Pytorch个人学习记录总结 06
目录
神经网络-卷积层 torch.nn.Conv2d
神经网络-最大池化的使用 torch.nn.MaxPool2d
神经网络-卷积层 torch.nn.Conv2d
torch.nn.Conv2d的官方文档地址
CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode=‘zeros’, device=None, dtype=None)
卷积动画的链接:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md![]() https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
注意:
- 默认
bias=True,这说明PyTorch中Con2d是默认给卷积操作加了偏置的。 - 还有一些默认值:stride=1,padding=0等。
- out_channels输出通道数,相当于就是卷积核的个数。
- dilation:需要使用空洞卷积时再进行设置。
import torch from torch import nn from torch.nn import Conv2d from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter from torchvision import datasets from torchvision.transforms import transforms# 1. 加载数据 dataset = datasets.CIFAR10('./dataset', train=False, transform=transforms.ToTensor(), download=True) dataloader = DataLoader(dataset, batch_size=64, shuffle=True, num_workers=0, drop_last=False)# 2. 构造模型 class Model(nn.Module):def __init__(self):super(Model, self).__init__()self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1)def forward(self, x):return self.conv1(x)writer = SummaryWriter('./logs/Conv2d')# 3. 实例化一个模型对象,进行卷积 model = Model() step = 0for data in dataloader:imgs, targets = datawriter.add_images('imgs_ch3', imgs, step)# 4. 用tensorboard打开查看图像。但是注意,add_images的输入图像的通道数只能是3 # 所以如果通道数>3,则可以先采用小土堆的这个不严谨的做法,在tensorboard中查看一下图片outputs = model(imgs)outputs = torch.reshape(outputs, (-1, 3, 30, 30))writer.add_images('imgs_ch6', outputs, step)step += 1writer.close()神经网络-最大池化的使用 torch.nn.MaxPool2d
池化也可成为下采样(就是缩小输入图像尺寸,但是不会改变输入图像的通道数)。常见的有MaxPool2d、AvgPool2d等。相反有上采样MaxUnPool2d。
MaxPool2d的官方文档地址:MaxPool2d — PyTorch 2.0 documentation
CLASS torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
注意:
- stride默认=kernel_size
- ceil_mode默认是False,也就是说事向下取整
pool和conv后的图像尺寸N计算公式是一样的:N = ( W − F + 2 ∗ P ) / S + 1 N=(W-F+2*P)/S+1N=(W−F+2∗P)/S+1,且都是默认N向下取整。
- 在构造tensor的时候,最好指定元素的数据类型是float,即在最后加上
dtype=torch.float32,这样后面有些操作才不会出错。 - 池化的作用:保持输入图像的特征,且减小输入量,能加快训练。(就类似于B站视频有10080P的也会有720P的,720P虽然不如1080P那么高清,但是仍然能够看出视频中物体的特征信息,有点像打了马赛克一样)
import torch import torchvision.datasets from torch import nn from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriterclass Model(nn.Module):def __init__(self):super(Model, self).__init__()self.maxpool1 = nn.MaxPool2d(kernel_size=3) # 默认:stride=kernel_size,ceil_mode=Falseself.maxpool2 = nn.MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, x):return self.maxpool1(x), self.maxpool2(x)model = Model()# -------------1.上图例子,查看ceil_mode为True或False的池化结果--------------- # input = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]], dtype=torch.float32)input = torch.reshape(input, (-1, 1, 5, 5)) out1, out2 = model(input) print('out1={}\nout2={}'.format(out1, out2))# --------------2.加载数据集,并放入tensorboard查看图片----------------------- # dataset = torchvision.datasets.CIFAR10('dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True) dataloader = DataLoader(dataset, batch_size=64, shuffle=True)writer = SummaryWriter('./logs/maxpool') step = 0 for data in dataloader:imgs, targets = datawriter.add_images('imgs', imgs, step)imgs, _ = model(imgs)writer.add_images('imgs_maxpool', imgs, step)step += 1writer.close()
相关文章:
Pytorch个人学习记录总结 06
目录 神经网络-卷积层 torch.nn.Conv2d 神经网络-最大池化的使用 torch.nn.MaxPool2d 神经网络-卷积层 torch.nn.Conv2d torch.nn.Conv2d的官方文档地址 CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride1, padding0, dilation1, groups1, biasTrue,…...
