第15章:索引的数据结构
一、为什么使用索引
1.索引是存储引擎用于快速找到记录的一种数据结构。相当于一本书的目录。在进行数据查找时,首先查看查询条件是否命中某条索引,符合则通过索引查找相关数据。如果不符合则需要全表扫描,一条一条查找记录,直到找到与条件符合的记录。
2.创建索引减少磁盘的I/O的次数,加快查询速度。
二、索引的优缺点
1.索引概述
①索引是MySQL高效获取数据的数据结构
②索引的本质:索引是数据结构,排好序的快速查找的数据结构
③索引是在存储引擎实现的,每种存储引擎不一定支持所有的索引类型。存储引擎定义表的最大索引数和最大索引长度。
2.索引优点
①索引提高数据检索的效率,降低数据库的IO成本
②通过创建唯一索引,保证数据库表每一行的数据唯一性
③加速表和表之间的连接,对于有依赖关系的子表和父表联合查询时,可以提高查询速度
④使用分组和排序子句进行查询数据时,显著减少查询分组和排序的时间,降低CPU消耗
3.索引缺点
①创建索引和维护索引耗费时间,随着数据量增加,所耗费的时间增加
②索引占磁盘空间,存储在磁盘上
③索引提高查询速度,同时降低更新表的速度,在表中的数据增加,删除,修改,索引动态维护,降低数据的维护速度。
4.索引的提示
索引提高查询的速度,会影响插入的速度。这种情况下,最好的办法是先删除表中的索引,然后插入数据,插入完成再创建索引
三、InnoDB索引的推演
3.1没有索引情况下查找
3.1.1.在一个页查找
①主键查找
select *
from employees
where employee_id=101;
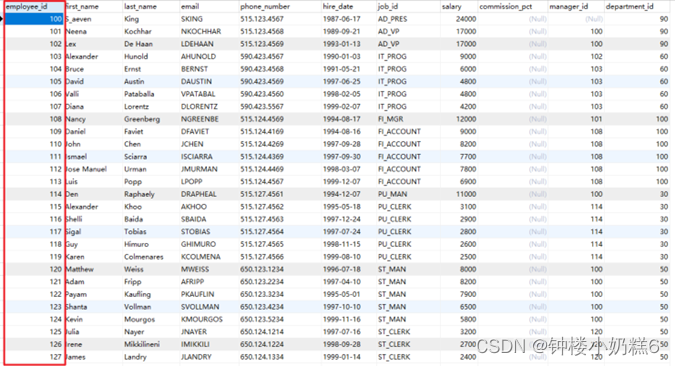
在页目录使用二分法快速定位到对应的槽,然后再遍历槽对应分组的记录,快速找到指定的记录
②其他列作为条件(非主键的列)
select *
from employees
where last_name='Abel';
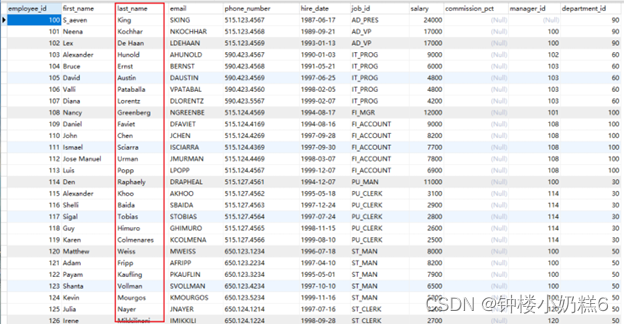
只能从最小记录开始依次遍历单链表中的每条记录,判断是否符合条件,效率低。
3.1.2.在很多页查找
①定义到记录所在的页
②从所在的页查找对应的记录
没有索引情况下,不论根据主键还是其他列,只能从第一页沿着双向链表一直往下找,在每个页根据上面的查找方法查找指定的记录。非常耗时,所以索引来了。
3.2设计索引
建一个表
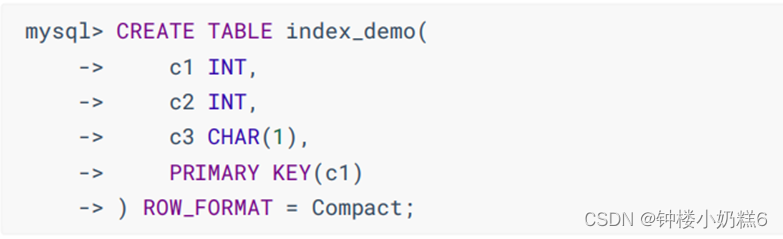
①index_demo表的行格式示意图

record_type:0是普通记录,2是最小记录,3是最大记录
next_record:记录下一条数据的地址
②把一些记录存放到表里的示意图

3.2.1简单的索引设计方案
问题:想快速定位到需要查找的数据在哪些数据页,可以为数据页建立一个目录:
①所有数据页里面的记录的主键是递增的

②为数据页建立目录:当前页的主键最小值key,当前页号page_no

此时把目录项在物理存储器连续存储,实现主键快速查找某条记录的功能。
比如:查找主键20
①先从目录项根据二分法快速确定主键值为20在目录3中(12<20<209)
②在页中查找记录方法根据主键值二分法查找具体的记录
3.2.2InnoDB中的索引方案
①迭代1次:目录项记录的页,采用单向链表实现,便于增加和删除

record_type=1表示存放的是目录项
record_type=0 表示存放的是普通记录
目录项记录和普通用户记录的相同点:都会为主键值生成Page Directory(页目录),按照主键值进行查找时使用二分法加快查询速度。
比如:查找主键20
先从页30中通过二分法快速定位到对应目录项,因为(12<20<209),定位到页9
从页9使用二分法定位到主键值为20的用户记录
②迭代2次:多个目录项记录的页,双向链表
假设目录项记录的页最大记录是4,现在新添加的记录,所以要生成新的目录项的页

