【Neo4j教程之CQL命令基本使用】

| 🚀 Neo4j 🚀 |
🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀
🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨
🌲 作者简介:硕风和炜,CSDN-Java领域优质创作者🏆,保研|国家奖学金|高中学习JAVA|大学完善JAVA开发技术栈|面试刷题|面经八股文|经验分享|好用的网站工具分享💎💎💎
🌲 恭喜你发现一枚宝藏博主,赶快收入囊中吧🌻
🌲 人生如棋,我愿为卒,行动虽慢,可谁曾见我后退一步?🎯🎯
| 🚀 Neo4j 🚀 |


🍔 目录
- 🌟 Neo4j的CQL详细使用教程
- 🚩 Neo4j官方CQL手册
- 🌟 CQL 基本语法
- 🥗 创建节点
- 🥗 创建关系
- 🥗 查询节点
- 🥗 修改节点
- 🥗 DELETE命令
- 🍗 CQL中的DELETE基本语法
- 🍗 CQL案例演示
- 🌭 案例一:删除节点
- 🌭 案例二:删除一类节点
- 🌭 案例三:删除关系
- 🌭 案例四:批量删除
- 🥗 REMOVE命令
- 🍗 CQL中的REMOVE基本语法
- 🍗 CQL案例演示
- 🌭 案例一:移除节点属性
- 🌭 案例二:移除节点列表属性
- 🥗 ORDER BY排序
- 🥗 UNION合并
- 🍗 UNION合并命令的语法
- 🍗UNION合并命令的案例演示
- 🌭 案例一:合并两个查询结果集
- 🌭 案例二:合并多个查询结果集
- 🌭 案例三:合并多个关系查询结果集
- 🥗 UNION ALL子句
- 🍗 UNION ALL合并命令的语法
- 🍗UNION ALL合并命令的案例演示
- 🌭 案例一:合并两个查询结果集
- 🌭 案例二:合并多个查询结果集
- 🌭 合并多个关系查询结果集
- 🥗 LIMIT和SKIP子句
- 🍗 CQL中的LIMIT和SKIP基本语法
- 🍗 CQL案例演示
- 🌭 案例一:使用LIMIT和SKIP合并命令限制查询结果
- 🌭 案例二:使用LIMIT和SKIP合并命令控制返回的关系
- 🌭 案例三:使用组合LIMIT和SKIP合并命令实现分页
- 🥗 Merge合并
- 🍗 CQL中的MERGE基本语法
- 🍗 CQL案例演示
- 🌭 案例一:使用MERGE创建新节点
- 🌭 案例二:使用MERGE更新现有节点
- 🌭 案例三:使用MERGE创建或更新关系
- 🥗 NULL值
- 🥗 IN操作符
- 🌟 总结
- 💬 共勉
🌟 Neo4j的CQL详细使用教程
Neo4j是一款高度可伸缩的图形数据库,它使用Cypher查询语言处理图形数据。但是,Neo4j还可以使用CQL(Cypher Query Language)作为处理和查询数据的替代方式。本篇博客将介绍如何使用CQL查询语言在Neo4j中创建、修改和查询数据,以及一些常见的案例演示。
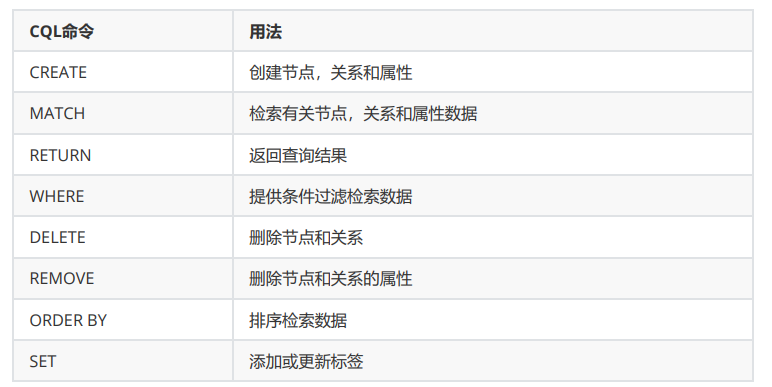
🚩 Neo4j官方CQL手册
Neo4j官方指导手册
🌟 CQL 基本语法
在学习CQL之前,有必要先学习一些基本的语法、键和操作符。
🥗 创建节点
要在Neo4j中创建一个节点,需要使用以下语法:
CREATE (node_name:label_type {property:value});
其中:
CREATE: 创建新节点。node_name: 节点的名称。label_type: 节点所属的标签类型。property:value: 节点属性和值。
例如,要创建一个名为John的人员节点,具有名为age的属性和值为30的值,可以使用以下命令:
CREATE (John:Person { age: 30 });
如果要创建多个带有相同标签的节点,则可以使用以下语法:
CREATE (node_name_1:label_type {property:value}), (node_name_2:label_type {property:value}), ...;
例如,要创建两个分别名为John和Sandra的人员节点,都属于Person标签,可以使用以下命令:
CREATE (John:Person { age: 30 }), (Sandra:Person { age: 25 });
🥗 创建关系
在Neo4j中,关系是将两个节点连接在一起的东西。要在Neo4j中创建关系,需要使用以下语法:
CREATE (node_name_1:label_type)-[:relationship_type {property:value}]->(node_name_2:label_type);
其中:
node_name_1: 路径的开始节点。label_type: 开始节点的标签类型。relationship_type: 路径的关系类型。property:value: 关系属性和值。
例如,要在两个已经创建的节点之间创建FRIENDS_WITH关系,可以使用以下命令:
MATCH (node1:Person {name: "John"}), (node2:Person {name: "Sandra"})
CREATE (node1)-[:FRIENDS_WITH {years:3}]->(node2);
🥗 查询节点
要在Neo4j中查询节点,需要使用以下语法:
MATCH (node_name:label_type) WHERE node_name.property = value RETURN node_name;
其中:
MATCH: 匹配查询模式。node_name: 匹配节点的名称。label_type: 匹配节点所属标签类型。WHERE: 匹配额外的条件。property: 节点属性。value: 节点属性的值。RETURN: 返回匹配到的结果。
例如,要查询某条关系的节点,可以使用以下命令:
MATCH (:Person {name: "John"})-[:FRIENDS_WITH]->(p:Person) RETURN p;
🥗 修改节点
要在Neo4j中修改节点信息,需要使用以下语法:
MATCH (node_name:label_type {property:value}) SET node_name.new_property = new_value;
其中:
MATCH: 匹配查询模式。node_name: 匹配节点的名称。label_type: 匹配节点所属标签类型。property: 节点属性。value: 节点属性的值。SET: 设置节点的新属性。new_property: 节点新的属性。new_value: 节点新属性的值。
例如,要更改John节点的年龄属性为40,可以使用以下命令:
MATCH (p:Person {name: 'John'})
SET p.age = 40
RETURN p;
🥗 DELETE命令
在Neo4j的CQL(Cypher Query Language)中,DELETE命令是用于删除节点和关系的重要命令。本篇博客将介绍如何使用DELETE命令在Neo4j中删除数据,以及一些实际的案例演示。
🍗 CQL中的DELETE基本语法
要在Neo4j中删除节点和关系,您可以使用以下语法:
MATCH (node_name:label_type {property:value}) OPTIONAL MATCH (node_name)-[relation:relationship_type]-()
DELETE node_name, relation;
其中:
MATCH: 匹配查询模式。node_name: 匹配节点的名称。label_type: 匹配节点所属标签类型。property: 节点属性。value: 节点属性的值。OPTIONAL MATCH: 连接可选的查询模式。relationship_type: 查询模式中的关系类型。relation: 匹配的关系。DELETE: 删除匹配的节点和关系。
例如,要删除节点名称为Jane的Person节点和连接至该节点的所有关系,可以使用以下命令:
MATCH (p:Person {name: 'Jane'})
OPTIONAL MATCH (p)-[r]-()
DELETE p, r;
这将删除节点p以及与之相关的所有关系。
🍗 CQL案例演示
接下来,我们将介绍一些关于使用CQL进行删除的实际案例。
🌭 案例一:删除节点
假设我们要删除一个标签类型为Person的节点。以下是删除节点操作的示例代码:
MATCH (p:Person {name: 'John'})
OPTIONAL MATCH (p)-[r]-()
DELETE p, r;
这将删除名为John的Person节点及其连接的关系。
🌭 案例二:删除一类节点
假设我们要删除标签类型为Person的所有节点。以下是删除所有Person节点及其关系的示例代码:
MATCH (p:Person)
OPTIONAL MATCH (p)-[r]-()
DELETE p, r;
这将删除所有标签类型为Person的节点及其与之关联的关系。
🌭 案例三:删除关系
此时,我们要删除John节点和Sandra节点之间的FRIENDS_WITH关系。以下是删除指定关系的示例代码:
MATCH (:Person {name: "John"})-[r:FRIENDS_WITH]-(:Person {name: "Sandra"})
DELETE r;
这将删除John和Sandra节点之间的FRIENDS_WITH关系。
🌭 案例四:批量删除
有时候,我们需要根据某些条件,对数据进行批量删除。例如,我们要删除所有Person节点的年龄小于30岁或超过40岁的节点。以下是示例代码:
MATCH (p:Person)
WHERE p.age < 30 OR p.age > 40
OPTIONAL MATCH (p)-[r]-()
DELETE p, r;
这将删除所有Person节点的年龄小于30岁或大于40岁的节点及其与之关联的所有关系。
🥗 REMOVE命令
🍗 CQL中的REMOVE基本语法
要在Neo4j中修改节点属性,可以使用以下语法:
MATCH (node_name:label_type {property:value})
REMOVE node_name.property_name;
其中:
MATCH: 匹配查询模式。node_name: 匹配节点的名称。label_type: 匹配节点所属标签类型。property: 节点属性。value: 节点属性的值。REMOVE: 删除匹配节点的指定属性名及其值。
例如,要删除名为John的Person节点的age属性,可以使用以下命令:
MATCH (p:Person {name: 'John'})
REMOVE p.age;
这将删除名为John的Person节点的age属性。
🍗 CQL案例演示
接下来,我们将介绍一些关于使用CQL进行属性修改的实际案例。
🌭 案例一:移除节点属性
此时,我们要移除名为John的Person节点的age属性。以下是移除指定属性的示例代码:
MATCH (p:Person {name: 'John'})
REMOVE p.age;
这将删除名为John的Person节点的age属性。
🌭 案例二:移除节点列表属性
如果要删除节点上的列表属性中的某个元素,可以使用以下语法:
MATCH (n {name: 'Alice'})
REMOVE n.prop[index];
例如,在删除一个名为Alice节点上的列表属性prop的第二个元素时,可以使用以下命令:
MATCH (n {name: 'Alice'})
REMOVE n.prop[1];
这将删除节点n上prop列表属性的第二个元素。
🥗 ORDER BY排序
CQL还提供了用于排序结果的功能。
- 过滤条件可以使用
WHERE语句指定,例如根据属性值过滤节点或关系。 - 排序可以使用
ORDER BY语句指定,例如按属性值对结果进行升序或降序排序。
MATCH (node:Label)
WHERE node.property = value
RETURN node
ORDER BY node.property ASC|DESC
