k8s Service网络详解(一)
k8s Service网络详解(一)
- 有关K8s网络的几个概念
- K8s网络模型
- k8s网络插件
- Service
- Service的访问方式
- Service的种类
- 无头服务(Headless Services)
- 带选择算符的服务
- 无选择算符的服务
- Service的类型
- ClusterIP
- Nodeport
- LoadBalancer
- ExternalName
- 多端口的service
- Endpoint
- Endpoint资源对象
- 端点列表(EndpointsList)
- Endpoints 端点 API使用
- EndpointSlice
- EndpointSlice状态
有关K8s网络的几个概念
Service:服务
Endpoint:端点
Ingress:和Service类似,基于OSI(Open System Interconnection)网络模型的七层协议数据(如HTTP)的转发
Kube Proxy:负载均衡
Pod DNS:Service名称解析
Service Selector:Service 通过标签来选取服务后端
K8s网络模型
Kubernetes 强制要求所有网络设施都满足以下基本要求:
-
各个Node节点上的Pod之间不需要网络地址转换(NAT)可以直接通信
-
Node节点上的代理(如:系统守护进程、Kubelet)可以和Node节点上的Pod通信
Kubernetes 网络解决四方面的问题:
-
Pod中的容器之间的通信(一个 Pod 中的容器之间通过本地回路(loopback)通信)——容器网络接口(CNI)
-
不同Pod之间的通信——Pod网络
-
外部网络访问集群Service——Service网络/Ingress网络
-
可以使用 Service 来发布仅供集群内部使用的服务
Pod中的容器之间的通信
容器共享Pod的网络命名空间(Network Namespace)-包括它们的 IP 地址和 MAC 地址。 这就意味着 Pod 内的容器都可以通过 localhost 到达对方端口。
k8s网络插件
Kubernetes网络的设计目标是支持多种网络模型,并提供可插拔的网络插件,从而使Kubernetes能够在不同的云和物理环境中运行。以下是几种常用的 Kubernetes 网络插件
- Kube-router
- Flannel
- Calico
- Weave Net
- Cilium
Service
Service网络是Pod网络和Node节点网络的桥梁,Node上的kube-proxy监听着k8s-apiserver,一旦service资源发生变化(调k8s-api修改service信息),kube-proxy就会生成对应的负载调度的调整,保证service的最新状态。
k8s集群内的service:selector指定pod,自动创建Endpoints
k8s集群外的service:手动创建Endpoints,指定外部服务的ip,端口和协议
Service的访问方式
访问Service可以使用两种方式
1.通过IP方式
2.通过域名方式
通过域名的方式访问Service,k8s 为 Service 和 Pod 创建 DNS 记录。
Service的种类
1.无头Service
2.普通Service
无头服务(Headless Services)
有时不需要或不想要负载均衡,以及单独的 Service IP。 遇到这种情况,可以通过显式指定 Cluster IP(spec.clusterIP)的值为 "None" 来创建 Headless Service。
你可以使用一个无头 Service 与其他服务发现机制进行接口,而不必与 Kubernetes 的实现捆绑在一起。
无头 Services 不会获得 Cluster IP,kube-proxy 不会处理这类服务, 而且平台也不会为它们提供负载均衡或路由。 DNS 如何实现自动配置,依赖于 Service 是否定义了选择算符。
这种Service可以解决的问题:
- 同时访问所有Pod
- 一个Service内部的Pod互相访问
对于其他Service来说,客户端在访问服务时,DNS查询时只会返回Service的ClusterIP地址,具体访问到哪个Pod是由集群转发规则(IPVS或iptables)决定的。而Headless Service并不会分配单独的ClusterIP,在进行DNS查询时会返回所有Pod的DNS记录,这样就可查询到每个Pod的IP地址。StatefulSet中StatefulSet正是使用Headless Service解决Pod间互相访问的问题。
带选择算符的服务
对定义了选择算符的无头服务,Kubernetes 控制平面在 Kubernetes API 中创建 EndpointSlice 对象, 并且修改 DNS 配置返回 A 或 AAAA 条记录(IPv4 或 IPv6 地址),这些记录直接指向 Service 的后端 Pod 集合。
无选择算符的服务
对没有定义选择算符的无头服务,控制平面不会创建 EndpointSlice 对象。 然而 DNS 系统会查找和配置以下之一:
- 对于
type: ExternalName服务,查找和配置其 CNAME 记录 - 对所有其他类型的服务,针对 Service 的就绪端点的所有 IP 地址,查找和配置 DNS A / AAAA 条记录
