Kafka与Flume的对比分析
Kafka与Flume的对比分析
- 一、Kafka和Flume
- 1. Kafka架构
- 2. Flume架构
- 3. Kafka和Flume异同点
- 二、Kafka和Flume的性能对比
- 1. 数据处理性能对比
- 2. 大规模数据流处理的性能对比
- 三、性和稳定性对比
- 1. 高可用集群的搭建
- Kafka
- Flume
- 2. 数据丢失和重复消费的问题处理
- Kafka
- Flume
- 四、适用场景对比
- 1. Kafka的适用场景
- 2. Flume的适用场景
- 3. Kafka和Flume适用场景的异同点
- 五、生态系统对比
- 1. Kafka的生态系统
- 2. Flume的生态系统
- 3. Kafka和Flume生态系统的异同点
- 六、Kafka和Flume的优缺点对比
- 1. Kafka的优缺点
- 优点
- 缺点
- 2. Flume的优缺点
- 优点
- 缺点
一、Kafka和Flume
1. Kafka架构
Kafka是一个分布式、高吞吐量的消息队列,在架构上主要由生产者、消费者和中间件组成,其中:
- 生产者:将数据发布到指定的topic,同时支持数据压缩、异步发送等特性
- 消费者:从指定的topic订阅数据,并能够实现数据的自动负载均衡、复制和容错等功能
- 中间件:实现了数据的存储和传输,并保证了数据可靠性、顺序性等特点
Kafka的工作流程如下:
- 生产者将消息发布到topic中
- 中间件负责存储和管理消息
- 消费者从topic中订阅消息,进行消费
2. Flume架构
Flume是一个分布式、高可靠性的大数据采集系统,在架构上主要由三个组件组成,包括:
- Agent:采集数据的代理,由source、sink和channel三部分构成,可以实现数据的过滤、转换、聚合和分发等功能
- Collector:用于收集 Flume Agent 产生的数据,负责多个Agent之间的协调和管理
- Receiver:将Collector获取到的数据传输给HDFS或其他目标存储
Flume的工作流程如下:
- Agent采集数据,通过source过滤等处理后,将数据存储到channel中
- Collector协调多个Agent,将数据转发给Receiver
- Receiver将数据传输至目标存储(如HDFS)
3. Kafka和Flume异同点
Kafka与Flume最大的不同在于基础架构的设计不同。Kafka是一种更通用的系统,可用于更广泛的事物(包括消息队列、事件存储或日志存储),而Flume则是专门为日志存储及采集而设。
在数据处理中,Kafka具有更高的吞吐量和更低的延迟,同时也支持更高级别的语义保证。而Flume在安全性和数据处理的多样性方面更具优势,并且易于部署和管理。具体使用要视需要和场景而定。
二、Kafka和Flume的性能对比
1. 数据处理性能对比
针对结构化数据和非结构化数据的处理性能,根据实验测试结果,可以得出以下结论:
- 对于结构化数据,Kafka具有更高的处理性能和更低的延迟,Flume的性能比较平稳,但相对较低。
- 就非结构化数据处理而言,Kafka和Flume的性能差异并不明显,2者差异不到1000tps。
2. 大规模数据流处理的性能对比
在大规模数据流处理方面,Kafka具有更高的性能稳定性和编写程序复杂度的简单性。Kafka相对于Flume而言,支持分布式消费、重平衡等特性,适合应用在数据采集、实时计算等大数据场景。同时,Kafka的生态也更加完善丰富,支持更多的数据类型和协议。
三、性和稳定性对比
在数据管道架构中Kafka和Flume是两个非常流行的开源工具,用于在分布式环境下高效地传递数据。虽然它们都有着类似的目标,但它们之间有一些关键性的不同点和优缺点。
1. 高可用集群的搭建
Kafka
Kafka使用Zookeeper作为协调器,通过选举机制来实现高可用性。Kafka集群至少需要3个Broker才能保证高可用性。当其中一个Broker宕机时,Zookeeper会协调新的Leader的选举过程。