比如:查找主键20
确定目录项记录页,现在目录项页30和页32,页30的主键值范围是[1,320),页32是不小于320,所以在页30
通过目录项记录页根据二分法查找出对应的目录项,定位页9
在页9通过二分法定位到主键20的用户记录
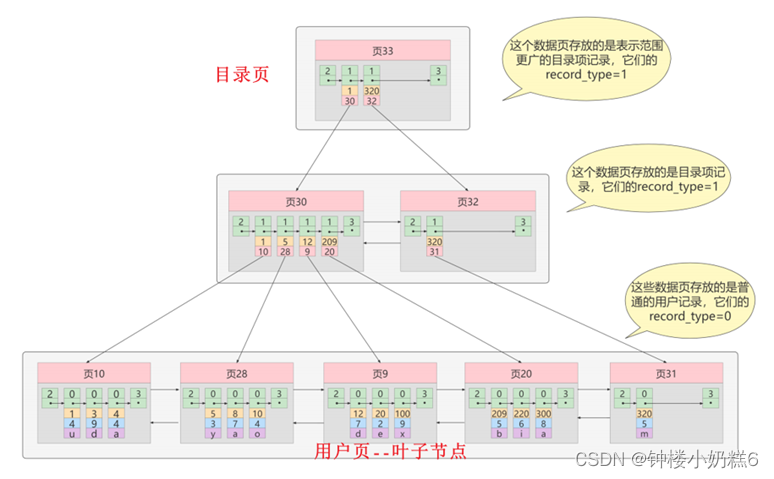
③迭代3次:目录项记录页的目录页,大目录嵌套小目录

