深度学习一些简单概念的整理笔记
大概看了一点动手学深度学习,简单整理一些概念。
一些问题
测试结果
Precision-Recall曲线定性分析模型精度average precision(AP) 平均精度
Precision :检索出来的条目中有多大比例是我们需要的。
一些概念
- 损失函数(loss function,或cost function):一个可优化的目标函数,量化目标的实际值与预测值之间的差距。
- 张量(tensor):n维数组。
- 维度:向量的维度指向量的元素数量,张量的维度指其具有的轴(向量)数。
- 梯度(gradient):指向变化最大的方向。
- 梯度下降法:在每个步骤中,检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,在可以减少损失的方向上优化参数。
- 训练误差和泛化误差(generalization error):前者是在训练集上的误差,后者是测试的误差。
- 学习率太小导致更新慢,需要更多迭代,太大会难以收敛。
监督学习
在给定输入特征的情况下预测标签(可以是已知输入的,也可以是作为预测结果输出的)。
- 回归(regression)问题:标签是任意数值。预测所依据的自变量称为特征。
- 分类(classification)问题:标签是类别。
- 层次分类(hierarchical classification):宁愿错误地分入一个相关的类别,也不愿错误地分入一个遥远的类别。
- 序列学习:输入是连续的,例如通过前一帧的图像,对后一帧作出更好的预测。序列学习需要摄取输入序列或预测输出序列,或两者兼而有之。
无监督学习
没有标签,数据中不含目标的机器学习。
强化学习
智能体(agent)在一系列的时间步骤上与环境交互。 在每个特定时间点,智能体从环境接收一些观察(observation),并且必须选择一个动作(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励(reward)。
问gpt下面这段话中端到端的具体含义:
毋庸置疑,深度学习方法中最显著的共同点是使用端到端训练。 也就是说,与其基于单独调整的组件组装系统,不如构建系统,然后联合调整它们的性能。 例如,在计算机视觉中,科学家们习惯于将特征工程的过程与建立机器学习模型的过程分开。 Canny边缘检测器 (Canny, 1987) 和SIFT特征提取器 (Lowe, 2004) 作为将图像映射到特征向量的算法,在过去的十年里占据了至高无上的地位。 在过去的日子里,将机器学习应用于这些问题的关键部分是提出人工设计的特征工程方法,将数据转换为某种适合于浅层模型的形式。 然而,与一个算法自动执行的数百万个选择相比,人类通过特征工程所能完成的事情很少。 当深度学习开始时,这些特征抽取器被自动调整的滤波器所取代,产生了更高的精确度。
pytorch一些数学知识
A = torch.arange(20).reshape(5, 4) # 得到一个5x4矩阵
# axis = 几,哪一个轴(维度)就会被降维而消失
row_sum = A.sum(axis = 0) # 按行求和,即将一列中的所有元素求和,且降维成一个向量,得到[40, 45, 50, 55]
col_sum = A.sum(axis = 1, keepdims = True) # 按行求和,且不降维,得到一个5x1矩阵
# 广播机制: 当用一个向量加一个标量时,标量会被加到向量的每个分量上。
范数
向量的范数将其映射为标量,反映向量的大小。
L 2 L_2 L2范数=各元素平方和的平方根。torch.norm(x)
L 1 L_1 L1范数=各元素绝对值之和。torch.abs(x).sum()
矩阵的Frobenius范数是其元素平方和的平方根。
线性神经网络
线性回归
仿射变换通过加权和对特征进行线性变换(linear transformation), 并通过偏置(bias)项来进行平移(translation)。
线性回归与其他大部分模型不同的是,它的解可以用一个公式简单地表达出来, 这类解叫作解析解(analytical solution)或显式解。
梯度下降法
