Lucene学习笔记
lucene结构
索引:概念上的一个表,现实体现就是一个文件目录,一个目录代表一个索引,也视作documents文档集合
文档:document,为索引中的一条数据,一个document可以拥有多个filed(域),甚至可以完全相同。
域:field,一个field即为一个字段
是否分词:tokenized
是否索引:indexed
是否存储:stored
倒排索引
所谓倒排索引, 就是从文档内容,通过分词器分出不重复关键字,以关键字作为主键查询到具有关键字的文档id列表,查询到出具有关键词的文档。因此:倒排索引是用于模糊查询大量数据得到列表结果的,而非精确查询。
常用Field类型
类型 是否分词 是否索引 是否存储
StringField N Y Y或N
TextField Y Y Y或N
FloatPoint Y Y N
DoublePoint
LongPoint
IntPoint
StoredField N N Y
NumericDocValuesField 配合其他域使用
分词器
分词: 采集到的数据会存储道document对象的Field域中,分词就是将Document中的Field的value值切分成一个一个的词。分词就是为了查询,不作为查询条件的不要分词。
过滤:标点符号去除,停用词过滤,大写转小写,词的形还原
Analyzer使用时机:索引时使用/搜索时使用(两者所用分词器必须一致)
扩展词典:
放专有名词,或者我们认为需要强制将某一些词拆成一个关键字
凡是出现在扩展词典的词,就会强制分成一个关键字
停用词典:
凡是出现在停用词点的词,都会被过滤掉(节省存储空间,提高搜索效率)
存储结构
一个目录一个索引,一个逻辑索引由多个段segment组成,多个段可以合并减少读取内存时候的IO。Lucene数据先写入buffer缓冲区,到达一定数量后写入segment段,segment内部的数据不可以被修改,但可以被删除,删除为逻辑删除。新增家的document单独在一个新生的段中,随着段的合并写入到一个段中。
词典数据结构
跳跃表 占用内存小,且可调,但是对模糊查询支持不好。3.0之前使用
排序列表Array/List 使用二分法查找,不平衡字典树 查询效率跟字符串长度有关,但只适合英文词典
哈希表 性能高,内存消耗大,几乎是原始数据的三倍
双数组字典树 适合做中文词典,内存占用小,很多分词工具均采用此种算法
Finite State Transducers (FST) 一种有限状态转移机,Lucene 4有开源实现,并大量使用
B树 磁盘索引,更新方便,但检索速度慢,多用于数据库
lucene优化
解决大量磁盘IO
indexWriterConfig.setMaxBufferedDocs(10000); // 配置写入segment前缓冲区doc最大数目
indexWriter.forceMerge(1000); // 多少个文档合并一个段 越大索引越快 搜索越慢
TermQuery更快 QueryParser更强大
相关度排序
计算出词的权重 Term(tf – 此文档中词出现次数越高越大, df — 越多文档包含,得分越低)
根据词的权重值,计算文档相关度得分
boost加权(默认加权值为1.0f)
在索引时对某个文档中的filed设置加权重,搜索匹配到时这个文档就可能排在前面
在搜索时对某个域进行加权,在进行组合域查询时,匹配到加权值高的域最后计算的相关度得分就高。
设置boost是给域(field)或者Document设置的。
注意事项
-
关键词区分大小写 OR AND TO等关键词是区分大小写的,lucene只认大写的,小写的当做普通单词。
-
读写互斥性
同一时刻只能有一个对索引的写操作,在写的同时可以进行搜索 文件锁在写索引的过程中强行退出将在tmp目录留下一个lock文件,使以后的写操作无法进行,可以将其手工删除时间格式 -
lucene只支持一种时间格式yyMMddHHmmss,所以你传一个yy-MM-dd
HH:mm:ss的时间给lucene它是不会当作时间来处理的 -
设置boost
有些时候在搜索时某个字段的权重需要大一些,例如你可能认为标题中出现关键词的文章比正文中出现关键词的文章更有价值,你可以把标题的boost设置的更大,那么搜索结果会优先显示标题中出现关键词的文章
代码演示:
/*** 新增文档/索引* @throws IOException*/
@Test
public void createIndexTest() throws IOException {// 1.采集数据// 2.创建文档对象Document document = new Document();document.add(new TextField("id", "12345", Field.Store.YES));document.add(new TextField("name", "第二份文档数据", Field.Store.YES));document.add(new TextField("time", "2023-01-27", Field.Store.YES));// 3.创建分词器 标准分词器对英文分词效果好 对中文是单字分词StandardAnalyzer standardAnalyzer = new StandardAnalyzer();IKAnalyzer smartChineseAnalyzer = new IKAnalyzer();// 4.创建Directory目录对象 目录对象表示索引库的位置Directory fsDirectory = FSDirectory.open(Paths.get("/opt/lucene_dir"));// 5.创建IndexWriterConfig对象 这个对象中指定且分次使用的分词器IndexWriterConfig indexWriterConfig = new IndexWriterConfig(smartChineseAnalyzer);indexWriterConfig.setMaxBufferedDocs(10000); // 配置写入segment前缓冲区doc最大数目// 6.创建IndexWriter输出流对象 指定输出的位置和使用的config初始化对象IndexWriter indexWriter = new IndexWriter(fsDirectory, indexWriterConfig);indexWriter.forceMerge(1000); // 多少个文档合并一个段 越大索引越快 搜索越慢// 7.写入文档到索引库indexWriter.addDocument(document);// 8.释放资源indexWriter.close();
}/*** 搜索*/
@Test
