AI大模型落地不远了!首个全量化Vision Transformer的方法FQ-ViT(附源代码)
点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式

论文地址:https://arxiv.org/pdf/2111.13824.pdf
项目代码:https://github.com/megvii-research/FQ-ViT
计算机视觉研究院专栏
Column of Computer Vision Institute
将算法网络进行量化和模型转换可以显着降低模型推理的复杂性,并在实际部署中得到了广泛的应用。然而,大多数现有的量化方法主要是针对卷积神经网络开发的,并且在完全量化的vision Transformer上应用时会出现严重的掉点。今天我们就分享一个新技术,实现高精度量化的Vit部署。AI大模型落地使用离我们还远吗?

01
总 述
Transformer 是现在火热的AIGC预训练大模型的基础,而ViT(Vision Transformer)是真正意义上将自然语言处理领域的Transformer带到了视觉领域。从Transformer的发展历程就可以看出,从Transformer的提出到将Transformer应用到视觉,其实中间蛰伏了三年的时间。而从将Transformer应用到视觉领域(ViT)到AIGC的火爆也差不多用了两三年。其实AIGC的火爆,从2022年下旬就开始有一些苗条,那时就逐渐有一些AIGC好玩的算法放出来,而到现在,AIGC好玩的项目真是层出不穷。
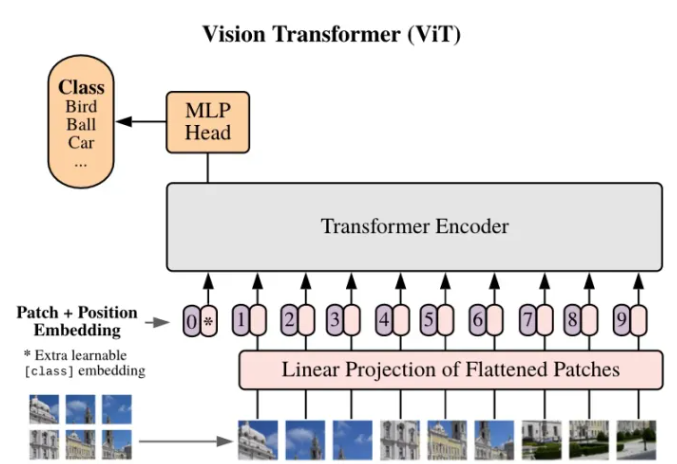
随着近两年来对视觉Transformer模型(ViT)的深入研究,ViT的表达能力不断提升,并已经在大部分视觉基础任务 (分类,检测,分割等) 上实现了大幅度的性能突破。然而,很多实际应用场景对模型实时推理的能力要求较高,但大部分轻量化ViT仍无法在多个部署场景 (GPU,CPU,ONNX,移动端等)达到与轻量级CNN(如MobileNet) 相媲美的速度。
