注意力机制(一)SE模块(Squeeze-and-Excitation Networks)论文总结和代码实现
Squeeze-and-Excitation Networks(压缩和激励网络)
论文地址:Squeeze-and-Excitation Networks
论文中文版:Squeeze-and-Excitation Networks_中文版
代码地址:GitHub - hujie-frank/SENet: Squeeze-and-Excitation Networks
目录
一、论文出发点
二、论文的主要工作
三、Squeeze-and-Excitation模块
(1)Transformation(Ftr): 转型
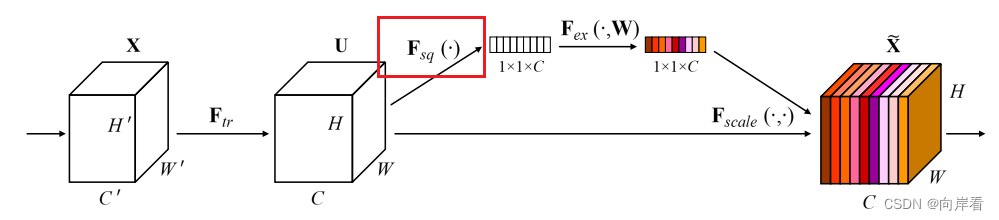
(2)Squeeze:全局信息嵌入
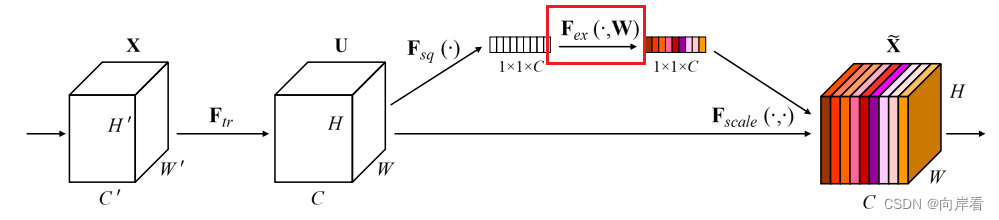
(3)Excitation:自适应重新校正
(4)Scale:重新加权
四、模型:SE-Inception和SE-ResNet
五、实验
六、结论
七、源码分析
(1)SE模块
(2)SE-ResNet完整代码
一、论文出发点
为了提高网络的表示能力,许多现有的工作已经显示出增强空间编码的好处。而作者专注于通道,希望能够提出了一种新的架构单元,通过显式地建模出卷积特征通道之间的相互依赖性来提高网络的表示能力。
这里引用“博文:Squeeze-and-Excitation Networks解读”中的总结:核心思想是不同通道的权重应该自适应分配,由网络自己学习出来的,而不是像Inception net一样留下过多人工干预的痕迹。
二、论文的主要工作
1.提出了一种新的架构单元Squeeze-and-Excitation模块,该模块可以显式地建模卷积特征通道之间的相互依赖性来提高网络的表示能力。
2.提出了一种机制,使网络能够执行特征重新校准,通过这种机制可以学习使用全局信息来选择性地强调信息特征并抑制不太有用的特征。
三、Squeeze-and-Excitation模块
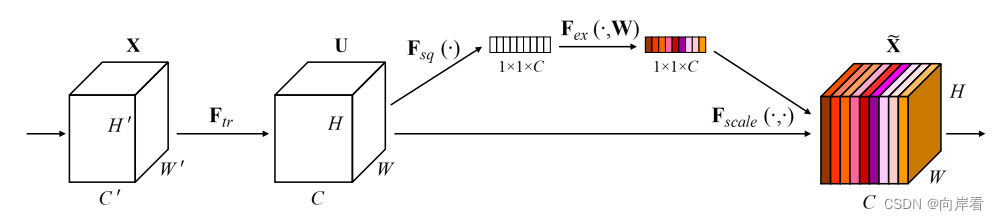
(1)Transformation(Ftr): 转型
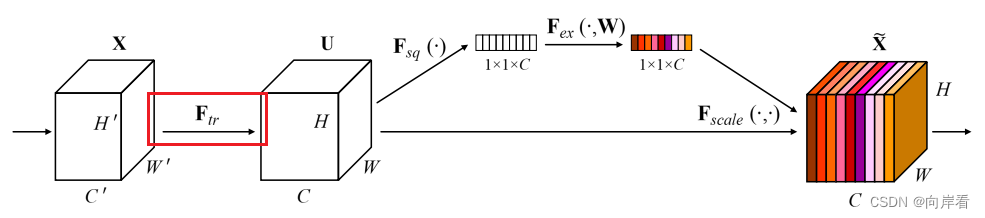
,经过
特征图X变为特征图U。
。
其中:
1.
,这里
指输出特征图的一个单通道2D特征层。
2.
表示学习到的一组滤波器核,Vc指的是第c个滤波器的参数,此外
,这里
是指一个通道数为1的2D空间核。
3.
,这里
是指输入特征图的一个单通道2D特征层。
该卷积算子公式表示,输入特征图X的每一层都经过一个2D空间核的卷积最终得到C个输出的feature map,组成特征图U。
原文内容如下:

- X∈R^(H′×W′×C′):输入特征图
- U∈R^(H×W×C):输出特征图
- V:表示学习到的一组滤波器核
- Vc:指的是第c个滤波器的参数
- *:卷积操作
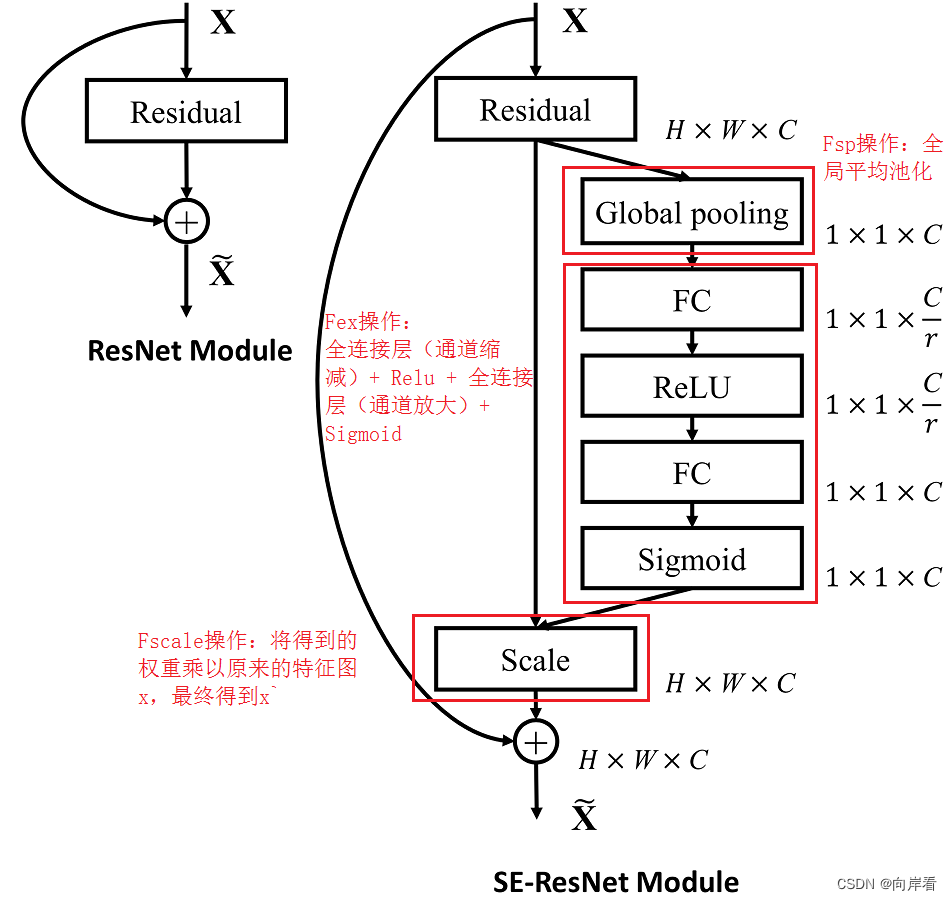
(2)Squeeze:全局信息嵌入
![]()
(3)Excitation:自适应重新校正
![]()
为什么这里要有两个FC,并且通道先缩小,再放大?
因为一个全连接层无法同时应用relu和sigmoid两个非线性函数,但是两者又缺一不可。为了减少参数,所以设置了r比率。
(4)Scale:重新加权
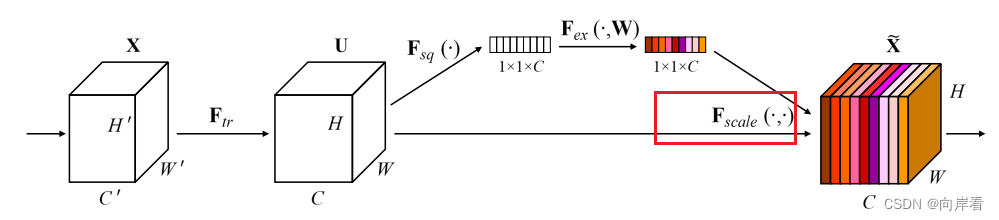
目的:最后是Scale操作,将前面得到的注意力权重加权到每个通道的特征上。
![]()
四、模型:SE-Inception和SE-ResNet
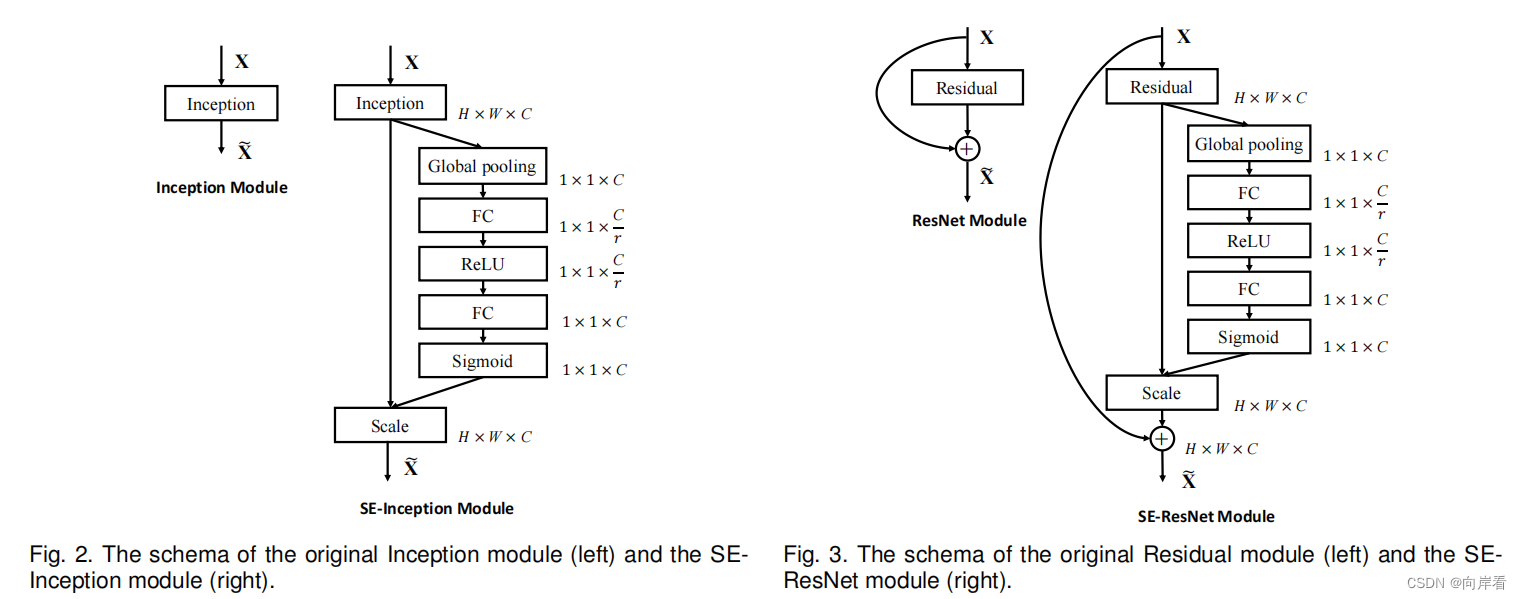
通过将一个整体的Inception模块看作SE模块中,为Inception网络构建SE模块。
同理, 将一个整体的Residual模块看作SE模块中,为ResNet网络构建SE模块。
五、实验
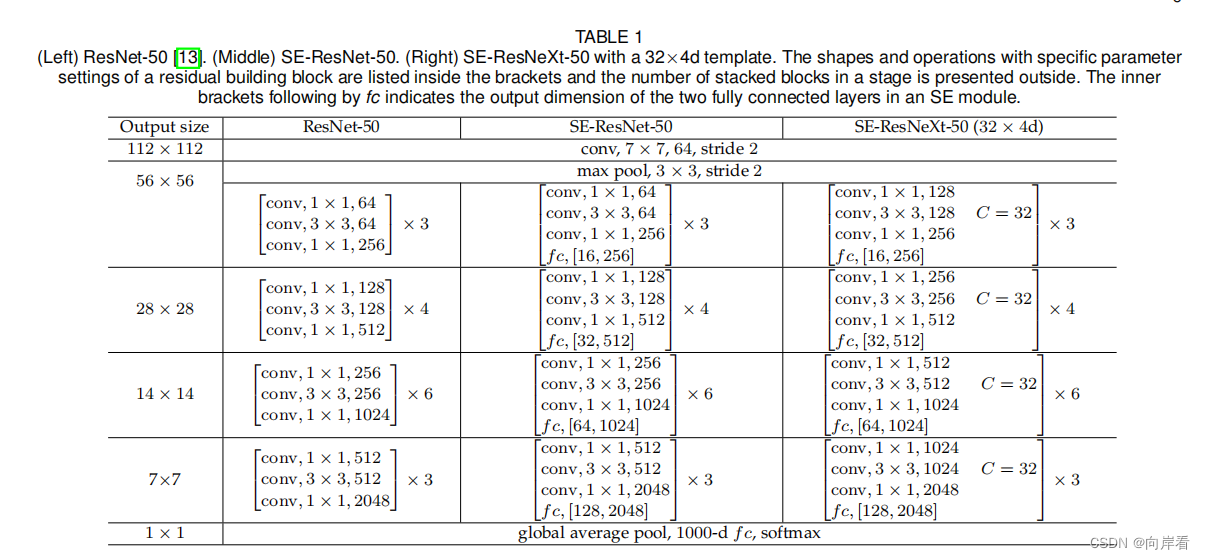
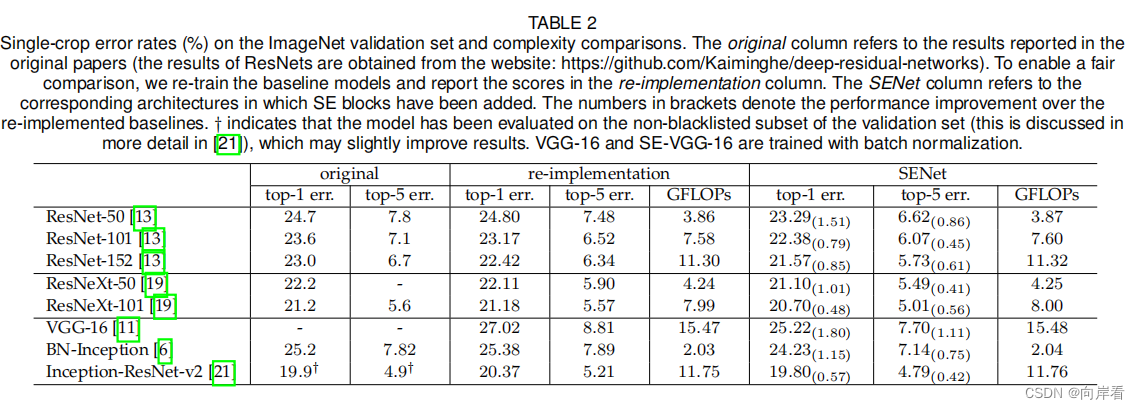
六、结论
本文提出的SE模块,这是一种新颖的架构单元,旨在通过使网络能够执行动态通道特征重新校准来提高网络的表示能力。大量实验证明了SENets的有效性,其在多个数据集上取得了最先进的性能。
七、源码分析
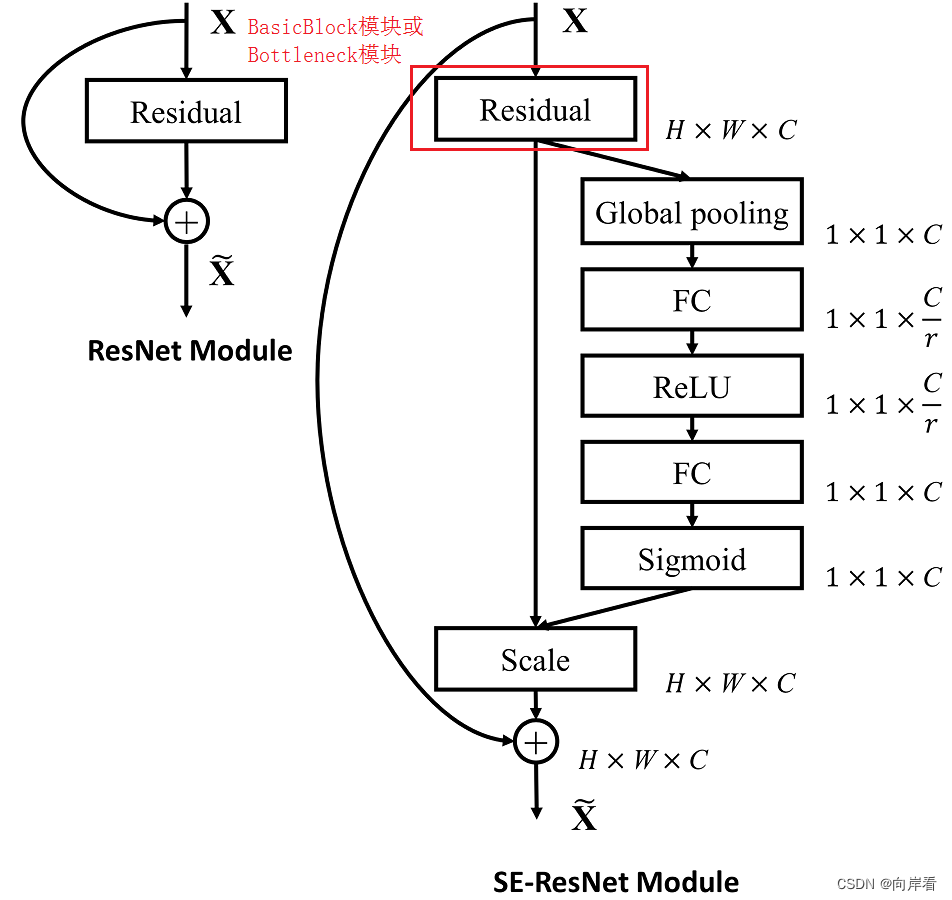
将SEblock嵌入ResNet的残差模块中
(1)SE模块
'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):def __init__(self, inchannel, ratio=16):super(SE_Block, self).__init__()# 全局平均池化(Fsq操作)self.gap = nn.AdaptiveAvgPool2d((1, 1))# 两个全连接层(Fex操作)self.fc = nn.Sequential(nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/rnn.ReLU(),nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> cnn.Sigmoid())def forward(self, x):# 读取批数据图片数量及通道数b, c, h, w = x.size()# Fsq操作:经池化后输出b*c的矩阵y = self.gap(x).view(b, c)# Fex操作:经全连接层输出(b,c,1,1)矩阵y = self.fc(y).view(b, c, 1, 1)# Fscale操作:将得到的权重乘以原来的特征图xreturn x * y.expand_as(x)
(2)SE-ResNet完整代码
不同版本的ResNet各层主要是由BasicBlock模块(18-layer、34-layer)或Bottleneck模块(50-layer、101-layer、152-layer)构成的,因此只要在BasicBlock模块或Bottleneck模块尾部添加SE模块即可,但是要注意放在shortcut之前,因为shortcut仅是为了保存梯度,把SE模块加在作为提取信息的主干上即可。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchsummary import summary'''-------------一、SE模块-----------------------------'''