public void testSearch() throws ParseException, IOException {// 1. 创建分词器(对搜索的关键词进行分词使用)// 注意: 分词器需要跟创建索引时的分词器一模一样IKAnalyzer analyzer = new IKAnalyzer();// 2. 创建查询对象, 第一个参数: *默认*查询域, 第二个参数, 使用的分词器QueryParser parser = new QueryParser("id", analyzer);// 3. 设置搜索关键词 可指定查询域 如"id:123" 不指定时用默认查询域Query query = parser.parse("123456");// 4. 创建Directory目录, 指定索引库的位置Directory directory = FSDirectory.open(Paths.get("D:\\dir"));// 5. 创建输入流对象IndexReader indexReader = DirectoryReader.open(directory);// 6. 创建搜索对象IndexSearcher indexSearcher = new IndexSearcher(indexReader);// 7. 搜索, 并返回结果TopDocs docs = indexSearcher.search(query, 10);System.out.println("查询到数据:" + docs.totalHits);// 8. 获取结果集ScoreDoc[] scoreDocs = docs.scoreDocs;// 9. 遍历结果集if (scoreDocs != null) {for (ScoreDoc scoreDoc : scoreDocs) {// 获取查询到的文档id, 该id为lucene创建文档时自动分配的idint docId = scoreDoc.doc;// 通过文档id,读取文档Document doc = indexSearcher.doc(docId);System.out.println(doc.get("name"));System.out.println(doc.get("time"));System.out.println(doc.get("id"));}}
}/*** 索引库修改*/
@Test
public void updateIndexTest() throws IOException {// 需要变更成的内容Document document = new Document();document.add(new TextField("id", "123456",Field.Store.YES));document.add(new TextField("name", "修改后的名称", Field.Store.YES));// 创建分词器IKAnalyzer analyzer = new IKAnalyzer();// 创建目录对象FSDirectory directory = FSDirectory.open(Paths.get("D:\\dir"));// 创建配置对象IndexWriterConfig config = new IndexWriterConfig(analyzer);// 创建输出流对象IndexWriter indexWriter = new IndexWriter(directory, config);// 修改, 第一个参数: 修改条件,第二个参数: 修改成的内容indexWriter.updateDocument(new Term("id", "123456"), document);// 关闭资源indexWriter.close();
}/*** 索引库删除*/
@Test
public void deleteTest() throws IOException {// 创建分词器IKAnalyzer analyzer = new IKAnalyzer();// 创建目录对象FSDirectory directory = FSDirectory.open(Paths.get("D:\\dir"));// 创建配置对象IndexWriterConfig config = new IndexWriterConfig(analyzer);// 创建输出流对象IndexWriter indexWriter = new IndexWriter(directory, config);// 修改, 第一个参数: 修改条件,第二个参数: 修改成的内容indexWriter.deleteDocuments(new Term("id", "123456"));// 关闭资源indexWriter.close();
}/*** 使用第三方分词器(IK分词)*/
@Test
public void testIkAnalyzer() throws IOException {// 创建分词器Analyzer analyzer = new IKAnalyzer();// 创建Directory对象 声明索引库的位置Directory directory = FSDirectory.open(Paths.get("/opt/lucene_dir"));// 创建indexWriterConfigIndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// 6.创建IndexWriter输出流对象 指定输出的位置和使用的config初始化对象IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);Document document = new Document();document.add(new TextField("id", "12346", Field.Store.YES));document.add(new TextField("name", "华为手机4G至尊P30", Field.Store.YES));document.add(new IntPoint("price", 9999));document.add(new StoredField("price", 9999));// 7.写入文档到索引库indexWriter.addDocument(document);// 8.释放资源indexWriter.close();
}/*** 高级查询(文本搜索)*/
@Test
public void testTextSearch() throws IOException, ParseException {// 1. 创建分词器(对搜索的关键词进行分词使用)// 注意: 分词器需要跟创建索引时的分词器一模一样IKAnalyzer analyzer = new IKAnalyzer();// 2. 创建查询对象, 第一个参数: *默认*查询域, 第二个参数, 使用的分词器// QueryParser parser = new QueryParser("name", analyzer);// 3. 设置搜索关键词 可指定查询域 如"id:123" 不指定时用默认查询域// AND 取交集 OR 取并集// QueryParser只能对文本进行搜索String[] fields = {"id", "name", "brand"};Map<String, Float> boost = new HashMap<>();// 设置权重boost.put("brand", 10000f);MultiFieldQueryParser parser = new MultiFieldQueryParser(fields, analyzer, boost);Query query = parser.parse("最新 or 华为");// 4. 