- 对于 IPv4 端点,DNS 系统创建 A 条记录。
- 对于 IPv6 端点,DNS 系统创建 AAAA 条记录。
当你定义无选择算符的无头服务时,port 必须与 targetPort 匹配。
Service的类型
-
ClusterIP
-
nodeport
-
LoadBalancer
-
ExternalName
另外,也可以将已有的服务以 Service 的形式加入到 Kubernetes 集群中来,只需要在创建 Service 的时候不指定 Label selector,而是在 Service 创建好后手动为其添加 endpoint。
ClusterIP
默认类型,自动分配一个仅 cluster 内部可以访问的虚拟 IP
可以选择自定义一个IP,在 Service 创建的请求中,可以通过设置 spec.clusterIP 字段来指定自己的集群 IP 地址。用户选择的 IP 地址必须合法,并且这个 IP 地址在 service-cluster-ip-range CIDR 范围内,如果 IP 地址不合法,API 服务器会返回 HTTP 状态码 422,表示值不合法。
- ClusterIP 是默认和最常见的服务类型。
- Kubernetes 会为 ClusterIP 服务分配一个集群内部 IP 地址。 这使得服务只能在集群内访问。
- 您不能从集群外部向服务(pods)发出请求。
- 您可以选择在服务定义文件中设置集群 IP。
使用场景
集群内的服务间通信。 例如,应用程序的前端(front-end)和后端(back-end)组件之间的通信。
示例
apiVersion: v1
kind: Service
metadata:name: my-backend-service
spec:type: ClusterIP # Optional field (default)clusterIP: 10.10.0.1 # within service cluster ip rangeports:- name: httpprotocol: TCPport: 80targetPort: 8080
保留源IP
各种类型的 Service 对源 IP 的处理方法不同:
ClusterIP Service:使用 iptables 模式,集群内部的源 IP 会保留(不做 SNAT)。如果 client 和 server pod 在同一个 Node 上,那源 IP 就是 client pod 的 IP 地址;如果在不同的 Node 上,源 IP 则取决于网络插件是如何处理的,比如使用 flannel 时,源 IP 是 node flannel IP 地址。
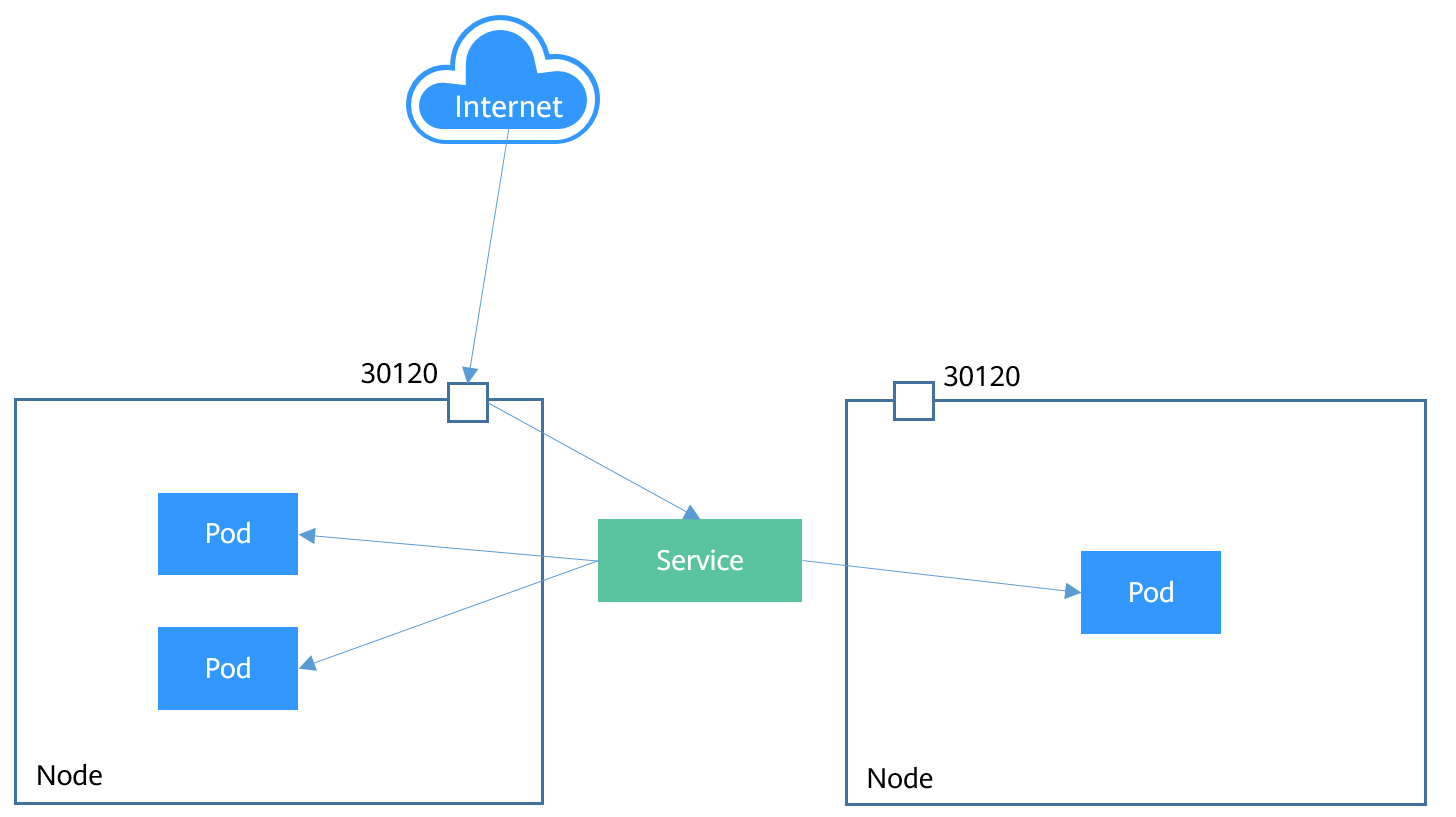
Nodeport
可以在k8s集群外部,通过k8s分配的端口号,或者自定义的端口来访问k8s集群内部的容器。NodePort类型的Service可以让Kubernetes集群每个节点上保留一个相同的端口, 外部访问连接首先访问节点IP:Port,然后将这些连接转发给服务对应的Pod。
k8s 将在指定的范围内分配端口(默认值:30000-32767),端口范围可以通过 --service-node-port-range 字段进行自定义
apiVersion: v1
kind: Service
metadata:name: my-service
spec:type: NodePortselector:app.kubernetes.io/name: MyAppports:# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。- port: 80targetPort: 80# 可选字段# 默认情况下,为了方便起见,Kubernetes 控制平面会从某个范围内分配一个端口号(默认:30000-32767)nodePort: 30007
- NodePort 服务是 ClusterIP 服务的扩展。 NodePort服务路由到的 ClusterIP 服务会自动创建。
- 它通过在 ClusterIP 之上添加一个集群范围的端口来公开集群外部的服务。
- NodePort 在静态端口(NodePort)上公开每个节点 IP 上的服务。每个节点将该端口代理到您的服务中。因此,外部流量可以访问每个节点上的固定端口。这意味着对该端口上的集群的任何请求都会转发到该服务。
- 您可以通过请求 : 从集群外部联系 NodePort 服务。
- 节点端口必须在 30000-32767 范围内。手动为服务分配端口是可选的。如果未定义,Kubernetes 会自动分配一个。
- 如果您要明确选择节点端口,请确保该端口尚未被其他服务使用。
使用场景
- 当您想要启用与您的服务的外部连接时。
- 使用 NodePort 可以让您自由地设置自己的负载平衡解决方案,配置 Kubernetes 不完全支持的环境,甚至直接公开一个或多个节点的 IP。
- 最好在节点上方放置负载均衡器以避免节点故障。
示例
apiVersion: v1
kind: Service
metadata:name: my-frontend-service
