Numpy学习
Numpy官方手册:
Array objects — NumPy v1.24 Manual
创建数组
1.1 从现有数据创建
- 重要类型 np.ndarray
# 判断是否可以迭代 注意0维标量不可以遍历
print('__iter__' in dir(np.ndarray) and '__getitem__' in dir(np.ndarray))
- np.array(object, dtype=None)
- object:array_like,类似于数组的对象可以是列表元组可迭代对象。如果object是标量,则返回包含object的0维数组
- dtype:data-type,数组所需的数据类型。如果没有给出,会从输入数据推断数据类型 创建一个数组对象并返回(ndarray实例对象)
#利用列表生成array
arr = np.array([1,2,3,4],dtype=np.int32)arr2 = np.array([[1,2,3],[4,5,6],[7,8,9]])
np.shape #(0轴元素数,1轴元素数)
- 注意array和python的list的区别
- 数组每个大小一致,列表可以放任意类型元素
- 数组是固定大小,调整大小或形状需要使用reshape和resize;列表是动态的,可以使用append和extend随意添加
- ndarray的切片是引用,对切片操作会影响原array。而python中的列表不会
- 常用属性和方法:
- ndim, shape, size, dtype, itemsize
ndarray.shape: 返回形状,一个元组ndarray.astype(type): 改变类型,返回数值变为type类型的新数组
1.2 从形状或值创建
- 创建空数组
np.empty(shape, dtype=np.float64):返回给定形状和类型且未初始化的新数组np.empty_like(prototype, dtype=None):返回形状和类型与给定 prototype 相同的新数组,prototype:array_like
- 创建填充数值的数组
np.zeros(shape, dtype=np.float64):返回给定形状和类型的新数组,并用零填充np.ones(shape, dtype=np.float64):返回给定形状和类型的新数组,并用1填充np.full(shape, fill_value, dtype=None):返回给定形状和类型的新数组,并用fill_value 填充
- 创建特殊矩阵数组
np.eye(N, M=None, k=0, dtype=np.float64):返回单位矩阵,注意k值,为索引np.identity(n, dtype=np.float64):返回 n*n 的单位数组(主对角线为1,其他元素为0的方形数组)
1.3 从数值范围创建数组
np.arange([start,] stop[, step,], dtype=None)- 返回给定区间内的均匀间隔值构成的数组
- 和python的 range 区别在于可以使用浮点数或其他类型
np.arange(1.,11.,2.,np.dtype=float32)
#对比
np.array(range(1,11,2))
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=np.float64)- 把给定区间分成 num 个均匀间隔的样本,构成数组并返回(等差数列)
- num:生成的样本数量
- endpoint:如果为 True, 则stop 为最后一个样本。否则,stop值不包括在内
- retstep:如果为 True,返回 (samples, step), step 是样本之间的间隔
- dtype:如果没有给出dtype,则从 start 和 stop 推断数据类型。注意整数数值会被推断成 np.float64
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None)- 把给定区间分成 num 个按对数尺度均匀间隔的样本,构成数组并返回
- 对应等比数列,乘数是base
关于形状
- 形状可以从轴和维度去理解,3维的
shape(1(0轴),2(1轴),3(2轴)) = [ [0,0,0] , [0,0,0] ];在打印时,array的打印会带有最外层[ ],注意去掉后再理解维数。 np.reshape(a, newshape):- 保证 size 不变,在不更改数据的情况下为数组赋予新的形状
- newshape的一个形状维度可以是-1,值将自行推断
arr = np.arange(0,24).reshape(2,12) #ndarray.reshape
print(arr.size) #24
arr1 = arr.reshape(4,2,3)
print(arr1.size) #24#注意newshape可以为一个整数,会自动成为元组
#np.reshape(arr,6) == np.reshape(arr,(6,)) np.reshape(arr,(2,-1)) #此时-1位置值自动判断,大致为size/2
np.resize(a, new_shape): 返回具有指定形状的新数组ndarray.resize(new_shape): 直接修改原数组的形状,无返回值- 注意resize和reshape区别:
- resize 可以形状不同,并添加元素,是原地操作
- reshape 在原来size大小基础上操作
运算操作
算术和比较操作 ndarrays 被定义为逐元素操作
- 形状一样可以操作
- 同时满足广播机制则可以操作
广播机制
后缘维度:比如(3,4)可以广播成(2,3,4),从后往前看,看短的一端
后缘维度相同或者不同的维度有1,可以广播
可以理解为 1=赖子
比如(1,3,4)也可以广播成(2,3,4),1可以在任何位置,可以变换为任何数字
比如(2,1,4),(1,3,4)也可以互相广播
索引切片
- 规则
- 切片不降维(锁定形状),索引降维
- 数组切片不会复制内部数组数据,只会生成原始数据的新视图