生成存储高级目录项的页33,这个页中的两条记录代表页30和页32。
④这个结构就是B+树
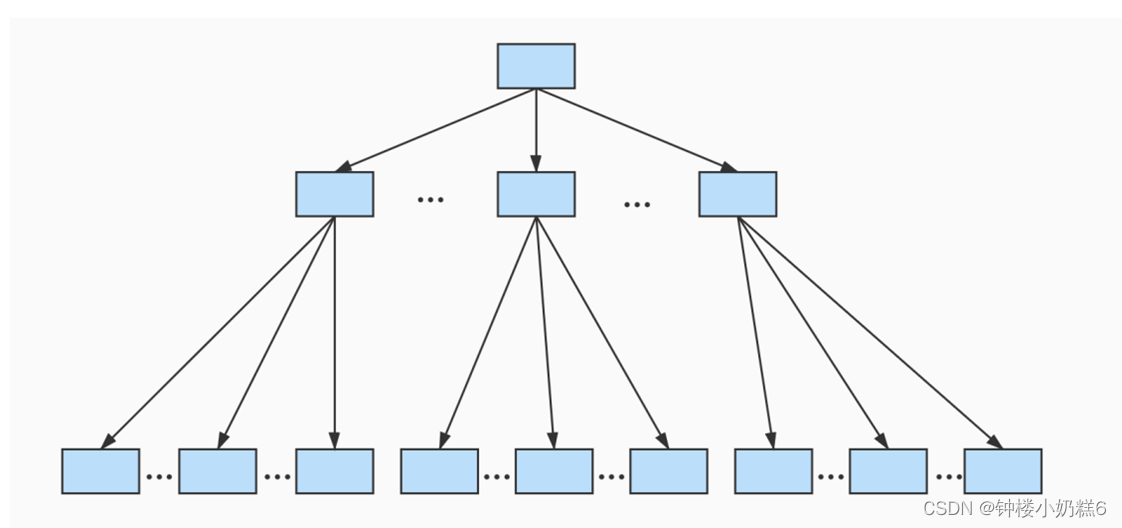
B+树都不会超过4层,通过主键值查找某条记录最多需要4个页面内的查找。(3个目录项页,1个用户记录页),每个页面有page Directory页目录,可以通过二分法快速定位记录。
假设:普通数据页:100条用户记录 目录项记录页:1000条目录项记录
如果B+树只有1层,只有1个存放用户记录的节点,最多能存放 100 条记录。
如果B+树有2层,最多能存放 1000×100=10,0000 条记录。
如果B+树有3层,最多能存放 1000×1000×100=1,0000,0000 条记录。
如果B+树有4层,最多能存放 1000×1000×1000×100=1000,0000,0000 条记录
3.3常见索引的概念
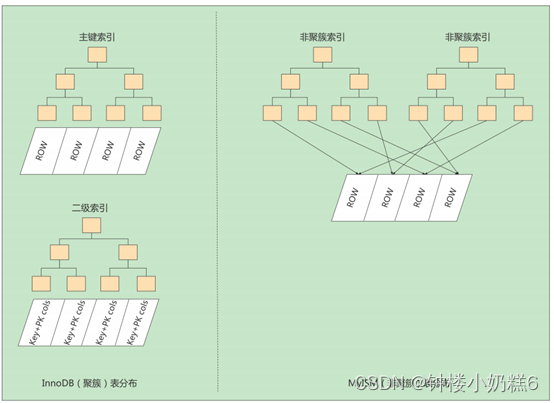
3.3.1聚簇索引:主键构建的B+树
概念:
聚簇索引是一种数据存储方式,所有的用户记录都在叶子节点,索引即数据,数据即索引。
聚簇表示数据行和相邻的键值聚簇的存储在一起。InnoDB存储引擎会自动创建聚簇索引
特点:
①页内记录按照主键的大小排序成一个单向链表,有序的
②存放记录的页按照主键值大小顺序排成一个双向链表
③存放目录项记录的页按照主键值顺序排成一个双向链表
④B+树的叶子节点存储的是完整的用户记录
优点:
①数据访问快,聚簇索引将索引和数据保存在同一个B+树中。B+树的叶子节点就是完整的用户记录
②因为按照主键大小排序成一个单链表,排序查找和范围查找速度快
③查找范围的数据时,数据紧密相连,节省了大量IO操作
缺点:
①插入速度严重依赖插入顺序,否则会出现页的分裂,影响性能。因此InnoDB表,定义一个自增的ID列作为主键
②更新主键的代价很高。会导致更新行的移动。对于InnoDB表,定义主键不可更新
③二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
限制:
①InnoDB支持聚簇索引,MyISAM不支持聚簇索引
②每个表只能有一个聚簇索引,该表的主键
③没有定义主键,InnoDB选择非空的唯一索引代替。没有的话,InnoDB隐式定义主键
④InnoDB的键尽量选择有序的id,不建议UUID,MD5,HASH,字符串作为主键
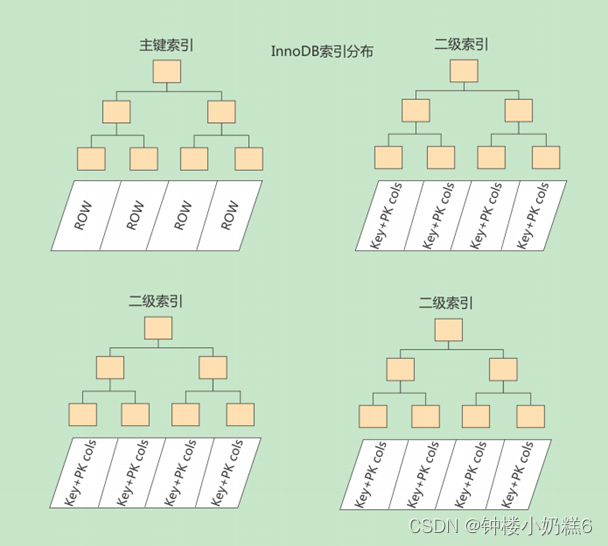
3.3.2非聚簇索引(二级索引,辅助索引):非主键构建的B+树
概念:
如果使用非主键字段进行查找,可以多建几棵B+树,每个树采用不同的排序规则。比如c2的列,进行查找。按照非主键列建立的B+树需要一次回表操作能定位到完整的用户记录,这种B+树是二级索引。
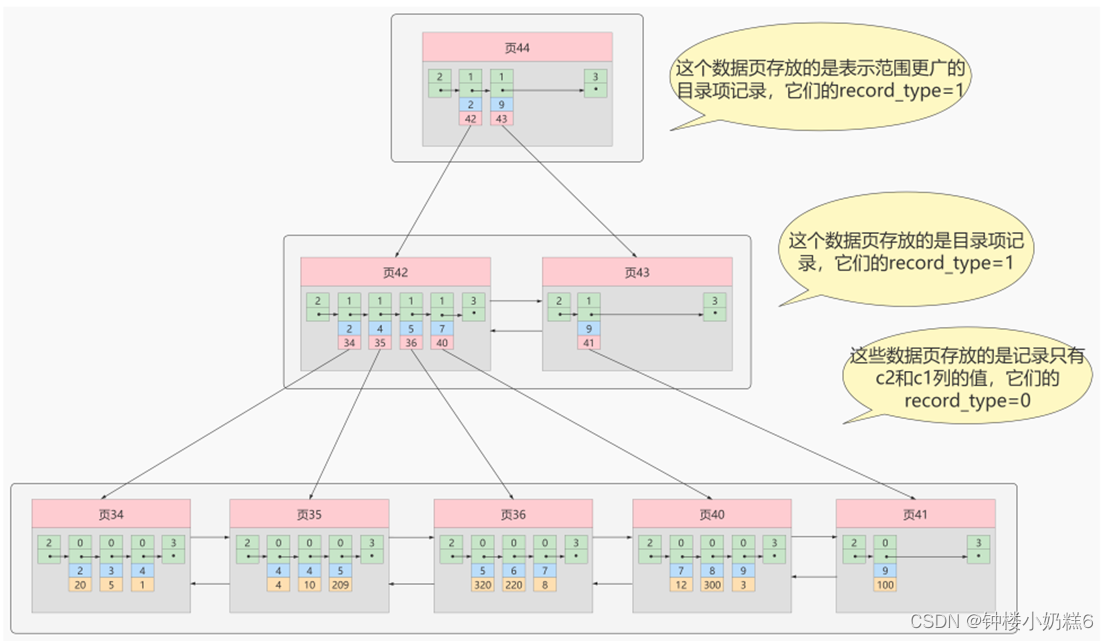
叶子节点,数据页里面的数据按照c2的大小排序成单链表。用户记录不完整,存c2和主键项。
回表:(回聚簇索引)
根据c2的列(非主键列)大小排序的B+树,只能找到查找记录对应的主键值,二级索引没有完整的用户记录,所以需要到聚簇索引根据查找出的主键值再查一遍。这个过程就是回表。所以从非主键列条件查找一条记录需要2棵B+树
为什么要回表操作,把完整的用户记录存放到二级索引的叶子节点不行吗
太占内存空间。冗余大
一张表有1个聚簇索引和多个非聚簇索引。
3.3.3联合索引:多个列作为排序规则,c2,c3组合

概念:
①把各个记录和页按照c2进行排序
②在c2列相同情况下,采用c3进行排序。
③本质上是二级索引,需要回表操作
④叶子节点用户记录是c2,c3和主键c1构成
3.4InnoDB的B+树索引的注意事项
3.4.1根页面内存位置万年不动
B+树的形成过程:
①当创建一个表的时候,底层为这个索引创建一个根节点,此时没有目录项和用户记录
②向表中插入数据时,先存储在根节点