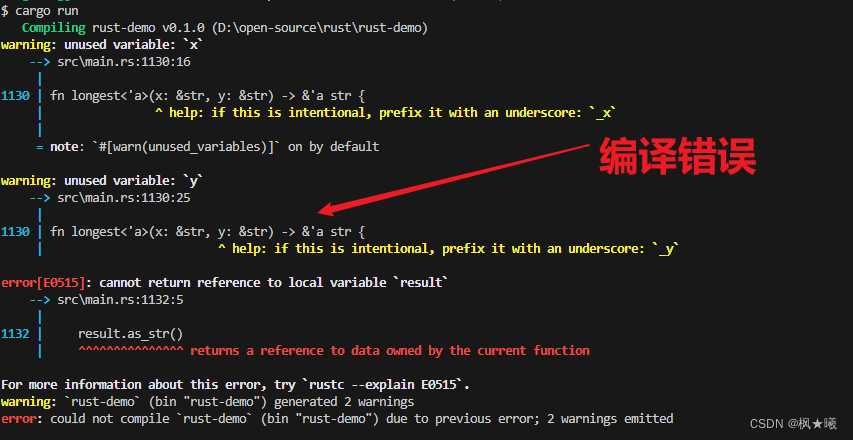
Rust之泛型、特性和生命期(四):验证有生存期的引用
开发环境 Windows 10Rust 1.71.0 VS Code 1.80.1 项目工程 这里继续沿用上次工程rust-demo 验证具有生存期的引用 生存期是我们已经在使用的另一种泛型。生存期不是确保一个类型具有我们想要的行为,而是确保引用在我们需要时有效。 我们在第4章“引用和借用”一…...
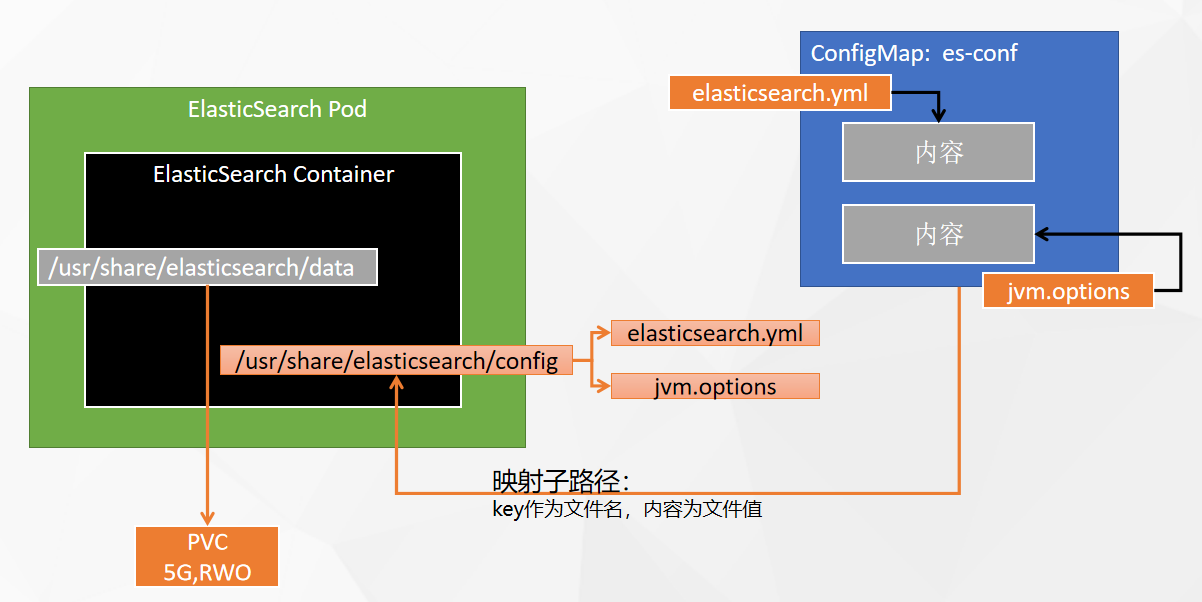
kubesphere安装中间件
kubesphere安装mysql 创建configMap [client] default-character-setutf8mb4[mysql] default-character-setutf8mb4[mysqld] init_connectSET collation_connection utf8mb4_unicode_ci init_connectSET NAMES utf8mb4 character-set-serverutf8mb4 collation-serverutf8mb4_…...