因此,重新审视了ViT的2个专属模块,并发现了退化原因如下:
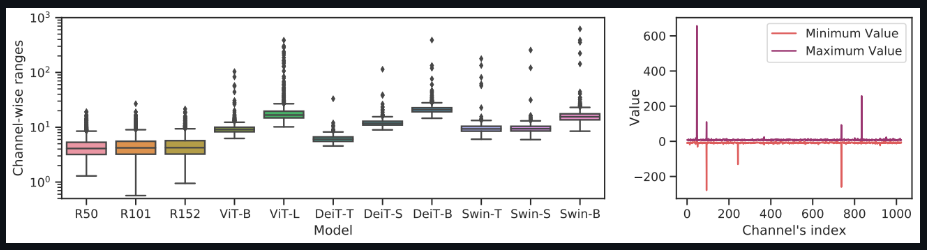
研究者发现LayerNorm输入的通道间变化严重,有些通道范围甚至超过中值的40倍。传统方法无法处理如此大的激活波动,这将导致很大的量化误差
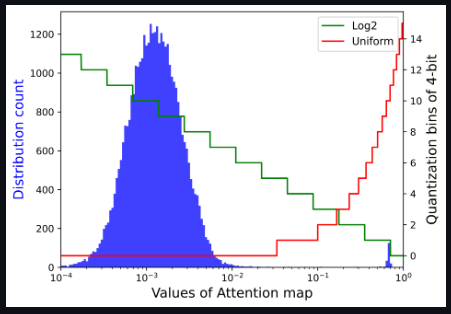
还发现注意力图的值具有极端的不均匀分布,大多数值聚集在0~0.01之间,少数高注意力值接近1
基于以上分析,研究者提出了Power-of-Two Factor(PTF)来量化LayerNorm的输入。通过这种方式,量化误差大大降低,并且由于Bit-Shift算子,整体计算效率与分层量化的计算效率相同。此外还提出了Log Int Softmax(LIS),它为小值提供了更高的量化分辨率,并为Softmax提供了更有效的整数推理。结合这些方法,本文首次实现了全量化Vision Transformer的训练后量化。
02
新框架
下面的这两张图表明,与CNN相比,视觉转换器中存在严重的通道间变化,这导致了分层量化的不可接受的量化误差。
首先解释网络量化符号。假设量化位宽为b,量化器Q(X|b)可以公式化为将浮点数X∈R映射到最近量化仓的函数:
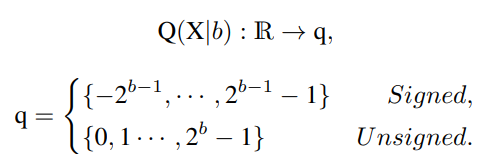
Uniform Quantization
Uniform Quantization在大多数硬件平台上都得到了很好的支持。它的量化器Q(X|b)可以定义为:
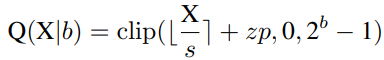
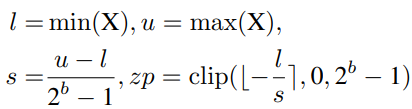
