Elasticsearch数据库
目录
- 1. 什么是ElasticSearch
- 1.1 概念及特点
- 1.2 ElasticSearch适用场景概述
- 2. 安装ElasticSearch
- 2.1 下载安装包
- 2.2 环境说明
- 2.3 创建es的用户
- 2.4 创建es存储位置
- 2.5 安装es
- 2.5 修改配置文件
- 2.6 系统优化
- 2.7 安装jdk环境
- 2.8 切换es用户启动数据库
- 2.9 systemctl管理
- 2.10 访问
- 3. kibana
- 3.1 kibana介绍
- 3.2 安装kibana
- 3.3 上传安装包
- 3.4 解压文件
- 3.5 修改配置文件
- 3.6 启动
- 3.7 浏览器访问
- 4. Elasticsearch高可用集群
- 4.1 ES是如何解决高并发
- 4.2 ES基本概念名词
- 4.3 ES为什么要实现集群
- 5. 高可用ES集群部署
- 5.1 环境说明
- 5.2 安装过程
- 5.3 修改配置文件
- 5.4 启动es数据库
- 5.5 集群测试
- 5.6 验证ES集群故障转移
- 6. 配置kibana监控集群
- 6.1 修改配置文件
- 6.2 访问
- 6.3 验证分片
1. 什么是ElasticSearch
1.1 概念及特点
-
Elasticsearch和MongoDB/Redis/Memcache一样,是非关系型数据库。是一个接近实时的搜索平台,从索引这个文档到这个文档能够被搜索到只有一个轻微的延迟,企业应用定位:采用Restful API标准的可扩展和高可用的实时数据分析的全文搜索工具。
-
可拓展:支持一主多从且扩容简易,只要cluster.name一致且在同一个网络中就能自动加入当前集群;本身就是开源软件,也支持很多开源的第三方插件。
-
高可用:在一个集群的多个节点中进行分布式存储,索引支持shards和复制,即使部分节点down掉,也能自动进行数据恢复和主从切换。
-
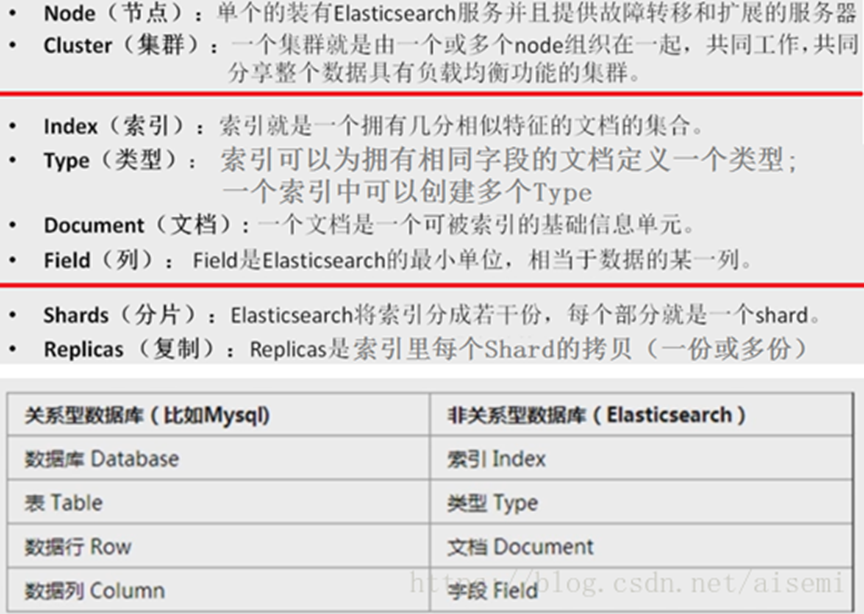
数据存储的最小单位是文档,本质上是一个JSON 文本:
1.2 ElasticSearch适用场景概述
-
维基百科,类似百度百科,全文检索,高亮,搜索推荐
-
The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
-
Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
-
GitHub(开源代码管理),搜索上千亿行代码
-
电商网站,检索商品
-
国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
2. 安装ElasticSearch
2.1 下载安装包
官网下载地址:
https://www.elastic.co/cn/downloads/past-releases
2.2 环境说明
//系统版本
[root@localhost ~]# cat /etc/redhat-release
CentOS Linux release 7.8.2003 (Core)
//关闭防火墙
[root@localhost ~]# systemctl stop firewalld && systemctl disable firewalld
[root@localhost ~]# sed -i '7s/enforcing/disabled/g' /etc/selinux/config
[root@localhost ~]# setenforce 0
[root@localhost ~]# getenforce
Permissive
2.3 创建es的用户
[root@localhost ~]# groupadd es
[root@localhost ~]# useradd -g es -s /bin/bash -md /home/es es
2.4 创建es存储位置
//存放在/var/es(根据实际需求)
[root@localhost ~]# mkdir /var/es && cd /var/es
[root@localhost es]# mkdir data && mkdir log
[root@localhost es]# chown -Rf es:es /var/es/
2.5 安装es
//创建文件夹,并将安装包上传到这里
[root@localhost ~]# mkdir /usr/local/es && cd /usr/local/es
//上传安装包
[root@localhost src]# ls
debug elasticsearch-6.8.20.tar.gz kernels
//解压安装包
[root@localhost src]# tar xf elasticsearch-6.8.20.tar.gz -C /usr/local/es/
[root@localhost src]# cd /usr/local/es/
[root@localhost es]# chown -Rf es:es /usr/local/es/elasticsearch-6.8.20/
2.5 修改配置文件
//编辑配置文件
[root@localhost es]# vim /usr/local/es/elasticsearch-6.8.20/config/elasticsearch.yml
//取消cluster.name前的#号注释,改成自己起的名字。(注意前面的数字代表行号)
17 cluster.name: my-application
//node.name取消#号
23 node.name: node-1
//设置path.data,取消#号,改为如下的
33 path.data: /var/es/data