不断地在损失函数递减的方向上更新参数来降低误差。最简单的方法是计算损失函数(数据集中所有样本的损失均值) 关于模型参数的导数(在这里称为梯度)。 但因为在每一次更新参数之前必须遍历整个数据集,所以实际中的执行会非常慢。因此,通常采用小批量随机梯度下降(minibatch stochastic gradient descent)在每次需要计算更新的时候随机抽取一小批样本,每个小批量中的样本数即batch size。batch size太小不利于并行计算,太大则浪费资源。并且公式中的伊塔表示学习率,这些训练前手动设置,不在训练中更新的参数称为超参数。
- 全连接层(fully-connected layer):每个输入都通过矩阵向量乘法得到每个输出。
softmax回归
对于分类问题,采用独热编码(one-hot encoding)表示类别,独热编码是一个向量,其分量和类别一样多。例如要识别的分类为{猫,狗,鸡},对应的标签y就分别是(1, 0, 0), (0, 1, 0)和(0, 0, 1)。
作为输出,数据本身可能是任意的值,但我们想要将其视为概率,这就需要校准(calibration)来将其变为非负且总和为1,softmax函数完成了该功能。它首先做求幂变成非负,然后除以总和来规范化到0~1的范围。
多层感知机
在输入层和输出层之间可以加上若干个隐藏层,来实现从线性到非线性的转变,隐藏层不能使用线性函数,否则会等价于不使用隐藏层。
激活函数
因此隐藏层使用非线性函数,即激活函数(activation function)来确定神经元是否应该被激活,激活函数的输出
称为活性值(activations)。
过拟合(overfitting)
模型在训练集上表现良好,但不能推广到测试集。表现的形式就是训练集的损失函数正常下降,但测试集的损失函数并没有,甚至上升,且高于训练集的损失函数。
以下情况容易过拟合。
- 可调整参数的数量(自由度)很大时。
- 权重的取值范围较大时。
- 训练样本少时。
正则化用于解决过拟合问题。
权重衰退(weight decay)
权重衰退是正则化的技术之一,也叫L2正则化。主要是针对上述提到的第二点情况进行优化。给损失函数加上一个惩罚项,将原来的训练目标最小化训练标签上的预测损失,调整为最小化预测损失和惩罚项之和。
L o s s ( ) + l a m b d a / 2 ∗ ∣ ∣ w ∣ ∣ 2 Loss() + lambda / 2 * ||w||^2 Loss()+lambda/2∗∣∣w∣∣2其中lambda用来控制衰退的程度,过小就丧失了意义,过大则可能欠拟合。在pytorch框架中一般用weight_decay表示。
暂退法(dropout)
将一些输出项随机置为0,将其他的项扩大以保持数学期望不变。常作用在多层感知机的隐藏层输出上。实际上就是在向前传播的过程中,计算每一内部层的同时丢弃一些神经元。
卷积神经网络(convolutional neural networks,CNN)
- 平移不变性(translation invariance):不论检测对象在图像中的哪里,神经网络的前面几层应该对相同的图像区域具有相似的反应。
- 局部性:神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系。最终可以聚合这些局部特征,以在整个图像级别进行预测。
卷积层
对全连接层利用以上两点得到卷积层。因此也可以看出,卷积层是对全连接层的简化,需要更少的参数。
卷积层将输入和卷积核矩阵进行卷积,加上偏移后得到输出。其中卷积核和偏移是可学习的参数,而核矩阵的大小是超参数。
卷积层的输出有时被称为特征映射(feature map)。而在卷积神经网络中,某一层的任意元素x,其感受野(receptive field)是指在前向传播期间可能影响x计算的所有元素(来自x的所有先前层)。
在卷积时可能会丢失边界信息,针对于此可以采用填充(padding)操作。从另一个角度想,卷积也会减少输出的
大小,而如果要输出较少的维度,就需要作大量的卷积计算,这时就可以用到步幅,来让卷积核每次移动不止一个像素。
卷积核不一定是一个二维的,在处理多通道图像时也可以是纵向的。1x1卷积核通常用于调整网络层的通道数量和控制模型复杂性。移除全连接层可减少过拟合。
池化(pooling)层
池化(也叫汇聚)层通常放在卷积层之后,目的是降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