#全局平均池化+1*1卷积核+ReLu+1*1卷积核+Sigmoid
class SE_Block(nn.Module):def __init__(self, inchannel, ratio=16):super(SE_Block, self).__init__()# 全局平均池化(Fsq操作)self.gap = nn.AdaptiveAvgPool2d((1, 1))# 两个全连接层(Fex操作)self.fc = nn.Sequential(nn.Linear(inchannel, inchannel // ratio, bias=False), # 从 c -> c/rnn.ReLU(),nn.Linear(inchannel // ratio, inchannel, bias=False), # 从 c/r -> cnn.Sigmoid())def forward(self, x):# 读取批数据图片数量及通道数b, c, h, w = x.size()# Fsq操作:经池化后输出b*c的矩阵y = self.gap(x).view(b, c)# Fex操作:经全连接层输出(b,c,1,1)矩阵y = self.fc(y).view(b, c, 1, 1)# Fscale操作:将得到的权重乘以原来的特征图xreturn x * y.expand_as(x)'''-------------二、BasicBlock模块-----------------------------'''
# 左侧的 residual block 结构(18-layer、34-layer)
class BasicBlock(nn.Module):expansion = 1def __init__(self, inchannel, outchannel, stride=1):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(inchannel, outchannel, kernel_size=3,stride=stride, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(outchannel)self.conv2 = nn.Conv2d(outchannel, outchannel, kernel_size=3,stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(outchannel)# SE_Block放在BN之后,shortcut之前self.SE = SE_Block(outchannel)self.shortcut = nn.Sequential()if stride != 1 or inchannel != self.expansion*outchannel:self.shortcut = nn.Sequential(nn.Conv2d(inchannel, self.expansion*outchannel,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion*outchannel))def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))SE_out = self.SE(out)out = out * SE_outout += self.shortcut(x)out = F.relu(out)return out'''-------------三、Bottleneck模块-----------------------------'''