其中s(标度)和zp(零点)是由X的下界l和上界u确定的量化参数,它们通常是最小值和最大值。
Log2 Quantization
Log2 Quantization将量化过程从线性变化转换为指数变化。其量化器Q(X|b)可定义为:
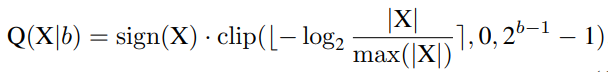
为了实现完全量化的视觉变换器,研究者对所有模块进行量化,包括Conv、Linear、MatMul、LayerNorm、Softmax等。特别是,对Conv、线性和MatMul模块使用均匀的Min-Max量化,对LayerNor和Softmax使用以下方法。
Power-of-Two Factor for LayerNorm Quantization
在推理过程中,LayerNorm计算每个正向步骤中的统计量µX,σX,并对输入X进行归一化。然后,仿射参数γ,β将归一化输入重新缩放为另一个学习分布。
如刚开始解释分析一样,与神经网络中常用的BatchNorm不同,LayerNorm由于其动态计算特性,无法折叠到前一层,因此必须单独量化它。然而,在对其应用训练后量化时观察到显著的性能下降。查看LayerNorm层的输入,发现存在严重的通道间变化。
研究者提出了一种简单而有效的层范数量化方法,即Power-of-Two Factor(PTF)。PTF的核心思想是为不同的信道配备不同的因子,而不是不同的量化参数。给定量化位宽b,输入活动X∈RB×L×C,逐层量化参数s,zp∈R1,以及PTFα∈NC,则量化活动XQ可以公式化为:
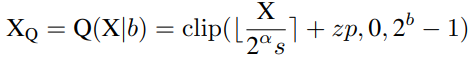
其中部分参数如下:
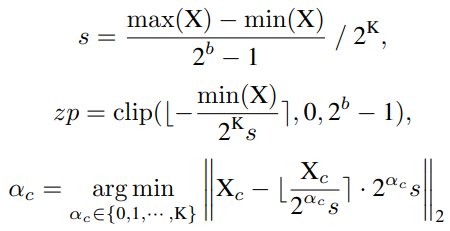
Softmax quantized with Log-Int-Softmax (LIS)