🥗 UNION合并
UNION合并命令是CQL中的一种关键字,它将两个或多个相同类型的查询结果合并成一个结果集返回给用户。UNION合并命令通常用于将多个子查询的结果集合并为一个完整的结果集,并对这些结果进行排序和筛选。
🍗 UNION合并命令的语法
MATCH (n:Label)
WHERE n.property = 'value'
RETURN n.property
UNION
MATCH (m:Label)
WHERE m.property = 'other_value'
RETURN m.other_property
ORDER BY n.property DESC
🍗UNION合并命令的案例演示
假设我们有一个图,其中包含了多个节点和关系,我们需要查询这个图中与“Tom”节点和“Jerry”节点相连的所有节点,并将结果用UNION合并命令合并起来。
🌭 案例一:合并两个查询结果集
假设我们需要查询两个标签类型为Person的节点集合,并将它们合并为一个结果集。以下是合并两个查询结果集的示例代码:
MATCH (p:Person)
WHERE p.age > 30
RETURN p.name
UNION
MATCH (p:Person)
WHERE p.gender = 'male'
RETURN p.name;
这将返回age大于30岁和性别为male的所有人的名称,其中重复的结果会被合并成一个结果。
🌭 案例二:合并多个查询结果集
如果我们想从多个标签类型为Person的节点集合中检索信息,比如想查看所有age超过40岁或者性别为female的人。以下是合并多个查询结果集的示例代码:
MATCH (p:Person)
WHERE p.age > 40
RETURN p.name
UNION
MATCH (p:Person)
WHERE p.gender = 'female'
RETURN p.name
UNION
MATCH (p:Person)
WHERE p.nationality = 'USA'
RETURN p.name;
这将返回满足年龄、性别和国籍条件的所有人的名称,其中重复的结果会被合并成一个结果。
🌭 案例三:合并多个关系查询结果集
此时,我们想要找到与特定节点相关联的所有朋友和家庭成员。以下是基于关系合并多个查询结果集的示例代码:
MATCH (n:Person {name: 'John'})-[:FRIENDS_WITH]->(f)
RETURN f.name
UNION
MATCH (n:Person {name: 'John'})-[:IS_FAMILY_OF]->(f)
RETURN f.name;
这将返回名称为John的Person节点的朋友和家庭成员名称。
🥗 UNION ALL子句
在Neo4j的CQL(Cypher Query Language)中,UNION ALL是一种用于合并多个查询结果集的关键字,它与UNION的区别是它不会合并重复的结果。本篇博客将介绍如何使用UNION ALL命令在Neo4j中合并多个查询结果集,以及一些实际的案例演示。
🍗 UNION ALL合并命令的语法
要在Neo4j中将多个查询结果集合并,可以使用以下语法:
QUERY1
UNION ALL
QUERY2
UNION ALL
QUERY3
...
其中,QUERY1,QUERY2,QUERY3等都是要合并的查询语句,UNION ALL命令用于合并这些查询结果集并返回一个整体的结果集,不去除任何重复的结果。
🍗UNION ALL合并命令的案例演示
接下来,我们将介绍一些使用CQL进行结果集合并的实际案例。
🌭 案例一:合并两个查询结果集
假设我们需要查询两个标签类型为Person的节点集合,并将它们合并为一个结果集。以下是合并两个查询结果集的示例代码:
MATCH (p:Person)
WHERE p.age > 30
RETURN p.name AS name
UNION ALL
MATCH (p:Person)
WHERE p.gender = 'male'
RETURN p.name AS name;
这将返回age大于30岁和性别为male的所有人的名称,没有去除任何重复的结果。
🌭 案例二:合并多个查询结果集
如果我们想从多个标签类型为Person的节点集合中检索信息,比如想查看所有age超过40岁或者性别为female的人。以下是合并多个查询结果集的示例代码:
MATCH (p:Person)
WHERE p.age > 40
RETURN p.name AS name
UNION ALL
MATCH (p:Person)
WHERE p.gender = 'female'
RETURN p.name AS name
UNION ALL
MATCH (p:Person)
WHERE p.nationality = 'USA'
RETURN p.name AS name;
这将返回满足年龄、性别和国籍条件的所有人的名称,并将它们合并为一个结果集,没有去除任何重复的结果。
🌭 合并多个关系查询结果集
此时,我们想要找到与特定节点相关联的所有朋友和家庭成员。以下是基于关系合并多个查询结果集的示例代码:
MATCH (n:Person {name: 'John'})-[:FRIENDS_WITH]->(f)
RETURN f.name AS name
UNION ALL
MATCH (n:Person {name: 'John'})-[:IS_FAMILY_OF]->(f)
RETURN f.name AS name;
这将返回名称为John的Person节点的朋友和家庭成员名称,并将它们合并为一个结果集,没有去除任何重复的结果。
🥗 LIMIT和SKIP子句
在Neo4j的CQL(Cypher Query Language)中,LIMIT和SKIP是两个用于控制查询结果集返回的子句,可以被组合在一起使用来限制查询的结果。本篇博客将介绍如何使用LIMIT和SKIP子句合并命令来控制查询结果集的返回顺序,以及一些实际的案例演示。
🍗 CQL中的LIMIT和SKIP基本语法
