MapReduce paper(2004)-阅读笔记
文章目录
- 前言
- 摘要(Abstract)
- 一、引言( Introduction)
- 二、编程模型(Programming Model)
- 三、实现(Implementation)
- 3.1、执行概述(Execution Overview)
- 3.2、主节点数据结构(Master Data Structures)
- 3.3、容错(Fault Toleran)
- 3.4、局部性
- 3.5、任务粒度
- 3.6、 备用任务
- 四、技巧
- 4.1、划分函数
- 4.2、顺序保证
- 4.3、合并函数
- 4.4、输入和输出类型
- 4.5、边界效应
- 4.6、略过错误的记录
- 4.7、本地执行
- 4.8、状态信息
- 4.9、计数器
- 五、性能
- 六、经验(运用)
- 七、相关性
- 八、总结
前言
大抵只有一直忙下去,才能保持内心的平静了…后面有空打算就更些笔记,也会穿插些个人的理解。
摘要(Abstract)
MapReduce论文地址
MapReduce 是一个分布式运算程序的编程框架,可以处理并生成巨大的数据集。用户可以在输入端利用指定map函数,该函数可以处理KV键值对,生成一组中间值,而下一阶段的reduce函数则可以合并同一hash的中间值(相当于分组合并)最后得到结果。因此可以看出其的核心思想则是分而治之。将庞大的数据,拆分成相同的任务,再进行分组计算,汇合结果,而这也是分布式系统下的经典的并行处理方式,并且它是自动进行并行的,也因此就算不具有并行和分布式系统的经验,能够轻松利用大型分布式系统的资源。
一、引言( Introduction)
在实现mapreduce之前,google的作者与其他许多人,实现数百个处理大型原始数据的专用计算(爬取文档,web请求日志。)并得到各种衍生数据,如分析后的倒排索引,web文档的结构化表示…而往往原始数据都会数量庞大,则必须分布在数百台至数千台机器上,进行分布式计算。而为了这一系列的场景,则进行了新的抽象,这就是MapReduce。
二、编程模型(Programming Model)
用户分别编写map、reduce函数。用户输入一组Key/Value,map将会计算输入,并生成一组中间值的K/V,**而这个K生成的规则可以类似于哈希值之类,非常关键。**后续reduce则可以通过相同的k合并value,最终返回结果。
- 对于单词计数应用case,这里简单画一个图:
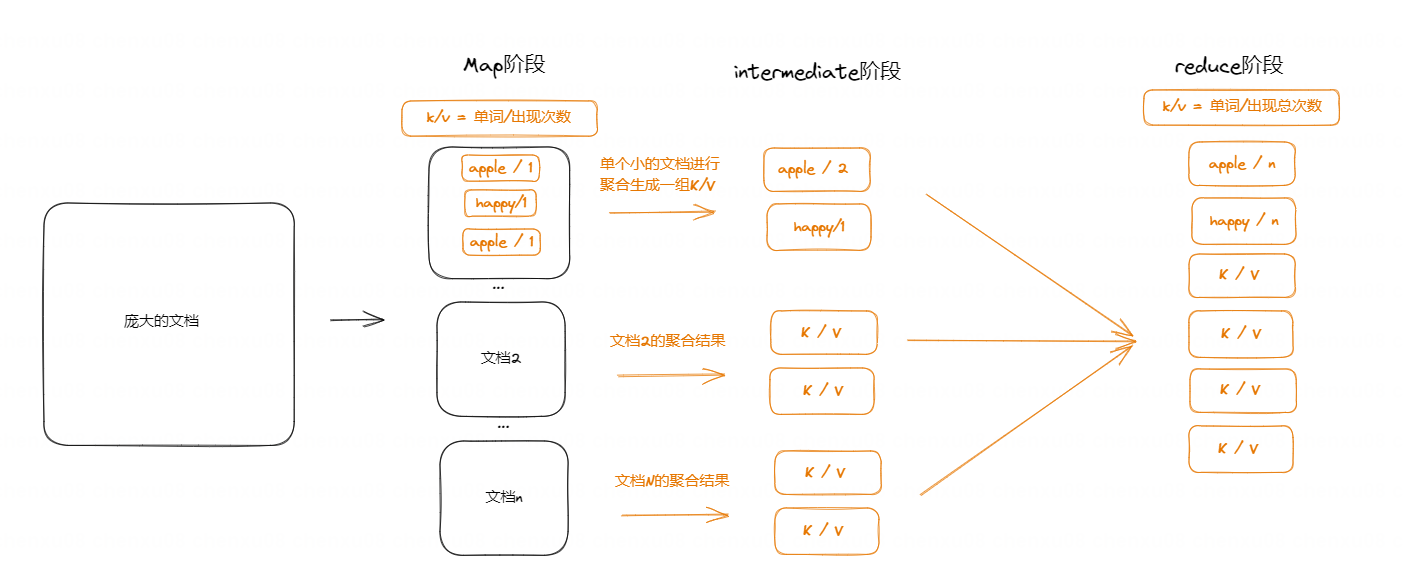
map(String key, String value):// key: document name// value: document contentsfor each word w in value:EmitIntermediate(w, "1");
reduce(String key, Iterator values):// key: a word// values: a list of countsint result = 0;for each v in values:result += ParseInt(v);Emit(AsString(result));
而这拆分的文档的位置其实也可以看做前面提到的分布式的节点(机器上)。 且按理来说应该是map(k1,v1) => mediate(k2,list1) => reduce(k2,list2)。只是论文中提到的例子k1=k2,也可以理解为,容量足够大,自身即为哈希值。
其他的例子:
- 分布式的Grep: Map函数输出匹配某个模式的一行,Reduce函数是一个恒等函数,即把中间数据复制到输出。
