SpringCloud学习路线(12)——分布式搜索ElasticSeach数据聚合、自动补全、数据同步
一、数据聚合
聚合(aggregations): 实现对文档数据的统计、分析、运算。
(一)聚合的常见种类
- 桶(Bucket)聚合: 用来做文档分组。
- TermAggregation: 按照文档字段值分组
- Date Histogram: 按照日期阶梯分组,例如一周一组,一月一组
- 度量(Metric)聚合: 用以计算一些值,比如最大值、最小值、平均值等。
- Avg: 求平均值
- Max: 求最大值
- Min: 求最小值
- Stats: 同时求max、min、avg、sum等
- 管道(pipeline)聚合: 其它聚合的结果为基础的聚合。
参与聚合的字段类型:
- keyword
- 数值
- 日期
- 布尔
(二)DSL实现聚合
1、桶聚合
当我们统计所有数据中的酒店品牌有几种,此时可以根据酒店品牌的名称做聚合。
(1)基本实现
GET /hotel/_search
{"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { // 给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", //参与聚合的字段"size": 20 // 希望获取的聚合结果数量}}}
}
(2)Bucket聚合结果排序
默认情况下,Bucket聚合会统计Bucket内的文档数量,记为_count,并且按照_count降序排序。
那么如何修改排序?
GET /hotel/_search
{"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { // 给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", //参与聚合的字段,"order": { # 排序"_count": "asc"},"size": 20 // 希望获取的聚合结果数量}}}
}
(3)限定聚合范围
默认情况下,Bucket聚合是对索引库的所有文档做聚合,可以限定聚合的文档范围,只要添加query条件。
GET /hotel/_search
{"query": {"range": {"price": {"lte": 200 # 只对200元以下的文档聚合}}}"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果"aggs": { // 定义聚合"brandAgg": { // 给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand", //参与聚合的字段,"order": { # 排序"_count": "asc"},"size": 20 // 希望获取的聚合结果数量}}}
}
2、Metrics聚合
需求: 要求获取每个品牌的用户评分的min、max、avg等值。
GET /hotel/_search
{"size": 0,"aggs": { // 定义聚合"brandAgg": { // 给聚合起个名字"terms": { // 聚合的类型,按照品牌值聚合,所以选择term"field": "brand","order": { # 排序"scoreAgg.avg": "desc"},"size": 20},"aggs": { #是brands聚合的子聚合,也就是对分组后对每组分别计算"score_stats": { #聚合名称“stats”: { #聚合类型,这里的stats可以同时计算min、max、avg等"field": "score" #聚合字段,这里是score}}}}}
}
(三)RestClient实现聚合
1、桶聚合
//1、创建request对象
SearchRequest request = new SearchRequest("hotel");
//2、DSL组装
request.source().size(0);
request.source().aggregation(AggregationBuilders.term("brand_agg").field("brand").size(20)
);//3、发起请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4、解析结果
Aggregations aggregations = response.getAggregations();//5、根据名称获取聚合结果
Terms brandTerms = aggregations.get("brand_agg");//6、获取桶
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();//7、遍历
for (Terms.Bucket bucket : buckets) {//获取品牌信息String brandName = bucket.getKeyAsString();
}二、自动补全
(一)拼音分词器
1、离线安装拼音分词器

