SpringBoot集成kafka全面实战
本文是SpringBoot+Kafka的实战讲解,如果对kafka的架构原理还不了解的读者,建议先看一下《大白话kafka架构原理》、《秒懂kafka HA(高可用)》两篇文章。
一、生产者实践
普通生产者
带回调的生产者
自定义分区器
kafka事务提交
二、消费者实践
简单消费
指定topic、partition、offset消费
批量消费
监听异常处理器
消息过滤器
消息转发
定时启动/停止监听器
一、前戏
1、在项目中连接kafka,因为是外网,首先要开放kafka配置文件中的如下配置(其中IP为公网IP),
advertised.listeners=PLAINTEXT://112.126.74.249:90922、在开始前我们先创建两个topic:topic1、topic2,其分区和副本数都设置为2,用来测试,
[root@iZ2zegzlkedbo3e64vkbefZ ~]# cd /usr/local/kafka-cluster/kafka1/bin/
[root@iZ2zegzlkedbo3e64vkbefZ bin]# ./kafka-topics.sh --create --zookeeper 172.17.80.219:2181 --replication-factor 2 --partitions 2 --topic topic1
Created topic topic1.
[root@iZ2zegzlkedbo3e64vkbefZ bin]# ./kafka-topics.sh --create --zookeeper 172.17.80.219:2181 --replication-factor 2 --partitions 2 --topic topic2
Created topic topic2.当然我们也可以不手动创建topic,在执行代码kafkaTemplate.send("topic1", normalMessage)发送消息时,kafka会帮我们自动完成topic的创建工作,但这种情况下创建的topic默认只有一个分区,分区也没有副本。所以,我们可以在项目中新建一个配置类专门用来初始化topic,如下,
@Configuration
public class KafkaInitialConfiguration {// 创建一个名为testtopic的Topic并设置分区数为8,分区副本数为2@Beanpublic NewTopic initialTopic() {return new NewTopic("testtopic",8, (short) 2 );}
// 如果要修改分区数,只需修改配置值重启项目即可// 修改分区数并不会导致数据的丢失,但是分区数只能增大不能减小@Beanpublic NewTopic updateTopic() {return new NewTopic("testtopic",10, (short) 2 );}
}3、新建SpringBoot项目
① 引入pom依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>② application.propertise配置(本文用到的配置项这里全列了出来)
###########【Kafka集群】###########
spring.kafka.bootstrap-servers=112.126.74.249:9092,112.126.74.249:9093
###########【初始化生产者配置】###########
# 重试次数
spring.kafka.producer.retries=0
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
spring.kafka.producer.acks=1
# 批量大小
spring.kafka.producer.batch-size=16384
# 提交延时
spring.kafka.producer.properties.linger.ms=0
# 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
# linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory = 33554432
# Kafka提供的序列化和反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 自定义分区器
# spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
###########【初始化消费者配置】###########
# 默认的消费组ID
spring.kafka.consumer.properties.group.id=defaultConsumerGroup
# 是否自动提交offset
spring.kafka.consumer.enable-auto-commit=true
# 提交offset延时(接收到消息后多久提交offset)
spring.kafka.consumer.auto.commit.interval.ms=1000
# 当kafka中没有初始offset或offset超出范围时将自动重置offset
# earliest:重置为分区中最小的offset;
# latest:重置为分区中最新的offset(消费分区中新产生的数据);
# none:只要有一个分区不存在已提交的offset,就抛出异常;
spring.kafka.consumer.auto-offset-reset=latest
# 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
spring.kafka.consumer.properties.session.timeout.ms=120000
# 消费请求超时时间
spring.kafka.consumer.properties.request.timeout.ms=180000
# Kafka提供的序列化和反序列化类
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 消费端监听的topic不存在时,项目启动会报错(关掉)
spring.kafka.listener.missing-topics-fatal=false
# 设置批量消费
# spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
# spring.kafka.consumer.max-poll-records=50二、Hello Kafka
1、简单生产者