spec:type: NodePortselector:app: webports:- name: httpprotocol: TCPport: 80targetPort: 8080nodePort: 30000 # 30000-32767, Optional field
保留源IP
默认情况下,源 IP 会做 SNAT,server pod 看到的源 IP 是 Node IP。为了避免这种情况,可以给 service 设置 spec.ExternalTrafficPolicy=Local (1.6-1.7 版本设置 Annotation service.beta.kubernetes.io/external-traffic=OnlyLocal),让 service 只代理本地 endpoint 的请求(如果没有本地 endpoint 则直接丢包),从而保留源 IP。
LoadBalancer
LoadBalancer类型的Service其实是NodePort类型Service的扩展,通过一个特定的LoadBalancer访问Service,这个LoadBalancer将请求转发到节点的NodePort。
在 NodePort 的基础上,借助 cloud provider 创建一个外部的负载均衡器,并将请求转发到 <NodeIP>:NodePort
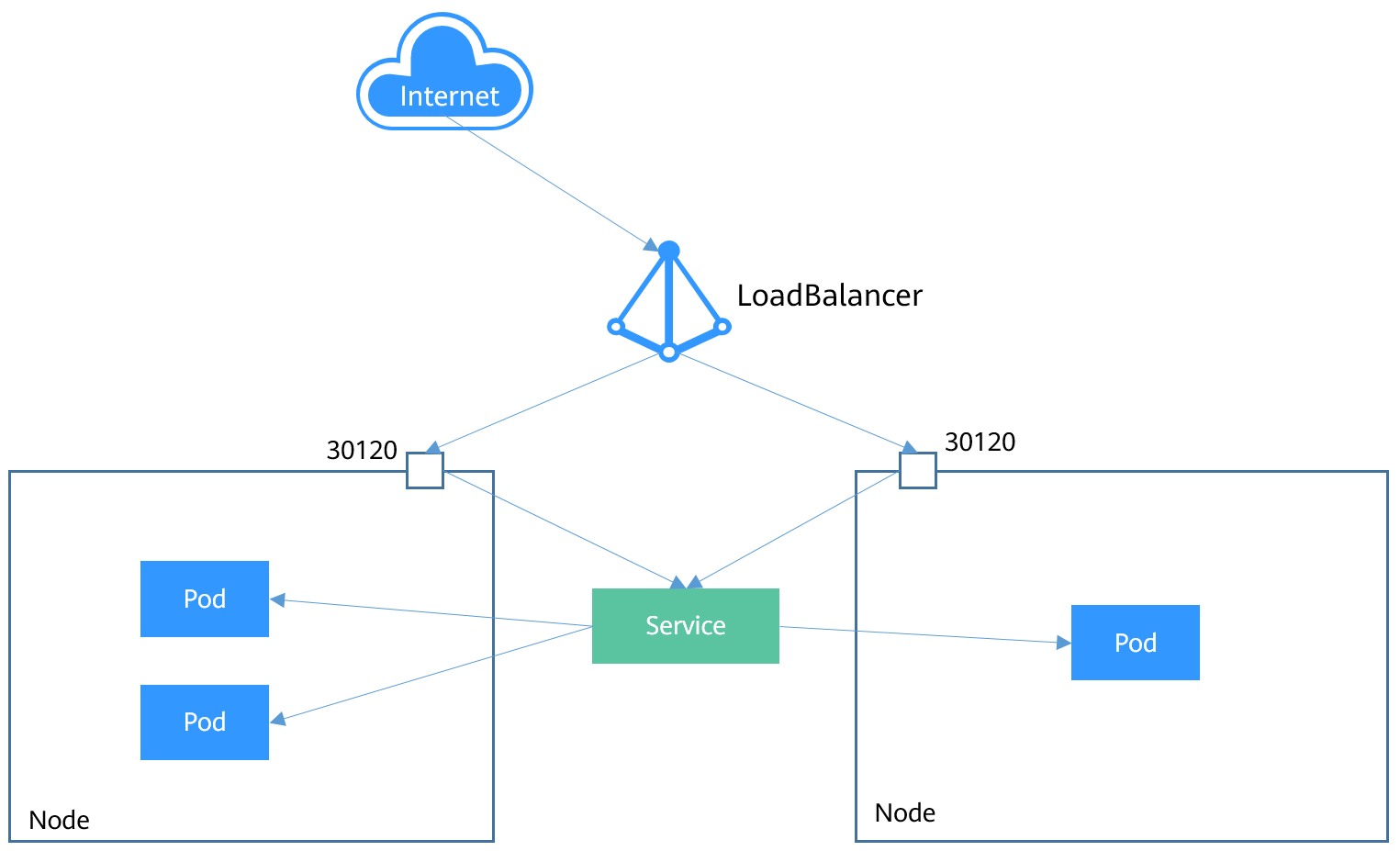
- LoadBalancer 服务是 NodePort 服务的扩展。 外部负载均衡器路由到的 NodePort 和 ClusterIP 服务是自动创建的。
- 它将 NodePort 与基于云的负载均衡器集成在一起。
- 它使用云厂商的负载均衡器在外部公开服务。
- 每个云厂商(AWS、Azure、GCP 、阿里云、腾讯云等)都有自己的原生负载均衡器实现。 云厂商将创建一个负载均衡器,然后它会自动将请求路由到您的 Kubernetes 服务。
- 来自外部负载均衡器的流量被定向到后端 Pod。 云厂商决定如何进行负载平衡。
- 负载均衡器的实际创建是异步发生的。
- 每次要向外界公开服务时,都必须创建一个新的 LoadBalancer 并获取 IP 地址。
使用场景
当您使用云厂商来托管您的 Kubernetes 集群时。
举例
apiVersion: v1
kind: Service
metadata:name: my-frontend-service
spec:type: LoadBalancerclusterIP: 10.0.171.123loadBalancerIP: 123.123.123.123selector:app: webports:- name: httpprotocol: TCPport: 80targetPort: 8080
保留源IP
默认情况下,源 IP 会做 SNAT,server pod 看到的源 IP 是 Node IP。设置 service.spec.ExternalTrafficPolicy=Local 后可以自动从云平台负载均衡器中删除没有本地 endpoint 的 Node,从而保留源 IP。
ExternalName
将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定)。需要 kube-dns 版本在 1.7 以上
- ExternalName 类型的服务将 Service 映射到 DNS 名称,而不是典型的选择器,例如 my-service。
- 您可以使用
spec.externalName参数指定这些服务。- 它通过返回带有其值的 CNAME 记录,将服务映射到 externalName 字段(例如 foo.bar.example.com)的内容。
- 没有建立任何类型的代理。
使用场景
- 这通常用于在 Kubernetes 内创建服务来表示外部数据存储,例如在 Kubernetes 外部运行的数据库。
- 当来自一个命名空间的 Pod 与另一个命名空间中的服务通信时,您可以使用该 ExternalName 服务(作为本地服务)。
示例
apiVersion: v1
kind: Service
metadata:name: my-service
spec:type: ExternalNameexternalName: my.database.example.com
多端口的service
对于某些服务,你需要公开多个端口。 Kubernetes 允许你在 Service 对象上配置多个端口定义。 为服务使用多个端口时,必须提供所有端口名称,以使它们无冲突。 例如:
apiVersion: v1
kind: Service
metadata:name: my-service
spec:selector:app.kubernetes.io/name: MyAppports:- name: httpprotocol: TCPport: 80targetPort: 9376- name: httpsprotocol: TCPport: 443targetPort: 9377
Endpoint
Kubernetes正是通过Endpoints监控到Pod的IP,从而让Service能够发现Pod。
在 Kubernetes API 中,Endpoints 定义了网络端点的列表(EndpointsList),通常由 Service 引用,以定义可以将流量发送到哪些 Pod。
推荐用 EndpointSlice API 替换 Endpoints
