pythonweek1
引言
做任何事情都要脚踏实地,虽然大一上已经学习了python的基础语法,大一下也学习了C加加中的类与对象,但是自我觉得基础还不太扎实,又害怕有什么遗漏,所以就花时间重新学习了python的基础,学习Python的基本语法,如变量、数据类型(如列表、字典、元组)、控制结构(如if语句、for和while循环)和函数。掌握Python的面向对象编程,包括类的定义、对象的创建以及继承和多态的概念。除此之外,还有文件和文件夹以及批量化处理文件以及外包和装饰器
1.python基本语法
#输出
#python第一个程序
print("你好,世界")#输出字符串中的内容
#输出语句中的常见的参数及转义字符
print("hello world",end="\t")#尾部默认的是end="\n"
#当多个字符串连接在一起的时候#多对象字符串分隔符
print("你好","世界")#默认是以空格隔开sep=" "
print("你好","世界",sep=',')
print("你好,世界"*3)#字符串的复制
print("520"+"1314")#字符串的拼接,字符串不能进行运算
#转义字符
print("C:\abc\def\ndad")#会乱码,需要使用转义字符
print("C:\\abc\def\\ndad")#第一种方法\\=\ 并不建议
print(r"C:\abc\def\ndad")#第二种方法在字符串前面加小写r 建议
#单行注释
#多行注释,注释是不会被输出的
"""
1.
2.
3.
"""
"""变量
变量名规则:支持汉字,并且可以由字母,数字,下划线构成,但是不能以数字开头,而且区分大小写。
#给变量赋值
a=5
print(a)#打印出a的值来
#给多个变量赋值
a1,b1,c1=7,3,0
print(a1)#7
print(b1)#3
print(c1)#0
b,c,d=2,2,2
print(b)#2
print(c)#2
print(d)#2
a2=b2=c2=2;
print(a2)#2
print(b2)#2
print(c2)#2
#两个变量的值进行交换
x=5
y=2
print(x)#5
print(y)#2
x,y=y,x#两个变量互相交换赋值
print(x)#2
print(y)#5
#变量名字
姓名="陈惠婷"
年龄=17
#格式化字符串
#print(f'xxx{变量名})
print(f'我的名字叫{姓名},今年的年龄是{年龄}岁')
print(f'我的名字叫{姓名},明年的年龄是{年龄+1}岁')
输入
输入是用户手动输入键盘,用的是input(),返回的是以字符串的形式来返回,在使用的时候,注意记得把用户输入的内容赋值给一个变量。
#输入
#注意:被用户输入的内容,默认都是字符串格式
#字符串是不能进行运算的
#输入的内容默认是字符串格式
#姓名=input()#输入用户的姓名
#年龄=input()#输入用户的年龄
姓名="陈惠婷"
年龄=17
print(type(年龄))
print(f'我的名字叫{姓名},今年的年龄是{年龄}岁')
#数据类型转换
#int()转整型
年龄1=float(年龄)
print(年龄1)#17.0
print(type(年龄1))#float
年龄2=str(年龄)
print(年龄2)
print(type(年龄2))#str
#float()转浮点型
#str()转字符型数学运算符
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Fbglc4Ag-1690385710664)(C:\Users\86185\Desktop\python\图片1.png)]
复合运算符
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-utw7Az8y-1690385710666)(C:\Users\86185\Desktop\python\图片2.png)]
比较运算符(注意他返回的值是逻辑值True或False)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3UkLs4lY-1690385710666)(C:\Users\86185\Desktop\python\图片3.png)]
逻辑运算符
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3p30Hz0F-1690385710667)(C:\Users\86185\Desktop\python\图片4.png)]
and运算符:只要有一个是0,那么就返回0,否则结果为最后一个非0数字
or运算符:只有所有值为0,否则就返回第一个非0数字
#数学运算符
#运算符+---加 运算符- 减 *乘 /除
#整除// %取余 **指数 ()小括号,用来提高运算优先级
#复合运算符
#a+=1,相当于a=a+1
#a-=1,相当于a=a-1
#a+=1+2 相当于a+=(1+2)相当于a=a+3
#比较运算符
#==,!=,>,>=,<,<=返回的值是True和False
#逻辑运算符
#and运算符:只要有一个值为0,则结果为0,否则结果为最后一个非0数字
#or运算符:只有所有值为0则结果为0,否则结果为第一个非0数字
print(1 and 2)#2
print(0 and 1)#0
print(1 and 0)#0
print(1 or 1)#1
print(1 or 0)#1
print(0 or 0)#0
#优先级顺序
#幂运算 正负号 算术运算 比较运算 逻辑运算2.字符串,列表,元组,字典,集合
序列:序列是一个存放多个值的连续内存空间。
有序序列:有序,意味着有下标,可以进行下标操作、切片操作,列表、元组、字符串…
无序序列:字典、集合…
可变类型与不可变类型
可变类型:列表、字典、集合
不可变类型:整型、浮点型、字符串、元组
所谓可变与不可变:数据能直接进行修改就是可变,否则就是不可变。
科学解释:可变类型:当变量值改变,id内存地址不变。不可变类型:当变量值改变,id内存地址就改变了。**使用****id(变量名)可以查询id内存地址,**也就是说可变类型就是当变量值改变的时候,他的变量名没有变。但是如果是不可变类型的话,当变量值发生了改变,那么他的变量名就不是原来的那个变量名了
字符串
字符串是python中最常用的数据类型,使用引号来创建字符串,单引,双引,三引号都可以
1.单和双引在单独使用上没有区别,区别在于配合使用
2.三引号字符串支持换行
#转义字符\‘=’创建字符串I‘m bigtom
print('I\'m bigtom')#’I‘m bigtom
#1.下标
姓名="你好,我叫陈惠婷"#创建一个变量
print(姓名[0])#你
print(姓名[2])#,
下标特点
#1.从0开始
#2.标点算一位
#3.英文字母也算一位
#4.一个汉字也算一位
切片特点
语法:可以暂时理解为变量名(序列)(开始位置下标:结束位置下标:步长)
开始位置下标:注意:如果省略起始值,那么默认从0开始
结束位置下标:不包括结束位置下标对应的数据,正负数均可,默认是最后
也就是左闭右开
步长:步长是选取间隔,,默认是1
#2.切片
a="0123456"
print(a[1:4:1])#123
print(a[:6])#012345
#步长加了负号就要从尾部开始数,倒着数
print(a[::-1])#6543210
print(a[::-2])#6 4 2 0
字符串的常用操作方法(查找,修改,判断)
查找find()
find()是从左向右查找,而rfind()是从右向左查找
查询某个子串是否包含在这个字符串中,如果在,那么就返回这个子串开始的位置下标,否则返回-1;如果有重复的就返回第一个的最开始的下标
语法:字符串序列.find(子串,开始位置下标,结束位置下标)
注意:开始和结束位置下标可以省略,表示在整个字符串串序列列中查找。
*计数count()
count():返回某个子串在字符串中出现的次数
语法:字符串序列.count(子串,开始位置下标,结束位置下标)
**注意:**开始和结束位置下标可以省略,表示在整个字符串串序列列中查找。
a="do you hope to further future"
print(a.find('o'))#1
print(a.find("z"))#-1
print(a.count('d'))#1
print(a.count("z"))#0
替换replace()
语法:字符串序列.replace(旧子串,新子串,替换次数)
注意:替换数次如果超过了子串的出现次数,就替换所有子串。省略替换次数就是全部替换。
a = "do you hope a further future"
print(a.replace("further","promised"))#do you have a promised future
split():分割
语法:字符串序列.split(分割字符,分割次数)
注意:返回的是一个列表
a = "do you hope a further future"
print(a.split(" ",2))#['do', 'you', 'hope a further future']
print(a.split(" "))#['do', 'you', 'hope', 'a', 'further', 'future']join():合并
语法:字符或者子串.join(字符串1,字符串2,字符串3)#以什么样子的形式连接字符串
a = "do you hope a further future"
print(a.split(" ",2))#['do', 'you', 'hope a further future']
b=a.split()