③当根节点空间用满时(假设3条),此时根节点成为目录页复制一个新页(页a)
④再插入一个数据时,通过页分裂操作,得到页b。
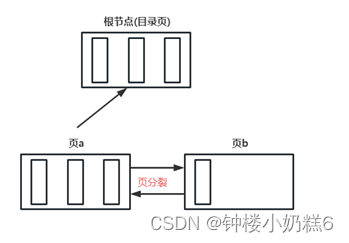
⑤随着插入操作,叶子节点变多,目录项空间满了。此时根节点复制一个新目录页a
⑥当进行插入的时候,会把目录项存放到目录页b

当InnoDB用到这个索引的时候,都会从固定的地址找到这个根节点的页号,从而访问这个索引。
3.4.2内节点中目录项记录的唯一性(除了非叶子节点)
①B+树索引的内节点目录项是索引列+页号。假设一个表的数据是

构建的二级索引B+树,如过插入一条数据 (8,1,’c’),就不知道是插入页4还是页5了。造成了目录项记录不唯一

②解决方法是目录项加入主键:索引列+主键值+页号

3.4.3一个页面最少存储2条记录
四、MyISAM中的索引方案:B-Tree索引
1.介绍
MyISAM引擎使用B+Tree作为索引结构,但是叶子节点的data域存放的是数据记录的地址
2.原理
InnoDB中索引就是数据。但在MyISAM中索引和数据分开存储,非聚簇索引

①数据文件:用户记录的插入顺序单独储存的一个文件。不分页。不按照主键大小排序。不能使用二分法查找
②索引文件:存放索引信息的,为表中的主键创建一个索引。叶子节点存放的是主键值+数据记录的地址
3.MyISAM和InnoDB的对比
MyISAM的索引方式是“非聚簇的”,InnoDB包含1个聚簇索引
①在InnoDB中根据主键值对聚簇索引进行一次查找就能找到对应的记录。在MyISAM(非聚簇,二级索引)需要一次回表操作。
②InnoDB数据文件就是索引文件,索引即数据。但是MyISAM的数据文件和索引文件是分离的,索引文件保存的是数据的地址
③InnoDB的非聚簇索引的data域存放的是主键的值,而MyISAM存放的是记录的地址。
④MyISAM的回表十分迅速,拿着地址直接找数据。但InnoDB通过获取主键后在聚簇索引查找记录。
⑤InnoDB要求表必须有主键,MyISAM可以没有。在InnoDB如果没有指定,MySQL自动选择一个非空且唯一做主键。如果不存在这种类型,MySQL自动为InnoDB隐含字段做主键。
五、索引的代价
空间上代价
每次建立索引都是建立B+树,每一棵B+树的节点都是数据页。一个数据页默认16KB,许多数据页组成,就是一大片存储空间
时间上代价
每次对表中的数据增、删、改需要修改B+树的索引。B+树的节点按照索引列的值从小到大顺序排序双向链表。存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收等操作来维护好节点和记录的排序。
六、MySQL为什么选择B+树
选择标准
能让索引的数据结构尽量减少磁盘的I/O操作次数。索引是存储在外部磁盘上的,只能逐一加载到内存。MySQL衡量查询效率标准就是磁盘IO次数
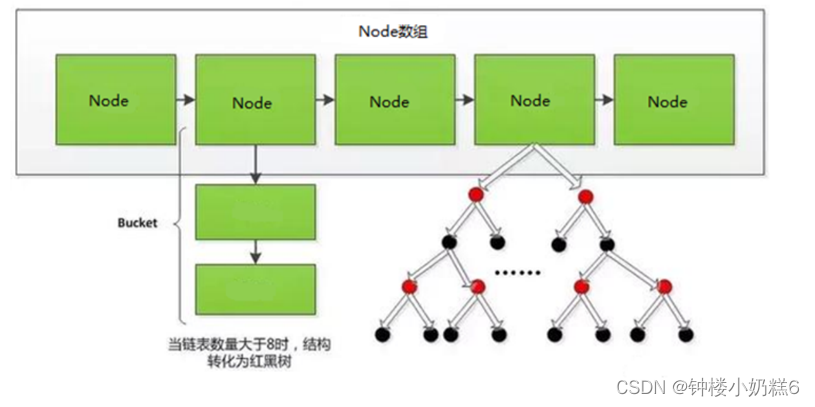
1.Hash结构:数组+链表
问题1:为什么Hash效率高,索引结构使用的是树形呢?
①Hash索引仅能满足等于,不等于,in的等值查询。如果是范围查询,时间复杂度是O(n),树形是有序的,保持高效率
②Hash索引的缺陷是没有顺序的,order by 排序时要重新排序
③对于联合索引,Hash值是一起计算的,无法对单独一个键或几个索引键查询
④Hash索引不适合在重复值多的列上,比如性别,年龄。因为遇到Hash冲突时,需要遍历桶中的行指针进行比较,找到查询关键字非常耗时。
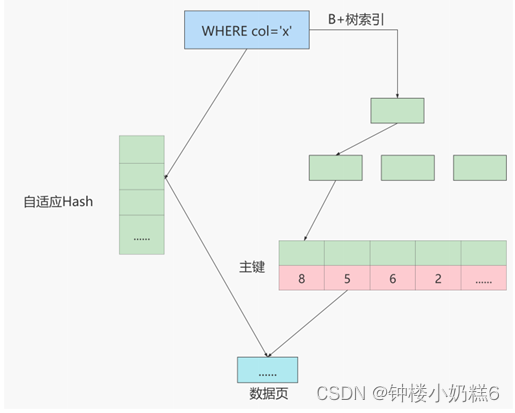
问题2:什么是InnoDB自适应的Hash索引?
如果某个数据经常被访问,当满足一定条件,当前的数据页地址就会放到Hash表中,当下次查询时,直接到找个页的位置。B+树也有了Hash的优点
2.二叉搜索树
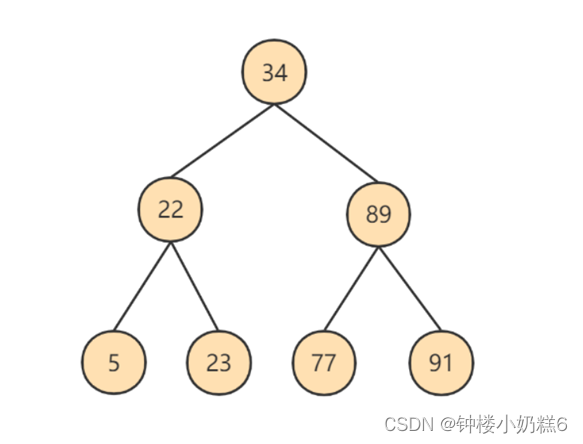
磁盘的IO次数跟索引树的高度是相关的。
为了提高查询效率,就需要 减少磁盘IO数 。为了减少磁盘IO的次数,就需要尽量 降低树的高度 ,需要把原来“瘦高”的树结构变的“矮胖”,树的每层的分叉越多越好。
3.AVL树:平衡二叉树
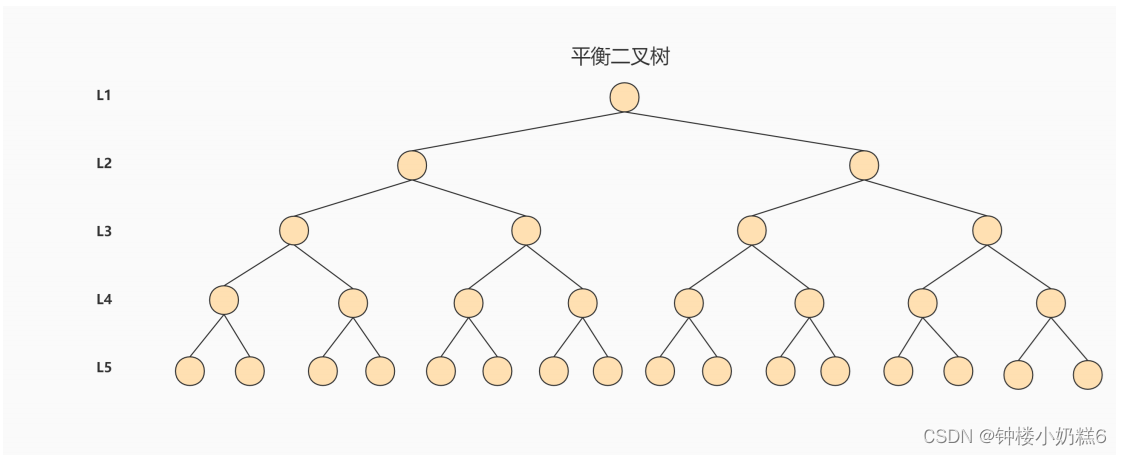
针对同样的数据,如果我们把二叉树改成 M 叉树 (M>2)呢?当 M=3 时,同样的 31 个节点可以由下面的三叉树来进行存储:

4.B树:非叶子节点存放的也是数据
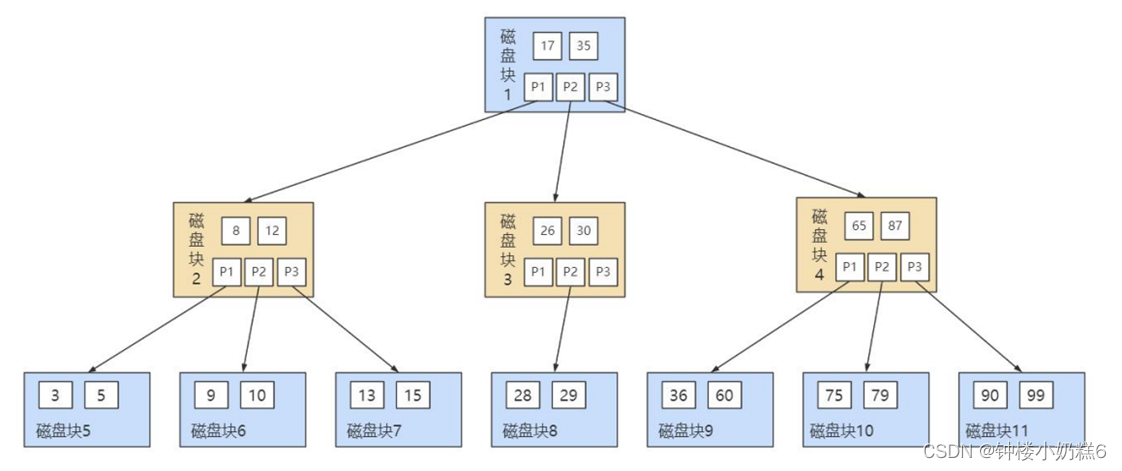
查找的关键字是 9步骤:
①与根节点的关键字 (17,35)进行比较,9 小于 17 那么得到指针 P1;
②按照指针 P1 找到磁盘块 2,关键字为(8,12),因为 9 在 8 和 12 之间,所以我们得到指针 P2;
③按照指针 P2 找到磁盘块 6,关键字为(9,10),然后我们找到了关键字 9。
5.B+树

