JVM理论(六)执行引擎--垃圾回收
概述
- 垃圾: 指的是在运行程序中没有任何指针指向的对象
- 垃圾回收目的: 为了及时清理空间使得程序可以正常运行
- 垃圾回收机制: JVM采取的是自动内存管理,即JVM负责对象的创建以及回收,将程序员从繁重的内存管理释放出来,更加专注业务的开发
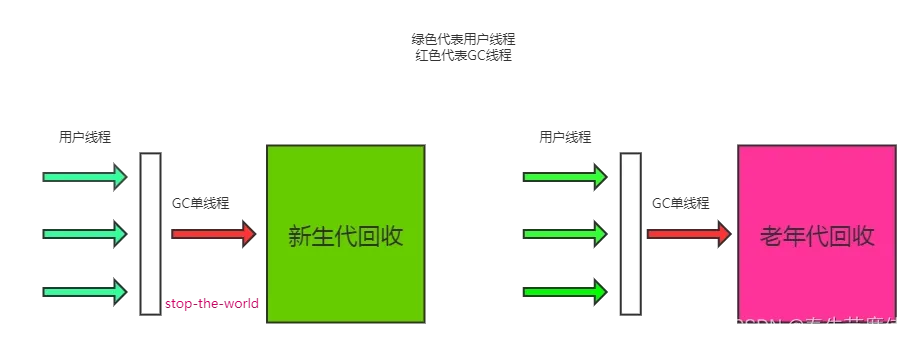
- 垃圾回收区域: 频繁收集Young区(新生代),较少收集Old区(老年代),基本不动永久代/元空间
- 垃圾回收算法
- 标记阶段
- 引用计数算法
- 可达性分析算法
- 清除阶段
- 标记-清除算法
- 复制算法
- 标记压缩算法
- 分代收集算法
- 增量收集算法
- 分区算法
- 标记阶段
-
垃圾回收finalization机制
- java提供了对象终止(finalization)机制允许开发人员提供对象被销毁前的自定义处理逻辑
- 当垃圾对象被回收之前一定会调用finalize()方法
- 不要主动调用对象的finalize方法,交由垃圾回收机制执行,原因如下
- 极端情况下,若没发生GC,则finalize将不会执行
- finalize方法中可以使得对象复活
- finalize方法影响GC性能
- 由于finalize方法的存在,JVM中的对象一般处于三种可能的状态,且只有不可触及的对象才会被垃圾回收
- 可触及的: 从根节点开始,可以到达这个对象
- 可复活的: 对象的引用都被释放,但有可能在finalize方法中复活
- 不可触及的: 对象没有在finalize方法中复活,即进入不可触及状态,不可触及状态的对象不可能被复活,因为finalize方法只会被调用一次
- System.gc:会显示触发Full GC,但无法保证垃圾收集器实时调用,开发人员一般不会主动调用
- 内存溢出: 没有可用的内存,并且垃圾收集器无法提供更多的内存(即无法有效回收内存空间),没有空闲的内存情况原因如下
- Java虚拟机堆内存设置不足(可通过-Xms、-Xmx来调整)
- 代码中创建了大量大对象,并且长时间无法被垃圾收集器收集
- 内存泄漏:对象不会被程序用到了,但GC又不能进行回收;内存泄漏不会立刻引起程序崩溃,但它会逐渐蚕食内存空间,直至内存耗尽,最终出现OOM;常见内存泄漏情况
- 单例模式: 单例生命周期和应用程序一样长,若单例程序持有对外部对象的引用,那该外部对象在程序正常运行过程中永远也不会被回收
- 一些提供close的资源未关闭:数据连接,网络连接和io连接以及报表workbook对象必须手动close,否则不会被回收
- STW:stop the world,指的是GC事件发生过程中应用程序会产生停顿(任何GC都会产生STW),且停顿产生时整个应用程序线程都会被暂停,GC完成后会恢复应用程序,频繁中断会让用户体验不好,所以我们需要尽可能缩短STW的时间
- 并发和并行对比
- 并发:多个事件在同一时间段内发生(CPU时间片段极速切换);并发的多个任务之间是互相抢占资源的
- 并行:多个事件在同一时间点同时发生;并行的多个任务不会互相抢占资源
- 只有在多CPU或者一个CPU多核情况下才会发生并行,否则看似同时发生的事情都是并发执行的
- 安全点:程序在运行时并非在所有地方都能停顿下来进行GC,只有在特定位置才可以,这些位置称为安全点(safe point),若安全点过少可能导致GC等待时间太长,过多可能导致性能降低,所以我们通常选择一些执行时间较长的指令作为安全点,比如方法调用、循环跳转、异常跳转等
- 安全区域:在一段代码片段中,对象的引用关系不会发生变化,在这个区域中的任何位置开始GC都是安全的,也可以看做被扩展的安全点
- java中四种对象引用
- 强引用、软引用、弱引用、虚引用共4种引用,强度依次逐渐减弱;除了强引用,其他3种引用类均包含在java.lang.ref包下
- 强引用(StrongReference): 程序中普遍存在的引用关系(程序中99%都是强引用),如Object obj = new Object(),只要引用关系存在,垃圾收集器永远不会回收掉,强引用是造成内存溢出的主要原因
- 软引用(SoftReference): 内存不足即回收,在JVM内存不足时,进行垃圾回收时才进行二次回收(一次回收是针对不可达对象);主要用于高速缓存场景
- 弱引用(WeakReference): 发现即回收,无论JVM内存是否充足,在进行垃圾回收时对只被弱引用关联的对象进行回收
- 虚引用(PhantomReference): 对象回收跟踪,对象是是否有虚引用对其生命时间无任何影响,虚引用的目的就是在该对象被回收时发出系统通知,即跟踪垃圾回收过程
- 强引用、软引用、弱引用、虚引用共4种引用,强度依次逐渐减弱;除了强引用,其他3种引用类均包含在java.lang.ref包下
垃圾回收算法
标记阶段-引用计数算法(Python采用的算法,Java未使用)
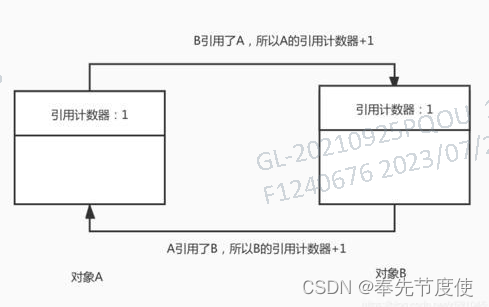
引用计数算法比较简单,通过对每个对象保存一个整型的引用计数器属性,用于记录对象被引用的情况,比如对于一个对象A,只要有一个对象引用A,则A的引用计数器就加1,当引用失效时就减1,当对象A的引用计数器值为0,即表示对象A不可能再被使用,可进行回收
- 优点
- 实现简单,垃圾对象便于辨识
- 判定效率较高,回收没有延迟性
- 缺点:
- 需要单独存储计数器,增加了存储空间的开销
- 每次赋值需要更新计数器,增加了时间开销
- 最严重的是无法处理循环引用的情况(导致Java垃圾回收器没有使用该算法)
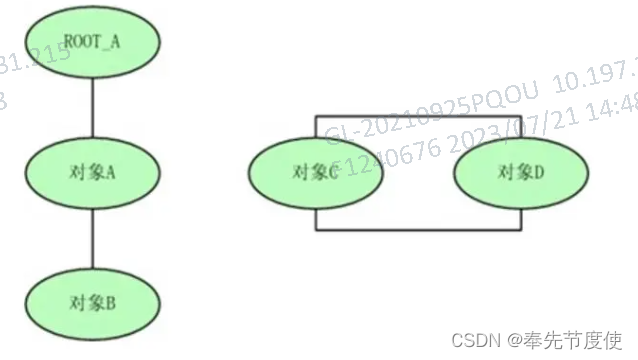
- 扩展: 人工智能中Python则使用该算法进行垃圾回收,它解决循环引用问题的策略
- 手动解除,在合适时机解除引用关系
- 使用弱引用,weakref是python提供的标准库,旨在解决循环引用
- 扩展: 人工智能中Python则使用该算法进行垃圾回收,它解决循环引用问题的策略
标记阶段-可达性分析算法/根搜索算法/追踪性垃圾收集(Java采用))
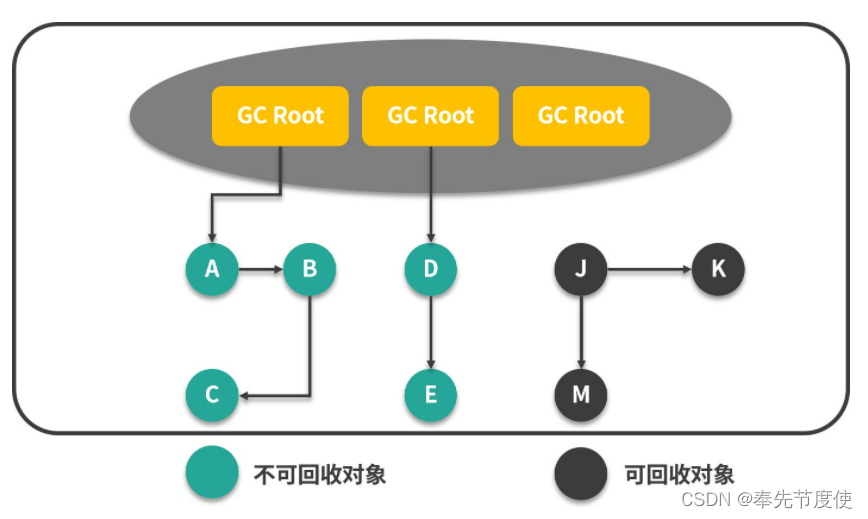
可达性分析算法是以根对象集合GC Roots为起点,按照从上至下的方式搜索被根对象集合中所连接的对象是否可达;如果该对象没有任何引用链相连,则是不可达,意味着该对象已经死亡可以标记为垃圾对象;可达性分析算法有效的解决在引用计数算法中循环引用的问题,防止内存泄漏的发生.
GC Roots包括的类或者对象
- 虚拟机栈中引用的对象:各个方法中使用到的参数、局部变量(即栈帧中局部变量表中的引用对象)
- 本地方法栈引用的对象
- 方法区中类静态属性引用的对象: java类静态变量
- 方法区中常量引用的对象: 字符串常量池的里的引用
- 同步锁synchronized持有的对象
清除阶段-标记-清除(Mark-Sweep)算法