Endpoint资源对象
apiVersion: v1
kind: Endpoints
metadata (ObjectMeta)Name: "mysvc",Subsets: [{Addresses: [{"ip": "10.10.1.1"}, {"ip": "10.10.2.2"}],Ports: [{"name": "a", "port": 8675}, {"name": "b", "port": 309}]},{Addresses: [{"ip": "10.10.3.3"}],Ports: [{"name": "a", "port": 93}, {"name": "b", "port": 76}]},
]
metadata (ObjectMeta)
subsets ([]EndpointSubset)
所有 subsets 的并集组成所有端点的集合,不同的IP地址放入不同子集,对应一个IP开放多个端口,就绪的端口,放入addresses 中;未就绪的端口,放入notReadyAddress中
EndpointSubset 是一组具有公共端口集的地址。扩展的端点集是 addresses 和 ports 的笛卡尔乘积。例如假设:
{ Addresses: [{"ip": "10.10.1.1"}, {"ip": "10.10.2.2"}], Ports: [{"name": "a", "port": 8675}, {"name": "b", "port": 309}] }
则最终的端点集可以看作:
a: [ 10.10.1.1:8675, 10.10.2.2:8675 ], b: [ 10.10.1.1:309, 10.10.2.2:309 ]*
subsets.addresses ([]EndpointAddress):提供标记为就绪的相关端口的 IP 地址。 这些端点应该被认为是负载均衡器和客户端可以安全使用的。
subsets.notReadyAddresses ([]EndpointAddress):提供相关端口但由于尚未完成启动、最近未通过就绪态检查或最近未通过活跃性检查而被标记为当前未就绪的 IP 地址
subsets.ports ([]EndpointPort):相关 IP 地址上可用的端口号。
端点列表(EndpointsList)
apiVersion: v1
kind: EndpointsList
metadata (ListMeta)
items ([]Endpoints)
ListMeta:描述了合成资源必须具有的元数据,包括列表和各种状态对象。 一个资源仅能有 {ObjectMeta, ListMeta} 中的一个。
continue (string)
通过
continue设置返回的条目数量,表示服务器有更多可用的数据。 该值是不透明的,可用于向提供此列表服务的端点发出另一个请求,以检索下一组可用的对象。 如果服务器配置已更改或时间已过去几分钟,则可能无法继续提供一致的列表。 除非你在错误消息中收到此令牌(token),否则使用此continue值时返回的resourceVersion字段应该和第一个响应中的值是相同的。remainingItemCount (int64)
remainingItemCount是列表中未包含在此列表响应中的后续项目的数量。 如果列表请求包含标签(tag)或字段选择器(selector),则剩余项目的数量是未知的,并且在序列化期间该字段将保持未设置和省略。 如果列表是完整的(因为它没有分块或者这是最后一个块),那么就没有剩余的项目,并且在序列化过程中该字段将保持未设置和省略。 早于 v1.15 的服务器不设置此字段。remainingItemCount的预期用途是估计集合的大小。 客户端不应依赖于设置准确的remainingItemCount。resourceVersion (string)
标识该对象的服务器内部版本的字符串,客户端可以用该字段来确定对象何时被更改。 该值对客户端是不透明的,并且应该原样传回给服务器。该值由系统填充,只读。 更多信息: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#concurrency-control-and-consistency 。
selfLink (string)
selfLink 表示此对象的 URL,由系统填充,只读。
已弃用:selfLink 是一个遗留的只读字段,不再由系统填充。
超出容量的端点
Kubernetes 限制单个 Endpoints 对象中可以容纳的端点数量。 当一个服务有超过 1000 个后备端点时,Kubernetes 会截断 Endpoints 对象中的数据。
对于旧版本的 Endpoints ,超过1000 后备端点的情况,流量仍会发送到后端,Kubernetes 选择最多 1000 个可能的后端端点来存储到 Endpoints 对象中,并在 Endpoints: endpoints.kubernetes.io/over-capacity: truncated 上设置注解如果后端 Pod 的数量低于 1000,控制平面也会移除该注解。
Endpoints 端点 API使用
list 列出或监测 Endpoints 类型的对象
GET /api/v1/namespaces/{namespace}/endpoints
参数:
allowWatchBookmarks (查询参数):boolean
continue (查询参数):string
fieldSelector (查询参数):string
labelSelector (查询参数):string
limit (查询参数):integer
pretty (查询参数):string
resourceVersion (查询参数):string
resourceVersionMatch (查询参数):string
sendInitialEvents (查询参数): boolean
timeoutSeconds (查询参数):integer
watch (查询参数):boolean
响应
200 (EndpointsList): OK
401: Unauthorized
create 创建 Endpoints
POST /api/v1/namespaces/{namespace}/endpoints
参数
namespace (路径参数):string,必需
body: Endpoints, 必需
dryRun (查询参数):string
fieldManager (查询参数):string
fieldValidation (查询参数):string
pretty (查询参数):string
响应
200 (Endpoints): OK
201 (Endpoints): Created
202 (Endpoints): Accepted
401: Unauthorized
update 替换指定的 Endpoints
PUT /api/v1/namespaces/{namespace}/endpoints/{name}
参数
name (路径参数):string,必需 Endpoints 名称
namespace (路径参数):string,必需
body: Endpoints, required
dryRun (查询参数):string
fieldManager (查询参数):string
fieldValidation (查询参数):string
pretty (查询参数):string
响应
200 (Endpoints): OK
201 (Endpoints): Created
401: Unauthorized
delete 删除 Endpoints
DELETE /api/v1/namespaces/{namespace}/endpoints/{name}
参数
name (路径参数):string,必需 Endpoints 名称
namespace (路径参数):string,必需
body: DeleteOptions
dryRun (查询参数):string
gracePeriodSeconds (查询参数):integer
pretty (查询参数):string
propagationPolicy (查询参数):string
响应
200 (Status): OK
202 (Status): Accepted
401: Unauthorized
EndpointSlice
Kubernetes 的 EndpointSlice API 提供了一种简单的方法来跟踪 Kubernetes 集群中的网络端点(network endpoints)。EndpointSlices 为 Endpoints 提供了一种可扩缩、可拓展的替代方案。
API Server 自动为设置了选择算符的 Kubernetes Service 创建 EndpointSlice。EndpointSlice 通过唯一的 协议、端口号和 Service 名称将网络端点(network endpoints)组织在一起。
默认情况下,API Server 创建和管理的 EndpointSlice 将包含不超过 100 个Pod。 可以使用 kube-controller-manager的 --max-endpoints-per-slice 标志设置此值,最大值为 1000
EndpointSlice状态
Ready(就绪)
ready状况是映射 Pod 的Ready状况的。对于处于运行中的 Pod,它的Ready状况被设置为True,应该将此 EndpointSlice 状况也设置为true。
Serving(服务中)
如果 EndpointSlice API 的使用者关心 Pod 终止时的就绪情况,就应检查
serving状况
Terminating(终止中)
特性状态:
Kubernetes v1.22 [beta]
Terminating是表示端点是否处于终止中的状况。 对于 Pod 来说,这是设置了删除时间戳的 Pod
参阅:
k8s中的endpoint
k8s 理解Service工作原理
K8s 核心组件讲解——kube-proxy
详解k8s 4种类型Service
kubernetes集群内部DNS解析原理、域名解析超时问题记录
CoreDNS简介
Kubernetes网络
Service
相关文章:
k8s Service网络详解(一)
k8s Service网络详解(一) 有关K8s网络的几个概念K8s网络模型k8s网络插件ServiceService的访问方式Service的种类无头服务(Headless Services)带选择算符的服务无选择算符的服务 Service的类型ClusterIPNodeportLoadBalancerExtern…...