与卷积核不同的是,池化层不包含参数,只在原输入上进行运算。池化层分为最大池化(max pooling)和平均池化(average pooling)。 使用max pooling以及大于1的步幅,可减少空间维度。
批量归一化(batch normalization)
训练时,数据在最底部,而损失出现在最后。反向传播时后面的层训练得快,底部则较慢,但底部层一经变化,后面的所有都要跟着重新学习,因此导致收敛的速度变慢。
批量归一化放在激活函数前,通过固定批量中的均值和方差,可以持续加速深层网络的收敛速度。
另外,注意若batch_size为1,那么批量归一化是无效的。因为并不存在均值方差。
计算机视觉
图像增广
对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模。且可以减少模型对某些属性的依赖,从而提高模型的泛化能力。
常见的做法如翻转,切割,变色等。
微调(fine-tuning)
一个神经网络一般可以分为两块:很多层的特征提取将原始像素变成容易线性分割的特征(变得可学习),以及一个线性分类器。
假设现在要训练的模型是目标模型,微调的思路是,在另一个源数据集上训练源模型,将其特征提取层的参数直接复制到目标模型上(使用相同的网络架构),此时在目标数据集上进行训练的话,输出层将从头开始进行训练,而所有其他层的参数将根据源模型的参数进行微调。这也就是迁移学习(transfer learning),即将从源数据集学到的知识迁移到目标数据集(源数据集和目标数据集应该是相似的东西,如猫和狗,或热狗和香蕉)。
总结地说,微调通过使用在大数据上得到的预训练好的模型来初始化模型权重来提升精度。
锚框
用边界框(bounding box)描述位置。
在输入图像中,以每个像素为中心生成多个放缩比和宽高比(aspect ratio)不同的边界框,即锚框(anchor box)。然后判断锚框中是否有目标,若有则调整边界从而更精准地预测目标的真实边界框(ground-truth bounding box)。
以每个像素为中心会生成过多的锚框,因此对于大目标可以采样较少的区域,小目标可以采样较大的区域。
在训练集中,将每个锚框视为一个训练样本。 训练时,需要每个锚框的类别(class)和偏移量(offset)标签,其中前者是与锚框相关的对象的类别,后者是真实边界框相对于锚框的偏移量。 在预测时,为每个图像生成多个锚框,预测所有锚框的类别和偏移量,根据预测的偏移量调整它们的位置以获得预测的边界框,最后只输出符合特定条件的预测边界框。
IoU
用交并比(intersection over union,IoU)衡量锚框覆盖目标的程度。具体地说就是用锚框和真实边界框的相交面积比上相并面积,0表示无重合,1表示完全重合。给每个锚框要么标注成背景,要么关联到一个边界框。背景类别的锚框通常被称为负类锚框,其余的被称为正类锚框。
假设有n个真实边界框,m个锚框,计算每个锚框对每个真实边界框的IoU,生成一个mxn的矩阵。每次从中选取最大的IoU,将其对应的真实边界框分配给对应的锚框,并删除该元素所在的行列。
非极大值抑制
当有许多锚框时,可能会输出许多相似的具有明显重叠的预测边界框,都围绕着同一目标。 为了简化输出,就需要使用非极大值抑制(non-maximum suppression,NMS)合并属于同一目标的类似的预测边界框。
R-CNN算法
区域卷积神经网络(region-based CNN,R-CNN)。
若每个锚框不一样大,怎么让他们可以在一个batch里训练呢,就要用到兴趣区域(region of interest, RoI)池化层(相当于一个max pooling),将他们变成固定大小。
语义分割
语义分割(semantic segmentation)识别每一个像素并将其分类。
全卷积网络
卷积不会增加输入的高宽,有时候需要将图片放大,即上采样(upsampling)。可以用转置卷积(transposed convolution)增大高宽。
全卷积网络(fully convolutional network,FCN)通过1x1卷积将通道数变为类别数,然后利用转置卷积将中间层特征图的高和宽变换回输入图像的尺寸。
风格迁移
风格迁移(style transfer)使用内容损失、风格损失和全变分损失将内容图像的风格转为风格图像。
合成的图像中会有大量高频噪点,需要用全变分损失来进行全变分去噪(total variation denoising)。
相关文章:

深度学习一些简单概念的整理笔记
大概看了一点动手学深度学习,简单整理一些概念。 一些问题 测试结果 Precision-Recall曲线定性分析模型精度average precision(AP) 平均精度 Precision :检索出来的条目中有多大比例是我们需要的。 一些概念 损失函数(loss function&…...

Vue3中引入Element-plus
安装 npm install element-plus --save完整引入 打包后体积很大,适合学习,不适合生产。 此方法对于 vite 和 cli 脚手架创建的vue3均适用 // main.ts import { createApp } from vue //引入element-plus import ElementPlus from element-plus //引入…...

如何查看 Facebook 公共主页的广告数量上限?
作为Facebook的资深人员,了解如何查看公共主页的广告数量上限对于有效管理和优化广告策略至关重要。本文将详细介绍如何轻松查看Facebook公共主页的广告数量上限,以帮助您更好地掌握广告投放策略。 一、什么是Facebook公共主页的广告数量上限?…...
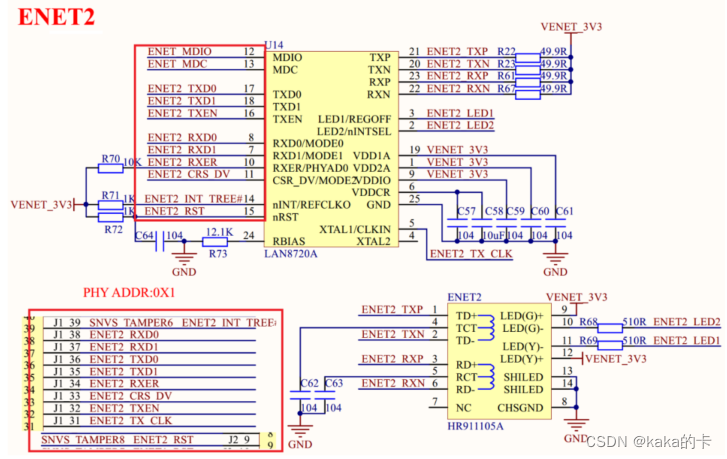
U-Boot移植 (2)- LCD 驱动修改和网络驱动修改
文章目录 1. LCD 驱动修改1.1 修改c文件配置1.2 修改h文件配置1.3 编译测试 2. 网络驱动修改2.1 I.MX6U-ALPHA 开发板网络简介2.2 网络 PHY 地址修改2.3 删除 uboot 中 74LV595 的驱动代码2.4 添加开发板网络复位引脚驱动2.5 更新 PHY 的连接状态和速度2.6 烧写调试2.7 测试一下…...

Ubuntu 23.10 现在由Linux内核6.3提供支持
对于那些希望在Ubuntu上尝试最新的Linux 6.3内核系列的人来说,今天有一个好消息,因为即将发布的Ubuntu 23.10(Mantic Minotaur)已经重新基于Linux内核6.3。 Ubuntu 23.10的开发工作于4月底开始,基于目前的临时版本Ubu…...