//设置path.logs,取消#号,改为如下的
37 path.logs: /var/es/log
//network.host取消#号,改为0.0.0.0(允许所有ip访问)
55 network.host: 0.0.0.0
//取消http.port#
59 http.port: 9200
//在文件的最后添加以下配置89 bootstrap.memory_lock: false90 bootstrap.system_call_filter: false
2.6 系统优化
//修改文件1
[root@localhost es]# vi /etc/security/limits.conf
末尾添加
62 es soft nofile 65536
63 es hard nofile 65536
64 es soft nproc 4096
65 es hard nproc 4096
//修改文件2
[root@localhost es]# vim /etc/sysctl.conf
末尾添加
11 vm.max_map_count = 655360
[root@localhost es]# sysctl -p
vm.max_map_count = 655360
2.7 安装jdk环境
//上传jdk安装包
[root@localhost src]# ls
debug elasticsearch-6.8.20.tar.gz jdk-8u131-linux-x64.tar.gz kernels
//解压安装包
[root@localhost src]# tar xf jdk-8u131-linux-x64.tar.gz -C /usr/local/
//添加环境变量
[root@localhost src]# vim /etc/profile
末尾添加78 #JAVA_HOME79 export JAVA_HOME=/usr/local/java80 #JRE_HOME81 export JRE_HOME=/usr/local/java/jre82 #CALSSPATH83 export CLASSPATH=$CLASSPATH:${JAVA_HOME}/lib:${JRE_HOME}/lib84 #PATH85 export PATH=$PATH:${JAVA_HOME}/bin:${JRE_HOME}/bin//重命名
[root@localhost ~]# mv /usr/local/jdk1.8.0_131/ /usr/local/java
[root@localhost ~]# source /etc/profile
[root@localhost ~]# java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
2.8 切换es用户启动数据库
[root@localhost ~]# su es
[es@localhost root]$ /usr/local/es/elasticsearch-6.8.20/bin/elasticsearch &
2.9 systemctl管理
2.10 访问
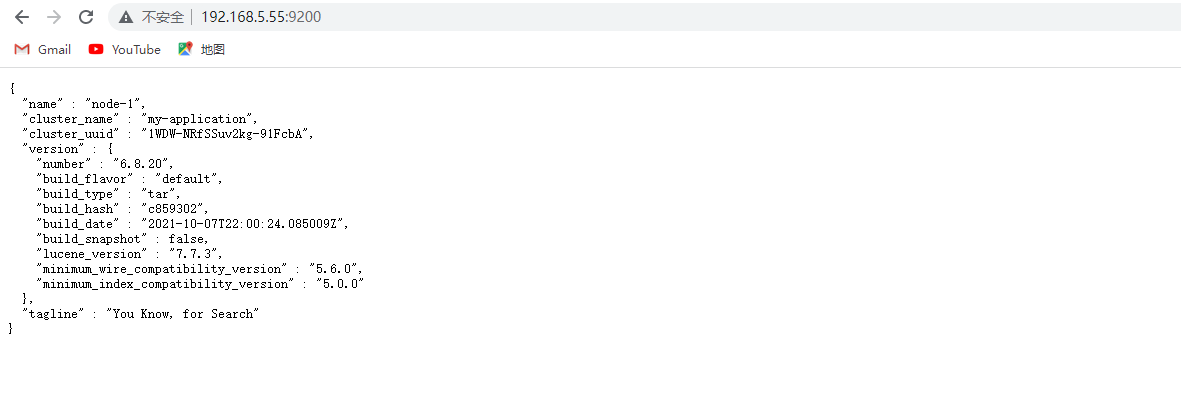
用浏览器访问ip:9200(安装的设备9200端口),看到如下的说明安装成功:
3. kibana
3.1 kibana介绍
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据分析与可视化的目的。
Elasticsearch、Logstash和Kibana这三个技术就是我们常说的ELK技术栈,可以说这三个技术的组合是大数据领域中一个很巧妙的设计。一种很典型的MVC思想,模型持久层,视图层和控制层。Logstash担任控制层的角色,负责搜集和过滤数据。Elasticsearch担任数据持久层的角色,负责储存数据。而我们这章的主题Kibana担任视图层角色,拥有各种维度的查询和分析,并使用图形化的界面展示存放在Elasticsearch中的数据。
3.2 安装kibana
官网下载地址:
https://www.elastic.co/cn/downloads/past-releases#kibana
3.3 上传安装包
//使用rz命令或者xftp上传
[root@localhost src]# ls
debug elasticsearch-6.8.20.tar.gz jdk-8u131-linux-x64.tar.gz kernels kibana-6.8.20-linux-x86_64.tar.gz
3.4 解压文件
[root@localhost src]# tar xf kibana-6.8.20-linux-x86_64.tar.gz -C /usr/local/
3.5 修改配置文件
//下列的序号为行号
[root@localhost src]# vim /usr/local/kibana-6.8.20-linux-x86_64/config/kibana.yml
7 server.host: "192.168.5.55" //ES服务器主机地址
28 elasticsearch.hosts: ["http://192.168.5.55:9200"] //ES服务器地址
3.6 启动
[root@localhost src]# cd /usr/local/kibana-6.8.20-linux-x86_64/
[root@localhost kibana-6.8.20-linux-x86_64]# ./bin/kibana &
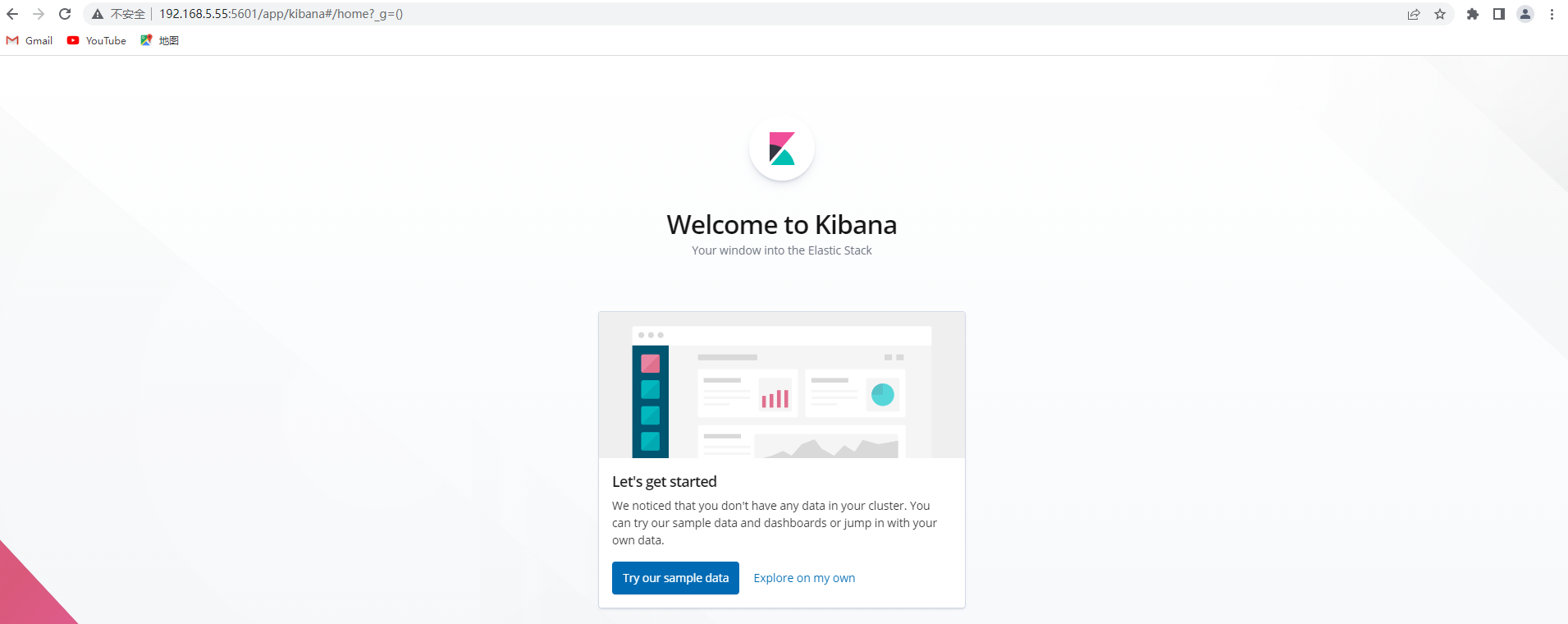
3.7 浏览器访问
http://192.168.5.55:5601/app/kibana
4. Elasticsearch高可用集群