@RestController
public class KafkaProducer {@Autowiredprivate KafkaTemplate<String, Object> kafkaTemplate;
// 发送消息@GetMapping("/kafka/normal/{message}")public void sendMessage1(@PathVariable("message") String normalMessage) {kafkaTemplate.send("topic1", normalMessage);}
}2、简单消费
@Component
public class KafkaConsumer {// 消费监听@KafkaListener(topics = {"topic1"})public void onMessage1(ConsumerRecord<?, ?> record){// 消费的哪个topic、partition的消息,打印出消息内容System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());}
}上面示例创建了一个生产者,发送消息到topic1,消费者监听topic1消费消息。监听器用@KafkaListener注解,topics表示监听的topic,支持同时监听多个,用英文逗号分隔。启动项目,postman调接口触发生产者发送消息,
三、生产者
1、带回调的生产者
kafkaTemplate提供了一个回调方法addCallback,我们可以在回调方法中监控消息是否发送成功 或 失败时做补偿处理,有两种写法,
@GetMapping("/kafka/callbackOne/{message}")
public void sendMessage2(@PathVariable("message") String callbackMessage) {kafkaTemplate.send("topic1", callbackMessage).addCallback(success -> {// 消息发送到的topicString topic = success.getRecordMetadata().topic();// 消息发送到的分区int partition = success.getRecordMetadata().partition();// 消息在分区内的offsetlong offset = success.getRecordMetadata().offset();System.out.println("发送消息成功:" + topic + "-" + partition + "-" + offset);}, failure -> {System.out.println("发送消息失败:" + failure.getMessage());});
}@GetMapping("/kafka/callbackTwo/{message}")
public void sendMessage3(@PathVariable("message") String callbackMessage) {kafkaTemplate.send("topic1", callbackMessage).addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {@Overridepublic void onFailure(Throwable ex) {System.out.println("发送消息失败:"+ex.getMessage());}@Overridepublic void onSuccess(SendResult<String, Object> result) {System.out.println("发送消息成功:" + result.getRecordMetadata().topic() + "-"+ result.getRecordMetadata().partition() + "-" + result.getRecordMetadata().offset());}});
}2、自定义分区器
我们知道,kafka中每个topic被划分为多个分区,那么生产者将消息发送到topic时,具体追加到哪个分区呢?这就是所谓的分区策略,Kafka 为我们提供了默认的分区策略,同时它也支持自定义分区策略。其路由机制为:
① 若发送消息时指定了分区(即自定义分区策略),则直接将消息append到指定分区;
② 若发送消息时未指定 patition,但指定了 key(kafka允许为每条消息设置一个key),则对key值进行hash计算,根据计算结果路由到指定分区,这种情况下可以保证同一个 Key 的所有消息都进入到相同的分区;
③ patition 和 key 都未指定,则使用kafka默认的分区策略,轮询选出一个 patition;
※ 我们来自定义一个分区策略,将消息发送到我们指定的partition,首先新建一个分区器类实现Partitioner接口,重写方法,其中partition方法的返回值就表示将消息发送到几号分区,
public class CustomizePartitioner implements Partitioner {@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 自定义分区规则(这里假设全部发到0号分区)// ......return 0;}
@Overridepublic void close() {
}
@Overridepublic void configure(Map<String, ?> configs) {
}
}在application.propertise中配置自定义分区器,配置的值就是分区器类的全路径名,
# 自定义分区器
spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner3、kafka事务提交
如果在发送消息时需要创建事务,可以使用 KafkaTemplate 的 executeInTransaction 方法来声明事务,
@GetMapping("/kafka/transaction")
public void sendMessage7(){// 声明事务:后面报错消息不会发出去kafkaTemplate.executeInTransaction(operations -> {operations.send("topic1","test executeInTransaction");throw new RuntimeException("fail");});