print(a.split(" "))#['do', 'you', 'hope', 'a', 'further', 'future']
print("-".join(b))
print(a)#值没有变,说明字符串的确是一个不可变序列
判断
检查字符串是否以子串开头:startswith()
检查字符串是否以子串结尾:endswith()
语法:变量名.startswith(子串,开始位置下标,结束位置下标)
语法:变量名.endswith(子串,开始位置下标,结束位置下标),返回的是True或False
注意:如果省略位置那么就是判断全部位置
a="what is your name?"
print(a.startswith('w'))#T
print(a.startswith('ss'))#F
print(a.endswith('?'))#T
print(a.endswith('e'))#F以下可迭代对象就不一一说明他的增删查改了了,只是给个总结
列表(可变序列)
创建列表:中括号
a=[],列表可以一次性存储多个数据
1、列表格式,用中括号存数据,每个数据用逗号隔开 [数据1,数据2,数据3]2、常用操作方法:(1)Index() 查找数据在列表中第一次出现的位置
(2)len() 返回列表的数据个数
(3)append 在列表末尾追加单个数据
(4)extend 在列表末尾追加多个数据
(5)insert 在指定位置增加数据
(6)del 删除列表或删除列表指定下标
(7)remove 删除列表第一个指定的数据
(8)sort 列表排序元组(不可变序列)
a=(111,)
b=()
元组的常见操作,因为他不可以被修改,所以他的操作方法就只有查询了!变量名 = ('孙悟空','猪八戒','沙和尚','白龙马','孙悟空')print(变量名[1]) # 使用下标查找数据,返回:猪八戒print(变量名[开始位置下标:结束位置下标:步长]) # 切片的方式print(变量名.index('沙和尚')) # 查找某个数据在元组中的下标,与字符串和列表使用方法相同print(变量名.count('孙悟空')) # 统计某个数据在元组中出现的次数print(len(变量名) # 统计元组数据的个数del 变量名元组只可读取里面的数据,不能修改,所以不支持清空元组数据的操作字符串,列表,元组统称为序列!
list(序列名) # 将序列转为列表tuple(序列名) # 将序列转为元组
字典
创建空字典
a=dict() b={}
字典不支持下标,字典是数据以键值对的方式来创建字典
1.增加和修改数据:语法: 字典序列名[键] = 值如果键存在则修改对应的值,如果键不存在新增这个键和值
2.删数据:删除字典内数据语法:del字典序列名[键] # 只需要写键,它会把键和值一起删除 删除整个字典的语法:del 字典序列名清空字典:clear( ) 字典序列名.clear( )
3.查数据:注意只能用键查值,不能用值查键,因为键是唯一的,值可能是重复的。字典序列名 = {'华为':520,'小米':520,'苹果':14,'三星':24}print(字典序列名['小米']) 返回:520print(字典序列名['诺基亚']) 返回:报错 总结:如果键存在,我们返回值,否则报错。
4.字典的查询方法:(1)get( ) 语法: 字典序列名.get(键,随便写)
如果键存在,返回值。如果键不存在,返回默认值,默认值是你随便写的内容,如果省略了这个参数,返回None。(2)values( ) 语法: 字典序列名.values( ) # 返回字典中所有的值(3)items( ) 语法:字典序列名.items( ) #可迭代对象(里面的数据是元组),迭代就是重复反馈过程集合
创建集合:可以用{ } 或 set( )创建集合,但是创建空集合必需用set( ),因为{ }创建的是空字典集合的特点:
(1)自动去除重复数据
(2)顺序是随机的,所以不支持下标
增加数据:集合名.add(数据) # 因为集合自动去重复,所以增加重复内容时不进行任何操作追加数据序列:集合名.update(数据序列) # 数据序列:列表,字符串,元组删除数据:集合名.remove(数据) # 如果数据不存在,报错集合名.discard(数据) # 如果数据不存在,不报错集合名.pop( ) # 随机删除集合中某个数据,并返回这个数据
查看返回数据 变量名 =集合名.pop( )
查看被删除的数据 print(变量名)
查看集合还剩下什么 print(集合名) 查找数据:in: 判断数据是否在集合序列中not in: 判断数据不在集合序列中print( 数据 in 集合名 ) # 返回 True 或 False print( 数据 not in 集合名 ) # 返回 True 或 False set(序列名) # 将某个序列转换成集合注意:集合自动去重复,但不支持下标,没有顺序一些常用的可迭代对象的特点总结和区别
1、字符串:不能修改的字符序列。除了不能修改,可把字符串当成列表一样处理。
2、列表:我觉得列表就是我们日常生活中经常见到的清单。比如,统计过去一周我们买过的东西,把这些东西列出来,就是清单。由于我们买一种东西可能不止一次,所以清单中是允许有重复项的。
3、元组:用来存放不能被轻易修改的数据,例如身份证号
4、字典:是除列表外python中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
5、集合:目的就是去重复。
3.分支语句和循环语句
分支语句
if 条件: 、
条件成立执行的代码1
条件成立执行的代码2
条件是否成立都执行的代码
如果条件成立,就执行缩进后的代码,否则不执行,但是未缩进的代码与条件无关。怎么样都会执行
if 条件:
条件成立执行的代码1
条件成立执行的代码2
else:
条件不成立执行的代码1
条件不成立执行的代码2
如果条件成立,就执行if下方的代码,如果条件不成立,就执行else下方的代码
if 条件1:
条件1成立执行的代码1
条件1成立执行的代码2 …
elif 条件2:
条件2成立执行的代码1
条件2成立执行的代码2 …
else:
以上条件都不成立执行的代码 ……
age=int(input("请输入您的年龄:"))
if(age<18):{print(f'您的年龄是{age}岁,你不能考驾照,还需要等{18-age}年')}
elif(age>=70):{print(f'您的年龄是{age}岁,您再也不能考驾照了')}
else:{print(f'您的年龄是{age}岁,可以考驾照了')}分支语句的嵌套
if 条件1:
条件1成立执行的代码
if 条件2:
条件2成立执行的代码
else:
如果条件2不成立执行的代码
else:
如果条件1不成立执行的代码
三目运算符
a = 3
b = 5
c = a if a > b else b(如果a>b是真的那么就返回a,如果a>b是假的那么就返回b
print©#5
循环语句(for循环)
在这里for循环的语法以及break还有continue就不一一说明了
for 临时变量 in 序列:重复执行的代码……..
else:循环正常结束之后要执行的代码#如果有break的话,循环不能正常结束,所以不能执行else缩进下的代码#如果是continue的话,循环就可以正常结束,所以可以执行else缩进下的代码
while循环()类似
j=1
while j<=5:
#打一行i=1while i<=5:print("*",end='')i=i+1print()#换行j=j+1 *************************
j=1
while j<=5:
#打一行i=1while i<=j:print("*",end='')i=i+1print()#换行j=j+1 ***************
公共操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HTHaE65L-1690385710669)(C:\Users\86185\Desktop\python\图片1.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PNjfHS7D-1690385710669)(C:\Users\86185\Desktop\python\图片2.png)]
fruits=["apple","orange","bananna"]
for i,j in enumerate(fruits):print(f'下标是{i},所对应的元素是{j}')#下标是0, 所对应的元素是apple#下标是1, 所对应的元素是orange#下标是2, 所对应的元素是bananna
for i, j in enumerate(fruits,start=8):print(f'下标是{i},所对应的元素是{j}')#下标是8, 所对应的元素是apple#下标是9, 所对应的元素是orange#下标是10, 所对应的元素是bananna
推导式
什么是推导式?:推导式是用来简化代码的
列表推导式
一、列表推导式列表名 = [ i for i in range(0,11) ]得到0-10内只有偶数的列表
1.[ i for i in range(0,11,2) ]
2.[i for i in range(0,11)if i %2==0]
二.字典推导式 【作用:快速合并列表为字典或提取字典中目标数据】将两个列表快速合并成一个字典:
列表1 = [ '华为' , '小米' , '苹果' ,' 三星' ]
列表2 = [ 520 , 520 , 14 , 24 ]
字典名 = { 列表1[i]:列表2[i] for i in range(len(列表1)) }(指的是最短的长度的那个列表,一般是键值)提取字典中的目标数据:
字典名 = { '华为' : 520, '小米' : 520, '苹果' : 14,'三星' : 24 }
# 提取销售数量大于100台的字典数据
新字典名 = { i:j for i,j in 字典名.items( ) if j >= 100 }print(新字典名) 4.文件和文件夹
一、文件的3种操作(打开,读写,关闭)
1、文件打开 (注意:不带路径的文件名默认去找该文件夹)文件对象=open( ‘文件名’ , ‘访问模式’)
(1)访问模式(三个主访问模式)‘r’ 只读:如果文件不存在报错,不支持写’w’ 写入:如果文件不存在新建文件,写入时覆盖原有内容’a’ 追加:如果文件不存在新建文件,写入时在原有内容基础上追加新内容总结:访问模式可以省略,默认为’r’模式
(2)访问模式特点(‘b’ 二进制、‘+’ 可读可写)r、rb、r+、rb+:只要文件不存在都报错,文件指针(光标的位置)放在文件开头w、wb、w+、wb+:只要文件不存在就新建文件,文件指针在开头,用新内容覆盖原内容a、ab、a+、ab+:只要文件不存在新建文件,文件指针在结尾,
2.文件对象.write(‘内容’)文件对象.
read(num) # num表示要从文件中读取数据的长度(单位是字节)【换行\n占一个字节】,省略就表示读取所有数据文件对象.
readlines( ) # 需要赋值给一个变量# 将整个文件中的内容一次性读取,并返回一个列表,原文件中每一行的数据为一个元素,例如[‘aaa\n’,‘bbb\n’,ccc]# 每一行都有换行自带\n,最后一行没有换行不带\n文件对象
readline( ) # 需要赋值给一个变量# 一次性读取一行内容,第一次调用读取第一行,第二次调用读取第二行,不带换行符\n
3、关闭文件对象.close( )
4、seek( )移动文件指针文件对象.seek(偏移量,起始位置) # 起始位置:0开头,1当前位置,2文件结尾# 偏移量:假设起始位置是开头,偏移量是5,那文件指针就在第6个字节上# 偏移量和起始位置都为0时,可以只写一个0
例如:文件对象 = open(‘文件名’,‘r+’)
文件对象.seek(2,0)#第三个字节上
print(文件对象.read())
文件对象.close
5、文件备份
(1)用户输入目标文件文件名 = input(‘请输入您要备份的文件名:’)
(2)规划备份文件的名字
( 2.1)提取后缀,找到名字中最右侧的点,名字和后缀分离点的位置 = 文件名.rfind(‘.’)
(2.2)组织新名字 = 原名字 + [备份] + 后缀
if 点的位置 >0:#不能等于0 不能是.txt
后缀=文件名[点的位置:]
else:
print(‘文件名输入错误’)
新名字 = 文件名[:点的位置]+‘[备份]’ + 后缀
3)备份文件写入数据(数据和原文件一样)
(3.1)打开原文件和备份文件文件对像旧 = open(文件名,‘rb’)文件对像新 = open(新文件,‘wb’)(
3.2)原文件读取,新文件写入如果不确定目标文件大小,循环读取写入,当读取出来的数据没有了终止循环while True:
读取数据=文件对象旧.read(1024)
if len(读取数据) == 0: # 读取完成
break
文件对象新.write(读取数据)
(3.3)关闭文件文件对像旧.close( )
文件对像新.close( )
6、文件和文件夹操作
(1)os模块:操作文件和文件夹import os # 导入模块os.函数名( ) # 使用os模块相关功能
(2)文件和文件夹重命名os.rename(‘旧文件名’,‘新文件名’) # 目标文件名可以写路径,否则默认当前文件夹下 面os.rename(‘旧文件夹名’,‘新文件夹名’)
(3)删除文件 (没有指定文件会报错)os.remove(目标文件名)
(4)创建文件夹 (重复创建相同名字的文件夹报错)os.mkdir(文件夹名字)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bV1Jrr6Q-1690385710670)(C:\Users\86185\Desktop\python\屏幕截图 2023-07-22 124828.png)]
5.闭包和装饰器
#闭包:内部函数引入了外部函数的局部变量,那么内部函数就被认为是闭包
#闭包的作用:
#1、外部函数中定义了内部函数
#2、外部函数是有返回值的
#3、返回值是:内部函数名
#4、内部函数使用了外部函数的变量值def fun1():a =1def fun2(b,c):print(a+b+c)#代码一直到这指的都是fun1()的过程return fun2
fun1()#调用fun1(),返回的是fun2
fun1()(2,3)#1+2+3
#6
语法糖,也译为糖衣语法,是由英国计算机科学家彼得·约翰·兰达发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会
装饰器:把被装饰的函数名当做参数传递给装饰器所对应的函数,并且返回包装后被装饰的函数
def fun1(x):a =1def fun2(name):print(a)x(name)return fun2
@fun1#将fun3作为形参传递到x中然后返回的是包装后被装饰的函数
def fun3(name):print("fun3()的调用")
fun3("陈惠婷")
#当有多个装饰器和参数的时候
def fun1(x):a =1def fun2(*args,**kwargs):print(a)x(*args,**kwargs)#x是函数3的名字,要加参数,所以fun2也要有参数return fun2
@fun1#将fun3作为形参传递到x中然后返回的是包装后被装饰的函数
def fun3(name,age):print(f'你的名字是{name},你的年龄是{age}')
fun3("陈惠婷",17)#@fun1
def fun4(sex):print(f'你的性别是{sex}')
fun4('女')@fun1
def fun5(*args,**kwargs):print(args)print(kwargs)
fun5("陈惠婷",'女',18,a=1,b=2,c=3)
#1
#你的名字是陈惠婷,你的年龄是17
#1
#你的性别是女
#1
#('陈惠婷', '女', 18)
#{'a': 1, 'b': 2, 'c': 3}
6.函数
def 函数名(a,b): # 定义函数,同时设置两个形参,a和b用于接收用户数据
变量名 = a + b # 将a + b赋值给一个变量
print(变量名) ## 打印这个变量
函数名(520,1314)# 调用函数时,传入了真实数据520和1314,真实数据是实参
【定义函数说明文档】
def 函数名(形参)
“”“说明文档位置”“” #一定要在定义函数的下一行写,在别的位置写是没有任何效果的
代码 …….
【查看函数的说明文档】
help(函数名)
def fun(a,b):"""相加函数"""print(a+b)#3
fun(1,2)
help(fun)#Help on function fun in module __main__:#fun(a, b)#相加函数
#1.位置参数:在定义函数时,参数的名字和位置已被确定。def 函数名(姓名,年龄,性别):print(f'您的姓名是{姓名},性别是{性别},年龄是{年龄}')函数名('陈惠婷',17,'女')#2.关键字参数:传入实参时,明确形参的变量名,参数之间不存在先后顺序def 函数名(姓名,年龄,性别):print(f'您的姓名是{姓名},性别是{性别},年龄是{年龄}')函数名('孙兴华',性别='男',年龄='20')函数调用时,通过“键=值”的形式加以指定,清除了参数的顺序问题。注意:调用函数时,如果有位置参数,位置参数必需在关键字参数的前面,否则会报错#默认参数(缺省参数):参数指定默认值,调用时不传实参,就用默认值。def 函数名(姓名,年龄,性别="男"):print(f'您的姓名是{姓名},性别是{性别},年龄是{年龄}')函数名('孙兴华',20)函数名('赵丽颖',33,性别='女')注意:调用函数时,如果有位置参数,位置参数必需在默认参数的前面,否则会报错可变参数
可变参数(收集参数):1、位置可变参数(接收所有的位置参数,返回一个元组)def 函数名(*args):print(args)函数名()
2、关键字可变参数(接收所有关键字,返回一个字典)def 函数名(**kwargs):print(kwargs)函数名(name='陈惠婷',age=17,sex='女')
def fun(*a):print(a)
fun(1,2,3,4)
#(1, 2, 3, 4)#{'a': 1, 'b': 2}
def fun1(**b):print(b)
fun1(a=1,b=2)
#关于拆包
a,b=(520,1314)#元组拆包
print(a)
print(b)
x,y,z=a={'姓名':'陈惠婷','年龄':17,'性别':'女'}#字典拆包
print(x)#这样打印出来的是每一个数据的键
print(y)
print(z)
print(a[x])#字典名加键返回的就是值
print(a[y])
print(a[z])
函数的递归
函数的递归:函数自己调用自己,而且必须留有出口
lambda
print(lambda a,b:a+b(1,2))#3
#lambda只是为了简化代码
#a,b都是形参
#a+b都是return后面的表达式
#1和2都是实参
lambda a,b:a+b相当于函数名字开始调用
还学习了函数式编程的内置高阶函数filter(),map(),functools的reduce()
7.面向对象
关于面向对象;
首先要定义一个类,然后再创建对象,最后将类进行一个实例化