2、重启ES即可
(二)自定义分词器
1、直接使用拼音分词器的问题:
- 拼音分词器不分词,只分拼音
- 每一个字都形成了拼音
- 没有汉字
2、分词器的组成
- character filters: 在tokenizer之前对文本进行处理。例如删除字符、替换字符。
- tokenizer: 将文本按照一定规则切割词条(term)。例如keyword、ik_smart
- tokenizer filter: 将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理。
3、自定义实现结构
在创建索引库时, 通过settings来配置自定义的analyzer(分词器)
PUT /test
{"settings": { #设置配置"analysis": { #解析组"analyzer": { #自定义解析器"my_analyzer": { #分词器名称,按照character 》 tokenizer 》 filter 顺序进行配置"tokenizer": "ik_max_word","filter": "pinyin"}}}}
}
拓展自定义分词器
PUT /test
{"settings": { #设置配置"analysis": { #解析组"analyzer": { #自定义解析器"my_analyzer": { #分词器名称,按照character 》 tokenizer 》 filter 顺序进行配置"tokenizer": "ik_max_word","filter": "py"}},"filter": { #自定义tokenizer filter"py": { #过滤器名称"type": "pinyin", # 过滤器类型,设置为pinyin"keep_full_pinyin": false, # 是否开启单字拼音"keep_joined_full_pinyin": true, # 是否开启全拼"keep_original": true, # 是否保留中文"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}}
}
现在直接使用拼音分词器的问题:
当我们插入两个拼音相同,字义不同的词汇,那么在我们搜索一个同音词汇时,就会出现两者都被搜索出来,显然这是错误的搜索结果。
所以我们需要在创建索引时使用拼音分词器,在搜索索引时使用中文分词器。
"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer", # 在索引创建时使用自定义分词器"search_analyzer": "ik_smart" # 在搜索时使用中文分词器}}
}
(三)自动补全查询
ES 提供 Completion Suggester 查询来实现自动补全功能。
这个查询会匹配以用户输入内容开头的词条并返回。
为了提高补全查询的效率,对于文档中字段的类型有一些约束:
- 参与补全查询的字段必须是completion类型
- 字段的内容一般是用来补全多个词条形成的数组
#创建索引库
PUT test
{"maapings": {"properties": {"title": {"type": "completion"}}}
}# 示例数据
POST test/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{"title": ["SK-II", "PITERA"]
}
POST test/_doc
{"title": ["Nintendo", "switch"]
}
查询示例
GET /test/_search
{"suggest": {"title_suggest": {"text": "s", # 关键字"completion": {"field": "title", # 补全查询的字段"skip_duplicates": true, # 跳过重复的"size": 10 # 获取前10条结果}}}
}
(四)RestClient实现自动补全
//1、准备请求
SearchRequest request = new SearchRequest("hotel");//2、请求参数
request.source().suggest(new SuggestBuilder().addSuggestion("mySuggestion", SuggestBuilders.completionSuggestion("title").prefix("h").skipDuplicates(true).size(10)
));//3、发送请求
client.search(request, RequestOptions.DEFAULT);//4、解析结果
Suggest suggest = response.getSuggest();//5、根据名称获取补全结果
CompletionSuggestion suggestion = suggest.getSuggestion("title_suggest");//6、获取options并遍历
for (CompletionSuggestion.Entry.Option option : suggestion.getOptions()){//获取option的textString text = option.getText().string();
}
三、数据同步
ES的数据来自数据库,而数据库数据发生改变时,ES也必须改变,这个就是ES与数据库的数据同步。
在微服务中,负责 数据操作业务 与 数据搜索业务 可能会出现在两个不同的微服务中,数据同步如何实现?
(一)数据同步思路
方式一:同步调用
新增数据 》 数据管理业务(直接写入数据库) 》 调用更新索引库接口 》 数据搜索服务(更新ES)
- 优点: 实现简单,粗暴
- 缺点: 数据耦合,业务耦合,性能下降。
方式二:异步通知(现阶段最为推荐的一种方式)
新增数据 》 数据管理业务(直接写入数据库,并给MQ发送消息) 》 MQ(搜索服务订阅) 》 数据搜索服务(更新ES)
- 优点: 低耦合,实现难度一般
- 缺点: 依赖mq的可靠性
方式三:监听binlog
新增数据 》 数据管理业务(直接写入mysql数据库,mysql数据库监听binlog库) 》 canal(中间件,通知搜索服务数据变更) 》 数据搜索服务(更新ES)
- 优点: 完全解除服务间的耦合
- 缺点: 开启binlog增加数据库负担,实现复杂度高
(二)实现ES与数据库数据同步
我们采用的是异步通知的方式进行数据同步
实现数据同步
- 声明交换机,queue,RoutingKey
- 在admin中的增删改业务中完成消息发送
- 完成消息监听,并更新ES数据
相关文章:
SpringCloud学习路线(12)——分布式搜索ElasticSeach数据聚合、自动补全、数据同步
一、数据聚合 聚合(aggregations): 实现对文档数据的统计、分析、运算。 (一)聚合的常见种类 桶(Bucket)聚合: 用来做文档分组。 TermAggregation: 按照文档字段值分组…...