// 不声明事务:后面报错但前面消息已经发送成功了kafkaTemplate.send("topic1","test executeInTransaction");throw new RuntimeException("fail");
}四、消费者
1、指定topic、partition、offset消费
前面我们在监听消费topic1的时候,监听的是topic1上所有的消息,如果我们想指定topic、指定partition、指定offset来消费呢?也很简单,@KafkaListener注解已全部为我们提供,
/*** @Title 指定topic、partition、offset消费* @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8* @Author long.yuan* @Date 2020/3/22 13:38* @Param [record]* @return void**/
@KafkaListener(id = "consumer1",groupId = "felix-group",topicPartitions = {@TopicPartition(topic = "topic1", partitions = { "0" }),@TopicPartition(topic = "topic2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))
})
public void onMessage2(ConsumerRecord<?, ?> record) {System.out.println("topic:"+record.topic()+"|partition:"+record.partition()+"|offset:"+record.offset()+"|value:"+record.value());
}属性解释:
① id:消费者ID;
② groupId:消费组ID;
③ topics:监听的topic,可监听多个;
④ topicPartitions:可配置更加详细的监听信息,可指定topic、parition、offset监听。
上面onMessage2监听的含义:监听topic1的0号分区,同时监听topic2的0号分区和topic2的1号分区里面offset从8开始的消息。
注意:topics和topicPartitions不能同时使用;
2、批量消费
设置application.prpertise开启批量消费即可,
# 设置批量消费
spring.kafka.listener.type=batch
# 批量消费每次最多消费多少条消息
spring.kafka.consumer.max-poll-records=50接收消息时用List来接收,监听代码如下,
@KafkaListener(id = "consumer2",groupId = "felix-group", topics = "topic1")
public void onMessage3(List<ConsumerRecord<?, ?>> records) {System.out.println(">>>批量消费一次,records.size()="+records.size());for (ConsumerRecord<?, ?> record : records) {System.out.println(record.value());}
}3、ConsumerAwareListenerErrorHandler 异常处理器
通过异常处理器,我们可以处理consumer在消费时发生的异常。
新建一个 ConsumerAwareListenerErrorHandler 类型的异常处理方法,用@Bean注入,BeanName默认就是方法名,然后我们将这个异常处理器的BeanName放到@KafkaListener注解的errorHandler属性里面,当监听抛出异常的时候,则会自动调用异常处理器,
// 新建一个异常处理器,用@Bean注入
@Bean
public ConsumerAwareListenerErrorHandler consumerAwareErrorHandler() {return (message, exception, consumer) -> {System.out.println("消费异常:"+message.getPayload());return null;};
}
// 将这个异常处理器的BeanName放到@KafkaListener注解的errorHandler属性里面
@KafkaListener(topics = {"topic1"},errorHandler = "consumerAwareErrorHandler")
public void onMessage4(ConsumerRecord<?, ?> record) throws Exception {throw new Exception("简单消费-模拟异常");
}
// 批量消费也一样,异常处理器的message.getPayload()也可以拿到各条消息的信息
@KafkaListener(topics = "topic1",errorHandler="consumerAwareErrorHandler")
public void onMessage5(List<ConsumerRecord<?, ?>> records) throws Exception {System.out.println("批量消费一次...");throw new Exception("批量消费-模拟异常");
}4、消息过滤器
消息过滤器可以在消息抵达consumer之前被拦截,在实际应用中,我们可以根据自己的业务逻辑,筛选出需要的信息再交由KafkaListener处理,不需要的消息则过滤掉。
配置消息过滤只需要为 监听器工厂 配置一个RecordFilterStrategy(消息过滤策略),返回true的时候消息将会被抛弃,返回false时,消息能正常抵达监听容器。
@Component
public class KafkaConsumer {@AutowiredConsumerFactory consumerFactory;