创建Directory目录, 指定索引库的位置Directory directory = FSDirectory.open(Paths.get("/opt/lucene_dir"));// 5. 创建输入流对象IndexReader indexReader = DirectoryReader.open(directory);// 6. 创建搜索对象IndexSearcher indexSearcher = new IndexSearcher(indexReader);// 7. 搜索, 并返回结果TopDocs docs = indexSearcher.search(query, 10);System.out.println("查询到数据:" + docs.totalHits);// 8. 获取结果集ScoreDoc[] scoreDocs = docs.scoreDocs;// 9. 遍历结果集if (scoreDocs != null) {for (ScoreDoc scoreDoc : scoreDocs) {// 获取查询到的文档id, 该id为lucene创建文档时自动分配的idint docId = scoreDoc.doc;// 通过文档id,读取文档Document doc = indexSearcher.doc(docId);System.out.println(doc.get("name"));System.out.println(doc.get("time"));System.out.println(doc.get("id"));}}
}/*** 高级查询(范围搜索)*/
@Test
public void testRangeSearch() throws IOException, ParseException {// 1. 创建分词器(对搜索的关键词进行分词使用)// 注意: 分词器需要跟创建索引时的分词器一模一样IKAnalyzer analyzer = new IKAnalyzer();// 2. 创建查询对象, 第一个参数: *默认*查询域, 第二个参数, 使用的分词器Query query = IntPoint.newRangeQuery("price", 100, 9998);// 4. 创建Directory目录, 指定索引库的位置Directory directory = FSDirectory.open(Paths.get("/opt/lucene_dir"));// 5. 创建输入流对象IndexReader indexReader = DirectoryReader.open(directory);// 6. 创建搜索对象IndexSearcher indexSearcher = new IndexSearcher(indexReader);// 7. 搜索, 并返回结果TopDocs docs = indexSearcher.search(query, 10);System.out.println("查询到数据:" + docs.totalHits);// 8. 获取结果集ScoreDoc[] scoreDocs = docs.scoreDocs;// 9. 遍历结果集if (scoreDocs != null) {for (ScoreDoc scoreDoc : scoreDocs) {// 获取查询到的文档id, 该id为lucene创建文档时自动分配的idint docId = scoreDoc.doc;// 通过文档id,读取文档Document doc = indexSearcher.doc(docId);System.out.println(doc.get("name"));System.out.println(doc.get("time"));System.out.println(doc.get("id"));System.out.println(doc.get("price"));}}
}/*** 高级查询(组合搜索)*/
@Test
public void testComplexSearch() throws IOException, ParseException {// 1. 创建分词器(对搜索的关键词进行分词使用)// 注意: 分词器需要跟创建索引时的分词器一模一样IKAnalyzer analyzer = new IKAnalyzer();// 2. 创建查询对象, 第一个参数: *默认*查询域, 第二个参数, 使用的分词器Query query1 = IntPoint.newRangeQuery("price", 100, 9998);QueryParser parse = new QueryParser("name", analyzer);Query query2 = parse.parse("华为");// 3. 组合查询条件 MUST 必须 SHOULD 或 MUST_NOT 必须不// 注意:如果查询条件都是must not, 则查询不到结果BooleanQuery.Builder builder = new BooleanQuery.Builder();builder.add(query1, BooleanClause.Occur.SHOULD);builder.add(query2, BooleanClause.Occur.SHOULD);BooleanQuery query = builder.build();// 4. 创建Directory目录, 指定索引库的位置Directory directory = FSDirectory.open(Paths.get("/opt/lucene_dir"));// 5. 创建输入流对象IndexReader indexReader = DirectoryReader.open(directory);// 6. 创建搜索对象IndexSearcher indexSearcher = new IndexSearcher(indexReader);// 7. 搜索, 并返回结果TopDocs docs = indexSearcher.search(query, 10);System.out.println("查询到数据:" + docs.totalHits);// 8. 获取结果集ScoreDoc[] scoreDocs = docs.scoreDocs;// 9. 遍历结果集if (scoreDocs != null) {for (ScoreDoc scoreDoc : scoreDocs) {// 获取查询到的文档id, 该id为lucene创建文档时自动分配的idint docId = scoreDoc.doc;// 通过文档id,读取文档Document doc = indexSearcher.doc(docId);System.out.println(doc.get("name"));System.out.println(doc.get("time"));System.out.println(doc.get("id"));System.out.println(doc.get("price"));}}
}
相关文章:

Lucene学习笔记
lucene结构 索引:概念上的一个表,现实体现就是一个文件目录,一个目录代表一个索引,也视作documents文档集合 文档:document,为索引中的一条数据,一个document可以拥有多个filed(域&a…...

动态规划【Day01】| 669 · 换硬币、114 · 不同的路径、116 · 跳跃游戏
秘诀:确定状态转移方程初始条件和边界情况计算顺序 669 换硬币 669 换硬币 题目描述: 给出不同面额的硬币以及一个总金额. 写一个方法来计算给出的总金额可以换取的最少的硬币数量. 如果已有硬币的任意组合均无法与总金额面额相等, 那么返回 -1。 样…...

1.Hello Python
Python Python 在网络爬虫、数据分析、AI、机器学习、Web开发、金融、运维、测试等多个领域都有不俗的表现,从来没有哪一种语言可以同时在这么多领域扎根。 Python基本语法 python关键字 关键字即保留字,和其他语言一样,这些关键字…...
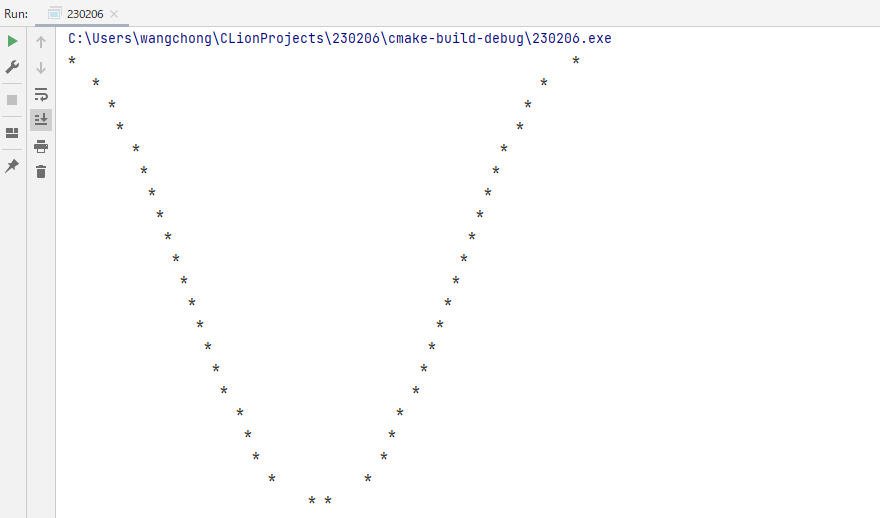
C语言实例|编写C程序在控制台打印余弦曲线
C语言文章更新目录 C语言学习资源汇总,史上最全面总结,没有之一 C/C学习资源(百度云盘链接) 计算机二级资料(过级专用) C语言学习路线(从入门到实战) 编写C语言程序的7个步骤和编程…...