cloudstack的PlugNicCommand的作用
PlugNicCommand是CloudStack中的一个命令,用于将一个网络接口卡(NIC)插入到虚拟机实例中。它的作用是将一个已存在的NIC连接到指定的虚拟机,以扩展虚拟机的网络功能。 具体来说,PlugNicCommand可以完成以下几个步骤&a…...
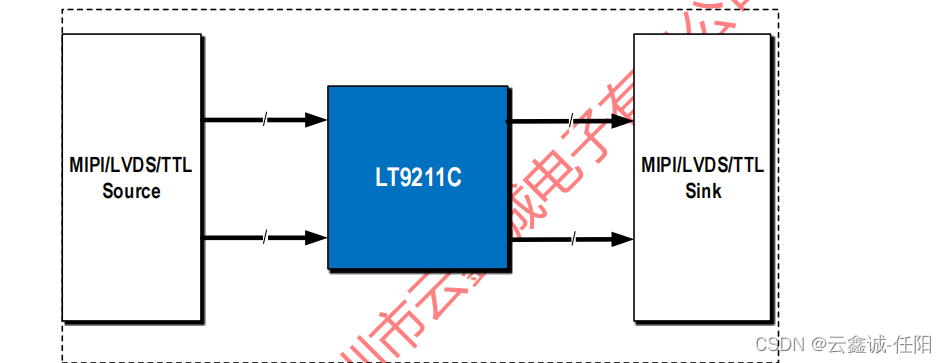
LT9211C 是一款MIPI/RGB/2PORT LVDS互转的芯片
LT9211C 1.描述: Lontium LT9211C是一个高性能转换器,可以在MIPI DSI/CSI-2/双端口LVDS和TTL之间相互转换,除了24位TTL到24位TTL,并且不推荐同步和DE的2端口10位LVDS和24位TTL之间的转换。LT9211C反序列化输入的MIPI/LVDS/TTL视…...
)
【Rust 基础篇】Rust 通道(Channel)
导言 在 Rust 中,通道(Channel)是一种用于在多个线程之间传递数据的并发原语。通道提供了一种安全且高效的方式,允许线程之间进行通信和同步。本篇博客将详细介绍 Rust 中通道的使用方法,包含代码示例和对定义的详细解…...
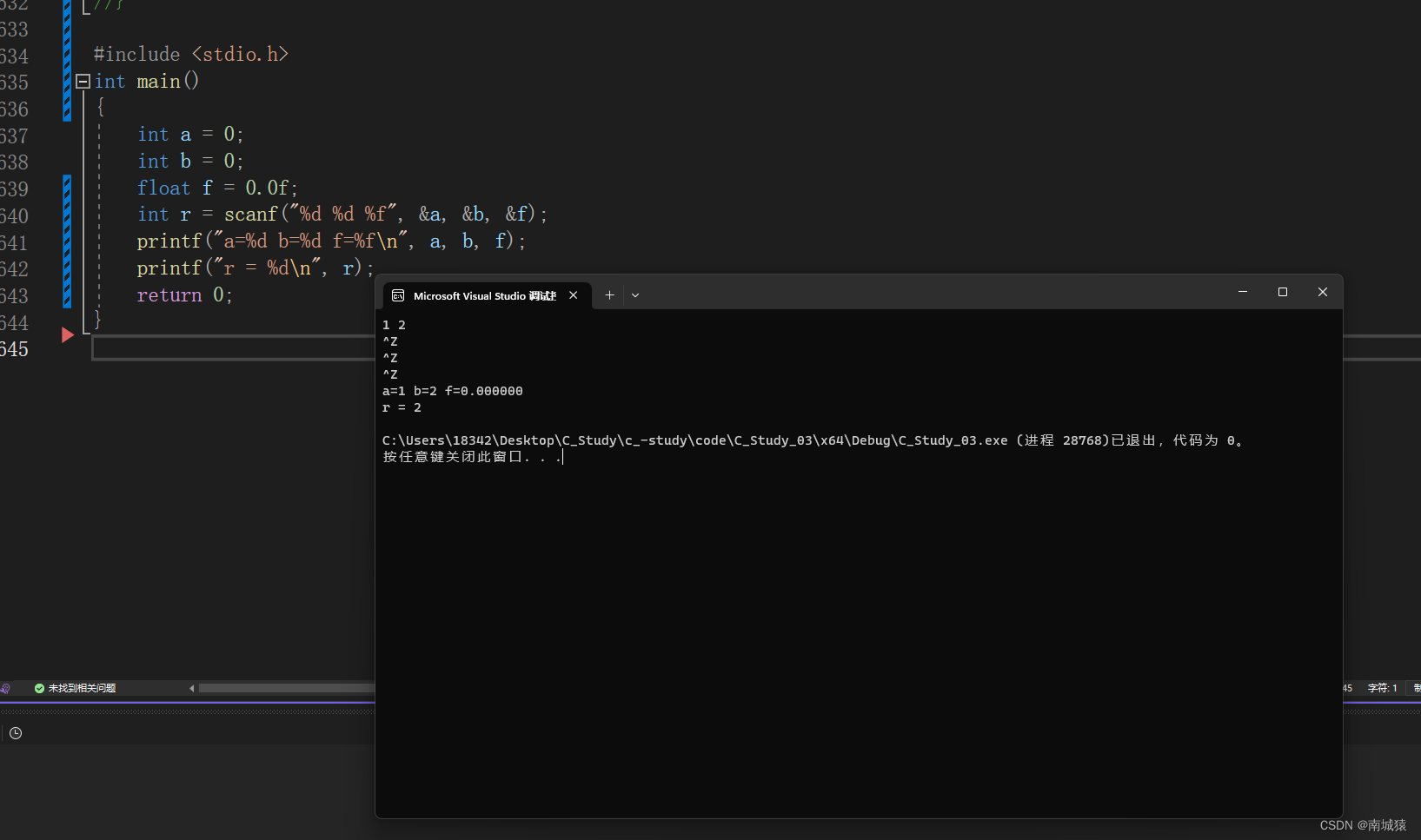
学习 C语言第二天 :C语言数据类型和变量(下)
目录: 1.变量的介绍以及存储 2.算术操作符、赋值操作符、单目操作符 3.scanf和printf的介绍 1.变量的介绍以及存储 1.1.变量的创建 了解了什么是类型了,类型是用来创建变量的。 变量是什么呢?在C语言当中不经常变的量称为常量,经常…...
【Kubernetes资源篇】ingress-nginx最佳实践详解
文章目录 一、Ingress Controller理论知识1、Ingress Controller、Ingress简介2、四层代理与七层代理的区别3、Ingress Controller中封装Nginx,为什么不直接用Nginx呢?4、Ingress Controller代理K8S内部Pod流程 二、实践:部署Ingress Control…...