注意图的存储和计算是变压器结构的瓶颈,因此研究者希望将其量化到极低的位宽(例如4位)。然而,如果直接实现4位均匀量化,则会出现严重的精度退化。研究者观察到分布集中在Softmax输出的一个相当小的值上,而只有少数异常值具有接近1的较大值。基于以下可视化,对于具有密集分布的小值区间,Log2保留了比均匀更多的量化区间。
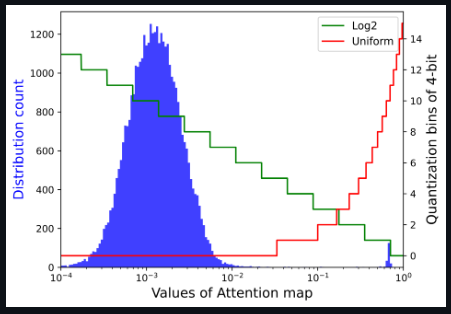
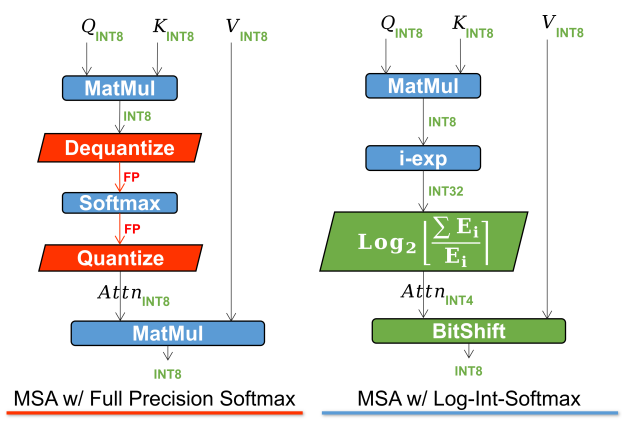
将Log2量化与i-exp(i-BERT提出的指数函数的多项式近似)相结合,提出了LIS,这是一个仅整数、更快、低功耗的Softmax。
整个过程如下所示。
03
实验&可视化
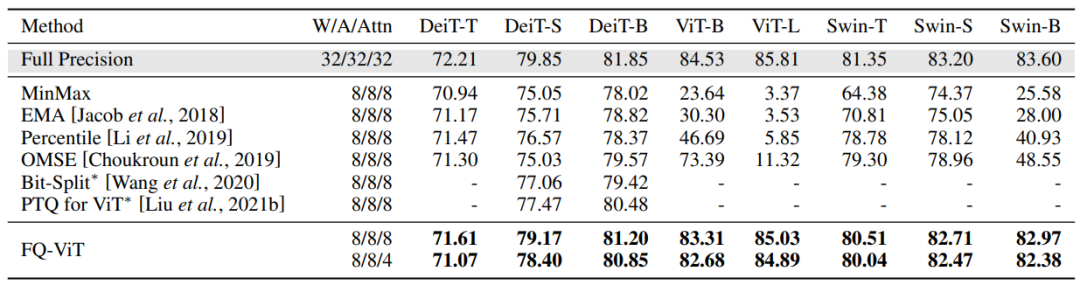
Comparison of the top-1 accuracy with state-of-the-art methods on ImageNet dataset
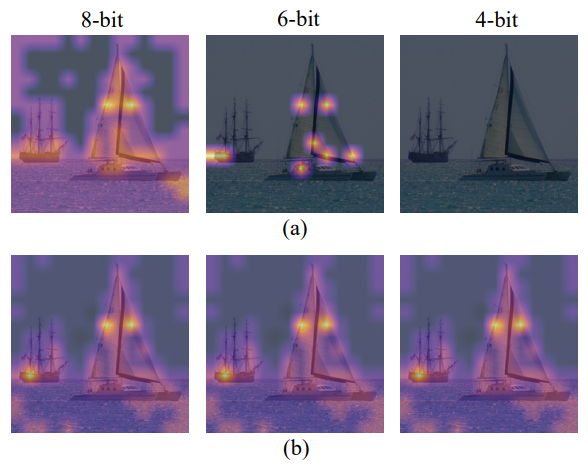
将注意力图可视化,以查看均匀量化和LIS之间的差异,如上图所示。当两者都使用8位时,均匀量化集中在高激活区域,而LIS在低激活区域保留更多纹理,这保留了注意力图的更多相对秩。在8位的情况下,这种差异不会产生太大的差异。然而,当量化到较低的位宽时,如6位和4位的情况所示,均匀量化会急剧退化,甚至使所有关注区域失效。相反,LIS仍然表现出类似于8位的可接受性能。
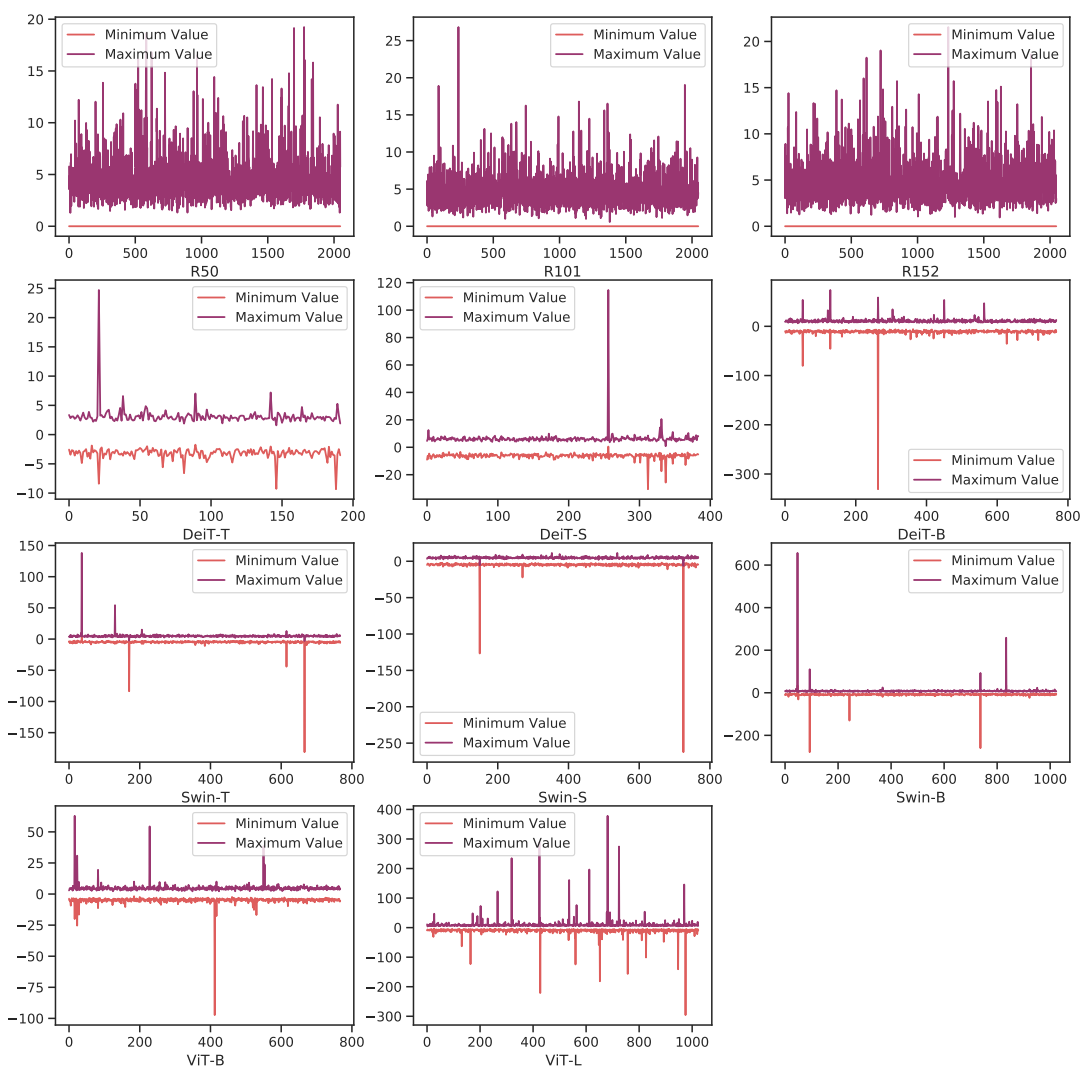
Channel-wise minimum and maximum values of Vision Transformers and ResNets
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!


