Django实现接口自动化平台(十四)测试用例模块Testcases序列化器及视图【持续更新中】
相关文章:
Django实现接口自动化平台(十三)接口模块Interfaces序列化器及视图【持续更新中】_做测试的喵酱的博客-CSDN博客
本章是项目的一个分解,查看本章内容时,要结合整体项目代码来看:
python django vue httprunner 实现接口自动化平台(最终版)_python+vue自动化测试平台_做测试的喵酱的博客-CSDN博客
一、Testcases应用及相关接口
| 请求方式 | URI | 对应action | 实现功能 |
| GET | /testcases/ | .list() | 查询testcase列表 |
| POST | /testcases/ | .create() | 创建一条数据 |
| GET | /testcases/{id}/ | .retrieve() | 检索一条testcase的详细数据 |
| PUT | /testcases/{id}/ | update() | 更新一条数据中的全部字段 |
| PATCH | /testcases/{id}/ | .partial_update() | 更新一条数据中的部分字段 |
| DELETE | /testcases/{id}/ | .destroy() | 删除一条数据 |
| POST | /testcases/{id}/run/ | 运行某个接口下的所有case |
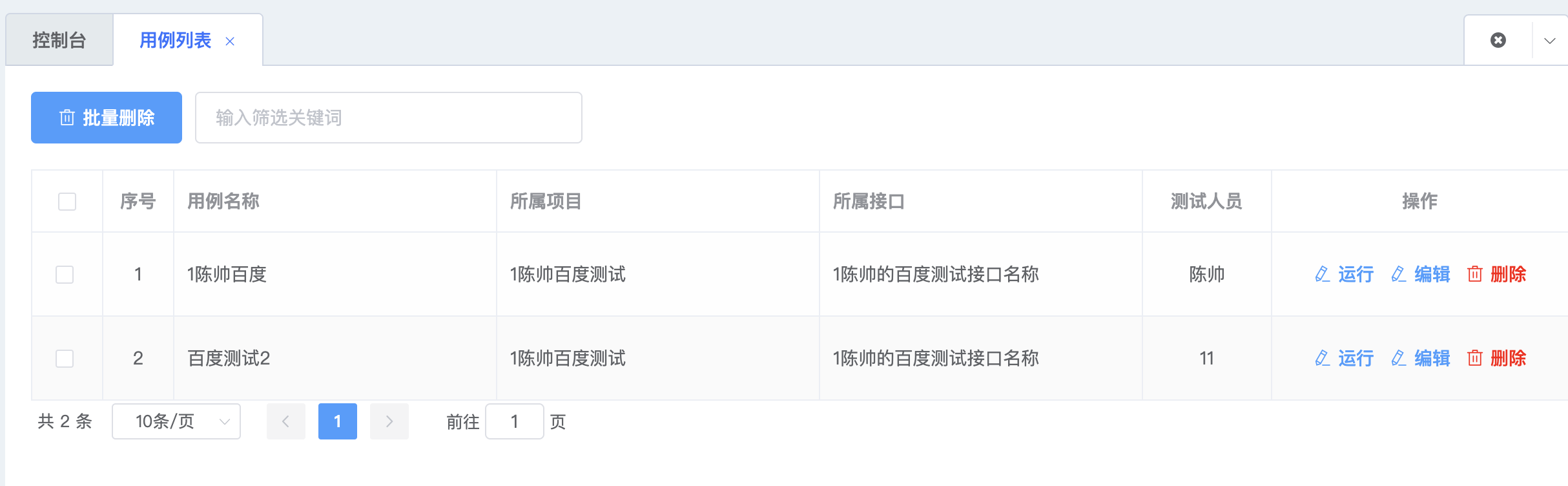
1.1 用例列表
| GET | /testcases/ | .list() | 查询testcase列表 |
1.2 创建用例
1.2.1 基本信息
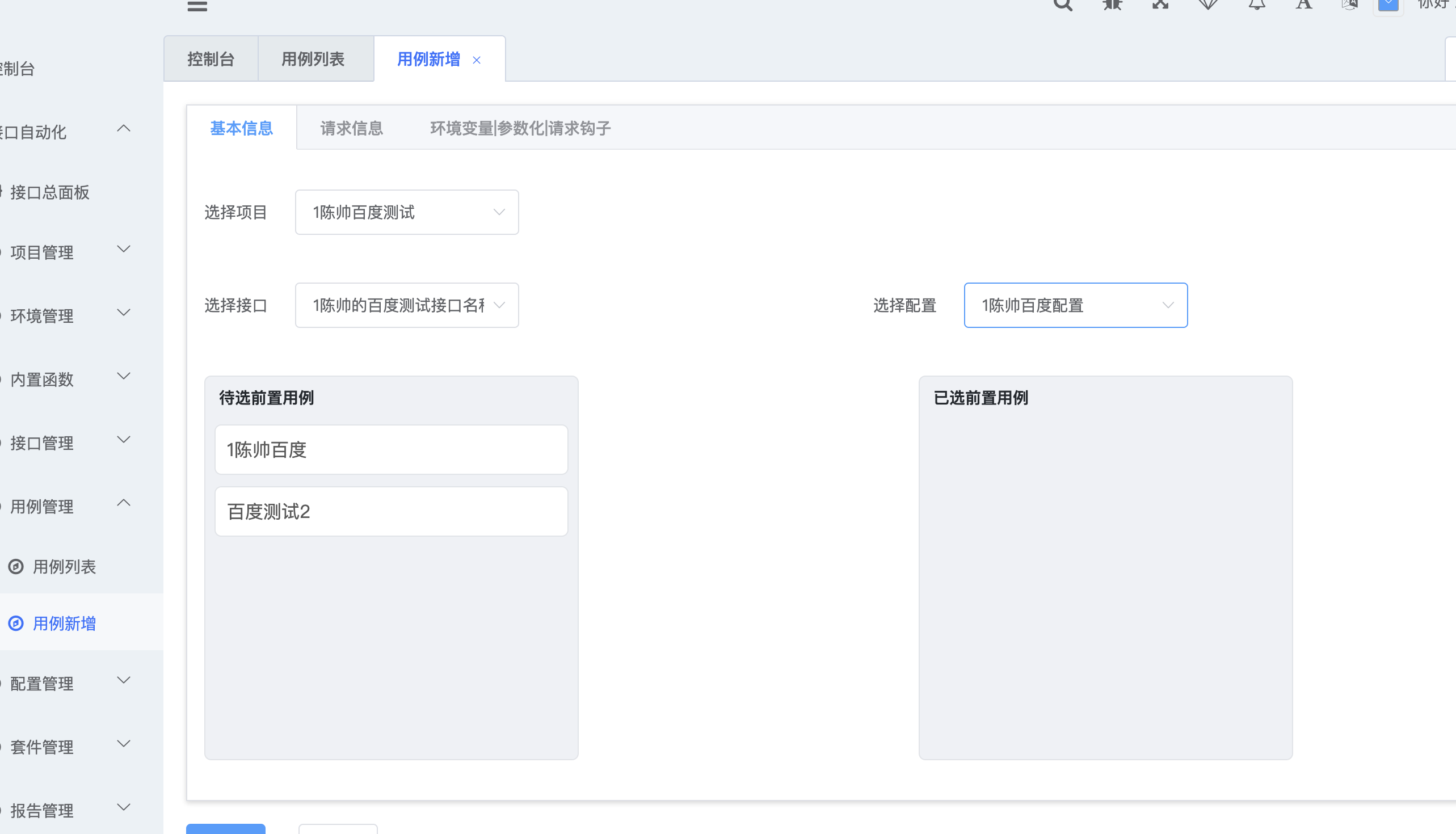
1、拉取了项目列表
2、拉取了项目下的接口列表
3、前置用例列表
4、拉取了所有的配置列表
1.2.2 基本信息