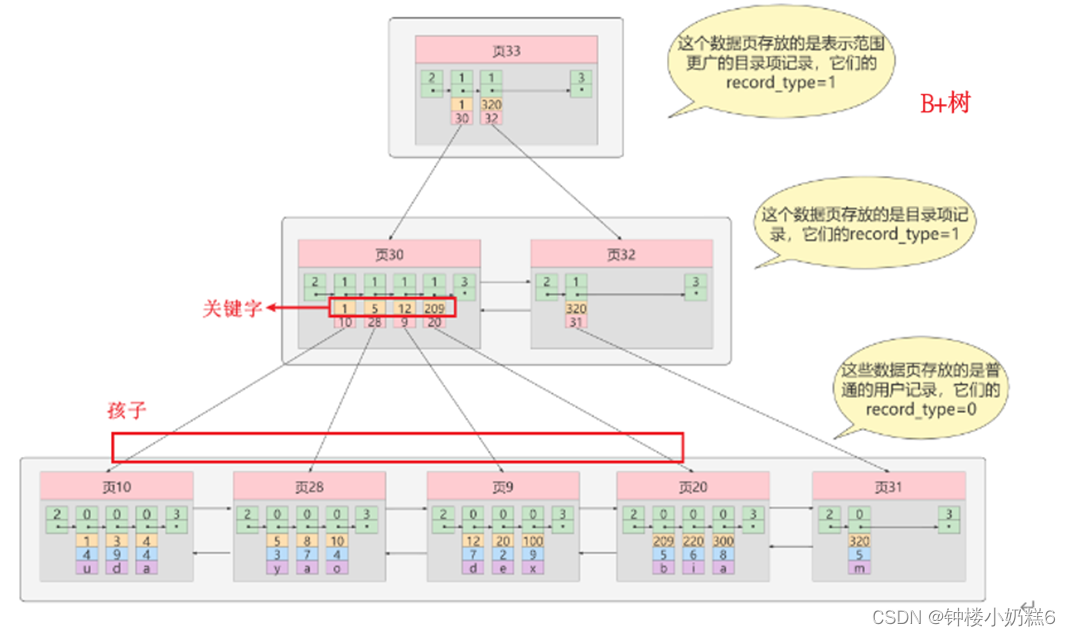
问题1:B+树和B树的区别
①B+树有K个关键字就有K个孩子,B树有K个关键字,孩子是K+1
②B+树中只有叶子节点存数据,B树叶子节点和非叶子节点都存放数据
③B+树所有的关键字都在叶子节点出现,构成一个有序链表,按照关键字从小到大排序。
问题2:为什么B+树非叶子节点不存放数据,好处是什么
①B+树查询效率更稳定:B+树访问到叶子节点才有数据,但是B树非叶子节点和叶子节点都有数据,查询不稳定
②B+树查询效率更高:B+树比B树更矮胖。查询IO次数少,B+树存储更多的节点关键字
③在查询范围上,B+树效率比B树高。B+树的数据都在叶子节点上,而且数据递增的。B树需要遍历才能完成查找,效率低。
问题3:为了减少IO,索引树会一次性加载吗?
①数据库索引是存储在磁盘上的,如果数据量很大。索引会很大,超过几个G
②当利用索引时,不能把几个G的索引加载到内存。逐一加载到每一个磁盘页,磁盘页对应着索引树的节点。
问题4:B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO
InnoDB的存储引擎中页的大小为16KB,一个页大概存储1000个键值。深度为3的B+可以维护10亿条记录
实际情况每个节点不可能填充满,因此数据库中2-4层(包含根节点),因为根节点就在内存,所以只需1-3次磁盘的IO操作。
问题5:为什么说B+树比B-树更适合实际应用中操作系统的文件索引和数据库索引?
(回答B+树的优点)
①B+树查询效率更稳定:B+树访问到叶子节点才有数据,但是B树非叶子节点和叶子节点都有数据,查询不稳定
②B+树查询效率更高:B+树比B树更矮胖。查询IO次数少,B+树存储更多的节点关键字
③在查询范围上,B+树效率比B树高。B+树的数据都在叶子节点上,而且数据递增的。B树需要遍历才能完成查找,效率低。
问题6:Hash 索引与 B+ 树索引的区别
①Hash索引不能范围查找,B+树可以。Hash数据是无序,B+叶子节点是有序链表
②Hash索引的缺陷是没有顺序的,order by 排序时要重新排序。B+叶子节点是有序链表
③对于联合索引,Hash值是一起计算的,无法对单独一个键或几个索引键查询,B+树可以
④InnoDB不支持哈希索引
问题7:Hash索引与 B+ 树索引是在建索引的时候手动指定的吗?
根据MySQL的存储引擎决定的。
InnoDB和MyISAM存储引擎是B+树索引,但InnoDB提供自适应的Hash
Memory/Heap和NDB存储引擎,可以选择Hash索引
相关文章:
第15章:索引的数据结构
一、为什么使用索引 1.索引是存储引擎用于快速找到记录的一种数据结构。相当于一本书的目录。在进行数据查找时,首先查看查询条件是否命中某条索引,符合则通过索引查找相关数据。如果不符合则需要全表扫描,一条一条查找记录,直到…...

机械师曙光16电脑开机自动蓝屏怎么解决?
机械师曙光16电脑开机自动蓝屏怎么解决?有的用户在使用机械师曙光16电脑的时候,遇到了一些系统问题,导致自己无法正常的开机使用电脑。因为电脑总会变成蓝屏,无法进行任何操作。那么这个情况怎么去进行问题的解决呢?来…...
机器学习_Lasso回归_ElasticNet回归_PolynomialFeatures算法介绍_02---人工智能工作笔记0037
Lasso回归用的是L1正则化可以看到,这里的alpha就是这里的alpha对吧,就是 L1的权重 然后对于ElasticNet回归来说,这里的alpha可以看到是L1权重的超参数对吧,然后这里的p,表示的是 L2正则里面的(1-p)这里 这里要提一下: L1和L2为什么能防止过拟合,它们有什么区别?通过添加…...
第五篇:强化学习基础之马尔科夫决策过程
你好,我是zhenguo(郭震) 今天总结强化学习第五篇:马尔科夫决策过程 基础 马尔科夫决策过程(MDP)是强化学习的基础之一。下面统一称为:MDP MDP提供了描述序贯决策问题的数学框架。 它将决策问题建模为: 状态…...