要在Neo4j中限制查询结果集返回的数量,可以使用以下语法:
MATCH (n)
RETURN n.property
LIMIT n
SKIP m
其中,n表示要返回的结果集数量,m表示要跳过的结果集数量。使用LIMIT和SKIP子句时,返回的结果集将会是从跳过指定数量的结果集之后的前n个结果集。
🍗 CQL案例演示
接下来,我们将介绍一些使用CQL进行结果集控制的实际案例。
🌭 案例一:使用LIMIT和SKIP合并命令限制查询结果
假设我们需要查询标签类型为Person的节点集中年龄大于30岁的前5个结果。以下是限制查询结果的示例代码:
MATCH (p:Person)
WHERE p.age > 30
RETURN p.name AS name
ORDER BY p.age DESC
SKIP 0
LIMIT 5;
这将返回年龄大于30岁的前5个人的名称,并按照年龄降序排序。
🌭 案例二:使用LIMIT和SKIP合并命令控制返回的关系
假设我们需要查询与标签类型为Person的节点集中Tom节点相邻的所有节点,并且我们想返回这些节点的前3个结果。以下是控制返回关系的示例代码:
MATCH (n:Person { name: "Tom" })--(m)
RETURN m.name AS name
LIMIT 3;
这将返回与名称为Tom的Person节点相邻的前3个节点的名称。
🌭 案例三:使用组合LIMIT和SKIP合并命令实现分页
假设我们希望为查询结果分页,每页显示5个结果集,我们可以使用组合LIMIT和SKIP子句的方法实现分页。以下是对查询结果分页的示例代码:
MATCH (p:Person)
WHERE p.age > 30
RETURN p.name AS name, p.age AS age
ORDER BY p.age DESC
SKIP 5
LIMIT 5;
这将返回年龄大于30岁的结果中的第二页(跳过前5个结果集)中的前5个结果,以姓名和年龄的形式呈现。
🥗 Merge合并
在Neo4j的CQL(Cypher Query Language)中,MERGE是一种用于创建或更新节点和关系的关键字。它可以用于合并现有的节点和关系,也可以用于创建新的节点和关系。本篇博客将介绍如何使用MERGE子句合并命令来创建或更新节点和关系的操作,以及一些实际的案例演示。
🍗 CQL中的MERGE基本语法
要在Neo4j中使用MERGE子句创建或更新节点和关系,可以使用以下语法:
MERGE (n:Node { property: value })
ON CREATE SET n.property_1 = value_1, n.property_2 = value_2, ...
ON MATCH SET n.existing_property = value
其中,n表示要创建或更新的节点,Node表示节点的标签,property表示节点的属性,value表示属性的值。ON CREATE和ON MATCH子句分别表示在创建和更新节点时设置属性的值。
🍗 CQL案例演示
接下来,我们将介绍一些使用CQL进行节点和关系处理的实际案例。
🌭 案例一:使用MERGE创建新节点
假设我们要在名称为Person的节点集合中创建一个名为Tom的新节点,并将它的年龄设置为28岁。以下是创建新节点的示例代码:
MERGE (p:Person {name: 'Tom'})
ON CREATE SET p.age = 28;
这将在名称为Person的节点集合中创建一个名为Tom的新节点,并将它的属性age设置为28岁。
🌭 案例二:使用MERGE更新现有节点
假设我们要更新名称为Person的节点集合中名称为Tom的节点的属性age为29岁。以下是更新现有节点的示例代码:
MERGE (p:Person {name: 'Tom'})
ON MATCH SET p.age = 29;
这将查询名称为Person的节点集合中名称为Tom的节点,如果它已经存在,则更新它的age属性为29岁。
🌭 案例三:使用MERGE创建或更新关系
此时,我们想要查找标志为Person的节点集合中的两个节点之间是否存在关系FRIENDS_WITH,如果不存在,则创建这个关系。以下是创建或更新关系的示例代码:
MATCH (p:Person {name: 'Tom'}), (q:Person {name: 'Jerry'})
MERGE (p)-[r:FRIENDS_WITH]->(q)
ON CREATE SET r.type = 'friendship', r.since = '2020'
ON MATCH SET r.type = 'friendship';
这将在节点Tom和Jerry之间创建一个带有类型和时间戳的FRIENDS_WITH关系。如果已经存在该关系,则只更新它的type属性。
注意:
可以使用MERGE命令来查找现有的节点和关系,如果它们不存在,则创建它们;如果它们已经存在,则更新它们的属性。读者可以用这些命令来创建新节点和关系,更新现有节点和关系,在节点集合中搜索和处理数据。相信通过本篇博客的学习,读者已经能够熟练使用CQL中的MERGE子句合并命令了。
🥗 NULL值
-
Neo4j CQL将空值视为对节点或关系的属性的缺失值或未定义值。
-
当我们创建一个具有现有节点标签名称但未指定其属性值的节点时,它将创建一个具有NULL属性值的新节点。
-
还可以用null 作为查询的条件。
🥗 IN操作符
与SQL一样,Neo4j CQL提供了一个IN运算符,以便为CQL命令提供值的集合。
IN [<Collection-of-values>]
案例:
MATCH (e:Employee)
WHERE e.id IN [12,34]
RETURN e.id,e.name,e.sal,e.deptno
🌟 总结
本篇博客向读者介绍了CQL基本语法,包括创建节点、创建关系、查询节点、修改节点等基础操作。相信通过本篇博客的学习,读者已经掌握了如何在Neo4j中使用CQL进行数据处理和查询。
💬 共勉
| 最后,我想和大家分享一句一直激励我的座右铭,希望可以与大家共勉! |


