MySQL 中的 distinct 和 group by 哪个效率更高
先说大致的结论(完整结论在文末):
在语义相同,有索引的情况下:group by和distinct都能使用索引,效率相同。
在语义相同,无索引的情况下:distinct效率高于group by。原因是distinct 和 group by都会进行分组操作,但group by可能会进行排序,触发filesort,导致sql执行效率低下。
基于这个结论,你可能会问:
为什么在语义相同,有索引的情况下,group by和distinct效率相同?
在什么情况下,group by会进行排序操作?
带着这两个问题找答案。接下来,我们先来看一下distinct和group by的基础使用。另外,如果你近期准备面试跳槽,建议在Java面试库小程序在线刷题,涵盖 2000+ 道 Java、MySQL 面试题,几乎覆盖了所有主流技术面试题。
distinct的使用
distinct用法
SELECT DISTINCT columns FROM table_name WHERE where_conditions;例如:
mysql> select distinct age from student;+------+| age |+------+| 10 || 12 || 11 || NULL |+------+4 rows in set (0.01 sec)DISTINCT 关键词用于返回唯一不同的值。放在查询语句中的第一个字段前使用,且作用于主句所有列。
如果列具有NULL值,并且对该列使用DISTINCT子句,MySQL将保留一个NULL值,并删除其它的NULL值,因为DISTINCT子句将所有NULL值视为相同的值。
distinct多列去重
distinct多列的去重,则是根据指定的去重的列信息来进行,即只有所有指定的列信息都相同,才会被认为是重复的信息。
SELECT DISTINCT column1,column2 FROM table_name WHERE where_conditions;
mysql> select distinct sex,age from student;
+--------+------+
| sex | age |
+--------+------+
| male | 10 |
| female | 12 |
| male | 11 |
| male | NULL |
| female | 11 |
+--------+------+
5 rows in set (0.02 sec)
group by的使用
对于基础去重来说,group by的使用和distinct类似:
单列去重
语法:
SELECT columns FROM table_name WHERE where_conditions GROUP BY columns;
执行:
mysql> select age from student group by age;
+------+
| age |
+------+
| 10 |
| 12 |
| 11 |
| NULL |
+------+
4 rows in set (0.02 sec)
多列去重
语法:
SELECT columns FROM table_name WHERE where_conditions GROUP BY columns;执行:
mysql> select sex,age from student group by sex,age;+--------+------+| sex | age |+--------+------+| male | 10 || female | 12 || male | 11 || male | NULL || female | 11 |+--------+------+5 rows in set (0.03 sec)区别示例
两者的语法区别在于,group by可以进行单列去重,group by的原理是先对结果进行分组排序,然后返回每组中的第一条数据。且是根据group by的后接字段进行去重的。
例如:
mysql> select sex,age from student group by sex;+--------+-----+| sex | age |+--------+-----+| male | 10 || female | 12 |+--------+-----+2 rows in set (0.03 sec)distinct和group by原理
在大多数例子中,DISTINCT可以被看作是特殊的GROUP BY,它们的实现都基于分组操作,且都可以通过松散索引扫描、紧凑索引扫描(关于索引扫描的内容会在其他文章中详细介绍,就不在此细致介绍了)来实现。
另外,如果你近期准备面试跳槽,建议在Java面试库小程序在线刷题,涵盖 2000+ 道 Java、MySQL 面试题,几乎覆盖了所有主流技术面试题。
DISTINCT和GROUP BY都是可以使用索引进行扫描搜索的。例如以下两条sql(只单单看表格最后extra的内容),我们对这两条sql进行分析,可以看到,在extra中,这两条sql都使用了紧凑索引扫描Using index for group-by。
所以,在一般情况下,对于相同语义的DISTINCT和GROUP BY语句,我们可以对其使用相同的索引优化手段来进行优化。
mysql> explain select int1_index from test_distinct_groupby group by int1_index;+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+| 1 | SIMPLE | test_distinct_groupby | NULL | range | index_1 | index_1 | 5 | NULL | 955 | 100.00 | Using index for group-by |+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+1 row in set (0.05 sec)mysql> explain select distinct int1_index from test_distinct_groupby;+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+| 1 | SIMPLE | test_distinct_groupby | NULL | range | index_1 | index_1 | 5 | NULL | 955 | 100.00 | Using index for group-by |+----+-------------+-----------------------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+1 row in set (0.05 sec)但对于GROUP BY来说,在MYSQL8.0之前,GROUP Y默认会依据字段进行隐式排序。