Java基础阶段学习哪些知识内容?
Java是一种面向对象的编程语言,刚接触Java的人可能会感觉比较抽象,不要着急可以先从概念知识入手,先了解Java,再吃透Java,本节先来了解下Java的基础语法知识。 对象:对象是类的一个实例,有状态…...

【HISI IC萌新虚拟项目】ppu整体uvm验证环境搭建
关于整个虚拟项目,请参考: 【HISI IC萌新虚拟项目】Package Process Unit项目全流程目录_尼德兰的喵的博客-CSDN博客 前言 本篇文章完成ppu整体uvm环境搭建的指导,在进行整体环境搭建之前,请确认spt_utils、cpu_utils和ral_model均已经生成。此外,如果参考现在的工程目录…...

图像处理之hough圆形检测
hough检测原理 点击图像处理之Hough变换检测直线查看 下面直接描述检测圆形的方法 基于Hough变换的圆形检测方法 对于一个半径为 r r r,圆心为 ( a , b ) (a,b) (a,b)的圆,我们将…...
 vue3+vite+ts)
el-upload文件上传(只能上传一个文件且再次上传替换上一个文件) vue3+vite+ts
组件: <template><el-upload class"upload-demo" v-model:file-list"fileList" ref"uploadDemo" action"/public-api/api/file" multiple:on-preview"handlePreview" :on-remove"handleRemove&quo…...

随手笔记——根据点对来估计相机的运动综述
随手笔记——根据点对来估计相机的运动综述 说明计算相机运动 说明 简单介绍3种情况根据点对来估计相机运动所使用的方法 计算相机运动 有了匹配好的点对,接下来,要根据点对来估计相机的运动。这里由于相机的原理不同分为: 当相机为单目时…...