二、模型类
from django.db import modelsfrom utils.base_models import BaseModelclass Interfaces(BaseModel):id = models.AutoField(verbose_name='id主键', primary_key=True, help_text='id主键')name = models.CharField('接口名称', max_length=200, unique=True, help_text='接口名称')project = models.ForeignKey('projects.Projects', on_delete=models.CASCADE,related_name='interfaces', help_text='所属项目')tester = models.CharField('测试人员', max_length=50, help_text='测试人员')desc = models.CharField('简要描述', max_length=200, null=True, blank=True, help_text='简要描述')class Meta:db_table = 'tb_interfaces'verbose_name = '接口信息'verbose_name_plural = verbose_nameordering = ('id',)def __str__(self):return self.name这段代码定义了一个名为Testcases的Django模型类,继承了BaseModel。
首先,通过from django.db import models导入了Django的models模块和自定义的BaseModel模块。
然后,定义了Testcases模型类,它包含了以下字段:
- id:主键字段,使用AutoField类型生成自增的id。
- name:用例名称字段,使用CharField类型,最大长度为50,设置为唯一值。
- interface:外键字段,关联到interfaces.Interfaces模型,表示该用例所属的接口。
- include:前置字段,使用TextField类型,允许为空,保存用例执行前需要执行的顺序信息。
- author:编写人员字段,使用CharField类型,最大长度为50,保存编写该用例的人员信息。
- request:请求信息字段,使用TextField类型,保存请求的详细信息。
接下来,定义了该模型类的Meta类,包含了一些元数据:
- db_table:数据库表的名称,设置为tb_testcases。
- verbose_name:该模型的可读名称,设置为'用例信息'。
- verbose_name_plural:该模型的复数形式名称,与verbose_name相同。
- ordering:查询结果的默认排序规则,按照id字段进行升序排序。
最后,定义了__str__方法,返回用例的名称,用于在后台管理界面和其他地方显示该模型对象的可读信息。
通过以上定义,您可以使用Django框架创建一个名为Testcases的数据表,其中包含了上述定义的字段,并且可以进行数据操作和查询。
注意:
所有请求相关的信息,如header、URI、请求体、断言等等,全部在模型类 request字段中。
request的值,是一个json字符串。如:
{"test": {"name": "1陈帅百度","request": {"url": "/mcp/pc/pcsearch","method": "POST","json": {"invoke_info": {"pos_1": [{}],"pos_2": [{}],"pos_3": [{}]}}},"validate": [{"check": "status_code","expected": 200,"comparator": "equals"}]}
}包含了请求与断言的信息。
底层使用的httprunner 1.0 做的接口自动化驱动,case的形式,就是json格式的。
相关资料:
httprunner 2.x的基本使用(二)_做测试的喵酱的博客-CSDN博客
三、序列化器类
class TestcaseModelSerializer(serializers.ModelSerializer):interface = InterfaceProjectModelSerializer(label='所属项目和接口信息', help_text='所属项目和接口信息')class Meta:model = Testcasesexclude = ('create_datetime', 'update_datetime')extra_kwargs = {'request': {'write_only': True},'include': {'write_only': True},}# def validate_request(self, attr):# # TODO# return attr## def validate(self, attrs):# # TODO# return attrsdef to_internal_value(self, data):result = super().to_internal_value(data)iid = data.get('interface').get('iid')result['interface'] = Interfaces.objects.get(id=iid)return result# def create(self, validated_data):# pass# class TestcaseRunSerializer(serializers.ModelSerializer):
# env_id = serializers.IntegerField(label="所属环境id", help_text="所属环境id",
# validators=[ManualValidateIsExist('env')])
#
# class Meta:
# model = Testcases
# fields = ('id', 'env_id')class TestcaseRunSerializer(RunSerializer):class Meta(RunSerializer.Meta):model = Testcases
四、视图
import json
import os
from datetime import datetimefrom django.conf import settings
from django.http import JsonResponse
from rest_framework import viewsets
from rest_framework import permissions
from rest_framework.response import Response
from rest_framework.decorators import actionfrom .models import Testcases
from envs.models import Envs
from . import serializers
from utils import handle_datas, common