- 计算URL访问频率: Map函数处理日志中web页面请求的记录,然后输出(URL,1)。Reduce函数把相同URL的value值都累加起来,产生(URL,记录总数)结果。
- 倒转网络链接图: Map函数在源页面(source)中搜索所有的链接目标(target)并输出为(target,source)。Reduce函数把给定链接目标(target)的链接组合成一个列表,输出(target,list(source))。
- 每个主机的检索词向量: 检索词向量用一个(词,频率)列表来概述出现在文档或文档集中的最重要的一些词。Map函数为每一个输入文档输出(主机名,检索词向量),其中主机名来自文档的URL。Reduce函数接收给定主机的所有文档的检索词向量,并把这些检索词向量加在一起,丢弃掉低频的检索词,输出一个最终的(主机名,检索词向量)。
- 倒排索引: Map函数分析每个文档输出一个(词,文档号)的列表,Reduce函数的输入是一个给定词的所有(词,文档号),排序所有的文档号,输出(词,list(文档号))。所有的输出集合形成一个简单的倒排索引,它以一种简单的算法跟踪词在文档中的位置。
- 分布式排序: Map函数从每个记录提取key,输出(key,record)。Reduce函数不改变任何的值。这个运算依赖分区机制(在4.1描述)和排序属性(在4.2描述)。
三、实现(Implementation)
MapReduce可以有很多实现,这取决于不同的环境,例如有的实现可以适用于small shared-memory machine,也可基于NUMA multi-processor或者更大的networked machines。
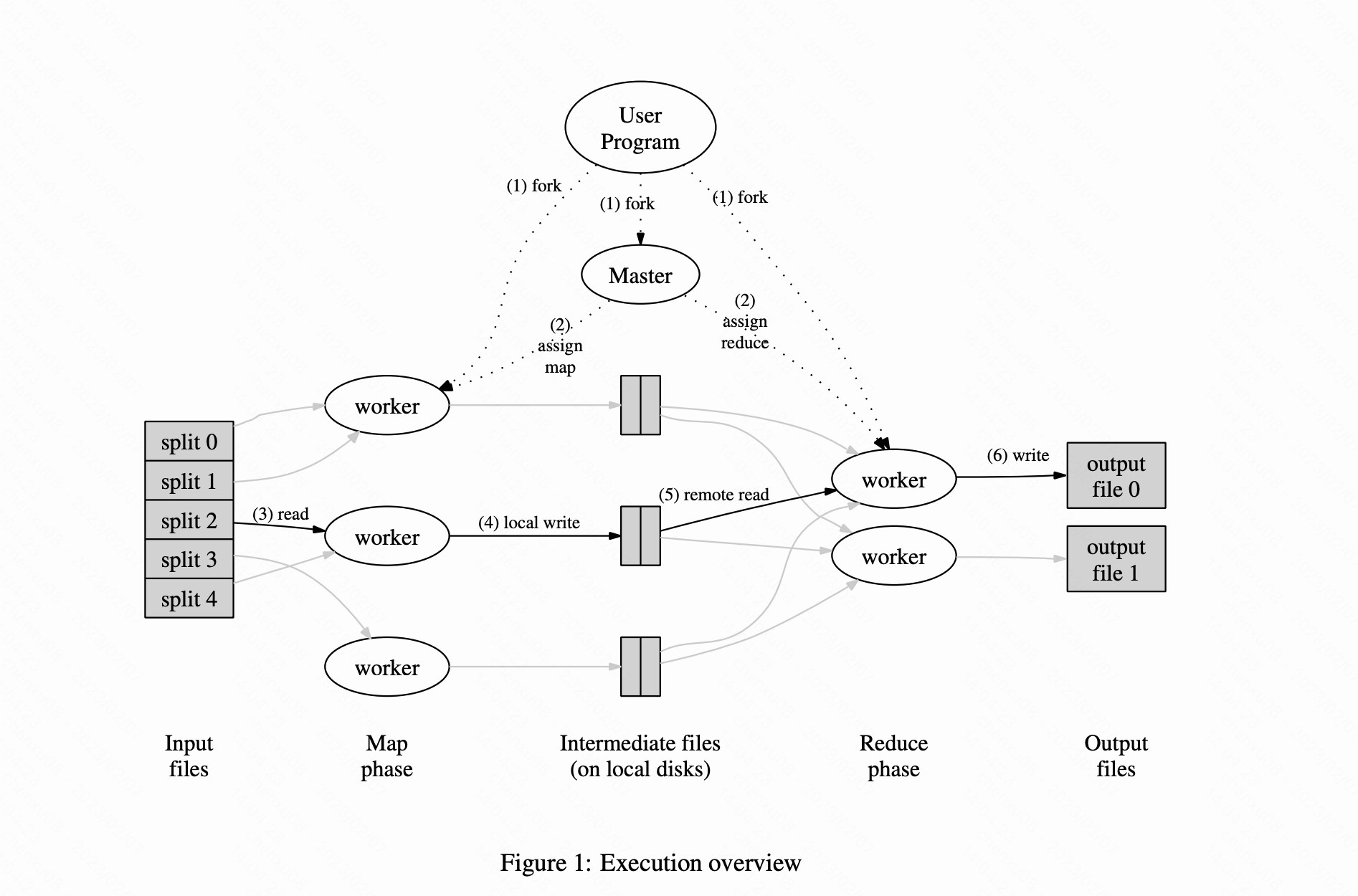
3.1、执行概述(Execution Overview)
-
1、用户程序中的MapReduce库首先将输入文件切分为M块,每块的大小从16MB到64MB(用户可通过一个可选参数控制此大小)。然后MapReduce库会在一个集群的若干台机器上启动程序的多个副本。
-
2、程序的各个副本中有一个是特殊的——Master,其它的则是worker。主节点将M个map任务和R个reduce任务分配给空闲的worker,每个节点一项任务。
-
3、被分配map任务的工作节点读取对应的输入区块内容。它从输入数据中解析出key/value对,然后将每个对传递给用户定义的map函数。由map函数产生的中间key/value对都缓存在内存中。
-
4、缓存的数据对会被周期性的由划分函数分成R块,并写入本地磁盘中。这些缓存对在本地磁盘中的位置会被传回给Master,Master负责将这些位置再传给reduce工作节点。
-
5、当一个reduce工作节点得到了Master的这些位置通知后,它使用RPC调用去读map工作节点的本地磁盘中的缓存数据。当reduce工作节点读取完了所有的中间数据,它会将这些数据按中间key排序,这样相同key的数据就被排列在一起了。同一个reduce任务经常会分到有着不同key的数据,因此这个排序很有必要。如果中间数据数量过多,不能全部载入内存,则会使用外部排序。而这重新排序的过程也喜欢被称作shuffle。
-
6、reduce工作节点遍历排序好的中间数据,并将遇到的每个中间key和与它关联的一组中间value传递给用户的reduce函数,reduce将数据对应的key合并后返回最终数据。
-
7、当所有的map和reduce任务都完成后,主节点唤醒用户程序。此时,用户程序中的MapReduce调用返回到用户代码中。
3.2、主节点数据结构(Master Data Structures)