抖音账号矩阵系统开发源码
一、技术自研框架开发背景: 抖音账号矩阵系统是一种基于数据分析和管理的全新平台,能够帮助用户更好地管理、扩展和营销抖音账号。 部分源码分享: ic function indexAction() { //面包屑 $breadcrumbs [ [tit…...

Python+Texturepacker自动化处理图片
前言 本篇在讲什么 PythonTexturepacker自动化处理图片 本篇需要什么 对Python语法有简单认知 依赖Python2.7环境 依赖Texturepacker工具 本篇的特色 具有全流程的图文教学 重实践,轻理论,快速上手 提供全流程的源码内容 ★提高阅读体验★ &…...
K8s Service网络详解(二)
K8s Service网络详解(二) Kube Proxy调度模式Kube-proxy IptablesKube-proxy IPVS Service SelectorPod DNS种常见的 DNS 服务Kube-DNSCoreDNSCorefile 配置 DNS 记录DNS 记录 ServiceDNS 记录 PodDNS 配置策略 Pod 的主机名设置优先级 Ingress Kube Pro…...

Rust vs Go:常用语法对比
这个网站 可以列出某门编程语言的常用语法,也可以对比两种语言的基本语法差别。 在此对比Go和Rust 1. Print Hello World 打印Hello World package mainimport "fmt"func main() { fmt.Println("Hello World")} fn main() { println!("…...

