硬件设备写入是不够的,还必须要在系统中安装一个软件处理例程。如果没有通知 Linux 内核等待用户的中断,那么内核只会简单应答并忽略该中断。
中断信号线是非常珍贵且有限的资源,尤其是在系统上只有 15 根或 16 根中断信号线时更是如此。内核维护了一个中断信号线的注册表,该注册表类似于 I/O 端口的注册表。模块在在使用中断前要先请求一个中断通道(或者中断请求 IRQ),然后在使用后释放该通道。我们将会在后面看到,在很多场合下,模块也希望可以和其他的驱动程序共享中断信号线。下列在头文件 <linux/sched.h> 中声明的函数实现了该接口:
int request_irq(unsigned int irq, irqreturn_t (*handler)(int, void *, struct pt_regs *),unsigned long flags, const char *dev_name, void *dev_id);
void free_irq(unsigned int irq, void *dev_id);
通常,从 request_irq 函数返回给请求函数的值为 0 时表示申请成功,为负值时表示错误码。函数返回 -EBUSY 表示已经有另一个驱动程序占用了你要请求的中断信号线。这些函数的参数如下:
unsigned int irq
这是要申请的中断号。
irqreturn_t (*handler)(int, void *, struct pt_regs *)
这是要安装的中断处理函数指针。我们会在本章的后面部分讨论这个函数的参数含义。
unsigned long flags
如读者所想,这是一个与中断管理有关的位掩码选项(将在后面描述)。
const char *dev_name
传递给 request_irq 的字符串,用来在 /proc/interrupts 中显示中断的拥有者(参见下节)。
void *dev_id
这个指针用于共享的中断信号线。它是唯一的标识符,在中断信号线空闲时可以使
用它,驱动程序也可以使用它指向驱动程序自己的私有数据区(用来识别哪个设备
产生中断)。在没有强制使用共享方式时,dev_id 可以被设置为 NULL,总之用它
来指向设备的数据结构是一个比较好的思路。我们会在本章后面的 “实现处理例
程” 一节中看到 dev_id 的实际应用。
可以在 flags 中设置的位如下所示:
SA_INTERRUPT
当该位被设置时,表明这是一个 “快速” 的中断处理例程。快速处理例程运行在中
断的禁用状态下(更详细的主题将在本章后面的 “快速和慢速处理例程” 一节中讨论)。
SA_SHIRQ
该位表示中断可以在设备之间共享。共享的概念将在本章后面的 “中断共享” 一节描述。
SA_SAMPLE_RANDOM
该位指出产生的中断能对 /dev/random 设备和 /dev/urandom 设备使用的熵池
(entropy pool)有贡献。从这些设备读取,将会返回真正的随机数,从而有助于应
用软件选择用于加密的安全密钥。这些随机数是从一个熵池中得到的,各种随机事
件都会对该熵池作出贡献,如果读者的设备以真正随机的周期产生中断,就应该设
置该标志位。另一方面,如果中断是可预期的(列如,帧捕捉卡的垂直消隐),就
不值得设置这个标志位 —— 它对系统的熵没有任何贡献。能受到攻击者影响的设
备不应该设置该位,例如,网络驱动程序会被外部的事件影响到预定的数据包的时
间周期,因而也不会对熵池有贡献,更详细的信息请参见 drivers/char/random.c 文
件中的注释。
中断处理例程可在驱动程序初始化时或者设备第一次打开时安装。虽然在模块的初始化函数中安装中断处理例程看起来是个好主意,但实际上并非如此。因为中断信号线的数量是非常有限的,我们不想肆意浪费。计算机拥有的设备通常要比中断信号线多得多,如果一个模块在初始化时请求了 IRQ,那么即使驱动程序只是占用它而从未使用,也将会阻止任意一个其他的驱动程序使用该中断。而在设备打开的时候申请中断,则可以共享这些有限的资源。
这种情况很可能出现,例如,在运行一个与调制解调器共用同一中断的帧捕捉卡驱动程序时,只要不同时使用这两个设备就可以共享同一中断。用户在系统启动时装载特殊的设备模块是一种普遍做法,即使该设备很少使用。数据捕捉卡可能会和第二个串口使用相同的中断,我们可以在捕获数据时,避免使用调制解调器连接到互联网服务供应商(ISP),但是如果为了使用调制解调器而不得不卸载一个模块,总是令人不快的。
调用 request_irq 的正确位置应该是在设备第一次打开、硬件被告知产生中断之前。调用 free_irq 的位置是最后一次关闭设备、硬件被告知不用再中断处理器之后。这种技术的缺点是必须为每个设备维护一个打开计数,这样我们才能知道什么时候可以禁用中断。
尽管我们已经讨论了不应该在装载模块时调用 request_irq,但 short 模块还是在装载时请求了它的中断信号线,这样做的方便之处是,我们可以直接运行测试程序,而不需要额外运行其他的进程来保持设备的打开状态。因此,short 在它自己的初始化函数(short_init)中请求中断,而不是像真正的设备驱动那样在 short_open 中请求中断。
下面这段代码要请求的中断是 short_irq,对这个变量的实际赋值操作(例如,决定使用哪个 IRQ)会在后面给出,因为它与当前的讨论无关。short_base 是并口使用的 I/O 地址空间的基地址;向并口的 2 号寄存器写入,可以启用中断报告。
if (short_irq >= 0)result = request_irq(short_irq, short_interrupt, SA_INTERRUPT, "short", NULL);if (result) {printk(KERN_INFO "short: can't get assigned irq %i\n", short_irq);short_irq = -1;} else {/* 真正启用中断 —— 假定这是一个并口 */outb(0x10, short_base + 2);}
}
(1)内核帮助下的探测
Linux 内核提供了一个底层设施来探测中断号。它只能在非共享中断的模式下工作,但是大多数硬件有能力工作在共享中断的模式下,并可提供更好的找到配置中断号的方法。内核提供的这一设施由两个函数组成,在头文件 <linux/interrupt.h> 中声明(该文件也描述了探测机制):
unsigned long probe_irq_on(void) ;
这个函数返回一个未分配中断的位掩码。驱动程序必须保存返回的位掩码,并且将它传递给后面的 probe_irq_off 函数,调用该函数之后,驱动程序要安排设备产生至少一次中断。
int probe_irq_off(unsigned long);
在请求设备产生中断之后,驱动程序调用这个函数,并将前面 probe_irq_on 返回的位掩码作为参数传递给它。probe_irq_off 返回 “probe_irq_on” 之后发生的中断编号。如果没有中断发生,就返回 0(因此,IRQ 0 不能被探测到,但在任何已支持的体系结构上,没有任何设备能够使用 IRQ 0)。如果产生了多次中断(出现二义性),probe_irq_off 会返回一个负值。
程序员要注意在调用 probe_irq_on 之后启用设备上的中断,并在调用 probe_irq_off之前禁用中断。此外要记住,在 probe_irq_off 之后,需要处理设备上待处理的中断。
(2)x86 平台上中断处理的内幕
下面的描述是从 2.6 内核中的文件 arch/i386/kernel/irq.c、arch/i386/kernel/apic.c、arch/i386/kernel/entry.S、arch/i386/kernel/i8259.c 以及 include/asm-i386/hw_irq.h 中得出的。虽然基本概念是相同的,但是硬件细节还是与其他平台有所区别。
最底层的中断处理代码可见 entry.S 文件,该文件是一个汇编语言文件,完成了许多机器级的工作。这个文件利用几个汇编技巧及一些宏,将一段代码用于所有可能的中断。在所有情况下,这段代码将中断编号压入栈,然后跳转到一个公共段,而这个公共段会调用在 irq.c 中定义的 do_IRQ 函数。
do_IRQ 做的第一件事是应答中断,这样中断控制器就可以继续处理其他的事情了。然后该函数对于给定的 IRQ 号获得一个自旋锁,这样就阻止了任何其他的 CPU 处理这个 IRQ。接着清除几个状态位(包括一个我们很快会讲到的 IRQ_WAITING),然后寻找这个特定 IRQ 的处理例程。如果没有处理例程,就什么也不做;自旋锁被释放,处理任何待处理的软件中断,最后 do_IRQ 返回。
通常,如果设备有一个已注册的处理例程并且发生了中断,则函数:handle_IRQ_event 会被调用以便实际调用处理例程。如果处理例程是慢速类型(即 SA_INTERRUPT 未被设置),将重新启用硬件中断,并调用处理例程。然后只是做一些清理工作,接着运行软件中断,最后返回到常规工作。作为中断的结果(例如,处理例程可以 wake_up 一个进程),“常规工作” 可能已经被改变,所以,从中断返回时发生的最后一件事情可能就是一次处理器的重新调度。
IRQ 的探测是通过为每个缺少中断处理例程的 IRQ 设置 IRQ_WAITING 状态位来完成的。当中断产生时,因为没有注册处理例程,do_IRQ 请除该位然后返回。当 probe_irq_off 被一个驱动程序调用的时候,只需要搜索那些没有设置 IRQ_WAITING 位的 IRQ。
2、 顶半部和底半部
中断处理的一个主要问题是怎样在处理例程内完成耗时的任务。响应一次设备中断需要完成一定数量的工作,但是中断处理例程需要尽快结束而不能使中断阻塞的时间过长,这两个需求(工作和速度)彼此冲突,让驱动程序的作者多少有点困扰。
Linux(连同很多其他的系统)通过将中断处理例程分成两部分来解决这个问题。称为 “顶半部” 的部分,是实际响应中断的例程,也就是用 request_irq 注册的中断例程;而所谓的 “底半部” 是一个被顶半部调度,并在稍后更安全的时间内执行的例程。顶半部处理例程和底半部处理例程之间最大的不同,就是当底半部处理例程执行时,所有的中断都是打开的 —— 这就是所谓的在更安全时间内运行。典型的情况是顶半部保存设备的数据到一个设备特定的缓冲区并调度它的底半部,然后退出: 这个操作是非常快的。然后,底半部执行其他必要的工作,例如唤醒进程、启动另外的 I/O 操作等等。这种方式允许在底半部工作期间,顶半部还可以继续为新的中断服务。
几乎每一个严格的中断处理例程都是以这种方式分成两部分的。例如,当一个网络接口报告有新数据包到达时,处理例程仅仅接收数据并将它推到协议层上,而实际的数据包处理过程是在底半部执行的。
Linux 内核有两种不同的机制可以用来实现底半部处理、我们已经在第七章介绍过这两种机制了。tasklet 通常是底半部处理的优选机制;因为这种机制非常快,但是所有的 tasklet 代码必须是原子的。除了 tasklet 之外,我们还可以选择工作队列,它可以具有更高的延迟,但允许休眠。
下面再次用 short 驱动程序来进行我们的讨论。在使用某个模块选项装载时,可以通知 short 模块使用顶 / 底半部的模式进行中断处理,并采用 tasklet 或者工作队列处理例程。因此,顶半部执行得就很快,因为它仅保存当前时间并调度底半部处理。然后底半部负责这些时间的编码、并唤醒可能等待数据的任何用户进程。
(1)tasklet
记住 tasklet 是一个可以在由系统决定的安全时刻在软件中断上下文被调度运行的特殊函数。它们可以被多次调度运行,但 tasklet 的调度并不会累积;也就是说,实际只会运行一次,即使在激活 tasklet 的运行之前重复请求该 tasklet 的运行也是这样。不会有同一 tasklet 的多个实例并行地运行,因为它们只运行一次,但是 tasklet 可以与其他的 tasklet 并行地运行在对称多处理器(SMP)系统上。这样,如果驱动程序有多个 tasklet、它们必须使用某种锁机制来避免彼此间的冲突。
tasklet 可确保和第一次调度它们的函数运行在同样的 CPU 上。这样,因为 tasklet 在中断处理例程结束前并不会开始运行,所以此时的中断处理例程是安全的。不管怎样,在 tasklet 运行时,当然可以有其他的中断发生,因此在 tasklet 和中断处理例程之间的锁还是需要的。
必须使用宏 DECLARE_TASKLET 声明 tasklet:
DECLARE_TASKLET(name, function, data);
name 是给 tasklet 起的名字,function 是执行 tasklet 时调用的函数(它带有一个 unsigned long 型的参数并且返回 void),data 是一个用来传递给 tasklet 函数的 unsigned long 类型的值。
驱动程序 short 如下声明它自己的 tasklet:
void short_do_tasklet(unsigned long);
DECLARE_TASKLET(short_tasklet, short_do_tasklet, 0);
函数 tasklet_schedule 用来调度一个 tasklet 运行。如果指定 tasklet=1 选项装载 short,它就会安装一个不同的中断处理例程,这个处理例程保存数据并如下调度 tasklet:
irqreturn_t short_tl_interrupt(int irq, void *dev_id, struct pt_regs *regs) {/* 强制转换以免出现 "易失性" 警告 */do_gettimeofday((struct timeval *) tv_head);short_incr_tv(&tv_head);tasklet_schedule(&short_tasklet);short_wq_count++; /* 记录中断的产生 */return IRQ_HANDLED;
}
实际的 tasklet 例程,即 short_do_tasklet,将会在系统方便时得到执行。就像先前提到的,这个例程执行中断处理的大多数任务,如下所示:
void short_do_tasklet(unsigned long unused) {int savecount = short_wq_count, written;short_wq_count = 0; /* 已经从队列中移除 *//** 底半部读取由顶半部填充的 tv 数组,* 并向循环文本缓冲区中打印信息,而缓冲区的数据则由* 读取进程获得*//* 首先将调用此 bh 之前发生的中断数量写入 */written = sprintf((char *)short_head, "bh after %6i\n", savecount);short_incr_bp(&short_head, written);/** 然后写入时间值。每次写入 16 字节,* 所以它与 PAGE_SIZE 是对齐的*/ do {written = sprintf((char *)short_head, "%08u.%06u\n",(int)(tv_tail->tv_sec % 100000000),(int)(tv_tail->tv_usec));short_incr_bp(&short_head, written);short_incr_tv(&tv_tail);} while (tv_tail != tv_head);wake_up_interruptible(&short_queue); /* 唤醒任何读取进程 */
}
在其他动作之外,这个 tasklet 记录了自从它上次被调用以来产生了多少次中断。一个类似于 short 的设备可以在很短的时间内产生很多次中断、所以在底半部被执行前,肯定会有多次中断发生。驱动程序必须一直对这种情况有所准备,并且必须能根据顶半部保留的信息知道有多少工作需要完成。
// include/linux/interrupt.h
static inline void tasklet_schedule(struct tasklet_struct *t)
{if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))__tasklet_schedule(t);
}// kernel/softirq.c
void __tasklet_schedule(struct tasklet_struct *t)
{unsigned long flags;local_irq_save(flags);t->next = NULL;*__get_cpu_var(tasklet_vec).tail = t;__get_cpu_var(tasklet_vec).tail = &(t->next);raise_softirq_irqoff(TASKLET_SOFTIRQ);local_irq_restore(flags);
}EXPORT_SYMBOL(__tasklet_schedule);
(2)工作队列
读者应该记得,工作队列会在将来的某个时间、在某个特殊的工作者进程上下文中调用一个函数。因为工作队列函数运行在进程上下文中,因此可在必要时休眠。但是我们不能从工作队列向用户空间复制数据,除非使用将在第十五章中描述的高级技术,要知道,工作者进程无法访问其他任何进程的地址空间。
如果在装载 short 驱动程序时将 wq 选项设置为非零值,则该驱动程序将使用工作队列作为其底半部进程。它使用系统的默认工作队列,因此不需要其他特殊的设置代码;但是,如果我们的驱动程序具有特殊的延迟需求(或者可能在工作队列函数中长时间休眠),则应该创建我们自己的专用工作队列。我们需要一个 work_struct 结构,该结构如下声明并初始化:
static struct work_struct short_wq;
/* 下面这行出现在 short_init() 中 */
INIT_WORK(&short_wq, (void (*)(void *)) short_do_tasklet, NULL);
我们的工作者函数是 short_do_tasklet,该函数已经在先前的小节中介绍过了。
在使用工作队列时,short 构造了另一个中断处理例程,如下所示:
irqreturn_t short_wq_interrupt(int irq, void *dev_id, struct pt_regs *regs) {/* 获取当前的时间信息。 */do_gettimeofday((struct timeval *) tv_head);short_incr_tv(&tv_head);/* 排序 bh,不必关心多次调度的情况 */schedule_work(&short_wq);short_wq_count++; /* 记录中断的到达 */return IRQ_HANDLED;
}
读者可以看到,该中断处理例程和 tasklet 版本非常相似,唯一的不同是它调用 schedule_work 来安排底半部处理。
// kernel/workqueue.c
int schedule_work(struct work_struct *work)
{return queue_work(keventd_wq, work);
}
EXPORT_SYMBOL(schedule_work);int queue_work(struct workqueue_struct *wq, struct work_struct *work)
{int ret;ret = queue_work_on(get_cpu(), wq, work);put_cpu();return ret;
}
EXPORT_SYMBOL_GPL(queue_work);int
queue_work_on(int cpu, struct workqueue_struct *wq, struct work_struct *work)
{int ret = 0;if (!test_and_set_bit(WORK_STRUCT_PENDING, work_data_bits(work))) {BUG_ON(!list_empty(&work->entry));__queue_work(wq_per_cpu(wq, cpu), work);ret = 1;}return ret;
}
EXPORT_SYMBOL_GPL(queue_work_on);static void __queue_work(struct cpu_workqueue_struct *cwq,struct work_struct *work)
{unsigned long flags;debug_work_activate(work);spin_lock_irqsave(&cwq->lock, flags);insert_work(cwq, work, &cwq->worklist);spin_unlock_irqrestore(&cwq->lock, flags);
}static void insert_work(struct cpu_workqueue_struct *cwq,struct work_struct *work, struct list_head *head)
{trace_workqueue_insertion(cwq->thread, work);set_wq_data(work, cwq);/** Ensure that we get the right work->data if we see the* result of list_add() below, see try_to_grab_pending().*/smp_wmb();list_add_tail(&work->entry, head);wake_up(&cwq->more_work);
}
3、中断共享
“IRQ 冲突” 这种说法和 “PC 架构” 几乎是同义语。通常,PC 上自 IRQ 信号线不能为一个以上的设备服务,它们从来都是不够用的,结果,许多没有经验的用户总是花费很多时间试图找到一种方法使所有的硬件能够协同工作,因此他们不得不总是打开自己计算机的外壳。
当然,现代硬件已经能允许中断的共享了,比如 PCL 总线就要求外设可共享中断。因此,Linux 内核支持所有总线的中断共享,即使在类似 ISA 这样原先并不支持共享的总线上。针对 2.6 内核的设备驱动程序,应该在目标硬件可以支持共享中断操作的情况下处理中断的共享。幸运的是,大多数情况下很容易使用共享的中断。
(1)安装共享的处理例程
就像普通非共享的中断一样,共享的中断也是通过 request_irq 安装的,但是有两处不同:
- 请求中断时,必须指定 flags 参数中的 SA_SHIRQ 位。
- dev_id 参数必须是唯一的。任何指向模块地址空间的指针都可以使用,但 dev_id 不能设置成 NULL 。
内核为每个中断维护了一个共享处理例程的列表,这些处理例程的 dev_id 各不相同,就像是设备的签名。如果两个驱动程序在同一个中断上都注册 NULL 作为它们的签名,那么在卸载的时候引起混淆,当中断到达时造成内核出现 oops 消息。由于这个原因,在注册共享中断时如果传递了值为 NULL的 dev_id,现代的内核就会给出警告。当请求一个共享中断时,如果满足下面条件之一,那么 request_irq 就会成功:
- 中断信号线空闲。
- 任何已经注册了该中断信号线的处理例程也标识了 IRQ 是共享的。
无论何时,当两个或者更多的驱动程序共享同一根中断信号线,而硬件又通过这根信号线中断处理器时,内核会调用每一个为这个中断注册的处理例程,并将它们自己的 dev_id 传回去。因此,一个共享的处理例程必须能够识别属于自己的中断,并且在自己的设备没有被中断的时候迅速退出。
如果读者在请求中断请求信号线之前需要探测设备的话,则内核不会有所帮助,对于共享的处理例程是没有探测函数可以利用的。仅当要使用的中断信号线处于空闲时,标准的探测机制才能工作。但如果信号线已经被其他具有共享特性的驱动程序占用的话,即使你的驱动已经可以很好的工作了,探测也会失败。幸运的是,多数可共享中断的硬件能够告诉处理器它们在使用哪个中断,这样就消除了显式探测的必要。
释放处理例程同样是通过执行 free_irq 来实现的。这里 dev_id 参数被用来从该中断的共享处理例程列表中选择正确的处理例程来释放,这就是为什么 dev_id 指针必须唯一的原因。
使用共享处理例程的驱动程序需要小心一件事情:不能使用 enable_irq 和 disable_irq。如果使用了,共享中断信号线的其他设备就无法正常工作了;即使在很短的时间内禁用中断,也会因为这种延迟而为设备和其用户带来问题。通常,程序员必须记住他的驱动程序并不独占 IRQ,所以它的行为必须比独占中断信号线时更 “社会化” 。
(2)运行处理例程
如上所述,当内核收到中断时,所有已注册的处理例程都将被调用。一个共享中断处理例程必须能够将要处理的中断和其他设备产生的中断区分开来。
装载 short 时,如果指定 shared=1 选项,则将安装下面的处理例程而不是默认的处理例程:
irqreturn_t short_sh_interrupt(int irq, void *dev_id, struct pt_regs *regs) {int value, written;struct timeval tv;/* 如果不是 short 产生的, 则立即返回 */value = inb(short_base);if (!(value & 0x80))return IRQ_NONE;/* 清除中断位 */outb(value & 0x7F, short_base);/* 其余部分没有什么变化 */do_gettimeofday(&tv);written = sprintf((char *)short_head,"%08u.%06u\n",(int)(tv.tv_sec 100000000), (int)(tv.tv_usec));short_incr_bp(&short_head, written);wake_up_interruptible(&short_queue); /* 唤醒任何的读取进程 */return IRQ_HANDLED;
}
4、快速参考
本章介绍了与中断管理相关的符号:
#include <linux/interrupt.h>
int request_irq(unsigned int irq, irqreturn_t (*handler)(), unsigned long flags, const char *dev_name, void *dev_id);
void free_irq(unsigned int irq, void *dev_id);
// 上面这些调用用来注册和注销中断处理例程。#include <linux/irq.h>
int can_request_irq(unsigned int irq, unsigned long flags);
// 上述函数只在 i386 和 x86_64 体系架构上可用。当试图分配某个给定中断线的请求成功时,则返回非零值。#include <asm/signal.h>
SA_INTERRUPT
SA_SHIRQ
SA_SAMPLE_RANDOM
// request_irq 函数的标志。SA_INTERRUPT要求安装一个快速的处理例程(相对于慢速的)。SA_SHIRQ
// 安装一个共享的处理例程,而第三个标志表明中断时间戳可用来产生系统熵。
/proc/interrupts
/proc/stat
这些文件系统节点用于汇报关于硬件中断和已安装处理例程的信息。
unsigned long probe_irq_on(void);
int probe_irq_off(unsigned long);
// 当驱动程序不得不探测设备,以确定该设备使用哪根中断信号线时,可以使用上述
// 函数。在中断产生之后,probe_irq_on 的返回值必须传回给 probe_irq_off,而
// probe_irq_off 的返回值就是检测到的中断号。
IRQ_NONE
IRQ_HANDLED
IRQ_RETVAL(int x)
中断处理例程的可能返回值,它们表示是否是一个真正来自设备的中断。
void disable_irq(int irq);
void disable_irq_nosync(int irq);
void enable_irq(int irq);
// 驱动程序可以启用和禁用中断报告。如果硬件试图在中断被禁用的时候产生中断,
// 中断将永久丢失。使用共享处理例程的驱动程序不能使用这些函数。void local_irq_save(unsigned long flags);
void local_irq_restore(unsigned long flags);
// 使 local_irq_save 可禁用本地处理器上的中断,并记录先前的状态。flags 可传
// 递给 local_irq_restore 以恢复先前的中断状态。void local_irq_disable(void);
void local_irq_enable(void);
// 用于无条件禁用和启用当前处理器中断的函数。
十一、内核的数据类型
1、快速参考
本章介绍了如下符号:
#include <linux/types.h>
typedef u8;
typedef u16;
typedef u32;
typedef u64;
// 确保是 8、16、32 和 64 位的无符号整数值类型。对应的有符号类型同样存在。在
// 用户空间,读者可以使用 __u8 和 __u16 等类型。#include <asm/page.h>
PAGE_SIZE
PAGE_SHIFT
// 定义了当前体系架构的每页字节数和页偏移位数 (4 KB 页为 12、8 KB 页为 13) 的符号。#include <asm/byteorder.h>
__LITTLE_ENDIAN
__BIG_ENDIAN
// 这两个符号只有一个被定义,取决于体系架构。#include <asm/byteorder.h>
u32 __cpu_to_le32(u32);
u32 __le32_to_cpu(u32);
// 在已知字节序和处理器字节序之间进行转换的函数。有超过 60 个这样的函数;
// 关于它们的完整列表和如何定义,请查阅 include/linux/byteorder/ 下的各种
// 文件#include <asm/unaligned.h>
get_unaligned(ptr);
put_unaligned(val, ptr);
// 某些体系架构需要使用这些宏来保护未对齐的数据。对于允许访问未对齐数据的
// 体系架构,这些宏扩展为普通的指针取值。#include <linux/err.h>
void *ERR_PTR(long error);
long PTR_ERR(const void *ptr);
long IS_ERR(const void *ptr);
// 这些函数允许从返回指针值的函数中获得错误编码。#include <linux/list.h>
list_add(struct list_head *new, struct list_head *head);
list_add_tail(struct list_head *new, struct list_head *head);
list_del(struct list_head *entry);
list_del_init(struct list_head *entry);
list_empty(struct list_head *head);
list_entry(entry, type, member);
list_move(struct list_head *entry, struct list_head *head);
list_move_tail(struct list_head *entry, struct list_head *head);
list_splice(struct list_head *list, struct list_head *head);
// 操作循环、双向链表的函数list_for_each(struct list_head *cursor, struct list_head *list)
list_for_each_prev(struct list_head *cursor, struct list_head *list)
list_for_each_safe(struct list_head *cursor, struct list_head *next, struct list_head *list)
list_for_each_entry(type *cursor, struct list_head *list, member)
list_for_each_entry_safe(type *cursor, type *next, struct list_head *list, member)
十二、PCI驱动程序
1、PCI接口
外围设备互联 PCI (Peripheral Component Interconnect)。
(1)PCI 寻址
每个 PCI 外设由一个总线编号、一个设备编号及一个功能编号来标识。PCI 规范允许单个系统拥有高达 256 个总线,但是因为 256 个总线对于许多大型系统而言是不够的,因此,Linux 目前支持 PCI 域。每个 PCI 域可以拥有最多 256 个总线。每个总线上可支持 32 个设备,而每个设备都可以是多功能板(例如音频设备外加 CD-ROM 驱动器),最多可有八种功能。所以,每种功能都可以在硬件级由一个 16 位的地址(或键)来标识。不过,为 Linux 编写的设备驱动程序无需处理这些二进制的地址,因为它们使用一种特殊的数据结构(名为 pci_dev)来访问设备。
当前的工作站一般配置有至少两个 PCI 总线。在单个系统中插入多个总线,可通过桥(bridge)来完成,它是用来连接两个总线的特殊 PCI 外设。PCI 系统的整体布局组织为树型,其中每个总线连接到上一级总线,直到树根的 0 号总线。CardBus PC 卡系统也是通过桥连接到 PCI 系统的。典型的 PCI 系统可见图 12-1,其中标记出了各种不同的桥。
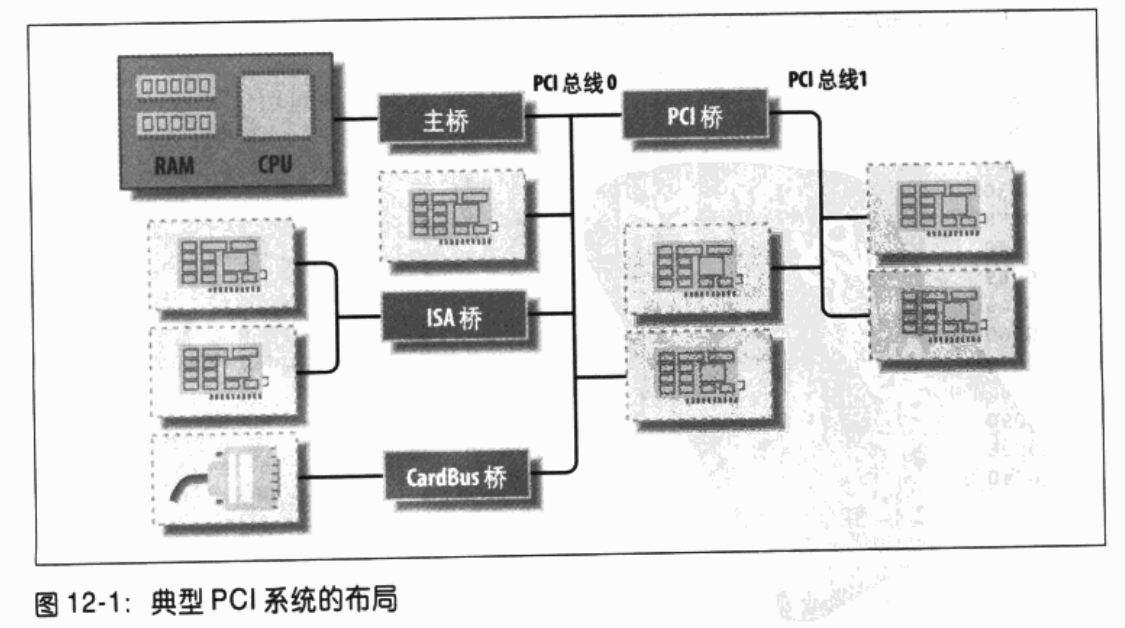
尽管和 PCI 外设关联的 16 位硬件地址通常隐藏在 struct pci_dev 对象中,但有时仍然可见,尤其是这些设备正在被使用时。Ispci(pciutils 包的一部分,包含在大多数发行版中)的输出以及 /proc/pci 和 /proc/bus/pci 中信息的布局就是这种情况。PCI 设备在 sysfs 中的表示同样展现了这种寻址方案,此外还有 PCI 域的信息(注1)。在显示硬件地址时,有时显示为两个值(一个 8 位的总线编号和一个 8 位的设备及功能编号),有时显示为三个值(总线、设备和功能),有时显示为四个值(域、总线、设备和功能);所有的值通常都以 16 进制显示。
例如,/proc/bus/pci/devices 使用单个16 位字段(便于解析及排序),而 /proc/bus/busnumber 将地址划分成了三个字段。下面说明了这些地址如何出现,只列出了输出行的开始部分:

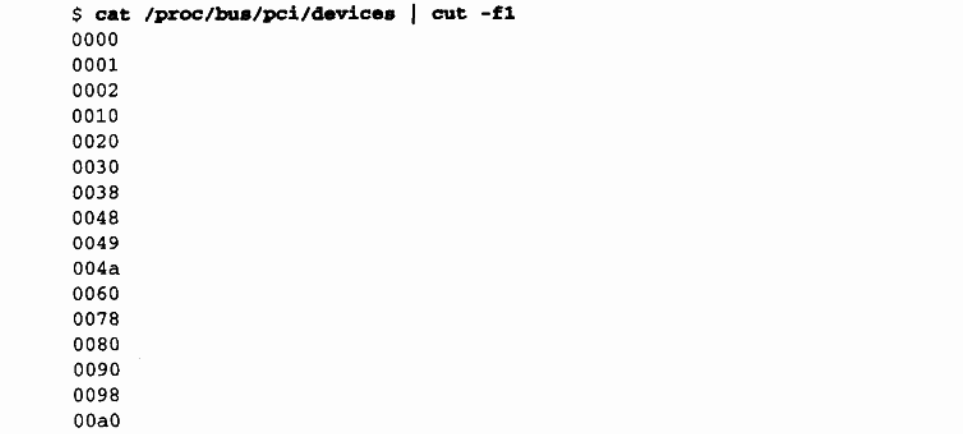
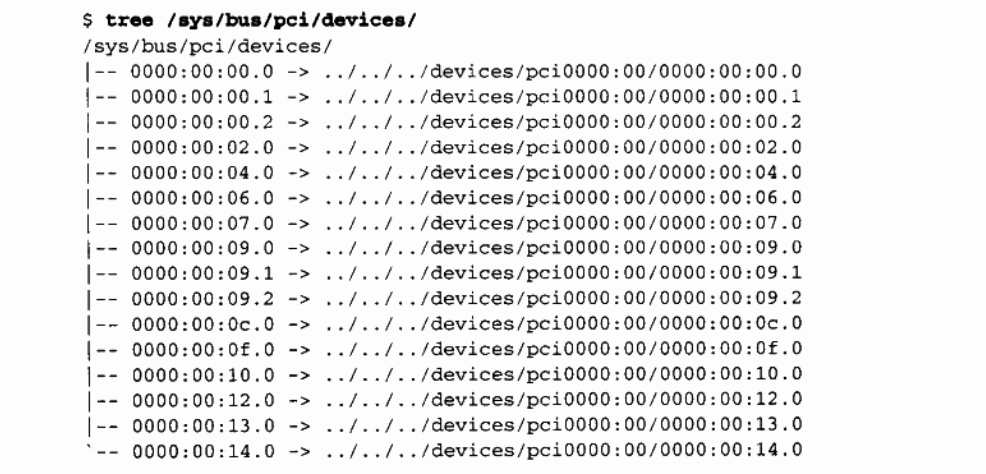
这三个设备清单以相同的顺序排列、因为 Ispci 使用 /proc 文件作为其信息来源。以 VGA 视频控制器为例,当划分为域(16 位)、总线(8 位)、设备(5 位)和功能(3 位)时,0x00a0 表示 0000:00:14.0。
每个外设板的硬件电路对如下三种地址空间的查询进行应答:内存位置、I/O 端口和配置寄存器。前两种地址空间由同一 PCI 总线上的所有设备共享(也就是说,在访问内存位置时,该 PCI 总线上的所有设备将在同一时间看到总线周期)。另一方面,配置空间利用了地理寻址(geographical addressing)。配置查询每次只对一个槽寻址,因此它们根本不会发生任何冲突。
对驱动程序而言,内存和 I/O 区域是以惯常的方式,即通过 inb 和 readb 等等进行访问的。另一方面,配置事务是通过调用特定的内核函数访问配置寄存器来执行的。关于中断,每个 PCI 槽有四个中断引脚,每个设备功能可使用其中的一个,而不用考虑这些引脚如何连接到 CPU。这种路由是计算机平台的职责,实现在 PCI 总线之外。因为 PCI 规范要求中断线是可共享的,因此,即使是 IRQ 线有限的处理器(例如 x86)仍然可以容纳许多 PCI 接口板 (每个有四个中断引脚)。
PCI 总线中的 I/O 空间使用 32 位地址总线(因此可有 4 GB 个端口),而内存空间可通过 32 位或 64 位地址来访问。64 位地址在较新的平台上可用。通常假定地址对设备是唯一的,但是软件可能会错误地将两个设备配置成相同的地址,导致无法访问这两个设备。但是,如果驱动程序不去访问那些不应该访问的寄存器,就不会发生这样的问题。幸好,接口板提供的每个内存和 I/O 地址区域,都可以通过配置事务的方式进行重新映射。就是说,固件在系统引导时初始化 PCI 硬件,把每个区域映射到不同的地址以避免冲突(注 2)。这些区域所映射到的地址可从配置空间中读取,因此,Linux 驱动程序不需要探测就能访问其设备。在读取配置寄存器之后,驱动程序就可以安全访问其硬件。
注 2: 实际上,配置并不限于系统引导阶段,比如热插拔设备在引导阶段并不存在,而是在后来才会出现。这里的要点是,设备驱动程序不能修改 I/O 和内存区域的地址。
PCI 配置空间中每个设备功能由 256 个字节组成(除了 PCI 快速设备以外,它的每个功能有 4 KB 的配置空间),配置寄存器的布局是标准化的。配置空间的 4 个字节含有一个独一无二的功能 ID,因此,驱动程序可通过查询外设的特定 ID 来识别其设备(注 3)。概言之,每个设备板是通过地理寻址来获取其配置寄存器的;这些寄存器中的信息随后可以被用来执行普通的 I/O 寻址,而不再需要额外的地理寻址。
注 3:我们可从设备自己的硬件手册中找到 ID。文件 pci.ids 中包含有一个清单,该文件是 pciutils 包和内核源代码的一部分。该文件并不完整,而只是列出了最著名的制造商及设备。该文件的内核版本将在术来的版本中删除。
到此应该清楚的是,PCI 接口标准在 ISA 之上的主要创新在于配置地址空间。因此,除了通常的驱动程序代码之外,PCI 驱动动程序还需要访问配置空间的能力,以便免去冒险探测的工作。
在本章其余内容中,我们将使用 “设备” 一词来表示一种设备功能,因为多功能板上的每个功能都可以担当一个独立实体的角色。我们谈到设备时,表示的是一组 “域编号、总线编号、设备编号和功能编号”。
(2)引导阶段
为了解 PCI 的工作原理,我们需要从系统引导开始讲起,因为这是配置设备的阶段。
当 PCI 设备上电时,硬件保持未激活状态。换句话说,该设备只会对配置事务做出响应。上电时,设备上不会有内存和 I/O 端口映射到计算机的地址空间;其他设备相关功能,例如中断报告,也被禁止。
幸运的是,每个 PCI 主板均配备有能够处理 PCI 的固件,称为 BIOS 、NVRAM 或 PROM,这取决于具体的平台。固件通过读写 PCI 控制器中的寄存器,提供了对设备配置地址空间的访问。
系统引导时,固件(或者 Linux 内核,如果这样配置的话话)在每个 PCI 外设上执行配置事务,以便为它提供的每个地址区域分配一个安全的位置。当驱动程程序访问设备的时候,它的内存和 I/O 区域已经被映射到了处理器的地址空间。驱动程序可以修改这个默认配置,不过从来不需要这样做。
我们曾经讲过,用户可以通过读取 /proc/bus/pci/devices 和 /proc/bus/pci/*/* 来查看 PCI 设备清单和设备的配置寄存器。前者是个包含有十六进制的设备信息的文本文件,而后者是若干二进制文件,报告了每个设备的配置寄存器快照,每个文件对应一个设备。sysfs 树中的个别 PCI 设备目录可以在 /sys/bus/pci/devices 中找到。一个 PCI 设备目录包含许多不同的文件:

config 文件是一个二进制文件,使原始 PCI 配置信息可以从设备读取(就像 /proc/bus/pci/*/* 所提供的)。vendor、device、subsystem_device、subsystem_vendor 和 class 都表示该 PCI 设备的特定值(所有的 PCI 设备都提供这个信息)。irq 文件显示分配给该 PCI 设备的当前 IRQ,resource 文件显示该设备所分配的当前内存资源。
(3)配置寄存器和初始化
在本节中我们将查看 PCI 设备包含的配置寄存器。所有的 PCI 设备都有至少 256 字节的地址空间。前 64 字节是标准化的,而其余的是设备相关的。图 12-2 显示了设备无关的配置空间的布局。
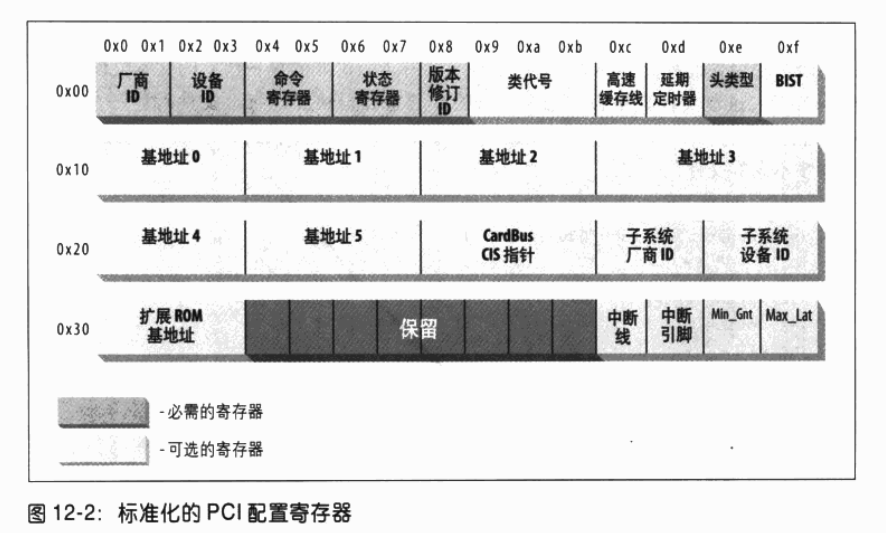
如图 12-2 所示,某些 PCI 配置寄存器是必需的,而某些是可选的。每个 PCI 设备必须在必需的寄存器中包含有效值,而可选寄存器中的内容依赖于外设的实际功能。可选字段通常无用,除非必需字段的内容表明它们是有效的。这样,必需的字段声明了板子的功能,包括其他字段是否有用。
值得注意的是,PCI 寄存器始终是小头的。尽管标准被设计为体系结构无关的,但 PCI 设计者仍然有点偏好 PC 环境。驱动程序编写者在访问多字节的配置寄存器时,要十分注意字节序,因为能够在 PC 上工作的代码到其他平台上可能就无法工作。Linux 开发人员已经注意到了字节序问题(见下一节 “访问配置空间” ),但是这个问题必须被牢记心中。如果需要把数据从系统固有字节序转换成 PCI 字节序,或者相反,则可以借助定义在 <asm/byteorder.h> 中的函数,这些函数在第十一章中介绍过了,注意 PCI 字序是小头的。
对这些配置项的描述已经超过了本书讨论的范围。通常,随设备一同发布的技术文档会详细描述已支持的寄存器。我们所关心的是,驱动程序如何查询设备,以及如何访问设备的配置空间。
用三个或五个 PCI 寄存器可标识一个设备: vendorID、deviceID 和 class 是常用的三个寄存器。每个 PCI 制造商会将正确的值赋予这三个只读寄存器,驱动程序可利用它们查询设备。此外,有时厂商利用 subsystem vendorID 和 subsystem deviceID 两个字段来进一步区分相似的设备。
下面是这些寄存器的详细介绍。
-
vendorID
这是一个 16 位的寄存器,用于标识硬件制造商。例如,每个 Intel 设备被标识为同一个厂商编号,即 0x8086。PCI Special Interest Group 维护有一个全球的厂商编号注册表,制造商必须申请一个唯一编号并赋于它们的寄存器。 -
deviceID
这是另外一个 16 位寄存器,由制造商选择;无需对设备 ID 进行官方注册。该 ID 通常和厂商 ID 配对生成一个唯一的 32 位硬件设备标识符。我们使用签名(signature)一词来表示一对厂商和设备 ID。设备驱动程序通常依靠于该签名来识别其设备;可以从硬件手册中找到目标设备的签名值。 -
class
每个外部设备属于某个类(class),class 寄存器是一个 16 位的值,其中高 8 位标识了 “基类(base class)”、或者组。例如,“ethernet(以太网)” 和 “token ring(令牌环)” 是同属 “network(网络)” 组的两个类,而 “serial(串行)” 和 “parallel(并行)” 类属 “communication(通信)” 组。某些驱动程序可支持多个相似的设备,每个具有不同的签名,但都属于同一个类;这些驱动程序可依靠 class 寄存器来识别它们的外设,如后所述。 -
subsystem vendorID
-
subsystem deviceID
这两个字段可用来进一步识别设备。如果设备中的芯片是一个连接到本地板载(onboard)总线上的通用接口芯片,则可能会用于完全不同的多种用途,这时,驱动程序必须识别它所关心的实际设备。子系统标识符就用于此目的。
PCI 驱动程序可以使用这些不同的标识符来告诉内核它支持什么样的设备。struct pci_device_id 结构体用于定义该驱动程序支持的不同类型的 PCI 设备列表。该结构体包含下列字段:
// include/linux/mod_devicetable.h
struct pci_device_id {__u32 vendor, device; /* Vendor and device ID or PCI_ANY_ID*/__u32 subvendor, subdevice; /* Subsystem ID's or PCI_ANY_ID */__u32 class, class_mask; /* (class,subclass,prog-if) triplet */kernel_ulong_t driver_data; /* Data private to the driver */
};
- __u32 vendor;
- __u32 device;
它们指定了设备的 PCI 厂商和设备 ID。如果驱动程序可以处理任何厂商或者设备 ID、这些字段应该使用值 PCI_ANY_ID。 - __u32 subvendor;
- __u32 subdevice;
它们指定设备的 PCI 子系统厂商和子系统设备 ID。如果驱动程序可以处理任何类型的子系统 ID,这些字段应该使用值 PCI_ANY_ID。 - __u32 class;
- __u32 class_mask;
这两个值使驱动程序可以指定它支持一种 PCI 类(class)设备。PCI 规范中描述了不同类的 PCI 设备(例如 VGA 控制器)。如果驱动程序可以处理任何类型的子系统 ID,这些字段应该使用值 PCI_ANY_ID。 - kernel_ulong_t driver_data;
该值不是用来和设备相匹配的,而是用来保存 PCI 驱动程序用于区分不同设备的信息,如果它需要的话。
应该使用两个辅助宏来进行 struct pci_device_id 结构体的初始化:
- PCI_DEVICE(vendor, device)
它创建一个仅和特定厂商及设备 ID 相匹配的 struct pci_device_id 。这个宏把结构体的 subvendor 和 subdevice 字段设置为 PCI_ANY_ID。 - PCI_DEVICE_CLASS(device_class, device_class_mask)
它创建一个和特定 PCI 类相匹配的 struct pci_device_id 。
下面的内核文件中给出了一个使用这些宏来定义驱动程序支持的设备类型的例子:
// drivers/usb/host/ehci-hcd.c:
static const struct pci_device_id pci_ids[ ] = { {/* 由任何 USB 2.0 EHCI 控制器处理 */PCI_DEVICE_CLASS(((PCI_CLASS_SERIAL_USB << 8) | 0x20), ~0),.driver_data = (unsigned long) &ehci_driver,},{ /* 结束: 全部为零 */ }
};// drivers/i2c/busses/i2c-i810.c:
static struct pci_device_id i810_ids[ ] = {{ PCI_DEVICE(PCI_VENDOR_ID_INTEL, PCI_DEVICE_ID_INTEL_82810_IG1) },{ PCI_DEVICE(PCI_VENDOR_ID_INTEL, PCI_DEVICE_ID_INTEL_82810_IG3) ),{ PCI_DEVICE(PCI_VENDOR_ID_INTEL, PCI_DEVICE_ID_INTEL_82810E_IG) },{ PCI_DEVICE(PCI_VENDOR_ID_INTEL, PCI_DEVICE_ID_INTEL_82815_CGC) },{ PCI_DEVICE(PCI_VENDOR_ID_INTEL, PCI_DEVICE_ID_INTEL_82845G_IG) },{ 0, },
}
这些例子创建了一个 struct pci_device_id 结构体数组,数组的最后一个值是全部设置为 0 的空结构体。这个 ID 数组被用在 struct pci_driver 中(稍后描述),它还被用于告知用户空间这个特定的驱动程序支持什么设备。
(4)MODULE_DEVICE_TABLE
这个 pci_device_id 结构体需要被导出到用户空间,使热插拔和模块装载系统知道什么模块针对什么硬件设备。宏 MODULE_DEVICE_TABLE 完成这个工作。例子:
MODULE_DEVICE_TABLE(pci, i810_ids);
该语句创建一个名为 __mod_pci_device_table 的局部变量,指向 struct pci_device_id 数组。在稍后的内核构建过程中,depmod 程序在所有的模块中搜索符号 __mod_pci_device_table。如果找到了该符号,它把数据从该模块中抽出,添加到文件 /lib/modules/KERNEL_VERSION/modules.pcimap 中。当 depmod 结束之后,内核模块支持的所有 PCI 设备连同它们的模块名都在该文件中被列出。当内核告知热插拔系统一个新的 PCI 设备已经被发现时,热插拔系统使用 modules.pcimap 文件来寻找要装载的恰当的驱动程序。
(5)注册 PCI 驱动程序
为了正确地注册到内核,所有的 PCI 驱动程序都必须创建的主要结构体是 struct pci_driver 结构体。该结构体由许多回调函数和变量组成,向 PCI 核心描述了 PCI 驱动程序。下面列出了该结构体中 PCI 驱动程序必须注意的字段:
// include/linux/pci.h
struct pci_driver {struct list_head node;char *name;const struct pci_device_id *id_table; /* must be non-NULL for probe to be called */int (*probe) (struct pci_dev *dev, const struct pci_device_id *id); /* New device inserted */void (*remove) (struct pci_dev *dev); /* Device removed (NULL if not a hot-plug capable driver) */int (*suspend) (struct pci_dev *dev, pm_message_t state); /* Device suspended */int (*suspend_late) (struct pci_dev *dev, pm_message_t state);int (*resume_early) (struct pci_dev *dev);int (*resume) (struct pci_dev *dev); /* Device woken up */void (*shutdown) (struct pci_dev *dev);struct pci_error_handlers *err_handler;struct device_driver driver;struct pci_dynids dynids;
};
-
const char *name;
驱动程序的名字。在内核的所有 PCI 驱动程序中它必须是唯一的,通常被设置为和驱动程序的模块名相同的名字。当驱动程序运行在内核中时,它会出现在 sysfs 的 /sys/bus/pci/drivers/ 下面。 -
const struct pci_device_id *id_table;
指向本章前面介绍的 struct pci_device_id 表的指针。 -
int (*probe) (struct pci_dev *dev, const struct pci_device_id *id);
指向 PCI 驱动程序中的探测函数的指针。当 PCI 核心有一个它认为驱动程序需要控制的 struct pci_dev 时,就会调用该函数。PCI 核心用来做判断的 struct pci_device_id 指针也被传递给该函数。如果 PCI 驱动程序确认传递给它的 struct pci_dev,则应该恰当地初始化设备然后返回 0。如果驱动程序不确认该设备,或者发生了错误,它应该返回一个负的错误值。本章稍后将对该函数做更详细的介绍。 -
void (*remove) (struct pci_dev *dev);
指向一个移除函数的指针,当 struct pci_dev 被从系统中移除,或者 PCI 驱动程序正在从内核中卸载时,PCI 核心调用该函数。本章稍后将对该函数做更详细的介绍。 -
int (*suspend) (struct pci_dev *dev, u32 state);
指向一个挂起函数的指针,当 struct pci_dev 被挂起时 PCI 核心调用该函数。挂起状态以 state 变量来传递。该函数是可选的,驱动程序不一定要提供。 -
int (*resume) (struct pci_dev *dev);
指向一个恢复函数的指针,当 struct pci_dev 被恢复时 PCI 核心调用该函数。它总是在挂起函数已经被调用之后被调用。该函数是可选的,驱动程序不一定要提供。
概言之,为了创建一个正确的 struct pci_driver 结构体,只需要初始化四个字段:
static struct pci_driver pci_driver = {.name = "pci_skel"..id_table = ids,.probe = probe,.remove = remove,
};
为了把 struct pci_driver 注册到 PCI 核心中,需要调用以 struct pci_driver 指针为参数的 pci_register_driver 函数。通常在 PCI 驱动程序的模块初始化代码中完成该工作:
static int __init pci_skel_init(void) {return pci_register_driver(&pci_driver);
}
注意,如果注册成功,pci_register_driver 函数返回 0;否则,返回一个负的错误编号。它不会返回绑定到驱动程序的设备的数量,或者在没有设备绑定到驱动程序时返回一个错误编号。这是 2.6 发布之后的一个变化,基于下列情形的考虑:
-
在支持 PCI 热插拔的系统或者 CardBus 系统上,PCI 设备可以在任何时刻出现或者消失。如果驱动程序能够在设备出现之前被装载的话是很有帮助的,这样可以减少初始化设备所花的时间。
-
2.6 内核允许在驱动程序被装载之后动态地分配新的 PCI ID 给它。这是通过文件 new_id 来完成的,该文件位于 sysfs 的所有 PCI 驱动程序目录中。这是非常有用的,如果正在使用的新的设备还没有被内核所认知的话。用户可以把 PCI ID 的值写到 new_id 文件,之后驱动程序就可绑定新的设备。如果在设备没有出现在系统中之前不允许装载驱动程序的话,该接口将不起作用。
当 PCI 驱动程序将要被卸载的时候,需要把 struct pci_driver 从内核注销。这是通过调用 pci_unregister_driver 来完成的。当该函数被调用时,当前绑定到该驱动程序的任何 PCI 设备都被移除,该 PCI 驱动程序的移除函数在 pci_unregister_driver 函数返回之前被调用。
static void __exit pci_skel_exit(void) {pci_unregister_driver(&pci_driver);
}
(6)激活 PCI 设备
在 PCI 驱动程序的探测函数中,在驱动程序可以访问 PCI 设备的任何设备资源之前(I/O 区域或者中断),驱动程序必须调用 pci_enable_device 函数:
int pci_enable_device(struct pci_dev *dev);
该函数实际地激话设备。它把设备唤醒,在某些情况下还指派它的中断线和 I/O 区域。CardBus 设备就是这种情况(在驱动程序层和 PCI 完全一样)。
(7)访问配置空间
在驱动程序检测到设备之后,它通常需要读取或写入三个地址空间:内存、端口和配置。对驱动程序而言,对配置空间的访问至关重要,因为这是它找到设备映射到内存和 I/O 空间的什么位置的唯一途径。
因为处理器没有任何直接访问配置空间的途径,因此,计算机厂商必须提供一种办法。为了访问配置空间,CPU 必须读取或写入 PCI 控制器的寄存器,但具体的实现取决于计算机厂商,和我们这里的讨论无关,因为 Linux 提供了访问配置空间的标准接口。
对于驱动程序而言,可通过 8 位、16 位或 32 位的数据传输访问配置空间。相关函数的原型定义在 <linux/pci.h> 中:
int pci_read_config_byte(struct pci_dev *dev, int where, u8 *val);
int pci_read_config_word(struct pci_dev *dev, int where, u16 *val);
int pci_read_config_dword(struct pci_dev *dev, int where, u32 *val);
从由 dev 标识的设备配置空间读入一个、两个或四个字节。where 参数是从配置空间起始位置计算的字节偏移量。从配置空间获得的值通过 val 指针返回,函数本身的返回值是错误码。word 和 dword 函数会将读取到的 little-endian 值转换成处理器固有的字节序,因此,我们自己无需处理字节序。
int pci_write_config_byte(struct pci_dev *dev, int where, u8 val);
int pci_write_config_word(struct pci_dev *dev, int where, u16 val);
int pci_write_config_dword(struct pci_dev *dev, int where, u32 val);
向配置空间写入一个、两个或四个字节。和上面的函数一样,dev 标识设备,要写入的值通过 val 传递。word 和 dword 函数在把值写入外设之前,会将其转换成小头字节序。
所有前面的函数都实现为 inline 函数,它们实际上调用下面的函数。在驱动程序不能访问 struct pci_dev 的任何时刻,都可以使用这些函数来代替上述函数。
int pci_bus_read_config_byte(struct pci_bus *bus, unsigned int devfn,int where, u8 *val);
int pci_bus_read_config_word(struct pci_bus *bus, unsigmed int devfn,int where, u16 *val);
int pci_bus_read_config_dword(struct pci_bus *bus, unsigned int devfn,int where, u32 *val);
类似于 pci_read_ 函数,但需用到 pci_bus * 和 devfn 变量,而不用 struct pci_dev *
int pci_bus_write_config_byte (struct pci_bus *bus, unsigned int devfn,int where, u8 val);
int pci_bus_write_config_word (struct pci_bus *bus, unsigned int devfn,int where, u16 val);
int pci_bus_write_config_dword (struct pci_bus *bus, unsigned int devfn,int where, u32 val);
和 pci_write_ 系列函数类似,但是需要 struct pci_bus * 和 devfn 变量,而不是 struct pci_dev* 。
使用 pci_read 系列函数读取配置变量的首选方法,是使用 <linux/pci.h> 中定义的符号名。例如,下面的函数通过给 pci_read_config_byte 函数的 where 参数传递一个符号名来获取设备的修订号 ID。
static unsigned char skel_get_revision(struct pci_dev *dev) {u8 revision;pci_read_config_byte(dev, PCI_REVISION_ID, &revision);return revision;
}
(8)访问 I/O 和内存空间
一个 PCI 设备可实现多达 6 个 I/O 地址区域。每个区域可以是内存也可以是 I/O 地址。大多数设备在内存区域实现 I/O 寄存器,因为这通常是一个更明智的方法(如第九章的 “I/O 端口和 I/O 内存” 一节所述)。但是,不像常规内存,I/O 寄存器不应该由 CPU 缓存,因为每次访问都可能有边际作用。将 I/O 寄存器实现为内存区域的 PCI 设备通过在其配置寄存器中设置 “内存是可预取的(memory-is-prefetchable)” 标志来标记这个不同(注 4)。如果内存区域被标记为可预取(prefetchable),则 CPU 可缓存共内容,并进行各种优化。另一方面,对非可预取的(nonprefetchable)内存的访问不能被优化,因为每个访问都可能有边际作用、就像 I/O 端口。把控制寄存器映射到内存地址范围的外设把该范围声明为非可预取的,不过像 PCI 板载视频内存这样的东西是可预取的。在本节中,我们使用 “区域” 一词来表示一般的 I/O 地址空间、包括内存映射的和端口映射。
注 4:该信息保存在 PCI 寄存器基地址的低位中,这些位定义在 <linux/pci.h> 中。
一个接口板通过配置寄存器报告其区域的大小和当前位置 —— 即图 12-2 中的 6 个 32 位寄存器,它们的符号名称为 PCI_BASE_ADDRESS_0 到 PCI_BASE_ADDRESS_5。因为 PCI 定义的 I/O 空间是 32 位地址空间,因此,内存和 I/O 使用相同的配置接口是有道理的 。 如果设备使用 64 位的地址总线,它可以为每个区域使用两个连续的 PCI_BASE_ADDRESS 寄存器来声明 64 位内存空间中的区域(低位优先)。对一个设备来说,既提供 32 位区域也提供 64 位区域是可能的。
在内核中,PCI 设备的 I/O 区域已经被集成到通用资源管理。因此,我们无需访问配置变量来了解设备被映射到内存或 I/O 空间的何处。获得区域信息的首选接口由如下函数组成:
unsigned long pci_resource_start(struct pci_dev *dev, int bar);
该函数返回六个 PCI I/O 区域之一的首地址(内存地址或 I/O 端口号)。该区域由
整数的 bar(base address register,基地址寄存器)指定,bar 的取值为 0 到 5。
unsigned long pci_resource_end(struct pci_dev *dev, int bar);
该数返回第 bar 个 I/O 区域的尾地址。注意这是最后一个可用的地址,而不是该区域之后的第一个地址。
unsigned long pci_resource_flags(struct pci_dev *dev, int bar);
该函数返回和该资源相关联的标志。
资源标志用来定义单个资源的某些特性。对与 PCI I/O 区域相关联的 PCI 资源,该信息从基地址寄存器中获得,但对于和 PCI 设备无关的资源,它可能来自其他地方。
所有资源标志定义在 <linux/ioport.h> 中;下面列出其中最重要的几个:
-
IORESOURCE_IO
-
IORESOURCE_MEM
如果相关的 I/O 区域存在,将设置这些标志之一。 -
IORESOURCE_PREFETCH
-
IORESOURCE_READONLY
这些标志表明内存区域是否为可预取的和/或是写保护的。对 PCI 资源来说,从来不会设置后面的那个标志。
通过使用 pci_resource_ 系列函数,设备驱动程序可完全忽略底层的 PCI 寄存器,因为系统已经使用这些寄存器构建了资源信息。
(9)PCI 中断
很容易处理 PCI 的中断。在 Linux 的引导阶段,计算机固件已经为设备分配了一个唯一的中断号,驱动程序只需使用该中断号。中断号保存在配置寄存器 60( PCI_INTERRUPT_LINE)中,该寄存器为一个字节宽。这允许多达 256 个中断线,但实际的限制取决于所使用的 CPU。驱动程序无需检测中断号,因为从 PCI_INTERRUPT_LINE 中找到的值肯定是正确的。
如果设备不支持中断,寄存器 61 (PCI_INTERRUPT_PIN)是 0;否则为非零。但是,因为驱动程序知道自己的设备是否是中断驱动的,因此,它通常不需要读取 PCI_INTERRUPT_PIN 寄存器。
这样,处理中断的 PCI 特定代码仅仅需要读取配置字节,以获取保存在一个局部变量中的中断号,如下面的代码所示。否则,要利用第十章的内容。
result = pci_read_config_byte(dev, PCI_INTERRUPT_LINE, &myirq);
if (result) {/* 处理错误 */
}
本节的剩余内容为好奇的读者提供了一些附加信息,但它们对编写驱动程序没有多少帮助。
PCI 连接器有四个中断引脚,外设板可使用其中任意一个或者全部。每个引脚被独立连接到主板的中断控制器,因此,中断可被共享而不会出现任何电气问题。然后,中断控制器负责将中断线(引脚)映射到处理器硬件;这一依赖于平台的操作由控制器来完成,这样,总线本身可以获得平台无关性。
位于 PCI_INTERRUPT_PIN 的只读配置寄存器用来告诉计算机实际使用的是哪个引脚。要记得每个设备板可容纳最多 8 个设备;而每个设备使用单独的中断引脚,并在自己的配置寄存器中报告引脚的使用情况。同一设备板上的不同设备可使用不同的中断引脚,或者共享同一个中断引脚。
另一方面,PCI_INTERRUPT_LINE 寄存器是可读 / 写的。在计算机的引导阶段,固件扫描其 PCI 设备,并根据中断引脚如何连接到它的 PCI 槽来设置每个设备的寄存器。这个值由固件分配,因为只有固件知道主板如何将不同的中断引脚连接至处理器。但是,对设备驱动程序而言,PCI_INTERRUPT_LINE 是只读的。有趣的是,新近的 Linux 内核在某些情况下无需借助于 BIOS 就可以分配中断线。
(10)硬件抽象
到此为止,我们通过了解系统如何处理市场上各种各样的 PCI 控制器,已经完整地讨论了 PCI 总线。本节只是提供一些资料,以帮助感兴趣的读者了解内核是如何将面向对象的布局扩展至最底层的。
用于实现硬件抽象的机制,就是包含方法的普通结构。这是一种强有力的技术,它只是在普通的函数调用开销之上增加了对指针取值这样一点最小的开销。在 PCI 管理中,唯一依赖于硬件的操作是读取和写入配置寄存器,因为 PCI 世界中的任何其他工作,都是通过直接读取和写入 I/O 及内存地址空间来完成的,而这些工作是由 CPU 直接控制的。
为此,用于配置寄存器访问的相关结构仅包含 2 个字段:
struct pci_ops {int (*read) (struct pci_bus *bus, unsigned int devfn, int where, int size, u32 *val);int (*write) (struct pci_bus *bus, unsigned int devfn, int where,int size, u32 val);