Master存储了Map与Reduce的多种任务状态(空闲、处理中、完成)。并且Master需要将map处理好的缓存数据传递给reduce,也因此还需要存储已完成的map任务产生的R个中间文件的位置于大小。
3.3、容错(Fault Toleran)
-
工作节点失败(Worker Failure)
Master节点会对每个worker周期性的进行心跳,如果一定时间没有收到回复,则Master会认为这个worker已经crash,不管其map任务做完没,都会将其状态初始化为空闲。将其分给其他可用的worker进行重做。而对Reduce任务则是如果这个任务已经在节点crash前做好了,则不需要重做。 这是由于每个worker可以相当于每台分布式机器,而map任务完成则是存在worker的本地磁盘上。而crash的worker是访问不到的。而对于reduce处理后,则是汇总在一个GFS上,因此不需要redo。 -
主节点失败(Master Failure)
对于中心化的系统,Master发生crash几率会比worker小很多,几乎不会发生,如果发生了则会暂停整个MapReduce的计算。对于Master则是定期store有关的数据结构,如果crash了,则返回上一个checkpoint储存的结构。 -
出现故障的语义(Locality)
-
当用户提供的map和reduce操作对于它们输入的值都是确定性的,我们的分布式实现产生的输出值就如同将整个程序分成一个不间断的串行执行过程一样。 对于这个实现依赖于GFS底层文件的原子系统,使得即使有多个同样的reduce完成,可是最终只会有一个文件被使用。
-
当用户提供的map和reduce操作对于它们输入的值不是确定性的,且执行顺序会对结果进行改变(如运算符等),那么分布式下的实现,只能保证这是某一个串行执行化后的结果。
3.4、局部性
当在一个集群的相当一部分节点上运行MapReduce操作时,大多数输入数据都是本地读取,并不消耗网络带宽。 这是因为输入数据(由GFS管理)就存储在组成集群的机器的本地磁盘上,如果一个map失败了,就由同一集群下的其他机器代劳。而在GFS中一般则是将每个文件分成64MB的chunk,并存储上三台机器上。
3.5、任务粒度
Map与Reduce的任务数通常比工作比工作节点大很多,因为每个worker都应该处理很多个任务。 对于实际M、R数量的选取应该有实际的上线,因为Master节点要做O(M+R)的调度,在内存中也需要保持O(MR)个状态。(但是一般保持这个状态则是一组任务对只需要1byte)。由于MR(一个M任务都可能会出现n个R),所以通常考虑M的数量,由于局限性的原因,所以一般将任务分成16~64MB此时局部性优化效果最好 ,对R考虑的数量则是最好为待适用的工作节点数量较小的整数倍。 由此一般为M = 20000 , R = 5000 , worker = 2000(具体还应考虑M、R的任务复杂度,不一定要像paper中那样定死)。
3.6、 备用任务
由于有些worker会因为磁盘损坏等,其性能会下降到很低此时这个节点就会被称作“落后者”,那么整个快结束的MapReduce就会开启备用任务。将其他空闲worker,也投入正在执行的任务中。简单点则是增大cpu计算负担,但是可以加快整个任务进程的速度。
四、技巧
4.1、划分函数
可以根据key的特征选择其的hash函数,例如有时输出的key都是URL,而我们想让所有来自同一主机的项最后都在同一个输出文件中。这时可以使用其主机进行hash。
4.2、顺序保证
保证生成中间的K/V是有序(如升序)的,则reduce利用这些任务生成的文件会是高效的。
4.3、合并函数
