Java的集合
1. HashMap排序题,上机题。
已知一个HashMap<Integer,User>集合, User有name(String)和age(int)属性。请写一个方法实现对HashMap 的排序功能,该方法接收 HashMap<Integer,User>为形参,返回类型为 HashMap<Integer,User>,要求对HashMap中的User的age倒序进行排序。排序时key=value键值对不得拆散。
注意:要做出这道题必须对集合的体系结构非常的熟悉。HashMap 本身就是不可排序的,但是该道题偏偏让给HashMap排序,那我们就得想在API中有没有这样的Map结构是有序的,LinkedHashMap,对的,就是他,他是Map结构,也是链表结构,有序的,更可喜的是他是HashMap的子类,我们返回LinkedHashMap<Integer,User>
即可,还符合面向接口(父类编程的思想)。
但凡是对集合的操作,我们应该保持一个原则就是能用JDK中的API就有JDK中的API,比如排序算法我们不应
该去用冒泡或者选择,而是首先想到用Collections集合工具类。
1. public class HashMapTest {
2. public static void main(String[] args) {
3. HashMap<Integer, User> users = new HashMap<>();
4. users.put(1, new User("张三", 25));
5. users.put(3, new User("李四", 22));
6. users.put(2, new User("王五", 28));
7. System.out.println(users);
8. HashMap<Integer,User> sortHashMap = sortHashMap(users);
9. System.out.println(sortHashMap);
10. /**
11. * 控制台输出内容
12. * {1=User [name=张三, age=25], 2=User [name=王五, age=28], 3=User [name=李四, age=22]}
13. {2=User [name=王五, age=28], 1=User [name=张三, age=25], 3=User [name=李四, age=22]}
14. */
15. }
16.
17. public static HashMap<Integer, User> sortHashMap(HashMap<Integer, User> map) {
18. // 首先拿到map的键值对集合
19. Set<Entry<Integer, User>> entrySet = map.entrySet();
20.
21. // 将set集合转为List集合,为什么,为了使用工具类的排序方法
22. List<Entry<Integer, User>> list = new ArrayList<Entry<Integer, User>>(entrySet);
23. // 使用Collections集合工具类对list进行排序,排序规则使用匿名内部类来实现
24. Collections.sort(list, new Comparator<Entry<Integer, User>>() {
25.
26. @Override
27. public int compare(Entry<Integer, User> o1, Entry<Integer, User> o2) {
28. //按照要求根据User的age的倒序进行排
29. return o2.getValue().getAge()-o1.getValue().getAge();
30. }
31. });
32. //创建一个新的有序的HashMap子类的集合
33. LinkedHashMap<Integer, User> linkedHashMap = new LinkedHashMap<Integer, User>();
34. //将List中的数据存储在LinkedHashMap中
35. for(Entry<Integer, User> entry : list){
36. linkedHashMap.put(entry.getKey(), entry.getValue());
37. }
38. //返回结果
39. return linkedHashMap;
40. }
41. }
42.
2. 集合的安全性问题
请问ArrayList、HashSet、HashMap是线程安全的吗?如果不是我想要线程安全的集合怎么办?
我们都看过上面那些集合的源码(如果没有那就看看吧),每个方法都没有加锁,显然都是线程不安全的。话又说
过来如果他们安全了也就没第二问了。
在集合中 Vector 和 HashTable 倒是线程安全的。你打开源码会发现其实就是把各自核心方法添加上了
synchronized关键字。
Collections工具类提供了相关的API,可以让上面那3个不安全的集合变为安全的。
1. // Collections.synchronizedCollection(c)
2. // Collections.synchronizedList(list)
3. // Collections.synchronizedMap(m)
4. // Collections.synchronizedSet(s)
上面几个函数都有对应的返回值类型,传入什么类型返回什么类型。打开源码其实实现原理非常简单,就是将集
合的核心方法添加上了synchronized关键字。
3. ArrayList内部用什么实现的?(2015-11-24)
(回答这样的问题,不要只回答个皮毛,可以再介绍一下ArrayList内部是如何实现数组的增加和删除的,因为数
组在创建的时候长度是固定的,那么就有个问题我们往ArrayList中不断的添加对象,它是如何管理这些数组呢?)
ArrayList内部是用Object[]实现的。接下来我们分别分析ArrayList 的构造、add、remove、clear方法的实现
原理。
一、构造函数
1)空参构造
/**
* Constructs a new {@code ArrayList} instance with zero initial capacity.
*/
public ArrayList() {
array = EmptyArray.OBJECT;
}
array是一个Object[]类型。当我们new一个空参构造时系统调用了EmptyArray.OBJECT属性,EmptyArray仅
仅是一个系统的类库,该类源码如下:
public final class EmptyArray {
private EmptyArray() {}
public static final boolean[] BOOLEAN = new boolean[0];
public static final byte[] BYTE = new byte[0];
public static final char[] CHAR = new char[0];
public static final double[] DOUBLE = new double[0];
public static final int[] INT = new int[0];
public static final Class<?>[] CLASS = new Class[0];
public static final Object[] OBJECT = new Object[0];
public static final String[] STRING = new String[0];
public static final Throwable[] THROWABLE = new Throwable[0];
public static final StackTraceElement[] STACK_TRACE_ELEMENT = new StackTraceElement[0]; }
也就是说当我们new 一个空参ArrayList的时候,系统内部使用了一个new Object[0]数组。
2)带参构造1
/**
* Constructs a new instance of {@code ArrayList} with the specified * initial capacity.
*
* @param capacity
* the initial capacity of this {@code ArrayList}.
*/
public ArrayList(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("capacity < 0: " + capacity);
}
array = (capacity == 0 ? EmptyArray.OBJECT : new Object[capacity]); }
该构造函数传入一个int值,该值作为数组的长度值。如果该值小于0,则抛出一个运行时异常。如果等于0,则
使用一个空数组,如果大于0,则创建一个长度为该值的新数组。
3)带参构造2
/**
* Constructs a new instance of {@code ArrayList} containing the elements of * the specified collection.
*
* @param collection
* the collection of elements to add.
*/
public ArrayList(Collection<? extends E> collection) {