类的定义中就是进行封装代码的,类里面有类的特征就是属性就是变量,行为即方法就是函数,也就是说,类和对象是通过实例化关联在一起的
在Python中,xx( )的函数叫做魔法方法,指的是具有特殊功能的函数。
魔法方法1:构造函数__init__():构造函数是用来初始化变量的,在创建一个对象的时候默认被调用,不需要手动进行调用
1、在创建一个对象时默认被调用,不需要手动调用
2、init(self )参数,不需要开发者传递,Python解释器会自动把当前的对象引用传递过去
3、一个类可创建多个对象,对不同的对象设置不同的初始化属性需要传参数
self指的是调用该函数的对象 【self = 对象名】由于打印对象名和打印self得到的内存地址相同,所以self指的是调用该函数的对象
一个类可以创建多个对象,但是,self地址不相同,因为不同的对象存储的地址不一样
对象名1 = 类名( )
对象名2 = 类名( )
魔法方法2
如果类定义了__str__方法,那么就会打印在这个方法中的return的数据。
class student():name=''#直接和类关联在一起的叫做类变量,也可以直接看做全局变量age=0def __init__(self,name,age):self.name=name#实例变量 #语法:self.变量名self.age=age#在创建对象的时候对对象进行初始化def __str__(self):return f'你的名字是{self.name},你的年龄是{self.age}'
a=student("cht",'17')#创建对象并进行初识化#对象名=类名(参数)
print(a)
class student():name=''#直接和类关联在一起的叫做类变量,也可以直接看做全局变量age=0def __init__(self,name,age):self.name=name#实例变量 #语法:self.变量名self.age=age#在创建对象的时候对对象进行初始化def __str__(self):return f'你的名字是{self.name},你的年龄是{self.age}'
a=student("cht",'17')#创建对象并进行初识化#对象名=类名(参数)
print(a)
面向对象&类的继承
继承的概念:如果两个类存在父子级继承的关系,子类即便没有任何的属性和方法,那么用子类继承了某一个父类,并且此子类创建了一个对象,那么这个对象就拥有父类当中的所有属性和方法的使用权。
在Python中,所有类默认继承object类,object类是顶级类或基类;其它子类叫做派生类。
所谓多继承:就是一个类同时继承了多个父类。注意:当一个类有多个父类的时候,默认使用第一个父类的同名属性和方法。
利用__mro__进行手查找继承的顺序
print(类名.mro)#得出继承的顺序
class 叶问(object):#作为基类def __init__(self):self.功夫='咏春'def get(self):print(f'使用{self.功夫}')
class 李小龙(叶问):def __init__(self):self.功夫="截拳道"def get(self):print(f'使用{self.功夫}')
class 陈惠婷(李小龙,叶问):pass
a=陈惠婷()#创建对象
a.get()#当子类有多个父类的时候,一般是默认使用继承的第一个类的属性个方法
#使用截拳道
print(陈惠婷.__mro__)#(<class '__main__.陈惠婷'>, <class '__main__.李小龙'>, <class '__main__.叶问'>, <class 'object'>)
子类和父类具有同名属性和方法:
默认使用子类的同名属性和方法。
需求:既能调用子类的,也能调用父类的
class 叶问(object):#作为基类def __init__(self):self.功夫='咏春'def get(self):print(f'使用{self.功夫}')
class 李小龙(object):def __init__(self):self.功夫="截拳道"def get(self):print(f'使用{self.功夫}')
class 陈惠婷(李小龙,叶问):def __init__(self):self.功夫='健身'def get(self):self.__init__()print(f'使用{self.功夫}')def get1(self):叶问.__init__(self)叶问.get(self)def get2(self):李小龙.__init__(self)李小龙.get(self)
a=陈惠婷()#创建对象
a.get()#当子类有多个父类的时候,一般是默认使用继承的第一个类的属性个方法
a.get1()
a.get2()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-85Rq8JHy-1690385710672)(C:\Users\86185\Desktop\python\图片1.png)]
1、私有权限的作用:如果在继承关系中,某些属性或方法不想继承给子类时,我们把这些属性和方法添加私有权限。
2、设置私有权限的方法:在属性名和方法名 前面 加上两个下划线__。
3、注意:私有属性和方法只能在类里面访问和修改
4、在Python中,一般定义函数名get_xx用来获取私有属性,定义set_xx用来修改私有属性值。用get和set是工作习惯,可以改名,但是看到这两个单词大家都知道是获取和修改
5、先获取后修改
使用super()可以自动查找父类。调用顺序遵循mro类属性的顺序。比较适合单继承使用。
面向对象&类的多态
多态:调用不同子类对象的相同父类方法。步骤:
(1)定义父类,并提供公共方法
(2)定义子类,并重写父类方法
(3)传递子类对象给调用者,可以看到不同子类执行效果不同class balls(object):def __init__(self):self.ball="球"def get(self):print(f'走吧,我们一起去打{self.ball}')
class basketball(balls):def __init__(self):self.ball="篮球"def get(self):print(f'走吧,我们一起去打{self.ball}')
class badminton(balls):def __init__(self):self.ball="羽毛球"def get(self):#函数重写print(f'走吧,我们一起去打{self.ball}')
class volleyball(balls):def __init__(self):self.ball="排球"def get(self):print(f'走吧,我们一起去打{self.ball}')def gogogo(x):#子类对象传进来print(x.get())#实现多态a=balls()
b=basketball()
c=badminton()
d=volleyball()
gogogo(a)#打球
gogogo(b)#打篮球
gogogo(c)#打羽毛球
gogogo(d)#打排球
结尾
子类时,我们把这些属性和方法添加私有权限。
2、设置私有权限的方法:在属性名和方法名 前面 加上两个下划线__。
3、注意:私有属性和方法只能在类里面访问和修改
4、在Python中,一般定义函数名get_xx用来获取私有属性,定义set_xx用来修改私有属性值。用get和set是工作习惯,可以改名,但是看到这两个单词大家都知道是获取和修改
5、先获取后修改
使用super()可以自动查找父类。调用顺序遵循mro类属性的顺序。比较适合单继承使用。
面向对象&类的多态
多态:调用不同子类对象的相同父类方法。步骤:
(1)定义父类,并提供公共方法
(2)定义子类,并重写父类方法
(3)传递子类对象给调用者,可以看到不同子类执行效果不同class balls(object):def __init__(self):self.ball="球"def get(self):print(f'走吧,我们一起去打{self.ball}')
class basketball(balls):def __init__(self):self.ball="篮球"def get(self):print(f'走吧,我们一起去打{self.ball}')
class badminton(balls):def __init__(self):self.ball="羽毛球"def get(self):#函数重写print(f'走吧,我们一起去打{self.ball}')
class volleyball(balls):def __init__(self):self.ball="排球"def get(self):print(f'走吧,我们一起去打{self.ball}')def gogogo(x):#子类对象传进来print(x.get())#实现多态a=balls()
b=basketball()
c=badminton()
d=volleyball()
gogogo(a)#打球
gogogo(b)#打篮球
gogogo(c)#打羽毛球
gogogo(d)#打排球
结尾
上面就是我这一周所有学习的内容,也是相当于复习了吧,学的时候发现,东西是学不完的,也是不可能都记住的,只要我们做到学过了解过并且当要用到的时候回来查找的程度就可以了,也不能死记硬背,做到会用就可以了,这也是很多初学者在学习编程中非常非常容易放弃学下去的一个原因。**下周计划:**重新系统地学习python三件套numpy,pandas,matplotlib。在github上找几个关于图像特征提取以及红外小目标检测的小项目,不要着急,循序渐进。
相关文章:

pythonweek1
引言 做任何事情都要脚踏实地,虽然大一上已经学习了python的基础语法,大一下也学习了C加加中的类与对象,但是自我觉得基础还不太扎实,又害怕有什么遗漏,所以就花时间重新学习了python的基础,学习Python的基…...
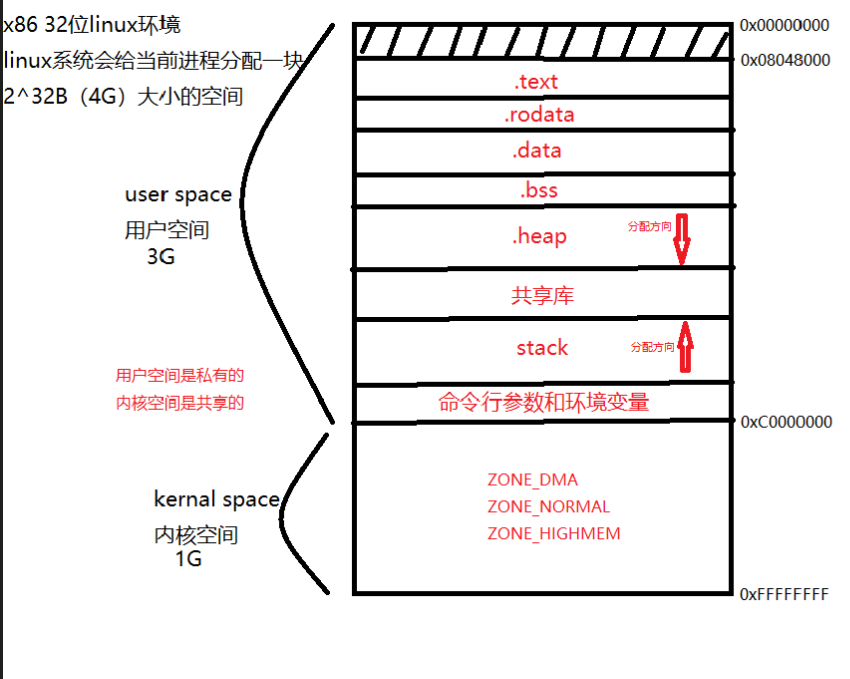
进程虚拟地址空间区域划分
目录 图示 详解 代码段 备注:x86 32位linux环境下,进程虚拟地址空间区域划分 图示 详解 用户空间 用于存储用户进程代码和数据,只能由用户进程访问 内核空间 用于存储操作系统内核代码和数据,只能由操作系统内核访问 text t…...
OpenAI Code Interpreter 的开源实现:GPT Code UI
本篇文章聊聊 OpenAI Code Interpreter 的一众开源实现方案中,获得较多支持者,但暂时还比较早期的项目:GPT Code UI。 写在前面 这篇文章本该更早的时候发布,但是 LLaMA2 发布后实在心痒难忍,于是就拖了一阵。结合 L…...