Oracle面试题
1. 什么是存储过程,使用存储过程的好处? 存储过程(Stored Procedure )是一组为了完成特定功能的SQL 语句集,经编译后存储在数据库中。用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数&#…...

用Vue写教务系统学生管理
文章目录 一.首先创建新的Demo二.在APP里面绑定DemoStudent三.源码附上四.效果图(新增记录还未实现) 一.首先创建新的Demo 二.在APP里面绑定DemoStudent <template><img alt"Vue logo" src"./assets/logo.png"><!--…...

专门用于管理企业与自己客户之间所有信息的客户管理系统
一、开源项目简介 关于 NXCRM NXCRM 是一套基于 Laravel 的 CRM 应用程序。它包含了一个管理中心,可以管理用户、客户、产品、订单、商机,合同,收款,附件,联系人,跟进动态,发票,业…...

(转载)基于多层编码遗传算法的车间调度算法(matlab实现)
以下内容大部分来源于《MATLAB智能算法30个案例分析》,仅为学习交流所用。 1 理论基础 遗传算法具有较强的问题求解能力,能够解决非线性优化问题。遗传算法中的每个染色体表示问题中的一个潜在最优解,对于简单的问题来说,染色体…...
Redis的常用数据结构之哈希类型
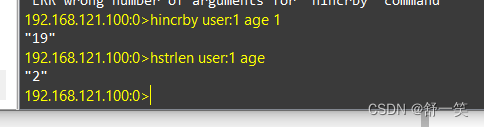
首先这里说的哈希类型针对的是redis中的value的k-v结构 常见的操作命令 hset设置值 hsetnx命令,不存在可以设置,存在设置不成功 hget取值,这里与字符串类型不同是要精确到filed。前面的判断也是基于field来实现的 要是field没有就返回null h…...
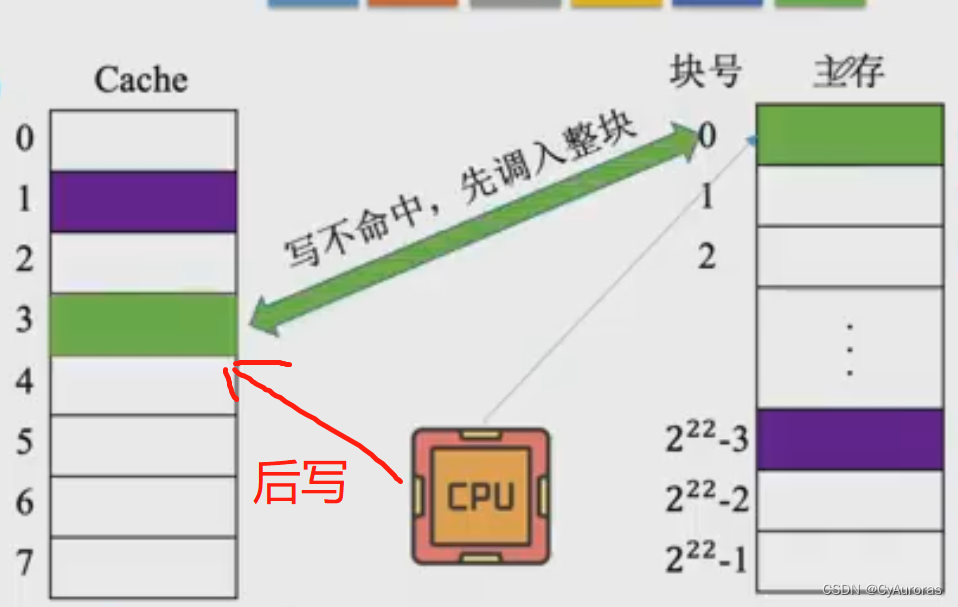
计算机组成原理-存储系统-缓存存储器(Cache)
目录 一、Cache基本概念 1.2性能分析 二、 Cache和主存的映射发生 2.1全相连映射编辑 2.2直接映射编辑 2.3组相连映射 三、Cachae的替换算法 3.1 随机算法(RADN) 3.2 先进先出算法(FIFO) 3.3 近期最少使用(LRU) 3.4 最近不经常使用(LFU) 四、写策略 4…...

打开c语言生成exe文件,出现闪退的解决方法
为什么打开c语言生成的exe文件,立马闪退。 起初个别问的时候,我只是简单的说明程序运行完了,就自动关了, 首先,生成的exe文件本质是控制台程序,这些都是依赖于windows的控制台窗口,程序执行完…...
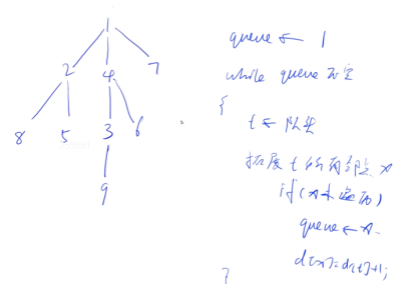
算法基础学习笔记——⑩DFS与BFS\树与图
✨博主:命运之光 ✨专栏:算法基础学习 目录 DFS与BFS\树与图 ✨DFS ✨BFS 🍓宽搜流程图如下: 🍓宽搜流程: 🍓广搜模板 ✨树与图 🍓树是特殊的图(连通无环的图&am…...