- 数组的特殊索引、切片
- arr[1,0] 第一个维度取索引1,第二个维度取索引0
- arr[:2,1:2] 第一个维度取切片 :2,第二个维度取切片 1:2
- 花式索引:
- arr[[0,2]] 等价于arr[0]和arr[2]的结果合并
- arr[[0,2],[1,0]] 等价于a[0,1]和arr[2,0]的结果合并
- arr[[0,2,1],[1,1,0]] 等价于a[0,1]和arr[2,1]和arr[1,0]的结果合并
- 布尔索引:arr[[True,False,True]] 将True的结果合并
import numpy as np
lis = [[1, 2], [3, 4], [5, 6]]
arr = np.array(lis)
print(arr[1, 0])
print(arr[1][0])
print(arr[:2, 1:2])
print(arr[:2][1:2])
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6]])
print(x[[1, 2]]) # 等价于x[1]和x[2]组成的数组
print(x[[0, 1, 2], [0, 1, 0]]) # 等价于x[0, 0]、x[1, 1]和x[2, 0]组成的数组
print(x[[True, False, True]])
print(x < 4)
print(x[x < 4])
print(x[np.array([[True, True], [True, False], [False,False]])])
常用操作
ndarray.flatten(): 拍扁成一维ndarray.T: (1,2,3,4)->(4,3,2,1)np.swapaxes(a,axis1,axis2): (1,2,3)->(1,3,2)只能交换两个轴np.transpose(a,axes=None): 默认为转置,可以交换更多轴 使用元组编号排序np.expend_dims(arr,axis=n):添加维度,相当于在axis的索引位置插入1值np.squeeze(arr,axis=None): 删除值为1的维度, 相当于在axis的索引位置删除1值,None则1值全部删除,删除位置不等于1则报错np.concatenate((a1,a2,...),axis=0): 拼接a1,a2,a3… 沿着指定轴。
- 按哪个轴拼接,则按哪个轴相加。
- 条件:除了拼接的那个轴不同,其他轴都必须相同
- 拼接后维度不变
- 拼接自己注意参数为(a1,)
np.stack(arr,axis): 堆叠
- 会改变维度
- 形状必须相同
np.matmul(a,b) : ‘a@b’ 两个数组的矩阵乘积
- 高维矩阵相乘 https://zhuanlan.zhihu.com/p/337829793
- 基本是最后两维为(m,n)(n,k)->(m,k) 以矩阵做操作
- matmul 保证最后两维,其他维度需要可广播
- dot 保证最后两维,其他维无关
np.max(arr,axis=0,keepdims=True):
- 返回沿给定轴的最大值,axis没有指定时,默认为None,表示返回所有元素的最大值
- axis指定哪个轴则消灭哪个轴,keepdims则将该轴保留为1
- np.mean,var,std 参数同max
np.prod(a, axis=None, keepdims=np._NoValue, initial=np._NoValue):
- 返回给定轴上数组元素的乘积
- 默认的axis=None将计算输入数组中所有元素的乘积
- np.sum 参数同
np.nonzero(a) :返回非0元素的索引,主要用于获取True的索引np.where(condition, x=None, y=None) :
- 根据条件获取索引, x和y同时传参或同时不传
- 注意: np.where(x!=0) == np.nonzero(x)
np.argwhere(a): 找出数组中按元素分组的非零元素索引
import numpy as npx = np.array([[3,0,0],[0,4,0],[5,6,0]])
print(np.nonzero(x)) #[0, 1, 2, 2],[0, 1, 0, 1]
print(x[np.nonzero(x)]) #花式索引
print()
print(np.where(x>3)) #[1, 2, 2] [1, 0, 1]print(np.where( [[True,False],[True,True]],[[1,2],[3,4]],[[5,6],[7,8]] ))
#[[1 6] [3 4]] 为true的地方为x的值,false的地方为y的值print(np.argwhere(x))
'''
[[0 0][1 1][2 0][2 1]]
'''np.argmax(a,axis=None): 返回沿轴的最大值的索引np.maximum(x1,x2): 返回x1和x2逐个元素比较中的最大值
生成随机数
对象 np.randomnp.random.normal(miu=0.0, scale=1.0, shape=None): normal是正态分布,miu为期望值,scale是标准差,size是想生成的shapenp.random.randn(shape):从标准正态分布中取样本, 即默认miu=0.0, scale=1.0np.random.randint(low, high=None, size=None): 从[low,high)范围的离散均匀分布中获取随机数,整数型np.random.uniform(low=0.0, high=1.0, size=None): 返回从 [low, high) 均匀分布中抽取的随机样本,实数型np.random.permutation(x): x是int 或者array_like;只对x的第一个维度0轴进行随机排列,返回新的数组np.random.seed(x): 随机数种子 x为int;固定随机数(每次刷新运行值不变),解除固定可使用seed() 不传参
相关文章:

Numpy学习
Numpy官方手册:Array objects — NumPy v1.24 Manual 创建数组 1.1 从现有数据创建 重要类型 np.ndarray # 判断是否可以迭代 注意0维标量不可以遍历 print(__iter__ in dir(np.ndarray) and __getitem__ in dir(np.ndarray))np.array(object, dtypeNone) objec…...
IDC机房相电压与线电压的关系
380V电动机(三相空调压缩机)的电流计算公式为:Ⅰ=额定功率(1.732额定电压功率因数效率)。 功率因数是电力系统的一个重要的技术数据。功率因数是衡量电气设备效率高低的一个系数。功率因数低,说…...

chatgpt赋能python:Python如何设置输入的SEO
Python如何设置输入的SEO Python是一种高级的编程语言,具有容易上手、可扩展和开源等特点,因此在软件开发过程中得到广泛的应用。然而,如果您想让您的Python项目在搜索引擎上获得更好的排名和流量,您需要考虑如何设置输入的SEO。…...

Spring Cloud Alibaba — Nacos 构建服务注册中心
文章目录 Nacos Server下载启动登录创建命名空间 Nacos Client启动样例Nacos 服务发现配置项 集成 OpenFeign 远程接口调用添加 OpenFeign 依赖开启 EnableFeignClients 注解编写远程服务接口远程接口调用 集成 Sentinel 熔断降级添加 Sentinel 依赖开启 Sentinel 熔断降级编写…...
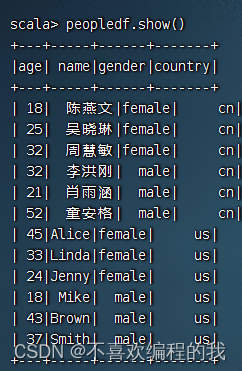
4.2 Spark SQL数据源 - 基本操作
一、默认数据源 案例演示读取Parquet文件 查看Spark的样例数据文件users.parquet 1、在Spark Shell中演示 启动Spark Shell 查看数据帧内容 查看数据帧模式 对数据帧指定列进行查询,查询结果依然是数据帧,然后通过write成员的save()方法写入HDF…...

事件相关功能磁共振波谱技术(fMRS)
导读 质子磁共振波谱(MRS)是一种非侵入性脑成像技术,用于测量不同神经化学物质的浓度。“单体素”MRS数据通常在几分钟内采集,然后对单个瞬态进行平均,从而测量神经化学物质浓度。然而,这种方法对更快速的神经化学物质的时间动态…...

跨境电商客户服务五步法
互联网技术的革新与升级对商务客服产生了巨大的影响,过去由在线客服与客户直接电联的单一服务形式被全渠道客服系统所替代。在电子商务时代,商家与客户之间的互动变得尤为重要:一方面,卖家通过分析客户喜好及消费趋向来针对性处理…...

hadoop环境配置及HDFS配置
环境与配置 ubuntu 20.04.6 /centos8hadoop 3.3.5 指令有部分不一样但是,配置是相同的 安装步骤 创建一个虚拟机,克隆三个虚拟机,master内存改大一点4G,salve内存1Gj修改主机名和配置静态ip(管理员模式下)) hostnamectl set-hostname node1 # 修改主机名 sudo passwd root …...

HTML中 meta的基本应用
meta 标签的定义 meta 标签是 head 部分的一个辅助性标签,提供关于 HTML 文档的元数据。它并不会显示在页面上,但对于机器是可读的。可用于浏览器(如何显示内容或重新加载页面),搜索引擎(SEO)或…...

docker compose 下 Redis 主备配置
1、准备两台虚拟机或者物理机 node1 IP:192.168.123.78 node2 IP:192.168.123.82 2、安装docker和docker compose 3、安装node1,配置docker-compose.yml version: 3services:redis-rs1:container_name: redis_node1image: redis:5.0.3rest…...