Python 学习之NumPy(一)
文章目录 1.为什么要学习NumPy2.NumPy的数组变换以及索引访问3.NumPy筛选使用介绍筛选出上面nb数组中能被3整除的所有数筛选出数组中小于9的所有数提取出数组中所有的奇数数组中所有的奇数替换为-1二维数组交换2列生成数值5—10,shape 为(3,5)的二维随机浮点数 NumP…...
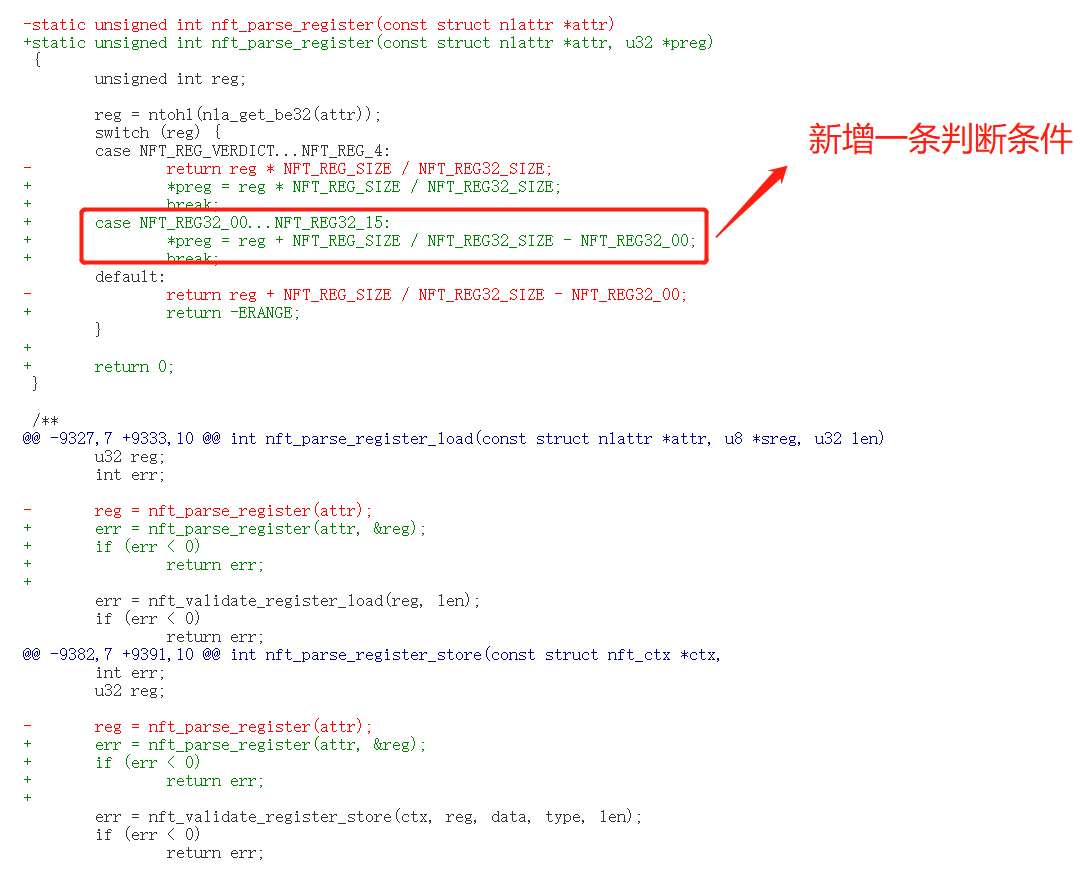
Nftables栈溢出漏洞(CVE-2022-1015)复现
背景介绍 Nftables Nftables 是一个基于内核的包过滤框架,用于 Linux 操作系统中的网络安全和防火墙功能。nftables 的设计目标是提供一种更简单、更灵活和更高效的方式来管理网络数据包的流量。 钩子点(Hook Point) 钩子点的作用是拦截数…...
【C++】 Qt-事件(上)(事件、重写事件、事件分发)
文章目录 事件重写事件事件分发 事件 事件(event)是由系统或Qt本身在不同的时刻发出的。比如,当用户按下鼠标,敲下键盘,或窗口需要重新绘制的时候,都会发出一个相应的事件。一些事件是在对用户操作做出响应…...
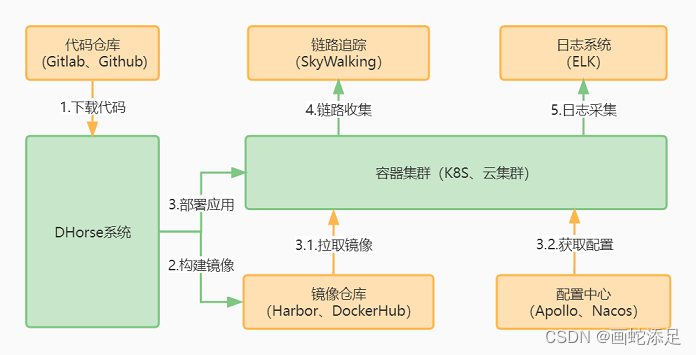
k8s部署springboot
前言 首先以SpringBoot应用为例介绍一下k8s的部署步骤。 1.从代码仓库下载代码,比如GitLab; 2.接着是进行打包,比如使用Maven; 3.编写Dockerfile文件,把步骤2产生的包制作成镜像; 4.上传步骤3的镜像到远程…...

备战秋招002(20230704)
文章目录 前言一、今天学习了什么?二、关于问题的答案1.线程池2.synchronized关键字3、volatile 总结 前言 提示:这里为每天自己的学习内容心情总结; Learn By Doing,Now or Never,Writing is organized thinking. …...