if (collection == null) {
throw new NullPointerException("collection == null");
}
Object[] a = collection.toArray();
if (a.getClass() != Object[].class) {
Object[] newArray = new Object[a.length];
System.arraycopy(a, 0, newArray, 0, a.length);
a = newArray;
}
array = a;
size = a.length;
}
如果调用构造函数的时候传入了一个Collection的子类,那么先判断该集合是否为null,为null则抛出空指针异
常。如果不是则将该集合转换为数组a,然后将该数组赋值为成员变量array,将该数组的长度作为成员变量size。这
里面它先判断a.getClass是否等于Object[].class,其实一般都是相等的,我也暂时没想明白为什么多加了这个判断,
toArray方法是Collection接口定义的,因此其所有的子类都有这样的方法,list集合的toArray和Set集合的toArray
返回的都是Object[]数组。
这里讲些题外话,其实在看Java源码的时候,作者的很多意图都很费人心思,我能知道他的目标是啥,但是不知道他为何这样写。比如对于ArrayList, array是他的成员变量,但是每次在方法中使用该成员变量的时候作者都会重
新在方法中开辟一个局部变量,然后给局部变量赋值为array,然后再使用,有人可能说这是为了防止并发修改array,
毕竟array是成员变量,大家都可以使用因此需要将array变为局部变量,然后再使用,这样的说法并不是都成立的,
也许有时候就是老外们写代码的一个习惯而已。
二、add方法
add方法有两个重载,这里只研究最简单的那个。
/**
* Adds the specified object at the end of this {@code ArrayList}.
*
* @param object
* the object to add.
* @return always true
*/
@Override public boolean add(E object) {
Object[] a = array;
int s = size;
if (s == a.length) {
Object[] newArray = new Object[s +
(s < (MIN_CAPACITY_INCREMENT / 2) ?
MIN_CAPACITY_INCREMENT : s >> 1)];
System.arraycopy(a, 0, newArray, 0, s);
array = a = newArray;
}
a[s] = object;
size = s + 1;
modCount++;
return true;
}
1、首先将成员变量array赋值给局部变量a,将成员变量size赋值给局部变量s。
2、判断集合的长度s是否等于数组的长度(如果集合的长度已经等于数组的长度了,说明数组已经满了,该重新
分配新数组了) ,重新分配数组的时候需要计算新分配内存的空间大小,如果当前的长度小于
MIN_CAPACITY_INCREMENT/2(这个常量值是12,除以2就是6,也就是如果当前集合长度小于6)则分配12个
长度,如果集合长度大于6则分配当前长度s的一半长度。这里面用到了三元运算符和位运算,s >> 1,意思就是将
s往右移1位,相当于s=s/2,只不过位运算是效率最高的运算。
3、将新添加的object对象作为数组的a[s]个元素。
4、修改集合长度size为s+1
5、modCotun++,该变量是父类中声明的,用于记录集合修改的次数,记录集合修改的次数是为了防止在用迭代
器迭代集合时避免并发修改异常,或者说用于判断是否出现并发修改异常的。
6、return true,这个返回值意义不大,因为一直返回true,除非报了一个运行时异常。
三、remove方法
remove方法有两个重载,我们只研究remove(int index)方法。
/**
* Removes the object at the specified location from this list.
*
* @param index
* the index of the object to remove.
* @return the removed object.
* @throws IndexOutOfBoundsException
* when {@code location < 0 || location >= size()} */
@Override public E remove(int index) {
Object[] a = array;
int s = size;
if (index >= s) {
throwIndexOutOfBoundsException(index, s);
}
@SuppressWarnings("unchecked")
E result = (E) a[index];
System.arraycopy(a, index + 1, a, index, --s - index);
a[s] = null; // Prevent memory leak
size = s;
modCount++;
return result;
}
1、先将成员变量array和size赋值给局部变量a和s。
2、判断形参index是否大于等于集合的长度,如果成了则抛出运行时异常
3、获取数组中脚标为index的对象result,该对象作为方法的返回值
4、调用System的arraycopy函数,拷贝原理如下图所示。
5、接下来就是很重要的一个工作,因为删除了一个元素,而且集合整体向前移动了一位,因此需要将集合最后一
个元素设置为null,否则就可能内存泄露。
6、重新给成员变量array和size赋值
7、记录修改次数
8、返回删除的元素(让用户再看最后一眼)
四、clear方法
/**
* Removes all elements from this {@code ArrayList}, leaving it empty.
*
* @see #isEmpty
* @see #size
*/
@Override public void clear() {
if (size != 0) {
Arrays.fill(array, 0, size, null);
size = 0;
modCount++;
}
}
如果集合长度不等于0,则将所有数组的值都设置为null,然后将成员变量size设置为0即可,最后让修改记录加1。
4. 并发集合和普通集合如何区别?(2015-11-24)
并发集合常见的有ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque等。并发集合
| 位 于 | java.util.concurrent | 包 下 , 是 | jdk1.5 | 之 后 才 有 的 , 主 要 作 者 是 | Doug | Lea |
完成的。
在java中有普通集合、同步(线程安全)的集合、并发集合。普通集合通常性能最高,但是不保证多线程的安全性和并发的可靠性。线程安全集合仅仅是给集合添加了synchronized同步锁,严重牺牲了性能,而且对并发的效率就更低了,并发集合则通过复杂的策略不仅保证了多线程的安全又提高的并发时的效率。
参考阅读:
ConcurrentHashMap 是线程安全的 HashMap 的实现,默认构造同样有 initialCapacity 和 loadFactor 属性,不过还多了一个 concurrencyLevel 属性,三属性默认值分别为 16、0.75 及 16。其内部使用锁分段技术,维持这锁Segment的数组,在Segment数组中又存放着Entity[]数组,内部hash算法将数据较均匀分布在不同锁中。
put操作:并没有在此方法上加上synchronized,首先对key.hashcode进行hash操作,得到key的hash值。hash操作的算法和map也不同,根据此hash值计算并获取其对应的数组中的Segment对象(继承自ReentrantLock),接着调用此Segment对象的put方法来完成当前操作。
ConcurrentHashMap 基于 concurrencyLevel 划分出了多个 Segment 来对 key-value 进行存储,从而避免每次put操作都得锁住整个数组。在默认的情况下,最佳情况下可允许16个线程并发无阻塞的操作集合对象,尽可能地减少并发时的阻塞现象。
get(key)
首先对 key.hashCode 进行 hash 操作,基于其值找到对应的 Segment 对象,调用其 get 方法完成当前操作。而 Segment 的 get 操作首先通过 hash 值和对象数组大小减 1 的值进行按位与操作来获取数组上对应位置的HashEntry。在这个步骤中,可能会因为对象数组大小的改变,以及数组上对应位置的HashEntry产生不一致性,那么ConcurrentHashMap是如何保证的?
对象数组大小的改变只有在 put 操作时有可能发生,由于 HashEntry 对象数组对应的变量是 volatile 类型的,因此可以保证如HashEntry对象数组大小发生改变,读操作可看到最新的对象数组大小。
在获取到了 HashEntry 对象后,怎么能保证它及其 next 属性构成的链表上的对象不会改变呢?这点ConcurrentHashMap采用了一个简单的方式,即HashEntry对象中的hash、key、next属性都是final的,这也就意味着没办法插入一个HashEntry对象到基于next属性构成的链表中间或末尾。这样就可以保证当获取到HashEntry对象后,其基于next属性构建的链表是不会发生变化的。