对于一些map函数,生成的key重复值很高,由此可以先在map中先进行局部合并,再发送给reduce。局部合并的函数与reduce的函数应该一样,与其不同的只是一个输出到本地磁盘,一个是输出GFS中。
4.4、输入和输出类型
MapReduce库支持多种不同格式输入数据的读取。
4.5、边界效应
笔者的理解就是trade off,在某些情况下MapReduce生成的辅助文件会比较有用,但是也需要利用原子性,保证这些文件的一致性与幂等性。
4.6、略过错误的记录
有时在整个框架的计算中会出现错误记录或者运行时错误,可能会使整个MapReduce计算进程阻塞,一般时候可能会去想着如何解决,可在某些时候可以catch这个错误,因为发生的bug源于第三方库。并且对于统计分析场景来说,略过一两条错误是不影响的。
4.7、本地执行
由于MapReduce可能会部署在几千台机器上运行,所以其bug的排错会比较困难,因此可以进行某些配置,使其在本地调用,以便本地在开发
4.8、状态信息
Master节点内置了一个Http服务器,可以将当前一组状态值输出为一个网页,网页显示了框架的各种计算信息。(例如有多少任务被完成,多少正在处理,输入数据大小,中间数据大小,输出数据大小,处理速度等。)并且可以显示有多少个工作节点失败了,这会有利于进行debug。
4.9、计数器
MapReduce提供计数器机制,可以用来统计某种事件的次数例如(已处理的单词总数,或被索引的德语文献的数)则可以用这些计数判断框架计算的程度。
五、性能
paper中这里的部分类似于针对前面的小点进行实验test,这里则不再赘述。
六、经验(运用)
对于MapReduce已经有以下几个运用:
-
大规模机器学习问题;
-
针对Google News和Froogle产品的集群问题;
-
用于产生流行需求报告的数据提取(例如Google Zeitgeist);
-
针对新的尝试和产品的网页属性提取(例如,从大量的定位搜索中提取出地理位置信息);
-
大规模的图计算;
对于我们目前最重要的一个例子是:利用MapReduce重写了生产环境下的索引系统,这个索引系统是为google web search提供服务,它的文档来源于爬虫系统,然后最终储存下来后被GFS文件系统排序。MapReduce替换后有底下几个优点:
- 关于索引处理逻辑的代码规模会更简单,更加少,更加抽象去易于理解,因为关于容错、分布式并行处理的逻辑封装在MapReduce库中,其中一个计算阶段的代码使用了MapReduce后从3800行降低到700行。
- 得益于MapReduce库的高性能,我们可以将与业务无关的计算逻辑分离开,避免所有的计算逻辑混在一起。以往我们修改一个索引进程只需要几个月,现在只需要几天。
- 索引进程变得更简单去操作,因为索引系统频发的问题通常是因为机器的故障、机器的延迟,以及网络抖动,现在都由MapReduce进行统一的处理。也因为简易了操作的难度,向集群中增加一台机器便能直观的感受到性能的提升。
七、相关性
- Bulk Synchronous Programming和一些MPI原语提供了更高层次的抽象,更容易写出并行程序。这些系统和MapReduce的一个关键区别是MapReduce利用了一个受约束的程序模型去自动并行化用户程序,并提供透明的容错机制。
- 局部性优化受到了诸如活动磁盘等技术的启发,即将计算推给靠近本地磁盘的处理单元,来减少要跨过I/O子系统或网络发送的数据总量。区别是用运行在直接连接了少量磁盘的商用处理器上替代了直接运行在磁盘控制处理器上。
- 备用任务机制与Charlotte系统上的eager调度机制类似。但eager调度系统有一个缺点,就是如果某个任务导致了多次失败,整个计算都会失败。我们通过自己的略过bad records的机制解决了一些这类问题。