# 右侧的 residual block 结构(50-layer、101-layer、152-layer)
class Bottleneck(nn.Module):expansion = 4def __init__(self, inchannel, outchannel, stride=1):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(inchannel, outchannel, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(outchannel)self.conv2 = nn.Conv2d(outchannel, outchannel, kernel_size=3,stride=stride, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(outchannel)self.conv3 = nn.Conv2d(outchannel, self.expansion*outchannel,kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(self.expansion*outchannel)# SE_Block放在BN之后,shortcut之前self.SE = SE_Block(self.expansion*outchannel)self.shortcut = nn.Sequential()if stride != 1 or inchannel != self.expansion*outchannel:self.shortcut = nn.Sequential(nn.Conv2d(inchannel, self.expansion*outchannel,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion*outchannel))def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = F.relu(self.bn2(self.conv2(out)))out = self.bn3(self.conv3(out))SE_out = self.SE(out)out = out * SE_outout += self.shortcut(x)out = F.relu(out)return out'''-------------四、搭建SE_ResNet结构-----------------------------'''
class SE_ResNet(nn.Module):def __init__(self, block, num_blocks, num_classes=10):super(SE_ResNet, self).__init__()self.in_planes = 64self.conv1 = nn.Conv2d(3, 64, kernel_size=3,stride=1, padding=1, bias=False) # conv1self.bn1 = nn.BatchNorm2d(64)self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) # conv2_xself.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) # conv3_xself.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) # conv4_xself.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) # conv5_xself.