 集群模式安装)
zookeeper学习(二) 集群模式安装
前置环境 三台centos7服务器 192.168.2.201 192.168.2.202 192.168.2.150三台服务器都需要安装jdk1.8以上zookeeper安装包 安装jdk 在单机模式已经描述过,这里略过,有需要可以去看单机模式中的这部分,注意的是三台服务器都需要安装 安装…...
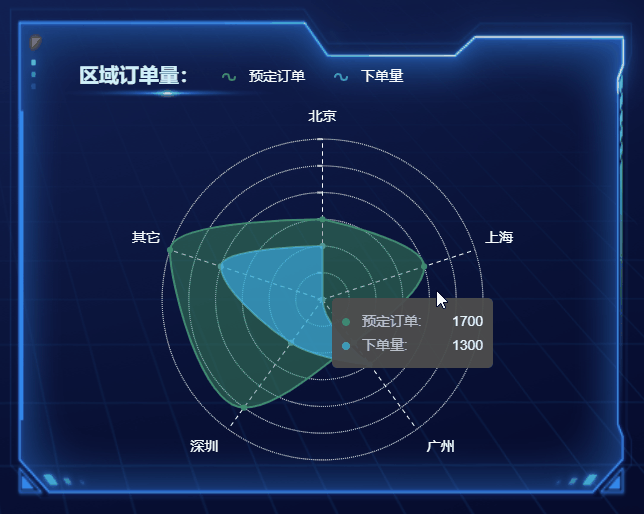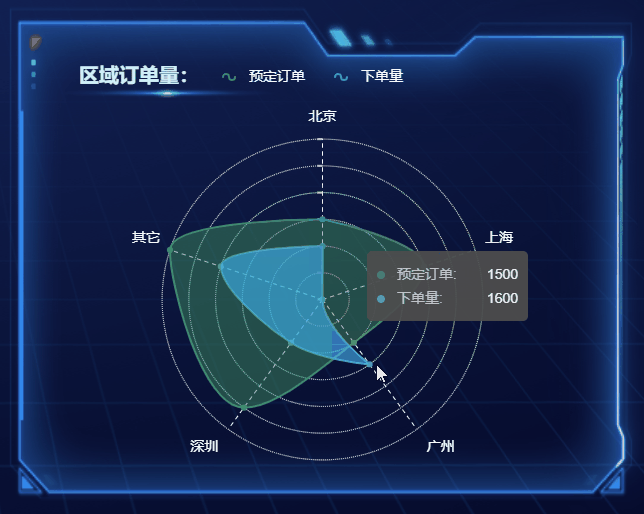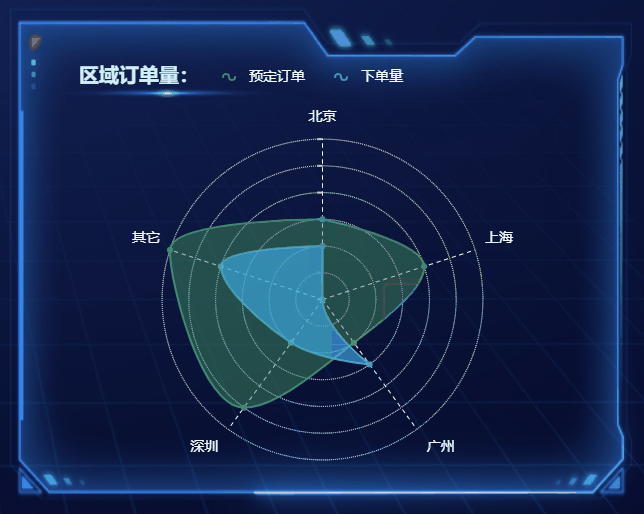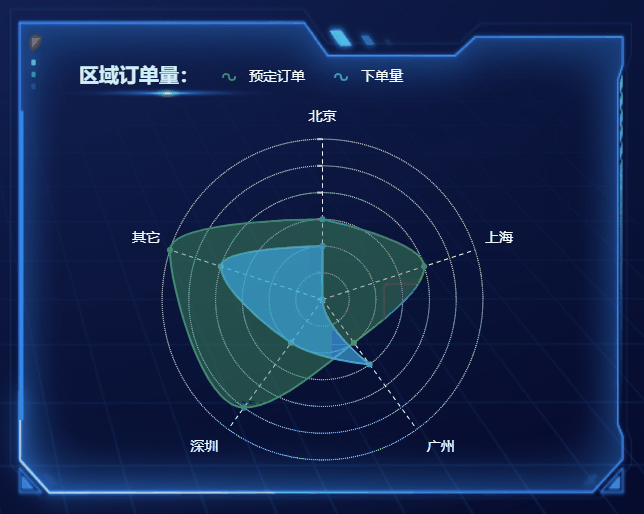