Kafka还有一种生产者确认机制:acks。它决定了生产者发送消息之后是否需要接收Broker的确认信息。确认级别可以设置成0,1或all。
Flume
Flume有多种配置方式,其中一种是主备结构。当主服务不可用时,备份服务器将自动接管流程,以保证数据丢失的最小化降低。
2. 数据丢失和重复消费的问题处理
Kafka
Kafka通过写入磁盘文件来持久化消息,并在各Partition中处理消息,以防止数据丢失和重复消费。每个Partition都有一个Offset,消费者可以跟踪每个Partition的Offset,以确保数据的正确性。
Flume
在默认配置下,Flume不支持在数据处理过程中的重复消费。当Flume Server停止并重新启动时,可以通过记录已经发送给Sink的最后一个事件的时间戳来减少重复消费。另外,可以使用消息标记(Mark)来管理消息的偏移量,确保消息传递的顺序
四、适用场景对比
1. Kafka的适用场景
Kafka通常被用于以下场景:
- 适用于高吞吐量、低延迟的工作负载;
- 能够很好地处理不同来源(如流、批处理、数据仓库等)的大量数据,并且可以提供可靠的消息传递保证;
- 适用于需要使用Spark, Flink等分布式计算系统进行实时数据处理的场景;
- 可以用于解耦消息发送和接收者,因为发送方不需要等待返回值。
2. Flume的适用场景
Flume适用于以下场景:
- 适用于采集少量数据,如单个文件或少量的实时数据;
- 它被广泛用于将日志收集到Hadoop上并进行自动化的ETL处理;
- Flume还可以用于连接各种传感器,传输一些非结构化的日志信息或文本格式的数据。
3. Kafka和Flume适用场景的异同点
- 对于大规模数据传输,或具有可靠消息传递保证的高吞吐量工作负载,Kafka更为合适;
- 对于小规模数据传输和Hadoop日志收集等ETL处理,Flume更为适合;
- 如果需要对数据进行实时处理,并且需要使用Spark、Flink等分布式处理系统,则Kafka是首选。
五、生态系统对比
1. Kafka的生态系统
Kafka是一个分布式流处理平台,它的生态系统非常丰富。以下是Kafka的主要组件和功能:
- 生产者:将消息发布到Kafka话题。
- 消费者:从Kafka话题消费消息。
- Kafka Connect:可与各种数据系统(如关系型数据库和Hadoop)集成的插件框架。
- Kafka Streams:用于构建实时流处理应用程序的客户端库。
- KSQL:基于流的SQL引擎,可用于实时数据分析和处理。
2. Flume的生态系统
Flume是一款大数据采集工具,它的生态系统相对简单。以下是Flume的主要组件和功能:
- Source:从数据源(如本地日志或网络传输)采集数据。
- Channel:缓存正在传输的事件,确保事件不会在不同组件之间丢失。
- Sink:将事件转发给目标,如HDFS或Kafka。
3. Kafka和Flume生态系统的异同点
Kafka和Flume生态系统的最大的区别在于定位和功能。Kafka更专注于流处理和分布式数据管道,而Flume则更加偏向于数据采集和传输。
六、Kafka和Flume的优缺点对比
1. Kafka的优缺点
优点
- 高吞吐量:Kafka可以处理大量数据并获得高吞吐量。
- 可伸缩性:可以水平扩展Kafka集群,以满足存储和吞吐量要求的不断增长。
- 可靠性:对于数据丢失,Kafka使用复制机制和持久性存储来保证数据安全性。
缺点
- 复杂性高:Kafka需要专业技能才能有效地配置和管理。
- 可视化工具缺少:除了Kafka Manager外,Kafka没有很多可视化管理工具。
2. Flume的优缺点
优点
- 易于使用:相对来说,Flume的配置和管理较为简单。
- 能够在不同数据源之间移动数据:Flume可以从多个不同的来源采集数据,并将其发送到目标地点,如Hadoop或Kafka。
缺点
- 吞吐量限制:Flume的吞吐量相较于Kafka较低。
- 不适合流处理:Flume不是一个用于流处理的设计工具。
相关文章:

Kafka与Flume的对比分析
Kafka与Flume的对比分析 一、Kafka和Flume1. Kafka架构2. Flume架构3. Kafka和Flume异同点 二、Kafka和Flume的性能对比1. 数据处理性能对比2. 大规模数据流处理的性能对比 三、性和稳定性对比1. 高可用集群的搭建KafkaFlume 2. 数据丢失和重复消费的问题处理KafkaFlume 四、适…...
)
docker启动redis哨兵报错(sentinel.conf is not writable: Permission denied)
Sentinel config file /usr/local/sentinel/sentinel.conf is not writable: Permission denied. Exiting… 用这个命令不报错:docker run --net host -p 6666:6666–name redis-sentinel -v /usr/mcc/redis/conf:/usr/local/sentinel/ -v /usr/mcc/redis/data/sent…...

如何编写优秀代码
最近在阅读别人写的代码,进行相应功能的修改。发现很多不规范或者比较绕的地方,总有那么几句看着多此一举,阅读别人的代码就是这样,有时候真的不懂写代码的人当时怎么想的。 例如有这么一段: 用户输入一个名字&#…...

信道编码:Matlab RS编码、译码使用方法
Matlab RS编码、译码使用方法 1. 相关函数 在MATLAB中进行RS编码的过程可以使用rsenc()函数或者comm.RSEncoder()函数。 1.1 rsenc()函数使用方法 在MATLAB中帮助中可以看到有三种使用形式,分别为 code rsenc(msg,n,k) code rsenc(msg,n,k,genpoly) code rs…...
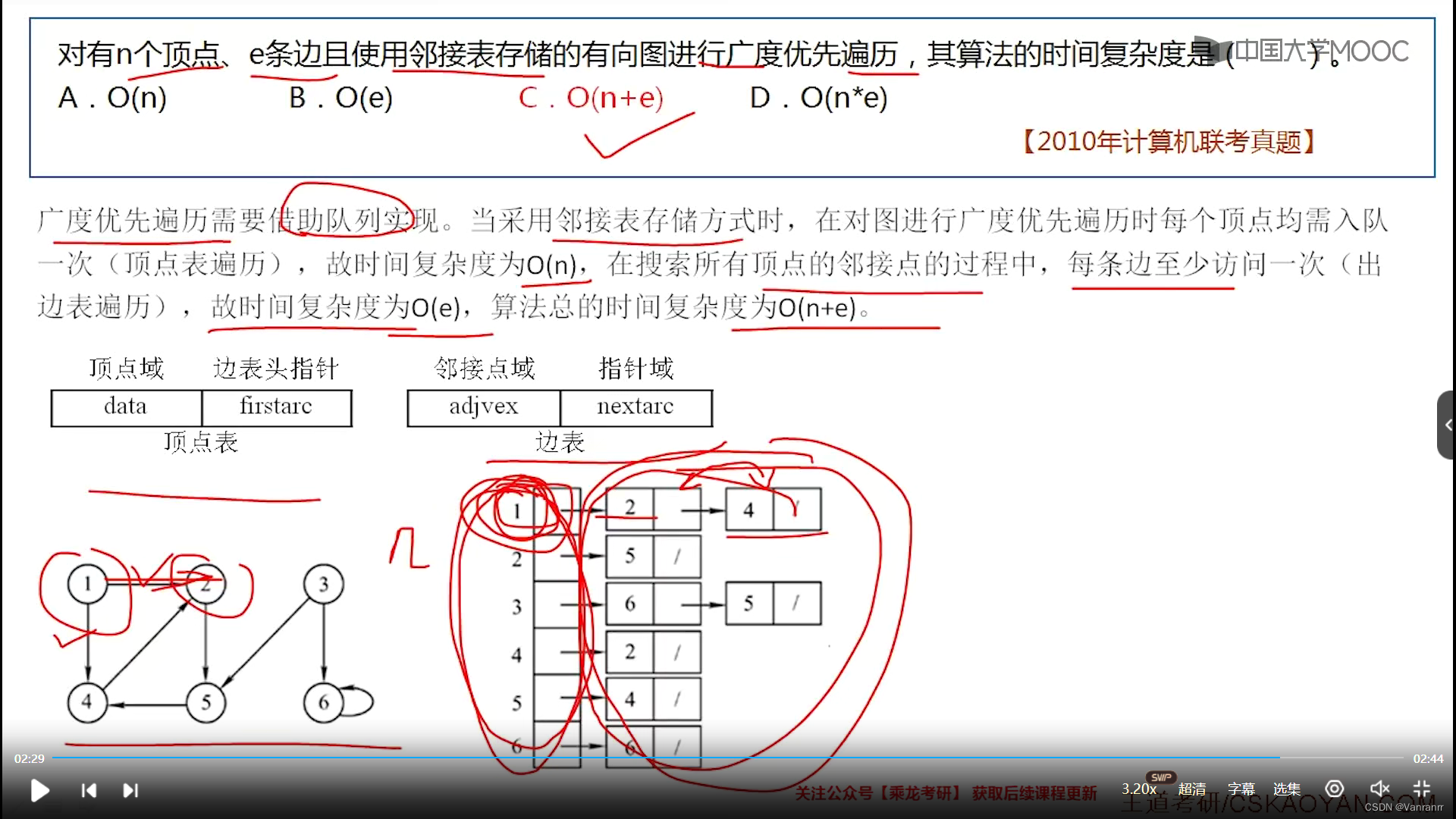
数据结构第六章 图 6.1-6.3 错题整理
6.1 6.C 加上一个点实现非连通 去除每个边都是一颗不同的生成树 一共n条边 13.C n个顶点、e条边的无向图,森林。树的角度看,除了根节点没有一条边与其对应,其他顶点都对应一条边,用顶点-边得出有多少颗树 14.A II 等于 也可以…...
12 MFC常用控件(一)
文章目录 button 按钮设置默认按钮按下回车后会响应禁用开启禁用设置隐藏设置显示设置图片设置Icon设置光标 Cbutton 类创建按钮创建消息单选按钮多选按钮 编辑框组合框下拉框操作 CListBox插入数据获取当前选中 CListCtrl插入数据设置表头修改删除 button 按钮 设置默认按钮按…...
Springboot搭配Redis实现接口限流
目录 介绍 限流的思路 代码示例 必需pom依赖 自定义注解 redis工具类 redis配置类 主拦截器 注册拦截器 介绍 限流的需求出现在许多常见的场景中: 秒杀活动,有人使用软件恶意刷单抢货,需要限流防止机器参与活动 某 api 被各式各样…...