《Hadoop篇》------大数据及Hadoop入门
目录 一、大数据及Hadoop入门 1.1 单节点、分布式、集群 1.1.1 大数据的概念 1.1.2 大数据的本质 二、HDFS Shell命令 2.1、常用相关命令 2.2、上传文件 2.2.1、上传文件介绍 2.2.2上传文件操作 2.3、下载文件 2.4、删除文件 2.5、创建目录 2.6、查看文件系统 2.…...
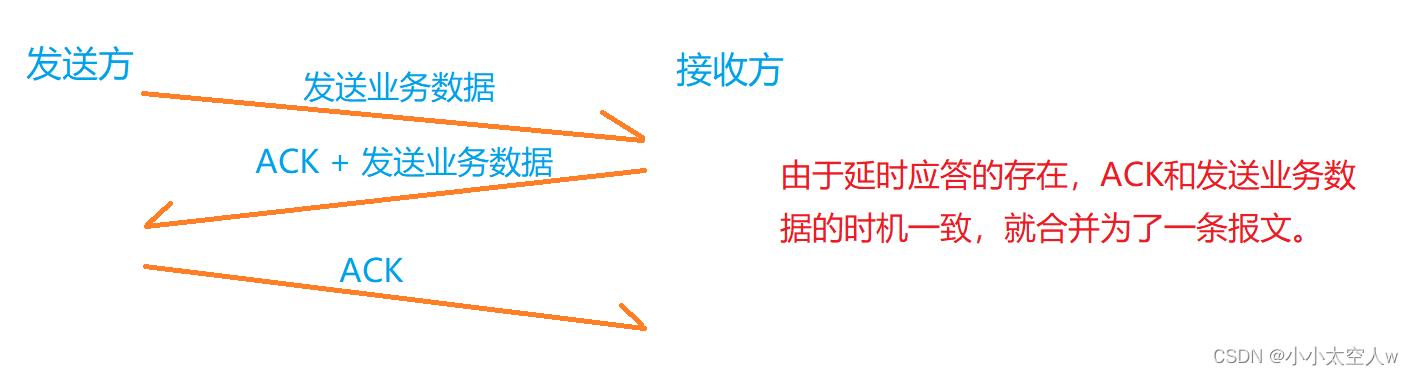
TCP核心机制详解(三)
目录 前言: 滑动窗口 滑动窗口处理丢包问题 流量控制 拥塞控制 延时应答 捎带应答 面向字节流 异常情况 小结: 前言: 前两篇文章讲述了,TCP十种核心机制的前三种。这篇文章详细介绍其他的一些核心机制,让我们…...
)
最易上手的爬虫请求库:Requests核心功能速览(下)
上一个章节我们讲了如何快速使用Requests发送网络请求、处理URL参数和提取响应内容,这些是最基本的操作。 然而还有很多场景下,我们的网络请求更加复杂。比如我们必须要定制请求头来假装成浏览器,不然可能会被网站识别为机器并且被屏蔽;又比如我们需要在发送请求时以表单形…...
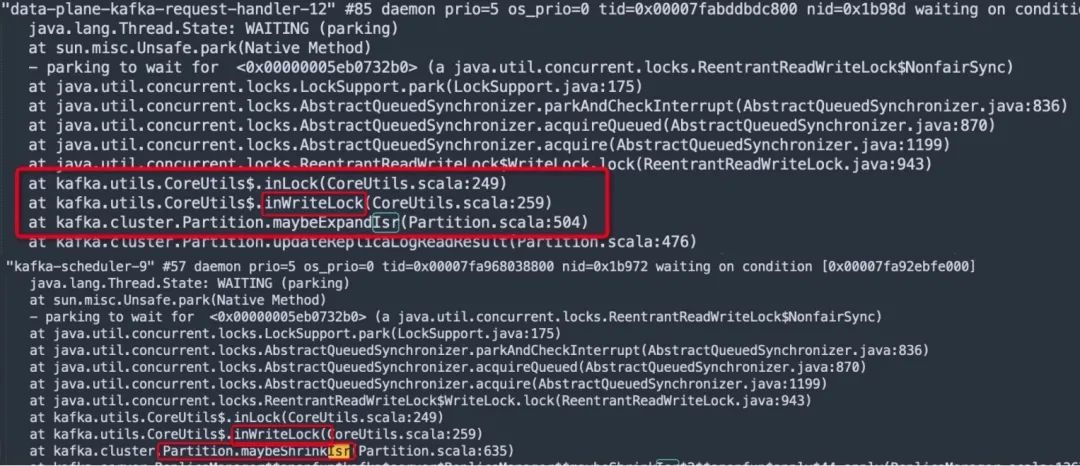
生产故障|Kafka ISR频繁伸缩引发性能急剧下降