from utils.mixins import RunMixinclass TestcasesViewSet(RunMixin, viewsets.ModelViewSet):queryset = Testcases.objects.all()serializer_class = serializers.TestcaseModelSerializerpermission_classes = [permissions.IsAuthenticated]# 删除def destroy(self, request, *args, **kwargs):response = super().destroy(request, *args, **kwargs)response.status_code = 200response = {"code":2000,"msg":"删除成功"}response =JsonResponse(response)return response# 获取单个详情def retrieve(self, request, *args, **kwargs):instance = self.get_object() # type: Testcasestry:testcase_include = json.loads(instance.include, encoding='utf-8')except Exception:testcase_include = dict()try:testcase_request = json.loads(instance.request, encoding='utf-8')except Exception:return Response({'msg': '用例格式有误', 'status': 400}, status=400)testcase_request_data = testcase_request.get('test').get('request')# 获取json参数json_data = testcase_request_data.get('json')json_data_str = json.dumps(json_data, ensure_ascii=False)# 获取extract参数extract_data = testcase_request.get('test').get('extract')extract_data = handle_datas.handle_data3(extract_data)# 获取validate参数validate_data = testcase_request.get('test').get('validate')validate_data = handle_datas.handle_data1(validate_data)# 获取variables参数variables_data = testcase_request.get('test').get('variables')variables_data = handle_datas.handle_data2(variables_data)# 获取parameters参数parameters_data = testcase_request.get('test').get('parameters')parameters_data = handle_datas.handle_data3(parameters_data)# 获取setup_hooks参数setup_hooks_data = testcase_request.get('test').get('setup_hooks')setup_hooks_data = handle_datas.handle_data5(setup_hooks_data)# 获取teardown_hooks参数teardown_hooks_data = testcase_request.get('test').get('teardown_hooks')teardown_hooks_data = handle_datas.handle_data5(teardown_hooks_data)data = {"author": instance.author,"testcase_name": instance.name,"selected_configure_id": testcase_include.get('config'),"selected_interface_id": instance.interface_id,"selected_project_id": instance.interface.project_id,"selected_testcase_id": testcase_include.get('testcases', []),"method": testcase_request_data.get('method'),"url": testcase_request_data.get('url'),"param": handle_datas.handle_data4(testcase_request_data.get('params')),"header": handle_datas.handle_data4(testcase_request_data.get('headers')),"variable": handle_datas.handle_data2(testcase_request_data.get('data')),"jsonVariable": json_data_str,"extract": extract_data,"validate": validate_data,# 用例的当前配置(variables)"globalVar": variables_data,"parameterized": parameters_data,"setupHooks": setup_hooks_data,"teardownHooks":teardown_hooks_data}return Response(data, status=200)# @action(methods=['post'], detail=True)# def run(self, request, *args, **kwargs):# # 1、取出用例模型对象并获取env_id# # instance = self.get_object() # type: Testcases# # serializer = self.get_serializer(data=request.data)# # serializer.is_valid(raise_exception=True)# # env_id = serializer.validated_data.get('env_id')# # env = Envs.objects.get(id=env_id)## # 2、创建以时间戳命名的目录# # dirname = datetime.strftime(datetime.now(), "%Y%m%d%H%M%S")# # testcase_dir_path = os.path.join(settings.PROJECT_DIR, datetime.strftime(datetime.now(), "%Y%m%d%H%M%S"))# # os.makedirs(testcase_dir_path)## # 3、创建以项目名命名的目录# # 4、生成debugtalks.py、yaml用例文件# # common.generate_testcase_file(instance, env, testcase_dir_path)## # 5、运行用例并生成测试报告# # return common.run_testcase(instance, testcase_dir_path)# qs = [self.get_object()]# return self.execute(qs)def get_serializer_class(self):if self.action == "run":return serializers.TestcaseRunSerializerelse:return super().get_serializer_class()def get_testcase_qs(self):return [self.get_object()]# return self.queryset.filter(id=self.get_object().id)
这段代码是一个Django视图集,用于处理测试用例的增删改查操作。它继承了RunMixin类,并且使用了ModelViewSet视图集来简化代码。
该视图集定义了以下几个方法:
- destroy: 重写了父类的destroy方法,删除指定的测试用例,并返回一个删除成功的响应。
- retrieve: 重写了父类的retrieve方法,获取单个测试用例的详情,并将相关数据进行处理后返回。
- get_serializer_class: 根据请求的动作不同,选择不同的序列化器进行序列化。
- get_testcase_qs: 获取测试用例的查询集。
除此之外,还有一段被注释掉的代码,它包含了运行测试用例的逻辑,根据时间戳创建目录、生成测试用例文件,并运行测试用例生成测试报告。
需要注意的是,这段代码中使用了一些自定义的工具类和函数,如handle_datas、common等,未提供相关代码,可能需要根据实际情况自行补充。
相关文章:
Django实现接口自动化平台(十四)测试用例模块Testcases序列化器及视图【持续更新中】
相关文章: Django实现接口自动化平台(十三)接口模块Interfaces序列化器及视图【持续更新中】_做测试的喵酱的博客-CSDN博客 本章是项目的一个分解,查看本章内容时,要结合整体项目代码来看: python django…...