可以看到,下面这条sql语句在使用了临时表的同时,还进行了filesort。
mysql> explain select int6_bigger_random from test_distinct_groupby GROUP BY int6_bigger_random;+----+-------------+-----------------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-----------------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+| 1 | SIMPLE | test_distinct_groupby | NULL | ALL | NULL | NULL | NULL | NULL | 97402 | 100.00 | Using temporary; Using filesort |+----+-------------+-----------------------+------------+------+---------------+------+---------+------+-------+----------+---------------------------------+1 row in set (0.04 sec)隐式排序
对于隐式排序,我们可以参考Mysql官方的解释:
https://dev.mysql.com/doc/refman/5.7/en/order-by-optimization.html
GROUP BY implicitly sorts by default (that is, in the absence of ASC or DESC designators for GROUP BY columns). However, relying on implicit GROUP BY sorting (that is, sorting in the absence of ASC or DESC designators) or explicit sorting for GROUP BY (that is, by using explicit ASC or DESC designators for GROUP BY columns) is deprecated. To produce a given sort order, provide an ORDER BY clause.
大致解释一下:
GROUP BY 默认隐式排序(指在 GROUP BY 列没有 ASC 或 DESC 指示符的情况下也会进行排序)。然而,GROUP BY进行显式或隐式排序已经过时(deprecated)了,要生成给定的排序顺序,请提供 ORDER BY 子句。
所以,在Mysql8.0之前,Group by会默认根据作用字段(Group by的后接字段)对结果进行排序。在能利用索引的情况下,Group by不需要额外进行排序操作;但当无法利用索引排序时,Mysql优化器就不得不选择通过使用临时表然后再排序的方式来实现GROUP BY了。
且当结果集的大小超出系统设置临时表大小时,Mysql会将临时表数据copy到磁盘上面再进行操作,语句的执行效率会变得极低。这也是Mysql选择将此操作(隐式排序)弃用的原因。
另外,如果你近期准备面试跳槽,建议在Java面试库小程序在线刷题,涵盖 2000+ 道 Java、MySQL 面试题,几乎覆盖了所有主流技术面试题。
基于上述原因,Mysql在8.0时,对此进行了优化更新:
https://dev.mysql.com/doc/refman/8.0/en/order-by-optimization.html
Previously (MySQL 5.7 and lower), GROUP BY sorted implicitly under certain conditions. In MySQL 8.0, that no longer occurs, so specifying ORDER BY NULL at the end to suppress implicit sorting (as was done previously) is no longer necessary. However, query results may differ from previous MySQL versions. To produce a given sort order, provide an ORDER BY clause.
大致解释一下:
从前(Mysql5.7版本之前),Group by会根据确定的条件进行隐式排序。在mysql 8.0中,已经移除了这个功能,所以不再需要通过添加order by null 来禁止隐式排序了,但是,查询结果可能与以前的 MySQL 版本不同。要生成给定顺序的结果,请按通过ORDER BY指定需要进行排序的字段。
因此,我们的结论也出来了:
在语义相同,有索引的情况下:
group by和distinct都能使用索引,效率相同。因为group by和distinct近乎等价,distinct可以被看做是特殊的group by。
在语义相同,无索引的情况下:
distinct效率高于group by。原因是distinct 和 group by都会进行分组操作,但group by在Mysql8.0之前会进行隐式排序,导致触发filesort,sql执行效率低下。
但从Mysql8.0开始,Mysql就删除了隐式排序,所以,此时在语义相同,无索引的情况下,group by和distinct的执行效率也是近乎等价的。
推荐group by的原因
group by语义更为清晰
group by可对数据进行更为复杂的一些处理
相比于distinct来说,group by的语义明确。且由于distinct关键字会对所有字段生效,在进行复合业务处理时,group by的使用灵活性更高,group by能根据分组情况,对数据进行更为复杂的处理,例如通过having对数据进行过滤,或通过聚合函数对数据进行运算。
相关文章:

MySQL 中的 distinct 和 group by 哪个效率更高
先说大致的结论(完整结论在文末):在语义相同,有索引的情况下:group by和distinct都能使用索引,效率相同。在语义相同,无索引的情况下:distinct效率高于group by。原因是distinct 和 …...

计算机相关专业毕业论文选题推荐
计算机科学以下是我推荐的20个计算机科学专业的本科论文选题:基于机器学习的推荐算法研究与实现基于区块链技术的数字身份认证方案设计与实现基于深度学习的图像识别技术研究与应用基于虚拟现实技术的教育培训平台设计与实现基于物联网技术的智能家居系统研究与开发…...
网络编程套接字之TCP
文章目录一、TCP流套接字编程ServerSocketSocketTCP长短连接二、TCP回显服务器客户端服务器客户端并发服务器UDP与TCP一、TCP流套接字编程 我们来一起学习一下TCP socket api的使用,这个api与我们之前学习的IO流操作紧密相关,如果对IO流还不太熟悉的&am…...

网络与串口调试工具TCPCOM
TCPCOM,网络与串口二合一调试助手,将网络调试助手与串口调试助手合二为一,绿色软件,简单高效。【软件特色】 1. 支持中英文双语言,自动根据操作系统环境选择系统语言类型; 2. 支持ASCII/Hex发送,发送和接收…...
数据库常用命令
文章目录1. 数据库操作命令1.进入数据库2.查看数据库列表信息3.查看数据库中的数据表信息2.SQL语句命令1. 创建数据表2. 基本查询语句3. SQL排序4. SQL分组统计5. 分页查询6. 多表查询7.自关联查询8.子查询1. 数据库操作命令 1.进入数据库 mysql -uroot -p2.查看数据库列表信…...

PTA复习
函数 6-1 学生类的构造与析构 #include<bits/stdc.h> using namespace std; class Student {int num;string name;char sex; public:Student(int n,string nam,char s):num(n),name(nam),sex(s){cout<<"Constructor called."<<endl;}void display…...

TypeScript 学习之接口
接口:对值所具有的结构进行类型检查,称为“鸭式变型法”或“结构性子类型化” 基本使用 interface LabelledValue {label: string; }function printLabel(labelledObj: LabelledValue) {console.log(labelledObj.label); }let myObj {size: 10, label:…...

原码反码补码
在计算机中,负数都是以补码的形式存放的, 正数的原码、反码、补码完全一致。 原码:指的是正数的二进制或负数的二进制, 负数的二进制(原码),其实就是在正数的二进制的最高位前面加一个符号位 1。…...
大数据选股智能推荐系统V1.0-1
很长时间没有发布博客了,这段时间个人确实有点忙。另外一方面在这段时间我也没有闲着。自己研发了一套大数据选股的智能推荐系统。废话不说,我们先来看这套系统:登录页面:(技术点:验证码的生成)…...

调研生成GIF表情包之路
调研阶段 gifshot.js合成GIF 可以从媒体流、视频或图像创建动画 GIF 的 JavaScript 库。 csdn地址:https://blog.csdn.net/qq_16494241/article/details/125717405 分解GIF图片、合成GIF图片 两步走: 1、分解GIF图片 libgif-js:JavaScrip…...

【RocketMQ】源码详解:生产者启动与消息发送流程
消息发送 生产者启动 入口 : org.apache.rocketmq.client.impl.producer.DefaultMQProducerImpl#start(boolean) 生产者在调用send()方法发送消息之前,需要调用start进行启动, 生产者启动过程中会启动一些服务和线程 启动过程中会启动MQClientInstance, 这个实例是针对一个项…...
信息安全(一)
思维导图 一、AES加解密 1.概述 1.1 概念 AES: 高级加密标准(Advanced Encryption Standard)是一种对称加密的区块加密标准。 (1)替代DES的新一代分组加密算法 (2)支持三种长度密钥&#x…...

企业多会场视频直播(主会场、分会场直播)实例效果
阿酷TONY 2023-2-16 长沙 活动直播做多会场切换功能(主会场、分会场、会场一、会场二、会场三自由切换) 企业多会场视频直播(主会场、分会场直播)实例效果 特点:支持PC端,也支持移动端观看,会…...
行列式)
线性代数速览(一)行列式
文章目录行列式🌻 行列式的定义🌼 行列式的性质🌷 一些定理🥀 行列式的计算🌺 克莱姆法则行列式 行列式的本质,就是一个数值。 🌻 行列式的定义 有三种定义:1、按行展开ÿ…...