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.linear = nn.Linear(512 * block.expansion, num_classes)def _make_layer(self, block, planes, num_blocks, stride):strides = [stride] + [1]*(num_blocks-1)layers = []for stride in strides:layers.append(block(self.in_planes, planes, stride))self.in_planes = planes * block.expansionreturn nn.Sequential(*layers)def forward(self, x):x = F.relu(self.bn1(self.conv1(x)))x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = torch.flatten(x, 1)out = self.linear(x)return outdef SE_ResNet18():return SE_ResNet(BasicBlock, [2, 2, 2, 2])def SE_ResNet34():return SE_ResNet(BasicBlock, [3, 4, 6, 3])def SE_ResNet50():return SE_ResNet(Bottleneck, [3, 4, 6, 3])def SE_ResNet101():return SE_ResNet(Bottleneck, [3, 4, 23, 3])def SE_ResNet152():return SE_ResNet(Bottleneck, [3, 8, 36, 3])'''
if __name__ == '__main__':model = SE_ResNet50()print(model)input = torch.randn(1, 3, 224, 224)out = model(input)print(out.shape)
# test()
'''
if __name__ == '__main__':device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")net = SE_ResNet50().to(device)# 打印网络结构和参数summary(net, (3, 224, 224))相关文章:
注意力机制(一)SE模块(Squeeze-and-Excitation Networks)论文总结和代码实现
Squeeze-and-Excitation Networks(压缩和激励网络) 论文地址:Squeeze-and-Excitation Networks 论文中文版:Squeeze-and-Excitation Networks_中文版 代码地址:GitHub - hujie-frank/SENet: Squeeze-and-Excitation Ne…...
L2-001 紧急救援(dijkstra算法练习)
作为一个城市的应急救援队伍的负责人,你有一张特殊的全国地图。在地图上显示有多个分散的城市和一些连接城市的快速道路。每个城市的救援队数量和每一条连接两个城市的快速道路长度都标在地图上。当其他城市有紧急求助电话给你的时候,你的任务是带领你的…...
redis问题汇总
redis的优点 读写性能优异。十万/s的量级; 支持数据持久化。AOF,RDB 支持丰富的数据类型; 支持集群,可以实现主从复制,哨兵机制迁移,扩容等 缺点: 因为是基于内存的,所以虽然redis本身有key过期…...