选择合适的图表,高效展现数据魅力
随着大数据时代的来临,数据的重要性愈发凸显,数据分析和可视化成为了决策和传递信息的重要手段。在数据可视化中,选择合适的图表是至关重要的一环,它能让数据更加生动、直观地呈现,为观众提供更有说服力的信息。本文将…...
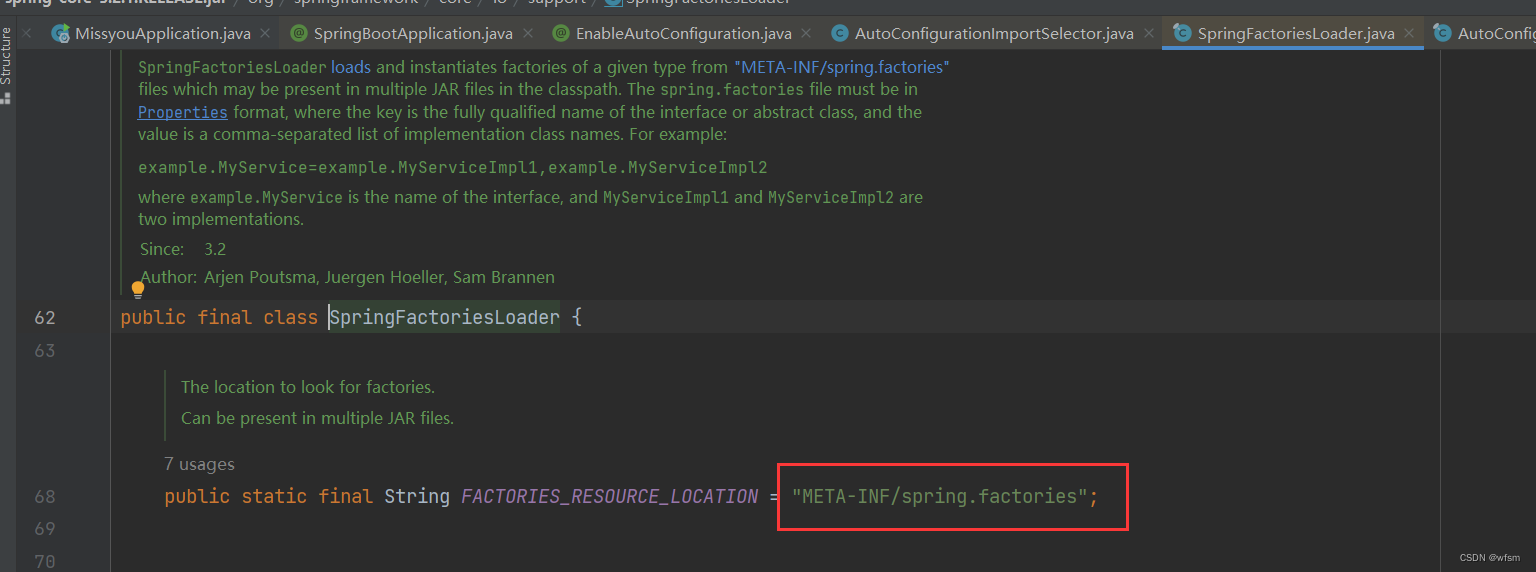
springboot自动装配
SPI spi : service provider interface : 是java的一种服务提供机制,spi 允许开发者在不修改代码的情况下,为某个接口提供实现类,来扩展应用程序 将实现类独立到配置文件中,通过配置文件控制导入ÿ…...