当堆中有效空间被耗尽的时候,就会停止用户线程(STW),然后进行标记和清除操作;
- 标记:垃圾回收器Collector从GC Root开始遍历,标记所有被引用的对象,一般会在对象头中记录为可达对象
- 清除:垃圾回收器Collector对堆内存从头到尾进行线性遍历,如果发现某个对象在它的对象头中没有标记为可达对象,则将其视为垃圾进行回收(注意:清除并非真的置空,而是把需要清除的对象地址保存在空闲地址列表中,下次有新对象需要存储时,会判断该垃圾所在的内存位置是否能够存储,若能则覆盖原有垃圾)
缺点
- 效率不算高
- 进行GC需要停止整个应用程序,导致用户体验差
- 空闲内存不连续会产生内存碎片,需要JVM维护一个空闲列表
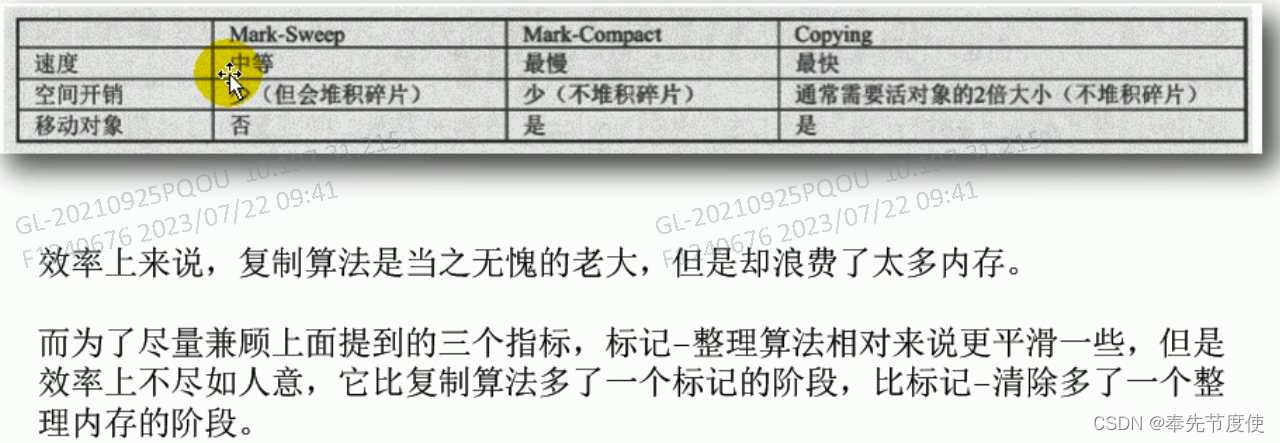
清除阶段-复制(Copy)算法
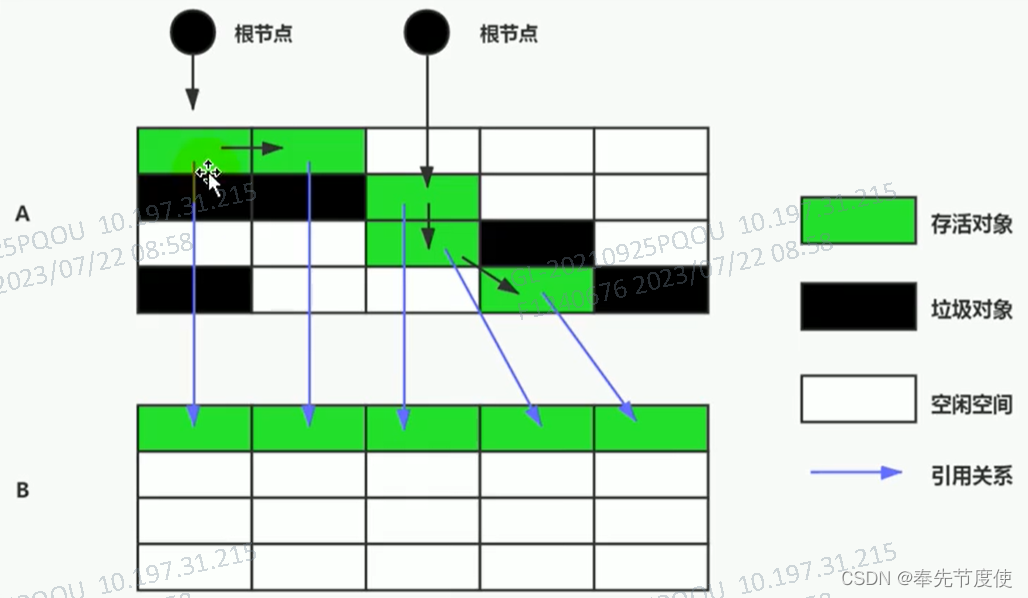
该算法核心思想是将可用的内存空间分为两块,在垃圾回收时将正在使用的内存中的存活对象复制到未被使用的内存块中,之后清除正在使用的内存块中的所有对象,交换两个内存角色,最后完成垃圾回收(复制算法适用于复制没有存在很多存活的对象,即新生代)
优点
- 没有标记和清除过程,实现简单,运行高效
- 复制以后保证空间的连续性,不会出现“碎片”问题
缺点
- 需要两倍的内存空间
清除阶段-标记-压缩(Mark-Compact)算法
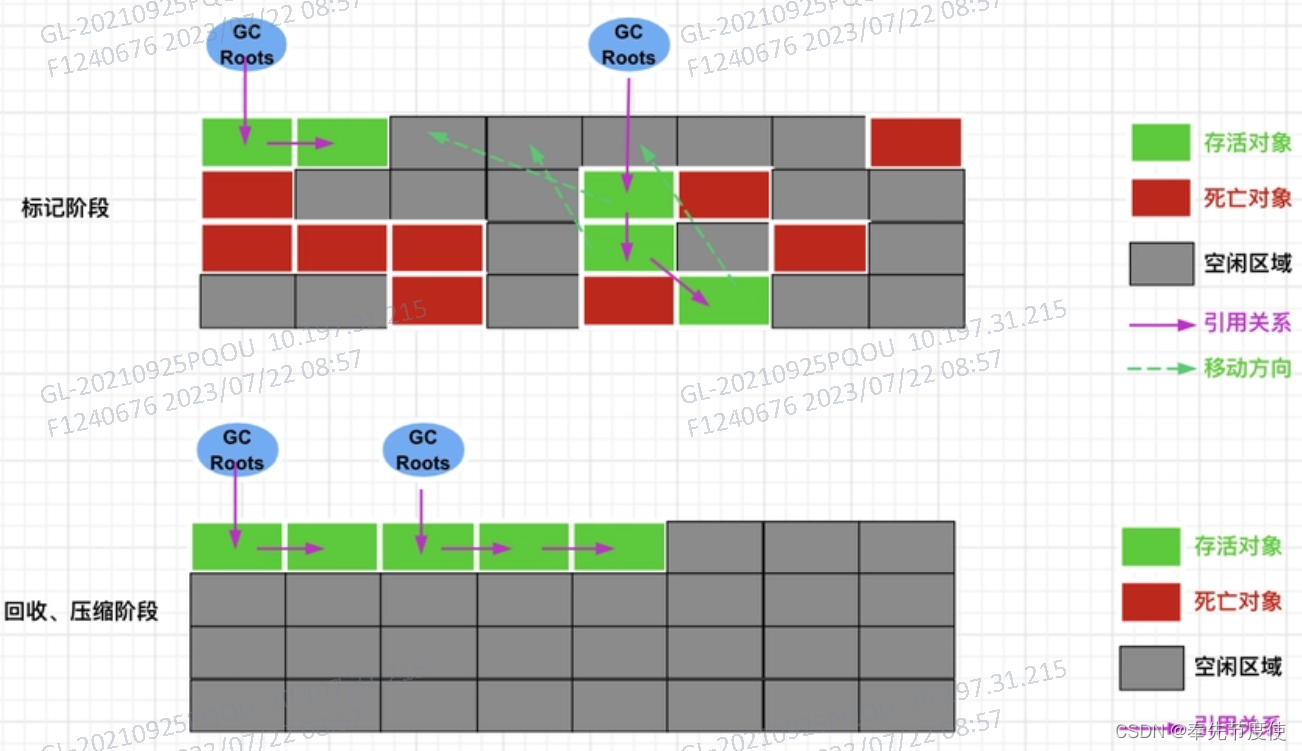
由于标记清除算法会产生碎片化,所以设计者在此基础上进行了改进诞生了标记压缩算法,所以标记压缩算法最终效果=标记-清除算法+内存碎片整理,即标记压缩算法也可以称为标记-清除-压缩算法
标记压缩过程
- 标记阶段和标记清除算法一样,从根节点开始标记所有被引用的对象
- 压缩/整理:将所有存活的对象压缩到内存的一端,按顺序排列存储
- 最后清理边界外所有内存空间
优点
- 消除了标记-清除算法中内存区域碎片化的缺点,我们给新对象分配内存空间时,JVM只需要持有一个内存起始地址即可
- 消除了复制算法中内存减半的高额代价
缺点
- 效率上标记-压缩算法低于复制算法
- 压缩/整理过程中,若对象被其他对象引用,则还需要调整引用的地址
- 需要全称暂停用户应用你程序,即STW
分代收集算法(CMS垃圾回收器)
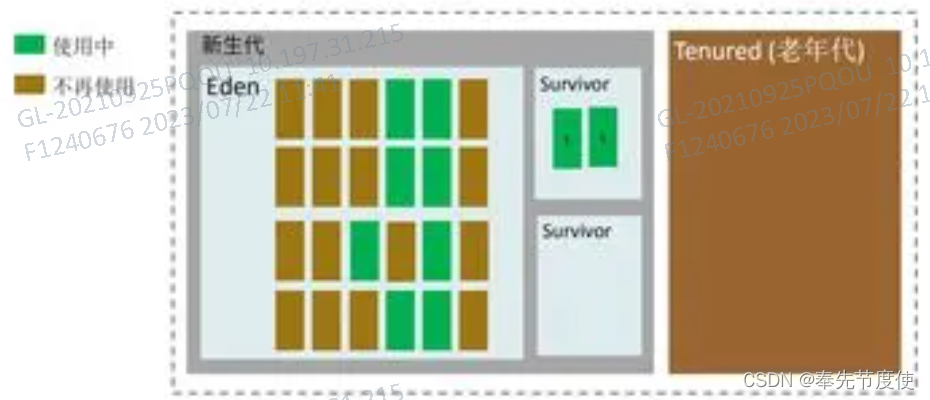
由于不同的对象生命周期是不一样的,因此不同生命周期的对象可以采取不同的收集方式,以便提高回收效率;目前几乎所有的GC都是采用分代收集算法执行垃圾回收的,Hotspot中基于分代概念,对于新生代和老年代各自特点就采用了不同的算法