ConcurrentHashMap 默认情况下采用将数据分为 16 个段进行存储,并且 16 个段分别持有各自不同的锁Segment,锁仅用于 put 和 remove 等改变集合对象的操作,基于 volatile 及 HashEntry 链表的不变性实现了读取的不加锁。这些方式使得ConcurrentHashMap能够保持极好的并发支持,尤其是对于读远比插入和删除频繁的Map而言,而它采用的这些方法也可谓是对于Java内存模型、并发机制深刻掌握的体现。
5. List的三个子类的特点
ArrayList 底层结构是数组,底层查询快,增删慢。
LinkedList 底层结构是链表型的,增删快,查询慢。
voctor 底层结构是数组 线程安全的,增删慢,查询慢。
6. List和Map、Set的区别(2017-11-22-wzz)
6.1 结构特点
List 和Set是存储单列数据的集合,Map是存储键和值这样的双列数据的集合;List中存储的数据是有顺序,并且允许重复;Map 中存储的数据是没有顺序的,其键是不能重复的,它的值是可以有重复的,Set 中存储的数据是无序的,且不允许有重复,但元素在集合中的位置由元素的hashcode决定,位置是固定的(Set集合根据hashcode来
进行数据的存储,所以位置是固定的,但是位置不是用户可以控制的,所以对于用户来说set中的元素还是无序的);
6.2 实现类
List接口有三个实现类(LinkedList:基于链表实现,链表内存是散乱的,每一个元素存储本身内存地址的同时还存储下一个元素的地址。链表增删快,查找慢;ArrayList:基于数组实现,非线程安全的,效率高,便于索引,但不便于插入删除;Vector:基于数组实现,线程安全的,效率低)。
Map 接口有三个实现类(HashMap:基于 hash 表的 Map 接口实现,非线程安全,高效,支持 null 值和 null键;HashTable:线程安全,低效,不支持null值和null键;LinkedHashMap:是HashMap的一个子类,保存了记录的插入顺序;SortMap接口:TreeMap,能够把它保存的记录根据键排序,默认是键值的升序排序)。
Set 接口有两个实现类(HashSet:底层是由 HashMap 实现,不允许集合中有重复的值,使用该方式时需要重写 equals()和 hashCode()方法;LinkedHashSet:继承与HashSet,同时又基于LinkedHashMap来进行实现,底层使用的是LinkedHashMp)。
6.3 区别
List 集合中对象按照索引位置排序,可以有重复对象,允许按照对象在集合中的索引位置检索对象,例如通过list.get(i)方法来获取集合中的元素;Map中的每一个元素包含一个键和一个值,成对出现,键对象不可以重复,值对象可以重复;Set集合中的对象不按照特定的方式排序,并且没有重复对象,但它的实现类能对集合中的对象按照特定的方式排序,例如TreeSet类,可以按照默认顺序,也可以通过实现Java.util.Comparator<Type>接口来自定义排序方式。
7. HashMap 和HashTable有什么区别?
HashMap是线程不安全的,HashMap是一个接口,是Map的一个子接口,是将键映射到值得对象,不允许键值重复,
允许空键和空值;由于非线程安全,HashMap的效率要较HashTable的效率高一些.
HashTable 是线程安全的一个集合,不允许null值作为一个key值或者Value值;
HashTable 是 sychronize,多个线程访问时不需要自己为它的方法实现同步,而 HashMap 在被多个线程访问的时候需要自己为它的方法实现同步;
8. 数组和链表分别比较适合用于什么场景,为什么?
8.1 数组和链表简介
在计算机中要对给定的数据集进行若干处理,首要任务是把数据集的一部分(当数据量非常大时,可能只能一部分一部分地读取数据到内存中来处理)或全部存储到内存中,然后再对内存中的数据进行各种处理。
例如,对于数据集 S{1,2,3,4,5,6},要求 S 中元素的和,首先要把数据存储到内存中,然后再将内存中的数据相加。
当内存空间中有足够大的连续空间时,可以把数据连续的存放在内存中,各种编程语言中的数组一般都是按这种方式存储的(也可能有例外),如图 1(b);当内存中只有一些离散的可用空间时,想连续存储数据就非常困难了,这时能想到的一种解决方式是移动内存中的数据,把离散的空间聚集成连续的一块大空间,如图1(c)所示,这样做当然也可以,但是这种情况因为可能要移动别人的数据,所以会存在一些困难,移动的过程中也有可能会把一些别人的重要数据给丢失。另外一种,不影响别人的数据存储方式是把数据集中的数据分开离散地存储到这些不连续空间中,如图(d)。这时为了能把数据集中的所有数据联系起来,需要在前一块数据的存储空间中记录下一块数据的地址,这样只要知道第一块内存空间的地址就能环环相扣地把数据集整体联系在一起了。C/C++中用指针实现的链表就是这种存储形式。
由上可知,内存中的存储形式可以分为连续存储和离散存储两种。因此,数据的物理存储结构就有连续存储和离散存储两种,它们对应了我们通常所说的数组和链表,
8.2 数组和链表的区别
数组是将元素在内存中连续存储的;它的优点:因为数据是连续存储的,内存地址连续,所以在查找数据的时候效率比较高;它的缺点:在存储之前,我们需要申请一块连续的内存空间,并且在编译的时候就必须确定好它的空间的大小。在运行的时候空间的大小是无法随着你的需要进行增加和减少而改变的,当数据两比较大的时候,有可能会出现越界的情况,数据比较小的时候,又有可能会浪费掉内存空间。在改变数据个数时,增加、插入、删除数据效率比较低 链表是动态申请内存空间,不需要像数组需要提前申请好内存的大小,链表只需在用的时候申请就可以,根据需要来动态申请或者删除内存空间,对于数据增加和删除以及插入比数组灵活。还有就是链表中数据在内存中可以在任意的位置,通过应用来关联数据(就是通过存在元素的指针来联系)
8.3 链表和数组使用场景
数组应用场景:数据比较少;经常做的运算是按序号访问数据元素;数组更容易实现,任何高级语言都支持;构建的线性表较稳定。
链表应用场景:对线性表的长度或者规模难以估计;频繁做插入删除操作;构建动态性比较强的线性表。
8.4 跟数组相关的面试题
用面向对象的方法求出数组中重复value 的个数,按如下个数输出: 1 出现:1 次
3 出现:2 次
8 出现:3 次
2 出现:4 次
int[] arr = {1,4,1,4,2,5,4,5,8,7,8,77,88,5,4,9,6,2,4,1,5};
9. Java中ArrayList和Linkedlist区别?
ArrayList和Vector使用了数组的实现,可以认为ArrayList或者Vector封装了对内部数组的操作,比如向数组中添加,删除,插入新的元素或者数据的扩展和重定向。
LinkedList使用了循环双向链表数据结构。与基于数组的ArrayList相比,这是两种截然不同的实现技术,这也决定了它们将适用于完全不同的工作场景。
LinkedList链表由一系列表项连接而成。一个表项总是包含3个部分:元素内容,前驱表和后驱表,如图所示:
在下图展示了一个包含3个元素的LinkedList的各个表项间的连接关系。在JDK的实现中,无论LikedList是否为空,链表内部都有一个header表项,它既表示链表的开始,也表示链表的结尾。表项header的后驱表项便是链表中第一个元素,表项header的前驱表项便是链表中最后一个元素。
10. List a=new ArrayList()和ArrayList a =new ArrayList()的区别?
List list = new ArrayList();这句创建了一个ArrayList的对象后把上溯到了List。此时它是一个List对象了,有些ArrayList 有但是 List 没有的属性和方法,它就不能再用了。而 ArrayList list=new ArrayList();创建一对象则保留了ArrayList的所有属性。 所以需要用到ArrayList独有的方法的时候不能用前者。实例代码如下:
1.List list = new ArrayList();
2.ArrayList arrayList = new ArrayList();
3.list.trimToSize(); //错误,没有该方法。
4.arrayList.trimToSize(); //ArrayList里有该方法。
11. 要对集合更新操作时,ArrayList和LinkedList哪个更适合?(2017-2-24)
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
2.如果集合数据是对于集合随机访问get和set,ArrayList绝对优于LinkedList,因为LinkedList要移动指针。
3.如果集合数据是对于集合新增和删除操作 add 和 remove,LinedList 比较占优势,因为 ArrayList 要移动数据。
ArrayList和 LinkedList 是两个集合类,用于存储一系列的对象引用(references)。例如我们可以用ArrayList 来存储一系列的String或者Integer。那 么ArrayList和LinkedList在性能上有什么差别呢?什么时候应该用ArrayList什么时候又该用LinkedList呢?
一.时间复杂度