};
该结构在 <linux/pci.h> 中定义,并由 drivers/pci/pci.c 使用,后者定义了实际的公共函数。
作用于 PCI 配置空间的这两个函数比对指针取值要花费更多的开销;因为代码是高度面向对象的,它们使用了级联指针,但该开销对于执行次数极少而且从来不会在速度要求很高的路径上执行的操作来说并不是一个问题。例如,pci_read_config_byte(dev, where,val) 的实际实现扩展为:
dev->bus->ops->read (bus, devfn, where, 8, val);
系统中的各种 PCI总线在系统引导阶段得到检测,这时,struct pci_bus 项被创建并与其功能关联起来,其中包括 ops 字段。
通过 “硬件操作” 数据结构实现硬件抽象在 Linux 中很典型。一个重要的例子是 struct alpha_machine_vector 数据结构。该结构体在 <asm-alph/machvec.h> 中定义,并用来处理各种 Alpha 计算机之间的不同。
2、ISA回顾
3、PC/104 和 PC/104+
4、其他的PC总线
- MCA
- EISA
- VLB
5、SBus
6、NuBus
7、外部总线
8、快速参考
本节总结本章中介绍过的符号:
#include <linux/pci.h>
// 这个头文件包含 PCI 寄存器的符号名称,以及若干厂商和设备 ID 值。struct pci_dev;
// 代表内核中 PCI 设备的结构体。struct pci_driver;
// 代表 PCI 驱动程序的结构体。所有的 PCI 驱动程序必须定义该结构体。struct pci_device_id:
// 描述该驱动程序所支持的 PCI 设备类型的结构体。int pci_register_driver(struct pci_driver *drv);
int pci_module_init(struct pci_driver *drv);
void pci_unregister_driver(struct pci_driver *drv);
// 从内核注册或者注销 PCI 驱动程序的函数。struct pci_dev *pci_find_device(unsigned int vendor, unsiged int device,struct pci_dev *from);
struct pci_dev *pci_find_device_reverse(unsigned int vendor, unsigned int device,const struct pci_dev *from);
struct pci_dev *pci_find_subsys (unsigned int vendor, unsigned int device,unsigned int ss_vendor, unsigned int ss_device, const struct pci_dev *from);
struct pci_dev *pci_find_class(unsigned int class, struct pci_dev *from) ;
// 在设备列表中查找具有特定签名或者属于某一特定类的设备的函数。如果没有找
// 到,返回值为 NULL。 from 被用来继续查找;在第一次调用函数时它必须为 NULL,
// 如果想要查找更多的设备,它必须指向前一个找到的设备。这些函数不建议使用,
// 应该用 pci_get_ 系列面数代替。struct pci_dev *pci_get_device(unsigned int vendor, unsigned int device,struct pci_dev *from);
struct pci_dev *pci_get_subsys(unsigned int vendor, unsigned int device,unsigned int ss_vendor, unsigned int ss_device, struct pci_dev *from);
struct pci_dev *pci_get_slot(struct pci_bus *bus, unsigned int devfn);
// 在设备列表中查找具有特定签名或者属于某一特定类的设备的函数。如果没有找
// 到,返回值为 NULL。 from 被用来继续查找;在第一次调用函数时它必须为 NULL,
// 如果想要查找更多的设备,它必须指向前一个找到的设备。返回的结构体的引用计
// 数被增加、在使用完该结构体之后,必须调用 pci_dev_put 函数。int pci_read_config_byte(struct pci_dev *dev, int where, u8 *val);
int pci_read_config_word(struct pci_dev *dev, int where, u16 *val);
int pci_read_config_dword(struct pci_dev *dev, int where, u32 *val);
int pci_write_config_byte (struct pci_dev *dev, int where, u8 *val);
int pci_write_config_word (struct pci_dev *dev, int where, u16 *val);
int pci_write_config_dword (struct pci_dev *dev, int where, u32 *val);
// 读取或者写入 PCI 配置寄存器的函数。尽管 Linux 内核处理了字节序问题,但从单
// 字节装配多字节值时,程序员必须小心处理字节序问题。PCI 总线是小头的。int pci_enable_device(struct pci_dev *dev);
// 激活一个 PCI 设备。unsigned long pci_resource_start(struct pci_dev *dev, int bar);
unsigned long pci_resource_end(struct pci_dev *dev, int bar);
unsigned long pci_resource_flags(struct pci_dev *dev, int bar);
// 处理 PCI 设备资源的函数。
十三、USB驱动程序
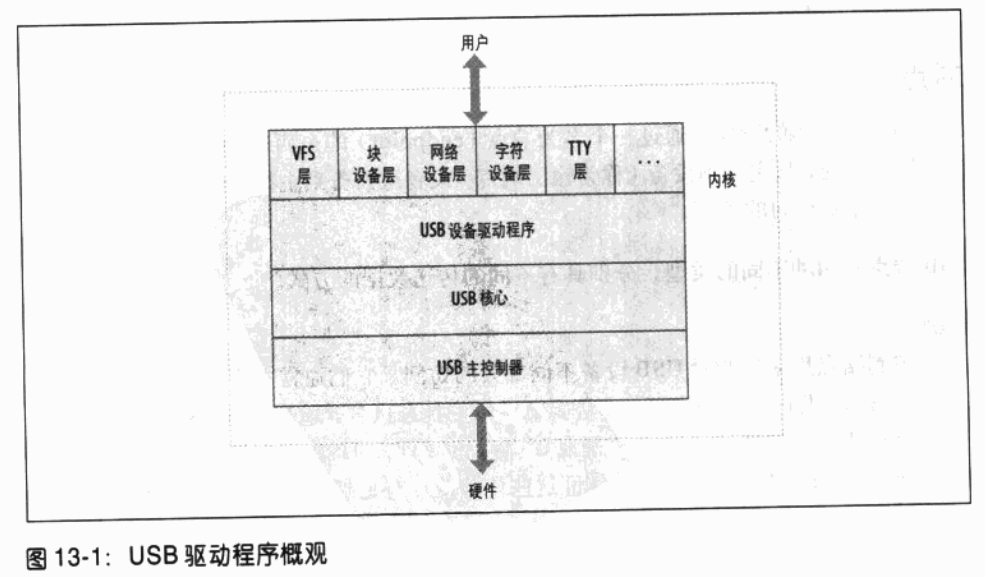
1、 USB设备基础
- 端口
- 接口
- 配置
Linux 使用 struct usb_host_config 结构体来描述 USB 配置,使用 struct usb_device 结构体来描述整个 USB 设备。USB 设备驱动程序通常不需要读取或者写入这些结构体中的任何值,因此这里就不详述它们了。想要深入探究的读者可以在内核源代码树的 include/linux/usb.h 文件中找到对它们的描述。
USB 设备驱动程序通常需要把一个给定的 struct usb_interface 结构体的数据转换为一个 struct usb_device 结构体,USB 核心在很多函数调用中都需要该结构体。 interface_to_usbdev 就是用于该转换功能的函数。
可以期待的是,当前需要 struct usb_device 结构体的所有 USB 调用将来会变为使用一个 struct usb_interface 参数,而且驱动程序不再需要去做转换的工作。
概言之,USB 设备是非常复杂的,它由许多不同的逻辑单元组成。这些逻辑单元之间的关系可以简单地描述如下:
- 设备通常具有一个或者更多的配置
- 配置经常具有一个或者更多的接口
- 接口通常具有一个或者更多的设置
- 接口没有或者具有一个以上的端点
2、 USB和Sysfs
由于单个 USB 物理设备的复杂性,在 sysfs 中表示该设备也相当复杂。无论是物理 USB 设备(用 struct usb_device 表示)还是单独的 USB 接口(用 struct usb_interface 表示),在 sysfs 中均表示为单独的设备(这是因为这些结构体都包含一个 struct device 结构体)。以仅包含一个 USB 接口的简易 USB 鼠标为例,下面是该设备的 sysfs 目录树:
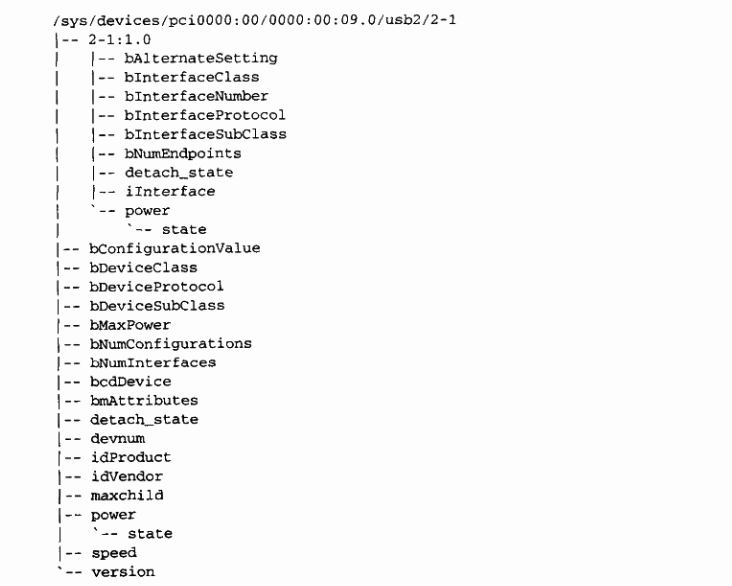
struct usb_device 表示为目录树中的:
/sys/devices/pci0000:00/0000:00:09.0/usb2/2-1
而鼠标的 USB 接口(USB 鼠标驱动程序所绑定的接口)位于如下目录:
/sys/devices/pci0000:00/0000:00:09.0/usb2/2-1/2-1:1.0
我们将描述内核如何分类 USB 设备,以帮助理解上面这些长长的设备路径名的含义。
第一个 USB 设备是一个根集线器(root hub)。这是一个 USB 控制器,通常包含在一个 PCI 设备中。之所以这样命名该控制器,是因为它控制着连接到其上的整个 USB 总线。该控制器是连接 PCI 总线和 USB 总线的桥,也是该总线上的第一个 USB 设备。
所有的根集线器都由 USB 核心分配了一个独特的编号。在我们的例子中,根集线器名为 usb2,因为它是注册到 USB 核心的第二个根集线器。单个系统中可以包含的根集线器的编号在任何时候都是没有限制的。
USB 总线上的每个设备都以根集线器的编号作为其名字中的第一个号码。该号码随后是一个横杠字符和设备所插入的端口号。因为我们例子中的设备插入到第一个端口,1 被添加到了名字中。因此,主 USB 鼠标设备的设备名是 2-1。因为该 USB 设备包含一个接口,导致了树中的另一个设备被添加到 sysfs 路径中。USB 接口的命名方案是设备名直到该接口为止:在我们的例子中,是 2-1 后面加一个冒号和 USB 配置的编号,然后是一个句点和接口的编号。因此对于本例而言,设备名是 2-1:1.0,因为它是第一个配置,具有接口编号零。
概言之,USB sysfs 设备命名方案为:
根集线器 - 集线器端口号 : 配置 . 接口
随着设备更深地进入 USB 树,和越来越多的 USB 集线器的使用,集线器的端口号被添加到跟随着链中前一个集线器端口号的字符串中。对于一个内层的树,其设备名类似于:
根集线器 - 集线器端口号 - 集线器端口号:配置 . 接口
从前面的 USB 设备和接口的目录列表可以看到,所有的 USB 特定信息都可以从 sysfs 直接获得(例如,idVendor、idProduct 和 bMaxPower 信息)。这些文件中的一个,即 bConfigurationValue,可以被写入以改变当前使用的活动 USB 配置。当内核不能够确定选择哪一个配置以恰当地操作设备时,这对于具有多个配置的设备很有用。许多 USB 调制解调器需要向该文件中写入适当的配置值,以便把恰当的 USB 驱动程序绑定到该设备。
sysfs 并没有展示 USB 设备所有的不同部分,它只限于接口级别。设备可能包含的任何可选配置都没有显示,还有和接口相关联的端点的细节。这个信息可以从 usbfs 文件系统找到,该文件系统被挂装到系统的 /proc/bus/usb/ 目录。/proc/bus/usb/devices 文件确实显示了和 sysfs 所展示的所有信息相同的信息,还有系统中存在的所有 USB 设备的可选配置和端点信息。usbfs 还允许用户空间的程序直接访问 USB 设备,这使得许多内核驱动程序可以迁移到用户空间,从而更加容易维护和调试。USB 扫描仪是一个很好的例子,它不再存在于内核中,因为它的功能现在包含在了用户空间的 SANE 库程序中。
3、 USB urb
Linux 内核中的 USB 代码通过一个称为 urb (USB 请求块)的东西和所有的 USB 设备通信。这个请求块使用 struct urb 结构体来描述,可以从 include/linux/usb.h 文件中找到。
urb 被用来以一种异步的方式往 / 从特定的 USB 设备上的特定 USB 端点发送 / 接收数据。它的使用和文件系统异步 I/O 代码中的 kiocb 结构体以及网络代码中的 struct skbuff 很类似。USB 设备驱动程序可能会为单个端点分配许多 urb,也可能对许多不同的端点重用单个的 urb,这取决于驱动程序的需要。设备中的每个端点都可以处理一个 urb 队列,所以多个 urb 可以在队列为空之前发送到同一个端点。一个 urb 的典型生命周期如下:
- 由 USB 设备驱动程序创建。
- 分配给一个特定 USB 设备的特定端点。
- 由 USB 设备驱动程序递交到 USB 核心。
- 由 USB 核心递交到特定设备的特定 USB 主控制器驱动程序。
- 由 USB 主控制器驱动程序处理,它从设备进行 USB 传送。
- 当 urb 结束之后,USB 主控制器驱动程序通如 USB 设备驱动程序。
urb 可以在任何时刻被递交该 urb 的驱动程序取消掉,或者被 USB 核心取消,如果该设备已从系统中移除。urb 被动态地创建,它包含一个内部引用计数,使得它们可以在最后一个使用者释放它们时自动地销毁。
本章描述的处理 urb 的过程是很有用的,因为它使得流处理和其他复杂的、重叠的通信成为可能,而这使驱动程序可以获得最高可能的数据传输速度。不过如果只是想要发送单独的数据块或者控制消息,而不关心数据的吞吐率,过程就不必如此繁琐。(请参考 “不使用 urb 的 USB 传输” 一节)。
(1)struct urb
// include/linux/usb.h
struct urb {/* private: usb core and host controller only fields in the urb */struct kref kref; /* reference count of the URB */void *hcpriv; /* private data for host controller */atomic_t use_count; /* concurrent submissions counter */atomic_t reject; /* submissions will fail */int unlinked; /* unlink error code *//* public: documented fields in the urb that can be used by drivers */struct list_head urb_list; /* list head for use by the urb's* current owner */struct list_head anchor_list; /* the URB may be anchored */struct usb_anchor *anchor;struct usb_device *dev; /* (in) pointer to associated device */struct usb_host_endpoint *ep; /* (internal) pointer to endpoint */unsigned int pipe; /* (in) pipe information */int status; /* (return) non-ISO status */unsigned int transfer_flags; /* (in) URB_SHORT_NOT_OK | ...*/void *transfer_buffer; /* (in) associated data buffer */dma_addr_t transfer_dma; /* (in) dma addr for transfer_buffer */struct usb_sg_request *sg; /* (in) scatter gather buffer list */int num_sgs; /* (in) number of entries in the sg list */u32 transfer_buffer_length; /* (in) data buffer length */u32 actual_length; /* (return) actual transfer length */unsigned char *setup_packet; /* (in) setup packet (control only) */dma_addr_t setup_dma; /* (in) dma addr for setup_packet */int start_frame; /* (modify) start frame (ISO) */int number_of_packets; /* (in) number of ISO packets */int interval; /* (modify) transfer interval* (INT/ISO) */int error_count; /* (return) number of ISO errors */void *context; /* (in) context for completion */usb_complete_t complete; /* (in) completion routine */struct usb_iso_packet_descriptor iso_frame_desc[0];/* (in) ISO ONLY */
};
struct urb 结构体中 USB 设备驱动程序需要关心的字段有:
-
struct usb_device *dev
urb 所发送的目标 struct usb_device 指针。该变量在 urb 可以被发送到 USB 核心之前必须由 USB 驱动程序初始化。 -
unsigned int pipe
urb 所要发送的特定目标 struct usb_device 的端点信息。该变量在 urb 可以被发送到 USB 核心之前必须由 USB 驱动程序初始化。
驱动程序必须使用下列恰当的数来设置该结构体的字段,具体取决于传输的方向。注意每个端点只能属于一种类型。
unsigned int usb_sndctrlpipe(struct usb_device *dev, unsigned int endpoint)
// 把指定 USB 设备的指定端点号设置为一个控制 OUT 端点。unsigned int usb_rcvctrlpipe(struct usb_device *dev, unsigned int endpoint)
// 把指定 USB 设备的指定端点号设置为一个控制 IN 端点。unsigned int usb_sndbulkpipe(struct usb_device *dev, unsigned int endpoint)
// 把指定 USB 设备的指定端点号设置为一个批量 OUT 端点。unsigned int usb_rcvbulkpipe(struct usb_device *dev, unsigmed int endpoint)
// 把指定 USB 设备的指定端点号设置为一个批量 IN 端点。unsigned int usb_sndintpipe(struct usb_device *dev, unsigned int endpoint)
// 把指定 USB 设备的指定端点号设置为一个中断 OUT 端点。unsigmed int usb_rcvintpipe(struct usb_device *dev, unsigned int endpoint)
// 把指定 USB 设备的指定端点号设置为一个中断 IN 端点。unsigned int usb_sndisocpipe(struct usb_device *dev, unsigned int endpoint)
// 把指定 USB 设备的指定端点号设置为一个等时 OUT 端点。unsigned int usb_rcvisocpipe(struct usb_device *dev, unsigmed int endpoint)
// 把指定 USB 设备的指定端点号设置为一个等时 IN 端点。
-
unsigned int transfer_flags
该变量可以被设置为许多不同的位值,取决于 USB 驱动程序对 urb 的具体操作。可用的值包括:- URB_SHORT_NOT_OK
如果被设置,该值说明任何可能发生的对 IN 端点的简短读取应该被 USB 核心当作是一个错误。该值只对从 USB 设备读取的 urb 有用,对用于写入的 urb 没意义。 - URB_ISO_ASAP
如果该 urb 是等时的,当驱动程序想要该 urb 被调度时可以设置这个位,只要带宽的利用允许它这么做,而且想要在此时设置 urb 中的 start_frame 变量。如果一个等时的 urb 没有设置该位,驱动程序必须指定 start_frame 的值,如果传输在当时不能启动的话必须能够正确地恢复。详情请参阅下一节的等时 urb 部分。 - URB_NO_TRANSFER_DMA_MAP
当 urb 包含一个即将传输的 DMA 缓冲区时应该设置该位。USB 核心使用 transfer_dma 变量所指向的缓冲区,而不是 transfer_buffer 变量所指向的。 - URB_NO_SETUP_DMA_MAP
和 URB_NO_TRANSFER_DMA_MAP 位类似,该位用于控制带有已设置好的 DMA 缓冲区的 urb。如果它被设置,USB 核心使用 setup_dma 变量所指向的缓冲区,而不是 setup_packet 变量。 - URB_ASYNC_UNLINK
如果被设置,对该 urb 的 usb_unlink_urb 调用几乎立即返回,该 urb 的链接在后台被解开。否则,此函数一直等到 urb 被完全解开链接和结束才返回。使用该位时要小心,因为它可能会造成非常难以调试的同步问题。 - URB_NO_FSBR
仅由 UHCI USB 主控制器驱动程序使用,指示它不要企图使用前端总线回收(Front Side Bus Reclamation)逻辑。该位通常不应该被设置,因为带有 UHCI 主控制器的机器会导致大量的 CPU 负荷,而 PCI 总线忙于等待一个设置了该位的 urb。 USB接口(2)——USB控制器EHCI、OHCI、UHCI与usb hub芯片 - URB_ZERO_PACKET
如果被设置,一个批量输出 urb 以发送一个不包含数据的小数据包来结束,这时数据对齐到一个端点数据包边界。一些断线的 USB 设备(例如许多 USB 到 IR 设备)需要该位才能正确地工作。 - URB_NO_INTERRUPT
如果被设置,当 urb 结束时,硬件可能不会产生一个中断。对该位的使用应当小心谨慎,只有把多个 urb 排队到同一个端点时才使用。USB 核心的函数使用该位来进行 DMA 缓冲区传输。
- URB_SHORT_NOT_OK
-
void *transfer_buffer
指向用于发送数据到设备(OUT urb)或者从设备接收数据(IN urb)的缓冲区的指针。为了使主控制器正确地访问该缓冲区,必须使用 kmalloc * 创建它,而不是在栈中或者静态内存中。对于控制端点,该缓冲区用于传输数据的中转。 -
dma_addr_t transfer_dma
用于以 DMA 方式传输数据到 USB 设备的缓冲区。 -
int transfer_buffer_length
transfer_buffer 或者 transfer_dma 变量所指向的缓冲区的大小(因为一个 urb 只能使用其中一个)。如果该值为 0、两个传输缓冲区都没有被 USB 核心使用。
对于一个 OUT 端点,如果端点的最大尺寸小于该变量所指定的值,到 USB 设备的传输将被分解为更小的数据块以便正确地传输数据。这种大数据量的传输以连续的 USB 帧的方式进行。在一个 urb 中提交一个大数据块然后让 USB 主控制器把它分割为更小的块,比以连续的次序发送更小的缓冲区的速度快得多。 -
unsigned char *setup_packet
指向控制 urb 的设置数据包的指针。它在传输缓冲区中的数据之前被传送。该变量只对控制 urb 有效。 -
dma_addr_t setup_dma
控制 urb 用于设置数据包的 DMA 缓冲区。它在普通传输缓冲区中的数据之前被传送。该变量只对控制 urb 有效。 -
usb_complete_t complete
指向一个结束处理例程的指针,当 urb 被完全传输或者发生错误时,USB 核心将调用该函数。在该函数内,USB 驱动程序可以检查 urb、释放它,或者把它重新提交到另一个传输中去。(有关结束处理例程的详情请参阅 “结束 urb: 结束回调处理例程” 一节)。
usb_complete_t 的类型定义为:
typedef void (*usb_complete_t)(struct urb *, struct pt_regs *);
-
void *context
指向一个可以被 USB 驱动程序设置的数据块。它可以在结束处理例程中当 urb 被返回到驱动程序时使用。有关该变量的详情请参阅随后的小节。 -
int actual_length
当 urb 结束之后,该变量被设置为 urb 所发送的数据(OUT urb)或者 urb 所接收的数据(IN urb)的实际长度。对于 IN urb,必须使用该变量而不是 transfer_buffer_length 变量,因为所接收的数据可能小于整个缓冲区的尺寸。 -
int status
当 urb 结束之后,或者正在被 USB 核心处理时,该变量被设置为 urb 的当前状态。USB 驱动程序可以安全地访问该变量的唯一时刻是在 urb 结束处理例程中(在 “结束 urb: 结束回调处理例程” 一节中描述)。该限制是为了防止当 urb 正在被 USB 核心处理时竞态的发生。对于等时 urb,该变量的一个成功值(0)只表示 urb 是否已经被解开链接。如果要获取等时 urb 的详细状态,应该检查 iso_frame_desc 变量。
该变量的有效值包括:- 0
urb 传输成功。 - -ENOENT
urb 被 usb_kill_urb 调用终止。 - -ECONNRESET
urb 被 usb_unlink_urb 调用解开链接,urb 的 transfer_flags 变量被设置为 URB_ASYNC_UNLINK。 - -EINPROGRESS
urb 仍然在被 USB 主控制器处理。如果驱动程序中检查到该值,说明存在代码缺陷。 - -EPROTO
urb 发生了下列错误之一:- 在传输中发生了 bitstuff 错误。
- 硬件没有及时接收到响应数据包。
- -EILSEQ
urb 传输中发生了 CRC 校验不匹配。 - -EPIPE
端点被中止。如果涉及的端点不是控制端点,可以调用 usb_clear_halt 函数来请除该错误。 - -ECOMM
传输时数据的接收速度比把它写到系统内存的速度快。该错误值仅发生在 IN urb 上。 - -ENOSR
传输时从系统内存获取数据的速度不够快,跟不上所要求的 USB 数据速率。该错误值仅发生在 OUT urb 上。 - -EOVERFLOW
urb 发生了 “串扰(babble)” 错误。“串扰” 错误发生在端点接收了超过端点指定最大数据包尺寸的数据时。 - -EREMOTEIO
仅发生在 urb 的 transfer_flags 变量被设置 URB_SHORT_NOT_OK 标志时,表示 urb 没有接收到所要求的全部数据量。 - - ENODEV
USB 设备已从系统移除。 - -EXDEV
仅发生在等时 urb 上,表示传输仅部分完成。为了确定所传输的内容,驱动程序必须查看单个帧的状态。 - -EINVAL
urb 发生了很槽糕的事情。USB 内核文档描述了该值的含义:
等时错乱、如果发生这种情况:退出系统然后回家