调用华为API实现情感分析
作者介绍 王新华,男,西安工程大学电子信息学院,2022级研究生 研究方向:人工智能与模式识别 电子邮件:996514274qq.com 魏小双,女,西安工程大学电子信息学院,2022级研究生 研究方向…...

C# 静态构造函数
静态构造函数用于初始化任何静态数据,或执行仅需要执行一次的特定操作。在创建第一个实例或引用任何静态成员之前,将自动调用它。 静态构造函数是在构造函数方法前面添加了static关键字之后形成的,并且没有修饰符(public,private),没有参数。…...

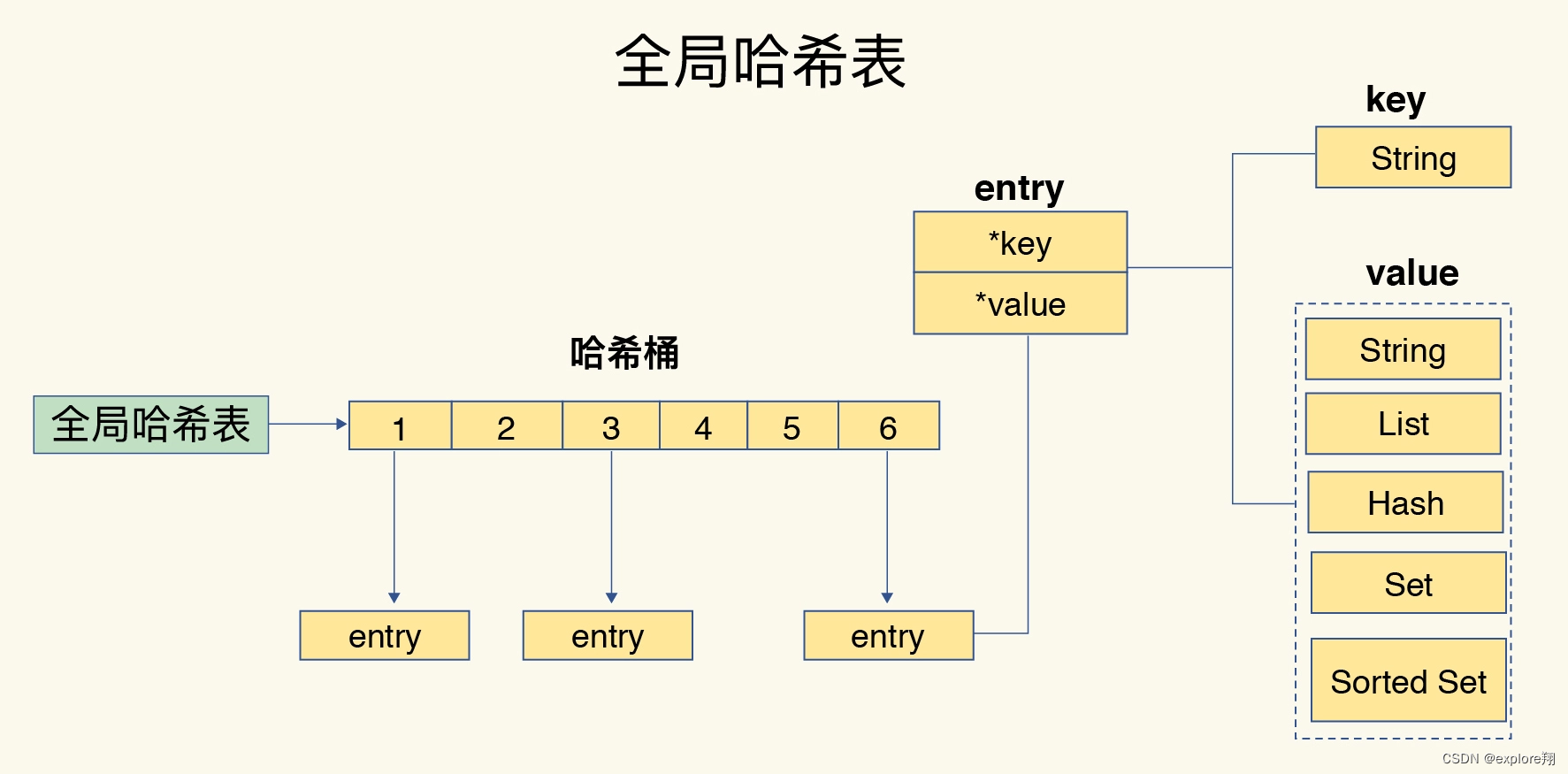
【C++】哈希表特性总结及unordered_map和unordered_set的模拟实现
✍作者:阿润菜菜 📖专栏:C 文章目录 前言一、哈希表的特性 - 哈希函数和哈希冲突1 哈希函数2. 哈希冲突 二、闭散列的实现 -- 开放地址法1. 定义数据结构2.insert()3.Find()4. Erase()5.仿函数处理key值不能取模无法映射 --- BKDRHash 三、开…...
)
Qt在Linux内核中的应用及解析(qtlinux内核)
Qt是跨平台开发的一种工具,尤其适合在Linux内核中的应用开发中使用。Qt能够让开发者在Linux桌面上开发出强大的图形化应用程序,为Linux系统用户提供更加人性化、实用、智能化的服务。本文将从Qt在Linux内核中的应用场景、应用程序开发中的具体使用、以及…...
Xpdf 阅读器源码编译后查看文件中文乱码问题解决
经查阅,是由于缺少中文字体包: 第一步:下载所需要的字体包 下载https://dl.xpdfreader.com/xpdf-t1fonts.tar.gz 包含下载中文字体包(非嵌入字体) http://ftp.gnu.org/gnu/non-gnu/chinese-fonts-truetype/gkai00mp…...
)
Java - AQS-CountDownLatch实现类(二)
前言 在Java中,AbstractQueuedSynchronizer(简称AQS)是一个用于实现同步器的抽象类,它为实现各种类型的同步器(如锁、信号量等)提供了基本的框架。AQS通过一个双向队列(等待队列)和…...