相关文章:
【Neo4j教程之CQL命令基本使用】
🚀 Neo4j 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,C…...
Apikit 自学日记:发起文档测试-TCP/UDP
进入某个TCP/UDP协议的API文档详情页,点击文档上方 测试 标签,即可进入 API 测试页,系统会根据API文档的定义的求头部、Query参数、请求体自动生成测试界面并且填充测试数据。 填写/修改请求参数 1.1设置请求参数 与发起HTTP协议测试类似&am…...

坚鹏:中国邮储银行金融科技前沿技术发展与应用场景第1期培训
中国邮政储蓄银行金融科技前沿技术发展与应用场景第1期培训圆满结束 中国邮政储蓄银行拥有优良的资产质量和显著的成长潜力,是中国领先的大型零售银行。2016年9月在香港联交所挂牌上市,2019年12月在上交所挂牌上市。中国邮政储蓄银行拥有近4万个营业网点…...
HBase分布式安装配置
首先 先安装zookeeper ZooKeeper配置 解压安装 解压 tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt 改名 mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7 在根目录下创建两个文件夹 mkdir Zlogs mkdir Zdata配置zoo.cfg文件,在解压后的ZooKeep…...

Microsoft365有用吗?2023最新版office有哪些新功能?
office自97版到现在已有20多年,一直是作为行业标准,格式和兼容性好,比较正式,适合商务使用。包含多个组件,除了常用的word、excel、ppt外,还有收发邮件的outlook、管理数据库的access、排版桌面的publisher…...