生产故障|Kafka ISR频繁伸缩引发性能急剧下降-阿里云开发者社区 本文是笔者双十一系列第二弹,源于一个双十一期间一个让笔者猝不及防的生产故障,本文将详细剖析Kafka的副本机制,以及ISR频繁变更(扩张与伸缩)为什么会导致集群不可…...
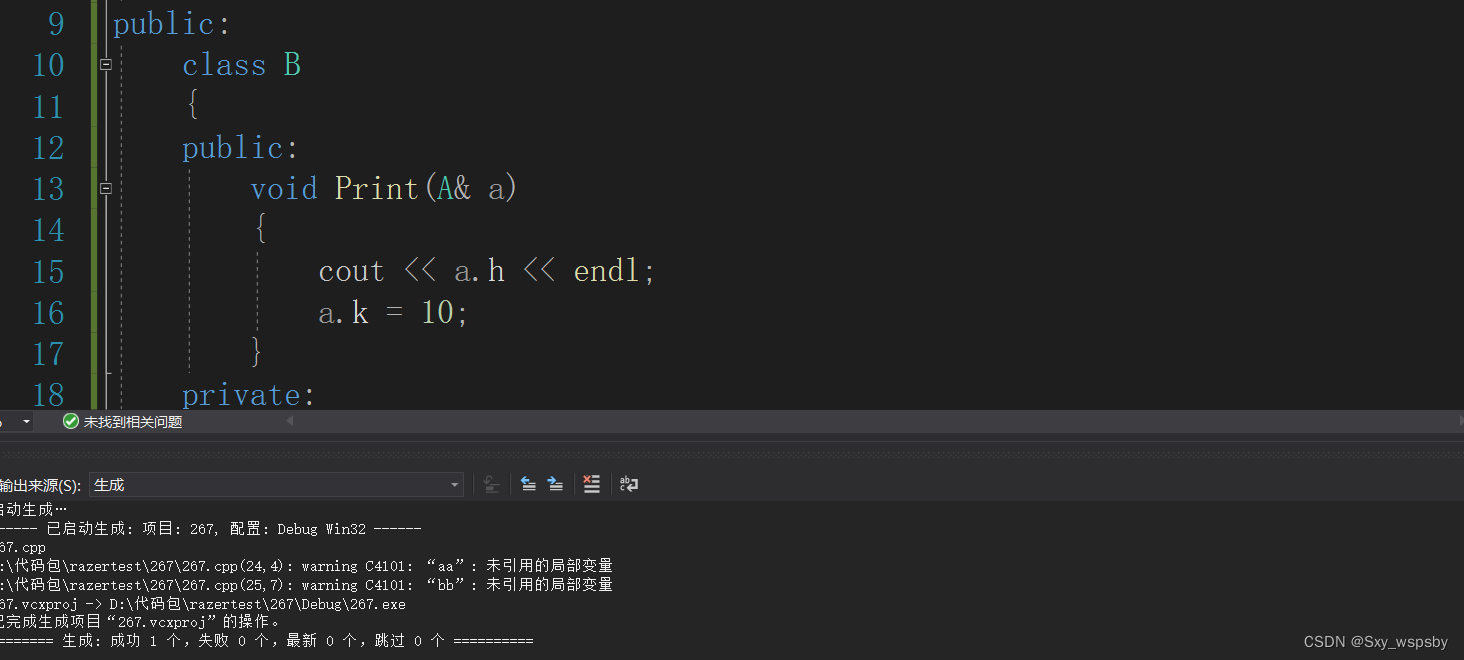
c++终极螺旋丸:₍˄·͈༝·͈˄*₎◞ ̑̑“类与对象的结束“是结束也是开始
文章目录 前言一.构造函数中的初始化列表 拷贝对象时的一些编译器优化二.static成员三.友元四.内部类总结前言 前两期我们将类和对象的重点讲的差不多了,这一篇文章主要进行收尾工作将类和对象其他的知识点拉出来梳理一遍,并且补充前两篇没有讲过的…...
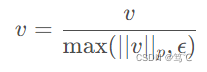
【Python--torch.nn.functional】F.normalize用法 + 代码说明
【Python–torch.nn.functional】F.normalize介绍 代码说明 文章目录【Python--torch.nn.functional】F.normalize介绍 代码说明1. 介绍2. 代码说明2.1 一维Tensor2.2 二维Tensor2.3 三维Tensor3. 总结1. 介绍 import torch.nn.functional as F F.normalize(input: Tensor, …...