点击“阅读原文”,立即合作咨询
相关文章:
AI大模型落地不远了!首个全量化Vision Transformer的方法FQ-ViT(附源代码)
点击蓝字 关注我们 关注并星标 从此不迷路 计算机视觉研究院 公众号ID|计算机视觉研究院 学习群|扫码在主页获取加入方式 论文地址:https://arxiv.org/pdf/2111.13824.pdf 项目代码:https://github.com/megvii-research/FQ-ViT 计…...

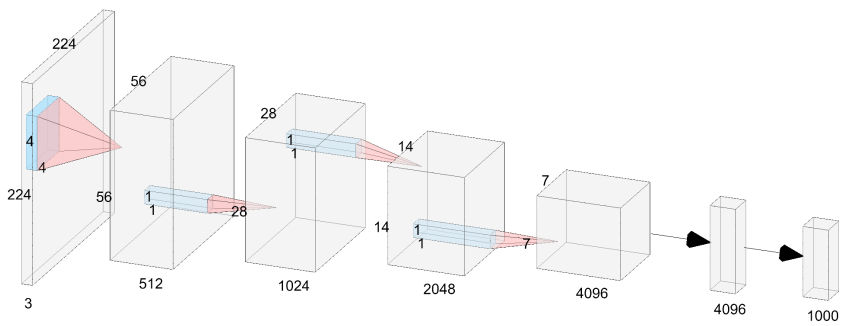
YouTubeDNN
这个youTubeDNN主要是工程导向,对于推荐方向的业界人士真的是必须读的一篇文章。它从召回到排序整个流程都做了描述,真正是在工业界应用的经典介绍。 作者首先说了在工业上YouTube视频推荐系统主要面临的三大挑战: 1.Scale(规模)࿱…...
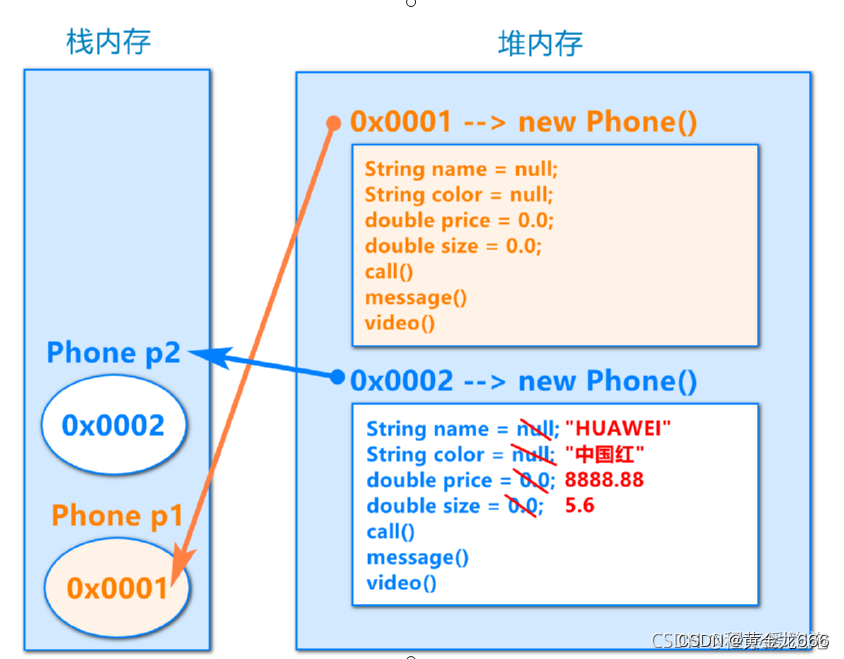
面向对象的介绍和内存
学习面向对象内容的三条主线 • Java 类及类的成员:(重点)属性、方法、构造器;(熟悉)代码块、内部类 • 面向对象的特征:封装、继承、多态、(抽象) • 其他关键字的使用…...