- 新生代:对象生命周期短,存活率低,回收频繁;采用复制算法回收效率最高,因为复制算法只和当前存活对象多少有关,且对于内存利用率不高的问题,hotspot也通过survivor区域进行缓解
- 老年代:对象生命周期长,存活率高,回收不及新生代频繁;一般采用标记-清除或者标记-压缩和标记-清除算法混合实现
分代收集案例
以hotspot中CMS垃圾回收器为例,CMS是基于Mark-Sweep算法实现,对于对象的回收效率很高.而对于碎片问题,CMS又采用了基于Mark-Compact算法的Serial old回收器作为补偿措施(当内存回收不佳时利用Serial old执行Full GC进行垃圾回收)
增量收集算法
基本思想
如果一次性将所有垃圾进行处理,需要造成系统长时间停顿,极大影响用户体验;因此我们可以让垃圾收集线程和应用程序线程交替执行,每次垃圾收集线程只收集一小片区域内存空间,接着切换到应用程序线程.依次反复执行知道垃圾收集完成。增量收集算法基础仍是标记清除和复制算法,它对线程间冲突进行了妥善处理,允许垃圾收集线程以分阶段的方式完成标记-清除和复制工作.
分区算法(G1垃圾回收器)
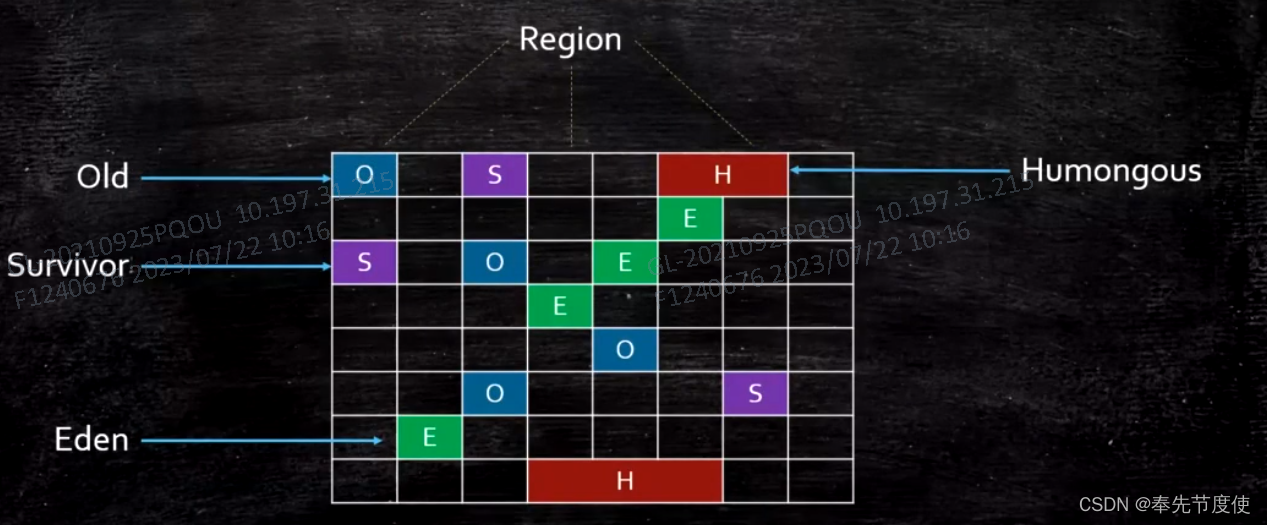
为了更好的控制GC产生的停顿时间,分区思想是将一块大的内存区域分割成多个小块,根据目标停顿时间,每次合理的回收若干个小区间region,而不是整个堆空间,从而减少一次GC所产生的STW
分代算法思想是按照对象生命周期长短划分成两个部分;而分区算法思想是将整个堆空间划分成连续不同的region;其中每个region独立使用,独立回收,这种方式可以控制一次回收一定数量的region,已达到更好的控制GC产生的停顿时间
垃圾回收器
GC核心性能指标
- 吞吐量:运行用户线程执行的时间占总运行时间的比例(总运行时间=用户线程执行时间+GC时间);适用于服务器端程序
- 暂停时间STW:执行垃圾回收时用户线程暂停的时间,即延迟时长;适用于交互式程序,如web应用
GC垃圾回收器的目标就是在保证最大吞吐量的情况下,最大化的降低STW
GC分类
- 按垃圾回收线程分类
- 串行垃圾回收器(同一时间段只允许一个CPU用于执行垃圾回收操作)
- 并行垃圾回收器(同一时间段允许多个CPU(或者单CPU多核)用于执行垃圾回收操作)
- 按工作模式分类
- 并发式垃圾回收器:垃圾回收线程和用户线程并发交替执行,减少STW
- 独占式垃圾回收器:只允许垃圾回收线程运行,停止所有用户线程直到垃圾回收结束
- 按工作内存区间
- 年轻代垃圾回收器和老年代垃圾回收器