// 消息过滤器@Beanpublic ConcurrentKafkaListenerContainerFactory filterContainerFactory() {ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();factory.setConsumerFactory(consumerFactory);// 被过滤的消息将被丢弃factory.setAckDiscarded(true);// 消息过滤策略factory.setRecordFilterStrategy(consumerRecord -> {if (Integer.parseInt(consumerRecord.value().toString()) % 2 == 0) {return false;}//返回true消息则被过滤return true;});return factory;}
// 消息过滤监听@KafkaListener(topics = {"topic1"},containerFactory = "filterContainerFactory")public void onMessage6(ConsumerRecord<?, ?> record) {System.out.println(record.value());}
}上面实现了一个"过滤奇数、接收偶数"的过滤策略,我们向topic1发送0-99总共100条消息,看一下监听器的消费情况,可以看到监听器只消费了偶数,
5、消息转发
在实际开发中,我们可能有这样的需求,应用A从TopicA获取到消息,经过处理后转发到TopicB,再由应用B监听处理消息,即一个应用处理完成后将该消息转发至其他应用,完成消息的转发。
在SpringBoot集成Kafka实现消息的转发也很简单,只需要通过一个@SendTo注解,被注解方法的return值即转发的消息内容,如下,
/*** @Title 消息转发* @Description 从topic1接收到的消息经过处理后转发到topic2* @Author long.yuan* @Date 2020/3/23 22:15* @Param [record]* @return void**/
@KafkaListener(topics = {"topic1"})
@SendTo("topic2")
public String onMessage7(ConsumerRecord<?, ?> record) {return record.value()+"-forward message";
}6、定时启动、停止监听器
默认情况下,当消费者项目启动的时候,监听器就开始工作,监听消费发送到指定topic的消息,那如果我们不想让监听器立即工作,想让它在我们指定的时间点开始工作,或者在我们指定的时间点停止工作,该怎么处理呢——使用KafkaListenerEndpointRegistry,下面我们就来实现:
① 禁止监听器自启动;
② 创建两个定时任务,一个用来在指定时间点启动定时器,另一个在指定时间点停止定时器;
新建一个定时任务类,用注解@EnableScheduling声明,KafkaListenerEndpointRegistry 在SpringIO中已经被注册为Bean,直接注入,设置禁止KafkaListener自启动,
@EnableScheduling
@Component
public class CronTimer {
/*** @KafkaListener注解所标注的方法并不会在IOC容器中被注册为Bean,* 而是会被注册在KafkaListenerEndpointRegistry中,* 而KafkaListenerEndpointRegistry在SpringIOC中已经被注册为Bean**/@Autowiredprivate KafkaListenerEndpointRegistry registry;
@Autowiredprivate ConsumerFactory consumerFactory;
// 监听器容器工厂(设置禁止KafkaListener自启动)@Beanpublic ConcurrentKafkaListenerContainerFactory delayContainerFactory() {ConcurrentKafkaListenerContainerFactory container = new ConcurrentKafkaListenerContainerFactory();container.setConsumerFactory(consumerFactory);//禁止KafkaListener自启动container.setAutoStartup(false);return container;}
// 监听器@KafkaListener(id="timingConsumer",topics = "topic1",containerFactory = "delayContainerFactory")public void onMessage1(ConsumerRecord<?, ?> record){System.out.println("消费成功:"+record.topic()+"-"+record.partition()+"-"+record.value());}
// 定时启动监听器@Scheduled(cron = "0 42 11 * * ? ")public void startListener() {System.out.println("启动监听器...");// "timingConsumer"是@KafkaListener注解后面设置的监听器ID,标识这个监听器if (!registry.getListenerContainer("timingConsumer").isRunning()) {registry.getListenerContainer("timingConsumer").start();}//registry.getListenerContainer("timingConsumer").resume();}
// 定时停止监听器@Scheduled(cron = "0 45 11 * * ? ")public void shutDownListener() {System.out.println("关闭监听器...");registry.getListenerContainer("timingConsumer").pause();}
}启动项目,触发生产者向topic1发送消息,可以看到consumer没有消费,因为这时监听器还没有开始工作,
11:42分监听器启动开始工作,消费消息,
11:45分监听器停止工作,
相关文章:
SpringBoot集成kafka全面实战
本文是SpringBootKafka的实战讲解,如果对kafka的架构原理还不了解的读者,建议先看一下《大白话kafka架构原理》、《秒懂kafka HA(高可用)》两篇文章。 一、生产者实践 普通生产者 带回调的生产者 自定义分区器 kafka事务提交…...