恭喜山东翰林“智慧园区管理系统”获易知微可视化设计大赛二等奖
数字化经济发展是全球经济发展的重中之重,“数字孪生(Digital Twin)”这一词汇正在成为学术界和产业界的一个热点。数字孪生作为近年来的新兴技术,其与国民经济各产业融合不断深化,推动着各大产业数字化、网络化、智能…...

gulp简单使用
gulp gulp的核心理念是task runner 可以定义自己的一系列任务 等待任务被执行 基于文件stream的构建流 我们可以使用gulp的插件体系来完成某些任务 webpack的核心理念是module bundler webpack是一个模块化的打包工具 可以使用各种各样的loader来加载不同的模块 可以使用各种…...

ce认证机构如何选择?
CE认证想必大家都已经有所了解,它是产品进入欧盟销售的通行证,那么我们在办理CE认证时该怎么进行选择?带大家了解一下CE认证机构,以及该怎么去进行选择? 以下信息由证果果编辑整理,更多认证机构信息请到证果果网站查看。找机构…...

全网招募P图高手!阿里巴巴持续训练鉴假AI
P过的证件如何鉴定为真?三千万网友都晒出了与梅西的合影?图像编辑技术的普及让人人都能P图,但也带来“假图”识别难题,甚至是欺诈问题。 为此,阿里安全联合华中科技大学国家防伪工程中心、国际文档分析识别方向的唯一顶…...
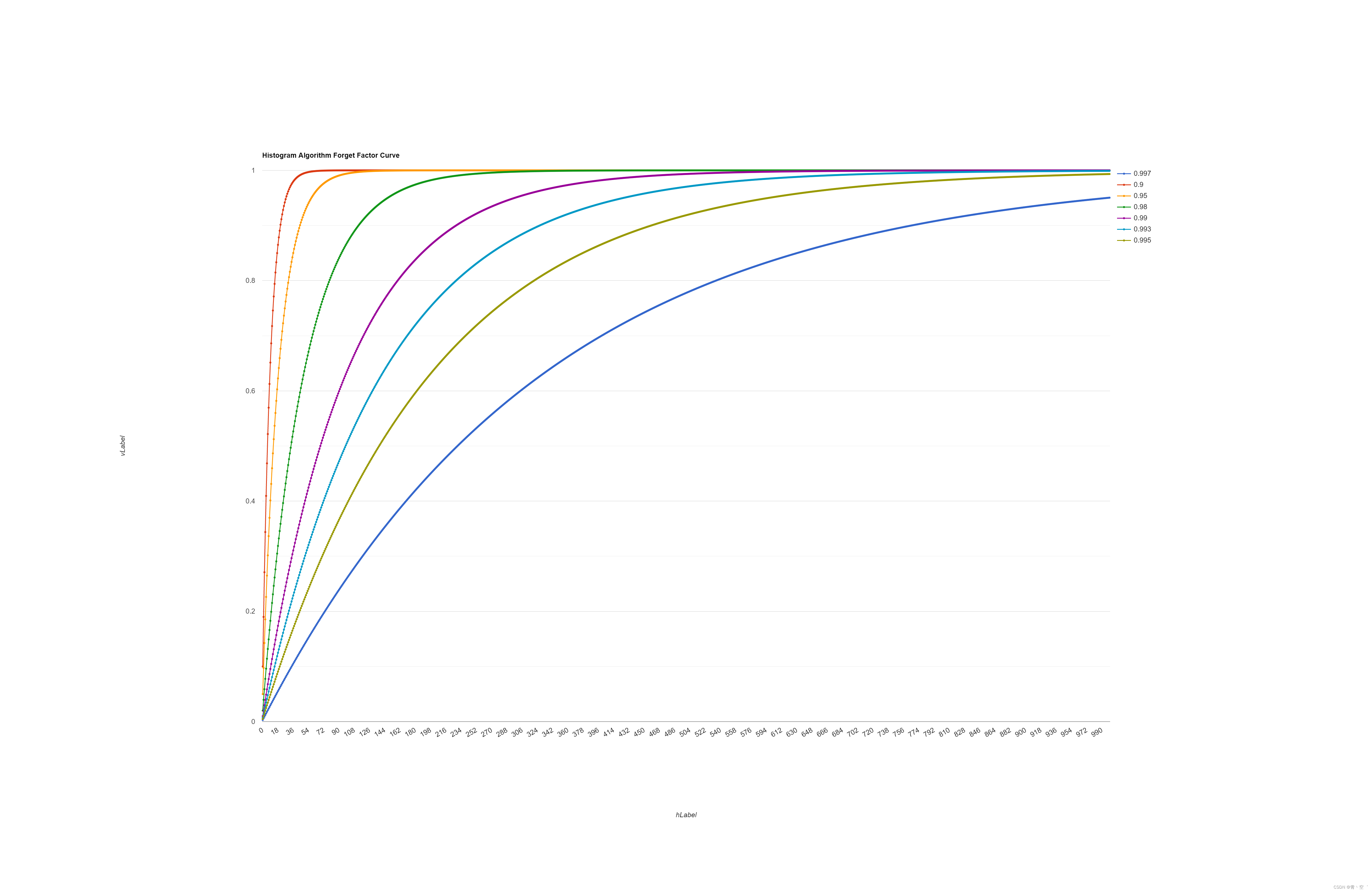
webrtc QOS笔记一 Neteq直方图算法浅读
webrtc QOS笔记一 Neteq直方图算法浅读 文章目录webrtc QOS笔记一 Neteq直方图算法浅读Histogram Algorithm获取目标延迟遗忘因子曲线Histogram Algorithm DelayManager::Update()->Histogram::Add() 会根据计算的iat_packet(inter arrival times, 实际包间间隔 / 打包时长…...

