Mysql sql优化
插入优化
1️⃣ 用批量插入代替单条插入
insert into 表明 values(1, 'xxx')
insert into 表明 values(2, 'xxx')
...
改为使用👇
insert into 表名 values(1, 'xxx'), (2, 'xxx')...
2️⃣ 手动提交事务
start tranaction;
insert into 表名 values(1, 'xxx'), (2, 'xxx')...
insert into 表名 values(1, 'xxx'), (2, 'xxx')...
commit;
3️⃣ 主键顺序插入
insert into 表名 values(1, 'xxx'), (4, 'xxx'), (2, 'xxx'), (3, 'xxx')...
改为使用👇
insert into 表名 values(1, 'xxx'), (2, 'xxx'), (3, 'xxx'), (4, 'xxx')...
4️⃣ 大批量数据插入时,使用数据库提供的load指令进行插入
# 客户端连接服务端时,加上参数 --local-infile
mysql --local-infile -u root -p
# 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile=1
# 执行load指令将准备好的数据加载到表结构中
load data local infile '/root/sql.log' into table `t_user` fields terminated by ',' lines terminated by '\n'
主键优化
✅ 优化方式
1️⃣ 满足业务需求的情况下,尽量降低主键长度
2️⃣ 插入数据时,尽量选择顺序插入,选择使用auto_increment自增主键。乱序插入会出现页分裂与页合并,影响效率。
3️⃣ 尽量不要使用UUID做主键或者是其他自然主键,如身份证号。首先是长,其次是乱序。
4️⃣ 业务操作时,避免对主键的修改。主键修改,索引结构也跟着改变。
order by排序优化
排序优化的思路就是让它走索引,如果没有走索引,mysql会将查询到的数据在排序缓冲区中进行排序操作,再将有序结果返回,而走索引之后,根据索引顺序扫描获取到的数据就是有序数据,这样就少了一个排序操作。
🛑 需要注意的是索引的建立默认是升序的,这说明如果根据两个字段排序,只能是两个都升序或者都是降序(mysql会倒着查询),如果要一个升序,一个倒序就需要建立索引时指定顺序。
🛑 如果两个排序我都需要呢?那就创建两个索引,一个默认,一个指定。
create index idx_uesr_age_phone on t_user(age, phone)
默认创建方式改为指定索引排序方式👇
create index idx_uesr_age_phone on t_user(age asc, phone desc)
✅ 优化方式
1️⃣ 根据排序字段建立索引,多字段排序要遵循最左前缀法则
2️⃣ 尽量使用覆盖索引,防止回表查询
3️⃣ 多字段排序,一个升序一个降序,创建索引时要指定顺序
4️⃣ 大数据排序时,如果不可避免的使用排序缓冲区时,可以适当的增加它的大小sort_buffer_size(默认256k),如果缓冲区满了,会在磁盘文件中进行排序,速度更慢
group by优化
✅ 优化方式
1️⃣ 对分组的字段创建索引,提高效率
2️⃣ 索引的使用要满足最左前缀法则
limit优化
当我们分页查询数据时,查询的起始记录越大,速度就越慢
select * from t_user limit 1000000, 10
👆查询时间 > 👇查询时间
select * from t_user limit 10, 10
因为我们查询从1000000开始的10条数据时,前999999条数据也会扫描一遍,所以越往后查询时间越长,官方给出的方式是使用覆盖索引 + 子查询来优化
select * from t_business order by id limit 10, 10
改为使用👇
select b1.* from t_business b1, (select id from t_business order by id limit 10, 10) b2 where b1.id = b2.id
✅ 优化方式
1️⃣ 使用覆盖索引 + 子查询
count优化
🛑count计数时,如果值为NULL,不会计数
🛑 MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高,但是mysql现在默认使用的InnoDB引擎,它执行count(*)的时候会把数据全部读出来,累计计数。然而没有好的优化方法,但是它的使用方式不同,效率是不同的
1️⃣ count(主键)
InnoDB引擎会遍历整张表,把主键取出来,返回给服务层,服务层拿到之后,直接进行累加(主键不为null)
2️⃣ count(字段)
没有not null约束时,InnoDB会便利整张表,将字段取出,返回服务层,服务层拿到之后,判断是否为空,不为空进行累加,没有not null约束时,直接进行累加,少一步判断是否为空
3️⃣ count(1)
InnoDB引擎会便利整张表,但不取值。服务层对于返回的每一行,放一个数字"1"进去,直接按行进行累加
4️⃣ count(*)
InnoDB专门做了优化,并不会把全部字段取出来,不取值,服务层直接按行进行累加
✅ 总结
效率: count(字段) < count(主键) < count(i) ≈ count(*), 所以尽量使用count(*)
update优化
在update使用时,要避免行级锁升级为表锁,update更新时更新的字段没有建立索引就会上升为表锁
begin # 开启事务
update t_user set uname = 'zdy' where uname = 'zzz' # 更新
正常来说,在客户端一没有执行commit操作之前,锁住的应该是uname='zzz’的这条数据,客户端二可以更新其他记录,但是由于uname没有建立索引,客户端二不管update哪条数据都会处于阻塞状态,客户端一commit之后,客户端二才能update,这样就会降低效率,解决方式就是建立索引。
✅ 优化方式
1️⃣ 对Update更新的字段建立索引
索引的使用
优化了一堆,发现很多优化都跟索引有关,那就了解一下如何高效使用索引吧
1️⃣ 不满足最左前缀法则,索引会失效
2️⃣ 不要对索引列上使用运算操作,否则索引会失效
3️⃣ 字符串要加引号,否则会进行隐式转换,索引将失效 ✅uname = ‘10’ ❎uname = 10
4️⃣ 模糊匹配不能使用尾部模糊匹配,否则索引会失效 ✅uname like = ‘zdy%’ ❎uname like = ‘%zdy’
5️⃣ 使用or连接的条件,如果其中一个没有建立索引,索引将失效,必须都建立索引
6️⃣ 如果mysql评估索引方式比全表查询要慢,就不会使用索引
7️⃣ 使用覆盖索引,即查询返回的列都建立了索引,减少select(*)的使用(返回的列没有建立索引时,需要进行回表查询,如果建立索引,那么需要的数据在索引中就能找到,不用进行回表查询)
8️⃣ 如果字符串作为索引时过长,会浪费磁盘空间,影响查询效率,此时可以只将字符串的一部分前缀做为索引,但是这一部分要保证足够的区分度
9️⃣ 推荐使用联合索引,而不是单列索引,即使条件中的多个字段都建立了单列索引,mysql也只会选择其中一个效率较高的作为索引,最后还需要回表查询
# 补充第八条 部分前缀最作为索引语法
create index 索引名称 on 表名(column(n))
相关文章:

Mysql sql优化
插入优化 1️⃣ 用批量插入代替单条插入 insert into 表明 values(1, xxx) insert into 表明 values(2, xxx) ... 改为使用👇 insert into 表名 values(1, xxx), (2, xxx)...2️⃣ 手动提交事务 start tranaction; insert into 表名 values(1, xxx), (2, xxx)... in…...

vnode 在 Vue 中的作用
vnode就是 Vue 中的 虚拟 dom 。 vnode 是怎么来的? 就是把 template 中的结构内容,通过 vue template complier 中的 render 函数(使用了 JS 中的 with 语法),来生成 template 中对应的 js 数据结构,举个例…...
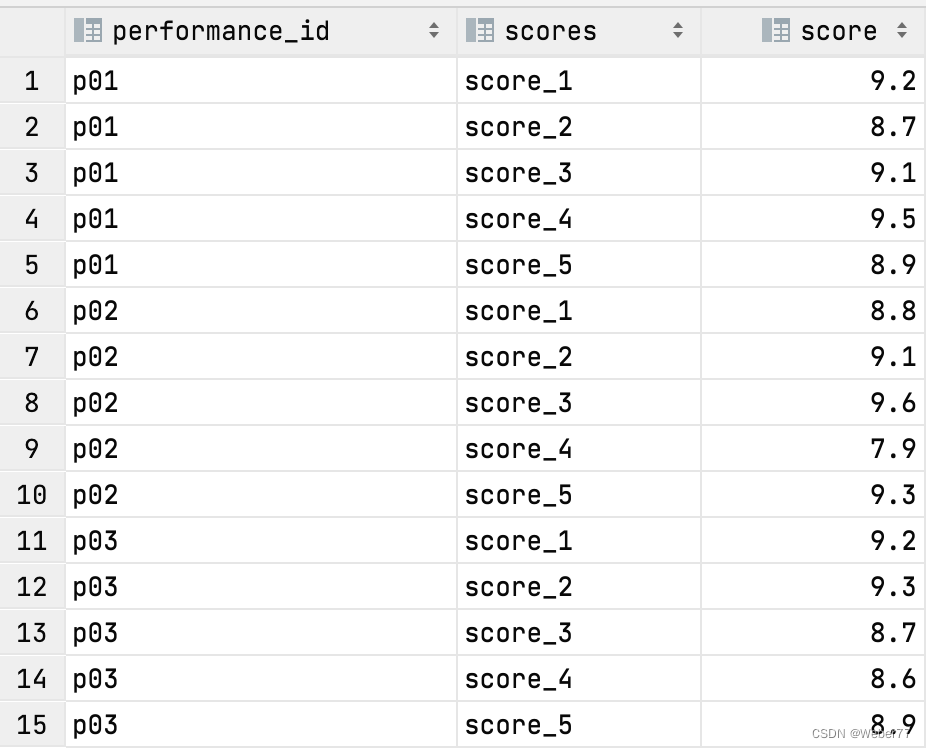
SQL语句实现找到一行中数据最大值(greatest)/最小值(least);mysql行转列
今日我在刷题时遇到这样一个题,它提到了以下需求: 有一场节目表演,五名裁判会对节目提供1-10分的打分,节目最终得分为去掉一个最高分和一个最低分后的平均分。 存在以下一张表performence_detail,包含字段有performa…...
记一次以小勃大,紧张刺激的渗透测试(2017年老文)
一、起因 emmm,炎炎夏日到来,这么个桑拿天干什么好呢? 没错,一定要坐在家里,吹着空调,吃着西瓜,然后静静地挖洞。挖洞完叫个外卖,喝着啤酒,撸着烧烤,岂不美…...

LeetCode 61. 旋转链表
原题链接 难度:middle\color{orange}{middle}middle 题目描述 给你一个链表的头节点 headheadhead ,旋转链表,将链表每个节点向右移动 kkk 个位置。 示例 1: 输入:head [1,2,3,4,5], k 2 输出:[4,5,1…...