ip校园广播音柱特点
ip校园广播音柱特点IP校园广播音柱是一种基于IP网络技术的音频播放设备,广泛应用于校园、商业区、公共场所等地方。它可以通过网络将音频信号传输到不同的音柱设备,实现远程控制和集中管理。IP校园广播音柱具备以下特点和功能:1. 网络传输&am…...
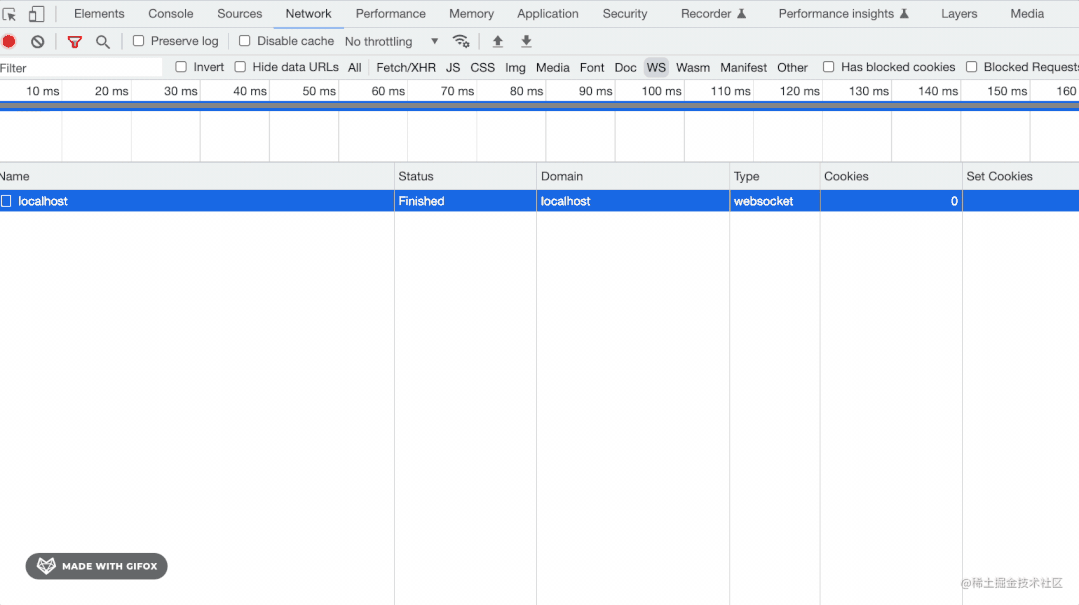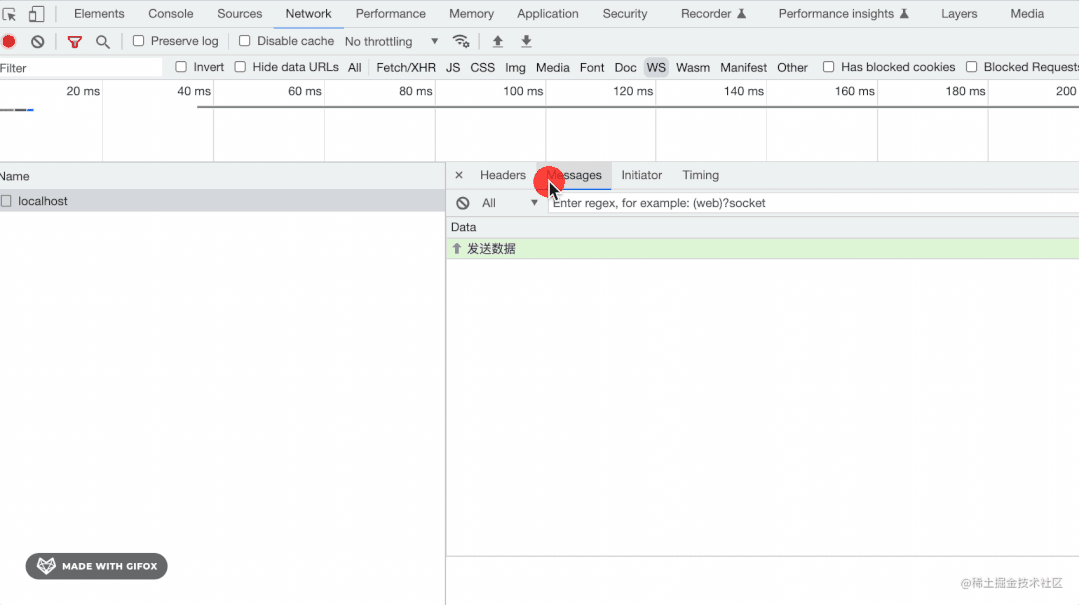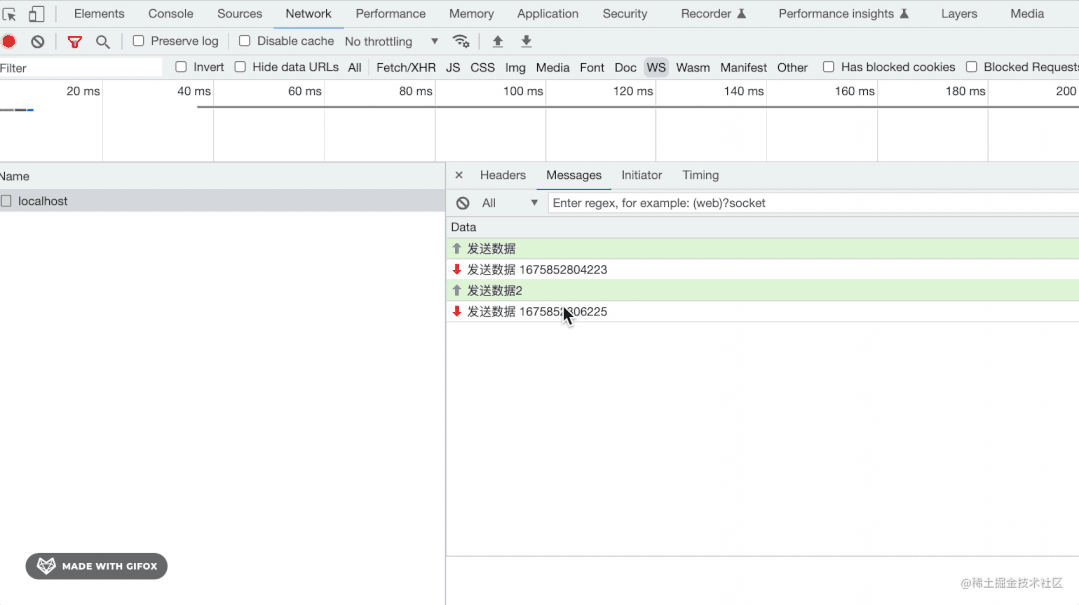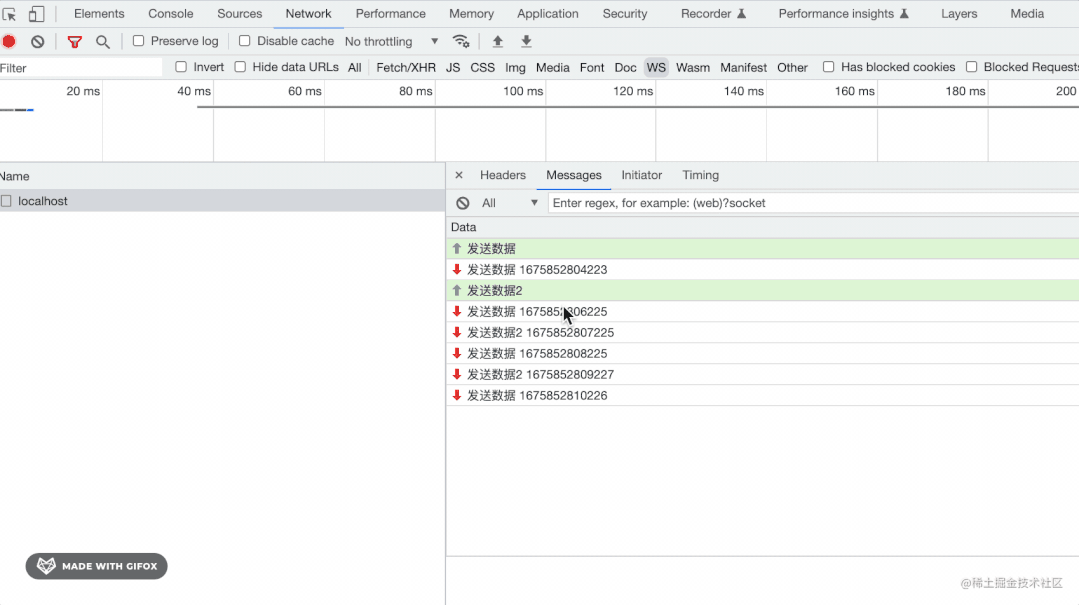
用 Node.js 手写 WebSocket 协议