如果 urb 结构体中的某一个参数没有被正确地设置或者 usb_submit_urb 调用中的不正确函数参数把 urb 提交到了 USB 核心,也可能发生这个错误。 - -ESHUTDOWN
USB 主控制器驱动程序发生了严重的错误;设备已经被禁止,或者从系统脱离,而 urb 在设备被移除之后提交。如果当 urb 被提交到设备时设备的配置被改变,也可能发生这个错误。
一般来说,错误值 -EPROTO、-EILSEQ 和 -EOVERFLOW 表示设备、设备的固件或者把设备连接到计算机的电缆发生了硬件故障。
- 0
-
int start_frame
设置或者返回初始的帧数量,用于等时传输。 -
int interval
urb 被轮询的时间间隔。仅对中断或者等时 urb 有效。该值的单位随着设备速度的不同而不同。对于低速和满速的设备,单位是帧,相当于毫秒。对于其他设备,单位是微帧(microframe),相当于毫秒的 1/8。对于等时或者中断 urb,在 urb 被发送到 USB 核心之前,USB 驱动程序必须设置该值。 -
int number_of_packets
仅对等时 urb 有效,指定该 urb 所处理的等时传输缓冲区的数量。对于等时 urb,在 urb 被发送到 USB 核心之前,USB 驱动程序必须设置该值。 -
int error_count
由 USB 核心设置,仅用于等时 urb 结束之后。它表示报告了任何一种类型错误的等时传输的数量。 -
struct usb_iso_packet_descriptor iso_frame_desc[0]
仅对等时 urb 有效。该变量是一个 struct usb_iso_packet_descriptor 结构体数组。该结构体允许单个 urb 一次定义许多等时传输。它还用于收集每个单独传输的传输状态。
struct usb_iso_packet_descriptor 由下列字段组成:
// include/linux/usb.h
struct usb_iso_packet_descriptor {unsigned int offset;unsigned int length; /* expected length */unsigned int actual_length;int status;
};
- unsigned int offset
该数据包的数据在传输缓冲区中的偏移量(第一个字节为 0)。 - unsigned int length
该数据包的传输缓冲区大小。 - unsigned int actual_length
该等时数据包接收到传输缓冲区中的数据长度。 - unsigned int status
该数据包的单个等时传输的状态。它可以把相同的返回值作为主 struct urb 结构体的状态变量。
(2)创建和销毁 urb
struct urb 结构体不能在驱动程序中或者另一个结构体中静态地创建,因为这样会
破坏 USB 核心对 urb 所使用的引用计数机制。它必须使用 usb_alloc_urb 函数来创建。该函数原型如下:
struct urb *usb_alloc_urb(int iso_packets, int mem_flags);
第一个参数,iso_packets,是该 urb 应该包含的等时数据包的数量。如果不打算创建等时 urb,该值应该设置为 0 。第二个参数,mem_flags,和传递给用于从内核分配内存的 kmalloc 函数(这些标志的详情参见第八章的 “标志参数” 一节)的标志有相同的类型。如果该函数成功地为 urb 分配了足够的内存空间,指向该 urb 的指针将被返回给调用函数。如果返回值为 NULL,说明 USB 核心内发生了错误,驱动程序需要进行适当的清理。
当一个 urb 被创建之后,在它可以被 USB 核心使用之前必须被正确地初始化。关于如何初始化不同类型的 urb,参见随后的小节。
驱动程序必须调用 usb_free_urb 函数来告诉 USB 核心驱动程序已经使用完 urb 。该函数只有一个参数:
void usb_free_urb(struct urb *urb);
这个参数是指向所需释放的 struct urb 的指针。在该函数被调用之后,urb 结构体就消失了,驱动程序不能再访问它。
(a)中断 urb
usb_fill_int_urb 是一个辅助函数,用来正确地初始化即将被发送到 USB 设备的中断端点的 urb:
void usb_fill_int_urb(struct urb *urb, struct usb_device *dev, unsigned int pipe, void *transfer_buffer, int buffer_length, usb_complete_t complete,void *context, int interval);
该函数包含很多的参数:
-
struct urb *urb
指向需初始化的 urb 的指针。 -
struct usb_device *dev
该 urb 所发送的目标 USB 设备。 -
unsigned int pipe
该 urb 所发送的目标 USB 设备的特定端点。该值是使用前述 usb_sndintpipe 或 usb_rcvintpipe 函数来创建的。 -
void *transfer_buffer
用于保存外发数据或者接收数据的缓冲区的指针。注意它不能是一个静态的缓冲区,必须使用 kmalloc 调用来创建。 -
int buffer_length
transfer_buffer 指针所指向的缓冲区的大小。 -
usb_complete_t complete
指向当该 urb 结束之后调用的结束处理例程的指针。 -
void *context
指向一个小数据块,该块被添加到 urb 结构体中以便进行结束处理例程后面的查找。 -
int interval
该 urb 应该被调度的间隔。有关该值的正确单位,请参考前面对 struct urb 结构体的描述。
(b)批量 urb
批量 urb 的初始化和中断 urb 很相似。所使用的相关函数是 usb_fill_bulk_urb,原型如下:
void usb_fill_bulk_urb(struct urb *urb, struct usb_device *dev, unsigned int pipe, void *transfer_buffer, int buffer_length, usb_complete_t complete, void *context);
该函数的参数和 usb_fill_int_urb 函数完全一样。不过,没有时间间隔参数,因为批量 urb 没有时间间隔值。请注意,无符号整型 pipe 变量必须使用 usb_sndbulkpipe 或 usb_rcvbulkpipe 函数来初始化。
usb_fill_int_urb 函数不在 urb 中设置 transfer_flags 变量,因此,驱动程序必须自已来修改该字段。
(c)控制 urb
控制 urb 的初始化方法和批量 urb 几乎一样,调用 usb_fill_control_urb 函数。
void usb_fill_control_urb(struct urb *urb, struct usb_device *dev, unsigned int pipe, unsigned char *setup_packet, void *transfer_buffer, int buffer_length, usb_complete_t complete, void *context);
函数参数和 usb_fill_bulk_urb 函数完全一样,除了一个新的参数,即 unsigned char *setup_packet,它指向即将被发送到端点的设置数据包的数据。同样,无符号整型 pipe 变量必须使用 usb_sndctrlpipe 或 usb_rcvictrlpipe 数来初始化。
usb_fill_control_urb 函数不设置 urb 中的 transfer_flags 变量,因此驱动程序必须自已修改该字段。大部分的驱动程序不使用该函数,因为使用 “不使用 urb 的 USB 传输” 一节中描述的同步 API 调用更加简单。
(d)等时 urb
不幸的是,等时 urb 没有和中断、控制和批量 urb 类似的初始化函数。因此它们在被提交到 USB 核心之前,必须在驱动程序中 “手工地” 进行初始化。下面是一个关于如何正确地初始化该类型 urb 的例子。它是从主内核源代码树的 drivers/usb/media 目录下的 konicawc.c 内核驱动程序中拿出来的。
urb->dev = dev;urb->context = uvd;urb->pipe = usb_rcvisocpipe(dev, uvd->video_endp-1);urb->interval = 1;urb->transfer_flags = URB_ISO_ASAP;urb->transfer_buffer = cam->sts_buf[i];urb->complete = konicawc_isoc_irq;urb->number_of_packets = FRAMES_PER_DESC;urb->transfer_buffer_length = FRAMES_PER_DESC;for (j=0; j < FRAMES_PER_DESC; j++) {urb->iso_frame_desc[j].offset = j;urb->iso_frame_desc[j].length = 1;}
(3)提交 urb
一旦 urb 被 USB 驱动程序正确地创建和初始化之后,就可以提交到 USB 核心以发送到 USB 设备了。这是通过调用 usb_submit_urb 函数来完成的。
int usb_submit_urb(struct urb *urb, int men_flags);
urb 参数是指向即将被发送到设备的 urb 的指针。mem_flags 参数等同于传递给 kmalloc 调用的同一个参数,用于告诉 USB 核心如何在此时及时地分配内存缓冲区。
当一个 urb 被成功地提交到 USB 核心之后,在接收函数被调用之前不能访问该 urb 结构体中的任何字段。因为 usb_submit_urb 函数可以在任何时刻调用(包括从一个中断上下文中),mem_flags 变量的内容必须是正确的。其实只有三个有效的值可以被使用,取决于 usb_submit_urb 何时被调用:
- GFP_ATOMIC
只要下列条件成立就应该使用该值:- 调用者是在一个 urb 结束处理例程、中断处理例程、底半部、tasklet 或者定时器回调函数中。
- 调用者正持有一个自旋锁或读写锁。注意如果持有了信号量,该值就不需要了。
- current->state 不是 TASK_RUNNING。该状态永远是 TASK_RUNNING,除非驱动程序自己改变了当前的状态。
- GFP_NOIO
如果驱动程序处于块 I/O 路径中应该使用该值。在所有存储类型的设备的错误处理路径中也应该使用它。 - GFP_KERNEL
该值应该在前述类别之外的所有情况中使用。
(4)结束 urb:结束回调处理例程
如果调用 usb_submit_urb 成功,把对 urb 的控制转交给 USB 核心,该函数返回 0;否则,返回负的错误号。如果函数调用成功,当 urb 结束的时候 urb 的结束处理例程(由结束函数指针指定)正好被调用一次。当该函数被调用时,USB 核心结束了对 URB 的处理,此刻对它的控制被返回给设备驱动程序。
只有三种结束 urb 和调用结束函数的情形:
- urb 被成功地发送到了设备,设备返回了正确的确认。对于 OUT urb 而言就是数据被成功地发送,对于 IN urb 而言就是所请求的数据被成功地接收到。如果确实这样,urb 中的 status 变量被设置为 0。
- 发送数据到设备或者从设备接收数据时发生了某种错误。错误情况由 urb 结构体中的 status 变量的错误值来指示。
- urb 从 USB 核心中被 “解开链接” 。当驱动程序通过 usb_unlink_urb 或 usb_kill_urb 调用告诉 USB 核心取消一个已提交的 urb 时,或者当设备从系统中被移除而一个 urb 已经提交给它时,会发生这种情况。
本章的稍后将给出一个如何在 urb 结束调用内检测各种不同的返回值的示例。
(5)取消 urb
应该调用 usb_kill_urb 或 usb_unlink_urb 函数来终止一个已经被提交到 USB 核心的 urb。
int usb_kill_urb(struct urb *urb);
int usb_unlink_urb(struct urb *urb);
这两个函数的 urb 参数是指向即将被取消的 urb 的指针。
如果调用 usb_kill_urb 面数,该 urb 的生命周期将被终止。通常是当设备从系统中被断开时,在断开回调函数中调用该函数。
对于某些驱动程序而言,应该使用 usb_unlink_urb 函数来告诉 USB 核心终止一个 urb。该函数并不等到 urb 完全被终止之后才返回到调用函数。这对于在中断处理例程中或者持有一个自旋锁时终止一个 urb 是很有用的,因为等待一个 urb 完全被终止需要 USB 核心具有使调用进程睡眠的能力。该函数需要被要求终止的 urb 中的 URB_ASYNC_UNLINK 标志值被设置才能正确地工作。
4、 编写USB驱动程序
编写一个 USB 设备驱动程序的方法和 pci_driver 类似:驱动程序把驱动程序对象注册到 USB 子系统中,稍后再使用制造商和设备标识来判断是否已经安装了硬件。
(1)驱动程序支持哪些设备?
struct usb_device_id 结构体提供了一列不同类型的该驱动程序支持的 USB 设备。USB 核心使用该列表来判断对于一个设备该使用哪一个驱动程序,热插拔脚本使用它来确定当一个特定的设备插入到系统时该自动装载哪一个驱动程序。
struct usb_device_id 结构体包括下列字段:
// include/linux/mod_devicetable.h
struct usb_device_id {/* which fields to match against? */__u16 match_flags;/* Used for product specific matches; range is inclusive */__u16 idVendor;__u16 idProduct;__u16 bcdDevice_lo;__u16 bcdDevice_hi;/* Used for device class matches */__u8 bDeviceClass;__u8 bDeviceSubClass;__u8 bDeviceProtocol;/* Used for interface class matches */__u8 bInterfaceClass;__u8 bInterfaceSubClass;__u8 bInterfaceProtocol;/* not matched against */kernel_ulong_t driver_info;
};
- __u16 match_flags
确定设备和结构体中下列字段中的哪一个相匹配。这是一个由 include/linux/mod_devicetable.h 文件中指定的不同的 USB_DEVICE_ID_MATCH_* 值定义的位字段。通常不直接设置该字段,而是使用稍后介绍的 USB_DEVICE 类型的宏来初始化。 - __u16 idVendor
设备的 USB 制造商 ID。该编号是由 USB 论坛指派给其成员的,不会由其他人指定。 - __u16 idProduct
设备的 USB 产品 ID。所有指派了制造商 ID 的制造商都可以随意地赋予其产品 ID。 - __u16 bcdDevice_lo
- __u16 bcdDevice_hi
定义了制造商指派的产品的版本号范围的最低和最高值。bcdDevice_hi 值包括在内;该值是最高编号的设备的编号。这两个值都以二进制编码的十进制(BCD)格式来表示。这些变量,加上 idVendor 和 idProduct ,用来定义设备的特定版本号。 - __u8 bDeviceclass
- __u8 bDeviceSubClass
- __u8 bDeviceProtocol
分别定义设备的类型、子类型和协议。这些编号由 USB 论坛指派,定义在 USB 规范中。这些值详细说明了整个设备的行为,包括该设备上的所有接口。 - __u8 bInterfaceClass
- __u8 bInterfaceSubClass
- __u8 bInterfaceProtocol
和上述设备特定的值很类似,这些值分别定义类型、子类型和单个接口的协议。这些编号由 USB 论坛指派,定义在 USB 规范中。 - kernel_ulong_t driver_info
该值不是用来比较是否匹配的,不过它包含了驱动程序在 USB 驱动程序的探测回调函数中可以用来区分不同设备的信息。
对于 PCI 设备,有许多用来初始化该结构体的宏:
USB_DEVICE(vendor, product)
// 创建一个 struct usb_device_id 结构体,仅和指定的制造商和产品 ID 值相匹配。
// 该宏常用于需要一个特定驱动程序的 USB 设备。USB_DEVICE_VER(vendor, product, lo, hi)
// 创建一个 struct usb_device_id 结构体,仅和某版本范围内的指定制造商和产
// 品 ID 值相匹配。USB_DEVICE_INFO(class, subclass, protocol)
// 创建一个 struct usb_device_id 结构体,仅和 USB 设备的指定类型相匹配。USB_INTERFACE_INFO(class, subclass, protocol)
// 创建一个 struct usb_device_id 结构体,仅和 USB 接口的指定类型相匹配。
因此,对于一个只控制来自单一制造商的单一 USB 设备的简单 USB 设备驱动程序来说,struct usb_device_id 表将被定义为:
/* 该驱动程序支持的设备列表 */
static struct usb_device_id skel_table [ ] = {{ USB_DEVICE(USB_SKEL_VENDOR_ID, USB_SKEL_PRODUCT_ID) },{ } /* 终止入口项 */
};
MODULE_DEVICE_TABLE(usb, skel_table);
对于 PC 驱动程序,MODULE_DEVICE_TABLE 宏是必需的,以允许用户空间的工具判断出该驱动程序可以控制什么设备。但是对于 USB 驱动程序来说,字符串 usb 必须是该宏中的第一个值。
(2)注册 USB 驱动程序
所有 USB 驱动程序都必须创建的主要结构体是 struct usb_driver。该结构体必须由 USB 驱动程序来填写,包括许多回调函数和变量,它们向 USB 核心代码描述了 USB 驱动程序。
// include/linux/usb.h
struct usb_driver {const char *name;int (*probe) (struct usb_interface *intf,const struct usb_device_id *id);void (*disconnect) (struct usb_interface *intf);int (*ioctl) (struct usb_interface *intf, unsigned int code,void *buf);int (*suspend) (struct usb_interface *intf, pm_message_t message);int (*resume) (struct usb_interface *intf);int (*reset_resume)(struct usb_interface *intf);int (*pre_reset)(struct usb_interface *intf);int (*post_reset)(struct usb_interface *intf);const struct usb_device_id *id_table;struct usb_dynids dynids;struct usbdrv_wrap drvwrap;unsigned int no_dynamic_id:1;unsigned int supports_autosuspend:1;unsigned int soft_unbind:1;
};
#define to_usb_driver(d) container_of(d, struct usb_driver, drvwrap.driver)
-
struct module *owner
指向该驱动程序的模块所有者的指针。USB 核心使用它来正确地对该 USB 驱动程序进行引用计数,使它不会在不合适的时刻被卸载掉。该变量应该被设置为 THIS_MODULE 。 -
const char *name
指向驱动程序名字的指针。在内核的所有 USB 驱动程序中它必须是唯一的,通常被设置为和驱动程序模块名相同的名字。如果该驱动程序运行在内核中,可以在 sysfs 的 /sys/bus/usb/drivers/ 下面找到它。 -
const struct usb_device_id *id_table
指向 struct usb_device_id 表的指针,该表包含了一列该驱动程序可以支持的所有不同类型的 USB 设备。如果没有设置该变量,USB 驱动程序中的探测回调函数不会被调用。如果想要驱动程序对于系统中的每一个 USB 设备都被调用,创建一个只设置 driver_info 字段的条目:
static struct usb_device_id usb_ids[ ] = {{.driver_info = 42},{ }
};
- int (*probe) (struct usb_interface *intf, const struct usb_device_id *id)
指向 USB 驱动程序中的探测函数的指针。当 USB 核心认为它有一个 struct usb_interface 可以由该驱动程序处理时,它将调用该函数(在 “探测和断开的细节” 一节中描述)。USB 核心用来作判断的指向 struct usb_device_id 的指针也被传递给该函数。如果 USB 驱动程序确认传递给它的 struct usb_interface, 它应该恰当地初始化设备然后返回 0。如果驱动程序不确认该设备,或者发生了错误,它应该返回一个负的错误值。
void (*disconnect) (struct usb_interface *intf)
指向 USB 驱动程序中的断开函数的指针。当 struct usb_interface被从系统中
移除或者驱动程序正在从 USB 核心中卸载时,USB 核心将调用该函数(在"探测
和断开的细节"一节中描述)。
因此,创建一个有效的 struct usb_driver 结构体只需要初始化五个字段:
static struct usb_driver skel_driver = {
.owner = THIS_MODULE,
.name = "skeleton".
.id_table = skel_table,
.probe = skel_probe,
.disconnect = skel_disconnect,
】;
struct usb_driver 还包含了另外几个回调函数,这些函数不是很常用,对于一个
USB 驱动程序的正常工作不是必需的:
int (*ioctl) (struct usb_interface *intf, unsigned int code, void *buf)
指向 USB 驱动程序中的 ioctl 函数。如果该自数存在,当用户空间的程序对 usbfs
文件系统中的设备文件进行了ioctl调用,而和该设备文件相关联的 USB 设备附着
在该 USB 驱动程序上时,它将被调用。实际上,只有 USB 集线器驱动程序使用该
ioctl,其他的 USB 驱动程序都没有使用它的真实需要。
int (*suspend) (struct usb_interface *intf, u32 state)
指向USB驱动程序中的挂起函数的指针。当设备将被USB核心挂起时调用该函数。
int (*resume) (struct usb_interface *intf)
指向USB驱动程序中的恢复函数的指针。当设备将被USB核心恢复时调用该函数。
以 struct usb_driver 指针为参数的 usb_register_driver 函数调用把 struct
usb_driver注册到 USB 核心。传统上是在 USB 驱动程序的模块初始化代码中完成该工
作的:
static int __init usb_skel_init(void)
int result;
/* 把该驱动程序注册到 USB 子系统 */
result = usb_register(&skel_driver);
if (result)
err("usb_register failed. Error number 8d", result);
return result;
当 USB 驱动程序将要被卸载时,需要把 struct usb_driver从内核中注销。通过调用
usb_deregister_driver 来完成该工作。当该调用发生时,当前绑定到该驱动程序上的任
何 USB 接口都被断开,断开开函数将被调用。
static void __exit usb_skel_exit(void)
/* 把该驱动程序从 USB 子系统注销 */
usb_deregister(&skel_driver);
)
(3)探测和断开的细节
上一节描述的 struct usb_driver结构体中,驱动程序指定了两个 USB 核心在适当时
间调用的函数。当一个设备被安装而USB核心认为该驱动程序应该处理时,探测函数被
调用;探测函数应该检查传递给它的设备信息,确定驱动程序是否真的适合该设备。当
驱动程序因为某种原因不应控制设备时,断开函数被调用,它可以做一些清理的工作。
探测和断开回调函数都是在USB集线器内核线程的上下文中被调用的,因此在其中睡眠
是合法的。然而,建议大部分的工作尽可能地在用户打开设备时完成,从而把USB 探测
的时间减到最少。因为 USB 核心在单一线程中处理 USB 设备的添加和删除,任何低速
的设备驱动程序都可以减慢 USB 设备的探测时间,从而影响用户的使用。
在探测回调函数中,USB 驱动程序应该初始化任何可能用于控制 USB 设备的局部结构
体。它还应该把所需的任何设备相关信息保存到局部结构体中,因为在此时做该工作是
比较容易的。例如,USB 驱动程序通常需要探测设备的端点地址和缓冲区大小,因为需
要它们才能和设备进行通信。这里是一些示例代码,它们探测批量类型的 IN 和 OUT 端
点,把相关的信息保存到一个局部设备结构体中:
/* 设置端点信息 */
/* 只使用第一个批量 IN 和批量 OUT 端点 */
iface_desc = interface->cur_altsetting;
for (i = 0; i < iface_desc->desc.bNumEndpoints; ++i) {
endpoint = &iface_desc->endpoint[i].desc;
if (!dev->bulk_in_endpointAddr &&
(endpoint->bEndpointAddress & USB_DIR_IN) &&
((endpoint->bmAttributes & USB_ENDPOINT_XFERTYPE_MASK)
= USB_ENDPOINT_XFER_BULK)){
/* 发现一个批量 IN 类型的端点 */
buffer_size endpoint->wMaxPacketSize;
dev->bulk_in_size = buffer_size;