python小记-队列
队列(Queue)是一种常见的数据结构,它遵循先进先出(First-In-First-Out,FIFO)的原则。在队列中,新元素(也称为项)总是添加到队列的末尾,而最早添加的元素总是在…...
SpringBoot——持久化技术
简单介绍 在之前我们使用的数据层持久化技术使用的是MyBatis或者是MyBatis-plus,其实都是一样的。在使用之前,我们要导入对应的坐标,然后配置MyBatis特有的配置,比如说Mapper接口,或者XML配置文件,那么除了…...

Kafka 入门到起飞 - 生产者参数详解 ,什么是生产者确认机制? 什么是ISR? 什么是 OSR?
上回书我们讲了,生产者发送消息流程解析传送门 那么这篇我们来看下,生产者发送消息时几个重要的参数详解 ,什么是生产者确认机制? 什么是ISR? 什么是 OSR? 参数: bootstrap.servers : Kafka 集…...
【文献分享】比目前最先进的模型轻30%!高效多机器人SLAM蒸馏描述符!
论文题目:Descriptor Distillation for Efficient Multi-Robot SLAM 中文题目:高效多机器人SLAM蒸馏描述符 作者:Xiyue Guo, Junjie Hu, Hujun Bao and Guofeng Zhang 作者机构:浙江大学CAD&CG国家重点实验室 香港中文大学…...
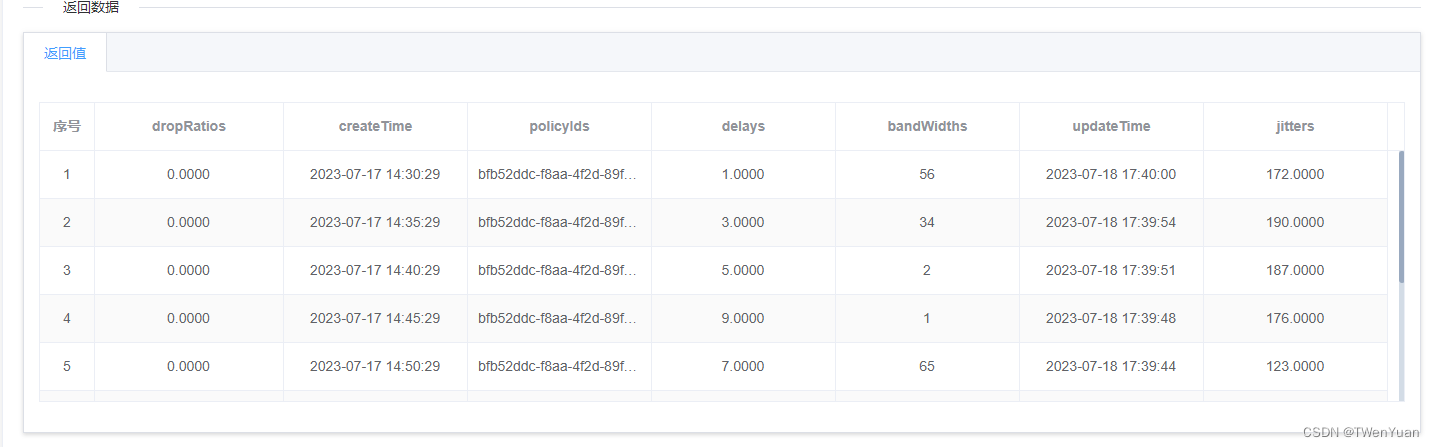
【数据动态填充到element表格;将带有标签的数据展示为文本格式】
一:数据动态填充到element表格; 二:将带有标签的数据展示为文本格式; 1、 <el-row><el-col :span"24"><el-tabs type"border-card"><el-tab-pane label"返回值"><el-…...