php中的双引号与单引号的基本使用
字符串,在各类编程语言中都是一个非常重要的数据类型 网页当中的图片,文字,特殊符号,HTMl标签,英文等都属于字符串 PHP字符串变量用于存储并处理文本, 在创建字符串之后,我们就可以对它进行操作。我们可以直接在函数中使用字符串,或者把它存储在变量中 字…...

【Neo4j教程之CQL命令基本使用】
🚀 Neo4j 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,C…...
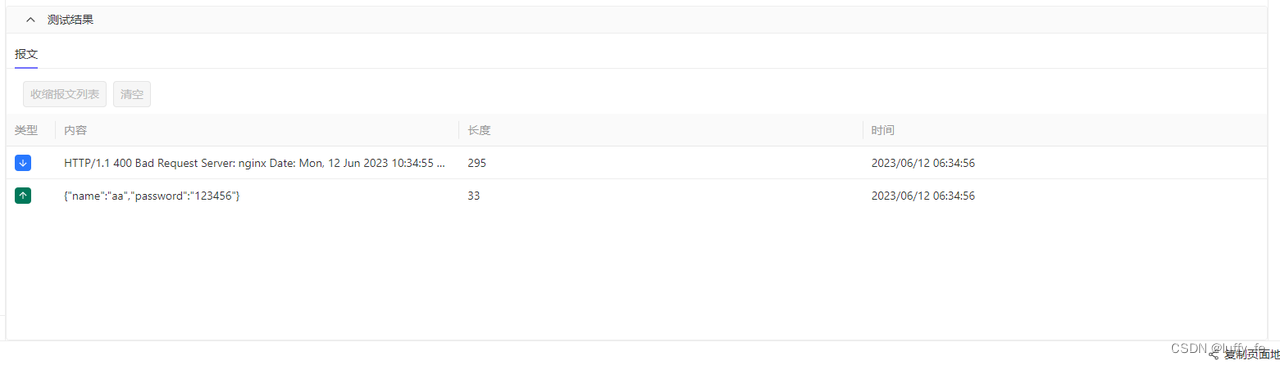
Apikit 自学日记:发起文档测试-TCP/UDP
进入某个TCP/UDP协议的API文档详情页,点击文档上方 测试 标签,即可进入 API 测试页,系统会根据API文档的定义的求头部、Query参数、请求体自动生成测试界面并且填充测试数据。 填写/修改请求参数 1.1设置请求参数 与发起HTTP协议测试类似&am…...