Vlan端口隔离(第二十四课)
一、端口隔离 1、端口隔离技术概述 1)端口隔离技术出现背景:为了实现报文之间的二层隔离,可以将不同的端口加入不同的VLAN,但这样会浪费有限的VLAN ID资源。 2)端口隔离的作用:采用端口隔离功能,可以实现同一VLAN内端口之间的隔离。 3)如何实现端口隔离功能:只需要…...

js实现框选截屏功能
实现的思路大概就是,先将dom转化为canvas画布,再对canvas进行裁切,然后通过canvas api生成图片,这里用到了一个库html2canvas 效果如图: 首先实现框选效果: const mousedownEvent (e) > {moveX 0;mo…...

Manjaro Linux 连接公司的 VPN 网络
注意:如果你公司的 VPN 网络是在苹果下使用的,本文可能不适用(苹果系统不支持 PPTP)。 用 Linux 和用 Windows/macOS 不一样,它真的需要用户操心很多东西。比如怎么连接公司的 VPN 网络…… 我是折腾了挺久࿰…...

Ama no Jaku
登录—专业IT笔试面试备考平台_牛客网 题目大意:有一个n*n且仅由0和1构成的矩阵,每次操作可以将一整行或一整列的所有数取反,问能否使所有行中构成的最小数>所有列中构成的最大数 1<n<2000 思路:首先,如果…...

视频基础知识
1.视频比特率 视频的比特率是指传输过程中单位时间传输的数据量。可以理解为视频的编码采样率。单位是kbps,即每秒千比特。视频比特率是决定视频清晰度的一个重要指标。比特率越高,视频越清晰,但数据量也会越大。比如一部100分钟的电影&#…...

安全渗透初级知识总结
Day1: xss详解:web攻防之XSS攻击详解——XSS简介与类型 - 知乎 (zhihu.com) Cookie:身份验证 网页元素属性: id: class:样式名称 console.log(div_class);----打印标签 tabindex"0"---这是…...

rocketmq客户端本地日志文件过大调整配置(导致pod缓存cache过高)
现象 在使用rocketmq时,发现本地项目中文件越来越大,查找发现在/home/root/logs/rocketmqlog目录下存在大量rocketmq_client.log日志文件。 配置调整 开启slf4j日志模式,在项目启动项中增加-Drocketmq.client.logUseSlf4jtrue因为配置使用的…...
Unity进阶-ui框架学习笔记
文章目录 Unity进阶-ui框架学习笔记 Unity进阶-ui框架学习笔记 笔记来源课程:https://study.163.com/course/courseMain.htm?courseId1212756805&_trace_c_p_k2_8c8d7393c43b400d89ae94ab037586fc 最上面的管理层(canvas) using System…...

Django实现接口自动化平台(十四)测试用例模块Testcases序列化器及视图【持续更新中】
相关文章: Django实现接口自动化平台(十三)接口模块Interfaces序列化器及视图【持续更新中】_做测试的喵酱的博客-CSDN博客 本章是项目的一个分解,查看本章内容时,要结合整体项目代码来看: python django…...

如何高效实现文件传输:小文件采用零拷贝、大文件采用异步io+直接io
一般会如何实现文件传输? 服务器提供文件传输功能,需要将磁盘上的文件读取出来,通过网络协议发送到客户端。如果需要你自己编码实现这个文件传输功能,你会怎么实现呢? 通常,你会选择最直接的方法…...

Docker运行MySQL5.7
步骤如下: 1.获取镜像: docker pull mysql:5.7 2.创建挂载目录: mkdir /home/mydata/data mkdir /home/mydata/log mkdir /home/mydata/conf 3.先启动docker把配置文件拷贝出来: docker run -it --name temp mysql:5.7 /bi…...

-jar和 javaagent命令冲突吗?
当使用 -jar 命令运行 Java 应用程序时,Java 虚拟机 (JVM) 会忽略任何设置的 -javaagent 命令。这是因为 -jar 命令会覆盖其他命令行选项,包括 -javaagent。 这是因为 -jar 命令是用于运行打包为 JAR 文件的 Java 应用程序的快捷方式。它会忽略其他命令…...