数据库(4)--视图的定义和使用
一、学习目的 加深对视图的理解,熟练视图的定义、查看、修改等操作 二、实验环境 Windows 11 Sql server2019 三、实验内容 学生(学号,年龄,性别,系名) 课程(课号,课名,…...
pandas表格并表(累加合并)
今天需求是用pandas的两张表格合并起来,其中重复的部分将数据进行相加。 用到的是combine()这个函数。 函数详细的使用可以看这个大佬的文章: https://www.cnblogs.com/traditional/p/12727997.html (这个文章使用的测…...
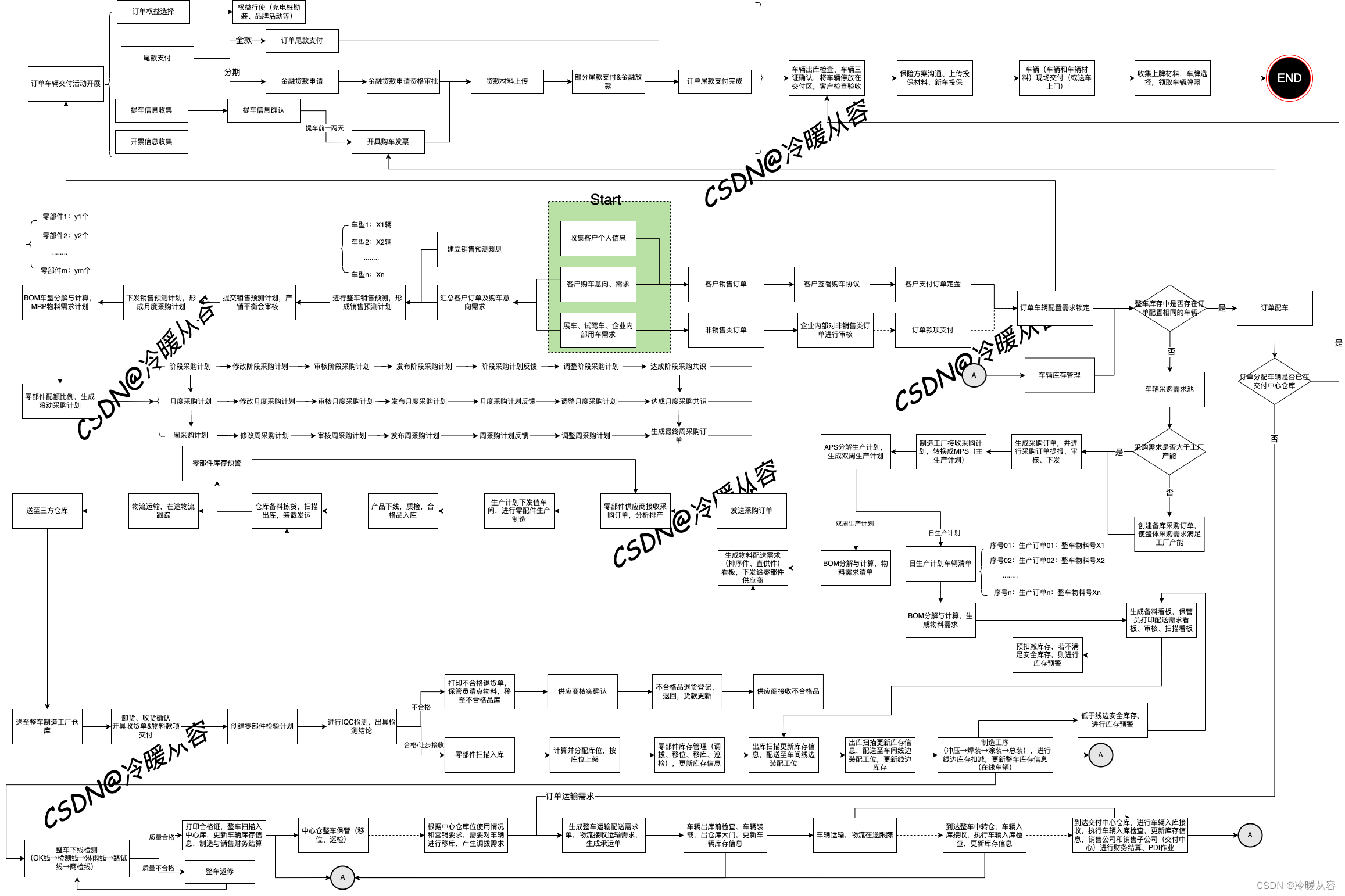
汽车直营模式下OTD全流程
概述 随着新能源汽车的蓬勃发展,造车新势力的涌入,许多新能源车企想通过直营的营销模式来解决新能源汽车市场推广速度缓慢问题,而直营模式下OTD(Order-To-Delivery,订单-交付)全流程的改革创新在这过程中无…...

如何在 Canvas 上实现图形拾取?
图形拾取,指的是用户通过鼠标或手指在图形界面上能选中图形的能力。图形拾取技术是之后的高亮图形、拖拽图形、点击触发事件的基础。 canvas 作为一个过于朴实无华的绘制工具,我们想知道如何让 canvas 能像 HTML 一样,知道鼠标点中了哪个 “…...