首先一点关键的是,ArrayList的内部实现是基于基础的对象数组的,因此,它使用get方法访问列表中的任意一个元素时(random access),它的速度要比LinkedList快。LinkedList中的get方法是按照顺序从列表的一端开始检查,直到另外一端。对LinkedList而言,访问列表中的某个指定元素没有更快的方法了。
假设我们有一个很大的列表,它里面的元素已经排好序了,这个列表可能是ArrayList类型的也可能是LinkedList
类型的,现在我们对这个列表来进行二分查找(binary search),比较列表是 ArrayList 和 LinkedList 时的查询速度,
看下面的程序:
1.public class TestList{
2. public static final int N=50000; //50000个数
3. public static List values; //要查找的集合
4. //放入50000个数给value;
5. static{
6. Integer vals[]=new Integer[N];
7. Random r=new Random();
8. for(int i=0,currval=0;i<N;i++)...{
9. vals=new Integer(currval);
10. currval+=r.nextInt(100)+1;
11. }
12. values=Arrays.asList(vals);
13. }
14. //通过二分查找法查找
15. static long timeList(List lst){
16. long start=System.currentTimeMillis();
17. for(int i=0;i<N;i++)...{
18. int index=Collections.binarySearch(lst, values.get(i));
19. if(index!=i)
20. System.out.println("***错误***");
21. }
22. return System.currentTimeMillis()-start;
23. }
24. public static void main(String args[])...{
25. System.out.println("ArrayList消耗时间:"+timeList(new ArrayList(values)));
26. System.out.println("LinkedList消耗时间:"+timeList(new LinkedList(values)));
27. }
28.}
得到的输出是:
1. ArrayList消耗时间:15
2. LinkedList消耗时间:2596
这个结果不是固定的,但是基本上 ArrayList 的时间要明显小于 LinkedList 的时间。因此在这种情况下不宜用
LinkedList。二分查找法使用的随机访问(random access)策略,而 LinkedList 是不支持快速的随机访问的。对一个
每个Entry对象reference列表 中的一个元素,同时还有在LinkedList中它的上一个元素和下一个元素。一个有1000个元素的LinkedList对象将有1000个链接在一起 的Entry对象,每个对象都对应于列表中的一个元素。这样的话,在一个LinkedList结构中将有一个很大的空间开销,因为它要存储这1000个 Entity对象的相关信息。
ArrayList使用一个内置的数组来存 储元素,这个数组的起始容量是10.当数组需要增长时,新的容量按如下公式获得:新容量=(旧容量*3)/2+1,也就是说每一次容量大概会增长50%。 这就意味着,如果你有一个包含大量元素的ArrayList对象,那么最终将有很大的空间会被浪费掉,这个浪费是由ArrayList的工作方式本身造成 的。如果没有足够的空间来存放新的元素,数组将不得不被重新进行分配以便能够增加新的元素。对数组进行重新分配,将会导致性能急剧下降。如果我们知道一个 ArrayList将会有多少个元素,我们可以通过构造方法来指定容量。我们还可以通过trimToSize方法在ArrayList分配完毕之后去掉浪 费掉的空间。
三.总结
ArrayList和LinkedList在性能上各有优缺点,都有各自所适用的地方,总的说来可以描述如下:
1.对ArrayList和 LinkedList而言,在列表末尾增加一个元素所花的开销都是固定的。对ArrayList而言,主要是在内部数组中增加一项,指向所添加的元素,偶 尔可能会导致对数组重新进行分配;而对LinkedList而言,这个开销是统一的,分配一个内部Entry对象。
2.在ArrayList的中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在LinkedList的中间插入或删除一个元素的开销是固定的。
3.LinkedList不支持高效的随机元素访问。
4.ArrayList的空间浪费主要体现在在list列表的结尾预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
可以这样说:当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
12. 请用两个队列模拟堆栈结构
两个队列模拟一个堆栈,队列是先进先出,而堆栈是先进后出。模拟如下
队列a和b
(1)入栈:a队列为空,b为空。例:则将”a,b,c,d,e”需要入栈的元素先放a中,a进栈为”a,b,c,d,e”
(2)出栈:a队列目前的元素为”a,b,c,,d,e”。将a队列依次加入Arraylist集合a中。以倒序的方法,将a中的集
合取出,放入b队列中,再将b队列出列。代码如下:
1. public static void main(String[] args) {
2. Queue<String> queue = new LinkedList<String>(); //a 队列
3. Queue<String> queue2=new LinkedList<String>(); //b队列
4. ArrayList<String> a=new ArrayList<String>(); //arrylist集合是中间参数
5. //往a队列添加元素
6. queue.offer("a");
7. queue.offer("b");
8. queue.offer("c");
9. queue.offer("d");
10. queue.offer("e");
11. System.out.print("进栈:");
12. //a队列依次加入list集合之中
13. for(String q : queue){
14. a.add(q);
15. System.out.print(q);
16. }
17. //以倒序的方法取出(a队列依次加入list集合)之中的值,加入b对列
18. for(int i=a.size()-1;i>=0;i--){
19. queue2.offer(a.get(i));
20. }
21. //打印出栈队列
22. System.out.println("");
23. System.out.print("出栈:");
24. for(String q : queue2){
25. System.out.print(q);
26. }
27. }
打印结果为(遵循栈模式先进后出):
进栈:a b c d e
出栈:e d c b a
13. Collection和Map的集成体系
Collection:
Map:
14. Map中的key和value可以为null么?
HashMap对象的key、value值均可为null。
HahTable对象的key、value值均不可为null。
且两者的的key值均不能重复,若添加key相同的键值对,后面的value会自动覆盖前面的value,但不会报错。
测试代码如下:
1. public class Test {
2.
3. public static void main(String[] args) {
4. Map<String, String> map = new HashMap<String, String>();//HashMap对象
5. Map<String, String> tableMap = new Hashtable<String, String>();//HashTable对象
6.
7. map.put(null, null);
8. System.out.println("hashMap的[key]和[value]均可以为null:" + map.get(null));
9.
10. try {
11. tableMap.put(null, "3");
12. System.out.println(tableMap.get(null));
13. } catch (Exception e) {
14. System.out.println("【ERROR】:hashTable的[key]不能为null");
15. }
16.
17. try {
18. tableMap.put("3", null);
19. System.out.println(tableMap.get("3"));
20. } catch (Exception e) {
21. System.out.println("【ERROR】:hashTable的[value]不能为null"); 22. }
23. }
24.
25. }
运行结果:
hashMap的[key]和[value]均可以为null:null
【ERROR】:hashTable的[key]不能为null
【ERROR】:hashTable的[value]不能为null
相关文章:

Java的集合
1. HashMap排序题,上机题。 已知一个HashMap<Integer,User>集合, User有name(String)和age(int)属性。请写一个方法实现对HashMap 的排序功能,该方法接收 HashMap<Intege…...

addr2line 使用,定位kernel panic 代码位置
在kernel崩溃时,方便定位代码。 需要打开kernel配置CONFIG_DEBUG_INFO。 需要有System.map和vmlinux文件,一般在out目录。 一般panic的时候会有给出panic的指针,如下down_write。 el1_data说明发生异常了,进入和entry.S文件&a…...

OpenAI目前所有模型介绍
目录 概述 GPT-4 (limted beta) GPT-3.5 GPT-3 各类模型介绍 DALLE Beta Whisper Beta Embeddings Moderation Codex (deprecated) 概述 模型描述GPT-4 Limited beta 一组在 GPT-3.5 上改进的模型,可以理解并生成自然语言或代码GPT-3.5一组在 GPT-3 上改…...

【P43】JMeter 吞吐量控制器(Throughput Controller)
文章目录 一、吞吐量控制器(Throughput Controller)参数说明二、测试计划设计2.1、Total Executions2.2、Percent Executions2.3、Per User 一、吞吐量控制器(Throughput Controller)参数说明 允许用户控制后代元素的执行的次数。…...