如何高效实现文件传输:小文件采用零拷贝、大文件采用异步io+直接io
一般会如何实现文件传输? 服务器提供文件传输功能,需要将磁盘上的文件读取出来,通过网络协议发送到客户端。如果需要你自己编码实现这个文件传输功能,你会怎么实现呢? 通常,你会选择最直接的方法…...

Docker运行MySQL5.7
步骤如下: 1.获取镜像: docker pull mysql:5.7 2.创建挂载目录: mkdir /home/mydata/data mkdir /home/mydata/log mkdir /home/mydata/conf 3.先启动docker把配置文件拷贝出来: docker run -it --name temp mysql:5.7 /bi…...

-jar和 javaagent命令冲突吗?
当使用 -jar 命令运行 Java 应用程序时,Java 虚拟机 (JVM) 会忽略任何设置的 -javaagent 命令。这是因为 -jar 命令会覆盖其他命令行选项,包括 -javaagent。 这是因为 -jar 命令是用于运行打包为 JAR 文件的 Java 应用程序的快捷方式。它会忽略其他命令…...

LLC和MAC子层的应用
计算机局域网标准IEEE802 由于局域网只是一个计算机通信网,而且局域网不存在路由选择问题,因此它不需要网络层,而只有最低的两个层次。然而局域网的种类繁多,其媒体接入控制的方法也各不相同。 为了使局域网中的数据链路层不致过…...
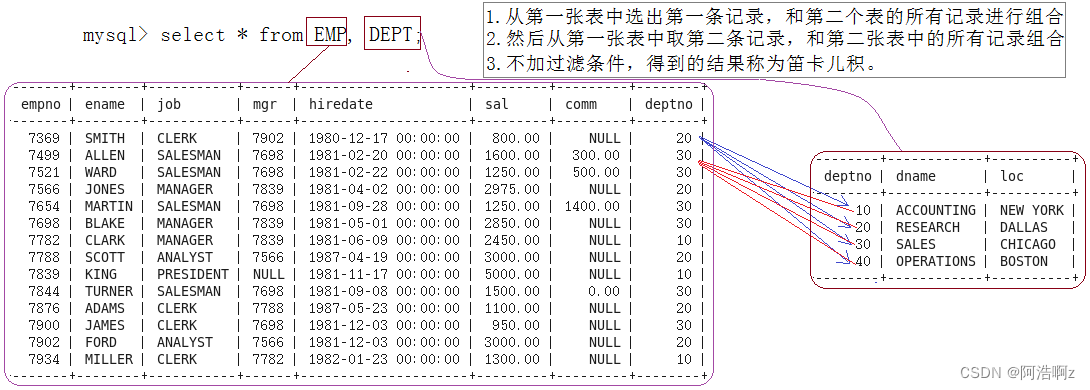
【MySQL】之复合查询
【MySQL】之复合查询 基本查询多表查询笛卡尔积自连接子查询单行子查询多行子查询多列子查询在from子句中使用子查询 合并查询小练习 基本查询 查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J按照部门号升序而雇员的工资降序排序使用…...
Vue系列第五篇:Vue2(Element UI) + Go(gin框架) + nginx开发登录页面及其校验登录功能
本篇使用Vue2开发前端,Go语言开发服务端,使用nginx代理部署实现登录页面及其校验功能。 目录 1.部署结构 2.Vue2前端 2.1代码结构 2.1源码 3.Go后台服务 3.2代码结构 3.2 源码 3.3单测效果 4.nginx 5.运行效果 6.问题总结 1.部署结构 2.Vue2…...
u盘里的数据丢失怎么恢复 u盘数据丢失怎么恢复
在使用U盘的时候不知道大家有没有经历过数据丢失或者U盘提示格式化的情况呢?U盘使用久了就会遇到各种各样的问题,而关于U盘数据丢失,大家又知道多少呢?当数据丢失了,我们应该怎样恢复数据?这个问题困扰了很…...

Mysql-约束
约束 概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。 目的:保证数据库中数据的正确、有效性和完整性。 分类: 约束描述关键字非空约束限制该字段的数据不能为nullNOT NULL唯一约束保证该字段的所有数据都是唯一…...

数据结构问答7
1. 图的定义和相关术语 答: 定义:图是由顶点集V和边集E组成,其中V为有限非空集。 相关术语:n个顶点,e条边,G=(V,E) ① 邻接点和端点:无向图中,若存在一条边(i, j),则称i,j为该边的端点,且它们互为邻接点;在有向图中,若存在一条边<i, j>,则称i,j分别为…...

[Spark] 大纲
1、Spark任务提交流程 2、SparkSQL执行流程 2.1 RBO,基于规则的优化 2.2 CBO,基于成本的优化 3、Spark性能调优 3.1 固定资源申请和动态资源分配 3.2 数据倾斜常见解决方法 3.3 小文件优化 4、Spark 3.0 4.1 动态分区裁剪(Dynamic Partition Pr…...
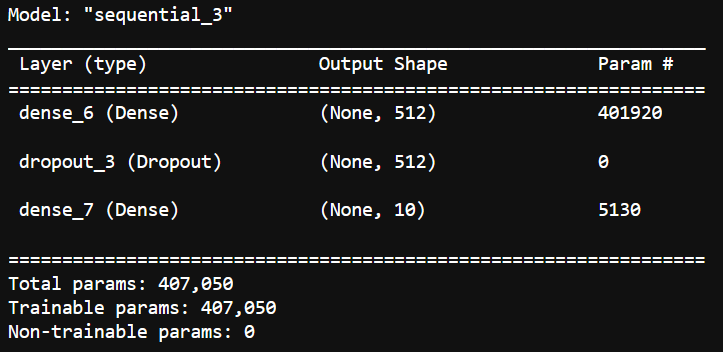
【NLP】使用 Keras 保存和加载深度学习模型
一、说明 训练深度学习模型是一个耗时的过程。您可以在训练期间和训练后保存模型进度。因此,您可以从上次中断的地方继续训练模型,并克服漫长的训练挑战。 在这篇博文中,我们将介绍如何保存模型并使用 Keras 逐步加载它。我们还将探索模型检查…...