Tomcat ServletConfig和ServletContext接口概述
ServletConfig是一个接口,是Servlet规范中的一员 WEB服务器实现了ServletConfig接口,这里指的是Tomcat服务器 一个Servlet对象中有一个ServletConfig对象,Servlet和ServletConfig对象是一对一 ServletConfig对象是Tomcat服务器创建的…...

linux内核open文件流程
打开文件流程 本文基本Linux5.15 当应用层通过open api打开一个文件,内核中究竟如何处理? 本身用来描述内核中对应open 系统调用的处理流程。 数据结构 fdtable 一个进程可以打开很多文件, 内核用fdtable来管理这些文件。 include/linu…...
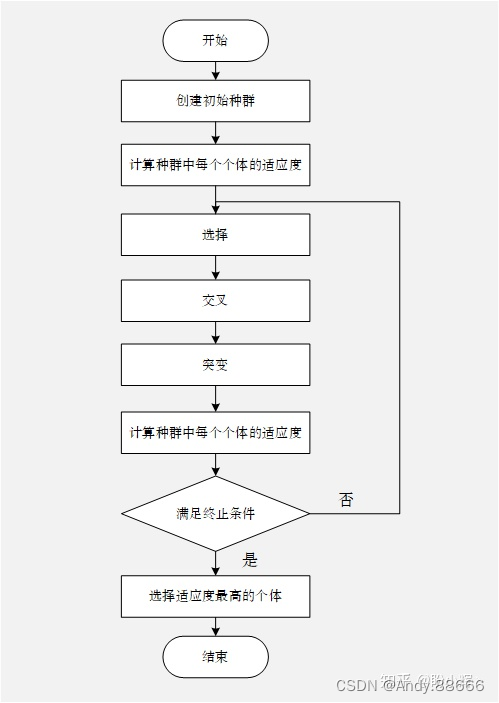
遗传算法讲解
遗传算法(Genetic Algorithm,GA) 是模拟生物在自然环境中的遗传和进化的过程而形成的自适应全局优化搜索算法。它借用了生物遗传学的观点,通过自然选择、遗传和变异等作用机制,实现各个个体适应性的提高。 基因型 (G…...
)
PostgreSQL修炼之道之高可用性方案设计(十六)
20 高可用性方案设计(一) 在一个生产系统中,通常都需要用高可用方案来保证系统的不间断运行。本章将详细介绍如何实现PostgreSQL数据库的高可用方案。 20.1 高可用架构基础 通常数据库的高可用方案都是让多个数据库服务器协同工作࿰…...

Bybit面经
缘起 V2EX有广告内推,看描述还挺不错 贴主5 年半工作经验,有两年大厂工作经历,20 年 11 月来到新加坡分公司开始工作 后来是猎头Jeff找的我 0318 主面 主要一个面试官是后端开发金融背景 某条金融线的负责人;其余是交叉面试。面…...
GORM---创建
目录 模型定义使用Create创建记录一次性创建多条数据批量插入数据时开启事务默认值问题 模型定义 定义一个PersonInfo结构体。 type PersonInfo struct {Id uint64 gorm:"column:id;primary_key;NOT NULL" json:"id"UserName string gorm:"co…...

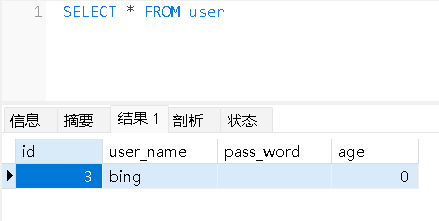
高级查询 — 分组汇总
关于分组汇总 1.概述 将查询结果按某一列或者多列的值分组。 group by子句 分组后聚合函数将作用于每一个组,即每一组都有一个函数值。 语法 select 字段列表 from 表名 where 筛选条件 group by 分组的字段;select 字段列表 from 表名 group by 分组的字段 hav…...