坚鹏:中国邮储银行金融科技前沿技术发展与应用场景第1期培训
中国邮政储蓄银行金融科技前沿技术发展与应用场景第1期培训圆满结束 中国邮政储蓄银行拥有优良的资产质量和显著的成长潜力,是中国领先的大型零售银行。2016年9月在香港联交所挂牌上市,2019年12月在上交所挂牌上市。中国邮政储蓄银行拥有近4万个营业网点…...
HBase分布式安装配置
首先 先安装zookeeper ZooKeeper配置 解压安装 解压 tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt 改名 mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7 在根目录下创建两个文件夹 mkdir Zlogs mkdir Zdata配置zoo.cfg文件,在解压后的ZooKeep…...

Microsoft365有用吗?2023最新版office有哪些新功能?
office自97版到现在已有20多年,一直是作为行业标准,格式和兼容性好,比较正式,适合商务使用。包含多个组件,除了常用的word、excel、ppt外,还有收发邮件的outlook、管理数据库的access、排版桌面的publisher…...

结构体的定义与实例化
结构体的定义与实例化 在Go语言中,结构体是一种用户自定义的数据类型(复合类型,而非引用类型),可以用来封装多个不同类型的数据成员。结构体的定义和实例化分别如下: 结构体的定义 结构体的定义使用关键…...

canvas详解03-绘制图像和视频
canvas 更有意思的一项特性就是图像操作能力。可以用于动态的图像合成或者作为图形的背景,以及游戏界面(Sprites)等等。浏览器支持的任意格式的外部图片都可以使用,比如 PNG、GIF 或者 JPEG。你甚至可以将同一个页面中其他 canvas 元素生成的图片作为图片源。 引入图像到 …...

VB+ACCESS高校题库管理系统设计与实现
开发数据库题库管理系统主要是为了建立一个统一的题库,并对其用计算机进行管理,使教师出题高效、快捷。 其开发主要包括后台数据库的建立、维护以及前端应用程序的开发两个方面。对于前者要求建立起数据一致性和完整性强、数据安全性好的库。而对于后者则要求应用程序功能完…...
centos 安装 nginx
1.下载nginx安装包 wget -c https://nginx.org/download/nginx-1.24.0.tar.gz 下载到了当前目录下 2.解压安装包 解压后的结果 3.安装依赖 yum -y install gcc gcc-c make libtool zlib zlib-devel openssl openssl-devel pcre pcre-devel 4. ./configure --prefix/usr/lo…...
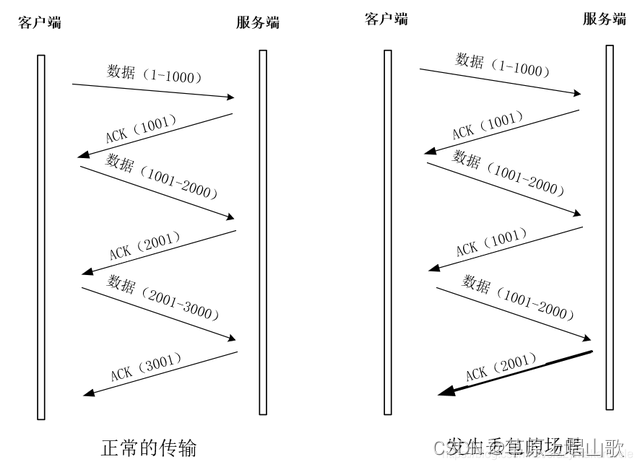
TCP/IP详解(一)
TCP/IP协议是Internet互联网最基本的协议,其在一定程度上参考了七层OSI(Open System Interconnect,即开放式系统互联)模型 OSI参考模型是国际组织ISO在1985年发布的网络互联模型,目的是为了让所有公司使用统一的规范来…...

three.js的学习
Threejs 1 前言 Three.js是基于原生WebGL封装运行的三维引擎,在所有WebGL引擎中,Three.js是国内文资料最多、使用最广泛的三维引擎。 既然Threejs是一款WebGL三维引擎,那么它可以用来做什么想必你一定很关心。所以接下来内容会展示大量基于…...
Spark
Spark 概述 Apache Spark是用于大规模数据处理的统一分析计算引擎 Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量硬件之上,形成集群。 spark与Hadoop的…...