新建Git仓库,将本地文件上传至仓库
1、新建仓库,勾选初始化仓库 2、复制仓库链接 3、打开本地文件目录 右键选择 Git Bash Here 打开命令窗口 4、依次按照下面的步骤(*如果报错,看原目录下是否存在 .git 需要删除) // 生成git文件 git init // 把文件加入暂存区 g…...

算法练习——力扣随笔【LeetCode】【C++】
文章目录 LeetCode 练习随笔力扣上的题目和 OJ题目相比不同之处?定义问题排序问题统计问题其他 LeetCode 练习随笔 做题环境 C 中等题很值,收获挺多的 不会的题看题解,一道题卡1 h ,多来几道,时间上耗不起。 力扣上的题…...

web服务器(Tomcat)
目录 一、web服务器 1. 常见web服务器 2. web服务器简介 二、 Apache Tomcat服务器 1. Tomcat服务器简介 2. Tomcat服务器基本使用 3. 启动tomcat常见问题 (1)启动tomcat控制台乱码 (2)启动tomcat闪退问题 (…...

测试方案、功能测试报告、性能测试报告
测试方案内容概要: 项目内容介绍,测试计划安排(人员时间),测试环境(系统配置)需求功能点(内容介绍,测试安排),重点难点场景,系统集成…...
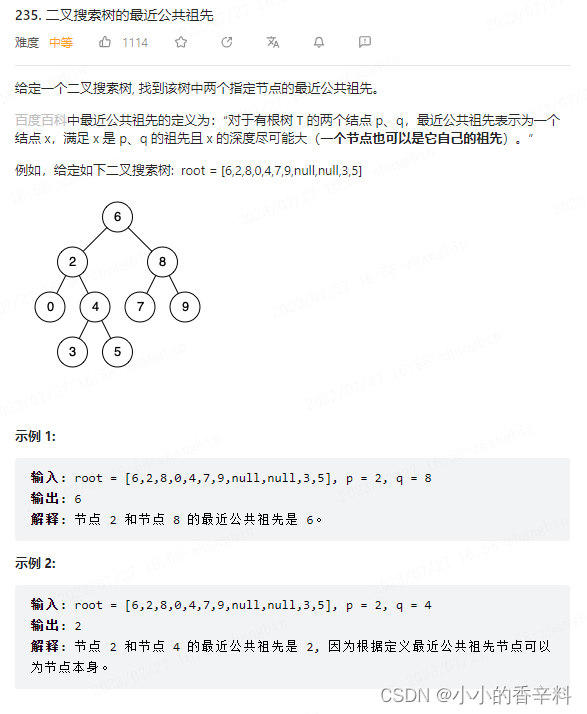
【代码随想录day21】二叉搜索树的最近公共祖先
题目 思路 解题的关键是知道自顶向低递归遍历,第一次遇到root在p和q的区间中时,则root就是p和q的最近公共祖先节点。 递归法 # Definition for a binary tree node. # class TreeNode: # def __init__(self, x): # self.val x # …...
ssm文章发布管理系统java小说作品发表jsp源代码mysql
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 ssm文章发布管理系统 系统有2权限:前台账…...

AXI协议之AXILite开发设计(二)
微信公众号上线,搜索公众号小灰灰的FPGA,关注可获取相关源码,定期更新有关FPGA的项目以及开源项目源码,包括但不限于各类检测芯片驱动、低速接口驱动、高速接口驱动、数据信号处理、图像处理以及AXI总线等 二、AXI-Lite关键代码分析 1、时钟与…...
Qgis二次开发-QgsMapTool地图交互工具详解
1.简介 QgsMapTool地图工具是用于操作地图画布的用户交互式工具。例如,地图平移和缩放功能被实现为地图工具。 QgsMapTool是抽象基类,以下是类的继承关系: 2.常用接口 virtual void canvasDoubleClickEvent (QgsMapMouseEvent *e)重写鼠标…...