目录 引言 从 http 到 websocekt 的切换 Sec-WebSocket-Key 与 Sec-WebSocket-Accept 全新的二进制协议 自己实现一个 websocket 服务器 按照协议格式解析收到的Buffer 取出opcode 取出MASK与payload长度 根据mask key读取数据 根据类型处理数据 frame 帧 数据的发…...
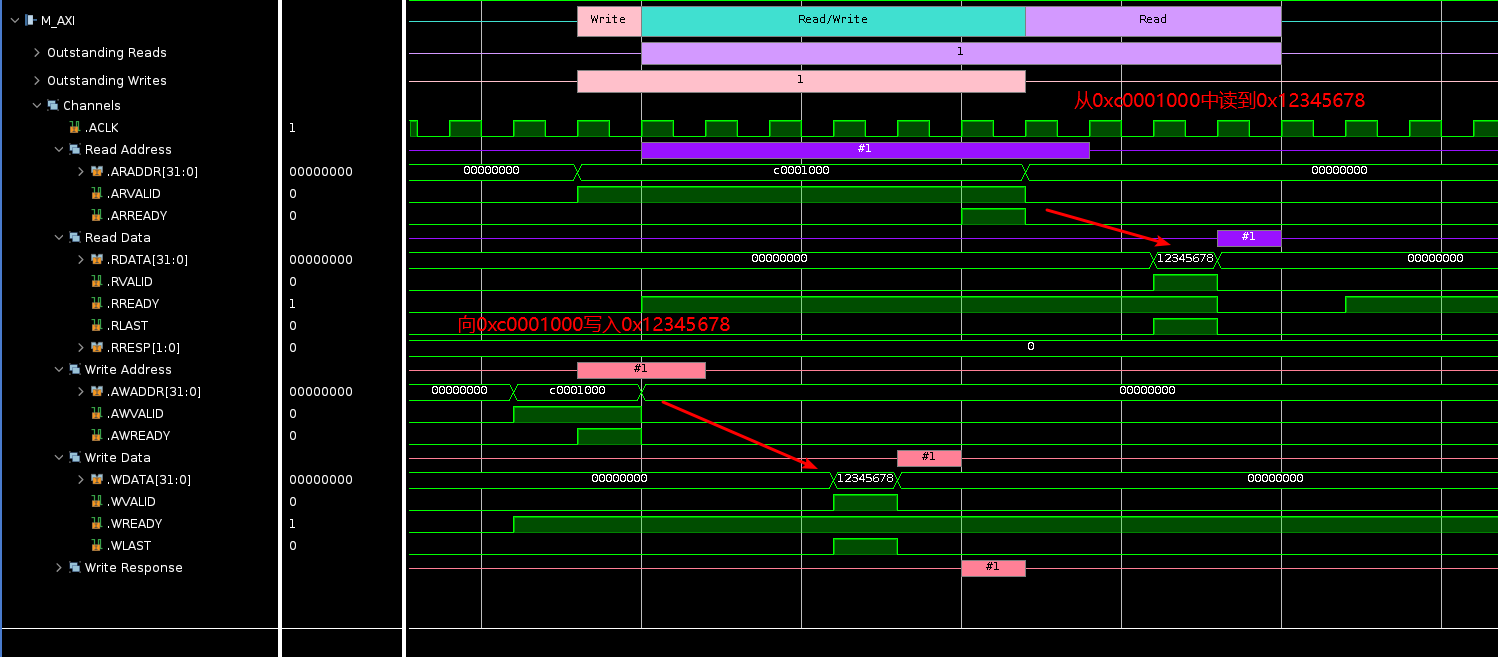
Xilinx AXI VIP使用教程
AXI接口虽然经常使用,很多同学可能并不清楚Vivado里面也集成了AXI的Verification IP,可以当做AXI的master、pass through和slave,本次内容我们看下AXI VIP当作master时如何使用。 新建Vivado工程,并新建block design,命…...