rsut基础
这篇文章是实战性质的,也就是说原理部分较少,属于经验总结,rust对于模块的例子太少了。rust特性比较多(悲),本文的内容可能只是一部分,实现方式也不一定是这一种。 关于 rust 模块的相关内容&a…...

高压放大器和示波器的关系是什么
高压放大器和示波器是电子工程领域中常见的两种设备,它们在实际的电路设计、测试和分析中都扮演着重要的角色。下面安泰电子将从定义、功能、应用场景等方面为您介绍高压放大器和示波器的关系。 图:ATA-7000系列高压放大器 一、高压放大器的定义及功能 高…...
5个超实用视频素材网站,免费下载~
推荐几个高清无水印的视频素材网站,重点是可以免费下载使用,建议收藏! 菜鸟图库 https://www.sucai999.com/video.html?vNTYxMjky 可以称之为最大素材库,在这里你可以找到设计、办公、图片、视频、音频等各种素材。视频素材就有…...
(BoW、N-gram、tf-idf))
【NLP模型】文本建模(1)(BoW、N-gram、tf-idf)
目录 一、说明 二、BoW模型产生发展 2.1 产生和历史 2.2 原理介绍 三、具体实现...

Java——网络编程套接字
目录 一、网络编程基础 1.1 为什么需要网络编程?——丰富的网络资源 二、什么是网络编程? 三、网络编程中的基本概念 3.2 请求和响应 3.3 客户端和服务端 常见的客户端服务端模型 四、Socket套接字 五、通信模型 5.1 Java数据报套接字通信模型 5.2 Java流…...
160套小程序源码
源码列表如下: AppleMusic (知乎日报) 微信小程序 d artand 今日更新求职招聘类 医药网 口碑外卖点餐 城市天气 外卖小程序 定位天气 家居在线 微信小程序-大好商城,wechat-weapp 微信小程序的掘金信息流 微信跳一跳小游戏源码 微票源码-demo 急救应急处…...

有效项目进度管理的 10 条规则
项目进度管理是项目中比较关键的方面之一,因为它将决定事情的进展方式、进展速度以及是否会取得进展。换句话说,它可以让你较好地控制项目,帮助你预测不可预测的情况,并使所有相关团队能够高效地协同工作。 以下是有效项目进度管…...
javaWebssh服装租赁店信息管理系统台myeclipse开发mysql数据库MVC模式java编程计算机网页设计
一、源码特点 java ssh服装租赁店信息管理系统是一套完善的web设计系统(系统采用ssh框架进行设计开发),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要 采用B/S模式开发。开发环境为TO…...
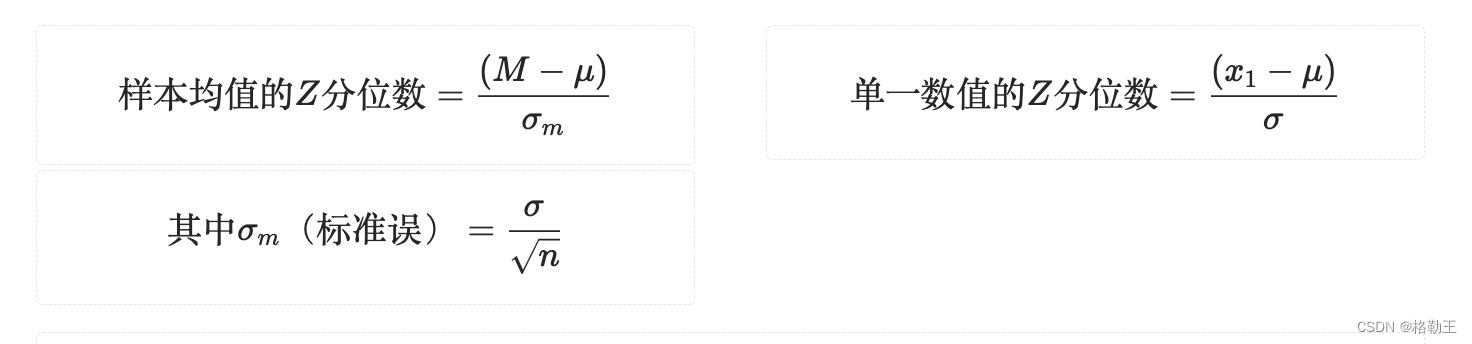
概率论:样本与总体分布,Z分数与概率
参考书目:《行为科学统计精要》(第八版)——弗雷德里克J格雷维特 数据及其样本的分布 描述一组数据分布 描述一组样本数据的分布 描述样本数据的均值和整体数据一样,但是样本标准差的公式除以了n-1,这里引入自由度的…...
【JavaSE】Java基础语法(十二):ArrayList
文章目录 1. ArrayList的构造方法和添加方法2. ArrayList类常用方法3. ArrayList存储学生对象并遍历 集合和数组的区别 : 共同点:都是存储数据的容器不同点:数组的容量是固定的,集合的容量是可变的 1. ArrayList的构造方法和添加方法 ArrayL…...