- MapReduce的实现依赖于一个内部的集群管理系统,负责在一组数量很多的共享机器上分布运行用户任务,与Condor等其它系统在原理上是类似的。
- 排序机制作为MapReduce库的一部分,每个reduce节点在本地排序它的数据(尽量存放在内存中),这与NOW-Sort操作是类似的。只不过NOW-Sort没有自定义的map与reduce函数。
八、总结
MapReduce成功的被谷歌运用在各种领域,他的成功应有以下几个原因:
- 首先,该模型即使是对于没有并行和分布式系统经验的程序员也是很易于使用的,因为它隐藏了并行化、容错机制、局部性优化、以及负载平衡的细节。
- 其次,很多种类的问题都很容易表示成MapReduce计算。例如,MapReduce被用于为Google的网络搜索服务的数据产生、排序、数据挖掘、机器学习、以及许多其它系统。
- 第三,我们已经开发了一个MapReduce的实现,可以扩展到包含上千台机器的大型集群。该实现可以高效使用这些机器的资源,因此适合于Google遇到的很多大型计算问题。
同时对于在调研MapReduce,我们应该有一些通用型上的反思学习:
- 约束整个编程模型,使其在并发计算的部分更简单,并且使其可容错。
- 网络带宽通常是稀缺的资源,那么我们就应该减少网络数据的发送。因此我们使用了局部性优化使我们可以在本地读取数据。同时将中间文件写入本地磁盘也能减少本地带宽。
- 备用执行可以用于减小缓慢的机器的影响,及应对机器失败和数据丢失。
对于paper中提到了很多点,其实直白的来说,对于容错来说最直白简单的方法就是进行备份,消耗一定的存储资源,或者计算资源换取可备份计算的资源或者可重新执行调度任务。但也因为你进行容错操作,系统的性能也会随之下降。
同时也补充下MapReduce的缺点:
-
高延迟:MapReduce 的处理过程需要将数据从存储设备(如硬盘)中读取,经过 Map 和 Reduce 阶段的计算,然后再将结果写回存储设备,这个过程会导致很高的延迟,特别是对于需要迭代处理的应用。
-
繁琐的编程模型:使用 MapReduce 编写程序需要遵循一定的编程模型,例如将计算分解成 Map 和 Reduce 阶段,以及合并和排序操作等,这些操作对于初学者来说可能比较繁琐和复杂。
-
低效的迭代处理:MapReduce 框架不擅长处理需要迭代计算的应用,因为每次迭代都需要重新读取数据和执行计算,导致迭代计算的效率很低。
-
不支持交互式查询:由于 MapReduce 的计算过程是离线的,需要将数据从存储设备读取到内存中,再进行计算,因此不适合支持实时或交互式查询。
-
存储开销大:MapReduce 框架需要将计算结果写回到存储设备中,导致存储开销较大,对于大规模数据处理的应用,这个问题可能会更加明显。
总之,虽然 MapReduce 在处理大规模数据方面有很大优势,但也存在一些限制和不足,需要根据具体的应用场景来选择适合的分布式计算框架。
相关文章:
MapReduce paper(2004)-阅读笔记
文章目录前言摘要(Abstract)一、引言( Introduction)二、编程模型(Programming Model)三、实现(Implementation)3.1、执行概述(Execution Overview)3.2、主节点数据结构(Master Data…...
【蒸滴C】C语言指针入门很难?看这一篇就够了
目录 一、前言 二、指针是什么 小结: 三、指针变量是什么 小结: 四、指针在32位机器和64位机器中的差别 32位机器: 64位机器: 小结: 五、指针和指针类型 (1)指针的意义 (2ÿ…...