垃圾回收器和JVM有紧密的联系,不同的JVM之间的GC有一定的区别,基于hotspot虚拟机有7种经典的垃圾收集器
- 串行GC: Serial、Serial Old
- 并行GC: ParaNew、Parallel Scavenge、Parallel Old
- 并发GC: CMS、G1
GC组合关系
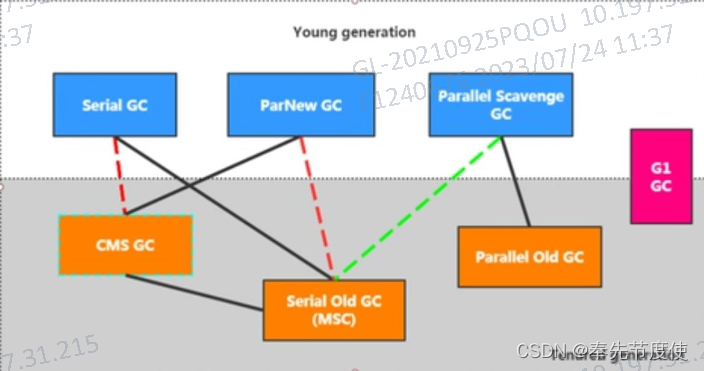
- 其中serial old作为CMS出现“Concurrent Mode Failure”的后备方案(即会执行FGC回收可用内存空间)
- 红色虚线:JDK8/JDK9后废弃/移除了serial GC搭配CMS GC以及ParaNew 搭配Serial old使用
- 绿色虚线:JDK14弃用Parallel Scavenge GC搭配SerialOld GC,以及移除了CMS回收器
由于Java使用场景很多,所以需要针对不同场景提供不同的垃圾回收器以实现更高垃圾收集的性能
垃圾回收器说明
Serial 回收器(串行回收)
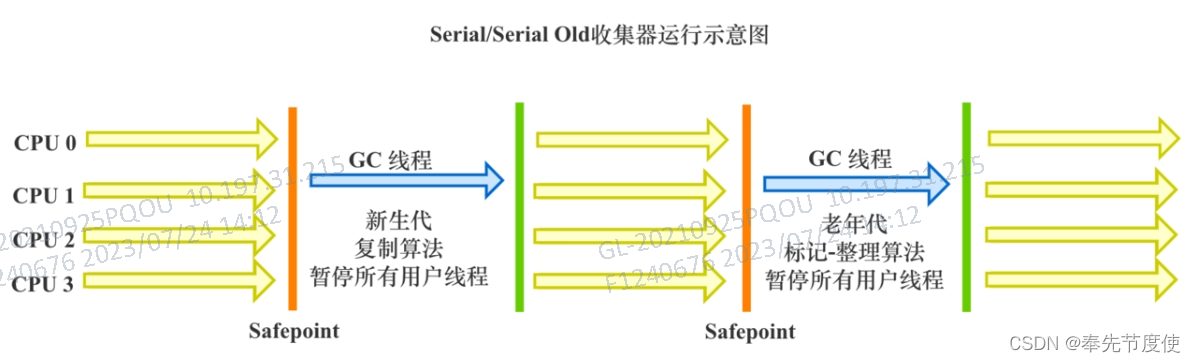
- Serial 收集器是最基本、历史最悠久的垃圾收集器,简单高效
- hotspot中client模式(32位操作系统)下的默认新生代垃圾收集器
- 采用复制算法,串行回收以及采用STW机制方式执行内存回收
- Serial old收集器也采用了串行回收和STW,不过采用的是标记-压缩算法
- Serial old是client模式(32位操作系统)下的默认老年代垃圾收集器
- Serial old是server模式(64位操作系统)下的用途
- 与新生代的parallel scavenge配合使用
- 作为老年代CMS的后备垃圾收集方案
-
-XX:+UserSerialGC 指定年轻代和老年代都使用串行收集器,即新生代使用Serial GC,老年代使用Serial Old GC
ParaNew回收器(并行回收)
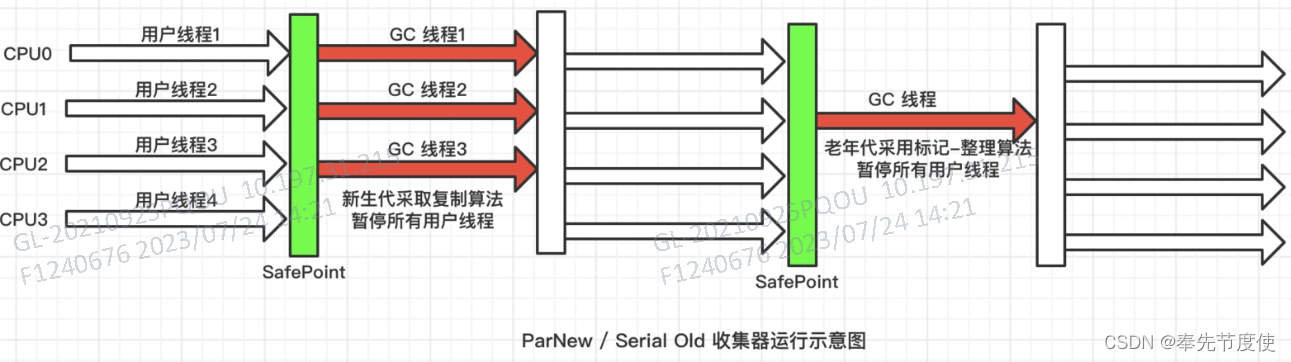
- Serial GC是以单线程方式回收新生代,而ParaNew则是它的多线程版本,且只能回收新生代
- 同样采用复制算法和STW机制
- 很多JVM运行在Server模式下新生代默认垃圾回收器
-
ParaNew收集器适合多CPU环境,可以更快速完成垃圾收集提升程序的吞吐量
-
-XX:+UserParaNewGC 指定年轻代采用的收集器,即新生代使用Serial GC,不影响老年代
Parallel回收器(并行回收且追求高吞吐量)
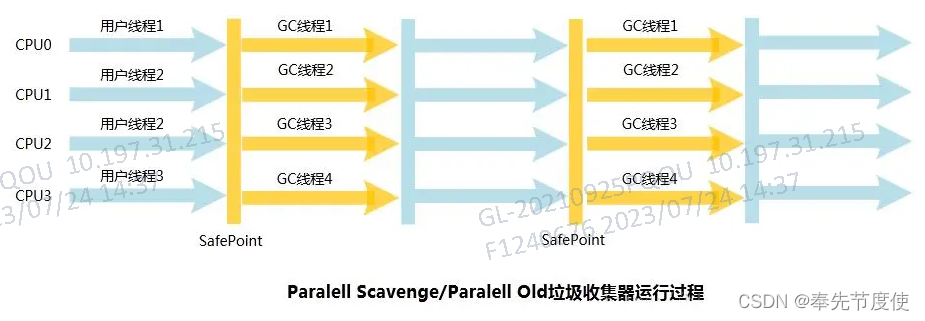
- Parallel Scavenge回收器(并行回收且更追求吞吐量)
- Parallel Scavenge也属于并行回收年轻代的方式
- 同样采用复制算法和STW机制
- Parallel Scavenge相比ParaNew是一种吞吐量优先的GC
- 更适合后台运算而不需要太多交互的任务,常用与服务器环境
- Parallel Old代替了Serial old采用并行方式回收老年代
- Parallel Old采用了标记-压缩算法
- Parallel Old同样采用复制算法和STW机制
-
-XX:+UserParallelGC 指定年轻代采用的并行收集器
-XX:+UserParallelOldGC 指定老年代采用的收集器,jdk8中默认的回收器,与年轻代设置其中一个即可,会互相激活
CMS回收器(追求低延迟)
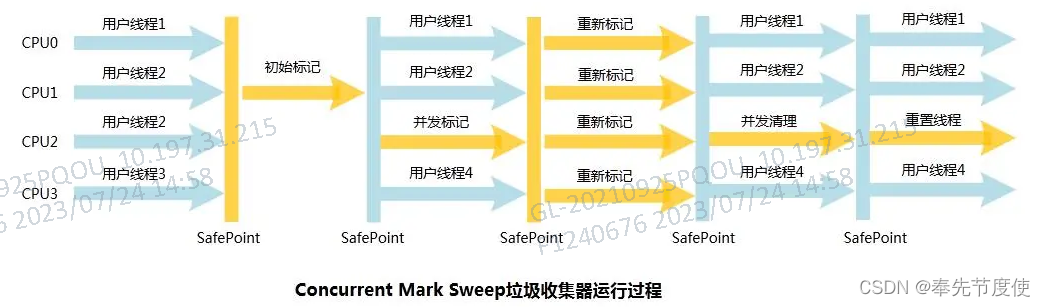
- jdk5版本中hotspot推出了强交互应用场景下的划时代的垃圾回收器,实现了垃圾线程和用户线程同时工作
- 尽可能缩短垃圾收集时的STW
- 采用标记-清除算法,也存在STW
- 由于Parallel Scavenge无法和CMS配合使用(底层框架不同),所以后来推出了ParaNew适配CMS
CMS工作原理
CMS执行流程主要包含4个过程,初始标记、并发标记、重新标记、并发清理(其中只有初始标记和重新标记存在STW)
- 初始标记:也称为initial-mark,该阶段会STW,且仅仅是标记GC Roots能直接关联到的对象,标记完成则恢复之前被暂停的所有用户线程,由于直接关联对象比较小,所以该阶段标记速度很快
- 并发标记:通过初始标记的对象开始遍历整个对象图的过程,该阶段耗时长但不需要停顿用户线程,可以并发执行用户线程和垃圾回收线程
- 重新标记:由于并发标记阶段中用户线程和垃圾线程同时执行,可能存在一些标记的对象产生变动,所以需要进行修正,该阶段时长比初始时间长但远远小于并发标记时长
- 并发清理:清理删除掉标记阶段判断的已经死亡的对象,释放内存空间.由于采用的标记-清除算法不涉及移动内存空间,所以该阶段可以和用户线程并发执行
优点
- 并发收集
- 低延迟(STW短)
缺点
- 采用的标记-清除算法会产生内存碎片
- 降低系统的吞吐量: 并发阶段垃圾线程会占用一定的资源,所以总的吞吐量会减少