视频标注是什么?和图像数据标注的区别?
视频数据标注是对视频剪辑进行标注的过程。进行标注后的视频数据将作为训练数据集用于训练深度学习和机器学习模型。这些预先训练的神经网络之后会被用于计算机视觉领域。 自动化视频标注对训练AI模型有哪些优势 与图像数据标注类似,视频标注是教计算机识别对象…...
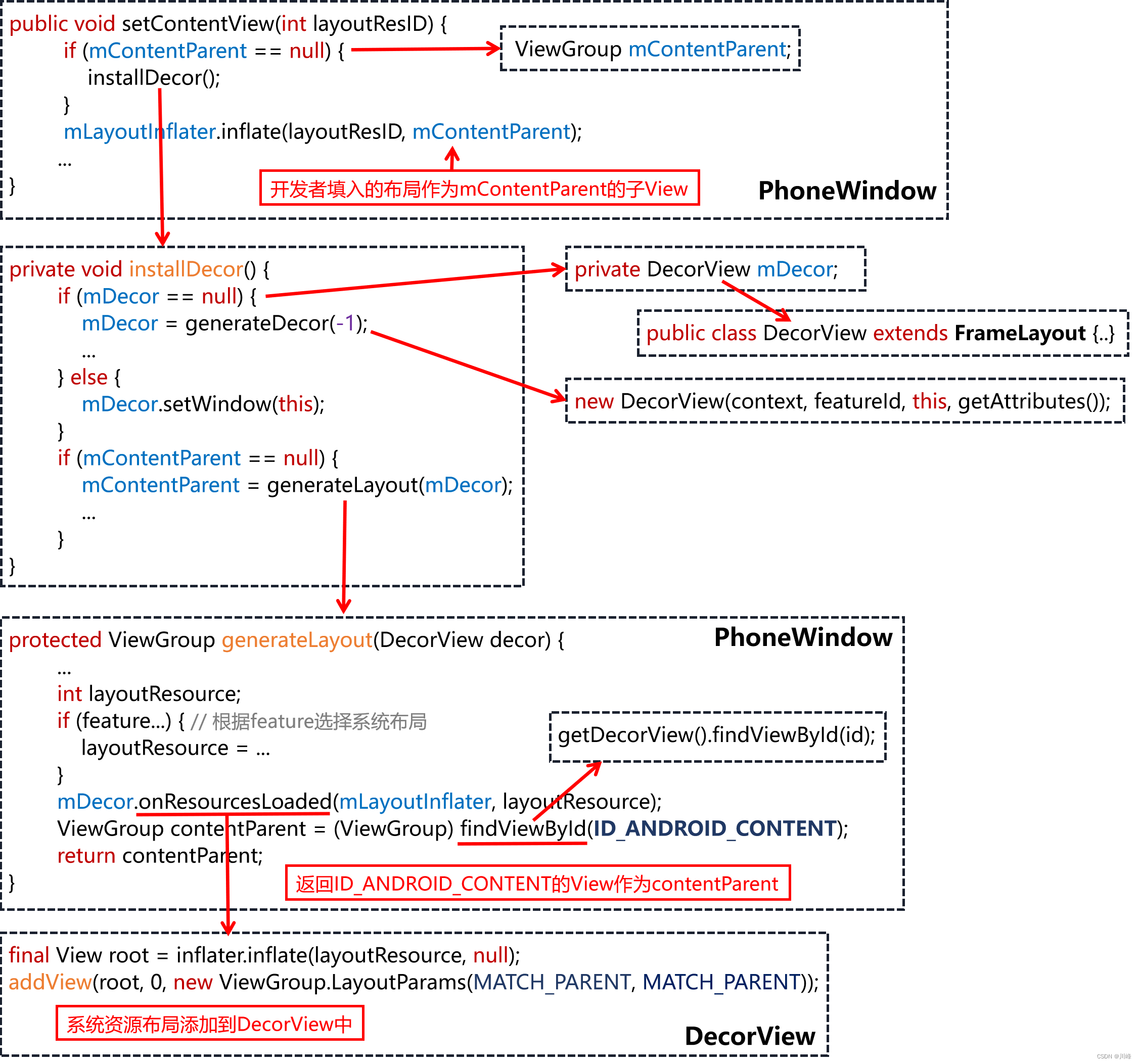
【Android知识笔记】UI体系(一)
Activity的显示原理 setContentView 首先开发者Activity的onCreate方法中通常调用的setContentView会委托给Window的setContentView方法: 接下来看Window的创建过程: 可见Window的实现类是PhoneWindow,而PhoneWindow是在Activity创建过程中执行attach Context的时候创建的…...