macOS Ventura 13.5 (22G74) 正式版发布,ISO、IPSW、PKG 下载
macOS Ventura 13.5 (22G74) 正式版发布,ISO、IPSW、PKG 下载 本站下载的 macOS Ventura 软件包,既可以拖拽到 Applications(应用程序)下直接安装,也可以制作启动 U 盘安装,或者在虚拟机中启动安装。另外也…...

Electron 主进程和渲染进程传值及窗口间传值
1 渲染进程调用主进程得方法 下面是渲染进程得代码: let { ipcRenderer} require( electron ); ipcRenderer.send( xxx ); //渲染进程中调用 下面是主进程得代码: var { ipcMain } require( electron ); ipcMain.on("xxx",function () { } )...

C#设计模式之---建造者模式
建造者模式(Builder Pattern) 建造者模式(Builder Pattern)是将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。建造者模式使得建造代码与表示代码的分离,可以使客户端不必知道…...

output delay 约束
output delay 约束 一、output delay约束概述二、output delay约束系统同步三、output delay约束源同步 一、output delay约束概述 特别注意:在源同步接口中,定义接口约束之前,需要用create_generated_clock 先定义送出的随路时钟。 二、out…...
html2Canvas+jsPDF 下载PDF 遇到跨域的对象存储的图片无法显示
一、问题原因 对象存储的域名和你网址的域名不一样,此时用Canvas相关插件 将DOM元素转化为PDF,就会出现跨域错误。 二、解决办法 两步 1. 图片元素上设置属性 crossorigin"anonymous" 支持原生img和eleme组件 2. 存储桶设置资源跨域访问…...
【C#】并行编程实战:异步流
本来这章该讲的是 ASP .NET Core 中的 IIS 和 Kestrel ,但是我看了下这个是给服务器用的。而我只是个 Unity 客户端程序,对于服务器的了解趋近于零。 鉴于我对服务器知识和需求的匮乏,这里就不讲原书(大部分)内容了。本…...
在家下载论文使用哪些论文下载工具比较好
在家下载论文如果不借助论文下载工具是非常艰难的事情,因为很多查找下载论文的数据库都是需要账号权限才可使用的。 例如,我们查找中文论文常用的知网、万方等数据库以及众多国外论文数据库。 在家下载知网、万方数据库论文可用下面的方法:…...