MySQL基础(四)数据库备份
目录 前言 一、概述 1.数据备份的重要性 2.造成数据丢失的原因 二、备份类型 (一)、物理与逻辑角度 1.物理备份 2.逻辑备份 (二)、数据库备份策略角度 1.完整备份 2.增量备份 三、常见的备份方法 四、备份(…...
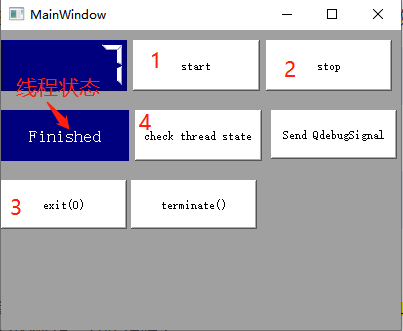
子类化QThread来实现多线程,moveToThread函数的作用
子类化QThread来实现多线程, QThread只有run函数是在新线程里的,其他所有函数都在QThread生成的线程里。正确启动线程的方法是调用QThread::start()来启动。 一、步骤 子类化 QThread;重写run,将耗时的事件放到此函数执行&#…...
经典面试题(力扣,接雨水)
接雨水 方法一思路测试代码复杂度测试结果 方法二思路测试代码复杂度测试结果 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1]…...

2023年深圳杯数学建模C题无人机协同避障航迹规划
2023年深圳杯数学建模 C题 无人机协同避障航迹规划 原题再现: 平面上A、B两个无人机站分别位于半径为500 m的障碍圆两边直径的延长线上,A站距离圆心1 km,B站距离圆心3.5 km。两架无人机分别从A、B两站同时出发,以恒定速率10 m/s…...
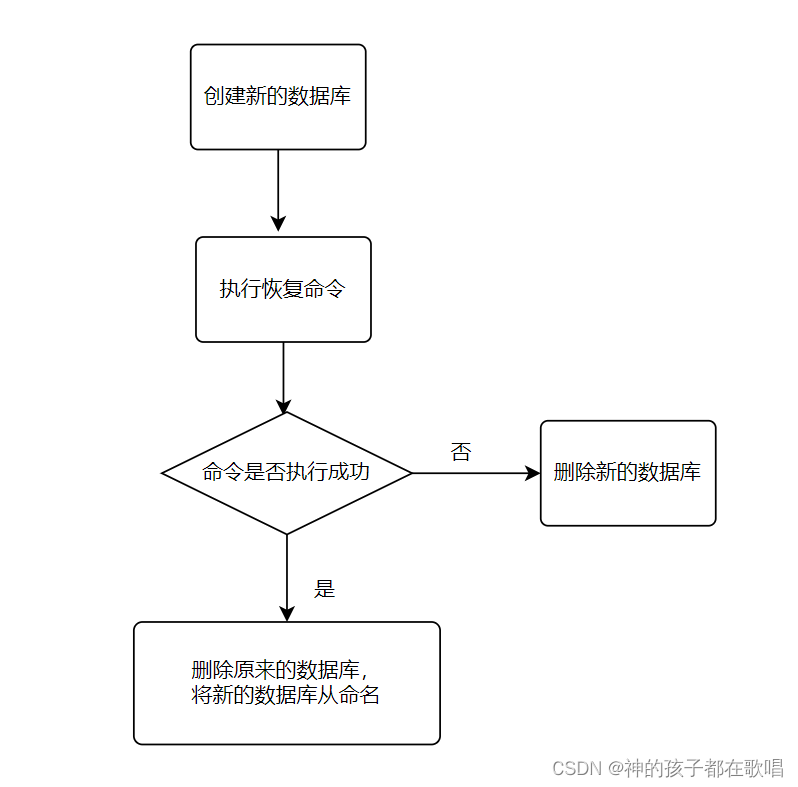
PostgreSQL--实现数据库备份恢复详细教学
前言 这是我在这个网站整理的笔记,关注我,接下来还会持续更新。 作者:RodmaChen PostgreSQL--实现数据库备份恢复详细教学 一. 数据库备份二. 数据库恢复三. 存留问题 数据库备份恢复功能是每个产品所需的,以下是简单的脚本案例&a…...