【数据可视化】Plotly Express绘图库使用
Plotly Express是一个基于Plotly库的高级Python可视化库。它旨在使绘图变得简单且直观,无需繁琐的设置和配置。通过使用Plotly Express,您可以使用少量的代码创建具有丰富交互性和专业外观的各种图表。以下是Plotly Express的一些主要特点和优势…...

小红书企业号限流原因有哪些,限流因素
作为企业、品牌在小红书都有官方账号,很多人将注册小红书企业号看作是获取品牌宣推“特权”的必行之举。事实真的如此吗,那为什么小红书企业号限流频发,小红书企业号限流原因有哪些,限流因素。 一、小红书企业号限流真的存在吗 首…...

1.6C++双目运算符重载
C双目运算符重载 C中的双目运算符重载指的是重载二元运算符,即有两个操作数的运算符,如加减乘除运算符“”、“-”、“*”和“/”等。 通过重载双目运算符,可以实现自定义类型的运算符操作。 比如可以通过重载加减运算符实现自定义类型的向…...

CDD诊断数据库的简单介绍
1. 什么是数据库? 数据库是以结构化方式组织的一个数据集合。 比如DBC数据库: Network nodes Display Rx Messages EngineState(0x123) 通过结构化的方式把网络节点Display里Rx报文EngineState(0x123)层层展开。这种方 式的好处是:层次清晰,结构分明,易于查找。 2. 什么…...

【笔试强训选择题】Day25.习题(错题)解析
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:笔试强训选择题 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!ÿ…...

Python心经(6)
目录 callable super type()获取对应类型 isinstance判断对象是否是某个类或者子类的实例 issubclass,判断对象是不是类的子孙类 python3的异常处理 反射: 心经第三节和第五节都写了些面向对象的,这一节补充一…...

MMPose安装记录
参考:GitHub - open-mmlab/mmpose: OpenMMLab Pose Estimation Toolbox and Benchmark. 一、依赖环境 MMPose 适用于 Linux、Windows 和 macOS。它需要 Python 3.7、CUDA 9.2 和 PyTorch 1.6。我的环境: Windows 11 Python 3.9 CUDA 11.6 PyTorch 1.13 …...

梯度下降优化
二阶梯度优化 1.无约束优化算法1.1最小二乘法1.2梯度下降法1.3牛顿法/拟牛顿法 2.一阶梯度优化2.1梯度的数学原理2.2梯度下降算法 3.二阶梯度优化梯度优化3.1 牛顿法3.2 拟牛顿法 1.无约束优化算法 在机器学习中的无约束优化算法中,除了梯度下降以外,还…...