4.1 ES是如何解决高并发
ES是一个分布式全文检索框架,隐藏了复杂的处理机制,核心内容 分片机制、集群发现、分片负载请求路由。
4.2 ES基本概念名词
Cluster
代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
Shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改
replicas
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
Recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
4.3 ES为什么要实现集群
ES集群中索引可能由多个分片构成,并且每个分片可以拥有多个副本。通过将一个单独的索引分为多个分片,我们可以处理不能在一个单一的服务器上面运行的大型索引,简单的说就是索引的大小过大,导致效率问题。不能运行的原因可能是内存也可能是存储。由于每个分片可以有多个副本,通过将副本分配到多个服务器,可以提高查询的负载能力。
ES集群核心原理分析:
-
每个索引会被分成多个分片shards进行存储,默认创建索引是分配5个分片进行存储。
每个分片都会分布式部署在多个不同的节点上进行部署,该分片成为primary shards。
注意:索引的主分片primary shards定义好后,后面不能做修改。 -
为了实现高可用数据的高可用,主分片可以有对应的备分片replics shards,replic shards分片承载了负责容错、以及请求的负载均衡。
注意: 每一个主分片为了实现高可用,都会有自己对应的备分片,主分片对应的备分片不能存放同一台服务器上(单台ES没有备用分片的)。主分片primary shards可以和其他replics shards存放在同一个node节点上。
在往主分片服务器存放数据时候,会对应实时同步到备用分片服务器:
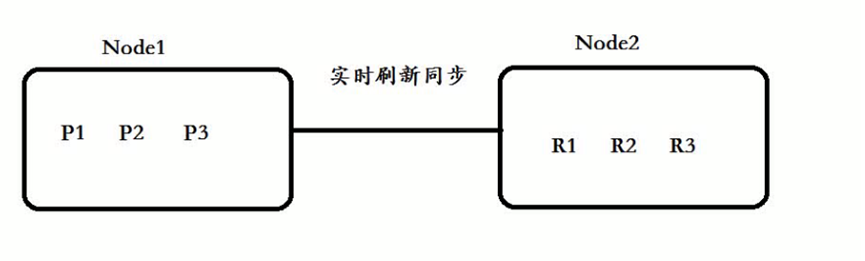
但是查询时候,所有(主、备)都进行查询。
主的可以存放副的:
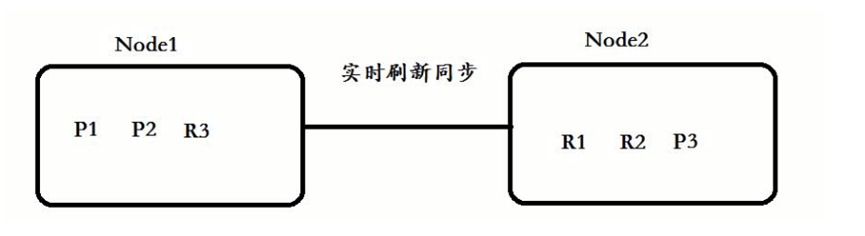
Node1 :P1+P2+R3组成了完整 的数据! 分布式存储
ES核心存放的核心数据是索引!
如果ES实现了集群的话,会将单台服务器节点的索引文件使用分片技术,分布式存放在多个不同的物理机器上。
分片就是将数据拆分成多台节点进行存放
在ES分片技术中,分为主(primary)分片、副(replicas)分片。这样做是为了容错性
5. 高可用ES集群部署
5.1 环境说明
系统环境:
[es@localhost root]$ cat /etc/redhat-release
CentOS Linux release 7.8.2003 (Core)
主机:
| IP地址 | 节点 | 数据库版本 | 可视化工具 |
|---|---|---|---|
| 192.168.5.55 | node1(主) | elasticsearch-6.8.20 | kibana-6.8.20 |
| 192.168.5.56 | node2 | elasticsearch-6.8.20 | |
| 192.168.5.100 | node3 | elasticsearch-6.8.20 |
5.2 安装过程
需要准备好三台主机已经安装好ES数据库,安装的过程请查看目录第二节
注:关闭防火墙
5.3 修改配置文件
修改192.168.5.55配置文件
[root@localhost config]# pwd
/usr/local/es/elasticsearch-6.8.20/config
[root@localhost config]# vim elasticsearch.yml
注:前面的序号为行号,标记多少行前面省略……
17 cluster.name: myes //集群名称,保证三台集群名字相同
23 node.name: node-1 //当前节点名称,集群内节点名字不能相同
33 path.data: /var/es/data //数据存放目录
37 path.logs: /var/es/log //日志存放目录
55 network.host: 0.0.0.0 //主机
59 http.port: 9200 //端口号
68 discovery.zen.ping.unicast.hosts: ["192.168.5.55", "192.168.5.56","192.168.5.100"] //多个服务集群ip
72 discovery.zen.minimum_master_nodes: 1 //最少主节点数量
89 bootstrap.memory_lock: false //添加以下两行,开放网络权限
90 bootstrap.system_call_filter: false剩下的两台利用scp命令远程覆盖配置文件
注意:记得修改节点名称,集群内节点名字不能相同
[root@localhost ~]# cd /usr/local/es/elasticsearch-6.8.20/config/
[root@localhostconfig]# scp elasticsearch.yml root@192.168.5.56:/usr/local/es/
elasticsearch-6.8.20/config/
5.4 启动es数据库
三台依次启动
[root@localhost config]# su es
[es@localhost config]$ /usr/local/es/elasticsearch-6.8.20/bin/elasticsearch &
5.5 集群测试
通过浏览器访问如下地址查看集群启动状态
192.168.5.55:9200/_cat/health?v