结构体的定义与实例化
结构体的定义与实例化 在Go语言中,结构体是一种用户自定义的数据类型(复合类型,而非引用类型),可以用来封装多个不同类型的数据成员。结构体的定义和实例化分别如下: 结构体的定义 结构体的定义使用关键…...

canvas详解03-绘制图像和视频
canvas 更有意思的一项特性就是图像操作能力。可以用于动态的图像合成或者作为图形的背景,以及游戏界面(Sprites)等等。浏览器支持的任意格式的外部图片都可以使用,比如 PNG、GIF 或者 JPEG。你甚至可以将同一个页面中其他 canvas 元素生成的图片作为图片源。 引入图像到 …...

VB+ACCESS高校题库管理系统设计与实现
开发数据库题库管理系统主要是为了建立一个统一的题库,并对其用计算机进行管理,使教师出题高效、快捷。 其开发主要包括后台数据库的建立、维护以及前端应用程序的开发两个方面。对于前者要求建立起数据一致性和完整性强、数据安全性好的库。而对于后者则要求应用程序功能完…...
centos 安装 nginx
1.下载nginx安装包 wget -c https://nginx.org/download/nginx-1.24.0.tar.gz 下载到了当前目录下 2.解压安装包 解压后的结果 3.安装依赖 yum -y install gcc gcc-c make libtool zlib zlib-devel openssl openssl-devel pcre pcre-devel 4. ./configure --prefix/usr/lo…...
TCP/IP详解(一)
TCP/IP协议是Internet互联网最基本的协议,其在一定程度上参考了七层OSI(Open System Interconnect,即开放式系统互联)模型 OSI参考模型是国际组织ISO在1985年发布的网络互联模型,目的是为了让所有公司使用统一的规范来…...