小程序轮播图的两种后台方式(PHP)--【浅入深出系列008】
微信目录集链接在此: 详细解析黑马微信小程序视频–【思维导图知识范围】难度★✰✰✰✰ 不会导入/打开小程序的看这里:参考 让别人的小程序长成自己的样子-更换window上下颜色–【浅入深出系列001】 文章目录 本系列校训学习资源的选择啥是轮播图轮播…...
使用ComPDFKit PDF SDK 构建iOS PDF阅读器
在当今以移动为先的世界中,为企业和开发人员创建一个iOS应用程序是必不可少的。随着对PDF文档处理需求的增加,使用ComPDFKit这个强大的PDF软件开发工具包(SDK)来构建iOS PDF阅读器和编辑器可以让最终用户轻松查看和编辑PDF文档。 …...

一套流程6个步骤,教你如何正确采购询价
采购询价(RFQ)是一种竞争性投标文件,用于邀请供应商或承包商就标准化或重复生产的产品或服务提交报价。 询价通常用于大批量/低价值项目,买方必须提供技术规格和商业要求,该文件有时也称为招标书或投标邀请书。询价流…...

git使用
常用命令 git init git库初始化,初始化后会在文件中出现一个.git的隐藏文件 git clone 从远程克隆仓库 git pull 从远程库中拉取 git commit 将暂存提交到本地仓库 git push 提交本地仓库到远程 git branch 查看当前分支 git branch <branchName> 切换分支 …...
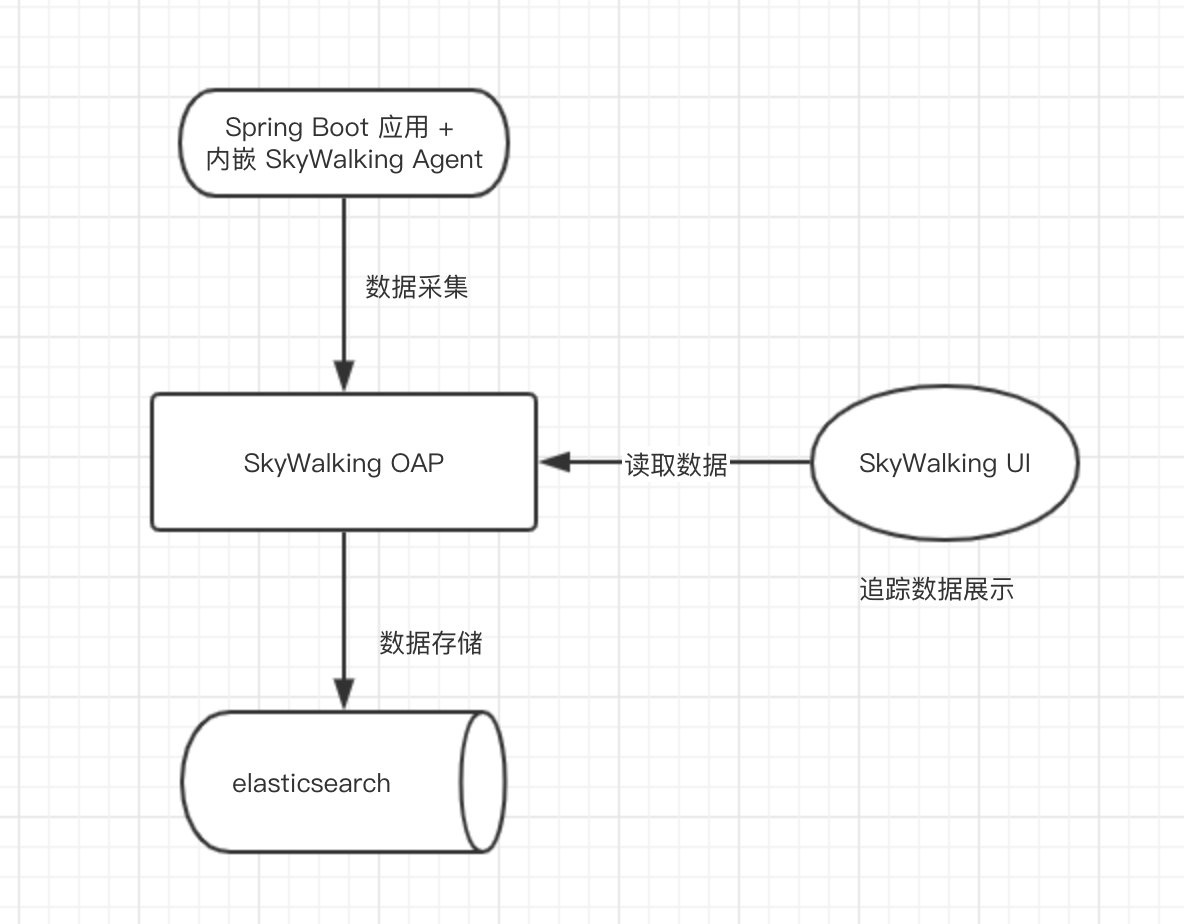
SkyWalking链路追踪-搭建-spring-boot-cloud-单机环境 之《10 分钟快速搭建 SkyWalking 服务》