mysql主主架构搭建,删库恢复
mysql主主架构搭建,删库恢复 搭建mysql主主架构环境信息安装msql服务mysql1mysql2设置mysql2同步mysql1设置mysql1同步mysql2授权测试用账户 安装配置keepalivedmysql1检查脚本mysql2检查脚本 备份策略mysqldump全量备份mysqldump增量备份数据库目录全量备份 删除my…...

pythonweek1
引言 做任何事情都要脚踏实地,虽然大一上已经学习了python的基础语法,大一下也学习了C加加中的类与对象,但是自我觉得基础还不太扎实,又害怕有什么遗漏,所以就花时间重新学习了python的基础,学习Python的基…...
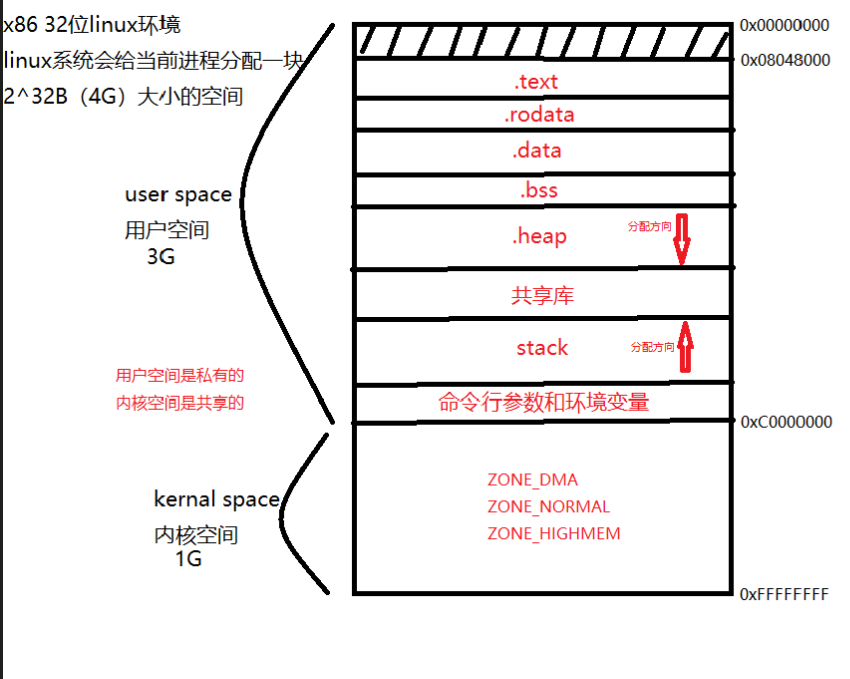
进程虚拟地址空间区域划分
目录 图示 详解 代码段 备注:x86 32位linux环境下,进程虚拟地址空间区域划分 图示 详解 用户空间 用于存储用户进程代码和数据,只能由用户进程访问 内核空间 用于存储操作系统内核代码和数据,只能由操作系统内核访问 text t…...
OpenAI Code Interpreter 的开源实现:GPT Code UI
本篇文章聊聊 OpenAI Code Interpreter 的一众开源实现方案中,获得较多支持者,但暂时还比较早期的项目:GPT Code UI。 写在前面 这篇文章本该更早的时候发布,但是 LLaMA2 发布后实在心痒难忍,于是就拖了一阵。结合 L…...