【LeetCode 算法】Handling Sum Queries After Update 更新数组后处理求和查询-Segment Tree
文章目录 Handling Sum Queries After Update 更新数组后处理求和查询问题描述:分析代码线段树 Tag Handling Sum Queries After Update 更新数组后处理求和查询 问题描述: 给你两个下标从 0 开始的数组 n u m s 1 和 n u m s 2 nums1 和 nums2 nums1…...

基于Linux操作系统中的MySQL数据库SQL语句(三十一)
MySQL数据库SQL语句 目录 一、SQL语句类型 1、DDL 2、DML 3、DCL 4、DQL 二、数据库操作 1、查看 2、创建 2.1、默认字符集 2.2、指定字符集 3、进入 4、删除 5、更改 6、练习 三、数据表操作 (一)数据类型 1、数值类型 1.1、TINYINT …...
)
【Matlab】基于BP神经网络的数据回归预测新数据(Excel可直接替换数据)
【Matlab】基于BP神经网络的数据回归预测新数据(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码5.1 main.m5.2 NewData.m6.完整代码6.1 main.m6.2 NewData.m7.运行结果1.模型原理 基于BP神经网络的数据回归预测是一种常见的机器学习方法,用于处…...
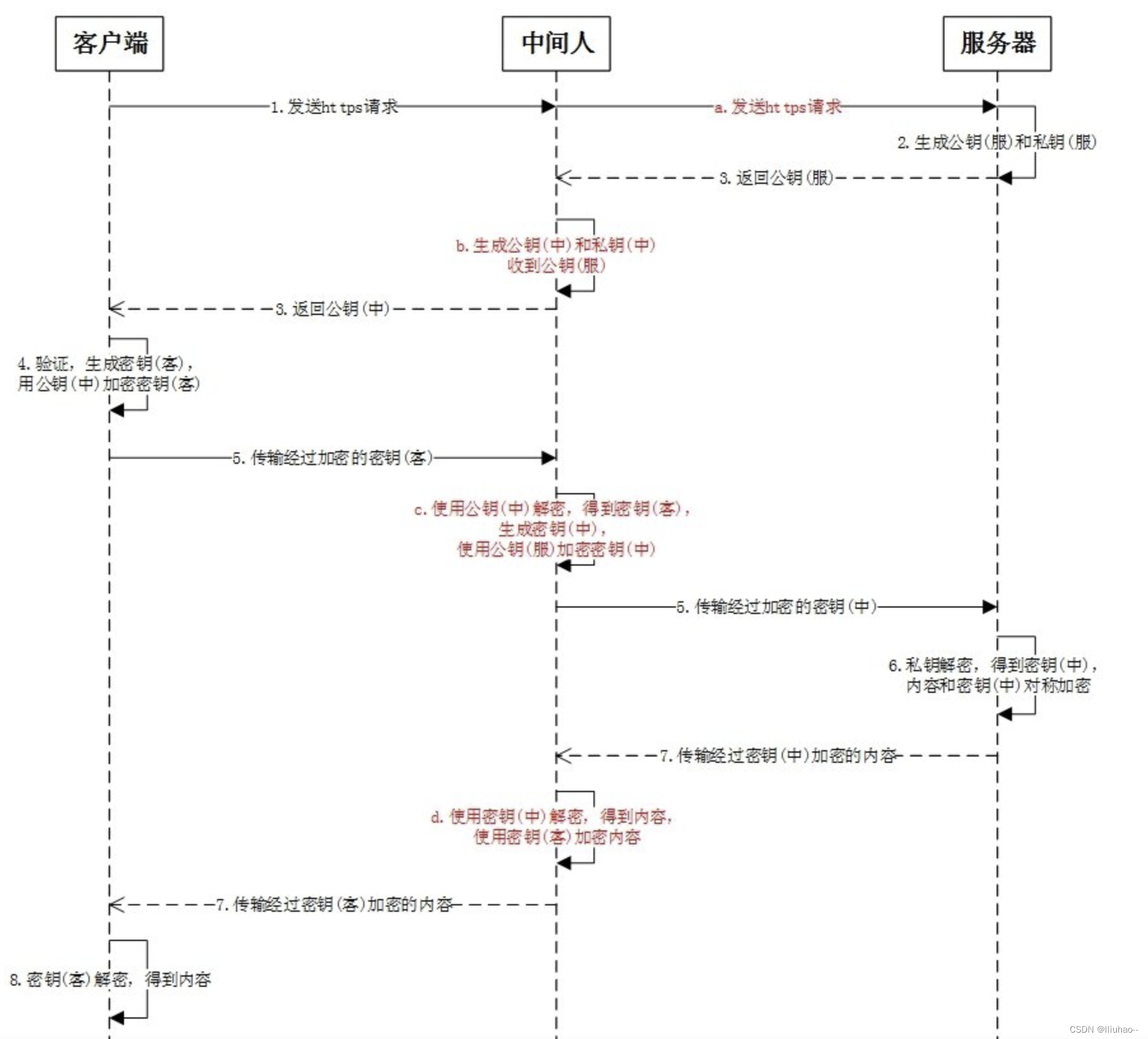
HTTPS连接过程中的中间人攻击
HTTPS连接过程中的中间人攻击 HTTPS连接过程中间人劫持攻击 HTTPS连接过程 https协议就是httpssl/tls协议,如下图所示为其连接过程: HTTPS连接的整个工程如下: https请求:客户端向服务端发送https请求;生成公钥和私…...
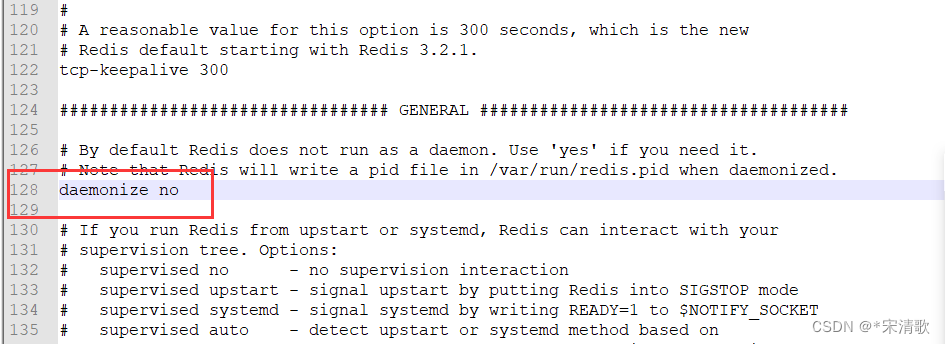
redis启动失败,oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
在redis文件夹下,启动redis正常。 但是加入到system后启动redis失败。 一直处于starting状态。 对比正常redis服务的配置之后,把redis.conf里的守护进程关掉就可以了(但是没用system管理之前,直接./redis.server启动是可以的&…...
milvus: 专为向量查询与检索设计的向量数据库
1. 什么是milvus? milvus docs milvus release Milvus的目标是:store, index, and manage massive embedding vectors generated by deep neural networks and other machine learning (ML) models. Milvus 向量数据库专为向量查询与检索设计…...
【C# 数据结构】Heap 堆
【C# 数据结构】Heap 堆 先看看C#中有那些常用的结构堆的介绍完全二叉树最大堆 Heap对类进行排序实现 IComparable<T> 接口 对CompareTo的一点解释 参考资料 先看看C#中有那些常用的结构 作为 数据结构系类文章 的开篇文章,我们先了解一下C# 有哪些常用的数据…...