- CMS无法处理浮动垃圾: 并发阶段可能产生新的垃圾对象,CMS无法及时回收这些垃圾,只能在下一次GC时回收
注意
- 由于在垃圾收集阶段用户线程没有中断,所以在CMS回收郭过程中,必须确保应用程序拥有足够的内存空间.因此当堆内存使用率达到某一阈值时,便开始进行回收,以确保在CMS期间依然有足够的内存空间支持程序运行;在CMS期间预留的内存无法满足应用程序需求时,就会出现“concurrent Mode failure"失败,这时虚拟机将启动后备预案,临时启用Serial old 收集器重新进行老年代的垃圾回收,此时STW耗时就比较长了
- 由于采用标记-清除算法,所以内存会产生碎片化,在为新对象分配空间时将无法使用指针碰撞技术,而只能选择空闲列表执行内存的分配
G1回收器(区域分代化)
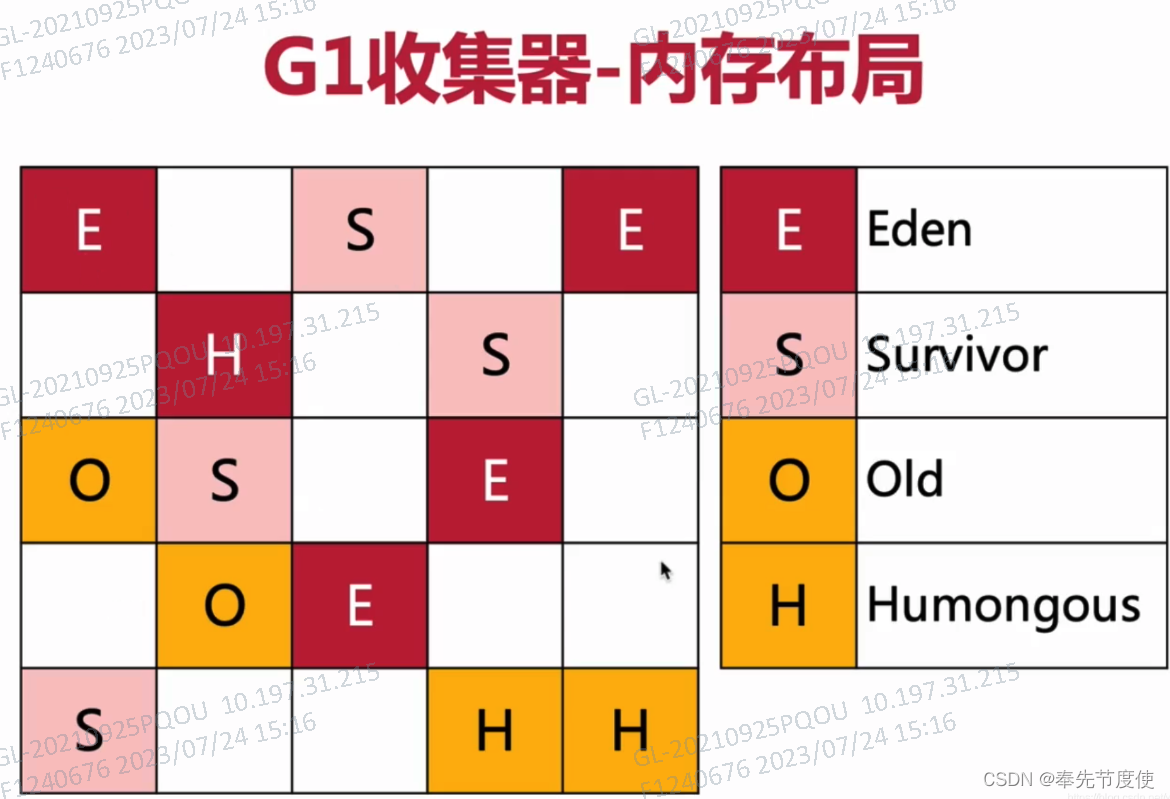
为了适应现在不断扩大的内存和不断增加的处理器数量,进一步降低暂停时间并且兼顾良好的吞吐量。官方给G1设定的目标就是在延迟可控的情况下获得尽可能高的吞吐量,称其为“全功能收集器”
- G1是一个并行回收器,它把堆内存分割成代表Eden,Survivor,old的region
- G1 GC避免在整个堆区进行垃圾收集,G1跟踪各个Region垃圾的价值(内存空间大小)以及回收所需的时间,在后台维护一个有限列表,每次根据允许的收集时间,优先回收价值最大的region
- G1主要针对配备多核CPU及大容量内存的机器,兼具高吞吐量和低延迟
- G1是JDK9以后的默认垃圾回收器,且CMS在JDK9中被标记为废弃(JDK14已移除)
优点
- 并行与并发
- 并行性:G1在回收期间,可以有多个GC线程同时工作,有效利用多核计算能力
- 并发性:G1可以和用户线程交替工作
- 分代收集:G1仍然区分年轻代和老年代,同时不要求它们都必须是连续等
- 空间整合:将内存划分一个个region,内存回收以region为基本单位,region之间是复制算法,整体上采用标记-压缩算法,避免内存碎片化,对于大堆时G1优势更加明显
- 可预测的停顿时间模型:由于分区以及每次根据允许的收集时间,优先回收价值最大的region,获取最高的收集效率
缺点
G1相比CMS,在用户程序运行过程中,需要占用额外执行负载(比如:G1需要通过记忆集Rset存储其他region的引用进而不必全堆扫描)
相比CMS,如下场景更适合G1
- 超过50%的Java堆被活动数据占用
- 对象分配频率或年代提升频率变化很大
- GC停顿时间过长(0.5-1s)
- 经验上来看,在6-8G之间,G1和CMS表现差不多,而小于此区间CMS更优秀,否则G1更优秀
常见问题
Serial GC、Parallel GC、CMS区别
- 如果追求最小化使用内存和并行开销,选择Serial GC
- 如果追求组嗲话应用程序的吞吐量,选择Parallel GC
- 如果追求最小化的GC中断或停顿时间,请选择CMS GC
MinorGC、MajorGC、FullGC区别
JVM在进行GC时,并非每次都对新生代、老年代、方法区区域一起回收的,大部分时候回收都是指新生代,而针对Hotspot VM的实现,按照回收区域分为Partial GC部分收集和Full GC整堆回收;
- 部分收集又分为新生代收集和老年代收集以及混合收集
- 新生代收集:Minor GC/YGC,对新生代的Eden和S0以及S1的垃圾回收
- 老年代收集:Major GC/Old GC,对老年代区域的垃圾回收,目前只有CMS GC会有单独收集老年代行为
- 混合收集: Mixed GC,对新生代以及部分老年代垃圾收集,目前只有G1 GC会有这种方式
- 整堆收集: Full GC,收集整个Java堆和方法区的垃圾收集,因为方法区几乎不执行GC,所以我们常常将Major GC和Full GC视为同一个含义
垃圾回收条件
- 新生代收集触发条件
- 当新生代中的Eden区域满的时候触发YGC
- Survivor区不会触发GC;而且YGC非常频繁且速度很快
- YGC会引发STW,直到垃圾回收完成用户线程才恢复运行
- 老年代收集触发条件
- 老年代空间不足时会发生Major GC
- 通常在发生Major GC前会进行一次YGC
- Major GC速度一般比YGC慢10倍以上,STW时间更长
- 整堆收集触发条件
- 调用System.gc(),系统建议执行Full GC,但不一定执行
- 老年代空间不足
- 通过YGC进入老年代的平均大小大于老年代的可用内存
- Eden和S0存货对象复制到S1时,S1空间不能够存放该对象,则会把对象转存到老年代,且此时老年代可用内存大小小于该对象大小
- 方法区空间不足
注意:我们开发中针对JVM调优,就是减少Full GC进而减少STW
相关文章:
JVM理论(六)执行引擎--垃圾回收
概述 垃圾: 指的是在运行程序中没有任何指针指向的对象垃圾回收目的: 为了及时清理空间使得程序可以正常运行垃圾回收机制: JVM采取的是自动内存管理,即JVM负责对象的创建以及回收,将程序员从繁重的内存管理释放出来,更加专注业务的开发垃圾回收区域: 频繁收集Young区(新生代)…...