【多线程】阻塞队列
1. 认识阻塞队列和消息队列 阻塞队列也是一个队列,也是一个特殊的队列,也遵守先进先出的原则,但是带有特殊的功能。 如果阻塞队列为空,执行出队列操作,就会阻塞等待,阻塞到另一个线程往阻塞队列中添加元素(…...

python2升级python3
查看当前版本 [roottest-01 node-v18.16.0]# python -V Python 2.7.5 安装依赖 [roottest-01 node-v18.16.0]# yum install -y gcc gcc-c zlib zlib-devel readline-devel 已加载插件:fastestmirror, langpacks Loading mirror speeds from cached hostfile * base…...
(与spark的结合)--非bulk_insert模式)
Apache Hudi初探(八)(与spark的结合)--非bulk_insert模式
背景 之前讨论的都是’hoodie.datasource.write.operation’:bulk_insert’的前提下,在这种模式下,是没有json文件的已形成如下的文件: /dt1/.hoodie_partition_metadata /dt1/2ffe3579-6ddb-4c5f-bf03-5c1b5dfce0a0-0_0-41263-0_202305282…...

从UHS-II到DDR4:2014年存储技术演进与工程实践启示
1. 项目概述:一次2014年秋的存储技术快照九月的风刚带起一丝凉意,存储半导体领域却热闹非凡。作为一名长期跟踪硬件发展的从业者,我习惯定期梳理行业动态,而2014年9月这份来自EE Times的“Memory Product Round Up”产品汇总&…...

芯片巨头并购软件公司:从硬件竞赛到软硬协同的产业变革
1. 行业现象背后的深层逻辑最近和几个在芯片设计公司和EDA软件公司工作的老朋友聊天,大家不约而同地提到了一个趋势:芯片巨头们的手,伸得越来越长了。以前是买IP核、买制造厂,现在则是频频出手,将一家家软件公司收入囊…...

深入解析WeChatFerry:基于RPC与进程注入的微信自动化框架
1. 项目概述:一个为微信自动化而生的强力引擎如果你正在寻找一个能够稳定、高效地控制微信客户端进行自动化操作的解决方案,那么lich0821/WeChatFerry这个项目绝对值得你花时间深入研究。它不是一个简单的消息发送工具,而是一个基于 RPC&…...

VESC驱动无刷电机入门避坑:从看不懂ChibiOS源码到5分钟搞定CAN通讯
VESC驱动无刷电机入门避坑:从看不懂ChibiOS源码到5分钟搞定CAN通讯 第一次接触VESC驱动无刷电机时,面对满屏的ChibiOS源码和复杂的CAN通讯协议,很多嵌入式新手都会感到无从下手。特别是当你已经能用VESC Tool让电机转起来,但想通过…...

小熊猫Dev-C++:5个理由让你爱上这款轻量级C++开发工具
小熊猫Dev-C:5个理由让你爱上这款轻量级C开发工具 【免费下载链接】Dev-CPP A greatly improved Dev-Cpp 项目地址: https://gitcode.com/gh_mirrors/dev/Dev-CPP 在C编程的世界里,寻找一个既功能强大又简单易用的开发环境常常让初学者望而却步。…...

如何快速掌握歌词滚动姬:新手到专家的5个终极秘籍
如何快速掌握歌词滚动姬:新手到专家的5个终极秘籍 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为音乐配上精准的LRC歌词而烦恼吗?歌词…...

Intel Wi-Fi 6 AX201网卡‘代码10’通病?华硕/戴尔/联想多品牌用户自救指南
Intel Wi-Fi 6 AX201网卡‘代码10’故障全解析与跨品牌解决方案 当你的笔记本突然无法连接Wi-Fi,设备管理器中那个带着黄色感叹号的Intel Wi-Fi 6 AX201网卡图标格外刺眼,显示着"该设备无法启动(代码10)"的提示——这不…...
)
告别付费电话!手把手教你用Linphone+SIP搭建免费语音视频通话系统(附服务器配置)
零成本构建企业级音视频通信系统:LinphoneSIP全栈实战指南 在远程协作成为主流的今天,企业每年为商业通信软件支付的订阅费用往往高达数万元。我曾为一家20人团队优化通信成本时发现,仅视频会议一项的年支出就超过3万元——而这一切完全可以通…...

基于MCP协议连接AI与CDP:BlueConic-MCP项目实战解析
1. 项目概述:当营销技术遇上AI代理最近在折腾AI应用开发,特别是围绕OpenAI的Assistant API和各类AI Agent框架时,有一个痛点越来越明显:这些智能体能力再强,如果它们对业务的核心数据一无所知,那也只是一个…...

从零构建Simscape自定义物理模块:核心语法与实战指南
1. 为什么需要自定义Simscape模块? 在工程仿真领域,Simscape作为MATLAB/Simulink生态系统中的物理建模利器,已经内置了大量基础模块。但真实工程问题往往需要处理特殊结构——比如非标齿轮箱的振动分析、微型热管的热传导模拟,或是…...