JDK工具之jstack说明
JDK工具之jstack说明 前言什么是jstack?如何使用jstack?获取Java进程的PID分析jstack输出 常用的jstack命令选项jstack的应用场景结论 前言 作为Java开发人员,在开发和维护复杂的Java应用程序时,我们经常会遇到各种各样的问题&am…...

34 | 牛顿迭代法
文章目录 牛顿迭代法一、原理二、Python实现三、练习题四、总结牛顿迭代法 一、原理 牛顿迭代法(Newton’s Method)是一种用于寻找方程的实根的数值方法。其基本思想是通过一系列逼近来求解方程的根。对于方程 f ( x ) = 0 f(x) = 0 f(x...

ChatGPT如何帮助学生学习
一些教育工作者担心学生可能使用ChatGPT作弊。因为这个AI工具能写报告和计算机代码,画出复杂图表……甚至已经有许多学校把ChatGPT屏蔽。 研究发现,学生作弊的主要原因是想考得好。是否作弊与作业和考试的打分方式有关,所以这与技术的便…...

easyexcel导出excel-50行代码搞定大量数据导出
文章目录 一、写在前面二、使用步骤定义导出的数据实体导出 一、写在前面 场景: 当数据量导出过大时如果一次从数据库取出所有数据会导致内存飙升导致系统奔溃,所以我们采取循环读取和循环写入。 准备: mave导入:easyexcel:3.0.5 二、使用…...
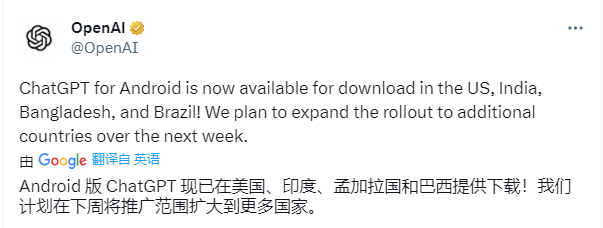
OpenAI宣布安卓版ChatGPT正式上线;一站式 LLM底层技术原理入门指南
🦉 AI新闻 🚀 OpenAI宣布安卓版ChatGPT正式上线 摘要:OpenAI今日宣布,安卓版ChatGPT已正式上线,目前美国、印度、孟加拉国和巴西四国的安卓用户已可在谷歌Play商店下载,并计划在下周拓展到更多地区。Chat…...
)
Rust vs Go:常用语法对比(二)
21. Swap values 交换变量a和b的值 a, b b, a package mainimport "fmt"func main() { a : 3 b : 10 a, b b, a fmt.Println(a) fmt.Println(b)} 103 fn main() { let a 3; let b 10; let (a, b) (b, a); println!("a: {a}, b: {b}", aa,…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...
)
第二周(第12周)
1.单电源供电的二阶低通滤波器2.功率放大电路...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

2026长沙智能家居品牌实测,这些本地老牌值得选
2026年,长沙的智能家居市场已经从“概念热”转向“落地战”。我走访了长沙多个本地服务商,实测了不同品牌在别墅、酒店、大平层等场景的真实表现。今天,结合数据与案例,分享几个值得关注的本地品牌,尤其是深耕8年以上的…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

量子纠错码VarQEC:原理、实现与硬件优化
1. 量子纠错码基础与实验背景量子纠错码(Quantum Error Correction Codes, QEC)是量子计算中保护量子信息免受噪声影响的核心技术。与经典纠错码不同,量子纠错需要应对量子态特有的退相干和纠缠特性。传统QEC如[[5,1,3]]完美码虽然理论完备&a…...
)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)在科幻题材的游戏开发中,激光雷达扫描特效是营造科技感的经典元素。从《赛博朋克2077》的战术目镜到《看门狗》的环境扫描,这种动态…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...