LLC和MAC子层的应用
计算机局域网标准IEEE802 由于局域网只是一个计算机通信网,而且局域网不存在路由选择问题,因此它不需要网络层,而只有最低的两个层次。然而局域网的种类繁多,其媒体接入控制的方法也各不相同。 为了使局域网中的数据链路层不致过…...
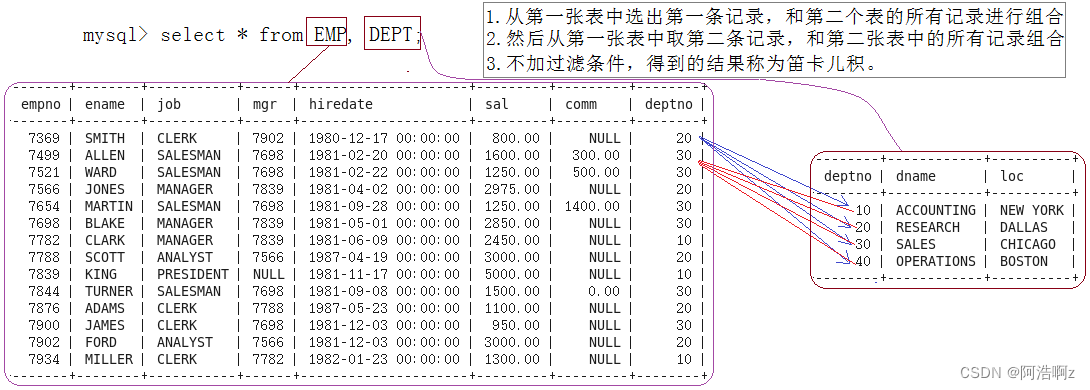
【MySQL】之复合查询
【MySQL】之复合查询 基本查询多表查询笛卡尔积自连接子查询单行子查询多行子查询多列子查询在from子句中使用子查询 合并查询小练习 基本查询 查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J按照部门号升序而雇员的工资降序排序使用…...
Vue系列第五篇:Vue2(Element UI) + Go(gin框架) + nginx开发登录页面及其校验登录功能
本篇使用Vue2开发前端,Go语言开发服务端,使用nginx代理部署实现登录页面及其校验功能。 目录 1.部署结构 2.Vue2前端 2.1代码结构 2.1源码 3.Go后台服务 3.2代码结构 3.2 源码 3.3单测效果 4.nginx 5.运行效果 6.问题总结 1.部署结构 2.Vue2…...

用快马平台十分钟复刻lostlife:快速构建你的首个交互式游戏原型
最近想尝试做个简单的交互式游戏原型,正好看到InsCode(快马)平台可以快速生成项目代码,就试了试复刻类似lostlife的玩法。整个过程比想象中顺利,分享下我的实现思路: 确定核心交互逻辑 游戏的核心是点击角色触发反馈,所…...

开源工具提升下载效率:多网盘直链获取方案实现下载效率提升60%
开源工具提升下载效率:多网盘直链获取方案实现下载效率提升60% 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

3步搞定知识星球爬虫:让付费知识变成你的私人电子书库
3步搞定知识星球爬虫:让付费知识变成你的私人电子书库 【免费下载链接】zsxq-spider 爬取知识星球内容,并制作 PDF 电子书。 项目地址: https://gitcode.com/gh_mirrors/zs/zsxq-spider 你是否在知识星球上订阅了多个优质专栏,却苦于无…...

Dell G15终极散热控制:tcc-g15开源方案完全指南
Dell G15终极散热控制:tcc-g15开源方案完全指南 【免费下载链接】tcc-g15 Thermal Control Center for Dell G15 - open source alternative to AWCC 项目地址: https://gitcode.com/gh_mirrors/tc/tcc-g15 你是否厌倦了Dell G15游戏本自带的AWCC软件那臃肿的…...

Swin2SR小白快速上手:无需代码,在线修复低清图片
Swin2SR小白快速上手:无需代码,在线修复低清图片 1. 什么是Swin2SR图像修复技术 Swin2SR是一种基于Swin Transformer架构的AI图像超分辨率技术,它能将低质量图片无损放大4倍。与传统的插值放大方法不同,Swin2SR能够"理解&q…...

javaweb学习资料资源分享共享平台的研究和实现
目录同行可拿货,招校园代理 ,本人源头供货商功能需求分析核心技术实现特色功能设计扩展性考虑项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作同行可拿货,招校园代理 ,本人源头供货商 功能需求分析 JavaWeb学习资料共享平台的…...

智慧井盖传感器震动倾斜溢水监测:传统市政设施的智慧化升级典范
市政设施是城市运行的基石,而井盖作为地下管网的“出入口”,是传统市政设施中不可或缺的一环。长期以来,传统井盖受技术限制,依赖人工巡检维护,普遍存在震动破损、倾斜移位、井下溢水预警不及时等痛点,不仅…...

Qwen3-Reranker-0.6B实战案例:跨语言技术文档智能筛选系统
Qwen3-Reranker-0.6B实战案例:跨语言技术文档智能筛选系统 1. 引言:技术文档管理的痛点与解决方案 在全球化技术团队协作中,工程师们经常面临这样的困境:当需要查找某个技术问题的解决方案时,面对的是分散在Confluen…...

Wan2.2-I2V-A14B Anaconda虚拟环境管理:隔离依赖与复现实验
Wan2.2-I2V-A14B Anaconda虚拟环境管理:隔离依赖与复现实验 1. 为什么需要虚拟环境 在AI项目开发中,依赖管理是个让人头疼的问题。想象一下这样的场景:你花了两周时间调试好的模型,换台机器就跑不起来了;或者更新了某…...

HY-Motion-1.0本地部署全流程:Docker镜像快速启动教程
HY-Motion-1.0本地部署全流程:Docker镜像快速启动教程 1. 引言 想用简单的文字描述就能生成专业的3D角色动画吗?HY-Motion 1.0让这个想法变成了现实。这是一个基于先进AI技术的文本生成3D动作模型,只需要输入英文描述,就能自动生…...