//查看集群信息
[root@localhost config]# curl 192.168.5.55:9200/_cat/nodes
192.168.5.56 14 96 1 0.05 0.15 0.13 mdi - node-2
192.168.5.100 14 90 0 0.00 0.06 0.06 mdi - node-3
192.168.5.55 23 97 2 0.00 0.04 0.05 mdi * node-1 带*号表示主节点
//检查分片是否正常[root@localhost ~]# curl 192.168.5.55:9200/_cat/shards
.kibana_task_manager 0 p STARTED 2 6.8kb 192.168.5.55 node-1
.kibana_task_manager 0 r STARTED 2 6.8kb 192.168.5.56 node-2
.kibana_1 0 p STARTED 4 19.8kb 192.168.5.56 node-2
.kibana_1 0 r STARTED 4 19.8kb 192.168.5.100 node-3
.monitoring-kibana-6-2023.05.15 0 p STARTED 2194 747.9kb 192.168.5.55 node-1
.monitoring-kibana-6-2023.05.15 0 r STARTED 2194 680.4kb 192.168.5.100 node-3
.monitoring-kibana-6-2023.05.12 0 p STARTED 1180 420kb 192.168.5.56 node-2
.monitoring-kibana-6-2023.05.12 0 r STARTED 1180 420kb 192.168.5.100 node-3
.monitoring-es-6-2023.05.15 0 p STARTED 28065 14mb 192.168.5.55 node-1
.monitoring-es-6-2023.05.15 0 r STARTED 28065 14mb 192.168.5.56 node-2
.monitoring-es-6-2023.05.12 0 p STARTED 11490 5.6mb 192.168.5.55 node-1
.monitoring-es-6-2023.05.12 0 r STARTED 11490 5.6mb 192.168.5.100 node-3P 表示primar shard 主分片,前面的数字表示分片数量
R 表示 replica shard 副本分片
5.6 验证ES集群故障转移
注意实心星号的是主节点,我们尝试将 192.168.5.55 节点服务关闭,验证,主节点是否进行重新选举,并再次启动 192.168.5.55,看看是否变成候选节点:
[root@localhost ~]# ps -ef | grep /usr/local/es/ela
[root@localhost ~]# kill -9 3184[es@localhost config]$ curl 192.168.5.56:9200/_cat/nodes
192.168.5.56 21 96 1 0.03 0.02 0.05 mdi - node-2
192.168.5.100 24 95 1 0.30 0.10 0.07 mdi * node-3
发现 192.168.5.100变成了主节点,然后启动 192.168.5.55,验证其是否变成了候选节点
[root@localhost ~]# curl 192.168.5.55:9200/_cat/nodes
192.168.5.100 27 94 2 0.08 0.08 0.07 mdi * node-3
192.168.5.55 26 96 1 0.97 0.25 0.12 mdi - node-1
192.168.5.56 22 96 1 0.03 0.03 0.05 mdi - node-2
6. 配置kibana监控集群
6.1 修改配置文件
安装过程请查看目录第三部分
修改配置kibana配置文件
[root@localhost ~]# vim /usr/local/kibana-6.8.20-linux-x86_64/config/kibana.yml
7 server.host: "0.0.0.0" //服务器主机地址
//集群ip端口号
28 elasticsearch.hosts: ["http://192.168.5.55:9200","http://192.168.5.56:9200",
"http://192.168.5.100:9200"]
[root@localhost ~]# cd /usr/local/kibana-6.8.20-linux-x86_64/bin/
[root@localhost bin]# ./bin/kibana &
6.2 访问
成功监控到整个集群
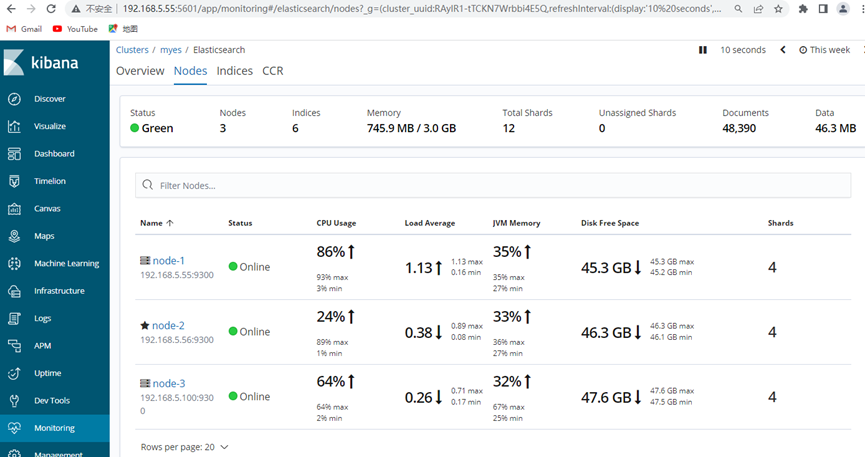
6.3 验证分片
三个节点正常的时候下面显示是16个分片
Node1:5个
Node2: 6个
Node3:5个
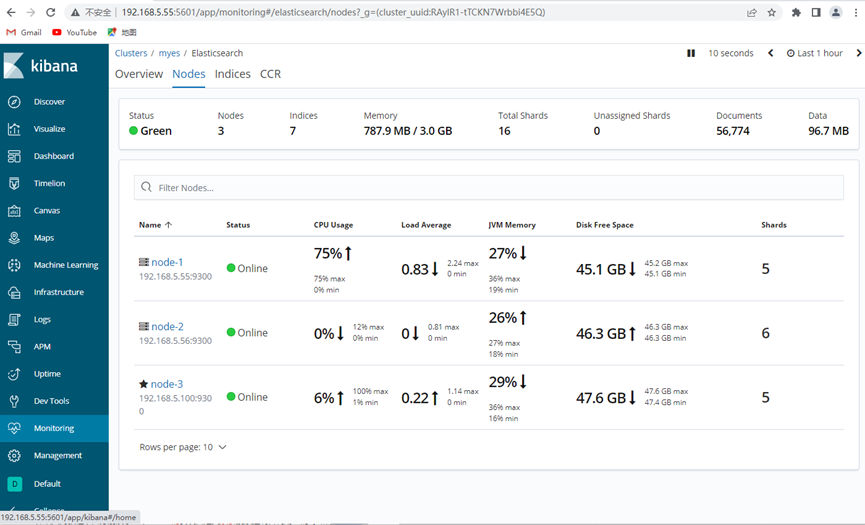
模拟故障:
现在把node1节点关掉,正常应该是node1节点的五个分片会重新分配给剩下的两个节点,使总数到达16个分片
[root@localhost kibana-6.8.20-linux-x86_64]# netstat –tunlp
[root@localhost kibana-6.8.20-linux-x86_64]# kill -9 2036
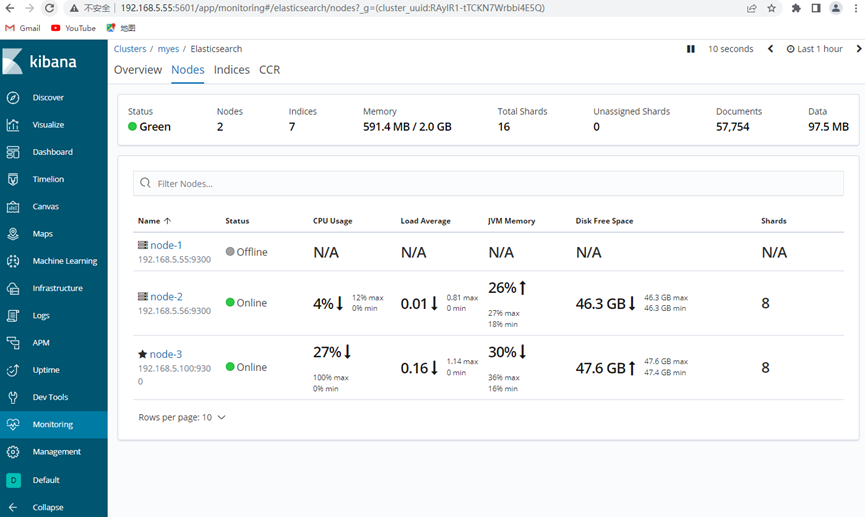
验证成功,可以看到node1挂了,剩下的两个节点各自分配了8个分片
相关文章:
Elasticsearch数据库
目录 1. 什么是ElasticSearch1.1 概念及特点1.2 ElasticSearch适用场景概述 2. 安装ElasticSearch2.1 下载安装包2.2 环境说明2.3 创建es的用户2.4 创建es存储位置2.5 安装es2.5 修改配置文件2.6 系统优化2.7 安装jdk环境2.8 切换es用户启动数据库2.9 systemctl管理2.10 访问 3…...