dev->bulk_in_endpointAddr endpoint->bEndpointAddress;
dev->bulk_in_buffer = kmalloc(buffer_size, GFP_KERNEL);
if (!dev->bulk_in_buffer){
err("Could not allocate bulk_in_buffer");
goto error;
)
if (!dev->bulk_out_endpointAddr &&
!(endpoint->bEndpointAddress & USB_DIR_IN) &&
《(endpoint->bmAttributes & USB_ENDPOINT_XFERTYPE_MASK)
= USB_ENDPOINT_XFER_BULK)) {
/* 发现一个批量 OUT 类型的端点 */
dev->bulk_out_endpointAddr = endpoint->bEndpointAddress;
)
if (1(dev->bulk_in_endpointAddr && dev->bulk_out_endpointAddr))
err("Could not find both bulk-in and bulk-out endpoints");
goto error;
)
该代码块首先循环访问该接口中存在的每一个端点,赋予该端点结构体的局部指针以使
稍后的访问更加容易:
for (i = 0; i < iface_desc->desc.bNumEndpoints; ++i) {
endpoint = &iface_desc->endpoint[i].desc;
然后,在我们有了一个端点,而还没有发现批量 IN 类型的端点时,查看该端点的方向是
否为IN。这可以通过检查位掩码USB_DIR_IN是否包含在 bEndpointaddress端点
变量 中 来 确 定 。如 果 是的 话 ,我 们 测 定 该 端点 类 型 是 否 批量 , 这 通 过 首 先以以。
USB_ENDPOINT_XFERTYPE_MASK位掩码来取bmAttributes变量的值,然后检查
它是否和 USB_ENDPOINT_XFER_BULK 值匹配来完成:
if(idev->bulk_in_endpointAddr &&
(endpoint->bEndpointAddress & USB_DIR_IN) &&
((endpoint->bmAttributes & USB_ENDPOINT_XFERTYPE_MASK)
= USB_ENDPOINT_XFER_BULK)) {
如果所有这些检测都通过了,驱动程序就知道它已经发现了正确的端点类型,可以把该
端点的相关信息保存到一个局部结构体中,以便稍后使用它来和端点进行通信:
/* 发现一个批量 IN 类型的端点 */
buffer_size endpoint->wMaxPacketSize;
dev->bulk_in_size = buffer_size;
dev->bulk_in_endpointAddr endpoint->bEndpointAddress;
dev->bulk_in_buffer = kmalloc(buffer_size, GFP_KERNEL);
if (!dev->bulk_in_buffer){
err("Could not allocate bulk_in_buffer");
goto error:
因为 USB 驱动程序需要在设备生命周期的稍后时间获取和该 struct usb_interface
相关联的局部数据结构体,所以可以调用 usb_set_intfdata 函数:
/* 把数据指针保存到这个接口设备中 */
usb_set_intfdata(interface, dev);
该函数接受一个指向任意数据类型的指针,把它保存到struct usb_interface结构体
中以方便后面的访问。应该调用 usb_get_intfdata 函数来获取数据:
struct usb_skel *dev;
struct usb_interface *interface;
int subminor;
int retval = 0;
subminor iminor(inode);
interface = usb_find_interface(&skel_driver, subminor);
if (!interface){
err ("ts - error, can't find device for minor td",
__FUNCTION__, subminor);
retval = -ENODEV;
goto exit;
dev = usb_get_intfdata(interface);
if (idev){
retval = -ENODEV;
goto exit;
usb_get_intfdata 通常在 USB 驱动程序的打开函数和断开函数中被调用。正是归功于这
两个函数,USB驱动程序不需要维护一个静态的指针数组来存储系统中所有当前设备的
设备结构体。对设备信息的非直接引用使得任何USB驱动程序都可以支持数量不限的设
备。
如果 USB 驱动程序没有和处理设备与用户交互(例如输入、tty、视频等等)的另一种
类型的子系统相关联,驱动程序可以使用USB 主设备号,以便在用户空间使用传统的字。
符驱动程序接口。如果要这么做,USB驱动程序必须在探测函数中调用usb_register_devo
函数来把设备注册到USB核心。只要该函数被调用,就要确保设备和驱动程序都处于可
以处理用户访问设备的要求的恰当状态。
/* 现在可以注册设备了,它已准备好了 */
retval = usb_register_dev(interface, &skel_class);
if (retval){
/* 某些情况造成我们不能注册该驱动程序 */
err("Not able to get a minor for this device.");
usb_set_intfdata(interface, NULL);
goto error;
)
usb_register_dev函数需要一个指向 struct_usb_interface的指针和一个指向struct
usb_class_driver 结构的指针。这个 struct usb_class_driver 用于定义许多不同
的参数,在注册一个次设备号时 USB 驱动程序需要 USB 核心知道这些参数。该结构体
包括如下的变量:
char *name
sysfs 用来描述设备的名字。前导路径名,如果存在的话,只用在 devfs 中,本书不
涉及该内容。如果设备的编号需要出现在名字中,名字字符串应该包含字符d。例
如,为了创建 devfs 名字 usb/foo1 和sysfs 类型名字 foo1,名字字符串应该设置
为 usb/foosd。
struct file_operations *fops;
指向 struct file_operations 的指针,驱动程序定义该结构体,用它来注册为
字符设备。有关该结构体的更多情况请参阅第三章。
mode_t mode;
为该驱动程序创建的 devfs 文件的模式;在其他情况下没有使用。该变量的一个典
型设置是 S_IRUSR 和 S_IWUSR 值的组合,只提共了设备文件属主的读和写访问
权限。
int minor_base;
这是为该驱动程序指派的次设备号范围的开始值。和该驱动程序相关联的所有设备都是以唯一的、以该值开始的递增的次设备号来创建的。任何时刻只能允许有 16
个设备和该驱动程序相关联,除非内核的CONFIG_USB_DYNAMIC_MINORS配置
选项被打开。如果如此,该变量将被忽略,以先来先办的方式来分配设备的所有次
设备号。建议打开了该选项的系统使用类似 udev 这样的程序来管理系统中的设备
节点,因为一个静态的 Idev 树不会工作正常。
当一个 USB 设备被断开时,和该设备相关联的所有资源都应该被尽可能地清理掉。在此
时,如果已经在探测函数中调用了 usb_register_dev来为该USB 设备分配一个次设备号
的话,必须调用 usb_deregister_dev函数来把次设备号交还 USB 核心。
在断开函数中,从接口获取之前调用 usb_set_intfdata设置的任何数据也是很重要的。然
后设置 struct usb_interface 结构体中的数据指针为 NULL,以防止任何不适当
的对该数据的进行的错误访问。
static void skel_disconnect(struct usb_interface *interface)
struct usb_skel *dev;
int minor = interface->minor;
/* 防止skel_open()和 skel_disconnect()竞争 */
lock_kernel();
dev = usb_get_intfdata(interface);
usb_set_intfdata(interface, NULL);
/* 返回次设备号 */
usb_deregister_dev(interface, &skel_class);
unlock_kernel();
/* 减小使用计数 */
kref_put (&dev->kref, skel_delete);
info("USB Skeleton #8d now disconnected", minor);
注意上述代码片段中的lock_kernel调用。它获取了大内核锁,以使断开回调函数在试图
获取一个正确的接口数据结构体指针时不会和打开调用遭遇竞态。因为打开函数是在大
内核锁被获取的情况下被调用的,如果断开函数也获取了同一个锁,驱动程序中只有一
个部分可以访问和设置接口数据指针。
就在 USB 设备的断开回调函数被调用之前,所有正在传输到设备的 urb 都被 USB 核心。
取消,因此驱动程序不必要对这些 urb 显式地调用 usb_kill_urb。在 USB 设备已经被断
开之后,如果驱动程序试图通过调用 usb_submit_urb 来提交一个 urb 给它、提交将会失
并返回错误值 -EPIPE。
(4)提交和控制 urb
当驱动程序有数据要发送到 USB 设备时(典型地发生在驱动程序的写函数中)、必须分
配一个 urb 来把数据传输给设备:
urb = usb_alloc_urb(0, GFP_KERNEL);
if (:urb) {
retval -ENOMEM;
goto error;
在 urb 被成功地分配之后,还应该创建一个 DMA 缓冲区来以最高效的方式发送数据到
设备,传递给驱动程序的数据应该复制到该缓冲区中:
buf = usb_buffer_alloc(dev->udev, count, GFP_KERNEL, &urb->transfer_dma);
if (!buf) {
retval = -ENOMEM;
goto error;
if (copy_from_user(buf, user_buffer, count)) {
retval = -EFAULT:
goto error;
一且数据从用户空间正确地复制到了局部缓冲区中,urb必须在可以被提交给 USB 核心。
之前被正确地初始化:
/* 正确地初始化 urb */
usb_fill_bulk_urb(urb, dev->udev,
usb_sndbulkpipe(dev->udev, dev->bulk_out_endpointAddr),
buf, count, skel_write_bulk_callback, dev);
urb->transfer_flags |= URB_NO_TRANSFER_DMA_MAP;
现在 urb 被正确地分配了,数据被正确地复制了,urb被正确地初始化了,它就可以被提
交给 USB 核心以传输到设备:
/* 把数据从批量端口发出 */
retval = usb_submit_urb(urb, GFP_KERNEL);
if (retval){
err("%s - failed submitting write urb, error sd", __FUNCTION___, retval);
goto error;
在 urb 被成功地传输到 USB 设备之后(或者传输中发生了某些事情),urb 回调函数将
被USB核心调用。在我们的例子中,我们初始化urb,使之指向skel_write_bulk_callback
函数、它就是被调用的函数:
static void skel_write_bulk_callback(struct urb *urb, struct pt_regs *regs)/*sync/async 解链接故障不是错误 *
if (urb->status&&
I(urb->status =
-ENOENT ||
urb->status =
= -ECONNRESET ||
urb->status = = -ESHUTDOWN)){
dbg("%s - nonzero write bulk status received: sd",
__FUNCTION__, urb->status);
/* 释放已分配的缓冲区 */
usb_buffer_free(urb->dev, urb->transfer_buffer_length,
urb->transfer_buffer, urb->transfer_dma);
回调函数中做的第一件事情是检查 urb 的状态,以确定该 urt 是否已经成功地结束。错
误值,-ENOENT、-ECONNRESET 和 - ESHUTDOWN 不是真的传输错误,只是报告一次
成功的传输的相关情况(请参考"struct urb"一节中描述的urb 可能的错误的列表)。之
后回调函数释放传输时分配给该 urb 的缓冲区。
当 urb 回调函数正在运行时另一个 urb 被提交到设备是很常见的。这对于发送流式数据
到设备很有用。不要忘了 urb 回调函数是运行在中断上下文中的,因此它不应该进行任
何内存分配、持有任何信号量或者做任何其他可能导致进程睡眠的事情。当在回调函数
内提交一个 urb时,如果它在提交过程中需要分配新的内存块的话,使用GFP_ATOMIC
标志来告诉 USB 核心不要睡眠。
5、 不使用urb的USB传输
有时候 USB 驱动程序只是要发送或者接收一些简单的 USB 数据,而不想把创建一个。
struct urb、初始化它、然后等待该 urb 接收函数运行这些麻烦事都走一遍。有两个。
提供了更简单接口的函数可以使用。
(1)usb_bulk_msg
usb_bulk_msg 创建一个 USB 批量 urb,把它发送到指定的设备,然后在返回调用者之前
等待它的结束。它定义为:
int usb_bulk_msg(struct usb_device *usb_dev, unsigned int pipe,
void *data, int len, int *actual_length,
int timeout);
该通数的参数为:
struct usb_device *usb_dev
指向批量消息所发送的目标 USB 设备的指针。
unsigned int pipe
该批量消息所发送的目标 USB 设备的特定端点。该值是调用 usb_sndbulkpipe 或
usb_rcvbulkpipe 来创建的。
void *data
如果是一个 OUT端点,它是指向即将发送到设备的数据的指针。如果是一个 IN 端
点,它是指向从设备读取的数据应该存放的位置的指针。
int len
data 参数所指缓冲区的大小。
int *actual_length
指向保存实际传输字节数的位置的指针,至于是传输到设备还是从设备接收取决于
端点的方向。
int timeout
以jiffies 为单位的应该等待的超时时间。如果该值为0,该函数将一直等待消息的
结束。
如果函数调用成功,返回值为 0;否则,返回一个负的错误值。该错误值和"struct urb"
一节中描述的 urb 错误编号相匹配。如果成功1,actual_1ength参数包含从该消息发
送或者接收的字节数。
下面是一个使用该函数调用的例子:
/* 进行阻塞的批量读以从设备获取数据 * /
retval = usb_bulk_msg(dev->udev,
usb_rcvbulkpipe(dev->udev, dev->bulk_in_endpointAddr),
dev->bulk_in_buffer,
min(dev->bulk_in_size, count),
&count, HZ*10);
/* 如果读成功,复制数据到用户空间 */
if (!retval)
if (copy_to_user(buffer, dev->bulk_in_buffer, count))
retval -EFAULT;
else
retval = count;
该例子说明了一个从 IN端点的简单的批量读。如果读取成功,数据被复制到用户空间。
通常在 USB 驱动程序的读函数中完成这个工作。
不能在一个中断上下文中或者在持有自旋锁的情况下调用usb_bulk_msg函数。同样,该
函数不能被任何其他函数取消,因此使用它的时候要小心;确保驱动程序的断开函数了
解足够的信息,在允许自身从内存中被卸载之前等待该调用的结束。
(2)usb_control_msg
除了允许驱动程序发送和接收 USB 控制消息之外,usb_control_msg 函数的运作和。
usb_bulk_msg 函数类似:
int usb_control_msg(struct usb_device *dev, unsigned int pipe,
__u8 request,
_u8 requesttype,
__u16 value,
_u16 index,
void *data, __u16 size, int timeout);
该函数的参数和 usb_bulk_msg 很相似,但有几个重要的区别:
struct usb_device *dev
指向控制消息所发送的目标 USB 设备的指针。
unsigned int pipe
该控制消息所发送的目标 USB 设备的特定端点。该值是调用 usb_sndctrlpipe 或
usb_revetrlpipe 来创建的。
__u8 request
控制消息的 USB 请求值。
_u8 requesttype
控制消息的 USB 请求类型值。
_u16 value
控制消息的 USB 消息值。
_u16 index
控制消息的 USB 消息索引值。
void *data
如果是一个 OUT端点,它是指向即将发送到设备的数据的指针。如果是一个 IN 端
点,它是指向从设备读取的数据应该存放的位置的指针。
__u16 size
data 参数所指缓冲区的大小。
int timeout
以jiffies 为单位的应该等待的超时时间。如果该值为0,该函数将一直等待消息的
结束。
如果函数调用成功,它返回传输到设备或者从设备读取的字节数;如果不成功,它返回
一个负的错误值。
request、requesttypevalue 和 index 参数都直接映射到 USB 规范的 USB 控
制消息定义处。关于这些参数的有效值和如何使用,请参考 USB 规范的第九章。
和 usb_bulk_msg 函数一样,usb_control_msg 函数不能在一个中断上下文中或者持有自
旋锁的情况下调用。同样,该函数不能被任何其他函数取消,因此使用它的时候要小心;
确保驱动程序的断开函数了解足够的信息,在允许自身从内存中被卸载之前等待该调用。
的结束。
(3)其他 USB 数据函数
USB 核心中的许多辅助函数可以用来从所有 USB 设备中获取标准的信息。这些函数不。
能在一个中断上下文中或者持有自旋锁的情况下调用。
usb_get_descriptor 函数从指定的设备获取指定的 USB 描述符。该函数定义为:
int usb_get_descriptor(struct usb_device *dev, unsigned char type,
unsigned char index, void *buf, int size);
USB 驱动程序可以使用该函数来从 struct usb_device结构体中获取任何没有存在于
已有 struct usb_device和 struct usb_interface结构体中的设备描述符,例如音
频描述符或者其他的类型特定信息。该函数的参数为:
struct usb_device *usb_dev
指向想要获取描述符的目标 USB 设备的指针。
unsigned char type
描述符的类型。该类型在 USB 规范中有描述,可以是下列类型中的一种:
USB_DT_DEVICE
USB_DT_CONFIG
USB_DT_STRING
USB_DT_INTERFACE
USB_DT_ENDPOINT
USB_DT_DEVICE_QUALIFIER
USB_DT_OTHER_SPEED_CONFIG
USB_DT_INTERFACE_POWER
USB_DT_OTG
USB_DT_DEBUG
USB_DT_INTERFACE_ASSOCIATION
USB_DT_CS_DEVICE
USB_DT_CS_CONFIG
USB_DT_CS_STRING
USB_DT_CS_INTERFACE
USB_DT_CS_ENDPOINT
unsigned char index
应该从设备获取的描述符的编号。
void *buf
指向复制描述符到其中的缓冲区的指针。
int size
buf 变量所指内存的大小。
如果该函数调用成功,它返回从设备读取的字节数。否则,它返回一个由该函数调用的
底层的 usb_control_msg 函数返回的一个负的错误值。
usb_get_descriptor 调用更常用于从 USB 设备获取一个字符串。因为这很常见,所以提
供了一个名为 usb_get_string 的辅助函数来完成该工作:
int usb_get_string(struct usb_device *dev, unsigned short langid,
unsigned char index, void *buf, int size);
如果成功,该函数返回从设备接收的字符串的字节数。否则,它返回一个由该函数调用
的底层的 usb_control_msg 函数返回的一个负的错误值。
如果该函数调用成功,它返回一个以 UTF-16LE 格式(Unicode,每个字符 16 位,小端
字节序)编码的字符串,保存在 buf参数所指的缓冲区中。因为这种格式不是很有用,有
另一个名为 usb_string 的函数返回从 USB 设备读取的已经转换为 ISO 8859-1 格式的字
符串。这种字符集是 Unicode 的一个 8 位的子集,是英语和其他西欧语言字符串的最常
见格式。因为它是 USB 设备的字符串的典型格式,建议使用 usb_string 函数而不是
usb_get_string函数。
6、 快速参考
本节总结本章中介绍的符号:
#include <linux/usb.h>
和 USB 相关的所有内容所在的头文件。所有的 USB 设备驱动程序都必须包括该文
件。
struct usb_driver;
描述 USB 驱动程序的结构体。
struct usb_device_id;
描述该驱动程序支持的 USB 设备类型的结构体。
int usb_register(struct usb_driver *d);
void usb_deregister(struct usb_driver *d);
用于往 USB 核心注册和注销 USB 驱动程序的函数。
struct usb_device *interface_to_usbdev(struct usb_interface *intf);
从一个 struct usb_interface *获取一个控制的 struct usb_device *。
struct usb_device;
控制整个 USB 设备的结构体。
struct usb_interface;
主要的 USB 设备结构体,所有的 USB 驱动程序都用它来和 USB 核心进行通信。
void usb_set_intfdata(struct usb_interface *intf, void *data);
void *usb_get_intfdata(struct usb_interface *intf);
用于设置和获取 struct usb_interface 内私有数据指针段的函数。
struct usb_class_driver;
描述了想要使用 USB 主设备号和用户空间程序进行通信的 USB 驱动程序的结构
体。
int usb_register_dev(struct usb_interface *intf, struct usb_class_driver
*class_driver);
void usb_deregister_dev(struct usb_interface *intf, struct usb_class_driver
*class_driver);
用于注册和注销特定的struct usb_interface *结构体的函数,使用一个struct
usb_class_driver *结构体。
struct urb;
描述一个 USB 数据传输的结构体。
struct urb *usb_alloc_urb(int iso_packets, int mem_flags);
void usb_free_urb(struct urb *urb);
用于创建和销毁一个 struct urb *的函数。
int usb_submit_urb(struct urb *urb, intmem_flags);
int usb_kill_urb(struct urb *urb);
int usb_unlink_urb(struct urb *urb);
用于开始和终止一个 USB 数据传输。
void usb_fill_int_urb(struct urb *urb, struct usb_device *dev, unsigned int
pipe, void *transfer_buffer, int buffer_length, usb_complete_t complete,
void *context, int interval);
void usb_fill_bulk_urb(struct urb *urb, struct usb_device *dev, unsigned int
pipe, void *transfer_buffer, int buffer_length, usb_complete_t complete,
void *context);
void usb_fill_control_urb(struct urb *urb, struct usb_device *dev, unsigned
int pipe, unsigned char *setup_packet, void *transfer_buffer, int
buffer_ length, usb_complete_t complete, void *context);
int usb_bulk_msg(struct usb_device *usb_dev, unsigned int pipe, void *data,
int len, int *actual_length, int timeout);
int usb_control_msg(struct usb_device *dev, unsigned int pipe, _u8 request,
_u8 requesttype, _u16 value, _u16 index, void *data, _u16 size,
int timeout);
struct urbAFRUSB
相关文章:
Linux 设备驱动程序(二)
系列文章目录 Linux 内核设计与实现 深入理解 Linux 内核(一) 深入理解 Linux 内核(二) Linux 设备驱动程序(一) Linux 设备驱动程序(二) Linux设备驱动开发详解 文章目录 系列文章目…...