智慧园区楼宇合集:数字孪生管控系统
智慧园区是指将物联网、大数据、人工智能等技术应用于传统建筑和基础设施,以实现对园区的全面监控、管理和服务的一种建筑形态。通过将园区内设备、设施和系统联网,实现数据的传输、共享和响应,提高园区的管理效率和运营效益,为居…...

Ajax 黑马学习
Ajax 资源 数据是服务器对外提供的资源,通过 请求 - 处理 - 响应方式获取 请求服务器数据, 用到 XMLHttpRequest 对象 XMLHttpRequest 是浏览器提供的js成员, 通过它可以请求服务器上的数据资源 let xmlHttpRequest new XMLHttpRequest(); 请求方式 : get向服务器获取数据…...

软件应用开发的常见环境
一般来说,在小型项目中可能只有开发环境和生产环境;在中型项目中会有开发环境、staging environment、生产环境;在大型项目中会有开发环境、测试环境、staging environment、生产环境。 一、Dev Env / Development Environment 开发环境 开…...

飞书机器人接入OpenClaw:千问3.5-35B-A3B-FP8实现群聊问答自动化
飞书机器人接入OpenClaw:千问3.5-35B-A3B-FP8实现群聊问答自动化 1. 为什么选择OpenClaw飞书千问3.5组合? 去年我在团队内部尝试用各种工具搭建智能问答系统时,发现三个核心痛点:一是公有云API调用成本高且数据要出域࿰…...

Kratos 的config.proto 修改后 windows 下重新生成
protoc --proto_path. --proto_path./third_party --go_outpathssource_relative:. internal/conf/conf.proto...

小白也能玩转零售AI:Ostrakon-VL-8B快速上手,实测效果超预期
小白也能玩转零售AI:Ostrakon-VL-8B快速上手,实测效果超预期 1. 零售AI新选择:Ostrakon-VL-8B简介 1.1 什么是Ostrakon-VL-8B? Ostrakon-VL-8B是一款专为零售和餐饮行业设计的智能视觉理解系统。简单来说,它就像是一…...

手柄适配终极方案:DS4Windows实现跨平台控制器无缝体验
手柄适配终极方案:DS4Windows实现跨平台控制器无缝体验 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 当你兴冲冲地将PlayStation手柄连接到PC,却发现游戏完全没有…...

04月06日AI每日参考:Gemma4颠覆参数论 阿里OpenAI频放新动作
今日概览今日AI圈迎来技术与商业双重爆发,谷歌Gemma 4以小参数模型打破行业"参数迷信",为端侧AI普及按下加速键。阿里、OpenAI等头部玩家同步放出新动作,国产大模型与芯片的组合也传来突破性消息,全行业的技术路线和市场…...

4个高效步骤实现HMCL启动器数据无忧迁移全攻略
4个高效步骤实现HMCL启动器数据无忧迁移全攻略 【免费下载链接】HMCL A Minecraft Launcher which is multi-functional, cross-platform and popular 项目地址: https://gitcode.com/gh_mirrors/hm/HMCL 当你终于升级了新电脑,兴冲冲地安装好HMCL启动器准备…...

WarcraftHelper:经典游戏现代重生的兼容性解决方案
WarcraftHelper:经典游戏现代重生的兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 让魔兽争霸III完美适配Windows 10/11系…...

烟台GEO搜索优化服务商链接烟台GEO搜索优化服务商
在当今数字化时代,越来越多的商家开始重视线上推广,希望通过互联网吸引更多潜在客户。然而,在实际操作中,很多商家面临着传统广告投放广撒网、预算浪费在非目标人群等问题。如何解决这些痛点,实现高效精准的营销呢&…...

春联生成模型安装包制作:一键部署exe工具开发
春联生成模型安装包制作:一键部署exe工具开发 1. 引言 每年春节前,很多朋友都想自己动手写春联,但要么字写得不够好看,要么想不出有新意的词句。现在有了AI春联生成模型,这个问题就简单多了。不过,对于不…...

Qwen3-14B私有部署镜像Node.js环境配置与API服务搭建
Qwen3-14B私有部署镜像Node.js环境配置与API服务搭建 1. 开篇:为什么选择Node.js对接Qwen3-14B 如果你正在寻找一个高效的方式来将Qwen3-14B大模型集成到你的应用中,Node.js可能是最合适的选择。作为现代JavaScript运行时,Node.js的非阻塞I…...