首先了解一下单机环境 第一步,搭建一个 Elasticsearch 服务。第二步,下载 SkyWalking 软件包。第三步,搭建一个 SkyWalking OAP 服务。第四步,启动一个 Spring Boot 应用,并配置 SkyWalking Agent。第五步,…...
Rabbit MQ整合springBoot
一、pom依赖二、消费端2.1、application.properties 配置文件2.2、消费端核心组件 三、生产端3.1、application.properties 配置文件2.2、生产者 MQ消息发送组件四、测试1、生产端控制台2、消费端控制台 一、pom依赖 <dependency><groupId>org.springframework.boo…...
:time.Time)
Golang 中的 time 包详解(一):time.Time
在日常开发过程中,会频繁遇到对时间进行操作的场景,使用 Golang 中的 time 包可以很方便地实现对时间的相关操作。接下来的几篇文章会详细讲解 time 包,本文先讲解一下 time 包中的结构体 time.Time。 time.Time time.Time 类型用来表示一个…...
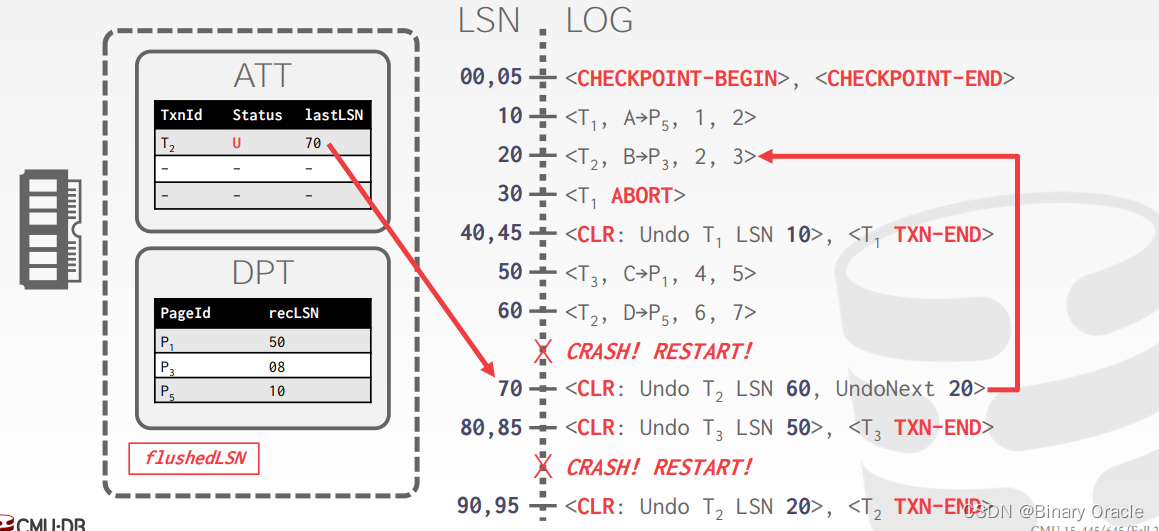
CMU 15-445 -- Database Recovery - 18
CMU 15-445 -- Database Recovery - 18 引言ARIESLog Sequence NumbersNormal ExecutionTransaction CommitTransaction AbortCompensation Log Records Non-fuzzy & fuzzy CheckpointsSlightly Better CheckpointsFuzzy Checkpoints ARIES - Recovery PhasesAnalysis Phas…...