适用于媒体行业的管理数据解决方案—— StorageGRID Webscale
主要优势 1、降低媒体存储库的复杂性 • 借助真正的全局命名空间在全球范围内存储数据并在本地进行访问。 • 实施纠删编码和远程复制策略。 • 通过单一管理平台管理策略和监控存储。 2、优化媒体工作流 • 确认内容在合适的时间处于合适的位置。 • 支持应用程序直接通过 A…...

Springboot+ElasticSearch构建博客检索系统-学习笔记01
课程简介:从实际需求分析开始,打造个人博客检索系统。内容涵盖:ES安装、ES基本概念和数据类型、Mysql到ES数据同步、SpringBoot操作ES。通过本课,让学员对ES有一个初步认识,理解ES的一些适用场景,以及如何使…...
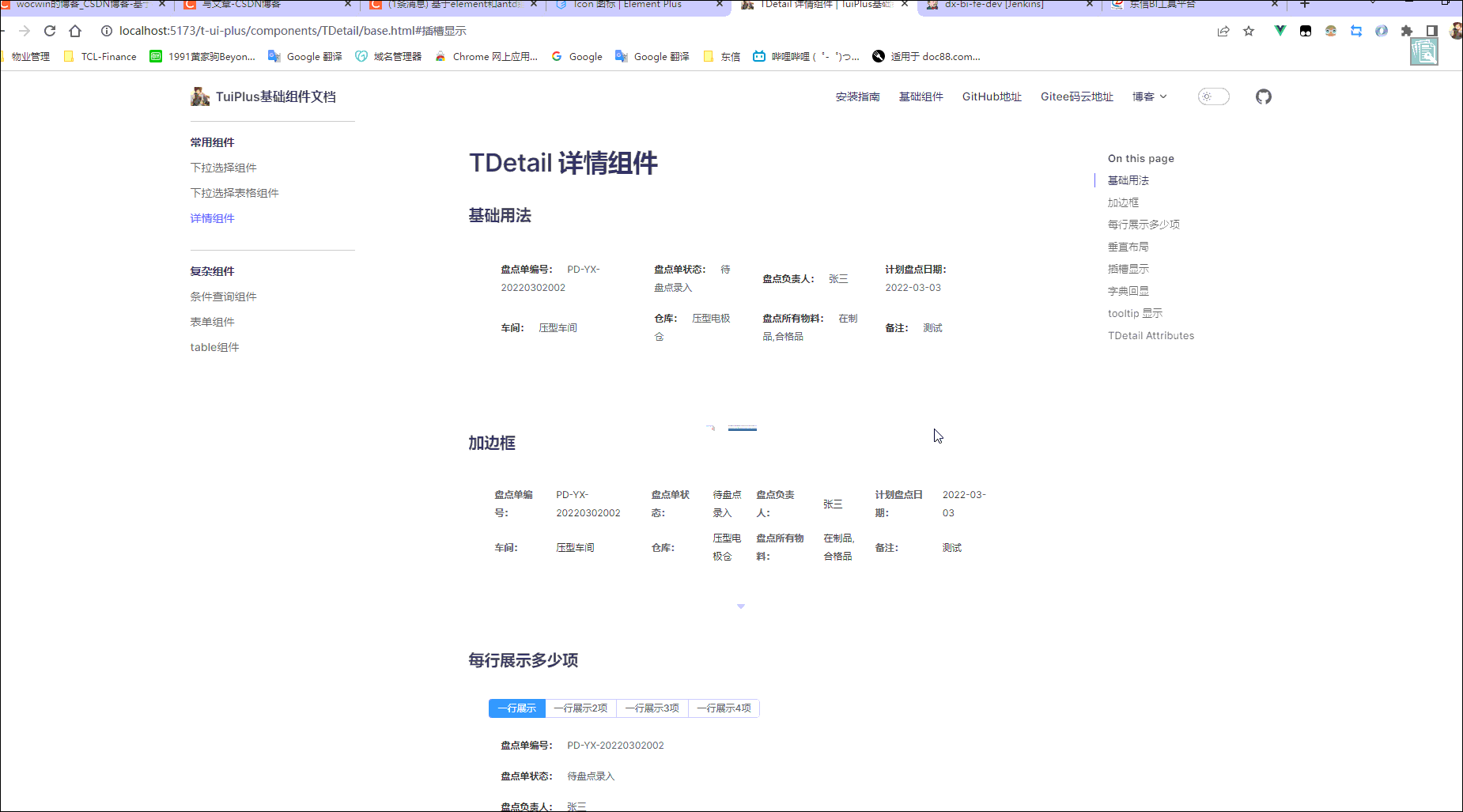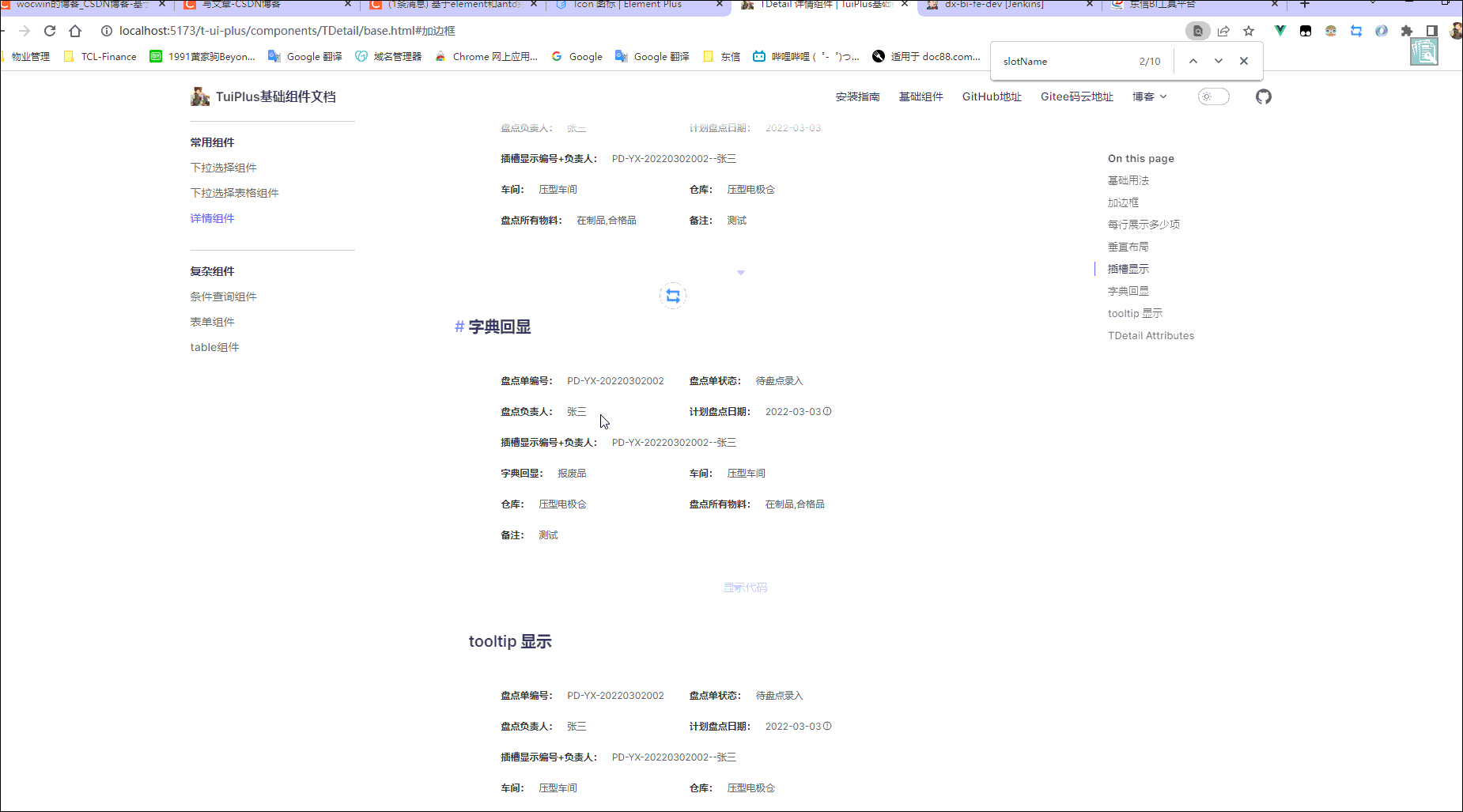