游泳买耳机买什么的比较好,列举几款实战性好的游泳耳机
对于运动用户来说,在运动时都会选择听一些节奏感比较强的音乐,让自己运动是更有活力。现在已经是三伏天中的前伏期间,不少人会选择在三伏天的日子里进行减肥瘦身,耳游泳已经成为很多人都首选运动,游泳是非常好的有氧运…...
【无线传感器】使用 MATLAB和 XBee连续监控温度传感器无线网络研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Java基础-多线程JUC-生产者和消费者
1. 生产者与消费者 实现线程轮流交替执行的结果; 实现线程休眠和唤醒均要使用到锁对象; 修改标注位(foodFlag); 代码实现: public class demo11 {public static void main(String[] args) {/*** 需求&#…...
day2 QT按钮与容器
目录 按钮 1、QPushButton 2、QToolButton 3、QRadioButton 4、QCheckBox 示例 容器 编辑 1. QGroupBox(分组框) 2. QScrollArea(滚动区域) 3. QToolBox(工具箱) 4. QTabWidget(选…...
JPA 批量插入较大数据 解决性能慢问题
JPA 批量插入较大数据 解决性能慢问题 使用jpa saveAll接口的话需要了解原理: TransactionalOverridepublic <S extends T> List<S> saveAll(Iterable<S> entities) {Assert.notNull(entities, "Entities must not be null!");List<…...

为啥离不了 linux
Linux与Windows都是十分常见的电脑操作系统,相信你对它们二者都有所了解!在你的使用过程中,是否有什么事让你觉得在Linux上顺理成章,换到Windows上就令你费解?亦或者关于这二者你有任何想要分享的,都可以在…...

基于分形的置乱算法和基于混沌系统的置乱算法哪种更安全?
在信息安全领域中,置乱算法是一种重要的加密手段,它可以将明文进行混淆和打乱,从而实现保密性和安全性。常见的置乱算法包括基于分形的置乱算法和基于混沌系统的置乱算法。下面将从理论和实践两方面,对这两种置乱算法进行比较和分…...

pve使用cloud-image创建ubuntu模板
首先连接pve主机的终端 下载ubuntu22.04的cloud-image镜像 wget -P /opt https://mirrors.cloud.tencent.com/ubuntu-cloud-images/jammy/current/jammy-server-cloudimg-amd64.img创建虚拟机,id设为9000,使用VirtIO SCSI控制器 qm create 9000 -core…...
shiro入门
1、概述 Apache Shiro 是一个功能强大且易于使用的 Java 安全(权限)框架。借助 Shiro 您可以快速轻松地保护任何应用程序一一从最小的移动应用程序到最大的 Web 和企业应用程序。 作用:Shiro可以帮我们完成 :认证、授权、加密、会话管理、与 Web 集成、…...
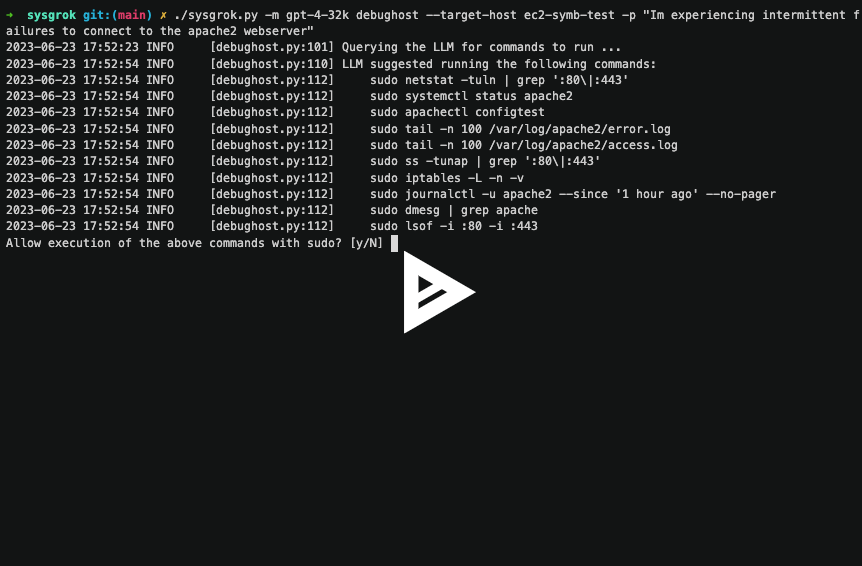
开源 sysgrok — 用于分析、理解和优化系统的人工智能助手
作者:Sean Heelan 在这篇文章中,我将介绍 sysgrok,这是一个研究原型,我们正在研究大型语言模型 (LLM)(例如 OpenAI 的 GPT 模型)如何应用于性能优化、根本原因分析和系统工程领域的问题。 你可以在 GitHub …...