性价比提升15%,阿里云发布第八代企业级计算实例g8a和性能增强型实例g8ae
5 月 17 日,2023 阿里云峰会常州站上,阿里云正式发布第八代企业级计算实例 g8a 以及性能增强性实例 g8ae。两款实例搭载第四代 AMD EPYC 处理器,标配阿里云 eRDMA 大规模加速能力,网络延时低至 8 微秒。其中,g8a 综合性…...

Unity VR开发教程 OpenXR+XR Interaction Toolkit 番外(一)用 Grip 键, Trigger 键和摇杆控制手部动画
文章目录 📕制作手部动画📕设置 Animation Controller📕添加触摸摇杆的 Input Action📕代码部分 在大部分 VR 游戏中,手部的动画通常是由手柄的三个按键来控制的。比如 Grip 键控制中指、无名指、小拇指的弯曲…...
H.265/HEVC编码原理及其处理流程的分析
H.265/HEVC编码原理及其处理流程的分析 H.265/HEVC编码的框架图,查了很多资料都没搞明白,各个模块的处理的分析网上有很多,很少有把这个流程串起来的。本文的主要目的是讲清楚H.265/HEVC视频编码的处理流程,不涉及复杂的计算过程。…...

数据结构初阶--链表OJⅡ
目录 前言相交链表思路分析代码实现 环形链表思路分析代码实现 环形链表Ⅱ思路分析代码实现 复制带随机指针的链表思路分析代码实现 前言 本篇文章承接上篇博客,继续对部分经典链表OJ题进行讲解 相交链表 先来看题目描述 思路分析 这道题我们还是首先来判断一…...