方正书版命令详解
方正书版常用的排版符包括: 空格:表示文字之间的间距,不同字号的文字需要适当调整空格大小。 省略号:用于省略一段文字,通常用三个点表示(…)。 破折号:用于表示强调或者断句&…...
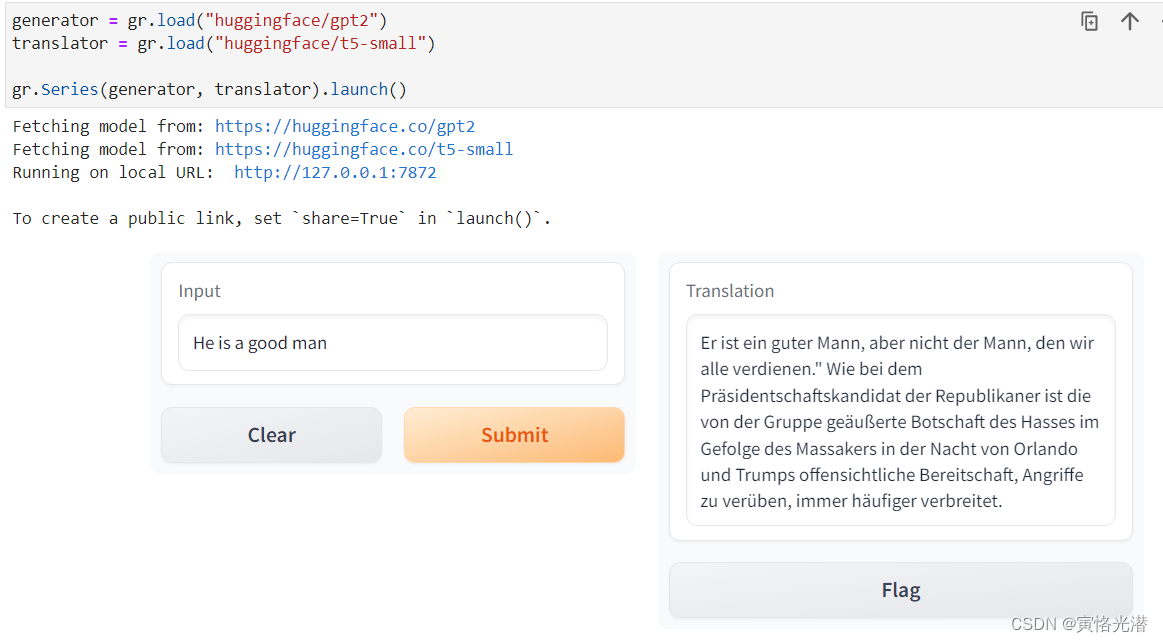
Gradio的web界面演示与交互机器学习模型,高级接口特征《6》
大多数模型都是黑盒,其内部逻辑对最终用户是隐藏的。为了鼓励透明度,我们通过简单地将Interface类中的interpretation关键字设置为default,使得向模型添加解释变得非常容易。这允许您的用户了解输入的哪些部分负责输出。 1、Interpret解释 …...
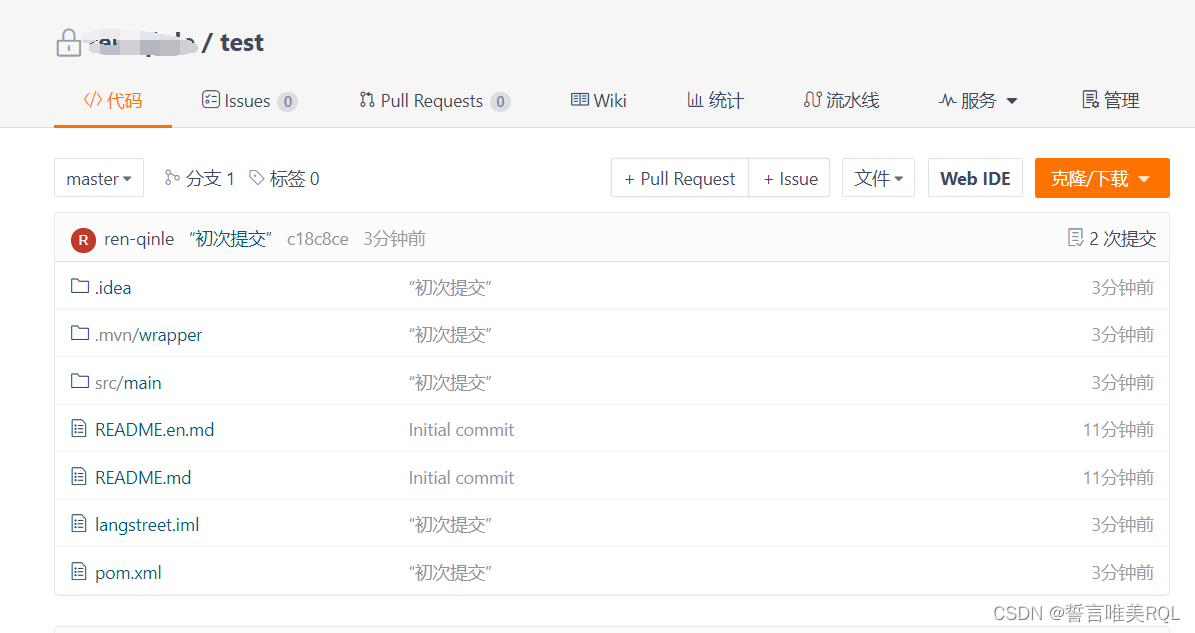
本地项目上传到Git(Gitee)仓库
一、步骤解答(详细图解步骤见第二大点) 1、打开我们的项目所在文件夹,我们发现是不存在.git文件 2、在你的项目文件夹外层【鼠标右击】弹出菜单,在【鼠标右击】弹出的菜单中,点击【Git Bash Here】,弹出运…...

Android 12.0屏蔽掉SystemUI的某些通知提示音
1.概述 在12.0的系统开发中,在系统SystemUI中会发一些通知的声音,但是同时也会在开机的时候,会有一些通知的声音,特别是不想要的一些通知的声音, 这些对于产品还是有一些影响的,所以为了产品体验,就需要屏蔽掉一些开机的通知的声音 2.屏蔽某些通知的提示音的核心代码 …...