Axure教程—表格(中继器)
本文将教大家如何用AXURE中的中继器制作表格 一、效果介绍 如图: 预览地址:https://oc3e6a.axshare.com 下载地址:https://download.csdn.net/download/weixin_43516258/87854863?spm1001.2014.3001.5501 二、功能介绍 可以在表格中插入…...

Linux转HTTP代理服务器
在 Linux 上搭建 HTTP 代理服务器,可以使用 Squid 或者 Nginx 等软件来实现。以下是使用 Squid 搭建 HTTP 代理服务器的步骤: 1. 安装 Squid 在终端中输入以下命令安装 Squid: sudo apt-get update sudo apt-get install squid 2. 配置 Sq…...
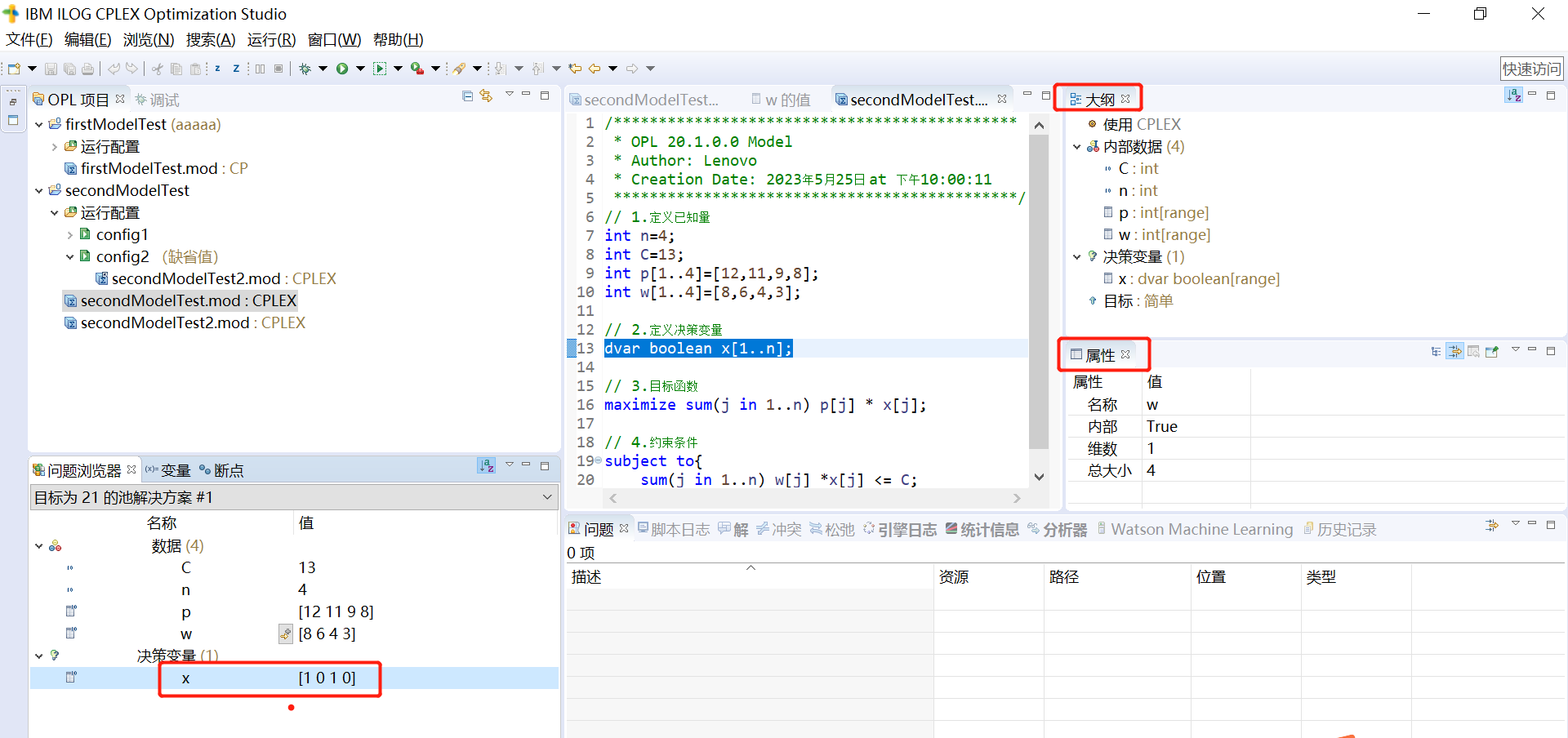
CPLEX Studio 集成开发环境 (IDE) 介绍
CPLEX Studio 集成开发环境 (IDE) 介绍 参考B站视频:cplex入门到精通 1.CPLEX Studio IDE 实现的功能 IBM ILOG CPLEX Studio IDE 是一个用于数学规划、约束规划以及一般组合优化应用程序的集成开发环境。 它是适用于 OPL(优化编程语言)和…...