c++—封装:运算符重载、友元
1. 友元 (1)友元函数 ①是一种允许非类成员函数访问类的私有成员的一种机制;可以把一个函数指定为类的友元,也可以把整个类指定为另一个类的友元; ②友元函数在类作用域外定义,但需要在类体中进行声明&…...

深度学习结合CT图像预测岩石渗透率:从孔隙网络到升尺度计算
1. 项目概述:当深度学习遇见岩石CT图像 在油气勘探、地热开发乃至二氧化碳地质封存这些领域,我们这些从业者最头疼的问题之一,就是如何准确知道一块岩石的“透水能力”,也就是渗透率。传统上,我们依赖实验室岩心驱替实…...

模拟神经计算电路:噪声与非均匀性挑战下的网络架构优化与再训练策略
1. 项目概述与核心挑战在材料科学、药物发现乃至自动驾驶的实时决策中,我们常常需要模型以极高的速度处理海量数据,进行预测或推理。传统的数字计算机在执行这类任务时,面临着功耗和计算延迟的瓶颈。于是,一个极具吸引力的替代方案…...

CentOS7 搭建 Kubernetes 集群
CentOS7 搭建 Kubernetes 集群完整指南 基于提供的文档,本文提供kubeadm快速搭建(推荐新手)和二进制手动搭建(生产可控)两种方案,所有步骤均适配CentOS7系统。 一、通用前置准备(两种方式都需执…...

Unity InputSystem避坑指南:用Shift+1实现组合键,为什么我的数字键1会触发两次?
Unity InputSystem组合键触发异常解析:从现象到解决方案的深度实践刚接触Unity InputSystem的开发者,在实现组合键功能时经常会遇到一个令人困惑的现象:明明只按下了Shift1组合键,为什么数字键1对应的Action会被触发两次ÿ…...

拉格朗日平衡传播:动态系统的梯度估计新方法
1. 拉格朗日平衡传播的理论框架1.1 能量基模型与平衡传播基础能量基模型(Energy-Based Models, EBMs)的核心思想是将预测问题转化为能量最小化问题。这类模型通过定义能量函数E(s,θ,x)来描述系统状态s与参数θ、输入x之间的关系,模型的预测输…...
)
别再让Ubuntu卡成PPT!手把手教你用swapfile把交换空间从1G扩容到64G(附权限修复)
Ubuntu系统Swap空间扩容实战:从1G到64G的完整解决方案当你在Ubuntu上运行内存密集型任务时,是否遇到过系统突然变得异常缓慢,甚至完全卡死的情况?很多拥有大内存(如32GB或更高)的用户可能会惊讶地发现&…...

别急着重装系统!记一次 Ubuntu 22.04 上 gcc 与 cpp 版本依赖冲突的排查与修复实录
从依赖地狱到编译自由:Ubuntu 22.04下gcc与cpp版本冲突的深度修复指南那天下午,当我正准备为新的C项目搭建开发环境时,终端里那行刺眼的红色错误提示让我的咖啡瞬间不香了。作为一个自诩"Linux老司机"的开发者,我没想到…...
)
【AI问答/前端】前端瞒天过海局(三)
问三:还有一件事,就是浏览器按钮的前进后退,他真实还原了js改前端的过程,就好像真的有过访问纪录,这个是JS纪录下了自己的路由操作历史,改的浏览器地址栏?还是这个路由操作历史真的是写进了浏览…...

VideoSrt终极指南:3步实现视频自动字幕生成,告别手动打轴烦恼
VideoSrt终极指南:3步实现视频自动字幕生成,告别手动打轴烦恼 【免费下载链接】video-srt-windows 这是一个可以识别视频语音自动生成字幕SRT文件的开源 Windows-GUI 软件工具。 项目地址: https://gitcode.com/gh_mirrors/vi/video-srt-windows …...

专业级AI音频处理实战指南:OpenVINO插件让Audacity变身智能音频工作站 [特殊字符]
专业级AI音频处理实战指南:OpenVINO插件让Audacity变身智能音频工作站 🎵 【免费下载链接】openvino-plugins-ai-audacity A set of AI-enabled effects, generators, and analyzers for Audacity. 项目地址: https://gitcode.com/gh_mirrors/op/openv…...