贪心算法重点内容
贪心算法重点内容 4.1部分背包 按照单位重量的价值排序 4.2最小生成树 两种算法 4.3单源最短路径 4.4哈夫曼树...

基于深度学习的高精度交通信号灯检测系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度交通信号灯检测识别可用于日常生活中检测与定位交通信号灯目标,利用深度学习算法可实现图片、视频、摄像头等方式的交通信号灯目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检…...
【3D目标检测】DSVT-2023CVPR
论文:https://arxiv.org/pdf/2301.06051.pdf 作者:北大,华为 代码:https://github.com/Haiyang-W/DSVT ( OpenPCDet 框架已集成) 讲解:实时部署!DSVT:3D动态稀疏体素Tr…...
我在VScode学Python(Python函数,Python模块导入)
我的个人博客主页:如果’真能转义1️⃣说1️⃣的博客主页 (1)关于Python基本语法学习---->可以参考我的这篇博客《我在VScode学Python》 (2)pip是必须的在我们学习python这门语言的过程中Python ---->&a…...

【目标跟踪】1、基础知识
文章目录 一、卡尔曼滤波二、匈牙利匹配 一、卡尔曼滤波 什么是卡尔曼滤波?——状态估计器 卡尔曼滤波用于在包含不确定信息的系统中做出预测,对系统下一步要做什么进行推测,且会结合推测值和观测值来得到修正后的最优值卡尔曼滤波就是利用…...

33. 搜索旋转排序数组
题目描述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], ..., nums[n-1], nums[0], n…...

接口自动化测试要做什么?8个步骤讲的明明白白(小白也能看懂系列)
先了解下接口测试流程: 1、需求分析 2、Api文档分析与评审 3、测试计划编写 4、用例设计与评审 5、环境搭建(工具) 6、执行用例 7、缺陷管理 8、测试报告 那"接口自动化测试"怎么弄?只需要在上篇文章的基础上再梳理下就…...