一起看 I/O | 将 Kotlin 引入 Web
作者 / 产品经理 Vivek Sekhar 我们将在本文为您介绍 JetBrains 和 Google 的早期实验性工作。您可以观看今年 Google I/O 大会中的 WebAssembly 相关演讲,了解更多详情: https://youtu.be/RcHER-3gFXI?t604 应用开发者想要尽可能地在更多平台上最大限度地吸引用户…...
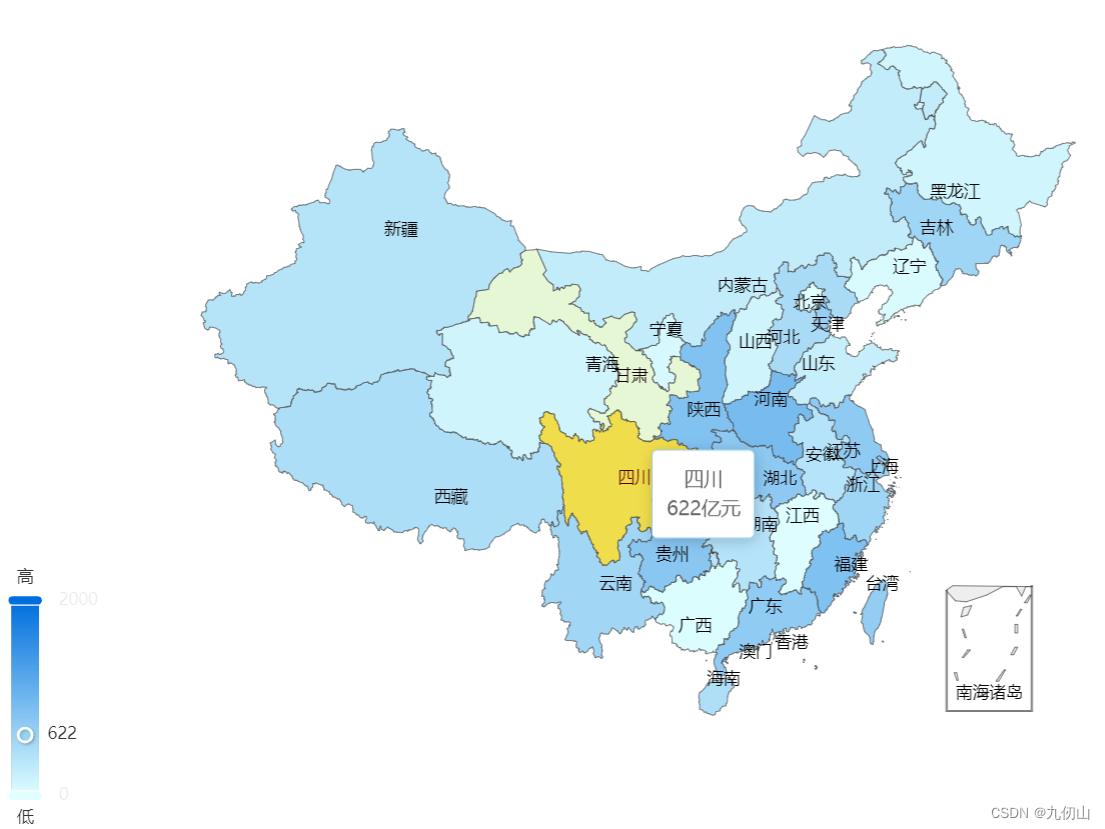
极致呈现系列之:Echarts地图的浩瀚视野(一)
目录 Echarts中的地图组件地图组件初体验下载地图数据准备Echarts的基本结构导入地图数据并注册展示地图数据结合visualMap展示地图数据 Echarts中的地图组件 Echarts中的地图组件是一种用于展示地理数据的可视化组件。它可以显示全国、各省市和各城市的地图,并支持…...
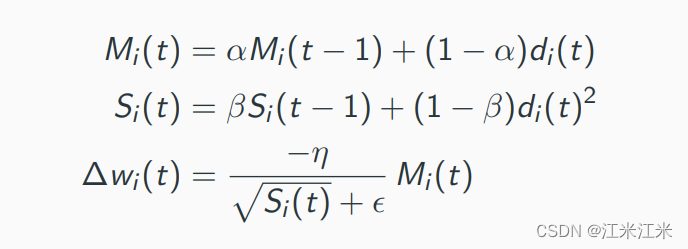
第四章 模型篇:模型训练与示例
文章目录 SummaryAutogradFunctions ()GradientBackward() OptimizationOptimization loopOptimizerLearning Rate SchedulesTime-dependent schedulesPerformance-dependent schedulesTraining with MomentumAdaptive learning rates optim.lr_scheluder Summary 在pytorch_t…...
利用人工智能模型学习Python爬虫
爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 网络爬虫(又称为网页蜘蛛,网络机器人)是其中一种类型。 爬虫可以自动化浏览网络中的信息,当然浏览信息的时候需要按照我们制定的规则进行,这些规则我们称之为网络…...

.Net泛型详解
引言 在我们使用.Net进行编程的过程中经常遇到这样的场景:对于几乎相同的处理,由于入参的不同,我们需要写N多个重载,而执行过程几乎是相同的。更或者,对于几乎完成相同功能的类,由于其内部元素类型的不同&…...
——存储类)
C++ 教程(10)——存储类
存储类定义 C 程序中变量/函数的范围(可见性)和生命周期。这些说明符放置在它们所修饰的类型之前。下面列出 C 程序中可用的存储类: autoregisterstaticexternmutablethread_local (C11) 从 C 17 开始,auto 关键字不再是 C 存储…...

vue3+vite+element-plus创建项目,修改主题色
element-plus按需引入,修改项目的主题色 根据官方文档安装依赖 npm install -D unplugin-vue-components unplugin-auto-import vite.config.js配置 // vite.config.ts import { defineConfig } from vite import AutoImport from unplugin-auto-import/vite …...

mysql select是如何一步步执行的呢?
mysql select执行流程如图所示 server侧 在8.0之前server存在查询语句对应数据的缓存,不过在实际使用中比较鸡肋,对于更新比较频繁、稍微改点查询语句都会导致缓存无法用到 解析 解析sql语句为mysql能够直接执行的形式。通过词法分析识别表名、字段名等…...