如何在Linux机器中测试存储/磁盘I/O性能?
在Linux环境中,了解存储/磁盘I/O性能对于评估系统性能和优化存储子系统非常重要。通过测试存储/磁盘I/O性能,我们可以确定磁盘的读写速度、延迟和吞吐量等指标。本文将介绍几种常用的方法来测试Linux机器中的存储/磁盘I/O性能。 方法一:使用d…...
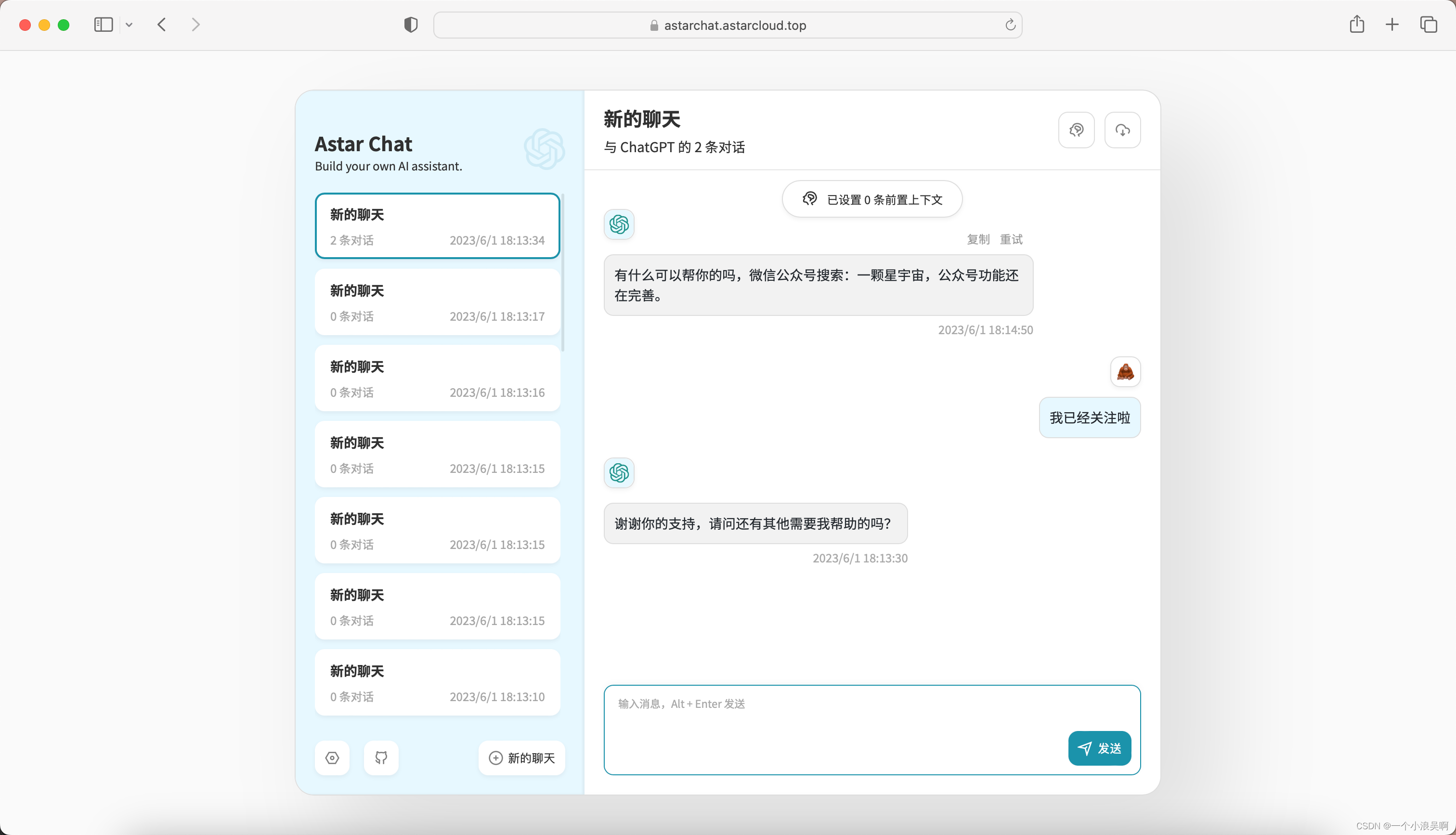
ChatGPT国内免费使用方法【国内免费使用地址】
当下人工智能技术的快速发展,聊天机器人成为了越来越多人们日常生活和工作中的必备工具。如何在国内免费使用ChatGPT聊天机器人,成为了热门话题。本文将为你详细介绍ChatGPT国内免费使用方法,让你轻松拥有聊天机器人助手,提高工作…...