three.js的学习
Threejs 1 前言 Three.js是基于原生WebGL封装运行的三维引擎,在所有WebGL引擎中,Three.js是国内文资料最多、使用最广泛的三维引擎。 既然Threejs是一款WebGL三维引擎,那么它可以用来做什么想必你一定很关心。所以接下来内容会展示大量基于…...
Spark
Spark 概述 Apache Spark是用于大规模数据处理的统一分析计算引擎 Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量硬件之上,形成集群。 spark与Hadoop的…...
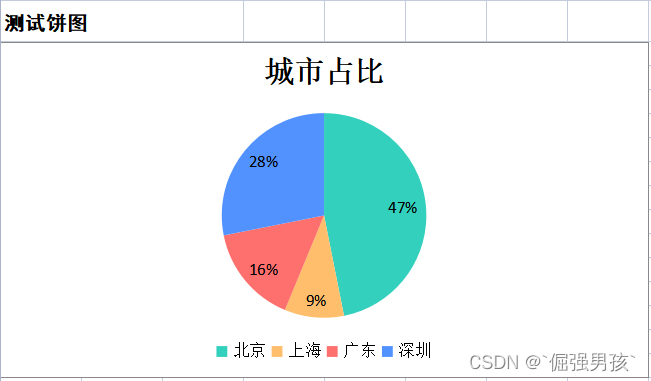
poi生成excel饼图设置颜色
效果 实现 import com.gideon.entity.ChartPosition; import com.gideon.entity.LineChart; import com.gideon.entity.PieChart; import org.apache.poi.ss.usermodel.*; import org.apache.poi.ss.util.CellRangeAddress; import org.apache.poi.xddf.usermodel.PresetColo…...
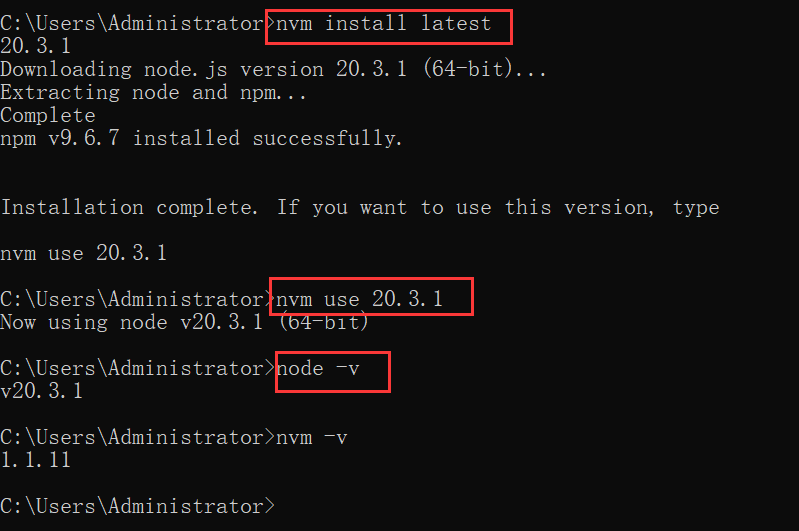
多版本管理node.js
多版本管理node.js 1. 安装2. 配置使用2.1 修改node源2.2 常用命令 在Windows 计算机上管理node.js的多个安装版本。 这是朋友推荐的,就是自己在升级node的时候给搞崩了, 不得不提升效率,于是发现了这个好工具,可以反过来理解&…...
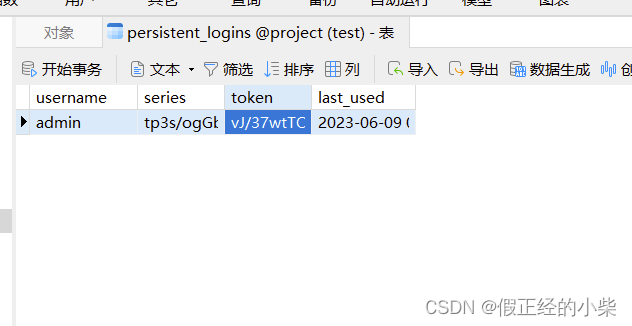
【深入浅出 Spring Security(七)】RememberMe的实现原理详讲
RememberMe 的实现原理 一、RememberMe 的基本使用二、RememberMeAuthenticationFilter 源码分析RememberMeServicesTokenBasedRememberMeServicesTokenBasedRememberMeServices 中对 processAutoLoginCookie 方法的实现总结原理图式 三、提高安全性PersistentTokenBasedRememb…...

Cesium 实战 - 使用 gltf-vscode 查看、预览以及编辑 glTF 和 GLB 模型
Cesium 实战 - 使用 gltf-vscode 查看、预览以及编辑 glTF 和 GLB 模型 VScode(Visual Studio Code) 安装模型必要插件VScode 预览自定义关节(articulations)动作VScode 导入 GLB 格式模型VScode 导出 GLB 格式模型 模型渲染作为 …...

Python自动化测试框架:Pytest和Unittest的区别
pytest和unittest是Python中常用的两种测试框架,它们都可以用来编写和执行测试用例,但两者在很多方面都有所不同。本文将从不同的角度来论述这些区别,以帮助大家更好地理解pytest和unittest。 1. 原理 pytest是基于Python的assert语句和Pytho…...
考研算法29天:希尔排序 【希尔排序】
算法介绍 希尔排序 等差数列 普通版插入排序 循环数组 第一次每n/2为间隔分为4组,然后组内排序。 第二次每n/4为间隔分为2组。然后组内排序 第三次n/8为间隔分为一组。然后组内排序。 组内排序用插入排序来排序。 注:也可以第一次为n/3为间隔&am…...
RN 学习小记之使用 Expo 创建项目
本文Hexo博客链接🔗 https://ysx.cosine.ren/react-native-note-1 xLog链接🔗 https://x.cosine.ren/react-native-note-1 RSS订阅 📢 https://x.cosine.ren/feed/xml 由于业务需要,开始学习RN以备后面的需求,而虽然之…...

python爬虫从入门到精通
目录 一、正确认识Python爬虫 二、了解爬虫的本质 1. 熟悉Python编程 2. 了解HTML 3. 了解网络爬虫的基本原理 4. 学习使用Python爬虫库 三、了解非结构化数据的存储 1. 本地文件 2. 数据库 四、掌握各种技巧,应对特殊网站的反爬措施 1. User-Agent 2. C…...