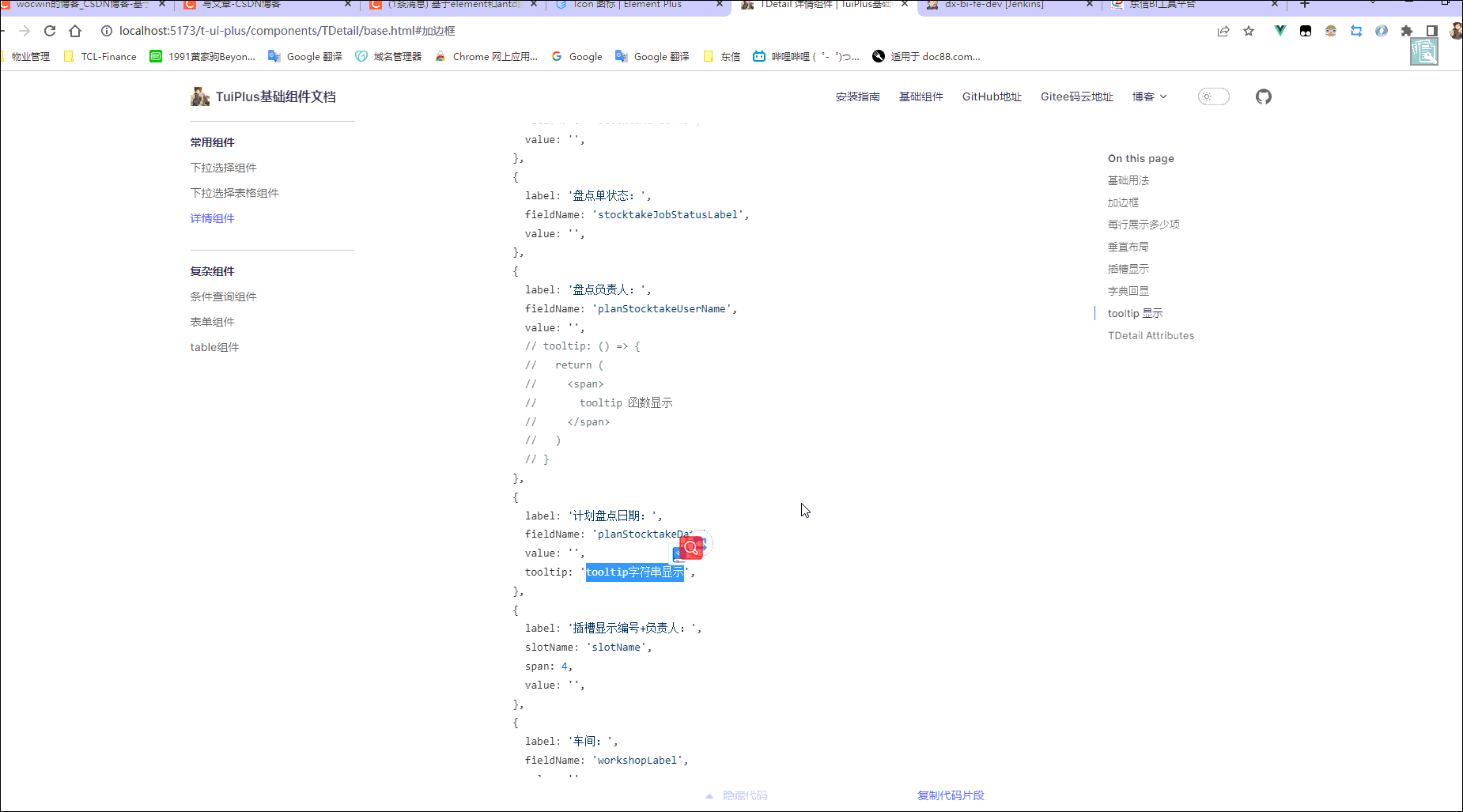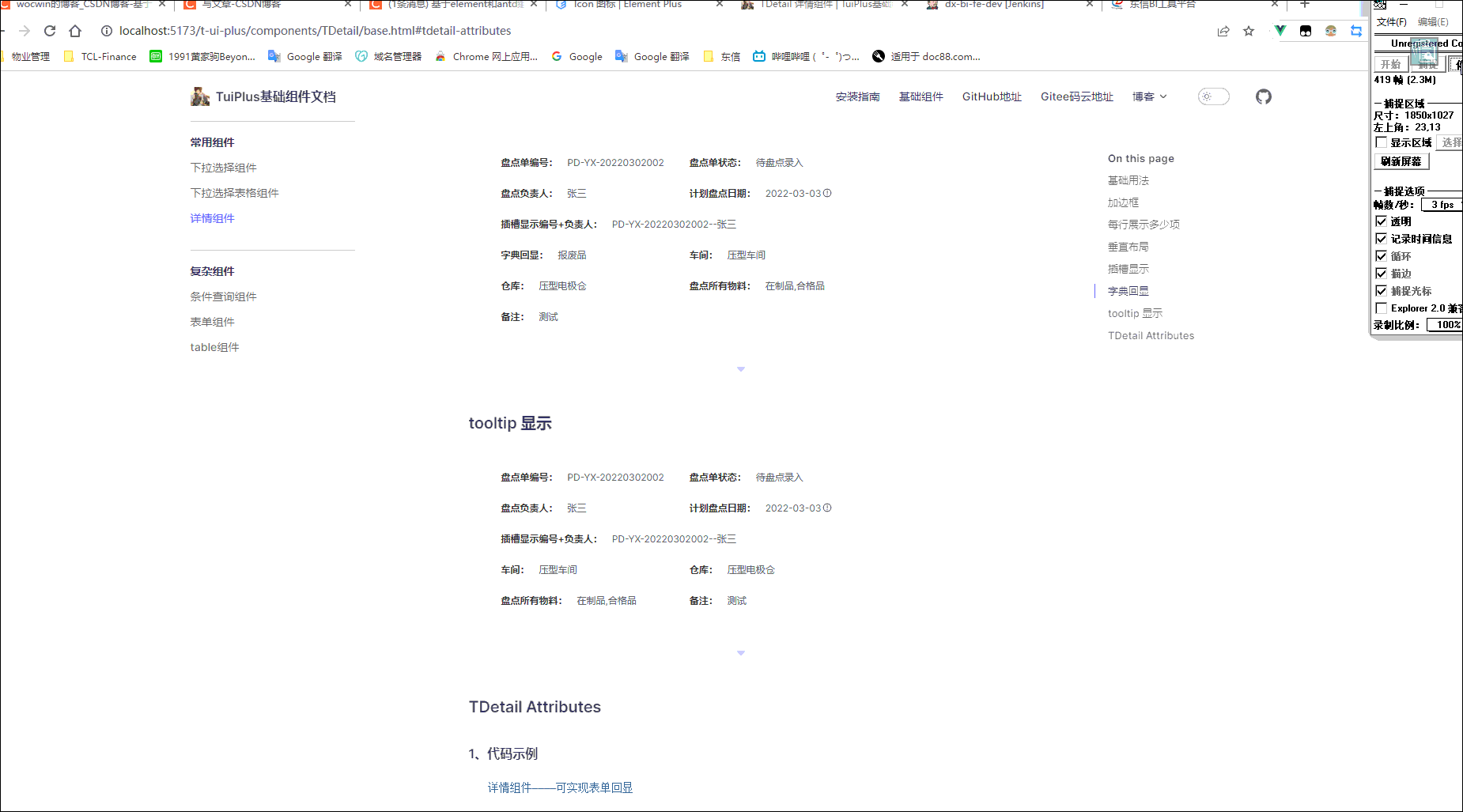
vue3+element-plus el-descriptions 详情组件二次封装(vue3项目)
最终效果 一、需求 一般后台管理系统,通常页面都有增删改查;而查不外乎就是渲染新增/修改的数据(由输入框变成输入框禁用),因为输入框禁用后颜色透明度会降低,显的颜色偏暗;为解决这个需求于是封…...