macOS Ventura 13.5 (22G74) 正式版发布,ISO、IPSW、PKG 下载
macOS Ventura 13.5 (22G74) 正式版发布,ISO、IPSW、PKG 下载 本站下载的 macOS Ventura 软件包,既可以拖拽到 Applications(应用程序)下直接安装,也可以制作启动 U 盘安装,或者在虚拟机中启动安装。另外也…...

Electron 主进程和渲染进程传值及窗口间传值
1 渲染进程调用主进程得方法 下面是渲染进程得代码: let { ipcRenderer} require( electron ); ipcRenderer.send( xxx ); //渲染进程中调用 下面是主进程得代码: var { ipcMain } require( electron ); ipcMain.on("xxx",function () { } )...
)
别再到处找瓦片服务地址了!手把手教你用OpenLayers 7.x集成天地图和高德地图(附完整代码)
OpenLayers 7.x实战:深度解析天地图与高德地图集成方案 第一次接触地图开发时,最让我头疼的不是写代码,而是找不到正确的瓦片服务地址。那些看似简单的URL背后,藏着各种参数玄机——为什么别人的地图能正常显示中文标注࿱…...

深入TC3xx安全机制:从WDT密码访问到Endinit保护,如何构建防误写屏障?
TC3xx芯片安全架构深度解析:Endinit机制与汽车电子功能安全实践 在汽车电子系统设计中,功能安全从来不是可选项而是必选项。随着ADAS和自动驾驶技术的快速发展,ECU的复杂性和安全性要求呈指数级增长。TC3xx系列芯片作为汽车电子领域的核心处…...

DepotDownloader核心功能解析:从App下载到工作坊内容获取的完整指南
DepotDownloader核心功能解析:从App下载到工作坊内容获取的完整指南 【免费下载链接】DepotDownloader Steam depot downloader utilizing the SteamKit2 library. 项目地址: https://gitcode.com/gh_mirrors/de/DepotDownloader DepotDownloader是一款功能强…...

ai辅助arm7开发:向快马描述需求,智能生成pwm电机控制代码与方案
最近在做一个基于ARM7的直流电机控制项目,需要用到PWM来控制电机转速。作为一个嵌入式开发新手,对定时器配置这块一直不太熟悉。好在发现了InsCode(快马)平台,它集成的AI辅助功能帮我快速解决了这个问题。 PWM基础配置 ARM7的定时器模块功能…...

终极指南:5步快速上手SillyTavern打造个性化AI对话体验
终极指南:5步快速上手SillyTavern打造个性化AI对话体验 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern SillyTavern是一款专为高级用户设计的LLM前端界面,让你能够轻…...

3步解锁魔兽争霸3性能潜力:从60帧到300帧的现代硬件优化实战
3步解锁魔兽争霸3性能潜力:从60帧到300帧的现代硬件优化实战 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸3作为经典RTS游戏&am…...
)
Python实战:5分钟搞定微博爬虫,自动备份你的微博内容(附完整代码)
Python实战:5分钟搞定微博个人内容备份(零基础友好版) 每次刷微博时,看到自己多年前发的动态总有种时光穿越的错觉。那些深夜的碎碎念、旅行的打卡照、突发奇想的段子,都是珍贵的数字记忆。但平台内容随时可能调整展示…...

OpenClaw资源监控方案:Qwen3.5-9B运行时性能调优
OpenClaw资源监控方案:Qwen3.5-9B运行时性能调优 1. 为什么需要关注资源监控? 去年冬天,我第一次在本地MacBook Pro上部署Qwen3.5-9B模型时,系统突然卡死的经历让我记忆犹新。当时我正在运行一个简单的文档摘要任务,…...

Python实战:利用imageio与PIL打造高效图片转视频工具
1. 为什么需要图片转视频工具? 在日常工作和生活中,我们经常会遇到需要将多张图片合成为视频的场景。比如制作产品演示视频、创建旅行相册、生成数据可视化动画等。手动使用视频编辑软件处理这些需求不仅效率低下,而且难以实现批量自动化处理…...

Hotkey Detective终极指南:3步快速解决Windows热键冲突问题
Hotkey Detective终极指南:3步快速解决Windows热键冲突问题 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...