C++11新的类功能
文章首发公众号:iDoitnow 1. 特殊的成员函数 C11在原有的4个特殊成员函数(默认构造函数、复制构造函数、复制赋值运算符和析构函数)的基础上新增了移动构造函数和移动赋值运算符。这些特殊成员函数在各种情况下是会通过编译器自动提供的。 …...
Laravel创建定时任务
创建一个任务,创建成功后会在App/Console/Commands中生成一个以Test命名的文件,我们可以在这里面写我们的任务指令。 php artisan make:command Test 运行这个定时任务 run 是运行一次,我们可以用来测试是否成功,work是一直运行&a…...

SaveInstanceState
1. 保存与读取当前状态,MainActivity.java public class MainActivity extends AppCompatActivity {private String TAG "MyLog";TextView textView;Button button;Overrideprotected void onCreate(Bundle savedInstanceState) {super.onCreate(savedI…...

Fluent Python 笔记 第 16 章 协程
从句法上看,协程与生成器类似,都是定义体中包含 yield 关键字的函数。可是,在协程中,yield通常出现在表达式的右边(例如,datum yield),可以产出值,也可以不产出——如果 yield 关键字后面没有表…...
山东科技大学校历 代码分析 获得以前学期学年的老版校历
校历-山东科技大学网络安全与信息化办公室http://tech.sdust.edu.cn/wlfw/xl.htm JavaScript var studyStart new Date(2021, 8-1, 30);//8-1 -1没有意义,30代表30号,2021年8月30号开始这个学期 var commonWeeks 19;//这个学期有多少周 var s…...
第五章.与学习相关技巧—权重初始值(随机初始值,Xavier初始值,He初始值)
第五章.与学习相关技巧 5.2 权重初始值 本节将介绍权重初始值的推荐值,并通过实验确认神经网络的学习是否会快速进行。 1.权值衰减 权值衰减就是一种以减少权重参数的值为目的进行学习的方法,通过减少权重参数值来抑制过拟合的情况发生。 2.权重初始值不…...