【算法题】1887. 使数组元素相等的减少操作次数
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 题目: 给你一个整数数组 nums ࿰…...

GD库图片裁剪指定形状解决办法(PHP GD库 海报)
需求描述:需要把图片裁剪成一个指定的平行四边形,目的是使用GD库,把裁剪后的图片放在底图上面,使最终合成的图片看起来是一个底图平行四边形的样子提示:可以结合本作者的其他文章,来生成一个定制化的海报&a…...

redis的简介及应用场景
1、基本信息 Redis英文官网介绍: Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queri…...
实现时间计数戳)
2、HAL库利用滴答定时器systick(1ms中断)实现时间计数戳
文档说明:通过滴答定时器的1ms中断实现时间计数,标记需要的时间标志,在主函数中查询标志,避免延时函数消耗CPU 1、HAL库systick定时器说明 在CubeMx生成的代码main()函数首先执行的函数为HAL_Init();里面会进行滴答定时器初始化…...

Spring入门学习
Spring入门学习 文章目录Spring入门学习Spring概述Spring FrameworkIOCIOC容器DIIOC容器的实现类①FileSystemXmlApplicationContext②ClassPathXmlApplicationContext基于XML管理bean入门案例创建类创建xml在Spring配置文件中配置bean测试Spring概述 Spring 是最受欢迎的企业级…...
webpack(4版本)使用
webpack简介:webpack 是一种前端资源构建工具,一个静态模块打包器(module bundler)。在 webpack 看来, 前端的所有资源文件(js/json/css/img/less/...)都会作为模块处理。它将根据模块的依赖关系进行静态分析,打包生成对应的静态资源(bundle)…...

Linux安装ElasticSearch
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch 1 版本选择 ElasticSearch 7 及以上版本都是自带的 jdk,假如需要配置指定的 jdk 版本的话,可以在 es 的 bin 目录下找到elasticsearch-env.bat 这个文件&#x…...

Linux中C语言编程经验总结
修改记录 版本号日期更改理由V1.02022-03-15MD化 总则 仅总结一些常用且实用的编程规范和技巧,且避免记忆负担,聚焦影响比较大的20% ! 编译器 打开全warning编译器开关 正例 gcc -W -Wall -g -o someProc main.c反例 gcc -g -o someProc main…...
jvisualvm工具使用
jdk自带的工具jvisualvm,可以分析java内存使用情况,jvm相关的信息。 1、设置jvm启动参数 设置jvm参数**-Xms20m -Xmx20m -XX:PrintGCDetails** 最小和最大堆内存,打印gc详情 2、测试代码 TestScheduleClassGc package com.core.schedule;…...
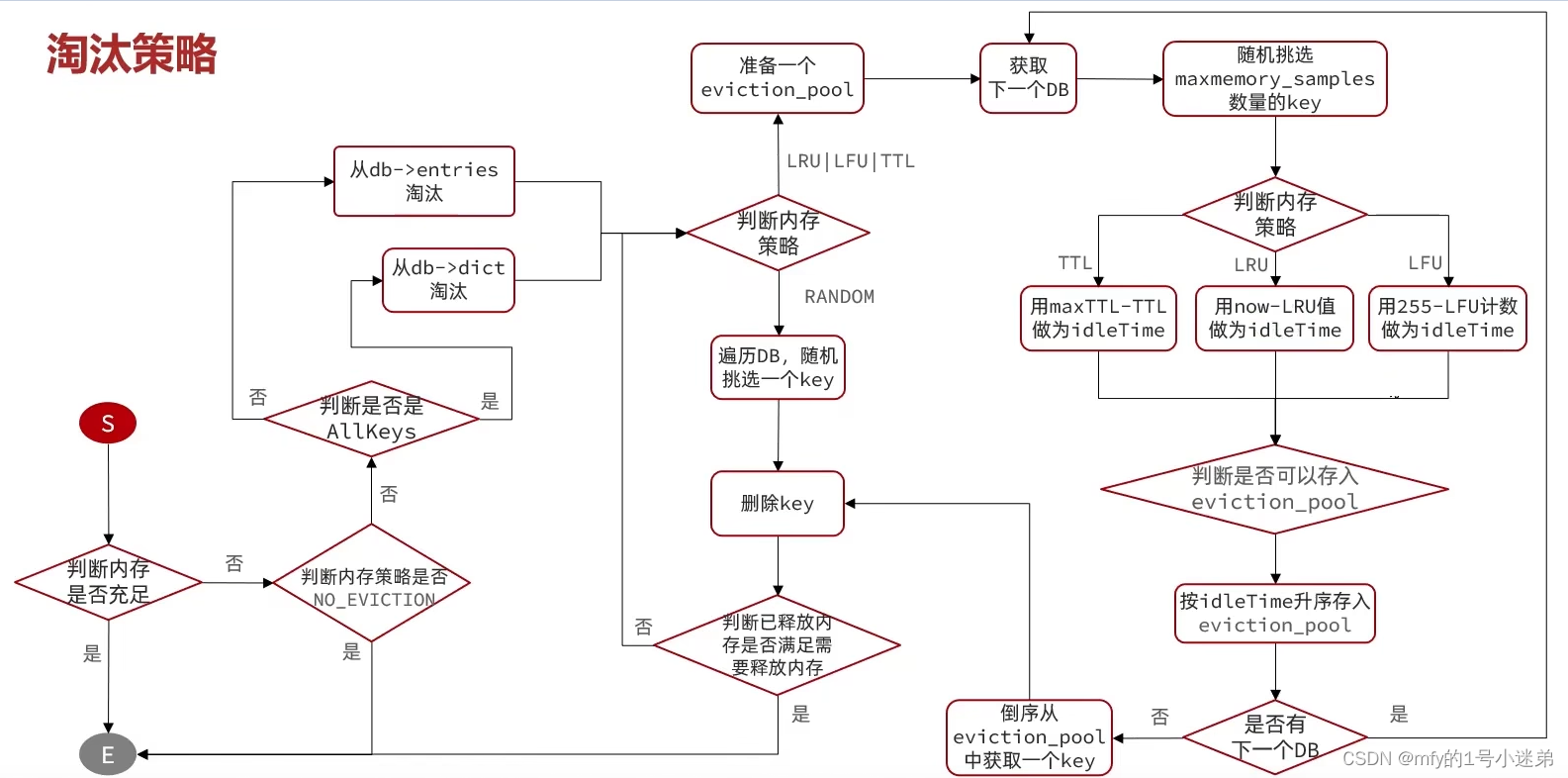
redis五大IO网络模型、内存回收
目录1.0用户空间和内核态空间1.1 网络模型-阻塞IO1.2 网络模型-非阻塞IO1.3 网络模型-IO多路复用1.3.1 网络模型-IO多路复用-select方式1.3.2 网络模型-IO多路复用模型-poll模式1.3.3 网络模型-IO多路复用模型-epoll函数1.3.4 网络模型-epoll中的ET和LT1.3.5 网络模型-基于epol…...
)
告别启动盘识别难题:手把手教你搞定CentOS 7在SR650上的UEFI启动与自定义分区(含/dev/sdX查找技巧)
告别启动盘识别难题:手把手教你搞定CentOS 7在SR650上的UEFI启动与自定义分区(含/dev/sdX查找技巧) 在服务器运维领域,系统安装看似基础却暗藏玄机。特别是当面对企业级硬件如Lenovo SR650时,UEFI启动模式与传统BIOS的…...