避坑指南:通达信DLL加密常见的5大误区与替代方案
通达信指标加密实战:5种DLL开发陷阱与零代码解决方案 在量化交易领域,指标公式的保护一直是开发者面临的棘手问题。最近三个月内,某金融开发者社区关于"通达信DLL加密失败"的求助帖增长了47%,暴露出传统加密方案存在显…...

《数据驱动防折叠:利用企微API与数据分析平台构建智能发送决策系统》
一、问题背景企微群发折叠与用户的历史互动行为紧密相关。对长期未交互的用户发送营销内容,折叠概率极高;而对活跃用户发送相似内容,则可能正常显示。因此,单纯从发送端进行策略优化是不够的,必须引入用户维度的数据&a…...

超轻量级OpenClaw与LaTeX结合:学术文档自动化处理
超轻量级OpenClaw与LaTeX结合:学术文档自动化处理 科研工作者每天需要处理大量的文献整理、公式编辑和文档排版工作,传统手动方式耗时且容易出错。本文将展示如何用超轻量级OpenClaw实现学术文档的自动化处理,让LaTeX文档编写变得轻松高效。 …...

价值投资中的智能城市废水处理与再利用系统分析
价值投资中的智能城市废水处理与再利用系统分析 关键词:价值投资、智能城市、废水处理、废水再利用、系统分析 摘要:本文聚焦于价值投资视角下的智能城市废水处理与再利用系统。首先介绍了研究的背景,包括目的、预期读者、文档结构和相关术语。接着阐述了智能城市废水处理与…...

OpenClaw开源项目深度体验:对比其与星图GPU平台Qwen3-14B-Int4-AWQ部署差异
OpenClaw开源项目深度体验:对比其与星图GPU平台Qwen3-14B-Int4-AWQ部署差异 1. 项目概览与核心功能 OpenClaw是近期备受关注的开源大模型项目,主打轻量化和易部署特性。它采用混合专家架构(MoE),在保持模型性能的同时显著降低了计算资源需求…...

如何通过InstantClick事件回调实现精准的性能监控:开发者必备指南
如何通过InstantClick事件回调实现精准的性能监控:开发者必备指南 【免费下载链接】instantclick InstantClick makes following links in your website instant. 项目地址: https://gitcode.com/gh_mirrors/in/instantclick InstantClick是一款能让网站链接…...

Qwen3-Reranker-0.6B一文详解:轻量0.6B参数如何实现SOTA级重排序性能
Qwen3-Reranker-0.6B一文详解:轻量0.6B参数如何实现SOTA级重排序性能 1. 引言:为什么你需要关注这个0.6B的小模型? 如果你用过搜索引擎,肯定有过这样的体验:输入一个问题,搜出来一堆结果,但真…...

Wan2.2-I2V-A14B部署教程:解决OOM/驱动报错/端口冲突三大常见问题
Wan2.2-I2V-A14B部署教程:解决OOM/驱动报错/端口冲突三大常见问题 1. 镜像概述与核心优势 Wan2.2-I2V-A14B是一款专为文生视频任务优化的私有部署镜像,特别针对RTX 4090D 24GB显存配置进行了深度优化。这个镜像最大的特点是解决了AI视频生成领域常见的…...

保姆级教程:用PtitPrince的RainCloud函数,5步搞定分组数据可视化
5步精通RainCloud Plot:用PtitPrince实现专业级分组数据可视化 第一次看到同事用雨云图展示A/B测试结果时,我被这种"既见森林又见树木"的呈现方式震撼了——左侧的密度曲线如山脉般起伏,中间的箱线图标出关键分位点,右侧…...

3个创新方法:用Krita AI Diffusion插件实现智能动画制作
3个创新方法:用Krita AI Diffusion插件实现智能动画制作 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: https://gitco…...