No.14新一代信息技术
新一代信息技术产业包括:加快建设宽带、泛在、融合、安全的信息忘了基础设施,推动新一代移动通信、下一代互联网核心设备和智能终端的研发及产业化,加快推进三网融合,促进物联网、云计算的研发和示范应用。 大数据、云计算、互联…...
微信小程序开发(五)小程序代码组成2
微信小程序开发(五)小程序代码组成2 为了进一步加深我们对小程序基础知识的了解和掌握,需要更进一步的了解小程序的代码组成以及一些简单的代码的编写。 参考小程序官方的的代码组成文档:https://developers.weixin.qq.com/ebook?…...
关于tensorboard --logdir=logs的报错解决办法记录
我在运行tensorboard --logdirlogs时,产生了如下的报错,找遍全网后,解决办法如下 先卸载 pip uninstall tensorboard再安装 pip install tensorboard最后出现如下报错 Traceback (most recent call last): File “d:\newanaconda\envs\imo…...

em,rem,px,rpx,vw,vh的区别与使用
在css中单位长度用的最多的是px、em、rem,这三个的区别是:一、px是固定的像素,一旦设置了就无法因为适应页面大小而改变。二、em和rem相对于px更具有灵活性,他们是相对长度单位,意思是长度不是定死了的,更适…...
Vue+node.js医院预约挂号信息管理系统vscode
网上预约挂号系统将会是今后医院发展的主要趋势。 前端技术:nodejsvueelementui,视图层其实质就是vue页面,通过编写vue页面从而展示在浏览器中,编写完成的vue页面要能够和控制器类进行交互,从而使得用户在点击网页进行操作时能够正…...

Java真的不难(五十四)RabbitMQ的入门及使用
RabbitMQ的入门及使用 一、什么是RabbitMQ? MQ全称为Message Queue,即消息队列。消息队列是在消息的传输过程中保存消息的容器。它是典型的:生产者、消费者模型。生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。…...
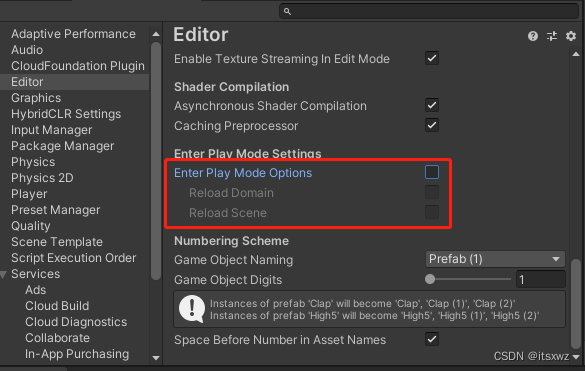
Unity | Script Hot Reload
官网地址:https://hotreload.net/ 一、作用 Unity在运行时,可以直接修改代码,避免等待过长的编译时间。 二、说明 1、支持的平台? Windows、MacOS、Linux 2、支持的Unity版本? 2018.4 (LTS)2019.4 (LTS)2020.3 (L…...
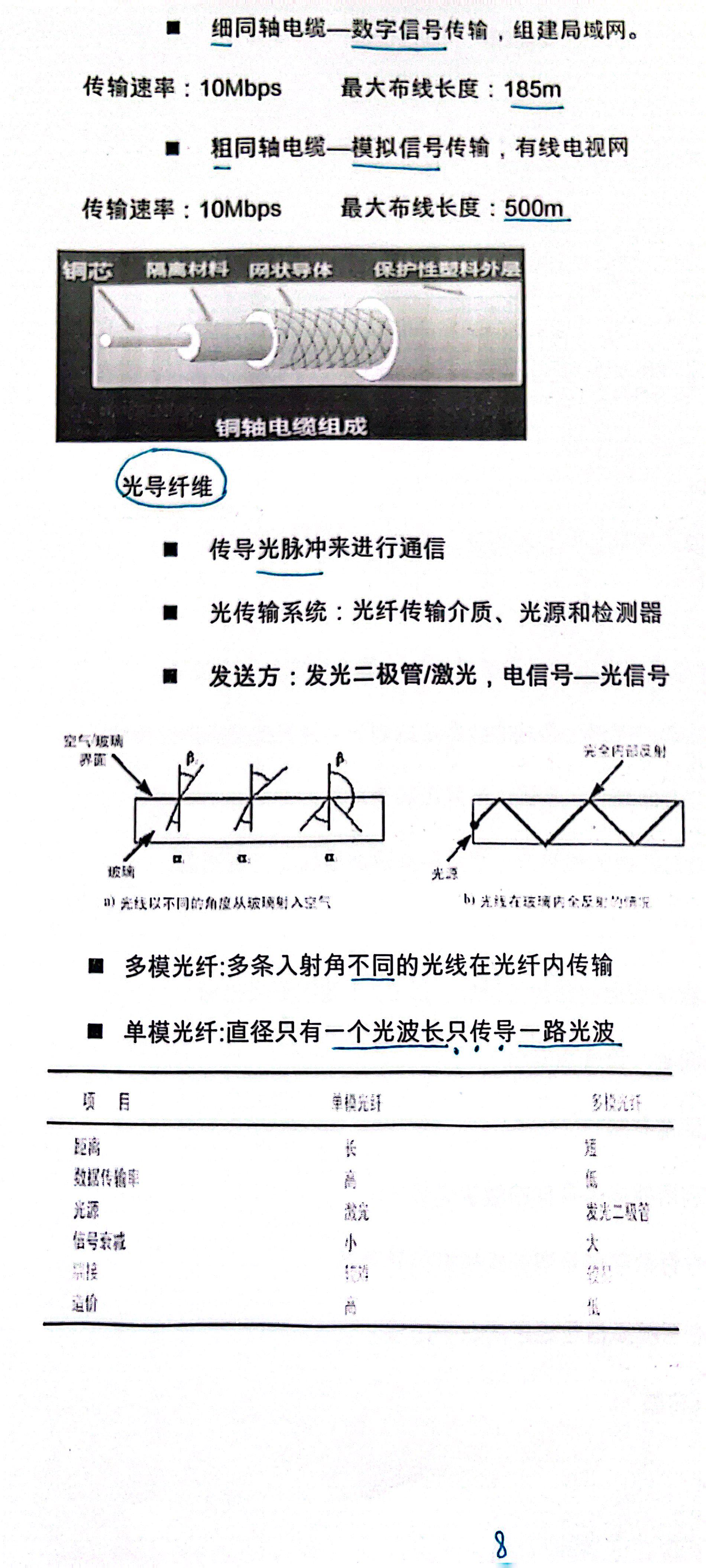
3|射频识别技术|第五讲:数据通信和编码技术|第九章:编码与调制|重点理解掌握传输介质中的有线传输介质
计算机网络部分:https://blog.csdn.net/m0_57656758/article/details/128943949传输介质分为有线传输介质和无线传输介质两大类;有线传输介质通常包含双绞线、同轴电缆和光导纤维;无线传输介质包含微波、红外线等。传输介质的选择和连接是网络…...