找到距离最近的点,性能最好的方法
要找到距离最近的点并且性能最好,一种常用的方法是使用空间数据结构来加速搜索过程。以下是两个常见的数据结构和它们的应用: KD树(KD-Tree):KD树是一种二叉树数据结构,用于对k维空间中的点进行分割和组织…...

【实战指南】Ubuntu SSH服务配置与XShell/Xftp高效连接全解析
1. 为什么需要SSH远程连接Ubuntu? 作为开发者或运维人员,我们经常需要管理远程服务器。想象一下,你正在咖啡馆用Windows笔记本,突然需要紧急修改线上Ubuntu服务器的配置——这时候SSH就是你的救命稻草。它就像一把安全钥匙&#x…...

基于Lepton AI构建对话式搜索引擎:RAG技术实践指南
1. 项目概述:用Lepton AI构建你的对话式搜索引擎 如果你对AI应用开发感兴趣,尤其是想快速搭建一个能理解自然语言、并能联网搜索的智能助手,那么“Search with Lepton”这个项目绝对值得你花时间研究。它本质上是一个开源的对话式搜索引擎框…...
)
AI大模型赋能数据治理:小白也能掌握的5个高频场景与避坑指南(收藏备用)
数据治理是企业数字化转型难题,AI大模型带来破局点。本文阐述大模型如何解决效率低、门槛高、适配弱等痛点,提供3个高价值落地场景(非结构化数据治理、数据质量治理、数据资产化治理)及5个高频踩坑陷阱,并给出最佳实践…...

体验Taotoken聚合路由在单一模型临时故障时的自动容灾效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 体验Taotoken聚合路由在单一模型临时故障时的自动容灾效果 在实际的AI应用开发与集成过程中,服务的稳定性是开发者关注…...

5步实现Cursor Pro永久免费:终极破解工具完整指南
5步实现Cursor Pro永久免费:终极破解工具完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial r…...

Axure RP中文语言包技术深度解析:从键值对到国际化架构的工程实践
Axure RP中文语言包技术深度解析:从键值对到国际化架构的工程实践 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 在…...

PowerBI主题模板终极指南:35款可视化模板快速美化报表
PowerBI主题模板终极指南:35款可视化模板快速美化报表 【免费下载链接】PowerBI-ThemeTemplates Snippets for assembling Power BI Themes 项目地址: https://gitcode.com/gh_mirrors/po/PowerBI-ThemeTemplates 还在为PowerBI报表的单调外观而烦恼吗&#…...

2026年十大主流需求管理工具深度测评:哪款更适合你的研发团队?
在软件研发日益复杂化、团队协作边界不断拓展的今天,需求管理不仅是产品经理的基本功,更是整个产品生命周期管理的“神经中枢”。你是否经历过这些问题:版本上线后,发现遗漏了某个关键需求?需求记录散落在 Excel、微信…...

VS2019编译OpenSceneGraph 3.6.5踩坑全记录:从CMake配置到解决第三方库缺失
VS2019编译OpenSceneGraph 3.6.5实战避坑指南 第一次在Windows平台用VS2019编译OpenSceneGraph 3.6.5时,我原以为按照官方文档就能轻松搞定。直到CMake报出一连串第三方库缺失的红色警告,才意识到这趟编译之旅远没有想象中简单。如果你也正对着Could NOT…...

Go语言构建高效命令行工具集:claworc项目架构解析与实战应用
1. 项目概述:一个为开发者赋能的命令行工具集 最近在GitHub上闲逛,发现了一个名为 gluk-w/claworc 的项目。乍一看这个标题,有点摸不着头脑, claworc 听起来像是个自造词,结合 gluk-w 这个用户名,感觉…...