SpringBoot 整合Docker Compose
Docker Compose是一种流行的技术,可以用来定义和管理你的应用程序所需的多个服务容器。通常在你的应用程序旁边创建一个 compose.yml 文件,它定义和配置服务容器。 使用 Docker Compose 的典型工作流程是运行 docker compose up,用它连接启动…...
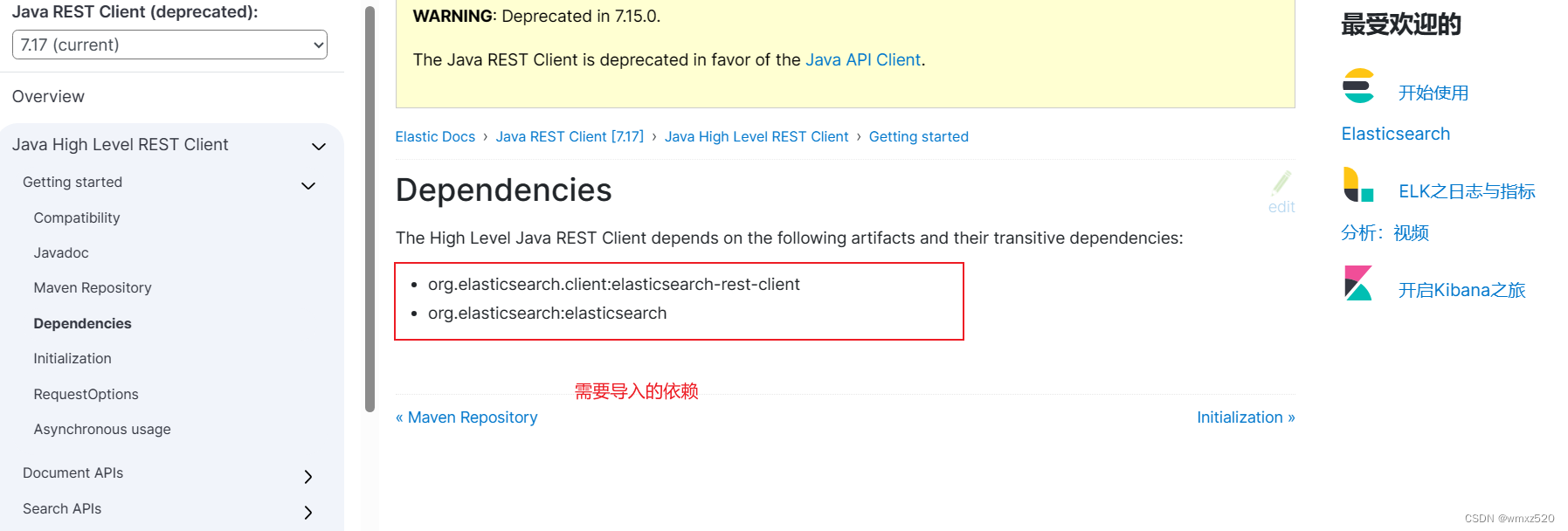
SpringBoot整合Elasticsearch
SpringBoot整合Elasticsearch SpringBoot整合Elasticsearch有以下几种方式: 使用官方的Elasticsearch Java客户端进行集成 通过添加Elasticsearch Java客户端的依赖,可以直接在Spring Boot应用中使用原生的Elasticsearch API进行操作。参考文档 使用Sp…...

【R3F】0.9添加 shadow
开启使用shadow 在 canvas 设置属性shadows 在对应的 mesh 中设置 产生阴影castShadow和接收阴影receiveShadow 设置完成之后,即可实现阴影 ...<Canvas shadows > <mesh castShadow ><boxGeometry /><meshStandardMaterial color="mediumpurple&qu…...
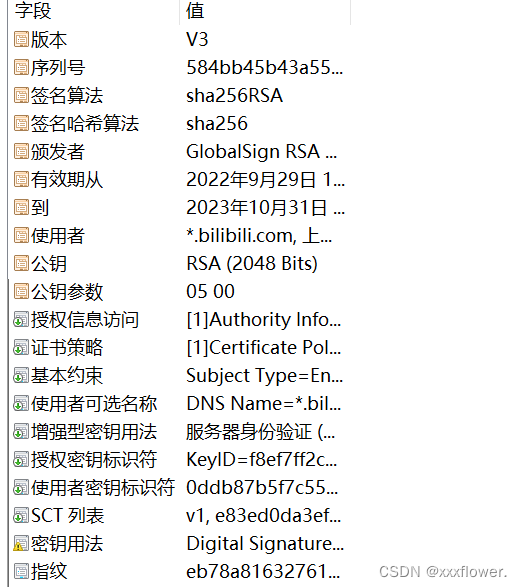
【JavaEE初阶】HTTP请求的构造及HTTPS
文章目录 1.HTTP请求的构造1.1 from表单请求构造1.2 ajax构造HTTP请求1.3 Postman的使用 2. HTTPS2.1 什么是HTTPS?2.2 HTTPS中的加密机制(SSL/TLS)2.2.1 HTTP的安全问题2.2.2 对称加密2.2.3 非对称加密2.2.3 中间人问题2.2.5 证书 1.HTTP请求的构造 常见的构造HTTP 请求的方…...