Cursor Pro破解工具:5步实现永久免费使用的完整指南
Cursor Pro破解工具:5步实现永久免费使用的完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial…...

从零到一:Windows环境下Oracle19c的完整部署与实战配置
1. 环境准备:搭建Oracle19c的Windows温床 第一次在Windows上装Oracle数据库就像给新房子铺水电——基础没打好,后面全是坑。我见过太多人因为忽略环境检查,导致安装到一半报错重来的惨剧。这里分享几个实测有效的准备工作: 硬件配…...

Axure RP中文语言包技术深度解析:从键值对到国际化架构的工程实践
Axure RP中文语言包技术深度解析:从键值对到国际化架构的工程实践 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 在…...

ComfyUI-FramePackWrapper终极指南:8GB显存玩转高质量AI视频生成
ComfyUI-FramePackWrapper终极指南:8GB显存玩转高质量AI视频生成 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper 想要在有限硬件条件下实现专业级AI视频生成吗?ComfyUI-Fram…...
)
告别手动建模!用ArcGIS+SWMM+慧天平台,5步搞定城市内涝模拟(附实战数据)
城市内涝模拟实战:ArcGISSWMM慧天平台高效协同工作流 暴雨过后街道成河、地下车库变泳池的场景,已成为许多城市规划者和工程师的噩梦。传统的内涝模拟方法需要手动处理海量管网数据,不仅耗时费力,还容易在数据转换过程中丢失关键信…...

音频算法调试利器:用Android App实时绘制EQ/DRC曲线,告别Matlab依赖
移动端音频算法调试革命:Android实时EQ/DRC可视化工具开发实战 在音频算法开发领域,调试环节长期被桌面级工具垄断,工程师们不得不忍受开发板与工作站之间的频繁切换。这种工作模式不仅效率低下,更无法满足现代音频产品快速迭代的…...
)
从App Inventor到数据解析:打造一个专属的Android蓝牙温湿度监测App(适配HC-05+Arduino)
从零构建Android蓝牙温湿度监测系统:App Inventor与Arduino实战指南 在物联网技术快速普及的今天,将传感器数据可视化呈现已成为许多创客和教育场景中的常见需求。本文将以DHT-11温湿度传感器为核心,通过HC-05蓝牙模块搭建Arduino与Android设…...

从火箭背包到现代VTOL飞行器:FPGA飞控与传感器融合技术解析
1. 从科幻到现实:个人喷气背包的工程梦想每次看到老式喷气背包的影像,比如那些在早期007电影里出现的、两侧喷着火焰的装置,心里总会涌起一股混合着兴奋与敬畏的复杂情绪。那种感觉,就像小时候第一次拆开收音机,既惊叹…...

Vivado里FIFO IP核的Standard和FWFT模式到底怎么选?一个波形对比就懂了
Vivado中FIFO IP核模式选择:Standard与FWFT的深度解析与实战指南 在FPGA开发中,数据缓冲是几乎所有高速数据处理系统不可或缺的一环。作为Xilinx工具链中的核心IP之一,FIFO Generator提供了灵活的数据缓冲解决方案。但当面对Standard FIFO和F…...

03-从Chat到Act-Agent行动闭环的产品心理学拆解
从Chat到Act:Agent行动闭环的产品心理学拆解系列一:AI Agent GAP模型 | 第3篇(深度型) 从"一问一答"到"自主行动",拆解Agent行动闭环背后的行为设计逻辑。本文你将获得 🔄 Agent行动闭…...