Linux进程间通信(管道)
进程间通信的目的 数据传输:一个进程需要将它的数据发送给另一个进程 资源共享:多个进程之间共享同样的资源。 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如…...
)
写一个基于node.js的api后台管理系统(三)
创建登录页面 在项目目录下创建一个名为public的文件夹,并在其中创建一个HTML文件login.html。添加以下代码: <!DOCTYPE html> <html> <head><title>Login - Task Management</title> </head> <body><h1…...

【23种设计模式】行为型模式详细介绍(上)
前言 本文为 【23种设计模式】行为型模式 相关内容介绍,下边将对访问者模式,模板模式,策略模式,状态模式,观察者模式,备忘录模式,中介者模式,迭代器模式,解释器模式&…...
PID控制算法进阶
关于PID控制算法基础概念在本文不再重复了,详情可参考:PID控制算法基础介绍 本文主要从PID算法代码实现,代码解析,理论进阶,PID调参等方向进行阐述。 目录位置式PID和增量式PID1.1 位置式PID1.2 增量式PID1.3 位置式和…...

嵌入式工程师有什么值得一看的网站和书籍吗?
原文直达: 嵌入式工程师有什么值得一看的网站和书籍吗? - CodeAllen的回答 - 知乎 https://www.zhihu.com/question/68423119/answer/2885623392 我是资深网站保存爱好者,浏览器分门别类存了应该有几百个网址,关于嵌入式的也有很…...

操作系统的四个特征
一、并发 并发:是指两个或多个事件在同一时间间隔内发生。这些事件宏观上是同时发生的,但微观上是交替发生的。 并行:指两个或多个事件在同一时刻同时发生。 操作系统的并发性指计算机系统中同时存在着多个运行的程序。操作系统和程序并发…...
Django框架之模型shell工具和查看MySQL数据库日志
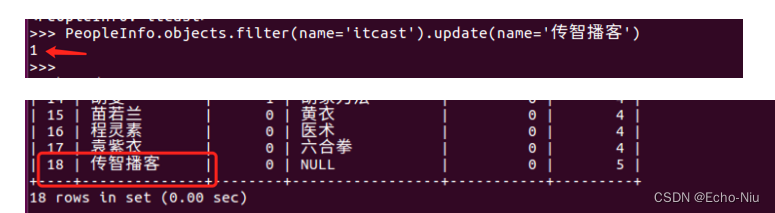
shell工具和查看MySQL数据库日志 1 shell工具 Django的manage工具提供了shell命令,帮助我们配置好当前工程的运行环境(如连接好数据库等),以便可以直接在终端中执行测试python语句。 通过如下命令进入shell python manage.py …...
电脑录屏怎样不录到外界声音?调整这一个开关,即可实现
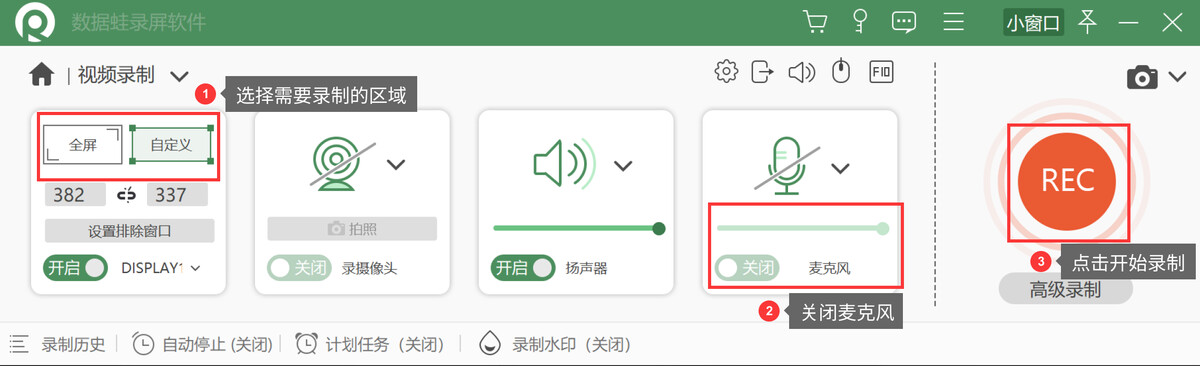
有很多小伙伴希望自己电脑录屏的时候,不要录制自己的声音,而是通过后期配音的方式完成视频创作。电脑录屏怎样不录到外界声音?其实只需要调整这一个开关,就能实现不录外界声音,一起来看看吧。 不录外界声音1…...

无需登录复制网站文字的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理…...
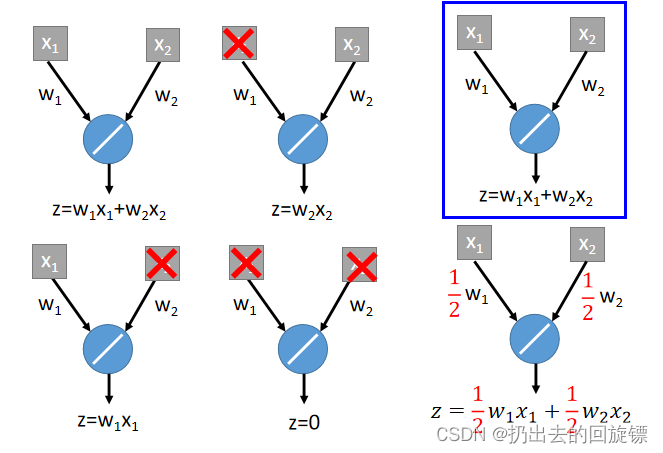
ccc-Tips for Deep Learning-李宏毅(8)
文章目录Recipe of Deep LearningGood Results on Training DataNew activation functionAdaptive Learning RateGood Results on Testing DataEarly StoppingRegularizationDropoutwhy Dropout work?Reason for bias&varianceDropout is a kind of ensembleRec…...