探索和实践:基于Python的TD-PSOLA语音处理算法应用与优化
今天我将和大家分享一个非常有趣且具有挑战性的主题:TD-PSOLA语音处理算法在Python中的应用。作为一种在语音合成和变换中广泛使用的技术,TD-PSOLA (Time-Domain Pitch-Synchronous Overlap-Add) 提供了一种改变语音音高和时间长度而不产生显著失真的有效方法。在本篇博客中,…...
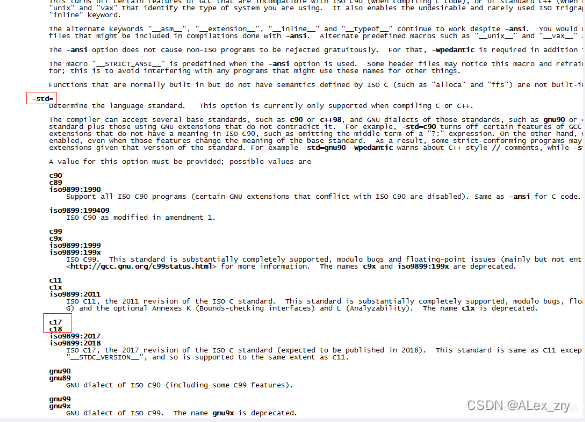
Linux 下centos 查看 -std 是否支持 C17
实际工作中,可能会遇到c的一些高级特性,例如std::invoke,此函数是c17才引入的,如何判断当前的gcc是否支持c17呢,这里提供两种办法。 1.根据gcc的版本号来推断 gcc --version,可以查看版本号,笔者…...

实战应用:利用快马平台模拟鸿蒙pc版与手机的笔记跨设备同步功能
最近在研究鸿蒙系统的跨设备协同功能,特别是PC端和手机端之间的数据同步场景。作为一个开发者,我很好奇这种分布式能力在实际项目中如何落地。于是我用InsCode(快马)平台快速搭建了一个模拟原型,下面分享下实现思路和过程。 项目整体设计 这个…...

KuiTest:基于大模型通识的UI交互遍历测试
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

Soundflower:解锁macOS音频路由的神奇工具
Soundflower:解锁macOS音频路由的神奇工具 【免费下载链接】Soundflower MacOS system extension that allows applications to pass audio to other applications. Soundflower works on macOS Catalina. 项目地址: https://gitcode.com/gh_mirrors/so/Soundflow…...

如何在10分钟内构建高质量AI语音克隆模型:Retrieval-based-Voice-Conversion-WebUI完全指南
如何在10分钟内构建高质量AI语音克隆模型:Retrieval-based-Voice-Conversion-WebUI完全指南 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI Easily train a good VC model with voice data < 10 mins! 项目地址: https://gitcode.com/GitHub_Trendi…...

玩转线控转向:从方向盘到轮胎的数学游戏
线控转向系统模型simulink, 以及理想传动比,变传动比,变角传动比simulink模块,分别在低速工况,中速工况,高速工况下进行对比仿真,结果较好 有对应绘图代码m脚本文件,模型对应的论文最近在Simuli…...

从序列到结构:ESM蛋白质语言模型核心原理与实践解析
1. 蛋白质语言模型为何成为研究热点 最近几年,蛋白质语言模型突然在生物信息学领域火了起来。作为一个长期关注AI在生命科学领域应用的开发者,我发现这背后有两个关键驱动力:一是蛋白质结构预测的世纪难题有了新解法,二是Transfor…...

Formbricks v3.5.0发布:移动端体验革命与缓存性能倍增
Formbricks v3.5.0发布:移动端体验革命与缓存性能倍增 【免费下载链接】formbricks Open Source Qualtrics Alternative 项目地址: https://gitcode.com/GitHub_Trending/fo/formbricks Formbricks作为一款开源的Qualtrics替代方案,在v3.5.0版本中…...

SenseVoice-Small ONNX模型效果惊艳展示:中英粤日韩五语种同步识别样例
SenseVoice-Small ONNX模型效果惊艳展示:中英粤日韩五语种同步识别样例 今天,我想带大家看一个让我眼前一亮的语音识别模型——SenseVoice-Small的ONNX版本。它最吸引我的地方,是能同时识别中文、英文、粤语、日语和韩语,而且速度…...

PPT如何设置部分内容不可编辑?教你锁定部分对象,只允许修改指定区域
制作好的PPT发给同事或客户后,最担心的就是对方随意拖动图片、删除Logo、修改背景或打乱排版,导致精心设计的页面面目全非。很多人以为PPT没有类似Word的“部分限制编辑”功能,其实不然——PPT提供了多种灵活的保护方式,可以让你锁…...

OpenClaw毕业设计利器:Qwen3-14B辅助论文写作与查重
OpenClaw毕业设计利器:Qwen3-14B辅助论文写作与查重 1. 为什么选择OpenClaw做论文助手 去年帮学弟调试毕业论文时,我看着他反复在Word和查重网站间切换,突然意识到:学术写作的本质是信息处理——收集资料、组织逻辑、规避重复&a…...