Flutter 自定义 虚线 分割线
学习使用Flutter 进行 虚线 自定义控件 练习 // 自定义虚线 (默认是垂直方向) class DashedLind extends StatelessWidget {final Axis axis; // 虚线方向final double dashedWidth; // 根据虚线的方向确定自己虚线的宽度final double dashedHeight; //…...

Java毕业设计—爱宠医院管理系统设计与实现
爱宠医院管理系统 获取数论文、代码、答辩PPT、安装包,可以查看文章底部 一、 如何安装及配置环境 要运行整个爱宠医院管理系统需要安装数据库:MySQL 5.5,开发工具:JDK 1.8,开发语开发平台:Eclipse&…...
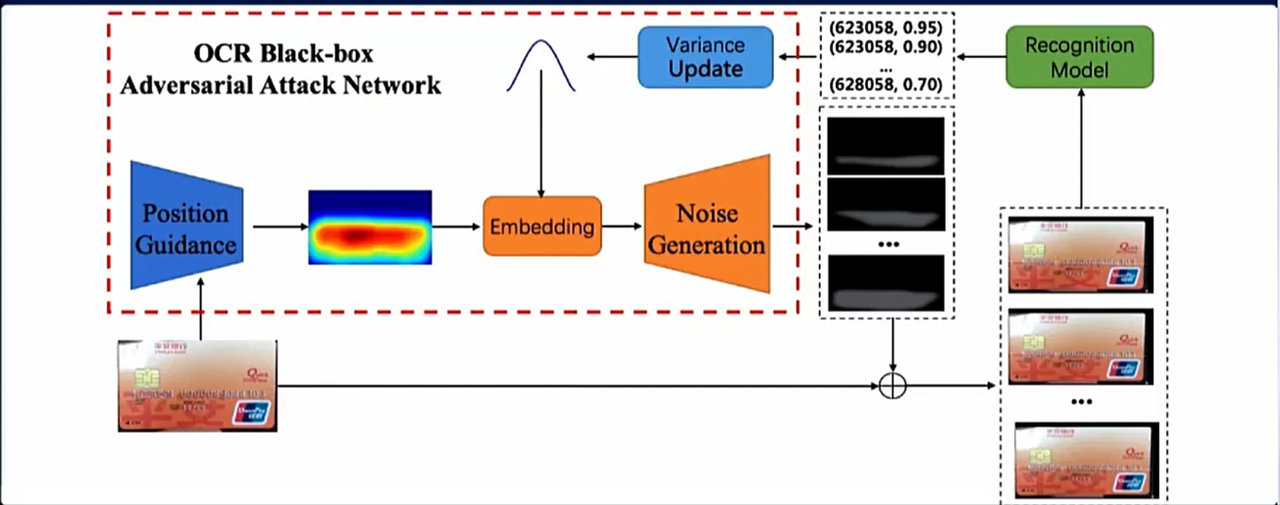
AI时代带来的图片造假危机,该如何解决
一、前言 当今,图片造假问题非常泛滥,已经成为现代社会中一个严峻的问题。随着AI技术不断的发展,人们可以轻松地通过图像编辑和AI智能生成来篡改和伪造图片,使其看起来真实而难以辨别,之前就看到过一对硕士夫妻为了骗…...
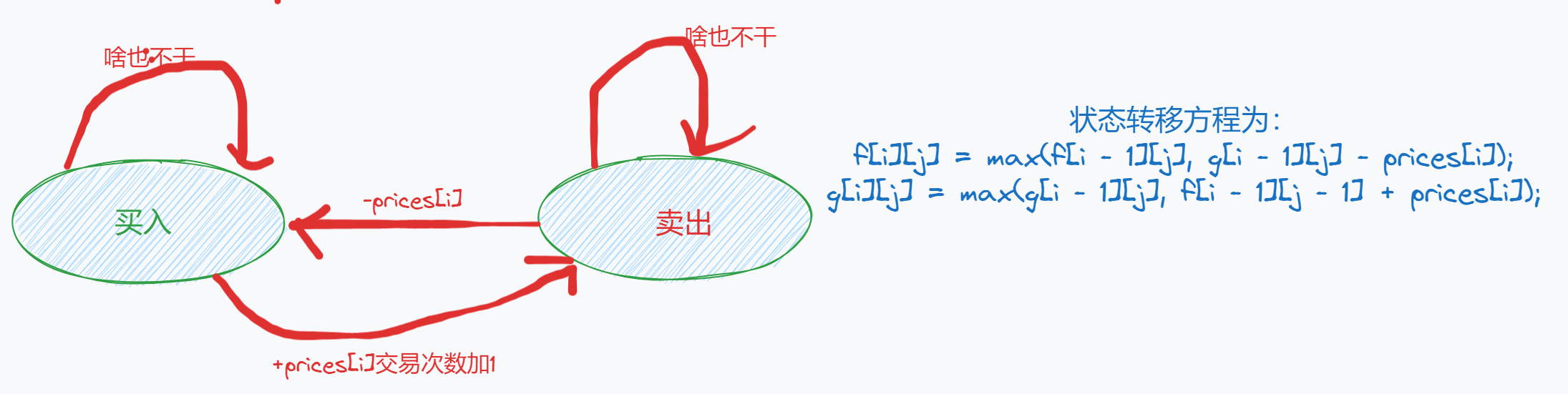
【动态规划】简单多状态
文章目录 动态规划(简单多状态)1. 按摩师2. 打家劫舍 ||3. 删除并获得点数4. 粉刷房子5. 最佳买卖股票时机含冷冻期6. 买卖股票的最佳时机含手续费7. 买卖股票的最佳时机 |||8. 买卖股票的最佳时机 IV 动态规划(简单多状态) 1. 按…...

科技资讯|苹果计划本月推出Vision Pro头显开发套件,电池有重大更新
根据消息源 aaronp613 分享的信息,苹果计划本月底面向开发者,发布 Vision Pro 头显开发套件。消息源还指出苹果更新了 Vision Pro 头显电池组的代号,共有 A2781,A2988 和 A2697 三种不同的型号,目前尚不清楚三者之间的…...

k8s 将pod节点上的文件拷贝到本地
要将 Kubernetes(k8s)中 Pod 节点上的文件拷贝到本地,可以通过使用 kubectl cp 命令来实现。kubectl cp 命令允许你在本地系统和 Pod 之间复制文件和目录。 下面是使用 kubectl cp 命令的语法: kubectl cp <namespace>/&l…...

Git简介与工作原理:了解Git的基本概念、版本控制系统和分布式版本控制的工作原理
🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁 🦄 个人主页——libin9iOak的博客🎐 🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~ἳ…...

java篇 类的进阶0x02:方法重载
文章目录 方法重载 overload方法签名返回值不属于方法签名的原因: 重载的参数匹配规则 方法重载 overload 多个方法功能很相似,但不完全一样,可以考虑使用方法的重载。 同一个类中,方法可以重名,但是签名不可以重复。…...