离职or苟住?
面对不太好的大环境,我们什么时候该离职,什么时候不应该离职呢?分享几个观点,希望对你有所启发。 以前就有大佬讲过,离职无非是两个原因,一是因为薪资不到位,二是因为受委屈了,总之&…...
微服务之以nacos注册中心,以gateway路由转发服务调用实例(第一篇)
实现以nacos为注册中心,网关路由转发调用 项目版本汇总项目初始化新建仓库拉取仓库项目父工程pom初始化依赖版本选择pom文件如下 网关服务构建pom文件启动类配置文件YMLnacos启动新建命名空间配置网关yml(nacos)网关服务启动 用户服务构建pom文件启动类配置文件YML新增url接口配…...

主成分分析(PCA)直观理解与数学推导
近期在完成信息论的作业,发现网上的资料大多是直观解释,对其中的数学原理介绍甚少,并且只介绍了向量降维,而没有介绍向量重构的问题(重构指的是:根据降维后的低维向量来恢复原始向量)࿰…...

什么是合伙企业?普通合伙和有限合伙区别?
1.什么是合伙企业? 合伙企业是指由各合伙人订立合伙协议,共同出资,共同经营,共享收益,共担风险,并对企业债务承担无限连带责任的营利性组织。合伙企业一般无法人资格,不缴纳企业所得税,缴纳个…...

系统结构考点之不明白的点
系统结构考点系列 计算机系统结构的定义计算机组成的定义计算机实现的定义计算系统的定量设计?1. 哈夫曼压缩原理2. Amdahl定律3. cpu性能公式4. 程序访问局部性定理 这样的题已经不多了,主要是要了解下概念。打下一个好的基础。 2023年4月份成绩已经…...

Android中AIDL的简单使用(Hello world)
AIDL:Android Interface Definition Language(Android接口定义语言) 作用:跨进程通讯。如A应用调用B应用提供的接口 代码实现过程简述: A应用创建aidl接口,并且创建一个Service来实现这个接口(…...

ZED使用指南(五)Camera Controls
七、其他 1、相机控制 (1)选择视频模式 左右视频帧同步,以并排格式作为单个未压缩视频帧流式传输。 在ZED Explorer或者使用API可以改变视频的分辨率和帧率。 (2)选择输出视图 ZED能以不同的格式输出图像…...

wrk泛洪攻击监控脚本
wrk泛洪攻击介绍 WRK泛洪攻击(WRK Flood Attack)是一种基于WRK工具进行的DDoS攻击(分布式拒绝服务攻击)。WRK是一个高度并行的HTTP负载生成器,可以模拟大量用户访问一个网站,从而导致该网站服务器瘫痪或失效…...
软件I2C读写MPU6050代码
1、硬件电路 SCL引到了STM32的PB10号引脚,SDA引到了PB11号引脚软件I2C协议: 用普通GPIO口,手动反转电平实现协议,不需要STM32内部的外设资源支持,故端口是可以任意指定MPU605在SCL和SDA自带了两个上拉电阻,…...

销售/回收DSOS254A是德keysight MSOS254A混合信号示波器
Agilent DSOS254A、Keysight MSOS254A、 混合信号示波器,2.5 GHz,20 GSa/s,4 通道,16 数字通道。 Infiniium S 系列示波器 信号保真度方面树立新标杆 500 MHz 至 8 GHz 出色的信号完整性使您可以看到真实显示的信号࿱…...

RIDGID里奇金属管线检测仪故障定位仪维修SR-20KIT
里奇RIDGID管线定位仪/检测仪/探测仪维修SR-20 SR-24 SR-60 美国里奇SeekTech SR-20管线定位仪对于初次使用定位仪的用户或经验丰富的用户,都同样可以轻易上手使用SR-20。SR-20提供许多设置和参数,使得大多数复杂的定位工作变得很容易。此外,…...
NodeJs之调试
关于调试 当我们只专注于前端的时候,我们习惯性F12,这会给我们带来安全与舒心的感觉。 但是当我们使用NodeJs来开发后台的时候,我想噩梦来了。 但是也别泰国担心,NodeJs的调试是很不方便!这是肯定的。 但是还好&…...
Java面试知识点(全)- Java并发-多线程JUC二-原子类/锁
Java面试知识点(全) 导航: https://nanxiang.blog.csdn.net/article/details/130640392 注:随时更新 JUC原子类 什么是CAS CAS的全称为Compare-And-Swap,直译就是对比交换。是一条CPU的原子指令,其作用是让CPU先进行比较两个值…...

CSS--移动web基础
01-移动 Web 基础 谷歌模拟器 模拟移动设备,方便查看页面效果 屏幕分辨率 分类: 物理分辨率:硬件分辨率(出厂设置)逻辑分辨率:软件 / 驱动设置 结论:制作网页参考 逻辑分辨率 视口 作用&a…...
Appuploader 常见错误及解决方法
转载:Appuploader 常见错误及解决方法 问题解决秘籍 遇到问题,第一个请登录苹果开发者官网 检查一遍账号是否有权限,是否被停用,是否过期,是否有协议需要同意,并且在右上角切换账号后检查所有关联的账号是否…...

基于2D工程图几何特征与梯度提升模型的制造成本智能预测
1. 项目概述:从图纸到报价的智能革命在制造业,尤其是像汽车零部件这样的离散制造领域,报价速度直接决定了订单的生死。传统上,拿到一张新的2D工程图(DWG格式),成本工程师需要花上几天甚至几周时…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...

DMA-330地址空间限制与扩展方案解析
1. DMA-330地址空间限制解析DMA-330作为Arm CoreLink系列中的直接内存访问控制器,其物理寻址能力直接由AxADDR信号宽度决定。这个32位地址总线宽度意味着它原生仅支持4GB(2^32字节)的物理地址空间访问。在实际嵌入式系统设计中,这…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...

保姆级教程:在Windows 10上用QEMU+Kylin搭建可内外网访问的完整开发环境
在Windows 10上构建QEMUKylin全功能开发环境的终极指南当开发者需要在本地快速搭建一个隔离的国产操作系统开发环境时,QEMU虚拟化方案配合银河麒麟系统能提供高度灵活的沙箱体验。本文将手把手带你完成从零配置到内外网联通的完整工作流,涵盖虚拟化环境部…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...