测试计划模板二
XXX测试计划 文档作者: 编写日期: 项目经理: 批准日期: 文档模板修改纪录表 日期 修改人 修改内容描述...

华为OD机试真题B卷 Java 实现【分奖金】,附详细解题思路
一、题目描述 公司老板做了一笔大生意,想要给每位员工分配一些奖金,想通过游戏的方式来决定每个人分多少钱。按照员工的工号顺序,每个人随机抽取一个数字。按照工号的顺序往后排列,遇到第一个数字比自己数字大的,那么…...
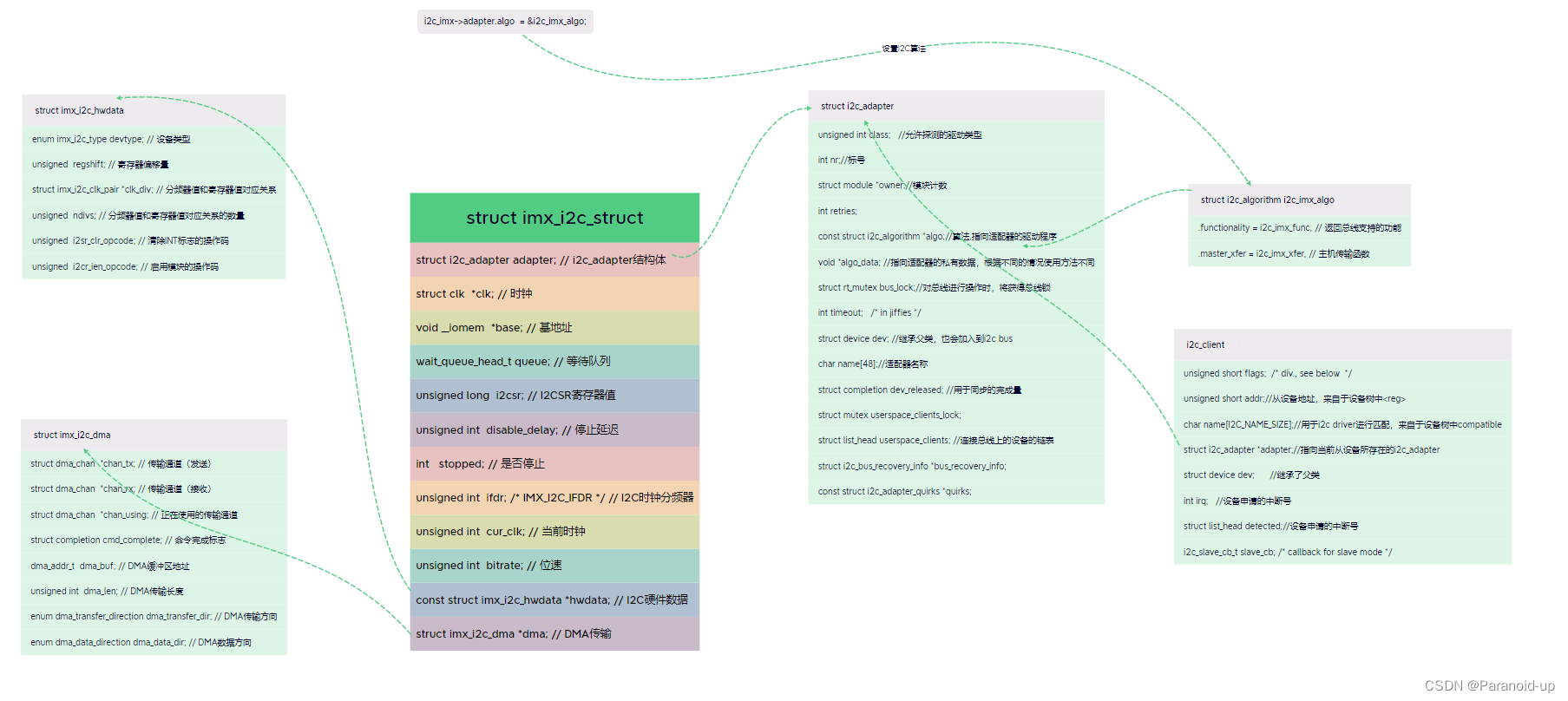
IMX6ULL平台I2C数据结构分析
IMX6ULL平台I2C数据结构分析 文章目录 IMX6ULL平台I2C数据结构分析i2c_clienti2c_adapterimx_i2c_structimx_i2c_hwdataimx_i2c_dma 在 i.MX 平台的 I2C 驱动中,存在多个相关的结构体,它们之间的联系和在内核中的作用如下: struct i2c_client…...
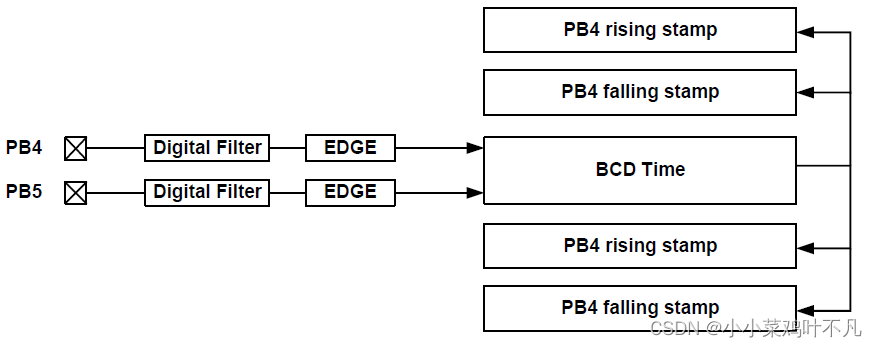
实时时钟 RTC(2)
RTC 使能与停止 RTC 上电后立即启动,不可关闭,软件应在32K 晶体振荡器完全起振后再设置当前时间;在晶体振荡器起振之前芯片使用内部环振计时,偏差较大。 RTC 时间设置 软件可以在任意时刻直接设置RTC 时间寄存器;由于…...
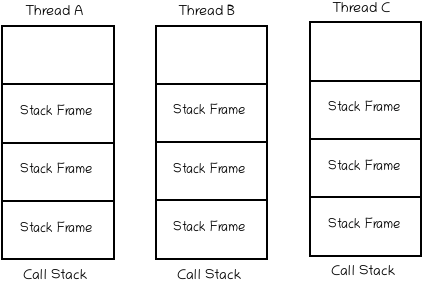
弄懂局部变量
成员变量和局部变量的区别 多个线程调用同一个对象的同一个方法时: 如果方法里无成员变量,那么不受任何影响 如果方法里有成员变量,只有读操作,不受影响 存在写操作,考虑多线程影响值 多线程调用…...
倾斜摄影三维模型数据的高程偏差修正的几何纠正技术方法探讨
倾斜摄影三维模型数据的高程偏差修正的几何纠正技术方法探讨 倾斜摄影是一种先进的数字摄影技术,可以生成高分辨率、高精度的三维模型数据。然而,在倾斜摄影中,由于相机的倾斜角度和地形的高程差异,可能会出现高程偏差问题。为了…...