Android11 相机拍照权限,以及解决resolveActivity返回null
一、配置拍照和读写权限 <uses-permission android:name"android.permission.CAMERA"/> <uses-feature android:name"android.hardware.camera" /><uses-permission android:name"android.permission.WRITE_EXTERNAL_STORAGE"/&…...
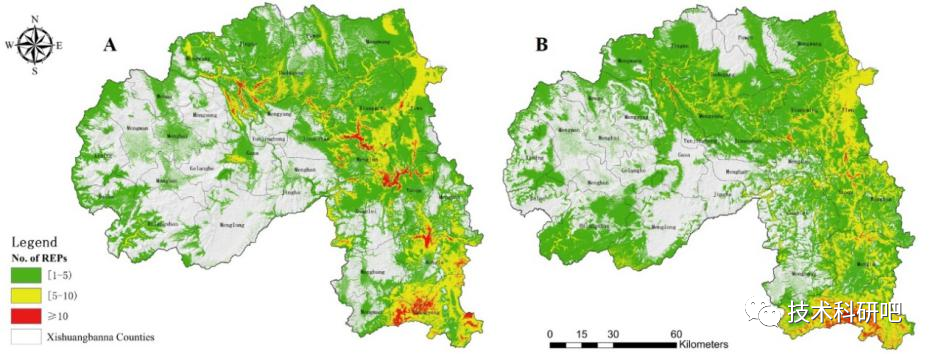
MAXENT模型的生物多样性教程
详情点击链接:基于MAXENT模型的生物多样性生境模拟与保护优先区甄选、自然保护区布局优化及未来气候变化下评估中的应用及论文写作 一:生物多样性保护格局与自然保护区格局优化 1.我国生物多样性格局与分布; 2.我国自然保护区格局与分布&…...
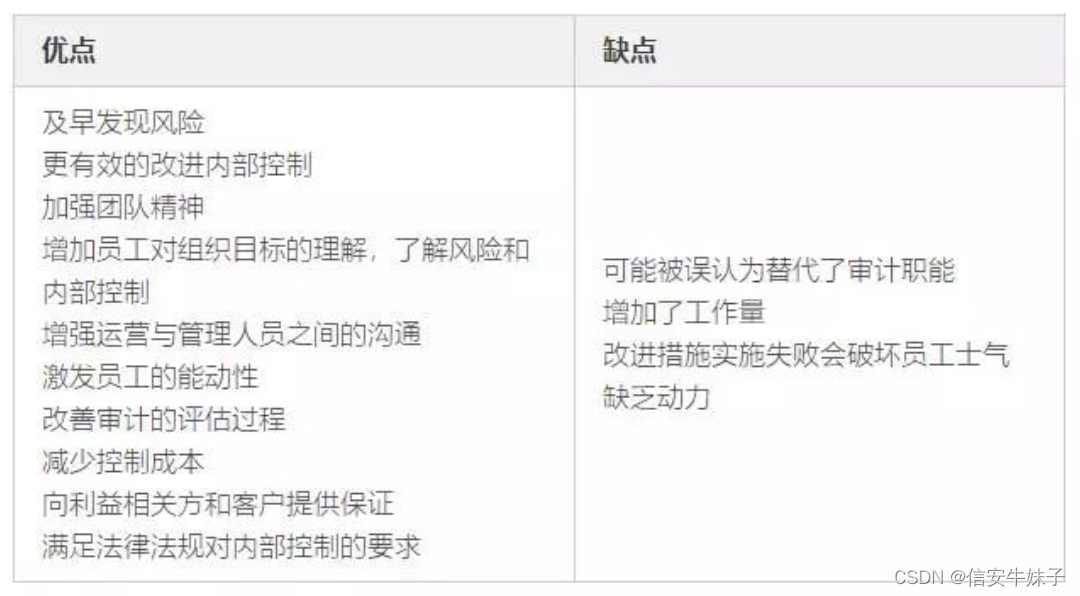
CISA学习笔记-第一章、信息系统审计过程
传统的审计三方关系理论指明,审计作为独立于会计记录之外的一项重要职能,是公司财务信息公允可靠的有力保障,制约着会计行为,制衡了会计权力。 1. IS审计和保障标准、指南、工具 职业道德规范 信息技术保证框架(ITAF&a…...
回调函数的使用:案例一:c语言简单信号与槽机制。
系列文章目录 文章目录 系列文章目录前言一、回调函数1.1 回调函数基本概念1.2 简单实现 二、代码案例1.代码示例 总结 前言 了解回调函数的基本概念,函数指针的使用、简单信号与槽的实现机制; 一、回调函数 1.1 回调函数基本概念 回调函数就是一个通…...

一文讲清楚 OpenClaw 是什么,以及 Windows 下的部署
OpenClaw 到底是什么1. 它在系统里干的事:接入层 运行时管理很多人第一次看到 OpenClaw,会把它当成“一个聊天 UI”。更工程化的视角是:它负责把外部请求接进来,并把后面的执行系统跑起来、管起来。接入层:把外部入口…...

YOLOv8模型训练避坑指南:GTX16系列显卡兼容性问题解决方案
GTX16系列显卡用户必读:YOLOv8模型训练全流程避坑手册 当你在GTX16系列显卡上运行YOLOv8训练脚本时,是否遇到过这样的场景:训练过程看似正常,但最终输出的P(精确率)、R(召回率)、mAP…...

GLM-Image WebUI快速上手:无需代码,浏览器直连http://localhost:7860
GLM-Image WebUI快速上手:无需代码,浏览器直连http://localhost:7860 1. 引言:让AI绘画像上网一样简单 想象一下,你有一个绝妙的创意画面在脑海中盘旋——一只戴着礼帽的猫在月球上喝下午茶,或者一座漂浮在云端的未来…...

BERT 模型:自然语言处理的新篇章
BERT模型:自然语言处理的新篇章 在人工智能领域,自然语言处理(NLP)一直是研究的热点之一。2018年,谷歌推出的BERT模型彻底改变了NLP的发展方向,成为该领域的重要里程碑。BERT(Bidirectional En…...

s2-pro音色复用效果实测:同一参考音频在不同文本长度下的泛化能力
s2-pro音色复用效果实测:同一参考音频在不同文本长度下的泛化能力 1. 测试背景与目的 s2-pro作为Fish Audio开源的专业级语音合成模型镜像,其核心亮点之一是支持通过参考音频复用音色。这项功能在实际应用中极为实用,比如: 企业…...

SUPER COLORIZER项目实战:使用LaTeX撰写技术报告与效果论文
SUPER COLORIZER项目实战:使用LaTeX撰写技术报告与效果论文 你是不是也遇到过这种情况?辛辛苦苦做完了SUPER COLORIZER的实验,效果数据也整理好了,但一到写报告或论文的时候就头疼。用Word吧,格式调整起来太麻烦&…...

FLUX.1-dev零基础入门:5分钟学会用ComfyUI生成高质量AI图片
FLUX.1-dev零基础入门:5分钟学会用ComfyUI生成高质量AI图片 1. 为什么选择FLUX.1-dev FLUX.1-dev是由Black Forest Labs开发的开源AI图像生成模型,以其出色的图像质量和类似照片的真实感而闻名。与其他模型相比,它能够更高效地生成艺术感强…...

LaTeX表格缩放实战:从手动微调到智能适配
1. LaTeX表格缩放的核心挑战 写论文时最头疼的莫过于遇到超宽表格——明明数据很清晰,一放到LaTeX里就溢出页面边界,要么被拦腰截断,要么挤得文字重叠。我审过上百篇学术论文,发现90%的表格排版问题都源于没有掌握正确的缩放技巧。…...
及一键配置心得)
不只是PointNet++:盘点那些依赖pointnet2_ops_lib的热门点云项目(PCT/SnowflakeNet)及一键配置心得
点云深度学习生态中的关键组件:pointnet2_ops_lib深度解析与实战指南 在三维视觉领域,点云数据处理一直是研究热点。不同于传统图像数据,点云具有无序性、稀疏性和非结构化的特点,这给深度学习模型的设计带来了独特挑战。PointNet…...

弦音墨影保姆级教程:解决‘米色宣纸背景不显示’‘朱砂按钮无响应’等常见问题
弦音墨影保姆级教程:解决‘米色宣纸背景不显示’‘朱砂按钮无响应’等常见问题 1. 引言:优雅水墨AI的实用指南 「弦音墨影」是一款将尖端人工智能技术与中国传统美学深度融合的视频理解与视觉定位系统。它以"水墨丹青"为视觉灵魂,…...