【可分离架构物理信息神经网络:破解维度灾难的分离变量方法论】第2章 SPINN:可分离物理信息神经网络架构
目录 (Chapter 2: SPINN: Separable Physics-Informed Neural Networks) 2.1 SPINN的架构设计原理 2.1.1 按坐标轴的体网络(Body Networks)设计 2.1.2 特征融合机制与参数效率 2.2 前向模式自动微分与计算优化 2.2.1 前向自动微分在分离架构中的优势 2.2.2 超大规模配…...

Boomer:轻量高效的Linux屏幕放大镜工具
Boomer:轻量高效的Linux屏幕放大镜工具 【免费下载链接】boomer Zoomer application for Linux 项目地址: https://gitcode.com/gh_mirrors/boo/boomer 当你需要精准查看屏幕细节时是否常感到操作繁琐?无论是设计工作中的像素级调整、编程时的代码…...

N_m3u8DL-CLI-SimpleG:让M3U8视频下载变得简单高效的图形化工具
N_m3u8DL-CLI-SimpleG:让M3U8视频下载变得简单高效的图形化工具 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 在数字内容日益丰富的今天,我们经常遇到需…...

如何快速配置Windows三指拖动功能:ThreeFingerDragOnWindows完整指南
如何快速配置Windows三指拖动功能:ThreeFingerDragOnWindows完整指南 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/Thre…...

ClaudeCode 入门详细教程,手把手带你Vibe Coding
本文使用 Mac 进行演示。主要是在安装环节有环境差异。 1. Claude Code 简介 Claude Code 是 Anthropic 推出的面向开发者的 AI 编程协作工具。Claude Code 的核心目标是理解你的整个项目,并参与到真实的编码、修改和重构过程中。Claude Code 不是一个代码生成器&…...
)
从‘翻车’到稳定:手把手教你用Matlab极点配置驯服小车倒立摆(附Simulink模型)
用Matlab极点配置实现小车倒立摆的精准控制:从理论到Simulink实战 倒立摆系统作为控制理论中的经典案例,完美展现了动态系统稳定控制的挑战与魅力。想象一下,一根垂直向上的杆子放在移动小车上,任何微小的扰动都会导致杆子倾倒——…...

Qwen3.5-9B Java面试宝典生成器:动态定制八股文与场景题
Qwen3.5-9B Java面试宝典生成器:动态定制八股文与场景题 1. 为什么需要智能面试助手 Java开发者求职路上,最头疼的莫过于海量面试题的整理和记忆。传统方式要么依赖网上零散的八股文合集,要么自己手动整理知识点,效率低下且难以…...

HunyuanVideo-Foley高算力适配:RTX4090D显存利用率优化至92%实测
HunyuanVideo-Foley高算力适配:RTX4090D显存利用率优化至92%实测 1. 镜像概述与核心优势 HunyuanVideo-Foley私有部署镜像专为视频与音效生成任务深度优化,基于RTX 4090D 24GB显存硬件平台打造。经过CUDA 12.4与驱动550.90.07的针对性调优,…...

EPWM模块影子寄存器的加载机制与应用场景解析
1. EPWM模块影子寄存器基础概念 第一次接触EPWM模块的影子寄存器时,我也被这个"影子"的概念绕晕了。后来在实际项目中调试电机控制才发现,这个机制简直是PWM波形控制的"安全气囊"。简单来说,影子寄存器就是活动寄存器的&…...

JienDa聊PHP:ThinkPHP 8.0 企业级API开发与性能调优实战
1. ThinkPHP 8.0企业级API开发基础 ThinkPHP 8.0作为现代化PHP框架的代表,在企业级API开发领域展现出强大的优势。我最近刚用TP8完成了一个日活50万的电商平台API重构,实测下来性能提升非常明显。相比传统开发方式,TP8的API开发流程更加规范…...