macOS桌面歌词终极解决方案:LyricsX 2.0完整指南
macOS桌面歌词终极解决方案:LyricsX 2.0完整指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics 你是否曾经在听音乐时,想要跟着歌词一起唱却发现…...

BBDown终极指南:5分钟掌握B站视频本地化完整解决方案
BBDown终极指南:5分钟掌握B站视频本地化完整解决方案 【免费下载链接】BBDown Bilibili Downloader. 一个命令行式哔哩哔哩下载器. 项目地址: https://gitcode.com/gh_mirrors/bb/BBDown 在数字内容爆炸的时代,你是否曾为无法离线观看B站优质视频…...

告别答辩PPT焦虑:百考通AI如何帮你高效搞定毕业答辩
简洁专业的PPT模板,精准的AI内容生成,在线编辑与一键美化——让毕业答辩的最后一步走得更从容。 又到了一年毕业季,当论文终于定稿,你是否发现自己又面临一座新的大山——毕业答辩PPT?面对几十页的论文文档,…...

终极实时窗口分辨率调整工具SRWE:打破屏幕限制的完整指南
终极实时窗口分辨率调整工具SRWE:打破屏幕限制的完整指南 【免费下载链接】SRWE Simple Runtime Window Editor 项目地址: https://gitcode.com/gh_mirrors/sr/SRWE 你是否曾为游戏截图分辨率太低而烦恼?是否需要在不同设备上测试UI布局却要反复重…...

AI如何重塑科学创新:从构思成本坍塌到知识组合爆炸
1. 科学创新的范式转移:从“不确定性”到“风险”在过去的科研实践中,我们常常面临一个根本性的困境:不确定性。这并非指我们不知道某个实验的结果,而是指我们连可能的结果是什么、其发生的概率有多大,都无从知晓。这就…...

Mem Reduct:让电脑告别卡顿的必备内存清理神器
Mem Reduct:让电脑告别卡顿的必备内存清理神器 【免费下载链接】memreduct Lightweight real-time memory management application to monitor and clean system memory on your computer. 项目地址: https://gitcode.com/gh_mirrors/me/memreduct 你的电脑是…...

AI和大模型——拟合
一、拟合 Fitting,中文翻译成拟合,这个翻译还是比较贴切的。怎么理解拟合呢?其实非常好理解,如果接受过九年义务教育,基本都有极限或微积分的概念。有没有想起过积分中用高低不等的小矩形来拼凑出曲线面的面积,那个过程…...
)
专利技术复杂性地级市面板(2001-2025)
核心速览数据编号:2323时间跨度:2001–2025空间尺度:中国全部地级市数据格式:Excel 年度面板测算依据:Research Policy 2026 顶刊范式(Frigon)测算方法(可直接写论文)以I…...

常见的 17 种 RAG 方案解析
近年来,随着大语言模型(LLM)的广泛应用,检索增强生成(Retrieval-Augmented Generation,RAG)系统逐渐成为连接私有知识库与智能问答的核心架构。RAG 不仅弥补了大模型在实时性与事实性上的不足&a…...