怎么发表CCF期刊?CCF期刊有什么不同之处? - 易智编译EaseEditing
发表CCF期刊,可以参考一下步骤: 选择目标期刊: 首先选择一个适合自己的目标期刊,可以是CCF推荐的高水平期刊,也可以是其他被广泛认可的期刊。 撰写论文: 根据目标期刊的要求,撰写论文。确保论…...

feat:使用企业微信JS-SDK的onMenuShareAppMessage()实现点击转发自定义分享内容(TypeScript)
背景:企业微信应用使用企业微信JS-SDK的分享接口实现分享样式自定义 原生: 需要实现成: 企业微信JS-SDK 是企业微信面向网页开发者提供的 基于企业微信内 的网页开发工具包。 通过使用企业微信JS-SDK,网页开发者 可借助企业微信…...

Java键盘事件处理及监听机制解析
文章目录 概念KeyEventKeyListener代码演示总结 概念 Java事件处理采用了委派事件模型。在这个模型中,当事件发生时,产生事件的对象将事件信息传递给事件的监听者进行处理。在Java中,事件源是产生事件的对象,比如窗口、按钮等&am…...

Git详解——安装、使用、搭建、IDEA集成
Git 看目录,篇幅挺长,越往后面越重要 目录一、git是什么?二、为什么要使用Git?三、版本控制工具四、git下载安装以及环境配置五、git基本命令六、git项目搭建七、远程仓库怎么搞?git,gitlab,github,gitee区别八、ide…...

【JavaSE】Java基础语法(二十一):内部类
文章目录 1. 内部类的基本使用2. 成员内部类3. 局部内部类4. 匿名内部类5. 匿名内部类在开发中的使用(应用) 1. 内部类的基本使用 内部类概念 在一个类中定义一个类。举例:在一个类A的内部定义一个类B,类B就被称为内部类 内部类定…...

Ceph应用
//存储类型 块存储 一对一,只能被一个主机挂载使用,数据以块为单位进行存储,典型代表: 硬盘 文件存储 一对多,能被多个主机同时挂载使用,数据以文件的形式存储的(元数据和实际数据是分开存储的),并且有…...

LinkSwift网盘直链下载助手:一站式解决9大网盘下载难题
LinkSwift网盘直链下载助手:一站式解决9大网盘下载难题 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

如何在Mac上免费运行Windows游戏与应用:Whisky完整指南
如何在Mac上免费运行Windows游戏与应用:Whisky完整指南 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 还在为Mac无法运行Windows专属软件而烦恼吗?Whisky为你…...

MPC-BE播放器完全手册:打造极致影音体验的终极解决方案
MPC-BE播放器完全手册:打造极致影音体验的终极解决方案 【免费下载链接】MPC-BE MPC-BE – универсальный проигрыватель аудио и видеофайлов для операционной системы Windows. 项目地址: h…...

如何用3个步骤建立完全私有的点对点文件同步网络?
如何用3个步骤建立完全私有的点对点文件同步网络? 【免费下载链接】syncthing-android Wrapper of syncthing for Android. 项目地址: https://gitcode.com/gh_mirrors/sy/syncthing-android 你是否曾因云端服务的隐私隐患而犹豫不决?是否厌倦了每…...

3分钟搞定:终极免费DeepL Chrome翻译插件安装指南
3分钟搞定:终极免费DeepL Chrome翻译插件安装指南 【免费下载链接】deepl-chrome-extension A DeepL Translator Chrome extension 项目地址: https://gitcode.com/gh_mirrors/de/deepl-chrome-extension 还在为浏览外文网页而烦恼吗?想要获得专业…...

m4s-converter:让B站缓存视频重获新生的终极解决方案
m4s-converter:让B站缓存视频重获新生的终极解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾遇到过这样的情况&…...

卖包装薄膜怎么找客户?下游工厂在哪里
卖包装薄膜找客户,本质是找用膜的下游工厂,核心难点是把这些真实在产、真实消耗薄膜的下游厂的名单和联系人系统拿到手——报价单发不出去、拜访找不到门,问题往往出在名单环节而不是产品本身。 包装薄膜的下游客户到底是谁 包装薄膜品类多样…...
ATB:让 Transformer 推理快得像开了挂——昇腾算子加速库技术解析
Transformer 模型推理的瓶颈在哪里?KV Cache 管理、算子融合、分布式调度。ATB(ascend-transformer-boost)把这些问题一次性解决,让推理性能提升 2-3 倍。 上个月帮一个团队做推理优化,他们的 LLaMA-2 70B 模型在 NPU …...
)
Sora 2视频音频不同步?深度解析OpenAI未公开的时间戳嵌入机制,3分钟强制同步方案(含Python自动校准工具)
更多请点击: https://codechina.net 第一章:Sora 2视频音频不同步现象的系统性归因 视频与音频流在 Sora 2 模型推理及播放阶段出现时间偏移,是影响用户体验的关键缺陷。该现象并非单一环节导致,而是由多层级时序建模、硬件调度、…...

如何在Windows电脑上安装安卓应用:APK安装器完整教程
如何在Windows电脑上安装安卓应用:APK安装器完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer APK安装器是一款专为Windows系统设计的安卓应用安装工…...