常微分方程ODE和Neural Ordinary Differential Equations
微分方程(英語:Differential equation,DE)是一種數學方程,用來描述某一類函数與其导数之间的关系。微分方程的解是一個符合方程的函數。而在初等数学的代数方程裡,其解是常数值。 常微分方程(英…...
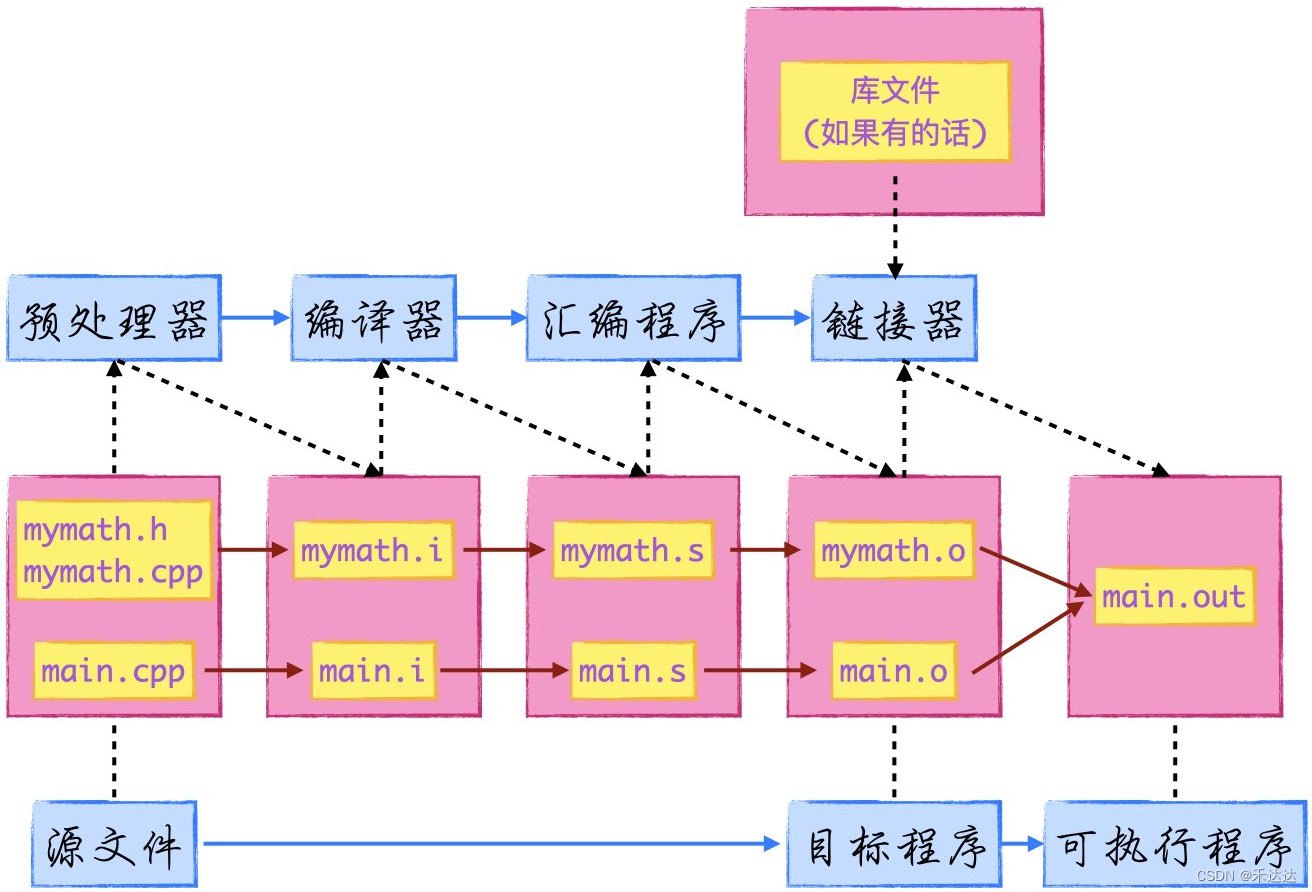
C++ 编译过程(附简单实例)
C 采用分离编译模式,分离编译指的是,一个程序/项目是由若干个源文件共同实现,编译时先把每个源文件单独编译生成目标文件,再将所有目标文件连接起来,形成单一的可执行文件。 C 编译的四个阶段:预处理、编译…...
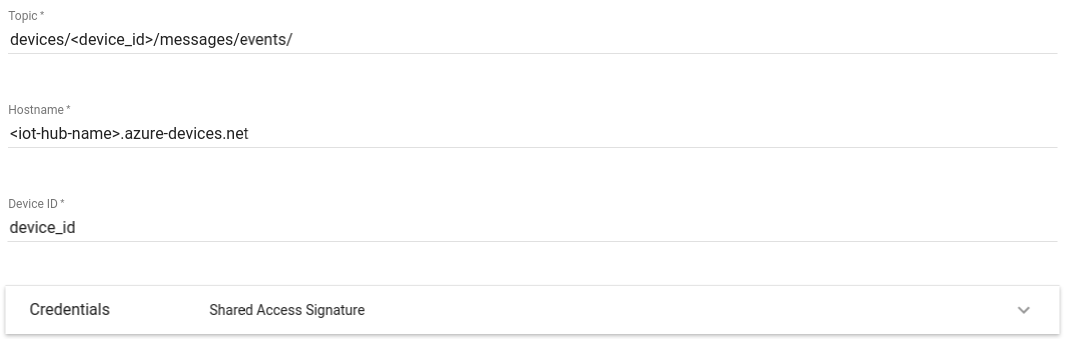
ThingsBoard教程(五四):规则节点解析 Azure IoT Hub Node, RabbitMQ Node
Azure IoT Hub Node Since TB Version 2.5.3 配置 主题 - 获取有关IoT Hub主题的更多信息,请使用以下链接。主机名 - Azure IoT Hub主机名。设备ID - 来自Azure IoT Hub的设备ID。凭据 - Azure IoT Hub连接凭据。可以是共享访问签名或PEM格式证书。Azure IoT Hub支持不同的…...