大多数团队不是“用不好 PPO”,而是“用错了 PPO”
更多时候,你会听到的是: “PPO 太复杂了,算了”“调了一轮,模型变怪了”“感觉不如再多搞点 SFT 数据” 于是 PPO 很容易被贴上一个标签: “理论上很强,工程上很坑。” 但这个结论,其实并不公…...
)
手把手教你配置Figma MCP:打造属于你自己的AI驱动设计组件库(以阅读题为例)
智能设计革命:用Figma MCP构建AI驱动的交互式学习组件库 当设计系统遇上生成式AI,一场关于效率与智能化的变革正在悄然发生。在Figma中构建可动态响应数据的智能组件库,已成为中高级UI/UX设计师突破传统设计边界的必备技能。本文将深入解析如…...
)
STM32CubeMX项目实战:从新建工程到驱动LED,一步步教你玩转HAL库(附代码解析)
STM32CubeMX实战指南:HAL库驱动LED的底层逻辑与工程化思维 第一次打开STM32CubeMX时,那种面对密密麻麻的配置选项却不知从何下手的焦虑感,相信每位嵌入式开发者都记忆犹新。不同于传统寄存器操作的直白,HAL库和图形化配置工具带来…...

电子电路中的“心脏”:电源
一、语言特性:Java 26 与模式匹配进化 1.1 Java 26 语言级别支持 IDEA 2026.1 EAP 最引人注目的变化之一,就是新增 Java 26 语言级别支持。这意味着开发者可以提前体验和测试即将在 JDK 26 中正式发布的语言特性。 其中最重要的变化是对 JEP 530 的全面支…...
的完整指南)
SAP-FICO LSMW实战:批量导入财务凭证与固定资产主数据(AS91)的完整指南
1. LSMW基础概念与适用场景 第一次接触LSMW这个工具时,我也被它复杂的界面吓到过。但用顺手后发现,这简直是SAP数据迁移的"瑞士军刀"。简单来说,LSMW(Legacy System Migration Workbench)是SAP系统内置的数…...

windows java jar 包后台运行
使用 javaw 实现后台运行(简单场景)这是最简单的方法。Java 自带的 javaw.exe 是 java.exe 的变体,它运行程序时不会打开任何控制台窗口。操作步骤:创建一个新的文本文件,命名为 start.bat。在文件中写入以下内容&…...

群晖7.2 Docker小白也能搞定:手把手教你部署WPS Office并绑定自己的域名
群晖7.2 Docker部署WPS Office全攻略:从零搭建专属云端办公平台 在数字化办公时代,拥有一个随时可访问的私有化办公套件不仅能提升团队协作效率,更能确保数据安全。本文将带你一步步在群晖NAS上通过Docker部署WPS Office,并绑定专…...

3个高效技巧:百度网盘秒传工具实现跨平台文件管理
3个高效技巧:百度网盘秒传工具实现跨平台文件管理 【免费下载链接】baidupan-rapidupload 百度网盘秒传链接转存/生成/转换 网页工具 (全平台可用) 项目地址: https://gitcode.com/gh_mirrors/bai/baidupan-rapidupload 在数字化时代,高效文件传输…...

终极指南:Lottie动画版本管理的5个专业技巧
终极指南:Lottie动画版本管理的5个专业技巧 【免费下载链接】lottie Lottie documentation for http://airbnb.io/lottie. 项目地址: https://gitcode.com/gh_mirrors/lo/lottie Lottie是Airbnb开发的开源动画库,它能让开发者轻松地在移动应用和网…...
)
Java开发必看:解决国密SM2算法报错‘Unknown named curve‘的完整指南(附Bouncy Castle配置)
Java开发实战:国密SM2算法Unknown named curve报错深度解析与Bouncy Castle最佳配置指南 金融级Java应用开发中,国密算法SM2的集成就像在钢筋森林里铺设光纤——看似简单却暗藏技术陷阱。当控制台突然抛出Unknown named curve: 1.2.156.10197.1.301这个看…...