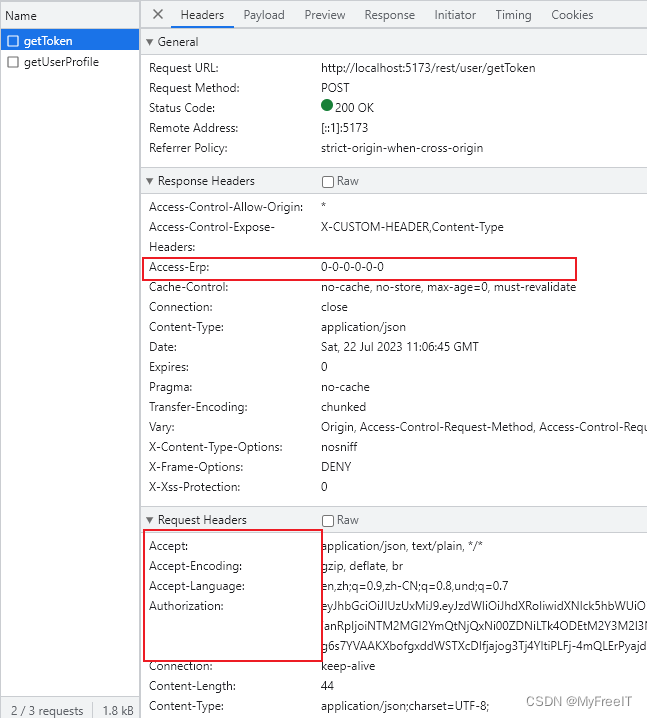
HTTP Header定制,客户端使用Request,服务器端使用Response
在服务器端通过request.getHeaders()是无效的,只能使用response.getHeaders()。 Overridepublic Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType mediaType,Class selectedConverterType, ServerHttpRequest request, ServerHttpRespo…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑
用C语言解决‘换硬币’问题?我来教你如何调试和验证你的循环逻辑 当你第一次面对"换硬币"这类组合问题时,那种既兴奋又困惑的感觉我至今记忆犹新。作为C语言初学者,理解多重循环的运作机制就像在迷宫中寻找出口——每次你以为找到了…...

Obsidian PDF++:如何在Obsidian中实现PDF与笔记的无缝双向链接?
Obsidian PDF:如何在Obsidian中实现PDF与笔记的无缝双向链接? 【免费下载链接】obsidian-pdf-plus PDF: the most Obsidian-native PDF annotation & viewing tool ever. Comes with optional Vim keybindings. 项目地址: https://gitcode.com/gh_…...

基于Arduino与应变片传感器的高精度厨房电子秤DIY全攻略
1. 项目概述:用Arduino打造一台高精度厨房电子秤作为一个喜欢在厨房里折腾的硬件爱好者,我经常遇到需要精确称量食材的场合。市面上的电子秤要么精度不够,要么价格不菲,要么功能单一。于是,我萌生了自己动手做一台的想…...

小米MIMO最新邀请码
欢迎使用,各得10元体验金...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...

CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战
CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战 【免费下载链接】CSharpVerbalExpressions 项目地址: https://gitcode.com/gh_mirrors/cs/CSharpVerbalExpressions CSharpVerbalExpressions是一个强大的C#库,它通过类自然语…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...

【DeepSeek漏洞扫描辅助实战指南】:20年安全专家亲授3大避坑法则与5步提效流程
更多请点击: https://intelliparadigm.com 第一章:DeepSeek漏洞扫描辅助的核心价值与适用边界 DeepSeek漏洞扫描辅助并非通用型渗透测试引擎,而是一个聚焦于大语言模型(LLM)应用层安全的轻量级分析工具。其核心价值在…...