元素偏移量offset
文章目录 1. offset概述2. offset与style的区别 1. offset概述 offset就是偏移量,我们使用offset系列相关属性可以动态的得到该属性的位置(偏移)、大小等。 element.offsetParent 返回作为该元素带有定位的父级元素,如果父级都没…...
如何让自动化测试框架更自动化?
一、引言 对于大厂的同学来说,接口自动化是个老生常谈的话题了,毕竟每年的MTSC大会议题都已经能佐证了,不是大数据测试,就是AI测试等等(越来越高大上了)。不可否认这些专项的方向是质量智能化发展的方向&…...

无屏幕实现连接树莓派
无屏幕实现连接树莓派 欢迎来到我的博客!今天我将与大家分享如何无需使用屏幕,实现与树莓派的连接。对于那些在树莓派项目中不方便使用屏幕的人来说,这将是一个有用的技巧。 材料清单 在开始之前,让我们先准备好所需的材料&…...
系统启动流程)
【Android】AMS(一)系统启动流程
前言 AMS(Activity Manager Service)即活动管理器服务,是Android系统中的一个核心服务。它主要负责管理应用程序的生命周期,包括启动应用程序、切换应用程序、管理任务栈等。 Android启动流程 Android程序的启动流程可以概括为…...

FineBI6.0基础学习第一课 数据门户
PC端门户使用示例 首先,以管理员身份登录FineBI系统,安装数据门户,安装步骤见官网 新建一个数据门户...
如何部署项目到Tomcat + 第一个Servlet程序
博主简介:想进大厂的打工人博主主页:xyk:所属专栏: JavaEE初阶 目录 文章目录 一、Tomcat 1.1 Tomcat是什么 1.2 下载安装 1.3 部署项目 二、第一个Servlet程序 2.1 Servlet是什么 2.2 创建Maven项目 2.3 引入依赖 2.4 创建目录 2.5 编写类方法 2.6 打包…...
)
牛客刷题(HTML-Day1)
第一题: 1.下列代码在页面中显示的内容为( ) <!DOCTYPE html> <html> <body> <p>hello<q>html</q></p> </body> </html> A hello“html” B hello html C hello“”html D 其他几…...

性能测试如何入门?熬夜7天整理出这一份3000字超全学习指南
赶鸭子上架要我搞性能测试,怎么办? 我第一次真正意义上搞性能测试是在2014年。项目组要求搞性能测试,我之前也没搞过,对服务端也不熟悉。就那么一脸懵逼地开始搞性能。当时我连linux上有哪些能看系统资源的命令都不知道。稀里糊涂…...
信息安全实践1.2(重放攻击)
前言 这个实验是看一本书做的,就是李华峰老师的书——《Metasploit Web 渗透测试实战》,我之前写过一篇Slowloris DoS攻击的博客,也是看这本书写的,总的来说,有用处。这篇博客其实也只是很浅显的去做一下重放攻击。 要…...
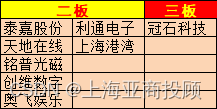
上海亚商投顾:沪指高开高走 地产股迎来久违反弹
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 市场情绪 三大指数今日高开高走,沪指午后涨近1%,深成指、创业板指涨超1.2%,上证50盘中大…...
Vim学习笔记【Ch02】
Vim学习笔记 系列笔记链接Ch02 Buffers, Windows, TabsBuffers什么是buffer查看所有bufferbuffer之间的切换删除buffer退出所有窗口 Windows窗口的创建窗口切换快捷键其他快捷键 Tabs什么是tabtab相关命令 window和buffer结合的3D移动小结 系列笔记链接 Ch00,Ch01 …...

3个关键步骤解锁Axure中文界面:从专业术语到流畅体验的完整指南
3个关键步骤解锁Axure中文界面:从专业术语到流畅体验的完整指南 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn Axur…...

如何快速下载并配置TaoToken命令行工具实现一键接入
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何快速下载并配置TaoToken命令行工具实现一键接入 对于需要在本地或服务器环境接入多个大模型的开发者而言,手动配置…...

暗黑破坏神2现代适配指南:如何使用d2dx解锁宽屏视野、提升帧率与画质
暗黑破坏神2现代适配指南:如何使用d2dx解锁宽屏视野、提升帧率与画质 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx …...
)
别再乱装WinPcap了!手把手教你为华为eNSP Cloud正确配置虚拟网卡(Win7/Win10兼容方案)
华为eNSP Cloud虚拟网卡配置全指南:从原理到避坑实践 当你第一次打开华为eNSP Cloud功能时,是否也遇到过网卡显示不全的困扰?这个问题困扰过无数网络学习者和备考者,而90%的根源都指向同一个错误——WinPcap的安装方式。本文将彻底…...

League Akari:5个核心功能彻底改变你的英雄联盟游戏体验
League Akari:5个核心功能彻底改变你的英雄联盟游戏体验 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit League Akari是一款基于官…...

别再瞎调参了!用Python实战Sensitivity Analysis,5分钟找出模型最怕哪个变量
用Python实战全局敏感性分析:5步锁定模型关键变量 当你的机器学习模型表现不如预期时,第一反应是什么?大多数数据科学家的选择是:调参。但随机调整超参数就像在黑暗房间里找开关——效率低下且充满挫败感。本文将带你用Python实施…...

构建高性能医疗对话数据引擎:792,099条中文医疗问答数据集的技术架构与应用
构建高性能医疗对话数据引擎:792,099条中文医疗问答数据集的技术架构与应用 【免费下载链接】Chinese-medical-dialogue-data Chinese medical dialogue data 中文医疗对话数据集 项目地址: https://gitcode.com/gh_mirrors/ch/Chinese-medical-dialogue-data …...

小红书下载神器XHS-Downloader:3分钟解锁隐藏的高级玩法
小红书下载神器XHS-Downloader:3分钟解锁隐藏的高级玩法 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&a…...

以下是 MaxWell 工业上位机项目的最终完整补充
以下是 MaxWell 工业上位机项目的最终完整补充:1. Region 管理面板(Region Management Panel) 这是一个用于运行时监控和管理 Region 的调试/管理界面,适合工业项目开发和维护阶段使用。 RegionManagementView.xaml <!-- Views…...

网盘直链解析工具完整指南:告别下载限速,实现高速下载
网盘直链解析工具完整指南:告别下载限速,实现高速下载 【免费下载链接】netdisk-fast-download 聚合多种主流网盘的直链解析下载服务, 一键解析下载,已支持夸克网盘/uc网盘/蓝奏云/蓝奏优享/小飞机盘/123云盘等. 支持文件夹分享解析. 体验地址…...