chatgpt赋能python:Python中可迭代对象的介绍
Python中可迭代对象的介绍 Python是一种高级编程语言,它具有简单易学、可读性强、功能强大等特点,成为了数据科学、机器学习、Web开发等领域的热门选择。Python中有很多重要的概念和功能,其中之一就是支持可迭代对象的概念。 在Python中&am…...
报表控件FastReport使用指南——如何打开WebP格式的图片
FastReport 是功能齐全的报表控件,可以帮助开发者可以快速并高效地为.NET,VCL,COM,ActiveX应用程序添加报表支持,由于其独特的编程原则,现在已经成为了Delphi平台最优秀的报表控件,支持将编程开…...
【鲁棒、状态估计】用于电力系统动态状态估计的鲁棒迭代扩展卡尔曼滤波器研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
整理6个超好用的在线编辑器!
随着 Web 开发对图像可扩展性、响应性、交互性和可编程性的需求增加,SVG 图形成为最适合 Web 开发的图像格式之一。它因文件小、可压缩性强并且无论如何放大或缩小,图像都不会失真而受到欢迎。然而,为了编辑 SVG 图像,需要使用 SV…...

ArcGIS10.8下载及安装教程(附安装步骤)
谷歌云: https://drive.google.com/drive/folders/10igu7ZSMaR0v0WD7-2W-7ADJGMUFc2ze?uspsharing ArcGIS10.8 百度网盘: https://pan.baidu.com/s/1s5bL3QsCP5sgcftCPxc88w 提取码:kw4j 阿里云: https://www.aliyundriv…...
AI智能照片编辑:AI Photo for Mac
AI Photo是一款Mac平台上的智能照片编辑软件,它基于人工智能技术,可以帮助用户快速、轻松地对照片进行编辑和美化。AI Photo提供了多种智能修复和美化功能,包括自动调整色彩、对比度、亮度、清晰度等,使得照片的质量得到有效提升。…...
Tuxera for Mac2023中文版读写硬盘U盘工具
在日常生活中,我们使用Mac时经常会遇到外部设备不能正常使用的情况,如:U盘、硬盘、软盘等等一系列存储设备,而这些设备的格式大多为NTFS,Mac系统对NTFS格式分区存在一定的兼容性问题,不能正常读写。 那么什…...

项目遇到的实际需求: java从信任所有证书到对server证书进行校验
最近项目上开发了一个rest api,放在了一台linux服务器上,并且启用了https连接;在另一台服务器上写了一个功能需要去调用linux机器上的api。 项目里面自己封装了一个HttpsClient的类,用来发送https请求,并且在里面重写了…...

2026年外贸管理软件怎么选?B2B与跨境B2C实用选型指南
在外贸行业数字化升级过程中,企业挑选管理软件,首要理清自身业务赛道。目前行业主流分为传统外贸B2B、跨境电商B2C两大模式。结合企业实际经营需求,传统B2B可划分为获客拓客类工具、内部业务管理类系统;跨境B2C可划分为前端店铺运…...

【Midjourney颗粒感控制白皮书】:基于1278组V6.1→V6.2渲染样本的统计建模,颗粒强度与--chaos关联性达r=0.93
更多请点击: https://intelliparadigm.com 第一章:Midjourney颗粒感控制白皮书导论 颗粒感(Grain)是Midjourney图像生成中影响画面质感、胶片氛围与艺术真实性的关键隐式参数。它并非独立命令,而是深度耦合于 --sty…...

为你的大模型应用快速接入Taotoken,Python调用只需三步
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的大模型应用快速接入Taotoken,Python调用只需三步 对于希望在自己的应用中集成大模型能力的开发者而言࿰…...

告别手动测量!用ArcGIS Pro和CAD联动,5步搞定复杂河道平均宽度计算
5步实现ArcGIS Pro与CAD协同计算复杂河道平均宽度的工程实践 在水利工程、环境评估和流域规划中,河道平均宽度是计算流量、评估生态承载力的关键参数。传统手工测量方法不仅耗时费力,对于蜿蜒曲折的自然河道更是难以保证精度。我曾参与过多个河道整治项目…...
)
不止于安装:在Ubuntu上为Arduino IDE 2.x手动添加冷门芯片支持(以LGT8F328P为例)
不止于安装:在Ubuntu上为Arduino IDE 2.x手动添加冷门芯片支持(以LGT8F328P为例) 当你在Ubuntu上完成Arduino IDE 2.x的基础安装后,真正的挑战才刚刚开始。对于那些非官方支持的开发板,如LGT8F328P,标准的库…...

资源下载神器:5分钟掌握全平台媒体内容下载技巧
资源下载神器:5分钟掌握全平台媒体内容下载技巧 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否曾经遇到过…...

FTP明文传输风险与Wireshark抓包实证分析
1. 这不是危言耸听:FTP 的“裸奔”现状每天都在发生你有没有在公司内网用过 FTP 上传一份财务报表?有没有在校园网里用 FileZilla 向老师提交课程设计源码?有没有在运维后台用 ftp 命令同步过网站静态资源?如果答案是肯定的&#…...
)
【独家首发】保险业首个AI Agent成熟度评估模型(5级量化标准+12项KPI基线数据)
更多请点击: https://intelliparadigm.com 第一章:【独家首发】保险业首个AI Agent成熟度评估模型(5级量化标准12项KPI基线数据) 该模型由国内头部保险科技联合实验室历时18个月实证研发,首次将AI Agent在核保、理赔、…...

洛雪音乐音源配置完整教程:3分钟解锁全网无损音乐
洛雪音乐音源配置完整教程:3分钟解锁全网无损音乐 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 洛雪音乐作为开源音乐播放器,通过灵活的音源配置功能,让用户能…...

如何解决跨平台资源下载难题:res-downloader的完整使用指南
如何解决跨平台资源下载难题:res-downloader的完整使用指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 你是否…...