细分和切入点
本文重点介绍做SEO网站细分和切入点的方法:当我们的行业和关键词竞争性比较大的时候,我们可以考虑对行业或者产品做细分,从而找到切入点。可以按照以下三个方面进行细分。1、按城市细分例如:A:餐饮培训,当前…...

智慧工厂与养殖场的一体化光伏监控系统方案
某企业从事乳制品的生产、销售等全流程业务,新增一套分布式光伏发电系统以平衡能耗支出,主要覆盖乳制品生产加工厂、奶牛养殖场及生态观光牧场等场景,实现“自给自足、余电上网”等综合能源目标。现需要对光伏电站进行联网集中监控࿰…...

终极ViGEmBus驱动指南:如何让Windows完美识别任何游戏控制器
终极ViGEmBus驱动指南:如何让Windows完美识别任何游戏控制器 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的情况&#x…...

Sunshine流媒体服务器深度配置指南:10个性能优化技巧与实战配置
Sunshine流媒体服务器深度配置指南:10个性能优化技巧与实战配置 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款开源的游戏流媒体服务器,支持…...
)
8086/8088单板机VSCode集中环境开发编译(第二版整理)
对于8086/8088单板机而言,集中的开发环境方便友好。下面是使用VSCode集中开发环境对8086/8088单板机集中编辑、编译、串口下载的使用步骤第一步,在VSCode文件中,选择打开例程文件夹第二部,根据需要对例程main.c进行编辑修改第三步…...

如何利用TortoiseSVN高效生成分支对比与历史变更的差异报告
1. TortoiseSVN简介与差异报告的价值 版本控制系统就像代码的时光机,它能完整记录每次修改的"快照"。我在团队协作中深刻体会到,没有比清晰的变更记录更能提高代码审查效率的工具了。TortoiseSVN作为Subversion的Windows客户端,最…...

政府AI决策透明度如何影响公众信任?实证研究揭示关键机制
1. 项目概述:当算法成为“看不见的法官”在公共服务的数字化转型浪潮中,人工智能(AI)正从辅助工具演变为核心决策者。想象一下这样的场景:你提交了一份社会福利申请,原本需要数周的人工审核,现在…...

智能网联时代的分心驾驶:技术悖论、工程困境与系统化安全框架
1. 项目概述:一个被忽视的致命悖论 作为一名在汽车电子和智能网联领域摸爬滚打了十几年的工程师,我见过太多关于“未来出行”的炫酷概念和激动人心的技术路线图。从早期的车载信息娱乐系统,到后来的高级驾驶辅助系统,再到如今如火…...

SpringBoot项目里用Sharding-JDBC做分库分表,这5个配置项最容易踩坑
SpringBoot整合Sharding-JDBC分库分表:五大高频配置陷阱与实战解决方案 当数据库单表数据量突破千万级大关时,分库分表几乎是每个Java开发者必须面对的课题。作为Apache ShardingSphere的核心模块,Sharding-JDBC以其轻量级、低侵入的特性成为…...

静态页面构建优化:从核心技能到自动化部署实践
1. 项目概述:一个被低估的静态页面技能集 最近在整理自己的前端工具箱时,发现了一个挺有意思的仓库: jieshu666/ShipPage-Skill 。乍一看名字,你可能会觉得这又是一个关于“Ship”(部署)某个“Page”&…...

学生党福音:用最便宜的TT马达和STM32F103C8T6,我焊出了能遥控的平衡小车
低成本DIY平衡小车:TT马达与STM32的极致性价比方案 当我在宿舍里第一次看到那辆价值近千元的商业平衡小车时,脑海中立刻浮现出一个问题:能不能用更便宜的材料实现类似功能?作为一名预算有限的学生,我开始探索如何用最…...