ArkUI新能力,助力应用开发更便捷
ArkUI是一套构建分布式应用的声明式UI开发框架。它具备简洁自然的UI信息语法、丰富的UI组件、多维的状态管理,以及实时界面预览等相关能力,帮助您提升应用开发效率,并能在多种设备上实现生动而流畅的用户体验。随着HarmonyOS 3.1版本的发布&a…...

vue面试题大全
Vue面试题大全一.vue的基本原理二.双向数据绑定的原理三.使用object.defineProperty()来进行数据劫持有什么缺点?一.vue的基本原理 当一个vue实例创建的时候,vue会遍历data中的属性,用object.defineProperty,将它们转为getter/se…...

温室大棚结构设计与选型指南:从荷载计算到智能控制系统
摘要 温室大棚作为现代农业的核心基础设施,其结构设计、材料选型及环境调控系统的合理性直接影响作物产量与运营成本。本文从工程技术角度出发,系统介绍日光温室、智能连栋温室、菌菇专用大棚等常见类型的技术特点、结构参数、荷载计算要点及智能控制系统…...

构建飞书双向集成中继器:Node.js实现企业内外系统自动化连接
1. 项目概述:一个连接飞书与外部服务的“中继器” 最近在做一个挺有意思的小项目,叫 gainly-playreading188/clawrelay-feishu-server 。光看这个名字,可能有点摸不着头脑,我来拆解一下。 clawrelay 这个词组,可以…...

别再死记硬背了!手把手教你选对PPP定位模型:UC、UD、UofC、SD到底怎么用?
精密单点定位模型实战指南:如何根据场景选择UC、UD、UofC与SD 在GNSS高精度定位领域,精密单点定位(PPP)技术已成为科研与工程应用的核心工具。面对UC、UD、UofC、SD四种主流模型,许多工程师常陷入选择困境——不同模型…...

扰动补偿自触发MPC控制器设计【附代码】
✨ 长期致力于永磁同步电机、模型预测控制、扰动补偿、死区时间优化、自触发控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于预测误差驱动的扰…...

非洲车商采购中国二手车的完整流程:从找车到提车七步走
操作目标:帮助非洲车商、进口商、批发商及其采购代理,系统性地完成中国二手车采购。适用对象:想了解采购中国二手车完整流程的海外B端买家。采购流程SOP第一步:找车源渠道说明适用场景广州出口基地南沙、番禺、白云实地考察线上平…...

【claude code agent 实践7】后台任务机制深度解析: 从S02到S08的演进
后台任务机制深度解析 文章目录后台任务机制深度解析🔄 s02 vs s08 核心变化对比🔍 新增核心逻辑详解1. BackgroundManager类(后台任务管理器)2. agent_loop关键变化 - 每次LLM调用前排空队列📊 后台任务完整工作流程图…...

im2col算法实现:从原理到代码的逐行剖析
1. im2col算法原理揭秘 想象你正在整理一副扑克牌,需要把相邻的几张牌快速组合起来。im2col算法的核心思想与此类似——它将图像中相邻的像素区域重新排列成矩阵的列,从而将卷积运算转化为高效的矩阵乘法。这个"image to column"的转换过程&am…...

光伏电站实现IEC104数据采集远程监控系统案例
在某山地光伏电站,由于占地广阔且地处丘陵地带,植被茂密、地形起伏大,运维团队在进行设备巡检时十分劳累,工作强度较大,数据汇总缓慢;同时对于突发的异常故障往往不能及时发现并采取措施,各种因…...

终极PT资源管理指南:如何用auto_feed_js实现100+站点一键转载
终极PT资源管理指南:如何用auto_feed_js实现100站点一键转载 【免费下载链接】auto_feed_js PT站一键转载脚本 项目地址: https://gitcode.com/gh_mirrors/au/auto_feed_js 在PT(Private Tracker)社区中,资源分享是核心价值…...
深度探秘:以一次文件打开操作为例)
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例 当我们在终端输入cat /etc/shadow时,系统背后究竟发生了什么?这个看似简单的操作,实际上触发了一系列精妙的安全检查机制。本文将带您深入Linux内…...